Embed Size (px)
Citation preview

570 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
Parameterized Schemes of Metaheuristics: BasicIdeas and Applications With Genetic Algorithms,
Scatter Search, and GRASPFrancisco Almeida, Domingo Giménez, Jose Juan López-Espín, and Melquíades Pérez-Pérez
Abstract—Some optimization problems can be tackled only withmetaheuristic methods, and to obtain a satisfactory metaheuristic,it is necessary to develop and experiment with various methodsand to tune them for each particular problem. The use of aunified scheme for metaheuristics facilitates the development ofmetaheuristics by reutilizing the basic functions. In our proposal,the unified scheme is improved by adding transitional parameters.Those parameters are included in each of the functions, in such away that different values of the parameters provide different meta-heuristics or combinations of metaheuristics. Thus, the unifiedparameterized scheme eases the development of metaheuristicsand their application. In this paper, we expose the basic ideasof the parameterization of metaheuristics. This methodology istested with the application of local and global search methods(greedy randomized adaptive search procedure [GRASP], geneticalgorithms, and scatter search), and their combinations, to threescientific problems: obtaining satisfactory simultaneous equationmodels from a set of values of the variables, a task-to-processor as-signment problem with independent tasks and memory constrains,and the p-hub median location–allocation problem.
Index Terms—Genetic algorithms (GAs), greedy randomizedadaptive search procedure (GRASP), parameterized metaheuris-tics, scatter search (SS), unified metaheuristics.
I. INTRODUCTION
IN RECENT decades, metaheuristics have proven their effec-tiveness as generic problem-solving methods by being suc-
cessfully applied to many optimization problems. Since theirappearance in the 1970s, a large number of studies have beenpublished where individual metaheuristics (or hybrid methods[1], [2]) show the advantages of one approach over others.Although they are generic methods, it is, however, true thatthe efficacy of many of these methods lies in the fact thatthey have been tuned and tailored to the specific problem tobe solved [3], [4]. The effectiveness of the metaheuristics is
Manuscript received January 5, 2012; revised May 15, 2012; acceptedJune 5, 2012. Date of publication February 1, 2013; date of current versionApril 12, 2013. This work was supported in part by Fundación Séneca, Comu-nidad Autónoma de la Región de Murcia, 08763/PI/08, and in part by Ministeriode Educación of Spain, TIN2012-38341-C04-03 and TIN2011-24598. Thispaper was recommended by Associate Editor J. Wu.
F. Almeida is with the Departamento de Estadística, Investigación Operativay Computación, University of La Laguna, 38271 La Laguna, Spain (e-mail:[email protected]).
D. Giménez is with the Departamento de Informática y Sistemas, Universityof Murcia, 30100 Murcia, Spain (e-mail: [email protected]).
J. J. López-Espín is with the Centro de Investigación Operativa, UniversidadMiguel Hernández, 03202 Elche, Spain (e-mail: [email protected]).
M. Pérez-Pérez is with the University of Las Palmas de Gran Canaria, 35001Las Palmas, Spain (e-mail: [email protected]).
Digital Object Identifier 10.1109/TSMCA.2012.2217322
often compromised when the methods are used in a differentproblem domain than the one for which they where originallydesigned.
From this standpoint, some well-known drawbacks of meta-heuristics are [5] as follows:
1) they can be too problem specific or too knowledgeintensive to be implemented in cheap and easy-to-usecomputational systems;
2) we can find metaheuristics that are very easy to imple-ment but have low performances without fine tuning;
3) we can find knowledge-intensive metaheuristics withgood performances but which can be difficult to imple-ment and maintain;
4) many metaheuristics are problem tailored;5) many metaheuristics perform well with some optimiza-
tion problems but not with others.
We would like to take advantage of the favorable features ofthe metaheuristics while trying to avoid most of the aforemen-tioned drawbacks, and we pursue the idea of increasing the levelof genericity at which metaheuristics operate without loss ofperformance while keeping them easy enough to be applicablefor a wide domain of problems rather than for a specific classof problems.
In connection with these ideas, we find the concept of hy-perheuristic associated to the intelligent selection of the properheuristic or algorithm for a given situation. Frequently, a hyper-heuristic is conceived as a metaheuristic that operates over someother metaheuristics. The underlying idea is that the strengthof a method is found in its capacity to take good decisions inthe path to finding a good metaheuristic. Hyperheuristics allowrapid portability to other application domains. The move to anew domain implies the implementation of low-level heuristics.If these low-level heuristics keep standard interfaces, it is notnecessary to modify the hyperheuristic [5]. Therefore, ourproposal can be used for hyperheuristics development, whichcan work by selecting appropriate values of the parameters inthe parameterized metaheuristic scheme.
We also find frameworks or libraries that allow differentmethods to be combined. They manage an abstraction levelthat, in some cases, could work independently of the problemto be solved. The general strategies used for implementationand specific operators must be provided for the particularinstantiations [6], [7].
The parameterization of algorithms is used in different fieldsand with different goals. The parameters can be selected to
2168-2216/$31.00 © 2013 IEEE

ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 571
reduce the execution time [8]–[10] or to select a satisfactorymetaheuristic or hybridization [11]–[13]. In some cases, theparameters are considered as tuning configuration parametersin automated processes [14], [15].
We propose the generalization of the parameterization ap-proach through a unified parameterized scheme so that we canwork at a very high generic abstraction level. Therefore, specificoperators are provided when needed, and the scheme is tunedor tailored to different problem domains when required. Thelow-level operators can be shared, and implementations can bereused among the different methods. This general algorithmicscheme is absolutely open, and the search for a good method isguided through the proper selection of the values for the param-eters. The method allows us to produce pure metaheuristics, likegenetic or scatter search (SS) methods, or even hybrid methodscombining several of them merely by introducing differentvalues of the parameters during the invocation. One certainlyinteresting feature of our approach is the ability to produce newalgorithms that are not exactly pure or hybrid metaheuristics.As an important contribution in our proposal, we introducea novelty parameterization that allows the generation of newmetaheuristics that could be considered as something betweenseveral pure methods, i.e., a metaheuristic that could be, forexample, like a genetic algorithm (GA) or SS (or any other)but different. This feature admits the eventual generation of aset of methods (including the classical metaheuristics) that canbe used in many different scenarios. We find that this unifiedparameterized scheme achieves a good balance between easeof use, performance, and portability to new problem domains.Therefore, another contribution in our proposal is the fact thatour unified parameterization constitutes, in itself, a method-ology for rapid development and fast prototyping that can beused in a wide range of optimization problems. Moreover, thismethod may constitute the basis for high-level metaheuristicframeworks.
The unified parameterized scheme is applied in this paper, asproof of concept, to problems in different domains: obtainingsatisfactory simultaneous equation models (SEMs) from a setof values of the variables, a task-to-processor assignment (TAP)problem with independent tasks and memory constraints, andthe p-hub median location–allocation problem (HMLA).
This paper is organized as follows. In Section II, a uni-fied metaheuristic scheme is presented, and the parameterizedscheme obtained from it is discussed. Section III presents thethree applications used as proof of concept and analyzes theadaptation of the unified parameterized scheme to the problems.In Section IV, the results of some experiments are summarized,and the application of the metaheuristics to the problems isstatistically analyzed. Finally, in Section V, the conclusions aresummarized, and some research lines are outlined.
II. UNIFIED SCHEMES OF METAHEURISTICS
The idea of representing different metaheuristics under acommon scheme is not new. The work developed by Raidl [16]and Vaessens et al. [17] already uses this approach and presentsalgorithmic schemes such as that shown in Algorithm 1.
Algorithm 1. General scheme for metaheuristicsInitialize(S)while (notEndCondition(S)) {
SS = Select(S)SS1 = Combine(SS)SS2 = Improve(SS1)S = Include(SS2)
}
The interest of this approach is twofold. The abstraction levelinvolved allows us to analyze and visualize the metaheuristicsfrom a generic perspective because the same scheme representsseveral metaheuristics (heuristics like SS or simulated anneal-ing, to name just two, are well suited for the scheme), andsecond, the general scheme can be viewed as a mechanism forreusing elements among the different techniques. Although thescheme is generally considered from the perspective of severaltechniques under a unified model, in this work, we focus onthe context of reusability and transformation among differentmethods.
The scheme considers a set of basic functions(Initialize, EndCondition, Select, Combine,Improve, and Include) whose instantiation determines theparticular metaheuristic that is being implemented. Comparingthe unified scheme with those of the GAs (Algorithm 2),SS (Algorithm 3), and greedy randomized adaptive searchprocedure (GRASP) (Algorithm 4), the correspondence of thefunctions in the basic metaheuristics with those in the unifiedscheme is established.
1) Initialize: In a GA, a population is randomly gen-erated. In SS, a set of elements is generated, and theelements are improved. Moreover, in GRASP, a set offeasible elements is generated, and the elements are im-proved with a greedy method.
2) EndCondition: This function can have the same formin the three metaheuristics; a maximum number of it-erations and a maximum number of iterations withoutimproving the best solution are established.
3) Select: In GAs, pairs of elements are selected to gen-erate descendants. In SS, groups of elements are selectedfor combination. Moreover, a GRASP can work by select-ing one element to be improved with a greedy method.
4) Combine: The combination is done by crossover in GAs.A different method can be used in SS, for example,combining more than two elements, and no combinationis in GRASP.
5) Improve: The mutation in a GA can be considered aspart of the improvement. In SS, each generated elementis improved, and in GRASP, the selected element isimproved with a greedy method.
6) Include: In GAs, the best elements from those gener-ated substitute the worst elements in the population, whilein SS, the best elements are included in the reference settogether with those most scattered with respect to the bestones. There is no inclusion in this GRASP scheme.

572 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
Algorithm 2. Scheme of GAsGeneratePopulation(S)while (notEndCondition(S)) {
SS = SelectParents(S)SS1 = Crossover(SS)SS2 = Mutation(SS1)S = SelectBestElements(SS2)
}
Algorithm 3. Scheme of SSGenerateSet(S)ImproveElements(S)while (notEndCondition(S)) {
SS = SelectElements(S)SS1 = CombineElements(SS)SS2 = Improve(SS1)S = SelectBestElements(SS2) +SelectMostScatteredElements(SS2)
}
Algorithm 4. Scheme of GRASPGenerateFeasibleElements(S)ApplyGreedyMethod(S)while (notEndCondition(S)) {
S = SelectElement(S)S = ApplyGreedyMethod(S)
}
At the same time, the same functions can be used in onemethod or another. Moreover, several implementations of thesame basic function, for example, Combine, could be usedin different GAs (since they use different Combine operators,selecting the best method) while maintaining the capacity touse the different Combine functions in a GA and in an SS.Therefore, with the same pattern, one metaheuristic or anothercan be instantiated as required. Note that this scheme is alsovalid as a generic mechanism in metaheuristic hybridizationwhen, for example, the basic functions are composed of othermetaheuristics or the same element of a different metaheuristic.
The arguments S, SS, SS1, and SS2 appearing in the basicfunctions in Algorithm 1 correspond to the sets of solutions thatthe method generates and manipulates in successive iterations.The sizes of these sets vary with the metaheuristic. While|S|, the size of the population, usually takes the value of 100or higher in a GA, in an SS, the number of elements in thereference set, S, is usually well below this. However, the sizesof the sets SS, SS1, and SS2 are generally higher in the SS thanthose found in a GA. In a simulated annealing or in a GRASPalgorithm, the size of the sets is equal to 1. When using basicfunctions, sets and their sizes must be known in advance.
To adapt a metaheuristic to a particular problem, it is sim-ply necessary to implement (or choose from the implementedfunctions) the set of basic functions compatible with the meta-heuristic and, if necessary, perform the tuning to the problem inquestion. Obviously, the various combinations would providedifferent results, and eventually, one may want to find the bestoption for the problem. Under the typical development cycle,given the metaheuristic scheme and a problem to be solvedby metaheuristic methods, the functions in the scheme areinstantiated to some functions appropriate for the problem, andsome values of the parameters in the scheme are also selected.Experiments are carried out for the different combinations offunctions and values of the parameters, for some instances ofthe problem, and a satisfactory metaheuristic for the problemis selected and tuned by selecting satisfactory instances ofthe functions and values of the parameters, possibly by astatistical analysis. Examples of statistical analyses are shownin the experiment section with the three problems used asproof of concept. This approach includes the typical tuningof metaheuristics but incorporates the possibility of basic orhybrid metaheuristics selection by choosing the values of thetransitional parameters.
A. Unified Parameterized Scheme
A first observation to be made is that the basic functionspresented in Algorithm 1 could receive additional parameters,as shown in Algorithm 5.
Algorithm 5. General unified parameterized schemeInitialize(S, ParamIni)while (notEndCondition(S, ParamEnd)) {
SS = Select(S, ParamSel)SS1 = Combine(SS, ParamCom)SS2 = Improve(SS1, ParamImp)S = Include(SS2, ParamInc)
}
Moreover, when adapting a metaheuristic, we could chooseto include parameters in the metaheuristic that are varied togenerate combinations providing satisfactory solutions. Someof these parameters are common (but not their values) to severalmetaheuristics, for example, the number of elements in theinitial set, the number of iterations without improving the bestsolution, the number of elements selected to be improved, etc.However, although many of these are common parameters,the instantiation of the method with one value or anothermay transform the general scheme from one metaheuristic toanother. For instance, if the number of elements selected toimprove is 1, we could be dealing with the mutation operatorin a genetic algorithm, while if this number is equal to thenumber of elements in the set of solutions, we could be closerto an SS. A notable aspect is that, if the number of elementsto be improved has a value between 1 and the total number ofsolutions, the instantiated metaheuristic would not be exactlya GA, nor would it be a pure SS, nor a hybrid algorithm inthe classical sense. In this case, we have an algorithm that is

ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 573
Fig. 1. Use of transitional parameters to combine metaheuristics.
on the path linking the two methods. Accordingly, the param-eterization would go beyond a simple hybridization (throughcombination or composition) since it allows the generation offamilies of metaheuristics that are found between two or severalof them. We will use transitional parameters to refer to thoseparameters that allow a continuous transition from one meta-heuristic to another in the general scheme. Fig. 1 illustrates theeffect of the transitional parameters. The figure shows differentcombinations for the case in which there are two transitionalparameters, but when the number of parameters is n, the spaceof possible combinations is of dimension n, and the distancein this n-space of two n-tuples representing two metaheuristicscan be considered as the distance between the metaheuristics.In the figure, two metaheuristics MH1 and MH2, each with twoparameters with values P11 and P12 for MH1 and P21 and P22
for MH2, are combined in different ways (four combinations inthe figure) by obtaining the values of the two parameters aslinear combinations αP11 + βP12 and γP21 + δP22 of thevalues on the two metaheuristics. When α = γ, β = δ, α+β = 1, 0 < α < 1, and 0 < β < 1, the combinations are in thepath connecting MH1 and MH2 (MHCom1 and MHCom2), and othercombinations generate metaheuristics in the neighborhood ofthe basic metaheuristics (MHCom3 and MHCom4).
In what follows, we will try to characterize and classify theparameters usually involved in a metaheuristic to get a betterdefinition of the transitional parameters. The parameters areparticular for the basic metaheuristics under consideration andthe implementation of the functions in these metaheuristics, butthe proposed methodology is general and can be applied forother metaheuristics and implementations.
In general, when a metaheuristic is instantiated, severalgroups of parameters can be involved. First, we can find, as inany other algorithm, those parameters that adapt the algorithmto several inputs or outputs. These parameters will be referredto as input/output parameters, and they are used to gatherproblem-specific arguments such as the size of the problem,the data set to solve a particular instance, or the solution givenby the algorithm. On the other hand, the method may havebeen designed to be generic enough to tackle different classes
of problems. For example, a GA can be formulated so thatthe method is adapted to one problem or another in termsof the configuration parameters. This happens, for example,with the skeletons or programming patterns, where the methodis configurated according to specification parameters for theproblem, encoding solutions and parameters that the operatorin question gathers [6]. Therefore, the use of binary solutionsthat are combined in a certain manner determines that we aredealing with a problem of maximization instead of minimiza-tion. In this case, the objective function to evaluate the solutionsis required from the end user.
With the generation of a parameterized scheme which in-cludes GAs, SS, and GRASP and its application to the problemsused as proof of concept, we illustrate how to identify a set ofparameters and elements common to different metaheuristicsthat can transform one method into another depending onthe values of the parameters (transitional parameters). Theseparameters are essentially different from the aforementionedinput/output and configuration parameters. The final goalwould be to build the unified metaheuristic parameterizedmethod shown in Algorithm 5. In addition to the reusabilityshown in Algorithm 1, the method has as added value notonly the transformation of metaheuristics but also the capac-ity to consider new alternative methods to the well-knownmetaheuristics, so opening up the possibility of assaying withfamilies of metaheuristics when considering the whole traverseof the values for the parameters. We enumerate some of theadvantages of the approach.
1) The selection of one metaheuristic or another accordingto the values of the parameters.
2) Obtaining multiple hybridization through the selectionof parameters that provide elements from different tech-niques in different sections of the scheme.
3) Obtaining mixed techniques (not exactly by hybridiza-tion) by including in a metaheuristic concepts belongingto another metaheuristic. Moreover, if any of the pa-rameters have a gradation with ends that correspond todifferent metaheuristics, we will have a family of mixedtechniques between these two metaheuristics.
4) Starting from a set of fixed parameters, a search methodcan be found that provides the best combination for theproblem to be solved. A tuning process on the parametersresults, which is focused on the search for the best meta-heuristic, or the best hybrid or mixed algorithm, and alsothe best values for their parameters.
5) The possibility of a statistical study of the influence of theparameters in the value of the fitness function, which canguide the search of the best parameter combination.
Note that, although the strategy might present some similar-ity to the concept of hyperheuristic, it is an entirely differentapproach where we have only one metaheuristic scheme thatcan be instantiated in several directions. A hyperheuristic canbe developed based on the metaheuristic scheme. The best com-bination of the transitional parameters for the problem that weare working with can be searched for with some metaheuristicand with intensification in the parameters that the statisticalstudy determines as the most influential.

574 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
B. Identification of Parameters
Next, we analyze each function of the basic scheme, theirvariants and the common parameters for the metaheuristicsconsidered (GAs, SS, and GRASP), and the possibility ofreusing basic functions. The intention is not to provide a preciseand comprehensive list of all the feasible parameters for allthe possible metaheuristics but to show the methodology inthe most general manner so that it can be illustrated withspecific use cases and the set of parameters may be extendedor modified if necessary. Some of the parameters considered aretypical parameters for basic metaheuristics, but they can also betreated as transitional parameters because different values givedifferent basic metaheuristics in our parameterized scheme.
1) Initialize: This function generates the feasible so-lutions to build the initial set of solutions. This can bea random generation, or it can be developed accord-ing to different criteria. The number of elements in theinitial set of solutions (INEIni) is a parameter thatcan be varied to adapt the algorithm to the problem.Generally, INEIni has a high value in GAs, but in SSand GRASP, it is usually lower. Occasionally, it is alsohigh in these methods for the subsequent selection ofa smaller set (in SS) or for the selection of elementsto develop improvements (GRASP). We then introducea second parameter, FNEIni, as the final number ofelements, |S| in Algorithm 1. Some methods incorporatean improvement of the elements of the initial set S,for example, in SS, GRASP, or greedy algorithms. Theparameter PEIIni holds the percentage of elements toimprove in the initial set. If PEIIni = 0, it means thatwe are dealing with a pure GA, and if PEIIni = 100,the algorithm involved could be an SS or a GRASP. Notethat this is a case where we may have a gradation of valuesbetween 0 and 100, leading to many alternative algo-rithms which are very different to the classical ones. Theimprovement may be more or less intensive, a breadthneighborhood can be considered, or a greedy depth-intensive strategy can be applied. This is reflected by thevariable IIEIni, the intensification of the improvementfor the elements in the initial set. IIEIni assumes highvalues in a GRASP for example, and lower values inan SS. We consider the tuple ParamIni ≡ (INEIni,FNEIni, PEIIni, IIEIni) as the parameters for theInitialize basic function. The values for these pa-rameters give the features for the different metaheuristics,and the reference values for the three basic metaheuris-tics considered could be the following: ParamIniGA ≡(100, 100, 0, 0), ParamIniSS ≡ (100, 20, 100, 10) andParamIniGRASP ≡ (100, 10, 100, 10). In some prob-lems, the initialization may support parameterizationsto create the initial set. For example, sometimes, it isappropriate to include in the initial set some solutionsknown in advance, making the number of these solutionsa new candidate to be a parameter. However, we considerthat this is a parameter that depends on the specific prob-lem and not a transitional parameter whose modificationtransforms one metaheuristic into another.
2) EndCondition: The end condition typically consistsof a maximum number of iterations (MNIEnd) or amaximum number of iterations without improving thebest solution (NIREnd). The condition is usually thesame for different metaheuristics that work iteratively andfor different problems. In our case, we can consider that avalue of zero for any of the parameters would correspond,for example, to a GRASP method if the greedy algorithmsof the initialization step have been developed by set-ting high values for PEIIni and IIEIni. Intermediatevalues for these parameters could correspond to hybridmethods composed of an initial GRASP followed byanother metaheuristic. The end condition can be thencharacterized by the tuple ParamEnd ≡ (MNIEnd,NIREnd), which can have reference values of (100, 10)for GAs and SS and (0, −) for GRASP if all the greedyimprovements are carried out in the initialization.
3) Select: The elements of the solution set can be groupedinto two sets, the best and the worst elements, accordingto the evaluation of the objective function. The number ofbest elements would be NBESel, the number of worstelements would be NWESel, and normally, NBESel+NWESel=FNEIni. In a GA, NBESel=FNEIni,and in an SS, we can have NBESel=NWESel=FNEIni/2. The tuple of parameters for this functionwould be ParamSel≡(NBESel,NWESel), withParamSelGA≡(FNEIni, 0), with ParamSelSS≡(FNEIni/2, FNEIni/2) and no significance in aGRASP without iterations apart from the initial im-provements, or with ParamSelGRASP ≡ (NBESel,FNEIni−NBESel) if additional improvements areconsidered.
4) Combine: Once the two subsets have been selected,it has to be decided how they could be paired (ofcourse, they are not always combined in pairs, but wewill consider only this situation for simplicity). Thenumber of pairs between the best elements (PBBCom),the number of pairs between the best and the worst(PBWCom), and the number of pairs between theworst elements (PWWCom) must be stated. For a GA,typical values would be PBBCom = FNEIni/2 andPBWCom=PWWCom=0, but some other possibili-ties can be considered. In an SS, a combination between thebest and the worst ones would come from PBBCom=PWWCom=0 and PBWCom=FNEIni2/4, and anall-to-all combination from PBBCom=PWWCom =FNEIni/2 ∗ (FNEIni/2− 1) and PBWCom =FNEIni2/4, or other combinations according to thediversity or intensity factors involved in the method. Thecombination admits several procedures, but we considerthat having multiple combination basic functionsdoes not imply that we have different metaheuristics.The tuple of parameters for this function would beParamSel ≡ (PBBCom,PBWCom,PWWCom),with ParamSelGA≡(NBESel/2, 0, 0), ParamSelSS≡(NBESel ∗ (NBESel − 1)/2, NBESel ∗NWESel,NWESel∗(NWESel−1)/2), and ParamSel≡(NBESel/2, 0, 0) in a GRASP with improvement in the iterations.

ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 575
5) Improve: In an SS algorithm, the improvement couldconsist of applying a greedy algorithm or a local searchstarting from the elements generated by combination, andin GAs, the diversification obtained with the mutation andthe posterior improvement of the elements obtained bymutation can be considered as being in the improvement.We could perform intensification from those elementsobtained through generation or from those elementsobtained from the combination, and in both cases, wecould consider a percentage of elements to manageand an intensification parameter, as in the functionInitialize. Moreover, the improving function couldbe the same as that in the initialization procedure.Thus, we have the parameters PEIImp and IIEImpfor the percentage of elements to improve and theintensification of the improvement for elements obtainedin the combination and PEDImp and IIDImp for thepercentage of elements to diversify (mutation in a GA)and the intensification in the improvement of the elementsso obtained. The parameter tuple for the improvefunction is as follows: ParamImp ≡ (PEIImp,PEDImp, IIEImp, IIDImp), and ParamImpGA ≡(0, 5,−, 0), ParamImpSS ≡ (100, 0, 10,−), andParamImpGRASP ≡ (0, 0,−,−). The values inthe middle can be considered, thus obtaining mixedmetaheuristics. For example, a GA with PEDImp about50% and a low value for IIDImp can be consideredclose to an SS since half of the elements will be mutated,giving elements that may be far from the optimalelements. A gradation of the GA with SS is obtainedwith ParamImpGA+SS,α ≡ (100α, 5− 5α, 10α, 0),0 ≤ α ≤ 1.
6) Include: In this function, we consider a single pa-rameter, NBEInc, representing the number of bestelements that are included in the reference set. In aGA, it would be NBEInc = FNEIni, and in an SS,NBEInc = FNEIni/2. In this case, ParamInc ≡(NBEInc), ParamIncGA, and ParamIncGRASP are≡ (FNEIni) and ParamIncSS ≡ (FNEIni/2).
With the aforementioned considerations, we have a set of pa-rameters that allow experiments to hybridize, mix, and adapt themetaheuristics to the target problem. Other parameters couldbe considered, and the inclusion of new pure metaheuristicswould generate additional parameters. What we want is not toenumerate an exhaustive list of possible parameters (a completelist may be quite large) but to show how the methodology worksfor the basic metaheuristics considered here.
To summarize, Table I shows the names and meanings ofthe parameters considered. The unified parameterized schemerepresented by Algorithm 5 constitutes, in itself, a methodologyfor rapid development and fast prototyping of metaheuristicsthat can be used in a wide range of optimization problems.
III. APPLICATION EXAMPLES
To validate our proposal, some experiments have been car-ried out with three problems: obtaining a satisfactory SEM
TABLE IPARAMETERS CONSIDERED FOR THE FUNCTIONS IN ALGORITHM 5
from a set of values of the variables, a TAP problem withindependent tasks and memory constraints, and the HMLAproblem. These problems are from different fields, and theexperiments and analyses give different results, which serveto show how different statistical experiments can be carriedout on the parameters in the unified scheme. The applicationof different metaheuristics to these problems has been done inother papers referenced hereinafter, but the use of the parame-terized scheme and the statistical analysis are new. The detailedexplanation of these problems is not a goal of this paper, so theproblems are only briefly explained in this section, and somerelated works and basic references are included for readersinterested in a deeper understanding.
A. Obtaining SEMs
SEMs are a problem of great interest applied in several areaslike econometrics [18], [19], medicine [20], study of socialbehavior [21], etc. Normally, SEMs are developed by peoplewith a wealth of experience in the particular problem repre-sented by the model, but the use of automatic tools to providethe experts with satisfactory models is interesting in somecases, for example, when the dependence of the variables is notclear or when experiments are being carried out to determinevariables to be included in the model. To automatically obtainsatisfactory models, it is necessary to evaluate a large amountof candidate models and to measure their quality according tosome criteria, for example, the Akaike information criterion(AIC) [22]
AIC = d ln |Σ̂e|+ 2N∑i=1
(ni + ki − 1) +N(N + 1) (1)
which is used as a fitness function in our metaheuristicapproach.
GAs have been applied to this problem [23], [24], and usingthe parameterized scheme presented here, the application ofdifferent metaheuristics to the problem is made easier, so thesolutions previously obtained are improved.

576 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
There are different methods to solve a SEM (maximumlikelihood, indirect least square, two-step least square (2SLS),three-step least square, etc.), and of these, the 2SLS methodwas used in our experiments [25]. This method is more appli-cable than others (it can be applied to all the equations in theSEM), and while its computational cost is high (O(NK2d)),its execution time is lower than that of other methods [26].The method selected for solving the SEM does not determinethe general conclusions on the application of metaheuristicsto the problem, but with different methods, the execution timewould change.
1) Metaheuristics to Obtain SEMs From a Set of Values ofthe Variables: Our problem is, given a set of values of theexogenous and endogenous variables (obtained by experimen-tation, etc.), obtaining the variables that appear in each equationin the system, which means the model which best represents thevariable dependences.
To apply metaheuristic methods to obtain SEMs, a set ofmodels is explored. Each element in the set is a candidate tobe the best model. An element is defined as a matrix. In eachrow, an equation is represented using ones and zeros. If variablej appears in equation i, the value for the (i, j) position is oneand zero if not. The first N columns of an element represent theendogenous variables, and the other K columns represent theexogenous ones. In equation i, the main endogenous variablewill be variable i. Thus, if equation i is in the system, theposition (i, i) must be one.
The functions in Algorithm 5 for the problem of obtainingSEMs are now analyzed.
1) Initialize: Each element in the initial set comprisesN(N +K) randomly generated digits (0/1). Not all thepossible combinations give candidate elements. There-fore, if an element does not satisfy range and orderconditions [18], new elements are generated.
After the set has been generated, some elements areimproved to a certain degree of intensification. The im-provement is made by random local search, where theneighborhood of an element is obtained by randomlyselecting an equation e, and two elements are neighborsif they differ only in one component of equation e (theother equations are equal in both elements). Therefore,each neighborhood is formed by N +K elements. All theelements in the neighborhood are evaluated, which meansthat the SEMs that they represent are solved (using the2SLS method) and the criteria (AIC) are calculated. If thebest element in the neighborhood is better than the initialone, the process continues with the best element until nobetter elements are found. The intensification establishesthe number of times that the previous process is appliedto the final element provided by the local search.
2) Select: Some elements are selected from the best, andsome are selected from the worst. The fitness functionmust be calculated, which means that the SEM associatedto each element is solved and its AIC (fitness value) iscalculated.
3) Combine: The combination is made by crossing pairs ofelements. Different crossing functions can be applied, and
the best from those analyzed in [23] is used. Basically,two elements generate two new elements equal to them-selves, with the only difference in equation e (randomlyselected), where the endogenous variables are crossed byselecting a crossing point (1 ≤ c1 ≤ N), and the samehappens with the endogenous variables (1 ≤ c2 ≤ K).
4) Improve: The improvement is made as in the initializa-tion, but in the elements generated in the combination andalso in the elements generated by mutation. An elementis obtained in the mutation merely by switching the bit inone randomly selected position in the 0–1 matrix.
5) Include: The best elements are selected to be includedin the reference set, and the other selected elements arethe worst, on the basis of some distance. The distancebetween two elements is the number of different digitsthat they have, and for each element, the sum of thedistances to the selected best elements is computed.
B. Task-to-Processor Assignment With Memory Constraints
Metaheuristic methods have been traditionally used inscheduling and planning, particularly in the solution ofTAPs with processors with different computational capacities[27], [28].
The particular problem that we tackle here has been pre-viously broached [29], [30] with different metaheuristics byusing a unified metaheuristic scheme. In this problem, a setof T independent tasks is assigned to a set of P processors.Each task has certain memory requirements, and each processorhas a certain amount of memory, which restricts the processorsto which each task can be assigned. The tasks have arith-metic costs c = (c1, c2, . . . , cT ) and memory requirements r =(r1, r2, . . . , rT ). The costs of the basic arithmetic operationsin the processors are represented by tc = (tc1, tc2, . . . , tcP ),and the memory capacities are m = (m1,m2, . . . ,mP ). Fromall the mappings of tasks to processors, d = (d1, d2, . . . , dT )(1 ≤ di ≤ P represents the processor where task number iis assigned), with ri ≤ mdi
, the problem is to find d thatminimizes the modeled parallel execution time
min{drk
≤mdk,∀k=1,2,...,T
} maxi=1,...,P
⎧⎪⎨⎪⎩tci
T∑j=1dj=i
cj
⎫⎪⎬⎪⎭ . (2)
1) Application of Metaheuristics to TAP: There is a maxi-mum of PT assignments [the memory constraints may reducethe number of possibilities, (2)], and it is not possible to solvethe problem in a reasonable time by generating all the possiblemappings. An alternative is to obtain an approximate solutionusing some metaheuristic method.
The behavior of the functions in the scheme is as follows.1) Initialize: The elements of the initial set are gener-
ated by assigning tasks to processors with a probabilityproportional to the processor speed and taking into ac-count the memory restrictions.
Some of the elements in the initial set are selectedto be improved by local search. The neighborhood con-sists of the mappings obtained by assigning to another

ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 577
processor one of the tasks assigned to the processor withthe highest computational charge. As long as the mappingso obtained has a lower parallel cost than the previousmapping, the process continues with the new mapping.The number of repetitions is limited by the intensificationparameter.
2) Select: The best elements are those with the low-est theoretical parallel execution time associated to themapping that they represent, and the worst elements arethe elements following the best ones, with the elementssorted in increasing order in terms of the theoreticalexecution time.
3) Combine: Elements are combined with one point cross-ing. For a descendant, the processors where the first T/2tasks are assigned are taken from one ascendant, and theother assignments are those of the other ascendant.
4) Improve: The elements in the reference set and the ele-ments obtained by generation and mutation are improvedin the same way as in the initialization. An element ismutated by randomly selecting a task and assigning it to adifferent processor (considering the memory constraints).
5) Include: The best elements from those in the referenceset and from those obtained by combination and mutationare included in the reference set, and the 1-norm is usedto compute the distance to include the worst elements.
C. HMLA Problem
There are many real situations where several nodes mustinteract with each other by sending and receiving traffic flowof some nature. The flow exchanged may represent data,passengers, merchandise, express packages, etc. Generally, insituations like these, it is useful to find an optimal location ofseveral switching points called hubs that help to minimize thecost of the total exchanged flow.
In an HMLA, it is necessary to locate p hubs, which act asswitching points, and to allocate the remaining points to them,so minimizing an objective cost function. In general, the hubsare fully interconnected, and each nonhub point is allocated toone hub. Traffic can then be sent between any pair of points byusing the hubs as intermediate switching points.
The HMLA was first formulated as a quadratic integer pro-gram by O’Kelly [31], who proposed an enumeration-basedheuristic. For any two points i and j, we denote
Wij = number of units of traffic sent from i to j
Cij = standard cost per unit of traffic sent from i to j.
Typically, Wii = 0, Cii = 0, and the standard cost is Cij if i isallocated to hub j. If i and j are both hubs, the cost is αCij ,where α is a parameter. In general, α ≤ 1 to reflect the scaleeffects in interhub flows.
To formalize the solution and formulate the problem, thefollowing set of decision variables is considered:
Xij ={1 if point i is allocated to hub j0 otherwise
Yj ={1 if point j is a hub0 otherwise.
Then, the HMLA problem can be stated as
min f(X) =∑i
∑j
Wij
(∑k
XikCik +∑m
XjmCmj
+a∑k
∑m
XikXjmCkm
)
subject toXij ≤ Yj (3)∑
j
Xij = 1 (4)
∑j
Yj = p
Xij , Yj ∈ {0, 1}. (5)
Constraint (3) ensures that a nonhub point is allocated to alocation unless a hub is located at that site. Constraint (4)ensures that each point is served by one and only one hub.Constraint (5) generates the correct number of hubs.
1) Metaheuristics to Solve the HMLA Problem: TheHMLA is an NP-complete problem. Moreover, even if thehubs are located, the problem of allocating points to hubs is anNP-complete quadratic assignment problem. For these reasons,there is a need for research heuristic solution approaches. Weinclude the elements for the metaheuristics as follows.
1) Initialize: The initial population of solutions isgenerated using a multistart method. The method operatesas follows.a) Generate a random solution, and improve it with a
greedy procedure in the location phase and a greedyprocedure in the allocation phase. The greedy proce-dure in location was used previously in [32], with thename of LS1, and it is based on the resolution of the1-hub problems and 1-exchange moves.
b) If the improved solution does not belong to the popu-lation, it is updated with this new solution.
c) Steps a) and b) are repeated until the number ofelements in the initial population is equal to the pres-elected size.
2) Select: The selection of the elements is divided intotwo groups. The first group is formed by solutions withinthe population with the best objective value, and the sec-ond one consists of the solutions that are most disparatefrom those already selected. The distance function usedis defined as
d(t, s) = ρ · dloc(t, s) + (1− ρ) · das(t, s)
where dloc(t, s) is the number of different hubs in s andt and das(t, s) is the number of nodes with differentassignment in both solutions.
3) Combine: The combination is developed using a pair ofsolutions. The crossover function is determined by eachmetaheuristic, but basically, they select the common hubson each solution and interchange the noncommon hubs.The combination of the allocation array consists of theselection of a random position, and the two tail portionsare swapped.

578 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
4) Improve: As an improvement method, we use a greedyprocedure for location and allocation, solving the 1-hubproblems within the clusters formed by one hub and thenonhub nodes assigned to it.
5) Include: At the end of each iteration, the referenceset is updated with the best solutions (according to theobjective value) and the most distant solutions (accordingto the distance function defined earlier).
IV. EXPERIMENTAL RESULTS
As mentioned, the use of the parameterized scheme allows usto easily develop and experiment with different metaheuristicsand hybridizations/combinations, but it is also possible to carryout a statistical analysis of the preferred metaheuristics forthe problem and of the influence of each parameter in thegoodness of the solution or the execution time. The proposedmethodology is validated by applying it to the three problemsintroduced, and a statistical study is carried out for each ofthem. For each problem, a study is made of the goodness ofthe solution found, and we analyze the best metaheuristics,the parameters which most influence the fitness value, and therange of the values of the parameters with which best fitnessis obtained. Depending on the problem, the implementation ofthe metaheuristics, and the parameters considered to build theparameterized scheme, the statistical analysis to be carried outvaries, and the conclusions could be different. Our goal in thissection is not to obtain general conclusions about how well aparticular metaheuristic works, what the best metaheuristic, orwhat the best values of each of the parameters considered are(as mentioned, this depends on a large number of factors) but toshow how statistical analysis can be conducted for particularproblems, parameterized schemes, and metaheuristics imple-mentations and also the type of conclusions that could be drawnfrom that statistical analysis.
A. Methodology of the Experimentation
For the three problems, the basic metaheuristics consideredare a GRASP method, a GA, and an SS. Other metaheuristicscould be considered, but we want to show the advantage ofthe use of the unified parameterized scheme, not to developa general scheme including all the possible metaheuristics.Apart from these basic methods, combinations of two and threemethods are considered: GRASP+GA, GRASP+SS, GA+SS,and GRASP+GA+SS.
For each metaheuristic and combination, a reference value(RV ) for each of the parameters considered is fixed. Thereference values for the three basic metaheuristics consideredwere commented on in Section II-B. Furthermore, for eachparameter and metaheuristic, a range of values is given, withlower and upper bounds (LV and UV ). Therefore, we havea space of metaheuristics like that shown in Fig. 2. Each oneof the seven metaheuristics is determined by the 16 values(RV INEIni,RV FNEIni . . .), and the neighborhood foreach metaheuristic is formed by metaheuristics obtainedby generating values of the parameters in the ranges[LV INEIni, UV INEIni], [LV FNEIni, UV FNEIni] . . .
Fig. 2. Space of metaheuristics.
TABLE IIVALUES OF THE PARAMETERS PARAMINI FOR DEFINITION
OF THE NEIGHBORHOOD OF THE METAHEURISTICS
TABLE IIIVALUES OF THE PARAMETERS PARAMEND FOR DEFINITION
OF THE NEIGHBORHOOD OF THE METAHEURISTICS
The values established in the experiments for the referenceand lower and upper values for the different metaheuristics areshown in Tables II–VII (one table for each group of parametersin Algorithm 5). We do not comment on the values for eachparameter, but how the environments are establish can beillustrated with the parameters of the initialization and the GA:The reference values are (100, INEIni, 0, 0); the lower valuesare (50, 50, 0, 0), which means that more reduced populationsare allowed; and the upper values are (200, INEIni, 10, 5),which means that larger populations and a small percentage ofelements are improved with a moderate intensification.
ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 579
TABLE IVVALUES OF THE PARAMETERS PARAMSEL FOR DEFINITION
OF THE NEIGHBORHOOD OF THE METAHEURISTICS
TABLE VVALUES OF THE PARAMETERS PARAMCOM FOR DEFINITION
OF THE NEIGHBORHOOD OF THE METAHEURISTICS
In the experiments, we consider 700 combinations of theparameters (700 different metaheuristics), generating 100 com-binations in the neighborhood defined for each metaheuristic,and for each metaheuristic, a different input is generated. Thisallows us to statistically analyze the influence of the parameterson the final solution and also the best metaheuristics (as definedwith the ranges of the parameters) for the solution of theproblem.
B. Obtaining SEMs
Since our goal is to study different metaheuristics to obtainthe best SEM from a set of data of variables, the data used forevaluation have been randomly generated. Thus, to generatea SEM, once the problem size is established, i.e., given N ,K, and d, we randomly choose the number of exogenous and
TABLE VIVALUES OF THE PARAMETERS PARAMIMP FOR DEFINITION
OF THE NEIGHBORHOOD OF THE METAHEURISTICS
TABLE VIIVALUES OF THE PARAMETERS PARAMINC FOR DEFINITION
OF THE NEIGHBORHOOD OF THE METAHEURISTICS
endogenous variables in each equation, ni ∈ 1, 2, . . . , N andki ∈ 1, 2, . . . ,K, in such a way that equation i is identified(yi is the endogenous variable of equation i). For each row i,some randomly chosen entries of the system are set to zero.Finally, the values of the exogenous variables are randomlygenerated following a normal distribution, and the values of theendogenous variables are obtained from those of the exogenousvariables and using the generated system. The noise variablesalso follow a normal distribution. The problem size used in theexperiments is N = 10, K = 15, and d = 20.
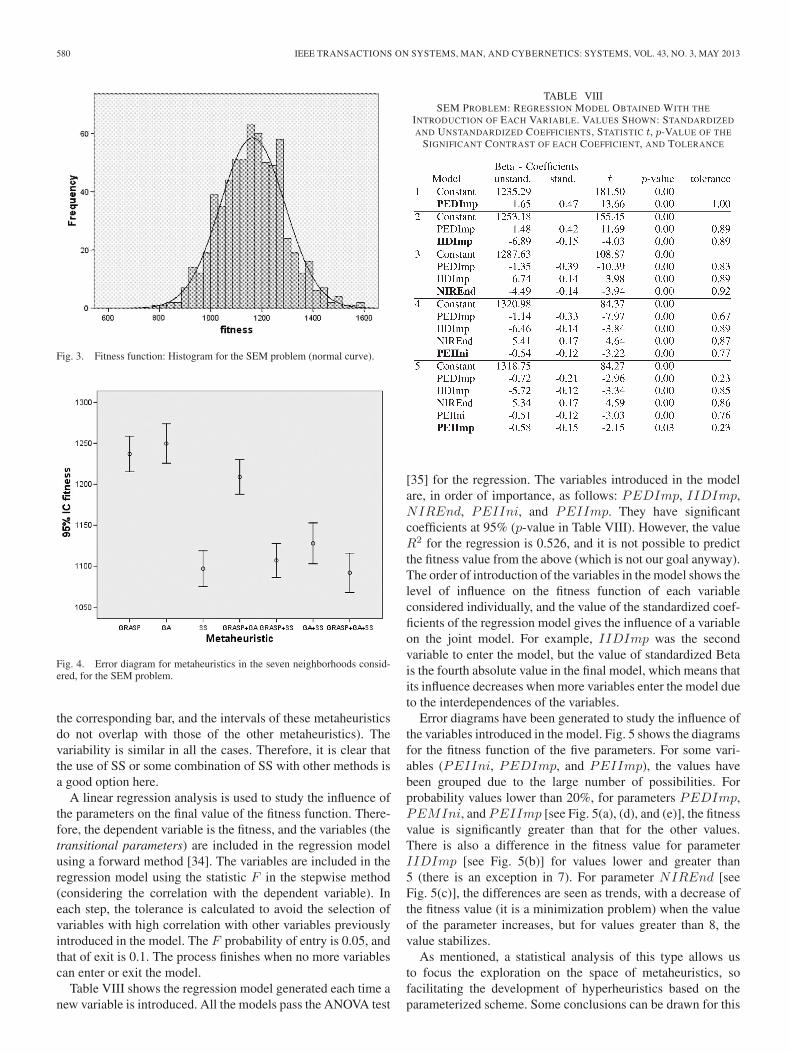
1) Statistical Analysis: We study the goodness of the so-lution obtained with the metaheuristics space represented inFig. 2, where seven neighborhoods are considered. Linearregression and ANOVA analysis are conducted on the fitnessfunction. Fig. 3 shows a histogram with the values of the fitnessfunction. The function follows a normal distribution (confirmedwith the Kolmogorov–Smirnov test [33]), and the normality ofthe variable is accepted as the null hypothesis.
An error bar diagram (see Fig. 4) is used to compare thefitness functions (which follow a normal distribution) of theseven metaheuristics. For each metaheuristic, the 100 exper-iments with values of the parameters in the neighborhood ofthe metaheuristic are grouped. The confidence interval is 95%for the mean. For GRASP, GA, and GRASP+GA, the valuesof the fitness function are significantly greater than the valuesfor the other metaheuristics (95% of the values of the fitnessfunction for each metaheuristic are in the interval given by
580 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
Fig. 3. Fitness function: Histogram for the SEM problem (normal curve).
Fig. 4. Error diagram for metaheuristics in the seven neighborhoods consid-ered, for the SEM problem.
the corresponding bar, and the intervals of these metaheuristicsdo not overlap with those of the other metaheuristics). Thevariability is similar in all the cases. Therefore, it is clear thatthe use of SS or some combination of SS with other methods isa good option here.
A linear regression analysis is used to study the influence ofthe parameters on the final value of the fitness function. There-fore, the dependent variable is the fitness, and the variables (thetransitional parameters) are included in the regression modelusing a forward method [34]. The variables are included in theregression model using the statistic F in the stepwise method(considering the correlation with the dependent variable). Ineach step, the tolerance is calculated to avoid the selection ofvariables with high correlation with other variables previouslyintroduced in the model. The F probability of entry is 0.05, andthat of exit is 0.1. The process finishes when no more variablescan enter or exit the model.
Table VIII shows the regression model generated each time anew variable is introduced. All the models pass the ANOVA test
TABLE VIIISEM PROBLEM: REGRESSION MODEL OBTAINED WITH THE
INTRODUCTION OF EACH VARIABLE. VALUES SHOWN: STANDARDIZED
AND UNSTANDARDIZED COEFFICIENTS, STATISTIC t, p-VALUE OF THE
SIGNIFICANT CONTRAST OF EACH COEFFICIENT, AND TOLERANCE
[35] for the regression. The variables introduced in the modelare, in order of importance, as follows: PEDImp, IIDImp,NIREnd, PEIIni, and PEIImp. They have significantcoefficients at 95% (p-value in Table VIII). However, the valueR2 for the regression is 0.526, and it is not possible to predictthe fitness value from the above (which is not our goal anyway).The order of introduction of the variables in the model shows thelevel of influence on the fitness function of each variableconsidered individually, and the value of the standardized coef-ficients of the regression model gives the influence of a variableon the joint model. For example, IIDImp was the secondvariable to enter the model, but the value of standardized Betais the fourth absolute value in the final model, which means thatits influence decreases when more variables enter the model dueto the interdependences of the variables.
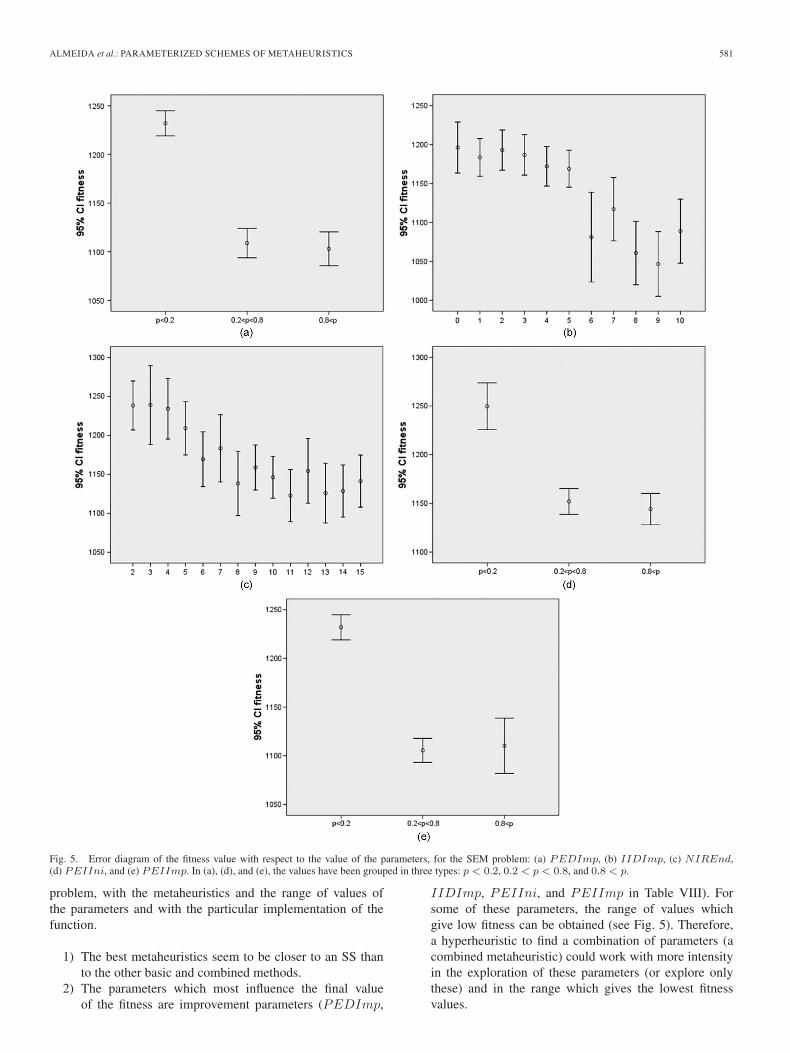
Error diagrams have been generated to study the influence ofthe variables introduced in the model. Fig. 5 shows the diagramsfor the fitness function of the five parameters. For some vari-ables (PEIIni, PEDImp, and PEIImp), the values havebeen grouped due to the large number of possibilities. Forprobability values lower than 20%, for parameters PEDImp,PEMIni, and PEIImp [see Fig. 5(a), (d), and (e)], the fitnessvalue is significantly greater than that for the other values.There is also a difference in the fitness value for parameterIIDImp [see Fig. 5(b)] for values lower and greater than5 (there is an exception in 7). For parameter NIREnd [seeFig. 5(c)], the differences are seen as trends, with a decrease ofthe fitness value (it is a minimization problem) when the valueof the parameter increases, but for values greater than 8, thevalue stabilizes.
As mentioned, a statistical analysis of this type allows usto focus the exploration on the space of metaheuristics, sofacilitating the development of hyperheuristics based on theparameterized scheme. Some conclusions can be drawn for this
ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 581
Fig. 5. Error diagram of the fitness value with respect to the value of the parameters, for the SEM problem: (a) PEDImp, (b) IIDImp, (c) NIREnd,(d) PEIIni, and (e) PEIImp. In (a), (d), and (e), the values have been grouped in three types: p < 0.2, 0.2 < p < 0.8, and 0.8 < p.
problem, with the metaheuristics and the range of values ofthe parameters and with the particular implementation of thefunction.
1) The best metaheuristics seem to be closer to an SS thanto the other basic and combined methods.
2) The parameters which most influence the final valueof the fitness are improvement parameters (PEDImp,
IIDImp, PEIIni, and PEIImp in Table VIII). Forsome of these parameters, the range of values whichgive low fitness can be obtained (see Fig. 5). Therefore,a hyperheuristic to find a combination of parameters (acombined metaheuristic) could work with more intensityin the exploration of these parameters (or explore onlythese) and in the range which gives the lowest fitnessvalues.
582 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
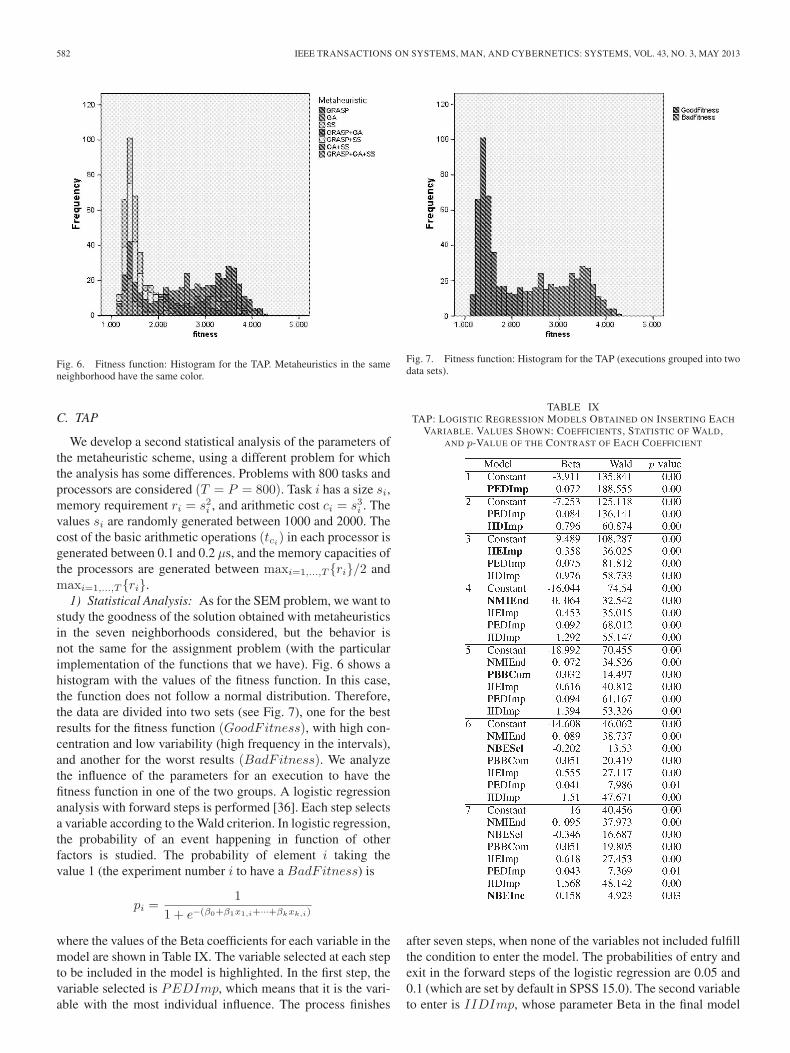
Fig. 6. Fitness function: Histogram for the TAP. Metaheuristics in the sameneighborhood have the same color.
C. TAP
We develop a second statistical analysis of the parameters ofthe metaheuristic scheme, using a different problem for whichthe analysis has some differences. Problems with 800 tasks andprocessors are considered (T = P = 800). Task i has a size si,memory requirement ri = s2i , and arithmetic cost ci = s3i . Thevalues si are randomly generated between 1000 and 2000. Thecost of the basic arithmetic operations (tci) in each processor isgenerated between 0.1 and 0.2 μs, and the memory capacities ofthe processors are generated between maxi=1,...,T {ri}/2 andmaxi=1,...,T {ri}.
1) Statistical Analysis: As for the SEM problem, we want tostudy the goodness of the solution obtained with metaheuristicsin the seven neighborhoods considered, but the behavior isnot the same for the assignment problem (with the particularimplementation of the functions that we have). Fig. 6 shows ahistogram with the values of the fitness function. In this case,the function does not follow a normal distribution. Therefore,the data are divided into two sets (see Fig. 7), one for the bestresults for the fitness function (GoodFitness), with high con-centration and low variability (high frequency in the intervals),and another for the worst results (BadFitness). We analyzethe influence of the parameters for an execution to have thefitness function in one of the two groups. A logistic regressionanalysis with forward steps is performed [36]. Each step selectsa variable according to the Wald criterion. In logistic regression,the probability of an event happening in function of otherfactors is studied. The probability of element i taking thevalue 1 (the experiment number i to have a BadFitness) is
pi =1
1 + e−(β0+β1x1,i+···+βkxk,i)
where the values of the Beta coefficients for each variable in themodel are shown in Table IX. The variable selected at each stepto be included in the model is highlighted. In the first step, thevariable selected is PEDImp, which means that it is the vari-able with the most individual influence. The process finishes
Fig. 7. Fitness function: Histogram for the TAP (executions grouped into twodata sets).
TABLE IXTAP: LOGISTIC REGRESSION MODELS OBTAINED ON INSERTING EACH
VARIABLE. VALUES SHOWN: COEFFICIENTS, STATISTIC OF WALD,AND p-VALUE OF THE CONTRAST OF EACH COEFFICIENT
after seven steps, when none of the variables not included fulfillthe condition to enter the model. The probabilities of entry andexit in the forward steps of the logistic regression are 0.05 and0.1 (which are set by default in SPSS 15.0). The second variableto enter is IIDImp, whose parameter Beta in the final model
ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 583
TABLE XTAP: SUCCESS IN THE CLASSIFICATION OF THE FITNESS OF EACH
EXECUTION IN GoodF itness AND BadFitness (USING THE
LOGISTIC REGRESSION MODEL OBTAINED IN EACH STEP)
(step 7) is 1.568. Since it is a positive value, when parameterIIDImp increases, the probability of the fitness function beingin the set of BadFitness also increases.
Table X shows the success in the prediction of the fitnessfunction when using the values of the parameters introduced inthe logistic regression model.
Once the fitness obtained in the experiments has been clas-sified into two groups, the influence of the parameters for theexperiments in the group GoodFitness can be analyzed in asimilar way to the SEM problem. The Kolmogorov–Smirnovtest confirms the normal distribution of the fitness variablewhen it is considered in that group, and a linear regressionanalysis with the fitness as a dependent variable and the othervariables as explicative can be made.
Table XI shows the parameters included at each step. Forall the models, the ANOVA test is significant, and the R2
coefficients are bigger than 0.5, with a value of 0.68 for thefinal model.
The first variable introduced in the model (step 1 in Table XI)is IIDImp, which also has the highest standardized value ofBeta (in absolute value) in the final model (step 6). Therefore, itis the variable with the highest influence in the linear regressionmodel and, consequently, the variable which most influencesthe fitness function in the GoodFitness group. The coefficientBeta of IIDImp is negative, which means that, when thevalue of IIDImp increases, the value of the fitness functiondecreases in the set of GoodFitness.
In the previous logistic regression analysis, we deduced that,when the value of IIDImp increases, so does the probabilityof the fitness function being in the group BadFitness. As aconclusion, there is an optimum point of this parameter forwhich the lowest value of the fitness function is obtained. Thispoint will be the maximum possible value of IIDImp whichlets the fitness function be in the set of GoodFitness andmakes the fitness function as small as possible.
TABLE XITAP: REGRESSION MODEL OBTAINED WITH THE INTRODUCTION OF
EACH VARIABLE WHEN ONLY EXECUTIONS WITH FITNESS IN
GoodF itness ARE CONSIDERED. VALUES SHOWN: STANDARDIZED AND
UNSTANDARDIZED COEFFICIENTS OF THE REGRESSION MODEL,STATISTIC t, AND p-VALUE FOR EACH COEFFICIENT
Fig. 8. Value of the fitness function for different combinations of two basicmetaheuristics. TAP problem.
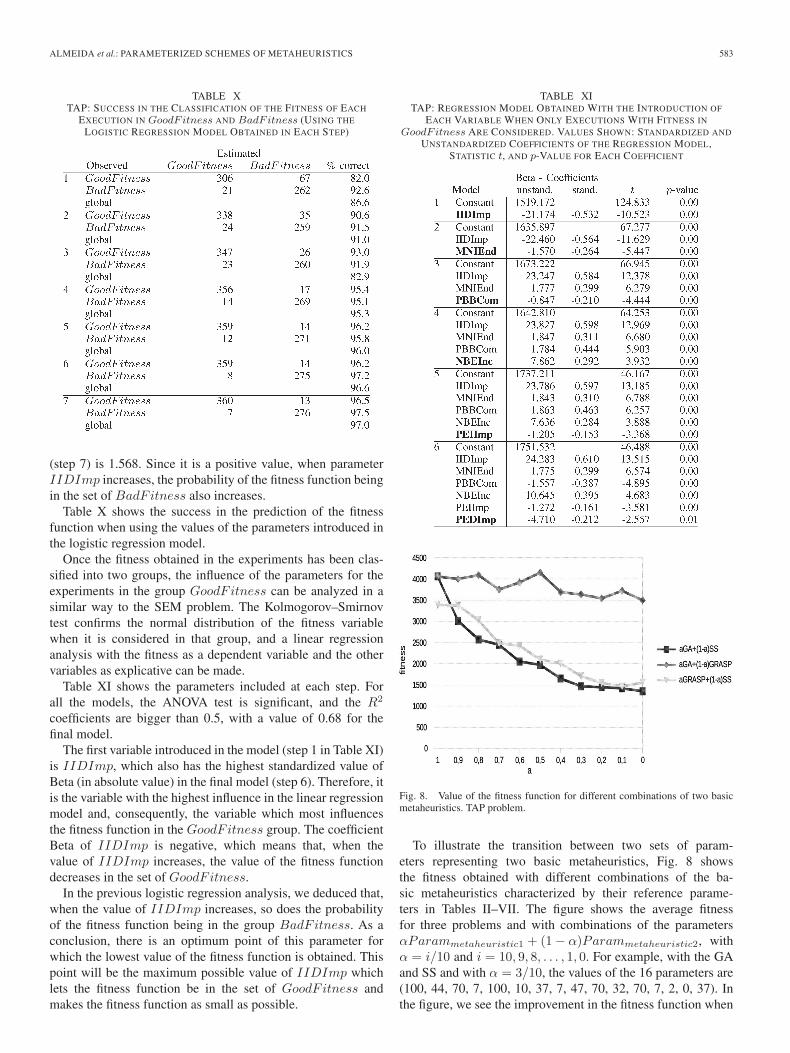
To illustrate the transition between two sets of param-eters representing two basic metaheuristics, Fig. 8 showsthe fitness obtained with different combinations of the ba-sic metaheuristics characterized by their reference parame-ters in Tables II–VII. The figure shows the average fitnessfor three problems and with combinations of the parametersαParammetaheuristic1 + (1− α)Parammetaheuristic2, withα = i/10 and i = 10, 9, 8, . . . , 1, 0. For example, with the GAand SS and with α = 3/10, the values of the 16 parameters are(100, 44, 70, 7, 100, 10, 37, 7, 47, 70, 32, 70, 7, 2, 0, 37). Inthe figure, we see the improvement in the fitness function when
584 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
Fig. 9. Histogram of the fitness function for the p-hub median problem.
passing from one metaheuristic to another, and the best resultsare obtained close to SS, which is the best basic metaheuristicfor the problem.
The general conclusions for this problem are as follows.1) The SS and its combination with other metaheuristics
usually give the best fitness functions, as what happensin the SEM problem.
2) Some improvement parameters (IIDImp, PEIImp,and PEDImp in Table XI) influence the value of thefitness function, but the maximum number of iterationsand the parameters regarding the number of combinations(PBBCom) or inclusions (NBEInc) of elements withlow fitness values also have a high influence.
D. HMLA Problem
With the SEM and the assignation problem, we haveseen two types of statistical analysis. Now, with the HMLAproblem, we consider the case in which the metaheuristics arealways used with the same entry. In that case, the statisticalconclusions are less general because there is no variety in thegeneration of the experiments. Even so, this method can beused to compare the metaheuristics and the parameters used inthe parameterized scheme.
1) Statistical Analysis: The histogram of the fitness functionvalues is shown in Fig. 9. The best results are obtained with themetaheuristics GRASP+SS and GRASP+GA+SS, which is notsurprising, because they combine the best of basic metaheuris-tics, and this coincides with the behavior observed in the otherproblems. Therefore, the statistical study will be centered onthese two metaheuristics. The variable fitness considering onlythe values for metaheuristics GRASP+SS and GRASP+GA+SSdoes not follow a normal distribution (see Fig. 10). However,the distribution of the residuals in the estimation of this variableby linear regression follows a normal distribution (see Fig. 11) ofmean zero (white noise variable). Therefore, a stepwise linearregression analysis like that conducted for the SEM problem isused to identify the parameters with the highest influence.
Table XII shows the variables introduced at each step. All themodels pass the ANOVA test, and in the final step, R2 = 0.583.
Fig. 10. Histogram of the fitness function for the p-hub median prob-lem, with the outlier values eliminated, for metaheuristics GRASP+SS andGRASP+GA+SS.
Fig. 11. Histogram of the residuals obtained in the linear regression model inthe last step in Table XII.
TABLE XIIMODELS OBTAINED IN THE SUCCESSIVE STEPS IN THE REGRESSION
ANALYSIS FOR THE p-HUB MEDIAN PROBLEM
The variables in the model are PBWCom, PEIImp, andMNIEnd (they enter in that order). Furthermore, the order ofentry coincides with the weight determined by the standardizedcoefficients. To obtain lower fitness values, it is necessary toincrease the value of PBWCom (positive coefficient) anddecrease PEIImp and NMIEnd (negative coefficients).

ALMEIDA et al.: PARAMETERIZED SCHEMES OF METAHEURISTICS 585
The conclusion for this problem is that GRASP+SS andGRASP+GA+SS are the preferred metaheuristics, and the val-ues of the parameters PBWCom, PEIImp, and MNIEndshould be adjusted together to obtain better values of the fitnessfunction.
E. Comparison of Results
The statistical analysis for the three problems consideredshows some differences, and for other problems, pure meta-heuristics, basic functions, and set of parameters, the analysescould be different. Therefore, the conclusions that can be drawnfrom the analysis are dependent on the problem, the metaheuris-tics, functions, and parameters, but the statistical analysis canbe performed in a similar way for the different cases. Even so,some conclusions can be drawn from the comparison of theresults of the statistical study for the three problems.
1) In general, the best fitness function is obtained withcombinations of the three basic metaheuristics considered(GRASP, GA, and SS). This is not surprising becausethe positive characteristics of the three methods are com-bined, and the search is intensified at each stage of thealgorithm.
2) SS, alone or in combination with other metaheuristics, isa good option.
3) The parameters that most influence the fitness functionare different for different problems. This is normal sincethe influence of the parameters is determined not onlyby the problem but also by the particular implementationof the functions. It also depends on the input to be solved,and to minimize the influence of the input, a size has beenselected for each problem, and the inputs to be solvedhave been generated randomly.
4) In general, parameters which represent an intensificationin the improvement of the generated elements influ-ence the fitness function and appear in the final model:PEDImp, IIDImp, and PEIImp.
5) A statistical analysis of the type developed here can helpin the identification of the parameters and the best rangeof values for each parameter for a particular problem, setof metaheuristics, and implementation of the functions.This information can serve to develop hyperheuristicsbased on the parameterized scheme.
V. CONCLUSION AND RESEARCH LINES
A methodology to develop parameterized schemes of meta-heuristics has been introduced. With unified schemes, thedevelopment of metaheuristics and their tuning to particularproblems is facilitated, due to function reuse. Additionally, theinclusion of transitional parameters in the basic functions ofthe unified scheme eases the development of hybrid metaheuris-tics or their combinations, as well as the statistical study ofthe best metaheuristic or combination and the influence of theparameters in the goodness of the solutions.
The validity of the proposal has been tested through applica-tion to three scientific problems with GRASP, GAs, and SS andtheir combinations.
There are some open problems that we are working on.1) The parameterization of the unified scheme could be
extended by including new metaheuristics, and morescientific problems could be tackled with this approach.At present, we are working on including taboo searchin the application of the parameterized scheme to otheroptimization problems [37].
2) Hyperheuristics based on the parameterized schemecould be developed, and statistical studies of the typecarried out here could be used to guide the search forsatisfactory values of the transitional parameters.
3) With the parameterized scheme, the range of metaheuris-tics to experiment with increases, as does the numberof parameters to be tuned (including transitional param-eters). Therefore, the selection of a satisfactory meta-heuristic tuned for a particular problem demands a lotof computation, and to accelerate the process, parallelversions of the metaheuristics should be obtained. Theuse of the unified parameterized metaheuristic schemehere proposed facilitates the development of parallelversions that could be obtained with the independentparallelization of the basic parameterized functions in thesequential scheme [10].
REFERENCES
[1] L. Jourdan, M. Basseur, and E.-G. Talbi, “Hybridizing exact methods andmetaheuristics: A taxonomy,” Eur. J. Oper. Res., vol. 199, no. 3, pp. 620–629, Dec. 2009.
[2] C. Blum, J. Puchinger, G. R. Raidl, and A. Roli, “Hybrid metaheuristics incombinatorial optimization: A survey,” Appl. Soft Comput., vol. 11, no. 6,pp. 4135–4151, Sep. 2011.
[3] P. Morillo, J. M. Orduña, and J. Duato, “M-GRASP: A GRASP withmemory for latency-aware partitioning methods in DVE systems,” IEEETrans. Syst., Man, Cybern. A, Syst., Humans, vol. 39, no. 6, pp. 1214–1223, Nov. 2009.
[4] B. G. Tessema and G. G. Yen, “An adaptive penalty formulation forconstrained evolutionary optimization,” IEEE Trans. Syst., Man, Cybern.A, Syst., Humans, vol. 39, no. 3, pp. 565–578, May 2009.
[5] E. Burke, E. Hart, G. Kendall, J. Newall, P. Ross, and S. Schulenburg,“Hyper-heuristics: An emerging direction in modern search technology,”in Handbook of Metaheuristics, F. Glover and G. Kochenberger, Eds.Norwell, MA: Kluwer, 2003, ch. 16, pp. 457–474.
[6] E. Alba, F. Almeida, M. J. Blesa, C. Cotta, M. Díaz, I. Dorta, J. Gabarró,C. León, G. Luque, and J. Petit, “Efficient parallel LAN/WAN algorithmsfor optimization. The MALLBA project,” Parallel Comput., vol. 32,no. 5/6, pp. 415–440, Jun. 2006.
[7] A. Liefooghe, L. Jourdan, T. Legrand, J. Humeau, and E.-G. Talbi,“ParadisEO-MOEO: A software framework for evolutionary multi-objective optimization,” in Proc. Adv. Multi-Object. Nat. Inspired Com-put., 2010, pp. 87–117.
[8] R. C. Whaley, A. Petitet, and J. Dongarra, “Automated empirical opti-mizations of software and the ATLAS project,” Parallel Comput. , vol. 27,no. 1/2, pp. 3–35, Jan. 2001.
[9] A. Lastovetsky and V. Rychkov, “Accurate and efficient estimation ofparameters of heterogeneous communication performance models,” IJH-PCA, vol. 23, no. 2, pp. 123–139, May 2009.
[10] F. Almeida, D. Giménez, and J.-J. López-Espín, “A parameterized shared-memory scheme for parameterized metaheuristics,” J. Supercomput.,vol. 58, no. 3, pp. 292–301, Dec. 2011.
[11] M. Birattari, “The problem of tuning metaheuristics as seen from a ma-chine learning perspective,” Ph.D. dissertation, Univ. Libre de Bruxelles,Brussels, Belgium, 2004.
[12] C. A. Gil, M. Sellmann, and K. Tierney, “A gender-based genetic al-gorithm for the automatic configuration of algorithms,” in Proc. Intern.Conf. Principles Pract. Constraint Program., 2009, pp. 142–157.
[13] F. Hutter, H. H. Hoos, K. Leyton-Brown, and T. Stützle, “ParamILS:An automatic algorithm configuration framework,” J. Artif. Intell. Res.,vol. 36, no. 1, pp. 267–306, Sep. 2009.

586 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS: SYSTEMS, VOL. 43, NO. 3, MAY 2013
[14] S. Kadioglu, Y. Malitsky, M. Sellmann, and K. Tierney, “ISAC—Instance-specific algorithm configuration,” in Proc. ECAI, 2010, pp. 751–756.
[15] F. Hutter, H. H. Hoos, and K. Leyton-Brown, “Sequential model-basedoptimization for general algorithm configuration,” in Proc. LION, 2011,pp. 507–523.
[16] G. R. Raidl, “A unified view on hybrid metaheuristics,” in Proc. HybridMetaheurist., 3rd Int. Workshop, LNCS, 2006, vol. 4030, pp. 1–12.
[17] R. Vaessens, E. Aarts, and J. Lenstra, “A local search template,” in Proc.Parallel Prob. Solving Nat., 1992, pp. 67–76.
[18] W. Greene, Econometric Analysis, 3rd ed. Englewood Cliffs, NJ:Prentice-Hall, 1998.
[19] D. Gujarati, Basic Econometrics. New York: McGraw Hill, 1995.[20] R. Henry, I. Lu, L. Beightol, and D. Eckberg, “Interactions between CO2
chemoreflexes and arterial baroreflexes,” Amer. J. Physiol., vol. 274, no. 6,pp. H2177–H2187, Jun. 1998.
[21] W. R. Ressler and M. S. Waters, “Female earnings and the divorce rate:A simultaneous equation model,” Appl. Econ., vol. 32, no. 14, pp. 1889–1898, Nov. 2000.
[22] A. Gorobets, “The optimal prediction simultaneous equations selection,”Econ. Bull., vol. 3, no. 36, pp. 1–8, Aug. 2005.
[23] J. J. López-Espín and D. Giménez, “Genetic algorithms for simultaneousequation models,” in Proc. DCAI, 2008, pp. 215–224.
[24] J. J. López-Espín and D. Giménez, “Obtaining simultaneous equationmodels from a set of variables through genetic algorithms,” in Proc. Int.Conf. Comput. Sci., 2010, vol. 1, no. 1, pp. 427–435.
[25] J. J. López-Espín and D. Giménez, “Message-passing two steps leastsquare algorithms for simultaneous equations models,” in Proc. PPAM,2007, pp. 127–136.
[26] J. J. López-Espín, A. M. Vidal, and D. Giménez, “Two-stage least squaresand indirect least squares algorithms for simultaneous equations models,”J. Comput. Appl. Math., vol. 236, no. 15, pp. 3676–3684, 2012.
[27] W. Zhao and K. Ramamritham, “Simple and integrated heuristic algo-rithms for scheduling tasks with time and resource constraints,” J. Syst.Softw., vol. 7, no. 3, pp. 195–205, Sep. 1987.
[28] K. Seymour, H. You, and J. Dongarra, “A comparison of search heuris-tics for empirical code optimization,” in Proc. IEEE CLUSTER, 2008,pp. 421–429.
[29] J. Cuenca, D. Giménez, J. J. López-Espín, and J. P. Martínez-Gallar, “Aproposal of metaheuristics to schedule independent tasks in heterogeneousmemory-constrained systems,” in Proc. IEEE Int. Conf. Cluster Comput.,2007, pp. 422–427.
[30] F. Almeida, J. Cuenca, D. Giménez, A. Llanes-Castro, and J. P. Martínez-Gallar, “A framework for the application of metaheuristics to tasks-to-processors assignation problems,” J. Supercomput., pp. 1–26, Sep. 2009,published online.
[31] M. O’Kelly, “A quadratic integer program for the location of interatinghub facilities,” Eur. J. Oper. Res., vol. 32, no. 3, pp. 393–404, Dec. 1987.
[32] M. Pérez, F. Almeida, and J. M. Moreno-Vega, “Fast heuristics for thep-hub location problem,” in Proc. EWGLAX, Murcia, Spain, 1998.
[33] W. Mendenhall, R. J. Beaver, and B. M. Beaver, Introduction to Probabil-ity and Statistics. Independence, KY: Cengage Learning, 2008.
[34] N. R. Draper and H. Smith, Applied Regression Analysis. Hoboken, NJ:Wiley, 1998.
[35] D. R. Cox, Planning of Experiments. Hoboken, NJ: Wiley, 1958.[36] D. W. Hosmer and S. Lemeshow, Applied Logistic Regression. Hoboken,
NJ: Wiley, 2000.[37] L.-G. Cutillas-Lozano, J.-M. Cutillas-Lozano, and D. Giménez, “Model-
ing shared-memory metaheuristic schemes for electricity consumption,”in Proc. DCAI, 2012, pp. 1–38.
Francisco Almeida received the degree and M.Sc.degree in mathematics, and the Ph.D. degree incomputer science from the University of La Laguna,La Laguna, Spain, in 1989, 1992, and 1996,respectively.
He is currently a Professor with the Departmentof Statistics and Computer Science, University of LaLaguna. His research interests are primarily in theareas of parallel computing, parallel algorithms foroptimization problems, parallel system performanceanalysis and prediction, skeleton tools for parallel
programming, and web services for high performance computing and Gridtechnology.
Domingo Giménez received the degree in math-ematics from the University of Murcia, Murcia,Spain, in 1982 and the Ph.D. degree in computerscience from the Polytechnic University of Valencia,Valencia, Spain, in 1995.
He is currently a Senior Lecturer with the Com-puter Science Department, University of Murcia. Hehas been a faculty member of the university since1988, where he teaches algorithms and parallel com-puting. His research interests include scientific appli-cations of parallel computing, matrix computation,
scheduling, and software autotuning techniques.
Jose Juan López-Espín received the degree in math-ematics in 1999 and the Ph.D. degree in computerscience in 2009, both from the University of LaLaguna, La Laguna, Spain.
He has been a faculty member with the Universi-dad Miguel Hernández, Elche, Spain, since 2003, indifferent departments, where he has taught statistic,econometric, and computer science, and at present,he is an Assistant Professor in the Department ofStatistics, Computer Science and Mathematics. Hisresearch interests include parallel computing and
statistical models and applications in medicine.
Melquíades Pérez-Pérez received the degree inmathematics in 1996 and the degree in statisticalsciences and techniques and the Ph.D. degree inmathematics both in 2009, all from the University ofLa Laguna, La Laguna, Spain.
He has been working as an Associate Professorwith the Department of Economic Statistics andEconometrics, University of La Laguna, and withthe Department of Quantitative Methods in Eco-nomics and Management, University of Las Palmasde Gran Canaria, Las Palmas, Spain. He is currently
a Teacher of Mathematics in Secondary Education. His research interestsinclude applications of metaheuristics and algorithms to optimization problems,combinatorial optimization, nonlinear systems, optimal control, and machinelearning.




![ON THE PARAMETERIZED COMPLEXITY OF APPROXIMATE …matematicas.uis.edu.co/.../files/p-approx-counting.pdf · 1.1. Parameterized Complexity. Parameterized complexity theory [5], [3]](https://img.pdfslide.net/doc/110x75/5fa9b6c0f3b3624d395da859/on-the-parameterized-complexity-of-approximate-11-parameterized-complexity-parameterized.jpg)
























