Embed Size (px)
Citation preview

WHITE PAPER
Overview
Development teams are facing a gargantuan task: creating the 50-billion devices that will transform life, as we know it on the Internet of Things. Every single one of those devices requires software, with increasing complexity and expectations. The best efforts to measure and enhance programmer productivity and developer processes fall short in the face of an exponential rise in the demand for robust software. The only solution: more reuse.
There is hope, in the lessons learned from the success of system-on-chip (SoC) designs and the reuse of hardware IP blocks. That design process is producing more software to help verify designs, software leveraged by device developers. The question becomes how to develop, find, and reuse quality software, faster and easier.
The old make-buy thinking that originated with hardware is giving way to a “build-borrow-buy” approach to software, bringing IP creators from across the embedded computing industry together in new and exciting places – such as the Embedded Software Store. Here’s the story behind build-borrow-buy as the better approach for addressing software complexity.
Build, Borrow, Buy:
New Approaches to Addressing Software Complexity By Willard Tu, ARM Director of Embedded Segment Marketing May 2013

2
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Shifting embedded device design
With an exponential growth in embedded software needed to create 50-billion Internet of Thing (IoT) devices, and only a 5% annual improvement in software production capability under current estimates, the culture of software development has to evolve. Embedded engineering teams, trained for decades to develop code from scratch and understand the behavior of each and every line, now face a rapidly changing dynamic that calls for embracing a blended approach to software engineering. The situation for software parallels what the computer hardware industry faced for the last decade. At the high end, processors have transitioned from multibillion transistor CISC implementations pressing the boundaries of Moore’s Law to processors with more efficient RISC cores, flexible interconnect standards, and robust execution unit, memory, and peripheral intellectual property (IP). Those changes broke through the hardware producibility barrier, spawning a fabless semiconductor industry, and enabling a wide range of new system-on-chip (SoC) implementations. At the low end, where the bulk of the embedded opportunity lies, microcontroller (MCU) hardware has evolved from 8-bit execution units programmed in assembly language to a range of implementations with more powerful 32-bit cores, better mixed-signal capability, and improved power management. We are now witnessing the next evolution in MCUs bringing much of the same peripheral IP from their larger brethren to bear. These new parts find design wins in scenarios where all devices need to be connected with wired or wireless networks, and the expectations from a mobile-savvy generation drive user experience requirements down to even the smallest devices. Embedded software teams, usually armed with the traditional set of compile and debug tools, plow into this melee with great enthusiasm and creative ideas. The code-at-all-costs mindset soon runs into trouble as the complexity of newer hardware and diversity of requirements becomes evident, and the unrelenting demands of time-to-market and quality begin to weigh on projects. Well-planned processes augmented with superhuman efforts still get projects to the finish line much of the time, but the number of challenged and failing projects is increasing dramatically, and the costs are mounting. Just as the hardware discipline has had to accelerate reuse and foster interoperability, the software discipline now faces the same challenge on a much larger scale. Hardware only needs to account for compute capacity and interface flexibility; software needs to account for exact operational requirements and controlled behavior of a device. Paradoxically, that accountability has put reuse and risk at opposition in the minds of many software developers – the risks of using “other people’s code” have been too great for some teams who feel their situation is unique. While there are certainly facets of software that must be innovatively unique to differentiate a design in the marketplace, the value equation is shifting into a blended approach where software and hardware from a variety of sources including internal and external development combine to leverage functional knowledge and proven reliability. Co-verification – taking known-good IP blocks, creating an interconnect, adding new IP, and testing the entire solution with software and hardware all working
“[The “everyone should learn to code” initiative] assumes that coding is the goal. Software developers tend to be software addicts who think their job is to write code. But it's not. Their job is to solve problems.” Atwood, “Please Don’t Learn to Code”, 2012
3
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
together – goes beyond the traditional view of reuse, and is part of addressing the challenges of software complexity.
Defining IP reuse
Software reuse seems like a concept developers would embrace on a large scale, with commercial-off-the-shelf code integrating into rapid embedded application development. While there have been some successes in embedded applications, particularly where stringent certification requirements exist, software reuse hasn’t changed things enough yet. Why is software reuse so challenging? Three areas need exploration: the necessary conditions for IP reuse, the complexity of embedded software, and what it is that constitutes a successful development project. In his seminal 1992 paper “Software Reuse” [1], Charles Krueger includes a discussion of cognitive distance. Krueger provides a higher definition of the concept: in the simplest of terms, IP must “fit” into a designer’s vision for the project. If designers think the perceived distance between the requirements and the risk of IP not fitting is too great, they will not use it. Perceived cognitive distance is important for software vendors and developers to contend with and understand . The perception can be based on facts, such as code not meeting basic requirements. More likely, the sense of distance is based on a feeling of uncertainty over the effort to find and modify code, which makes writing code appear to be the less risky alternative to buy. That risk assessment tends to undervalue the robustness of commercial off-the-shelf code, in favor of upholding customized low-level project requirements and writing code, which may in fact be much riskier. The real test of reuse comes at a higher level, with wider ranging effects than simply coding to exact requirements considered in the assessment. In studying reuse successes, Krueger found four dimensions that must be satisfied:
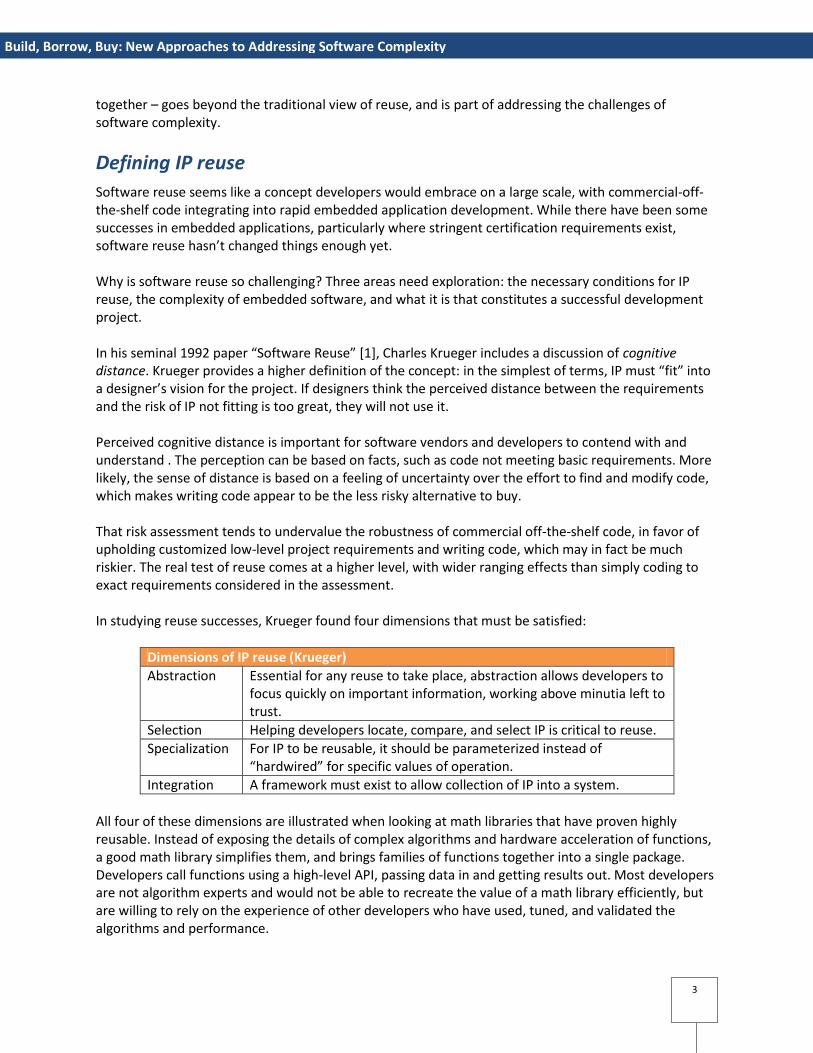
Dimensions of IP reuse (Krueger)
Abstraction Essential for any reuse to take place, abstraction allows developers to focus quickly on important information, working above minutia left to trust.
Selection Helping developers locate, compare, and select IP is critical to reuse.
Specialization For IP to be reusable, it should be parameterized instead of “hardwired” for specific values of operation.
Integration A framework must exist to allow collection of IP into a system.
All four of these dimensions are illustrated when looking at math libraries that have proven highly reusable. Instead of exposing the details of complex algorithms and hardware acceleration of functions, a good math library simplifies them, and brings families of functions together into a single package. Developers call functions using a high-level API, passing data in and getting results out. Most developers are not algorithm experts and would not be able to recreate the value of a math library efficiently, but are willing to rely on the experience of other developers who have used, tuned, and validated the algorithms and performance.
4
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
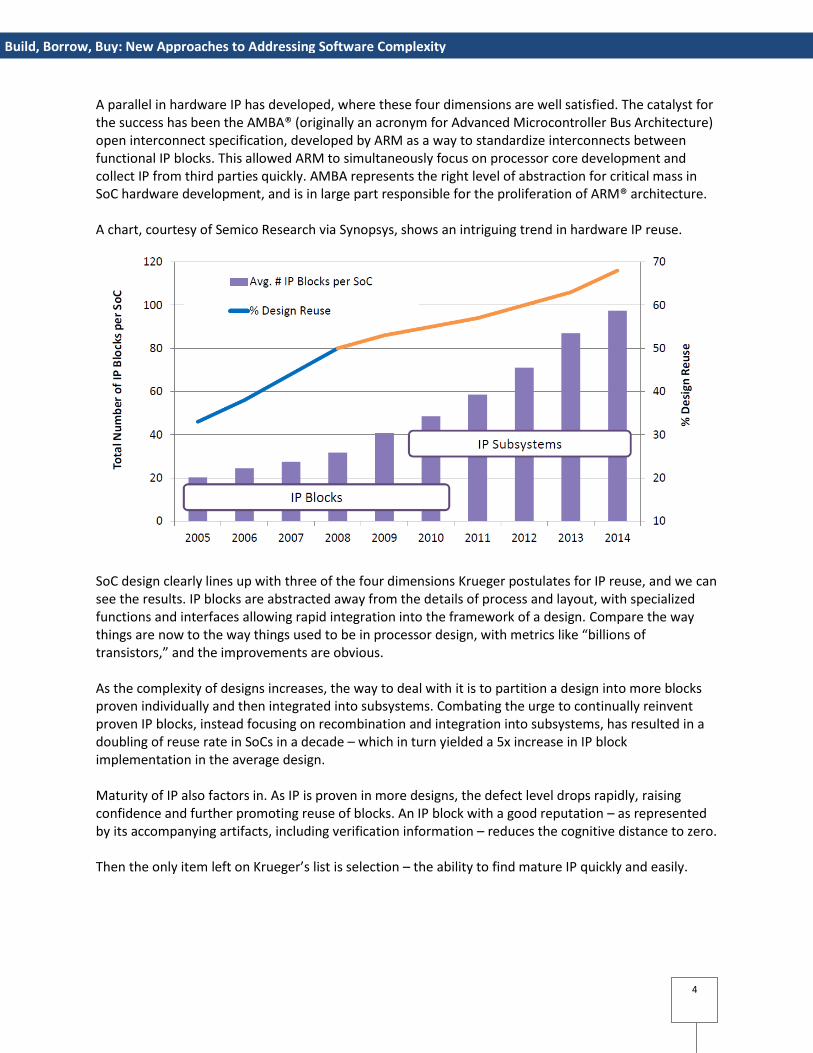
A parallel in hardware IP has developed, where these four dimensions are well satisfied. The catalyst for the success has been the AMBA® (originally an acronym for Advanced Microcontroller Bus Architecture) open interconnect specification, developed by ARM as a way to standardize interconnects between functional IP blocks. This allowed ARM to simultaneously focus on processor core development and collect IP from third parties quickly. AMBA represents the right level of abstraction for critical mass in SoC hardware development, and is in large part responsible for the proliferation of ARM® architecture. A chart, courtesy of Semico Research via Synopsys, shows an intriguing trend in hardware IP reuse.
SoC design clearly lines up with three of the four dimensions Krueger postulates for IP reuse, and we can see the results. IP blocks are abstracted away from the details of process and layout, with specialized functions and interfaces allowing rapid integration into the framework of a design. Compare the way things are now to the way things used to be in processor design, with metrics like “billions of transistors,” and the improvements are obvious. As the complexity of designs increases, the way to deal with it is to partition a design into more blocks proven individually and then integrated into subsystems. Combating the urge to continually reinvent proven IP blocks, instead focusing on recombination and integration into subsystems, has resulted in a doubling of reuse rate in SoCs in a decade – which in turn yielded a 5x increase in IP block implementation in the average design. Maturity of IP also factors in. As IP is proven in more designs, the defect level drops rapidly, raising confidence and further promoting reuse of blocks. An IP block with a good reputation – as represented by its accompanying artifacts, including verification information – reduces the cognitive distance to zero. Then the only item left on Krueger’s list is selection – the ability to find mature IP quickly and easily.

5
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Quick take on defining IP reuse:
Move away from low-level, custom requirements for most features
Seek higher value in abstracted and parameterized designs
Win with integrating robust, known-good IP blocks plus new innovation
Confusion over complexity measurements
Many popular software development theories have focused on complexity measurement, with the goal of better understanding and controlling development risk, and thereby productivity. The general idea is moving from requirements to production-ready code faster, with fewer defects and reduced costs. When it comes to productivity, management likes measurements. Popular measures defined by Halstead, McCabe, Henry-Kafura, and others analyze lines of code (LOCs) and programming constructs such as loops and branches, but don’t capture behaviors in dealing with real programming difficulties. In fact, these measures can contribute to the cognitive distance inhibiting software reuse, because they are easily misapplied to “other people’s code” and misunderstood even within the context of a project. In “Software Complexity Measurement” [2], Kearney et al, 1986, the author questions the usefulness of complexity measurements given different programming languages and diversity of requirements. They cite a study by Basili and Hutchens exploring a relationship between program changes and program defects, asking 19 programmers to implement the same problem. According to Kearney, the flawed conclusions show the difficulty in devising and interpreting measurements. Two programs of equal length (measured in LOCs), generated by different programmers, are considered to be of equal complexity regardless of actual constructs. If one programmer made more changes to get their working result, management deemed them “less competent” even if they produced fewer defects. As these inferences show, complexity measures often don’t even gauge productivity correctly. Fast-forward a generation to a 2010 article by Andy Oram in the O’Reilly Community titled “Do We Need More Software Complexity Metrics?” [3] With the benefit of hindsight from the open-source movement and years of subsequent attempts to measure complexity, Oram says that if C is the language of choice, most complexity metrics are highly correlated with LOCs and thereby redundant, and that “syntactic complexity metrics cannot capture the whole picture of software complexity.” The conclusion Oram draws: contrary to what complexity metrics say, if a programmer chooses one way to implement something and uses it in many parts of the program, this makes the code more redundant, more readable, and less complex – even though LOCs have increased by such reuse.
“It is possible to devise an enormous number of measures based on intuitions and introspection about programming. The likelihood that any one of these will reveal insights into a behavior as complex and intricate as programming is small.” Kearney, “Software Complexity Measurement”, 1986

6
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Quick take on confusion over complexity:
End game should be how much quality software can be produced quickly
Complexity measures on LOCs easily misapplied to “other people’s code”
Reuse often increases complexity, but reduces risk and improves producibility
Project success and modern development methodologies
With LOC measurements not revealing the answer, attention turned to software development methodologies like agile, iterative, and waterfall, focusing on teamwork, collaboration, and flexible processes. All modern methods try to deal with complexity and work toward a successful outcome. The Standish Group (http://blog.standishgroup.com/) issues a periodic “CHAOS Report” based on their survey of IT project success rates, which estimates over $275B being spent on 250,000 in-house IT software application development projects. Those high stakes and their surprisingly dismal findings of success from their survey cause them to take a radical position: “Never build. Always buy.” While that would be great news for the software vendor community, it is simply unrealistic for embedded development, a point we will explore shortly in discussing why a blended approach is required. Others think the Standish findings are a bit pessimistic, too. Scott Ambler does a similar survey, with his recent “2010 IT Project Success Rates” [4] published in Dr. Dobbs. Like Standish, Ambler groups projects into successful, challenged, and failed, but redefines success not to mean simply absolutely “on time, on budget, on specification.” Challenging the assumption is reasonable: success means different things to teams at different development stages, especially in an agile methodology with cycles of learning. Ambler asked questions to uncover success rates across methodology and team size. The good news is using iterative or agile methodologies improves the odds of project success. The bad news is even a relaxed definition of successful projects indicates only a 61% chance of success. There are projects that should fail, due to unclear requirements, or irretrievably late-to-market conditions, or other things which developers have limited control over. However, most developers take pride in their work, are paid to produce positive results, and would likely agree 61% isn’t good enough. While this is IT project data, there is no reason to believe that the success rate for embedded projects is much different. With exponentially more devices in development, and increased pressures from requirements such as usability, security, and connectivity, it is not a stretch to predict the number and percentage of challenged and failed embedded projects could easily grow out of control. Forestalling that means finding a new strategy beyond simplistic “build versus buy,” or yet another development methodology, or many more programmers, or superhuman increases in programmer productivity.
0% 20% 40% 60% 80% 100%
Traditional
Ad-Hoc
Agile
Iterative
Successful Challenged Failed

7
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Quick take on project success:
Methodologies are coping strategies; any can be successful
Success is relative, especially in agile environments with cycles of learning
61% success good, but not good enough with exponentially more projects
The big embedded picture and the underlying cost
We said earlier that software reuse and buy options haven’t changed the embedded picture enough yet. Stephen Balacco conducts an annual survey of embedded engineering [5]. His depiction of the embedded software spend resembles an iceberg, with the commercial spend (Buy) visible and a much larger mass of build resources hidden underneath.
Balacco estimates the labor costs to be 90% of the embedded software spend and that percentage has changed little over the last several years of the survey. The indications are business spend (Buy) primarily on operating systems, development tools, and some common functions like file systems, TCP/IP stacks, and USB connectivity stacks, to make a disproportionately large build effort feasible. By design, organizations are sized to build and not buy on a large scale. Developers have been educated to code, and are good at coding, therefore we code. But, look at the cost. Our love of code has become a hot meme, with good reason. Those not literate in programming will likely fall behind in the job market of the future. Even ARM is getting behind it, sponsoring Code Club helping UK schools with code education.
Jeff Atwood writes a tongue-in-cheek response to the meme in “Please Don’t Learn to Code” [6]. His key point is coding is not the goal – in fact, we should be writing as little code as possible. Atwood recognizes the benefits of laypeople having a basic understanding of code, and while encouraging that he is discouraging jumping straight into writing code without looking at the problem at hand. Implied in Atwood’s ideas is an important concept: someone else may have already solved the problem, and have code developers can buy or borrow to incorporate as part of a solution. This ties all the way back to the earlier findings from Krueger – to be reused, code must easier to find than it is to write from scratch, and it must come with information that makes it trustworthy and easy to integrate. With the software producibility shortfall now evident, inverting the above picture – where labor is the minority percentage, and buy or borrow and software reuse and integration becomes the focus – is the longer-term solution to addressing software complexity.
8
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Quick take on the big embedded picture:
Buy efforts have been mostly for tools to make build possible
Organizations are sized, designed to write and test new code
To reduce costs and produce more, write as little new code as possible
Co-verification now driving embedded device designs
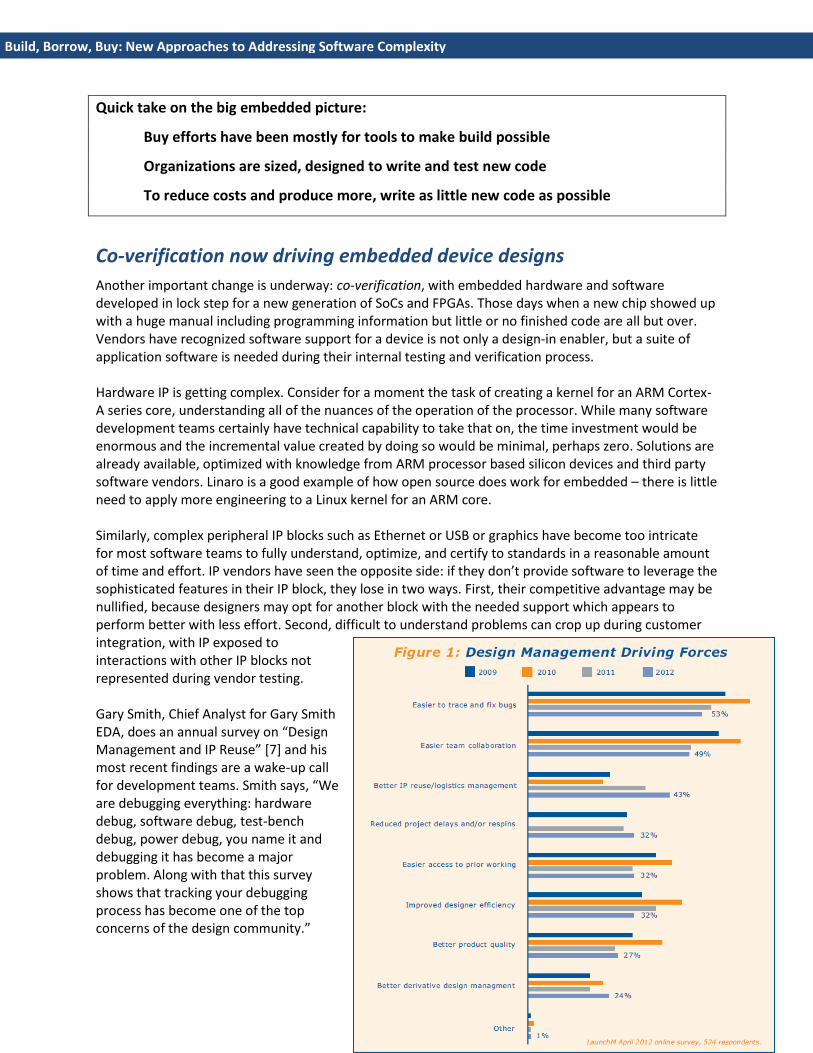
Another important change is underway: co-verification, with embedded hardware and software developed in lock step for a new generation of SoCs and FPGAs. Those days when a new chip showed up with a huge manual including programming information but little or no finished code are all but over. Vendors have recognized software support for a device is not only a design-in enabler, but a suite of application software is needed during their internal testing and verification process. Hardware IP is getting complex. Consider for a moment the task of creating a kernel for an ARM Cortex-A series core, understanding all of the nuances of the operation of the processor. While many software development teams certainly have technical capability to take that on, the time investment would be enormous and the incremental value created by doing so would be minimal, perhaps zero. Solutions are already available, optimized with knowledge from ARM processor based silicon devices and third party software vendors. Linaro is a good example of how open source does work for embedded – there is little need to apply more engineering to a Linux kernel for an ARM core. Similarly, complex peripheral IP blocks such as Ethernet or USB or graphics have become too intricate for most software teams to fully understand, optimize, and certify to standards in a reasonable amount of time and effort. IP vendors have seen the opposite side: if they don’t provide software to leverage the sophisticated features in their IP block, they lose in two ways. First, their competitive advantage may be nullified, because designers may opt for another block with the needed support which appears to perform better with less effort. Second, difficult to understand problems can crop up during customer integration, with IP exposed to interactions with other IP blocks not represented during vendor testing. Gary Smith, Chief Analyst for Gary Smith EDA, does an annual survey on “Design Management and IP Reuse” [7] and his most recent findings are a wake-up call for development teams. Smith says, “We are debugging everything: hardware debug, software debug, test-bench debug, power debug, you name it and debugging it has become a major problem. Along with that this survey shows that tracking your debugging process has become one of the top concerns of the design community.”
9
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
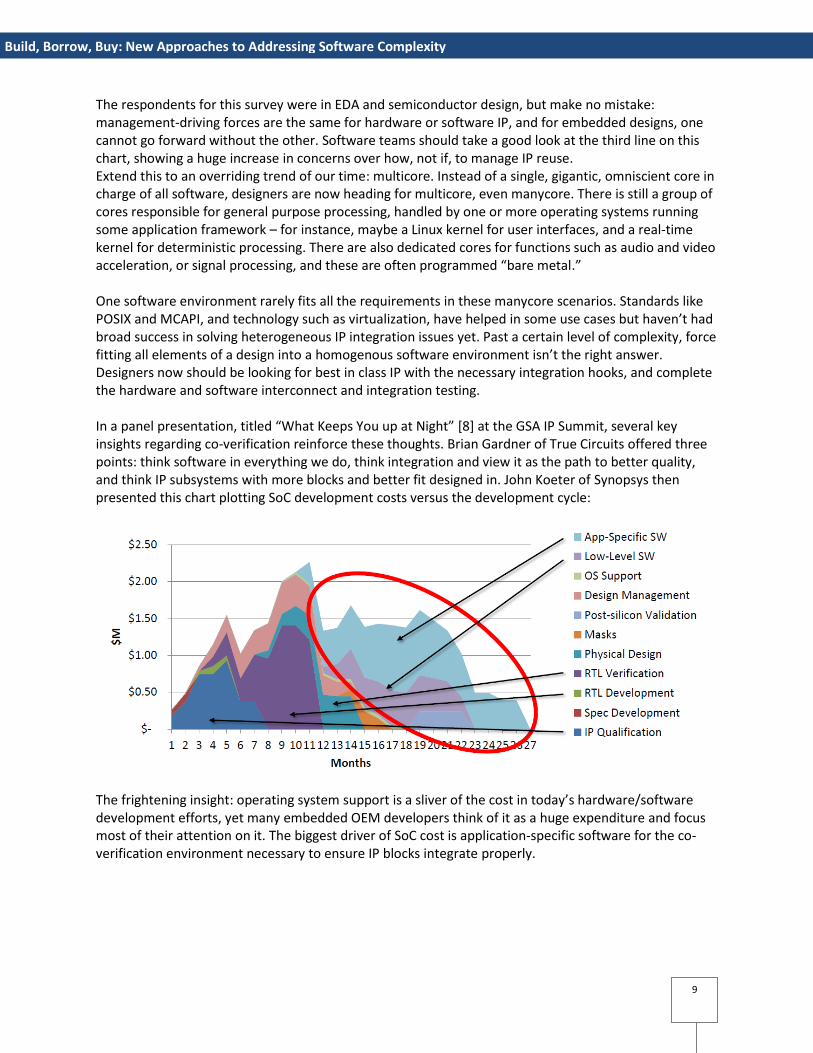
The respondents for this survey were in EDA and semiconductor design, but make no mistake: management-driving forces are the same for hardware or software IP, and for embedded designs, one cannot go forward without the other. Software teams should take a good look at the third line on this chart, showing a huge increase in concerns over how, not if, to manage IP reuse. Extend this to an overriding trend of our time: multicore. Instead of a single, gigantic, omniscient core in charge of all software, designers are now heading for multicore, even manycore. There is still a group of cores responsible for general purpose processing, handled by one or more operating systems running some application framework – for instance, maybe a Linux kernel for user interfaces, and a real-time kernel for deterministic processing. There are also dedicated cores for functions such as audio and video acceleration, or signal processing, and these are often programmed “bare metal.” One software environment rarely fits all the requirements in these manycore scenarios. Standards like POSIX and MCAPI, and technology such as virtualization, have helped in some use cases but haven’t had broad success in solving heterogeneous IP integration issues yet. Past a certain level of complexity, force fitting all elements of a design into a homogenous software environment isn’t the right answer. Designers now should be looking for best in class IP with the necessary integration hooks, and complete the hardware and software interconnect and integration testing. In a panel presentation, titled “What Keeps You up at Night” [8] at the GSA IP Summit, several key insights regarding co-verification reinforce these thoughts. Brian Gardner of True Circuits offered three points: think software in everything we do, think integration and view it as the path to better quality, and think IP subsystems with more blocks and better fit designed in. John Koeter of Synopsys then presented this chart plotting SoC development costs versus the development cycle:
The frightening insight: operating system support is a sliver of the cost in today’s hardware/software development efforts, yet many embedded OEM developers think of it as a huge expenditure and focus most of their attention on it. The biggest driver of SoC cost is application-specific software for the co-verification environment necessary to ensure IP blocks integrate properly.

10
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Quick take on co-verification:
New complex IP is difficult to understand, optimize, and certify quickly
Multicore is making heterogeneous software environments the norm
Biggest effort is application software, not operating system support
Blocking out an acquisition strategy
Different IP blocks call for different acquisition approaches. Teams should establish the functional requirements for a design, decompose those into IP blocks and IP subsystems, and evaluate one or more acquisition strategies for each block considering the entire development picture. One perspective on IP acquisition is a diagram Mark Downing, formerly of Silicon Labs shares, from the traditional viewpoint of a make-buy strategy. Keep in mind: what constitutes a core architectural component for a vendor (build) moves down the supply chain as a technology-driven functional block for OEMs (buy).
Most projects are not all-or-nothing decisions. The correct answer in acquiring IP is pursuing a build-borrow-buy decision for each block, likely engaging all three. Maturity is also a factor: an IP block, once built or bought and proven, becomes a reusable solution for subsequent projects. Skilled designers spot valuable IP blocks, and are willing to invest the right resources to integrate them into a solution. What shape that investment takes depends on a few factors, a big one being volume of the deployed solution. Traditionally, developers have drawn a build/buy line somewhere around 10,000 units, with volumes above that calling for build because the costs to buy become too large. However, that is dated, hardware-style thinking – most IP suppliers have created flexible licensing strategies including royalty-free options that don’t place an unfair burden on higher volume projects. Per-developer-seat or per-project models are now the norm for IP. Deployed volume now factors into thinking in a different way, looking at how many projects a team is pursuing in a portfolio of efforts, including both new development projects and sustaining deployed projects. Higher volume and longer life cycle products afford more room for build, where smaller and shorter life cycles demand more borrow or buy. Again, the idea is to move the needle on the 61% success rate – too many resources tied up in the wrong places can slow down an entire portfolio.

11
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Quick take on IP acquisition:
Projects are not all-or-nothing, but instead each IP block is evaluated individually
An IP block built, borrowed, or bought adds to a base of maturing, reusable IP
Old thinking of make vs. buy over/under a unit shipment threshold is disappearing
Changing the approach to software complexity
Code viewed as trustworthy for an embedded application is not an easy hurdle to clear. Patil and Kapaleshwari lay out seven points in “Embedded Software - Issues and Challenges” [9] that define what information developers typically look for to reduce perceived cognitive distance.
Embedded software issues and challenges (Patil and Kapaleshwari)
Reliability and robustness This ranges from debugging capability, error handling and fault recovery, to formal analysis techniques and certification to safety-critical standards.
Performance More than just speed, this also takes into consideration power consumption, memory footprint, and may be accompanied by modeling or simulation data.
Complexity Sophisticated functions and increasing expectations, driven by smartphones and other devices, are making their way into everything.
Requirements management An art unto itself, well-defined requirements and non-requirements reflecting the needs of customers are essential to any success.
Optimization One key difference from IT development, embedded systems are usually honed to fit within tight boundaries of cost, size, and performance, often through iteration.
Distributed development teams Collaboration and outsourced expertise make communication and process extremely important.
Verification and tools Defects become more expensive the longer they go undetected, and quality relies on testing individual IP blocks and integrated systems.
While these technical considerations are very valid and drive many development teams and their processes to build embedded software, they are only a part of the picture affecting software producibility. We are about to challenge the prevailing assumptions. In the introduction, we quoted an estimated 5% annual improvement in software production capability, which comes via consultant Donald Reifer as cited in a 2009 presentation “Roadmap for Producibility Technology” [10] by Grady Campbell. With the benefits of experience since the original Krueger paper on reuse, Campbell goes after the subject from a different angle. Campbell suggests three dimensions to the producibility equation: developer productivity, product value, and, what he calls, acquirer acuity. We have already discussed developer productivity and the attempts to quantify it, but
“{Producibility is} the ability to deliver needed capability in a timely, cost-effective, and predictable manner.” Campbell, “Roadmap for Producibility Technology”, 2009

12
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
in the context of software-intensive systems (SiS), the idea grows beyond development methodology and coding prowess. Productivity entails domain expertise, knowledge with both the technology base and leveragable resources (which he cites as legacy, commercial off-the-shelf, open source, and domain-specific), and an idea of addressing uncertainty, diversity, and change. When talking about product value, this is not in reference to the end product, but instead what we have been referring to as an IP block and its associated artifacts. Campbell is looking beyond just functionality, at deeper issues of quality in a system context, and compatibility not only with the system itself but also with the operational the system.is deployed in. Acquirer acuity relates to the insight and foresight needed to look at the value across the entire lifecycle, not just a point implementation to some requirements base. This includes better mechanisms for tradeoffs – a problem well suited for model-based development – and improvements in predictability. What, specifically, is in the way of better software producbility? Campbell summarizes nine symptomatic problems that can plague development efforts and result in challenged or failed projects:
Symptomatic software producibility issues (Campbell)
Requirements inadequately defining the problem and over-specifying a solution
Difficulties accommodating changing requirements or technology
Testing consuming inordinate resources to find product flaws late
Projects ineffectively balancing function, quality, and cost/schedule
Decisions made to achieve first delivery increasing life cycle costs
System designs failing to explore software alternatives and tradeoffs
Software not being engineered for system properties but being “fixed” through trial-and-error
Development tools failing to improve cost, time, or product quality
Acquisition focus on products versus investing in establishing domain-specific problem-solution specific expertise as a capital asset
Some of these are well-known issues, such as the concept of keeping costs low by finding and eliminating defects earlier in the development cycle. Some are less familiar, for example the idea that instead of reactively fixing issues, place more energy into evaluating implementation alternatives. The last point is very interesting – advocating a much broader use of domain-specific modeling not only as a development aid, but also as a way to capture organizational expertise and enable efficient evaluation of different implementations. Campbell states it best himself: “These producibility problems are not inevitable or unavoidable; they are the symptoms of a flawed approach to the production and evolution of software-intensive systems. Current approaches to software and systems engineering trace to a time when software was a minor element of systems and needs were modestly conceived and easily understood. However, completed software was not easily changed so requirements had to be fixed early for an effort to succeed.” Instead of viewing software as simply part of a product, and then part of the next product with redundant development efforts applied, view software as IP blocks deployable in many system environments. This doesn’t rule out build solutions innovating new features, but instead suggests the much stronger blended approach where modeling combines with targeted development and integration to streamline creation of more solutions.
13
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Quick take on changing the approach
System-level, top-down view of software development needed
Domain-specific modeling enables tradeoffs, captures expertise
A software IP block is not just part of a product, but of many solutions
The visible software IP market
With the ideas of better producibility in place, the blended “build-borrow-buy” approach emerges as the right acquisition strategy. In this new approach where value is decomposed into IP blocks taken one at a time and integrated into complex designs, the need to find code and artifacts quickly is the enabler to making things work. Working definitions of each of these facets are:
Facets of IP acquisition
Build A deep investment in targeted, innovative features with requirements development, modeling, integration of proven and new IP blocks, and co-verification of the entire design.
Borrow Reusing IP including open source with basic value fully captured as a way to jump-start new innovative ideas, exploring and evaluating tradeoffs quickly and inexpensively.
Buy Locating and leveraging third-party investment in standards, testing, interoperability, and ecosystem teaming, with robustness derived from exposure to multiple applications and fielded devices.
Until the advent of open source and licensable IP, finding code was more than a bit of a challenge. Vendors were reluctant to give much away, or expose their inner workings to scrutiny. Developers borrowed code from other projects within a company, or from peers in the industry willing to share. Ad-hoc sharing became structured as more developers and users got on board.
Contributed source – GitHub, SourceForge, and other communities such as the National Instruments LabVIEW resources have enabled developers to collaborate, share, and discuss ideas and code with peers and experts in a vast variety of projects.
Guided projects – Efforts such as the Eclipse Foundation and Android have fostered larger, commercial-ready projects targeting specific industry problems, aligning vendors and contributors in a consortia-driven effort with managed releases and milestones.
App markets – the success of Apple and Google in consumer markets have driven developers into a development and distribution framework for packaged, downloadable apps, and Microsoft, BlackBerry, and others are adopting a similar approach.
Open source is fantastic, but it does not and should not equate to no cost – “free as in freedom, not free as in beer.” Where it satisfies project needs, there are costs to freezing configurations supportable for an embedded device life cycle while the community continues to innovate on the main tree. There are also licensing considerations, a complex issue too broad for discussion here.

14
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
Maturity and robustness also have value. One developer said in a LinkedIn survey, “Never put a development hardware/software kit into production.” His point was that an open or inexpensive solution targeting easy software development might not have been designed or tested adequately to provide the necessary robustness in a fielded device. Additionally, complexity assessment and risk management colors the picture. Firms may want source code to satisfy their existing processes, but immediately go into sticker shock when vendors present “buy” offerings. The costs of object code can be a fraction of what in-house development, testing, and support actually entail – the iceberg discussed earlier. All things considered, a new gathering place is emerging for embedded developers looking to find and acquire valuable IP from a wider variety of sources, and for vendors bringing ideas to market. The Avnet/ARM Embedded Software Store is an online resource that uniquely recognizes the tight coupling between many variants of processor silicon and embedded software created for them. Several elements make the Embedded Software Store an innovative idea for the “build-borrow-buy” approach, with the process of finding and licensing software quicker and easier. Instead of facing the task of performing exhaustive online research followed by a painstaking process of working through multiple vendor relationships, the Embedded Software Store brings the following together in one site:
Elements of the Embedded Software Store
One-stop shopping A unified marketplace with multi-vendor support for numerous processor families within the ARM architecture, allowing visitors to search and find products quickly
New introductions When announcing new SoCs and MCUs, development kits, tools, and operating system support appear from a range of sources
Transparency Pricing is available for each listing, many in pre-packaged configurations – information often difficult to find without engaging vendor sales teams
One-click licensing Normally difficult parts of acquiring software, streamlined agreements deliver necessary licensing without complex contracts
Learning resources In addition to products, there are training classes available for purchase, along with free resources including white papers, blogs, videos, discussions, and more in the forum
The product offerings within the Embedded Software Store range from development kits and shareware, to pre-built and tested object code, to complete source code, to commercial off-the-shelf tools, operating systems, and applications. Service offerings including training and support are also available. Many of the listings are exclusive offerings not available for online purchase elsewhere.
For more information, visit http://www.embeddedsoftwarestore.com – registration is free. Combining all the ideas we’ve discussed, and solving the last piece of the reuse puzzle being the ability to find embedded software quickly and easily, leads to the way out of the shortfall in software for the Internet of Things. IP creators – developers and vendors – embracing new strategies can gain a significant advantage in producing more and better software.
“To reuse a software artifact effectively, you must be able to ‘find it’ faster than you could ‘build it’.” Krueger, “Software Reuse”, 1992

15
Build, Borrow, Buy: New Approaches to Addressing Software Complexity
References
[1] “Software Reuse”, Charles W. Krueger, Carnegie Mellon University, ACM Computing Surveys, Vol. 24, No. 2, June 1992. [2] “Software Complexity Measurement”, Joseph K, Kearney et al, Communications of the ACM, Vol. 29, No. 11, November 1986. [3] “Do We Need More Software Complexity Metrics”, Andy Oram, O’Reilly, http://answers.oreilly.com/topic/2258-do-we-need-more-software-complexity-metrics/, Nov 26, 2010. [4] “2010 IT Project Success Rates”, Scott Ambler, Dr. Dobbs, August 2, 2010. [5] “2011 Embedded Software & Tools Market Intelligence Service”, Select Findings: Embedded Engineering Survey, Stephen Balacco, VDC, August 2011, updated annually, available for purchase at http://www.vdcresearch.com/ [6] “Please Don’t Learn to Code”, Jeff Atwood, Coding Horror, http://www.codinghorror.com/blog/2012/05/please-dont-learn-to-code.html, May 15, 2012. [7] “Design Management and IP Reuse”, Gary Smith, Gary Smith EDA, http://garysmitheda.com/paper/DesignManagementIPReuse.pdf, 2012. [8] Global Semiconductor Alliance IP Summit, panel session on “What Keeps You Up at Night”, http://www.gsaglobal.org/ip/docs/PanelPresentation-WhatKeepsYouUpatNight.pdf, March 1, 2012. [9] “Embedded Software - Issues and Challenges”, Sheetal Patil and Laxman Kapaleshwari, SAE International, April 12, 2010. [10] “Roadmap for Producibility Technology”, Grady Campbell, Software Engineering Institute at Carnegie Mellon University, http://sstc-online.org/2009/index.cfm?fs=pres&aid=2413&ld=530, presented at Systems & Software Technology Conference, April 22, 2009.





























