Embed Size (px)
Citation preview

1
SOME WORKLOAD SCHEDULING ALTERNATIVES IN THE HIGH PERFORMANCE COMPUTING ENVIRONMENT
Tyler A. Simon, University of Maryland, Baltimore
CountyJim McGalliard, FEDSIM
CMG 2013 National ConferenceSession 424
November 7, 2013 - La Jolla

2
TOPICSHPC WORKLOADSBACKFILLMAPREDUCE & HADOOPHADOOP WORKLOAD SCHEDULINGALTERNATIVE PRIORITIZATIONSALTERNATIVE SCHEDULESDYNAMIC PRIORITIZATIONSOME DYNAMIC PRIORITIZATION RESULTSCONCLUSIONS

3
HPC WorkloadsCurrent generation HPCs have many CPUs – say,
1,000 or 10,000. Scale economies of clusters of commodity processors made price/performance of custom-designed processors too expensive.
Typical HPC applications map some system, e.g., a physical system like the Earth’s atmosphere – into a matrix.

4
HPC Workloadse.g., the Cubed Sphere…

5
HPC WorkloadsMathematical systems, such as systems of
linear equationsPhysical systems, such as particle or
molecular physicsLogical systems, including more recently web
activity, of which more later

6
HPC WorkloadsThe application software simulates the behavior or
dynamics of the system represented by assigning parts of the system to nodes of the cluster. After processing, final results are collected from the nodes.
Often, applications can represent the behavior of the system of interest more accurately by using more nodes.
Mainframes optimize the use of the expensive processor resource by dispatching new work on it when the current workload no longer requires it, e.g., at the start of an I/O operation

7
HPC WorkloadsIn contrast to a traditional mainframe workload, HPC jobs
may use hundreds or thousands of processor nodes simultaneously.
Halting job execution on 1,000 CPUs so that a single CPU can start an I/O operation is not efficient.
Some HPCs have checkpoint/restart capabilities that could allow job interruption and also easier recovery from a system failure. Most do not.
On an HPC system, typically, once a job is dispatched, it is allowed to run uninterrupted until completion.
(More on that later.)

8
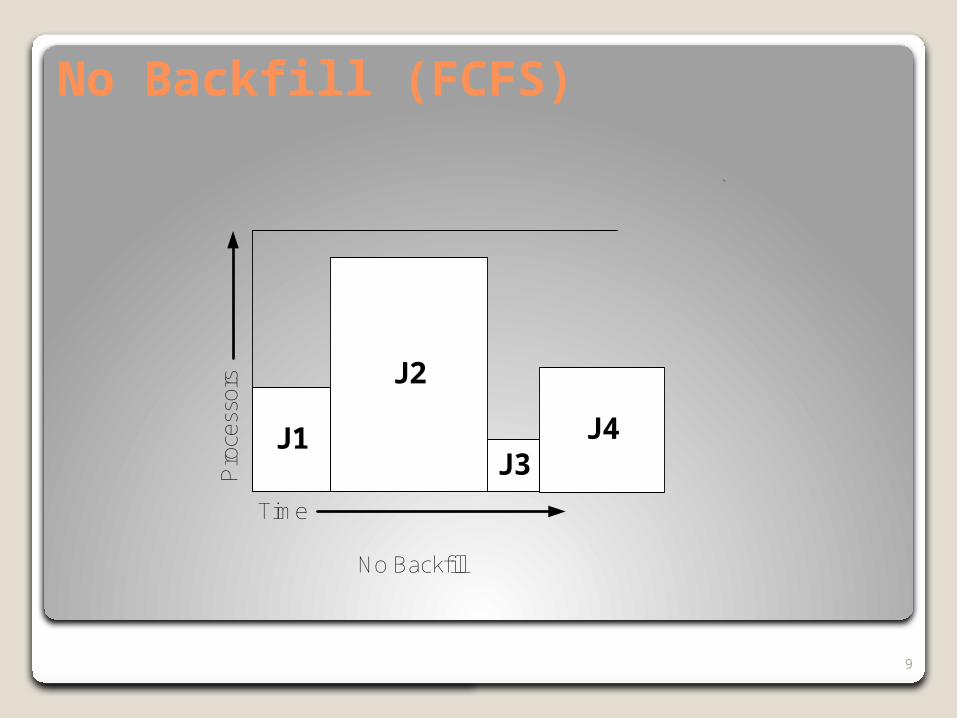
Backfill
HPCs are usually over-subscribed.
Backfill is commonly used to increase processor utilization in an HPC environment.
9
No Backfill (FCFS)
J1
J2
J3
Time
Pro
cess
ors
`
J4
No Backfill
10
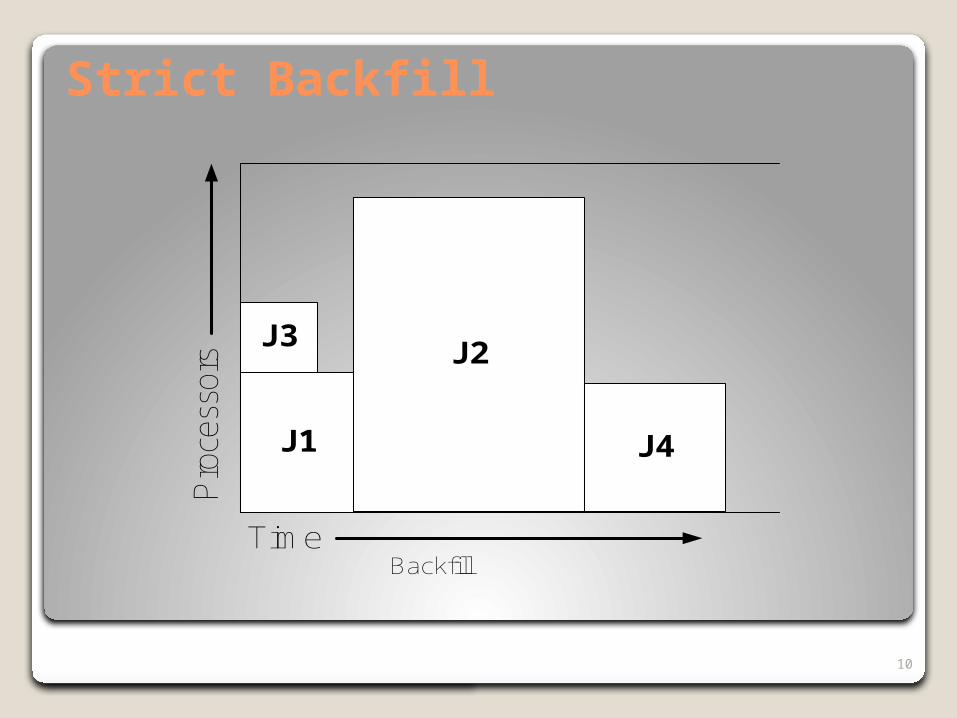
Strict Backfill
J1
J2J3
Time
Pro
cess
ors
J4
Backfill
11
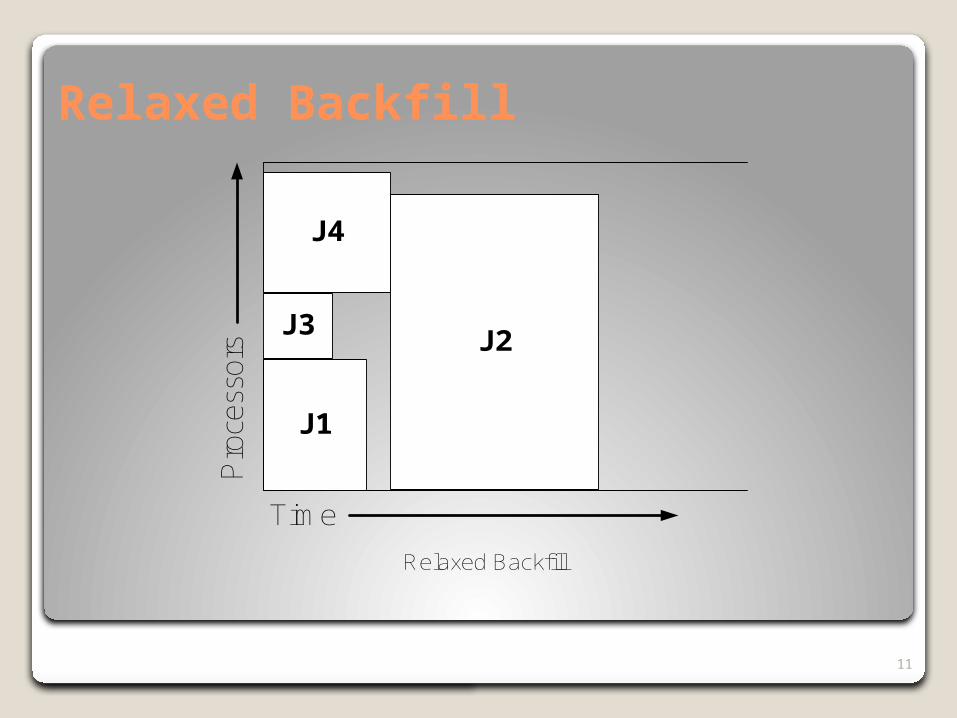
Relaxed Backfill
J1
J2J3
Time
Pro
cess
ors
J4
Relaxed Backfill

12
MapReduce
Amdahl’s Law explains why it is important in an HPC environment for the application to be coded to exploit parallelism.
Doing so – programming for parallelism - is an historically difficult problem.
MapReduce is a response to this problem.

13
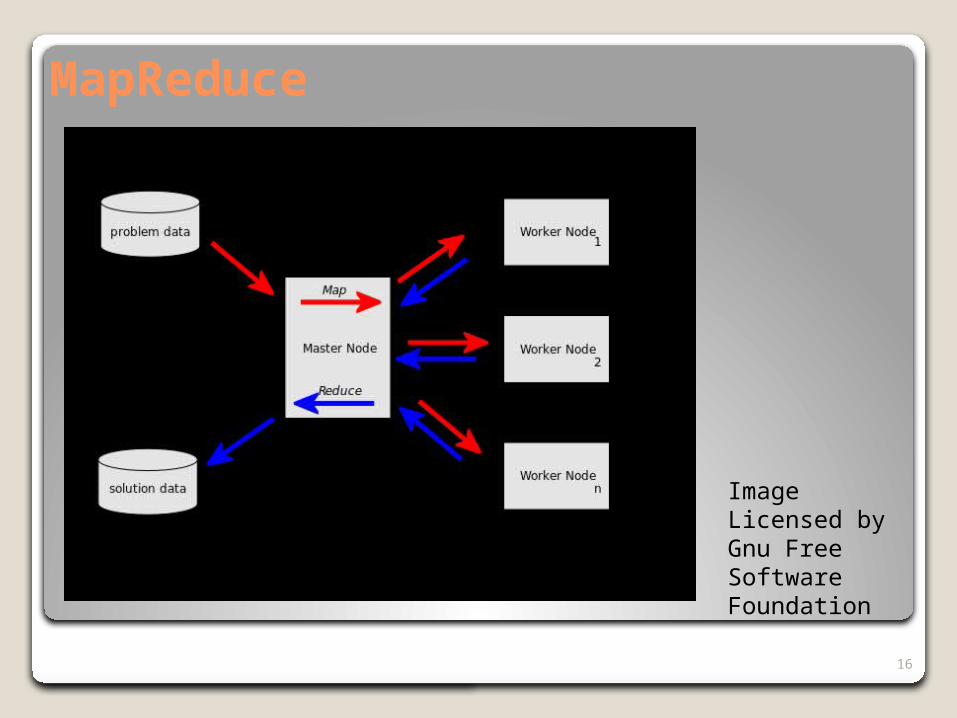
MapReduceMapReduce is a simple method for implementing
parallelism in a program. The programmer inserts map() and reduce() calls in the code. The compiler, dispatcher, and operating system take care of distributing the code and data onto multiple nodes.
The map() function distributes the input file data onto many disks and the code onto many processors. The code processes this data in parallel. For example, weather parameters in discrete patches of the surface of the globe.

14
MapReduce
The reduce() function gathers and combines the data from many nodes into one and generates the output data set.
MapReduce makes it easier for programmers to implement parallel versions of their applications by taking care of the distribution, management, shuffling, and return to and from the many processors and their associated data storage.

15
MapReduce
MapReduce also improves reliability by distributing the data redundantly.
And takes care of load-balancing and performance optimization by distributing the code and data fairly among the many nodes in the cluster.
MapReduce may also be used to implement prioritization by controlling the number of map and reduce slots created and allocated to various users, classes of users, or classes of jobs – the more slots allocated, the faster that user or job will run.
16
MapReduce
Image Licensed by Gnu Free Software Foundation

17
MapReduce
MapReduce was originally developed for use by small teams where FIFO or “social scheduling” was sufficient for workload scheduling.
It has grown to be used for very large problems, such as sorting, searching, and indexing large data sets.
Google uses MapReduce to index the world wide web and holds a patent on the method.
MapReduce is not the only framework for parallel processing and has opponents as well as advocates.

18
HADOOPHadoop is a specific open source implementation of
the MapReduce framework written in Java and licensed by Apache
It includes a distributed file systemDesigned for very large (thousands of processors)
systems using commodity processors, including grid systems
Implements data replication for checkpoint (failover) and locality
Locality of processors with their data help network bandwidth

19
Applications of Hadoop
Data intensive applicationsApplications needing fault
toleranceNot a DBMSYahoo; Facebook; LinkedIn;
AmazonWatson, the IBM system that won
on Jeopardy, used Hadoop
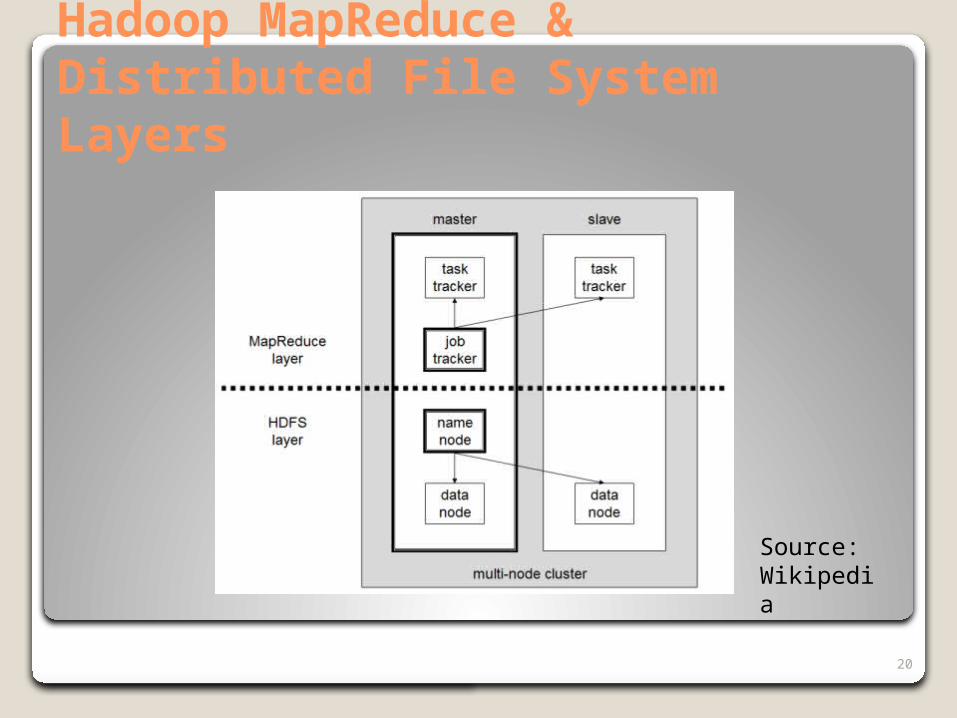
20
Hadoop MapReduce & Distributed File System Layers
Source: Wikipedia

21
Hadoop Workload Scheduling
Task Tracker attempts to dispatch processors on nodes near the data (e.g., same rack) the application requires. Hadoop HDFS is “rack aware”
Default Hadoop scheduling is FCFS=FIFOWorkload scheduling to optimize data locality and
also optimize processor utilization are in conflictThere are various alternatives to HDFS and the
default Hadoop scheduler

22
Some Prioritization Alternatives
Wait Time Run Time Number of ProcessorsQueueComposite PrioritiesDynamic PrioritiesEtc.

23
Some Scheduling Alternatives
Global Vs. Local Scheduling Resource-Aware Scheduling Phase-Based Scheduling Delay Scheduling Copy-Compute Splitting Preemption and Interruption Social Scheduling Budget-Based Scheduling

24
Dynamic Prioritization
Bill Ward and Tyler Simon, among others, have proposed setting job priorities as the function of multiple factors; these can change in real time:
(Est’d Proc Time)Proc Parameter
* (Wait Time)Wait Parameter
* (CPUs Requested)CPU Parameter
* Queue = Priority
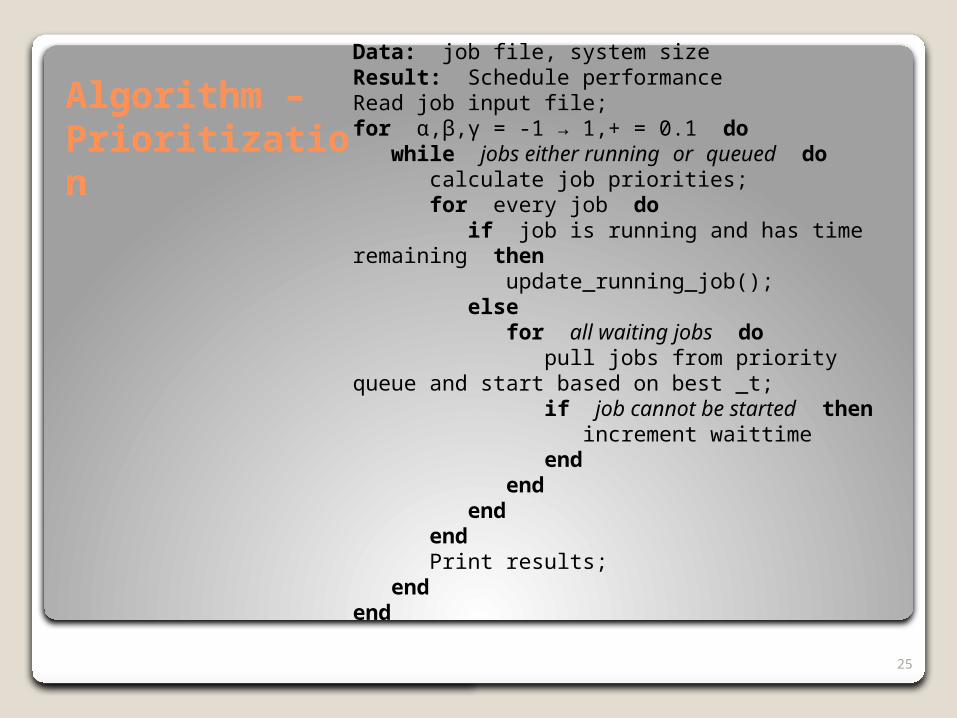
25
Algorithm – Prioritization
Data: job file, system sizeResult: Schedule performanceRead job input file;for α,β,γ = -1 → 1,+ = 0.1 do while jobs either running or queued do calculate job priorities; for every job do if job is running and has time remaining then update_running_job(); else for all waiting jobs do pull jobs from priority queue and start based on best _t; if job cannot be started then increment waittime end end end end Print results; endend

26
Algorithm – Cost EvaluationRequire: C, capacity of the knapsack, n, the number of tasks, a, array of tasks of size nEnsure: A cost vector containing Ef for each job class Cost (A, B, C, D,
WRT).1: i = 02: for α = -2 ≤ 2; α+=0.1 do3: for β = -2 ≤ 2; β+=0.1 do4: for γ = -2 ≤ 2; γ+=0.1 do5: Cost[i++] = schedule(α,β,γ) {For Optimization}6: if cost[i] < bestSoFar then7: bestSoFar = cost[i]8: end if9: end for10: end for11: end for
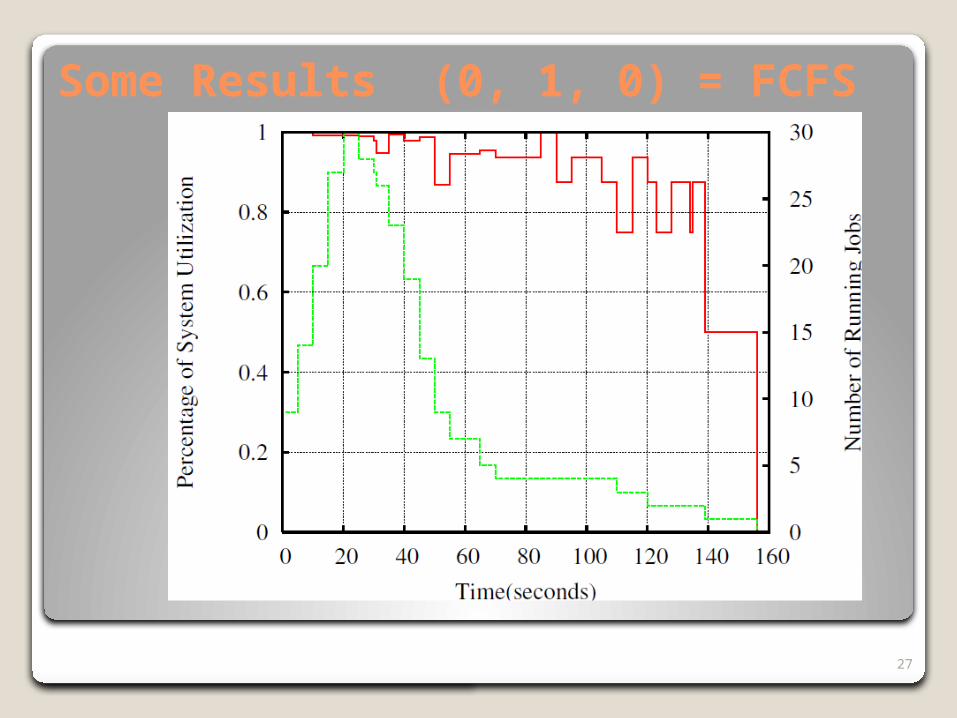
27
Some Results (0, 1, 0) = FCFS
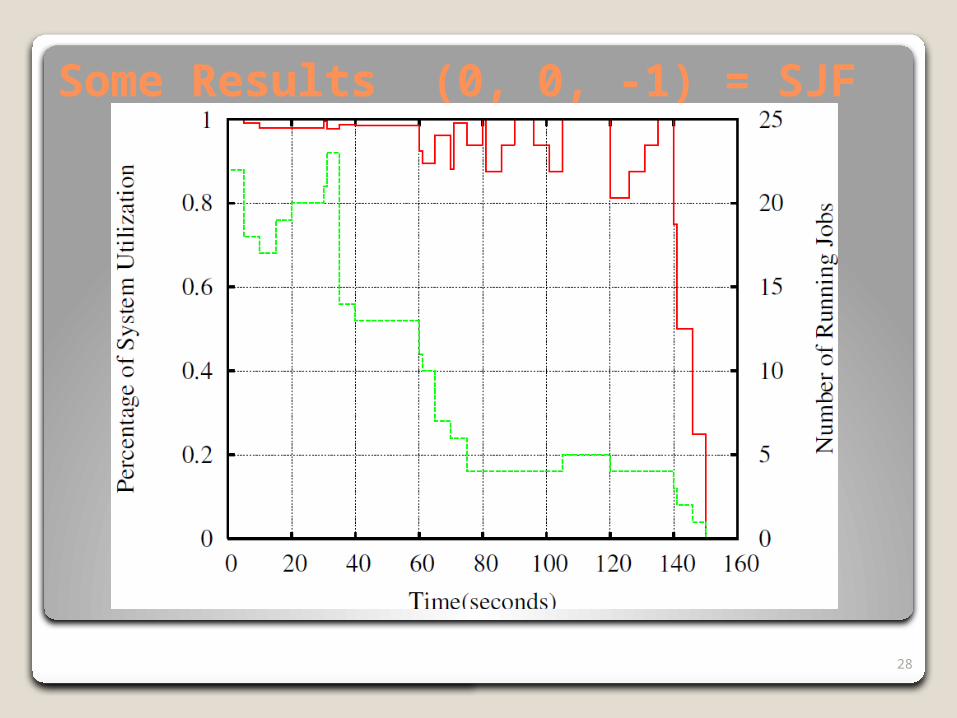
28
Some Results (0, 0, -1) = SJF
29
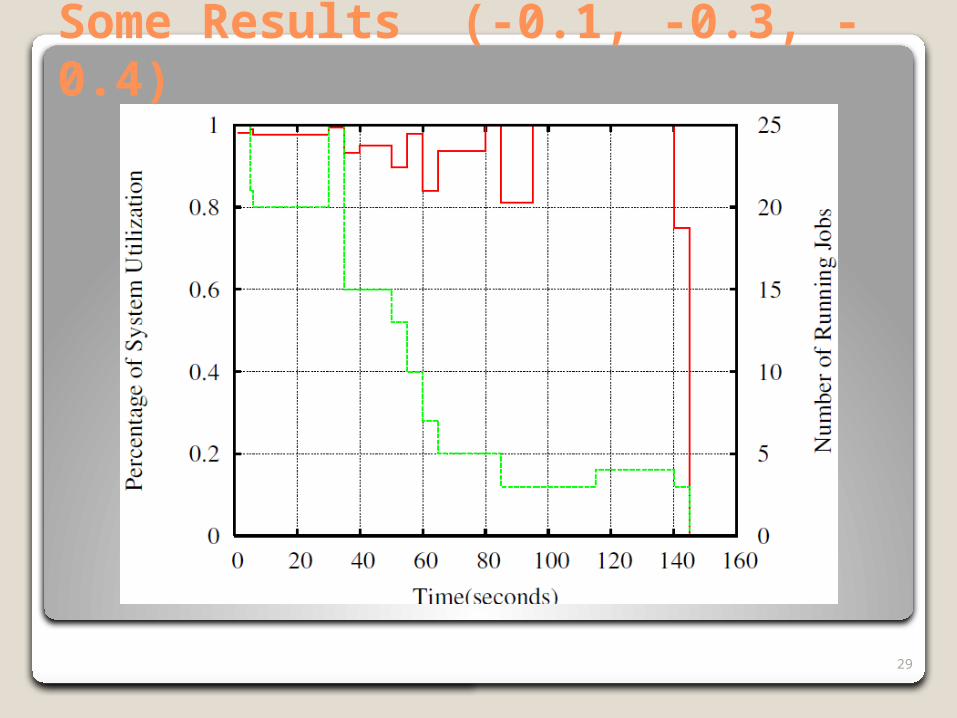
Some Results (-0.1, -0.3, -0.4)
30
Some Results
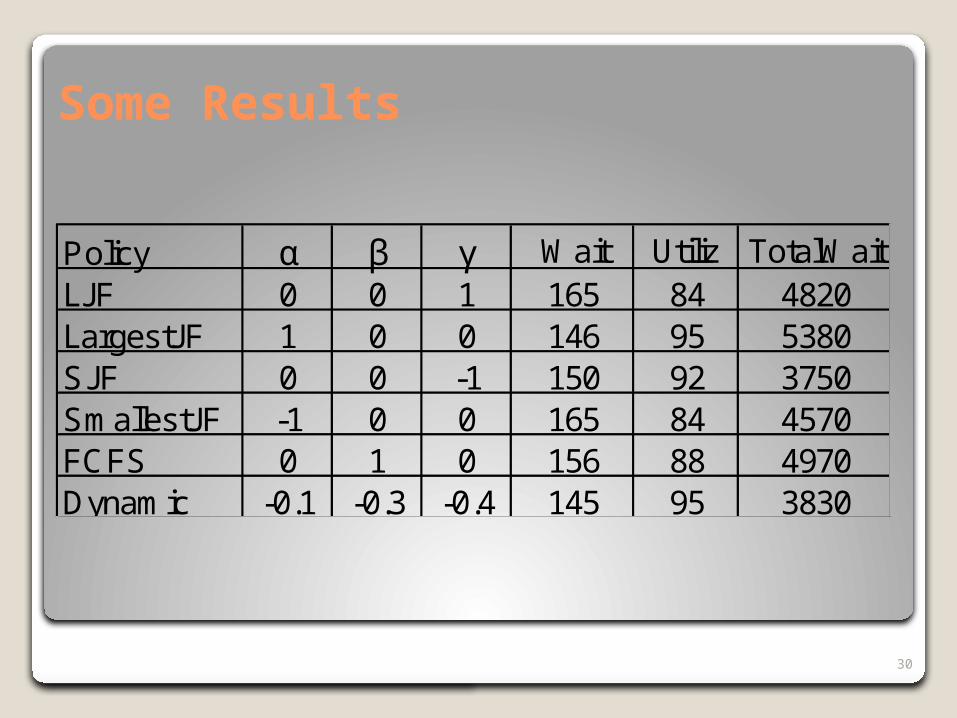
Policy α β γ Wait Utiliz TotalWaitLJF 0 0 1 165 84 4820LargestJF 1 0 0 146 95 5380SJF 0 0 -1 150 92 3750SmallestJF -1 0 0 165 84 4570FCFS 0 1 0 156 88 4970Dynamic -0.1 -0.3 -0.4 145 95 3830

31
Conclusions
Where data center management wants to maximize some calculable objective, it may be possible for an exhaustive search of the parameter space to constantly tune the system and provide near-optimal performance in terms of that function

32
Conclusions We expect new capabilities, e.g., commodity cluster
computers and Hadoop, to continue to inspire new applications. The proliferation of workload scheduling alternatives may be the result of (1) the challenges of parallel programming, (2) the popularity of open source platforms that are easy to customize, and (3) the brief lifespan of MapReduce that has not yet had the chance to mature.






























