Embed Size (px)
Citation preview

The State of Apache HBaseMichael Stack

Michael Stack <stack@{apache.org,cloudera.com}>
* Project Management Committee
● Chair of the Apache HBase PMC*● Caretaker/Janitor
● Member of the Hadoop PMC● Engineer at Cloudera in SF

What is it?

”... is an open source, distributed, scalable, consistent, low latency, non-relational, random access database”

Built on Apache
● Hadoop core:– Distributed file system (HDFS)– MapReduce
● HBase persists all data to HDFS● Uses Apache ZooKeeper
– Cluster coordination● Goal: “Billions of rows X millions of columns on
clusters of 'commodity hardware'”
ZK HDFS
App MR

Inspiration
A Google Technology described in a 2006 paper, Bigtable: A Distributed Storage System for Structured Data by Chang et al.?
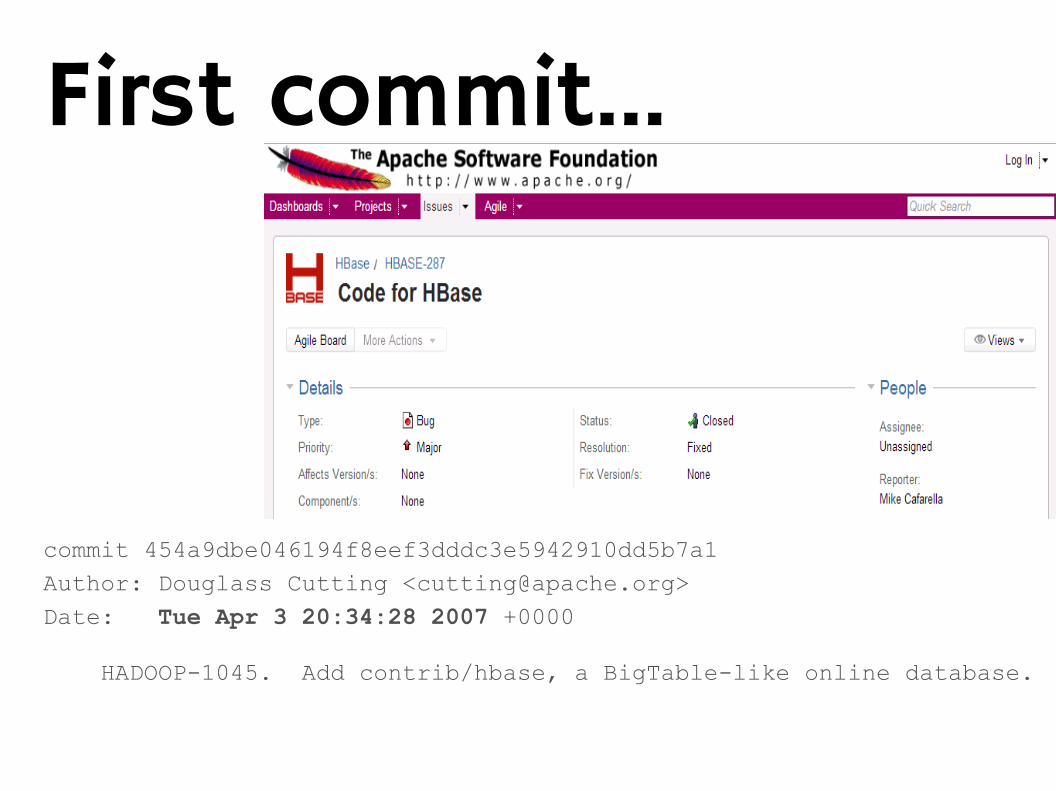
First commit...
commit 454a9dbe046194f8eef3dddc3e5942910dd5b7a1Author: Douglass Cutting <[email protected]>Date: Tue Apr 3 20:34:28 2007 +0000
HADOOP-1045. Add contrib/hbase, a BigTable-like online database.
DISTRIBUTIONS

When to use it?

BIG Data

scalE!

Low-latency, online, random read/writes

*Very like Google Bigtable model only different nomenclature
Datamodel*

DataModel: A Bigtable!
● 0-N Bigtable(s)● Rows x Column Families● Column Families
● Has columns● CF prefix and qualifier
● e.g. attribute:mimetype

Datamodel: Regions● Table splits into “regions”
● Automatically as table grows● Region has contiguous rows
● [startRow, endRow)

DataModel: Sorted & Versioned● All is byte []
● No native 'types'● Schema-less (NoSQL)
● All is SORTED● Rows in byte-lexographical order● Columns sorted along row
● VERSIONED● Cells are “versioned”● 3D (timestamp)

Datamodel: Strongly consistent● Row modifications are atomic
● Even if thousands of columns on a row● Favors consistency over availability
● “Designing applications to cope with concurrency anomalies in their data is very error-prone, time-consuming, and ultimately not worth the performance gains” -- F1: A Distributed SQL Database That Scales
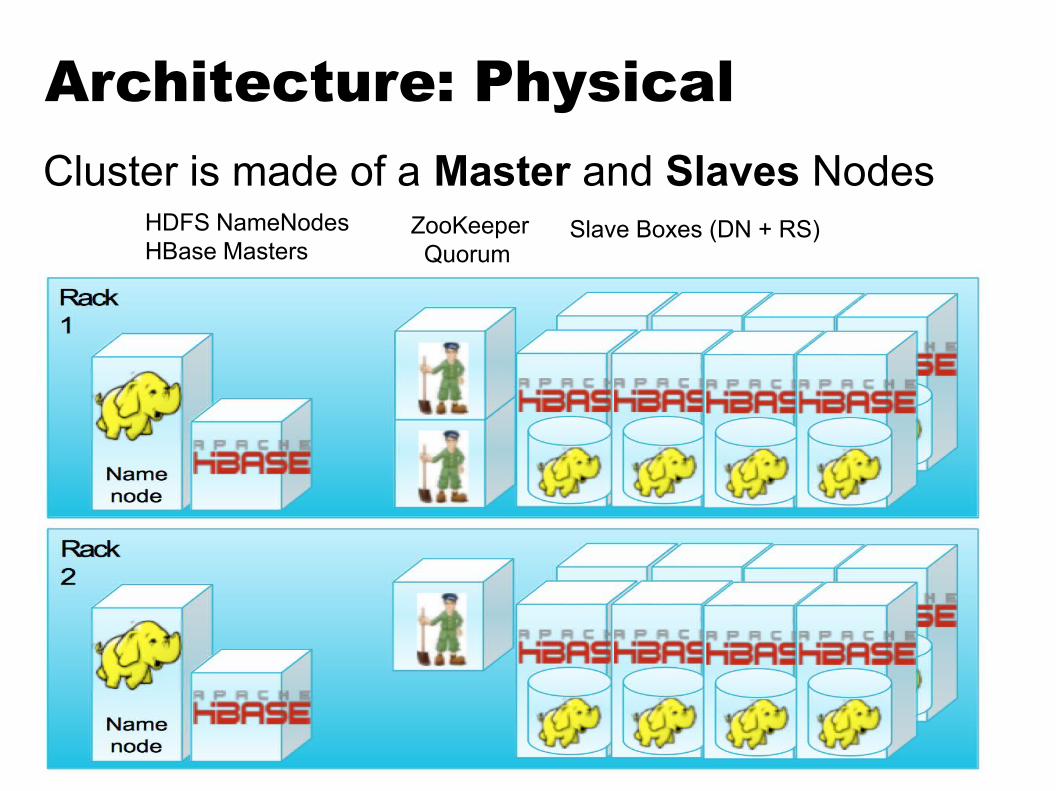
Architecture: Physical
HDFS NameNodesHBase Masters
ZooKeeper Quorum
Slave Boxes (DN + RS)
Cluster is made of a Master and Slaves Nodes

Features
•Classes to MapReduce HBase tables•Query predicate push down via server side filters •Coprocessors (stored procedures/triggers)•Extensible jruby-based (JIRB) shell•Replication•Security
– Table/Column Family– Kerberos Authentication, ACLs

What to expect• Writes:
– 1-3ms, 1k-20k writes/sec per node
• Reads:– 0-3ms cached, 10-30ms disk– 10-40k reads / second / node from cache– > if SSD
• Cell size• 0-3MB preferred
• Column-orientated so wide tables are OK• Sparsely populated rows OK

Who uses it?


In Production

● OLTP & Batch● Messages○ 1B+ users○ Tens of PBs (compressed)○ Thousands of machines, Pods of ~200
● ODS/Real-time monitoring/Timeseries○ Dual write two clusters○ Critical eyes and ears

● All on AWS● 5 production clusters and growing● Mix of SSD and SATA● Billions of page views per month

Users
● Long time HBase user● Two clusters of 1k nodes each
○ Master-Master replicating● Separate low-latency cluster
○ Up to 1M reads a second

Cassini● Ebay item search indexing● 600M active items in HBase tables● 1.4TB of data processed each day● 400M puts to HBase each day● 250M search metrics per day● Two datacenters● Growing clusters...
– 500->1k

Deploy types• Multitenant multifarious feature storeo a.k.a dumping groundo Stumbleupon, Y!, SalesForce
• Reconciliation storeo ebay
• Timeserieso SalesForce, FB ODS
• Lots-o-entities storeo Flurry, genomeo Lots-o-entities BLOBs, FB Messages

Who runs the project?

Diverse team*
* http://hbase.apache.org/team-list.html
COMMITTERS!
Preferably ALIVE!

Dev Rate
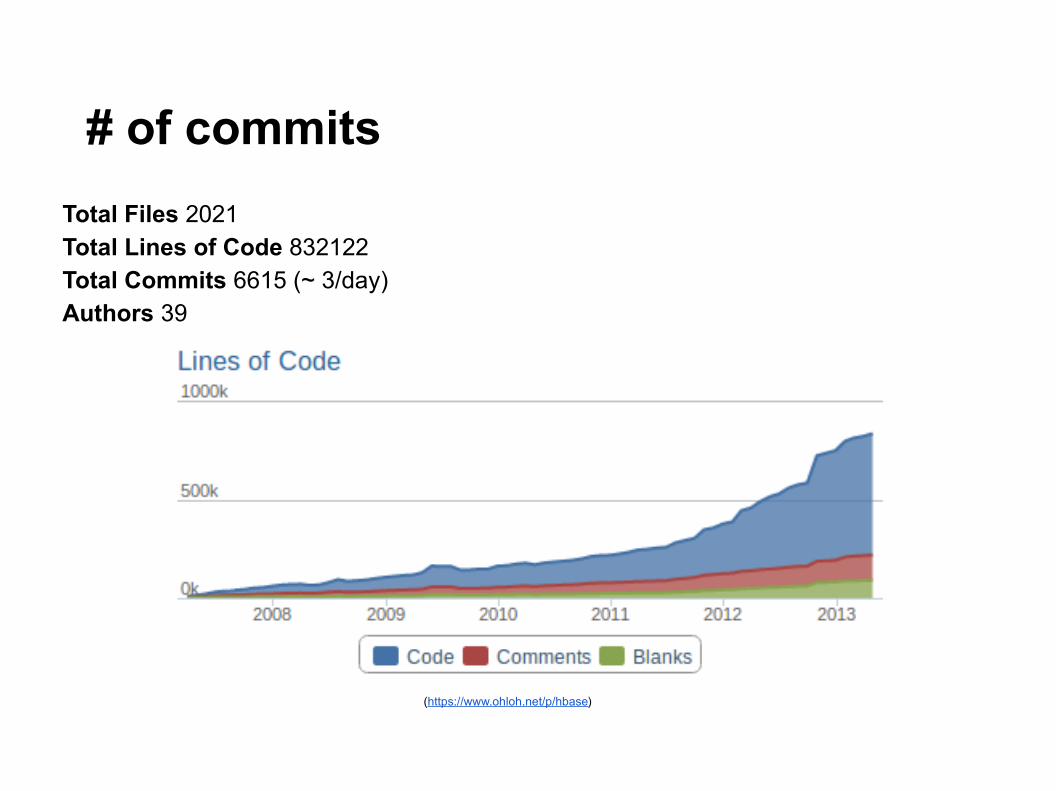
# of commits
Total Files 2021Total Lines of Code 832122Total Commits 6615 (~ 3/day)Authors 39
(https://www.ohloh.net/p/hbase)
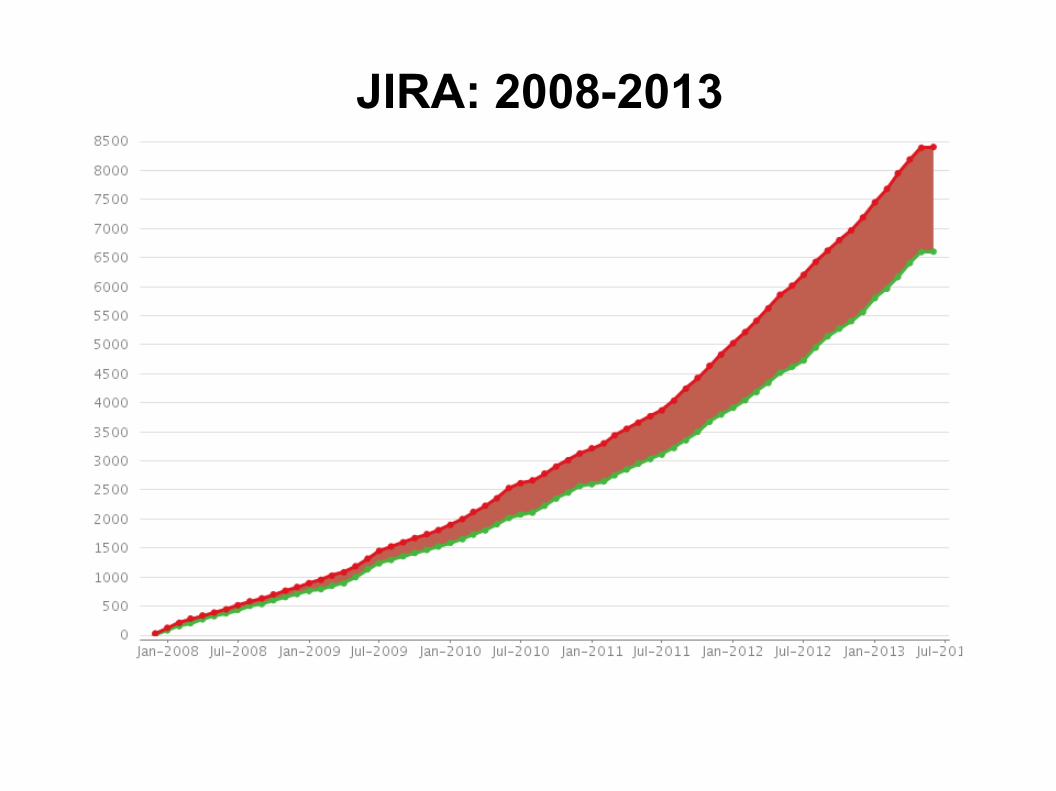
JIRA: 2008-2013
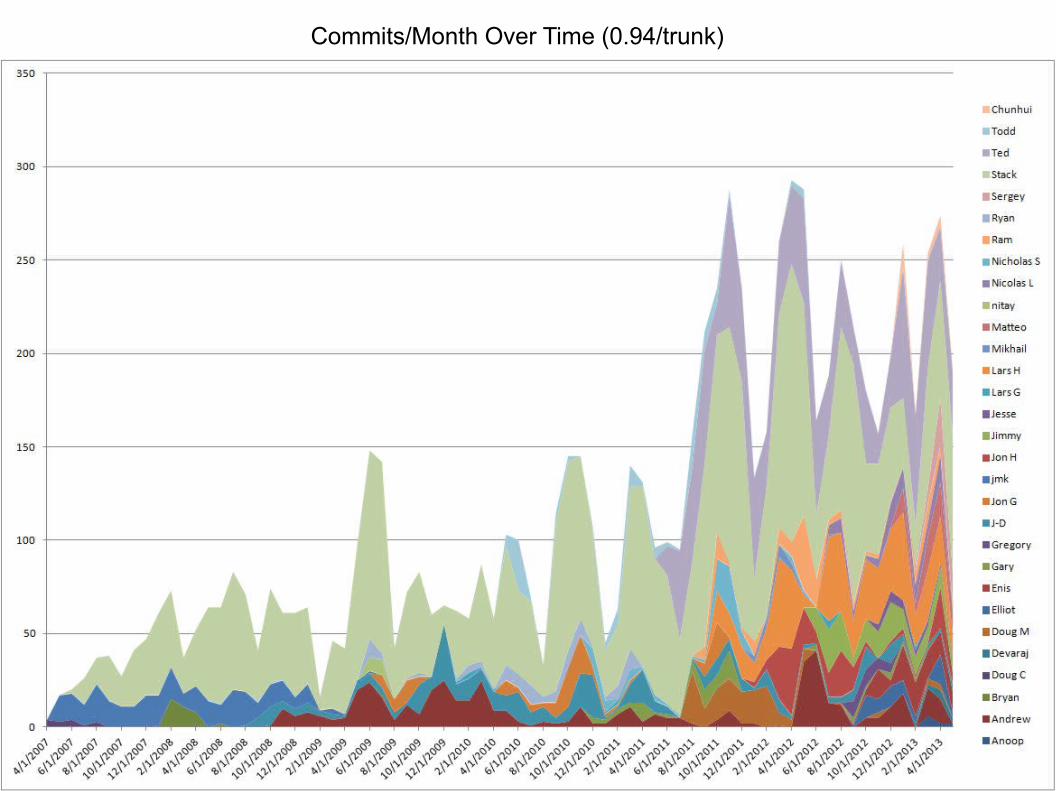
Commits/Month Over Time (0.94/trunk)

HBase Today


•Release every month• Each more stable•& more performant•Some features…• Wire compatible between releases
•Currently at 0.94.13

http://www.flickr.com/photos/sysli/3026288256/sizes/o/in/photostream/

● 0.96.0– Released October 19th, 2013– 18months in the making
● >2000 fixes

Big Themes● Stability● Operability
– Insight, tools● Scalability● Evolvability

● Pluggable Compression– Smarter triggers
● Hadoop1 AND Hadoop2● Smarter Region Balancer● Region Assignment Hardened● Coprocessors
– More hooks
Sampler

http://www.flickr.com/photos/allspaw/5815258929/sizes/o/in/photostream/


•System tables• Filesystem•Up in zookeeper•Over the wire

Namespaces• Grouping of tables
– Like database in mysql
• System/User– hbase:meta
• Quota• Coming
– Security by namespace– Grouping on cluster by namespace

And more...• X-row (in-region) Transactions• Query tracing• New UI• Online Merge• Hardened Replication• Off-heap bucket cache• Metrics2o Radical revamp


• By the end of the year• Rolling upgrade from 0.96.0
• In-line Cell-tags– Security++
● ACL down to the Cell-level● Cell-level visibility labels
• Reverse Scan

●HBase 1.0.0●Reining in the 99th percentiles
●Multi-WAL●Speculative replica reads
●More support for multi-tenancy●Off-heap
HBase 2014

HBaseEcosystem
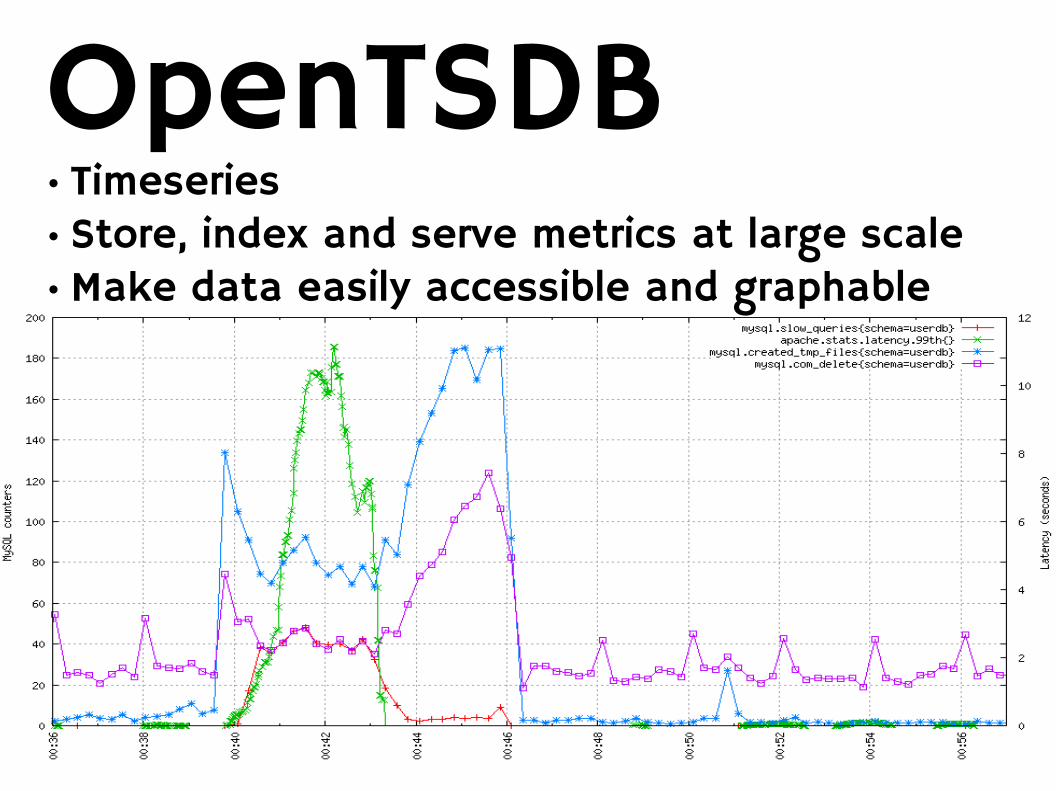
OpenTSDB● Timeseries● Store, index and serve metrics at large scale● Make data easily accessible and graphable

HaeinsaHaeinsa 란 무엇인가 ?
Is a linearly scalable multi-row, multi-table transaction library for HBase. Haeinsa uses two-phase locking and optimistic concurrency control for implementing transaction. The isolation level of transaction is serializable.
● Inspired by Google Percolator● VCNC

Chasm

How to make it easier writing applications against HBase?

Frameworks: Kiji.org• Entity-centric, simple modelo Types, complex, compound types.
• Each cell is schema versioned
• Works across MR & REST, etc.
• Machine-learning libs
• Examples, tutorials
• Production users
• Open-source

Frameworks: CDK
• APIs providing Dataset abstraction – get/put/delete API in AVRO objects
• Highlights: – Supports multiple components
● flume, morphlines, hive, crunch, hcat – Types using Avro and parquet formats– Manages schema evolution
• Open source by Cloudera
– http://cloudera.github.io/cdk/docs/current


● Client-embedded JDBC driver○ Connection conn =
DriverManager.getConnection("jdbc:phoenix:localhost");
● Alternate HBase Client API (SQL)● Fast!
○ Exploits HBase Coprocessors/Filters○ Types○ Aggregations○ Skip scans○ Secondary indices

Beyond...● Hadoop Family evolving, growing● No longer just Batch
– Real-time– Streaming
● October Apache Hadoop 2.0 release an inflection point– O'Reilly Strata + Hadoop World NYC 2013
● Coming out party● New distributions● Enterprise

Beyond: No longer just batch● YARN
● Distributed scheduling● Resource management● More than just MR on the cluster● Arbitrary Apps
● Hive speedup Tez/Stinger● Storm
● “Streaming” Hadoop● Storm on YARN

Beyond: No longer just batch
● Apache● Apache
● Cluster management● Cloudera Impala
● Scalable low-latency SQL query● HDFS (& HBase)
● Apache Drill● & HBase!

Thank [email protected]

TODO
● DBA: R (read), W (write), C (create), X (execute), A (admin). ● cell-level security. Every cell in an Accumulo store can have a label, stored effectively as part of
the key, which is used to determine whether a value is visible to a given subject or not. The label is not an ACL, it is a different way of expressing security policy.
● A label instead turns this on its head and describes the sensitivity of the information to a decision engine that then figures out if the subject is authorized to view data of that sensitivity based on (potentially, many) factors.
● Then, as of HBASE-7662, HBase can store into and apply ACLs from cell tags, extending the current HBase ACL model down to the cell.
● Finally, we have also contributed transparent server side encryption, as HBASE-7544, for additional assurance against accidental leakage of data at rest, which is at this time an HBase-only feature.
● Auto-manages partitioning● Storage machinery in the RS● I like the Latency/Throughput/Read/Write axis in Nick





























