Embed Size (px)
DESCRIPTION
In entrambi gli approcci, si usa p(ω i |x) come regola di classificazione La stima ML di θ è, per definizione, il valore ˆ θ che massimizza p(D|θ) Svantaggio: con trasformazioni non lineari arbitrarie dello spazio del parametro la densità cambia così come la soluzione Scopo: calcolare P(ω i |x, D) dato il campione D, la formula di Bayes permette di scrivere: Quindi sarà approssimativamente p(x|D) p(x| ˆ θ), risultato che si otterrebbe usando la stima ML come se fosse il valore reale:
Citation preview

Stima dei Parametri
Corso di Apprendimento AutomaticoLaurea Magistrale in Informatica
Nicola Fanizzi
Dipartimento di InformaticaUniversità degli Studi di Bari
14 gennaio 2009
Corso di Apprendimento Automatico Stima dei Parametri

Sommario
IntroduzioneStima dei parametri di massima verosimiglianzaStima dei parametri bayesiana
Corso di Apprendimento Automatico Stima dei Parametri

Introduzione I
In un contesto Bayesiano, si potrebbe progettare unclassificatore ottimo conoscendo:
p(ωi) (prob. a priori)
p(x |ωi) (densità condizionate)
Sfortunatamente, raramente si ha una informazione completa.
Progettare un classificatore a partire da un campione diesempi:
Nessun problema con la stima della prob. a priori
I campioni sono spesso troppo piccoli per la stima delledensità condizionate (grandi dimensioni dello spazio dellefeature)
Corso di Apprendimento Automatico Stima dei Parametri

Introduzione II
L’informazione a priori sul problema
Es. Una densità p(x |ωi)p(x |ωi) ∼ N(µi ,Σi) è caratterizzata da 2 parametri
Tecniche di stima:Massima verosimiglianza (Maximum-likelihood, ML) eBayesiana
Risultati pressochè identici, ma gli approcci sono diversi
Corso di Apprendimento Automatico Stima dei Parametri

Introduzione III
Nella stima ML, i parametri sono considerati fissati masconosciuti
Parametri migliori ottenuti massimizzando la probabilità diottenere i campioni osservati
Nella stima bayesiana, i parametri sono visti come variabilialeatorie dalla distribuzione sconosciuta
L’osservazione di esempi cambia la distribuzione aposteriori, con la stima dei valori dei parametriEffetto: assottigliamento della densità sui veri valori deiparametri
In entrambi gli approcci,si usa p(ωi |x) come regola di classificazione
Corso di Apprendimento Automatico Stima dei Parametri

Stima di massima verosimiglianza I
Buona proprietà di convergenza al crescere del campionedi esempiTecnica più semplice d’ogni altra alternativa
Principio generaleSi assuma di avere c classi e un dataset D = D1 ∪D2 ∪ · · · ∪Dcdi esempi indipendenti e identicamente distribuiti(i.i.d. se riguardati come var. aleatorie)
per denotare la dipendenza dal parametro, si scrive
p(x |ωj) ≡ p(x |ωj , θj)
es. p(x |ωj , θj) ∼ N(µj ,Σj) con:θ = (µj ,Σj) = (µ1
j , µ2j , . . . , σ
11j , σ22
j , cov(xnj , x
mj ), . . .)
Corso di Apprendimento Automatico Stima dei Parametri

Stima di massima verosimiglianza II
Usare l’informazione degli esempi di training per stimareθ = (θ1, θ2, . . . , θc), dove ogni θi è associato con unacategoria (i = 1,2, . . . , c)
Supponendo che D = {x1, x2, . . . , xn}, per l’indipendenzadegli esempi
p(D|θ) =n∏
k=1
p(xk |θ) = F (θ)
verosimiglianza di θ rispetto all’insieme di esempi
La stima ML di θ è, per definizione, il valore θ̂ chemassimizza p(D|θ)
”Valore di θ che meglio si accordacon il campione di training realmente osservato”
Corso di Apprendimento Automatico Stima dei Parametri
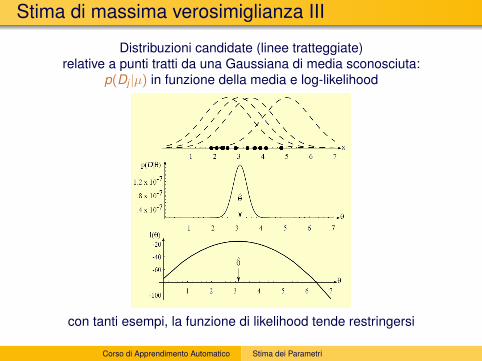
Stima di massima verosimiglianza III
Distribuzioni candidate (linee tratteggiate)relative a punti tratti da una Gaussiana di media sconosciuta:
p(Dj |µ) in funzione della media e log-likelihood
con tanti esempi, la funzione di likelihood tende restringersi
Corso di Apprendimento Automatico Stima dei Parametri

Stima ottimale I
Sia θ = (θ1, . . . , θp)t e sia ∇θ l’operatore di gradiente
∇θ =
[∂
∂θ1, . . . ,
∂
∂θp
]
Si definisce l(θ) come funzione di log-verosimiglianza(log-likelihood)
l(θ) = ln p(D|θ)
Nuova formulazione del problema:determinare θ che massimizza la log-likelihood
θ̂ = arg minθ
l(θ)
Corso di Apprendimento Automatico Stima dei Parametri

Stima ottimale II
Condizioni necessarie per l’ottimizzazione:
∇θ l = 0
con ∇θ l =∑n
i=1∇θ ln p(xk |θ)
Una soluzione θ̂ potrebbe essere
un vero massimo globale,
un minimo/massimo locale o
un flesso (raramente)
Bisogna anche controllare gli estremi dell’insieme di definizionedella funzione
Corso di Apprendimento Automatico Stima dei Parametri

Stima MAP (maximum a posteriori)
Gli stimatori maximum a posteriori (MAP) cercano il valore di θche massimizzi p(D|θ)p(θ) o anche l(θ) + ln p(θ)
Si può vedere uno stimatore ML come uno stimatore MAPper una densità a priori uniformeUno stimatore MAP cerca il picco (moda) di una densità aposterioriSvantaggio:con trasformazioni non lineari arbitrarie dello spazio delparametro la densità cambia così come la soluzione
Corso di Apprendimento Automatico Stima dei Parametri

Stima Bayesiana I
Apprendimento Bayesiano per problemi di classificazione
Nella stima ML θ è supposto prefissatonella stima Bayesiana θ è una variabile casuale
Nella classificazione Bayesiana il calcolo delle probabilità aposteriori P(ωi |x) è fondamentale
Scopo: calcolare P(ωi |x ,D)dato il campione D, la formula di Bayes permette discrivere:
P(ωi |x ,D) =p(x , ωi |D)
p(x |D)=
p(x |ωi ,D)P(ωi |D)∑cj=1 p(x |ωj ,D)P(ωj |D)
Corso di Apprendimento Automatico Stima dei Parametri

Stima Bayesiana II
Notando che
p(x ,D|ωi) = p(x |ωi ,D)P(ωi |D)
p(x |D) =∑c
j=1 p(x , ωi |D)
p(ωi |D) = p(ωi) ottenuti dal campione di training
P(ωi |x ,D) =p(x |ωi ,D)P(ωi)∑cj=1 p(x |ωj ,D)P(ωj)
Semplificando: c problemi della forma:usare un insieme D di esempi con distribuzione p(x) perdeterminare p(x |D)
Corso di Apprendimento Automatico Stima dei Parametri

Stima della densità a posteriori I
Il calcolo di p(x |D) è applicabile ad ogni situazione nella qualeuna densità sconosciuta sia parametrizzabile
Assunzioni di base
Si assume nota la forma di p(x |θ), ma non il parametro
La conoscenza su θ si assume contenuta in una densità apriori p(θ)
Il resto della conoscenza è contenuto in un insieme D di nvariabili casuali x1, x2, . . . , xn che segue p(x)
Corso di Apprendimento Automatico Stima dei Parametri

Stima della densità a posteriori II
Problema di baseCalcolare la densità a posteriori p(θ|D) per derivarne poip(x |D) (migliore approssimazione di p(x) con i dati disponibili)
Si può scrivere:
p(x |D) =
∫p(x , θ|D)dθ
ma p(x , θ|D) = p(x |θ,D)p(θ|D), quindi
p(x |D) =
∫p(x |θ,D)p(θ|D)dθ
L’integrale si calcola tramite metodi numerici (es. Monte Carlo)
Corso di Apprendimento Automatico Stima dei Parametri

Caso generale I
Abbiamo visto che
p(x |D) =
∫p(x |θ,D)p(θ|D)dθ
Usando la formula di Bayes:
p(θ|D) =p(D|θ)p(θ)∫p(D|θ)p(θ)dθ
Per l’assunzione di indipendenza:
p(D|θ) =n∏
k=1
p(xk |θ)
Corso di Apprendimento Automatico Stima dei Parametri

Caso generale II
Osservazioni
Se p(θ|D) ha un picco per il valore θ̂ con p(θ̂) 6= 0 enon cambia molto in un suo intorno,allora p(D|θ) ha anche essa un picco nello stesso punto
Quindi sarà approssimativamente p(x |D) ' p(x |θ̂),risultato che si otterrebbe usando la stima ML come sefosse il valore reale:
Se il picco di p(D|θ) è rilevante,allora l’influenza della densità a priori si può ignorare
Corso di Apprendimento Automatico Stima dei Parametri

Approccio ricorsivo-incrementale I
Separiamo i campioni per classi,indicando esplicitamente la cardinalità: Dn = {x1, . . . , xn}
Per n > 1 tramite l’eq. p(D|θ) =∏n
k=1 p(xk |θ):
p(Dn|θ) = p(xn|θ)p(Dn−1|θ)
Sostituendo nelle relazioni precedenti:
p(θ|Dn) =p(xn|θ)p(θ|Dn−1)∫p(xn|θ)p(θ|Dn−1)dθ
Notare che si può partire da p(θ|D0) = p(θ) e continuarecalcolando p(θ|x1),p(θ|x1, x2), . . .
Corso di Apprendimento Automatico Stima dei Parametri

Approccio ricorsivo-incrementale II
Parametri / statistiche sufficienti
Per calcolare p(θ|Dn) si preservano tutti gli esempi in Dn−1
Per alcune distribuzioni pochi parametri associati conp(θ|Dn−1) contengono tutta l’informazione necessaria
La sequenza di densità converge ad una funzione delta diDirac centrata sul valore vero del parametro: si dice in talcaso che p(x |D) è identificabile
Corso di Apprendimento Automatico Stima dei Parametri

Differenze
I metodi visti finora convergono solo asintoticamente dati moltiesempi
La stima ML e ’ preferibile in termini di complessità (ricercadi minimo contro integrazione multi-dimensionale) e diinterpretabilità (singolo modello contro media pesata dimodelli)L’info a priori è da assumere parametrica p(x |θ̂) per lastima ML, quella bayesiana p(x |D) sfrutta invece tuttal’informazione disponibilePer questo, se p(θ|D) è irregolare o asimmetrica, p(x |D)sarà molto variabile a seconda dei metodi (problemi di biase varianza)
Corso di Apprendimento Automatico Stima dei Parametri

Errori
Il classificatore determina in base alla densità a posteriori laclasse che massimizza la probabilità d’appartenenza
Possibili errori:errore di indistinguibilità densità p(x |ωi) che sisovrappongono per alcuni valori di i .Ineliminabile: dipende dal problemaerrore di modello occorre informazione sul dominio per lascelta del modello correttoerrore di stima dovuto alla limitatezza del campione;si attenua aumentando gli esempi
Corso di Apprendimento Automatico Stima dei Parametri

Problematiche I
Dimensionalità
Problemi che coinvolgono 50 o 100 caratteristiche (binarie)
L’accuratezza predittiva dipende dalla dimensione e delnumero dei dati di training
Le feature più utili sono quelle la cui differenza tra le medieè grande relativamente alla deviazione stdandard
In pratica oltre un certo punto, l’aggiunta di altre featureporta a peggiorare la performance: modello sbagliato
Corso di Apprendimento Automatico Stima dei Parametri

Problematiche II
Evitare il fenomeno dell’overfitting
riduzione della dimensionalità conservando solo le featurerilevanti o combinando più feature
condivisione della matrice di covarianza tra le varie classi
la matrice può essere sottoposta ad un meccanismo disoglia in modo da eliminare correlazioni accidentali
Corso di Apprendimento Automatico Stima dei Parametri
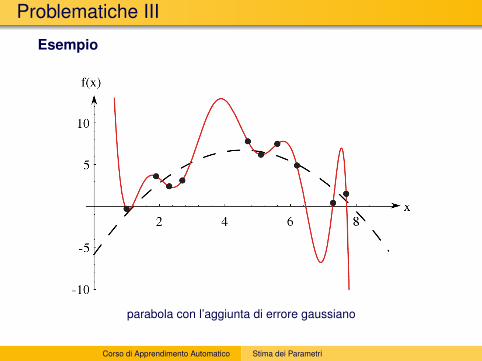
Problematiche III
Esempio
parabola con l’aggiunta di errore gaussiano
Corso di Apprendimento Automatico Stima dei Parametri

Problematiche IV
Si parte con un modello polynomiale (10 deg grado),per poi livellare (smoothing) o semplificare il modello,eliminando i termini di grado maggiore
NB: a volte anche una retta potrebbe avere prestazionisuperiori!
Questo in genere aumenta l’errore di training ma abbassaquello sugli esempi di test
Corso di Apprendimento Automatico Stima dei Parametri

Credits
R. Duda, P. Hart, D. Stork: Pattern Classification, Wiley
Corso di Apprendimento Automatico Stima dei Parametri





























