Embed Size (px)
Citation preview

NOAO Brown Bag
May 13, 2008 Tucson, AZ
1
Data Management Middleware
NOAO Brown BagTucson, AZ
May 13, 2008
Jeff KantorLSST Corporation
NOAO Brown Bag
May 13, 2008 Tucson, AZ
2
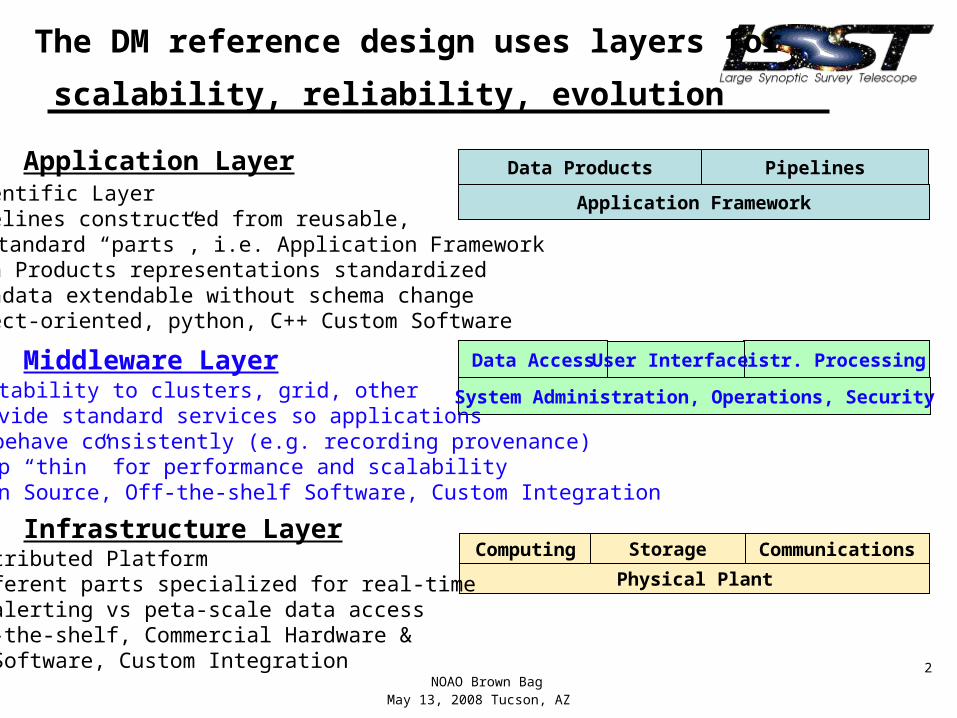
Data Products Pipelines
Application Framework
Application Layer
Middleware Layer Data Access Distr. Processing
System Administration, Operations, Security
User Interface
Infrastructure LayerComputing Communications
Physical Plant
Storage
The DM reference design uses layers for
scalability, reliability, evolution
• Scientific Layer• Pipelines constructed from reusable, standard “parts”, i.e. Application Framework• Data Products representations standardized• Metadata extendable without schema change• Object-oriented, python, C++ Custom Software
• Portability to clusters, grid, other• Provide standard services so applications behave consistently (e.g. recording provenance)• Keep “thin” for performance and scalability • Open Source, Off-the-shelf Software, Custom Integration
•Distributed Platform•Different parts specialized for real-time alerting vs peta-scale data access•Off-the-shelf, Commercial Hardware & Software, Custom Integration
NOAO Brown Bag
May 13, 2008 Tucson, AZ
3
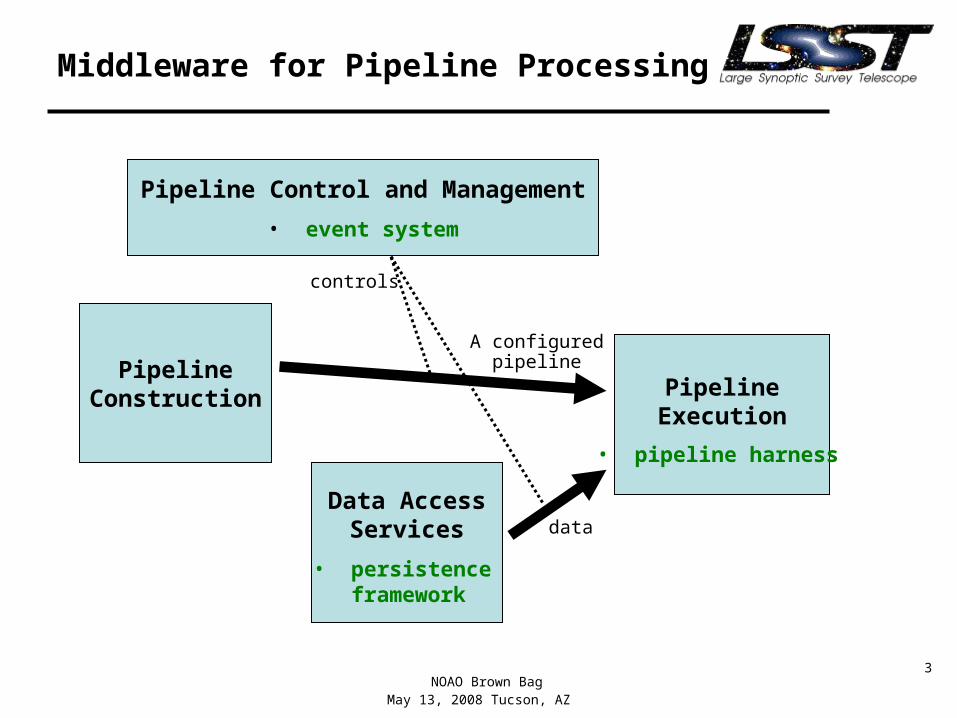
Middleware for Pipeline Processing
Pipeline Control and Management
• event system
PipelineConstruction
Data AccessServices
PipelineExecution
A configuredpipeline
data
controls
• pipeline harness
• persistence framework

NOAO Brown Bag
May 13, 2008 Tucson, AZ
4
Where we’ve been; where we’re going
• Middleware– In DC2, we proved out framework for automated processing
• Pipeline Harness: framework for run application code in a parallel environment
• Data Persistence framework: data I/O (Lim)• Event System: loosely coupled communications
– For DC3/PDR,
• Extend Harness, Persistence, & Event System to apply to more types of pipelines
• Pipeline Control and Management

NOAO Brown Bag
May 13, 2008 Tucson, AZ
5
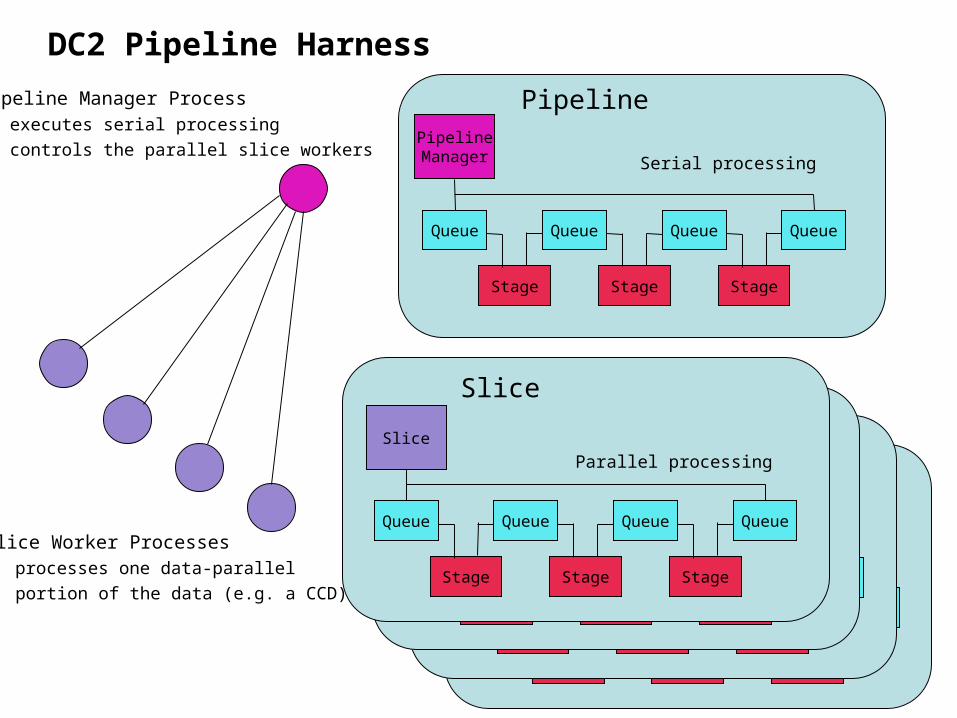
Pipeline Harness
• A processing framework for hosting scientific algorithms in a parallel environment– Developer creates pipeline pluggable modules in python
• A module (i.e., a Stage) operates on a data-parallel chunk of data• Developer does not worry about managing parallel processes or
data I/O• Provides facilities for configuration, accessing data, logging, etc.• Stages can be chained together into complete pipelines
– Harness handles execution on parallel platform• Operates on a stream of data, routing data in and out of modules• Uses Persistence Framework to do data I/O• Uses MPI to exchange signals and data between nodes.• Multiple pipelines running simultaneously can coordinate via Event
System
Parallel processing
Slice
Slice
Stage
QueueQueue Queue
Stage Stage
Queue
PipelineManager Serial processing
Pipeline
Parallel processing
Slice
Pipeline Manager Process• executes serial processing• controls the parallel slice workers
Slice Worker Processes• processes one data-parallel
portion of the data (e.g. a CCD)
Stage
QueueQueue Queue
Stage Stage
Queue
Slice
Stage
QueueQueue Queue
Stage Stage
Queue
Parallel processing
Slice
Slice
Stage
QueueQueue Queue
Stage Stage
Queue
Parallel processing
Slice
Slice
Stage
QueueQueue Queue
Stage Stage
Queue
DC2 Pipeline Harness

NOAO Brown Bag
May 13, 2008 Tucson, AZ
7
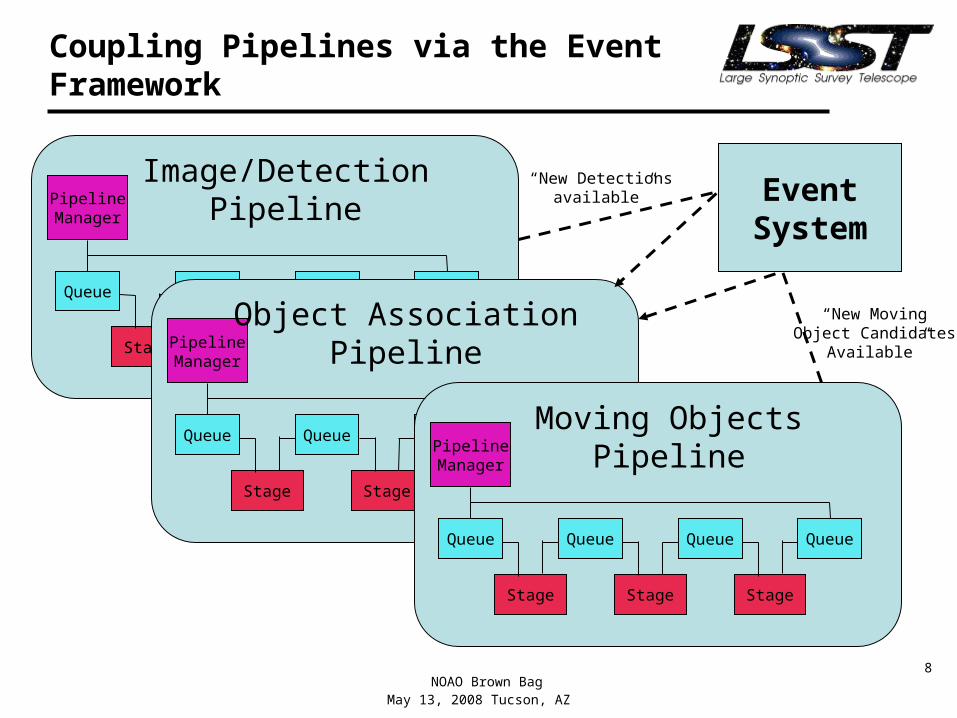
Event System
• System that allows loosely coupled components to talk to each other– e.g., Control systems and pipelines– Systems running on different sites
• DC2 use– Instructing the nightly pipelines that new data are ready for
processing– Passing data between separately running pipelines– Capturing log messages from many nodes
• Implementation– Based on widely used messaging framework– Leveraging some existing middleware that supports framework– All events captured into database
NOAO Brown Bag
May 13, 2008 Tucson, AZ
8
Coupling Pipelines via the Event Framework
PipelineManager
Image/DetectionPipeline
Stage
QueueQueue Queue
Stage Stage
Queue
PipelineManager
Object AssociationPipeline
Stage
QueueQueue Queue
Stage Stage
QueuePipelineManager
Moving ObjectsPipeline
Stage
QueueQueue Queue
Stage Stage
Queue
EventSystem
“New Detectionsavailable”
“New MovingObject Candidates
Available”

NOAO Brown Bag
May 13, 2008 Tucson, AZ
9
Pipeline Harness: What we learned
• Useful framework for developing pipelines– Successfully implemented and executed nightly pipelines
• Need better handling of exceptions when things go wrong– Improvements needed in configuring and testing pipeline instances– Association pipeline required more data sharing across nodes– Expect to work well for data release pipelines
• Good overall performance– Architecture makes it straight forward to measure time spent on different
operations• Logging system provides timestamps• Input and output are separate stages from processing
– Harness incurs low overhead
• Gotchas: how framework can affect performance– Need care when deploying pipeline to a set of processors to balance load– Slower Nodes or data chunks that need more processing can hold back
entire pipeline– When one pipeline requires information from another, their performance is
coupled.

NOAO Brown Bag
May 13, 2008 Tucson, AZ
10
Plans for DC3: Pipeline Harness and Control
• Apply Pipeline Harness to Data Release pipelines– Non-nightly pipelines; for producing products for data release
e.g., Astrometry, Deep Photometry, Data Quality Analysis, etc.
• Apply Harness to less-data-parallel applicationsAssociation, WCS determination, Cross-talk correction
– Requires greater amount of sharing data across nodes
• Develop Pipeline Control and Management System– Configures pipeline, deploys it onto a system, executes it,
monitors it, cleans up after completion.– Automated– Important for leveraging computing systems beyond the Base
Facility and Archive Center– Can leverage existing Grid Middleware

NOAO Brown Bag
May 13, 2008 Tucson, AZ
11
Plans for Data Challenge 3: Event System
• Event Monitoring System– Carries out actions in reaction to complex conditions
– Fault System: looking for signs of trouble
• Issues Fault Events when…– Systems go down (fails to hear from running systems)
– Pipeline stalls or runs too slowly (fails to receive sequence of status messages in required time)
• Can result in corrective measures…– Alert an operator
– Reschedule a pipeline
– Logging System: calculating performance statistics in real time.
• Eliminate post-processing analysis
NOAO Brown Bag
May 13, 2008 Tucson, AZ
12
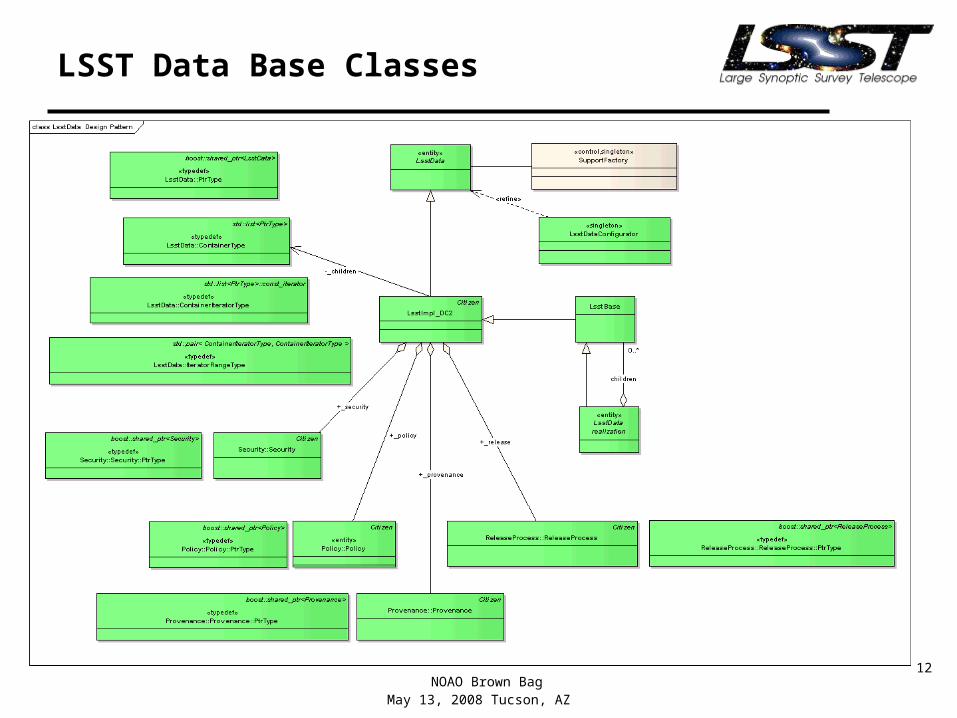
LSST Data Base Classes
NOAO Brown Bag
May 13, 2008 Tucson, AZ
13
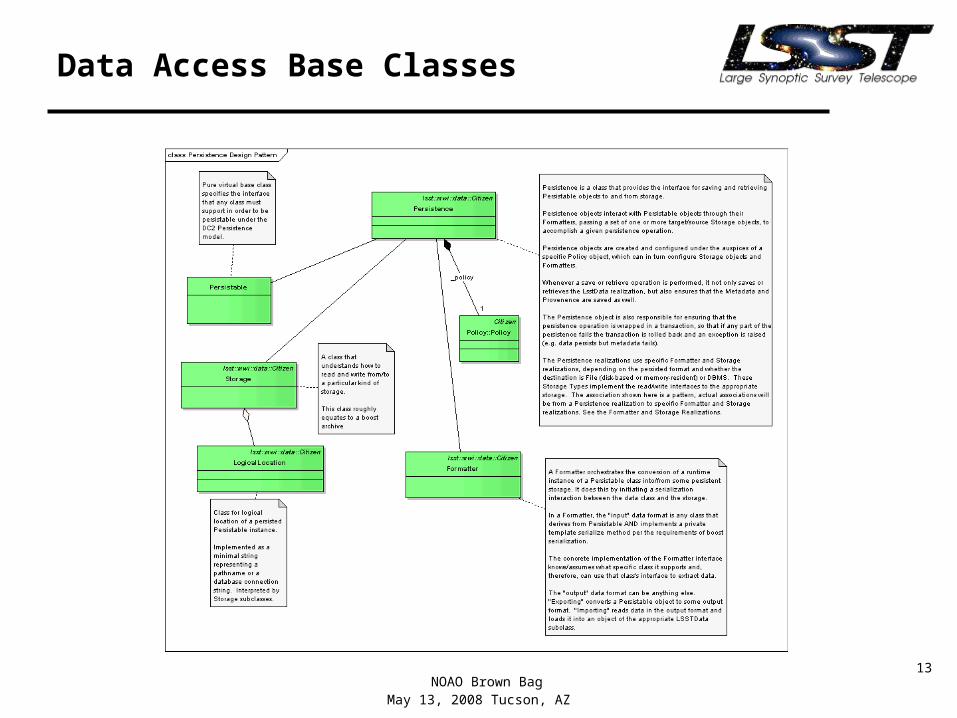
Data Access Base Classes

14 LSST All-Hands MeetingNational Center for Supercomputing Applications (NCSA)
May 19 - 23, 2008
Data Access Middleware Design
• Goal: Flexible, reconfigurable, high-performance persistence for application objects. Also used for inter-pipeline communication.
• InputStage and OutputStage handle persistence for pipelines.
• Persistence object coordinates transactions.• Formatter objects for each persistable class
translate C++ objects into calls to Storage objects.• Storage objects manage interactions with
persistent stores: database, FITS files, Boost archives.

15 LSST All-Hands MeetingNational Center for Supercomputing Applications (NCSA)
May 19 - 23, 2008
Plans for DC3: Data Access
• Add/modify Formatters– Objects for data release processing– ISR inputs– SDQA outputs
• Build image archive– Raw and science images– Template images– Cached image products
• Improve retrieval of split pixels/metadata• Keep as lightweight as possible
– Remove CORAL– Investigate runtime loading of Formatters

NOAO Brown Bag
May 13, 2008 Tucson, AZ
16
Additional Environment Elements
• Version Control• Build System• Coding and Review Standards• Defect Tracking• Automated unit and integration testing• Requirements/Design Traceability
• http://dev.lsstcorp.org/trac

NOAO Brown Bag
May 13, 2008 Tucson, AZ
17
Data
Challenge
Goals
#1
Jan 2006 -
Oct 2006
• Validate infrastructure and middleware scalability to 5% of LSST required rates
#2
Jan 2007 -
Jan 2008
• Validate nightly pipeline algorithms
• Create Application Framework and Middleware, validate by creating functioning
pipelines with them
• Validate infrastructure and middleware scalability to 10% of LSST required rates
#3
Mar 2008 -
Jun 2009
• Validate deep detection, calibration, SDQA pipelines
• Expand Middleware for Control & Management, Inter-slice Communications
• Validate infrastructure and middleware reliability
• Validate infrastructure and middleware scalability to 15% of LSST required rates
#4
Jul 2009 -
Jun 2010
• Validate open interfaces and data access
• Validate infrastructure and middleware scalability to 20% of LSST required rates
Validating the design - Data Challenges

NOAO Brown Bag
May 13, 2008 Tucson, AZ
18
Data Challenge Work Products
#1
Jan 2006 -
Oct 2006
• 3 Teragrid nodes used to simulate data transfer: Mountain (Purdue), Base (SDSC),
Archive Center (NCSA) using Storage Resource Broker (SRB)
• IA64 itanium 2 clusters at SDSC, NCSA, 32-bit Xeon cluster at Purdue
• MPI-based Pipeline Harness developed in C and python
• Simulated nightly processing application pipelines developed (CPU, i/o, RAM loads)
• Initial database schema designed and MySQL database configured
• Data ingest service developed
• Initial development environment configured, used throughout
#2
Jan 2007 -
Jan 2008
• 10-node, 60-core dedicated cluster acquired and configured at NCSA• Application Framework and Middleware developed and tested• Image Detection, Association pipelines developed• Moving object pipeline (jointly developed with Pan-STARRS) ported to DM
environment, modularized, and re-architected for nightly mode• Major schema upgrade and implementation in MySQL with CORAL • Acquired 2.5 TB pre-cursor data (CFHTLS-deep, TALCS) for testing• Complete development environment configured, standardized, used throughout
Validating the design -
Data Challenge work products to date
Full reports in LSST document archive

NOAO Brown Bag
May 13, 2008 Tucson, AZ
19
Data Challenge 1 Results
• Data Transfer• 70 megabytes/ second data transfers• >15% of LSST transfer rate
• Pipeline Execution• 192 CCDs (0.1 - 1.0 gigabytes each) runs processed across 16
nodes/32 itanium CPUs with latency and throughput of approximately
141.5 seconds• >42% of LSST per node image processing rate
• Data Ingest• 6.1 megabytes/ second source data ingest• >100% of LSST required ingest rate at the Base Facility

NOAO Brown Bag
May 13, 2008 Tucson, AZ
20
Data Challenge 2 Pipeline Results
• Performance Pipeline Runs• runId nVisits nAmps inputImages outputImages outputFrac • rlp0127 53 36 1908 1875 0.983 • rlp0128 62 36 2232 2228 0.998 • rlp0130 62 36 2232 2213 0.991 • Total - 108 6372 6316 0.991
Average time to process one visit* avg. time (s) 3sigma (s) Image Processing/Detection (IPD) 207.2 108.2 Moving Objects (MOPS) 52.9 4.1Association 207.4 108.5 Note: # visits = 177
Average overhead time per visit for each pipeline avg. time (s) 3sigma (s)Image Processing/Detection (IPD) 1.17 1.03Moving Objects (MOPS) 0.27 0.20Association 0.34 0.26Note: # visits = 177
* Note: Post-DC2 algorithm tweaks improved the IPD by factor of 6

NOAO Brown Bag
May 13, 2008 Tucson, AZ
21
Data Challenge 2 Data Access Results
• Read one slice’s 10.3 MB Exposure and 10.3 MB template Exposure from FITS files on NFS file system - 9.0 sec
• Write one slice’s 10.3 MB Exposure to FITS file on NFS file system and metadata to Database - 6.5 s
• Write one slice’s 10.3 MB difference Exposure to FITS file on NFS file system - 6.4 s
• Write one slice’s DIASources to database (average number of DIASources = 36) - 0.05 s
• Read all DIASources from database (average number of DIASources = 1321) - 0.16 s
• Write DIASource matches to database (average number of match pairs = 1082) - 0.03 s
• Write new Object identifier pairs to database (average number of pairs = 537) - 0.02 s





























