Embed Size (px)
Citation preview

Relações entre variáveis: Regressão
Prof.a Dr.a Simone Daniela Sartorio de Medeiros
DTAiSeR-Ar
Disciplina: 220124
1

2
Introdução
Considere uma variável aleatória Y de interesse. Já vimos que podemos
escrever essa variável como sendo:
Y
onde é o valor esperado desta variável e é o erro.
Esse modelo sugere que podemos utilizar a esperança e a variância de Y
para descrever essa variável de forma resumida.
No R:
y<- c(10,12,25,23,26,12,15)
ybarra = mean(y); ybarra
var(y)
e = y - ybarra ; e
round(mean(e),4)
var(e)
cbind(y, ybarra, e)
• Portanto podemos dizer que o erro é também uma
variável aleatória que tem média zero e variância
igual de a Y.
• Esse erro é geralmente chamado de resíduo e
representa os inúmeros fatores que, conjuntamente,
fazem as observações de Y oscilarem em torno de .
• No caso particular de Y ter distribuição Normal,
teremos também que:
),0(~ 2
yN

Modelo de Regressão Linear
Simples
Prof.a Dr.a Simone Daniela Sartorio de Medeiros
DTAiSeR-Ar
3

4
Uma variável auxiliar
Considere agora que exista uma outra variável X, com alguma relação com
a variável Y.
Isso sugere uma maneira alternativa de estudar Y tendo como base
informações sobre X. Portanto, as quantidades que descrevem Y são agora
esperanças e variâncias condicionadas a valores específicos de X, ou seja:
]|[]|[ xYVarexYE
onde x é um valor conhecido de X.
• Se existir uma certa associação entre X e Y,
talvez os valores de E[Y|x] sigam um padrão
e
os valores de Var[Y|x] sejam menores do que Var[Y]

História
Por isso, ele chamou de regressão, ou seja, existe uma
tendência de os dados regredirem à média.
A teoria de regressão teve origem no século
XIX com Galton.
Francis Galton foi um antropólogo,
meteorologista, matemático e
estatístico inglês.
Em um de seus trabalhos ele estudou a relação entre a
altura dos pais e dos filhos (Xi e Yi), procurando saber
como a altura do pais influenciava a altura do filho. Notou
que se os pais fossem muito alto ou muito baixo, o filho
teria uma altura tendendo à média.
5

Introdução
Frequentemente estamos interessados em avaliar a relação entre duas, ou mais
variáveis, como por exemplo:
Relação entre área foliar e o peso para diversas variedades de plantas;
Relação existente entre pressão sanguínea e idade;
Relação produção de uma certa variedade e certos níveis de adubação;
A população de bactérias pode ser predita a partir da relação entre população e o
tempo de armazenamento.
Concentrações de soluções de proteína de arroz integral e absorbâncias médias
corrigidas.
Relação entre textura e aparência.
Temperatura usada num processo de desodorização de um produto e cor do produto
final.
A porcentagem de acerto ou, então, bytes transferidos, podem estar relacionados com
o tamanho da cache (bytes), para um determinado tipo de pré-carregamento.
Análise de regressão é uma metodologia estatística que utiliza a relação entre
duas ou mais variáveis quantitativas (ou qualitativas), de tal forma que uma
variável pode ser predita a partir da outra (ou outras). 6

É muito útil quantificar essa associação.
Existem muitos tipos de associações possíveis, iremos apresentar o tipo de
relação mais simples, que é a relação linear simples.
Quantificando a associação entre 2 variáveis quantitativas
Objetivos – Modelo de Regressão Linear Simples
1) Determinar como duas variáveis se relacionam;
2) Estimar a função que determina a relação entre as variáveis;
3) Usar a equação ajustada para prever valores da variável dependente.
7

Definição:
Dados n pares de valores (x1 , y1), (x2 ,y2), …, (xn , yn), chama-se de coeficiente
de correlação linear de Pearson entre as duas variáveis X e Y a:
ou seja, a média dos produtos dos valores padronizados das variáveis.
yx
n
i
YiXi
ssn
mymx
YXcorrr)1(
)ˆ)(ˆ(
),( 1
Coeficiente de Correlação de Pearson
Esse mede o grau de associação entre 2 variáveis quantitativas e também da
proximidade dos dados a uma reta.
Esta medida avalia o quanto a nuvem de pontos do gráfico de dispersão se aproxima de
uma reta.
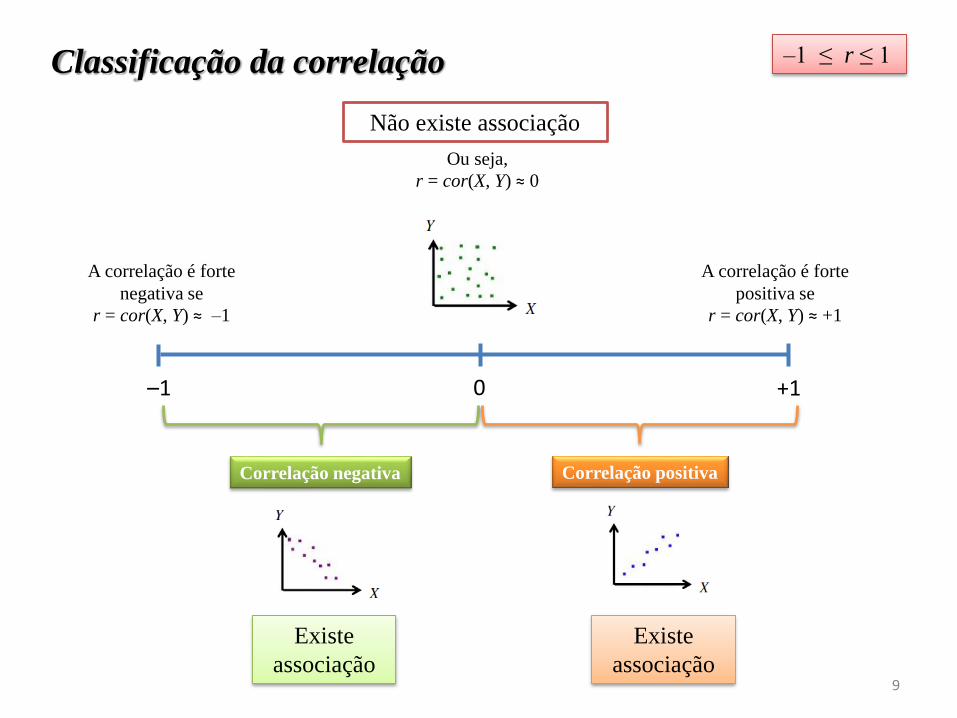
–1 ≤ r ≤ 1
No R:
cor(x,y)8
9
+1–1 0
Ou seja,
r = cor(X, Y) ≈ 0
Correlação negativa Correlação positiva
A correlação é forte
positiva se
r = cor(X, Y) ≈ +1
A correlação é forte
negativa se
r = cor(X, Y) ≈ –1
Classificação da correlação
Existe
associação
Existe
associação
Não existe associação
–1 ≤ r ≤ 1

CUIDADO
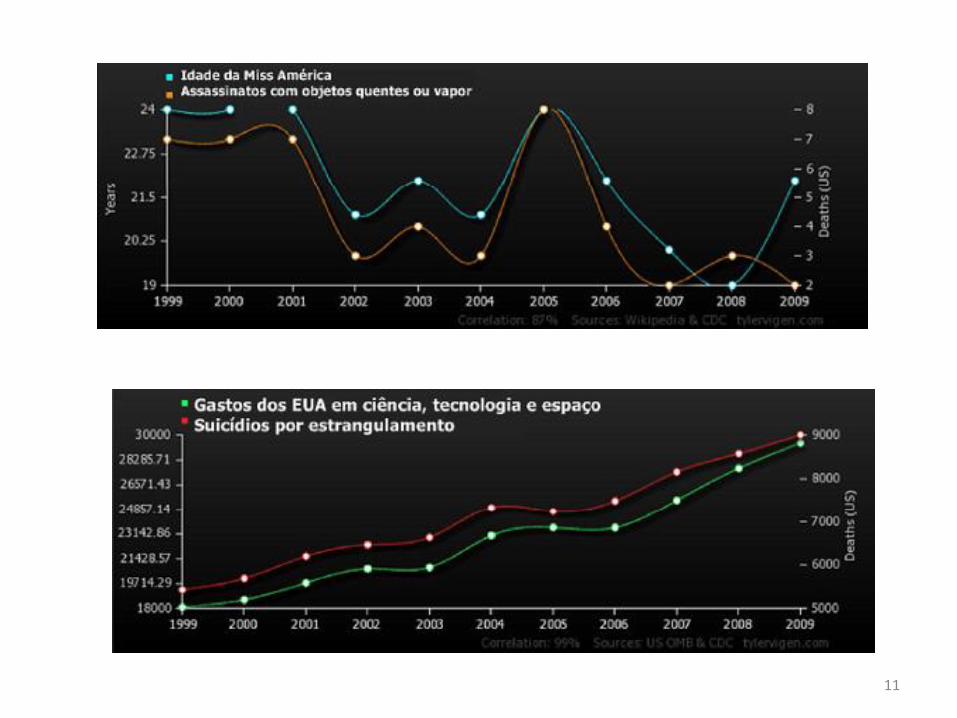
10Site: http://www.tylervigen.com/spurious-correlations
Você já deve ter visto inúmeras vezes estudos correlacionando coisas.
Mas sem saber tudo sobre os dois ou mais fatores, ou sem buscar saber,
você pode acabar sendo enganado achando que uma coincidência é
causalidade.
Pra provar isso, Tyler Vigen fez um site mostrando coisas
completamente aleatórias que se relacionam em gráfico, podendo ser uma
relação diretamente proporcional ou inversamente. Veja:
11

12
Assim, se pudermos descrever a E[Y|x] como:
XxYE ]|[
A variável aleatória Y será então descrita como:
]|[ xYEY
XY
Este modelo chama-se modelo de regressão linear simples

em que:
Y é a variável dependente (variável resposta, ou variável endógena);
X é a variável independente (covariável, variável explanatória, variável
regressora, ou variável exógena);
, e x são constantes;
é o intercepto (ou coeficiente linear), isto é, o valor de y quando x = 0;
é a declividade (ou coeficiente angular): quando x aumenta 1 unidade, y
aumenta unidades.
O modelo de regressão linear simples é dado por:
yi = + xi + i , i=1,2,...,n
Ou
Modelo de Regressão Linear Simples
y = + x +
13
14
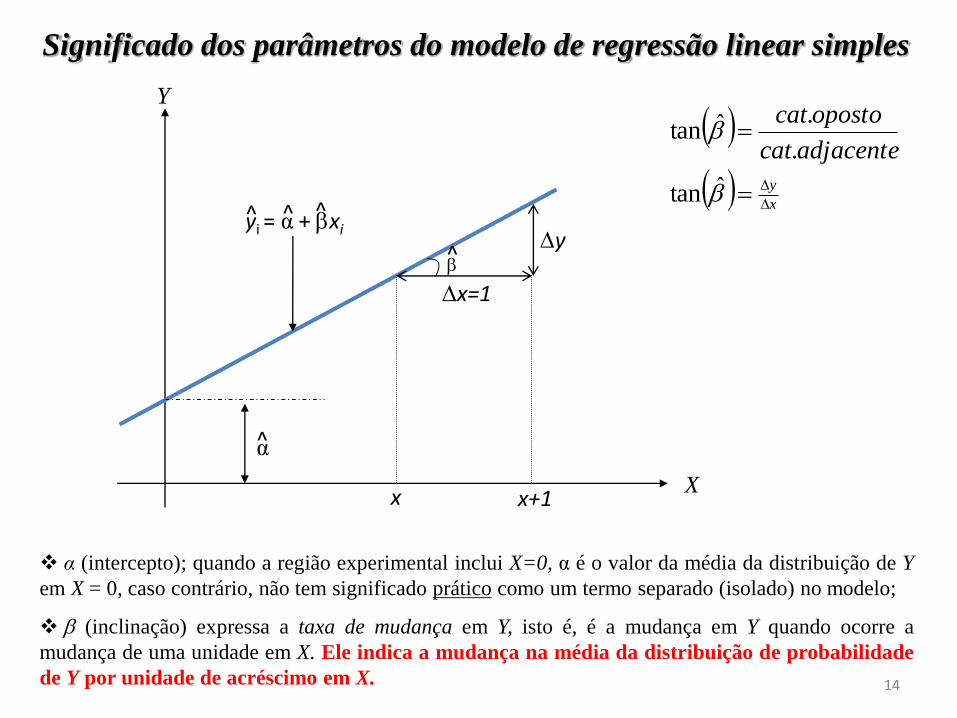
Significado dos parâmetros do modelo de regressão linear simples
α
x x+1
x=1
yyi = α + xi
x
y
adjacentecat
opostocat
ˆtan
.
.ˆtan
α (intercepto); quando a região experimental inclui X=0, α é o valor da média da distribuição de Y
em X = 0, caso contrário, não tem significado prático como um termo separado (isolado) no modelo;
(inclinação) expressa a taxa de mudança em Y, isto é, é a mudança em Y quando ocorre a
mudança de uma unidade em X. Ele indica a mudança na média da distribuição de probabilidade
de Y por unidade de acréscimo em X.
X
Y
^ ^ ^
^
^

Pressuposições do modelo de regressão
Para procedermos ao estudo da regressão linear simples, as seguintes
exigências do modelo devem ser satisfeitas:
1) Os erros ei são independentes Cov(ei, ej) = 0, todo i,j=1, ..., n; i j.
2) Os erros ei têm média nula E(ei) = 0;
3) Os erros ei possuem variância constante Var(ei) = 2 ;
4) Os erros ei possuem distribuição normal com média zero e variância
constante 2 ei ~ N(0, 2).
Além destas, poderíamos acrescentar:
a) Existe uma relação linear entre X e Y.
b) A variável X é pré-determinada com precisão (fixa), enquanto que Y é uma
variável aleatória.
OBS: Se X for uma variável aleatória, e, portanto, sujeita a erros de determinação,
podemos admitir os valores de X pré-determinados, isto é, fixos, sem prejudicar a
validade dos resultados. 15
16
Y
X
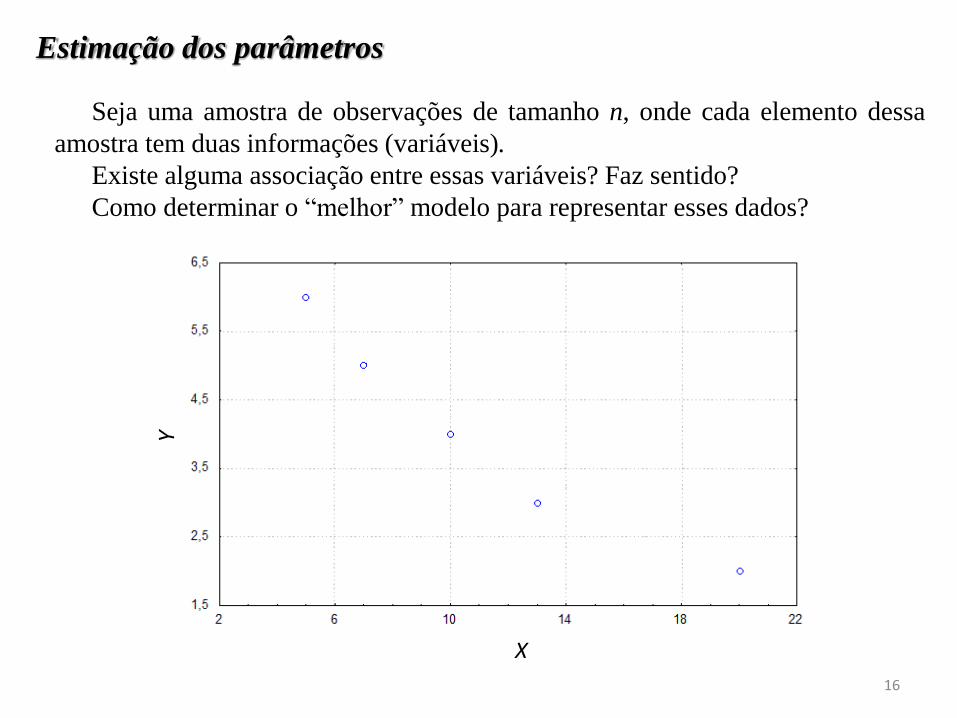
Estimação dos parâmetros
Seja uma amostra de observações de tamanho n, onde cada elemento dessa
amostra tem duas informações (variáveis).
Existe alguma associação entre essas variáveis? Faz sentido?
Como determinar o “melhor” modelo para representar esses dados?
17
Y
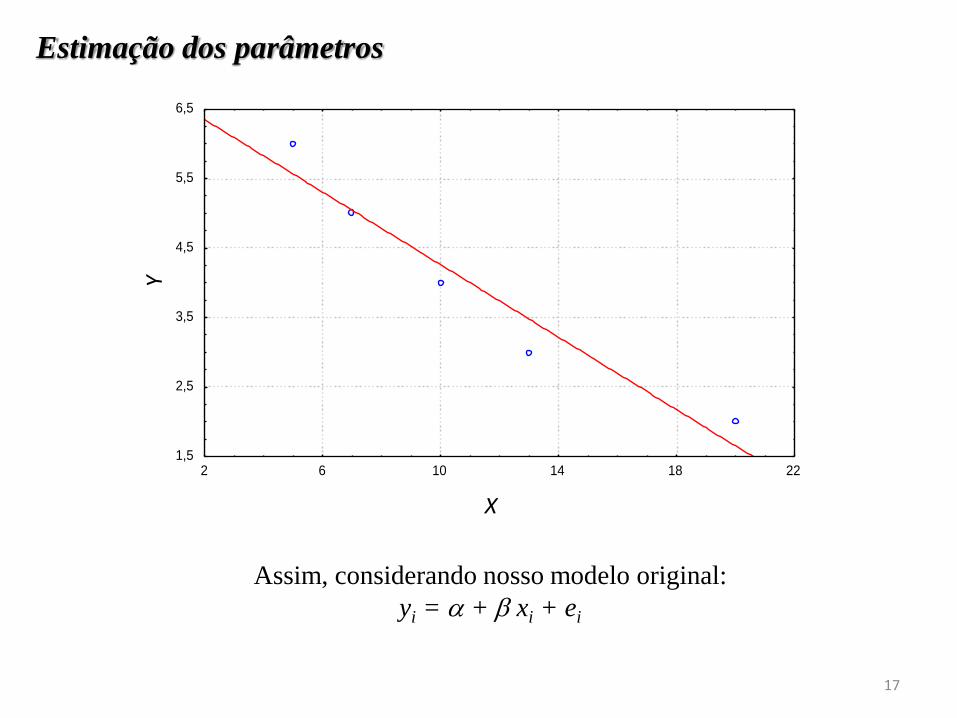
Estimação dos parâmetros
IDADE
VA
LO
R
1,5
2,5
3,5
4,5
5,5
6,5
2 6 10 14 18 22
X
Assim, considerando nosso modelo original:
yi = + xi + ei
n
i
n
i
iii xyeS1 1
22 )]([),(
IDADE
VA
LO
R
1,5
2,5
3,5
4,5
5,5
6,5
2 6 10 14 18 22
X
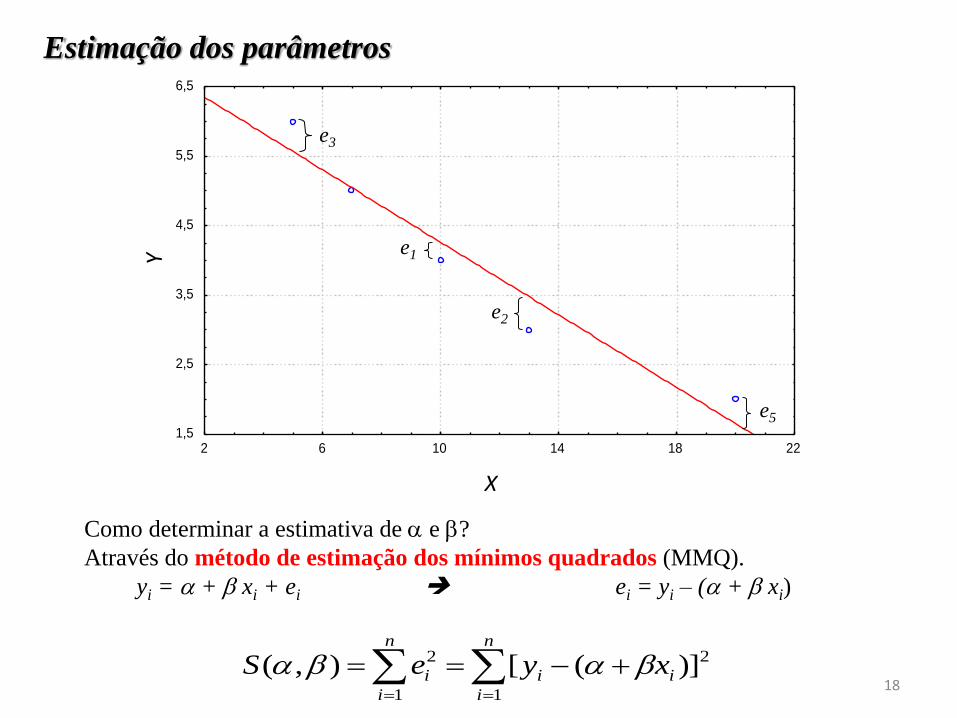
e5
e2
e1
e3
18
Estimação dos parâmetros
Como determinar a estimativa de e ?
Através do método de estimação dos mínimos quadrados (MMQ).
yi = + xi + ei ei = yi – ( + xi)

19
n
i
n
i
iii xyeS1 1
22 )]([),(
Deseja-se encontrar os valores de α e β que minimizem a
soma de quadrados dos desvios, S(,).
Para encontrar o mínimo, basta derivar S(,) em
relação a α e β e igualar a zero.
OBS: Lembre-se de verificar se este é mesmo um
ponto de mínimo!!!

n
x
x
n
xy
yx
n
i
in
i
i
n
i
i
n
i
in
i
ii
2
1
1
2
11
1ˆ
20
n
i
n
i
iii xyeS1 1
22 )]([),(
02)1(2),(
11
n
i
ii
n
i
ii xyxyS
02)(2),(
1
2
1
n
i
iiii
n
i
iii xxyxxxyS
(I)
(II)
(I)
Para minimizar S(,) temos:
0ˆˆ11
n
i
i
n
i
i xny
n
i
i
n
i
i xyn11
ˆˆ
xy ˆˆ
(II) 0ˆˆ1
2
11
n
i
i
n
i
i
n
i
ii xxyx
0ˆˆ
1
2
1
11
1
n
i
i
n
i
i
n
i
i
n
i
in
i
ii xxn
x
n
y
yx
0ˆ
2
1
1
211
1
n
x
xn
xy
yx
n
i
in
i
i
n
i
i
n
i
in
i
ii
Estimação dos parâmetros
xy ˆˆˆ
xyn
x
n
yn
i
i
n
i
i
ˆˆˆ 11
XX
XY
n
i
in
i
i
n
i
i
n
i
in
i
ii
s
s
n
x
x
n
yx
yx
2
1
1
2
11
1
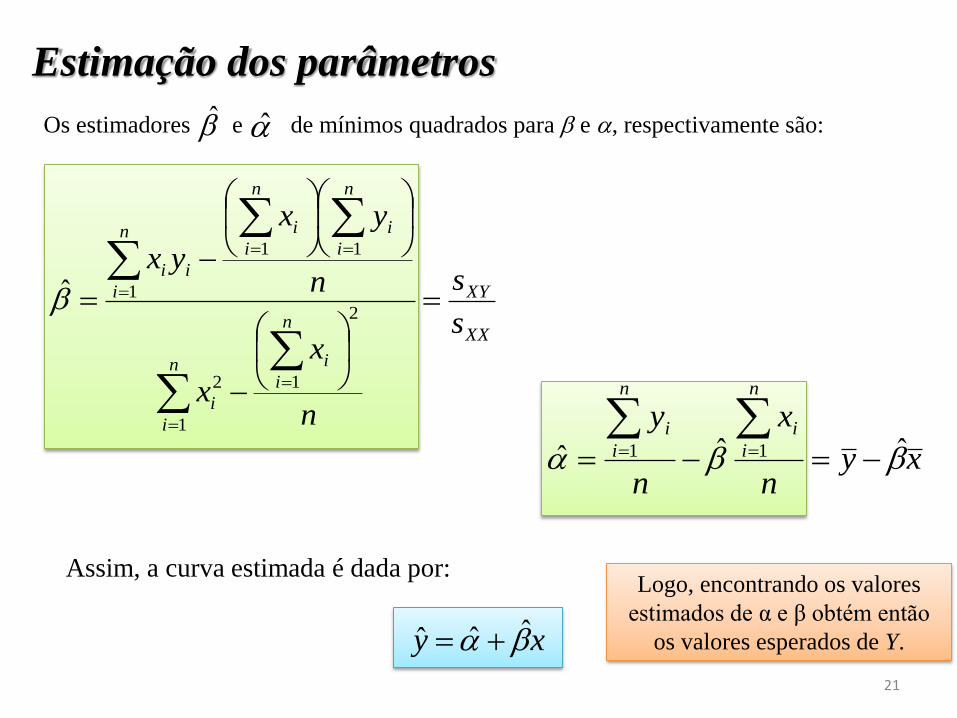
Assim, a curva estimada é dada por:Logo, encontrando os valores
estimados de α e β obtém então
os valores esperados de Y.
Os estimadores e de mínimos quadrados para e , respectivamente são:
21

22
Como obter na calculadora:
1) Limpar a memória:
2) Mudar para o módulo regressão (Reg) Linear (Lin):
3) Entrar com os dados
... ...
4) Pedir a função:
Modelo Cassio fx-82MS
SHIFT Scl =
Regressão linear: y = + x
MODE 3 1
M+coord x , coord y
M+coord x , coord y
SHIFT 1 =
SHIFT 2 =
Somatórios
Coeficiente de correlação linear

23
Como obter na calculadora:
Regressão
y = + x
Modelo Cassio fx-83WA
1) Limpar a memória:
2) Mudar para o módulo regressão (Reg) Linear (Lin):
3) Entrar com os dados
...
4) Funções:
MODE
SHIFT Scl =
3 1
M+coord x , coord y
M+coord x , coord y
SHIFT r = Coeficiente de correlação linear
SHIFT 1 = Somatórios

Nove amostras de solo foram preparadas com diversas quantidades de
fósforo inorgânico (X). Plantas de milho, que foram cultivadas em ambos os
solos, foram colhidas ao final do 38º dia e analisadas para verificar a quantidade
de fósforo que elas continham (Y). A partir daí foi estimada a quantidade de
fósforo disponível no solo. Os valores observados foram os que se seguem:
Objetivo: É possível prever o P nas plantas utilizando apenas a informação de P
inorgânico no solo?
Faça um gráfico de dispersão, verifique se as variáveis possuem alguma
relação. Se sim, encontre a equação que possa representar essa relação.
Exemplo
24
P inorgânico no solo (x) 1 4 5 9 11 13 23 23 28
P nas plantas (y) 64 71 54 81 76 93 77 95 109
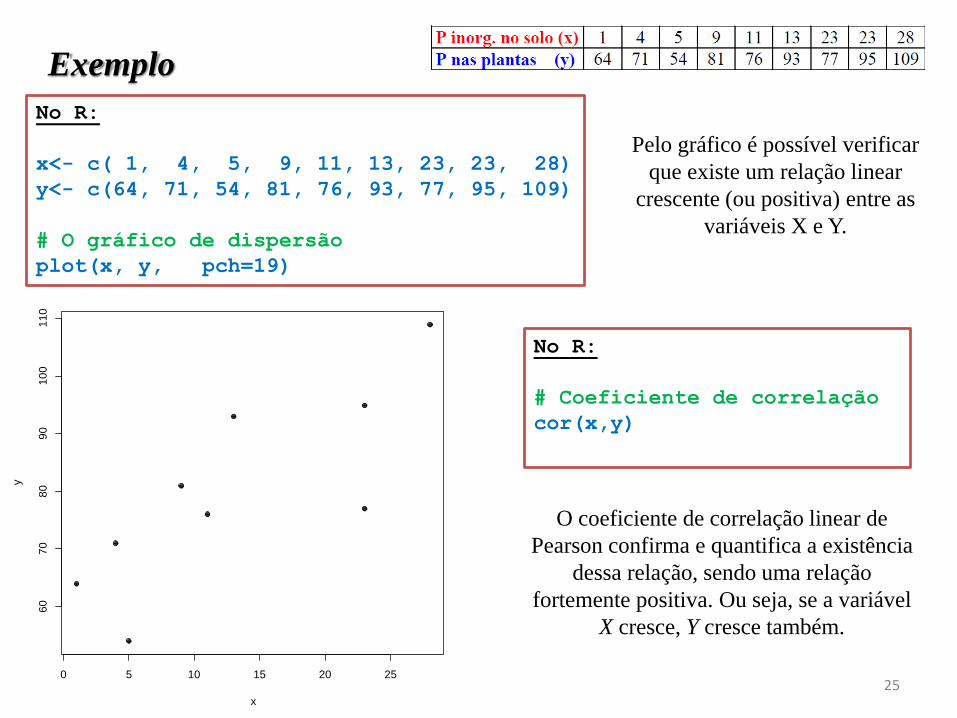
0 5 10 15 20 25
60
70
80
90
10
01
10
x
y
No R:
# Coeficiente de correlação
cor(x,y)
0.8049892
Exemplo
Pelo gráfico é possível verificar
que existe um relação linear
crescente (ou positiva) entre as
variáveis X e Y.
O coeficiente de correlação linear de
Pearson confirma e quantifica a existência
dessa relação, sendo uma relação
fortemente positiva. Ou seja, se a variável
X cresce, Y cresce também.
25
No R:
x<- c( 1, 4, 5, 9, 11, 13, 23, 23, 28)
y<- c(64, 71, 54, 81, 76, 93, 77, 95, 109)
# O gráfico de dispersão
plot(x, y, pch=19)
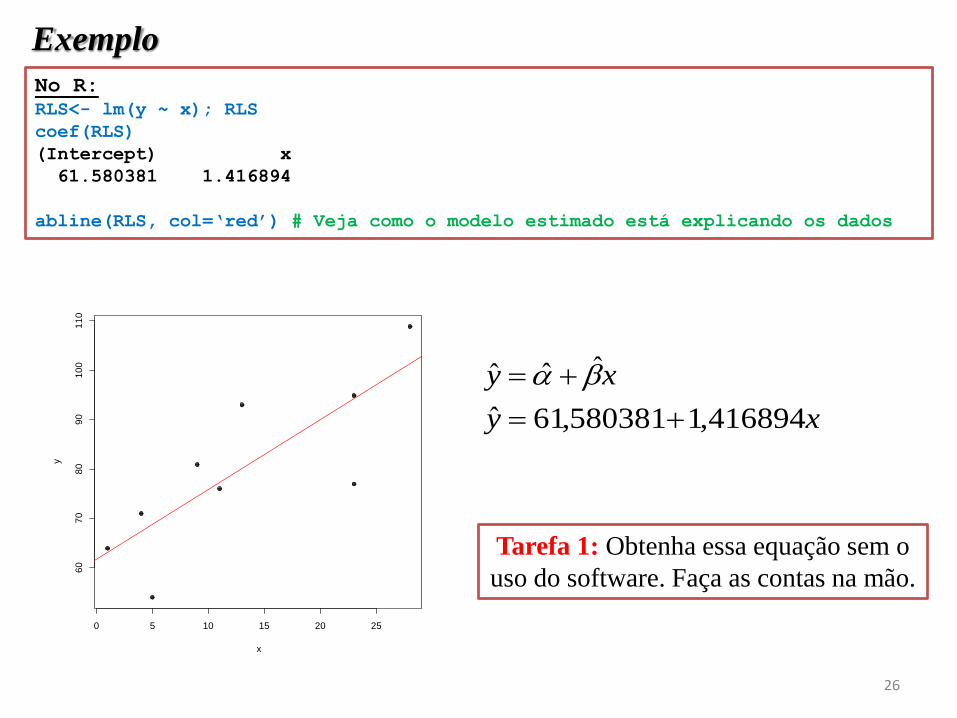
Exemplo
No R:
RLS<- lm(y ~ x); RLS
coef(RLS)
(Intercept) x
61.580381 1.416894
abline(RLS, col=‘red’) # Veja como o modelo estimado está explicando os dados
26
0 5 10 15 20 25
60
70
80
90
10
01
10
x
y
xy
xy
416894,1580381,61ˆ
ˆˆˆ
Tarefa 1: Obtenha essa equação sem o
uso do software. Faça as contas na mão.

Será que realmente existe uma relação entre Y e X?
Será que o coeficiente de inclinação da regressão linear é significativamente
diferente de zero?
Respondemos essas questões através da construção da análise de variância
(ANOVA) para testar o modelo de regressão linear.
Análise de Variância
A divisão da variação na amostra dos valores de
y em uma variação que pode ser atribuída à
regressão linear (chamada de Soma de
Quadrados de Regressão - SQReg) e uma
variação residual (variação dos pontos acima e
abaixo da reta de regressão - SQRes), ou seja:
SQTotal = SQReg + SQRes
27
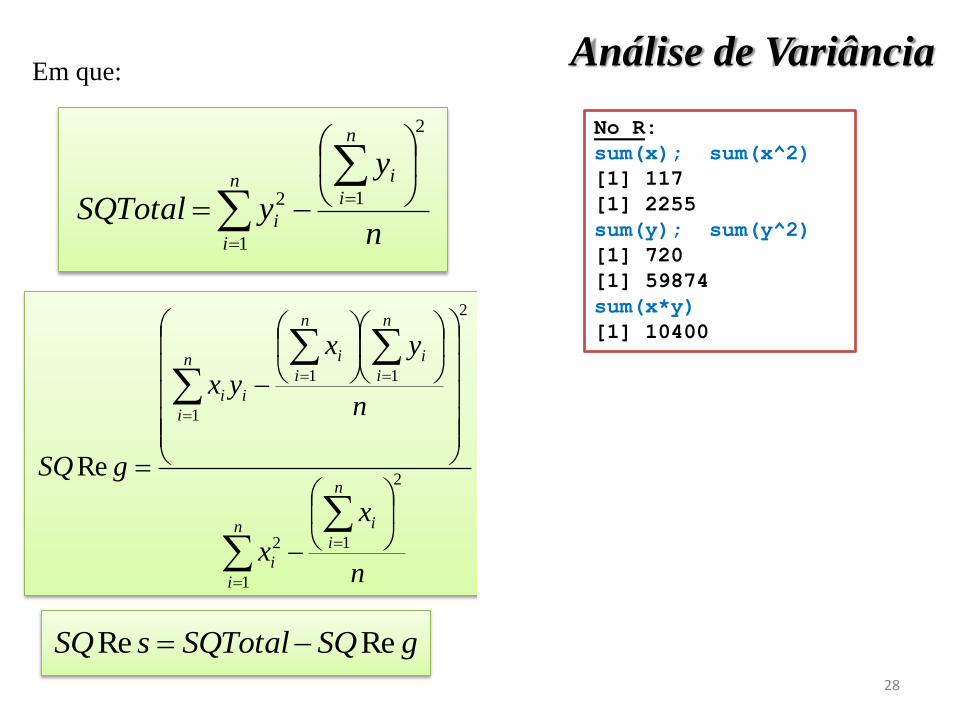
XX
XY
n
i
in
i
i
n
i
i
n
i
i
i
n
i
i
s
s
n
x
x
n
yx
yx
gSQ2
2
1
1
2
2
11
1
Re
Em que:Análise de Variância
n
y
ySQTotal
n
i
in
i
i
2
1
1
2
gSQSQTotalsSQ ReRe
28
No R:
sum(x); sum(x^2)
[1] 117
[1] 2255
sum(y); sum(y^2)
[1] 720
[1] 59874
sum(x*y)
[1] 10400

H0: β = 0
H0: β ≠ 0
FV gl. SQ QM Fcalc
Regressão linear 1 SQReg QMReg=SQReg/1 QMReg/QMRes
Resíduo n – 2 SQRes QMRes=SQRes/(n – 2) -
Total n – 1 SQTotal - -
Conclusão:
Rejeitaremos H0 a um nível de significância pré fixado α se Fcalc > F(1, n-2) ,
concluindo que β ≠ 0 e portanto, a regressão é significativa.
Caso contrario, aceitamos H0 .
Análise de Variância
Número de parâmetros do
modelo – 1 = 2 – 1 =1
29
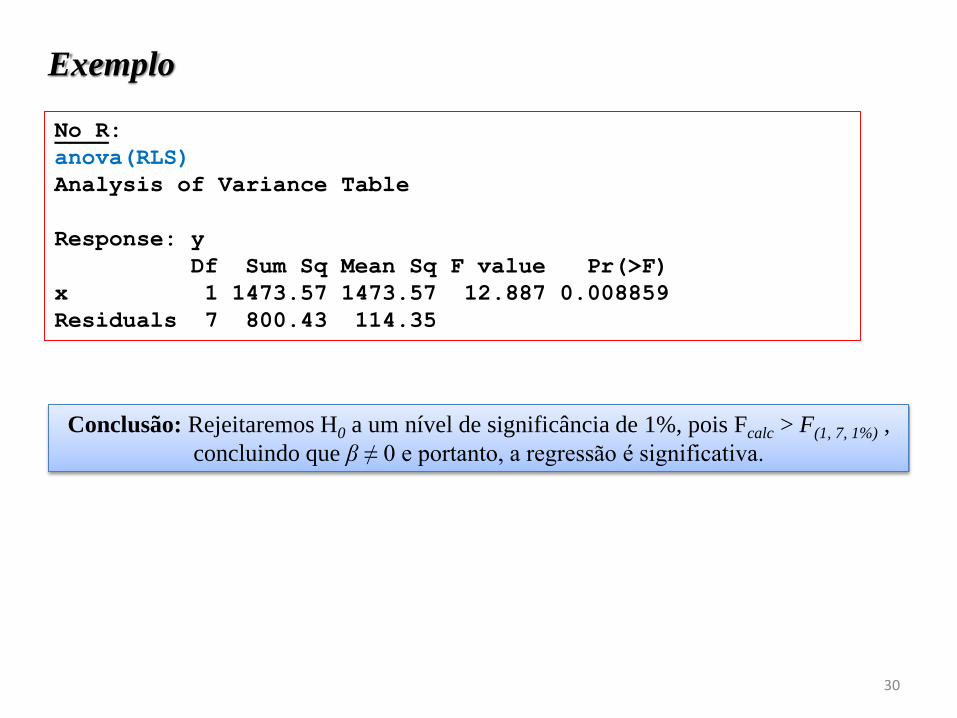
No R:
anova(RLS)
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
x 1 1473.57 1473.57 12.887 0.008859
Residuals 7 800.43 114.35
Exemplo
Conclusão: Rejeitaremos H0 a um nível de significância de 1%, pois Fcalc > F(1, 7, 1%) ,
concluindo que β ≠ 0 e portanto, a regressão é significativa.
30
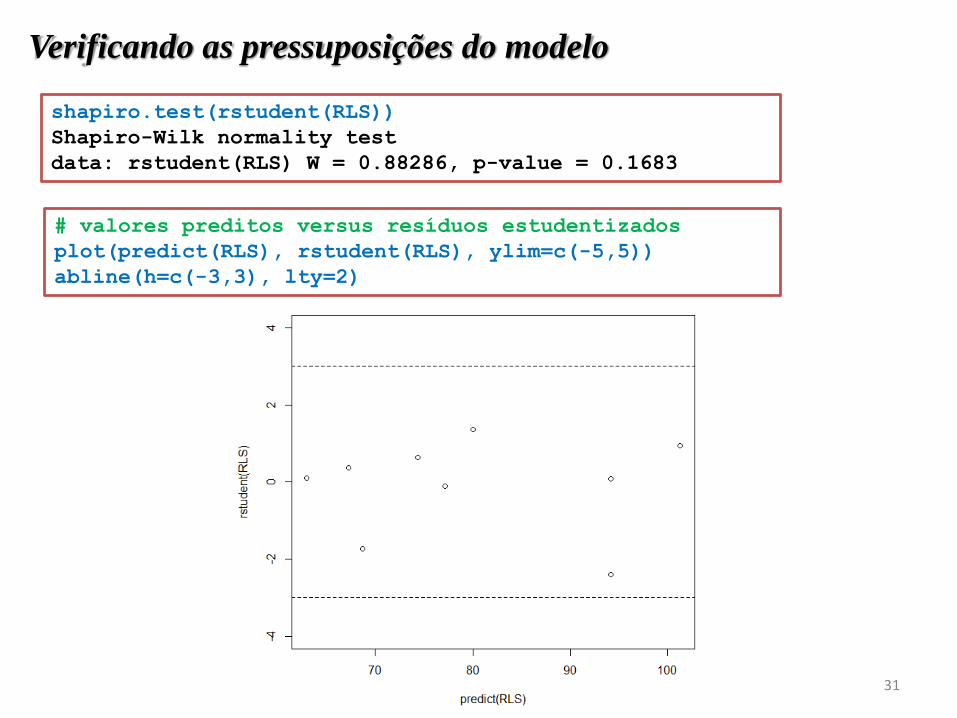
31
Verificando as pressuposições do modelo
shapiro.test(rstudent(RLS))
Shapiro-Wilk normality test
data: rstudent(RLS) W = 0.88286, p-value = 0.1683
# valores preditos versus resíduos estudentizados
plot(predict(RLS), rstudent(RLS), ylim=c(-5,5))
abline(h=c(-3,3), lty=2)

Intervalo de confiança para os α e
n
i
i
n
xx
sQMtIC
1
22/;2
)(
Reˆ:%);(
n
i
i
n
xx
x
nsQMtIC
1
2
2
2/;2
)(
1Reˆ:%);(
32
]4447,83;7171,39[734
169
9
1114,355809,61:%)99;(
2
%1,495,0;7
tIC
]7982,2;0356,0[734
35,1141,4169:%)99;( 495,0;7 tIC
confint(RLS, level=.99)
0.5 % 99.5 %
(Intercept) 39.71682983 83.443933
x 0.03565517 2.798132
=0,01
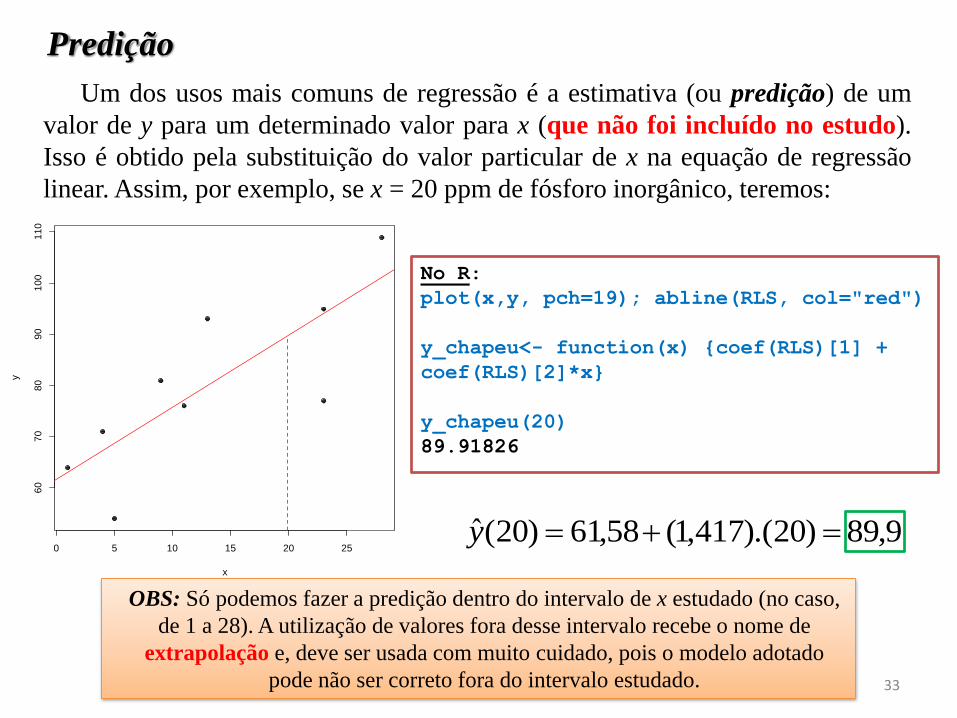
Predição
Um dos usos mais comuns de regressão é a estimativa (ou predição) de um
valor de y para um determinado valor para x (que não foi incluído no estudo).
Isso é obtido pela substituição do valor particular de x na equação de regressão
linear. Assim, por exemplo, se x = 20 ppm de fósforo inorgânico, teremos:
OBS: Só podemos fazer a predição dentro do intervalo de x estudado (no caso,
de 1 a 28). A utilização de valores fora desse intervalo recebe o nome de
extrapolação e, deve ser usada com muito cuidado, pois o modelo adotado
pode não ser correto fora do intervalo estudado.
9,89)20).(417,1(58,61)20(ˆ y0 5 10 15 20 25
60
70
80
90
10
01
10
x
y
No R:
plot(x,y, pch=19); abline(RLS, col="red")
y_chapeu<- function(x) {coef(RLS)[1] +
coef(RLS)[2]*x}
y_chapeu(20)
89.91826
33

34
No R:
cbind(y, y_chapeu(x))
y y_chapeu
[1,] 64 62.9973
[2,] 71 67.2480
[3,] 54 68.6649
[4,] 81 74.3325
[5,] 76 77.1663
[6,] 93 80.0001
[7,] 77 94.1691
[8,] 95 94.1691
[9,] 109 101.2536

Coeficiente de Determinação
A quantidade R2, ou r2, é conhecida como coeficiente de determinação. Essa
medida indica a proporção da variação na variável Y que é explicada pela
regressão em X, sendo dada por:
Quanto mais próximo de 1 maior é a relação entre X e Y.
SQTotal
gSQYXcorrrR
Re),( 222 0 ≤ R2 ≤ 1
648197,02274
1474Re2 SQTotal
gSQR
Interpretação:
64,8% da variação em Y é explicada pela relação linear com X.
Portanto, ainda permanecem 35,2% de variação devida ao acaso (inexplicada).
Assim, no exemplo:
35

Adequação do modelo
Para verificar se o modelo de regressão é adequado utilizamos o coeficiente
de determinação R2. Contudo, como o R2 depende do número de observações da
amostra, o coeficiente de determinação ajustado acaba sendo mais utilizado:
1
)1( 22
kn
kRnRajustado
Sendo:
k o número de parâmetros fixos desconhecidos do modelo menos 1.
Exemplo: Para a regressão linear simples k = 1;
n o tamanho da amostra observada.
0,5977119
164,0)19(2
ajustadoR
Assim, no exemplo:
OBS: Sua interpretação é a mesma do R2
36

Exemplo
No R:
summary(RLS)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-17.169 -1.166 1.003 6.668 13.000
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 61.5804 6.2477 9.857 2.35e-05 ***
x 1.4169 0.3947 3.590 0.00886 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 10.69 on 7 degrees of freedom
Multiple R-squared: 0.648, Adjusted R-squared: 0.5977
F-statistic: 12.89 on 1 and 7 DF, p-value: 0.008859
37
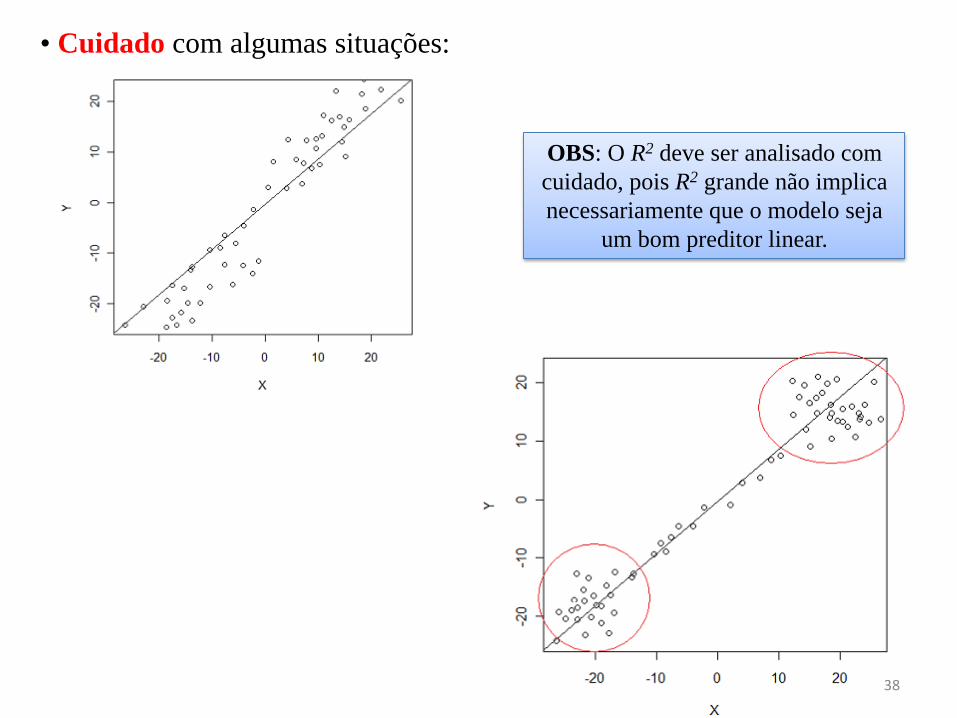
• Cuidado com algumas situações:
OBS: O R2 deve ser analisado com
cuidado, pois R2 grande não implica
necessariamente que o modelo seja
um bom preditor linear.
38
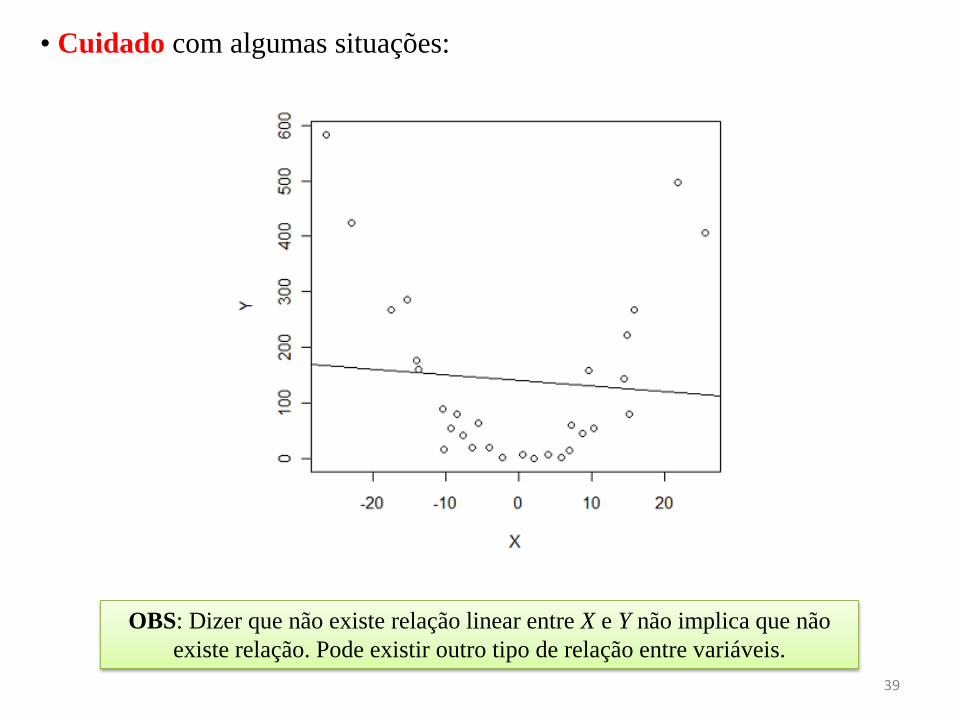
OBS: Dizer que não existe relação linear entre X e Y não implica que não
existe relação. Pode existir outro tipo de relação entre variáveis.
• Cuidado com algumas situações:
39
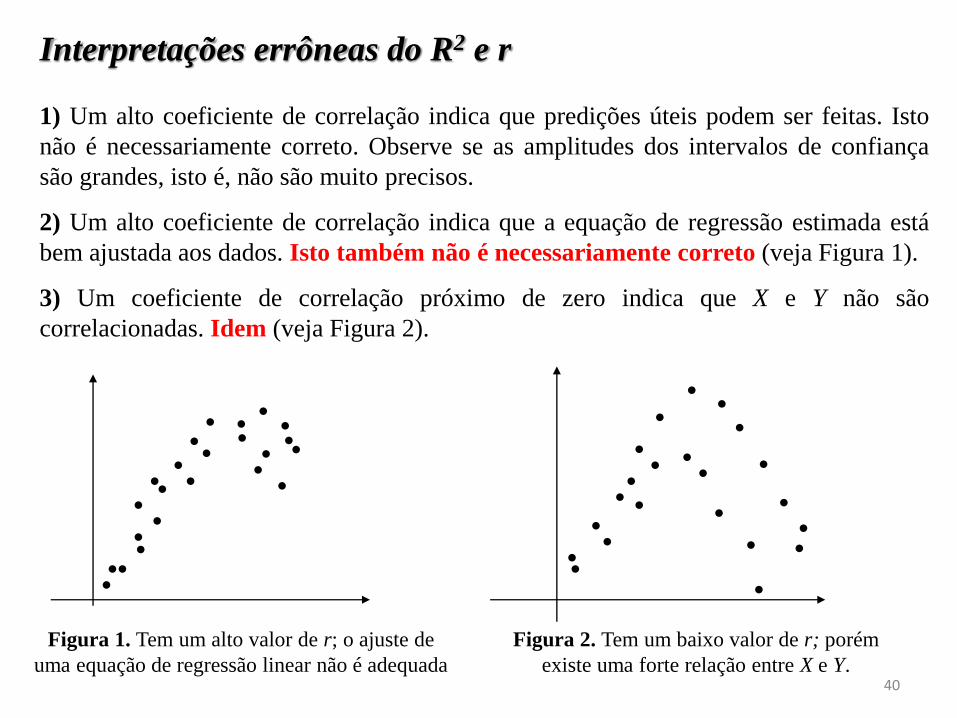
Interpretações errôneas do R2 e r
1) Um alto coeficiente de correlação indica que predições úteis podem ser feitas. Isto
não é necessariamente correto. Observe se as amplitudes dos intervalos de confiança
são grandes, isto é, não são muito precisos.
2) Um alto coeficiente de correlação indica que a equação de regressão estimada está
bem ajustada aos dados. Isto também não é necessariamente correto (veja Figura 1).
3) Um coeficiente de correlação próximo de zero indica que X e Y não são
correlacionadas. Idem (veja Figura 2).
Figura 1. Tem um alto valor de r; o ajuste de
uma equação de regressão linear não é adequada
Figura 2. Tem um baixo valor de r; porém
existe uma forte relação entre X e Y.
40

Calibração ou capacidade de predição de novas observações, pode ser feita
usando uma nova amostra e comparando os valores estimados com os
observados.
Ou seja, dado um valor de Y0, para o qual o correspondente valor de X0 é
desconhecido, estimar o valor de X0.
Calibração
41

Tipos de modelos de regressão
• Regressão linear simples: quando há relação de um única variável resposta (Y)
com uma única variável explanatória (X)
y = 0 + 1 x +
• Regressão linear múltipla: quando há relação de um única variável resposta
(Y) com duas ou mais variável explanatória (X1 , X2 , ..., Xp)
y = 0 + 1 x1 + 2 x2 + ... + p xp +
• Regressão linear multivariada: quando há relação de um conjunto de duas ou
mais variáveis respostas (Y1 , Y2 , ..., Yk) com um conjunto de duas ou mais
variável explanatória (X1 , X2 , ..., Xp) sendo que este último conjunto pode ser
diferente (ou igual) para cada uma das variáveis.
• Regressão não linear: ocorre quando pelo menos uma das primeiras derivadas
parciais referentes aos parâmetros desconhecidos (0 , 1 , 2 , ...,p ) dependem
de algum parâmetro desconhecido. Exemplo:
y = 0 + 1 [1 – exp(– 2 x)] +
OBS: Considere que cada unidade
amostral pode ser escrita como:
42