Embed Size (px)
Citation preview

Presenting Results and Training Data of Expanded Evaluation Experiment of
HMM-Based Arabic Omni Font-Written OCR
Mohamed Attia & Mohamed El-Mahallawy
RDI ’s Meeting Room; Oct. 2007
بسم الله الرحمن الرحيم
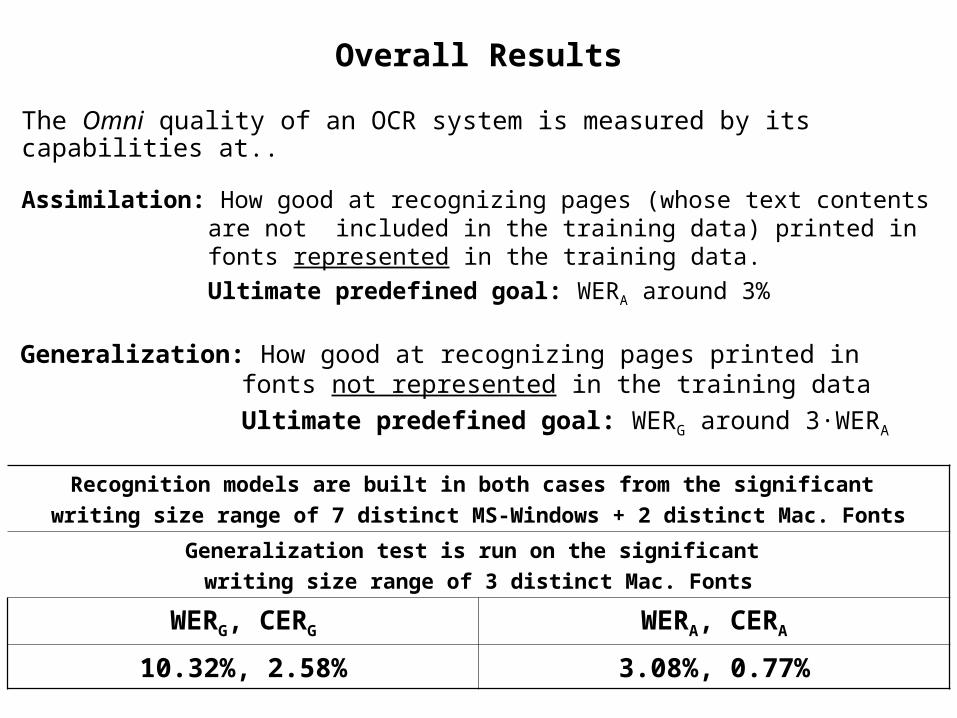
Overall Results
The Omni quality of an OCR system is measured by its capabilities at..
Recognition models are built in both cases from the significant writing size range of 7 distinct MS-Windows + 2 distinct Mac. Fonts
Generalization test is run on the significant writing size range of 3 distinct Mac. Fonts
WERA, CERAWERG, CERG
3.08%, 0.77%10.32%, 2.58%
Generalization: How good at recognizing pages printed in fonts not represented in the training dataUltimate predefined goal: WERG around 3·WERA
Assimilation: How good at recognizing pages (whose text contents are not included in the training data) printed in fonts represented in the training data.Ultimate predefined goal: WERA around 3%
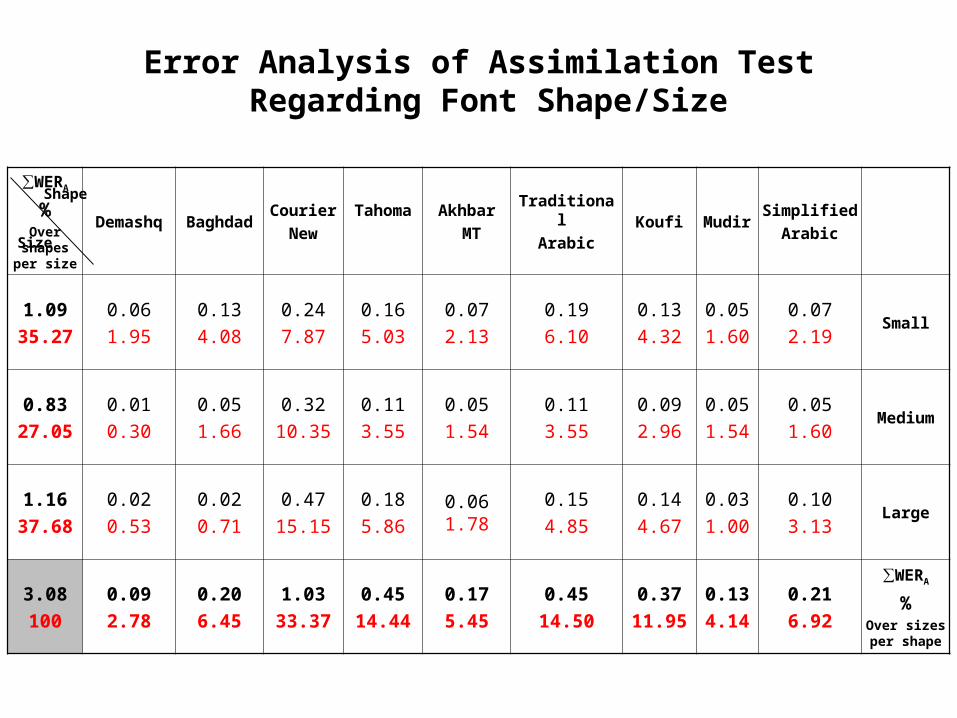
Error Analysis of Assimilation Test Regarding Font Shape/Size
SimplifiedArabic
Mudir KoufiTraditional
ArabicAkhbar
MTTahomaCourier
NewBaghdadDemashq
∑WERA
%Over
shapes per size
Small0.072.19
0.051.60
0.134.32
0.196.10
0.072.13
0.165.03
0.247.87
0.134.08
0.061.95
1.09
35.27
Medium0.051.60
0.051.54
0.092.96
0.113.55
0.051.54
0.113.55
0.3210.35
0.051.66
0.01
0.30
0.83
27.05
Large0.103.13
0.031.00
0.144.67
0.154.85
0.061.78
0.185.86
0.4715.15
0.020.71
0.02
0.53
1.16
37.68
∑WERA
%Over sizes per shape
0.21
6.92
0.13
4.14
0.37
11.95
0.45
14.50
0.17
5.45
0.45
14.44
1.03
33.37
0.20
6.45
0.09
2.78
3.08
100
Shape
Size
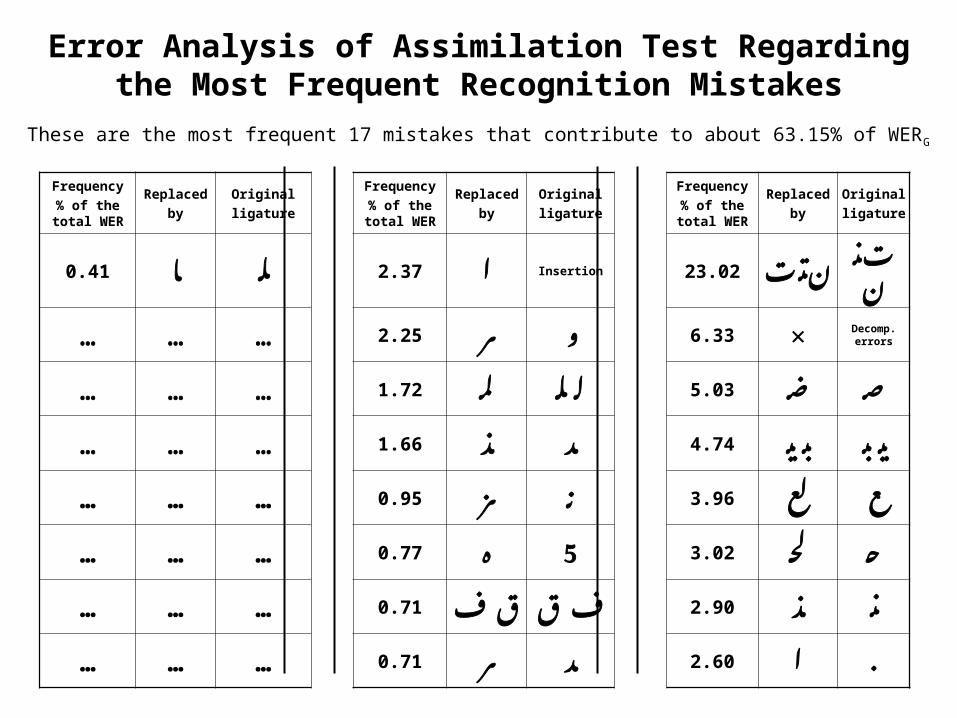
Error Analysis of Assimilation Test Regarding the Most Frequent Recognition Mistakes
These are the most frequent 17 mistakes that contribute to about 63.15% of WERG
Originalligature
Replacedby
Frequency% of the
total WER
Originalligature
Replacedby
Frequency% of the
total WER
Originalligature
Replacedby
Frequency% of the
total WER
ت ـنـ ن
ن ـتـ ت
23.02Insertion0.41ـاـلـ2.37ا
Decomp. errors×6.332.25ـرـو………
………1.72لمـلـ ـلـ5.03ضـصـ
ـيـ ـبـ
ـبـ ـيـ
………1.66ـذـد4.74
………0.95ـزنـ3.96لعـع
………0.77ه3.025لحـحـ
2.90ـذـنـف
قق ف
0.71………
………0.71ـرـد2.60ا.
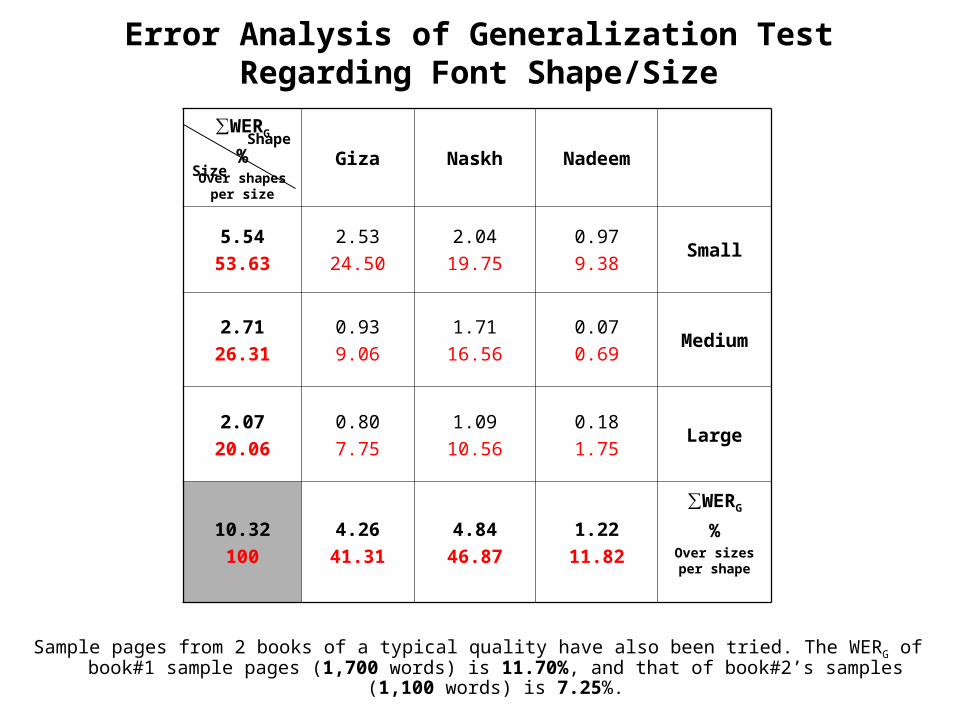
Error Analysis of Generalization TestRegarding Font Shape/Size
NadeemNaskhGiza
∑WERG
%Over shapes
per size
Small0.979.38
2.0419.75
2.5324.50
5.54
53.63
Medium0.070.69
1.7116.56
0.939.06
2.71
26.31
Large0.181.75
1.0910.56
0.807.75
2.07
20.06
∑WERG
%Over sizes per shape
1.22
11.82
4.84
46.87
4.26
41.31
10.32
100
Shape
Size
Sample pages from 2 books of a typical quality have also been tried. The WERG of book#1 sample pages (1,700 words) is 11.70%, and that of book#2’s samples (1,100 words) is 7.25%.
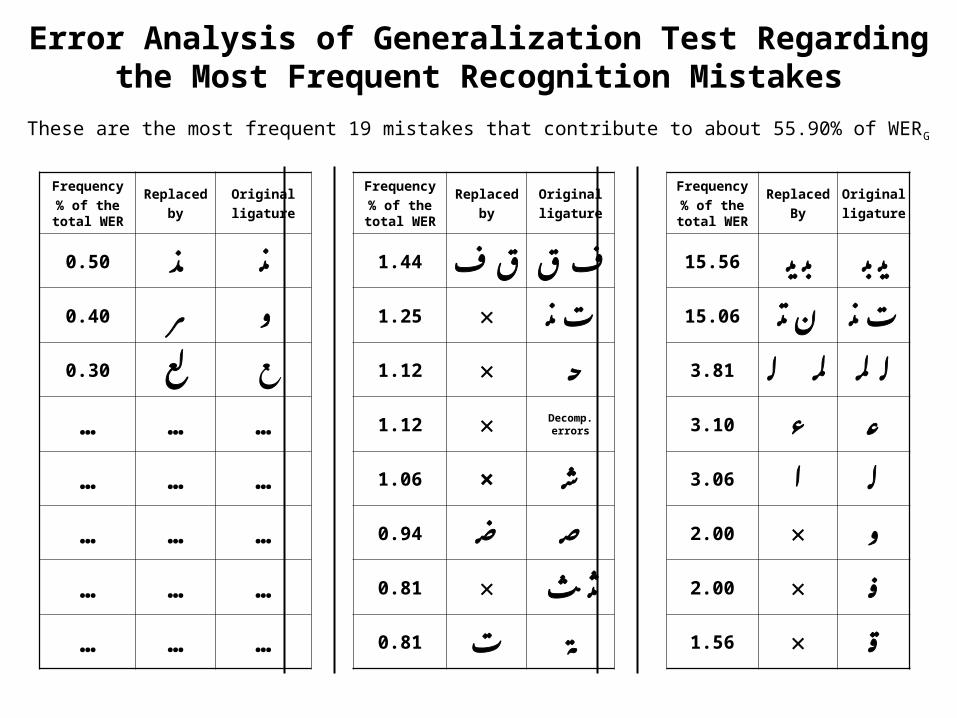
Error Analysis of Generalization Test Regarding the Most Frequent Recognition Mistakes
These are the most frequent 19 mistakes that contribute to about 55.90% of WERG
Originalligature
ReplacedBy
Frequency% of the
total WER
Originalligature
Replacedby
Frequency% of the
total WER
Originalligature
Replacedby
Frequency% of the
total WER
ـيـ ـبـ
ـبـ ـيـ
15.56ف
قق ف
0.50ـذـنـ1.44
ت ـنـ
ن ـتـ
15.06ت ـنـ
0.40ـرـو1.25×
لـ لمـ
لمـ لـ
0.30لعـع1.12×ـحـ3.81
.3.10Decompءعـerrors×1.12………
………1.06×ـش3.06الـ
………0.94ضـصـ2.00×و
2.00×فــثـ ـث
×0.81………
………0.81تـة1.56×قـ

Training and Evaluation Data
• 9 distinct fonts, with the significant writing size range of each, are used for training/building recognition models. 7 of them are MS-Windows ones and 2 fonts are Mac. ones.
At each size of each fonts; 25 different pages are used for training and other 5 different ones are used for assimilation test.This sums up to (9·6·25 = 1,350) pages
≈ 1,350·200 = 270,000 words ≈ 270,000·4 = 1,080,000 graphemes for training
and (9·6·5=270) pages ≈ 54,000 words ≈ 216,000 graphemes for assimilation testing
• 3 Mac. OS. fonts at their full size range are used for generalization test.
At each size of each font of these 3 fonts, 5 pages are used for generalization test.
This sums up to (5·6·3=90) pages ≈ 18,000 words ≈ 72,000 graphemes for generalization testing

Effect of Language Model
• Our language model is neither constrained by a certain lexicon nor by a set of linguistic rules; i.e. it is an open vocabulary language model.
• Our statistical language model (SLM) is an m-Gram one built using Bayes_Good-Turing_Back-Off methodology.
• The unit of our SLM is the grapheme; i.e. the ligature.
• The order of the deployed SLM in our system is 2.
• Our SLM is built from the NEMLAR raw text corpus with size of 550,000 words (≈ 2,200,000 graphemes) distributed over the 13 most significant domains of modern and heritage standard Arabic.
• Deploying/neutralizing the SLM has the following effect on the realized WER of our system:
WERA, WERG
SLM neutralized
WERA, WERG
SLM deployed
6.13%, 14.60%3.08%, 10.32%
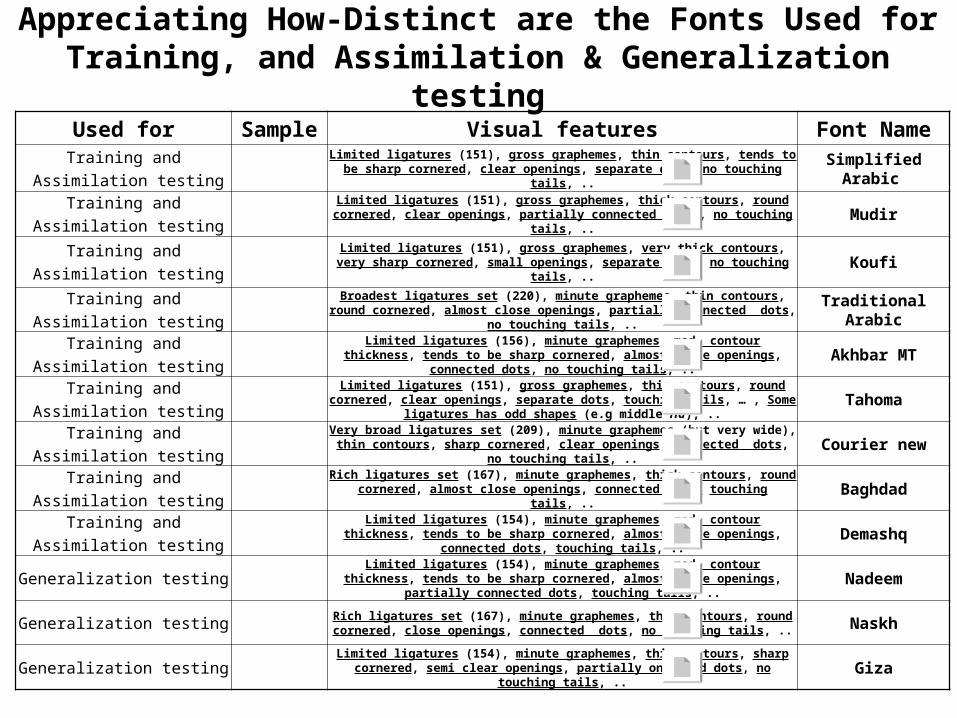
Appreciating How-Distinct are the Fonts Used for Training, and Assimilation & Generalization
testingFont NameVisual featuresSampleUsed for
Simplified Arabic
Limited ligatures (151), gross graphemes, thin contours, tends to be sharp cornered, clear openings, separate dots, no touching tails, ..
Training and Assimilation testing
MudirLimited ligatures (151), gross graphemes, thick contours, round cornered, clear openings, partially connected dots, no touching
tails, ..
Training and Assimilation testing
KoufiLimited ligatures (151), gross graphemes, very thick contours, very sharp cornered, small openings, separate dots, no touching tails, ..
Training and Assimilation testing
Traditional Arabic
Broadest ligatures set (220), minute graphemes, thin contours, round cornered, almost close openings, partially connected dots, no
touching tails, ..
Training and Assimilation testing
Akhbar MTLimited ligatures (156), minute graphemes, med. contour thickness, tends to be sharp cornered, almost close openings, connected dots,
no touching tails, ..
Training and Assimilation testing
TahomaLimited ligatures (151), gross graphemes, thin contours, round
cornered, clear openings, separate dots, touching tails, … , Some ligatures has odd shapes (e.g middle Ha), ..
Training and Assimilation testing
Courier newVery broad ligatures set (209), minute graphemes (but very wide), thin contours, sharp cornered, clear openings, connected dots, no
touching tails, ..
Training and Assimilation testing
BaghdadRich ligatures set (167), minute graphemes, thick contours, round cornered, almost close openings, connected dots touching tails, ..
Training and Assimilation testing
DemashqLimited ligatures (154), minute graphemes, med. contour thickness, tends to be sharp cornered, almost close openings, connected dots,
touching tails, ..
Training and Assimilation testing
NadeemLimited ligatures (154), minute graphemes, med. contour thickness,
tends to be sharp cornered, almost close openings, partially connected dots, touching tails, ..
Generalization testing
NaskhRich ligatures set (167), minute graphemes, thin contours, round cornered, close openings, connected dots, no touching tails, ..Generalization testing
GizaLimited ligatures (154), minute graphemes, thin contours, sharp
cornered, semi clear openings, partially onnected dots, no touching tails, ..
Generalization testing

Can our OCR System StatisticallyBuild Concepts of Font Shapes?
A Case Study
• Some fonts which are conceptually distinct from the ones comprising the training data, are very challenging to generalization testing; i.e. WERG>>WERA
• Upon our first trial to run a generalization test, the recognition models are built from the 7 MS-Windows fonts and the testing data was composed of 3 Mac. OS fonts. Under these conditions we got the poor results of WERG≈35%≈11·WERA (WERG>>WERA)
• After error analysis and some contemplation, we realized that Mac. OS fonts are built with different concepts not covered by the 7 MS-Windows fonts; e.g. connected dots, overlapping of the tails of some graphemes, …, etc.
• After adding 2 Mac. OS fonts to introduce those concepts in the training data, we have achieved the dramatic enhancement of WERG=10.32%≈3.4·WERA
Our OCR system can statistically build font shape concepts.
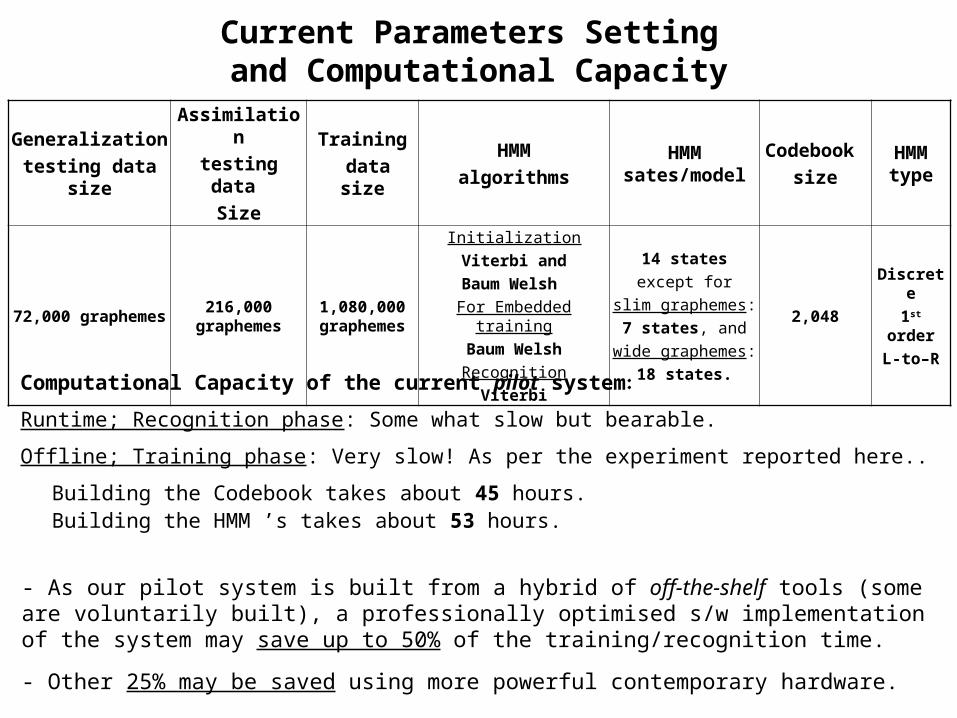
Current Parameters Setting and Computational Capacity
Computational Capacity of the current pilot system:
Runtime; Recognition phase: Some what slow but bearable.
Offline; Training phase: Very slow! As per the experiment reported here..
Building the Codebook takes about 45 hours.Building the HMM ’s takes about 53 hours.
HMM type
Codebook size
HMM sates/model
HMMalgorithms
Training data size
Assimilationtesting data
Size
Generalizationtesting data
size
Discrete1st
orderL-to–R
2,048
14 statesexcept for
slim graphemes:7 states, and
wide graphemes: 18 states.
InitializationViterbi and
Baum Welsh For Embedded training
Baum WelshRecognition
Viterbi
1,080,000 graphemes
216,000 graphemes
72,000 graphemes
- As our pilot system is built from a hybrid of off-the-shelf tools (some are voluntarily built), a professionally optimised s/w implementation of the system may save up to 50% of the training/recognition time.
- Other 25% may be saved using more powerful contemporary hardware.

Conclusion
• Is our OCR system truly omni? Yes
It can both assimilate and generalize at a remarkable WER under tough training and testing data sets.
In fact, the obtained WER ’s are the best reported in the published literature in this regard.
• Is there a room for further enhancement? Yes
Regarding Both:
- Reducing WERG by building recognition models from more distinct fonts (esp. Mac. ones), sizes, and writing styles.
- Reducing the training/recognition time by a professionally optimized re-build of the core system, as well as using a more powerful hardware.
WERA, CERAWERG, CERG
3.08%, 0.77%10.32%, 2.58%

Simplified Arabic

Mudir (MS-Windows)

Koufi (MS-Windows)

Traditional Arabic(MS-Windows)

Akhbar (MS-windows)

Tahoma (MS-Windows)

Courier new (MS-Windows)

Baghdad (Mac.)

Demashq (Mac.)

Nadeem (Mac.)

Naskh (Mac.)

Giza (Mac.)




![Nouveautés 4 trimestre 2015 - Archives de Lyon · Lyon Québec Passion / Mohamed Attia ; photographies de Jean-Claude Beck, Ahmed Debbouze, Thierry Fournier... [et al.]. - Lyon :](https://img.pdfslide.net/doc/110x75/5fad8aaad3187f4ee9549a8b/nouveauts-4-trimestre-2015-archives-de-lyon-qubec-passion-mohamed-attia.jpg)

























