Embed Size (px)
Citation preview

Data & Knowledge Engineering 69 (2010) 1158–1180
Contents lists available at ScienceDirect
Data & Knowledge Engineering
j ourna l homepage: www.e lsev ie r.com/ locate /datak
Reasoning with large ontologies stored in relational databases: TheOntoMinD approach
Lina Al-Jadir a,1, Christine Parent b,⁎, Stefano Spaccapietra a
a Database Laboratory, Ecole Polytechnique Fédérale de Lausanne, Station 14, 1015 Lausanne, Switzerlandb Information Systems Institute, Université de Lausanne, bâtiment Internef, 1015 Lausanne, Switzerland
a r t i c l e i n f o
⁎ Corresponding author. Tel.: +41 21 693 52 53; faE-mail addresses: [email protected] (L. Al-Jadir)
1 Present address: Centre Universitaire d'Informatiq
0169-023X/$ – see front matter © 2010 Elsevier B.V.doi:10.1016/j.datak.2010.07.006
a b s t r a c t
Available online 15 July 2010
A major obstacle to the development of ontologies in support of the Semantic Web is the poorcapability of current ontology techniques to handle very large ontologies, in particular regardingscalability of reasoners. This paper builds on the assumption that very large ontologies can beefficiently handled using database management systems (DBMS), designed to provide bestperformance in storing, updating, and managing large volumes of data. To enhance DBMS withthe reasoning functionality that characterizes ontologymanagement, we propose to implementreasoning into the DBMS via a set of PL/SQL stored procedures. These procedures support allusual reasoning tasks: Class subsumption, property subsumption, class satisfiability, ABoxconsistency, and ABox realization. They perform these tasks at update time and materialize allinferred knowledge (facts and axioms) in the database. Contrarily to the inferencing at querytime inmost of existingworks, our approach is designed to speed up ontology querying,which issupposed to represent the most frequent and therefore critical usage of ontologies. The paperdiscusses querying patterns and reports on benchmarking (with the LUBM benchmark) theperformance of our prototype, called OntoMinD, compared to Oracle with SemanticTechnologies. Benchmark results demonstrate the appropriateness of our approach.© 2010 Elsevier B.V. All rights reserved.
Keywords:Ontology storageOntology reasoningOntology queryingBenchmarkDatabase
1. Introduction
The Semantic Web aims at extending the current Web so that the content of web pages will not exclusively be meaningful forhumans, but also be machine processable, hence usable by software agents searching theWeb to find the information they need toanswer user queries. Ontologies, as meaning providers, play a key role in this context by providing the means to align theinterpretation of the knowledge accessed from heterogeneous repositories by heterogeneous agents. As the idea becomes morepopular, real ontologies tend to become very large to huge (millions of items) in order to cover larger knowledge domains atvarious levels of detail. Unfortunately, most of current reasoners that provide the inference techniques that are essential toontologies can hardly cope with very large ontologies. This lack of scalability is due to the complexity of reasoning and of datahandling when faced with very large numbers of instances and axioms. The data handling part of the problem can be solved byusing database management systems (DBMS), which are already tailored to manage large volumes of data. Traditional DBMS,however, do not support reasoning and thus fail to provide full support for ontologies. Recent trends in addressing both facets(reasoning and data handling) of the scalability issue for ontologies include:
• Using hybrid configurations that couple a reasoner and a DBMS [1,2] so that their combined functionality supports allrequirements in terms of capability as well as in terms of performance,
x: +41 21 693 51 95., [email protected] (C. Parent), [email protected] (S. Spaccapietra).ue, Université de Genève, 7 route de Drize, 1227 Carouge, Switzerland.
All rights reserved.

1159L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
• Translating the ontology axioms into rules supported by a deductive DBMS [3–5], a family of systems designed long ago for bothreasoning and performance, and
• Extending an existing relational DBMS with reasoning capabilities [6] that make it suitable to address storing, reasoning,querying and updating requirements for ontology management.
We believe that the last trend is the most promising one, as relying on a single, commercially widespread database systemoffers significant advantages over the alternative approaches, in particular:
• Enriching existing systems is the most natural path to evolve data management technology into knowledge managementtechnology. Past experience with object orientation clearly shows that building a new relational DBMS generation (object-relational) has been more successful than creating new (object-oriented) systems based on a non-traditional paradigm.Moreover, adding functionality for reasoning on ontological knowledge allows supporting applications that need bothtraditional proprietary data and ontological data captured for example on the web.
• The DBMS-based approach can indeed solve the scalability issue raised by real ontologies.• The DBMS-based approach makes well-established DBMS functionalities available for ontology management. This includesoptimized querying, concurrent access, recovery mechanisms, security, and access rights.
• Finally, from a business-oriented perspective, this approach facilitates the use of ontologies in the enterprises world. Enterprisesequipped with database systems and willing to install enterprise ontologies are likely to easily adopt an extended version of thesystem they already have, while adopting new tools specifically developed for ontology management purposes (e.g. ontologyeditors and reasoners) may be seen as a hazardous investment calling for new people and new know-how acquisition.
These advantages motivated us to propose an approach and develop a tool, called OntoMinD for Ontology Management inDatabases [7], that extends a relational DBMS to store an ontology—its schema (the TBox), and its instances (the ABox)—as tables,while adding reasoning support within the database system itself using PL/SQL stored procedures [8]. Thus users benefit from bothdatabase and ontology functionalities. To make the solution efficient, our approach combines three performance-orientedfeatures: storage of the ontology in multiple tables, materialization of inferred information, and reasoning in the DBMS done atupdate time (to favor query-intensive applications). The experiments we performed with the LUBM benchmark [9] show that thecombination of these features makes OntoMinD an efficient and scalable ontology management system. The contribution of thispaper can therefore be stated as the assessment, through development and experimentation, that extending a DBMS to coverontological knowledge management is both feasible and efficient.
OntoMinD supports DL-Lite(R,⊓) ontologies [10,11]. DL-Lite has been proved to be tractable and is more expressive than RDFS[12], while more expressive OWL-based formalisms remain untractable.2
OntoMinD performs TBox reasoning (class satisfiability, class subsumption, and property subsumption) and ABox reasoning(ABox consistency and ABox realization). Reasoning is performed while processing updates and not while processing queries. Themotivation for this choice is to achieve outmost performance for query-intensive applications, i.e. applications where dataquerying is much more frequent than data updating. In practice, reasoning is carried out by PL/SQL stored procedures that add orremove an axiom/fact in the ontology. These procedures, in addition to adding or removing an axiom/fact, enforce the consistencyof the ontology, and infer other axioms/facts in the ontology according to inference rules. Thus the inferred data are materialized(i.e. stored in the database) and incrementally maintained.
OntoMinD supports answering simple queries, such as finding the instances of a class or a property. It also supports a subset ofconjunctive queries, such as finding thewineswhich are produced in France. Mixed queries that involve ontological and non-ontologicaldata can also be answered. OntoMinD performance on storing ontology and on processing queries has been evaluated using the LUBMbenchmark and results are encouraging as they show better performance for OntoMinD than for Oracle Semantic Technologies [6].
The paper is organized as follows. Section 2 presents related work. A DL-Lite(R,⊓) ontology example is given in Section 3.Section 4 explains the ontology storage in OntoMinD. Section 5 describes the reasoning tasks in OntoMinD. Ontology querying inSQL is illustrated in Section 6. Section 7 briefly describes OntoMinD implementation. Section 8 relates the experimentswe didwiththe LUBM benchmark. Finally, Section 9 summarizes the paper and mentions future work.
2. Related work
Several approaches have been proposed to address the problem of storing and reasoning with large ontologies. They differ byhow they store the ontology, the way they perform reasoning, the ontology formalism they support, whether they materialize theinferences, and whether they offer an explanation mechanism. In this section we discuss each of these features.
2.1. ABox storage
To illustrate the different storage approaches, we consider a fragment of a wine ontology. This fragment contains three classesWine,WineBody,WineSugar and three properties body, sugar, bestYears. A wine is described by its body (full, medium, or light), its
2 Most real-world ontologies are expressed in RDFS [12] or OWL-Lite [13]. DL-Lite(R,⊓) is a subset of OWL-Lite and a superset of RDFS. According to [14], out of1211 real-world OWL ontologies collected using Swoogle, Google, Protégé OWL Library, etc., 46% are RDFS, 32% are OWL-Lite, 22% are OWL-DL, with few usingOWL-Full.
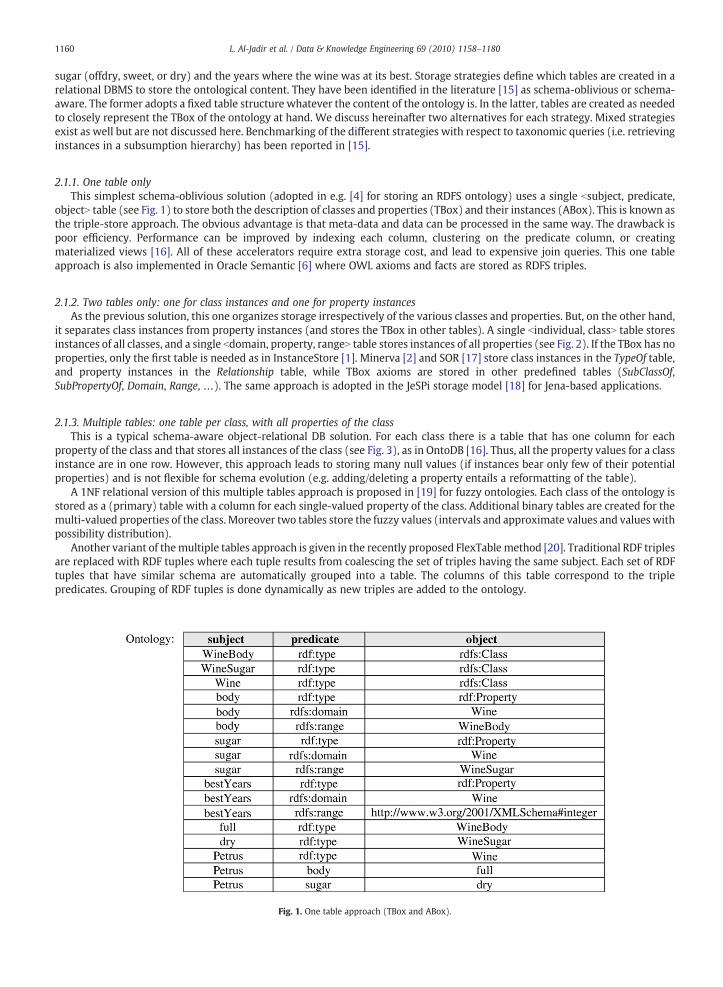
1160 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
sugar (offdry, sweet, or dry) and the years where the wine was at its best. Storage strategies define which tables are created in arelational DBMS to store the ontological content. They have been identified in the literature [15] as schema-oblivious or schema-aware. The former adopts a fixed table structure whatever the content of the ontology is. In the latter, tables are created as neededto closely represent the TBox of the ontology at hand. We discuss hereinafter two alternatives for each strategy. Mixed strategiesexist as well but are not discussed here. Benchmarking of the different strategies with respect to taxonomic queries (i.e. retrievinginstances in a subsumption hierarchy) has been reported in [15].
2.1.1. One table onlyThis simplest schema-oblivious solution (adopted in e.g. [4] for storing an RDFS ontology) uses a single bsubject, predicate,
objectN table (see Fig. 1) to store both the description of classes and properties (TBox) and their instances (ABox). This is known asthe triple-store approach. The obvious advantage is that meta-data and data can be processed in the same way. The drawback ispoor efficiency. Performance can be improved by indexing each column, clustering on the predicate column, or creatingmaterialized views [16]. All of these accelerators require extra storage cost, and lead to expensive join queries. This one tableapproach is also implemented in Oracle Semantic [6] where OWL axioms and facts are stored as RDFS triples.
2.1.2. Two tables only: one for class instances and one for property instancesAs the previous solution, this one organizes storage irrespectively of the various classes and properties. But, on the other hand,
it separates class instances from property instances (and stores the TBox in other tables). A single bindividual, classN table storesinstances of all classes, and a single bdomain, property, rangeN table stores instances of all properties (see Fig. 2). If the TBox has noproperties, only the first table is needed as in InstanceStore [1]. Minerva [2] and SOR [17] store class instances in the TypeOf table,and property instances in the Relationship table, while TBox axioms are stored in other predefined tables (SubClassOf,SubPropertyOf, Domain, Range, …). The same approach is adopted in the JeSPi storage model [18] for Jena-based applications.
2.1.3. Multiple tables: one table per class, with all properties of the classThis is a typical schema-aware object-relational DB solution. For each class there is a table that has one column for each
property of the class and that stores all instances of the class (see Fig. 3), as in OntoDB [16]. Thus, all the property values for a classinstance are in one row. However, this approach leads to storing many null values (if instances bear only few of their potentialproperties) and is not flexible for schema evolution (e.g. adding/deleting a property entails a reformatting of the table).
A 1NF relational version of this multiple tables approach is proposed in [19] for fuzzy ontologies. Each class of the ontology isstored as a (primary) table with a column for each single-valued property of the class. Additional binary tables are created for themulti-valued properties of the class. Moreover two tables store the fuzzy values (intervals and approximate values and values withpossibility distribution).
Another variant of themultiple tables approach is given in the recently proposed FlexTable method [20]. Traditional RDF triplesare replaced with RDF tuples where each tuple results from coalescing the set of triples having the same subject. Each set of RDFtuples that have similar schema are automatically grouped into a table. The columns of this table correspond to the triplepredicates. Grouping of RDF tuples is done dynamically as new triples are added to the ontology.
Fig. 1. One table approach (TBox and ABox).
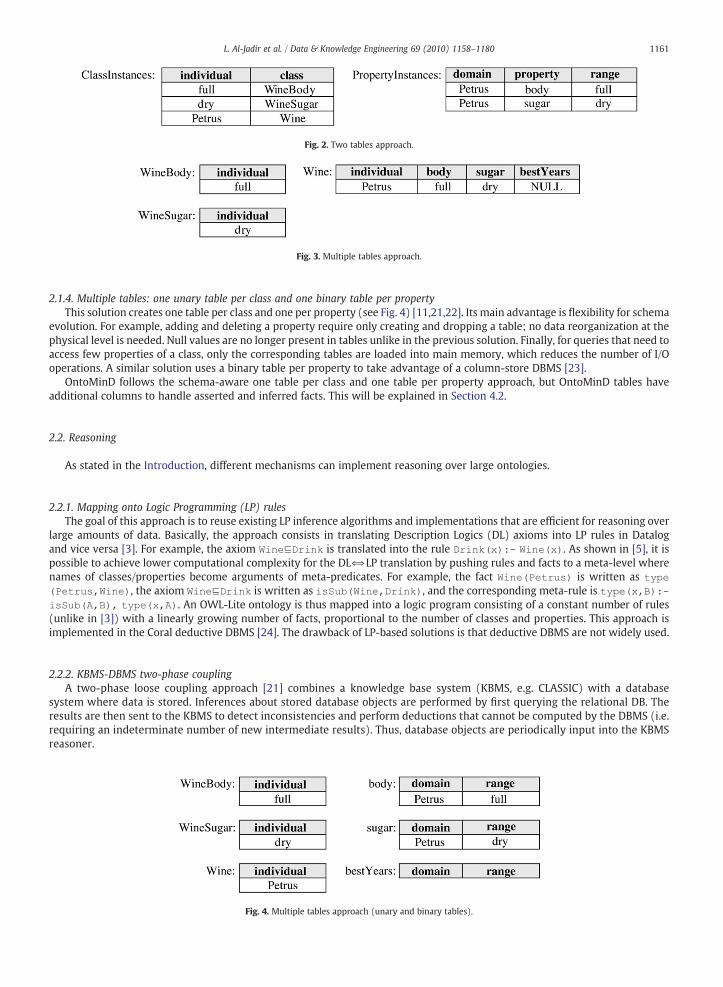
Fig. 2. Two tables approach.
Fig. 3. Multiple tables approach.
Fig. 4. Multiple tables approach (unary and binary tables).
1161L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
2.1.4. Multiple tables: one unary table per class and one binary table per propertyThis solution creates one table per class and one per property (see Fig. 4) [11,21,22]. Its main advantage is flexibility for schema
evolution. For example, adding and deleting a property require only creating and dropping a table; no data reorganization at thephysical level is needed. Null values are no longer present in tables unlike in the previous solution. Finally, for queries that need toaccess few properties of a class, only the corresponding tables are loaded into main memory, which reduces the number of I/Ooperations. A similar solution uses a binary table per property to take advantage of a column-store DBMS [23].
OntoMinD follows the schema-aware one table per class and one table per property approach, but OntoMinD tables haveadditional columns to handle asserted and inferred facts. This will be explained in Section 4.2.
2.2. Reasoning
As stated in the Introduction, different mechanisms can implement reasoning over large ontologies.
2.2.1. Mapping onto Logic Programming (LP) rulesThe goal of this approach is to reuse existing LP inference algorithms and implementations that are efficient for reasoning over
large amounts of data. Basically, the approach consists in translating Description Logics (DL) axioms into LP rules in Datalogand vice versa [3]. For example, the axiom Wine⊑Drink is translated into the rule Drink(x):- Wine(x). As shown in [5], it ispossible to achieve lower computational complexity for the DL⇔LP translation by pushing rules and facts to a meta-level wherenames of classes/properties become arguments of meta-predicates. For example, the fact Wine(Petrus) is written as type
(Petrus,Wine), the axiom Wine⊑Drink is written as isSub(Wine,Drink), and the corresponding meta-rule is type(x,B):-isSub(A,B), type(x,A). An OWL-Lite ontology is thus mapped into a logic program consisting of a constant number of rules(unlike in [3]) with a linearly growing number of facts, proportional to the number of classes and properties. This approach isimplemented in the Coral deductive DBMS [24]. The drawback of LP-based solutions is that deductive DBMS are not widely used.
2.2.2. KBMS-DBMS two-phase couplingA two-phase loose coupling approach [21] combines a knowledge base system (KBMS, e.g. CLASSIC) with a database
system where data is stored. Inferences about stored database objects are performed by first querying the relational DB. Theresults are then sent to the KBMS to detect inconsistencies and perform deductions that cannot be computed by the DBMS (i.e.requiring an indeterminate number of new intermediate results). Thus, database objects are periodically input into the KBMSreasoner.

1162 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
2.2.3. DL reasoner-DBMS couplingThe InstanceStore system [1] aims at answering instance retrieval queries over very large ABoxes. It combines a DL
reasoner (e.g. Racer [25], FaCT [26]) to classify the TBox and a relational DBMS to store the property-free ABox. A retrievalquery to compute the set of instances of a class is answered using a combination of database queries and TBox reasoning.More recently, Minerva [2] and its successor SOR [17] store ontologies as relational DB, support TBox reasoning using a DLreasoner (e.g. Pellet [27]) and perform ABox reasoning by applying iteratively inference rules in the relational DBMS. Rules areimplemented using SQL statements. Coupling approaches face potentially prohibitive costs for communication between thetwo components.
2.2.4. Embedding reasoning in DBMSUnlike the two previous ones, this approach in Oracle Semantic [6] aims at using a single system, a relational DBMS with an
embedded forward-chaining inference engine [28]. Oracle Semantic performs native OWLPrime inferencing and user-definedrules inferencing. It also allows selective inference (i.e. the user can choose the set of rules to fire). The PL/SQL procedure sem_apis.create_entailment performs inference and adds or removes inferred triples in the ontology, and the procedures sem_apis.validate_model and sem_apis.validate_entailment detect inconsistencies in the ontology.
OntoMinD also uses a single extended DBMS to avoid the overhead and mismatches due to the coupling of two systems. Thereasoner is embedded in the DBMS as PL/SQL procedures. But unlike Oracle Semantic, OntoMinD performs reasoningincrementally at update time. In [29] inference is also computed at update time thanks to database triggers (instead of an externalreasoner) in order to detect logical inconsistencies.
2.2.5. Performing reasoning during query evaluationIn this approach, reasoning is performed as part of query processing. In a first step the user's query is reformulated into a new
query that results from reasoning on the axioms defined in the TBox. For example, Q(?x)←Drink(?x) is rewritten to Q’(?x) ←
Drink(?x) ∪ Wine(?x) because of the axiom Wine⊑Drink. Thus the query returns the instances of Drink and the instances ofWine (wines are also drinks). In a second step, the reformulated query is translated to SQL and evaluated by the DBMS handlingthe ABox. This approach is implemented in the QuOnto prototype [11] and is able to handle conjunctive queries (e.g. Q(?x)←Wine(?x), body(?x,full), producedBy(?x,?y), locatedIn(?y,CoteDOr)), more complex than the instanceretrieval queries (e.g. Wine(?x)) in [1]. Query processing benefits from DBMS efficiency. A drawback of the QuOnto approachis that reasoning at query time (i.e. query reformulation) has to be repeated each time the same query or sub-query has to beevaluated.
2.3. Ontology formalism
While Description Logics (DL) forms the common substrate to most formal approaches to ontologies, different R&Dprojects use different DL formalisms according to the targeted compromise between expressiveness and complexity. Forexample, [3] and Minerva [2] adopt a subset of DL, the Description Horn Logic (DHL).3 The other proposals derive theirformalism from OWL specifications. OWL-Lite is supported in [5,30]. In [10], the DL-Lite family, a subset of OWL-Lite, isconsidered. InstanceStore [1] supports only property-free ABoxes. Oracle Semantic [6] supports OWLPrime. These ontologylanguages differ in the class and property constructs they support (see Fig. 54). A construct may be supported (✓), notsupported (×), or supported in a limited way, i.e. either on the left-hand side (LHS) or on the right-hand side (RHS) of a classinclusion axiom (CLHS⊑CRHS). OntoMinD supports DL-Lite(R,⊓) which belongs to the DL-Lite family and which is interestingsince it has low reasoning complexity.
2.4. Materialization
The term materialization is used to characterize approaches where the information that is inferred by deduction is stored inthe ontology and maintained when the TBox or the ABox are updated. If the query rate is high (which is likely to be the case ina Semantic Web with predominance of reading accesses), strategies based on materialization are expected to lead to betterperformance than earlier approaches [1,3,5,11] that perform reasoning (i.e. the computation of derived information) whenquerying the ontology. An incremental maintenance technique for materialized inferences in a deductive DBMS is proposed in[4]. Minerva [2] and Oracle Semantic [6] also materialize the inferences. When a TBox axiom is added or removed, Minervasends the TBox to the reasoner to recompute the subsumption graph. When an ABox fact is added or removed, Minerva re-runs ABox inference rules to get newly inferred data. Oracle Semantic stores the inferred triples in a partition of the triplestable [28], and updates them on user demand with the sem_apis.create_entailment procedure.
Materialization is the inspiring principle of OntoMinD, which materializes the inferred information and maintains it each timean axiom or fact is added to or removed from the ontology.
3 Minerva supports OWL-DL for TBox reasoning, but DHL for ABox reasoning.4 The union operator is always supported on the LHS of an inclusion axiom, since the axioms A⊑C and B⊑C are equivalent to A⊔B⊓C. The intersection operator
is always supported on the RHS of an inclusion axiom, since the axioms A⊑B and A⊑C are equivalent to A⊑B⊓C.
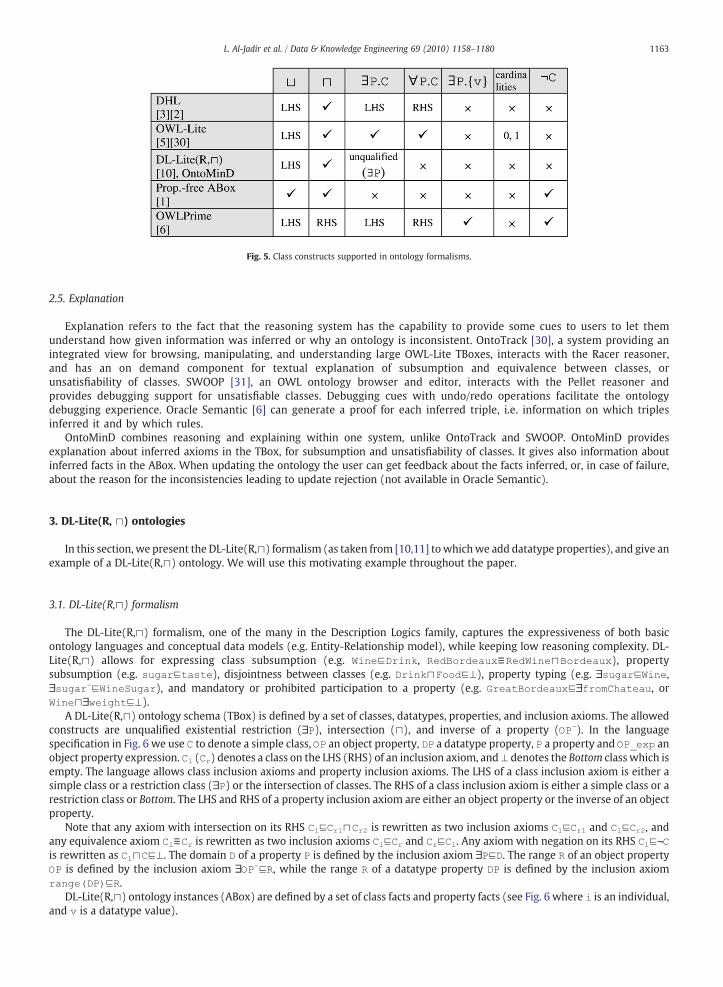
Fig. 5. Class constructs supported in ontology formalisms.
1163L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
2.5. Explanation
Explanation refers to the fact that the reasoning system has the capability to provide some cues to users to let themunderstand how given information was inferred or why an ontology is inconsistent. OntoTrack [30], a system providing anintegrated view for browsing, manipulating, and understanding large OWL-Lite TBoxes, interacts with the Racer reasoner,and has an on demand component for textual explanation of subsumption and equivalence between classes, orunsatisfiability of classes. SWOOP [31], an OWL ontology browser and editor, interacts with the Pellet reasoner andprovides debugging support for unsatisfiable classes. Debugging cues with undo/redo operations facilitate the ontologydebugging experience. Oracle Semantic [6] can generate a proof for each inferred triple, i.e. information on which triplesinferred it and by which rules.
OntoMinD combines reasoning and explaining within one system, unlike OntoTrack and SWOOP. OntoMinD providesexplanation about inferred axioms in the TBox, for subsumption and unsatisfiability of classes. It gives also information aboutinferred facts in the ABox. When updating the ontology the user can get feedback about the facts inferred, or, in case of failure,about the reason for the inconsistencies leading to update rejection (not available in Oracle Semantic).
3. DL-Lite(R, ⊓) ontologies
In this section, we present the DL-Lite(R,⊓) formalism (as taken from [10,11] towhichwe add datatype properties), and give anexample of a DL-Lite(R,⊓) ontology. We will use this motivating example throughout the paper.
3.1. DL-Lite(R,⊓) formalism
The DL-Lite(R,⊓) formalism, one of the many in the Description Logics family, captures the expressiveness of both basicontology languages and conceptual data models (e.g. Entity-Relationship model), while keeping low reasoning complexity. DL-Lite(R,⊓) allows for expressing class subsumption (e.g. Wine⊑Drink, RedBordeaux≡RedWine⊓Bordeaux), propertysubsumption (e.g. sugar⊑taste), disjointness between classes (e.g. Drink⊓Food⊑⊥), property typing (e.g. ∃sugar⊑Wine,∃sugar-⊑WineSugar), and mandatory or prohibited participation to a property (e.g. GreatBordeaux⊑∃fromChateau, orWine⊓∃weight⊑⊥).
A DL-Lite(R,⊓) ontology schema (TBox) is defined by a set of classes, datatypes, properties, and inclusion axioms. The allowedconstructs are unqualified existential restriction (∃P), intersection (⊓), and inverse of a property (OP-). In the languagespecification in Fig. 6 we use C to denote a simple class, OP an object property, DP a datatype property, P a property and OP_exp anobject property expression. Cl (Cr) denotes a class on the LHS (RHS) of an inclusion axiom, and⊥ denotes the Bottom class which isempty. The language allows class inclusion axioms and property inclusion axioms. The LHS of a class inclusion axiom is either asimple class or a restriction class (∃P) or the intersection of classes. The RHS of a class inclusion axiom is either a simple class or arestriction class or Bottom. The LHS and RHS of a property inclusion axiom are either an object property or the inverse of an objectproperty.
Note that any axiom with intersection on its RHS Cl⊑Cr1⊓Cr2 is rewritten as two inclusion axioms Cl⊑Cr1 and Cl⊑Cr2, andany equivalence axiom Cl≡Cr is rewritten as two inclusion axioms Cl⊑Cr and Cr⊑Cl. Any axiom with negation on its RHS Cl⊑¬Cis rewritten as Cl⊓C⊑⊥. The domain D of a property P is defined by the inclusion axiom ∃P⊑D. The range R of an object propertyOP is defined by the inclusion axiom ∃OP-⊑R, while the range R of a datatype property DP is defined by the inclusion axiomrange(DP)⊑R.
DL-Lite(R,⊓) ontology instances (ABox) are defined by a set of class facts and property facts (see Fig. 6 where i is an individual,and v is a datatype value).

Fig. 6. DL-Lite(R, ⊓) formalism.
1164 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
3.2. DL-Lite(R,⊓) ontology
A small example of a DL-Lite(R,⊓) ontology describing wines is given in Table 1). Every wine is a drink. Drinks and foods aredisjoint. There are different kinds of wines, such as red wines and Bordeaux wines. RedBordeaux wines are red wines andBordeaux wines. GreatBordeaux wines are Bordeaux wines that are produced in a chateau. A wine is described by its body and itssugar (giving its taste). The years in which a wine was excellent are recorded.
4. Storing the ontology
This section explains how the ontology schema and instances are stored in OntoMinD, illustrates it with an example, anddiscusses the storage cost in our approach. OntoMinD stores a DL-Lite(R,⊓) ontology as a relational database using the Oracle 11 gDBMS. The definitions of classes and properties, i.e. meta-data, are stored as rows in specific predefined tables. Similarly, class andproperty instances, i.e. data, are stored as rows in tables, one table per class and per property. OntoMinD stores both asserted(stated by the user) and inferred (deduced by reasoning) data and meta-data.
Table 1
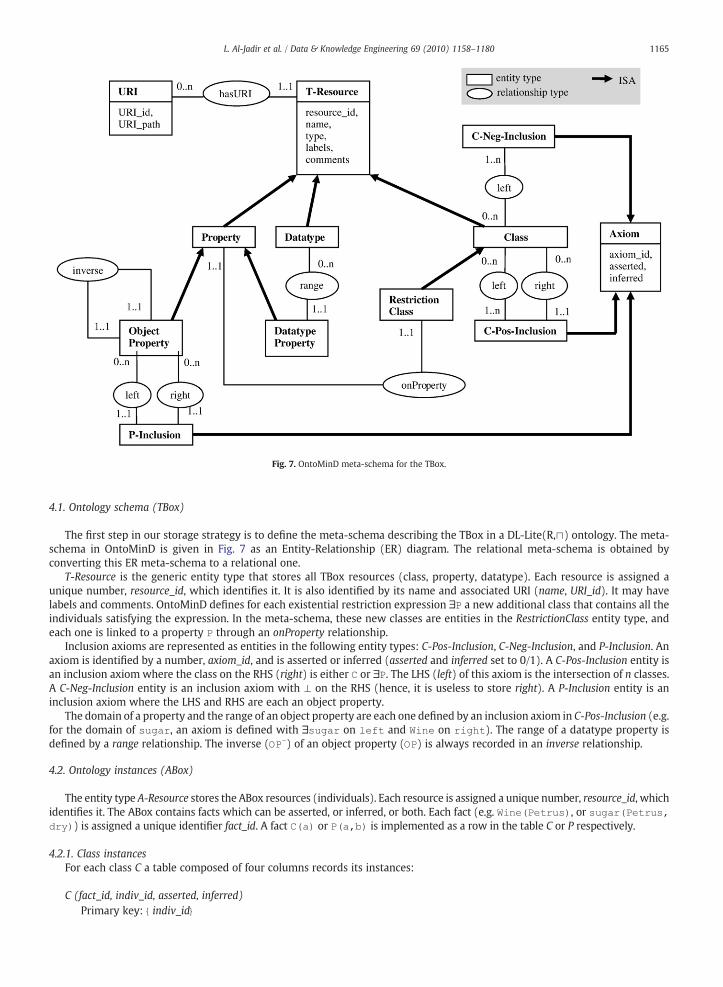
Fig. 7. OntoMinD meta-schema for the TBox.
1165L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
4.1. Ontology schema (TBox)
The first step in our storage strategy is to define the meta-schema describing the TBox in a DL-Lite(R,⊓) ontology. The meta-schema in OntoMinD is given in Fig. 7 as an Entity-Relationship (ER) diagram. The relational meta-schema is obtained byconverting this ER meta-schema to a relational one.
T-Resource is the generic entity type that stores all TBox resources (class, property, datatype). Each resource is assigned aunique number, resource_id, which identifies it. It is also identified by its name and associated URI (name, URI_id). It may havelabels and comments. OntoMinD defines for each existential restriction expression ∃P a new additional class that contains all theindividuals satisfying the expression. In the meta-schema, these new classes are entities in the RestrictionClass entity type, andeach one is linked to a property P through an onProperty relationship.
Inclusion axioms are represented as entities in the following entity types: C-Pos-Inclusion, C-Neg-Inclusion, and P-Inclusion. Anaxiom is identified by a number, axiom_id, and is asserted or inferred (asserted and inferred set to 0/1). A C-Pos-Inclusion entity isan inclusion axiom where the class on the RHS (right) is either C or ∃P. The LHS (left) of this axiom is the intersection of n classes.A C-Neg-Inclusion entity is an inclusion axiom with ⊥ on the RHS (hence, it is useless to store right). A P-Inclusion entity is aninclusion axiom where the LHS and RHS are each an object property.
The domain of a property and the range of an object property are each one defined by an inclusion axiom in C-Pos-Inclusion (e.g.for the domain of sugar, an axiom is defined with ∃sugar on left and Wine on right). The range of a datatype property isdefined by a range relationship. The inverse (OP-) of an object property (OP) is always recorded in an inverse relationship.
4.2. Ontology instances (ABox)
The entity type A-Resource stores the ABox resources (individuals). Each resource is assigned a unique number, resource_id, whichidentifies it. The ABox contains facts which can be asserted, or inferred, or both. Each fact (e.g. Wine(Petrus), or sugar(Petrus,dry)) is assigned a unique identifier fact_id. A fact C(a) or P(a,b) is implemented as a row in the table C or P respectively.
4.2.1. Class instancesFor each class C a table composed of four columns records its instances:
C (fact_id, indiv_id, asserted, inferred)Primary key: {indiv_id}
1166 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
Candidate key: {fact_id}Foreign key: {indiv_id} references A-Resource
where fact_id is a system identifier, indiv_id is the id of an individual (corresponds to a resource_id), asserted (0/1) indicateswhether the fact C(indiv_id) is asserted, and inferred (0/1) whether this fact is inferred.
An individual can be instance of several classes (e.g. C1 and C2), whether these classes are linked by subsumption links or not.This is referred to as multiple instantiation. In OntoMinD, this is implemented by two rows, one in table C1 and one in table C2,which take the same value on the column indiv_id.
4.2.2. Property instancesFor each property P a table composed of five columns records its instances:
P(fact_id, domain, range, asserted, inferred)Primary key: {domain, range}Candidate key: {fact_id}Foreign key: {domain} references A-Resource
where domain is an individual's id. In the case of an object property, range is the id of a second individual (and references A-Resource). In the case of a datatype property, range is an atomic value (e.g. an integer, a string). Asserted and inferred apply asbefore for the fact P (domain,range).
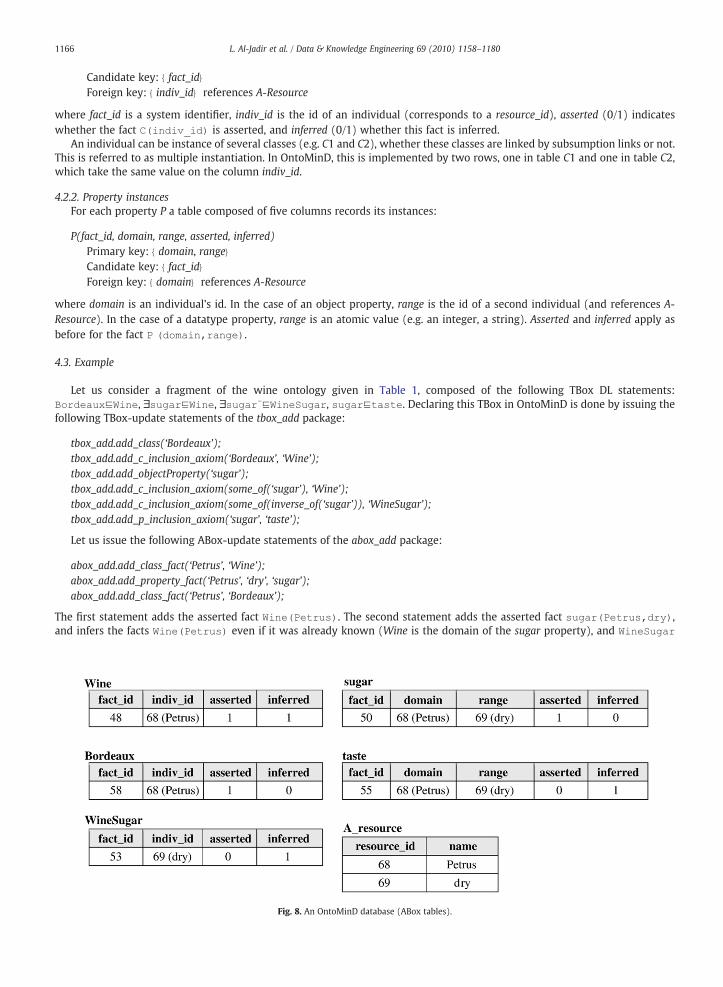
4.3. Example
Let us consider a fragment of the wine ontology given in Table 1, composed of the following TBox DL statements:Bordeaux⊑Wine, ∃sugar⊑Wine, ∃sugar-⊑WineSugar, sugar⊑taste. Declaring this TBox in OntoMinD is done by issuing thefollowing TBox-update statements of the tbox_add package:
tbox_add.add_class(‘Bordeaux’);tbox_add.add_c_inclusion_axiom(‘Bordeaux’, ‘Wine’);tbox_add.add_objectProperty(‘sugar’);tbox_add.add_c_inclusion_axiom(some_of(‘sugar’), ‘Wine’);tbox_add.add_c_inclusion_axiom(some_of(inverse_of(‘sugar’)), ‘WineSugar’);tbox_add.add_p_inclusion_axiom(‘sugar’, ‘taste’);
Let us issue the following ABox-update statements of the abox_add package:
abox_add.add_class_fact(‘Petrus’, ‘Wine’);abox_add.add_property_fact(‘Petrus’, ‘dry’, ‘sugar’);abox_add.add_class_fact(‘Petrus’, ‘Bordeaux’);
The first statement adds the asserted fact Wine(Petrus). The second statement adds the asserted fact sugar(Petrus,dry),and infers the facts Wine(Petrus) even if it was already known (Wine is the domain of the sugar property), and WineSugar
Fig. 8. An OntoMinD database (ABox tables).

1167L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
(dry) (WineSugar is the range of sugar). It also infers taste(Petrus,dry) (sugar is a subproperty of taste). The third statementadds the asserted fact Bordeaux(Petrus) (Bordeaux is a subclass of Wine, and the fact Wine(Petrus) is already inferred). Theresulting database is shown in Fig. 8 (the tables Top, some_sugar (∃sugar), some_inverse_sugar (∃sugar−), some_taste, andsome_inverse_taste are omitted).
4.4. Storage cost
As shown in the previous section, OntoMinD stores both asserted facts and inferred facts. The storage cost of thismaterialization is nowadays irrelevant. The needed storage capacity can be computed as follows.
Let us assume that the TBox, as defined by the users, contains n classes,m properties and k axioms. OntoMinD generates 2 newclasses for each property (∃P and ∃P-). Therefore, OntoMinD contains tables for n+2m classes, and m properties.
• Each class fact, e.g. C(a), infers at most n+2m−1 class facts (when C is subsumed by all the other classes).• Eachproperty fact, sayP(a,b), infers two class facts:∃P(a)and∃P-(b). Each of these class facts infers, like above, atmostn+2m−1 class facts. Thus P(a,b) infers 2n+4m class facts (i.e. a and b are both inferred as belonging to all classes). Moreover, in theworstcase, P is subsumedby all other properties and by their inverses, i.e. by 2m−1 other properties. Thatwill infer 2m−1 property facts.Note that these new property facts cannot infer new class facts that have not been already counted above (as we have alreadysupposed theworst casewhere a and b are inferred in all classes). Finally, the total number of inferred facts for an asserted propertyfact is: (2n+4m)+(2m−1)=6m+2n−1.
For an ontologywith: (i) a TBox containing n classes andm properties defined by the users, and (ii) an ABox containingN assertedclass facts and M asserted property facts, the resulting OntoMinD ABox will contain at most: (n+2m−1)⁎N+(6m+2n–1)⁎Minferred facts. Therefore the size of the OntoMinD ABox is, in the worst case, linear in the size of the original ABox containing only theasserted facts.
Similarly the size of the OntoMinD TBox is, in the worst case, quadratic in the size of the original TBox containing only theclasses, properties and axioms defined by the users. It is quadratic because the positive closure, in the worst case, for n classes suchthat C1⊑C2, C2⊑C3,…, Cn–1⊑Cn (n−1 axioms), infers (n−1)(n−2)/2 inclusion axioms.
5. Reasoning tasks
Reasoning is performed in order to provide answers to users' queries. Queries can be specific queries on the TBox, e.g. checkingits consistency or asking for completing the subsumption graph, or general queries on the ABox. ABox queries can be more or lesscomplex, ranging from simple queries requesting the set of instances of a class or property to complex queries. Each kind of queryrequires a specific level of reasoning. Many authors have studied the complexity of the reasoning tasks with respect to the kinds ofDL language and query language, e.g. [32,33]. In OntoMinD, we currently address all reasoning on the TBox (class satisfiability,class subsumption, and property subsumption) and, for the ABox, the subset of conjunctive queries that require reasoning only onexisting individuals. Formally speaking, this subset holds all conjunctive queries such that all the variables are in the head of thequery (see Sections 6.2 and 6.4).
This section describes the traditional ontological reasoning tasks [34] as performed by OntoMinD: Class satisfiability, classsubsumption, ABox consistency, and ABox realization (that computes the inferred facts that will be returned as parts of theanswers to the ABox queries). A class is satisfiable if it can contain instances. A class A subsumes a class B if B⊑A. An ABox isconsistent if no individual belongs to disjoint classes.
OntoMinD implements TBox reasoning using two internal PL/SQL stored procedures to check class satisfiability and computeclass subsumption. The first procedure, compute_negative_closure, computes the closure of negative inclusion axioms (i.e. axiomswhere the RHS is ⊥) in order to find out all the inferred disjointness axioms. For example, if the TBox contains the axioms A⊑B andB⊓C⊑⊥ (i.e. classes B and C are disjoint), then A⊓C⊑⊥ is added to the TBox as inferred axiom. A class D is not satisfiable if theaxiom D⊑⊥ belongs to the TBox. The second procedure, compute_positive_closure, computes the closure of positive inclusionaxioms in order to find out all the inferred subsumption axioms. For example, if the axioms A⊑B and B⊑C are in the TBox, then theaxiom A⊑C is inferred. OntoMinD implements ABox reasoning using four PL/SQL stored procedures: add_class_fact,add_property_fact, delete_class_fact, and delete_property_fact. These procedures allow addition and removal of any class fact orproperty fact to/from the ABox.
For DL-Lite(R,⊓) Calvanese et al. [11] have shown that the complexity of the reasoning tasks are polynomial in the size of theTBox and LOGSPACE in the size of the ABox.
5.1. Class satisfiability
In [11] the authors presented a sound and complete algorithm to compute the negative closure, i.e. the closure of negativeinclusion axioms. OntoMinD applies this algorithm to compute the negative closure NC of the TBox T. The rules (see Algorithm 1:lines 5 to 8) are applied as long as the NC changes. Once the negative closure has been computed, one can check the satisfiability ofa class: a class C is unsatisfiable if the axiom C⊑⊥ belongs to NC. The negative closure is computed when axioms are added to orremoved from the TBox.

1168 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
Algorithm 1. Compute_negative_closure5.
1. begin2. NC := empty3. add all negative inclusion axioms (asserted ones) of T to NC;4. while NC changes do5. if (B1⊓…⊓Bn⊑B in T and B1’⊓…⊓Bm’⊓B⊑⊥ in NC) then add B1’⊓…⊓Bm'⊓B1⊓…⊓Bn⊑⊥ to NC;6. if (R1⊑R2 in T and ∃R2⊓B1⊓…⊓Bn⊑⊥ in NC) then add ∃R1⊓B1⊓…⊓Bn⊑⊥ to NC;7. if (R1⊑R2 in T and ∃R2
-⊓B1⊓…⊓Bn⊑⊥ in NC) then add ∃R1-⊓B1⊓…⊓Bn⊑⊥ to NC;
8. if ∃R⊑⊥ in NC then add ∃R-⊑⊥ to NC;9. end10. end
5.2. Class subsumption
To get all the class subsumption links, OntoMinD computes the positive closure PC of the TBox T (see Algorithm 2), i.e. theclosure of positive inclusion axioms (Cl⊑Cr where Cr is C or ∃P). To check whether class C subsumes class D, OntoMinD searchesthe axiom D⊑C in the positive closure. The latter is computed when positive axioms are added to or removed from the TBox.
Computing the closure of property subsumption links is similar and even simpler than computing the positive closure; it istherefore omitted.
Algorithm 2. compute_positive_closure.
1. begin2. PC := empty3. add all positive inclusion axioms (asserted ones) of T to PC;4. while PC changes do5. if there is an axiom in PC with LHS B1⊓…⊓Bn then add B1⊓…⊓Bn⊑B1, …, B1⊓…⊓Bn⊑Bn to PC;6. if (B1⊓…⊓Bn⊑B in PC and B1’⊓…⊓Bm’⊓B⊑B’ in PC) then add B1'⊓…⊓Bm'⊓B1⊓…⊓Bn⊑B’ to PC;7. if R1⊑R2 in T then add ∃R1⊑∃R2, and ∃R1
-⊑∃R2- to PC;
8. end9. end
5.3. ABox consistency
The add_class_fact procedure adds an individual i to a class C. It ensures ABox consistency by preventing an individual tobelong to disjoint classes. To do so, it uses the negative closure (see Section 5.4.1, Algorithm 3: lines 11 to 14). If C appears in anaxiom of the negative closure (e.g. B⊓C⊓D⊑⊥), it checks whether i belongs to all the other classes of this axiom (e.g. B and D). Ifthis is true, the procedure raises an exception with an error message explaining the problem, and the add operation is rejected toavoid having an inconsistent ABox. This is different from the usual reasoners approach (e.g. Racer [25], Pellet [27]), where the ABoxconsistency is checked at query time after having added the fact, and the user is left with an inconsistent ABox.
5.4. ABox realization
OntoMinD implements ABox realization at update time by computing all possible inferences and storing them, a techniquecalled materialization. Practically each time a user adds a new fact, C(a) or P(a,b), all facts that can be inferred from this fact andthe actual ABox and TBox are added to the ABox. And when users withdraw a fact all the facts that have been inferred from it arewithdrawn too. For example, let us assume that the TBox contains the following two axioms that have been defined by users:Bordeaux⊑Wine, Wine⊑Drink. OntoMinD automatically closes the TBox by adding the inferred axiom: Bordeaux⊑Drink.Then when a user asserts: Bordeaux(ClosTrimoulet), this fact is added to the ABox with two inferred facts: Wine
(ClosTrimoulet) and Drink(ClosTrimoulet).As inferences are done and stored at update time, at query time the processing of queries is much simpler and faster: It is a
mere access to the tables that store the ABox. On the other hand, when using a reasoner that does not materialize theinferences, all the reasoning has to be performed at query time. Let us go back to the previous example. With this last kind ofreasoner, the TBox and ABox contain only the asserted axioms and facts: Bordeaux⊑Wine, Wine⊑Drink, Bordeaux(ClosTrimoulet). While in OntoMinD processing the query Q(?x)←Drink(?x) is a mere access to the Drink class, herereasoning is necessary in order to find out that the query has to access three classes, Drink, Wine and Bordeaux, and performtheir union. For instance QuOnto checks the TBox and rewrites the query, which in this case, becomes: Q(?x)←Drink(?x)∪Wine(?x)∪Bordeaux(?x).
5 In the closure algorithms (and inference rules in Section 5.4.1), the classes Bi and B are either a simple class C or a restriction class ∃P, and the properties Ri
are either an object property OP or the inverse of an object property OP-.

1169L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
Materialization can be handled as explained above in most of the cases, but not always. Tricky cases are those that involveknowledge about unknown individuals. For instance, let us assume the following axiom, asserted by the users: Great-
Bordeaux⊑∃fromChateau. This axiom says that the GreatBordeaux wines are always linked to at least a chateau. In OntoMinDthe fact GreatBordeaux(Petrus) generates the inferred fact ∃fromChateau(Petrus); both facts are stored in the ABox. Anotherpiece of knowledgemay be inferred from this axiom: Petrus is linked by the fromChateauproperty to a chateau, butwhich is unknown.Ifwewant tomaterialize all inferred facts,wehave to store the factfromChateau(Petrus,-)where the “−” represents anunknownindividual. It iswell known thatmanagingunknownvalues isnot easy. In thedatabase area a lot ofworkhas beendoneonNULLvalues,without endingwith a good solution [35]. One of themain classical problems generated by unknown individuals can be expressed asfollows: As soon as a second unknown individual has to be added, we do not know if it is the same as the previous one or a new one.Another problem - this one specific to ontologies - is the casewhere the TBox contains axioms that involve properties and thatmake acycle, e.g. ∃P⊑∃P-. Then a fact may generate an infinite set of unknown individuals.
Oracle Semantic chose a drastic solution: It ignores all axioms that would imply reasoning on unknown individuals, i.e. axioms with∃P on the RHS. The axiom GreatBordeaux⊑∃fromChateau of the above example is not used inOracle OWLPrime inferencing. Instead,Oracle users can add logical rules to be taken into account during inferencing. On the contrary, in order to provide a homogeneousand complete tool, OntoMinD supports these axioms that infer knowledge about unknown individuals. The actual version of OntoMinDsupports DL-Lite(R,⊓) (including axiomswith ∃P on the RHS), but restricts the query language to conjunctive queries that do not triggerinferences on unknown individuals.6 We are working on a next version of OntoMinD that supports all conjunctive queries.
The following sub-sections describe the inference rules that are triggered at update time and the procedures by which they areimplemented.
5.4.1. Adding and deleting factsDL-Lite(R,⊓) inference rules are implemented in the recursive add and delete procedures. For example, inference rule 1 (see
below) is implemented in add_class_fact (see Algorithm 3: lines 18 to 21) and delete_class_fact_step1 (see Algorithm 5: lines 16 to20). Thus if Bordeaux⊑Wine is in the TBox, adding/deleting the fact Bordeaux(ClosTrimoulet) will add/delete the fact Wine(ClosTrimoulet) to/from the ABox.
Inference rules (T: TBox, A: ABox):
1. if (B1⊓…⊓Bn⊑B in T and B1(x),…, Bn(x) in A) then add B(x) to A;2. if OP(x,y) in A then add ∃OP(x) and ∃OP-(y)to A;
if DP(x,v) in A then add ∃DP(x) to A;3. if ((OP1⊑OP2 in T or OP1-⊑OP2
- in T) and OP1(x,y) in A) then add OP2(x,y) to A;4. if ((OP1⊑OP2
- in T or OP1-⊑OP2 in T) and OP1(x,y) in A) then add OP2(y,x) to A;
Since the domain and the range of an object property are defined by inclusion axioms, e.g. ∃OP⊑B1 and ∃OP-⊑B2, adding thefact OP(x,y) infers ∃OP(x) and ∃OP-(y) by rule 2, and B1(x) and B2(y) by rule 1. Note that the classes ∃OP and ∃OP- areautomatically created when the property OP is added to the TBox.
Algorithm 3. add_class_fact(i, C, add_mode).
1. /* i: individual, C: class, add_mode is either ‘asserted’ (default) or ‘inferred’ */2. begin3. if C(i) exists then4. if (C(i) is asserted and add_mode= ‘asserted’) or (C(i) is inferred and add_mode= ‘inferred’) then return; /* nothing to do */5. f := the fact_id of C(i);6. /* update row in table C */7. if add_mode= ‘asserted’ then update row in table C: set asserted=1 where fact_id=f;8. else update row in table C: set inferred=1 where fact_id=f;9. else10. f := a new fact_id;11. /* check consistency */12. Neg_Axioms := (asserted and inferred) negative axioms that contain C;13. foreach ax in Neg_Axioms do14. if i belongs to each class (without C) in the LHS of ax then raise_exception;15. /* add row in table C */16. if add_mode= ‘asserted’ then add row (f, i, 1, 0) to table C;17. else add row (f, i, 0, 1) to table C;18. /* inference rule 1 */19. Pos_Axioms := (asserted) positive axioms where C belongs to the LHS;20. foreach ax in Pos_Axioms do21. if i belongs to each class in the LHS of ax then add_class_fact(i, RHS of ax, ‘inferred’); /* recursive call */22. endif23. end
6 Remark that only a few queries involve unknown individuals. For instance in the LUBM benchmark (see Section 8), none of the 14 queries does.

1170 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
The procedures delete_class_fact and delete_property_fact remove a fact from the ABox (but the fact may remain in the ABox asinferred), and apply the inference rules to un-infer the facts that were inferred by it (e.g. when deleting a class fact, see Algorithm5: lines 16 to 20). Then, they check if these facts can be re-inferred by other facts and re-infer them if needed. Indeed, un-inferred
facts are put in a CheckList in the procedure delete_class_fact_step1 (see Algorithm 5: line 14) and may be re-inferred in theprocedure re_infer_class_factswhich is called in delete_class_fact (see Algorithm 4: line 5). As example, the ABox in Section 4.3 (seeFig. 8) contains the asserted facts Wine(Petrus), sugar(Petrus,dry), and Bordeaux(Petrus). Running the statementabox_del.delete_class_fact(‘Petrus’, ‘Wine’) removes the fact Wine(Petrus) but the fact remains as inferred (since it was bothasserted and inferred). Then running the statement abox_del.delete_property_fact(‘Petrus’, ‘dry’, ‘sugar’) removes the fact sugar(Petrus,dry), un-infers the facts Wine(Petrus), WineSugar(dry) and taste(Petrus,dry)which are thus deleted, andthen re-infers Wine(Petrus) thanks to the fact Bordeaux(Petrus).Algorithm 4. delete_class_fact(i, C, del_mode).
1. /* i: individual, C: class, del_mode is either ‘asserted’ (default) or ‘inferred’ */2. begin3. CheckList := empty4. delete_class_fact_step1(i, C, del_mode) ;5. re_infer_class_facts;6. end
Algorithm 5. delete_class_fact_step1(i, C, del_mode).
1. /* i: individual, C: class, del_mode is either ‘asserted’ or ‘inferred’ */2. begin3. if (del_mode= ‘asserted’) and (C(i) is not asserted or does not exist) then raise_exception; /* user error */4. if (del_mode= ‘inferred’) and (C(i) is not inferred or does not exist) then return; /* fact already deleted in a cycle */5. f := fact_id of C(i);6. /* update or delete row in table C */7. if del_mode= ‘asserted’ then8. if C(i) is inferred then update row: set asserted=0 where fact_id=f;9. else delete row where fact_id=f;10. else11. if C(i) is asserted then update row: set inferred=0 where fact_id=f;12. else delete row where fact_id=f;13. /* add C(i) to the list of facts to check whether they can be re-inferred */14. add C(i) to CheckList;15. endif16. /* inference rule 1 */17. /* rem: inference applied even if the row is not deleted because of cyclic cases, e.g. A⊑B and B⊑A */18. Pos_Axioms := (asserted) positive axioms where C belongs to the LHS;19. foreach ax in Pos_Axioms do20. if i belongs to each class (without C) in the LHS of ax then delete_class_fact_step1(i, RHS of ax, ‘inferred’); /* recursive call */21. end
Algorithm 6. re_infer_class_facts.
1. /* called by delete_class_fact, uses CheckList */2. begin3. foreach fact B(j) in CheckList do4. if (B(j) is not inferred) or (B(j) does not exist) then /* is the fact still not inferred ? */5. /* inference rule 1 */6. Pos_Axioms := (asserted) positive axioms where RHS is B;7. foreach ax in Pos_Axioms do8. if j belongs to each class in the LHS of ax then add_class_fact(j, B, ‘inferred’) ;9. /* inference rule 2 */10. f B is a restriction class ∃P then11. if P(j,x) exists (with any x) then add_class_fact(j, B, ‘inferred’) ;12. if B is a restriction class ∃P- then13. if P(x,j) exists (with any x) then add_class_fact(j, B, ‘inferred’) ;14. endif15. end
5.4.2. Asserted and inferred factsA fact is added to the ABox as asserted (by the user) or as inferred (by reasoning). OntoMinD uses the same add procedures
which have an add_mode parameter that can take the value ‘asserted’ (by default) or ‘inferred’. If a fact is added for the first time,

1171L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
then a new row is added to the corresponding table (with asserted or inferred equal to 1 according to add_mode, see Algorithm 3:lines 16 to 17). If the fact already exists, the asserted or inferred value (according to add_mode) of the corresponding row is updatedfrom 0 to 1 (lines 7 to 8).
Similarly, a fact is deleted as asserted (by the user) or as inferred (by reasoning). The asserted or inferred value (according to thedel_mode parameter of the delete procedures) of the corresponding row is updated from 1 to 0 (see Algorithm 5: lines 8 and 11). Ifthe row is left with both values equal to zero, this means that the fact no longer exists. Consequently, the row is deleted from thetable (lines 9 and 12).
5.4.3. ExplanationsSince adding/removing a class or property fact can infer and store new facts or remove existing ones, it is important to provide
users explanations about these inferences. In OntoMinD a tracing functionality is available, so that users can know whichinformation is derived and added to (or removed from) the ABox as a consequence of the statement they run. Current reasonersprovide no or only limited support for the explanation of logical consequences [30].
For example, let us take the sequence of the three ABox-update statements in Section 4.3 where the user adds the facts: Petrusis a wine, it has dry sugar and it is a Bordeaux. For the second statement, if the tracing functionality is on, the explanation lists thenew inferred facts as shown below.
N exec abox_add.add_property_fact(‘Petrus’, ‘dry’, ‘sugar’)add_property_fact(‘Petrus’, ‘dry’, ‘sugar’, ‘asserted’)– add_class_fact(‘Petrus’, ‘some_sugar’, ‘inferred’)—— add_class_fact(‘Petrus’, ‘Wine’, ‘inferred’)– add_class_fact(‘dry’, ‘some_inverse_sugar’, ‘inferred’)—— add_class_fact(‘dry’, ‘WineSugar’, ‘inferred’)——— add_class_fact(‘dry’, ‘Top’, ‘inferred’)– add_property_fact(‘Petrus’, ‘dry’, ‘taste’, ‘inferred’)—— add_class_fact(‘Petrus’, ‘some_taste’, ‘inferred’)—— add_class_fact(‘dry’, ‘some_inverse_taste’, ‘inferred’)
Let us assume that after adding Petrus to the Bordeaux class, the user decides to remove this fact. The user can see theconsequences of this statement, i.e. the un-inferred and re-inferred facts.
N exec abox_del.delete_class_fact(‘Petrus’, ‘Bordeaux’)delete_class_fact_step1(‘Petrus’, ‘Bordeaux’, ‘asserted’)– delete_class_fact_step1(‘Petrus’, ‘Wine’, ‘inferred’)—— delete_class_fact_step1(‘Petrus’, ‘Top’, ‘inferred’)re_infer_class_facts– add_class_fact(‘Petrus’, ‘Wine’, ‘inferred’) /* because Petrus is in some_sugar */– add_class_fact(‘Petrus’, ‘Top’, ‘inferred’)
Suppose that the class Food is defined as disjoint withWine. If the user tries to add Petrus to Food, he/she gets an error message.
N exec abox_add.add_class_fact (‘Petrus’, ‘Food’)ORA-20006: cannot add this fact since bPetrusN belongs to the class bWineN which is disjoint with bFoodN
6. Querying the ontology
This section shows how OntoMinD users can easily query the ontology (TBox and ABox) in SQL. Moreover, they can writemixed queries that involve ontological and non-ontological data. Since reasoning is performed when updating the ontology andinferences are materialized in the ontology, querying provides fast response times (see experiments in Section 8.3).
6.1. Querying the TBox
Users can directly query the TBox using regular SQL queries on the OntoMinD tables containing the TBox. They can ask for thesuperclasses or subclasses of a given class C, and the disjoint classes with C, C being a named class (e.g. Wine) or an anonymousclass (e.g. Bordeaux⊓RedWine, Bordeaux⊓∃fromChateau). They can also ask for the super-properties or sub-properties of agiven property, its domain, its range, and its inverse.
For example, let us assume that a user wants to find all the superclasses (direct and indirect) of the Wine class. The OntoMinDrelational meta-schema contains the tables:
Class (resource_id, name)C_pos_inclusion_right (axiom_id, resource_id, asserted, inferred, nb_left_classes)C_pos_inclusion_left (axiom_id, resource_id)

1172 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
These tables are obtained when converting the ER meta-schema (see Fig. 7) to a relational one. For instance, the tableC_pos_inclusion_right is a translation of both the entity type C-Pos-Inclusion and the relationship type right. The Class table recordsthe names of the classes, and the two other tables record the class inclusion axioms (asserted and inferred). For example, theaxiom A⊓B⊑C is stored as one tuple (axiom#23, resource#C, 1, 0, 2) in C_pos_inclusion_right and two tuples (axiom#23,resource#A) and (axiom#23, resource#B) in C_pos_inclusion_left. To get the superclasses ofWine, the user can write the followingSQL query:
SELECT c2.name
FROM Class c1, C_pos_inclusion_right r, C_pos_inclusion_left l, Class c2
WHERE c1.name= ‘Wine’ AND
l.resource_id=c1.resource_id AND
r.axiom_id=l.axiom_id AND
r.nb_left_classes=1 AND
c2.resource_id=r.resource_id
The user will get a complete answer including reasoning (that has been done at TBox-update time).A less trivial example is asking for the superclasses of Bordeaux⊓RedWine. To do so, the user can write the following SQL
query:
SELECT c3.name
FROM Class c1, Class c2, Class c3,
C_pos_inclusion_right r, C_pos_inclusion_left l1, C_pos_inclusion_left l2
WHERE c1.name= ‘Bordeaux’ AND
l1.resource_id=c1.resource_id AND
c2.name= ‘RedWine’ AND
l2.resource_id=c2.resource_id AND
l2.axiom_id=l1.axiom_id AND
r.axiom_id=l1.axiom_id AND
r.nb_left_classes=2 AND
c3.resource_id=r.resource_id
6.2. Querying the ABox
A conjunctive query is composed of terms C(x) or ∃P(x) or OP(x,y) or DP(x,y) where C, P, OP, DP are respectively aclass, a property, an object property, and a datatype property, and x, y are either constants or variables (names of variablesare preceded by ‘?’). For example, the query “Find the sweet wines produced in a chateau, with the name of their chateau”is written: Q(?x,?y)←Wine(?x), sugar(?x,sweet), fromChateau(?x,?y). The LHS of the query is called its head, andthe RHS is called its body. The current version of OntoMinD supports answering a subset of conjunctive queries: thosewhere all the variables in the body are in the head. The other queries, where some body variables are not returned, mayinvolve unknown individuals and therefore require a special treatment. We call them non-ready queries and discuss them inSection 6.4.
The simplest conjunctive query has a single term. For example, Q(?x)←Wine(?x) that fetches all the instances of the Wineclass, may be written by the following SQL query:
SELECT r.name
FROM Wine w, A_Resource r
WHERE r.resource_id=w.indiv_id
Users will get a complete answer including reasoning (that has been done at ABox-update time). Users can refine theprevious query to get only the inferred facts by adding the condition w.inferred=1. To get all the classes to which theindividual Petrus belongs, OntoMinD has the function abox_qry.get_classes (in the abox_qry package) that looks in eachclass table whether a row with the id of Petrus belongs to it (and returns e.g. RedBordeaux, Bordeaux, RedWine, Wine, Drink,Top). The function abox_qry.get_mostspecific_classes returns only the most-specific classes to which Petrus belongs(RedBordeaux).
More complex conjunctive queries involve several classes and properties. For example, Q(?x,?y)←Wine(?x), sugar(?x,
sweet), body(?x,?y) that finds the body of the sweet wines, can be expressed in SQL by:
SELECT r1.name AS "wine", r3.name AS "body"
FROM Wine w, A_Resource r1, sugar s, A_Resource r2, body b, A_Resource r3
WHERE r1.resource_id=w.indiv_id AND

1173L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
s.domain=w.indiv_id AND
s.range=r2.resource_id AND
r2.name= ‘sweet’ AND
b.domain=w.indiv_id AND
b.range=r3.resource_id
6.3. Mixed queries
In OntoMinD, users can store ontological data and proprietary data in the same database. For example, a database could containthe wine ontology tables (Wine, Bordeaux, body, sugar, fromChateau, etc.) and other regular relational tables (Item, Purchase, etc.).Let us assume that the table Item(item_id, item_name, unitary_price) stores the wines available in a supermarket with their price. Auser wants to get the expensive wines (costing more than one thousand dollars) that are produced in a chateau (fromChateauproperty). Typically the needed information is in ontological tables and proprietary tables and requires a mixed query thataccesses both. The SQL query is:
SELECT i.item_name AS "wine", i.unitary_price AS "price", r2.name AS "chateau"
FROM Item i, A_Resource r1, fromChateau f, A_Resource r2
WHERE i.unitary_priceN1000 AND
r1.name=i.item_name AND
f.domain=r1.resource_id AND
f.range=r2.resource_id
6.4. Non-ready ABox queries
Queries where some body variables are not in the head may involve unknown individuals, and thus require some moreprocessing in order to provide complete answers. For instance, let us take a fragment of the ontology of Section 3.2:
TBox: GreatBordeaux⊑∃fromChateau, ∃fromChateau⊑Wine, ∃fromChateau-⊑Chateau
GreatBordeaux⊑Wine/* inferred axiom */ABox: GreatBordeaux(Petrus)
∃fromChateau(Petrus), Wine(Petrus)/* inferred facts */
If the query Q(?x)←fromChateau(?x,?y) were executed by directly accessing the fromChateau table, it wouldreturn an empty and incomplete answer because in the above OntoMinD ontology the fromChateau table is empty. Thistable does not contain a tuple (Petrus, unknown) since the current version of OntoMinD does not store unknownindividuals.
On the contrary, both queries: Q(?x)←Wine(?x), and Q(?x)←∃fromChateau(?x) answer correctly: {Petrus}. In fact, anyquery such that all its variables are in the head never involves any unknown individual. Therefore it can be directly processed bySQL. Indeed, variables that appear in the head can represent only existing individuals.
We are currently working on the non-ready queries issue for a future release of OntoMinD.
7. OntoMinD implementation
We have implemented our proposal as OntoMinD, an add-on to the regular relational DBMS Oracle, i.e. not using OracleSemantic Technologies functionality. The OntoMinD add-on consists in a set of meta-tables and a set of PL/SQL packagesthat run in Oracle's SQL-Plus environment. OntoMinD can be used by software agents via an API and by humans via a Webinterface. At this point the latter has been meant to provide easy access to the needed functionalities (see Fig. 9). Thedevelopment of a fully visual interface, alike those in existing ontology editors, has not been our priority and is left forfuture work.
The OntoMinD PL/SQL packages offer the following ontology functionalities:
• Ontology management: procedures to create an empty ontology and to delete an existing one. Importing an existing OWLontology (with DL-Lite(R,⊓) features) is also supported. It is done in 2 steps: the OWL file is translated to an SQL file by an XSLTprogram, then the SQL file is run in OntoMinD (see importing the benchmark ontologies in Section 8.2.1).
• TBox updating: procedures to add and delete classes, properties, and axioms.• ABox updating: procedures to add and delete class facts and property facts.Both TBox and ABox updating procedures perform reasoning and may add/delete inferred axioms and inferred facts.

Fig. 9. OntoMinD web interface.
1174 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
• TBox querying: functions to get the parents, children, ancestors, descendants of a class or a property, get the description of aproperty (e.g. its domain, range), get the definition of a class (e.g. equivalent to, disjoint with), etc.
• ABox querying: functions to get the instances of a given class or property, get all the classes or the most-specific classes a givenindividual belongs to, get the individuals that are related to a given individual via a given property, etc.TBox and ABox querying functions return both asserted and inferred information. Section 6 described how queryingfunctionality is also available via normal SQL queries.
OntoMinD can be easily installed in Oracle by running a script file that creates the OntoMinDmeta-tables and PL/SQL packages.
8. Experiments
To assess our work we run a comparative performance analysis based on the Lehigh University Benchmark (LUBM) [9] (http://swat.cse.lehigh.edu/projects/lubm). We compared OntoMinD with Oracle 11 g with Semantic Technologies. The fact that bothsystems use the same technical platform allows considering the comparison of performances as meaningful. It is worth recallingthat both approaches store the ontology in an Oracle database: OntoMinD uses themultiple tables approachwhile Oracle Semanticuses the one table approach. Both approaches perform reasoning inside the DBMS: OntoMinD applies reasoning incrementally atupdate time, while Oracle Semantic applies it on users' demand.
8.1. LUBM description
The LUBM benchmark aims to test the two basic requirements of a knowledge base system: scalability and efficiency, andreasoning capabilities. The ontology describes a university domain.
8.1.1. SchemaThe original ontology schema (TBox) is written in OWL-Lite. It includes 43 classes, and 32 properties (24 object properties and
8 datatype properties). It uses the following OWL constructs: intersectionOf, someValuesFrom, inverseOf, and transitiveProperty.We adapted the LUBM ontology schema to be in DL-Lite(R,⊓) as follows:
• we removed the transitive characteristic (not supported in DL-Lite(R,⊓)) of the subOrganizationOf property;

7 We replaced the axiom GraduateStudent⊑∃takesCourse.GraduateCourse by GraduateStudent ⊑ ∃takesGRCourse, the axiom ResearchAssis-
tant ⊑ ∃worksFor.ResearchGroup by ResearchAssistant ⊑ ∃worksForRG, and the axiom TeachingAssistant ⊑ ∃worksFor.Department byTeachingAssistant ⊑ ∃worksForDP; We replaced the axiom Student≡Person⊓∃takesCourse.Course by Student≡Person⊓∃takesCourse (sincethe range of takesCourse is Course) and the axiom TeachingAssistant≡Person⊓∃teachingAssistantOf.Course by TeachingAssistant≡Person⊓∃teachingAssistantOf (since the range of teachingAssistantOf is Course); We replaced the axiom Employee≡Person⊓∃worksFor.Organization byEmployee≡Person⊓∃worksFor since all the values of worksFor are in Organization; Since all the values of headOf are in Department, we removed the axiomDean≡∃headOf.College, we replaced the axiom Director≡Person⊓∃headOf.Program by Director⊑Person, and we replaced the axiomChair≡Person⊓∃headOf.Department by Chair≡Person⊓∃headOf.
Fig. 10. Translating OWL to ABox-update statements in OntoMinD.
1175L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
• we replaced the qualified existential restrictions (not supported in DL-Lite(R,⊓)) by unqualified existential restrictions.7 For thispurpose, we added 3 object properties and used them in unqualified existential restrictions: takesGRCourse is a subproperty oftakesCourse and has GraduateCourse as range, worksForRG and worksForDP are sub-properties of worksFor and haveResearchGroup and Department as range respectively.
These updates do not affect the query answers of the benchmark except for the query Q11 which involves the transitiveproperty.
8.1.2. InstancesThe LUBM ontology instances (ABox) consist in a synthetic data set generated by a program. Five ontology ABoxes are created
describing 1, 5, 10, 20, and 50 universities. As the number of universities grows, the number of asserted facts grows as shown inTable 3 in Section 8.2.2. (from 100 thousand facts in the 1-university ontology to 6.6 million facts in the 5-university ontology).
8.1.3. QueriesThe 14 queries of the benchmark vary by their input size, their selectivity, their complexity, the hierarchy of data used, and the
inference applied. The performance metrics include the query response time, the query answer completeness (does the systemreturn all the answers?), and the query answer soundness (does the system return only correct answers?).We omit the query Q11in our tests since DL-Lite(R,⊓) does not support transitive properties. The data loading time and the database size are alsomeasured.
8.1.4. Ontology systemsWe evaluate OntoMinD (release 2.0) and Oracle 11 g Semantic (release 11.1.0.6.0).
8.1.5. EnvironmentThe environment we used for OntoMinD and Oracle Semantic is: 2.6 GHz Intel Core2 Duo CPU, 3.49 GB RAM, 150 GB hard disk,
Windows XP Prof. OS.
8.2. Storing the ontology
8.2.1. Translating OWL files to SQL filesTo store the LUBM ontology in OntoMinD, we first wrote an XSLT program to translate the OWL file containing the ontology
schema to an SQL file containing OntoMinD TBox-update statements. We run this SQL file to store the TBox. Second, we wrote aXSLT program to translate the OWL files containing the ontology instances to SQL files containing ABox-update statements.We runthen these SQL files to store the ABox. An example showing the OWL translation to ABox-update statements is given in Fig. 10.
Oracle Semantic supports bulk loading, batch loading, and incremental loading using INSERT statements. To store the LUBMontology, we use the incremental loading to compare it on an even basis with OntoMinDwhich performs inserts one at a time. Wecreate first a tablespace and initialize a semantic data network. We create then the application table lubm_rdf_data to store the
-

Fig. 11. Translating OWL to SQL statements in Oracle Semantic.
1176 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
triples and create an associated model lubm. We wrote XSLT programs to translate the OWL files to SQL files containing INSERTstatements. We run the SQL files to store the TBox and ABox. An example showing the OWL translation to SQL statements is givenin Fig. 11.
8.2.2. Load times and DB sizesThe five ontology ABoxes differ by the number of universities they describe (and the number of files to load): 1 university (15
files), 5 universities (93 files), 10 universities (189 files), 20 universities (402 files), and 50 universities (999 files).OntoMinD displays good scalability in data loading. The load time grows linearly in OntoMinD unlike in Oracle Semantic (see
Fig. 12). Loading the ontologies incrementally is much faster in OntoMinD than in Oracle Semantic, although load times in OntoMinDinclude inference times, since reasoning is done in the abox_add.add_class_fact and abox_add.add_property_fact procedures. In OracleSemantic, load and inference times are separate since inference is done by the procedure sem_apis.validate_entailment (see Table 2).Load times in OntoMinD include checking duplicate factswhich are not inserted (primary key on tables, see Section 4.2), while OracleSemantic inserts them in the table lubm_rdf_data but discards them in the viewmdsys.semm_lubm.
The number of distinct asserted facts (class instances and property instances) is the same in OntoMinD and in Oracle Semantic,while the number of inferred facts differs in the two approaches (see Table 3). The difference comes from the number of inferredclass facts. First, OntoMinD adds two restriction classes ∃P and ∃P- for each property P and populates them, i.e. if P(a,b) is addedto the ontology, then ∃P(a) and ∃P-(b) are inferred, which is not done in Oracle Semantic. Second, OntoMinD unlike OracleSemantic stores the class Top (Thing in the OWL vocabulary). Third, Oracle Semantic does not support the intersection construct onthe LHS of an inclusion axiom, and consequently has incomplete Chair and Employee classes which are each defined by anequivalence axiom with an intersection.
The database size grows linearly in OntoMinD and in Oracle Semantic (see Fig. 12). The latter has a bigger database size for the10, 20, and 50-university ontologies than OntoMinD (see Table 2). The database size in both approaches takes into accountasserted and inferred data. It includes also the indexes size. In OntoMinD, there is an index for the primary key and candidate keyof each table. Candidate keys were deactivated during loading. After loading, we added an index on the column range for eachproperty table to speed up queries.
During ontology loading (n files) in OntoMinD, the table A_Resource which links individual names to individual ids is heavilyused. The index on the name column of this table is rearranged (coalesce) after loading each file. This helps to keep the n files loadtime constant. In Oracle Semantic, loading the last files is much slower than loading the first ones.
Fig. 12. Load time and DB size.
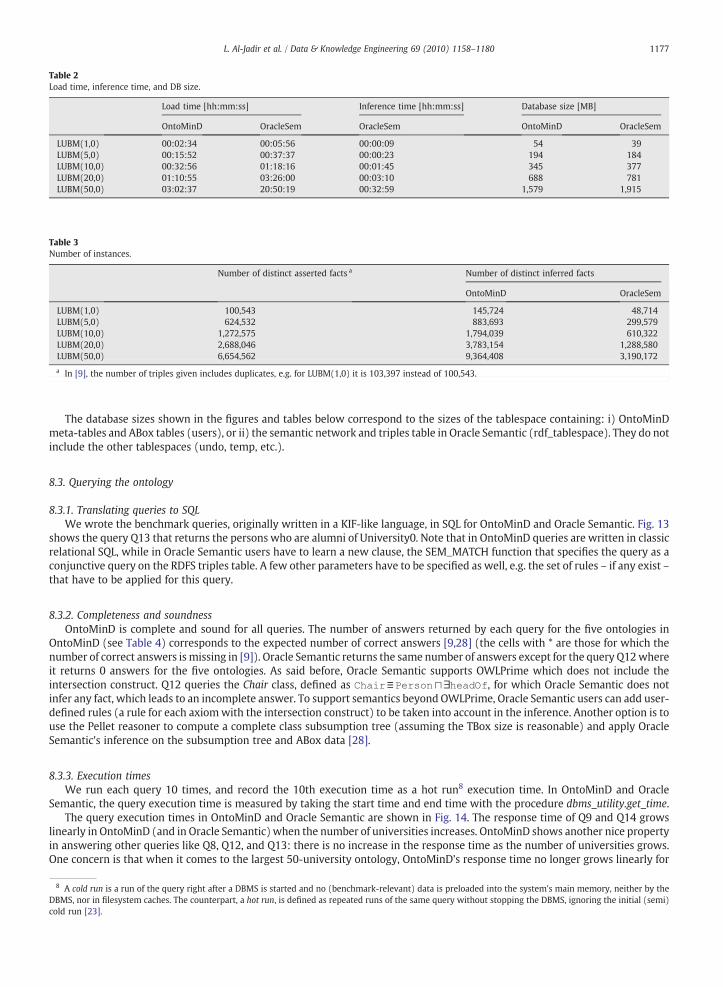
Table 2Load time, inference time, and DB size.
Load time [hh:mm:ss] Inference time [hh:mm:ss] Database size [MB]
OntoMinD OracleSem OracleSem OntoMinD OracleSem
LUBM(1,0) 00:02:34 00:05:56 00:00:09 54 39LUBM(5,0) 00:15:52 00:37:37 00:00:23 194 184LUBM(10,0) 00:32:56 01:18:16 00:01:45 345 377LUBM(20,0) 01:10:55 03:26:00 00:03:10 688 781LUBM(50,0) 03:02:37 20:50:19 00:32:59 1,579 1,915
Table 3Number of instances.
Number of distinct asserted facts a Number of distinct inferred facts
OntoMinD OracleSem
LUBM(1,0) 100,543 145,724 48,714LUBM(5,0) 624,532 883,693 299,579LUBM(10,0) 1,272,575 1,794,039 610,322LUBM(20,0) 2,688,046 3,783,154 1,288,580LUBM(50,0) 6,654,562 9,364,408 3,190,172
a In [9], the number of triples given includes duplicates, e.g. for LUBM(1,0) it is 103,397 instead of 100,543.
1177L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
The database sizes shown in the figures and tables below correspond to the sizes of the tablespace containing: i) OntoMinDmeta-tables and ABox tables (users), or ii) the semantic network and triples table in Oracle Semantic (rdf_tablespace). They do notinclude the other tablespaces (undo, temp, etc.).
8.3. Querying the ontology
8.3.1. Translating queries to SQLWe wrote the benchmark queries, originally written in a KIF-like language, in SQL for OntoMinD and Oracle Semantic. Fig. 13
shows the query Q13 that returns the persons who are alumni of University0. Note that in OntoMinD queries are written in classicrelational SQL, while in Oracle Semantic users have to learn a new clause, the SEM_MATCH function that specifies the query as aconjunctive query on the RDFS triples table. A few other parameters have to be specified as well, e.g. the set of rules – if any exist –that have to be applied for this query.
8.3.2. Completeness and soundnessOntoMinD is complete and sound for all queries. The number of answers returned by each query for the five ontologies in
OntoMinD (see Table 4) corresponds to the expected number of correct answers [9,28] (the cells with * are those for which thenumber of correct answers is missing in [9]). Oracle Semantic returns the same number of answers except for the query Q12whereit returns 0 answers for the five ontologies. As said before, Oracle Semantic supports OWLPrime which does not include theintersection construct. Q12 queries the Chair class, defined as Chair≡Person⊓∃headOf, for which Oracle Semantic does notinfer any fact, which leads to an incomplete answer. To support semantics beyond OWLPrime, Oracle Semantic users can add user-defined rules (a rule for each axiomwith the intersection construct) to be taken into account in the inference. Another option is touse the Pellet reasoner to compute a complete class subsumption tree (assuming the TBox size is reasonable) and apply OracleSemantic's inference on the subsumption tree and ABox data [28].
8.3.3. Execution timesWe run each query 10 times, and record the 10th execution time as a hot run8 execution time. In OntoMinD and Oracle
Semantic, the query execution time is measured by taking the start time and end time with the procedure dbms_utility.get_time.The query execution times in OntoMinD and Oracle Semantic are shown in Fig. 14. The response time of Q9 and Q14 grows
linearly in OntoMinD (and in Oracle Semantic) when the number of universities increases. OntoMinD shows another nice propertyin answering other queries like Q8, Q12, and Q13: there is no increase in the response time as the number of universities grows.One concern is that when it comes to the largest 50-university ontology, OntoMinD's response time no longer grows linearly for
8 A cold run is a run of the query right after a DBMS is started and no (benchmark-relevant) data is preloaded into the system's main memory, neither by theDBMS, nor in filesystem caches. The counterpart, a hot run, is defined as repeated runs of the same query without stopping the DBMS, ignoring the initial (semi)cold run [23].

Fig. 13. Query Q13 in SQL for: a) OntoMinD and b) Oracle Semantic.
Table 4Number of answers returned in OntoMinD.
Q1 Q2 Q3 Q4 Q5 Q6 Q7 Q8 Q9 Q10 Q12 Q13 Q14
LUBM(1,0) 4 0 6 34 719 7790 67 7790 208 4 15 1 5916LUBM(5,0) 4 9 6 34 719 48,582 67 7790 1245 4 15⁎ 21⁎ 36,682LUBM(10,0) 4 28 6 34 719 99,566 67 7790 2540 4 15⁎ 33⁎ 75,547LUBM(20,0) 4 59 6 34 719 210,603 67 7790 5479 4 15⁎ 86⁎ 160,120LUBM(50,0) 4 130 6 34 719 519,842 67 7790 13,639 4 15 228 393,730
1178 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
some queries, e.g., Q1, Q3, Q4, Q5, Q7, and Q10, while it is nearly zero in the smaller ontologies. Oracle Semantic has a similar non-linear behavior for queries Q2, Q4, and Q8.
OntoMinD is faster than Oracle Semantic in answering all queries for the 1, 5, 10, and 20-university ontologies as shown in Fig. 14.For the largest 50-university ontology, OntoMinD gives better response times for queries Q2, Q4, Q8, Q9, Q12, Q13 and Q14. Althoughboth approaches use the same underlying DBMS and both materialize the inferences, they have a different database design. Storingclass and property instances as triples in a single huge table is less efficient for querying than storing them in multiple tables. This istrue for queries that involve a single class or property (e.g. Q14) andqueries that involve several classes andproperties (e.g. Q4,Q8, andQ13). In the first case, selecting some rows in a huge table ismore expensive than retrieving the rows of a smaller table. In the secondcase, joining a huge table with itself several times is more expensive than joining several smaller tables.
Oracle Semantic has better execution times for queries Q1, Q3, Q5, Q7, and Q10 in the 50-university ontology, but note that theexecution times for Oracle Semantic provided in Fig. 14 do not take into account the inference times. In Oracle users have to call thereasoner in order to perform inference before querying. And in Oracle, this inference time for the 50-university ontology is almost33 minutes. If we add inference time to the query response time, then OntoMinD (in which inference is done at updates) is muchfaster than Oracle Semantic. For example, for Q1 Oracle takes 33 min, while OntoMinD takes 5.5 s. Thus when inference time isconsidered in querying, OntoMinD is considerably faster than Oracle Semantic in all tested cases.
9. Conclusion
Ontologies pave the way to the Semantic Web. They are promised to a brilliant future as a means to meaningfully exchangeinformation. But their successmaywell become their major problem, bymaking them overgrow beyond the capabilities of currenttools to reason about the knowledge they hold. Some research groups proposed to solve this scalability issue by coupling reasonerswith DBMS. Unfortunately, experience shows that efficient system coupling is a hard goal to achieve. Partial coupling as in SOR,where ABox reasoning is performed by the DBMS and TBox reasoning is performed by the reasoner, still faces the problem ofhandling ontologies with a large TBox.
The OntoMinD tool we have developed stems from the idea to use a single extended relational DBMS to store, reason and queryontologies. It performs reasoning at update time and consequently stores all asserted and inferred knowledge in the database. Thisdramatically increases performance in processing queries, which are expected to represent the dominant use of future ontologies.
OntoMinD provides robust, efficient, and scalable semantic datamanagement. It is scalable as it can handlemillions of triples. Itis efficient as it provides fast query response times. It is robust as it shows query completeness and soundness. It is available as itconsists of a set of tables and PL/SQL packages to add in Oracle. It is secure as it uses the security features of the DBMS.
Benchmarking enabled a comparative performance analysis between our OntoMinD prototype and the commercial solutionprovided by Oracle Semantic. Results show that OntoMinD outperforms Oracle Semantic in 50% of the benchmark queries when

Fig. 14. Query execution times in OntoMinD and Oracle Semantic.
1179L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
only query processing time is considered. When inference time is considered in querying, OntoMinD is considerably faster thanOracle Semantic in all tested cases.
Items on the agenda for future work include supporting a larger set of conjunctive queries, namely queries involving unknowns,and enriching theweb interfacewith a visual interface.Wewould also like to extend the LUBMbenchmarkwith updates, andmeasurethe update times for different kinds of updates. Another concern that remains to be addressed is handling the evolution of an ontologyschema so that the ontology instances remain consistent whenever users update the TBox of a populated ontology.
Acknowledgements
This work was supported by the European IST-6FP-014915 project GeoPKDD, http://www.geopkdd.eu/. The authors wouldlike to thank the anonymous reviewers for their constructive comments and suggestions.
References
[1] I. Horrocks, L. Li, D. Turi, S. Bechhofer, The instance store: DL reasoning with large numbers of individuals, DL, 2004.[2] J. Zhou, L. Ma, Q. Liu, L. Zhang, Y. Yu, Y. Pan, Minerva: a scalable OWL ontology storage and inference system, ASWC, 2006, pp. 429–443.[3] B.N. Grosof, I. Horrocks, R. Volz, S. Decker, Description logic programs: combining logic programs with description logic, WWW, 2003, pp. 48–57.[4] R. Volz, S. Staab, B. Motik, Incremental maintenance of materialized ontologies, ODBASE, 2003, pp. 707–724.[5] T. Weithöner, T. Liebig, G. Specht, Storing and querying ontologies in logic databases, SWDB, 2003, pp. 329–348.[6] Oracle Database, Semantic Technologies Developer's Guide, 11g Release 1, September, 2007.[7] L. Al-Jadir, O. Tajmouati, C. Parent, S. Spaccapietra, OntoMinD: ontology management in databases (poster and demo), ISWC, 2007.[8] Oracle Database, PL/SQL Language Reference, 11g Release 1, September, 2007.[9] Y. Guo, Z. Pan, J. Heflin, An evaluation of knowledge base systems for large OWL datasets, ISWC, 2004, pp. 274–288.

1180 L. Al-Jadir et al. / Data & Knowledge Engineering 69 (2010) 1158–1180
[10] D. Calvanese, G. De Giacomo, D. Lembo, M. Lenzerini, R. Rosati, Data complexity of query answering in description logics, KR, 2006, pp. 260–270.[11] D. Calvanese, G. De Giacomo, D. Lembo, M. Lenzerini, R. Rosati, Tractable reasoning and efficient query answering in description logics: the DL-Lite family, J.
Autom. Reason. 39 (3) (2007) 385–429.[12] W3C, in: P. Hayes (Ed.), RDF Semantics, W3C Recommendation, 10 February 2004, 2004, (http://www.w3.org/TR/rdf-mt/).[13] W3C, in: M.K. Smith, C. Welty, D.L. McGuiness (Eds.), OWLWeb Ontology Language Guide, W3C recommendation, 10 February 2004, 2004, (http://www.w3.
org/TR/2004/REC-owl-guide-20040210).[14] T.D. Wang, B. Parsia, J.A. Hendler, A survey of the web ontology landscape, ISWC, 2006, pp. 682–694.[15] Y. Theoharis, V. Christophides, G. Karvounarakis, Benchmarking database representations of RDF/S stores, ISWC, 2005, pp. 685–701.[16] H. Dehainsala, G. Pierra, L. Bellatreche, OntoDB: an ontology-based database for data intensive applications, DASFAA, 2007, pp. 497–508.[17] J. Lu, L. Ma, L. Zhang, J.-S. Brunner, C. Wang, Y. Pan, Y. Yu, SOR: a practical system for ontology storage, reasoning and search, VLDB, 2007, pp. 1402–1405.[18] D. Jeong, H. Shin, D.-K. Baik, Y.-S. Jeong, An efficient web ontology storage considering hierarchical knowledge for Jena-based applications, J. Inf. Process. Syst.
5 (1) (2009) 11–18.[19] Y. Lv, Z.M. Ma, X. Zhang, Fuzzy ontology storage in fuzzy relational database, FSKD, 2009, pp. 242–246.[20] Y. Wang, X. Du, J. Lu, X. Wang, FlexTable: using a dynamic relation model to store RDF data, DASFAA, 2010, pp. 580–594.[21] A. Borgida, R.J. Brachman, Loading data into description reasoners, SIGMOD, 1993, pp. 217–226.[22] Z. Pan, J. Heflin, DLDB: extending relational databases to support semantic web queries, PSSS, 2003.[23] L. Sidirourgos, R. Goncalves, M.L. Kersten, N. Nes, S. Manegold, Column-store support for RDF data management: not all swans are white, VLDB, 2008,
pp. 1553–1563.[24] R. Ramakrishnan, D. Srivastava, S. Sudarshan, P. Seshadri, Implementation of the CORAL deductive database system, SIGMOD, 1993, pp. 167–176.[25] Racer, http://www.racer-systems.com.[26] FaCT, http://www.cs.man.ac.uk/horrocks/FaCT/.[27] Pellet, pellet.owldl.com.[28] Oracle, in: A. Wu (Ed.), A Scalable RDBMS-Based Inference Engine for RDFS/OWL, 2007, (ontolog.cim3.net/file/work/DatabaseAndOntology/2007-10-
18_AlanWu/RDBMS-RDFS-OWL-InferenceEngine–AlanWu_20071018.pdf).[29] P. LePendu, D. Dou, D. Howe, Detecting inconsistencies in the gene ontology using ontology databases with Not-gadgets, ODBASE, 2009, pp. 948–965.[30] T. Liebig, O. Noppens, OntoTrack: combining browsing and editing with reasoning and explaining for OWL Lite ontologies, ISWC, 2004, pp. 244–258.[31] B. Parsia, E. Sirin, A. Kalyanpur, Debugging OWL ontologies, WWW, 2005, pp. 633–640.[32] M. Ortiz, D. Calvanese, T. Eiter, Data complexity of query answering in expressive description logics via tableaux, J. Autom. Reason. 41 (1) (2008) 61–98.[33] C. Lutz, The complexity of conjunctive query answering in expressive description logics, IJCAR, 2008, pp. 179–193.[34] F. Baader, W. Nutt, Basic description logics, in: F. Baader, D. Calvanese, D.L. McGuinness, D. Nardi, P.F. Patel-Schneider (Eds.), Description Logic Handbook,
Cambridge University Press, 2003, pp. 47–100.[35] W. Lipski Jr., On databases with incomplete information, JACM 28 (1) (1981) 41–70.
Lina Al-Jadir received amaster's degree and a PhD in Computer Science from the University of Geneva in 1990 and 1997. She served asa faculty member in the Computer Science Department of the American University of Beirut from 1998 to 2004. In 2004 she joined theDatabase Laboratory of the Ecole Polytechnique Fédérale de Lausanne as a senior researcher. She is currently a senior lecturer andresearcher at the University of Geneva. Her research interests include ontologies, XML, schema evolution, and database systems.
Christine Parent is a full professor at the Computer Science Department, University of Burgundy (France). She is currently on leaveand is professor at HEC, University of Lausanne (Switzerland). She has been teaching and researching in data management since 1970.She has been deeply involved in the development of an extended entity-relationship model (the ERC+model and later the MADSmodel) and of associated data manipulation languages. Her major current research interests are spatio-temporal databases, movingobjects, semantic trajectories, ontologies, multiple representations. She has (co-)authored many papers and two books, on conceptual
modeling and on modular ontologies.Stefano Spaccapietra is honorary professor at EPFL, Lausanne, Switzerland, where he served as full professor and chair of the DatabaseLaboratory from 1.10.1988 to 28.2.2010. His research always focused on data semantics. Jointly with Christine Parent he developed aconceptual spatio-temporal modeling approach supporting multi-representation, which gained worldwide reputation. Currently, hisresearch focuses on providing ontological services using database technology, and trajectory data representation and analysis. Heserved several times as Conference or Program Committee Chair. He is an IEEE Fellow, ER Fellow, and recipient of the IFIP Silver Core
Medal. He is Editor-in-chief for the Journal on Data Semantics.




























![Building Domain Ontologies From Relational Database Using ...€¦ · Automapper [12] is Semantic Web interface for gen- ... RDBToOnto [16] is a tool that uses RTAXON [14] method](https://img.pdfslide.net/doc/110x75/602e2d011990234ea432bb34/building-domain-ontologies-from-relational-database-using-automapper-12-is.jpg)