Embed Size (px)
Citation preview

Kapitel 11
Regressionsanalyse
Man taler om regression når man forsøger at forklare hver måling ud fra en vektoraf baggrundsvariable eller kovariater. De forskellige observationer har forskelligeværdier af disse kovariater, og tanken er at variationen i kovariaterne i større ellermindre grad forklarer variationen i selve målingerne, som vi i regressionssammen-hæng typisk kalder responsvariablen. Selve ordet regression betyder egentlig til-bageføring, og skal i statistisk sammenhæng forstås på den måde at man søger deegentlige målinger tilbageført til kovariaterne.
Begrebet er først brugt i statistisk sammenhæng af Francis Galton (ca. 1870) i en lidtanden betydning end hvad der nu er sædvane. Galton undersøgte forskellige arveligeegenskaber for mennesker, herunder højde. Han indsamlede højdeoplysninger for enrække far/søn par. Når han optegnede dem i et koordinatsystem, sås en monotonsammenhæng: jo højere far, jo højere søn. Denne monotone sammenhæng var dogoverlejret med en del støj: nogle høje fædre fik små sønner, andre fik høje sønner. Såsammenhængen trådte kun tydeligt frem som et statistisk fænomen.
Det specielle i Galtons undersøgelse var at de samhørende far/søn målinger lagde sigomkring en ret linie med en hældning der var skarpt mindre end 1. Høje fædre fiksønner, der var højere end gennemsnittet, men som på den anden side var mindre enddem selv. Dette fænomen døbte Galton regression towards the mean, han opfattededet altså som en tilbøjelighed til at alt bliver trukket ind mod centrum.
Galton var ikke nogen hvem som helst - han var primus motor i den kvantificering afbiologi som fandt sted i slutningen af det 19. århundrede, hvor det gik op for en række
397

398 Kapitel 11. Regressionsanalyse
biologer at evolutionen så at sige kunne betragtes direkte ved nøje gennemførte sta-tistiske eksperimenter. Galton (der var fætter til Charles Darwin) talte begejstret omat hvad mikroskopet var for mikrobiologien, var statistikken for evolutionsbiologien.Som alle i sin kreds var han stærkt optaget af arvehygiejniske ideer (han har opfundetordet eugenik, der er den tekniske betegnelse for arvehygiejne), og han fortolkederegression towards the mean fænomenet som et bevis på at en vis selektion i hvemder får lov at forplante sig, er nødvendig for at forhindre degeneration af en givenpopulation. I naturen virker det darwinistiske begreb survival of the fittest, men deter suspenderet blandt mennesker, og det må erstattes af en kontrolleret forplantning,med arrangerede ægteskaber mellem individer med gode arveegenskaber etc.
Kvantificeringen af biologi var en meget vigtig proces for skabelsen af statistik somet selvstændigt fagområde, og Galton var en af historiens helt store statistikere - uan-set at vi i dag kan have svært ved at acceptere hans arvehygiejniske overbygning.Men regression towards the mean fejlfortolkede han dramatisk: Som vi skal se, erdet et fuldstændigt naturligt fænomen, der afspejler at højde ikke er 100% genetiskbestemt, men i et vist omfang reflekterer miljøpåvirkninger, der kan opfattes somtilfældige. Den meget høje far er til dels høj af genetiske grunde. Men også fordi mil-jøpåvirkninger tilfældigvis har tilladt ham at realisere sit genetiske potentiale. Hanssøn har sikkert samme genetiske potentiale, og derfor bliver han høj. Men miljøpå-virkningerne har næppe alle gået i positiv retning, og derfor bliver sønnen lavere endfaderen. Når Galtons linie havde en hældning mindre end 1, så kan det altså opfattessom et udsagn om at højden kun for en vis del er genetisk bestemt, og den præcisehældning for linien kan endda forstås som et kvantitativt udsagn om hvor kraftig dengenetiske komponent er i bestemmelsen af et individs højde.
I moderne terminologi falder selve bestemmelsen af linien ind under hvad vi kalderregressionsanalyse, mens regression towards the mean fænomenet hører hjemme ifortolkningen af regressionsanalysens resultater. Fortolkningsprocessen er ofte van-skelig og fuld af faldgruber, hvoraf regression towards the mean blot er en. Efter atdenne specielle faldgrube har været kendt og studeret i 150 år, kunne man tro at folkikke længere faldt i den. Ikke desto mindre kan man stadig skabe sig en videnskabeligkarriere på at overse regression towards the mean.
For eksempel har man “bevist” effekten af en hel del pædagogiske læsesystemer vedat give en gruppe elever en læseprøve før og efter en træningsperiode med systemet.Og det viser sig uvægerligt at de dårligste læsere er blevet bedre i løbet af trænings-perioden. Hvilket man uden at blinke fortolker som en succes for det pædagogiskelæsesystem! Men regression towards the mean fænomenet går i denne sammenhæng

11.1. Simpel lineær regression 399
ud på at giver man de dårligste læsere en ny prøve, så vil de klare den bedre end denførste - helt uanset undervisningssystem. Tilsvarende vil de bedste læsere klare sigdårligere ved en ny prøve end de gjorde ved den første.
Regressionsmodeller findes i mange udformninger til brug i forskellige situationer.Vi har allerede i afsnit 6.3 stiftet bekendtskab med logistisk regression. Vi vil i detteafsnit beskæftige os med lineære normale modeller som regressionsmodeller. Vi an-tager altså at vi har uafhængige responsvariable X1, . . . , XN . Vi antager at disse re-sponsvariable er normalfordelte med samme varians σ2. Vi antager endvidere at
EXi = α +
k∑
j=1
β jti j for i = 1, . . . ,N,
hvor ti1, . . . , tik er de k kovariater knyttet til den i’te måling. Denne model omtalessædvanligvis som lineær regression, fordi middelværdivektoren afhænger lineært afparametrene α, β1, . . . , βk. Som vi skal se er der derimod essentielt ikke linearitetsbe-tingelser på den måde som kovariaterne indgår på.
11.1 Simpel lineær regression
En traditionelt meget vigtig model er den simple lineære regressionsmodel, hvor mankun har en kovariat knyttet til hver måling. Modellen er altså at X1, . . . , XN er uaf-hængige, normalfordelte med samme varians σ2 og at
EXi = α + β ti for i = 1, . . . ,N,
hvor ti er kovariaten knyttet til den i’te måling. Vi så i eksempel 10.4 at dette er enlineær normal model, og den valgte parametrisering af middelværdivektoren giverdesignmatricen
A =
1 t11 t2......
1 tN
.
Man refererer til det sande β som modellens hældning, mens α som regel omtalessom interceptet.
400 Kapitel 11. Regressionsanalyse
Eksempel 11.1 Ved fremstilling af cement iblandes gruspartikler, bl.a. for at få por-øsitet nok i materialet til at vand kan løbe igennem. Den færdige cements drænings-egenskaber afhænger af gruspartiklernes størrelse. I et eksperiment (udført af NaderGhafoori og Shivaji Dutta, og afrapporteret i artiklen “Pavement Thickness Designfor No-Fines Concrete Parking Lots”, Journal of Transportation Engineering, 1995,p. 476-484) undersøgte man porøsiteten for cement, fremstillet af grus med partikleraf kontrolleret størrelse. Resultaterne er gengivet i tabel 11.1.
Vægt Porøsitet Vægt Porøsitet Vægt Porøsitet
99.0 28.8 107.0 21.5 113.6 16.0101.1 27.9 108.7 20.9 113.8 16.7102.7 27.0 110.8 19.6 115.1 13.0103.0 25.2 112.1 17.1 115.4 13.6105.4 22.8 112.4 18.9 120.0 10.8
Tabel 11.1: Samhørende værdier af størrelsen af gruspartikler, der iblandes cementen, ogporøsitet af den færdige cement. Størrelsen af gruspartiklerne er opgjort som vægten af etstandardrumfang grus - jo mindre partiklerne er, jo mere kan de pakke sig, og jo mere vil etstandardrumfang veje. Porøsiteten af den færdige cement er opgjort som volumenprocentenaf luft i den stivnede cement.
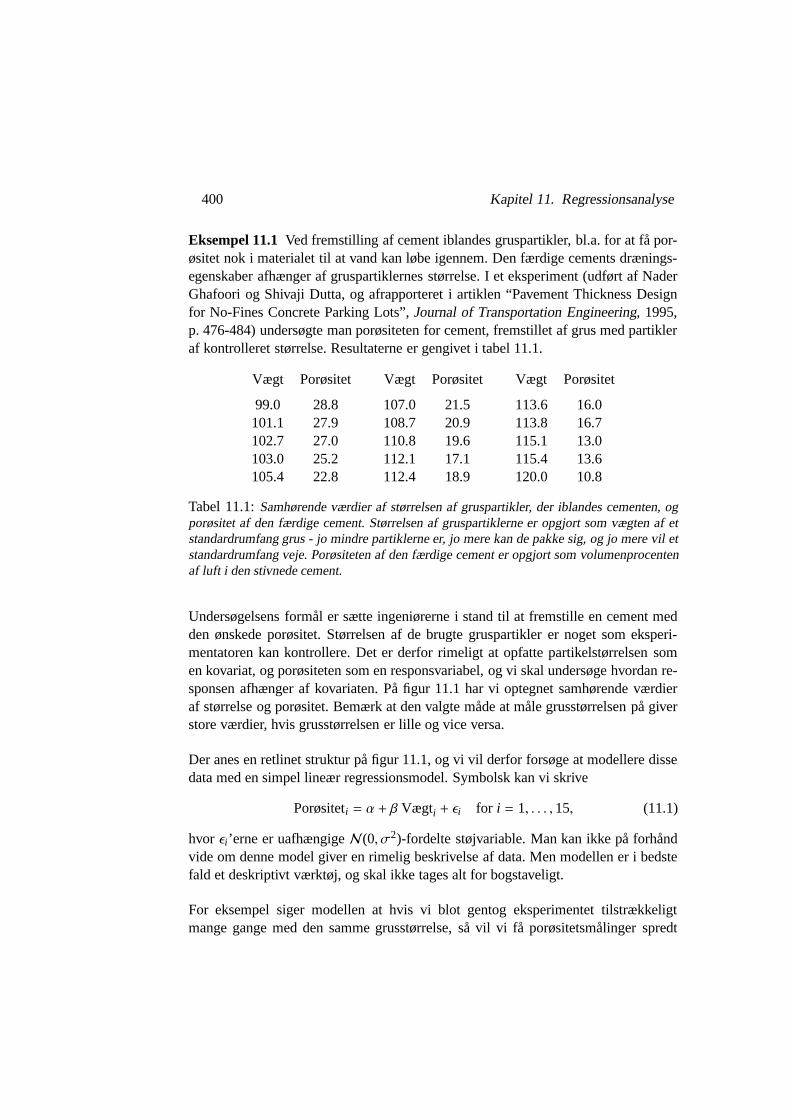
Undersøgelsens formål er sætte ingeniørerne i stand til at fremstille en cement medden ønskede porøsitet. Størrelsen af de brugte gruspartikler er noget som eksperi-mentatoren kan kontrollere. Det er derfor rimeligt at opfatte partikelstørrelsen somen kovariat, og porøsiteten som en responsvariabel, og vi skal undersøge hvordan re-sponsen afhænger af kovariaten. På figur 11.1 har vi optegnet samhørende værdieraf størrelse og porøsitet. Bemærk at den valgte måde at måle grusstørrelsen på giverstore værdier, hvis grusstørrelsen er lille og vice versa.
Der anes en retlinet struktur på figur 11.1, og vi vil derfor forsøge at modellere dissedata med en simpel lineær regressionsmodel. Symbolsk kan vi skrive
Porøsiteti = α + β Vægti + εi for i = 1, . . . , 15, (11.1)
hvor εi’erne er uafhængige N(0, σ2)-fordelte støjvariable. Man kan ikke på forhåndvide om denne model giver en rimelig beskrivelse af data. Men modellen er i bedstefald et deskriptivt værktøj, og skal ikke tages alt for bogstaveligt.
For eksempel siger modellen at hvis vi blot gentog eksperimentet tilstrækkeligtmange gange med den samme grusstørrelse, så vil vi få porøsitetsmålinger spredt
11.1. Simpel lineær regression 401
Vægt
Por
øsi
tet
100 105 110 115 120
1520
25
Figur 11.1: Samhørende værdier af vægt og porøsitet fra tabel 11.1.
ud over hele den reelle akse. Ganske vist ville majoriteten af målingerne koncentreresig på passende vis, men der ville være enkelte meget store og meget små målin-ger. Men responsvariablen er målt som et procenttal, og den vil altid ligge mellem 0og 100. Så går man helt ned i detaljen, er modellens fejlstruktur åbenlyst urimelig.Men vi har ikke særlig mange observationer, og normalfordelingsspecifikationen afstøjfordelingen kan være en udmærket approksimation til den sande fordeling.
En tilsvarende kritik kan rejses mod det forhold at hvis β er negativ (sådan som denmå være, hvis modellen skal fange det aftagende forløb på figur 11.1), så foreskri-ver modellen at man for meget små kornstørrelser (altså høj værdi af vægt-variablen)uvægerligt vil få negative porøsiteter, mens man for store kornstørrelser (altså lavværdi af vægt-variablen) formentlig vil få porøsiteter over 100. Dermed er den line-ære regressionsfunktion urimelig som et generelt udsagn om hvordan grusstørrelserog cementporøsitet ’i virkeligheden’ har det med hinanden. Men skønt den lineæresammenhæng måske ikke kan ekstrapoleres uden for det område hvor de faktiskeobservationer falder, så kan det jo godt være en glimrende approksimation for de ob-serverede data. Og hvis de observerede porøsiteter dækker over det spektrum, der errelevant for praktisk ingeniørarbejde, kan det sikkert være lige meget hvilken porøsi-tet cementen ville have, hvis man blandede kampesten i den.
◦

402 Kapitel 11. Regressionsanalyse
Som lineær normal model betragtet er den simple lineære regression exceptionel,fordi alle matrixformlerne fra kapitel 10 kan regnes igennem, og man kan på denmåde opnå “eksplicitte udtryk” for estimatorer, konfidensområder og teststørrelser. Idisse formler optræder traditionelt en række forkortelser: S for Sum,
S x =
N∑
i=1
Xi, S t =
N∑
i=1
ti,
S S for Sum of Squares,
S S x =
N∑
i=1
X2i , S S t =
N∑
i=1
t2i ,
og S P for Sum of Products,
S Ptx =
N∑
i=1
ti Xi.
Endvidere de afledte størrelser S S D for Sum of Squares of Deviation, og S PD forSum of Products of Deviation,
S S Dx =
N∑
i=1
(Xi − X•)2 = S S x − S x
2/N
S S Dt =
N∑
i=1
(ti − t•)2 = S S t − S t
2/N
S PDtx =
N∑
i=1
(ti − t•)(Xi − X•) = S Ptx − S t S x/N.
Med brug af disse symboler ser vi at
AT A =
N S t
S t S S t
og dermed
(AT A
)−1=
1
N S S t − S t2
S S t −S t
−S t N
=
1N +
t2•
S S Dt
−t•S S Dt
−t•S S Dt
1S S Dt
.
Tilsvarende er
AT X =
S x
S Ptx
.

11.1. Simpel lineær regression 403
Det følger nu af korollar 10.20 at maksimaliseringsestimatoren for middelværdipara-metrene er
(α̂
β̂
)=
(AT A
)−1AT X =
1N +
t2•
S S Dt
−t•S S Dt
−t•S S Dt
1S S Dt
S x
S Ptx
=
X• −
t• S PDtxS S Dt
S PDtxS S Dt
.
Fordelingen af denne estimator er
α̂
β̂
∼ N
α
β
, σ2
1N +
t2•
S S Dt
−t•S S Dt
−t•S S Dt
1S S Dt
. (11.2)
Den estimerede middelværdivektor er
ξ̂ = A
α̂
β̂
=
α̂ + β̂t1α̂ + β̂t2...
α̂ + β̂tN
.
Denne vektor ses efter en smule algebra at have længde
‖ξ̂‖2 = Nα̂2 + β̂2S S t + 2α̂β̂S t = N X2• +
S PDtx2
S S Dt.
Det naturlige, centrale variansestimat er derfor ifølge (10.32)
σ̃2 =‖X‖2 − ‖ξ̂‖2
N − 2=
S S x − N X2• −
S PD2tx
S S Dt
N − 2=
S S Dx −S PD2
txS S Dt
N − 2.
Nytten af disse meget konkrete formler er i høj grad diskutabel. Det er formentligmeget sundt at regne dem igennem en gang i livet, og det er formentlig også sundtat prøve at sætte ind i dem. Men i praksis spiller de stort set ingen rolle: dels fordiman i virkeligheden sjældent er interesseret i kun at lave simpel lineær regression (deinteressante spørgsmål har altid at gøre med modeller der er lidt udvidede, og somikke kan regnes igennem eksplicit), dels fordi det er temmelig uudholdeligt at sætteind i dem ved håndkraft, hvis man har mere end en snes observationer. Og har manalligevel gang i computeren, så har man meget større glæde af de generelle metodik-ker fra kapitel 10. Men formlerne spiller en voldsom rolle i lærebogslitteraturen, hvorde er med til at give statistik et dårligt ry som kogebogsagtigt formelrytteri.

404 Kapitel 11. Regressionsanalyse
Dog er der i visse sammenhænge gevinster ved de konkrete formler. De giver foreksempel indsigt i hvordan forsøgets design (dvs. valget af t’er) influererer på præ-cisionen af de udsagn man kan komme med. Hvis vi ser på fordelingen af α̂ og β̂,ser vi at variansen af parameterestimaterne mindskes ved at gøre SSDt stor. Man op-når en stor SSDt-værdi ved at have mange målinger (naturligvis) og ved at spredekovariaterne så meget som muligt.
I praktiske, eksperimentelle sammenhænge har man ofte mulighed for at vælge t-værdierne nogenlunde frit inden for et vist interval (Tmin,Tmax), mens det er besvær-ligt at få kovariater uden for dette interval. Klassisk eksperimentatorvisdom vil i såfald vide, at man skal lægge så mange kovariater som muligt i de ekstreme enderaf intervallet, hvor de bidrager til en kraftig vækst i SSDt, fremfor at klumpe demsammen på midten.
Ønsket om stor styrke bør dog afbalanceres af mulighederne for at kontrollere model-len: den lineære sammenhæng mellem kovariat og observation kan ikke verificereshvis alle kovariaterne ligger omkring Tmin eller Tmax - den sande regressionskurvekan i så fald have alle mulige krumninger, som man har forhindret sig selv i at op-dage. Man har behov for mellemkovariater - man har behov for at de brugte kovariateri så høj grad som muligt dækker hele det mulige interval.
Et andet eksempel på en indsigt, man kan opnå ved hjælp af de konkrete formler, eren forståelse af korrelationen mellem parameterestimaterne. Det fremgår af (11.2) atkorrelationen mellem α̂ og β̂ vil være negativ hvis t• > 0 - hvilket er den sædvanligesituation. Faktisk vil korrelationen være
corr(α̂, β̂) = −t•√
S S DtN + t2
•
,
så hvis t• er stor og S S Dt er lille (svarende til at kovariatværdierne ligger forholdsvissamlet omkring en værdi langt fra nul), så kan korrelationen være omtrent -1. Elleromtrent +1 i den mere usædvanlige situation, hvor t• er kraftigt negativ.
Den negative korrelationen for et design med positiv t•-værdi har følgende fortolk-ning: hvis vi gentager forsøget med præcis samme kovariater, vil vi ikke få heltsamme punktsky frem, og derfor vil vi heller ikke estimere helt samme linie. Menden nye punktsky ligger dog nogenlunde samme sted som den gamle, så de to linierbør ligge tæt ved hinanden i området med de kovariater, der indgår i eksperimen-tet. Hvis disse punktskyer ligger i et område med førstekoordinater langt fra nul, og

11.1. Simpel lineær regression 405
hvis den nye punktsky fører til et hældningsestimat, der er større end det gamle, såmå den større hældning være kompenseret af et lavere intercept, for at få linierne tilat mødes i omegnen af punktskyerne. Tilsvarende må en eventuel lavere hældningkompenseres af et højere intercept. Deraf den negative korrelation.
Vi ser således at den negative korrelation ikke i sig selv siger noget om at observa-tionerne er “dårlige”. Korrelationen har ikke noget at gøre med observationerne, dener et udtryk for designet af eksperimentet. Den kraftige negative korrelation optræderunder omstændigheder, som er nogenlunde sammenfaldende med de omstændighe-der, der gør interceptestimatet usikkert. Så hvis man har en ægte interesse i intercep-tet, er den kraftige korrelation en advarsel om at bør overveje at ændre designet. Menhvis hovedinteressen er rettet mod hældningen, så er den negative korrelation mellemparameterestimaterne et irrelevant forhold.
Eksempel 11.2 Lad os estimere i modellen for cementporøsitet fra eksempel 11.1,med data fra tabel 11.1. Vi finder
N = 15 S S Vægt = 179849.7
S Vægt = 1640.1 S S Porøsitet = 6430.06
S Porøsitet = 299.8 S PVægt, Porøsitet = 32308.59 .
Dermed er
S S DVægt = 521.196, S S DPorøsitet = 438.0573, S PDVægt, Porøsitet = −471.542.
Det leder til følgende estimater for middelværdiparametrene:
α̂ =299.8
15−
1640.1 · (−471.542)15 · 521.196
= 118.9 ,
der er en observation fra en N(α, 23.0 · σ2)-fordeling, og
β̂ =−471.542521.196
= −0.90,
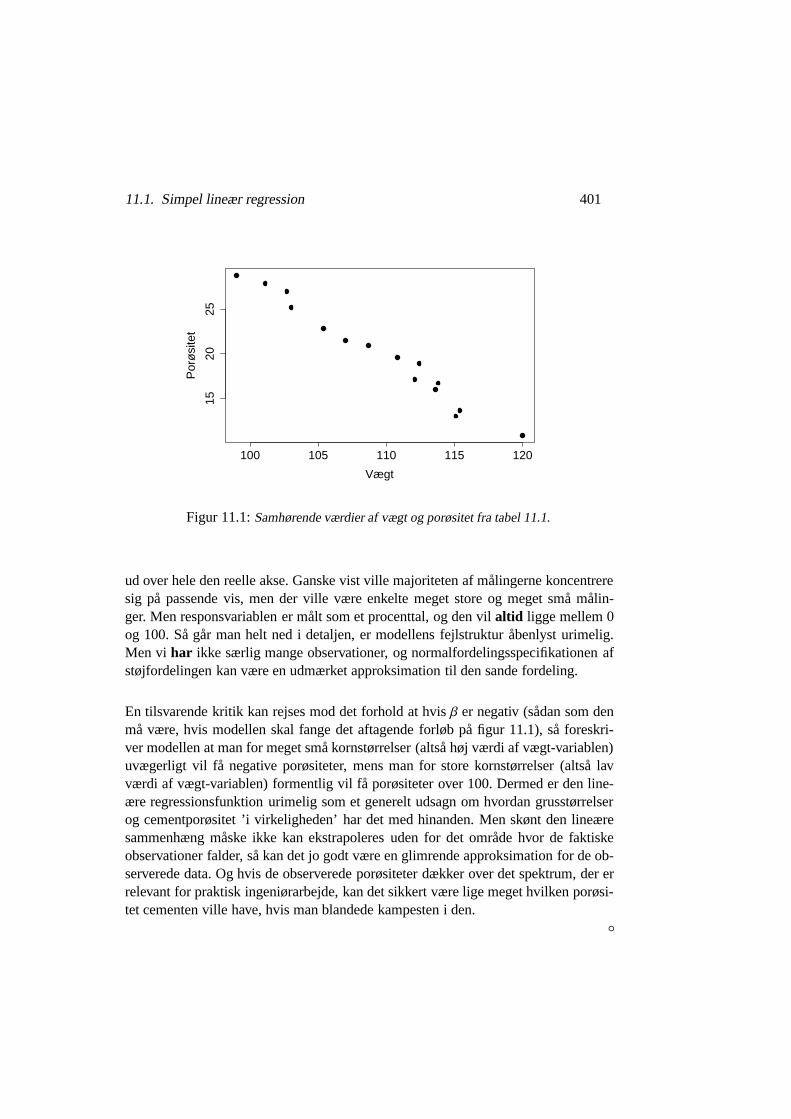
der er en observation fra enN(β, 0.0019 ·σ2)-fordeling. På figur 11.2 har vi optegnetobservationerne og den estimerede regressionslinie.
Estimatorerne for α og β har en korrelation på -0.9985. Denne korrelation er me-get tæt på -1, i fin overensstemmelse med ovenstående diskussion: det er den slagskorrelationer man får, når alle kovariatværdierne er kraftigt positive.
406 Kapitel 11. Regressionsanalyse
Vægt
Por
øsi
tet
100 105 110 115 120
1520
25
Figur 11.2: Samhørende værdier af vægt og porøsitet fra tabel 11.1 sammen med den esti-merede rette linie.
Vi kan udregne længden af den estimerede middelværdivektor
‖ξ̂‖2 = 15 ·
(299.8
15
)2
+(−471.542)2
521.196= 6418.621 .
Det centrale variansestimat er
σ̃2 =6430.06 − 6418.621
15 − 2= 0.88 ,
hvilket er en observation fra en χ2-fordeling med 13 frihedsgrader og skalaparameterσ2/13.
◦
Det naturlige spørgsmål i forbindelse med en simpel lineær regression er ofte omkovariaten overhovedet har en effekt på responsen. At svare på om der er en effekteller ej kommer ud på at teste hypotesen om at hældningen er nul,
H : β = 0 .
En anden måde at formulere denne hypotese på er at observationerne er identiskfordelte med ukendt middelværdi.

11.1. Simpel lineær regression 407
For at opstille F-testet for denne hypotese har vi behov for at kende tre størrelser:kvadratet på længden af observationsvektoren,
‖X‖2 = S S x ,
kvadratet på længden af den estimerede middelværdivektor under modellen,
‖ξ̂‖2 = N X2• +
S PDtx2
S S Dt, (11.3)
og kvadratet på længden af den estimerede middelværdivektor under hypotesen,
‖ ˆ̂ξ‖2 = NX•2 . (11.4)
Vi opstiller nu F-størrelsen
F =
(‖ξ̂‖2 − ‖ ˆ̂ξ‖2
)/(2 − 1)
(‖X‖2 − ‖ξ̂‖2)/(N − 2)=
S PDtx2
S S Dt
σ̃2,
der under hypotesen er F-fordelt med (1,N − 2) frihedsgrader. Store værdier fortol-kes som kritiske for hypotesen. Hvis man ønsker at teste på et 5% niveau, forkasteshypotesen hvis den observerede F-værdi er større end 95% fraktilen i en F-fordelingmed (1,N − 2) frihedsgrader.
I sjældne tilfælde giver det også mening at teste en hypotese om at interceptet er nul.Den eneste forskel fra ovenstående test, er at man skal have fat på en anden estimeretmiddelværdivektor under hypotesen.
Eksempel 11.3 I cementporøsitetsproblemet fra eksempel 11.1 er det ikke så spæn-dende at teste hypotesen om at kovariaten ikke har indflydelse på responsen. Delsvidste eksperimentatorerne på forhånd at kovariaten havde en effekt, og dels er detklart fra figur 11.1 at en sådan hypotese vil blive forkastet med et brag. For god ordensskyld vil vi dog opstille F-størrelsen:
F =(−471.542)2/521.196
0.88= 484.8 .
Denne størrelse skal i princippet holdes op mod 95%-fraktilen i en F-fordeling med(1, 13) frihedsgrader, der er 4.67. Den sammenligning er der ikke meget spøg ved,den observerede F-værdi er mange størrelsesordner over afskæringsgrænsen. Nor-malt vil man foretrække at afrapportere en p-værdi, der fortæller hvor langt ude i

408 Kapitel 11. Regressionsanalyse
halen af F-fordelingen den observerede F-størrelse befinder sig. Men selv det giverikke rigtig mening i denne situation, og man afrapporterer blot at p-værdien er væ-sentlig mindre end f.eks. 10−6. Under alle omstændigheder kan vi konkludere, at deter hysterisk signifikant at porøsiteten af den færdige cement varierer med størrelsenaf det benyttede grus.
En mere indholdsrig hypotese i det konkrete eksempel er nok
H′ : β = −1 .
Eftersom kovariaten i virkeligheden registrerer den reciprokke værdi af porøsiteten afgruset før det blandes i cementen, mens responsen måler porøsiteten af den færdigecement, fortæller H′ at ændringer i grusporøsiteten føres direkte over i en tilsvarendeændring af cementporøsiteten.
Det er en affin hypotese, og som gennemgået i afsnit 10.7, undersøges den nemmestved skifte responsvariabel,
Porøsitet′i = Porøsiteti + Vægti for i = 1, . . . , 15 .
Hvis der gælder en lineær regressionsmodel for den oprindelige respons, gælder derogså en lineær regressionsmodel for den nye respons,
Porøsitet′i = α + (β + 1)︸ ︷︷ ︸=γ
Vægti + εi for i = 1, . . . , 15,
hvor støjvariablene εi er de samme som i den oprindelige formulering (11.1). Udsag-net i H′ er simpelthen at den nye hældning γ er lig med nul, altså at kovariaten ikkehar nogen indflydelse på den transformerede respons.
Gennemfører man de nødvendige regninger, får man en F-størrelse på 5.38 for hypo-tesen om at γ = 0. Det er 96.3% fraktilen for F-fordelingen med (1, 13) frihedsgrader,så på et 5% niveau må vi forkaste H′. Men eftersom testet har en p-værdi på 3.7%må vi nok klassificere det som en grænsesignifikans, nærmere end som en mur- ognagelfast konklusion.
◦
Et simultant (1−δ)-konfidensområde for α og β, kan findes ud fra korollar 10.26. Deter givet som
C(X) =
(α
β
) ∣∣∣∣∣∣∣
(α − α̂
β − β̂
)T (N S t
S t S S t
) (α − α̂
β − β̂
)< 2 zδ σ̃2
,
11.1. Simpel lineær regression 409
hvor zδ er (1 − δ)-fraktilen for en F-fordeling med (2,N − 2) frihedsgrader. Det eren ellipse med centrum i de estimerede parameterværdier. Hvis S t , 0 er ellipsenshovedakser roteret i forhold til koordinatsystemet.
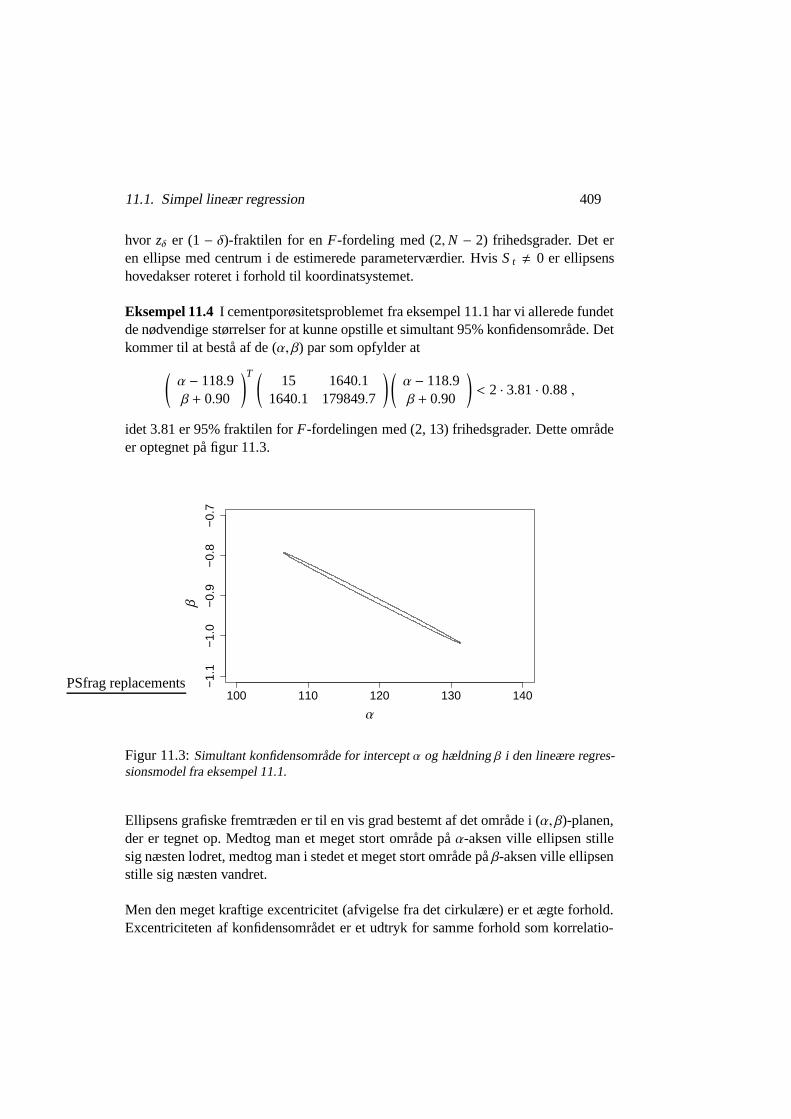
Eksempel 11.4 I cementporøsitetsproblemet fra eksempel 11.1 har vi allerede fundetde nødvendige størrelser for at kunne opstille et simultant 95% konfidensområde. Detkommer til at bestå af de (α, β) par som opfylder at
(α − 118.9β + 0.90
)T (15 1640.1
1640.1 179849.7
) (α − 118.9β + 0.90
)< 2 · 3.81 · 0.88 ,
idet 3.81 er 95% fraktilen for F-fordelingen med (2, 13) frihedsgrader. Dette områdeer optegnet på figur 11.3.
100 110 120 130 140
−1.
1−
1.0
−0.
9−
0.8
−0.
7
PSfrag replacements
α
β
Figur 11.3: Simultant konfidensområde for intercept α og hældning β i den lineære regres-sionsmodel fra eksempel 11.1.
Ellipsens grafiske fremtræden er til en vis grad bestemt af det område i (α, β)-planen,der er tegnet op. Medtog man et meget stort område på α-aksen ville ellipsen stillesig næsten lodret, medtog man i stedet et meget stort område på β-aksen ville ellipsenstille sig næsten vandret.
Men den meget kraftige excentricitet (afvigelse fra det cirkulære) er et ægte forhold.Excentriciteten af konfidensområdet er et udtryk for samme forhold som korrelatio-

410 Kapitel 11. Regressionsanalyse
nen mellem parameterestimaterne, altså at alle kovariaterne er kraftigt positive. Ex-centriciteten skyldes udelukkende designet af eksperimentet, og har intet at gøre medde observerede porøsitetsværdier.
Man kan bemærke at linien β = −1 faktisk skærer det simultane konfidensområde,men at det foregår helt ude i spidsen af ellipsen. Det er ikke i modstrid med hypo-tesetestet fra eksempel 11.3, hvor vi var mest tilbøjelige til at forkaste en hypoteseom at β = −1. Et marginalt 95% konfidensinterval for β bliver en smule smallere endprojektionen af det simultane konfidensområde ind på β-aksen, og blandt de punktersom ikke er med i det marginale konfidensområde er netop -1.
◦
Det er som regel mere informativt at finde konfidensområder for middelværdipara-metrene hver for sig end at betragte et simultant konfidensområde. Vi ser at β erparameterfunktionen af formen
β =
(01
)T (α
β
),
så denne parameterfunktion passer ind i den generelle ramme fra eksempel 10.29 -i hvert fald når man tager højde for at α og β bruges i en helt anden betydning iformel 10.43 end i den aktuelle sammenhæng. Får man oversat symbolerne rigtigt,ser man at et (1 − δ)-konfidensområde for β er givet som
β̂ −√
zδ σ̃2
S S Dt, β̂ +
√zδ σ̃2
S S Dt
.
hvor zδ er (1−δ)-fraktilen for F-fordelingen med (1,N−2) frihedsgrader. Vi ser hvor-dan meget spredte kovariater (det vil sige en stor S S Dt-værdi) giver en velbestemthældning mens kovariater tæt ved hinanden giver et bredt konfidensinterval.
Tilsvarende finder vi at et (1 − δ)-konfidensområde for α er
α̂ −
√√1N+
t2•
S S Dt
zδ σ̃2, α̂ +
√√1N+
t2•
S S Dt
zδ σ̃2
,
Også dette konfidensområde snævrer ind hvis kovariaterne spredes ud - skønt desig-nafhængigheden er mere kompliceret end dette simple udsagn lader ane.

11.1. Simpel lineær regression 411
Vi kan skrue op for blusset, og søge et konfidensområde for den såkaldte regressions-funktion ξ(t) = α + βt for en konkret t-værdi. Vi ser altså på parameterfunktionen
ξ(t) =
(1t
)T (α
β
),
så eksempel 10.29 giver at et (1 − δ)-konfidensområde for ξ(t) er
α̂ + β̂t −√(
1N+
(t − t•)2
S S Dt
)zδ σ̃2, α̂ + β̂t +
√(1N+
(t − t•)2
S S Dt
)zδ σ̃2
.
Som sædvanlig er konfidensintervallet snævert hvis S S Dt er stor, og bredt hvis S S Dt
er lille. Men her observerer vi tillige et interessant fænomen: Konfidensintervallet ersnævrest for t = t•, og bredden af intervallet vokser nogenlunde proportionalt medafstanden mellem t og t• - i hvert fald for store t.
I praksis er alle kovariaterne gerne positive, måske endda store og positive. I så faldbliver α = ξ(0) usikkert bestemt, som vi har bemærket nogle gange. Til denne usik-kerhed er associeret andre ubehageligheder, som korrelation mellem parameteresti-materne, kraftig excentricitet af konfidensområder, og så videre. Forholdet er grund-læggende, at inferens om α involverer en voldsom ekstrapolation af data.
Den interessante og opmuntrende konklusion, der kan drages på baggrund af kon-fidensintervallet for regressionsfunktionen, er nu, at selv om α er usikkert bestemt,så kan man alligevel komme med forholdsvis præcise udsagn, så længe de udsagnkun handler om regressionsfunktionens værdier i midten af det område som er blevetafdækket af eksperimentets kovariater.
Eksempel 11.5 I cementporøsitetsproblemet fra eksempel 11.1 finder vi at et 95%konfidensinterval for hældningen β er
−0.90 −
√4.67 · 0.88521.196
,−0.90 +
√4.67 · 0.88521.196
= (−0.99,−0.81) ,
hvilket lige præcis misser -1, i god overensstemmelse med at hypotesen om at β = −1lige præcis blev forkastet i eksempel 11.3.
Ved tilsvarende formelindsættelse finder vi et 95% konfidensområde for interceptet αsom (109.2, 128.6). Dette konfidensområde er temmelig bredt, hvilket er forventeligteftersom vi kun får viden om α ved at ekstrapolere de gjorte observationer voldsomt.
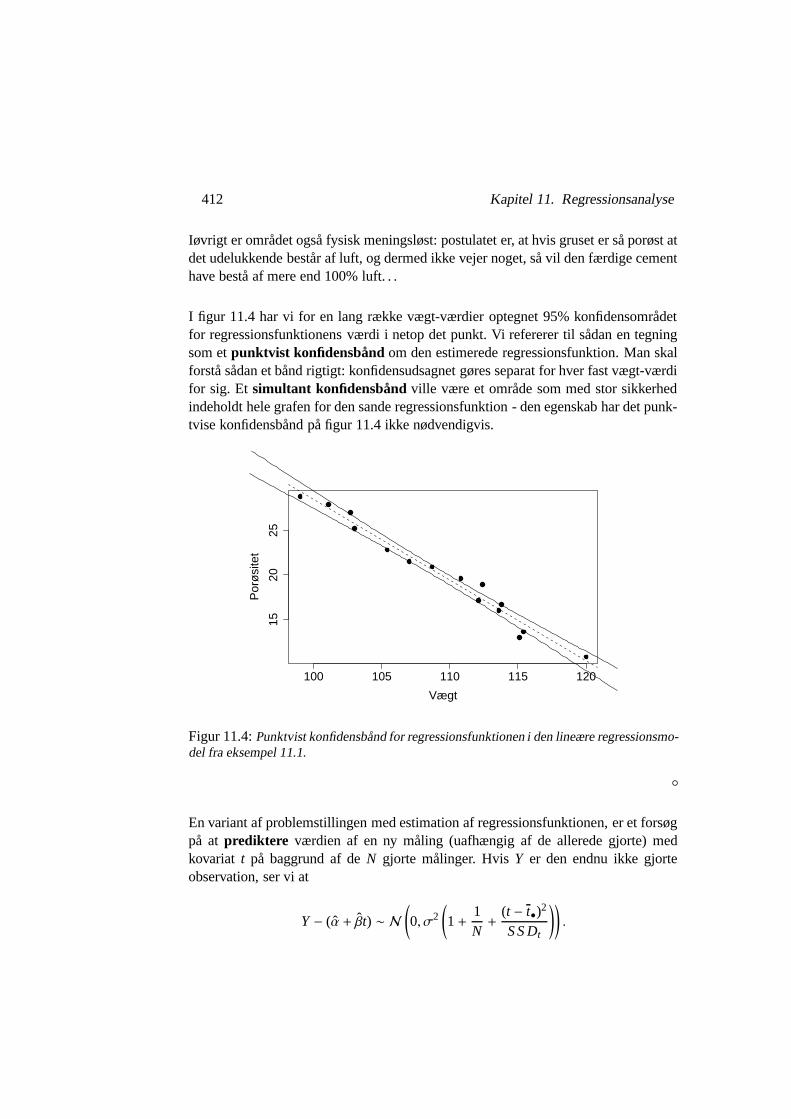
412 Kapitel 11. Regressionsanalyse
Iøvrigt er området også fysisk meningsløst: postulatet er, at hvis gruset er så porøst atdet udelukkende består af luft, og dermed ikke vejer noget, så vil den færdige cementhave bestå af mere end 100% luft. . .
I figur 11.4 har vi for en lang række vægt-værdier optegnet 95% konfidensområdetfor regressionsfunktionens værdi i netop det punkt. Vi refererer til sådan en tegningsom et punktvist konfidensbånd om den estimerede regressionsfunktion. Man skalforstå sådan et bånd rigtigt: konfidensudsagnet gøres separat for hver fast vægt-værdifor sig. Et simultant konfidensbånd ville være et område som med stor sikkerhedindeholdt hele grafen for den sande regressionsfunktion - den egenskab har det punk-tvise konfidensbånd på figur 11.4 ikke nødvendigvis.
Vægt
Por
øsi
tet
100 105 110 115 120
1520
25
Figur 11.4: Punktvist konfidensbånd for regressionsfunktionen i den lineære regressionsmo-del fra eksempel 11.1.
◦
En variant af problemstillingen med estimation af regressionsfunktionen, er et forsøgpå at prediktere værdien af en ny måling (uafhængig af de allerede gjorte) medkovariat t på baggrund af de N gjorte målinger. Hvis Y er den endnu ikke gjorteobservation, ser vi at
Y − (α̂ + β̂t) ∼ N
(0, σ2
(1 +
1N+
(t − t•)2
S S Dt
)).

11.1. Simpel lineær regression 413
Idet Y − (α̂ + β̂t) og σ̃2 er uafhængige, er
Y − (α̂ + β̂t)√σ̃2
(1 + 1
N +(t−t•)2
S S Dt
)
T -fordelt med N−2 frihedsgrader. I særdeleshed er denne størrelse en pivot. Hele ana-logt med arbejdsgangen i eksempel 7.13 - og den abstrakte beskrivelse i afsnit 10.9 -kan vi regne baglæns og konstatere at
α̂ + β̂t ± zα
√(1 +
1N+
(t − t•)2
S S Dt
)σ̃2
er et (1 − α)-prediktionsinterval, hvis zα er 1 − α/2-fraktilen i T -fordelingen medN − 2 frihedsgrader. Øjet læser uden videre denne formel som konfidensintervalletfor regressionsfunktionen plus ekstra støj, svarende til at Y-observationen også harvarians σ2.
I forbindelse med modelkontrol af den simple lineære regressionsmodel, er det nyt-tigt at finde residualerne. Ved vurderingen af disse residualer, bør man standardiseredem, ved at finde den enkelte observations leverage ud fra (10.45). Ved tilstrækkeligihærdighed (se opgave 11.2) finder man at leverage for den i’te observation er
hii =1N+
(ti − t•)2
S S Dt(11.5)
Typiske observationer vil således have en leverage af størrelsesorden 2N , men jo læn-
gere observationens kovariat ligger fra t•, jo større bliver leverage.
Det ekstremme tilfælde fås hvis N − 1 observationer har samme kovariat, mens densidste observation har sin egen kovariat-værdi. Den sidste observation får i så faldleve rage på knap 1, hvilket betyder at det tilhørende residual får varians omtrent 0!I dette specielle tilfælde tvinger estimationsproceduren den estimerede linie til at gågennem det specielle punkt, uanset hvordan målingerne i øvrigt ligger. Intuitivt erdet faktisk fornuftigt nok - men det er klart at analysen er meget sårbar overfor enfejlregistrering af netop denne måling.
Eksempel 11.6 I cementporøsitetsproblemet fra eksempel 11.1 ligger kovariaternemere eller mindre ækvidistant, og vi får derfor ret forudsigelige leverage af observa-tionerne: halvstore i enderne af kovariatområdet, små i midten. De konkrete leverage-værdier er optegnet i figur 11.5. Yderresidualerne har en leverage på omkring 0.25,
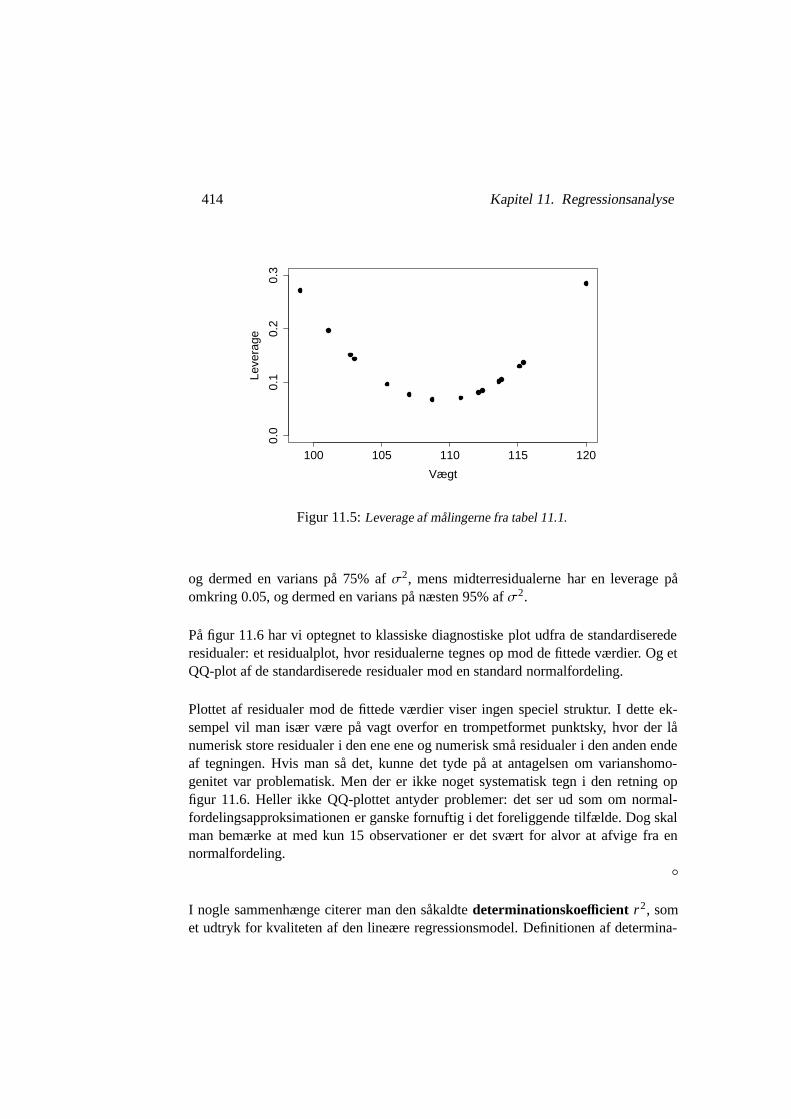
414 Kapitel 11. Regressionsanalyse
Vægt
Leve
rage
100 105 110 115 120
0.0
0.1
0.2
0.3
Figur 11.5: Leverage af målingerne fra tabel 11.1.
og dermed en varians på 75% af σ2, mens midterresidualerne har en leverage påomkring 0.05, og dermed en varians på næsten 95% af σ2.
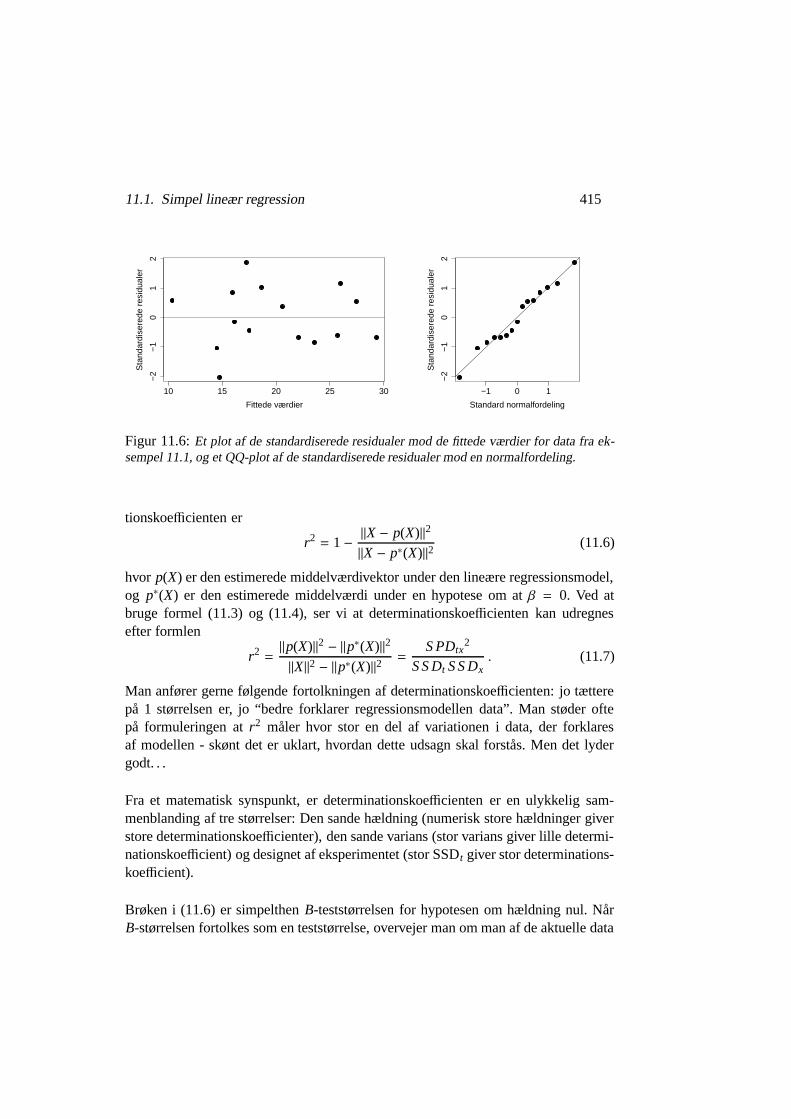
På figur 11.6 har vi optegnet to klassiske diagnostiske plot udfra de standardiserederesidualer: et residualplot, hvor residualerne tegnes op mod de fittede værdier. Og etQQ-plot af de standardiserede residualer mod en standard normalfordeling.
Plottet af residualer mod de fittede værdier viser ingen speciel struktur. I dette ek-sempel vil man især være på vagt overfor en trompetformet punktsky, hvor der lånumerisk store residualer i den ene ene og numerisk små residualer i den anden endeaf tegningen. Hvis man så det, kunne det tyde på at antagelsen om varianshomo-genitet var problematisk. Men der er ikke noget systematisk tegn i den retning opfigur 11.6. Heller ikke QQ-plottet antyder problemer: det ser ud som om normal-fordelingsapproksimationen er ganske fornuftig i det foreliggende tilfælde. Dog skalman bemærke at med kun 15 observationer er det svært for alvor at afvige fra ennormalfordeling.
◦
I nogle sammenhænge citerer man den såkaldte determinationskoefficient r2, somet udtryk for kvaliteten af den lineære regressionsmodel. Definitionen af determina-
11.1. Simpel lineær regression 415
Fittede værdier
Sta
ndar
dise
rede
res
idua
ler
10 15 20 25 30
−2
−1
01
2
Standard normalfordeling
Sta
ndar
dise
rede
res
idua
ler
−1 0 1
−2
−1
01
2Figur 11.6: Et plot af de standardiserede residualer mod de fittede værdier for data fra ek-sempel 11.1, og et QQ-plot af de standardiserede residualer mod en normalfordeling.
tionskoefficienten er
r2 = 1 −‖X − p(X)‖2
‖X − p∗(X)‖2(11.6)
hvor p(X) er den estimerede middelværdivektor under den lineære regressionsmodel,og p∗(X) er den estimerede middelværdi under en hypotese om at β = 0. Ved atbruge formel (11.3) og (11.4), ser vi at determinationskoefficienten kan udregnesefter formlen
r2 =‖p(X)‖2 − ‖p∗(X)‖2
‖X‖2 − ‖p∗(X)‖2=
S PDtx2
S S Dt S S Dx. (11.7)
Man anfører gerne følgende fortolkningen af determinationskoefficienten: jo tætterepå 1 størrelsen er, jo “bedre forklarer regressionsmodellen data”. Man støder oftepå formuleringen at r2 måler hvor stor en del af variationen i data, der forklaresaf modellen - skønt det er uklart, hvordan dette udsagn skal forstås. Men det lydergodt. . .
Fra et matematisk synspunkt, er determinationskoefficienten er en ulykkelig sam-menblanding af tre størrelser: Den sande hældning (numerisk store hældninger giverstore determinationskoefficienter), den sande varians (stor varians giver lille determi-nationskoefficient) og designet af eksperimentet (stor SSDt giver stor determinations-koefficient).
Brøken i (11.6) er simpelthen B-teststørrelsen for hypotesen om hældning nul. NårB-størrelsen fortolkes som en teststørrelse, overvejer man om man af de aktuelle data

416 Kapitel 11. Regressionsanalyse
kan se at hældningen skal være forskellig fra nul. Det gør man ved at sammenholdeden observerede værdi, med hvad man ville forvente at se, dersom hypotesen varsand. Hvad man forventer at se, afhænger af undersøgelsens design - antallet af ob-servationer indgår jo f.eks. i den B-fordeling, der slås op i, og går man så langt somtil at undersøge fordelingen af teststørrelsen uden for hypotesen, så kommer designettil at optræde meget eksplicit, i form at ikke-centralitetsparametre.
Men determinationskoefficienten fortolkes som om den har en mening i sig selv, uaf-hængig af det aktuelle design. Eftersom undersøgelsens design er blandet ind i de-terminationskoefficienten, står denne fortolkning ikke til troende: uanset hvor sandmodellen er, vil man opnå meget små determinationskoefficienter, hvis kovariaternekun varierer over et lille område.
Der må altså advares mod en ukritisk brug af determinationskoefficienten som etgenerelt udtryk for hvor godt den simple lineære regressionsmodel forklarer observa-tionerne. Men vi skal senere se, at der er eksperimentelle situationer, hvor determi-nationskoefficienten faktisk har en klar og nyttig fortolkning.
11.2 Observerede kovariater
Argumentationen i afsnit 11.1 tager som udgangspunkt at kovariaterne er determini-stiske. I eksempel 11.1 konstrueres grusblandingerne omhyggeligt sådan at vægtva-riablen får en foreskrevet værdi. Alle fordelingsudsagn handler om hvad der vil skeved hypotetiske gentagelser af eksperimentet, under forudsætning af at man ved dissegentagelser bruger præcis de samme grusblandinger som i det oprindelige eksperi-ment. Der er simpelthen ingen slør i kovariaterne - de er hvad de er, i en langt merefundamental forstand end målingerne.
Der er ikke mange eksperimenter der har denne karakter! Typisk er kovariaten ogsåbehæftet med målefejl og lignende. I nogle eksperimenter har eksperimentator en viskontrol over værdien af kovariaten, i andre optræder ’kovariat’ og ’respons’ på heltsymmetrisk facon - man måler to samhørende værdier i en række identiske gentagel-ser af eksperimentet. Vi skal nu argumenter for at der i begge tilfælde kan være en vismening i at analysere data med den simple lineære regressionsmodel. Blot skal mangøre sig klart, at der er et afgørende skel i fortolkningen af den lineære regression, altefter om kovariaterne er søgt kontrolleret eller ej.

11.2. Observerede kovariater 417
Først diskuterer vi situationen, hvor kovariaterne søges kontrolleret. Lad os antage atden lineære regressionsmodel er “sand”, i den forstand at hvis kovariaten virkelig ert, så vil den tilhørende observationen være
X = α + β t + ε ,
hvor ε er en N(0, σ2)-fordelt målestøjsvariabel. Lad t1, . . . , tN være kovariatværdier,som eksperimentatoren har lagt sig fast på, før forsøget går i gang, men som han ikkeer i stand til at ramme præcist, når han udfører eksperimentet. Disse ti’er har en slagsmoralsk karakter, og de er en del af designet.
En naturlig forestilling er, at eksperimentatoren rammer de moralske kovariater pånær en vis eksperimentfejl,
Ti = ti + δi , i = 1, . . . ,N ,
hvor δi’erne er uafhængige N(0, ν2)-fordelte støjvariable - man kunne kalde δi’ernefor indstillingsfejl. I så fald vil de tilhørende responsvariable være
Xi = α + βTi + εi = α + β ti + (β δi + εi) , i = 1, . . . ,N .
Hvis der er uafhængighed mellem målestøjen εi og indstillingsfejlen δi, ser vi atXi’erne i virkeligheden følger en simpel lineær regressionsmodel ud fra de moralskekovariater - blot skal man tænke på fejlstørrelserne som en kombination af egentligmålestøj på den ene side og indstillingsstøj på den anden.
Eftersom kombinationen af målestøj og indstillingsstøj er en integreret del af pro-blemstillingen, og også vil gentage sig i fremtidige varianter af forsøget, kan manaltså se helt bort fra den konceptuelle komplikation, der ligger i at de moralske kova-riater ikke er de “egentlige” kovariater.
Mere kompliceret bliver det, hvis kovariat og respons optræder på symmetrisk facon,og kovariaten er uden for eksperimentators kontrol, præcis ligesom responsen. Mantaler da om observerede kovariater, i modsætning til deterministiske kovariater. Ogformålet med eksperimentet er da at undersøge hvordan “responsen” og “kovariaten”samvarierer.
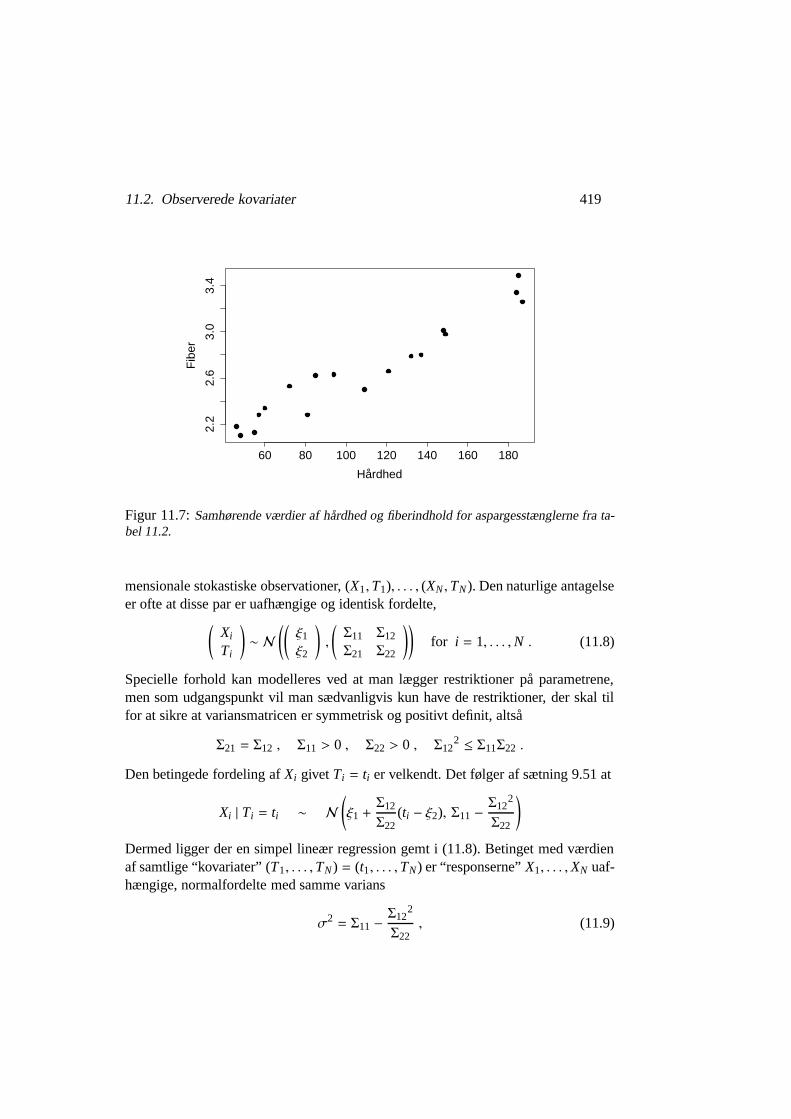
Eksempel 11.7 Ved dyrkning af grønne asparges betragter man sædvanligvis bådehårdhed og fiberindhold som kvalitetskriterier. I et eksperiment har man målt beggedele på 18 asparges. Resultaterne er gengivet i tabel 11.2.
418 Kapitel 11. Regressionsanalyse
Hårdhed Fiber Hårdhed Fiber Hårdhed Fiber46 2.18 81 2.28 137 2.8048 2.10 85 2.62 148 3.0155 2.13 94 2.63 149 2.9857 2.28 109 2.50 184 3.3460 2.34 121 2.66 185 3.4972 2.53 132 2.79 187 3.26
Tabel 11.2: Samhørende værdier af hårdhed og fiberindhold for en række grønne asparges-stængler. Hårheden er opgjort som den kraft, der skulle til for at bøje et stykke af stænglen affast længde, fiberindholdet er opgivet i procent tørvægt.
Behandler man de høstede aspargesstængler med glyfosfat, så forlænges deres hold-barhed. Undersøgelsens formål var at belyse i hvilket omfang denne glyfosfatbehand-ling sænker kvaliteten af aspargesstænglerne. For at kunne belyse det spørgsmål erdet nyttigt at vide om de forskellige kvalitetskriterier i virkeligheden siger det samme,eller om måler forskellige kvalitetsaspekter. På figur 11.7 har vi optegnet samhørendeværdier af hårdhed og fiberindhold.
Der er en iøjnefaldende voksende tendens på figur 11.7, så de to kvalitetskriterier føl-ges ad: En hård aspargesstængel vil også have et stort fiberindhold. Vi kan forsøge atbeskrive denne samvariation med en simpel lineær regressionsmodel, hvor vi model-lerer fiberindholdet som funktion af hårdheden. I så fald får vi et hældningsestimatpå 0.0083 med et 95% konfidensinterval på
(0.0072, 0.0095).
Det er hysterisk signifikant at denne hældning er forskellig fra nul. På denne mådehar vi kvantificeret det grafiske indtryk fra figur 11.7.
Men den valgte beskrivelse passer slet ikke ind i mønsteret fra afsnit 11.1, for vi haringen eksperimentel kontrol over “kovariaten” hårdhed. Vi kunne præcis lige så godthave udnævnt fiberindholdet til at være kovariat og hårdheden til at være respons. Detville have ført til et hældningsestimat på 112, med et 95% konfidensinterval på (96,128). Det er interessant at bemærke at de to estimerede hældninger ikke er hinandensreciproke, sådan som man umiddelbart kunne forestille sig at de skulle være det.
◦
I stedet for at have målinger X1, . . . , XN med tilførende deterministiske kovariatert1, . . . , tN , så har man i situationer med observerede kovariater i virkeligheden todi-
11.2. Observerede kovariater 419
Hårdhed
Fib
er
60 80 100 120 140 160 180
2.2
2.6
3.0
3.4
Figur 11.7: Samhørende værdier af hårdhed og fiberindhold for aspargesstænglerne fra ta-bel 11.2.
mensionale stokastiske observationer, (X1,T1), . . . , (XN ,TN ). Den naturlige antagelseer ofte at disse par er uafhængige og identisk fordelte,
(Xi
Ti
)∼ N
((ξ1ξ2
),
(Σ11 Σ12
Σ21 Σ22
))for i = 1, . . . ,N . (11.8)
Specielle forhold kan modelleres ved at man lægger restriktioner på parametrene,men som udgangspunkt vil man sædvanligvis kun have de restriktioner, der skal tilfor at sikre at variansmatricen er symmetrisk og positivt definit, altså
Σ21 = Σ12 , Σ11 > 0 , Σ22 > 0 , Σ122 ≤ Σ11Σ22 .
Den betingede fordeling af Xi givet Ti = ti er velkendt. Det følger af sætning 9.51 at
Xi | Ti = ti ∼ N
(ξ1 +
Σ12
Σ22(ti − ξ2), Σ11 −
Σ122
Σ22
)
Dermed ligger der en simpel lineær regression gemt i (11.8). Betinget med værdienaf samtlige “kovariater” (T1, . . . ,TN ) = (t1, . . . ,TN) er “responserne” X1, . . . , XN uaf-hængige, normalfordelte med samme varians
σ2 = Σ11 −Σ12
2
Σ22, (11.9)

420 Kapitel 11. Regressionsanalyse
og med varierende middelværdi,
E(Xi | (T1, . . . ,TN) = (t1, . . . , tN )
)= ξ1 −
Σ12
Σ22ξ2
︸ ︷︷ ︸= α
+Σ12
Σ22︸︷︷︸= β
ti (11.10)
Hvis vi gennemfører en simpel lineær regression med X som responsvariabel og Tsom kovariat, interesserer vi os således i virkeligheden for parametrene i den betin-gede fordeling af X’erne givet T ’erne.
Den marginale fordeling af T ’erne er naturligvis også velkendt, T1, . . . ,TN er uaf-hængige, identisk fordelte,
Ti ∼ N(ξ2,Σ22) .
Vi kan reparametrisere den simultane fordeling af alle (X,T )-parrene ved parame-trene i den marginale af T ’erne og parametrene i den betingede fordeling af X’ernegivet T ’erne. I stedet for de oprindelige fem parametre
( ξ1, ξ2,Σ11,Σ12,Σ22)
ser vi således på parametrene
(ξ2,Σ22, α, β, σ2) ,
hvor oversættelsen mellem de to sæt parametre er givet ved (11.9) og (11.10). De nyeparametre er for så vidt simplere at have med at gøre end de gamle, fordi det ikke-lineære bånd, der skal sikre at variansmatricen er positivt definit, tager vare på sigselv. I den nye parametrisering er det eneste krav at de to varianser Σ22 og σ2 beggeer positive.
Den primære gevinst i reparametriseringen er dog af mere indholdsmæssig karakter:vi ekspliciterer på denne måde at parametrene i den marginale fordeling af T ’erneopfattes som støjparametre, og at interesseparametrene er de parametre der indgår iden betingede fordeling af X’erne givet T ’erne.
Vi kan opskrive den fulde likelihoodfunktion på baggrund af parobservationerne(X1,T1), . . . , (XN ,TN) i den nye parametrisering, og vi får da
(Σ−N/222 e−
∑(Ti−ξ2)2/2Σ22
) ((σ2)−N/2e−
∑(Xi−α−βTi)/2σ2
). (11.11)
Første faktor repræsenterer den marginale fordeling af T ’erne, anden faktor den be-tingede fordeling af X’erne givet T ’erne. Vi konstaterer at anden faktor præcis er

11.2. Observerede kovariater 421
den sædvanlige likelihoodfunktion for en simpel lineær regression. Endvidere ser viat støjparametrene kun indgår i første faktor, mens interesseparametrene kun indgåri anden faktor. Så anden faktor er proportional med profillikelihoodfunktionen forinteresseparametrene.
Hvis vi gennemfører en simpel lineær regression, finder vi derfor maksimaliserings-estimatorerne for α, β og σ2, altså for parametrene i den betingede fordeling af re-sponserne givet kovariaterne. Vi har således redegjort for at den simple lineære re-gression giver fortræffelig mening, også i situationer med observerede kovariater, blotman er klar over fortolkningen.
Vi kan f.eks. forklare hvorfor de to hældninger i eksempel 11.7 ikke var hinandensreciprokke. Den teoretiske hældning for den ene lineære regression, henholdsvis denanden, er
Σ12
Σ22og
Σ12
Σ11.
Produktet af de to teoretiske hældninger er derfor
Σ122
Σ11 Σ22=
Cov(Xi,Ti)2
VXi VTi.
Dette udtryk genkendes som den kvadrerede korrelation mellem Xi og Ti. Så pro-duktet af de to hældninger vil i almindelighed være mindre end 1, ofte en hel delmindre.
Bemærk at relationerne (11.9) og (11.10) tillader os at udtrykke den kvadrerede kor-relation mellem Xi og Ti som
ρ2 =β2 Σ22
σ2 + β2 Σ22.
Her indgår der kun parametre fra den “nye” parametrisering, dvs. parametre,hvis maksimaliseringsparametre vi kan finde ved at maksimere likelihoodfunktio-nen (11.11). Vi kan finde maksimaliseringsestimatoren for ρ2 ved at indsætte maksi-maliseringsestimatorerne
β̂ =S PDtx
S S Dt, σ̂2 =
1N
(S S Dx −
S PDtx2
S S Dt
), Σ̂22 =
1N
S S Dt ,

422 Kapitel 11. Regressionsanalyse
i ovenstående formel (bemærk: vi har angivet maksimaliseringsestimatorerne for va-riansparametrene, ikke de sædvanlige centrale estimater). Det fører til følgende mak-simaliseringsestimator for ρ2:
ρ̂2 =β̂2 Σ̂22
σ̂2 + β̂2 Σ̂22
=S PDtx
2
S S Dt S S Dx.
Vi genkender dette formeludtryk fra (11.7). Vi har altså vist, at i det aktuelle set up, erdeterminationskoefficienten r2 lig med maksimaliseringsestimatoren for ρ2. Eftersomkorrelationen mellem Ti og Xi er det naturlige mål for i hvilken grad de to variable“følges ad”, giver denne relation en hel del mening til fortolkningen af determina-tionskoefficienten som et udtryk for hvor godt den lineære regressionsmodel passermed observationerne.
Vi kan dog kun lægge dette fortolkningsindhold i r2, hvis målingerne er udtryk for enligevægtstilstand, altså hvis kovariaterne har fået lov at indstille sig ved egen kraft.Det giver til gengæld store vanskeligheder med at fortolke parametrene i den lineæreregression kausalt, sådan som vi gjorde i den lineære regression med deterministiskekovariater. Hvis hældningen β er positiv, skal mange mennesker tage sig alvorligtsammen for ikke at betragte det som et udtryk for at hvis man på en eller anden mådeøger kovariaten, så vil man også øge responsen.
Men det er yderst tvivlsomt, om der er belæg for en sådan fortolkning, hvis kovari-aterne er observerede. Man postulerer en interventionseffekt, som man faktisk ikkehar undersøgt. I det eksperiment man har udført, har kovariat og respons indstilletsig selv i en form for ligevægt. Det er ikke til at vide hvad der sker hvis man bryderdenne ligevægt og tvinger kovariaten i en bestemt retning. Måske følger responsenmed, og måske gør den det ikke.
Et ekstremt eksempel, hvor en intervention ikke vil have de forventede konsekvenser,kunne man få i Galtons højdedata for far/søn par, omtalt p. 397. Den positive samva-riation kan næppe fortolkes sådan at sønnen bliver mindre, hvis man hugger beneneaf faderen! Heller ikke selv om man forkorter faderen før han forplanter sig.
Til gengæld kunne man nok sikre sig små sønner ved kun at tillade små fædre atforplante sig. Den form for selektion har trods alt dannet grundlag for forædling ilandbrugssektoren i 150 år. Så visse former for intervention har den forventede effekt,andre har det ikke.

11.3. Multipel regression 423
Et andet forhold, som man som statistiker skal være sig bevidst, er at den inferensman får i den simple lineære regression er anderledes end den man får ved sædvan-lige argumenter ud fra (11.11). Vi har overbevist os om at maksimaliseringsestimato-rerne for interesseparametrene er de samme. Men fordelingspostulaterne er forskel-lige, for de hypotetiske gentagelser, der ligger bag den simple lineære regression, erikke samme som de hypotetiske gentagelser (11.11) lægger op til.
Når vi i sædvanlig sprogbrug taler om at gentage eksperimentet, så vil det betyde nyeT ’er såvel som nye X’er. Men de hypotetiske gentagelser der ligger bag den simplelineære regression, insisterer på at det nye eksperiment skal have præcis samme ko-variater som det gamle. De to måder at forestille sig gentagelser på, vil være uenigeom størrelsen af konfidensintervaller og om hvordan man afgrænser acceptområderfor test. Så der er ikke tale om uskyldige smådivergenser.
Visse statistikere foretrækker den inferens der kommer ud af den fulde likelihood-funktion (11.11), andre påberåber sig det såkaldte betingningsprincip og foretræk-ker inferensen baseret på den simple lineære regression. Betingningsprincippet sigerat hvis en vis transformation af data har en fordeling, der ikke afhænger af interes-separametrene, så bør inferens om interesseparametrene foregå i den betingede for-deling af observationen givet denne transformation. Betingningsprincippets rolle erstærkt omdiskuteret i den teoretiske statistik.
11.3 Multipel regression
En forholdsvis behersket, men dog vidtrækkende udbygning af den simple lineæreregressionsmodel får man når hver måling har to kovariater knyttet til sig. Modellener altså at X1, . . . , XN er uafhængige, normalfordelte med samme varians σ2 og at
EXi = α + βti + γsi for i = 1, . . . ,N,
hvor ti og si er de to kovariater knyttet til den i’te måling. Et andet ord for kovariater,der ofte benyttes i forbindelse med multipel regression, er regressorer. Stillet op påmatrixform er middelværdispecifikationen
E
X1
X2...
XN
=
1 t1 s1
1 t2 s2.........
1 tN sN
α
β
γ
.

424 Kapitel 11. Regressionsanalyse
Der er altså tale om en lineær normal model. Hvis der er nogen rimelighed til, ermiddelværdiunderrummet tredimensionalt, og har f.eks. designmatrix
A =
1 t1 s1
1 t2 s2.........
1 tN sN
.
Men der kan opstå degenererede situationer, hvor f.eks. s-søjlen er en linearkombi-nation af 1-søjlen og t-søjlen. Så længe der kun er to kovariater kan man som regelgennemskue et sådant dimensionskollaps hvis det opstår - hvis man derimod har 50-100 søjler i “designmatricen” er det langt sværere at opdage en lineær afhængighedmellem dem.
Lineær regression med to kovariater kan ikke regnes igennem i hånden, i hvert faldkun under meget stort besvær. Men matrixformlerne fungerer uproblematisk, så medadgang til en computer er det en smal sag at gennemføre estimation og test i dennemodel. Udfordringen er derfor ikke så meget af teknisk karakter som af begrebsmæs-sig, udfordringen består i at forstå de relevante hypoteser og forholdet mellem dem.
Sædvanligvis vil man interessere sig for hypotesen om at t-kovariaten ikke har nogeneffekt,
H1 : β = 0 ,
eller for den tilsvarende hypotese om at s-kovariaten ikke har nogen effekt,
H′1 : γ = 0 .
Disse hypoteser er naturligvis helt analoge, og ud fra et teoretisk synspunkt kunneman nøjes med at behandle en af dem. Men kunsten stiger, for i visse situationerer man interesseret i både H1 og H′1 på en gang, og så er tingene naturligvis mereindviklede.
Eksempel 11.8 Et eksempel, hvor man har hovedinteressen rettet mod en hypoteseaf formen H1, kunne være et industrielt optimeringseksperiment. Man ønsker at findeproduktionsomstændigheder, der giver størst muligt udbytte. Man ved måske at kva-liteten af råvarerne, målt som renhedsgrad, er direkte aflæselig i hvor stort udbytteter, men er usikker på om produktionstemperaturen er væsentlig. Eksperimentet gårnu ud på at måle produktionsudbyttet for en række kombinationer af råvarekvalitetog produktionstemperatur. Vi forestiller os data indsamlet som et led i den faktiske

11.3. Multipel regression 425
produktionsproces, hvor der ikke gøres noget stort forsøg på at lade disse kovariaterantage bestemte værdier.
Data fra et sådan eksperiment kan tænkes at være udmærket modelleret ved en lineærregression med to kovariater, hvor den ene svarer til råvarekvalitet og den anden tilproduktionstemperatur. Eftersom man ved at råvarekvaliteten har indflydelse på re-sultatet, er det irrelevant at forsøge at teste en hypotese om at råvarekvaliteten ingenbetydning har. Interessen vil rette sig mod hypotesen om at temperaturen ingen be-tydning har.
Denne hypotese kunne man for så vidt teste indenfor rammerne af en simpel lineærregression, hvor kun temperaturvariablen indgik. Men det kunne give ganske vildle-dende resultater. Man kunne forestille sig at målingerne med høj temperatur tilfældig-vis også var dem med dårlig råvarekvalitet, og så ville en simpel lineær regression fådet til at se ud som om at høj temperatur gav dårligt udbytte - uanset om det er sandteller ej. Med mindre man har været meget omhyggelig med at justere de forskelligekovariat-værdier ind på en helt symmetrisk måde, vil den simple lineære regressiongive et upålideligt resultat.
Den multiple regression forsøger at komme ud af denne fælde. Man siger ofte at manundersøger effekten af den ene kovariat, kontrolleret for effekten af den anden. Omen simpel lineær kontrol er den rigtige måde at kontrollere på, afhænger selvfølgeligaf situationen. Men det er en meget robust måde at gøre det på, og den multipleregressionsmodel er ofte i stand til at fange relativt små kovariateffekter, selv om deer overlejret af meget større effekter af andre kovariater.
◦
Eksempel 11.9 Hvis man har registreret to kovariater, og ikke rigtig ved om nogenaf dem har indflydelse, og ikke på forhånd er mere interesseret i den ene fremfor denanden, så står man med et eksempel med to sideordnede hypoteser.
Man kunne i princippet stable to simple lineære regressionsmodeller på benene, ogundersøge effekten af hver kovariat for sig, men som i eksempel 11.8 ville man fådet problem at konklusionerne ville være utroværdige, fordi de ikke forholder sig tilsamvariationen af kovariaterne. I den multiple regression forsøger man i det mindsteat kontrollere for den eventuelle effekt af den ene kovariat, når man udtaler sig omden anden.
Men man havner let i følgende ubehagelige situation: Et test af om β = 0 accepteres,ligesom det parallelt udførte test om at γ = 0 også accepteres. Et skud fra hoften ville

426 Kapitel 11. Regressionsanalyse
i så fald være at ingen af de to kovariater har nogen effekt. Men det kan være heltforkert. Hvis man under hypotesen om at β = 0 tester den mindre hypotese om atβ = γ = 0, bliver den lille hypotese muligvis forkastet med et brag, ligesom den villeblive det, hvis den blev testet under γ = 0. Så den ene eller den anden kovariat (efterfrit valg) er altså uden betydning, men ikke dem begge! Problemstillingen opstår isærnår de to kovariatvektorer er næsten ensrettede.
Man kan tænke på målinger af alkoholprocent i blodet et vist tidsrum efter indtagel-sen. Hvis man har registreret forsøgspersonernes højde og vægt, vil man formentligfinde at ingen af disse kovariater er signifikante, når man kontrollerer for den anden.Men man kan ikke fjerne dem begge fra modellen. Både højde og vægt er udtryk forforsøgspersonens størrelse, men det virkeligt relevante størrelsesmål ville nok væreblodvolumen. Blodvolumen er ikke så nemt at måle, højde og vægt er derimod tilat komme i nærheden af, og de kan begge fungere som proxymål for det egentligebestemmende forhold. Der er derfor gevinst i at have en af dem med i modellen, mender er ikke nogen gevinst ved at have dem begge med. Og hvilken af dem man skaltage med, er hip som hap.
◦
Eksempel 11.10 I finansielle sammenhænge spiller den såkaldte Capital Asset Pri-cing Model (CAPM) en stor rolle. Det er en model der forbinder det forventedeafkast for et givet aktiv (typisk aktier i en bestemt virksomhed) med markedets be-vægelser. Modellen er aksiomatisk bygget op, med centrum i en række postulater omhvad den enkelte investors handlemuligheder er og hvordan han reagerer. Når manhar mange investorer og mange aktiver, får man på den måde et marked, og modellenbeskriver dette markeds matematiske egenskaber.
Postulaterne om den enkelte investors opførsel er meget idealiserede, og ærlig talter de temmelig urealistiske. Men de afledte markedegenskaber forekommer ganskefornuftige fra et økonomisk synspunkt. Man kan blandt andet udlede at der er enentydig størrelse, der kan opfattes som markedets afkast - teknisk vil det være afkastetaf en portefølje af samtlige markedets aktiver i en bestemt sammensætningsforhold.
En vigtig ingrediens i modellen er det såkaldte risikofri aktiv, et aktiv hvor man påforhånd kender afkastet - man kan tænke på at investoren sætter pengene i banken,i stedet for at investere dem. Dette aktiv er en økonomisk idealisering. Der kan kunvære et sådant aktiv - hvis der er flere, må de give samme afkast, for ellers ville mar-kedet øjeblikkeligt kollapse. I praksis volder det betydelige vanskeligheder i at findenoget der svarer til det risikofri aktiv, og man kommer hurtigt ud i meget vidtløftigediskussioner om såkaldte nulkupon rentestrukturer.

11.3. Multipel regression 427
Den fundamentale konklusion i CAPM er at hvis vi betegner afkastet af et bestemtaktiv med R, markedsafkastet med M og det risikofri afkast med r, så er
E(R − r) = β E(M − r). (11.12)
Koefficienten β er specifik for det konkrete aktiv, og repræsenterer hvor kraftigt akti-vet reagerer på markedets bevægelser. I finansielle aviser kan man dagligt læse esti-mater af β for en lang række aktiver, og disse estimater er en central ingrediens forde store investorer i deres fastlæggelsen af investeringspolitikken: hvis man har enide om hvordan markedet vil bevæge sig, så kan man ud fra β’erne sammensætte sinportefølje så hensigtsmæssigt som muligt.
I empirisk arbejde har man samhørende værdier Ri, Mi og ri til en række forskelligetidspunkter i = 1, . . . ,N. En partiel model for disse observationer kunne være at sigeat
Ri = α + βMi + γri + εi for i = 1, . . . ,N, (11.13)
hvor εi’erne er uafhængige N(0, σ2)-fordelte. Hvis man bliver gået på klingen omhvad man egentlig mener med denne relation, vil man sige at (Mi, ri) er lige så sto-kastisk som Ri, men at det vi interesserer os for, er den betingede fordeling af voresyndlingsaktivs opførsel givet markedets opførsel, jvnf. diskussionen p. 420 om lineærregression i tilfældet hvor såvel ’respons’ som ’kovariat’ er observerede størrelser.
En betinget fordeling af denne art opstår hvis triplerne (Ri,Mi, ri) er uafhængige,identisk fordelte med en tredimensional normalfordeling. Men den kan også opstå ien række andre situationer - og i økonomisk sammenhæng vil man som regel hel-lere flække en arm på langs end at antage at markedets opførsel til to tætliggendetidspunkter skulle være uafhængige. Men man er dog som regel parat til at antageat fordelingen af (Mi, ri) er stationær, det vil sige at den ikke varierer med i. Underalle omstændigheder vil man ved inferens om parametrene i (11.13) gå frem somom de observerede kovariater Mi og ri er deterministiske, f.eks. under henvisning tilbetingningsprincippet.
Ud fra relationen (11.13) ser vi at
E(Ri − ri) = α + βE(Mi − ri) + (γ + β − 1)Eri
Det vil sige at CAPM-relationen (11.12) er opfyldt hvis
α = 0 , γ + β = 1 .
428 Kapitel 11. Regressionsanalyse
Den empiriske model (11.13) har ikke samme aksiomatiske status som CAPM-relationen. Til gengæld er det en normalfordelingsmodel, og vi har et rigt arsenalaf teknikker til at undersøge den slags modeller. Hvis modellen overlever disse un-dersøgelser, så kan CAPM-relationen verificeres ved test af en affin hypotese i ennormalfordelingsmodel. Modellen giver os endvidere mulighed for at estimere akti-vets β-værdi.
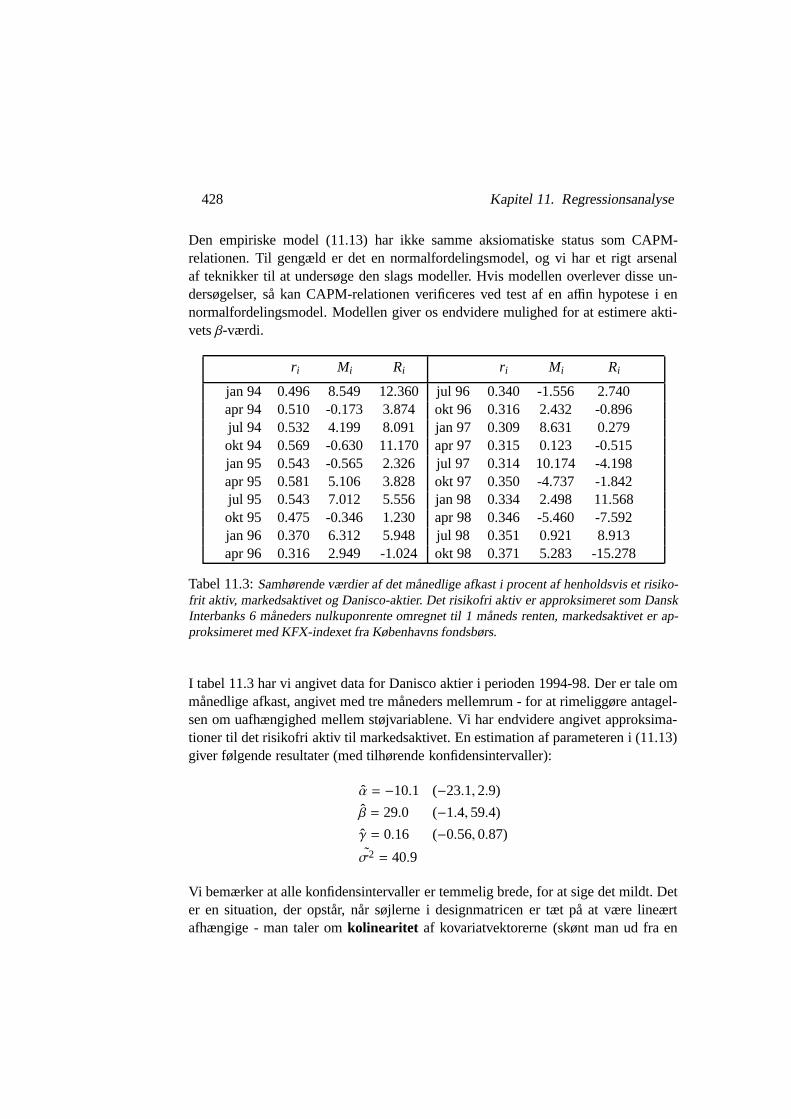
ri Mi Ri ri Mi Ri
jan 94 0.496 8.549 12.360 jul 96 0.340 -1.556 2.740apr 94 0.510 -0.173 3.874 okt 96 0.316 2.432 -0.896jul 94 0.532 4.199 8.091 jan 97 0.309 8.631 0.279okt 94 0.569 -0.630 11.170 apr 97 0.315 0.123 -0.515jan 95 0.543 -0.565 2.326 jul 97 0.314 10.174 -4.198apr 95 0.581 5.106 3.828 okt 97 0.350 -4.737 -1.842jul 95 0.543 7.012 5.556 jan 98 0.334 2.498 11.568okt 95 0.475 -0.346 1.230 apr 98 0.346 -5.460 -7.592jan 96 0.370 6.312 5.948 jul 98 0.351 0.921 8.913apr 96 0.316 2.949 -1.024 okt 98 0.371 5.283 -15.278
Tabel 11.3: Samhørende værdier af det månedlige afkast i procent af henholdsvis et risiko-frit aktiv, markedsaktivet og Danisco-aktier. Det risikofri aktiv er approksimeret som DanskInterbanks 6 måneders nulkuponrente omregnet til 1 måneds renten, markedsaktivet er ap-proksimeret med KFX-indexet fra Københavns fondsbørs.
I tabel 11.3 har vi angivet data for Danisco aktier i perioden 1994-98. Der er tale ommånedlige afkast, angivet med tre måneders mellemrum - for at rimeliggøre antagel-sen om uafhængighed mellem støjvariablene. Vi har endvidere angivet approksima-tioner til det risikofri aktiv til markedsaktivet. En estimation af parameteren i (11.13)giver følgende resultater (med tilhørende konfidensintervaller):
α̂ = −10.1 (−23.1, 2.9)
β̂ = 29.0 (−1.4, 59.4)
γ̂ = 0.16 (−0.56, 0.87)
σ̃2 = 40.9
Vi bemærker at alle konfidensintervaller er temmelig brede, for at sige det mildt. Deter en situation, der opstår, når søjlerne i designmatricen er tæt på at være lineærtafhængige - man taler om kolinearitet af kovariatvektorerne (skønt man ud fra en

11.3. Multipel regression 429
matematisk optik nok burde sige “approksimativ kolinearitet”, fordi kolinearitet foren algebraiker vil betyde ægte lineær afhængighed).
På figur 11.8 har vi optegnet de sædvanlige modelkontroltegninger, standardiserederesidualer mod de fittede værdier og et QQ-plot af de standardiserede residualer moden normalfordeling. Der er ikke noget i disse tegninger der tyder på at modellen(11.13) er decideret forkert. På den anden side er den estimerede varians betragtelig.I en seriøs modelkontrol, ville man også prøve at tegne residualerne op mod tiden(for at se om der er en stigende eller faldende tendens i dem) og mod kvartalet (for atse om der er typiske sæsonsvingninger), men heller ingen af disse tegninger tyder påat der er noget alvorligt galt med modellen.
Fittede værdier
Sta
ndar
dise
rede
res
idua
ler
10 15 20 25 30
−2
−1
01
2
Standard normalfordeling
Sta
ndar
dise
rede
res
idua
ler
−1 0 1
−2
−1
01
2
Figur 11.8: Et plot af de standardiserede residualer mod de fittede værdier for data fra ta-bel 11.3, og et QQ-plot af de standardiserede residualer mod en normalfordeling.
Et formelt test af den lineære CAPM-hypotesen om at α = 0 og β + γ = 1 får enF-værdi på 2.39, hvilket er 88%-fraktil i F-fordelingen med (2, 17) frihedsgrader.Det er altså svært på denne baggrund at indvende noget mod CAPM-hypotesen, ogunder denne estimeres β til
ˆ̂β = 0.31 (−0.36, 0.99)˜̃σ2 = 46.9
Bemærk hvor meget β-estimatet har ændret sig af at γ er blevet elimineret fra mo-dellen. Bemærk også at konfidensintervallet er snævret voldsomt ind, fordi en del afkolineariteten åbenbart er blevet fjernet fra modellen. Konfidensintervallet er dog for-sat bredere end godt er - og i særdeleshed indeholder det nul, så vi kan ikke afvise at

430 Kapitel 11. Regressionsanalyse
Danisco-aktivet er immunt overfor markedsbevægelserne! CAPM-relationen er søgtanskueliggjort på figur 11.9.
Markedsafkast − Riskofrit Aktiv
Dan
isco
afk
ast −
Ris
ikof
rit A
ktiv
−5 0 5 10
−15
−5
05
10
Figur 11.9: En illustration af CAPM-relationen på data fra tabel 11.3. Den indlagte rettelinie har hældning 0.31.
◦
11.4 Polynomiel regression
Et specielt eksempel på multipel regression, som vi anfører her for fuldstændighedensskyld, opstår hvis vi kun har en kovariat, som vi til gengæld lader indgå i flere led imiddelværdispecifikationen. Et oplagt eksempel er den kvadratiske regression, hvorman antager at X1, . . . , XN er uafhængige, normalfordelte med samme varians σ2 ogat
EXi = α + βti + γti2 for i = 1, . . . ,N,
Stillet op på matrixform er middelværdispecifikationen
E
X1
X2...
XN
=
1 t1 t12
1 t2 t22
.........
1 tN tN2
α
β
γ
.

11.5. Opgaver 431
Skønt kovariaten indgår på en højst ikke-lineær facon, er der stadig tale om en lineærnormal model, for de mulige middelværdivektorer udgør et lineært underrum af RN .I alle rimelige tilfælde er der tale om et tredimensionalt underrum - men selvfølgelig:hvis alle t’erne er ens, er underrummet etdimensionalt.
Betragtet som lineær normal model volder kvadratisk regression ikke nogen specielleproblemer. Den oplagte hypotese at teste er at γ, koefficienten foran kvadratleddet,er nul - accepteres denne hypotese, er det rimeligt at tro at sammenhængen mellemkovariat og respons er lineær. Det er derimod sjældent meningsfuldt at forsøge atteste β eller α væk. En hypotese om at β = 0 betyder at parablens toppunkt findes tilt = 0, og denne påstand er i de fleste tilfælde hverken meningsfuld eller interessant.
Man udvider let den kvadratiske regression til at omhandler polynomier af vilkårliggrad, ved blot at tilføje et passende antal søjler med kovariat-potenser til designma-tricen.
Man kan ligeledes udvide den “ægte” multiple regression med to kovariater til kva-dratisk regression, med en middelværdispecifikation af formen
EXi = α + β1ti + β2 si + γ1ti2 + γ2ti si + γ3s2
i for i = 1, . . . ,N.
Denne type modeller spiller under navnet responsflader en stor rolle i ingeniørmæs-sig optimering. Man ønsker at finde den kombination af kovariater der giver denmaksimale respons. Fremfor at prøve sig frem langs et fint gitter, prøver man sigfrem langs randen af en kasse - ofte nøjes man endda med hjørnerne (plus et enkeltpunkt mere, ellers bliver parametrene uidentificerbare). Man fitter en responsflade tilmålingerne, og givet at den estimerede responsflade har sit maksimum inde i kassen,så har man nu en forholdsvis klar ide om hvordan man skal maksimere responsen.
11.5 Opgaver
O 11.1. Opstil F-størrelsen for et test af hypotesen om at interceptet er nul, i ensimpel lineær regression.
O 11.2. Eftervis at leverage-værdierne i en simpel lineær regressionsmodel ergivet ved (11.5).Vink: Start med tilfældet hvor t• = 0. Det generelle tilfælde klares nemmest ved atskifte kovariat til si = ti − t•. At antage at middelværdien afhænger affint af ti er

432 Kapitel 11. Regressionsanalyse
det samme som at antage at den afhænger affint af si, og dette skift i parametriseringændrer ikke residualerne - og dermed heller ikke leverage-værdierne.
O 11.3. I et eksperiment har man målt det systoliske blodtryk for en rækkeerhvervsaktive mænd. Mændene fordelte sig i to faggrupper, de var journalister elleruniversitetlærere. Resultaterne er anført i tabel 11.4
Journalister Universitetslærere
Alder Blodtryk Alder Blodtryk
68 188.7 55 162.962 184.2 49 155.949 151.3 60 170.562 182.4 54 154.534 138.3 58 158.066 181.8 51 155.445 155.1 43 143.360 178.3 52 157.357 179.4 53 160.257 171.5 61 164.363 177.9 61 167.556 172.5 57 171.557 169.3 57 166.0
70 190.363 175.5
Tabel 11.4: Samhørende værdier af alder og blodtryk for en række mandlige forsøgsperso-ner. Alder er angivet i år, det systoliske blodtryk er angiver i mm Hg.
S 11.3(a). Optegn blodtryk mod alder for hver af de to faggrupper. Virker detrimeligt at analysere disse data med lineær regression?
S 11.3(b). Opstil en lineær regressionsmodel, kun for journalist-gruppen. Esti-mer parametrene.
S 11.3(c). Opstil en lineær regressionsmodel, kun for gruppen af universi-tetslærere. Estimer parametrene.
S 11.3(d). Opstil en fælles regressionsmodel for de to grupper, hvor middel-værdien i de to grupper modelleres med hver sin rette linie. Estimer parametrene.Vink: indse at estimater af hældninger og intercepts i den fælles model bliver iden-tiske med estimaterne fra de to separate modeller.

11.5. Opgaver 433
S 11.3(e). Opstil en fælles regressionsmodel for de to grupper, sådan at middel-værdien i de to grupper modelleres med samme rette linie. Estimer parametrene.
S 11.3(f). Opstil et test for om man med rimelighed kan bruge samme rettelinie i de to grupper.

434 Kapitel 11. Regressionsanalyse



























