Embed Size (px)
Citation preview

Simplify Your Fuzzy Duplicates Testing
Detecting Errors and Fraud
1

2
Why fuzzy testing?
▪ Detect fraud
▪ Identify errors
▪ Reduce false positives
2

3
Detect Fraud
▪ Multiple billings
▪ Vendors with same address
▪ Counterparties on watch lists (OFAC, GSA)
3

4
Identify Errors
▪ Input
▪ Optical character recognition (OCR)
▪ Multiple databases not synchronized
▪ Fatigue
4

5
Reduce False Positives
▪ Less time spent on dead ends
▪ Increased efficiency
5

6
Automated Analytics
▪ Weak or absent controls require continuous auditing/monitoring.
▪ Scripted solutions allow for complex algorithms to be run against data to mitigate these risks.
▪ Automation of best practices ensures consistency and adds to efficiency.
▪ Powerful DA tools include functionality that makes sophisticated testing and detection possible.
6

7
Analytic Functionality
▪ Functions
▪ Normalize()
▪ SortNormalize()
▪ Format()
▪ Include()/Exclude()
▪ Commands
▪ DUPLICATES with Different, Near, & Similar parameters
▪ JOIN
7
▪ Near()
▪ Similar()
▪ Difference()

8
Are these the same addresses?
Addr1: 2847 Congress Pkwy West
Addr2: Suite 201
Addr1: #201, 2847 W Congress Parkway
Addr2:
Addr1: 125 Fifth Str. E Addr1: 125 East 5th Street
Addr1: 707 Rooke Road Addr1: 707 Rook Rd
Addr1: 3960 Monjah Circle Addr1: 3960 Monja Circle

9
Normalizing Data
▪ Normalize( Vendor_Address,'addr2.txt’ )
16023, 40th Way South → 16023 40TH WAY S
#105, 1470 Boston Street → 105 1470 BOSTON ST
▪ SortNormalize( Vendor_Address,'addr2.txt’ )
16023, 40th Way South → WAY S 40TH 16023
#105, 1470 Boston Street → ST BOSTON 1470 105

10
Checking for Matching or Close Addresses
205 E. 10th St 205 10th Street East Original
205 E 10TH ST 205 10TH ST E Normalized
ST E 205 10TH ST E 205 10TH SortNormalized
Matched!
11
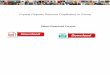
Elizabeth or Rick by any other name?
BESS LIB DICK
BESSIE LIBBY DICKIE
BET LIDDY BRODERICK
BETH LILIBET CEDRIC
BETSY LISBETH DERRICK
BETTE LISSIE ERIC
BETTY LIZ RICH
ELISE LIZA RICHARD
ELSA LIZBETH RICHIE
LIZZIE LIZZY RICKY

12
Normalizing Data
Normalize( First,'female name substitution table.sub,male name substitution table.sub’ )
JOHANN → JOHN
JOHNNY → JOHN
JON → JOHN
JONATHAN → JOHN
JENNIE → JEN
JENNY → JEN
JENNIFER → JEN
JENN → JEN

1313
Quick Lesson: A Usable Fuzzy Algorithm
▪ ‘Rob’ COMPARED TO ‘Robert’ = 3
▪ ‘Gary’ COMPARED TO ‘Mary’ = 1
▪ ‘Gary’ COMPARED TO ‘Gray’ = 1
▪ ‘123 Main Street’ COMPARED TO ‘123 Main St’ = 4
▪ In Arbutus used in NEAR , SIMILAR & DIFFERENCE functions/parameters

14
When to use Near and when to use Similar
▪ NEAR
▪ Character fields: Straight string/character data comparison
▪ Numeric fields: looks for numeric proximity
▪ Date fields: looks for date/time proximity
▪ SIMILAR
▪ Character fields: Pre-modifies data for visually similar characteristics before doing string comparison
▪ Numeric fields: converts to character data before processing
▪ Date fields: converts to character data before processing

15
Today’s Tests
1) Duplicate Payments (Identical)
2) Duplicate Payments with Near Dates
3) Duplicate Payments with Near Amounts and Dates
4) Duplicate Payments Similar Invoice Numbers
5) Duplicate Vendor Addresses
6) Duplicate/Similar Vendor-OFAC Addresses
7) Duplicate/Similar Vendor-OFAC Addresses (Word Match %)
8) Similar Vendor Phone Numbers
9) Similar Employee Names: HR vs PCard

16
Test #1: Duplicate Payments (Identical)▪ Same Date
▪ Same Vendor
▪ Same Amount
▪ Same Product Number
▪ Same Invoice Number
Run the DUPLICATES command, selecting these fields in the “Field(s) to test for Duplicates”
Select “All Fields” from the “List fields” list
Result: No identical payments

17
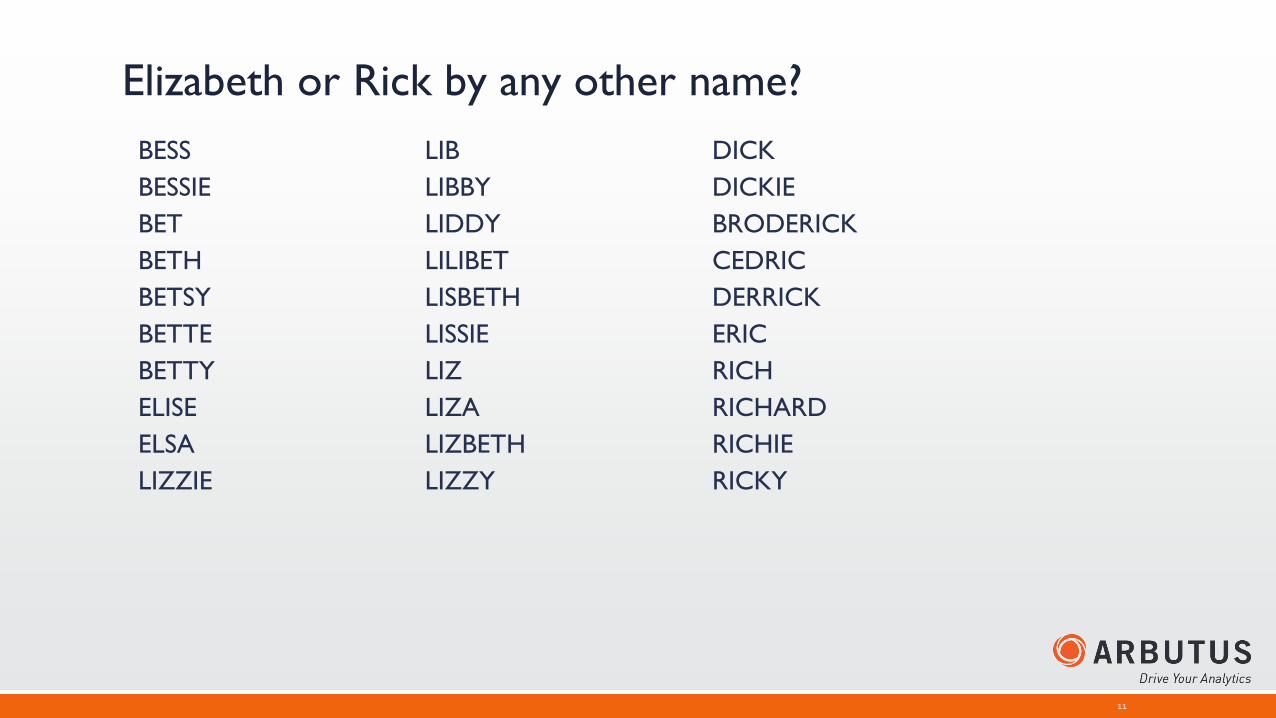
Test #2: Duplicate Payments with Near Dates▪ Same Vendor
▪ Same Amount
▪ Same Product Number
▪ Transaction dates within 5 days of each other (no exacts)
Run the DUPLICATES command, selecting these fields in this order in the “Field(s) to test for Duplicates”
Change the “Last duplicate field is” parameter to “Near” and change the value to 5.
Select Transaction Number and Invoice Number from the “List fields” list
Result: 3 pairs of possible duplicates
18
Test #2: Duplicate Payments with Near Dates

19
Test #3: Duplicate Payments with Near Amounts/Dates▪ Same Vendor
▪ Same Product Number
▪ Amount within $10
Run the DUPLICATES command, selecting the first three fields in this order in the “Field(s) to test for Duplicates”
Change the “Last duplicate field is” parameter to “Near” and change the value to 10.
Select Transaction Number and Transaction Date from the “List fields” list.
In the result create a filter ABS(Transaction Date 1 – Transaction Date 2) < 14
Result: 7239 pairs of possible duplicates

20
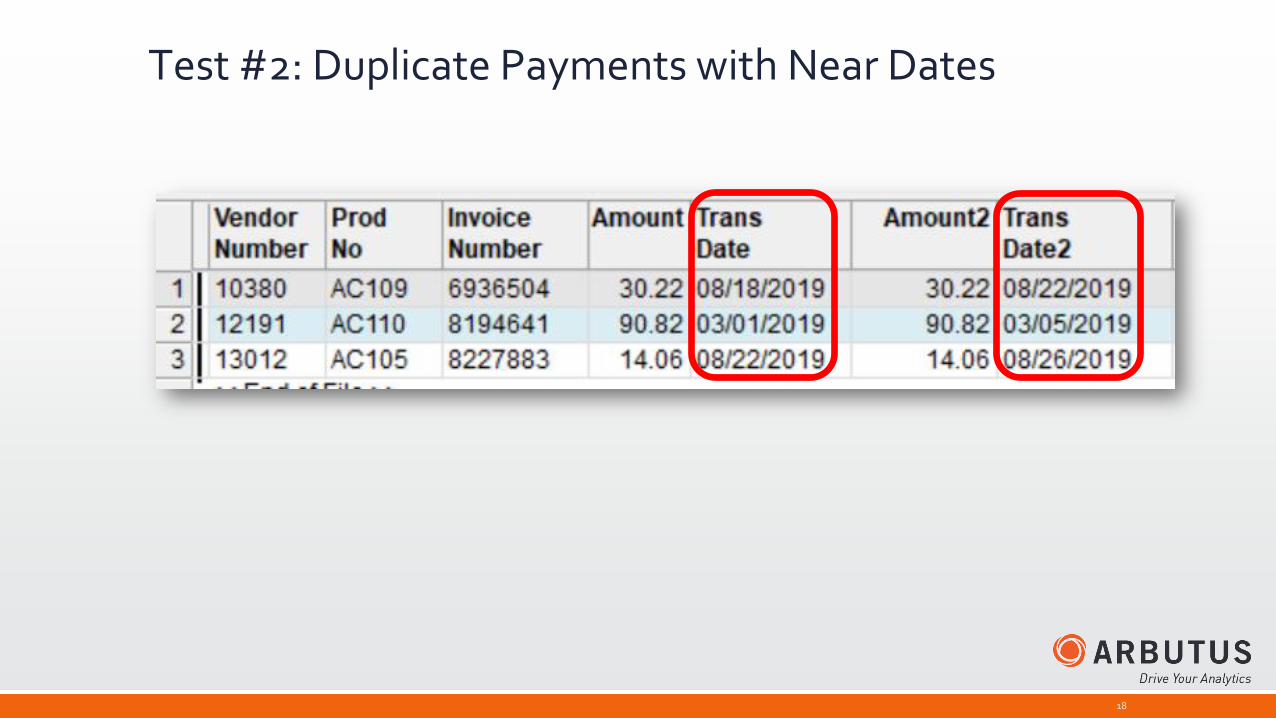
Test #4: Duplicate Payments Similar Invoice Numbers▪ Same Vendor
▪ Same Product Number
▪ Similar Invoice Number
Run the DUPLICATES command, selecting the first three fields in this order in the “Field(s) to test for Duplicates”
Change the “Last duplicate field is” parameter to “Similar” and change the value to 1.
Select Transaction Number and Transaction Date from the “List fields” list.
Result: 63 pairs of possible duplicates
21
Test #4: Duplicate Payments Similar Invoice Numbers
2

22
Test #5: Duplicate Vendor Addresses
Create a computed field to SortNormalize the Vendor Address:
SORTNORMALIZE(Vendor_Address,”ADDR.TXT”
Run the DUPLICATES command on this computed field. (You may want to include zip code.)
Select other fields from the “List fields” list.
Result: 39 possible duplicates

23
Test #5: Duplicate Vendor Addresses

24
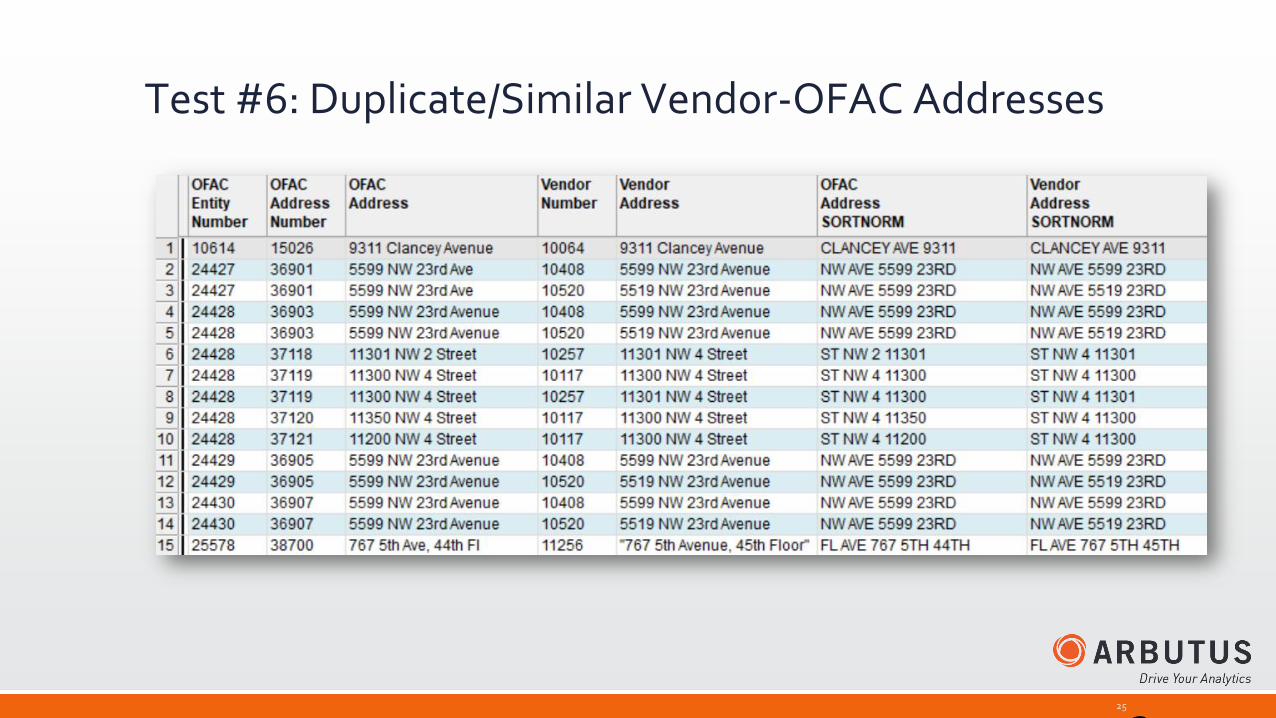
Test #6: Duplicate/Similar Vendor-OFAC Addresses
Create computed fields to SortNormalize the Vendor and OFAC Addresses:
Run a Many-to-Many JOIN using the computed fields as the key fields. Add a filter to the JOIN*
Difference(OFAC_Address_SORTNORM,Vendor_Master_Extract.Vendor_Address_SORTNORM) <= 1
Result: 15 pairs of possible duplicates
*Best Practice: If your JOIN includes computed fields, EXTRACT FIELDS for each file of only the minimum necessary fields. This will cause the computed fields to be written out as physical fields. Then execute the JOIN between the two new tables, including the zip codes in the filter for more precision. Physical fields process much faster than computed fields.
25
Test #6: Duplicate/Similar Vendor-OFAC Addresses
2

26
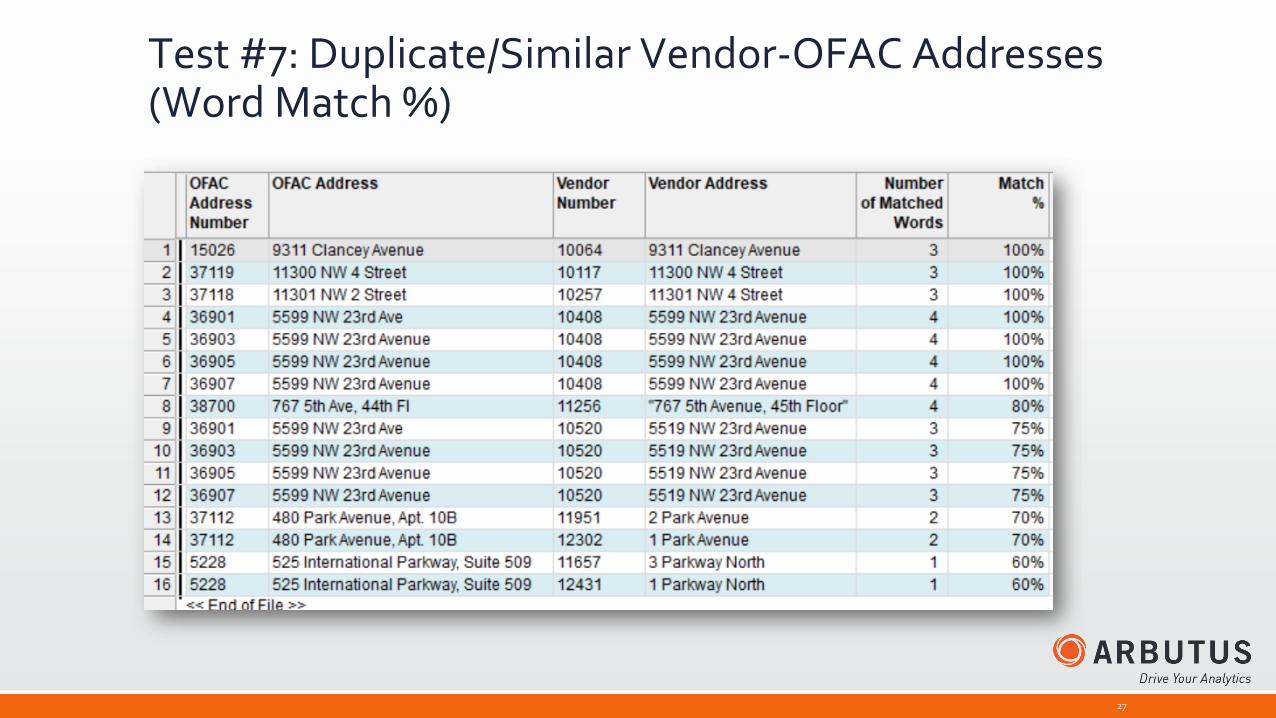
Test #7: Duplicate/Similar Vendor-OFAC Addresses (Word Match %)
The script will calculate the number of common words between all possible normalized address pairs.
It will then calculate the percent match for each address, which is the number of common words divided by the total number of words.
The final match score is the average of the two scores.
The final output includes exact matches and all other matches where the match score is greater than or equal to 75%.
27
Test #7: Duplicate/Similar Vendor-OFAC Addresses (Word Match %)

28
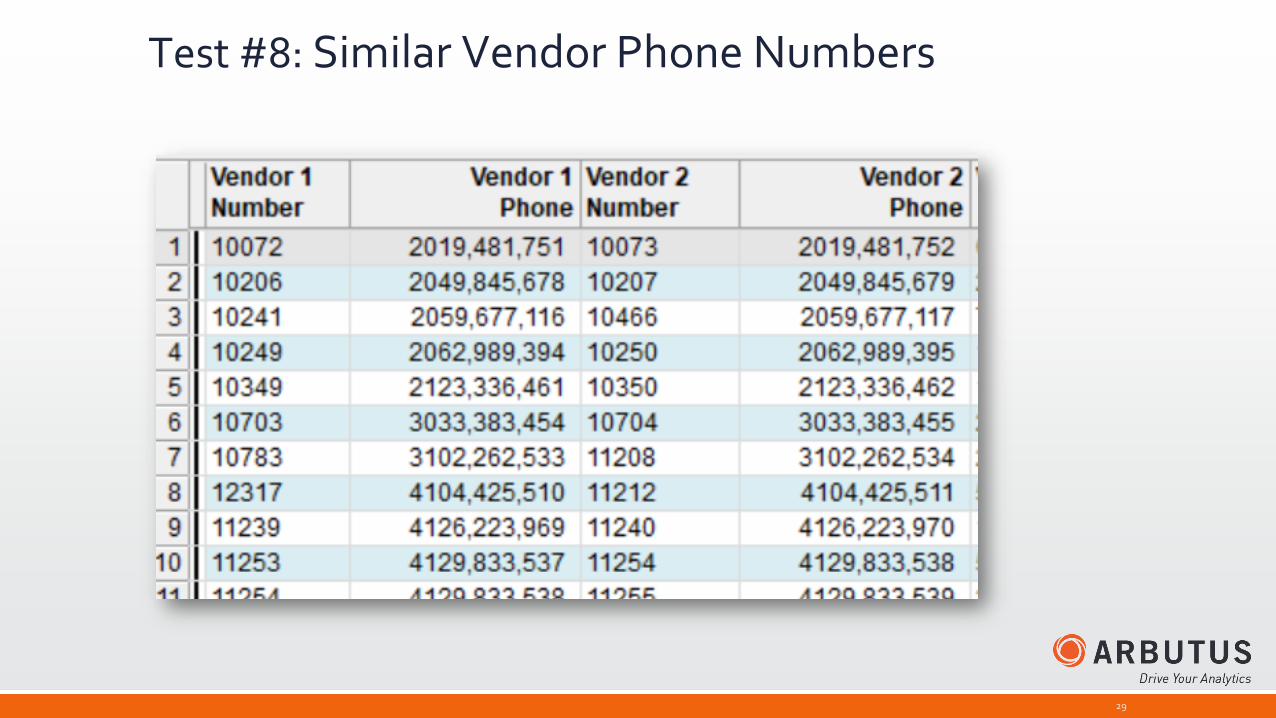
Test #8: Similar Vendor Phone Numbers
Convert phone numbers to numeric values in a computed field by:
1) Removing all non-numeric characters
2) Converting to a numeric value
3) Executing DUPLICATES on the new field with a NEAR parameter equal to 1.
Computed Field: VALUE(INCLUDE(Vendor Phone,”0~9”),0)
Result: 29 matched pairs
29
Test #8: Similar Vendor Phone Numbers

30
Test #9: Similar Employee Names: HR vs PCard
Two databases might not be in sync with regard to employee names: misspellings, marriage status change, “Von Bulow” vs “Vonbulow”.
PCard list doesn’t always include employee number, just first and last name in addition to last 4 digits of card. Last 4 digits of card not unique.
Testing Pcard list to match against HR data can result in unmatched cards when joining on combination of last 4 digits + first name + last name.
Card List Transactions

31
Test #9: Similar Employee Names: HR vs PCard
1) Identify which database stores last name as “Von Schmidt”
2) Create computed field that combines the two parts of the last name and convert to uppercase: UPPER(EXCLUDE(Last Name," "))
3) Rejoin the databases and isolate new unmatched.
4) Using new unmatched, execute a fuzzy join where the last 4 are the same and the names are within 1 character of each other.
5) Remnants (final unmatched) are likely due to name changes.
.

32
Summary
▪ Identify data where manual input has occurred or where counterparty has provided input.
▪ Test for consistency.
▪ Identify tests needed to reduce risk.
▪ Examine the functionality for ways to make necessary changes.
▪ Call Tech Support
3





















![[Webinar] Marketers vs. Duplicates: How You Can Win](https://img.pdfslide.net/doc/110x75/55d5018abb61eb4e7e8b4657/webinar-marketers-vs-duplicates-how-you-can-win.jpg)