Embed Size (px)
Citation preview

Available online at www.sciencedirect.com
Computer Networks 51 (2007) 5036–5056
www.elsevier.com/locate/comnet
Robust and efficient detection of DDoS attacksfor large-scale internet
Kejie Lu a, Dapeng Wu b,*, Jieyan Fan b, Sinisa Todorovic c, Antonio Nucci d
a Department of Electrical and Computer Engineering at the University of Puerto Rico at Mayaguez, Mayaguez, PR 00681, United Statesb Department of Electrical and Computer Engineering, University of Florida, Gainesville, FL 32611, United States
c Computer Vision and Robotics Laboratory, University of Illinois at Urbana-Champaign, Urbana, IL 61801, United Statesd Narus, Inc., 500 Logue Avenue, Mountain View, CA 94043, United States
Received 15 November 2006; received in revised form 21 May 2007; accepted 31 August 2007Available online 8 September 2007
Responsible Editor: R. Molva
Abstract
In recent years, distributed denial of service (DDoS) attacks have become a major security threat to Internet services.How to detect and defend against DDoS attacks is currently a hot topic in both industry and academia. In this paper, wepropose a novel framework to robustly and efficiently detect DDoS attacks and identify attack packets. The key idea ofour framework is to exploit spatial and temporal correlation of DDoS attack traffic. In this framework, we design a perim-eter-based anti-DDoS system, in which traffic is analyzed only at the edge routers of an internet service provider (ISP) net-work. Our framework is able to detect any source-address-spoofed DDoS attack, no matter whether it is a low-volumeattack or a high-volume attack. The novelties of our framework are (1) temporal-correlation based feature extractionand (2) spatial-correlation based detection. With these techniques, our scheme can accurately detect DDoS attacks andidentify attack packets without modifying existing IP forwarding mechanisms at routers. Our simulation results show thatthe proposed framework can detect DDoS attacks even if the volume of attack traffic on each link is extremely small. Espe-cially, for the same false alarm probability, our scheme has a detection probability of 0.97, while the existing scheme has adetection probability of 0.17, which demonstrates the superior performance of our scheme.� 2007 Elsevier B.V. All rights reserved.
Keywords: Distributed denial of service (DDoS) attacks; Detection; Machine learning; Spatial correlation
1389-1286/$ - see front matter � 2007 Elsevier B.V. All rights reserved
doi:10.1016/j.comnet.2007.08.008
* Corresponding author. Tel.: +1 352 392 4954; fax: +1 352 3920044.
E-mail addresses: [email protected] (K. Lu), [email protected](D. Wu), [email protected] (J. Fan), [email protected] (S.Todorovic).
URL: http://www.wu.ece.ufl.edu (D. Wu).
1. Introduction
In recent years, distributed denial of service
(DDoS) attacks have become a major security threatto Internet services. DDoS attacks can consume lotsof resources of a server, making legitimate usersunable to access the server. With the exponential
.

K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5037
increase of Internet-based e-business and e-com-mence, the damage caused by DDoS attacks is moresevere than ever before. Therefore, how to defendagainst DDoS attacks and protect the access of legit-imate users has attracted attention from both indus-try and academia. However, achieving this objectiveis not an easy task due to the difficulty in distinguish-ing attack traffic from normal traffic.
To address this problem, two types of anti-DDoSsystems, i.e., host-based systems and network-basedsystems [1,2], have been developed. Host-based sys-tems are deployed on end-hosts. These systems typ-ically use firewall and intrusion detection systems(IDS), and/or balance the load among multiple(geographically dispersed) servers to defend againstDDoS attacks. The host-based approach can helpprotect the server system; but it may not be ableto protect legitimate access to the server, becausehigh-volume attack traffic may congest the incom-ing link to the server.
On the other hand, network-based anti-DDoSsystems are deployed inside networks, e.g., on rou-ters. Network-based anti-DDoS techniques can beclassified into two categories: (1) detection/identifi-cation, and (2) defense. A detection/identificationmechanism is responsible for detecting DDoSattacks and identifying attack packets or attacksources. To detect DDoS attacks, signal processingtechniques (e.g., wavelet [3], spectral analysis [4,5],statistical methods [6–8]), and machine learningtechniques [9] can be used. To identify attacksources, IP traceback [10] is typically used. The IPtraceback techniques can help contain the attacksources; but it requires large-scale deployment ofthe same IP traceback technique and needs modifi-cation of existing IP forwarding mechanisms (e.g,IP header processing).
To defend against DDoS attacks, traffic controlmechanisms such as ingress filtering [11], route-based packet filtering [12], and rate limiting [13],are usually used. Ingress filters or packet filters[11,12] can drop packets with spoofed source IPaddresses that do not belong to the upstream net-works; but their effectiveness depends on globaldeployment of these filters in the Internet; with apartial deployment, spoofing source IP addresses ispossible. Rate limiter [13] are deployed at each linkof certain designated routers; they indistinguishablydrop some of the packets destined to a victim, whenthe victim is overwhelmed by (possible attack) traf-fic. In this way, the volume of attack traffic can belimited. Rate limiting is suitable for mitigating
attacks having high-data-rate on a link; but it isnot suitable for mitigating attacks having low-data-rate on a link, since attacks with low-data-rateon a link will not trigger rate limiting operation.
In this paper, we take a network-based approachand propose a novel framework to detect and iden-tify DDoS attacks. Our proposed approach is ableto detect any type of DDoS attacks such as TCPSYN flood, TCP RST flood, UDP flood, ICMPflood, and DNS flood, as long as they use spoofedsource IP addresses. The key idea of our frameworkis to exploit spatial and temporal correlation ofDDoS attack traffic. In this framework, we designa perimeter-based anti-DDoS system, in which traf-fic is analyzed only at the edge routers of an Internetservice provider (ISP) network. The anti-DDoS sys-tem consists of two major components: (1) featureextraction and (2) detection. Our feature extractionscheme exploits temporal correlation between theoutgoing traffic and the incoming traffic on a link,which makes distinct features between normal andattack traffic; we call these features 2D matching fea-
tures, which will be defined in Section 4.1.2. The 2Dmatching features are used by the detection module.In detection, our machine learning algorithm is ableto utilize the spatial correlation of DDoS attacktraffic at different routers. Our system has the fol-lowing advantages.
• Different from the existing network-based trafficcontrol systems, our system is able to accurately
detect attacks having low-data-rate on a linkand accurately identify legitimate flows. Accu-rately detecting attacks having low-data-rate ona link is important because DDoS attackers aregetting smarter and trying to hide their presenceby launching attacks from (geographically dis-persed) thousands of compromised machines,each of which generates low-rate attack traffic.Accurately identifying legitimate flows is criti-cal in defense since it can help filter out attacktraffic.
• Compared to IP traceback and egress filtering,our scheme can effectively detect attacks andidentify attack packets without modifying exist-ing IP forwarding mechanisms and without alarge-scale upgrade to backbone routers.
• Our network-based system has an advantageover a host-based system, in that designatedrouters can throttle the attack traffic by forward-ing packets from the identified legitimate flowsonly.

5038 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
Simulation results show that the proposed frame-work can detect DDoS attacks even if the volume ofattack traffic on each link is extremely small. Espe-cially, for the same false alarm probability, ourscheme has a detection probability of 0.97, whilethe existing scheme has a detection probability of0.17, which demonstrates the superior performanceof our scheme. Note that, although we use TCPSYN flood attacks during the experiments, ourmethod can actually detect any source-address-spoofed DDoS attack.
The rest of the paper is organized as follows. InSection 2, we briefly overview the related work. Sec-tion 3 presents our framework for detecting DDoSattacks. In Section 4, we describe our feature extrac-tion method. Section 5 presents our machine learn-ing algorithm for DDoS attack detection. In Section6, we discuss some important issues related to detec-tion algorithms. Section 7 shows our simulationresults and Section 8 concludes the paper.
2. Related work
In this section, we scan related work on featureextraction and detection.
2.1. Feature extraction
In [6], Wang et al. proposed to detect TCP SYNflood by using the ratio of the number of TCP SYNpackets to the number of TCP FIN and RST pack-ets. Ideally, if there are no SYN flood attacks, thisratio will be close to 1 for a period that is sufficientlylong, since most TCP sessions begin with an SYNpacket and end with an FIN packet. However,one of the main difficulties of this scheme is thatthe duration of some TCP sessions can be verylarge, which means that the ratio may not be closeto 1 for a short period. To overcome this problem,Wang et al. proposed to use the ratio of the numberof SYN packets (on the incoming direction of alink) to the number of SYN/ACK packets on theoutgoing direction of the link [14], since the timebetween the arrival of an SYN and the arrival ofthe corresponding SYN/ACK packet is related tothe round-trip time of the connection, which hasmuch less variation compared to the life-time ofTCP sessions. Nevertheless, this ratio of SYN toSYN/ACK does not make distinct features betweennormal and attack traffic since DDoS attackers canfool the system by generating attack traffic thatmakes the ratio of SYN to SYN/ACK close to 1,
just like normal traffic. This results in poor perfor-mance on detecting DDoS attacks.
It is well known that most DDoS attacks usespoofed source IP addresses. Moreover, the num-ber of packets from the same spoofed source IPaddress is relatively small, compared to the numberof packets of a real session. Consequently, to gen-erate a huge amount of attack traffic, a large num-ber of spoofed source IP addresses need to becreated. Based on this assumption, Peng et al.[7,15] proposed to use the ratio of the number ofnew IP address to the total number of IP addressesto detect attacks with spoofed source IP addresses.In their scheme, a database is required to store theinformation of all IP addresses that appeared in acertain period, which means that the requiredmemory size is very large for large-scale Internet.Hence, their scheme is not suitable for large-scaleISP networks.
Different from Ref. [7,15] that only consider newIP addresses, Ref. [16] uses entropy of the IPaddress distribution as a feature for detection; butthe complexity of calculating entropy for large-scaleInternet can be extremely high.
To summarize, the ratio of SYN to SYN/ACK[14], the percentage of new IP addresses [7,15],and entropy of the IP address distribution [16] havebeen used as features for detecting DDoS attacks.Features are important since they significantly affectthe performance of detectors. The aforementionedexisting features either do not lead to good perfor-mance of detectors, or require high storage/timecomplexity. To address these deficiencies, this paperproposes a hash-table/Bloom-filter based featureextraction scheme to efficiently extract so-called2D matching features, which makes distinct featuresbetween normal and attack traffic, thereby improv-ing accuracy of detecting attacks.
2.2. Detection
Once features are extracted from the measure-ment data (obtained by traffic measurementdevices), the features can be used in detecting DDoSattacks. To detect DDoS attacks, signal processingtechniques (e.g., wavelet [3], spectral analysis [4,5],statistical methods [6–8]), and machine learningtechniques [9] can be used.
In [3], Kim et al. proposed to use wavelet to ana-lyze traffic but it is not clear whether their schemecan detect attacks having low-data-rate on a link.In [4,5], spectral analysis was used to detect DDoS

Fig. 1. An ISP network architecture.
Fig. 2. Framework for detecting DDoS attacks.
K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5039
attacks; it is assumed that high-volume attack trafficcauses significant changes in the power spectral den-sity of traffic; but the technique was not designed todetect attacks having low-data-rate on a link, sinceattacks having low-data-rate may not cause largechanges in the power spectral density of traffic. Inthis paper, we design a detection technique thataddresses both high rate and low rate attacks.
A statistical method called change-point methodwas used to detect DDoS attacks [6–8]. Specifically,the change-point method is used to detect attack-induced abrupt changes in statistical patterns oftraffic, compared to the ‘‘normal traffic pattern’’.However, the parameters of the existing change-point algorithms [6–8] are constant and preset a pri-
ori for a given traffic pattern; it is not clear how todynamically adapt the values of these parameterswhen the traffic pattern changes. To address thisproblem, in this paper, we use machine learningtechniques to make our scheme robust againsttime-varying traffic patterns, which are inherent inreal Internet.
In [9], Mukkamala and Sung employed amachine learning technique called support vectormachine to detect DoS attacks; but their algorithmwas not tested for networks with a large IP addressspace, which may significantly increase the time/storage complexity of detection algorithms. In thispaper, we will test our machine learning algorithmfor networks with a large IP address space.
A simple method, known as egress filtering, canbe used to defend source-address-spoofed DDoSattacks by filtering unknown source IP addressesof all packets at edge routers. A more advancedmethod, called StackPi [17], inserts digital signatureto IP packets to prevent source address spoofing.Unfortunately, both methods need to be deployedto the whole Internet to be effective. Any ISP notsupporting these two methods will not be able to fil-ter out potential attack packets. In addition, thehigh complexity incurred by these two methodsmay be unacceptable as they need to modify eachIP packet at a router with these methods deployed.These limitations make these two methods impracti-cal, if not impossible.
3. Framework for detecting DDoS attacks
In this section, we present our framework fordetecting DDoS attacks.
Fig. 1 shows an ISP network architecture underour study, which consists of two types of IP routers,
namely, core routers and edge routers. Core routersinterconnect with one another to form a high-speedcore network. In contrast, edge routers are respon-sible for connecting subnets (i.e., customer networksor other ISP networks) with the core network. Inthis paper, a subnet can be either a customer net-work or an ISP network.
Given the ISP network architecture, we design aframework for detecting DDoS attacks. As shownin Fig. 2, our framework consists of three types ofcomponents: (1) traffic monitors, (2) local analyzers,and (3) a global analyzer, which are described asbelow.
3.1. Traffic monitor
A traffic monitor (represented by a filled oval inFig. 2) is responsible for:
• scanning partial or all packets of a single unidi-rectional link;
• summarizing traffic characteristics;• extracting simple features from the traffic
characteristic;• detect DDoS attacks based on simple online
detection algorithm; and

5040 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
• submit the summary of traffic information, sim-ple feature data, and detection results to a localanalyzer.
Fig. 3. An example of the asymmetric traffic.
1 Here, the upper layer can be either Layer 4 or Layer 7.
3.2. Local analyzer
A local analyzer is responsible for:
• extracting complicated features from traffic infor-mation obtained at a single edge router, and/or afew edge routers if they are co-located;
• detecting attacks with local information;• submit the detection results, feature data, and
traffic information (if necessary) to a globalanalyzer.
The local analyzer can utilize temporal correla-tion of traffic to generate feature data. Although alocal analyzer may also have spatial correlated traf-fic information, for example, the local analyzer ontop of Fig. 2, it is more appropriate to forwardthose information to a global analyzer because theglobal analyzer has the whole view of the network.
3.3. Global analyzer
A global analyzer is responsible for:
• extracting complicated features that requires glo-bal information, such as routing information,from traffic;
• analyzing feature data obtained from multiplelocal analyzers; and
• detecting anomalies with global informationobtained from multiple edge routers.
The global analyzer utilizes both temporal corre-lation and spatial correlation of traffic. Here it isimportant to note that, some feature data must beobtained at the global analyzer if global informationis required. For example, in Fig. 3, if the traffic fromsubnet A to server B passes through edge router X,and the traffic from server B to subnet A passesthrough edge router Y, then the 2D matching fea-tures between subnet A and server B shall beobtained at the global analyzer, which has the rout-ing information of the ISP network.
Compared to existing network-based anti-DDoSsystems, our framework does not require theupgrade of any router in the network.
Next, we describe feature extraction and detec-tion algorithms in Sections 4 and 5, respectively.
4. Feature generation
To efficiently extract features from traffic, wedesign a three-level hierarchical structure shown inFig. 4, where incoming packets are processed bylevel-one filters, then by level-two filters, and finallyby (level-three) feature extraction modules. Level-one filters and level-two filters are placed in trafficmonitors. A feature extraction module can beplaced in either a traffic monitor or a local analyzer,depending on the type of the feature.
Level-one filters select a packet based on itssource–destination pair, which is defined by thesource IP address, the source network mask, thedestination IP address, the destination networkmask. For example, if we are interested in packetsfrom 172.10.5.28 to 210.33.68.102, we can use255.255.255.255 as both the source network maskand the destination network mask; if we are inter-ested in packets from 172.10.x.x to 208.33.1.x, wecan use 255.255.0.0 as the source network maskand 255.255.255.0 as the destination network mask.In this way, we can monitor an end-host or a sub-net, giving much flexibility in configuring our detec-tion framework. The output of a level-one filter ispackets with the same source–destination pair,which are conveyed to level-two filters.
A level-two filter classifies the packets comingfrom level-one filters, based on the upper layer1 datafields, e.g., TCP SYN or FIN. The packets of ourinterest will be forwarded to one or multiple featureextraction modules. For example, the number ofTCP SYN packets can be used to generate both

Fig. 4. Hierarchical structure for feature extraction.
2 How to obtain this ratio can be found in [14].
K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5041
the TCP SYN rate feature and the TCP SYN/FIN(RST) ratio feature; hence, TCP SYN packetsare conveyed to both the TCP SYN rate moduleand the TCP SYN/FIN(RST) ratio module, asshown in Fig. 4. On the other hand, a feature mod-ule may need packets from multiple level-two filters.For example, the SYN/FIN(RST) ratio featureextraction requires packets from three filters, asshown in Fig. 4.
Compared to the packet classification schemes in[6,7], our hierarchical structure for feature extrac-tion is more general and efficient.
Next, we describe (level-three) feature extractionmodules and their implementations in Sections 4.1and 4.2, respectively.
4.1. Feature extraction module
Similar to previous studies [6,7], we generate fea-tures in a discrete manner, i.e., our feature extrac-tion module will generate a (feature) value or avector at the end of each time slot. Here we definethe duration of a time slot by Ts, which may varyfor different features. Intuitively, a shorter Ts mayreduce the detection delay, which is defined as theinterval from the epoch when the attack starts tothe epoch when the attack is detected; but a smallerTs may increase the computational complexity,since the detection algorithm needs to analyze morefeature data for the same time interval. On the otherhand, if a feature is represented by a ratio, Ts mustbe sufficiently large to avoid division by zero. Forexample, if we want to use the SYN/FIN(RST)ratio as in [6] to detect TCP SYN flood, then Ts can-not be too small, because the number of FIN pack-ets in a short period can be 0, which will result in afalse alarm even if the number of SYN packets isnot large.
Feature extraction can be done in a traffic moni-tor, a local analyzer, and a global analyzer, whichwe describe in Sections 4.1.1–4.1.3, respectively.
4.1.1. Feature extraction in a traffic monitorAs we mentioned earlier, some features are gener-
ated within a traffic monitor. These features are typ-ically simple and can be extracted from the traffic ona single unidirectional link.
In our framework, a traffic monitor can generatethe following features:
• Packet rate: defined by the number of packetarrivals in one time slot. This feature is simplebut useful for detecting high-volume DoS andDDoS attacks. But it can hardly help detectlow-volume attacks.
• Data rate: defined by the total number of bits ofall packets that arrive in one time slot.
• SYN/FIN(RST) ratio2: defined by the ratio ofthe number of TCP SYN packets in one time slotto the number of FIN (and a portion of RST)packets in the same time slot.
4.1.2. Feature extraction in a local analyzer
Although a traffic monitor can generate simplefeatures efficiently, these features may not be suffi-cient to detect attacks. In particular, the packet rateand data rate features may only be useful for detect-ing high-volume attacks; and SYN/FIN(RST) ratiohas a large variation even for normal traffic andhence cannot help accurately distinguish normalnetwork conditions from network anomalies. Toimprove detection accuracy, one can use a local ana-lyzer to generate more sophisticated features, for

5042 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
example, the SYN/SYN-ACK ratio proposed in[14] and the percentage of new IP addresses pro-posed in [7].
However, as discussed in Section 2.1, the existingfeatures such as the SYN/SYN-ACK ratio [14] andthe percentage of new IP addresses [7] either do notlead to good performance of detectors, or requirehigh storage/time complexity. To address these defi-ciencies, we propose a new type of feature called 2D
matching features, which can make distinct featuresbetween normal and attack traffic, thereby improv-ing accuracy of detecting attacks.
The motivation of proposing 2D matching fea-tures is the following. For most Internet applica-tions, packets are generated from both hosts thatare engaged in communication. Therefore, someinformation carried by packets on one directionshall match the corresponding information carriedby packets on the other direction. For example, ifstation A communicates with station B throughTCP, then we can observe packets with source Aand destination B on one direction, and we can alsoobserve packet with source B and destination A onthe opposite direction. On the other hand, if aDDoS attacker generates source A on one direction,the response packet may not reach the link on thereverse direction (where a traffic monitor is placed)if the attacker spoofs its source IP address. There-fore, we can utilize this feature to detect DDoSattacks.
To facilitate the discussion, we need to specify‘keys’ that contain the information that shall appearon both directions of a link. For instance, the keyfor TCP SYN packets on one direction can bedefined by
hsrcIP ; dstIP ; srcPort; dstPort; Seq#i
and the corresponding key for SYN-ACK packetson the opposite direction can be defined by
hdstIP ; srcIP ; dstPort; srcPort;Ack#� 1i:
Intuitively, by examining whether a key matches thecorresponding key on the opposite direction, we candetect the SYN flood or SYN-ACK flood attacks.Since the proposed feature is generated by matchingthe keys on two directions of a link, we call it 2D
matching feature.
4.1.3. Feature extraction in a global analyzer
From the discussion above, we can observe thatthe 2D matching features can be extracted by a localanalyzer if
1. the traffic is symmetric on a bi-directional link,i.e., if packets from host A to host B go througha link on one direction, then packets from host Bto host A must go through the link on the oppo-site direction; or
2. the traffic is asymmetric but the local analyzerhave all the traffic information from differentlinks, which are necessary for the 2D matchingfeature.
In practice, if the above conditions do not exist insome scenarios (for example, in the scenario illus-trated in Fig. 3), then the local analyzer can be setto forward the traffic information to a global ana-lyzer. Consequently, the global analyzer will beresponsible for extract the 2D matching features.
Next, we discuss how to implement featureextraction modules to extract the 2D matchingfeatures.
4.2. Implementation of 2D matching feature
extraction
In this section, we describe the implementation ata traffic monitor and at a local analyzer in Sections4.2.1 and 4.2.2, respectively. To simplify the discus-sion, we assume that the traffic is symmetrichereafter.
4.2.1. Implementation at a traffic monitor
To perform matching of the keys on two direc-tions, traffic monitors on two directions of a linkneed to record some traffic information. To dealwith high-speed data rates and a large number ofsource–destination pairs in large-scale networks,efficient traffic recording must be in place. Toachieve this, we use a hash table to store the neededinformation.
To update an (Pempty or non-empty) hash table,the following procedure is conducted.
• For each packet that passes through a level-twofilter, a hash function will be called to locatethe corresponding record in the hash table. Ifthe corresponding record is empty, then a keyextracted from the packet will be stored in therecord, and the counter of the record will be setto one; if the record is not empty and the keyof the packet and the key of the record are iden-tical, then the counter will be increased by one; ifthe record is not empty and the keys are different,then a collision occurs. The collision can be either

K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5043
resolved by some avoidance techniques such aslinear probing and rehashing, or can be simplyignored, which means that the key of the incom-ing packet will not be saved.
• At the end of each time slot, a traffic monitorsends all non-empty records to the correspondinglocal analyzer.
The performance of this implementation dependson three major factors:
• Memory requirement: Denote Nht the maximumnumber of records that could be stored in a hashtable; denote Lk the length (in bytes) of eachrecord. Then the total memory requirement isNht · Lk (in bytes). Here Lk depends on thelength of a key. For example, for the key ofSYN packets, we need 16 bytes of memory tostore the key and 4 bytes of memory to storethe status information and the counter. There-fore, Lk = 20 bytes.
• Processing speed: The main time complexity isdue to the calculation of the hash function andkey comparing, both of which can be imple-mented efficiently in software or hardware (ifnecessary).
• Data rate required for communication: At the endof each slot, the record information needs to betransmitted from the traffic monitor to the localanalyzer. In the worst case, the data rate require-ment for the communication is
8� Nht � Lk
T sðb=sÞ:
4.2.2. Implementation at a local analyzer
The major features to be extracted at a local ana-lyzer are the number of unmatched keys and thepercentage of unmatched keys. Other features,including the packet rate, can also be extracted ata local analyzer.
To achieve the functionality of key matching, webuild two key databases: one for the incoming trafficand the other for the outgoing traffic. Both theincoming key database and the outgoing key data-base use a sliding window mechanism to updatethe database. Specifically, the incoming key data-base always stores the latest Rf + 1 slots of keyrecords; e.g., if slot n is the current slot, the incom-ing key database stores key records from slot n � Rf
to slot n. The outgoing key database always storesthe latest Rb + Rf + 1 slots of key records. For each
slot, both the incoming key database and theoutgoing key database can store at most Nht keyrecords.
Now, we describe how to update the two key dat-abases. As mentioned in Section 4.2.1, a traffic mon-itor sends all non-empty records to thecorresponding local analyzer, at the end of eachtime slot. At the end of slot n, upon receiving anarray of key records from the incoming traffic mon-itor, a local analyzer updates the incoming key data-base by replacing the array of key records in slotn � Rf � 1 by the array of key records in slot n.For the outgoing key database, we use the datastructure of the celebrated Bloom filter [18] for effi-cient key matching. A Bloom filter consists of (1) abit-map for key records, and (2) multiple hash func-tions for storing key records in the bit-map and keysearching (i.e., membership query) [18]. So, at theend of slot n, upon receiving an array of key recordsfrom the outgoing traffic monitor, the local analyzerupdates the outgoing key database by Bloom filter’sstoring operation for the bit-map of slot n andreplacing the bit-map of slot n � Rb � Rf � 1 bythe bit-map of slot n.
Given the two key databases, we can do keymatching. To check whether a key is matched ornot, we need to consider the temporal correlationof packets. For example, in a normal procedure, aTCP SYN packet must be followed (in time) by aTCP SYN-ACK packet with the same key on theopposite direction of the link. Therefore, if we wantto determine whether a TCP SYN is matched, weneed to search for the corresponding TCP SYN-ACK in the later slots on the opposite direction ofthe link. On the other hand, if we want to determinewhether a TCP SYN-ACK is matched, we need tosearch for the corresponding TCP SYN in the previ-ous slots on the opposite direction of the link.Under this philosophy, we design three mechanismsfor key matching as below.
Assume that the current slot is slot n + Rf and weare searching for a key in the outgoing key databaseto match one intended key of slot n in the incomingkey database. Then our three key matching mecha-nisms are
• Forward matching: search all the slots m
(n 6 m 6 n + Rf) in the outgoing key databasefor the matching key. E.g., if the key in theincoming key database is TCP SYN, then weneed to use forward matching to search for thecorresponding TCP SYN-ACK.

Fig. 5. Graphical representation of the generative process, inwhich the state of traffic generates the stochastic process of traffic.
Fig. 6. The extended generative model including traffic-featurevectors.
5044 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
• Backward matching: search all the slots m
(n � Rb 6 m 6 n) in the outgoing key databasefor the matching key. E.g., if the key in theincoming key database is TCP SYN-ACK, thenwe need to use backward matching to searchfor the corresponding TCP SYN.
• Forward and backward matching: search all theslots m (n � Rb 6 m 6 n + Rf) in the outgoingkey database for the matching key. E.g., if wewant to check whether a source IP addressappears as a destination IP address in the oppo-site direction of the link, then we use forward &backward matching to search for the matchingdestination IP address.
The search in the above matching mechanisms isefficient due to the use of Bloom filter. When there isan unmatch, some counters will be updated; e.g.,when a TCP SYN is unmatched, the counter forunmatched TCP SYN packets will be increasedappropriately.
The memory requirement for a local analyzer isas below:
• Memory size for an outgoing key database isðRb þ Rf þ 1Þ � ð2ðLbf�3ÞÞ bytes, where Lbf is thelength (in bits) of the index, which is the outputof Bloom filter’s hash functions.
• Memory size for an incoming key database is(Rf + 1) * Nht * Lk bytes.
The minimum detection delay is upper boundedby (Rf + 1) · Ts.
Next, we present our machine learning algorithmfor detecting DDoS attacks.
5. Machine learning algorithm for detection
In this section, we present our machine learningalgorithm for detecting DDoS attacks. We organizethis section as follows. Section 5.1 outlines ourdetection approach. In Section 5.2, we formulatethe detection problem. Section 5.3 describes ourmachine learning algorithm.
5.1. Outline of our detection approach
To facilitate the discussion, we use the notion ofnetwork state. Specifically, the network is in thestate of ‘attack’ when there are DDoS attacks, andin the state of ‘normal’ when there is no DDoSattack. In our approach, we assume that different
network states have different statistics for some fea-tures. For example, the average number of TCPSYN packets destined to the victim in the case ofTCP SYN flooding attacks differs from that in thenormal network state.
Denote X the network state, and Y the trafficobserved by traffic monitors. Since different net-work state induces different stochastic process oftraffic, we employ the widely used graphic modelrepresentation [19] to depict this cause-effect rela-tionship in Fig. 5.
We represent features of multiple source–destina-tion pairs by a high-dimensional matrix F. An entryf in the mth row and nth column of this matrix rep-resents a feature vector that characterizes the trafficfrom source edge router m to destination edge rou-ter n. The details on feature extraction have beenexplained in Section 4. Most importantly, in selec-tion of the optimal features, we seek for the mostdiscriminative statistical properties of the corre-sponding origin–destination traffic. Since featuresare extracted from traffic data Y, we extend theabove model as illustrated in Fig. 6.
Our goal is to estimate X given Y and F, that is,to estimate state xi of each source–destination pair i,characterized by the ith entry fi in the traffic matrixF. Possible values that xi can take, in our two-classclassification problem, are {0,1}, where ‘0’ means‘normal’ and ‘1’ means ‘attack’.
Since DDOS attacks are distributed, wherenumerous compromised computers (zombies) runsimilar (or even the same) programs during the sameattack period, we hypothesize that the traffic of sev-eral origin–destination pairs is characterized by thesame statistical properties. Therefore, it seems rea-sonable to account for correlation among trafficpairs. Therein lies the novelty of our approach, aswe augment the model in Fig. 5 with yet anotherset of random variables, Z, that encode this correla-

Fig. 7. The complete generative model including traffic data,traffic states, and correlation among traffic states.
K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5045
tion, as depicted in Fig. 7. We anticipate that theintroduction of Z may lead to an improved estima-tion of X.
5.2. Formulation of the detection problem
Once F is extracted, we assume that F representswell data Y, such that we can operate only overlower-dimensional F, and in this manner reducecomputational load. Now, we formulate the net-work-state estimation as a machine learning prob-lem, where to each f we assign label x, which takesvales in the predefined set of classes x 2 {0,1}.The graphical representation of the outlined gener-ative model is depicted in Fig. 8. In the graph, nodesrepresent random variables (vectors), and the con-nections represent statistical dependencies amongrandom variables. Since feature vectors are measur-able, we call them observable random vectors, anddepict them as rectangular-shaped nodes. The statesof observable vectors need to be estimated; there-fore, we call them hidden variables, and depict themas round-shaped nodes. The model in Fig. 8 is infact the simplest possible generative model, sincethere are no lateral interdependencies among nodes.Consequently, the joint probability of the modelreads
P ðF ;X Þ ¼Y
i
P ðfijxiÞP ðxiÞ: ð1Þ
From Eq. (1), we observe that the network-stateestimation can be conducted for each traffic fi inde-pendently, by using the Maximum A Posteriori
(MAP) criterion given by
Fig. 8. The generative model that describes dependencies amongtraffic states and traffic-feature vectors.
x�i ¼ arg maxxi2f0;1g
P ðfijxiÞPðxiÞ: ð2Þ
To this end, it is necessary to learn likelihoodP(fijxi) and prior P(xi) in the training process off-line.
We extract yet another network feature—the cor-relation, nmn, between given traffic m and n over apredefined time interval. Consequently, in additionto matrix F, we have the correlation matrix, N, asnetwork features.
The reason for computing N stems from our goalto account for interdependencies among traffic pairsin the network. We speculate that this auxiliaryinformation may lead to a more accurate estima-tion. However, if we introduced additional connec-tions in the previous model, representing statisticaldependencies among all the nodes, we would arriveat computationally intractable model in Fig. 9.Here, in order to perform MAP estimation, wewould need to marginalize a very complex prior dis-tribution over network states X as
x�i ¼ arg maxxi2f0;1g
P ðfijxiÞX
jj6¼i
Xxj
P ðx1; x2; . . . ; xi; . . . xNÞ:
ð3Þ
Since the marginalization has to be done for everynode, such a model for a large network would notbe suitable.
Therefore, the most challenging task in network-state estimation lies in choosing a suitable statisticalmodel for specifying the joint probability distribu-tion over hidden and observable random variables,since this choice conditions the MAP estimation.Our goal is to preserve one-step connections, alsoknown as Markovian dependencies, since they pro-vide for a tractable MAP estimation. But, at thesame time, we would like to account for dependen-cies among as many nodes as possible. To balancethese two opposing goals, we propose to use a
Fig. 9. Complex generative model, where the MAP estimation isintractable.

Fig. 10. The quad-tree model for one-dimensional data, whereeach parent has exactly two children; pa(i) denotes the parent ofnode i.
Fig. 11. The irregular tree consists of a forest of subtrees, eachmarked by distinct shading; round- and square-shaped nodesindicate hidden and observable variables, respectively; trianglesindicate roots.
5046 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
multiscale tree model, an example of which isdepicted in Fig. 10. In the tree, the initial set of trafficstates X is augmented with so-called parents, grand-parents and further up until the root node. That is,hidden variables are organized in levels, where nodesat the finest scale represent states of each source–des-tination traffic, while nodes at higher levels representthe state of a group of traffic-feature vectors. Weassume that hidden variables at higher levels canalso take values in {0,1}. Connections are allowedonly between nodes that belong to adjacent levelsin the model. As such, we do not account explicitlyfor all possible dependencies among traffic states,but implicitly through parent nodes. In this manner,we preserve Markovian dependencies, while corre-lating all the nodes.
The next question is how to determine which par-ent–child pairs should be connected. One possibilityis to choose the fixed-structure tree, where, forexample, each parent has exactly four children. Thismodel is the well-known Hidden Markov Tree(a.k.a. quad-tree) used for image modeling. How-ever, it has been reported that due to the fixedstructure, quad-trees yield ‘‘blocky’’ estimates.Therefore, we propose to use irregular-structure tree(or short irregular tree), where connections betweenparent and children nodes are not fixed, but ratherestimated on a given data.
The novelty of our approach to multiscale statis-tical modeling is that we introduce connectivityvariables, zij, which regulate if there is a connectionbetween child i and parent j. The connectivity vari-ables, Z, are hidden, and need to be estimated,based on the correlation matrix N. In Fig. 7, wegraphically illustrate the dependencies between setsof variables F, X, and Z in the proposed multiscale
model. From Fig. 7, the joint probability of theirregular tree is given by
P ðF ;X ; Z;NÞ ¼ P ðF jX ÞP ðX jZÞP ðZjNÞPðNÞ: ð4ÞFrom Eq. (4), we observe that the irregular tree de-fines the distribution over connections betweennodes, and the distribution over node classes (i.e.,traffic states). Thus, for a given network data, weneed to estimate these two distributions simulta-neously. The problem of estimating the optimalmodel’s topology and its distributions is known tobe NP-hard. We propose to solve the problem byusing the Expectation–Maximization (EM) algo-rithm [19], which is a stage-wise optimization algo-rithm, guaranteed to increase the likelihood of themodel in each iteration step. Because of the Mar-kovian connections through scales, irregular treesare characterized by very fast inference algorithms,which makes them attractive tools for applicationswith stringent real-time constraints. The inferenceof model structure and distributions from the givendata produces a hierarchical model depicted inFig. 11. From the figure, we observe that the modelstructure adapts to encode underlying statisticalprocesses in the data. It consists of a forest of sub-trees, since there is no requirement that there beonly one root as in quad-trees.
For the Bayesian approach that we propose, it isnecessary to learn the parameters of the modelthrough training. To this end, it is necessary to pre-pare representative examples of the network datacontaining ‘attack’ and ‘normal’ states. Once theparameters of the irregular tree are learned, we arein a position to estimate the state of a given unseentraffic, by computing the posterior distribution ofeach node state. The probabilistic approach thatwe propose allows us to easily obtain the ROCcurve of our classifier, that is, to test false alarmand detection rate in a principled manner.

K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5047
5.3. Machine learning algorithm for network-state
estimation
5.3.1. Irregular treeIn this section we explain in greater detail the
irregular-tree model for estimating the networkstates, given traffic data. In order to fully character-ize the irregular tree (and any graphical model, forthat matter), it is necessary to learn both the graphtopology (structure) and the parameters of transi-tion probabilities between connected nodes fromtraining data. Usually, for this purpose, one maxi-mizes the likelihood of the model over training data,while at the same time minimizing the complexity ofmodel structure. Current methods are successful atlearning both the structure and parameters fromcomplete data. Unfortunately, when the data isincomplete (i.e., some random variables are hidden),optimizing both the structure and parametersbecomes NP-hard.
One of the major tasks of this paper is a solutionto the NP-hard problem of model-structure estima-tion. In our approach, we use a variant of theExpectation–Maximization (EM) algorithm, tofacilitate efficient search over large number of candi-date structures. In particular, the EM procedureiteratively improves its current choice of parametersby using the following two steps. In Expectationstep, current parameters are used for computingthe expected value of all the statistics needed to eval-uate the current structure. That is, the missing data(hidden variables) are completed by their mean val-ues. In Maximization step, we replace currentparameters with those that maximize the likelihoodover the complete data. This second step is essen-tially equivalent to learning model structure andparameters from complete data, and, hence, canbe done efficiently by using the Belief Propagation
algorithm [19], which is well known in the machinelearning community.
An irregular tree is a directed acyclic graph withV nodes, organized in hierarchical levels, V‘,‘ = {0,1, . . . ,L}, where V0 denotes the leaf level.The layout of nodes is identical to that of thequad-tree, such that the number of nodes at level ‘can be computed as jV‘j = jV‘�1j/4 = � � � = jV0j/4‘.Connections are established under the constraintthat a node at level ‘ can become a root or it canconnect only to the nodes at the next ‘+1 level.The network connectivity is represented by a ran-dom matrix, Z, where entry zij is an indicator ran-dom variable, such that zij = 1 if i 2 V‘ and
j 2 V‘+1 are connected. Z contains an additionalzero (‘‘root’’) column, where entries zi0 = 1 if i is aroot node.
Each node i is characterized by a network-staterandom variable, xi, which can take values in a finiteset C. In our case, C = {0,1}. For the given Z, thelabel xi of node i is conditioned on xj of its parentj, and is given by conditional probability tablesP(xijxj,zij = 1). For roots i, we have P(xijx0,zi0 = 1) , P(xi). The joint probability of all net-work-state variables X = {xi}, "i 2 V, is given by
P ðX jZÞ ¼YL
‘¼0
Yi2V ‘
P ðxijxj; zij ¼ 1Þ: ð5Þ
Next, leaf nodes are characterized by observablerandom variables F = {fi}, "i 2 V0. We assume thatobservable variables fi are conditionally indepen-dent given the corresponding xi:
P ðF jX Þ ¼Yi2V 0
P ðfijxiÞ; ð6Þ
P ðfijxi ¼ cÞ ¼XG
g¼1
pcðgÞNðfi; lcðgÞ;RcðgÞÞ; ð7Þ
where P(fijxi = c), c 2 C, is modeled as a mixture ofGaussians. The Gaussian-mixture parameters canbe grouped in h = {pc(g),lc(g),Rc(g),Gc}, "c 2 C.
Finally, we specify the connectivity distributionas
P ðZjNÞ ¼Yi;j2V
Pðzij ¼ 1jnijÞ ¼Yi;j2V
Nðnij; m;HÞ; ð8Þ
where nij is the observable correlation between childi and parent j, and m and H are the mean and var-iance of zij. Note that a higher-level node representsnetwork data at the corresponding coarse scale.Therefore, nij should be suitably extracted as a net-work feature to represent correlation between trafficof different source–destination pairs.
The irregular tree is fully characterized by thejoint prior P(F,X,ZjN) = P(FjX)P(XjZ)P(ZjN).The introduced parameters of the model can begrouped in the parameter set X. In the next sectionwe explain how to infer the ‘‘best’’ configuration ofZ and X from the observed data F and N.
5.3.2. Inference of the irregular tree
The standard Bayesian formulation of the infer-ence problem consists in minimizing the expectationof some cost function R, given the data

5048 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
ðbZ ; bX Þ ¼ arg minZ;X
EfRððZ;X Þ; ðZ 0;X 0ÞÞjF ;N;Xg;
ð9Þ
where R penalizes the discrepancy between the esti-mated configuration (Z,X) and the true one (Z 0,X 0).We propose the following cost function:
RððZ;X Þ;ðZ 0;X 0ÞÞ¼RðX ;X 0ÞþRðZ;Z 0Þ
¼XL
‘¼0
Xi2V ‘
½1�dðxi�xi0Þ�
þXL�1
‘¼0
Xði;jÞ2V ‘�f0;V ‘þ1g
½1�dðzij� z0ijÞ�;
ð10Þ
where 0 stands for true values, and d(Æ) is the Kro-necker delta function. From Eq. (10), the resultingBayesian estimator of X is
8i 2 V ; xi ¼ arg maxxi2C
P ðxijZ; F ;NÞ: ð11Þ
Next, given the constraints on connections in theirregular tree, discussed in Section 5.3.1, we derive
Fig. 12. Inference of t
that minimizing EfRðZ; Z 0ÞjF ;N;Xg is equivalentto finding a set of optimal parents j such that
ð8‘Þ ð8i 2 V ‘Þ ðzi 6¼ 0Þ j¼ arg maxj2f0;V ‘þ1g
P ðzij ¼ 1jnijÞ;
ð12Þ
where zi,P
k2V ‘�1 zki, and zi 5 0 represents the event‘‘node i has children’’, that is, ‘‘node i is included inthe irregular-tree structure’’. The global solution toEq. (12) is an open problem in many research areas.We propose a stage-wise optimization, where, as wemove upwards, starting from the leaf level‘ = {0,1, . . . ,L}, we include in the tree structureoptimal parents at V‘+1 according to
ð8i 2 V ‘Þ ðzi 6¼ 0Þ j ¼ arg maxj2f0;V ‘þ1g
P ðzij ¼ 1jnijÞ;
ð13Þ
where zi 6¼ 0 denotes an estimate that i has alreadybeen included in the tree structure when optimizingthe previous level V‘.
Eqs. (11) and (13) suggest that it is possible tosolve for ðbZ ; bX Þ in a recursive procedure until some
he irregular tree.

K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5049
convergence criterion is met. Thus, in a recursivestep t, we first assume that estimate Z(t � 1) of theprevious step t � 1 is known and then derive esti-mate X(t) using Eq. (11); then, substituting X(t) inEq. (13) we derive estimate Z(t). We consider thealgorithm converged if P(F,XjZ) does not varymore than some threshold e for N consecutive itera-tion steps t, where e and N are subject to specificapplication requirements. Although, the optimiza-tion given by Eqs. (11) and (13) requires simulta-neous optimization of bX and bZ , note that we inferthe irregular tree stage-wise, which may yield sub-optimal solutions. From our experience, though,the algorithm recovers from stationary points forsufficiently large N. The overall inference algorithmis summarized in Fig. 12.
Fig. 13. Steps 2 and 7 in Fig. 12: B
Steps 2 and 7 in the algorithm can be interpretedas inference of bX given F for a fixed-structure tree.In particular, for step 2, where the initial structureis the quad-tree, we can use the standard inferenceon quad-trees, where, essentially, belief messagesare propagated in only two sweeps up and downthe tree. For step 7, the irregular tree represents aforest of subtrees, which also have fixed, thoughirregular, structure; therefore, we can use the verysame tree-inference algorithm for each of the sub-trees. This algorithm is called Belief Propagation,which we present in Fig. 13. In the figure, we sim-plify notation as P(xijZ,F,N)! P(xijF) andP(xijxj,Z)! P(xijxj). Also, we denote with c(i) chil-dren of i, and with d(i) the set of all the descendantsdown the tree of node i including i itself. Thus, Fd(i)
elief Propagation for the tree.

5050 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
denotes a set of all observables down the subtreewhose root is i. Also, for computing P(xijFd(i)), inthe bottom-up pass, / means that equality holdsup to a multiplicative constant that does not dependon xi.
6. Discussion on detection algorithms
The aforementioned machine learning algorithmis used in a global analyzer to exploit both spatialand temporal correlation of traffic. In a local ana-lyzer, if detection of DDoS attacks must be con-ducted, one can employ (1) the threshold-basedalgorithm (to be defined in Sections 6.2) and 2 thechange-point algorithm [6–8]. Both algorithms canuse the feature data provided by the feature extrac-tion modules in our framework. However, we notethat an important issue has largely been ignored inthe literature, that is, how to set the parameters ofthese algorithms.
We organize this section as below. Section 6.1presents the performance metrics for detection algo-rithms. We describe how to set the parameters of thethreshold-based algorithm and the change-pointalgorithm in Sections 6.2 and 6.3, respectively.
6.1. Performance metrics
A typical method to quantify the performance ofdetection algorithms is to use so-called Receiver
Operating Characteristics (ROC) curve [20, p. 107].To obtain an ROC curve, we need the following
quantities
• Nf: the number of false alarms, i.e., the numberof slots in which the detection algorithm declares‘attack’ given that no attack actually happens inthese slots;
• Nn: the number of slots in which no attackhappens;
• Nd: the number of slots in which the detectionalgorithm declares ‘attack’ given that attacksactually happen in these slots;
• Na: the number of slots in which attacks happen.
The false alarm probability and the detectionprobability of the detection algorithm can be esti-mated by Nf/Nn and Nd/Na, respectively. By varyingthe detection threshold, we can obtain differentpairs of false alarm probability and detection prob-ability, which give the ROC curve [20, p. 107]. In
this paper, we will use the ROC curve to comparethe performance of different detection algorithms.
6.2. Threshold-based algorithm
The idea of the threshold-based algorithm is thatif the feature value exceeds a preset threshold,declare ‘attack’; otherwise, declare ‘normal’. Notethat the detection operation is conducted in eachslot. By varying the threshold for the feature value,we can obtain different pairs of false alarm probabil-ity and detection probability, resulting in the ROCcurve. Given the ROC curve and the desired falsealarm probability, one can determine the value ofthe threshold for detection operation. This is themethod to set the parameter of the threshold-basedalgorithm.
6.3. Change-point algorithm
In the literature, a simple change-point algo-rithm—non-parametric Cumulative Summation
(CUSUM) algorithm—has been widely used [6–8,14]. However, existing works have not provideda comprehensive study on how to set the parametersof CUSUM. Furthermore, these studies only con-sider the change from normal state to abnormalstate, which means that the number of false alarmscan be very large after attacks end. To facilitate thediscussion, we define the following parameters usedin CUSUM:
• Xn denotes the observed traffic variable at the endof slot n.
• X n denotes the expectation of Xn in normalstates.
• X a denotes the expectation of Xn in abnormalstates. Without losing generality, here we assumethat X n < X a.
• Yn denotes the adjusted variable, which is definedas
Y n ¼ X n � a;
where a is a parameter such that X n < a < X a.
Now define variable Sn by
Sn ¼ 0 n ¼ 0;
Sn ¼ maxð0; Sn�1 þ Y nÞ n > 0:
�ð14Þ
In the CUSUM algorithm, if Sn is smaller than athreshold H, declare that the network state is nor-mal; otherwise, declare that the state is abnormal.

K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5051
From the discussion above, we note that twoparameters, i.e., a and H, need to be determined.However, we cannot uniquely determine these twoparameters. To overcome this problem, we shallintroduce another parameter, i.e., the detectiondelay, denoted as D. According to the change-pointtheory, we have
DH! 1
ðX a � X nÞ � jX n � aj¼ 1
X a � a: ð15Þ
From Eq. (15), we can obtain
H ¼ D� ðX a � aÞ: ð16Þ
Hence, once D and a are given, we can determine H
through Eq. (16).3 Given a and H, we can use theCUSUM algorithm to detect network anomaly.
We notice that the existing CUSUM algorithms[6–8] only consider one change, i.e., from the nor-mal state to the abnormal state. In practice, thisapproach may lead to a large number of falsealarms after the end of attacks. To mitigate the falsealarm problem of the existing algorithms, which wecall single-CUSUM algorithms, we develop a dual-CUSUM algorithm. In this algorithm, one CUSUMwill be used to detect the change from the normal tothe abnormal state, while another CUSUM isresponsible for detecting the change from the abnor-mal to the normal state. The method of settingparameters for dual-CUSUM is similar to themethod described in this section.
7. Simulation results
In this section, we evaluate the performance ofthe proposed schemes through simulation. Due tothe space limit, in this paper, we only considerTCP SYN attacks with spoofed source IP addresses.
7.1. Experiment setting
In our study, we develop a testbed to (1) extractvarious feature information, and (2) analyze featuredata by our machine learning algorithm andCUSUM algorithms. Next, we describe the settingfor networks, traffic traces, and feature extractionused in our experiments.
3 In [6,7], a ¼ ðX a � X nÞ=2; thus only the detection delay isneeded.
7.1.1. Network
In our experiment, we assume that the ISP net-work consists of a core network, a victim network,and 16 edge routers that connect to 16 subnets, asillustrated in Fig. 14. At each edge router, two mon-itors are placed to measure the inbound and out-bound traffic between a subnet and the victimnetwork, respectively. To simplify the notation, wedenote link i (i = 1,2, . . . , 16) as the virtual connec-tion between subnet i and the victim network.Moreover, we define the inbound direction of linki as the direction from subnet i to the victim net-work; and the outbound direction of link i as thedirection from the victim network to subnet i.
7.1.2. Traffic
A link may carry traffic with no attack (calledbackground traffic) or traffic with TCP SYNattacks.
For the background traffic, we use the trace dataprovided by Auckland University [21]. This data setcontains packet header information of the real traf-fic between the Internet and Auckland University.The connection is OC-3 (155 Mb/s) for both direc-tions. Since we do not have real data traces obtainedfrom 16 different links, we use the real traffic tracemeasured on one link (between the Internet andAuckland University) to create traffic traces for 16different links. Specifically, we use traffic traces ofdifferent days to represent traffic traces of differentlinks. So we use a traffic trace of 16 days to repre-sent traffic traces of 16 different links. That is, thetraffic from the Internet to Auckland University inday i (i = 1,2, . . . , 16) corresponds to the inboundtraffic of link i; the traffic from Auckland Universityto the Internet in day i corresponds to the outboundtraffic of link i.
Fig. 14. Experiment network.

5052 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
To simulate TCP SYN attacks, we first generatea random number Nlink; then we randomly selectNlink links from the 16 links; for each of the selectedNlink links, we randomly add TCP SYN packetswith spoofed source IP addresses into the back-ground traffic of that link. The average packet rateof TCP SYN attack traffic on each of the selectedNlink links, is 1% of the total packet rate on the link.The attacks on each of the selected Nlink links arelaunched in almost the same period so that we havesynchronized DDoS attacks across the selected Nlink
links. Since the attack traffic on each link is low (just1%), we effectively simulate low-volume attack traf-fic. Note that, in this paper, we use TCP SYN floodattack as an example to demonstrate the perfor-mance of our DDoS detection method. Actually, itis able to detect any type of DDoS attacks, as longas it uses spoofed source IP addresses.
7.1.3. FeatureTo detect distributed TCP SYN attacks, we use
the 2D features described in Section 4.1.2, i.e., thenumber of unmatched SYN packets in one timeslot. Note that the number of SYN packets towardthe victim subnet can also be reported by our fea-ture extraction modules. So, both the number ofSYN packets and the number of unmatched SYNpackets can be used in our analysis. The parametersetting of our feature extraction module is listed inTable 1.
Given the parameters in Table 1, we can derivethat the memory requirement for each traffic moni-tor is
Nht � Lk ¼ 320 Kbyte;
the memory requirement for each local analyzer is
ðRb þ Rf þ 1Þ � 2Lbf�3 þ ðRf þ 1Þ � N ht � Lk
¼ 3:28 Mbytes;
and the minimum detection delay is upper boundedby
Table 1Parameter setting for feature extraction
Parameter Setting
Ts 10 sRf 9Rb 0Nht 214 = 16K
Lbf 16Lk 20 bytes
ðRf þ 1Þ � T s ¼ 100 s:
Fig. 15 shows the features of two links, specifically,the number of SYN packet arrivals and the numberof unmatched SYN packet arrivals during a slot,where the duration of a slot is 10 seconds. For thesetwo links, we launch (synchronized) attacks on bothlink 1 and link 2, during two periods, i.e., Slot 1400–1600 and Slot 2800–3200. In addition, asynchro-nous attacks are launched during Slot 5000–5200on link 1 and during Slot 5700–5900 on link 2.
From Fig. 15, it can be observed that the featuresare rather noisy, especially for the feature of thenumber of SYN packets. From Fig. 15a and c, wecan hardly distinguish the slots under the low-vol-ume synchronized attacks from the slots withoutattacks (by visual inspection). In comparison, it ismuch easier to identify the slots under the synchro-nized attacks (by visual inspection) when the num-ber of unmatched SYN packets is used as thefeature (see Slot 1400–1600 and Slot 2800–3200 inFig. 15b and d).
7.2. Performance comparison
Table 2 compares the performance of differentschemes, where the benchmark is the scheme in[6], i.e., the CUSUM scheme with SYN/FIN ratioas the feature; for the benchmark scheme, we usethe same parameter setting as that in [6]; we com-pare the benchmark with CUSUM and our machinelearning algorithm under different features. Tomake fair comparison, we make the false alarmprobability of each scheme almost the same andcompare the detection probability. From Table 2,it can be seen that, the benchmark scheme (‘SYN/FIN ratio’ + CUSUM) performs very poorly indetecting low-volume DDoS attacks. In contrast, aCUSUM algorithm with the number of SYN pack-ets or the number of unmatched SYN packets as thefeature can achieve much higher detection probabil-ity. More importantly, our machine learning algo-rithm can significantly outperform CUSUM, giventhe same feature data, no matter whether the featureis the number of SYN packets or the number ofunmatched SYN packets.
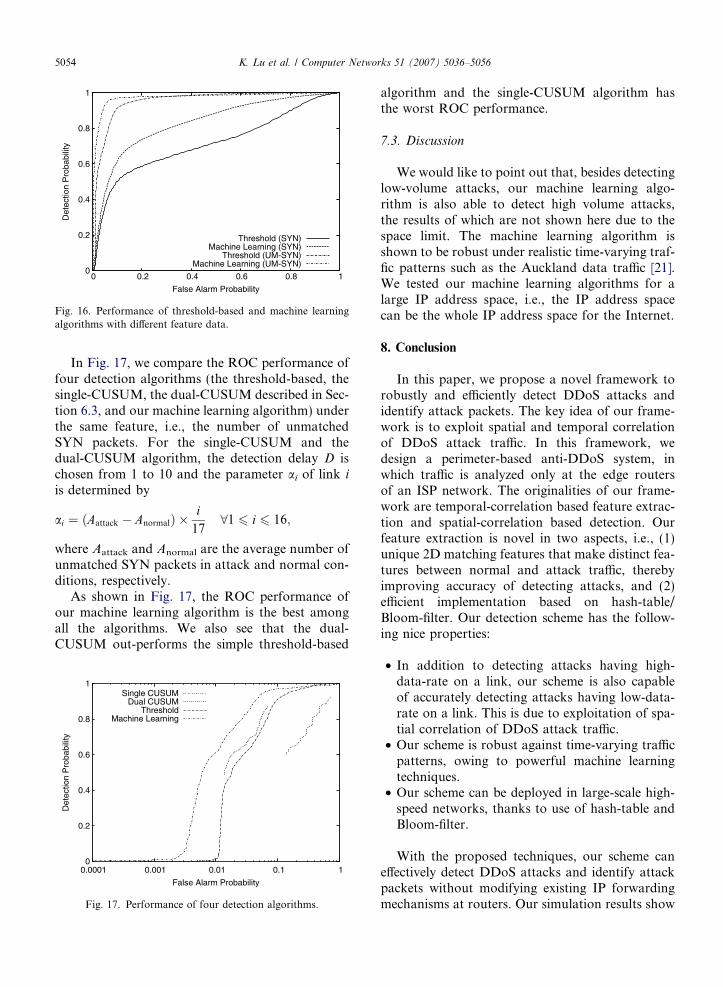
Fig. 16 compares the receiver operating charac-teristics (ROC) curve of the threshold-based schemedescribed in Section 6.2 and our machine learningalgorithm under two different features, i.e., thenumber of SYN packets (denoted by ‘SYN’) andthe number of unmatched SYN packets (denoted
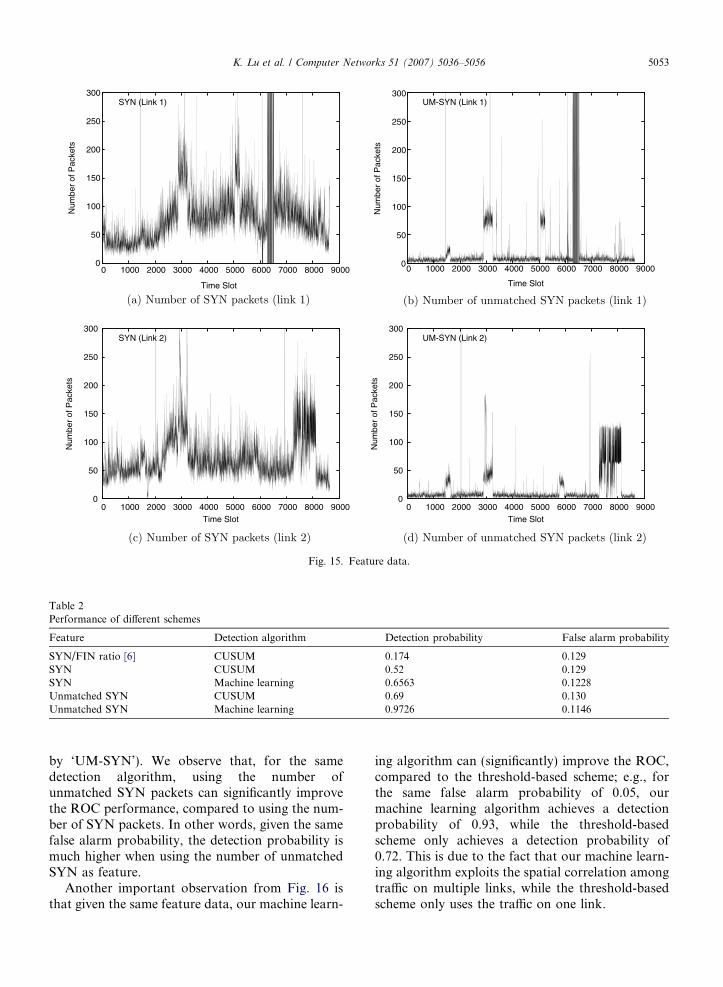
Table 2Performance of different schemes
Feature Detection algorithm Detection probability False alarm probability
SYN/FIN ratio [6] CUSUM 0.174 0.129SYN CUSUM 0.52 0.129SYN Machine learning 0.6563 0.1228Unmatched SYN CUSUM 0.69 0.130Unmatched SYN Machine learning 0.9726 0.1146
0
50
100
150
200
250
300
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
Num
ber
of P
acke
ts
Time Slot
SYN (Link 1)
0
50
100
150
200
250
300
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
Num
ber
of P
acke
ts
Time Slot
UM-SYN (Link 1)
0
50
100
150
200
250
300
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
Num
ber
of P
acke
ts
Time Slot
SYN (Link 2)
0
50
100
150
200
250
300
0 1000 2000 3000 4000 5000 6000 7000 8000 9000
Num
ber
of P
acke
ts
Time Slot
UM-SYN (Link 2)
Fig. 15. Feature data.
K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5053
by ‘UM-SYN’). We observe that, for the samedetection algorithm, using the number ofunmatched SYN packets can significantly improvethe ROC performance, compared to using the num-ber of SYN packets. In other words, given the samefalse alarm probability, the detection probability ismuch higher when using the number of unmatchedSYN as feature.
Another important observation from Fig. 16 isthat given the same feature data, our machine learn-
ing algorithm can (significantly) improve the ROC,compared to the threshold-based scheme; e.g., forthe same false alarm probability of 0.05, ourmachine learning algorithm achieves a detectionprobability of 0.93, while the threshold-basedscheme only achieves a detection probability of0.72. This is due to the fact that our machine learn-ing algorithm exploits the spatial correlation amongtraffic on multiple links, while the threshold-basedscheme only uses the traffic on one link.
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Det
ectio
n P
roba
bilit
y
False Alarm Probability
Threshold (SYN)Machine Learning (SYN)
Threshold (UM-SYN)Machine Learning (UM-SYN)
Fig. 16. Performance of threshold-based and machine learningalgorithms with different feature data.
5054 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
In Fig. 17, we compare the ROC performance offour detection algorithms (the threshold-based, thesingle-CUSUM, the dual-CUSUM described in Sec-tion 6.3, and our machine learning algorithm) underthe same feature, i.e., the number of unmatchedSYN packets. For the single-CUSUM and thedual-CUSUM algorithm, the detection delay D ischosen from 1 to 10 and the parameter ai of link i
is determined by
ai ¼ ðAattack � AnormalÞ �i
1781 6 i 6 16;
where Aattack and Anormal are the average number ofunmatched SYN packets in attack and normal con-ditions, respectively.
As shown in Fig. 17, the ROC performance ofour machine learning algorithm is the best amongall the algorithms. We also see that the dual-CUSUM out-performs the simple threshold-based
0
0.2
0.4
0.6
0.8
1
0.0001 0.001 0.01 0.1 1
Det
ectio
n P
roba
bilit
y
False Alarm Probability
Single CUSUMDual CUSUM
ThresholdMachine Learning
Fig. 17. Performance of four detection algorithms.
algorithm and the single-CUSUM algorithm hasthe worst ROC performance.
7.3. Discussion
We would like to point out that, besides detectinglow-volume attacks, our machine learning algo-rithm is also able to detect high volume attacks,the results of which are not shown here due to thespace limit. The machine learning algorithm isshown to be robust under realistic time-varying traf-fic patterns such as the Auckland data traffic [21].We tested our machine learning algorithms for alarge IP address space, i.e., the IP address spacecan be the whole IP address space for the Internet.
8. Conclusion
In this paper, we propose a novel framework torobustly and efficiently detect DDoS attacks andidentify attack packets. The key idea of our frame-work is to exploit spatial and temporal correlationof DDoS attack traffic. In this framework, wedesign a perimeter-based anti-DDoS system, inwhich traffic is analyzed only at the edge routersof an ISP network. The originalities of our frame-work are temporal-correlation based feature extrac-tion and spatial-correlation based detection. Ourfeature extraction is novel in two aspects, i.e., (1)unique 2D matching features that make distinct fea-tures between normal and attack traffic, therebyimproving accuracy of detecting attacks, and (2)efficient implementation based on hash-table/Bloom-filter. Our detection scheme has the follow-ing nice properties:
• In addition to detecting attacks having high-data-rate on a link, our scheme is also capableof accurately detecting attacks having low-data-rate on a link. This is due to exploitation of spa-tial correlation of DDoS attack traffic.
• Our scheme is robust against time-varying trafficpatterns, owing to powerful machine learningtechniques.
• Our scheme can be deployed in large-scale high-speed networks, thanks to use of hash-table andBloom-filter.
With the proposed techniques, our scheme caneffectively detect DDoS attacks and identify attackpackets without modifying existing IP forwardingmechanisms at routers. Our simulation results show

K. Lu et al. / Computer Networks 51 (2007) 5036–5056 5055
that the proposed framework can detect DDoSattacks even if the volume of attack traffic on eachlink is extremely small. Especially, for the same falsealarm probability, our scheme has a detection prob-ability of 0.97, while the existing scheme has a detec-tion probability of 0.17, which demonstrates thesuperior performance of our scheme.
Our future work will focus on designing defensemechanisms against DDoS attacks. The detectionframework proposed in this paper can facilitatedefense against DDoS attacks in the followingway. Since our framework can identify (1) matchedIP addresses/flows, and (2) unmatched IP addresses/flows. If a DDoS attack is detected, the defensemechanism (a simple packet filter based on IPaddresses) only allows matched flows to pass whileblocking unmatched flows. During a DDoS attackperiod, new legitimate users will not be allowed,i.e., packets from new legitimate users will bedropped, which is a limitation of this defense mech-anism. But such a defense mechanism can protectfrequent (old) users, which are, from the businessperspective, typically more important than newusers.
Acknowledgement
The authors would like to thank James Greco forconducting some of the experiments in this work.
References
[1] J. Mirkovic, P. Reiher, A taxonomy of DDoS attack andDDoS defense mechanisms, ACM SIGCOMM ComputerCommunications Review 34 (2) (2004) 39.
[2] L.-C. Chen, T.A. Longstaffv, K.M. Carley, Characterizationof defense mechanisms against distributed denial of serviceattacks, Computers & Security 23 (8) (2004) 665–678.
[3] S.S. Kim, A.L.N. Reddy, M. Vannucci, Detecting trafficanomalies using discrete wavelet transform, in: Proceedingsof International Conference on Information Networking(ICOIN), Busan, Korea, 2004, vol. III, pp. 1375–1384.
[4] C.-M. Cheng, H.T. Kung, K.-S. Tan, Use of spectral analysisin defense against dos attacks, in: Proceedings of IEEEGLOBECOM 2002, Taipei, Taiwan, 2002.
[5] A. Hussain, J. Heidemann, C. Papadopoulos, A frameworkfor classifying denial of service attacks, in: Proceedings ofACM SIGCOMM, Karlsruhe, Germany, 2003.
[6] H. Wang, D. Zhang, K.G. Shin, Detecting SYN floodingattacks, in: Proceedings of IEEE INFOCOM’2002, NewYork City, NY, 2002, pp. 1530–1539.
[7] T. Peng, C. Leckie, K. Ramamohanarao, Detecting distrib-uted denial of service attacks using source IP addressmonitoring, Tech. Rep., Department of Computer Scienceand Software Engineering, The University of Melbourne,2002. URL <http://www.cs.mu.oz.au/tpeng>.
[8] R.B. Blazek, H. Kim, B. Rozovskii, A. Tartakovsky, A novelapproach to detection of ‘‘denial-of-service attacks viaadaptive sequential and batch- sequential change-pointdetection methods, in: Proceedings of IEEE Workshop onInformation Assurance and Security, West Point, NY, 2001,pp. 220–226.
[9] S. Mukkamala, A.H. Sung, Detecting denial of serviceattacks using support vector machines, in: Proceedings ofIEEE International Conference on Fuzzy Systems, 2003.
[10] S. Savage, D. Wetherall, A. Karlin, T. Anderson, Practicalnetwork support for ip traceback, in: Proceedings of ACMSIGCOMM’2000, 2000.
[11] P. Ferguson, D. Senie, Network ingress filtering: Defeatingdenial of service attacks which employ ip source addressspoofing, IETF, RFC 2267.
[12] K. Park, H. Lee, On the effectiveness of route-based packetfiltering for distributed dos attack prevention in power-lawinternets, in: Proceedings of ACM SIGCOMM, 2001.
[13] S. Chen, Q. Song, Perimeter-based defense against highbandwidth DDoS attacks, IEEE Trans. Parallel Distrib.Syst. 16 (6) (2005) 526–537.
[14] H. Wang, D. Zhang, K.G. Shin, Change-point monitoringfor the detection of dos attacks, IEEE Transactions onDependable and Secure Computing (4) (2004) 193–208.
[15] T. Peng, C. Leckie, K. Ramamohanarao, Protection fromdistributed denial of service attacks using history-based IPfiltering, in: Proceedings of IEEE ICC 2003, Anchorage, AK,2003, pp. 482–486.
[16] L. Feinstein, D. Schnackenberg, R. Balupari, D. Kindred,Statistical approaches to DDoS attack detection andresponse, in: Proceedings of DARPA Information Surviv-ability Conference and Exposition, vol. 1, 2003, pp. 303–314.
[17] A. Yaar, A. Perrig, D. Song, Stackpi: New packet markingand filtering mechanisms for ddos and ip spoofing defense,Tech. Rep., Carnegie Mellon University, 2003.
[18] B.H. Bloom, Space/time trade-offs in hash coding withallowable errors, Communications of the ACM 13 (7) (1970)422–426.
[19] B.J. Frey, Graphical Models for Machine Learning andDigital Communication, MIT Press, Cambridge, MA, 1998.
[20] L.L. Scharf, Statistical Signal Processing: Detection, Esti-mation, and Time Series Analysis, Addison Wesley, 1991.
[21] Auckland-IV trace data, 2001. URL <http://wand.cs.waika-to.ac.nz/wand/wits/auck/4/>.
Kejie Lu received the B.S. and M.S.degrees in telecommunications engineer-ing from Beijing University of Posts andTelecommunications, Beijing, China, in1994 and 1997, respectively. He receivedthe Ph.D. degree in electrical engineeringfrom the University of Texas at Dallas in2003.
In 2004 and 2005, he was a Post-doctoral Research Associate in theDepartment of Electrical and Computer
Engineering, University of Florida. Currently, he is an AssistantProfessor in the Department of Electrical and Computer Engi-
neering, University of Puerto Rico at Mayaguez. His researchinterests include architecture and protocols design for computer
5056 K. Lu et al. / Computer Networks 51 (2007) 5036–5056
and communication networks, performance analysis, networksecurity, and wireless communications.
Dapeng Oliver Wu received B.E. inElectrical Engineering from HuazhongUniversity of Science and Technology,Wuhan, China, in 1990, M.E. in Elec-trical Engineering from Beijing Univer-sity of Posts and Telecommunications,Beijing, China, in 1997, and Ph.D. inElectrical and Computer Engineeringfrom Carnegie Mellon University, Pitts-burgh, PA, in 2003.
Since August 2003, he has been withElectrical and Computer Engineering Department at Universityof Florida, Gainesville, FL, as an Assistant Professor. His
research interests are in the areas of networking, communica-tions, multimedia, signal processing, and information and net-work security. He received the IEEE Circuits and Systems forVideo Technology (CSVT) Transactions Best Paper Award forYear 2001, and the Best Paper Award in International Confer-ence on Quality of Service in Heterogeneous Wired/WirelessNetworks (QShine) 2006.Currently, he serves as the Editor-in-Chief of Journal ofAdvances in Multimedia, and an Associate Editor for IEEETransactions on Wireless Communications, IEEE Transactionson Circuits and Systems for Video Technology, IEEE Transac-tions on Vehicular Technology, and International Journal of AdHoc and Ubiquitous Computing. He is also a guest-editor forIEEE Journal on Selected Areas in Communications (JSAC),Special Issue on Cross-layer Optimized Wireless MultimediaCommunications. He served as Program Chair for IEEE/ACMFirst International Workshop on Broadband Wireless Servicesand Applications (BroadWISE 2004); and as a technical programcommittee member of over 30 conferences. He is Vice Chair ofMobile and wireless multimedia Interest Group (MobIG),Technical Committee on Multimedia Communications, IEEECommunications Society. He is a member of the Best PaperAward Committee, Technical Committee on Multimedia Com-munications, IEEE Communications Society.
Jieyan Fan received B.E. and M.E. inElectrical Engineering from ShanghaiJiaotong University, Shanghai, China, in2001 and 2004, respectively. He is pur-suing Ph.D. degree in Electrical andComputer Engineering from Universityof Florida, Gainesville, FL. His researchinterests are in the areas of networksecurity, network traffic analysis, andpattern classification.
Sinisa Todorovic received his B.S. degreein electrical engineering at the Universityof Belgrade, Serbia, in 1994. From 1994until 2001, he worked as a softwareengineer in the communications indus-try. He earned his M.S. and Ph.D.degrees in electrical and computer engi-neering at the University of Florida, in2002, and 2005, respectively. Since 2005,he holds the position of PostdoctoralResearch Associate in the Beckman
Institute, University of Illinois at Urbana-Champaign. His mainresearch interests concern computer vision and machine learning,
with current focus on statistical image modeling for object/scenerecognition. He has published approximately 20 journal andrefereed conference papers.Antonio Nucci received the Dr. IngDegree in Electronics Engineering in1998 and the Ph.D. degree in telecom-munications engineering in 2002, bothfrom the Politecnico di Torino, Turin,Italy. In September 2001 he joined theSprint Advanced Technology Laborato-ries, Burlingame, CA, where he was aprincipal member of technical staff in theIP research group until February 2005.He currently holds a CTO position at
Narus Inc. His research interests include traffic measurement,characterization and analysis, performance evaluation, traffic
engineering, security and network design. He is a IEEE seniormember.




























