Embed Size (px)
Citation preview

Statistik fur IngenieureVorlesung 12
Prof. Dr. Hans-Jorg Starkloff
TU Bergakademie FreibergInstitut fur Stochastik
23. Januar 2017

5.1.1. Tests fur eine Stichprobe mit stetiger Skalaa) Shapiro-Wilk-Test
I Mit dem Shapiro-Wilk-Test uberpruft man, ob die Daten miteiner Normalverteilung vertraglich sind.
I Geg.: konkrete Stichprobe x1, . . . , xn .I Vor.: Merkmalszufallsgroße X auf stetiger Skala; reprasentative
Stichprobe.I Hyp.: H0 : X ist normalverteilt ; H1 : X ist nicht normalverteiltI R-Aufruf: shapiro.test()I Bem.:
I Die Parameter der vermuteten Normalverteilung (Erwartungswert undVarianz) mussen nicht bekannt sein.
I Der Test reagiert sensibel auf Ausreißer.I Der Test ist relativ anfallig gegenuber Bindungen, deshalb sollten die
Werte nicht stark gerundet sein.I Die Teststarke ist insbesondere bei kleinen Stichprobenumfangen
großer als bei allgemeinen Anpassungstests, wie demKolmogorow-Smirnow-Test oder dem χ2−Anpassungstest.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 2
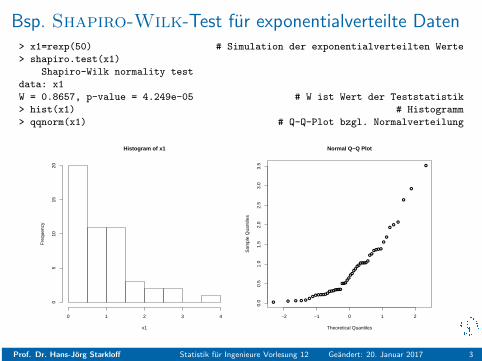
Bsp. Shapiro-Wilk-Test fur exponentialverteilte Daten> x1=rexp(50) # Simulation der exponentialverteilten Werte
> shapiro.test(x1)
Shapiro-Wilk normality test
data: x1
W = 0.8657, p-value = 4.249e-05 # W ist Wert der Teststatistik
> hist(x1) # Histogramm
> qqnorm(x1) # Q-Q-Plot bzgl. Normalverteilung
Histogram of x1
x1
Fre
quen
cy
0 1 2 3 4
05
1015
20
●
●
●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●●
● ●
●●
●
●
●●
●
●●●
−2 −1 0 1 2
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 3
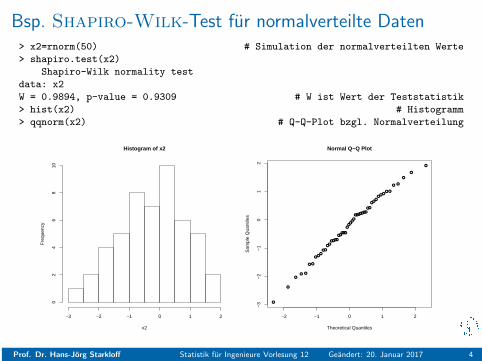
Bsp. Shapiro-Wilk-Test fur normalverteilte Daten> x2=rnorm(50) # Simulation der normalverteilten Werte
> shapiro.test(x2)
Shapiro-Wilk normality test
data: x2
W = 0.9894, p-value = 0.9309 # W ist Wert der Teststatistik
> hist(x2) # Histogramm
> qqnorm(x2) # Q-Q-Plot bzgl. Normalverteilung
Histogram of x2
x2
Fre
quen
cy
−3 −2 −1 0 1 2
02
46
810
●
●
●
●
●
●
●
●
●
●
●●●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
●
−2 −1 0 1 2
−3
−2
−1
01
2
Normal Q−Q Plot
Theoretical Quantiles
Sam
ple
Qua
ntile
s
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 4

b) Kolmogorow-Smirnow-Test
I Mit dem Kolmogorow-Smirnow-Test uberpruft man, ob dieDaten mit einer vorgebenen Verteilung vertraglich sind.
I Geg.: konkrete Stichprobe x1, . . . , xn .
I Vor.: Merkmalszufallsgroße X auf stetiger Skala; reprasentativeStichprobe.
I Hyp.:H0 : FX = F0 (Verteilungsfunktion von X ist F0) ;H1 : FX 6= F0 (Verteilungsfunktion von X ist nicht F0) .
I R-Aufruf: ks.test(,)
I Bem.:I Die Verteilungsfunktion F0 muss vollstandig bekannt sein,
insbesondere alle Parameter.I Es gibt Varianten des Tests fur spezielle Falle mit geschatzten
Parametern.I Der Test ist relativ anfallig gegenuber Bindungen, deshalb sollten die
Werte nicht stark gerundet sein.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 5

Bsp. Kolmogorow-Smirnow-Test mit R> x1=rexp(50) # Simulation der exponentialverteilten Werte (Parameter=1)
> ks.test(x1,"pexp") # Test auf Exponentialverteilung mit Parameter=1
One-sample Kolmogorov-Smirnov test
data: x1
D = 0.1029, p-value = 0.6279 # D ist Wert der Teststatistik
alternative hypothesis: two-sided
> ks.test(x1,"pexp",2) # Test auf Exponentialverteilung mit Parameter=2
One-sample Kolmogorov-Smirnov test
data: x1
D = 0.2696, p-value = 0.001061 # D ist Wert der Teststatistik
alternative hypothesis: two-sided
> x2=rnorm(50) # Simulation der normalverteilten Werte
> ks.test(x2,"pnorm")
One-sample Kolmogorov-Smirnov test
data: x2
D = 0.12592, p-value = 0.3747 # D ist Wert der Teststatistik
alternative hypothesis: two-sided
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 6

c) χ2− Anpassungstest
I Mit dem χ2− Anpassungstest uberpruft man, ob die Daten miteiner vorgebenen Verteilung vertraglich sind.
I Geg.: konkrete Stichprobe x1, . . . , xn .
I Vor.: Merkmalszufallsgroße X auf stetiger Skala (auch fur anderemoglich); reprasentative Stichprobe.
I Hyp.:H0 : FX = F0 (Verteilungsfunktion von X ist F0) ;H1 : FX 6= F0 (Verteilungsfunktion von X ist nicht F0) .
I R-Aufruf: chisq.test(,)
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 7

Bemerkungen zum χ2− Anpassungstest
I Der χ2−Anpassungstest fur stetige Daten basiert auf einerKlasseneinteilung der Stichprobe und dem Vergleich dertheoretischen Haufigkeiten der Werte in den Klassen mit denempirischen Haufigkeiten.
I Die Testgroße ist unter H0 asymptotisch χ2−verteilt, dies ist einehaufiger vorkommende statistische Prufverteilung mit einemParameter, der Anzahl der Freiheitsgrade genannt wird. Sie kann nurnichtnegative Werte annehmen.
I Die theoretische Haufigkeit sollte pro Klasse mindestens 5 sein.
I Der Wert der Testgroße (und damit ggf. das Testergebnis) hangtvon der gewahlten Klasseneinteilung ab, außerdem ist es nur einasymptotischer Test.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 8

Bsp. χ2− Anpassungstest mit R> x2=rnorm(50) # Simulation der normalverteilten Werte
> x2 cut=cut(x2,breaks=c(-3,-2,-1,0,1,2)) # Klasseneinteilung
> table(x2 cut)
x2 cut
(-3,-2] (-2,-1] (-1,0] (0,1] (1,2]
3 9 15 16 7
> freq emp=vector() # Vektor der empirischen Haufigkeiten
> for(i in 1:5) freq emp[i]=table(x2 cut)[[i]]
> freq emp
[1] 3 9 15 16 7
> freq th=c(pnorm(-2)-pnorm(-3),pnorm(-1)-pnorm(-2), pnorm(0)-pnorm(-1),
+ pnorm(1)-pnorm(0),pnorm(2)-pnorm(1))
> freq th # Vektor der theoretischen Haufigkeiten
[1] 0.02140023 0.13590512 0.34134475 0.34134475 0.13590512
> chisq.test(freq emp,freq th)
Pearson’s Chi-squared test
data: freq emp and freq th
X-squared = 10, df = 8, p-value = 0.265
Warnmeldung:
In chisq.test(freq emp, freq th) :
Chi-Quadrat-Approximation kann inkorrekt sein
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 9

d) Ein-Stichproben-t-Test
I Mit dem Ein-Stichproben-t-Test werden Annahmen uber denErwartungswert einer normalverteilten Grundgesamtheit beiunbekannter Varianz uberpruft.
I Geg.: konkrete Stichprobe x1, . . . , xn .
I Vor.: normalverteilte Merkmalszufallsgroße X mit unbekanntemErwartungswert µ und unbekannter Varianz σ2 ; reprasentativeStichprobe.
I Hyp.:H0 : µ = µ0 (µ0 ist gegebene (Soll-)Große) ;H1 : µ 6= µ0 (zweiseitig) bzw. µ < µ0 oder µ > µ0 (einseitig) .
I R-Aufruf: t.test()
I Bem.: Die Testgroße ist hier T =X − µ0
S
√n, diese ist unter H0
t−verteilt mit n − 1 Freiheitsgraden. Die t−Verteilung oderStudent-Verteilung ist eine weitere oft genutzte statistischePrufverteilung mit einem Parameter (
”Anzahl der Freiheitsgrade“).
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 10

Bsp. Ein-Stichproben-t-Test mit R
I Simulation von Realisierungen N(0, 1)-verteilter Zufallsgroßen.
x=rnorm(50)
I Zweiseitiger t−Test fur H0 : µ = 0 , H1 : µ 6= 0 :
> t.test(x)
One Sample t-test
data: x
t = -0.2207, df = 49, p-value = 0.8263
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.3017750 0.2420545
sample estimates:
mean of x
-0.02986026
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 11

Bsp. Ein-Stichproben-t-Test (einseitig) mit R
I Einseitiger t−Test fur H0 : µ = 0, H1 : µ < 0 :> t.test(x,alternative="less")
One Sample t-test
data: x
t = -0.2207, df = 49, p-value = 0.4131
alternative hypothesis: true mean is less than 0
95 percent confidence interval:
-Inf 0.1969931
sample estimates:
mean of x
-0.02986026
I Einseitiger t−Test fur H0 : µ = 0 , H1 : µ > 0 :> t.test(x,alternative="greater")
One Sample t-test
data: x
t = -0.2207, df = 49, p-value = 0.5869
alternative hypothesis: true mean is greater than 0
95 percent confidence interval:
-0.2567136 Inf
sample estimates:
mean of x
-0.02986026
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 12

Bsp. Ein-Stichproben-t-Test mit R Fortsetzung
I Zweiseitiger t−Test fur H0 : µ = 1 , H1 : µ 6= 1 :> t.test(x,mu=1)
One Sample t-test
data: x
t = -7.6111, df = 49, p-value = 7.546e-10
alternative hypothesis: true mean is not equal to 1
95 percent confidence interval:
-0.3017750 0.2420545
sample estimates:
mean of x
-0.02986026
I Zweiseitiger t−Test fur H0 : µ = −0.1 , H1 : µ 6= −0.1 :> t.test(x,mu=-0.1)
One Sample t-test
data: x
t = 0.5184, df = 49, p-value = 0.6065
alternative hypothesis: true mean is not equal to -0.1
95 percent confidence interval:
-0.3017750 0.2420545
sample estimates:
mean of x
-0.02986026
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 13

e) χ2-Test auf Streuung
I Mit dem χ2-Test auf Streuung werden Annahmen uber die Varianzeiner normalverteilten Grundgesamtheit bei unbekanntemErwartungswert uberpruft.
I Geg.: konkrete Stichprobe x1, . . . , xn .
I Vor.: normalverteilte Merkmalszufallsgroße X mit unbekanntemErwartungswert µ und unbekannter Varianz σ2 ; reprasentativeStichprobe.
I Hyp.:H0 : σ2 = σ20 (σ20 ist eine gegebene (Soll-)Große) ;H1 : σ2 6= σ20 (zweiseitig) bzw. σ2 < σ20 oder σ2 > σ20 (einseitig) .
I R-Aufruf: sigma.test() aus Zusatzpaket”TeachingDemos“.
I Die Testgroße ist hier T =(n − 1)S2
σ20, diese ist unter H0
χ2−verteilt mit n − 1 Freiheitsgraden.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 14

Bsp. 1 χ2-Test auf Streuung mit R
Voraussetzung ist, dass das Programmpaket”TeachingDemos“ vorher
installiert wurde.
> require(TeachingDemos) # Laden des Programmpakets
> x=rnorm(50) # Simulation der normalverteilten Werte
> sigma.test(x)
One sample Chi-squared test for variance
data: x
X-squared = 58.4113, df = 49, p-value = 0.3359
alternative hypothesis: true variance is not equal to 1
95 percent confidence interval:
0.8318045 1.8511005
sample estimates:
var of x
1.192068
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 15

Bsp. 2 χ2-Test auf Streuung mit R
> require(TeachingDemos) # Laden des Programmpakets
> x=rnorm(50) # Simulation der normalverteilten Werte
> sigma.test(x,sigmasq=1.5,alternative="less")
One sample Chi-squared test for variance
data: x
X-squared = 33.8897, df = 49, p-value = 0.04946
alternative hypothesis: true variance is less than 1.5
95 percent confidence interval:
0.000000 1.498204
sample estimates:
var of x
1.037439
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 16

f) Vorzeichentest
I Der Vorzeichentest oder Zeichentest dient als Test uber den Medianeiner stetigen Verteilung.
I Geg.: konkrete Stichprobe x1, . . . , xn .
I Vor.: Merkmalszufallsgroße X auf stetiger Skala; reprasentativeStichprobe.
I Hyp.:H0 : X0.5 = m (m ist ein vorgebener Wert fur den Median) ;H1 : X0.5 6= m .
I R-Aufruf: binom.test(table(x<m)) (fur Datenvektor x).
I Die Testgroße ist die Anzahl der Stichprobenwerte, die großer odergleich dem hypothetischen Wert m fur den Median sind. Sie istunter H0 binomialverteilt mit den Parametern n und p = 0.5 . DerTest heißt deshalb auch Binomialtest (bzw. ist ein Spezialfall davon).
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 17

Bsp. Vorzeichentest
I Der Vorzeichentest wird auf simulierte exponentialverteilte mitParameter λ = 1 Daten angewandt.
Der theoretische Median einer solchen exponentialverteiltenZufallsgroße ist X0.5 = ln(2) = 0.6931472 .
I >x=rexp(30) # Simulation der exponentialverteilten Werte
> binom.test(table(x<log(2)))
Exact binomial test
data: table(x < log(2))
number of successes = 14, number of trials = 30, p-value = 0.8555
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.2834181 0.6567448
sample estimates:
probability of success
0.4666667
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 18

Bsp. Vorzeichentest Fortsetzung
I Bei einem Test auf den (falschen) hypothetischen Medianwertm = 1 erhalt man fur diese Stichprobe folgenden Ausdruck.
I > binom.test(table(x<1))
Exact binomial test
data: table(x < 1)
number of successes = 9, number of trials = 30, p-value = 0.04277
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.1473452 0.4939590
sample estimates:
probability of success
0.3
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 19

Bsp. Vorzeichentest Erlauterung zur Fortsetzung
I Zur Erlauterung der R-Befehle seien hier die Stichprobe undZwischenergebnisse mit angegeben.
I > x
[1] 0.474913225 1.998718750 0.236340651 1.190075521 0.204773207
[6] 1.032235380 0.381776969 0.189361459 1.148530885 0.179905086
[11] 0.367202075 0.016486336 1.634640983 0.579307548 0.841339218
[16] 0.547713449 1.440086523 0.716338951 0.906362104 1.184678989
[21] 0.203456942 0.928086586 0.267522051 4.082806101 0.553727047
[26] 0.037520679 0.003251419 0.054086418 1.102460776 0.914379178
> x<1
[1] TRUE FALSE TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE
[11] TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE TRUE FALSE
[21] TRUE TRUE TRUE FALSE TRUE TRUE TRUE TRUE FALSE TRUE
> table(x<1)
FALSE TRUE
9 21
I Die Erfolgsanzahl im Test (hier 9, die erste der durch table(x<1)
zuruckgegebene Zahl) ist also die Anzahl der Stichprobenwerte, furdie die Bedingung (hier x < 1) nicht erfullt ist.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 20

Bsp. Vorzeichentest (einseitig)
I Einseitige Tests konnen auch durchgefuhrt werden.
I > binom.test(table(x<1),alternative="less")
Exact binomial test
data: table(x < 1)
number of successes = 9, number of trials = 30, p-value = 0.02139
alternative hypothesis: true probability of success is less than 0.5
95 percent confidence interval:
0.0000000 0.4650727
sample estimates:
probability of success
0.3
I Hier wird zum Niveau 0.05 die Hypothese H0 : P(X ≥ 1) = 0.5abgelehnt und die Alternative H1 : P(X ≥ 1) < 0.5 angenommen.Dies bedeutet auch fur den Median, dass er signifikant kleiner als 1ist.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 21

g) Wilcoxon-Vorzeichen-Rang-Test
I Beim Wilcoxon-Vorzeichen-Rang-Test werden Hypothesen uberdas Symmetriezentrum (und damit den Median) einer stetigenVerteilung gepruft.
I Geg.: konkrete Stichprobe x1, . . . , xn .
I Vor.: Merkmalszufallsgroße X mit stetiger und symmetrischerVerteilung ; reprasentative Stichprobe .
I Hyp.:H0 : X0.5 = m (m ist ein vorgebener Wert fur den Median);H1 : X0.5 6= m .
I R-Aufruf: wilcox.test() .
I Die Testgroße nutzt Rangzahlen der Werte xi −m, i = 1, . . . , nund damit mehr Informationen als der Vorzeichentest.
I Bindungen konnen problematisch sein.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 22

Bsp. Wilcoxon-Vorzeichen-Rang-Test
I Der Vorzeichentest wird auf simulierte t−verteilte (mit 10Freiheitsgraden) Daten angewandt. Dies ist eine symmetrischestetige Verteilung mit dem theoretischen Median X0.5 = 0 .
I >x=rt(n=50,df=10) # Simulation von 50 t-verteilten Werten
> wilcox.test(x)
Wilcoxon signed rank test with continuity correction
data: x
V = 627, p-value = 0.9231 # Annahme
alternative hypothesis: true location is not equal to 0
I Ein Test auf den (falschen) Median m = 1 ergibt:
> wilcox.test(x,mu=1)
Wilcoxon signed rank test with continuity correction
data: x
V = 207, p-value = 3.312e-05 # Ablehnung
alternative hypothesis: true location is not equal to 1
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 23

5.1.2. Tests fur eine gepaarte (verbundene) Stichprobe(stetige Skala)
I Gegeben sei nun eine konkrete Stichprobe (xi , yi ), i = 1, . . . , n alsRealisierungen von unabhangigen und identisch verteilten stetigenZufallsvektoren (Xi ,Yi ), i = 1, . . . , n . Fur jedes i beziehen sichdie Werte xi und yi auf ein und dasselbe statistische Individuum,so dass die Zufallsgroßen Xi und Yi nicht als unabhangigangesehen werden konnen.
I Macht die Differenzbildung Di = Xi − Yi , i = 1, . . . , n inhaltlichSinn, dann konnen die Tests aus 5.1.1. auf die neu berechneteStichprobe d1, . . . , dn (die nun univariat ist) angewandt werden,man untersucht somit ein Einstichprobenproblem.
I Dabei sind insbesondere die Tests bezuglich der Lageparameter vonInteresse, da dadurch eine eventuelle Verschiebung der Verteilungder Yi zu den Großen Xi mit Hilfe eines Tests auf einen Medianoder Erwartungswert 0 der Verteilung der DifferenzzufallsgroßenDi , i = 1, . . . , n uberpruft werden kann.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 24

a) Gepaarter t−Test
I Mit dem Ein-Stichproben-t-Test fur D = X − Y oder demgepaarten t−Test fur X und Y wird die Gleichheit derErwartungswerte von X und Y bei einer normalverteiltenDifferenz D = X − Y mit unbekannter Varianz uberpruft.
I Geg.: konkrete gepaarte Stichprobe (x1, y1) . . . , (xn, yn) .
I Vor.: normalverteilte Zufallsgroße D = X − Y mit unbekannterVarianz σ2 ; reprasentative Stichprobe .
I Hyp.:H0 : EX = EY , H1 : EX 6= EY (zweiseitiger Test) bzw.H1 : EX < EY oder H1 : EX > EY (einseitige Tests) .
I R-Aufruf: t.test(x,y,paired=TRUE)
bei Datenvektoren x und y .
I Ausreißer in den Daten konnen Probleme bereiten.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 25

Bsp. 1 gepaarter t−Test
I Simulation einer gepaarten Stichprobe durch Beziehung:fester Wert 2 + simulierte normalverteilte zufallige Fehlerfur die x− und y−Werte jeweils.
I > x=2+rnorm(30,sd=0.1)
> y=2+rnorm(30,sd=0.1)
I Berechnung der Differenzen und Shapiro-Wilk-Test aufNormalverteilung .
I > d=x-y
> shapiro.test(d)
Shapiro-Wilk normality test
data: d
W = 0.9745, p-value = 0.6694 # Annahme
I Durchfuhrung des Ein-Stichproben-t-Tests fur d und desaquivalenten gepaarten t−Tests fur x und y .
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 26
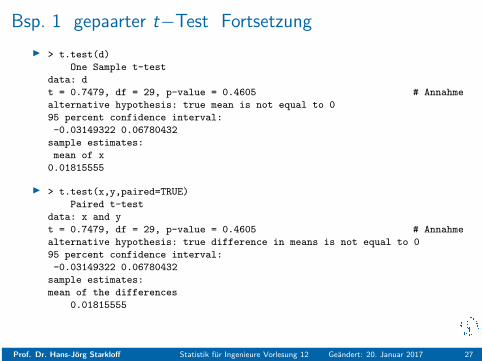
Bsp. 1 gepaarter t−Test Fortsetzung
I > t.test(d)
One Sample t-test
data: d
t = 0.7479, df = 29, p-value = 0.4605 # Annahme
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.03149322 0.06780432
sample estimates:
mean of x
0.01815555
I > t.test(x,y,paired=TRUE)
Paired t-test
data: x and y
t = 0.7479, df = 29, p-value = 0.4605 # Annahme
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.03149322 0.06780432
sample estimates:
mean of the differences
0.01815555
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 27

Bsp. 2 gepaarter t−Test
I Simulation einer gepaarten Stichprobe durch Beziehungen2 (bei x) bzw. 3 (bei y) + simulierte normalverteilte zufallige Fehler.
I > x=2+rnorm(30,sd=0.1)
> y=3+rnorm(30,sd=0.05)
I Berechnung der Differenzen und Shapiro-Wilk-Test aufNormalverteilung .
I > d=x-y
> shapiro.test(d)
Shapiro-Wilk normality test
data: d
W = 0.9887, p-value = 0.9826 # Annahme
I Durchfuhrung des Ein-Stichproben-t-Tests fur d und desaquivalenten gepaarten t−Tests fur x und y .
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 28

Bsp. 2 gepaarter t−Test Fortsetzung
I > t.test(d)
One Sample t-test
data: d
t = -55.026, df = 29, p-value < 2.2e-16 # Ablehnung
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-1.078750 -1.001433
sample estimates:
mean of x
-1.040091
I > t.test(x,y,paired=TRUE)
Paired t-test
data: x and y
t = -55.026, df = 29, p-value < 2.2e-16 # Ablehnung
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.078750 -1.001433
sample estimates:
mean of the differences
-1.040091
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 29

b) Vorzeichentest fur eine gepaarte Stichprobe
I Der Vorzeichentest fur eine gepaarte Stichprobe ist ein Test uber denMedian 0 der stetigen Verteilung von D = X − Y . Bei Ablehnungder Nullhypothese kann man folglich auf eine unterschiedliche
”mittlere Lage“ der x− und der y−Werte schließen.
I Geg.: konkrete gepaarte Stichprobe (x1, y1) . . . , (xn, yn) .
I Vor.: Die Zufallsgroße D = X − Y besitzt eine stetige Verteilung;es liegt eine reprasentative gepaarte Stichprobe vor.
I Hypothesen: H0 : D0.5 = 0 , H1 : D0.5 6= 0 .
I R-Aufruf: binom.test(table(x<y))
bei Datenvektoren x und y .
I Bindungen konnen problematisch sein.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 30

Bsp. Vorzeichentest fur eine gepaarte Stichprobe
I Das Vorgehen ist analog zum 2. Anwendungsbeispiel fur dengepaarten t−Test, jedoch mit exponentialverteilten Fehlern.
I > x=2+rexp(30) # verschobene Exponentialverteilung
> y=3+rexp(30) # verschobene Exponentialverteilung
> shapiro.test(x-y) # Test auf Normalverteilung
Shapiro-Wilk normality test
data: x - y
W = 0.8966, p-value = 0.00693 # Ablehnung
I Vorzeichentest fur eine gepaarte Stichprobe.I > binom.test(table(x<y))
Exact binomial test
data: table(x < y)
number of successes = 7, number of trials = 30, p-value = 0.005223
alternative hypothesis: true probability of success is not equal to 0.5
95 percent confidence interval:
0.09933786 0.42283652
sample estimates:
probability of success
0.2333333
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 31

c) Gepaarter Wilcoxon-Vorzeichen-Rang-Test
I Der gepaarte Wilcoxon-Vorzeichen-Rang-Test ist ein Test uberdas Symmetriezentrum 0 (und damit den Median 0) der stetigenVerteilung von D = X − Y . Bei Ablehnung der Nullhypothese kannman folglich auf eine unterschiedliche
”mittlere Lage“ der
x− und der y−Werte schließen.
I Geg.: konkrete gepaarte Stichprobe (x1, y1) . . . , (xn, yn) .
I Vor.: Die Zufallsgroße D = X − Y besitzt eine stetige undsymmetrische Verteilung; es liegt eine reprasentative gepaarteStichprobe vor.
I Hyp.:H0 : Die Verteilung von D = X − Y ist symmetrisch um 0 ;H1 : Die Verteilung von D = X − Y ist symmetrisch um c 6= 0 .
I R-Aufruf: wilcox.test(x,y,paired=TRUE)
bei Datenvektoren x und y .
I Bindungen konnen problematisch sein.
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 32

Bsp. gepaarter Wilcoxon-Vorzeichen-Rang-Test
I Das Vorgehen ist analog zum 2. Anwendungsbeispiel fur dengepaarten t−Test, jedoch werden hier t−verteilte Fehler verwendet.
I > x=2+0.1*rt(30,df=10) # t-Verteilung mit 10 Freiheitsgraden
> y=3+0.1*rt(30,df=10) # t-Verteilung ist symmetrisch
> d=x-y
> shapiro.test(d) # Test auf Normalverteilung
Shapiro-Wilk normality test
data: d
W = 0.9248, p-value = 0.0358 # Ablehnung
I Die Anwendung des Wilcoxon-Vorzeichen-Rang-Tests auf dieDifferenzen bzw. gepaart ergibt> wilcox.test(d)
Wilcoxon signed rank test
data: d
V = 0, p-value = 1.863e-09 # Ablehnung
alternative hypothesis: true location is not equal to 0
> wilcox.test(x,y,paired=TRUE)
Wilcoxon signed rank test
data: x and y
V = 0, p-value = 1.863e-09 # Ablehnung
alternative hypothesis: true location shift is not equal to 0
Prof. Dr. Hans-Jorg Starkloff Statistik fur Ingenieure Vorlesung 12 Geandert: 20. Januar 2017 33





























