Embed Size (px)
Citation preview

Parallel Programming with MPI
Prof. Sivarama Dandamudi
School of Computer Science
Carleton University

Carleton University © S. Dandamudi 2
Introduction Problem
Lack of a standard for message–passing routines Big issue: Portability problems
MPI defines a core set of library routines (API) for message passing (more than 125 functions in total!!) Several commercial and public domain implementations
Cray, IBM, Intel MPI-CH from Argonne National Laboratory LAM from Ohio Supercomputer Center/Indiana University

Carleton University © S. Dandamudi 3
Introduction (cont’d)
Some Additional Goals [Snir et al. 1996]
Allows efficient communicationAvoids memory-to-memory copyingAllows computation and communication overlap
Non-blocking communication
Allows implementation in a heterogeneous environment
Provides reliable communication interfaceUsers don’t have to worry about communication failures

Carleton University © S. Dandamudi 4
MPI MPI is large but not complex
125 functionsBut….
Need only 6 functions to write a simple MPI program MPI_Init MPI_Finalize MPI_Comm_size MPI_Comm_rank MPI_Send Mpi_Recv

Carleton University © S. Dandamudi 5
MPI (cont’d)
Before any other function is called, we must initialize
MPI_Init(&argc, &argc) To indicate end of MPI calls
MPI_Finalize()Cleans up the MPI stateShould be the last MPI function call

Carleton University © S. Dandamudi 6
MPI (cont’d)
A typical program structureint main(int argc, char **argv) { MPI_Init(&argc, &argv); . . . /* main program */ . . . MPI_Finalize();}

Carleton University © S. Dandamudi 7
MPI (cont’d)
MPI uses communicators to group processes that communicate with each other
Predefined communicator: MPI_COMM_WORLD
consists of all processes running when the program begins execution
Sufficient for simple programs

Carleton University © S. Dandamudi 8
MPI (cont’d)
Process rankSimilar to mytid in PVM
MPI_Comm_rank(MPI_Comm comm,
int *rank)First argument: CommunicatorSecond argument: returns process rank

Carleton University © S. Dandamudi 9
MPI (cont’d)
Number of processesMPI_Comm_size(MPI_Comm comm, int *size)
First argument: CommunicatorSecond argument: returns number of processesExample:
MPI_Comm_size(MPI_COMM_WORLD, &nprocs)
Carleton University © S. Dandamudi 10
MPI (cont’d)
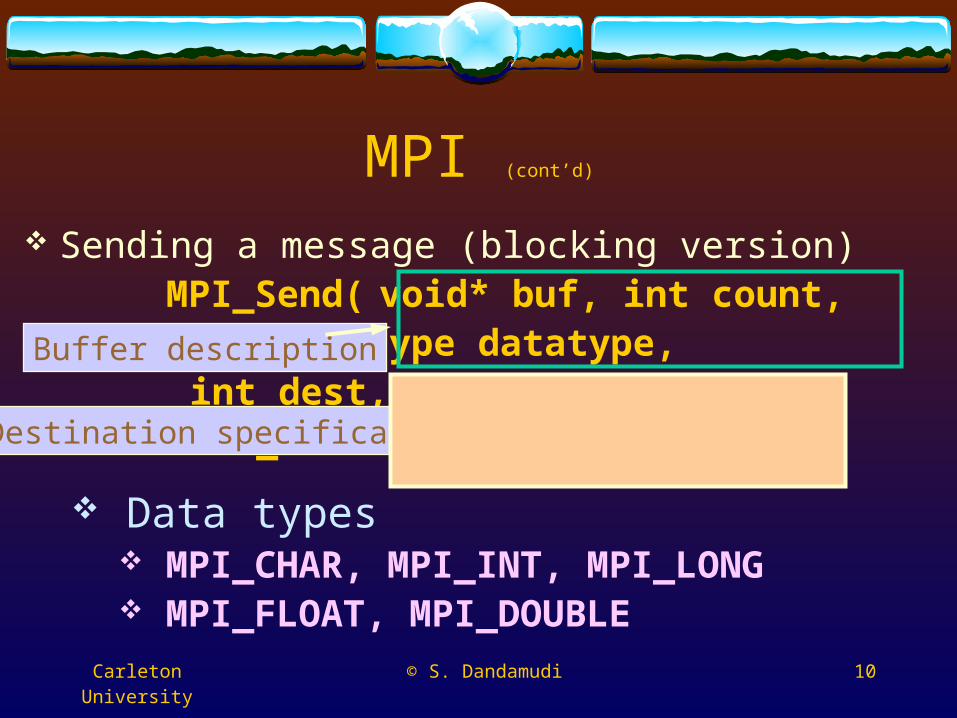
Sending a message (blocking version)MPI_Send( void* buf, int count,
MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm )
Data types
MPI_CHAR, MPI_INT, MPI_LONG MPI_FLOAT, MPI_DOUBLE
Buffer description
Destination specification
Carleton University © S. Dandamudi 11
MPI (cont’d)
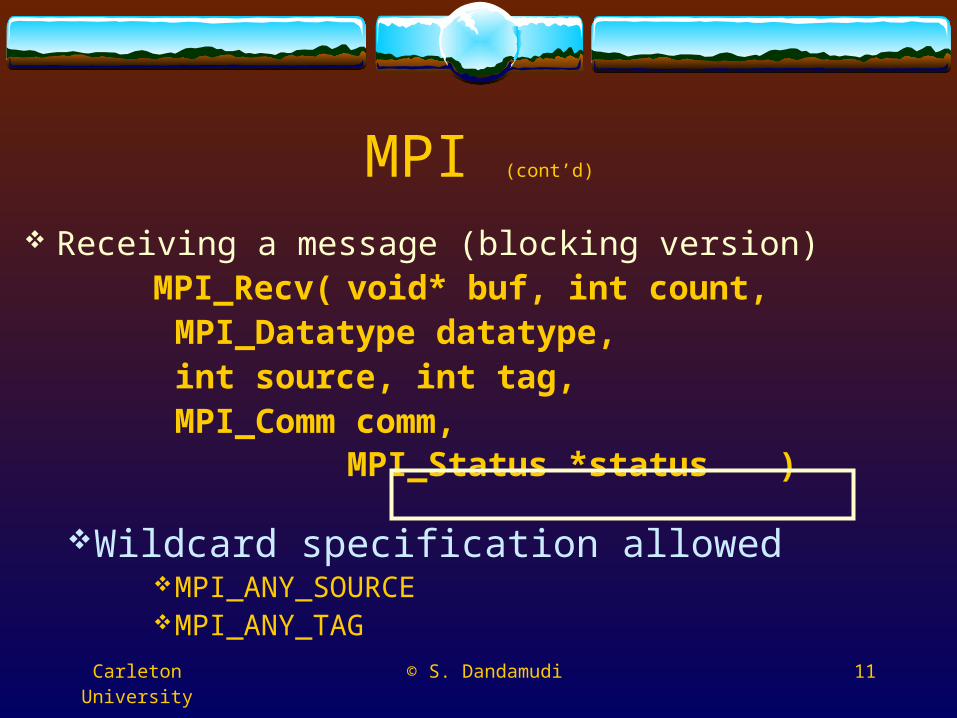
Receiving a message (blocking version)MPI_Recv( void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm,
MPI_Status *status )
Wildcard specification allowedMPI_ANY_SOURCEMPI_ANY_TAG

Carleton University © S. Dandamudi 12
MPI (cont’d)
Receiving a messageStatus of the received message
Status gives two pieces of information directly Useful when wildcards are used
status.MPI_SOURCE Gives identity of the source
status.MPI_TAG Gives the tag information
Carleton University © S. Dandamudi 13
MPI (cont’d)
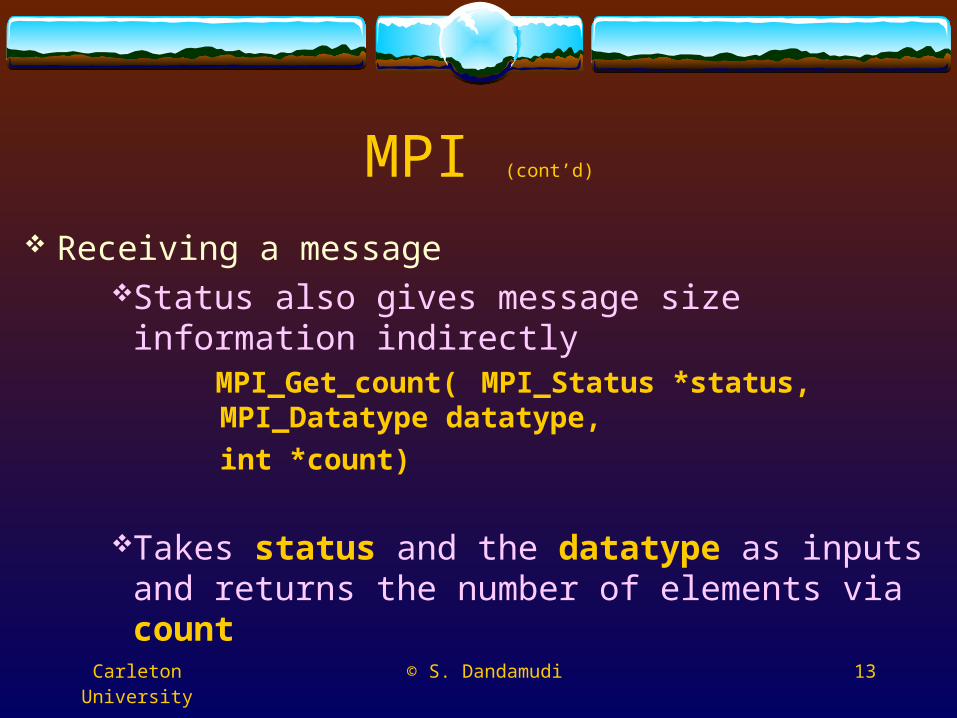
Receiving a messageStatus also gives message size information indirectly
MPI_Get_count( MPI_Status *status,
MPI_Datatype datatype,
int *count)
Takes status and the datatype as inputs and returns the number of elements via count

Carleton University © S. Dandamudi 14
MPI (cont’d)
Non-blocking communicationPrefix send and recv by “I” (for immediate)
MPI_IsendMPI_Irecv
Need completion operations to see if the operation is completed
MPI_WaitMPI_Test
Carleton University © S. Dandamudi 15
MPI (cont’d)
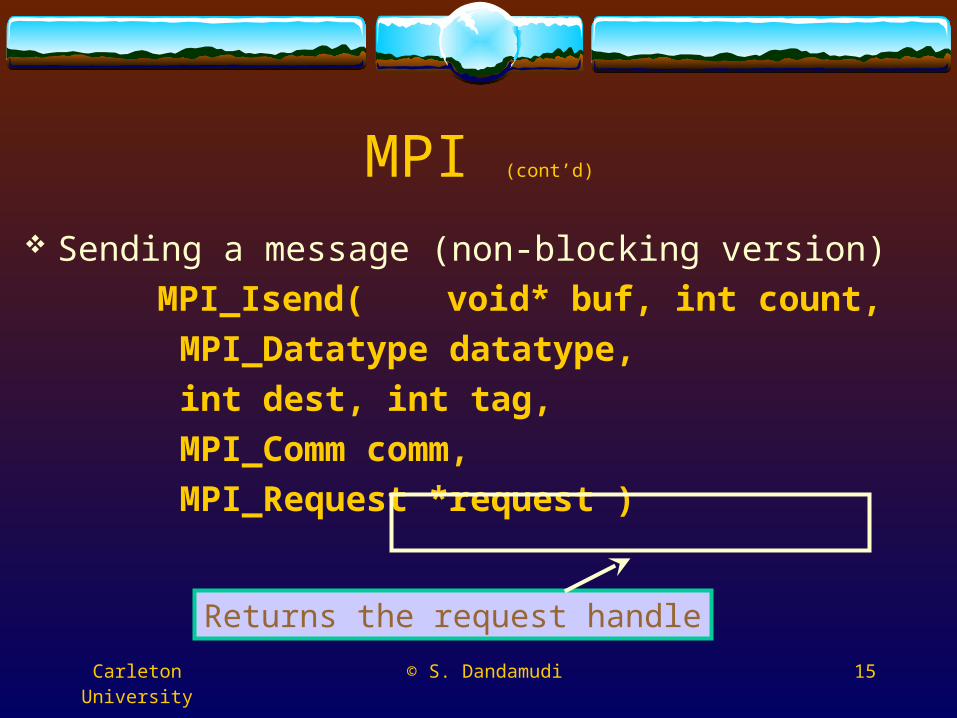
Sending a message (non-blocking version)
MPI_Isend( void* buf, int count,
MPI_Datatype datatype,
int dest, int tag,
MPI_Comm comm,
MPI_Request *request )
Returns the request handle

Carleton University © S. Dandamudi 16
MPI (cont’d)
Receiving a message (non-blocking version)
MPI_Irecv( void* buf, int count,
MPI_Datatype datatype,
int source, int tag,
MPI_Comm comm,
MPI_Request *request )
Same arguments as Isend

Carleton University © S. Dandamudi 17
MPI (cont’d)
How do we know when a non-blocking operation is done?
Use MPI_Test or MPI_Wait
Completion of a send indicates:Sender can access the send buffer
Completion of a receive indicatesReceive buffer contains the message
Carleton University © S. Dandamudi 18
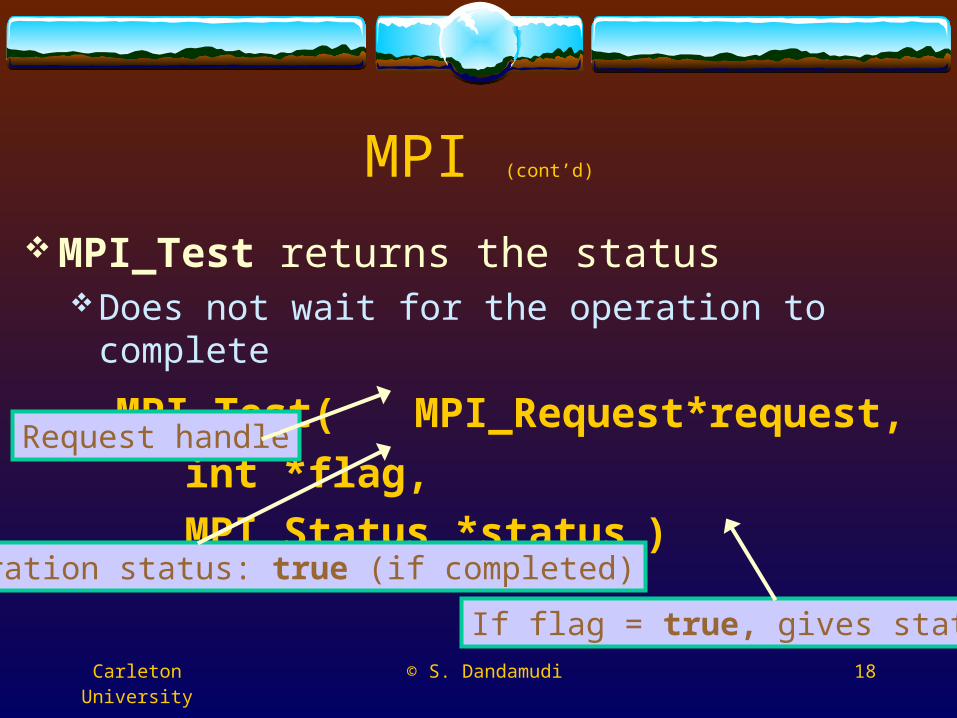
MPI (cont’d)
MPI_Test returns the statusDoes not wait for the operation to complete
MPI_Test( MPI_Request*request, int *flag,
MPI_Status *status )
Request handle
Operation status: true (if completed)
If flag = true, gives status
Carleton University © S. Dandamudi 19
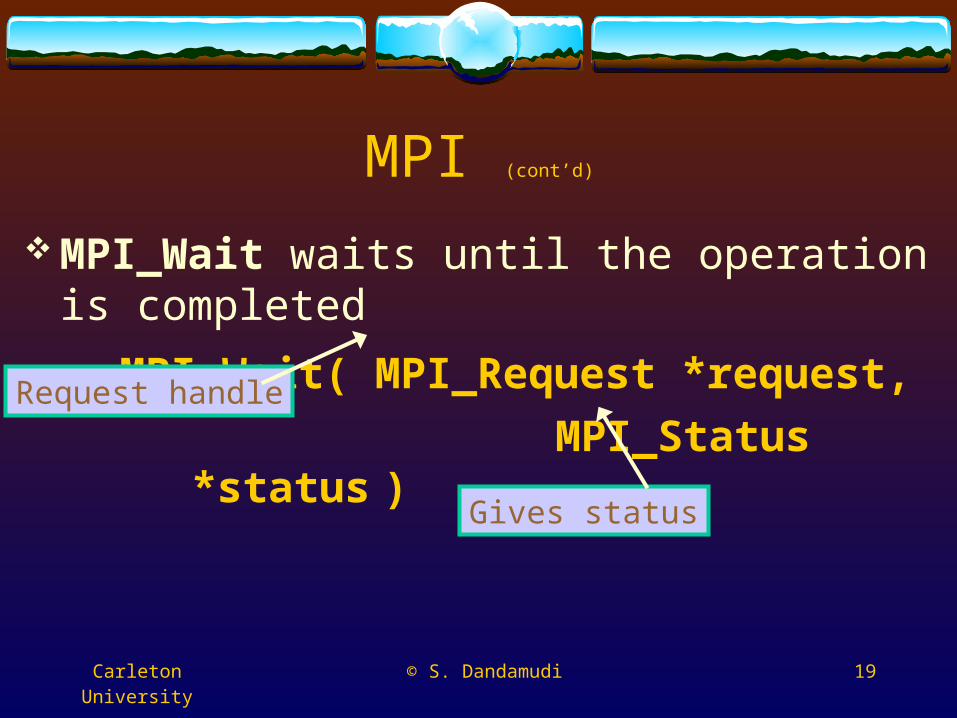
MPI (cont’d)
MPI_Wait waits until the operation is completed
MPI_Wait( MPI_Request *request, MPI_Status
*status )
Request handle
Gives status

Carleton University © S. Dandamudi 20
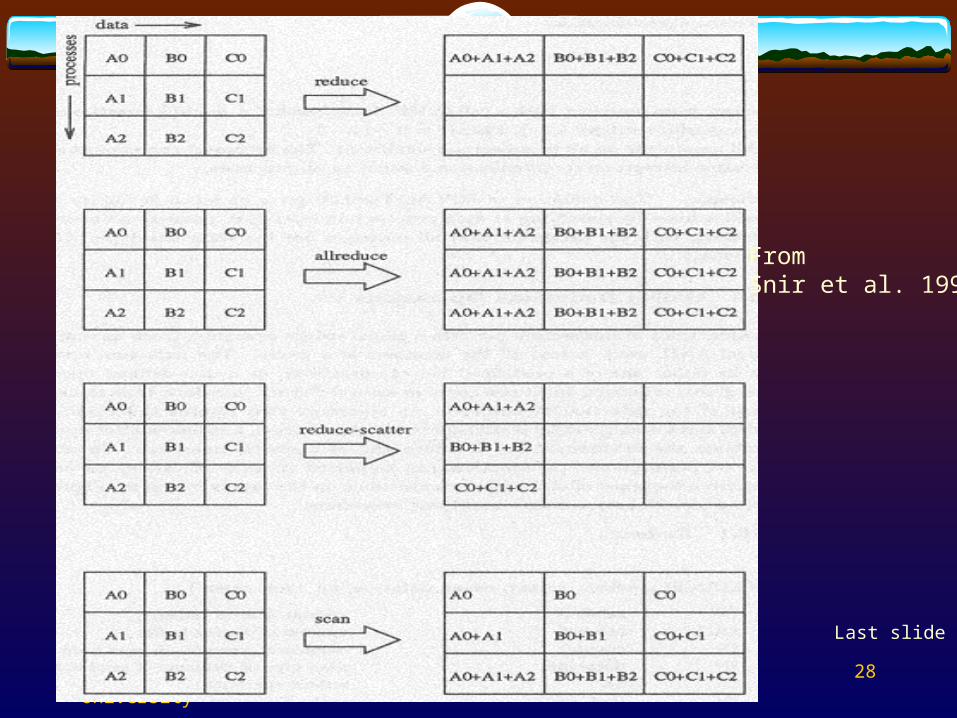
MPI Collective Communication Collective communication
Several functions are provided to support collective communication
Some examples are given here:MPI_BarrierMPI_BcastMPI_ScatterMPI_GatherMPI_Reduce
Broadcast
Barrier synchronization
Global reduction

Carleton University © S. Dandamudi 21
From Snir et al. 1996

Carleton University © S. Dandamudi 22
MPI Collective Communication (cont’d)
MPI_Barrier blocks the caller until all group members have called it
MPI_Barrier( MPI_Comm comm ) The call returns at any process only after all group
members have entered the call

Carleton University © S. Dandamudi 23
MPI Collective Communication (cont’d)
MPI_Bcast broadcasts a message from root to all processes of the group
MPI_Bcast( void* buf, int count,
MPI_Datatype datatype,
int root,
MPI_Comm comm )

Carleton University © S. Dandamudi 24
MPI Collective Communication (cont’d)
MPI_Scatter distributes data from the root process to all the others in the group
MPI_Scatter(void* send_buf, int send_count, MPI_Datatype send_type,
void* recv_buf, int
recv_count, MPI_Datatype recv_type,
int root, MPI_Comm comm )

Carleton University © S. Dandamudi 25
MPI Collective Communication (cont’d)
MPI_Gather inverse of the scatter operation (gathers data and stores it in rank order)
MPI_Scatter(void* send_buf, int send_count, MPI_Datatype send_type,
void* recv_buf, int
recv_count, MPI_Datatype recv_type,
int root, MPI_Comm comm )

Carleton University © S. Dandamudi 26
MPI Collective Communication (cont’d)
MPI_Reduce performs global reduction operations such as sum, max, min, AND, etc.
MPI_Reduce(void* send_buf,
void* recv_buf, int count, MPI_Datatype datatype,
MPI_Op operation,
int root, MPI_Comm comm )

Carleton University © S. Dandamudi 27
MPI Collective Communication (cont’d)
Predefined reduce operations includeMPI_MAX maximumMPI_MIN minimumMPI_SUM sum MPI_PROD productMPI_LAND logical ANDMPI_BAND bitwise ANDMPI_LOR logical ORMPI_BOR bitwise ORMPI_LXOR logical XORMPI_BXOR bitwise XOR
Carleton University © S. Dandamudi 28
FromSnir et al. 1996
Last slide





























