Embed Size (px)
Citation preview

myjournal manuscript No.(will be inserted by the editor)
Software Architecture Definition for On-demand Cloud Provisioning
Clovis Chapman · Wolfgang Emmerich · Fermın Galan Marquez · StuartClayman · Alex Galis
Received: date / Accepted: date
Abstract Cloud computing is a promising paradigm for theprovisioning of IT services. Cloud computing infrastructures,such as those offered by the RESERVOIR project, aim to fa-cilitate the deployment, management and execution of ser-vices across multiple physical locations in a seamless man-ner. In order for service providers to meet their quality ofservice objectives, it is important to examine how softwarearchitectures can be described to take full advantage of thecapabilities introduced by such platforms. When dealing withsoftware systems involving numerous loosely coupled com-ponents, architectural constraints need to be made explicitto ensure continuous operation when allocating and migrat-ing services from one host in the Cloud to another. In addi-tion, the need for optimising resources and minimising over-provisioning requires service providers to control the dy-namic adjustment of capacity throughout the entire servicelifecycle. We discuss the implications for software architec-ture definitions of distributed applications that are to be de-ployed on Clouds. In particular, we identify novel primitivesto support service elasticity, co-location and other require-ments, propose language abstractions for these primitivesand define their behavioural semantics precisely by estab-lishing constraints on the relationship between architecturedefinitions and Cloud management infrastructures using amodel denotational approach in order to derive appropriate
This research has been partly funded by the RESERVOIR EU FP7Project through Grant Number 215605.
Clovis Chapman· Wolfgang EmmerichDept. of Computer Science, UCL, Gower Street, London, UKE-mail: [email protected] E-mail: [email protected]
Fermın Galan MarquezTelefonica I+D, Emilio Vargas 6, Madrid, SpainE-mail: [email protected]
Stuart Clayman· Alex GalisDept. of Electronic Engineering, UCL, Gower Street, London, UKE-mail: [email protected] E-mail: [email protected]
service management cycles. Using these primitives and se-mantic definition as a basis, we define a service managementframework implementation that supports on demand cloudprovisioning and present a novel monitoring framework thatmeets the demands of Cloud based applications.
Keywords Cloud Computing, Service Definition, SoftwareArchitecture, Service Management, Monitoring System
1 Introduction
Cloud computing [35] is a promising paradigm for the pro-visioning of IT services. Cloud computing infrastructures,such as those offered by the RESERVOIR project [25], aimto facilitate the deployment, management and execution ofservices across multiple physical locations in a seamlessmanner.
Until recently, operating systems managed the alloca-tion of physical resources, such as CPU time, main memory,disk space and network bandwidth to applications. Virtuali-sation infrastructures, such as Xen [4] and VMWare [31] arechanging this by introducing a layer of abstraction knownas ahypervisor. A hypervisor runs on top of physical hard-ware, allocating resources to isolated execution environ-ments known asvirtual machines, which run their own in-dividual virtualised operating system. Hypervisors managethe execution of these operating systems, booting, suspend-ing or shutting down systems as required. Some hypervisorseven support replication and migration of virtual machineswithout stopping the virtualised operating system.
It turns out that the separation between resource pro-vision and operating systems introduced by virtualisationtechnologies is a key enabler for Cloud computing. Specif-ically, virtualisation is an enabler for Infrastructure-as-a-Service (IaaS) Clouds, the type on which this paper is fo-

2
cused. For a description of the different types of Cloud com-puting see [35].
Compute Clouds provide the ability to lease computa-tional resources at short notice, on either a subscription orpay-per-use model and without the need for any capital ex-penditure into hardware. A further advantage is that the unitcost of operating a server in a large server farm is lowerthan in small data centres. Examples of compute Clouds areAmazon’s Elastic Compute Cloud (EC2) [1] or IBM’s BlueCloud [15]. Organisations wishing to use computational re-sources provided by these Clouds supply virtual machineimages that are then executed by the hypervisors running inthe Cloud, which allocate physical resources to virtualisedoperating systems and control their execution.
With an increasing number of providers seeking to mi-grate services to the Cloud in order to save on deploymentcosts, cater for rapid growth or generally relieve themselvesfrom the responsibility of provisioning the infrastructural re-sources needed to support the service, whether related topower, bandwidth, software or hardware [3], there is a cru-cial need to ensure that a same service quality can be re-tained when relying upon Clouds while generally deliveringon the promise of lowering costs by minimising overprovi-sioning through efficient upscaling and downscaling of ser-vices.
In this paper we review the implications of the emer-gence of virtualisation and compute Clouds for software en-gineers in general and software architects in particular. Wefind that software architectures need to be described differ-ently if they are to be deployed into a Cloud. The reason isthat scalability, availability, reliability, ease of deploymentand total cost of ownership are quality attributes that needto be achieved by a software architecture and these are criti-cally dependent upon how hardware resources are provided.Virtualisation in general and compute Clouds in particularprovide a wealth of new primitives that software architectscan exploit to improve the way their architectures deliverthese quality attributes.
The principal contribution of this paper is a discussionof architecture definition for distributed applications that areto be deployed on compute Clouds. The key insight is thatthe architecture description needs to be reified at run-timeso that it can be used by the Cloud computing infrastructurein order to implement, monitor and preserve architecturalquality goals. This requires several advances over the stateof the art in software architecture. Architectural constraintsneed to be made explicit so that the Cloud infrastructure canobey these when it allocates, replicates, migrates and de-activates virtual machines that host components of the ar-chitecture. The architecture also needs to describe how andwhen it responds to load variations and faults; we proposethe concept of elasticity rules for architecture definitions sothat the Cloud computing infrastructure can replicate com-
ponents and provide additional resources as demand growsor components become unavailable. Finally, there must bean understanding of how a management cycle for a ser-vice deployed on a Cloud can be derived from a descrip-tion of these constraints and we demonstrate how this canbe achieved using amodel driven approach.
As such the overall contributions of the paper are as fol-lows: we identify a list of requirements and constraints that aprovider must describe when deploying and hosting a multi-component application on a Cloud. We present a languagefor the description of such requirements that builds on ex-isting standards and introduces new abstractions such as theability to specify on demand scaling. We define an archi-tecture for a Cloud infrastructure to support these abstrac-tions and specify clear behavioural semantics for our lan-guage with respect to this architecture using a model deno-tational approach. We then describe the overall implementa-tion of the service lifecycle management process, with par-ticular focus on service management components and themonitoring infrastructure which will address the scaling re-quirements and physical distribution of application services.Finally we evaluate our language primitives experimentallywith a distributed computational chemistry application.
This paper is an enhancement and extension to work pre-viously presented [5] and is structured as follows: In Sec-tion 2, we present the background to this research and inparticular the primitives that are now provided by modernvirtualisation and Cloud computing technologies in generaland the infrastructure developed by the RESERVOIR projectin particular. We then use a motivating example in Section 3to argue why architecture definition for Cloud computingdiffers from more conventional deployments. In Section 4,we describe our novel abstractions, such as co-location con-straints and elasticity rules for describing architectures thatare to be deployed in a Cloud. Section 5 presents the maincomponents of the architecture which manage the lifecycleof services within a cloud, namely the Service Manager andthe Monitoring Framework. In Section 6 we describe the ex-perimental evaluation of our approach by means of a com-putational chemistry application that we have deployed in acomputational Cloud. We discuss related work and presentconclusions in Sections 7 and 8.
2 Background
TheResources and Services Virtualization without Barriers(RESERVOIR) project is a European Seventh FrameworkProgramme (FP7) project which aims to promote throughstandardisation an open architecture for federated Cloudcomputing. It defines an open framework of modular com-ponents and APIs that enable a wide range of configurationswithin the Cloud space, focusing on Infrastructure as a Ser-vice (IaaS) Clouds [35].

3
��������
�������
�� ��������
�� ���� �� ����
��������
�������
�� ��������
�� ���� �� ����
�� �� ���� ��� ����� �� �� ���� ��� �����
��� ����� ������ ����� �
Fig. 1 RESERVOIR Architecture
The RESERVOIR architecture [25] aims to satisfy thevision of service oriented computing by distinguishing andaddressing the needs ofService Providers, who understandthe operation of particular businesses and offer suitableSer-vice applications, andInfrastructure Providers, who leasecomputational resources in the form of a Cloud computinginfrastructure. This infrastructure provides the mechanismsto deploy and manage self contained services, consisting ofaset of software components, on behalf of a service provider.
The Cloud computing abstractions supported by this in-frastructure and the architecture we have used to implementthese abstractions are described in detail in [26]. The archi-tecture is shown in Figure 1.
RESERVOIR builds upon generally available virtuali-sation products and hypervisors. The lowest layer of theRESERVOIR architecture is theVirtual Execution Environ-ment Host(VEEH). It provides plugins for different hy-pervisors and enables the upper layers of the architectureto interact with heterogeneous virtualisation products. Thelayer above is theVirtual Execution Environment Manager(VEEM), which implements the key abstractions needed forCloud computing. A VEEM controls the activation of vir-tualised operating systems, migration, replication and de-activation. A VEEM typically controls multiple VEEHswithin one site. The key differentiator from other Cloudcomputing infrastructure is RESERVOIR’s ability to feder-ate across different sites, which might be implementing dif-ferent virtualisation products. This is achieved by cross-siteinteractions between multiple different VEEMs operating onbehalf of different Cloud computing providers. This sup-ports replication of virtual machines to other locations forexample for business continuity purposes. The highest levelof abstraction in the RESERVOIR architecture is theSer-vice Manager. While the VEEM allocates services accord-ing to a given placement policy, it is the Service Managerthat interfaces with the Service Provider and ensures that re-quirements (e.g. resource allocation requested) are correctly
enforced. The Service Manager also performs other servicemanagement tasks, such as accounting and billing of serviceusage.
An implementation of the VEEM layer, OpenNebula,which we have used in our experimental evaluation de-scribed below is publicly available from [24]. It providesthe ability to interact with hypervisors such as Xen [4] orVMWare [31] via appropriate plugins and is included fromrelease 9.04 in the Ubuntu Linux distribution.
3 Motivation
How is a software development project now going to useCloud computing infrastructures, such as the one providedby RESERVOIR. We aim to answer this question and thenderive the main research questions for this paper using arunning example, an enterprise resource planning system,such as those provided by SAP [27]. A high-level architec-ture of an SAP system is illustrated in Figure 2. SAP ERPsystems have a multi-tiered software architecture with a re-lational database layer. On top of the database is an appli-cation layer that has aCentral Instance, which provides anumber of centralised services, such as synchronisation, reg-istration and spooling capabilities, and generally servesas adatabase gateway. Moreover SAP applications have a num-ber of Dialog Instances, which are application servers re-sponsible for handling business logic and generating HTTP-based dialogues that are shown in a browser. AWeb Dis-patchermay be used to balance workloads between mul-tiple dialog instances. To date SAP systems are hosted insubstantial data centres, but organisations (playing the roleof Service Provider) in the future might wish to deploy itin a compute Cloud in order to avoid the significant capitalinvestment associated with the construction of a data centre.
�������
������ �����
���
����� �
���� ���
�������
������
�����
������
� ���
���� ���
� ���
���� ���
� � � ����
���������
����
�������
�����������
����
� �������
����
���������
����
Fig. 2 SAP Three-Tiered Architecture
If the SAP system is handed over to a Cloud computingprovider that uses an infrastructure based on the RESER-

4
VOIR architecture, a number of architectural constraints ofthe SAP system will need to be obeyed by the Cloud. Forexample, the Central Instance will frequently make queriesto the database and in a typical SAP configuration the Cen-tral Instance and the database need to be co-located on thesame LAN subnet. When the VEEM allocates the virtualmachines for the Central Instance and the DBMS to particu-lar VEEHs, it will have to respect this co-location constraint.Another architectural constraint is that the Central Instancecan not be replicated in any SAP system. Dialog Instances,on the other hand are replicated to accommodate growingdemand. Therefore these architectural constraints have tobeexpressed by the SAP provider and made available to theService Manager so that it can obey these constraints at run-time.
This requires the software architecture to be expressedin terms of services, their relationship and their resourcere-quirements. While a traditional SAP deployment would re-quire that spare capacity is retained to deal with peaks in de-mand, Cloud computing introduces the ability to minimiseoverprovisioning by tying resource provision directly to theneeds of the application. Resource requirements, in this casedictated by the number of Dialog Instances required to han-dle the current load, can be scaled dynamically and adjustedto maximise cost savings. This requires means of describingthe state of the system and rules for adjustments.
4 Architecture definition
4.1 Requirements
Based on an understanding of the underlying hosting infras-tructure described in Section 2, and the example provided inSection 3, we can break down the core issues that must bedefined when deploying and running software systems ona Cloud computing infrastructure into the following high-level requirements, in order to provide a suitable definitionfor the terminology employed in later sections:
MDL1 Software composition: A software system may becomposed of one or moreloosely coupled components,which may have differingresource(e.g. CPU, memory)and software(e.g. operating system, libraries, disk im-age) requirements.
The components of the multi-layered SAP system, theWeb Dispatcher, Central Instance, Dialog Instance andDBMS, will have varying hardware and software re-quirements, but will nevertheless be required to be man-aged jointly. We can expect for example the DBMS ser-vice to be very I/O and memory intensive and with largestorage requirements. In contrast, the Dialog Instancesmay be more processor intensive, and hardware require-ments may be adjusted accordingly.
MDL2 Network topology: The system may require a spe-cific network topologyboth to interconnect componentsof the system and communicate with external systems.
With respect to the SAP system, the Web Dispatchershould provide an external interface and internal compo-nents should be at the very least interconnected, thoughexternal access may not necessarily be required.
MDL3 Capacity adjustment: Hardware requirementsmay evolve during the lifetime of the system accordingto workload, time or other application-level variables.
In order to deal with potential increases in requests, itmay be necessary to deploy additional Dialog Instancesin order to facilitate load balancing and ensure a certainlevel of performance.
MDL4 Dependencies: Deployment and un-deploymentdependencies may exist between components.
The order in which components of an SAP system arestarted or stopped may affect the overall operation of thesystem. The DBMS and Central Instance components,serving as the backbone of the system, should be activebefore individual Dialog Instances.
MDL5 Location constraints: Constraints on the distri-bution of service components across physical locationsmay exist.
Federation of Clouds is key to enabling scalable provi-sioning of services. However along with the ability toseamlessly deploy services across multiple physical andadministrative domains comes a need to allow serviceproviders to control the “spread” of the application bydefining clear constraints on the distribution of servicesacross sites. These constraints can be of a technical na-ture (e.g. deploy certain components on a same host) oradministrative (e.g. avoid un-trusted locations). Thoughwe have, for example, established that the Central In-stance and DBMS should be located on a same (virtual)network, a service provider may wish to minimise la-tency by ensuring proximity.
MDL6 Customisation: Components may be dependenton configuration parameters not known until deploy-ment.
When deploying multiple instances of a same compo-nent, certain application-level parameters may be in-stance specific. As such it may be necessary to customiseindividual instances upon their creation and deployment.Dialog Instances may for example require the IP ad-dresses of the Central Instance and DBMS to be pro-vided, if this information is not know at pre-deploymenttime (e.g. dynamic IP allocation via DHCP).
In order to automate the management of a software sys-tem on a Cloud infrastructure it is necessary for a serviceprovider to communicate both the software system stack

5
(OS, middleware, application, configuration, and data) pro-viding self contained services in the form of a virtualisedimage (addressing requirement MDL1) and a description ofthese requirements in the form of aService Definition Mani-fest(addressing requirements MDL2-MDL6). The manifesttherefore serves as a contract between service and infras-tructure providers regarding the correct provisioning of aservice. It hence reifies key architectural constraints andin-variants at run-time so that they can be used by the Cloud.
To define manifests, we require a declarative languagewhose syntax should be sufficiently flexible to cater for ageneral purpose service provisioning environment, and pro-vide the necessary abstractions to describe capacity and op-erational requirements of the software architecture both atdeployment time and throughout the entire lifecycle.
We rely in our implementation on theOpen Virtuali-sation Format(OVF) [10], a DMTF standard backed byVMWare and XenSource which aims to offer a packagingmechanism in a portable and platform neutral way. Build-ing on open standards facilitates interoperability particularlyin the context of federation and eases compatibility withexisting services and tools. In addition it ensures that asCloud technology matures, continued compliance with thestandard avoids vendor lock-in and potential deployment onnewer platforms. OVF hence serves as a building block forour manifest, and provides the syntax for the descriptionof virtual disks, networks, resource requirements and otherissues related to dependencies or customisation. However,OVF (as other service description languages for existing vir-tualisation technologies) primarily caters for the initial dis-tribution and deployment of fixed size services [10], whichdoes not by itself fully realise the vision of Cloud comput-ing.
Indeed, Clouds differ from traditional software deploy-ment in many ways. Beyond the impact of virtualisation onmulti-component architectures, existing deployment mech-anisms are typically one-way “channels” where a service isconfigured and deployed according to an initial deploymentdescriptor. There is no feedback mechanism to communicatespecific state, parameters and other information from a de-ployed service back to the infrastructure to adapt the execu-tion environment dynamically. The manifest should enablethe automation of provisioning and management throughtemplate based provisioning, where the service manifest isused as a template for easily provisioning instances of theapplication, and support for resource consumption control.
We hence need to add a number of abstractions to OVF,the primary beingelasticity specification in the form ofrules allowing conditions related to the state and operationof the service, such as application level workload, and asso-ciated actions to follow should these conditions be met,ap-plication domain description, which allow the state of theapplication to be described in the form of monitorable ap-
plication level parameters andplacement and co-locationconstraints, which identify sites that should be favoured oravoided when selecting a location for a service.In previous work [13], we have discussed a number of ad-ditional extensions to the OVF syntax to support Clouds,including attribute and section changes to incorporate sup-port for service components IDs in elastics arrays, cross vir-tual machines reference, IP dynamic addresses and elasticityrules and bounds. However, a syntactic definition of a de-ployment descriptor only forms part of what is necessary toensure these requirements are met with respect to the under-lying Cloud computing infrastructure.
Indeed, there must exist a clear understanding of howwe derive from the language used to express the require-ments of the Service Provider amanagement cycle, whichwill consist of several actions being taken throughout thelifetime of a service to ensure a certain service quality be-ing obtained. Using the RESERVOIR framework as a refer-ence, and examining specifically issues related to dynamiccapacity adjustment and service deployment, we now de-scribe how thebehavioural semanticsfor our manifest lan-guage are described and how they guide the operation ofunderlying Cloud components.
Focusing specifically on elasticity and application do-main description, as well as service deployment, we refineand extend in this paper our OVF based service definitionlanguage syntax to incorporate these abstractions.
4.2 Manifest Language Definition
In this section, we describe the overall approach undertakento define and provide support for theManifest Language.This is achieved through the specification of three com-plementary facets of the language: the abstract syntax, thewell-formedness rules, and the behavioural semantics. Theabstract syntax of the manifest language is modelled usingtheEssential Meta-Object Facility(EMOF), an OMG stan-dard part of the Model Driven Architecture initiative [22] fordescribing the structure of meta-data, and embedded withinan object-oriented model of the RESERVOIR architecture.Because the manifest describes the way in which a RESER-VOIR based infrastructure should provision a service appli-cation, the semantics of the language can be expressed in themodel denotational style to define semantics that we intro-duced in [29] as constraints between the abstract syntax anddomain elements that model the operation of Cloud infras-tructure components. These constraints are formally definedusing theObject Constraint Language(OCL) [23], a lan-guage for describing consistency properties, providing thestatic and behavioural semantics of the language. In thismanner the language serves to constrain the behaviour of theunderlying infrastructure, ensuring the correct provisioningof the software system services.

6
The motivations for this approach are two-fold: firstly bymodelling the syntax of the manifest language as an EMOFmodel, we seek to express the language in a way that is in-dependent of any specific implementation platform. Com-ponents of a Cloud infrastructure such as RESERVOIR mayrely on a number of different concrete languages, whetherimplementation languages (Java, C++, etc.), higher-level“meta” languages (HUTN, XML, etc.), or even differingstandards (WS-Agreement, OVF, etc.). A higher level of ab-straction ensures that we free ourselves from implementa-tion specific concerns, and allows seamless and automatedtransitions between platform specific models as required bycomponents.
Secondly, providing a clear semantic definition of themanifest using OCL allows us to identify functional char-acteristics that service management components shouldpresent in order to support capabilities such as applicationbased service elasticity, again irrespective of the implemen-tation platform. As such the definitions presented in this pa-per extend beyond the scope of RESERVOIR or any spe-cific Cloud infrastructure, instead providing a clear under-standing of expected provisioning behaviours, with respectto identified and required component interfaces.
Finally, we may also consider that clear semantics en-sure that we limit ambiguities when it comes to interpre-tation of the manifest. This is of crucial importance wherefinancial liabilities may exist; a formal understanding of thenature of the service being provided is required in order toensure that the service is provisioned as expected by bothparties, and in a way that both can evaluate to be correct,either through run-time monitoring capabilities or historicallogs. We achieve this by tying the specification of the mani-fest to the underlying model of the Cloud infrastructure.
4.2.1 Abstract syntax
The abstract syntax of the manifest describes the core el-ements of the language and their accompanying attributes.The core syntax relies upon, as previously stated, OVF [10].The OVF descriptor is an XML-based document composedof three main parts: description of the files included inthe overall service (disks, ISO images, etc.), meta-datafor all virtual machines included, and a description ofthe different virtual machine systems. The description isstructured into various “Sections”. Focusing primarily onthe most relevant, the<DiskSection> describes virtualdisks,<NetworkSection> provides information regardinglogical networks,<VirtualHardwareSection> describeshardware resource requirements of service components and<StartupSection> defines the virtual machine booting se-quence.
Incorporating the OVF standard ensures that we tackleseveral of the requirements identified in Section 4.1, pro-
viding the manifest language with a syntactic model forthe expression of physical resource requirements and hard-ware configuration issues. We introduce new abstractionsin the form of extensions to the standard rather than createnew independent specifications. OVF is extensible by designand doing so ensures continued compatibility with existingOVF-based systems.
We model these extensions using EMOF. EMOF modelsare very similar to UML class diagrams, in that they describeclasses, the data they contain and their relationships, butareat a higher level of abstraction: they describe the constructs,rules and constraints of a model. As such, EMOF is typicallyused to define the syntax of languages.
Application description languageReliance on Cloud com-puting introduces the opportunity to minimise overprovi-sioning through run-time reconfiguration of a service, effec-tively limiting resource consumption to only what is cur-rently required by the application. However, when dealingwith rapid changes in service context and load, timely ad-justments may be necessary to meet service level obliga-tions which cannot be met by human administrators. In sucha case, it may be necessary to automate the process of re-questing additional resources or releasing existing resourcesto minimise costs.
This automated scaling of service capacity to supportpotential variations in load and demand can be implementedin numerous ways. Application providers may implementsuch scaling at the application level, relying on an exposedinterface of the Cloud computing infrastructure to issuespecific reconfiguration requests when appropriate. Alterna-tively, they may have a desire to keep the application designfree of infrastructure specific constraints and opt insteadtodelegate such concerns to the infrastructure itself. With asufficient level of transparency at the application level forworkload conditions to be identified, and through the speci-fication of clear rules associating these conditions with spe-cific actions to undertake, the Cloud computing infrastruc-ture can handle dynamic capacity adjustment on behalf ofthe service provider.
It is the latter approach that we have chosen to adoptin the context of RESERVOIR. By providing a syntax andframework for the definition and support of elasticity rules,we can ensure the dynamic management of a wide rangeof services with little to no modification for execution on aCloud. With respect to the syntax, we can identify the twofollowing subsets of the language that would be required todescribe such elasticity: service providers must first be ableto describe the application state as a collection ofKey Per-formance Indicators(KPIs), and the means via which theyare obtained in the manifest. These will serve as a basis forthe formulation of the rules themselves, described in the fol-lowing subsection.

7
Because we do not want the manifest language to be tiedto any specific service architecture or design, it is necessaryto decouple the KPI descriptions from the application do-main via the use of anApplication Description Language(ADL). Though it is possible to build elasticity conditionsbased purely on infrastructure level performance indicators,this may prove limiting. Indeed, the disk space, memory orCPU load may not accurately reflect the current needs of theapplication, as will be seen in the evaluation. This languagewill allow the description of services in terms of compo-nents, parameters of interest and their monitoring require-ments.
Alongside the syntactic requirements, a suitable moni-toring framework must exist. A service provider is expectedto expose parameters of interest through localMonitoringAgents, responsible for gathering suitable application levelmeasurements and communicating these to the service man-agement infrastructure. Though communication protocolswith the underlying framework are outside the scope of themanifest language, there must exist a correlation betweenthe events generated by the monitors and the KPIs describedin the manifest. This is modelled in Figure 3.
���������� ���
�����������
�����������
����� �����
�� ����� �
���������������
��������
��� ������������
�� ������� �
�!!"#����$���������$�
������"#����
����������"#���
% �&������
%����&'(����)��!*���
%�$�&'�������$
%#����&������
%�������&'����
��� �����
����)$�"#����
��
% ������$&'�������$
%����&'(����)��!*���
%����&'+���
%)��,��� $&'!�����
��� ������� ������
-�������� ����
.-/"�#����
%)���&'/���0�)���� �12
%!�3&'��312
%���4��3&'*��4��312
%#�������$���&-�������$12
5��6
5��6
66
��� �����'������ ���#� �'����������
�)����� ������� �����'�� ������'��������
6
%����&'(����)��!*���
�7��
��� ��������#��
������ ���� �
������� ���� �
�������
''�&������ ���� ��
���
Fig. 3 Application Description Language
Based on our running example, the figure exempli-fies the relationship between the ADL, the RESERVOIRapplication-level monitoring infrastructure, and the appli-cation domain. The syntax of the ADL consists of one ormore named components, with a number of associated KPIs.These KPIs are identified using appropriate qualified names(e.g.com.sap.webdispatcher.kpis.sessions), that willallow the underlying infrastructure to identify correspondingevents obtained from an application level monitor and for-ward these to subscribers responsible for the enforcement ofelasticity rules.
We are concerned in the SAP example with the num-ber of simultaneous web sessions managed by the web dis-patcher, as there is a proportional relationship between re-source requirements and sessions. The number of simulta-neous sessions will be used as a basis for scaling the number
of Dialog Instances.However, directly monitoring the trafficto and from the web dispatcher would be impossible, as SAPuses proprietary protocols. The SAP system can nonethelessreport the number of sessions provided an appropriate queryis formulated. The monitoring agent would be responsiblefor such queries and forwarding obtained responses, bridg-ing the gap between application and monitoring infrastruc-ture.
KPI qualified names would be considered global withinthe scope of a service. If there exists a need to distinguishthe KPI measurements produced by multiple instances of asame component, this is achieved by using distinct quali-fied names. Monitoring agents can, for example, include in-stance IDs in the qualified name. The structure of the quali-fied name itself would not fall within the scope of the man-ifest specification. Instances of an application service asawhole however would be considered distinct. At the imple-mentation level, KPIs published within a network are taggedwith a particular service identifier, and rules, covered below,will also be associated with this same identifier. Multipleinstances of an application service would hence operate in-dependently.
Elasticity RulesWith respect to the rule syntax, we adopt anEvent-Condition-Actionapproach to rule specification. Thisis a widely adopted model for rule definition, adopted for ex-ample in active databases and rule engines, and suited in thisinstance. Based on monitoring events obtained from the in-frastructure, particular actions from the VEEM are to be re-quested when certain conditions relating to these events holdtrue. This requires rules to be expressed with respect to theinterface of the underlying VEEM and monitoring events.
A representation of the elasticity rules based on a gen-eral rule-base model and their relationship to monitoringevents and the Cloud infrastructure is illustrated in Figure 4.The syntax specifies conditions, based on monitoring eventsat the application layer or otherwise, which would lead tospecified actions, based on a set of operations presented bythe VEEM. The operations, modelled on the OpenNebulaframework capabilities will involve the submission, shut-down, migration, reconfiguration, etc. of VMs and shouldbe invoked within a particular time frame. The conditionsare expressed using a collection of nested expressions andmay involve numerical values, arithmetic and boolean oper-ations, and values of monitoring elements obtained. The re-lationship between KPIs specified in the manifest and theseevents has been described in the previous section. The elas-ticity rules will be supervised by the Cloud infrastructureatthe Service Manager layer during the running of the soft-ware system and it is expected that a rule interpreter will re-ceive events from the infrastructure or application monitorsand trigger such operations accordingly.

8
��������������
�� ����������
�������������
�����������
����� ���
�����������
������
������������� !��
"���������������� #� ��$���!�������������
%�
&�������������
'��� ���
%�(��������
�����%����)����
������
%��
�
�**+
���$��
� ����
��������������(��
����
$�����
�
����,����������
������������� ��
***
-
%�( ���(��
������������
)&
����./%����0
-
��1�� ������
������
�����./%����0
�
���������
����./%����0
2�������
����./%����0
�����./%����0
������
���3� �
������3� �
�� �3� �
���3� �
�(��)&
������)&
!����4�)&
�0����)&
� ����
-
-
�� ������/����/&����
5� !��
5� ������ !��
,����
,��
"��
����
"������
$��
��
������� !��
)������/��������/���������%������/&���0����
,���� ��������
&��������0����
�,'.%����0
����./���������"��
�����./1���0���
������.%����0
���� ���./'���
-
��00���
��������0������
����./%����0 ��� ���������� ����.)&
������ ���
�����6������������
Fig. 4 Elasticity Rules Syntax
With respect to the example, this language enables usto express that virtual machines with new Dialog Instancesshould be created as the number of user sessions maintainedby the SAP web dispatcher grows in order to handle the in-creased load. A concrete example of an elasticity rule willbe provided in Section 6.
It is worth briefly discussing the subject of time man-agement. The service provider controls the timeliness of theresponse in multiple ways. Firstly the rate at which mon-itoring events are sent by the application level monitor isentirely dictated by the application and this should be bal-anced against expected response time to avoid duplicateresponses. Secondly service providers can specify a timeframe within which particular actions should take place, asdescribed above. Finally, the current time can be introducedas a monitorable parameter if necessary.
Additionally service providers may prefer expressingconditions regarding a series of measurements within a timeframe rather than focusing on single events. We may be con-cerned here with the average number of active sessions in awindow in order to limit the impact of strong fluctuations.While the language is extensible and presents the oppor-tunity to provide such functionality, and we are currentlyworking on the ability to specify a time series and opera-tions related to that time series (mean, minimum, maximum,etc.), this can be achieved by aggregating measurements atthe application level, with the monitoring agent performingsuch tasks.
Elasticity rules can be a powerful tool to express ca-pacity constraints. The structure is kept purposely simple:not intended as a substitute for a programming language,elasticity rules only aim to inform the Cloud infrastructureof the corrective process to be undertaken. Auto-scaling isnot a form of capacity planning but it aids in introducing acertain degree of flexibility in resource allocation which en-sures that strong and often unexpected variations in demandcan be met. In general, more complex relationships between
performance indicators can be computed at the applicationlevel, before being forwarded to the service manager.
4.2.2 Semantic Definition
We examine in this section the dynamic semantics of themanifest language as OCL constraints on the relationshipbetween the syntactic model of the manifest and the infras-tructure and application domains. Dynamic semantics areconcerned with deployment and run-time operation. Thesewill specify behavioural constraints that the system shouldadhere to during its execution.
The question of how and when we verify that these con-straints hold true during the provisioning of a service shouldbe discussed briefly. Defined invariants should be true at anymoment in time, however it is not feasible in practice to con-tinuously check for this. Instead it is preferable to tie theverification to monitoring events or specific actions, such asa new deployment. Another question to be posed is whatshould be done when an evaluation of the state system doesnot fit the specified constraints. This will depend on the con-text: an exception may occur, or an operation should be in-voked to trigger some corrective action, as would be the casewith elasticity rules.
Service DeploymentAs the manifest is processed by thevarious independent components of the Service Managerto generate a deployment descriptor for submission to theVEEM, it becomes important to ensure that the final prod-uct, which may be expressed using a different syntax, is stillin line with the requirements of the service provider. In thecase of RESERVOIR, the VEEM would introduce it’s owndeployment template. Using OpenNebula as a reference im-plementation of a VEEM, the deployment template reliedupon by the system is roughly based on a Xen configura-tion file. The association between manifest and deploymenttemplate is illustrated in Figure 5.
It is presumed that the service manager’sManifestProcessor will be responsible for parsing

9
���������
��� ���� ��������
�������������
��������������
�������������������
��������������
!����������������
����"��������
#��� ���$������%
�������#��&�����������
������%�����'
�"$(�%��)��
�������%��)��
������%�����'
���*����������%�����'
������%+���
�'��&����%,��&���
����������
��������%�����'
��������%�����'
�������-����%�����'
����%�����'
�)��%�����'
������������
�����%�����'
�������%�����'
����'���%�����'
�)���%�����'
����������%)����
�+"
�����%�����'
�)���'��%�����'
����'���%�����'
�������%�����'
����������
���� ���
�������"� �'����'���
!��������
Fig. 5 Service Manifest and Deployment Descriptor
the manifest and generating one or more deploymenttemplates accordingly. TheServiceConfigAnalyzer maybe used to further optimise the placement with regards tothe multiple sites at which it may be deployed, though themanifest specification is not concerned with this. It is onlynecessary to ensure that the optimisation process respectscertain constraints regarding resource requirements. This isa design by contractapproach [36]. We are not concernedwith the actual transformation process, but rather that thefinal product, i.e. the deployment descriptor, respects certainconstraints. These can be expressed in OCL as follows:c on te x t A s s o c i a t i o ni nv :m a n i f e s t . vm−> f o r A l l ( v |
d e p d e s c r i p t o r . e x i s t s ( d|d . name = v . i d &&d . memory = v . v i r t u a l h a r d w a r e . memory &&d . d i s k . s ou rc e =
( m a n i f e s t . r e f s . f i l e−>a s S e t ()−>
s e l e c t ( i d = v . i d ))−> f i r s t ( ) . h r e f. . .)
This OCL description is a sample of what is required toestablish a relationship between manifest and deploymentdescriptor. Here, we describe that there should be at leastone deployment descriptor generated for every virtual sys-tem described in the manifest definition that has the sameidentifier and memory requirements. The full OCL specifi-cation contains a full mapping of attributes of our manifestlanguage to that of a VEEM deployment descriptor.
Service ElasticitySimilarly, we can specify the expectedoutcome of elasticity rule enforcement with respect to boththe syntax of the manifest and the underlying RESERVOIRcomponents. OCL operations areside effect free, as in theydo not alter the state of the system. Nevertheless they can beused to verify that the dynamic capacity adjustments haveindeed taken place when elasticity rule conditions have beenmet, using thepostcontext.
This is described in OCL as follows:−− C o l l e c t mon i t o r i ng r e c o r ds upon n o t i f i c a t i o nc on te x t R u l e I n t e r p r e t e r : : n o t i f y ( e : Event )pos t : mon i t o r i ngR e c o rds =
moni to r ingRecords@pre−>append ( e )−− E v a lua te e l a s t i c i t y r u l e s and check a d j u s t m e n tc on te x t R u l e I n t e r p r e t e r : : e v a l u a t e R u l e s ( )pos t : e l a s t i c i t y R u l e s−>f o r A l l ( e r |
i f s e l f . e v a l u a t e ( e r . expr )> 0 thene r . a c t i o n s−>f o r A l l ( a | veem ˆ invoke ( a . re q ) )
e l s e t r u ee nd i f )
−− Query s imp le t y p e v a luec on te x t R u l e I n t e r p r e t e r : : e v a l u a t e ( e l :
E lementSimpleType ) :Realpos t : r e s u l t = e l . va lue−− Obta in l a t e s t v a lue f o r mon i t o r i ng r e c o r d−− w i th s p e c i f i c q u a l i f i e d namec on te x t R u l e I n t e r p r e t e r : : e v a l u a t e ( qe :
Q u a l i f i e d E l e m e n t ) : Realpos t :i f mon i to r i ngR e c o rds−>s e l e c t ( name=qe . name )
−> l a s t ()−> e x i s t s ( ) thenr e s u l t = mon i t o r i ngR e c o rds
−>s e l e c t ( name=qe . name )−> l a s t ( ) . va lue
e l s e r e s u l t = qe . d e f a u l te nd i f−− E v a lua te e x p r e s s i o n s−− De f i ne d as p o s t i n o r de r to use r e c u r s i o nc on te x t R u l e I n t e r p r e t e r : : e v a l u a t e ( expr :
E xp re s s ion ) : Realpos t :
i f expr . op . oc l IsTypeOf ( Grea te rThan )theni f s e l f . e v a l u a t e ( ( op . e l−> f i r s t ( ) ) >
s e l f . e v a l u a t e ( ( op . e l−>l a s t ( ) ) thenr e s u l t = 1
e l s e r e s u l t = 0end i f
e l s e. . . .
e nd i f
This OCL pseudo-code is only a subset of the complete OCLspecification that aims to illustrate how we can specify thecorrect execution of elasticity rules with respect to the rulesyntax. The code is split into a number of individual seg-ments. The first simply states that monitoring events ob-tained are expected to be collected as records for the purposeof later evaluation. The second element states that if the con-ditional element of one of the elasticity rules is found to betrue, then particular actions should have been invoked. Toreiterate, the operations are side effect free, implying that noprocessing of any kind will take place in an OCL statement.Instead we only check that there has been communicationwith the VEEM to invoke certain operations if the condi-tions described hold true. How it is implemented is then leftto developers.
The final segments relate to the evaluation of the condi-tions themselves. TheRuleInterpreter: evaluate(qe:
QualifiedElement) describes that upon evaluation of therules, values for key performance indicators described in thedocument are obtained from the monitoring records, by ex-amining the latest monitoring event with matching qualifiedname. This defines the relationship between KPIs and mon-itoring events. This asynchronous model is chosen becausethe Cloud infrastructure does not control application levelmonitoring agents. As there is no guarantee over how oftenmonitoring information is provided, and rules may involvemeasurements from several services, it is for the implemen-tation to determine when the rules should be checked to fit

10
within particular timing constraints rather than tying checksto the reception of any specific monitoring event. Finally thelast segment illustrates the recursive evaluation of expres-sions based on the type of formula selected by the serviceprovider.
4.2.3 Concrete syntax
While the specification of our manifest language is keptfree of implementation concerns, the model-denotational ap-proach adopted here provides a basis for automatically de-riving concrete human or machine readable representationsof the language that can be manipulated by the end-user orprocessed directly by the RESERVOIR based infrastructure.Moreover, beyond creating and editing the manifest itself,the syntax and accompanying semantics can be used as in-put for a generative programming tool to automate the gen-eration of applications to control the provisioning process.
In practice, the RESERVOIR architecture may be im-plemented using a wide range of programming languagesand existing technologies. The semantic definition describedin this paper will generally serve as an important softwareengineering artefact, guiding the design and developmentof components. However, the potential for errors to occurduring the provisioning process always exists, due to im-plementation or a failure to correctly interpret the specifica-tion of our language. We can assist in identifying and flag-ging such errors byprogramaticallygenerating monitoringinstruments which will validate run-time constraints previ-ously described in Section 4.2.2. The process by which thisis achieved is illustrated in Figure 6.
�����������
������ ��������� ����
����������������������
����
���������
�������
���������
���� ���
����������������������������������
������
��������
��� ��������
��� ������
Fig. 6 Programatic Generation of Monitoring Instruments
In previous work, we have developed the UCL-MDAtools [28], a graphical framework for the manipulation ofEMOF and OCL implemented as a plug-in for the EclipseIDE. The framework relies on existing standards for thetransformation of EMOF models and OCL into code, such
as the Java Metadata Interface (JMI) standard and OCL in-terpreters, and is available at [34].
We have extended the framework for the purpose of thiswork. Our extensions introduce the ability to create, editand validate manifests describing services to be deployedon a RESERVOIR based infrastructure. Element attributevalues are input via the graphical interface in accordancewith the structure of the language. Infrastructure relatedat-tributes and configuration values may be included in orderto verify that OCL constraints are correctly maintained. Thismay be used amongst other things to verify that deploymentdescriptors generated by the infrastructure fit within the re-quirements specified by the manifest as covered.
Via the interface, users can additionally request the cre-ation of stand-alone monitoring instruments in Java capableof interaction with our implementation of the RESERVOIRframework, which will be described in detail in Section 5.These are currently of two forms. The first is simply respon-sible for gathering and reporting the values of specific KPIsdescribed in the manifest. The second will validate the cor-rect enforcement of elasticity rules by evaluating incomingmonitoring events and verifying where appropriate that suit-able adjustment operations were invoked by matching en-tries and time frames in infrastructural logs. The frameworkalso allows the generation of custom stubs which the ser-vice provider may used as a basis for the development bythe service provider of monitoring agents, handling issuessuch as communication protocols, measurement labellingand packaging, and providing a control interface to man-age frequency and operation. This would have to be supple-mented with appropriate probes responsible for the applica-tion level collection of measurements.
Java code is generated from a combination of data ob-tained from the specification, element values input by theuser and Java templates, the latter being used to bridge thegap between the abstract model of the infrastructure andthe actual implementation. As previously discussed, issuessuch as communication channels for the distribution of mon-itoring events fall outside the scope of the manifest lan-guage specification. Templates provide the necessary codeto gather KPI measurements or parse infrastructure logs andpass this information to OCL interpreters.
The tool hence serves the following purposes: firstly,it allows users to specify and manipulate manifests. Sec-ondly it allows the generation of code allowing the serviceprovider to verify the correct provisioning of a service atrun-time according to the semantics of the language. Fi-nally it provides the means of interfacing a service with theRESERVOIR monitoring architecture.

11
5 Service Lifecycle Management
The service lifecycle encapsulates the initial deploymentofa service, whereby a Service Provider sends a manifest de-scribed in the language detailed above to a cloud, through tothe first instantiation of one or more service components, themonitoring of said components, and finally the additionaldeployment, undeployment and resizing of service compo-nents as demand and workload evolves. All of these com-plex functions are undertaken through the collaboration ofthe Service Manager, the Monitoring Framework, and theVEEM, and are just one of the many control loops that arerequired within a cloud computing environment.
In this section we describe these components and dis-cuss the implementation decisions that were taken to ensurea scalable, manageable service management infrastructure.
5.1 Service Manager
Previous sections have dealt with the language to define ser-vice manifests, describing the requirements that have drivenits design along with its abstract and concrete syntax. In thecurrent subsection we describe in detail the Service Man-ager, which is the main component of the RESERVOIRmiddleware that processes descriptions in the manifest lan-guage, instantiates the services, and manages these servicesthroughout their lifecycles.
The Service Manager within the overall RESERVOIRstack has been already introduced in Figure 1, with a moredetailed architecture shown in Figure 7. It exposes a de-ployment interface to Service Providers, based on the OVF-based service manifest language discussed in Section 4.2.1.It interacts with the Virtual Execution Environment Manager(VEEM) via a REST based interface to handle the deploy-ment and management of the virtual machines composingthe application of the service providers .
The main components of the Service Manager are de-scribed below. Although it includes many additional com-ponents (e.g. for accounting and billing), we focus here onthe ones related to service deployment and elasticity for thesake of clarity. These are:
Manifest parser: The parser handles and processes the ser-vice specification (in OVF) provided by the ServiceProvider, extracting from it a suitable service lifecyclethat meets the provider requirements.
Service Lifecycle Manager: This component controls theservice lifecycle and is in charge of all service man-agement operations, including initial deployment, run-time scaling and service termination. The Service Life-cycle Manager orchestrates all the other Service Man-ager components and interfaces with the VEEM in orderto actually implement the management operations, e.g.
���
�������
�� ����� �
����������������
�� �����
������
�����
� ��� �
������
���
� �� �
���������� ����
��������������� �� ���� �� ���� ����
��� !�������"��� �
�� �������
����������#� ��$���%
��� ����� ��� �������
Fig. 7 Service Manager Architecture
sending individual deployment descriptors to create newVEEs.
Rule Engine: The rule engine enforces scaling rules duringservice runtime. It is based on a business engine (the cur-rent Service Manager implementation uses Drools [11])which takes KPI monitoring information as input for thegiven rule set derived from our specification, resulting inscaling operations when some rule is triggered.
HTTP internal server: The Service Manager includes aninternal HTTP server to provide virtual machine imagesthat the VEEM needs to deploy new virtual machines. Inparticular, the HTTP server is used to place both the baseimage containing operating system and service softwareand the image containing the customization data. Theserver is needed because it is preferable to include ref-erences to the images in the REST messages than pass-ing the actual images themselves, which are usually verylarge.
Taking into account these various components, we now de-scribe how the Service Manager implements the manifestlanguage semantics descibed in Section 4.2.2 for both ser-vice deployment and service elasticity.
5.1.1 Service Deployment
The service deployment process consists of 7 steps. Theseare illustrated in the left of Figure 8. The workflow is asfollows:
(1) The Service Provider issues a service deployment oper-ation to the Service Manager. The main parameter for

12
����������
�
��� ����
����� � ��
� ���� ������� �
����� �
��� �
�����
��� ����
� �� �
��
�����
� ���� ������ �
��������� �������������� �������� �
����������
�����
� ���� ����
!"
#" $" %"
&" '" ("
��� ����
����� � ��
� ���� ������� �
����� �
��� �
�����
��� ����
� �� �
��
�����
� ���� ������ �
��������� �������������� �������� �
����������
�����
� ���� ����
!"
#" $" %"
&" '" ("
� ���� ����
���)
Fig. 8 Service Deployment Workflow (left) and Service Elasticity Workflow (right)
this operation is the service manifest, expressed in OVF.The Manifest Parser processes the file and, as result ofthis task, an internal representation of the service man-ifest is built, to be used for the other Service Managercomponents.
(2) The service deployment command is issued to the Ser-vice Lifecycle Manager.
(3) The Service Lifecycle Manager sets up and installs theelasticity rules specified in the manifest in the Rule En-gine, so it starts enforcing them when the service getsdeployed.
(4) The Service Lifecycle Manager interacts with the HTTPserver to set up all the images required by the virtual ma-chines composing the service. For each virtual machine,two images are provided – the base image, and the diskcontaining the customisation data (e.g. IP address) ac-cording to the OVF Environment format (see [10]). Boththe reference to the base image and the customisationdata are extracted from the service manifest.
(5) The Service Lifecycle Manager sends a deployment de-scriptors to the VEEM to create a new VEE.
(6) The VEEM gets the base disk for the VEE, creates itand boots it. The created VEE is shown in a dashed linein the figure.
(7) The customization disk is attached to the VEE (typicallyas a virtual CD/DVD) so the Activation Engine that runsas part of the VEE boot procedure can access the cus-tomization data and configure the VEE properly (e.g.setting the assigned IP in the operating system configu-ration).
It is worth mentioning that, although we are showing just thecreation of a single virtual machine, the subflow composedby steps 5-to-7 repeat for every VEE needed for initial ser-vice deployment. For example, if the initial layout of theservice is composed of a load balancer, a web server, and adatabase, each with its own virtual machine, then three ofthese 5 to 7 cycles will be done.
5.1.2 Service Elasticity
When considering a running service, the process by whichelasticity is managed has a dedicated workflow, which isshown in the right hand side of Figure 8. The steps are asfollows:
(1) Monitoring probes running in the virtual machines arecontinuously sending KPI measures to the MonitoringFramework.
(2) The Monitoring Framework provides KPI informationto the Rule Engine running at the Service Manager level.
(3) When the KPI value triggers a given elasticity rule toscale up the service, the Rule Engine issues a commandto the Service Lifecycle Manager.
(4) A customization disk is generated for that image in theHTTP internal server.
(5) The Service Lifecycle Manager follows the conven-tional procedure (described in Section 5.1.1 workflowin steps 5-to-7) to deploy a new virtual machine.

13
5.2 Monitoring Framework
Key to facilitating the ow of information in a cloud basedenvironment is a monitoring process via which various met-rics regarding the operation of services and infrastructurecan be circulated to the required components in a scalableand effective way. We have already covered the relation-ship between provider requirements specified in the mani-fest and measurements obtained from the monitoring frame-work, and resulting scaling operations.
Here we discuss the implementation of the monitoringframework itself, and the design decisions that were taken toensure that its operation does not affect the performance ofthe network itself or the running service applications. This isachieved by ensuring that the management components onlyreceive data that is of relevance: In a large distributed systemthere may be hundreds or thousands of measurement probeswhich can generate data. It would not be effective to have allof these probes sending data all of the time, so a mechanismis needed that controls and manages the relevant probes.
Existing monitoring systems such as Ganglia [17], Na-gios [19], MonaLisa [20], and GridICE [2] have addressedmonitoring of large distributed systems. They are designedfor the fixed, and relatively slowly changing physical in-frastructure that includes servers, services on those servers,routers and switches. However, they have not addressed orassumed a rapidly changing and dynamic infrastructure asseen in virtual environments. In the physical world, new ma-chines do not appear or disappear very often. Sometimessome new servers are purchased and added to a rack, or aserver or two may fail. Also, it is rare that a server will movefrom one location to another. In the virtual world, the oppo-site is the case. Many new hosts can appear and disappearrapidly, often within a few minutes. Furthermore, the virtualhosts, can be migrated from one network to another, still re-taining their capabilities.
It is these characteristics that provide a focus for themonitoring framework. We have determined that the mainfeatures for monitoring in a virtualized environment whichneed to be taken account of are:
Scalability: to ensure that the monitoring can cope with alarge numbers of probes
Elasticity: so that virtual resources created and destroyedby expanding and contracting services are monitoredcorrectly
Migration: so that any virtual resource which moves fromone physical host to another is monitored correctly
Adaptability: so that the monitoring framework can adaptto varying computational and network loads in order tonot be invasive
Autonomic: so that the monitoring framework can keeprunning without intervention and reconfiguration
Federation: so that any virtual resource which reside onanother domain is monitored correctly
To establish such features in a monitoring framework re-quires careful architecture and design.
The RESERVOIR monitoring system covers all of thelayers and components presented in Figure 1 of Section 2.The following sections provide details of the design of theRESERVOIR monitoring system.
5.2.1 Producers and Consumers
The monitoring system itself is designed around the conceptof producers and consumers. That is there are producers ofmonitoring data, which collect data from probes in the sys-tem, and there are consumers of monitoring data, which readthe monitoring data. The producers and the consumers areconnected via a network which can distribute the measure-ments collected.
The collection of the data and the distribution of data aredealt with by different elements of the monitoring systemso that it is possible to change the distribution frameworkwithout changing all the producers and consumers. For ex-ample, the distribution framework can change over time, sayfrom IP multicast, to an event bus, or a publish / subscribeframework. This should not affect too many other parts ofthe system.
5.2.2 Data Sources and Probes
In many systems probes are used to collect data for systemmanagement [17] [9]. In this regard, this monitoring frame-work will follow suit. However, to increase the power andflexibility of the monitoring we introduce the concept of adata source. A data source represents an interaction and con-trol point within the system that encapsulates one or moreprobes. A probe sends a well defined set of attributes andvalues to the consumers, defined in a data dictionary. Thiscan be done by transmitting the data out at a predefined in-terval, or transmitting when some change has occured.
The measurement data itself is sent via a distributionframework. These measurements are encoded to be a smallas possible in order to maximise the network utilization.Consequently, the measurement meta-data is not transmittedeach time, but is kept separately in an information model.This information model can be updated at key points in thelifecycle of a probe and can be accessed as required by con-sumers.
5.2.3 Probe Data Dictionary
One of the important aspects of this monitoring design is thespecification of a Data Dictionary for each probe. The DataDictionary defines the attributes as the names, the types and

14
the units of the measurements that the probe will be sendingout. These consist essentially of the KPIs that are specifiedin the service manifest.
This is important because the consumers of the data cancollect this information in order to determine what will bereceived. In particular, for the Service Manager, this in-formation will allow specifications in the manifest to bechecked in elasticity and SLA rules. At present many mon-itoring systems have fixed data sets, with a the format ofmeasurements being pre-defined. The advantage here is thatas new probes are to added to the system or embedded in theapplication, it will be possible to introspect what is beingmeasured.
The measurements that are sent will have value fieldsthat relate directly to the data dictionary. To determine whichfield is which, the consumer can lookup in the data dictio-nary to elaborate the full attribute value set. Probes will beembedded in both the infrastructure and the application ser-vice components themselves. To manage scaling accordingto our process, it will be the responsibility of the serviceprovider to ensure that probes embedded in the virtual ma-chines to be deployed rely on a data dictionary that is con-sistent with the KPIs specified in the service manifest.
5.2.4 Measurements
The actual measurements that get sent from a probe willcontain the attribute-value fields together with a type anda timestamp, plus some identification fields. The attribute-values contain the information the probe wants to send, thetype indicates what kind of data it is, and the timestamp hasthe time that the data was collected, as modelled in Sec-tion 4.2.1.
The identification fields are used to determine for whichcomponent or which service and from which probe this datahas arrived from. We rely for this purpose on the qualifiednames discussed in Section 4.2.1. As there are multiple com-ponents which need monitoring and multiple running ser-vices, the consumer of the data must be able to differentiatethe arriving data into the relevant streams of measurements.
5.2.5 Distribution Framework
In order to distribute the measurements collected by themonitoring system, it is necessary to use a mechanism thatfits well into a distributed architecture such as the manage-ment overlay. We need a mechanism that allows for multiplesubmitters and multiple receivers of data without having vastnumbers of network connections. For example, having manyTCP connections from each producer to all of the consumersof the data for that producer would create a combinatorialexplosion of connections. Solutions to this include IP mul-ticast, Event Service Bus, or publish/subscribe mechanism.
Data Source
Probe
Probe Attribute
Measurement
Probe Value
Fig. 9 Relationship Model
In each of these, a producer of data only needs to send onecopy of a measurement onto the network, and each of theconsumers will be able to collect the same packet of dataconcurrently from the network.
5.2.6 Design and Implementation Overview
Within the monitoring framework there are implementationsof the elements presented in the relationship model shown infigure 9. In this model we see, a DataSource which acts asthe control point and a container for one or more Probes.Each Probe defines the attributes that it can send. These areset in a collection of ProbeAttribute objects, that specifythename, the type, and the units of each value that can be sentwithin a measurement.
When a Probe triggers a monitoring event by sending aMeasurement, the Measurement has a set of values calledProbe Values. The Probe Values that are sent are directlyrelated to the Probe Attributes defined within the Probe.
When the system is operating, each Probe reports thecollected measurement to the Data Source. The Data Sourcepasses these measurements to a networking layer, wherethey are encoded into an on-the-wire format, and then sentover the distribution network. The receiver of the monitor-ing data decodes the data and passes reconstructed Measure-ments to the monitoring consumer. Encoding measurementdata is a common function of monitoring systems [17] as itincreases speed and decreases network utilization.
In the monitoring framework, the measurement encod-ing is made as small as possible by only sending the valuesfor a measurement on the data distribution framework. Thedefinitions for the Probe Attributes, such as the name andthe units are not transmitted with each measurement, but areheld in the information model and are accessed as required.
The current implementation is written in Java, and theoutput for each type currently uses XDR [30]. As such eachtype defined uses the same byte layout for each type as de-fined in the XDR specification. All of this type data is usedby a measurement decoder in order to determine the actualtype and size of the next piece of data in a packet.

15
Key Value/datasource/datasource-id/name datasource name/probe/probe1-id/datasource datasource-id/probe/probe2-id/datasource datasource-id... .../probe/probeN-id/datasource datasource-id
Table 1 Information Model Entries for a Datasource
Key Value/probe/probe-id/name probe name/probe/probe-id/datarate probe data rate/probe/probe-id/on is the probe on or off/probe/probe-id/active is the probe active or inactive/schema/probe-id/size no of attributes N/schema/probe-id/0/name name of probe attribute 0/schema/probe-id/0/type type of probe attribute 0/schema/probe-id/0/units units for probe attribute 0/schema/probe-id/1/name name of probe attribute 1... .../schema/probe-id/N/units units for probe attribute 0
Table 2 Information Model Entries for a Datasource
5.2.7 Information Model Encoding
The Information Model for the Monitoring System holds allof the data about Data Sources, Probes, and Probe Data Dic-tionaries present in a running system. As Measurements aresent with only the values for the current reading, the meta-data needs to kept for lookup purposes. By having this In-formation Model, it allows consumers of measurements tolookup the meaning of each of the fields.
In many older monitoring systems this informationmodel is stored in a central repository, such as an LDAPserver. Newer monitoring systems use a distributed ap-proach to holding this data, with MonAlisa using JINI asits information model store.
For the implementation of the Information Model wehave used a Distributed Hash Table (DHT) for the dis-tributed information model. This allows the receivers ofMeasurement data to lookup the fields received to determinetheir names, types, and units. The information model nodesuses the DHT to interact among one another.
The implementation has a strategy for converting an ob-ject structure into a path-based taxonomy for use as keys inthe DHT. The IDs of the Data Sources and the IDs of theProbes are important elements of this taxonomy.
For each Data Source, the keys and values shown in table1 are added to the DHT. For each Probe, the keys and valuesshown in table 2 are added to the DHT. For each Probe, thekeys and values shown in table 2 are added to the DHT.
Using the encoded data from the information model, anyof the consumers of the monitoring data, in particular themanagement overlay, can evaluate all the meta-data of themeasurements.
The RESERVOIR monitoring system has been used suc-cessfully to provide data on all the elements of the cloudarchitecture and the running services [8] [16] [7]. The mea-surements supplied have been used for the service lifecyclemanagement, such as service elasticity, as well as for ac-counting and billing. In the following section on evaluation,these measurements are used for the real execution of a com-putational chemistry application.
6 Experimental Evaluation
In the evaluation of our work we aim to prove the follow-ing hypothesis: provided that an architecture definition cor-rectly specifies requirements and elasticity rules, and that theCloud computing infrastructure obeys the constraints iden-tified in the semantic definition, then thequality of servicethat can be obtained from a Cloud computing infrastructureshould be equivalent to that obtained were the applicationhosted on dedicated resources. In addition, through the spec-ification of elasticity rules, providers can considerably re-duce expenditure by minimising over-provisioning.
We will demonstrate this hypothesis by deploying a pro-duction level service on an infrastructure consisting of theRESERVOIR stack. The Service Manager of the RESER-VOIR stack incorporates monitors that validate the specifiedconstraints. The selected service is a grid based applicationresponsible for the computational prediction of organic crys-tal structures from the chemical diagram [12].
The application operates according to a predefinedworkflow involving multiple web based services and For-tran programs. Up to 7200 executions of these programsmay be required to run, as batch jobs, in both sequential andparallel form, to compute various subsets of the prediction.Web services are used to collect inputs from a user, coordi-nate the execution of the jobs, process and display results,and generally orchestrate the overall workflow. The actualexecution of batch jobs is handled by Condor [33], a jobscheduling and resource management system, which main-tains a queue of jobs and manages their parallel executionon multiple nodes of a cluster.
This case study provides many interesting challengeswhen deployed on a Cloud computing infrastructure suchas RESERVOIR. Firstly, the application consists of a num-ber of different components with very different resource re-quirements, which are to be managed jointly. Secondly, theresource requirements of the services will vary during thelifetime of the application. Indeed, as jobs are created, thenumber of cluster nodes required to execute them will vary.Our goal in relying upon a Cloud computing infrastructurewill be to create avirtualised cluster, enabling the size of thecluster to dynamically grow and contract according to load.
For this evaluation, we will compare the quality of ser-vice, i.e. the duration required to complete the prediction)

16
when executing this workflow on a dedicated cluster, com-pared to a Cloud computing infrastructure that provides sup-port for our abstractions. We are not concerned here withthe overhead of hypervisors such as Xen, which are welldocumented [6]. Instead we are concerned with evaluatingthe costs of dynamically adjusting the resource provisioningduring the application lifecycle and determining whether anappropriate level of service can still be obtained.
6.1 Testbed Architecture
6.1.1 Service components
��������
����
���
������
������������ �����
�����
���
����������
�����������
�������������
����������
��������������
������
��!������� �����
�����
���
��! ��
"�!���������
��!�#����!!
��!�#�������
��!�#���
"�!�������� �����
"�!�
��!�#�����!
�������������
������ ����� ����� ������
�� ��������
$�%
Fig. 10 Testbed Architecture
The testbed we use is illustrated in Figure 10. Threemain types of service components can be distinguished.The Orchestration Serviceis a web based server responsi-ble for managing the overall execution of the application. Itpresents an HTTP front end enabling users to trigger pre-dictions from a web page, with various input parametersof their choice. The Business Process Execution Language(BPEL) [21], is used to coordinate the overall execution ofthe polymorph search, relying on external services to gen-erate batch jobs, submit the jobs for execution, process theresults and trigger new computations if required.
TheGrid Management Serviceis responsible for coordi-nating the execution of batch jobs. It presents a web servicebased interface for the submission of jobs. Requests are au-thenticated, processed and delegated to a Condor scheduler,which will maintain a queue of jobs and manage their exe-cution on a collection of available remote execution nodes.It will match jobs to execution nodes according to workloadand other characteristics (CPU, memory, etc.). Once a targetnode has been selected it will transfer binary and input filesover and remotely monitor the execution of the job.
The last type of component is theCondor Execution Ser-vice, which runs the necessary daemons to act as a Condorexecution node. These daemons will advertise the node as anavailable resource on which jobs can be run, receive job de-
tails from the scheduler and run the jobs as local processes.Each node runs only a single job at a time and upon com-pletion of the job transfers the output back to the scheduler,and advertises itself as available.
6.1.2 Deployment
Packaged as individual virtual machines encapsulating oper-ating system and other necessary software components, thethree components are deployed on the RESERVOIR-basedinfrastructure. The associated manifest describes the capac-ity requirements of each component, including CPU andmemory requirements, references to the image files, start-ing order (based on service components dependencies), elas-ticity rules and customisation parameters. For the purposeof the experiment, the Orchestration and Grid ManagementServices will be allocated a fixed set of resources, with onlya single instance of each being required. The Condor exe-cution service however will be replicated as necessary, inorder to provide an appropriate cluster size for the parallelexecution of multiple jobs.
The elasticity rules will tie the number of required Con-dor execution service instances to the number of jobs inqueue as presented by the Condor scheduler. This enablesus to dynamically deploy new execution service instances asthe number of jobs awaiting execution increases. Similarlyas the number of jobs in the queue decreases it is no longernecessary to use the resources to maintain a large collectionof execution nodes, and hosts in the Cloud can be releasedaccordingly. This is expressed as follows in the manifest us-ing an XML concrete syntax, which conforms to the abstractsyntax described in Section 4.2.1. We use a similar elastic-ity rule for downsizing allocated capacity as the queue sizeshrinks.
<E l a s t i c i t y R u l e name=” Ad jus tC lus te rS i z e U p ”>
<T r i g g e r><T ime C ons t ra i n t u n i t =”ms”>5000</ T ime C ons t ra i n t><E xp re s s ion>
(@uk . uc l . condor . schedd . que ue s i z e /(@uk . uc l . condor . exec . i n s t a n c e s . s i z e +1)> 4) &&(@uk . uc l . condor . exec . i n s t a n c e s . s i z e< 16 )
</ E xp re s s ion></ T r i g g e r><Act ion run=
”deployVM ( uk . uc l . condor . exec . r e f ) ” />
<E l a s t i c i t y R u l e>
The elasticity rules will refer to key performance indi-cators that are declared within the context of the applicationstructure. This is expressed as follows:
<A p p l i c a t i o n D e s c r i p t i o nname=” polymorphGridApp”><Component name=” GridMgmtService ” o v f : i d =”GM”>
<Ke yPe r fo rma nc e Ind i c a to r c a t e g o r y=” Agent ” t ype =” i n t ”>
<Frequency u n i t =” s ”>30</ Frequency><QName>uk . uc l . condor . schedd . que ue s i z e</QName>
</ Ke yPe r fo rma nc e Ind i c a to r>
</ Component>. . .
</ A p p l i c a t i o n D e s c r i p t i o n>

17
All components and KPIs are declared in this man-ner. This enables the infrastructure to monitor KPI mea-surements being published by specific components and as-sociate them to the declared rules according to the previ-ously stated semantics. In this particular instance we arespecifying that a monitoring agent associated with the GridManagement Service will publish measurements under theuk.ucl.condor.schedd.queuesize qualified name every30 seconds as integers.
The overall management process can hence be describedas follows: upon submission of the manifest, the ServiceManager, which is responsible for managing the joint alloca-tion of service components and service elasticity, will parseand validate the document, generating suitable individualdeployment descriptors to be submitted to the VEEM be-ginning with the Orchestration and Grid Management com-ponents. The VEEM will use these deployment descriptorsto select a suitable physical host from the pool of knownresources. These resources are running appropriate hypervi-sor technology, in this case the Xen virtualisation system,to provide a virtualised hardware layer from which the cre-ation of new virtual machines can be requested. Upon de-ployment, the disk image is replicated and the guest operat-ing system is booted with the appropriate virtual hardwareand network configuration.
When the Grid Management component is operational,a monitoring agent, as described in Section 4.2.1, will be-gin the process of monitoring the queue length and broad-cast the number of jobs in the queue on a regular ba-sis (every 30 seconds) under the selected qualified name(uk.ucl.condor.schedd.queuesize). These monitoringevents, combined with appropriate service identifier infor-mation, will be recorded by the rule interpreter componentof the Service Manager to enforce elasticity rules. Whenconditions regarding the queue length are met (i.e. there aremore than 4 idle jobs in the queue), the Service Manager willrequest the deployment of an additional Condor Executioncomponent instances. Similarly, when the number of jobs inqueue falls below the selected threshold, it will request thedeallocation of virtual instances.
The actual physical resources which are managed by theRESERVOIR infrastructure used in this experiment consistof a collection of six servers, each of them presenting aQuad-Core AMD Opteron(tm) Processor 2347 HE CPU and8 GBs of RAM and with shared storage via NFS. OpenNeb-ula v1.2, as the VEEM implementation, is used to managethe deployment of virtual machines on these resources ac-cording to the requirements specified by a Service Manager.
Both the Orchestration and Grid Management compo-nents will be allocated the equivalent of a single physicalhost each, due to heavy memory requirements, and up to 4Condor Execution components may be deployed on a sin-gle physical host, limiting the maximum cluster size to 16
nodes. This mapping however is transparent to the ServiceManager, Service Provider and application.
6.1.3 Metrics
It is also important to briefly describe the characteristicsofthe overall application workflow, in order to determine ap-propriate metrics for the experiment. Our primary indica-tor of quality of service is the overallturn around timeofa prediction. The turn around time can be defined as theamount of time elapsed between the moment a client userrequests a search to the moment results are displayed on theweb page. As previously stated, the overall process com-bines functionality from a number of different Fortran pro-grams into a larger workflow. Based on our selected input,two long running jobs will first be submitted, followed byan additional set of 200 jobs being spawned with each com-pletion to further refine the input. We must also take intoaccount the additional processing time involved in orches-trating the service and gathering outputs.
Another important metric to consider is that of resourceusage. The goal of service elasticity is to reduce expendi-tures by allowing Service Providers to minimise overprovi-sioning. While the actual financial costs will be dependenton the business models employed by Cloud infrastructureproviders, we can at the very least rely upon resource usageas an indicator of cost.
6.1.4 Experiment results
We compare turn-around time and resource usage obtainedon our Cloud infrastructure with elasticity support withthat obtained in an environment with dedicated physical re-sources. The objective is to verify that there are no strongvariations in turn around time, but a significant reductionin resource usage. The results are illustrated in Figure 11.The number of queued jobs is plotted against the numberof Condor execution instances deployed. Both charts showlarge increases in queued jobs as the first long running jobscomplete and the larger sets are submitted. In addition, thefirst chart represents the execution of the application in adedicated environment and shows a set of 16 continuouslyallocated execution nodes. The second chart represents theexecution of the application with elasticity support, showsthe increase in the number of allocated nodes as jobs inqueue increases, and a complete deallocation as these jobscomplete. The overall turn around time and resource usageobtained is described in Table 3.
As we can see from the results, a 7.15% increase in turnaround time occurs. As there is little difference in executiontimes in the individual batches of jobs on either the ded-icated or virtual cluster, the increase in turn around timecomes primarily from the additional time that is taken to

18
!"
!#"
!##"
!###"#"
!#"
$#"
%#"
&#"
'#"
(#"
)#"
*#"
+#"
!##"
!!#"
!$#"
!%#"
!&#"
!'#"
!(#"
!"#$%&'$"()*'$+
,-.'+/.01+
23'*(4"0+5-67+8'8-*96'8+$'):-*'+
,-./"01"23434" 5311016"7-84/"
!"
!#"
!##"
!###"
#"
!#"
$#"
%#"
&#"
'#"
(#"
)#"
*#"
+#"
!##"
!!#"
!$#"
!%#"
!&#"
!'#"
!(#"
!"#$%&'$"()*'$+
,-.'+/.01+
23'*(4"0+5-67+890:.-*+$');-*'+8'<="9.'06+
,-./"01"23434" 5311016"78/"
Fig. 11 Job Submission and Resource Availability
Dedicated CloudEnvironment Infrastructure
Search turn around time (s) 8605 9220Complete shutdown time (s) N/A 9574
Average execution nodesfor run 16 10.49
until shutdown N/A 10.42Percentage differencesResource usage saving 34.46%
Extra run time (jobs) 7.15%
Table 3 Experiment Results
create and deploy new instances of the Condor executionservice as jobs are added in the queue. This can be verifiedin Figure 11, where a small delay can be observed betweenincreases in the number of jobs in queue, and the increasein Condor execution services. The overhead incurred is dueto the deployment process, which will involve duplicatingthe disk image of the service, deploying it on a local hyper-visor, and booting the virtual machine, and the registrationprocess, which is the additional time required for the serviceto become fully operational as the running daemons registerthemselves with the grid management service. There existsways of reducing this overhead independently of the Cloudcomputing infrastructure, at the expense of resource usage,such as relying on pre-existing images to avoid replication.
A 10 minute increase of time in can however be consti-tuted as reasonable considering the overall time frame of asearch, which is well over 2 hours. This is particularly trueas we consider the overall resource usage savings. Indeedas can be seen in the table, with respect to execution nodes,the overall resource usage decreases by 34.46% by relyingon service elasticity. This is because the totality of the exe-cution nodes are not required for the initial bulk of the run,where only 2 jobs are to be run. It is only in the second stagethat more nodes are required to handle the additional jobs.
Of course the savings here are only considered in thecontext of the run itself. If we consider the overall use of theapplication over the course of a randomly selected week on
a fully dedicated environment where resources are continu-ously available, even more significant cost savings will exist.Examining logs of searches conducted during this period,and based on cost savings obtained here, we have estimatedthat overall resource consumption would drop by 69.18%,due to the fact that searches are not run continuously; nosearches were run on two days of the week, and searches,though of varying size, were run only over a portion of theday, leaving resources unused for considerable amounts oftime.
7 Related Work
Much of this work builds on the foundation previously es-tablished with SLAs, where we used a model denotationalapproach to specify service level agreements for web-basedapplication services [29]. In this paper, we have aimed tobroaden the approach to encapsulate Cloud computing prim-itives and environment, providing a specification for a man-ifest language describing software architecture, physical re-quirements, constraints and elasticity rules.
In addition, it is worth examining research developmentsrelated to service virtualisation, grid computing and com-ponent based software architecture description languages.With respect to virtual environment deployment descrip-tions, the manifest language proposed here builds upon theOpen Virtualisation Format (OVF) [10], whose limitationshave already been discussed.
There exists a number of software architecture descrip-tion languages which serve as the run-time configurationand deployment of component based software systems. TheCDDLM Component Model [32], for example, outlines therequirements for creating a deployment object responsiblefor the lifecycle of a deployed resource with focus on gridservices. Each deployment object is defined using the CDLlanguage. The model also defines the rules for managing the

19
interaction of objects with the CDDML deployment API.Though the type of deployment object is not suited to vir-tual machine management, the relationship between objectsand the deployment API can be compared to our approachwe have undertaken here, providing a semantic definition forthe CDL language. However in our case the relationship be-tween domain and syntactic models is performed at a higherlevel of abstraction, relying on OCL to provide behaviouralconstraints. Our specification is hence free of implementa-tion specific concerns.
The general approach to dynamic and automated provi-sioning may also be compared to the self-managing com-puting systems associated with autonomic computing re-search [14]. While our approach to elasticity isexplicit, inthat providers define appropriate scaling rules based on anevent condition action model, we have laid a foundationfor further methods to be developed relying on predictiveand autonomic mechanisms to anticipate future allocationchanges and further minimise over-provisioning, providingmonitoring channels and a rule based framework for the dy-namic management of services.
Finally it is important to examine current developmentsin production level Cloud environments, such as Amazon’sEC2 offering [1]. In particular, auto-scaling has been intro-duced by Amazon to allow allocated capacity to be auto-matically scaled according to conditions defined by a serviceprovider. These conditions are defined based on observed re-source utilisation, such as CPU utilisation, network activityor disk utilisation. Whilst the approach laid out in this papercan be used to define elasticity rules based on such metrics,this can prove limiting. With respect to the evaluation, theneed to increase the cluster size cannot be identified throughthese metrics as we require an understanding of the schedul-ing process. The ability to describe and monitor applicationstate is crucial if we wish to correctly anticipate demand.
In addition, the focus of our paper has primarily beenon Infrastructure-as-a-Service Clouds. Nevertheless it is stillimportant to briefly discuss the relevance of this work withrespect to Platform-as-a-Service (PaaS) Clouds such as Win-dows Azure [18]. PaaS Clouds provide an additional levelof abstraction over IaaS Clouds, providing a runtime envi-ronment for the execution of application code and a set ofadditional software services, such as communication proto-cols, access control, persistence, etc. Windows Azure allowsservices to be described as distributed entities: clients canspecify the interfaces exposed by services, communicationend points, channels and roles (web or worker) and differenthardware requirements may be allocated. However a need tocontrol the management, distribution and lifecycle of multi-component systems still exists, though with the added bene-fit of application specific operations being more readily ex-posed to the infrastructure. How this is implemented will betied to the specifics of the platform itself but we do believe
there is potential to adapt many aspects of our approach tothe platform specific interfaces and tools.
8 Conclusion and Future Work
In this paper, we have proposed an abstract syntax and se-mantic definition for a service manifest language whichbuilds on the OVF standard and enables service re-quirements, deployment constraints (placement, co-locationand startup/stopping order) and elasticity rules to be ex-pressed. We believe that clear behavioural semantics are ofparamount importance to meet quality goals of both the Ser-vice and Infrastructure provider. Our model-driven approachaims to strengthen the design of the RESERVOIR stack,identifying functional capabilities that should be present andconstraints the system should observe. We also explored therelationship between a novel RESERVOIR monitoring in-frastructure and service manifest, focusing particularlyonnotions such as data dictionary and the KPIs defined at theabstract layer. Such relationship has served to drive the im-plementation of the monitoring infrastructure.
We have shown experimentally that the implementationof these concepts is feasible and that a complete architecturedefinition that uses our manifest syntax can enable Cloudcomputing infrastructure to realise significant savings inre-source usage, with little impact on overall quality of ser-vice. Given that a Cloud can deliver a near similar qualityof service as a dedicated computing resource, Clouds thenhave a substantial number of advantages. Firstly applica-tion providers do not need to embark on capital expendi-ture and instead can lease the infrastructure when they needit. Secondly, because the elasticity rules enable the appli-cation provider to flexibly expand and shrink their resourcedemands so they only pay the resources that they actuallyneed. Finally, the Cloud provider can plan its capacity moreaccurately because it knows the resource demands of the ap-plications it provides.
While Cloud computing is still a relatively newparadigm, and as such changes in standards, infrastructuralcapabilities and component APIs are inevitable, defining thesoftware architecture of services hosted on a Cloud with re-spect to the capabilities of the underlying infrastructureiskey to optimizing resource usage. This allows us to bridgethe gap between application and infrastructure and providesthe means for providers to retain some control over the man-agement process.
Our work paves the way towards quality of service awareservice provisioning. In future work, we aim to develop ap-propriate syntax and semantics for resource provisioningservice level agreements. Building upon the approach laidout here, we aim to provide a framework for the automatedmonitoring and protection of service level obligations basedon defined semantic constraints.

20
References
1. Amazon (2006) Amazon Elastic Compute Cloud (Ama-zon EC2). [Online] http://aws.amazon.com/ec2
2. Andreozzi S, De Bortoli N, Fantinel S, Ghis-elli A, Rubini GL, Tortone G, Vistoli MC (2005)GridICE: A monitoring service for grid systems.Future Gener Comput Syst 21(4):559–571, DOIhttp://dx.doi.org/10.1016/j.future.2004.10.005
3. Armbrust M, Fox A, Griffith R, Joseph AD,Katz RH, Konwinski A, Lee G, Patterson DA,Rabkin A, Stoica I, Zaharia M (2009) Abovethe clouds: A berkeley view of cloud computing.Tech. Rep. UCB/EECS-2009-28, EECS Depart-ment, University of California, Berkeley, URLhttp://www.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.html
4. Barham P, Dragovic B, Fraser K, Hand S, Harris T, HoA, Neugebauer R, Pratt I, Warfield A (2003) Xen andthe art of virtualization. In: SOSP ’03: Proceedings ofthe nineteenth ACM symposium on Operating systemsprinciples, ACM Press, New York, NY, USA, pp 164–177, DOI http://doi.acm.org/10.1145/945445.945462
5. Chapman C, Emmerich W, Marquez FG, Clayman S,Galis A (2010) Software Architecture Definition forOn-demand Cloud Provisioning. In: 19th ACM Inter-national Symposium on High Performance DistributedSystems, ACM
6. Cherkasova L, Gardner R (2005) Measuring CPU over-head for I/O processing in the Xen virtual machinemonitor. In: Proceedings of the USENIX annual tech-nical conference, pp 387–390
7. Clayman S, Galis A, Chapman C, Toffetti G, Rodero-Merino L, Vaquero L, Nagin K, Rochwerger B (2010)Monitoring service clouds in the future internet. In: To-wards the Future Internet - Emerging Trends from Eu-ropean Research, IOS Press
8. Clayman S, Galis A, Mamatas L (2010) Monitoring vir-tual networks with lattice. In: Management of Future In-ternet - ManFI 2010, URL http://www.manfi.org/2010/
9. Cooke A, Gray AJG, Ma L, Nutt W, et al (2003) R-GMA: An information integration system for grid mon-itoring. In: Proceedings of the 11th International Con-ference on Cooperative Information Systems, pp 462–481
10. DMTF (2009) Open Virtualization Format. Specifica-tion DSP0243 v1.0.0, Distributed Management TaskForce
11. DROOLS (2010) DROOLS. [Online]http://jboss.org/drools
12. Emmerich W, Butchart B, Chen L, Wassermann B,Price SL (2005) Grid Service Orchestration usingthe Business Process Execution Language (BPEL).
Journal of Grid Computing 3(3-4):283–304, URLhttp://dx.doi.org/10.1007/s10723-005-9015-3
13. Galan F, Sampaio A, Rodero-Merino L, Loy I, Gil V,Vaquero LM, Wusthoff M (2009) Service specificationin cloud environments based on extensions to open stan-dards. In: Fourth International Conference on COM-munication System softWAre and middlewaRE (COM-SWARE 2009)
14. Ganek A, Corbi T (2003) The dawning of the autonomiccomputing era. IBM Systems Journal 42(1):5–18
15. IBM (2007) IBM blue cloud. [Online] http://www-03.ibm.com/press/us/en/pressrelease/22613.wss
16. Mamatas L, Clayman S, Charalambides M, Galis A,Pavlou G (2010) Towards an information managementoverlay for the future internet. In: IEEE/IFIP NOMS2010
17. Massie ML, Chun BN, Culler DE (2003) The gangliadistributed monitoring system: Design, implementationand experience. Parallel Computing 30:2004
18. Microsoft (2008) Windows Azure Platform. [Online]http://www.microsoft.com/windowsazure/
19. Nagios (1999) Nagios. [Online] http://www.nagios.org/20. Newman H, Legrand I, Galvez P, Voicu R, Cirstoiu C
(2003) MonALISA : A distributed monitoring servicearchitecture. In: Proceedings of CHEP03, La Jolla, Cal-ifornia
21. OASIS (2007) Web Service Business Process ExecutionLanguage Version 2.0 Specification. OASIS standard
22. Object Management Group (2006) Meta Object FacilityCore Specification 2.0, OMG Document, formal/2006-01-01
23. Object Management Group (2006) Object ConstraintLanguage (OCL) 2.0, OMG Document, formal/2006-05-01
24. OpenNebula (2010) OpenNebula: The OpenSource Toolkit for Cloud Computing. [Online]http://www.opennebula.org
25. Rochwerger B, Breitgand D, Levy E, Galis A, Nagin K,Llorente L, Montero R, Wolfsthal Y, Elmroth E, CaceresJ, Ben-Yehuda M, Emmerich W, Galan F (2009) TheRESERVOIR Model and Architecture for Open Feder-ated Cloud Computing. IBM Systems Journal SpecialEdition on Internet Scale Data Centers 53(4)
26. Rochwerger B, Galis A, Levy E, Caceres J, BreitgandD, Wolfsthal Y, Llorente I, Wusthoff M, Montero R,Elmroth E (2009) RESERVOIR: Management Tech-nologies and Requirements for Next Generation ServiceOriented Infrastructures. In: The 11th IFIP/IEEE Inter-national Symposium on Integrated Management,(NewYork, USA), pp 1–5
27. SAP (2003) SAP Enterprise Resource Planning.[Online] http://www.sap.com/solutions/business-suite/erp/index.epx

21
28. Skene J, Emmerich W (2005) Engineering runtimerequirements-monitoring systems using MDA tech-nologies. Lecture notes in computer science 3705:319
29. Skene J, Lamanna DD, Emmerich W (2004) Preciseservice level agreements. In: ICSE ’04: Proceedingsof the 26th International Conference on Software En-gineering, IEEE Computer Society, Washington, DC,USA, pp 179–188
30. Srinivasan R (1995) XDR: eXternal Data Representa-tion standard
31. Sugerman J, Venkitachalam G, Lim BH (2001)Virtualizing I/O Devices on VMware Workstation’sHosted Virtual Machine Monitor. In: Proc. of the2001 USENIX Annual Technical Conference, Usenix,Boston, Mass
32. Tatemura J (2006) CDDLM Configuration DescriptionLanguage Specification 1.0. Tech. rep., Open Grid Fo-rum
33. Thain D, Tannenbaum T, Livny M (2002) Condor andthe Grid. In: Berman F, Fox G, Hey T (eds) Grid Com-puting: Making the Global Infrastructure a Reality, JohnWiley & Sons Inc.
34. UCL (2008) UCL MDA Tools. [Online]http://uclmda.sourceforge.net/
35. Vaquero LM, Rodero-Merino L, Caceres J, Lindner M(2009) A break in the clouds: towards a cloud definition.SIGCOMM Comput Commun Rev 39(1):50–55, DOIhttp://doi.acm.org/10.1145/1496091.1496100
36. Warmer J, Kleppe A (2003) The Object Constraint Lan-guage: Getting Your Models Ready for MDA. Addison-Wesley Longman Publishing Co., Inc., Boston, MA,USA













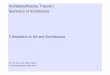












![CRM on Demand Architecture - McGuinness v03[1]](https://img.pdfslide.net/doc/110x75/55cf9d0f550346d033ac159d/crm-on-demand-architecture-mcguinness-v031.jpg)


