Embed Size (px)
Citation preview

Recent Trends in MT Evaluation: Linguistic Information and Machine LearningJason Adams11-7342008-03-05
Instructors:Alon Lavie
Stephan Vogel

Outline
Background Machine Learning Linguistic Information Combined Approaches Conclusions

Background
Fully automatic MT Eval is as hard as MT If we could judge with certainty that a
translation is correct, reverse the process and generate a correct translation
Reference translations help to close this gap

Background: Adequacy and Fluency Adequacy
How much of the meaning in the source sentence that is preserved in the hypothesis
Reference translations are assumed to achieve this sufficiently
Fluency How closely the hypothesis sentence conforms to the
norms of the target language Reference translations are a subset of target
language

Background: Human Judgments
Judge on a scale for adequacy and fluency
Agreement between judges is low Judgment scores normalized
Blatz et al (2003)

Background: Evaluating Metrics
Correlation with human assessments (judgments)Pearson CorrelationSpearman Rank Correlation
Adding more references helps BLEU but hurts NIST (Finch et al. 2004)

Background: BLEU
Papineni et al. (2001) First automatic MT metric to be widely adopted Geometric mean of modified n-gram precision Criticisms:
Poor sentence level correlation Favors statistical systems Ignores recall Local word choice more important than global
accuracy

Background: METEOR
Banerjee and Lavie (2005). Addresses some of the shortcomings of
BLEUUses recall of best referenceAttempts to align hypothesis and referenceBetter correlation with human judgments
Optionally uses WordNet and Porter stemming

Outline
Background Machine Learning Linguistic Information Combinations Conclusions

Machine Learning: Kulesza & Shieber (2004) Frame the MT Evaluation problem as a
classification task
Can we predict if a sentence is generated by a human or a machine by comparing against reference translations?

Machine Learning: Kulesza & Shieber (2004) Derived a set of features (partially based on
BLEU) Unmodified n-gram precisions (1 to 5) Min and max ratio of hypothesis to reference length Word error rate
minimum edit distance between hypothesis and any reference
Position-independent word error rate shorter translation removed from longer and size of
remaining set returned

Machine Learning: Kulesza & Shieber (2004) Trained an SVM using classification
Positive: human translation Negative: machine translation
Score is output of SVM Distance to hyperplane is treated as a measure of
confidence Classification Accuracy
~59% for human examples (positive) ~70% for machine examples (negative)
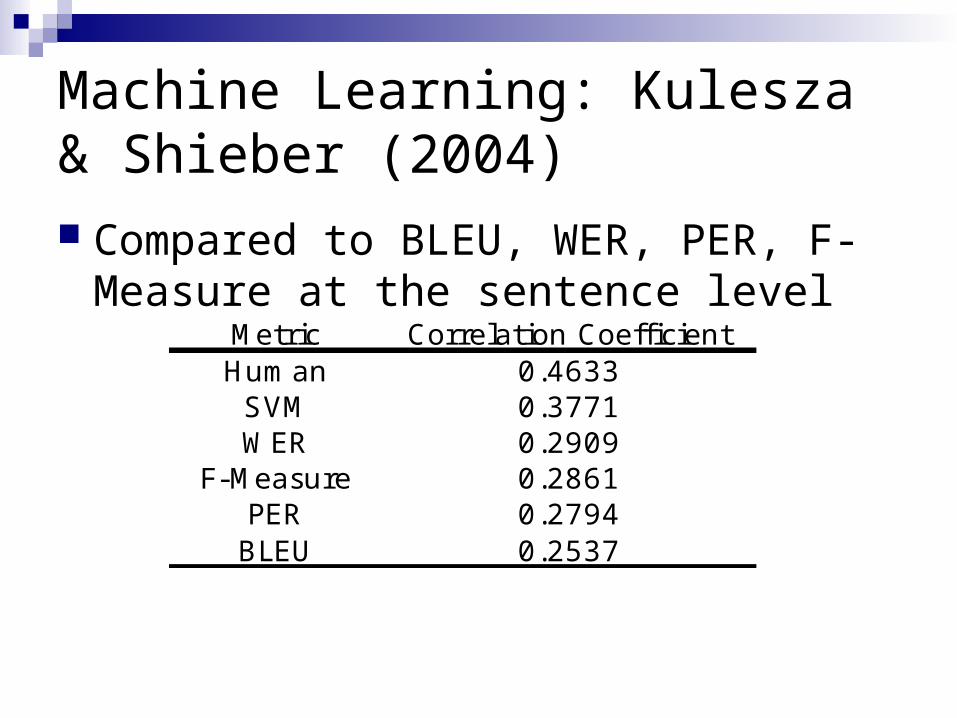
Machine Learning: Kulesza & Shieber (2004) Compared to BLEU, WER, PER, F-
Measure at the sentence levelMetric Correlation CoefficientHuman 0.4633
SVM 0.3771WER 0.2909
F-Measure 0.2861PER 0.2794
BLEU 0.2537

Outline
Background Machine Learning Linguistic Information Combinations Conclusions

Linguistic Information: Liu & Gildea (2005) Introduce syntactic information Use Collins parser on hypothesis and
reference translations Looked at three different metrics for
comparing trees

Linguistic Information: Liu & Gildea (2005) Subtree Metric (STM)
D – depth of trees considered Count is # times subtree appears in any
reference Clipped count limits count to the maximum
number of times it appears in any one reference

Linguistic Information: Liu & Gildea (2005) Kernel-based Subtree Metric (TKM)
H(t) is a vector of counts for all subtrees of t H(t1) · H(t2) counts subtrees in common
Use convolution kernels (Collins & Duffy, 2001) to compute in polynomial time counting all subtrees would be exponential in the size of the
trees

Linguistic Information: Liu & Gildea (2005) Headword Chain Metric (HWCM) Convert phrase-structure parse into dependency parse Each mother-daughter relationship in the dependency
parse is a headword chain of length 2 No siblings included in any headword chain
Score computed in the same fashion as STM
Other two metrics have dependency versions
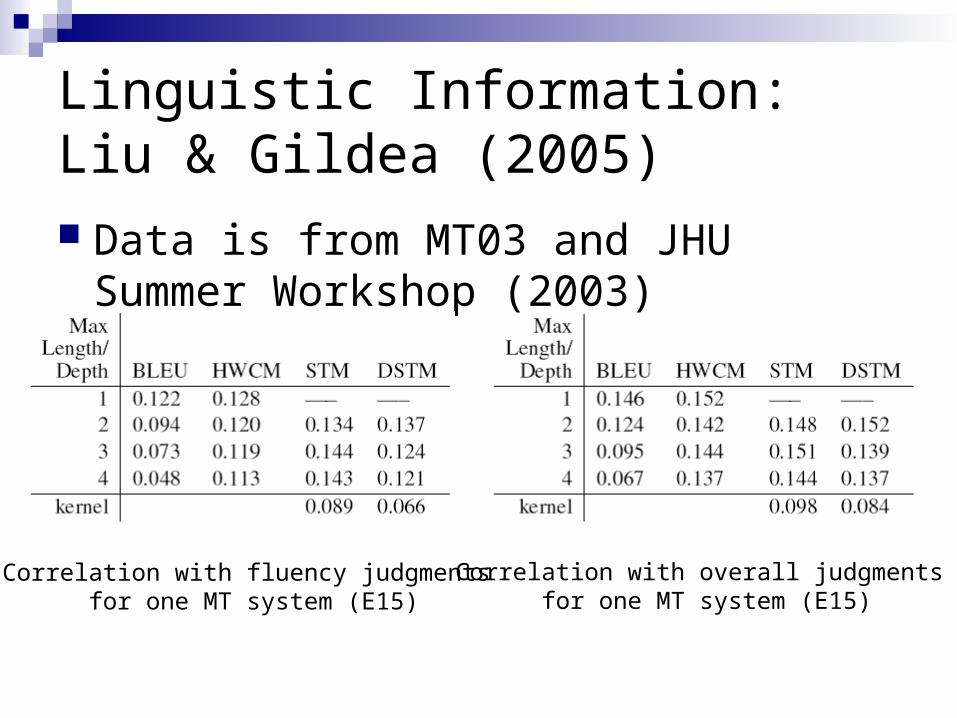
Linguistic Information: Liu & Gildea (2005) Data is from MT03 and JHU Summer
Workshop (2003)
Correlation with fluency judgments for one MT system (E15)
Correlation with overall judgments for one MT system (E15)

Linguistic Information: Liu & Gildea (2005) Corpus level judgments for MT03

Linguistic Information: Pozar & Charniak (2006) Propose the Bllip metric Intuition: meaning-preserving
transformations in sentences should not heavily impact dependency structurePerhaps intuitive, but unsubstantiated

Linguistic Information: Pozar & Charniak (2006) Parse hypothesis and reference translations with
the Charniak parser Construct dependency parses from the output
parse trees Given a lexical head pair (w1, w2) it is a
dependency if: w1 != w2 w1 is the lexical head of a constituent immediately
dominating the constituent of which w2 is the head

Linguistic Information: Pozar & Charniak (2006) Construct all dependency pairs for the
hypothesis and reference translation If multiple reference translations, compare
them one at a time Compute precision and recall to score
Formula for doing so not explicitly stated, but probably F1

Linguistic Information: Pozar & Charniak (2006) Evaluation was performed by comparing
the biggest discrepancies between Bllip and BLEU and determining which was more accurate
Results suggest Bllip makes better choices than BLEUResults aren’t directly given

Linguistic Information: Pozar & Charniak (2006) Fairly weak paper
Evaluation is basically just “eye-balled”
But, simple headword bi-chains seem to perform as well as BLEU
Unfortunately, cannot be reliably compared

Linguistic Information: Owczarzak et al. (2007) Extended work by Liu & Gildea (2005)
They used unlabeled dependency parses Insight: having more information about
grammatical relations might be helpfulX is the subject of YX is a determiner of Y
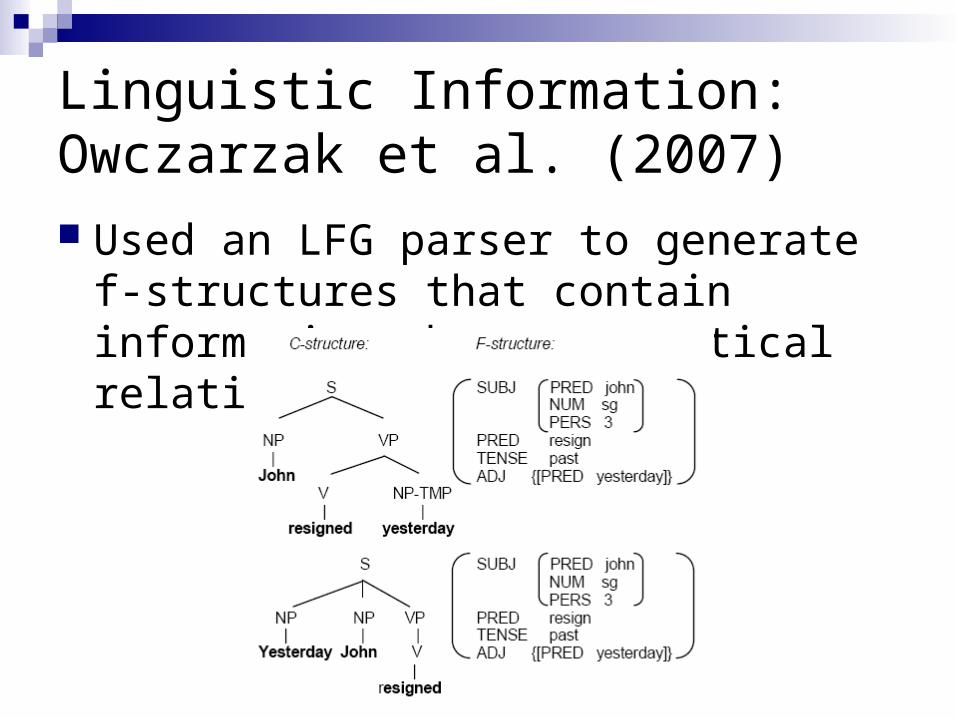
Linguistic Information: Owczarzak et al. (2007) Used an LFG parser to generate f-
structures that contain information about grammatical relations

Linguistic Information: Owczarzak et al. (2007) Types of dependencies
Predicate only Predicate-value pair, i.e. grammatical relations
Non-predicate Tense Passive Adjectival degree (comparative, superlative) Verb particle Etc.
Extended HWCM from Liu & Gildea (2005) to use these labeled dependencies

Linguistic Information: Owczarzak et al. (2007) How do you account for parser noise? The positions of adjuncts should not affect
f-structure in an LFG parse Constructed re-orderings for 100 English
sentencesRe-ordered sentence treated as translation
hypothesisOriginal sentence treated as reference
translation
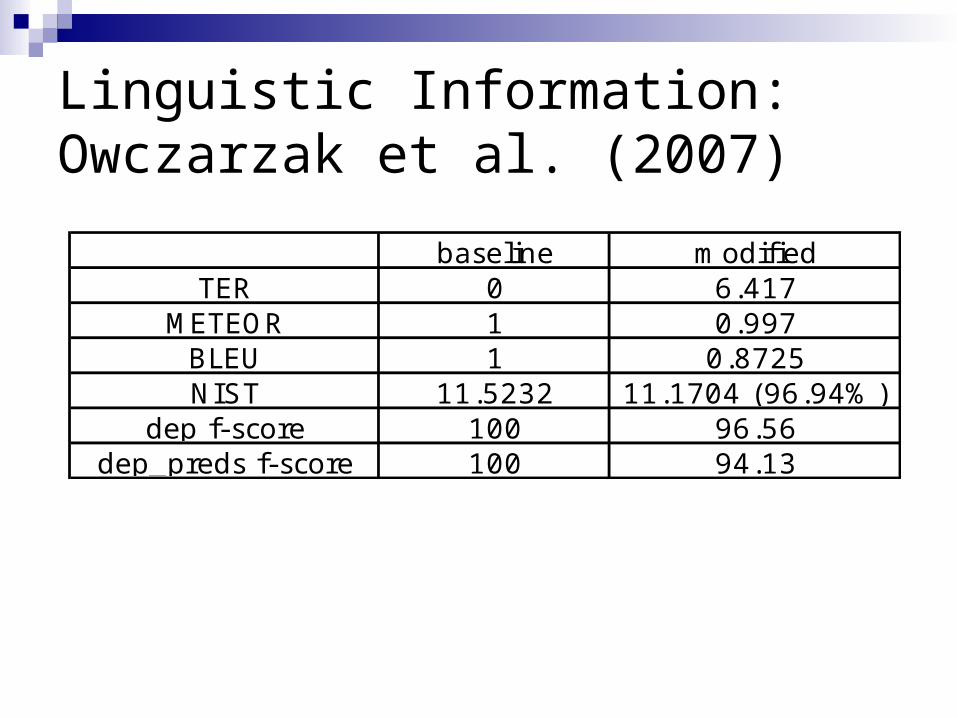
Linguistic Information: Owczarzak et al. (2007)
baseline modifiedTER 0 6.417
METEOR 1 0.997BLEU 1 0.8725NIST 11.5232 11.1704 (96.94%)
dep f-score 100 96.56dep_preds f-score 100 94.13
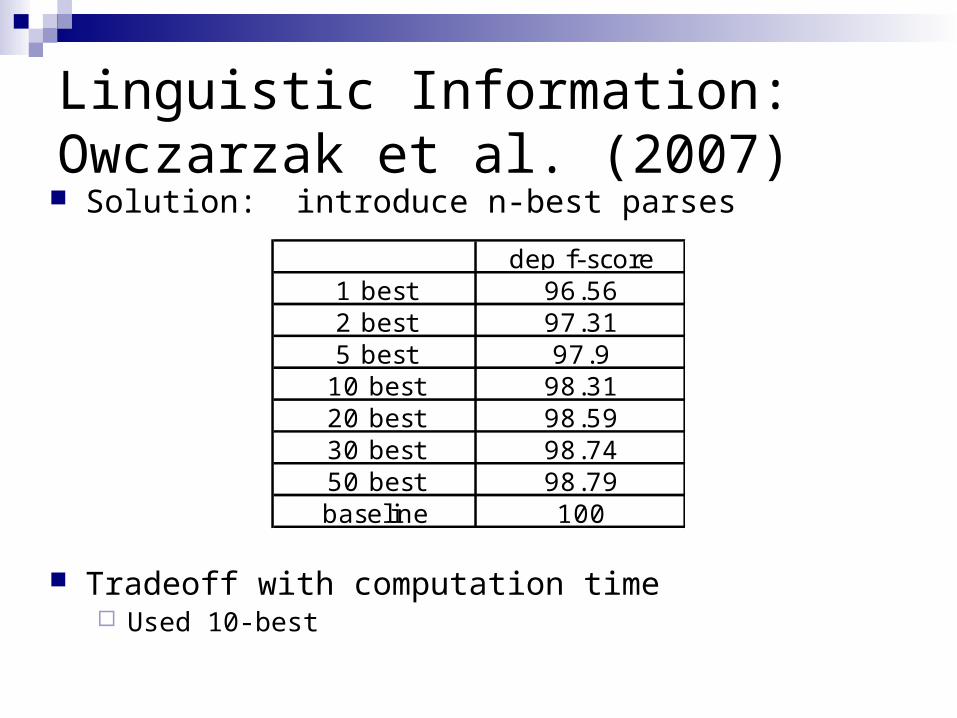
Linguistic Information: Owczarzak et al. (2007) Solution: introduce n-best parses
Tradeoff with computation time Used 10-best
dep f-score1 best 96.562 best 97.315 best 97.9
10 best 98.3120 best 98.5930 best 98.7450 best 98.79baseline 100

Linguistic Information: Owczarzak et al. (2007) Obtained precision and recall for each
hypothesis, reference pair Four examples for each machine hypothesis
Extended matching using WordNet synonyms Extended with partial matches
One part of a grammatical relation matches and the other may or may not
Computed F1 Tried different values for the weighted harmonic mean
but saw no significant improvement *
* Personal communication with Karolina Owczarzak

Linguistic Information: Owczarzak et al. (2007) Evaluated using Pearson correlation with un-
normalized human judgment scores Values ranging from 1 to 5
Their metric using 50-best parses and WordNet performed the best on fluency
METEOR with WordNet performed best on adequacy and overall
50-best + partial matching performed slightly lower than METEOR overall
Significantly outperformed BLEU
* Personal communication with Karolina Owczarzak

Outline
Background Machine Learning Linguistic Information Combinations Conclusions

Combinations: Albrecht & Hwa (2007) Extended work by Kulesza & Shieber
(2004) Included work by Liu and Gildea with
headword chains Compared classification to regression
using SVMs

Combinations: Albrecht & Hwa (2007) Classification attempts to learn decision
boundaries Regression attempts to learn a continuous
function MT evaluation metrics are continuous No clear boundary between “good” and “bad”
Instead of trying to classify as human or machine (Human-Likeness Classifier), try to learn the function of human judgments Score hypothesis according to a rating scale

Combinations: Albrecht & Hwa (2007) Features
Syntax based compared to reference HWCM STM
String-based metrics over large English corpus
Syntax-based metrics over a dependency treebank

Combinations: Albrecht & Hwa (2007) Data was LDC Multiple Translation
Chinese Part 4 Spearman correlation instead of Pearson Classification accuracy
Positively related but it’s possible to improve classification accuracy and not improve correlation
Human-Likeness classification seems inconsistent

Combinations: Albrecht & Hwa (2007) It is possible to train using regression with
reasonable size sets of training instances Regression generalizes across data sets Results showed highest correlation overall
of metrics compared
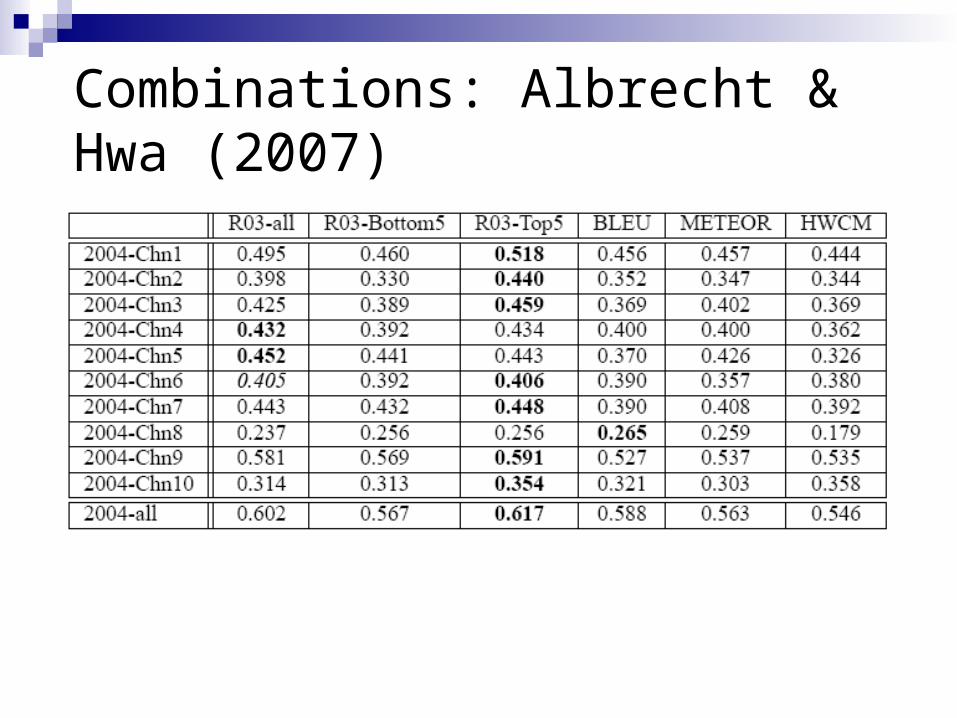
Combinations: Albrecht & Hwa (2007)

Outline
Background Machine Learning Linguistic Information Combinations Conclusions

Conclusions
Evaluating the performance of MT evaluation metrics still has plenty of room for improvement
Given that humans don’t agree well on MT quality, correlation with human judgments is inherently limited

Conclusions
Machine learningOnly scratching the surface of possibilities
Finding the right way to frame the problem is not straightforwardLearning the function of how humans assess
translations performs better than attempting to classify a translation as human or machine

Conclusions
Linguistic Information Intuitively, this should be helpfulMETEOR performs very well with limited
linguistic information (synonymy)Automatic parsers/NLP tools are noisy, so
possibly compound the problem

Conclusions
Linguistic Information and Machine LearningCombining the two leads to good results
(Albrecht & Hwa 2007)

Conclusions
New directions Machine learning with richer linguistic information
Labeled dependencies Paraphrases
Are other machine learning algorithms better suited than SVMs?
Are there better ways of framing the evaluation question?
How well can these approaches be extended to task-specific evaluation?

Questions?

References
Joshua S. Albrecht and Rebecca Hwa. 2007. A re-examination of machine learning approaches for sentence-level MT evaluation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics (ACL-2007).
Satanjeev Banerjee and Alon Lavie. 2005. Meteor: An automatic metric for MT evaluation with improved correlation with human judgments. In ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, June.
John Blatz, Erin Fitzgerald, George Foster, Simona Gandrabur, Cyril Goutte, Alex Kulesza, Alberto Sanchis, and Nicola Ueffing. 2003. Confidence estimation for machine translation. Technical Report Natural Language Engineering Workshop Final Report, Johns Hopkins University.
Alex Kulesza and Stuart M. Shieber. 2004. A learning approach to improving sentence-level MT evaluation. In Proceedings of the 10th International Conference on Theoretical and Methodological Issues in Machine Translation (TMI), Baltimore, MD, October.

References
Ding Liu and Daniel Gildea. 2005. Syntactic features for evaluation of machine translation. In ACL 2005 Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, June.
Karolina Owczarzak, Josef van Genabith, and Andy Way. 2007. Labelled Dependencies in Machine Translation Evaluation. Proceedings of the ACL 2007 Workshop on Statistical Machine Translation: 104-111. Prague, Czech Republic.
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA.
Michael Pozar and Eugene Charniak. 2006. Bllip: An Improved Evaluation Metric for Machine Translation. Master’s Thesis, Brown University.





























