Embed Size (px)
Citation preview

Relevance Feedback Retrieval Relevance Feedback Retrieval of Time Series Dataof Time Series Data
Eamonn J. Keogh & Michael J. PazzaniEamonn J. Keogh & Michael J. Pazzani
Prepared By/
Fahad Al-jutailySupervisor/
Dr. Mourad YkhlefIS531
Sunday, 16 April 2006

INTRODUCTION(1/2)INTRODUCTION(1/2)
• Time series account for a significant portion of the data stored in business, medical, engineering, and social science databases.
• There are innumerable statistical tests one can perform on time series, such as determining autocorrelation coefficients, measuring linear trends, etc.

INTRODUCTION(2/2)INTRODUCTION(2/2)
• Much of the utility of collecting this data, comes from the ability of humans to visualize the shape of the (suitably plotted) data. For example:– Cardiologists view ECGs to diagnose arrhythmias.– Chartists examine stock market data, searching for
certain shapes that are thought to be indicative of a stock’s future performance.
– Astronomers examine star light curves (the changes in frequency over time) to classify stars.

Issues in time series retrieval(1/2)Issues in time series retrieval(1/2)
• Two important issues in time series retrieval have not yet been explored.
1.1. Relevance Feedback:Relevance Feedback: In time series domains, as in text domains, users may not initially know how to form a query to retrieve precisely what they are looking for.
• The paper shows, the relevance feedback may be applied to retrieval of time series data to learn which sections of the time series are most significant.

Issues in time series retrieval(2/2)Issues in time series retrieval(2/2)
• Subjectivity of similarity: Subjectivity of similarity: Most work on retrieval of time series has used Euclidean distance as the distance measure. However, there is little evidence that Euclidean distance maps onto human intuition of similarity.

Example: Example: Clusters of four small data sets where Clusters of four small data sets where similarity is determined by Euclidean distance.similarity is determined by Euclidean distance.

Time Series Similarity SolutionTime Series Similarity Solution
• The “correctcorrect” distance measure depends upon the useruser and problemproblem, and it should be continuously learned as the user interactsinteracts with the system.

REPRESENTING TIME REPRESENTING TIME SERIES(1/2)SERIES(1/2)
• Using the original ‘raw’ data for query by content in time series databases is computationally expensive (especially for an interactive system) and fails to abstract key features of the data.
• What is needed?!!! is a higher-level representation.
REPRESENTING TIME REPRESENTING TIME SERIES(2/2)SERIES(2/2)
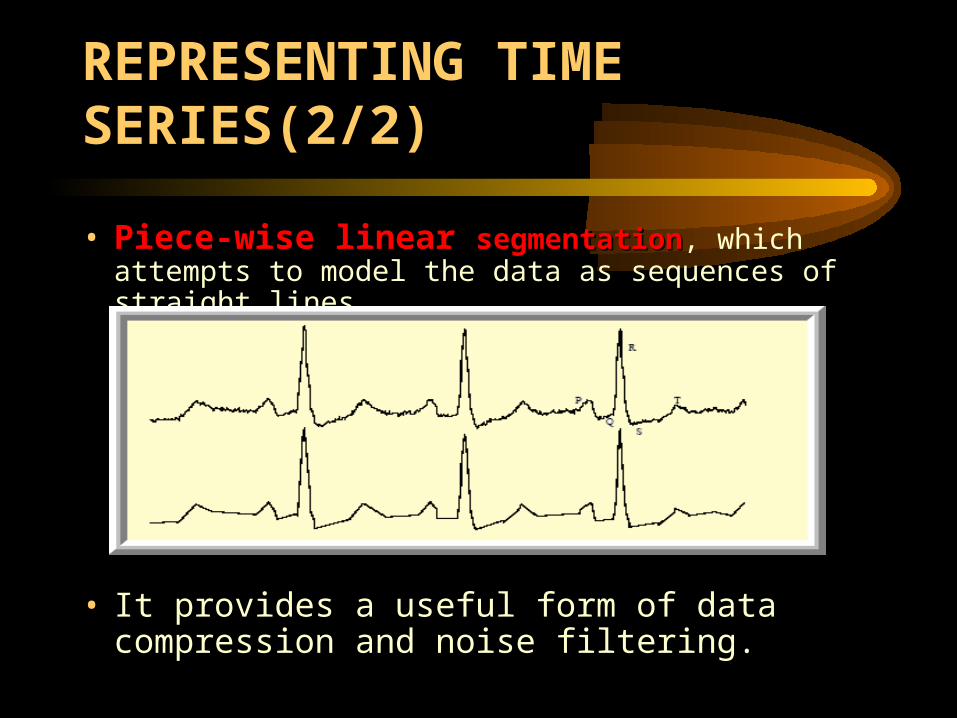
• Piece-wise linear Piece-wise linear segmentationsegmentation, which attempts to model the data as sequences of straight lines.
• It provides a useful form of data compression and noise filtering.

Notation(1/2)Notation(1/2)
• A time series, sampled at k points, is represented as an uppercase letter such as A.
• The segmented version of A, containing K linear segments, is denoted as a bold uppercase letter such as A.– where A is a 5-tuple of vectors of length K.– A => {AXL, AXR, AYL, AYR, AW}

Notation(2/2)Notation(2/2)
• The ith segment of sequence A is represented by the line between (AXLi AYLi) and (AXRi AYRi), and AWi, which represents the segment's weight.

Comparing Time Series(1/3)Comparing Time Series(1/3)
• To retrieve time series, we need a distance (or conversely similarity) measure to compare the query with segments stored in the database.
• Adopting a distance measure, DS, that approximates the Euclidean distanceEuclidean distance measure on the ‘raw’ data.

Comparing Time Series(2/3)Comparing Time Series(2/3)
• It is convenient for notational purposes to assume that the endpoints of the two sequences being compared are aligned in the X-axis.

Comparing Time Series(3/3)Comparing Time Series(3/3)
• The overall distance between two sequences is simply the square root of the summation over all such slices.
• The weighted distance between two sequences of length i is:

Merging Time Series(1/2)Merging Time Series(1/2)
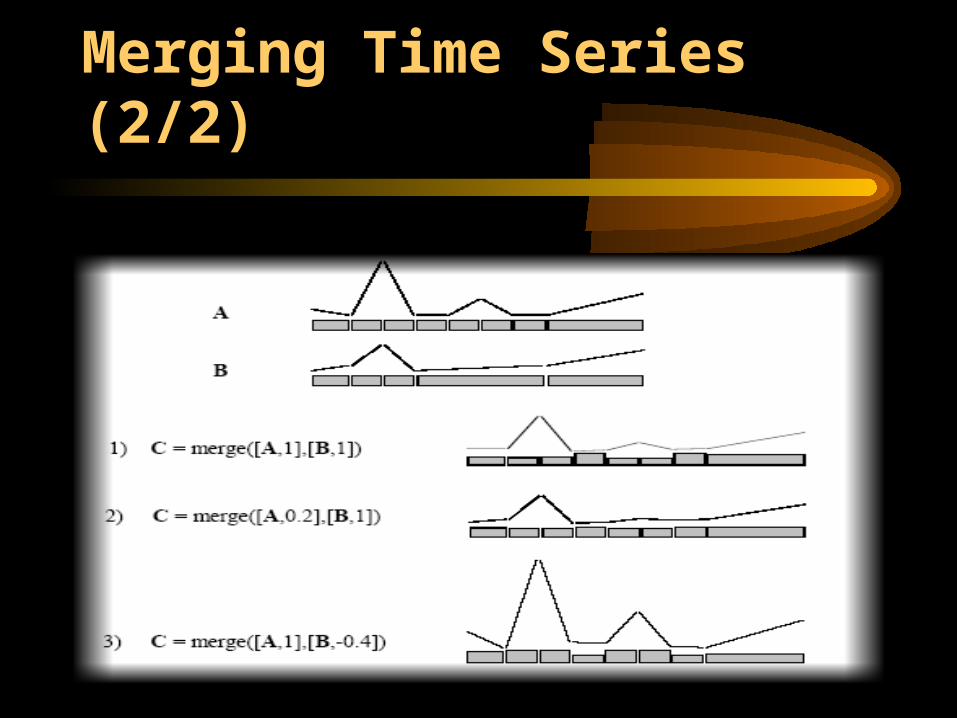
• The basic idea is that the merge operator takes two sequences as input and returns a single sequence whose shape is a compromise between the two original sequences.
Merging Time Series (2/2)Merging Time Series (2/2)

QUERY REFINEMENT VIAQUERY REFINEMENT VIARELEVANCE FEEDBACKRELEVANCE FEEDBACK
• Relevance feedback is the reformulation of a search query in response to feedback provided by the user for the results of previous versions of the query.
Query
Output
Feedback
Formulating a New Query(1/2)Formulating a New Query(1/2)
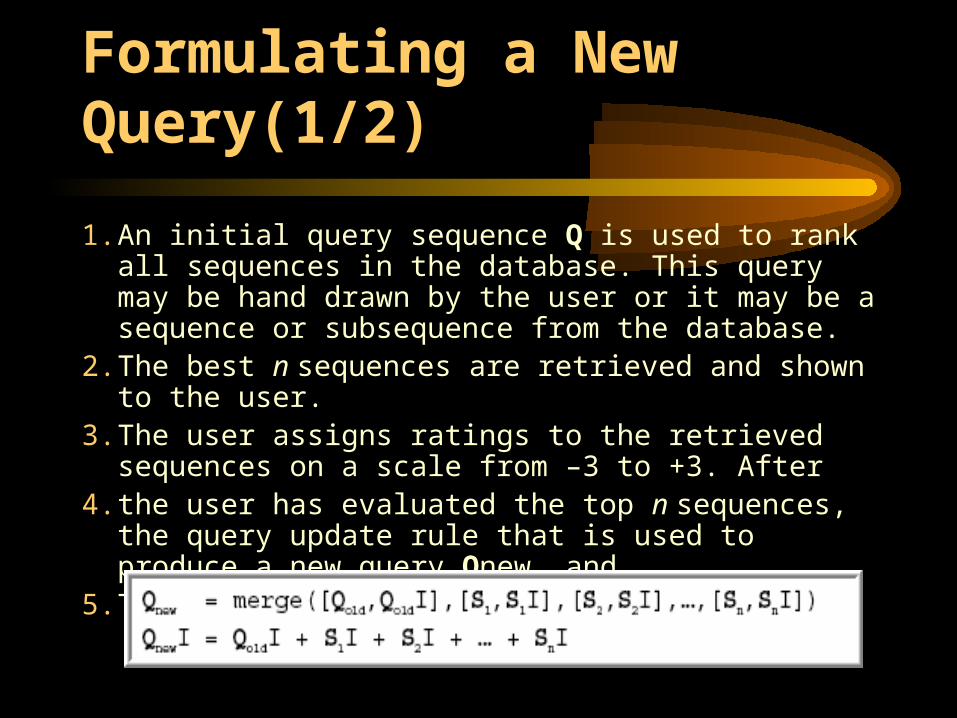
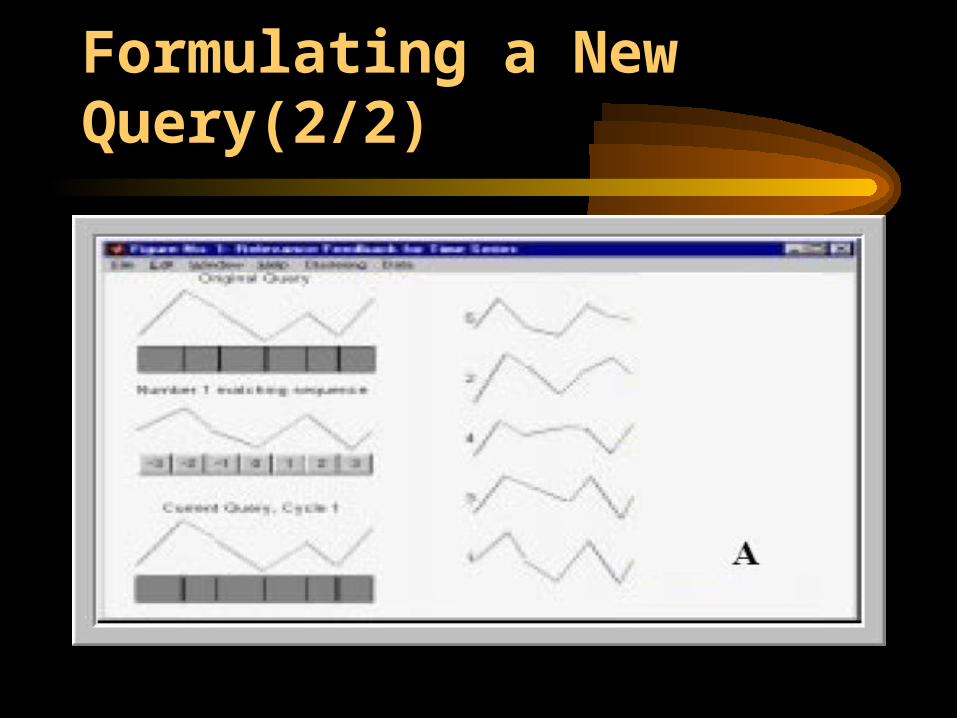
1. An initial query sequence Q is used to rank all sequences in the database. This query may be hand drawn by the user or it may be a sequence or subsequence from the database.
2. The best n sequences are retrieved and shown to the user. 3. The user assigns ratings to the retrieved sequences on a
scale from –3 to +3. After4. the user has evaluated the top n sequences, the query
update rule that is used to produce a new query Qnew, and5. The search process begins again.
Formulating a New Query(2/2)Formulating a New Query(2/2)

SUBJECTIVITY OF SIMILARITY(1/2)SUBJECTIVITY OF SIMILARITY(1/2)
• It is still possible that a query using this representation could failcould fail to retrieve an item that the user would have found relevant.
• Consider a problem of offset translation, Two similar (or even identical) shapes can have an arbitrarily large dissimilarity because they are separated in the Yaxis.
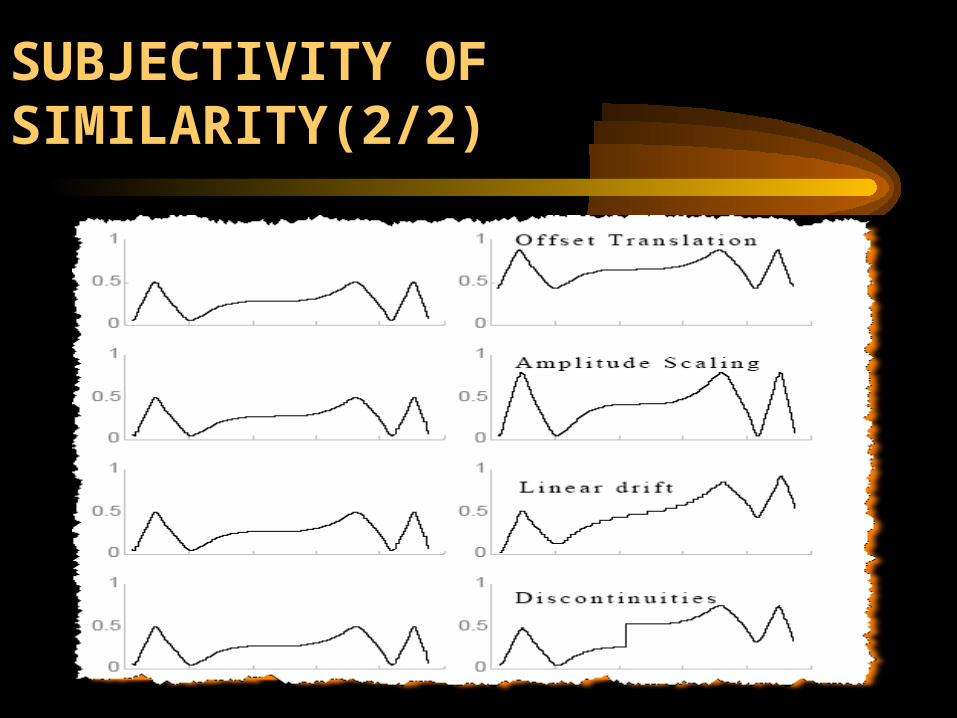
SUBJECTIVITY OF SIMILARITY(2/2)SUBJECTIVITY OF SIMILARITY(2/2)





























