Embed Size (px)
Citation preview

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 1
Reinforcement Learning
Slides fromR.S. Sutton and A.G. Barto
Reinforcement Learning: An Introduction
http://www.cs.ualberta.ca/~sutton/book/the-book.htmlhttp://rlai.cs.ualberta.ca/RLAI/RLAIcourse/RLAIcourse.html
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 2
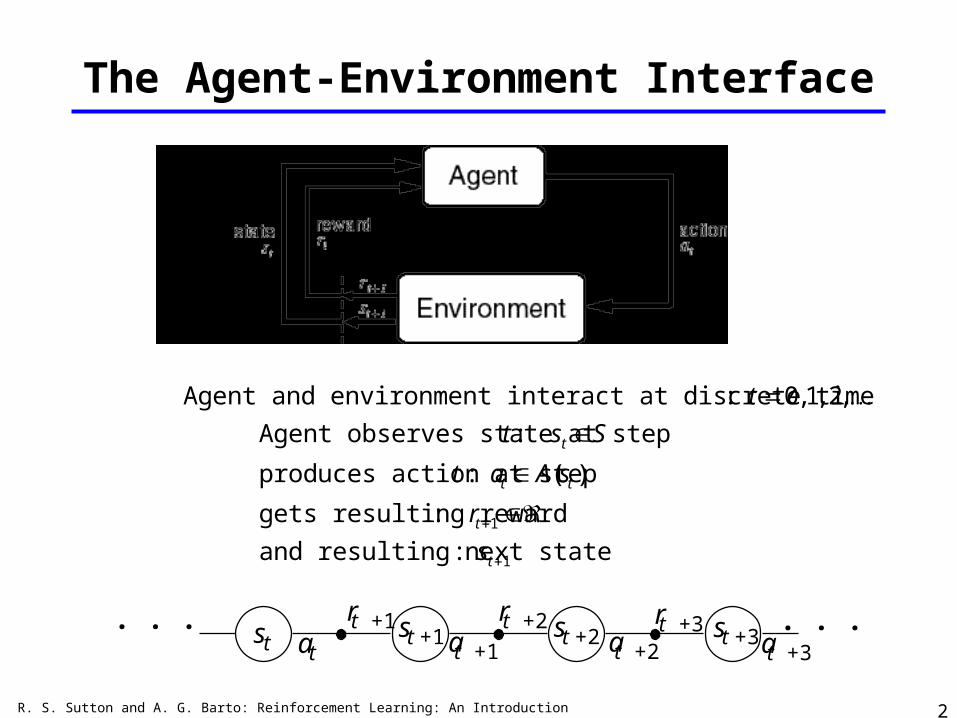
The Agent-Environment Interface
Agent and environment interact at discrete time steps : t 0,1, 2, Agent observes state at step t : st S
produces action at step t : at A(st )
gets resulting reward : rt1 and resulting next state : st1
t
. . . st art +1 st +1
t +1art +2 st +2
t +2art +3 st +3
. . .t +3a

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 3
Policy at step t, t :
a mapping from states to action probabilities
t (s, a) probability that at a when st s
The Agent Learns a Policy
Reinforcement learning methods specify how the agent changes its policy as a result of experience.
Roughly, the agent’s goal is to get as much reward as it can over the long run.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 4
Getting the Degree of Abstraction Right
Time steps need not refer to fixed intervals of real time. Actions can be low level (e.g., voltages to motors), or high
level (e.g., accept a job offer), “mental” (e.g., shift in focus of attention), etc.
States can be low-level “sensations”, or they can be abstract, symbolic, based on memory, or subjective (e.g., the state of being “surprised” or “lost”).
An RL agent is not like a whole animal or robot, which consist of many RL agents as well as other components.
The environment is not necessarily unknown to the agent, only incompletely controllable.
Reward computation is in the agent’s environment because the agent cannot change it arbitrarily.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 5
Goals and Rewards
Is a scalar reward signal an adequate notion of a goal?—maybe not, but it is surprisingly flexible.
A goal should specify what we want to achieve, not how we want to achieve it.
A goal must be outside the agent’s direct control—thus outside the agent.
The agent must be able to measure success: explicitly; frequently during its lifespan.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 6
Returns
Suppose the sequence of rewards after step t is :
rt1, rt2 , rt3,What do we want to maximize?
In general,
we want to maximize the expected return, E Rt , for each step t.
Episodic tasks: interaction breaks naturally into episodes, e.g., plays of a game, trips through a maze.
Rt rt1 rt2 rT ,
where T is a final time step at which a terminal state is reached, ending an episode.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 7
Returns for Continuing Tasks
Continuing tasks: interaction does not have natural episodes.
Discounted return:
Rt rt1 rt2 2rt3 krtk1,
k 0
where , 0 1, is the discount rate.
shortsighted 0 1 farsighted

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 8
An Example
Avoid failure: the pole falling beyonda critical angle or the cart hitting end oftrack.
reward 1 for each step before failure
return number of steps before failure
As an episodic task where episode ends upon failure:
As a continuing task with discounted return:reward 1 upon failure; 0 otherwise
return k , for k steps before failure
In either case, return is maximized by avoiding failure for as long as possible.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 9
Another Example
Get to the top of the hillas quickly as possible.
reward 1 for each step where not at top of hill
return number of steps before reaching top of hill
Return is maximized by minimizing number of steps reach the top of the hill.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 10
A Unified Notation
In episodic tasks, we number the time steps of each episode starting from zero.
We usually do not have distinguish between episodes, so we write instead of for the state at step t of episode j.
Think of each episode as ending in an absorbing state that always produces reward of zero:
We can cover all cases by writing
st st, j
Rt krtk 1,k 0
where can be 1 only if a zero reward absorbing state is always reached.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 11
The Markov Property
By “the state” at step t, the book means whatever information is available to the agent at step t about its environment.
The state can include immediate “sensations,” highly processed sensations, and structures built up over time from sequences of sensations.
Ideally, a state should summarize past sensations so as to retain all “essential” information, i.e., it should have the Markov Property:
Pr st1 s ,rt1 r st ,at ,rt , st 1,at 1,,r1,s0 ,a0 Pr st1 s ,rt1 r st ,at for all s , r, and histories st ,at ,rt , st 1,at 1,,r1, s0 ,a0.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 12
Markov Decision Processes
If a reinforcement learning task has the Markov Property, it is basically a Markov Decision Process (MDP).
If state and action sets are finite, it is a finite MDP. To define a finite MDP, you need to give:
state and action sets one-step “dynamics” defined by transition probabilities:
reward probabilities:
Ps s a Pr st1 s st s,at a for all s, s S, a A(s).
Rs s a E rt1 st s,at a,st1 s for all s, s S, aA(s).

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 13
Recycling Robot
An Example Finite MDP
At each step, robot has to decide whether it should (1) actively search for a can, (2) wait for someone to bring it a can, or (3) go to home base and recharge.
Searching is better but runs down the battery; if runs out of power while searching, has to be rescued (which is bad).
Decisions made on basis of current energy level: high, low. Reward = number of cans collected

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 14
Value Functions
State - value function for policy :
V (s)E Rt st s E krtk 1 st sk 0
Action - value function for policy :
Q (s, a) E Rt st s, at a E krtk1 st s,at ak0
The value of a state is the expected return starting from that state; depends on the agent’s policy:
The value of taking an action in a state under policy is the expected return starting from that state, taking that action, and thereafter following :

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 15
Bellman Equation for a Policy
Rt rt1 rt2 2rt3
3rt4
rt1 rt2 rt3 2rt4
rt1 Rt1
The basic idea:
So: V (s)E Rt st s E rt1 V st1 st s
Or, without the expectation operator:
V (s) (s,a) Ps s a Rs s
a V ( s ) s
a

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 16
More on the Bellman Equation
V (s) (s,a) Ps s a Rs s
a V ( s ) s
a
This is a set of equations (in fact, linear), one for each state.The value function for is its unique solution.
Backup diagrams:
for V for Q

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 17
Gridworld
Actions: north, south, east, west; deterministic. If would take agent off the grid: no move but reward = –1 Other actions produce reward = 0, except actions that
move agent out of special states A and B as shown.
State-value function for equiprobable random policy;= 0.9

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 18
if and only if V (s) V (s) for all s S
Optimal Value Functions
For finite MDPs, policies can be partially ordered:
There is always at least one (and possibly many) policies that is better than or equal to all the others. This is an optimal policy. We denote them all *.
Optimal policies share the same optimal state-value function:
Optimal policies also share the same optimal action-value function:
V (s) max
V (s) for all s S
Q(s,a)max
Q (s, a) for all s S and a A(s)
This is the expected return for taking action a in state s and thereafter following an optimal policy.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 19
Bellman Optimality Equation for V*
V (s) maxaA(s)
Q (s,a)
maxaA(s)
E rt1 V(st1) st s, at a max
aA(s)Ps s
a
s Rs s
a V ( s )
The value of a state under an optimal policy must equalthe expected return for the best action from that state:
The relevant backup diagram:
is the unique solution of this system of nonlinear equations.V

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 20
Bellman Optimality Equation for Q*
Q(s,a)E rt1 maxa
Q (st1, a ) st s,at a Ps s
a Rs s a max
a Q( s , a )
s
The relevant backup diagram:
is the unique solution of this system of nonlinear equations.Q*
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 21
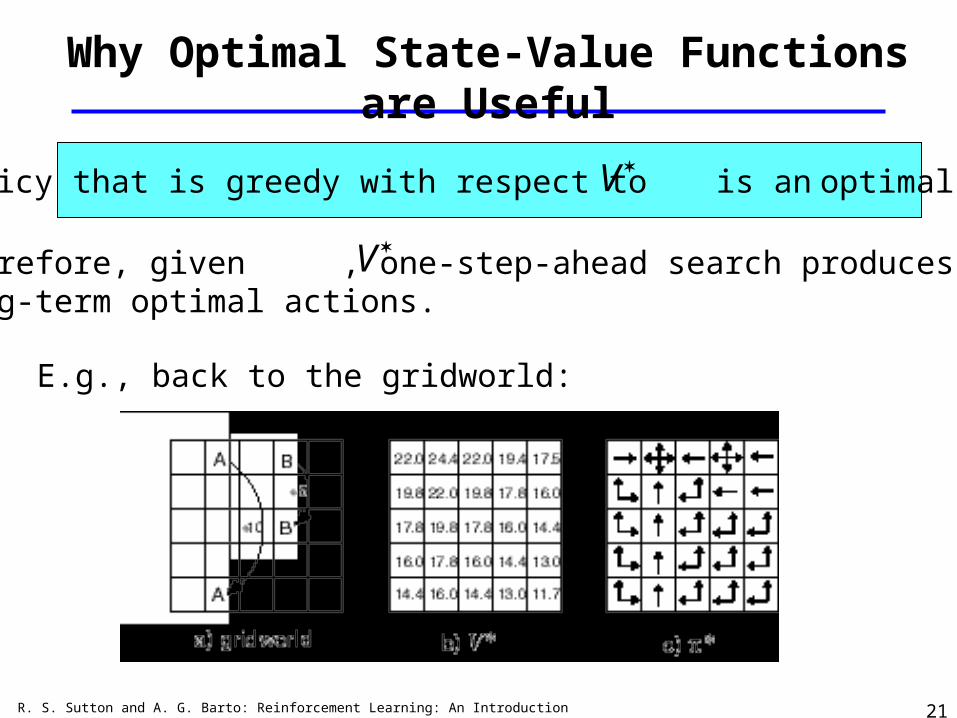
Why Optimal State-Value Functions are Useful
V
V
Any policy that is greedy with respect to is an optimal policy.
Therefore, given , one-step-ahead search produces the long-term optimal actions.
E.g., back to the gridworld:

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 22
What About Optimal Action-Value Functions?
Given , the agent does not evenhave to do a one-step-ahead search:
Q*
(s)arg maxaA (s)
Q(s,a)

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 23
Solving the Bellman Optimality Equation
Finding an optimal policy by solving the Bellman Optimality Equation requires the following: accurate knowledge of environment dynamics; we have enough space an time to do the computation; the Markov Property.
How much space and time do we need? polynomial in number of states (via dynamic programming
methods; Chapter 4), BUT, number of states is often huge (e.g., backgammon has
about 10**20 states). We usually have to settle for approximations. Many RL methods can be understood as approximately solving
the Bellman Optimality Equation.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 24R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 24
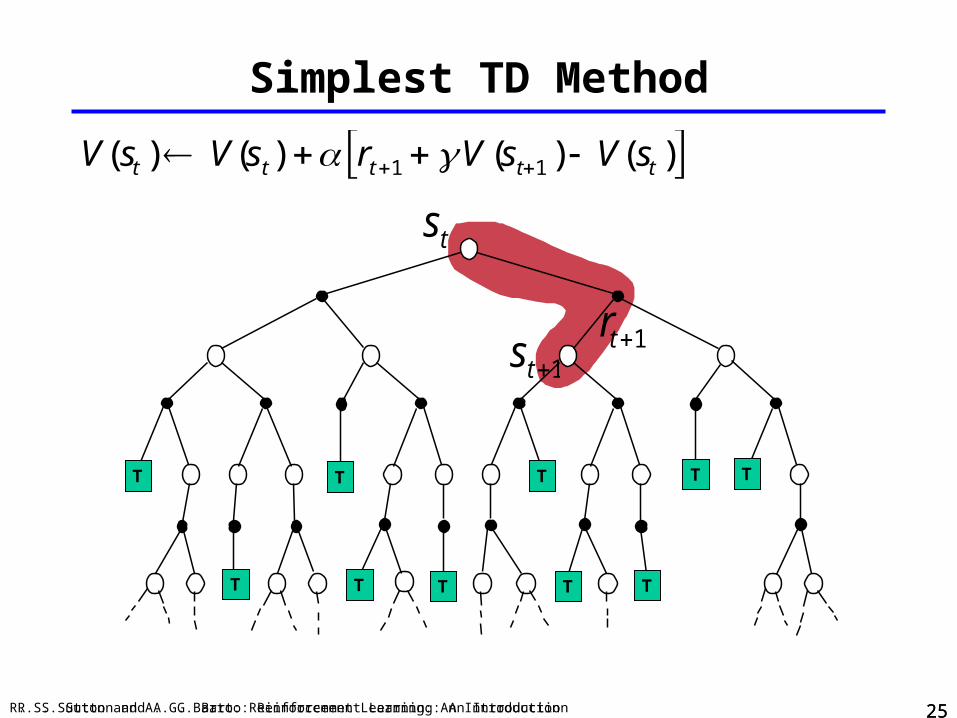
TD Prediction
Policy Evaluation (the prediction problem): for a given policy , compute the state-value function V
The simplest TD method, TD(0) :
V(st ) V(st) rt1 V (st1 ) V(st )
target: an estimate of the return
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 25R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 25
Simplest TD Method
T T T TT
T T T T T
st1
rt1
st
V(st ) V(st) rt1 V (st1 ) V(st )
TTTTT
T T T T T
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 26R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 26
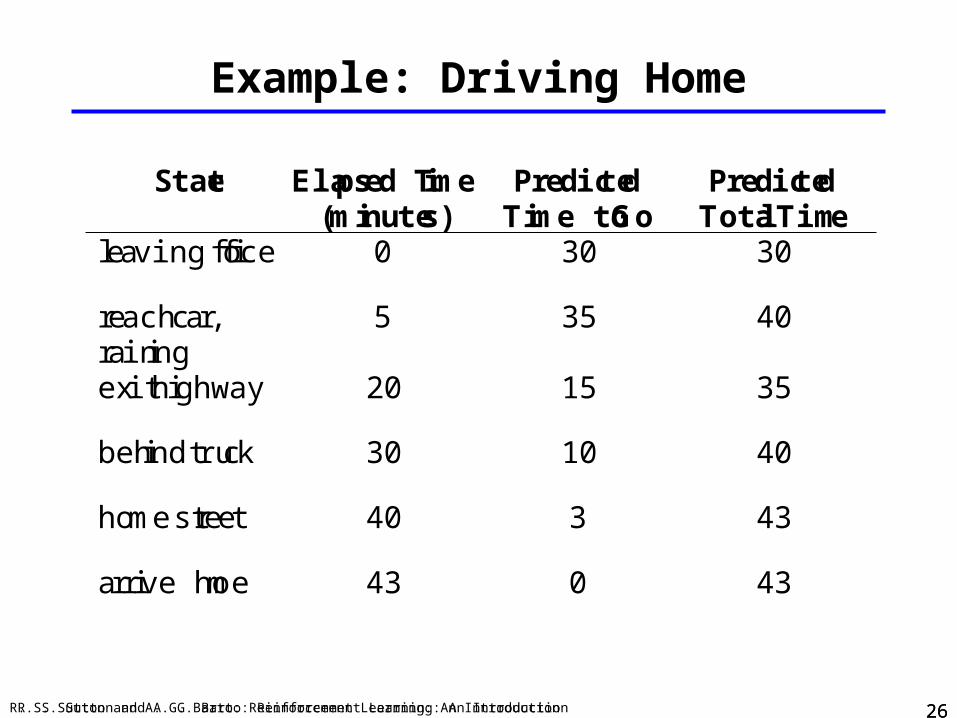
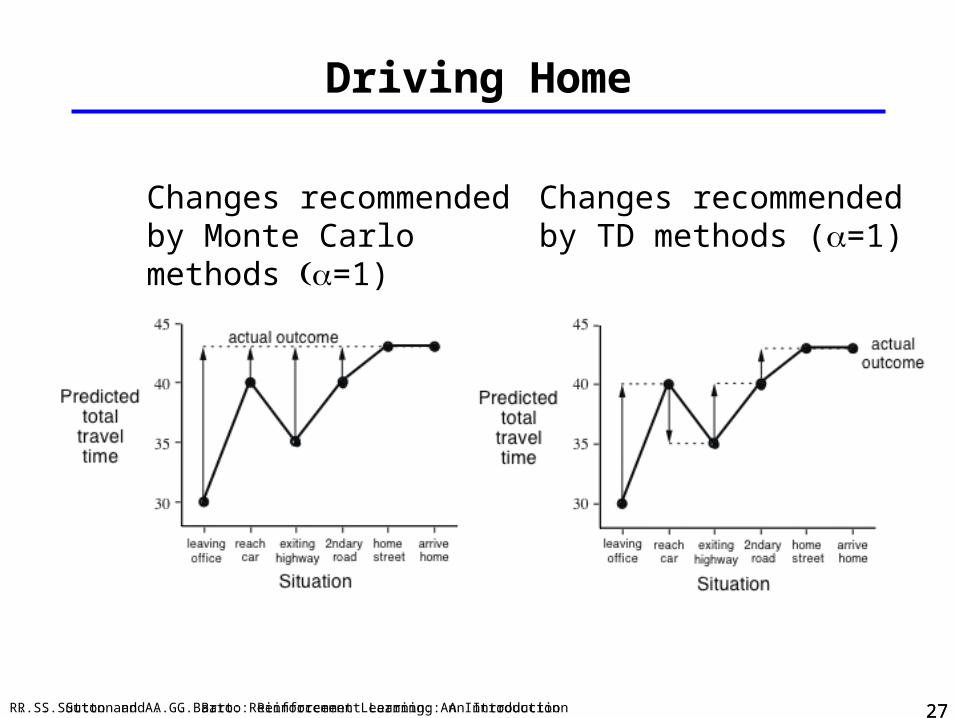
Example: Driving Home
State Elapsed Time(minutes)
PredictedTime to Go
PredictedTotal Time
leaving office 0 30 30
reach car,raining
5 35 40
exit highway 20 15 35
behind truck 30 10 40
home street 40 3 43
arrive home 43 0 43
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 27R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 27
Driving Home
Changes recommended by Monte Carlo methods =1)
Changes recommendedby TD methods (=1)

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 28R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 28
Advantages of TD Learning
TD methods do not require a model of the environment, only experience
TD methods can be fully incremental You can learn before knowing the final outcome
– Less memory
– Less peak computation You can learn without the final outcome
– From incomplete sequences
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 29R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 29
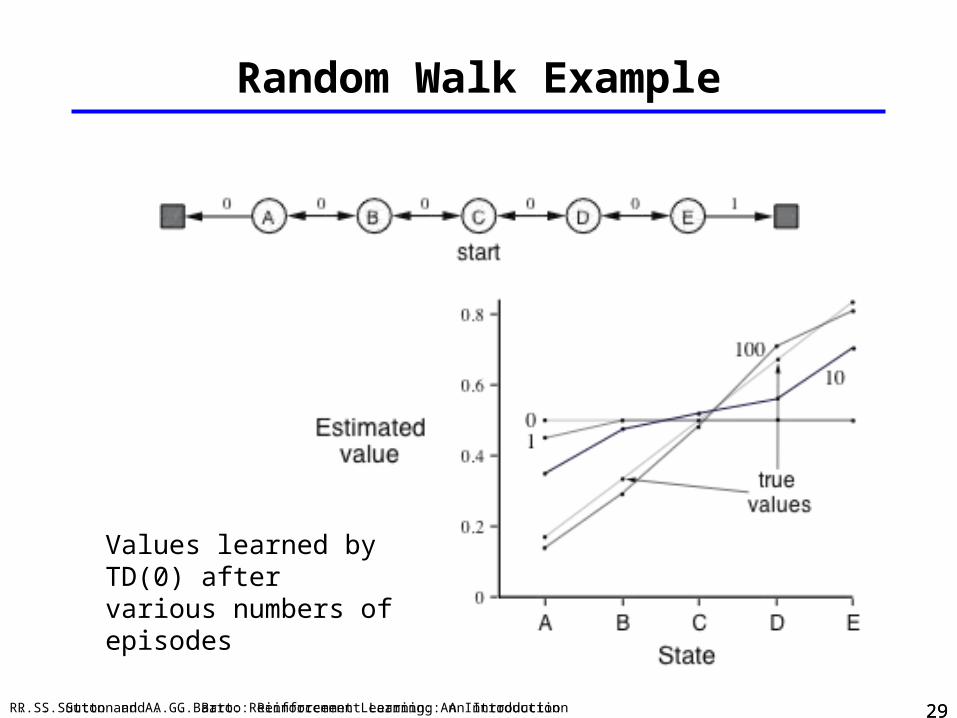
Random Walk Example
Values learned by TD(0) aftervarious numbers of episodes
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 30R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 30
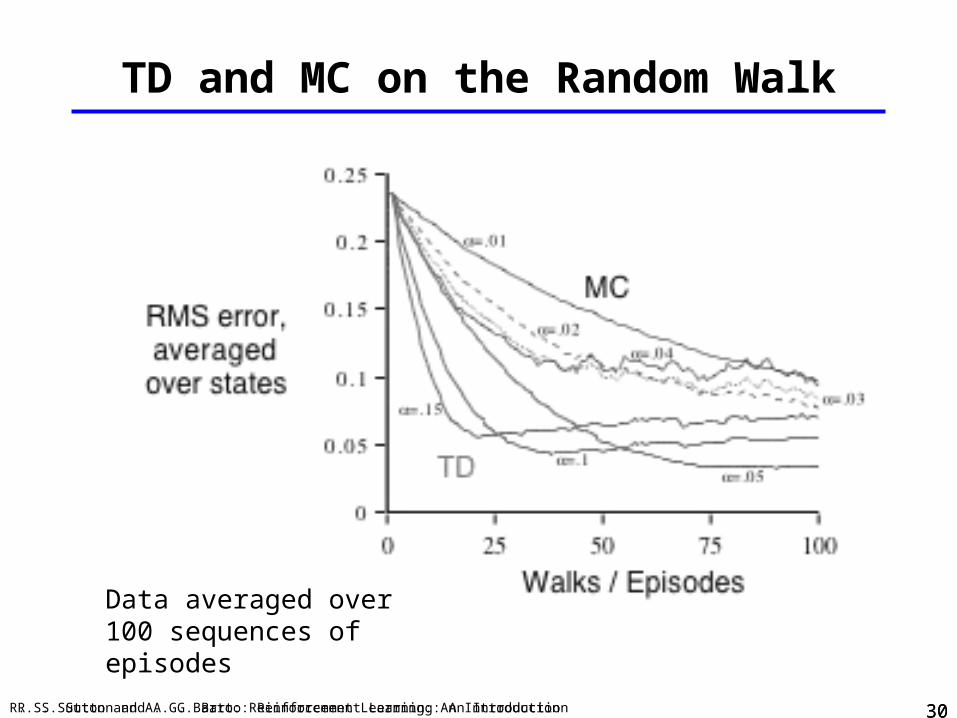
TD and MC on the Random Walk
Data averaged over100 sequences of episodes

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 31R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 31
Optimality of TD(0)
Batch Updating: train completely on a finite amount of data, e.g., train repeatedly on 10 episodes until convergence.
Compute updates according to TD(0), but only update estimates after each complete pass through the data.
For any finite Markov prediction task, under batch updating,TD(0) converges for sufficiently small .
Constant- MC also converges under these conditions, but toa difference answer!
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 32R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 32
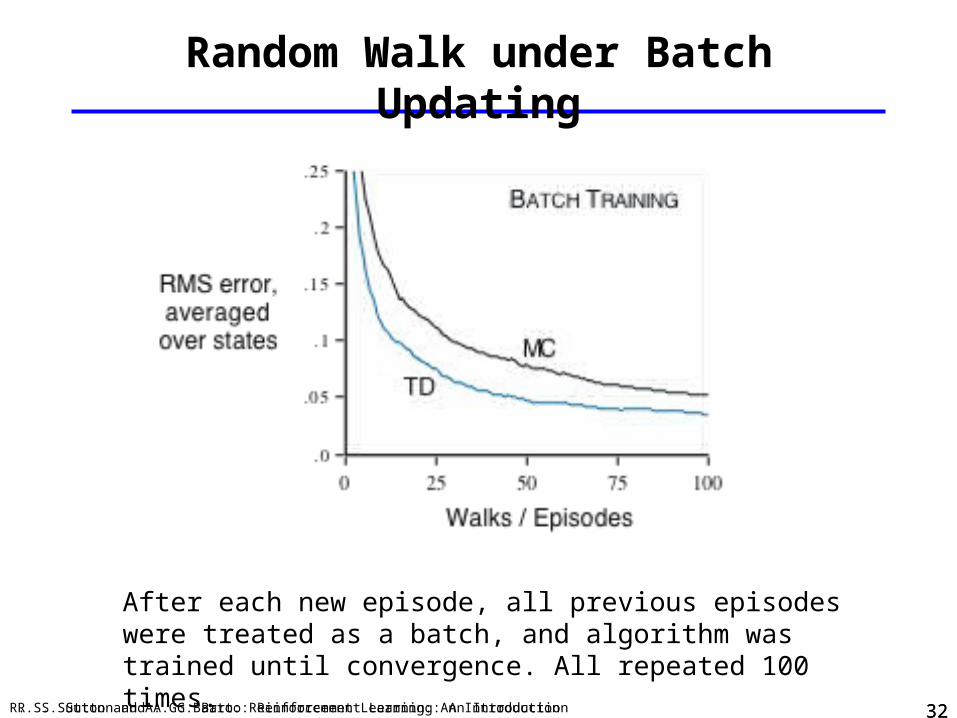
Random Walk under Batch Updating
After each new episode, all previous episodes were treated as a batch, and algorithm was trained until convergence. All repeated 100 times.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 33R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 33
Learning An Action-Value Function
Estimate Q for the current behavior policy .
After every transition from a nonterminal state st , do this :
Q st , at Q st , at rt1 Q st1,at1 Q st ,at If st1 is terminal, then Q(st1, at1 ) 0.

R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 34R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 34
Sarsa: On-Policy TD Control
Turn this into a control method by always updating thepolicy to be greedy with respect to the current estimate:
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 35R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 35
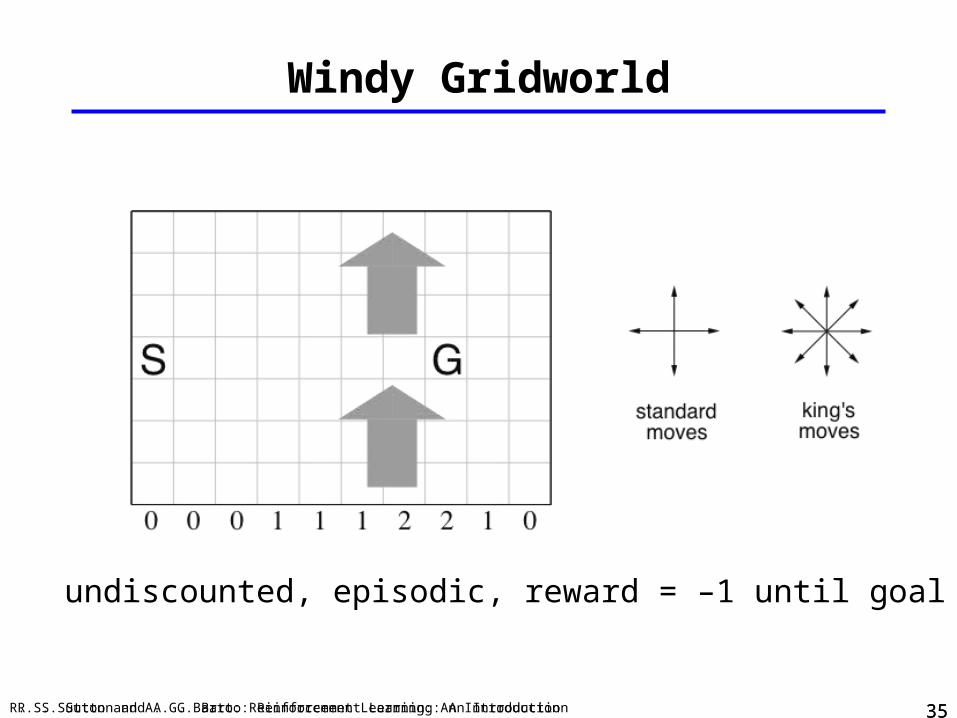
Windy Gridworld
undiscounted, episodic, reward = –1 until goal
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 36R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 36
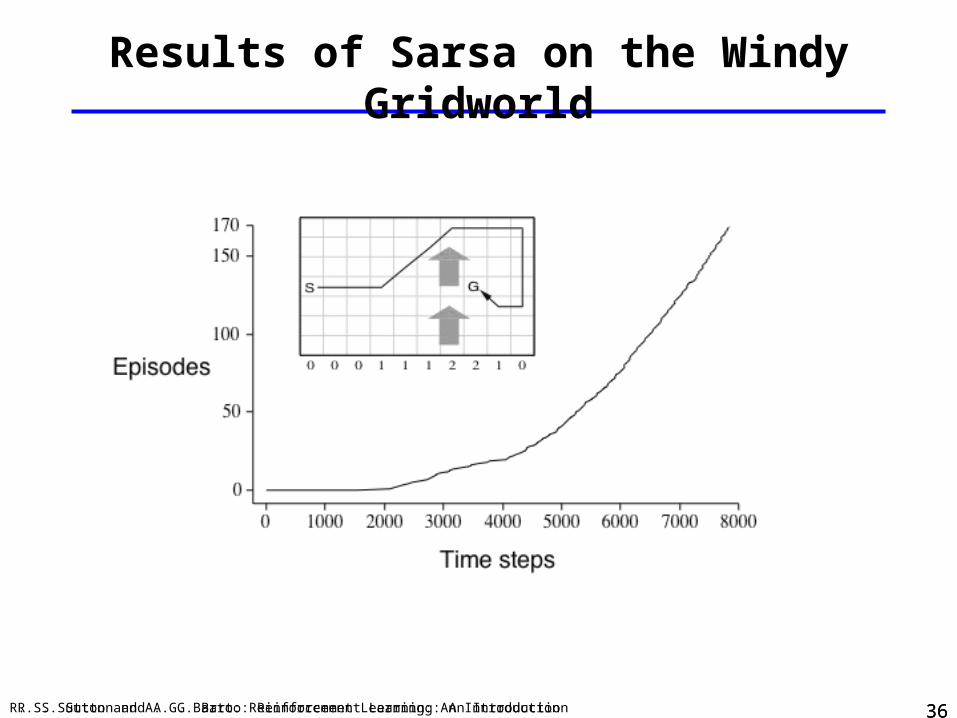
Results of Sarsa on the Windy Gridworld
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 37R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 37
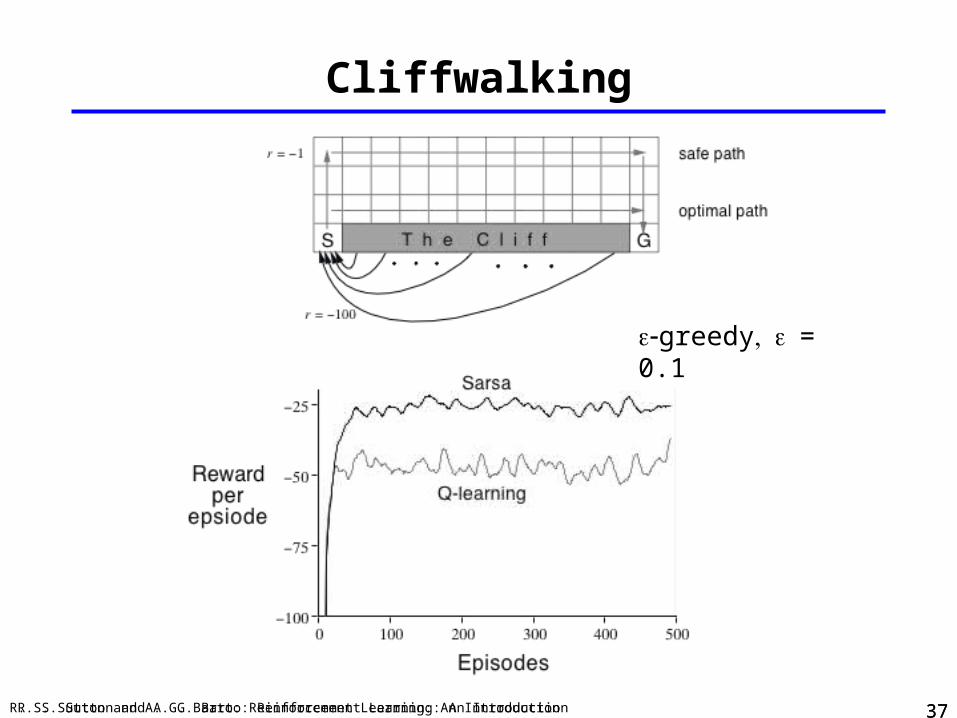
Cliffwalking
greedy= 0.1

![Reinforcement Learning for Learning Rate Control · learning rate falls into the scope of reinforcement learning (RL) [Sutton and Barto, 1998]. Inspired by the recent suc-cess of](https://img.pdfslide.net/doc/110x75/610b0ffe0e449d7d8b2b8f03/reinforcement-learning-for-learning-rate-control-learning-rate-falls-into-the-scope.jpg)



























