Embed Size (px)
Citation preview

SAP HANA Database - Data Management for ModernBusiness Applications
Franz Färber #1, Sang Kyun Cha +2, Jürgen Primsch ?3,Christof Bornhövd ∗4, Stefan Sigg #5, Wolfgang Lehner #6
#SAP – Dietmar-Hopp-Allee 16 – 69190, Walldorf, Germany+SAP – 63-7 Banpo 4-dong, Seochoku – 137-804, Seoul, Korea
?SAP – Rosenthaler Str. 30 – 10178, Berlin, Germany∗SAP – 3412 Hillview Ave – Palo Alto, CA 94304, USA
[email protected] [email protected] [email protected]@sap.com [email protected] [email protected]
ABSTRACTThe SAP HANA database is positioned as the core ofthe SAP HANA Appliance to support complex businessanalytical processes in combination with transactionallyconsistent operational workloads. Within this paper,we outline the basic characteristics of the SAP HANAdatabase, emphasizing the distinctive features that dif-ferentiate the SAP HANA database from other classicalrelational database management systems. On the tech-nical side, the SAP HANA database consists of mul-tiple data processing engines with a distributed queryprocessing environment to provide the full spectrum ofdata processing – from classical relational data support-ing both row- and column-oriented physical representa-tions in a hybrid engine, to graph and text processingfor semi- and unstructured data management within thesame system.
From a more application-oriented perspective, weoutline the specific support provided by the SAP HANAdatabase of multiple domain-specific languages with abuilt-in set of natively implemented business functions.SQL – as the lingua franca for relational database sys-tems – can no longer be considered to meet all require-ments of modern applications, which demand the tightinteraction with the data management layer. Therefore,the SAP HANA database permits the exchange of ap-plication semantics with the underlying data manage-ment platform that can be exploited to increase queryexpressiveness and to reduce the number of individualapplication-to-database round trips.
1. INTRODUCTIONData management requirements for enterprise appli-
cations have changed significantly in the past few years.For example, it is no longer reasonable to continue theclassical distinction between transactional and analyti-cal access patterns. From a business perspective, queries
in transactional environments on the one hand are build-ing the sums of already-delivered orders, or calculat-ing the overall liabilities per customer. On the otherhand, analytical queries require the immediate avail-ability of operational data to enable accurate insightsand real-time decision making. Furthermore, applica-tions demand a holistic, consistent, and detailed viewof its underlying business processes, thus leading tohuge data volumes that have to be kept online, readyfor querying and analytics. Moreover, non-standard ap-plications like planning or simulations require a flexi-ble and graph-based data model, e.g., to compute themaximum throughput of typical business relationshippatterns within a partner network. Finally, text re-trieval technology is a must-have in state-of-the-art datamanagement platforms to link unstructured or semi-structured data or results of information retrieval queriesto structured business-related contents.
In a nutshell, the spectrum of required applicationsupport is tremendously heterogeneous and exhibits ahuge variety of interaction patterns. Since classicalSQL-based data management engines are too narrowfor these application requirements, the SAP HANAdatabase presents itself as a first step towards a holis-tic data management platform providing robust and ef-ficient data management services for the specific needsof modern business applications [5].
The SAP HANA database is a component of theoverall SAP HANA Appliance that provides the datamanagement foundation for renovated and newly devel-oped SAP applications (see Section 4). Figure 1 out-lines the different components of the SAP HANA Ap-pliance. The SAP HANA Appliance comprises repli-cation and data transformation services to easily moveSAP and non-SAP data into the HANA system, model-ing services to create the business models that can bedeployed and leveraged during runtime, and the SAP
SIGMOD Record, December 2011 (Vol. 40, No. 4) 45

Figure 1: Components of the SAP HANA Appliance
HANA database as its core. For the rest of this paper,we specifically focus on the SAP HANA database.
Core Distinctive Features of the SAP HANADatabaseBefore diving into the details, we will outline some gen-eral distinctive features and design guidelines to showthe key differentiators with respect to common rela-tional, SQL-based database management systems. Webelieve that these features represent the cornerstones ofthe philosophy behind the SAP HANA database:
• Multi-engine query processing environment: In or-der to cope with the requirements of managing en-terprise data with different characteristics in dif-ferent ways, the SAP HANA database comprises amulti-engine query processing environment. In or-der to support the core features of enterprise appli-cations, the SAP HANA database provides SQL-based access to relationally structured data withfull transactional support. Since more and moreapplications require the enrichment of classicallystructured data with semi-structured, unstructured,or text data, the SAP HANA database provides atext search engine in addition to its classical rela-tional query engine. The HANA database enginesupports “joining” semi-structured data to rela-tions in the classical model, in addition to support-ing direct entity extraction procedures on semi-structured data. Finally, a graph engine nativelyprovides the capability to run graph algorithms onnetworks of data entities to support business ap-plications like production planning, supply chainoptimization, or social network analyses. Section2 will outline some of the details.
• Representation of application-specific businessobjects: In contrast to classical relationaldatabases, the SAP HANA database is able to pro-vide a deep understanding of the business objectsused in the application layer. The SAP HANAdatabase makes it possible to register “semantic
models” inside the database engine to push downmore application semantics into the data manage-ment layer. In addition to registering semanticallyricher data structures (e.g., OLAP cubes with mea-sures and dimensions), SAP HANA also providesaccess to specific business logics implemented di-rectly deep inside the database engine. The SAPHANA Business Function Library encapsulatesthose application procedures. Section 3 will ex-plain this feature from different perspectives.
• Exploitation of current hardware developments:Modern data management systems must con-sider current developments with respect to largeamounts of available main memory, the num-ber of cores per node, cluster configurations, andSSD/flash storage characteristics in order to effi-ciently leverage modern hardware resources andto guarantee good query performance. The SAPHANA database is built from the ground up to ex-ecute in parallel and main-memory-centric envi-ronments. In particular, providing scalable par-allelism is the overall design criteria for bothsystem-level up to application-level algorithms [6,7].
• Efficient communication with the applicationlayer: In addition to running generic applicationmodules inside the database, the system is requiredto communicate efficiently with the applicationlayer. To meet this requirement, plans withinSAP HANA development are, on the one hand, toprovide shared-memory communication with SAPproprietary application servers and more closelyalign the data types used within each. On the otherhand, we plan to integrate novel application servertechnology directly into the SAP HANA databasecluster infrastructure to enable interweaved execu-tion of application logic and database managementfunctionality.
2. ARCHITECTURE OVERVIEWThe SAP HANA database is a memory-centric data
management system that leverages the capabilities ofmodern hardware, especially very large amounts ofmain memory, multi-core CPUs, and SDD storage, inorder to improve the performance of analytical andtransactional applications. The HANA database pro-vides the high-performance data storage and processingengine within the HANA Appliance.
Figure 2 shows the architecture of the HANAdatabase system. The Connection and Session Man-agement component creates and manages sessions andconnections for the database clients. Once a sessionhas been established, database clients can use SQL (via
46 SIGMOD Record, December 2011 (Vol. 40, No. 4)

Figure 2: The SAP HANA database architecture
JDBC or ODBC), SQL Script, MDX or other domain-specific languages like SAP’s proprietary language FOXfor planning applications, or WIPE, which combinesgraph traversal and manipulation with BI-like data ag-gregation to communicate with the HANA database.SQL Script is a powerful scripting language to describeapplication-specific calculations inside the database.
SQL Script is based on side-effect-free functions thatoperate on database tables using SQL queries, and it hasbeen designed to enable optimization and paralleliza-tion.
As outlined in our introduction, the SAP HANAdatabase provides full ACID transactions. The Trans-action Manager coordinates database transactions, con-trols transactional isolation, and keeps track of run-ning and closed transactions. For concurrency con-trol, the SAP HANA database implements the classicalMVCC principle that allows long-running read transac-tions without blocking update transactions. MVCC, incombination with a time-travel mechanism, allows tem-poral queries inside the Relational Engine.
Client requests are parsed and optimized in the Opti-mizer and Plan Generator layer. Based on the optimizedexecution plan, the Execution Engine invokes the differ-ent In-Memory Processing Engines and routes interme-diate results between consecutive execution steps.
SQL Script and supported domain-specific languagesare translated by their specific compilers into an inter-nal representation called the “Calculation Model”. Theexecution of these calculation models is performed bythe Calculation Engine. The use of calculation modelsfacilitates the combination of data stored in different In-Memory Storage Engines as well as the easy implemen-tation of application-specific operators in the databaseengine.
The Authorization Manager is invoked by otherHANA database components to check whether a userhas the required privileges to execute the requested op-erations. A privilege grants the right to perform a spec-ified operation (such as create, update, select, or exe-cute). The database also supports analytical privilegesthat represent filters or hierarchy drill-down limitationsfor analytical queries as well as control access to val-ues with a certain combination of dimension attributes.Users are either authenticated by the database itself, orthe authentication is delegated to an external authentica-tion provider, such as an LDAP directory.
Metadata in the HANA database, such as table defi-nitions, views, indexes, and the definition of SQL Scriptfunctions, are managed by the Metadata Manager. Suchmetadata of different types is stored in one common cat-alogue for all underlying storage engines.
The center of Figure 2 shows the three In-MemoryStorage Engines of the HANA database, i.e., the Re-lational Engine, the Graph Engine, and the Text En-gine. The Relational Engine supports both row- andcolumn-oriented physical representations of relationaltables. The Relational Engine combines SAP’s P*Timedatabase engine and SAP’s TREX engine currently be-ing marketed as SAP BWA to accelerate BI queries inthe context of SAP BW. Column-oriented data is storedin a highly compressed format in order to improve theefficiency of memory resource usage and to speed up thedata transfer from storage to memory or from memoryto CPU. A system administrator specifies at definitiontime whether a new table is to be stored in a row- or ina column-oriented format. Row- and column-orienteddatabase tables can be seamlessly combined into oneSQL statement, and subsequently, tables can be movedfrom one representation form to the other [4]. As a
SIGMOD Record, December 2011 (Vol. 40, No. 4) 47

rule of thumb, user and application data is stored in acolumn-oriented format to benefit from the high com-pression rate and from the highly optimized access forselection and aggregation queries. Metadata or data withvery few accesses is stored in a row-oriented format.
The Graph Engine supports the efficient representa-tion and processing of data graphs with a flexible typingsystem. A new dedicated storage structure and a set ofoptimized base operations are introduced to enable ef-ficient graph operations via the domain-specific WIPEquery and manipulation language. The Graph Engine ispositioned to optimally support resource planning appli-cations with huge numbers of individual resources andcomplex mash-up interdependencies. The flexible typesystem additionally supports the efficient execution oftransformation processes, like data cleansing steps indata-warehouse scenarios, to adjust the types of the indi-vidual data entries, and it enables the ad-hoc integrationof data from different sources.
The Text Engine provides text indexing and searchcapabilities, such as exact search for words and phrases,fuzzy search (which tolerates typing errors), and lin-guistic search (which finds variations of words basedon linguistic rules). In addition, search results can beranked and federated search capabilities support search-ing across multiple tables and views. This functionalityis available to applications via specific SQL extensions.For text analyses, a separate Preprocessor Server is usedthat leverages SAP’s Text Analysis library.
The Persistency Layer, illustrated at the bottom ofFigure 2, is responsible for the durability and atomicityof transactions. It manages data and log volumes on diskand provides interfaces for writing and reading data thatare leveraged by all storage engines. This layer is basedon the proven persistency layer of MaxDB, SAP’s com-mercialized disk-centric relational database. The per-sistency layer ensures that the database is restored to themost recent committed state after a restart and that trans-actions are either completely executed or completely un-done. To achieve this efficiently, it uses a combinationof write-ahead logs, shadow paging, and savepoints.
To enable scalability in terms of data volumes andthe number of application requests, the SAP HANAdatabase supports scale-up and scale-out. For scale-up scalability, all algorithms and data structures are de-signed to work on large multi-core architectures espe-cially focusing on cache-aware data structures and codefragments. For scale-out scalability, the SAP HANAdatabase is designed to run on a cluster of individual ma-chines allowing the distribution of data and query pro-cessing across multiple nodes. The scalability featuresof the SAP HANA database are heavily based on theproven technology of the SAP BWA product.
3. SAP HANA DATABASE: BEYONDSQL
As outlined in our introduction, the SAP HANAdatabase is positioned as a modern data managementand processing layer to support complex enterprise-scale applications and data-intensive business processes.In addition to all optimizations and enhancements at thetechnical layer (modern hardware exploitation, colum-nar and row-oriented storage, support for text and irreg-ularly structured data, etc.), the core benefit of the sys-tem is its ability to understand and directly work withbusiness objects stored inside the database. Being ableto exploit the knowledge of complex-structured businessobjects and to perform highly SAP application-specificbusiness logic steps deep inside the engine is an impor-tant differentiator of the SAP HANA database with re-spect to classical relational stores.
More specifically, the “Beyond SQL” features of theSAP HANA database are revealed in multiple ways. Ona smaller scale, specific SQL extensions enable the ex-posure of the capabilities of the specific query process-ing engines. For example, an extension in the WHEREclause allows the expression of fuzzy search queriesagainst the text engine. An explicit “session” conceptsupports the planning of processes and What if? analy-ses. Furthermore, SQL Script provides a flexible pro-gramming language environment as a combination ofimperative and functional expressions of SQL snippets.The imperative part allows one to easily express dataand control flow logic by using DDL, DML, and SQL-Query statements as well as imperative language con-structs like loops and conditionals. Functional expres-sions, on the other hand, are used to express declarativelogics for the efficient execution of data-intensive com-putations. Such logic is internally represented as dataflows that can be executed in parallel. As a consequence,operations in a data flow graph must be free of side ef-fects and must not change any global states, neither inthe database nor in the application. This condition isenforced by allowing only a limited subset of languagefeatures to express the logic of the procedure.
On a larger scale, domain-specific languages can besupported by specific compilers to the same logical con-struct of a “Calculation Model” [2]. For example, MDXwill be natively translated into the internal query pro-cessing structures by resolving complex dimensional ex-pressions during the compile step as much as possibleby consulting the registered business object structuresstored in the metadata catalog. In contrast to classical BIapplication stacks, there is no need for an extra OLAPserver to generate complex SQL statements. In addition,the database optimizer is not required to “guess” the se-mantics of the SQL statements in order to generate thebest plan – the SAP HANA database can directly ex-
48 SIGMOD Record, December 2011 (Vol. 40, No. 4)
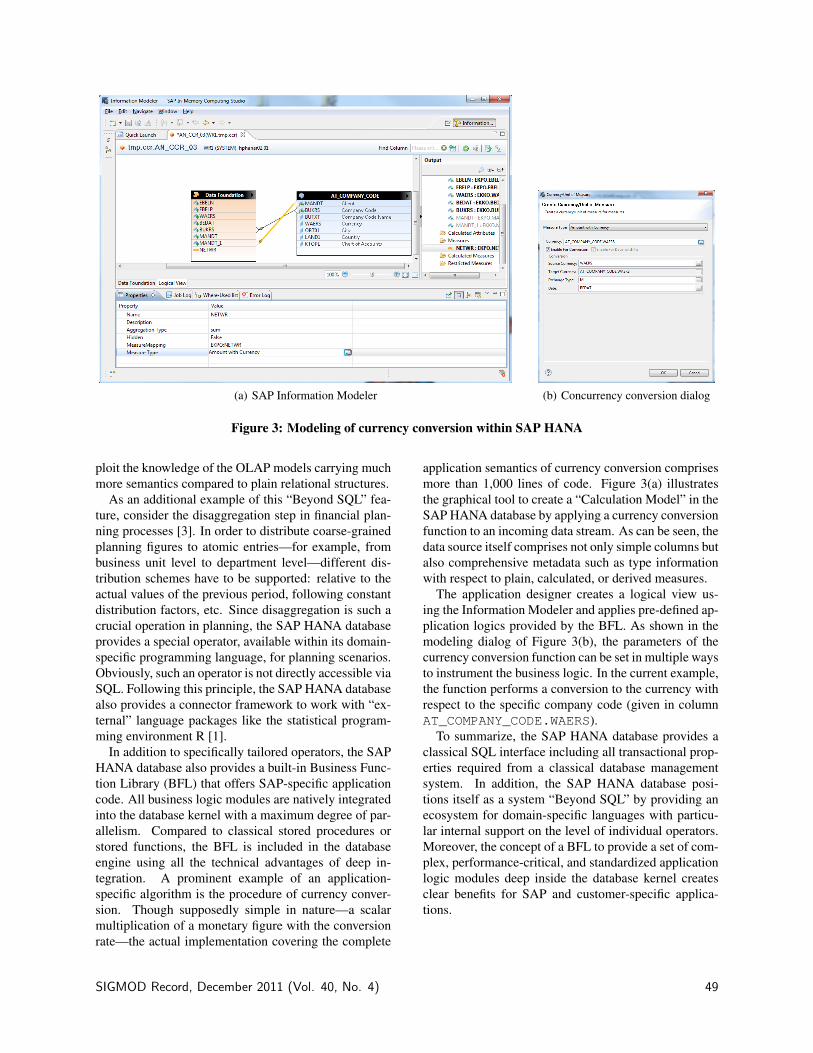
(a) SAP Information Modeler
type.
(b) Concurrency conversion dialog
Figure 3: Modeling of currency conversion within SAP HANA
ploit the knowledge of the OLAP models carrying muchmore semantics compared to plain relational structures.
As an additional example of this “Beyond SQL” fea-ture, consider the disaggregation step in financial plan-ning processes [3]. In order to distribute coarse-grainedplanning figures to atomic entries—for example, frombusiness unit level to department level—different dis-tribution schemes have to be supported: relative to theactual values of the previous period, following constantdistribution factors, etc. Since disaggregation is such acrucial operation in planning, the SAP HANA databaseprovides a special operator, available within its domain-specific programming language, for planning scenarios.Obviously, such an operator is not directly accessible viaSQL. Following this principle, the SAP HANA databasealso provides a connector framework to work with “ex-ternal” language packages like the statistical program-ming environment R [1].
In addition to specifically tailored operators, the SAPHANA database also provides a built-in Business Func-tion Library (BFL) that offers SAP-specific applicationcode. All business logic modules are natively integratedinto the database kernel with a maximum degree of par-allelism. Compared to classical stored procedures orstored functions, the BFL is included in the databaseengine using all the technical advantages of deep in-tegration. A prominent example of an application-specific algorithm is the procedure of currency conver-sion. Though supposedly simple in nature—a scalarmultiplication of a monetary figure with the conversionrate—the actual implementation covering the complete
application semantics of currency conversion comprisesmore than 1,000 lines of code. Figure 3(a) illustratesthe graphical tool to create a “Calculation Model” in theSAP HANA database by applying a currency conversionfunction to an incoming data stream. As can be seen, thedata source itself comprises not only simple columns butalso comprehensive metadata such as type informationwith respect to plain, calculated, or derived measures.
The application designer creates a logical view us-ing the Information Modeler and applies pre-defined ap-plication logics provided by the BFL. As shown in themodeling dialog of Figure 3(b), the parameters of thecurrency conversion function can be set in multiple waysto instrument the business logic. In the current example,the function performs a conversion to the currency withrespect to the specific company code (given in columnAT_COMPANY_CODE.WAERS).
To summarize, the SAP HANA database provides aclassical SQL interface including all transactional prop-erties required from a classical database managementsystem. In addition, the SAP HANA database posi-tions itself as a system “Beyond SQL” by providing anecosystem for domain-specific languages with particu-lar internal support on the level of individual operators.Moreover, the concept of a BFL to provide a set of com-plex, performance-critical, and standardized applicationlogic modules deep inside the database kernel createsclear benefits for SAP and customer-specific applica-tions.
SIGMOD Record, December 2011 (Vol. 40, No. 4) 49

(a) Supporting local BI
(b) Running SAP BW
(c) Platform for new applications
Figure 4: Planned SAP HANA roadmap
4. THE HANA ROADMAPAlthough, from a technology perspective, the SAP
HANA database is based on the SAP BWA system withits outstanding record of successful installations, thegenerally novel approach of a highly distributed systemwith an understanding of semantic business models re-quires time for customers to fully leverage their datamanagement infrastructure. SAP intends to pursue anevolutionary, step-wise approach to introduce the tech-nology to the market.
In a first step, the SAP HANA Appliance is posi-tioned to support local BI scenarios. During this step,customers can familiarize themselves with the technol-ogy exploiting the power of the new solution withouttaking any risk for existing mission-critical applications.SAP data of ERP systems will be replicated to the SAPHANA Appliance in real-time fashion. Data within theSAP HANA Appliance can be optionally enhanced byexternal non-SAP data sources and consumed using theSAP BOBJ analytical tools. Aside from new analyticalapplications on top of HANA, the primary use case hereis the acceleration of operational reporting processes di-rectly on top of ERP data.
The plan for the second phase of the roadmap, as
shown in Figure 4(b), comprises supporting the full SAPBW application stack. Step by step, the customer isable to move more critical applications (like data ware-housing) to the SAP HANA Appliance. This phasealso positions the SAP HANA Appliance as the pri-mary persistent storage layer for managed analyticaldata. Switching the data management platform will bea non-disruptive move from the application’s point ofview. In addition to providing the data managementlayer for a centralized data-warehouse infrastructure, theSAP HANA Appliance is also planned to be used to con-solidate local BI data marts exploiting a built-in multi-tenancy feature.
The third step in the current roadmap – introducingthe SAP HANA Appliance to the market in an evolution-ary way – consists of extending the HANA ecosystemwith new applications using the modeling and program-ming paradigm of the SAP HANA database in combina-tion with application servers. Depending on the specificcustomer setup, long-term plans are to put HANA alsounder the classical SAP ERP software stack.
To summarize, the basic steps behind the HANAroadmap are designed to integrate with customers’ SAPinstallations without disrupting existing software land-scapes. Starting small with local BI installations, puttingthe complete BW stack on top of HANA in combinationwith a framework to consolidate local BI installations, isconsidered a cornerstone in the SAP HANA roadmap.
5. SUMMARYProviding efficient solutions for enterprise-scale ap-
plications requires a robust and efficient data manage-ment and processing platform with specialized sup-port for transaction, analytical, graph traversal, and textretrieval processing. Within the SAP HANA Appli-ance, the HANA database represents the first step to-wards a new generation of database systems designedspecifically to provide answers to questions raised bydemanding enterprise applications. The SAP HANAdatabase, therefore, should not be compared to classicalSQL or typical key-value, document-centric, or graph-based NoSQL databases. HANA is a flexible data stor-age, manipulation, and analysis platform, comprehen-sively exploiting current trends in hardware to achieveoutstanding query performance and throughput at thesame time. The different engines within the distributeddata processing framework provide an adequate solu-tion for different application requirements. In this pa-per, we outlined our overall idea of the SAP HANAdatabase, sketched out its general architecture, and fi-nally gave some examples to illustrate how an SAPHANA database positions itself “Beyond SQL” by na-tively supporting performance-critical application logicsas an integral part of the database engine.
50 SIGMOD Record, December 2011 (Vol. 40, No. 4)

6. ACKNOWLEDGMENTSWe would like to express our sincere thanks to all of
our NewDB colleagues for making the HANA story areality. We also would like to thank Glenn Pauley, SIG-MOD Record Editor for Industrial Perspectives, for hishelpful comments.
7. REFERENCES[1] P. Grosse, W. Lehner, T. Weichert, F. Farber, and
W.-S. Li. Bridging two worlds with RICE. InVLDB Conference, 2011.
[2] B. Jaecksch, F. Farber, F. Rosenthal, andW. Lehner. Hybrid Data-Flow Graphs forProcedural Domain-Specific Query Languages. InSSDBM Conference, pages 577–578, 2011.
[3] B. Jaecksch, W. Lehner, and F. Farber. A plan forOLAP. In EDBT conference, pages 681–686, 2010.
[4] J. Kruger, M. Grund, C. Tinnefeld, H. Plattner,A. Zeier, and F. Faerber. Optimizing WritePerformance for Read Optimized Databases. InDASFAA Conference, pages 291–305, 2010.
[5] H. Plattner and A. Zeier. In-Memory DataManagement: An Inflection Point for EnterpriseApplications. Springer, Berlin Heidelberg, 2011.
[6] J. Schaffner, B. Eckart, D. Jacobs, C. Schwarz,H. Plattner, and A. Zeier. Predicting In-MemoryDatabase Performance for Automating ClusterManagement Tasks. In ICDE Conference, pages1264–1275, 2011.
[7] C. Weyerhauser, T. Mindnich, F. Farber, andW. Lehner. Exploiting Graphic Card ProcessorTechnology to Accelerate Data Mining Queries inSAP NetWeaver BIA. In ICDM Workshops, pages506–515, 2008.
SIGMOD Record, December 2011 (Vol. 40, No. 4) 51





























