Embed Size (px)
Citation preview

Sketching, Sampling and other Sublinear Algorithms:
Euclidean space: dimension reduction and NNS
Alex Andoni(MSR SVC)
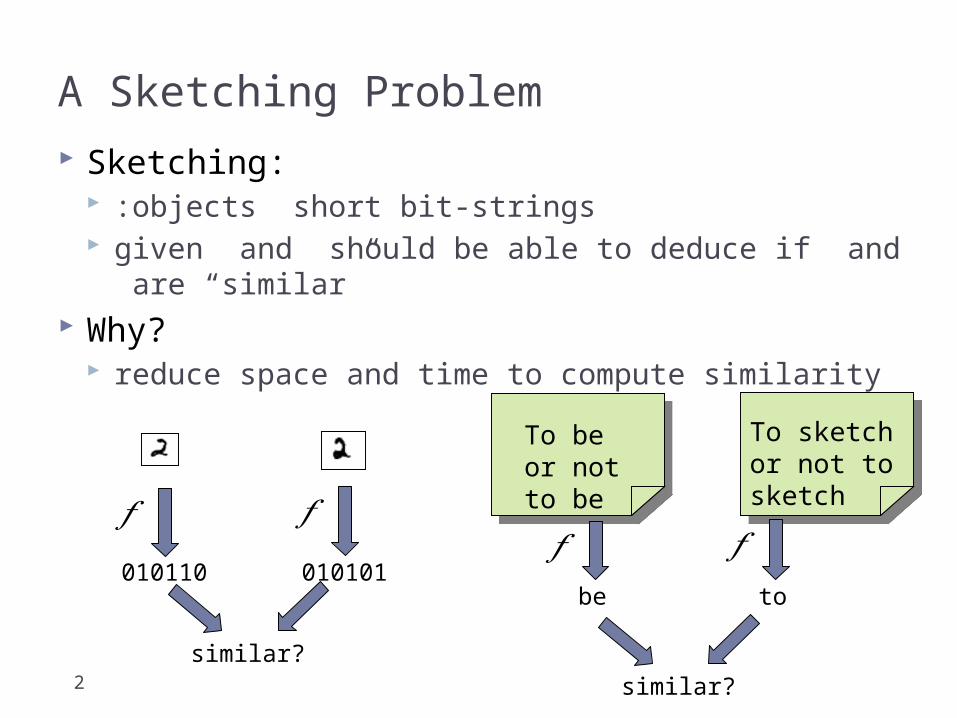
A Sketching Problem
2
Sketching: :objects short bit-strings given and should be able to deduce if and are
“similar” Why?
reduce space and time to compute similarity
𝑓 𝑓
010110 010101
similar?
To be or not to be
To sketch or not to sketch
𝑓 𝑓be to
similar?

Sketch from LSH
3
LSH often has property:
Sketching from LSH:
Estimate by the fraction of collisions between controls the variance of the estimate
𝑑𝑖𝑠𝑡 (𝑝 ,𝑞)
Pr [𝑔 (𝑝 )=𝑔 (𝑞)]1
[Broder’97]: for Jaccard coefficient

General Theory: embeddings The above map is an embedding General motivation: given distance (metric)
, solve a computational problem under
Euclidean distance (ℓ2)
Hamming distance
Edit distance between two strings
Earth-Mover (transportation) Distance
Compute distance between two points
Diameter/Close-pair of set S
Clustering, MST, etc
Nearest Neighbor Search
f
Reduce problem <P under hard metric> to <P under simpler metric>

Embeddings: landscape Definition: an embedding is a map of a metric into a host
metric such that for any :
where is the distortion (approximation) of the embedding .
Embeddings come in all shapes and colors: Source/host spaces Distortion Can be randomized: with probability Time to compute
Types of embeddings: From norm to the same norm but of lower dimension (dimension
reduction) From non-norms (edit distance, Earth-Mover Distance) into a norm (ℓ1) From given finite metric (shortest path on a planar graph) into a norm
(ℓ1) not a metric but a computational procedure sketches

Dimension Reduction Johnson Lindenstrauss Lemma: there is a linear
map , , that preserves distance between two vectors up to distortion with probability ( some constant)
Preserves distances among points for Motivation:
E.g.: diameter of a pointset in -dimensional Euclidean space
Trivially: time Using lemma: time for approximation MANY applications: nearest neighbor search, streaming,
pattern matching, approximation algorithms (clustering)…
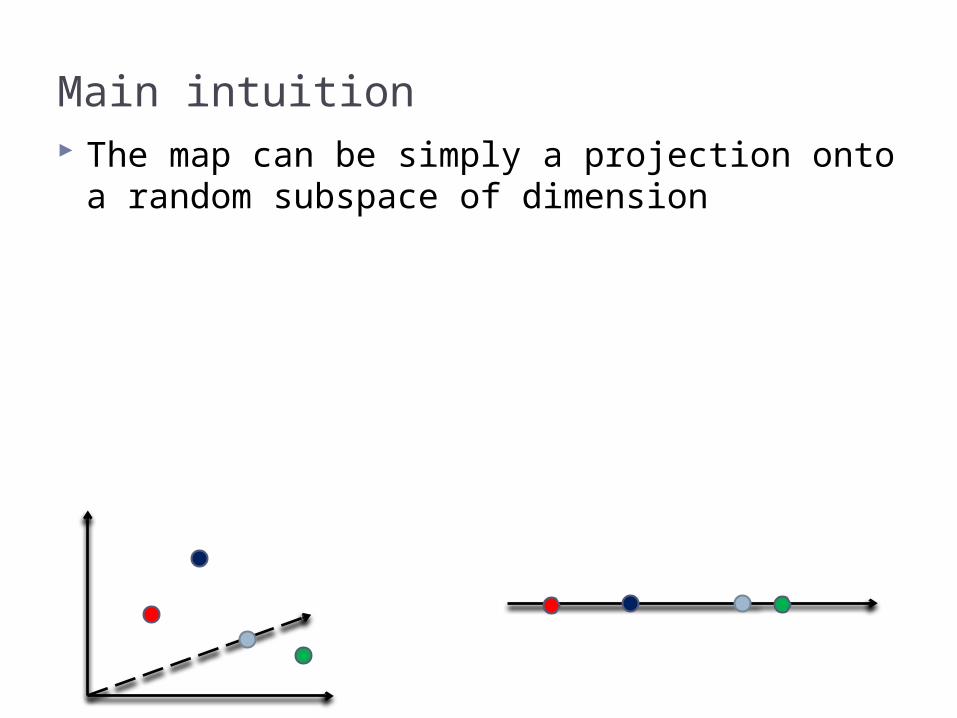
Main intuition The map can be simply a projection onto a
random subspace of dimension

1D embedding How about one dimension () ? Map
, where are iid normal (Gaussian) random variable
Why Gaussian? Stability property: is distributed as , where is also
Gaussian Equivalently: is centrally distributed, i.e., has
random direction, and projection on random direction depends only on length of
pdf = E[g]=0E[g2]=1

1D embedding Map ,
for any , Linear:
Want: Claim: for any , we have
Expectation: Standard deviation:
Proof: Prove for since linear Expectation
pdf = E[g]=0E[g2]=1
2 2

Full Dimension Reduction Just repeat the 1D embedding for times!
where is matrix of Gaussian random variables
Want to prove: with probability
OK to prove for fixed

Concentration is distributed as
where each is distributed as Gaussian Norm
is called chi-squared distribution with degrees Fact: chi-squared very well concentrated:
Equal to with probability Akin to central limit theorem

Dimension Reduction: wrap-up with high probability
Extra: Linear: can update as changes Can use instead of Gaussians [AMS’96, Ach’01,
TZ’04…] Fast JL: can compute faster than time [AC’06,
AL’07’09, DKS’10, KN’10’12…]

NNS for Euclidean space
13
Can use dimensionality reduction to get LSH for
LSH function : pick a random line , and quantize project point into
is a random Gaussian vector random in is a parameter (e.g., 4)
[Datar-Immorlica-Indyk-Mirrokni’04]
𝑝
ℓ
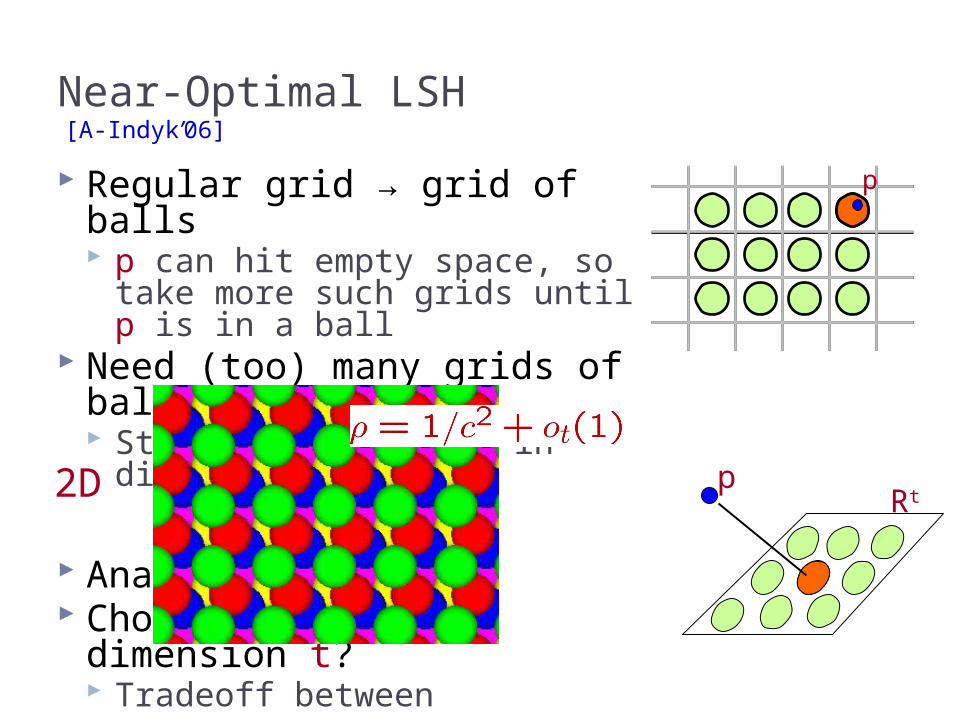
Regular grid → grid of balls p can hit empty space, so take
more such grids until p is in a ball
Need (too) many grids of balls Start by projecting in
dimension t
Analysis gives Choice of reduced dimension
t? Tradeoff between
# hash tables, n, and Time to hash, tO(t)
Total query time: dn1/c2+o(1)
Near-Optimal LSH
2D
p
pRt
[A-Indyk’06]
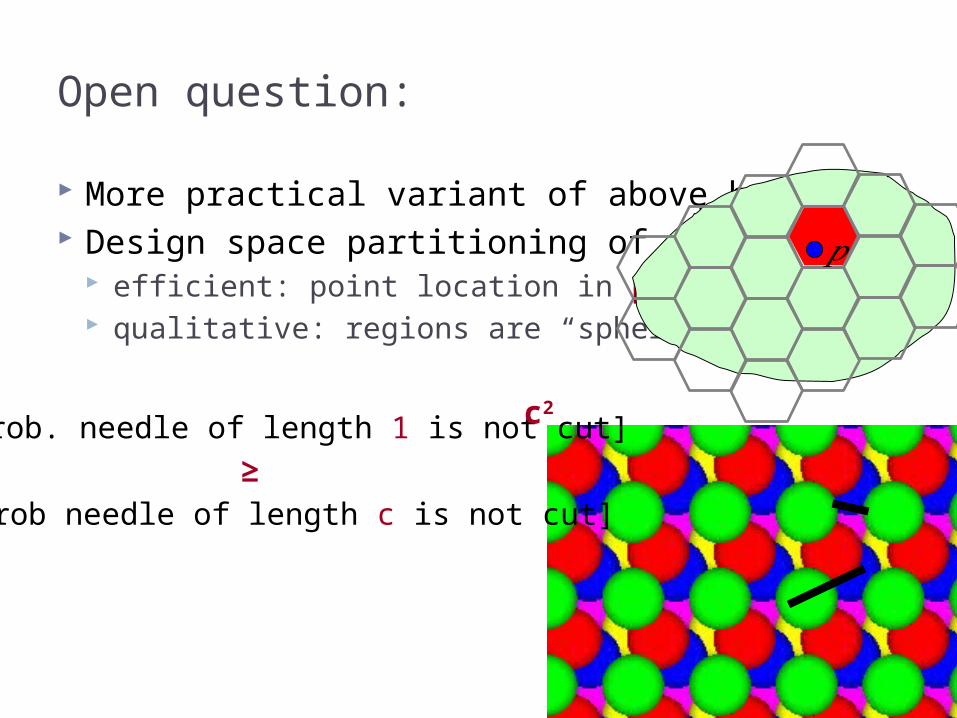
Open question:
More practical variant of above hashing? Design space partitioning of that is
efficient: point location in poly(t) time qualitative: regions are “sphere-like”
[Prob. needle of length 1 is not cut]
[Prob needle of length c is not cut]
≥
c2
𝑝
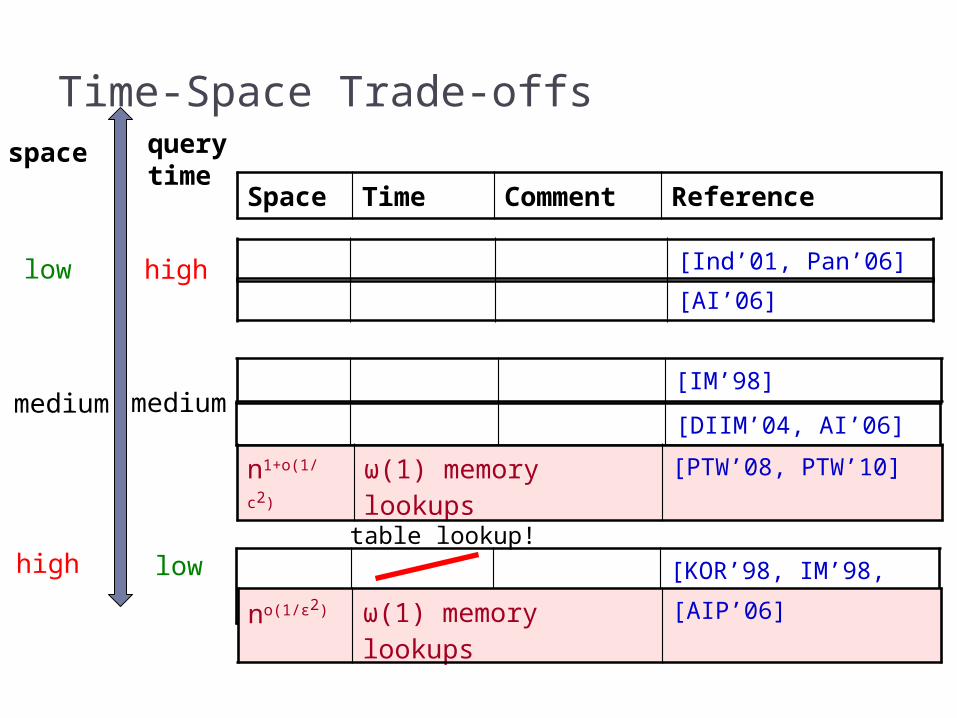
Time-Space Trade-offs
[AI’06]
[KOR’98, IM’98, Pan’06]
[Ind’01, Pan’06]
Space Time Comment Reference
[DIIM’04, AI’06]
[IM’98]
querytime
space
medium medium
lowhigh
highlow
one hash table lookup!
no(1/ε2) ω(1) memory lookups [AIP’06]
n1+o(1/c2) ω(1) memory lookups [PTW’08, PTW’10]

NNS beyond LSH
17
Data-dependent partitions…
Practice: Trees: kd-trees, quad-trees, ball-trees,
rp-trees, PCA-trees, sp-trees… often no guarantees
Theory: can improve standard LSH by random
data-dependent space partitions [A-Indyk-Nguyen-Razenshteyn’??]
tree-based approach to max-norm ()
ℓ

Finale Dimension Reduction in Euclidean space
, random projection preserves distances only dimensions for distance among points!
NNS for Euclidean space Random projections gives LSH Even better with ball partitioning
Or better with cool lattices?





























