Embed Size (px)
Citation preview

What is Computer Graphics (CG)
The generation of graphical images using a computer, as opposed to "image processing" which
manipulates images that are already in the computer. Creating a frame of "Toy Story" or
"Jurassic Park" is computer graphics; Comparing an image of a face from an ATM camera
against a database of known criminal mugshots is image processing. Note that the line between
the two can sometimes be hazy, and a given task may require both sets of skills.
Mathematics + computer science + art = computer graphics rendering of images on a device.
Rendering - creating images from models
models - objects constructed from geometric primitives (points, lines, polygons) specified by
their vertices
Models exist in n-dimensional 'mathematically pure' space
o n typically 2 or 3
o n can be > 3 with scientific data
Rendered version typically created on physical 2D media (e.g. a video screen.)
Rendered version can be simple or complex (lighting, shadows, colours, texture)
Rendering a single image can take from a small fraction of a second (say, a frame from 'Unreal')
to hours or days (say, a frame from 'Toy Story') depending on the complexity of the scene, the
amount of processing power available, and the needs of the user.
Common Uses
Movies, such as Toy Story, Who Framed Roger Rabbit, The Hollow Man, Shrek,
Monsters Inc, Jurassic Park, & The Perfect Storm
Advertisements
Football game annotations.
scientific/medical visualization
CAD/CAM
multimedia
computer interfaces (Windows, X, Aqua)
virtual reality
special effects
artistic expression
way cool video games

Software
Many application programs available to produce computer graphics, either as 2D images, 3D
models, or animated sequences (Corel Draw, Photoshop, AutoCAD, Maya, SoftImage, etc.)
We will deal with the lower level routines which do the work of converting models into a
displayable form on the display device.
Several 'common' graphics languages/libaries/APIs (Application Programming Interfaces.)
GKS
DirectX
X
Postscript
OpenGL
We will be using OpenGL in this course on the linux machines in the CS Computer Graphics lab
to give a common grading platform. OpenGL is availble for all the major platforms, and is
accelerated on almost all current graphics cards, but is not necessarily available on all of the
machines here in the university. If you want to work on your machine at home you should be
able to get OpenGL libraries for it for free. Otherwise there is Mesa. Mesa is virtually identical
to OpenGL, is free, and runs on a wider variety of platforms. For more information on Mesa you
can check out: http://www.mesa3d.org . The only thing that should need to change to compile
your code here is the Makefile.
Mesa, Codeblocks(Cross Platform) or VC++ like OpenGL, is usually accessed through function
calls from a C or C++ program.

Evolution of Video Display Hardware:
Text generated graphics
o Series of printed characters and spaces
o For example a simple plot of a sine functions.
o Some density images can be generated ( . versus # )
o + Fast, simple, and ( relatively ) easy
o + Requires no special hardware or libraries
o - Monochrome and crude.
1.0 | * | * | * | * 0.5 | * | * | * | * 0.0 +---*---------- | * | * | *
Special graphics characters
o Uses the extended ASCII character set, 128 to 255
o Special symbols mapped to extended ASCII codes.
o + Fast, easy, & simple
o +Works reasonably well for line boxes, smiley faces, etc.
o +Allows for color, & reverse video

Vector (calligraphic) displays
o lines drawn directly, no predefined grid
o commands tell the electron gun where to move and when to turn on/off
o + lines are smooth
o + close to the 'pure mathematics' of the model
o - slower with more elements to be drawn, can start to flicker
o - only lines possible, no filled polygons, or bitmaps
o - monocrome for each electron gun
Raster displays
o image represented by a rectangular grid of pixels (picture elements)
o image stored in a frame buffer
o electron gun(s) continually scanning in a regular pattern (line by line across entire
screen)
o + constant time to redraw any number of elements
o + no flicker
o - jagged edges from conversion to pixels
o - discretized version of the model

You need to keep redrawing the image on the screen to keep it from fading away. Vector
displays redraw as quickly as possible given the number of objects on the screen; CRT based
raster displays redraw the image (or refresh the screen) at a fixed rate (e.g. 60 times per second)
no matter how complex the scene.
For those who spent their early youth in the arcades, vector games included:
Asteroids
Battlezone
Lunar Lander
Star Trek
Star Wars
Tempest
Initially these games were monocrome (white, green, or some other single color), as in asteroids,
then coloured filters were used to colour different parts of the screen using the same monocrome
electron gun as in Battlezone, and finally when RGB electron guns were cheap enough, true
multi-colour vector games were possible.

Buffers in Raster Displays
Pretty much all CG done using raster displays. The screen is represented by a 2D array of
elements
Frame buffer - array of computer memory used to store an image to be displayed
The user manipulates the values in the frame buffer.
60 times a second (or at some other fixed rate) the frame buffer is copied onto the display device.
If video screen is 512 pixels wide by 512 pixels tall the frame buffer must be able to store 512 X
512 elements ... one element for each pixel on the screen
monocrome display:
512 x 512 x 1bit (bit is either 0=off, or 1=on.)
Each of the 512 x 512 pixels can be either on or off (white or black)
32768 bytes total
8 bit greyscale display:
512 x 512 x 8bit (each pixel is 8 bits deep so values 0-255 are possible.)
Each of the 512 x 512 pixels can be one of 256 shades of grey (from black to white.)
262,144 bytes total
24 bit colour display:

512 x 512 x 24bit (each pixel has 8 bits for red, 8 bits for green, and 8 bits for blue.)
Each pixel can be black->bright red (0-255) combined with black->bright green (0-255)
combined with black->bright blue (0-255)
786,432 bytes total
Each of the 512 x 512 pixels can be one of 16 million colours
note however, that a 512 x 512 display has only 262,144 pixels so only 262,144 colours
can be displayed simultaneously.
A 1280 x 1024 display (common workstation screen size) has only 1,310,720 pixels, far
fewer than the 16,000,000 possible colours. ( 3.75 MB for this configuration )
8 bit colour display using a colour map:
want benefits of 24 bit colour with only 8 bit display
512 x 512 x 8bit (each pixel is 8 bits deep so values 0-255 are possible.)
Each of the 512 x 512 pixels can be one of 256 index values into a video lookup table.
video lookup table has 256 24bit RGB values where each value has 8 bits for red, 8 bits
for green, and 8 bits for blue.
16 million colours are possible, but only 256 of them can be displayed at the same time.
Memory needs are 512x512x1byte plus 256x3bytes = 262,912 bytes, much less than the
786,432 needed without the colour map.
Here are 2 sample colourmaps each with 256 24bit RGB values:

depth of frame buffer (e.g. 8 bit) determines number of simultaneous colours possible
width of colour map (e.g. 24 bit) determines number of colours that can be chosen from
Size of various frame buffers:
screen size Monocrome 8-bit 24-bit
512 X 512 32K 256K 768K
640 X 480 38K 300K 900K
1280 X 1024 160K 1.3M 3.8M
Hardware affects on computer animation
A program may take several minutes, hours, or days to render a single image. These images can
then be stored and played back or recorded to create animation
A more interesting situation is when the animation is live with the computer generated image
changing while the user watches, or as the user interacts with the computer.
To do the more interactive kind of animation you really need a SECOND frame buffer ... this is
similar to how a motion picture works.
Movie theatre projectors show a new image 24 times per second in the following sequence; so
the patron sees only the moving images, not the movement of the film through the projector:
1. A new frame is moved in front of the lens
2. the shutter is opened to display the frame
3. the shutter is closed
In fact, at the movies you actually spend more time looking at a black screen than you do looking
at an image. Now that we are starting to see digital cinema, where there is no physical film to
move, which will move film more towards the way computers display images.
Similar problem in computer graphics. In the case of a film, each of the frames has already been
generated and its just a question of showing them; whereas in interactive computer graphics the
frames are being drawn one at a time. The frame buffer is regularly sent to the display device (eg
60 times per second) whether the frame buffer has been completely updated or not. We don't
want the user to see the screen being cleared and the new image being drawn on the screen each
time the display refreshes. We only want the user to see a sucession of completely drawn images.
Solution is to have two frame buffers.
User draws into one buffer while the other is being displayed.
When drawing is complete the buffers are swapped.
In OpenGL / Glut this is called "double buffering". It is set up with the GLUT_DOUBLE flag
when initializing the display, and then the buffers are swapped with "glutSwapBuffers( )".

We can only swap buffers in between screen refreshes - when electron gun of the CRT is off and
moving from bottom of screen to the top. Note that different CRT monitors refresh at different
rates. Also note that as we move more towards LCD displays and away from CRT displays that
the hardware changes, but there are still timing constraints. In the case of LCDs the refresh rate
is only important when the images are changing. For more info on the two types of displays the
following link gives a nice description:
http://www.ncdot.org/network/developers/guide/display_tech.html
If you can clear the frame buffer and the draw scene in less than 1/60th second you will get 60
frames per second.
If it takes longer than 1/60th of a second to draw the image (e.g. 1/59th of a second) then by the
time you are ready to swap frame buffers the electron gun is already redrawing the current frame
buffer again, so you must wait for it to finish before swapping buffers (e.g. 1/30th of a second
after the last swap buffers if the frame takes 1/59th of a second.)
If the screen refreshes 60 times a second you can have a new image on the screen:
1/60th of a second ... 60 frames per second if all frames take equal time
1/30th of a second ... 30 frames per second if all frames take equal time
1/20th of a second ... 20 frames per second if all frames take equal time
1/15th of a second ... 15 frames per second if all frames take equal time
1/12th of a second ... 12 frames per second if all frames take equal time
1/10th of a second ... 10 frames per second if all frames take equal time
One of the most obvious implications of this is that a very small change in the time it takes to
draw a scene into the frame buffer can have a major impact on the speed of the application.
Can your program run at 45 frames per second (fps)?
Yes. if 30 frames take 1/60th each and the next 15 frames take 1/30th each you will display 45
frames per second.
For smooth motion you want at least 10 frames per second, and preferably more than 15 frames
per second. More is better.

Mathematics VS Engineering
We like to think about a scene as mathematical primitives in a world-space. This scene is then
rendered into the frame buffer. This allows a logical separation of the world from the view of
that world.
mathematically, points are infinitely small
mathematically, line segments are infinitely thin
these mathematical elements need to be converted into discrete pixels
as usual, there is an obvious easy way of doing these conversions, and then there is the way it is
actually done (for efficiency.)
Scan Conversion (rasterization) of a line ( Foley 3.2 )
take an analytic (continuous) function and convert (digitize) it so appropriate pixels can be
illuminated in the frame buffer
In a language such as OpenGL a programmer can generate a 2D line segment in world-space
with code like the following:
glBegin(GL_LINE_STRIP);
glVertex2f(1.5, 3.0);
glVertex2f(4.0, 4.0);
glEnd();
Polygons are single closed loops of line segments, usually drawn with their interiors filled.
In a language such as OpenGL polygons are very restricted to improve speed:
edges can not intersect (simple polygons)
polygon must be convex, not concave
To generate the outline of a triangular 2D polygon in world-space using OpenGL a programmer
can write code like the following:

glBegin(GL_LINE_LOOP);
glVertex2f(1.5, 3.0);
glVertex2f(4.0, 4.0);
glVertex2f(4.0, 1.0);
glEnd();
To generate a filled triangular 2D polygon in world-space using OpenGL a programmer can
write code like the following:
glBegin(GL_POLYGON);
glVertex2f(1.5, 3.0);
glVertex2f(4.0, 4.0);
glVertex2f(4.0, 1.0);
glEnd();
We will not limit ourselves to these 'easier' polygons.
Note that large complex objects are often reduced down to a large number of triangles ( i.e.
triangulated ), for a number of reasons:
Triangles are guaranteed to be simple convex polygons.
All points in a triangle are guaranteed to be co-planar.
Most importantly, modern computer graphics hardware is often optimized to generate
large numbers of triangles very quickly, so it is actually faster to break a complex shape
down and then deal with a kazillion triangles than to deal with a smaller number of more
complicated shapes.
( The degenerate case, of three co-linear points is usually not a major problem. )
How are line segments and polygons in world-space converted into illuminated pixels on the
screen?
First these coordinates in world-space must be converted to coordinates in the viewport (ie pixel
coordinates in the frame buffer.) This may involve the conversion from a 2D world to a 2D
frame buffer (which we will study in a couple weeks), or the reduction from a 3D world to a 2D
frame buffer (which we will study a couple weeks later.)
Then these coordinates in the viewport must be used to draw lines and polygons made up of
individual pixels (rasterization.) This is the topic we will discuss now.

Most of the algorithms in Computer Graphics will follow the same pattern below. There is the
simple (braindead) algorithm that works, but is too slow. Then that algorithm is repeatedly
refined, making it more complicated to understand, but much faster for the computer to
implement.
Braindead Algorithm
given a line segment from leftmost (Xo,Yo) to rightmost (X1,Y1):
Y=mX+B
m = deltaY / deltaX = (Y1 - Yo) / ( X1 - Xo)
Assuming |m| <= 1 we start at the leftmost edge of the line, and move right one pixel-column at a
time illuminating the appropriate pixel in that column.
start = round(Xo)
stop = round(X1)
for (Xi = start; Xi <= stop; Xi++)
illuminate Xi, round(m * Xi + B);
Why is this bad? Each iteration has:
comparison
fractional multiplication
2 additions
call to round()
Addition is OK, fractional multiplication is bad, and a function call is very bad as this is done A
LOT. So we need more complex algorithms which use simpler operations to decrease the speed.
Why is the slope (m) important?

if m=1 then each row and each column have a pixel filled in
if 0 <= m< 1 then each column has a pixel and each row has >= 1, so we increment X each
iteration and compute Y.
if m > 1 then each row has a pixel and each column has >= 1, so we increment Y each iteration
and compute X.
Simple Incremental Algorithm ( Foley 3.2.1 )
The basic improvement of this algorithm over the purely braindead one is that instead of
calculating Y for each X from the equation of a line ( one multiplication and one addition ), we
will calculate it from the previous Y by just adding a fixed constant ( one addition only ). This
works because the delta change in X from one column to the next is known to be exactly 1.
given a line segment from leftmost (Xo,Yo) to rightmost (X1,Y1):
Y=mX+B
m = deltaY / deltaX = (Y1 - Yo) / ( X1 - Xo)
if deltaX is 1 -> deltaY is m
so if Xi+1 = Xi + 1 -> Yi+1 = Yi + m
Assuming |m| <= 1 we start at the leftmost edge of the line, and move right one pixel-column at a
time illuminating the pixel either in the current row or an adjacent row.
starting at the leftmost edge of the line:
X = round(Xo)
Y = Yo
while (X <= X1) repeatedly
illuminate X, round(Y)
add 1 to X (moving one pixel column to the right)
add m to Y
This guarantees there is one pixel illuminated in each column for the line
If |m| > 1 then we must reverse the roles of X and Y, incrementing Y by 1 and incrementing X by
1/m in each iteration.
Horizontal and vertical lines are subsets of the 2 cases given above.
need such a common, primitive function to be VERY fast.
features:
+ incremental
- rounding is a time consuming operation(Y)
- real variables have limited precision, can cause a cumulative error in long line segments
(e.g. 1/3)
- Y must be a floating point variables
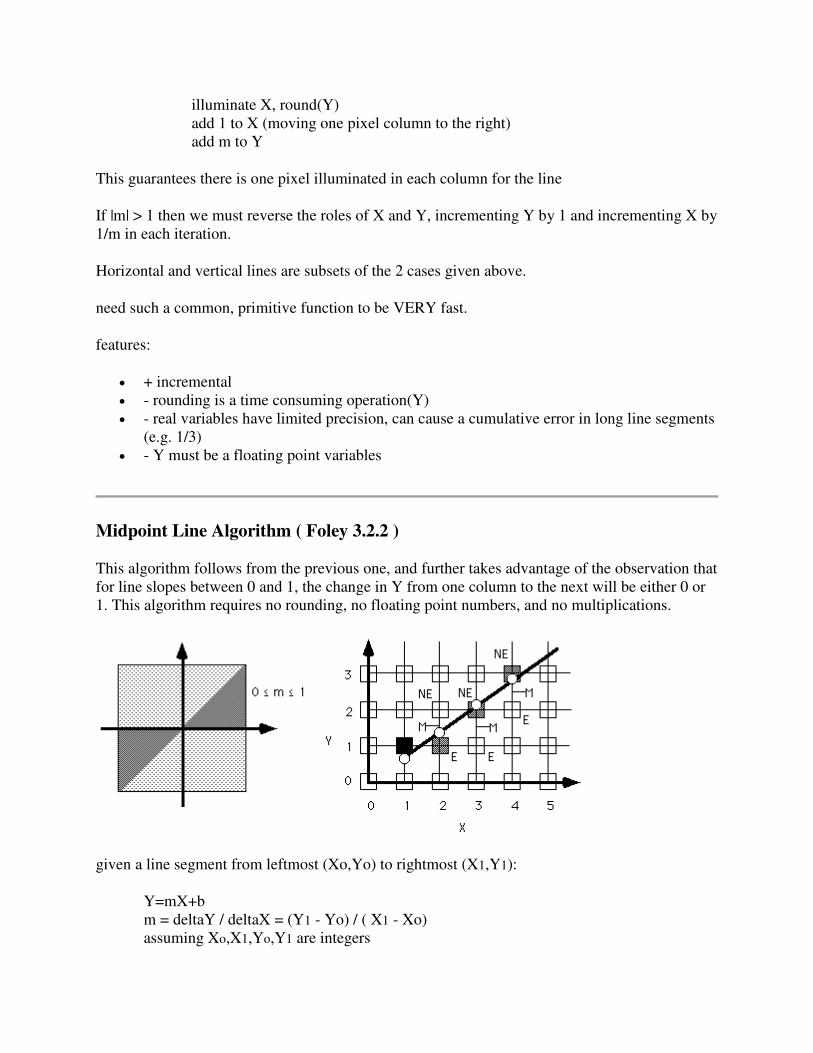
Midpoint Line Algorithm ( Foley 3.2.2 )
This algorithm follows from the previous one, and further takes advantage of the observation that
for line slopes between 0 and 1, the change in Y from one column to the next will be either 0 or
1. This algorithm requires no rounding, no floating point numbers, and no multiplications.
given a line segment from leftmost (Xo,Yo) to rightmost (X1,Y1):
Y=mX+b
m = deltaY / deltaX = (Y1 - Yo) / ( X1 - Xo)
assuming Xo,X1,Yo,Y1 are integers

Assuming 0 <= m <= 1 we start at the leftmost edge of the line, and move right one pixel-column
at a time illuminating the pixel either in the current row (the pixel to the EAST) or the next
higher row (the pixel to the NORTHEAST.)
Y=mX+B
m = deltaY / deltaX = (Y1 - Yo) / ( X1 - Xo)
can rewrite the equation in the form: F(X,Y) = ax + by + c = 0
Y = (deltaY / deltaX) * X + B
0 = (deltaY / deltaX) * X - Y + B
0 = deltaY * X - deltaX * Y + deltaX * B
F(X,Y) = deltaY * X - deltaX * Y + deltaX * B
so for any point (Xi,Yi) we can plug Xi,Yi into the above equation and
F(Xi,Yi) = 0 -> (Xi,Yi) is on the line
F(Xi,Yi) > 0 -> (Xi,Yi) is below the line
F(Xi,Yi) < 0 -> (Xi,Yi) is above the line
Given that we have illuminated the pixel at (Xp,Yp) we will next either illuminate
the pixel to the EAST (Xp+ 1,Yp)
or the pixel to the NORTHEAST (Xp+ 1,Yp+ 1)
To decide we look at the Midpoint between the EAST and NORTHEAST pixel and see which
side of the midpoint the line falls on.
line above the midpoint -> illuminate the NORTHEAST pixel
line below the midpoint -> illuminate the EAST pixel
line exactly on the midpoint -> CHOOSE TO illuminate the EAST pixel
We create a decision variable called d
We plug the Midpoint into the above F() for the line and see where the midpoint falls in relation
to the line.
d = F(Xp+1,Yp+0.5)
d > 0 -> pick NORTHEAST pixel
d < 0 -> pick EAST pixel
d = 0 -> ***CHOOSE*** to pick EAST pixel
That tells us which pixel to illuminate next. Now we need to compute what Midpoint is for the
next iteration.
if we pick the EAST pixel

Midpoint is incremented by 1 in X and 0 in Y
We want to compute the new d without recomputing d from the new Midpoint
We want to compute the new d only using current d
dcurrent= F(Xp + 1,Yp + 0.5)
using the function F(X,Y) = deltaY * X - deltaX * Y + deltaX * B we can expand this out
...
dcurrent= deltaY * (Xp + 1) - deltaX * (Yp + 0.5) + deltaX * B
dnew = F(Xp + 2, Yp + 0.5)
dnew = deltaY * (Xp + 2) - deltaX * (Yp + 0.5) + deltaX * B
when you simplify it you end up with: dnew = dcurrent + deltaY
so we create a new variable called deltaE where deltaE = deltaY
if we pick the NORTHEAST pixel
Midpoint is incremented by 1 in X and 1 in Y
We want to compute the new d without recomputing d from the new Midpoint, only
using current d
We want to compute the new d only using current d
dcurrent= F(Xp + 1,Yp + 0.5)
using the function F(X,Y) = deltaY * X - deltaX * Y + deltaX * B we can expand this out
...
dcurrent= deltaY * (Xp + 1) - deltaX * (Yp + 0.5) + deltaX * B
dnew = F(Xp + 2, Yp + 1.5)
dnew = deltaY * (Xp + 2) - deltaX * (Yp + 1.5) + deltaX * B
when you simplify it you end up with: dnew = dcurrent + deltaY - deltaX
so we create a new variable called deltaNE where deltaNE = deltaY - deltaX
initial point (Xo,Yo) is known
so initial M is at (Xo + 1, Yo + 0.5)
so initial d = F(Xo + 1,Yo + 0.5)
using the function F(X,Y) = deltaY * X - deltaX * Y + deltaX * B we can expand this out ...
= deltaY * (Xo + 1) - deltaX * (Yo + 0.5) + deltaX * B
= (deltaY * Xo - deltaX * Yo + deltaX * B) + deltaY - 0.5 * deltaX
= F(Xo,Yo) + deltaY - 0.5 * deltaX

since (Xo,Yo) is on the line -> F(Xo,Yo) = 0
so initial d = deltaY - deltaX / 2
the divion by 2 is still annoying, but we can remove it by being clever
we can avoid the division by 2 by multiplying F() by 2
this also multiplies d, deltaE, deltaNE by 2
but since d is only concerned with =0,< 0, or > 0 multiplication does not affect it
So now we can finally show the Midpoint Line algorithm
Assuming integral endpoints for the line segment (if not then make them integral)
starting at the leftmost edge of the line:
deltaX = X1 - Xo
deltaY = Y1 - Yo
d = deltaY * 2 - deltaX
deltaE = deltaY * 2
deltaNE = (deltaY - deltaX) * 2
X = Xo
Y = Yo
illuminate X, Y
while (X < X1) repeatedly
if ( d <= 0)
add deltaE to d
add 1 to X
else
add deltaNE to d
add 1 to X
add 1 to Y
illuminate X, Y

Drawing Circles
The algorithm used to draw circles is very similar to the Midpoint Line algorithm.
8 way-symmetry - for a circle centered at (0,0) and given that point (x,y) is on the circle, the
following points are also on the circle:
(-x, y) ( x,-y) (-x,-y) ( y, x) (-y, x) ( y,-x) (-y,-x)
So it is only necessary to compute the pixels for 1/8 of the circle and then simply illuminate the
appropriate pixels in the other 7/8.
given a circle centered at (0,0) with radius R:
R^2 = X^2 + Y^2
F(X,Y) = X^2 + Y^2 - R^2
We choose to work in the 1/8 of the circle (45 degrees) from x=0 (y-axis) to x = y = R/sqrt(2) (45
degrees clockwise from the y-axis.)
so for any point (Xi,Yi) we can plug Xi,Yi into the above equation and
F(Xi,Yi) = 0 -> (Xi,Yi) is on the circle
F(Xi,Yi) > 0 -> (Xi,Yi) is outside the circle
F(Xi,Yi) < 0 -> (Xi,Yi) is inside the circle
Given that we have illuminated the pixel at (Xp,Yp) we will next either illuminate

the pixel to the EAST (Xp + 1,Yp)
or the pixel to the SOUTHEAST (Xp+ 1,Yp - 1)
We again create a decision variable d set equal to the function evaluated at the midpoint (Xp+
1,Yp - 0.5)
d = F(Xp + 1,Yp - 0.5)
We plug the midpoint into the above F() for the circle and see where the midpoint falls in
relation to the circle.
d > 0 (midpoint is outside) -> pick SOUTHEAST pixel
d < 0 (midpoint is inside) -> pick EAST pixel
d = 0 (midpoint is on circle) -> ***CHOOSE*** to pick SOUTHEAST pixel
dcurrent = F(Xp + 1, Yp - 0.5)
dcurrent = (Xp + 1)^2 + (Yp - 0.5)^2 - R^2
dcurrent = Xp^2 + 2Xp + 1 + Yp^2 - Yp + 0.25 - R^2
if the EAST pixel is chosen then:
dnew = F(Xp + 2, Yp - 0.5)
dnew = (Xp + 2)^2 + (Yp - 0.5)^2 - R^2
dnew = Xp^2 + 4Xp + 4 + Yp^2 - Yp + 0.25 - R^2
dnew - dcurrent = deltaE = 2Xp + 3
if the SOUTHEAST pixel is chosen then:
dnew = F(Xp + 2, Yp - 1.5)
dnew = (Xp + 2)^2 + (Yp - 1.5)^2 - R^2
dnew = Xp^2 + 4Xp + 4 + Yp^2 - 3Yp + 2.25 - R^2
dnew - dcurrent = deltaSE = 2Xp - 2Yp + 5
Unlike the algorithm for lines, deltaE and deltaSE are not constant.
initial point (Xo,Yo) is known to be (0,R)
so initial M is at (1, R - 0.5)
so initial d = F(1, R - 0.5)
= 1^2 + (R - 0.5)^2 - R^2
= 1 + R^2 - R + 0.25 - R^2
= 1.25 - R
unfortunately while deltaSE and deltaE are integral, d is still a real variable, not an integer so:

h = d - 0.25
h is initialized as 1 - R (instead of 1.25 - R)
h is compared to as h < 0.25 (instead of d< 0)
but since h starts off as an integer (assuming an integral R) and h is only incremented by integral
amounts (deltaE and deltaSE) we can ignore the 0.25 and compare h < 0.
X = 0;
Y = radius;
d = 1 - radius;
draw8Points(X, Y);
while(Y > X)
if (d< 0)
add 2 * X + 3 to d
add 1 to X
else
add 2 * (X-Y) + 5 to d
add 1 to X
subtract 1 from Y
draw8Points(X, Y);
The full algorithm ( was ? ) given (in C) in the red book ( version ??? ) as program 3.4 on p.83.
The full algorithm is given (in C) in the white book as figure 3.16 on p.86.
This is still somewhat bad in that there is a multiplication to compute the new value of the
decision variable. The book shows a more complicated algorithm which does this multiplication
only once.
ellipses F(x,y) = b^2 X^2 + a^2 Y^2 - a^2 b^2 = 0 are handled in a similar manner, except that
1/4 of the ellipse must be dealt with at a time and that 1/4 must be broken into 2 parts based on
where the slope of the tangent to the ellipse is -1 (in first quadrant.)
Clipping
Since we have a separation between the models and the image created from those models, there
can be parts of the model that do not appear in the current view when they are rendered.
pixels outside the clip rectangle are clipped, and are not displayed.
can clip analytically - knowing where the clip rectangle is clipping can be done before scan-line
converting a graphics primitive (point, line, polygon) by altering the graphics primitive so the
new version lies entirely within the clip rectangle

can clip by brute force (scissoring) - scan convert the entire primitive but only display those
pixels within the clip rectangle by checking each pixel to see if it is visible.
clipping a point against a rectangle -> nothing or single point
clipping a line against a rectangle -> nothing or single line segment
clipping a rectangle against a rectangle -> nothing or single rectangle
o ( Assuming the rectangle is aligned. Otherwise treat as convex polygon. )
clipping a convex polygon against a rectangle -> nothing or single single convex polygon
clipping a concave polygon against a rectangle -> nothing or 1 or more concave polygons
as with scan conversion, this must be done as quickly as possible as it is a very common
operation.
Point Clipping
point (X,Y)
clipping rectangle with corners (Xmin,Ymin) (Xmax,Ymax)
point is within the clip rectangle if:
Xmin <= X<= Xmax
Ymin <= Y<= Ymax
Cohen-Sutherland Line Clipping ( Foley 3.12.3 )
given a line segment, repeatedly:
1. check for trivial acceptance
both endpoints within clip rectangle
2. check for trivial rejection
both endpoints outside clip rectangle IS NOT ENOUGH
both endpoints off the same side of clip rectangle IS ENOUGH
3. divide segment in two where one part can be trivially rejected
Clip rectangle extended into a plane divided into 9 regions
each region is defined by a unique 4-bit string
left bit = 1: above top edge (Y > Ymax)

o left bit = sign bit of (Ymax - Y)
2nd bit = 1: below bottom edge (Y < Ymin)
o 2nd bit = sign bit of (Y - Ymin)
3rd bit = 1: right of right edge (X > Xmax)
o 3rd bit = sign bit of (Xmax - X)
right bit = 1: left of left edge (X < Xmin)
o right bit = sign bit of (X - Xmin)
(the sign bit being the most significant bit in the binary representation of the value. This bit is '1'
if the number is negative, and '0' if the number is positive.)
The frame buffer itself, in the center, has code 0000.
1001 | 1000 | 1010 -----+------+----- 0001 | 0000 | 0010 -----+------+----- 0101 | 0100 | 0110
For each line segment:
1. each end point is given the 4-bit code of its region
2. repeat until acceptance or rejection
1. if both codes are 0000 -> trivial acceptance
2. if bitwise logical AND of codes is not 0000 -> trivial rejection
3. divide line into 2 segments using edge of clip rectangle
1. find an endpoint with code not equal to 0000
2. move left to right across the code to find a 1 bit -> the crossed edge
3. break the line segment into 2 line segments at the crossed edge
4. forget about the new line segment lying completely outside the clip rectangle
The full algorithm ( was? ) given (in C) in the red book ( ??? Edition ) as program 3.7 on p.105.
The full algorithm is given (in C) in the white book as figure 3.41 on p.116.
Sutherland-Hodgman Polygon Clipping ( Foley 3.14.1 )
Unlike line-clipping where we selectively clipped against each edge, here we sucessively clip a
polygon against all four edges of the clip rectangle
given a polygon with vertices V1, V2, ... Vn
and edges between vertices Vi and Vi+1, and from Vn to V1
for each of the four clipping edges
repeatedly for each vertex V = Vn, V1, V2, ... Vn

given an edge from vertex s to vertex p
assume s has already been dealt with
o if s and p are both inside the clip rectangle -> output p
o if s is inside and p is outside the clip rectangle -> output i (the intersection of edge sp
with the clip edge)
o if s and p are both outside the clip rectangle -> output nothing
o if s is outside and p is inside the clip rectangle -> output i (the intersection of edge sp
with the clip edge) and then p
output edges become new set of polygon edges
Coordinate System "Handedness"
In a 2-D coordinate system the X axis generally points from left to right, and the Y axis generally
points from bottom to top. ( Although some windowing systems will have their Y coordinates
going from top to bottom. )
When we add the third coordinate, Z, we have a choice as to whether the Z-axis points into the
screen or out of the screen:
Right Hand Coordinate System (RHS)
Z is coming out of the page
Counterclockwise rotations are positive
if we rotate about the X axis : the rotation Y->Z is positive
if we rotate about the Y axis : the rotation Z->X is positive
if we rotate about the Z axis : the rotation X->Y is positive
Left Hand Coordinate System (LHS)
Z is going into the page
Clockwise rotations are positive
if we rotate about the X axis : the rotation Y->Z is positive
if we rotate about the Y axis : the rotation Z->X is positive
if we rotate about the Z axis : the rotation X->Y is positive
so basically its the same thing ...

The important thing to note is what coordinate system is being used by the package you are
working with, both for the creation of models and the displaying of them. Also note that if the
two packages use different coordinate systems, then the model(s) may need to be inverted in
some fashion when they are loaded in for viewing.
OpenGL generally uses a right-hand coordinate system.
Multiple Coordinate Systems in a Graphics Program
In a typical graphics program, we may need to deal with a number of different coordinate
systems, and a good part of the work ( and the cause of many headaches ) is the conversion of
coordinates from one system to another. We'll learn about the conversion process a little later,
but in the meantime, here is a list of some of the coordinate systems you may encounter:
World Coordinate System - Also known as the "universe" or sometimes "model"
coordinate system. This is the base reference system for the overall model, ( generally in
3D ), to which all other model coordinates relate.
Object Coordinate System - When each object is created in a modelling program, the
modeller must pick some point to be the origin of that particular object, and the
orientation of the object to a set of model axes. For example when modelling a desk, the
modeller might choose a point in the center of the desk top for the origin, or the point in
the center of the desk at floor level, or the bottom of one of the legs of the desk. When
this object is moved to a point in the world coordinate system, it is really the origin of the
object ( in object coordinate system ) that is moved to the new world coordinates, and all
other points in the model are moved by an equal amount. Note that while the origin of the
object model is usually somewhere on the model itself, it does not have to be. For
example, the origin of a doughnut or a tire might be in the vacant space in the middle.
Hierarchical Coordinate Systems - Sometimes objects in a scene are arranged in a
hierarchy, so that the "position" of one object in the hierarchy is relative to its parent in
the hierarchy scheme, rather than to the world coordinate system. For example, a hand
may be positioned relative to an arm, and the arm relative to the torso. When the arm
moves, the hand moves with it, and when the torso moves, all three objects move
together.
Viewpoint Coordinate System - Also known as the "camera" coordinate system. This
coordinate system is based upon the viewpoint of the observer, and changes as they
change their view. Moving an object "forward" in this coordinate system moves it along
the direction that the viewer happens to be looking at the time.
Model Window Coordinate System - Not to be confused with desktop windowing
systems ( MS Windows or X Windows ), this coordinate system refers to the subset of
the overall model world that is to be displayed on the screen. Depending on the viewing
parameters selected, the model window may be rectalinear or a distorted viewing
frustrum of some kind.
Screen Coordinate System - This 2D coordinate system refers to the physical
coordinates of the pixels on the computer screen, based on current screen resolution. (
E.g. 1024x768 )

Viewport Coordinate System - This coordinate system refers to a subset of the screen
space where the model window is to be displayed. Typically the viewport will occupy the
entire screen window, or even the entire screen, but it is also possible to set up multiple
smaller viewports within a single screen window.

Transformations in 2 Dimensions
One of the most common and important tasks in computer graphics is to transform the
coordinates ( position, orientation, and size ) of either objects within the graphical scene or the
camera that is viewing the scene. It is also frequently necessary to transform coordinates from
one coordinate system to another, ( e.g. world coordinates to viewpoint coordinates to screen
coordinates. ) All of these transformations can be efficiently and succintly handled using some
simple matrix representations, which we will see can be particularly useful for combining
multiple transformations into a single composite transform matrix.
We will look first at simple translation, scaling, and rotation in 2D, then extend our results to 3D,
and finally see how multiple transformations can be easily combined into a composite transform.
Translation in 2D
point (X,Y) is to be translated by amount Dx and Dy to a new location (X',Y')
X' = Dx + X
Y' = Dy + Y
or P' = T + P where
_ _ P' = | X' | | Y' | - - _ _ T = | Dx | | Dy | - - _ _ P = | X | | Y | - -
Scaling in 2D
point (X,Y) is to be scaled by amount Sx and Sy to location (X',Y')
X' = Sx * X
Y' = Sy * Y
or P' = S * P where

_ _ P' = | X' | | Y' | - - _ _ S = | Sx 0 | | 0 Sy | - - _ _ P = | X | | Y | - -
scaling is performed about the origin (0,0) not about the center of the line/polygon/whatever
Scale > 1 enlarge the object and move it away from the origin.
Scale = 1 leave the object alone
Scale< 1 shrink the object and move it towards the origin.
uniform scaling: Sx = Sy
differential scaling Sx != Sy -> alters proportions
Rotation in 2D
point (X,Y) is to be rotated about the origin by angle theta to location (X',Y')
X' = X * cos(theta) - Y * sin(theta)
Y' = X * sin(theta) + Y *cos(theta)
note that this does involve sin and cos which are much more costly than addition or
multiplication
or P' = R * P where
_ _ P' = | X' | | Y' | - - _ _ R = | cos(theta) -sin(theta) | | sin(theta) cos(theta) | - - _ _ P = | X | | Y | - -
rotation is performed about the origin (0,0) not about the center of the line/polygon/whatever

Derivation of the 2D Rotation Equations
Where does this matrix come from?
(X,Y) is located r away from (0,0) at a CCW angle of phi from the X axis.
(X',Y') is located r away from (0,0) at a CCW angle of theta+phi from the X axis.
Since rotation is about the origin, (X',Y') must be the same distance from the origin as (X,Y).
from trigonometry we have:
X = r * cos(phi)
Y = r * sin(phi)
and
X' = r * cos(theta+phi)
Y' = r * sin(theta+phi)
Now making use of the following trigonometric identities:
cos(a+b) = cos(a) * cos(b) - sin(a) * sin(b)
sin(a+b) = sin(a) * cos(b) + cos(a) * sin(b)
and substituting in for the above equations for X' and Y', we get:
X' = r * cos(theta) * cos(phi) - r * sin(theta) * sin(phi)
Y' = r * sin(theta) * cos(phi) + r * cos(theta) * sin(phi)
Then we substitute in X and Y from their definitions above, and the final result simplifies to:
X' = X * cos(theta) - Y * sin(theta)
Y' = X * sin(theta) + Y * cos(theta)
Homogeneous Coordinates in 2 Dimensions
Scaling and rotations are both handled using matrix multiplication, which can be combined as we
will see shortly. The translations cause a difficulty, however, since they use addition instead of
multiplication.
We want to be able to treat all 3 transformations (translation, scaling, rotation) in the same way -
as multiplications.

The solution is to give each point a third coordinate (X, Y, W), which will allow translations to
be handled as a multiplication also.
( Note that we are not really moving into the third dimension yet. The third coordinate is being
added to the mathematics solely in order to combine the addition and multiplication of 2-D
coordinates. )
Two triples (X,Y,W) and (X',Y',W') represent the same point if they are multiples of each other
e.g. (1,2,3) and (2,4,6).
At least one of the three coordinates must be nonzero.
If W is 0 then the point is at infinity. This situation will rarely occur in practice in computer
graphics.
If W is nonzero we can divide the triple by W to get the cartesian coordinates of X and Y which
will be identical for triples representing the same point (X/W, Y/W, 1). This step can be
considered as mapping the point from 3-D space onto the plane W=1.
Conversely, if the 2-D cartesian coordinates of a point are known as ( X, Y ), then the
homogenous coordinates can be given as ( X, Y, 1 )
So, how does this apply to translation, scaling, and rotation of 2D coordinates?
Translation of 2D Homogenous Coordinates
point (X,Y) is to be translated by amount Dx and Dy to location (X',Y')
X' = Dx + X
Y' = Dy + Y
or P' = T * P where
_ _ P' = | X' | | Y' | | 1 | - - _ _ T = | 1 0 Dx | = T(Dx,Dy) | 0 1 Dy | | 0 0 1 | - - _ _ P = | X | | Y | | 1 |

- -
Hey Look! Translation is now a multiplication instead of an addition!
Scaling of 2D Homogenous Coordinates
P' = S * P where _ _ P' = | X' | | Y' | | 1 | - - _ _ S = | Sx 0 0 | = S(Sx,Sy) | 0 Sy 0 | | 0 0 1 | - - _ _ P = | X | | Y | | 1 | - -
Rotation of 2D Homogenous Coordinates
P' = R * P where _ _ P' = | X' | | Y' | | 1 | - - _ _ R = | cos(theta) -sin(theta) 0 | = R(theta) | sin(theta) cos(theta) 0 | | 0 0 1 | - - _ _ P = | X | | Y | | 1 | - -
Composition of 2D Transformations
There are many situations in which the final transformation of a point is a combination of several
( often many ) individual transformations. For example, the position of the finger of a robot
might be a function of the rotation of the robots hand, arm, and torso, as well as the position of
the robot on the railroad train and the position of the train in the world, and the rotation of the
planet around the sun, and . . .

Applying each transformation individually to all points in a model would take a lot of time.
Instead of applying several transformations matrices to each point we want to combine the
transformations to produce 1 matrix which can be applied to each point.
In the simplest case we want to apply the same type of transformation (translation, rotation,
scaling) more than once.
translation is additive as expected
scaling is multiplicative as expected
rotation is additive as expected
But what if we want to combine different types of transformations?
a very common reason for doing this is to rotate a polygon about an arbitrary point (e.g. the
center of the polygon) rather than around the origin.
Translate so that P1 is at the origin T(-Dx,-Dy)
Rotate R(theta)
Translate so that the point at the origin is at P1 T(Dx,Dy)
note the order of operations here is right to left:
P' = T(Dx,Dy) * R(theta) * T(-Dx,-Dy) * P
i.e.
P' = T(Dx,Dy) * { R(theta) * [ T(-Dx,-Dy) * P ] }
i.e.
P' = [ T(Dx,Dy) * R(theta) * T(-Dx,-Dy) ] * P
The matrix that results from these 3 steps can then be applied to all of the points in the polygon.
another common reason for doing this is to scale a polygon about an arbitrary point (e.g. the
center of the polygon) rather than around the origin.
Translate so that P1 is at the origin
Scale
Translate so that the point at the origin is at P1
How do we determine the 'center' of the polygon?
specifically define the center (e.h. the center of mass)
average the location of all the vertices
take the center of the bounding box of the polygon
Window to Viewport

Generally user's prefer to work in world-coordinates.
1 unit can be 1 micron
1 unit can be 1 meter
1 unit can be 1 kilometer
1 unit can be 1 mile
These coordinates must then be translated to screen coordinates to be displayed in a rectangular
region of the screen called the viewport
The objects are in world coordinates (with n dimensions)
The viewport is in screen coordinates (with n=2)
Want one matrix that can be applied to all points:
rectangular area of world from (Xmin,Ymin) to (Xmax,Ymax) - world-coordinate window
rectangular area of screen from (Umin,Vmin) to (Umax,Vmax) - viewport
need to rescale the world-coordinate rectangle to the screen rectangle
1. translate world-coordinate window to the origin of the world coordinate system.
2. rescale the window to the size and aspect ratio of the viewport.
3. translate the viewport to its position on the screen in the screen coordinate system.
Pscreen = M * Pworld
M = T(Umin,Vmin) * S(deltaU/deltaX, deltaV/deltaY) * T(-Xmin, -Ymin)

Transformations in 3D
3D Transformations
Similar to 2D transformations, which used 3x3 matrices, 3D transformations use 4X4 matrices
(X, Y, Z, W)
3D Translation: point (X,Y,Z) is to be translated by amount Dx, Dy and Dz to location (X',Y',Z')
X' = Dx + X
Y' = Dy + Y
Z' = Dz + Z
or P' = T * P where
_ _ P' = | X' | | Y' | | Z' | | 1 | - - _ _ T = | 1 0 0 Dx | = T(Dx,Dy,Dz) | 0 1 0 Dy | | 0 0 1 Dz | | 0 0 0 1 | - - _ _ P = | X | | Y | | Z | | 1 | - -
3D Scaling:
_ _ P' = | X' | | Y' | | Z' | | 1 | - - _ _ S = | Sx 0 0 0 | = S(Sx,Sy,Sz) | 0 Sy 0 0 | | 0 0 Sz 0 | | 0 0 0 1 | - -

_ _ P = | X | | Y | | Z | | 1 | - -
3D Rotation:
For 3D rotation we need to pick an axis to rotate about. The most common choices are the X-
axis, the Y-axis, and the Z-axis
_ _ P' = | X' | | Y' | | Z' | | 1 | - - _ _ Rz = | cos(theta) -sin(theta) 0 0 | = Rz(theta) | sin(theta) cos(theta) 0 0 | | 0 0 1 0 | | 0 0 0 1 | - - _ _ Rx = | 1 0 0 0 | = Rx(theta) | 0 cos(theta) -sin(theta) 0 | | 0 sin(theta) cos(theta) 0 | | 0 0 0 1 | - - _ _ Ry = | cos(theta) 0 sin(theta) 0 | = Ry(theta) | 0 1 0 0 | | -sin(theta) 0 cos(theta) 0 | | 0 0 0 1 | - - _ _ P = | X | | Y | | Z | | 1 | - -
Complex / Compound Rotations
Now what if rotations are to occur other than around one of the cartesian axes? There are two
ways of looking at this:
1. A series of rotations about cartesian axes, which can be combined by multiplying the
appropriate matrices together. Again, the righmost matrix is the operation that occurs
first. Note that with this approach there may be more than one combination of rotations
that yield the same end result.

2. An alternate axis of rotation can be chosen, other than the cartesian axes, and the point
rotated a given amount about this axis. For any given orientation change there exists a
single unique axis and rotation angle ( 0 <= theta <= 180 degrees ) that will yield the
desired rotation. This alternative approach is the basis for "quaternions", which will not
likely be discussed further in this course. ( Quaternions are used heavily in the
WorldToolKit package, which is no longer produced, and can be useful for interpolating
rotations between two oblique angles. )
Composition is handled in a similar way to the 2D case, multiplying the transformation matrices
from right to left.
OpenGL Transform Operations
In OpenGL translation, rotation, and scaling are performed using commands such as:
glTranslate{fd}(X,Y,Z) - glTranslatef(1.0, 2.5, 3.0)
glRotate{df}(Angle, X, Y, Z) - glRotatef(60.0, 0.0, 0.0, 1.0)
glScale{df}(X, Y, Z) - glScalef(1.0, 1.5, 2.0)
What these commands do in practice is to generate the corresponding transformation matrix for
the operation that was requested, multiply it by whatever matrix is currently on top of the
currently active matrix stack, and replace the matrix on the top of the stack with the result. If you
want to calculate and save the result of a complex series of transformations, one approach is to
push an identity matrix onto the stack, perform each of the operations in turn, and then save a
copy of the result from the top of the stack into a global or static variable, ( possibly popping it
off the stack if it won't be needed there immediately. )

Implementation: Applying Geometric Transformations
Changing Coordinate Systems
Last time we talked about transforms in terms of an object (polygon, line, point) in the same
coordinate system of the world, that is (0,0) for the object is the same as (0,0) for the world.
An alternative (and usually preferable) way is for each object to have its own local coordinate
system separate from all of the other objects and the world coordinate system. This allows each
object to be created separately and then added into the world, using transformations to place the
object at the appropriate point.
This is especially useful when you build larger objects out of reusable smaller objects.
For example we could have a square with 2 unit long sides and the center of the square at its
origin.
The vertices of the square are: (-1,-1) ( 1,-1) ( 1, 1) (-1, 1)
This is nice because the center of the square is where we probably want the center of
rotation/scaling to be. We can rotate/scale it where it is and then translate it where it belongs in
the world (e.g. T(5,5) to move the center to (5,5) in world-space)
When we design the object we place the center of rotation/scaling where we wish it to be. For a
wheel the center of rotation would be where the axle is to be attached, for a hinged gate the
center would be at the hinge.
Each object must then be translated/rotated/scaled (from its local co-ordinate system) to place it
at the proper location in the world (in the world co-ordinate system).
Say we are drawing an automobile and we want to draw the 4 tires. We can either draw each of
the 4 tires independently at the appropriate location, or draw the same tire centered at its origin 4
times, and each time move it to the appropriate location in the world.
OpenGL Example: Sun and Planet
Some OpenGL code to create a solar system with a single sun and a single planet in orbit about
it. We will bend the laws of physics slightly and say that the planet is orbiting about the center of
the sun rather than having the objects in orbit about their shared center of mass. We also assume
a circular orbit and that the plane of the solar system matches the Y=0 plane
We place the sun at 0,0,0 and it will be a sphere of radius 1
The planet has a radius of 0.2 and orbits the sun at a radius of 2

The planet rotates about its axis once per day
The planet revolves around the sun once each year
glPushMatrix(); // Copies the top matrix on the stack and pushes it.
glLoadIdentity(); //reset the matrix to the identity matrix
drawSphere(1.0) // user defined function to draw the sun
glRotatef(yearPercentage, 0.0, 1.0, 0.0); // Rotation about the sun
glTranslatef(2.0, 0.0, 0.0); // Translate to distance away from the sun
glRotatef(dayPercentage, 0.0, 1.0, 0.0); // Rotate about own axis.
drawSphere(0.2) // user defined function to draw the planet
glPopMatrix(); // Return stack to original condition
Note:
dayPercentage is the amount the planet rotates about ITS center.
yearPercentage is the amount the planet rotates about the center of the sun.
If you think about each object having its own coordinate system then the operations on the
matrix are done in the SAME order as they are called:
Initially the transformation matrix is the identity matrix
The sun is drawn as a circle with radius 1 at (0,0,0)
o The planet is rotated about its Y-axis by the percentage of year that has passed
turning its coordinate system in the process
o The planet is translated 2 units on its now rotated X-axis to its position in orbit
o The planet is rotated about its Y-axis by the percentage of day that has passed.
Since the planet is still at (0,0,0) by its coordinate system, it rotates about its
center.
o The planet is drawn as a circle with radius 0.2
If you think about the single coordinate system then the operations on the matrix are done in the
REVERSE order from which they are called:
Initially the transformation matrix is the identity matrix
The sun is drawn as a circle with radius 1 at (0,0,0)
o The planet is drawn as a circle with radius 0.2 at (0,0,0)
o The planet is rotated about the Y-axis by the percentage of day that has passed.
Since the planet is still at the origin this rotates the planet about its center.
o The planet is translated 2 units on the X-axis moving its center to (2, 0, 0)

o The planet is rotated about the Y-axis by the percentage of year that has passed.
Since the planet is no longer at the origin it rotates about the origin at a radius of
2.
if the matrix operations are not performed in reverse order then the year and day rotation
percentages get reversed.
Either way of thinking about it is equivalent, and irregardless of how you think about it, that is
how OpenGL function calls must be issued.
Say you have three polygonal drawing functions available to you:
Draw a square centered at the origin with sides of length 1
Draw a circle centered at the origin with diameter of length 1
Draw a equilateral triangle with the center of its base at the origin with sides of length 1
How can I draw the following scene?
Object Hierarchies
Single polygons are generally too small to be of interest ... its hard to think of a single polygon as
an 'object' unless you are writing Tetris(tm).
Even in a 2D world it is more convenient to think of objects which are a collection of polygons
forming a recognizable shape: a car, a house, or a laser-toting mutant monster from Nebula-9.
This object can then be moved/rotated/scaled as a single entity, at least at the conceptual level.
This is especially true in a 3D world where you need more than one (planar) polygon to create a
3D object.

Creating an object polygon by polygon is very slow when you want to create a very large
complex object. On the other hand it does give you much more control over the object than
creating it from higher-level primitives (cube, cone, sphere)
The following two examples are from Silicon Graphics' OpenInventor(tm) a library which sits on
top of OpenGL and allows higher-level objects to be created. The first shows a tree constructed
from a cube and a cone. The second shows the same tree but constructed from triangular
polygons.
pine tree built from objects
pine tree built from triangular polygons
note, triangular polygons are often used instead of 4-sided ones because the 3 vertices in the
triangle are guaranteed to form a plane, while the 4 vertices of a 4-sided polygon may not all fall
in the same plane which may cause problems later on.
Hierarchies are typically stored as Directed Acyclic Graphs, that is they are trees where a node
can have multiple parents as long as no cycle is generated.
Hierarchies store all information necessary to draw an object:
polygon information
material information
transformation information
Hierarchies are useful when you want to be able to manipulate an object on multiple levels:
With an arm you may want to rotate the entire arm about the shoulder, or just the lower
arm about the elbow, or just the wrist or just a finger. If you rotate the entire arm then
you want the rest of the arm parts to follow along as though they were joined like a real
arm - if you rotate the arm then the elbow should come along for the ride.
With a car the wheels should rotate but if the car body is moving then the wheels should
also be moving the same amount.
An object hierarchy gives a high degree of encapsulation.
An object heierarchy allows inheritance
Attributes to be set once and then used by multiple sub-objects.
For example, at the top of the hierarchy the object could be set to draw only as a
wireframe, or with different lighting models, or different colours, or different texture
maps. This would then be inherited by the sub-objects and not have to be explicitely set
each of them.

Hierarchies increase modularity.
Hierarchies decrease storage space
Only store one copy of each object in the hierarchy and then using pointers to that object.
Hierarchies make it easy to propagate changes.
For example if you decide to change the style of the 4 tires on your car model,the tire is
only stored once and referenced four times so only one model needs to be updated instead
of four.
Hierarchies are common in 'real life' so it can be easier to model hierarchical things in a
hierarchy.
How can I redraw the house and tree scene to make better use of objects?
Fonts
Text is handled in one of two ways.
Using a bitmap for each character in the font
Using lines / polygons for each character in the font
bitmaps:
rectangular array of 0s and 1s
00000000 00011000 00100100 01000010 01111110 01000010 01000010 01000010
need a set of bitmaps for each size and style of font
2D only
always aligned with the screen
dealt with specially, while manipulating the frame buffer
faster
polygons:
rescalable so that the definition can generate a 'smooth' character of any size

can be either 2D or 3D
can be rotated
treated like any other line/polygon to be displayed
slower
OpenGL provides minimal font support - only bitmapped fonts. Fortunately there are free 3D
fonts available such as the Hershey library.
General 3D Concepts
Taking 2D objects and mapping onto a 2D screen is pretty straightforward. The window is the
same plane as the 2D world. Now we are taking 3D objects and mapping them onto a 2D screen.
Here is where the advantage of separating the model world from its rendered image becomes
more obvious. The easiest way to think about converting 3D world into 2D image is the way we
do it in real life - with a camera.
Lets say we have an object in the real world (e.g. the Sears Tower.) The tower sits there in its
3Dness. You can move around the tower, on the ground, on the water, in the air, and take
pictures of it, converting it to a 2D image. Depending on where you put the camera and the
settings on the camera, and other factors such as light levels, you get different looking images.
In the computer we have a synthetic camera taking still or moving pictures of a synthetic
environment. While this synthetic camera gives you a much wider range of options than a real
camera, you will find it is VERY easy to take a picture of nothing at all.

Projections
projection is 'formed' on the view plane (planar geometric projection)
rays (projectors) projected from the center of projection pass through each point of the models
and intersect projection plane.
Since everything is synthetic, the projection plane can be in front of the models, inside the
models, or behind the models.
2 main types: perspective projection and parallel projection.
parallel :
o center of projection infinitely far from view plane
o projectors will be parallel to each other
o need to define the direction of projection (vector)
o 2 sub-types
orthographic - direction of projection is normal to view plane
oblique - direction of projection not normal to view plane
o better for drafting / CAD applications
perspective :
o center of projection finitely far from view plane
o projectors will not be parallel to each other
o need to define the location of the center of projection (point)
o classified into 1, 2, or 3-point perspective
o more visually realistic - has perspective foreshortening (objects further away
appear smaller)
which type of projection is used depends on the needs of the user - whether the goal is the
mathematically correct depiction of length and angles, or a realistic looking image of the object.
specifying a 3D view
Danger, watch out for acronyms being tossed out!
Need to know the type of projection
Need to know the clipping volume
in OpenGL there are the following functions:

glFrustum(left, right, bottom, top, near, far);
glOrtho(left, right, bottom, top, near, far);
View Plane defined by:
point on the plane - View Reference Point (VRP)
normal to the plane pointing towards the center of projection- View-Plane Normal
(VPN)
view plane can be anywhere in the world-space
The center of projection represents the location of the viewer's eye or the camera's lens.
Need to define a 3D Viewing Reference Coordinate system (VRC) which has axis u, v, n
Origin of VRC is the VRP
n axis of VRC is the VPN
v axis of VRC is called the View-UP vector (VUP)
u axis of VRC is defined to form a right-hand coordinate system with n and v
since the View Plane (n=0) is infinite (as it is a plane) we need to declare a region of that plane
to be our window.
(Umin, Vmin) to (Umax, Vmax)
Center of Window (CW) on View Plane does not have to be VRP
VRP may not even be within the window
Projection Reference Point (PRP) defines the Center of Projection and Direction of
Projection (DOP)
PRP given in VRC coordinate system (that is, its position is given relative to the VRP)
parallel projection - DOP is from PRP to CW, and all projectors are parallel.
perspective projection - Center of Projection is the PRP

n-point perspective
Perspective projections are categorized by the number of axes the view plane cuts (ie 1-point
perspective, 2-point perspective or 3-point perspective)
If the plane cuts the z axis only, then lines parallel to the z axis will meet at infinity; lines
parallel to the x or y axis will not meet at infinity because they are parallel to the view
plane. This is 1-point perspective.
If the plane cuts the x and z axes, then lines parallel to the x axis or the z axis will meet at
infinity; lines parallel to the y axis will not meet at infinity because they are parallel to
the view plane. This is 2-point perspective.
If the plane cuts the x, y, and z axis then lines parallel to the x, y, or z axis will meet at
infinity. This is 3-point perspective.
The n-point perspectives can work with any combination of the x, y, z axis.
View Volumes

The view volume in orthographic projection:
The view volume in perspective projection:
The front plane's location is given by the front distance F relative to the VRP
The back plane's location is given by the back distance B relative to the VRP
In both cases the positive direction is in the direction of the VPN
Viewing volume has 6 clipping planes (left, right, top, bottom, near (hither), far (yon)) instead of
the 4 clipping lines we had in the 2D case, so clipping is a bit more complicated
perspective - viewing volume is a frustum of a 4-sided pyramid
parallel - viewing volume is a rectangular parallelepiped (ie a box)
Parallel Examples
In the red version of the Foley vanDam book see P.211-212.
In the white version of the Foley vanDam book see P.250-252.
Perspective Examples

Here are some examples using the same house as in the book (figure 6.18 in the red version of
the Foley vanDam book, figure 6.24 in the white version of the Foley vanDam book, but using
Andy Johnson's solution to the former HW3 as the viewing program:
The object is a house with vertices:
0, 0,30 16, 0,30 16,10,30 8,16,30 0,10,30 0, 0,54 16, 0,54 16,10,54 8,16,54 0,10,54
VRP= 0 0 54 or VRP= 8 7 54 VPN= 0 0 1 VPN= 0 0 1 VUP= 0 1 0 VUP= 0 1 0 PRP= 8 7 30 PRP= 0 0 30 U: -1 to 17 U: -9 to 9 V: -2 to 16 V: -9 to 9
VRP= 16 0 54

VPN= 1 0 0 VUP= 0 1 0 PRP= 12 8 16 U: -1 to 25 V: -5 to 21
VRP= 16 0 54 VPN= 1 0 1 VUP= 0 1 0 PRP= 6 8 10 U: -22 to 22 V: -2 to 18
For other examples, in the red version of the Foley vanDambook see P.206-211.
In the white version of the Foley vanDam book see P.245-250.
Example with a Finite View Volume
In the red version of the Foley vanDam book see P.212-213.
In the white version of the Foley vanDam book see P.253.
Now, how do we actually IMPLEMENT this?!?!?!?
with lots and lots of matrices.
Method 1:
1. Extend 3D coordinates to homogeneous coordinates
2. Normalize the homogeneous coordinates
3. Go back to 3D coordinates
4. Clip

5. Extend 3D coordinates to homogeneous coordinates
6. Perform projection
7. Translate and Scale into device coordinates
8. Go to 2D coordinates
Method 2:
1. Extend 3D coordinates to homogeneous coordinates
2. Normalize the homogeneous coordinates
3. Clip
4. Translate and Scale into device coordinates
5. Go to 2D coordinates
The First Two Steps are Common to Both Methods
1. Extend 3D coordinates to homogeneous coordinates
This is easy we just take (x, y, z) for every point and add a W=1 (x, y, z, 1)
As we did previously, we are going to use homogeneous coordinates to make it easy to compose
multiple matrices.
2. Normalizing the homogeneous coordinates
It is hard to clip against any view volume the user can come up with, so first we normalize the
homogeneous coordinates so we can clip against a known (easy) view volume (the canonical
view volumes).
That is, we are choosing a canonical view volume and we will manipulate the world so that the
parts of the world that are in the existing view volume are in the new canonical view volume.
This also allows easier projection into 2D.

In the parallel projection case the volume is defined by these 6 planes:
x = -1 y = -1 z = 0 x = 1 y = 1 z = -1
In the perspective projection case the volume is defined by these 6 planes:
x = -z y = -z z = -zmin x = z y = z z = -1
We want to create Npar and Nper, matrices to perform this normalization.
For Npar the steps involved are:
1. Translate VRP to the origin
2. Rotate VRC so n-axis (VPN) is z-axis, u-axis is x-axis, and v-axis is y-axis
3. Shear so direction of projection is parallel to z-axis (only needed for oblique parallel projections -
that is where the direction of projection is not normal to the view plane)
4. Translate and Scale into canonical view volume
Step 2.1 Translate VRP to the origin is T(-VRP)
Step 2.2 Rotate VRC so n-axis (VPN) is z-axis, u-axis is x-axis, and v-axis is y-axis uses unit
vectors from the 3 axis:
Rz = VPN / || VPN || (so Rz is a unit length vector in the direction of the VPN)
Rx = VUP x Rz / || VUP x Rz || (so Rx is a unit length vector perpendicular to Rz and Vup)
Ry = Rz x Rx (so Ry is a unit length vector perpendicular to the plane formed by Rz and Rx)

giving matrix R:
_ _ | r1x r2x r3x 0 | | r1y r2y r3y 0 | | r1z r2z r3z 0 | | 0 0 0 1 | - -
with rab being the ath element of Rb
VPN rotated into Z axis, U rotated into X, V rotated into Y
now the PRP is in world coordinates
Step 2.3 Shear so direction of projection is parallel to z-axis (only needed for oblique parallel
projections - that is where the direction of projection is not normal to the view plane) makes
DOP coincident with the z axis. Since the PRP is now in world coordinates we can say that:
DOP is now CW - PRP
_ _ _ _ _ _ |DOPx| | (umax+umin)/2 | | PRPu | |DOPy| = | (vmax+vmin)/2 | - | PRPv | |DOPz| | 0 | | PRPn | | 0 | | 1 | | 1 | - - - - - -
We need DOP to be:
_ _ | 0 | | 0 | |DOPz'| | 1 | - -
The shear is performed with the following matrix:
_ _ | 1 0 shx 0 | | 0 1 shy 0 | | 0 0 1 0 | | 0 0 0 1 | - -
where:
shx = - DOPx / DOPz
shy = - DOPy / DOPz

note that if this is an orthographic projection (rather than an oblique one) DOPx = DOPy=0 so
shx = shy = 0 and the shear matrix becomes the identity matrix.
*** note that the red book has 2 misprints in this section. Equation 6.18 should have dopx as the
first element in the DOP vector, and equation 6.22 should have dopx / dopz. The white book has
the correct versions of the formulas
Step 2.4 Translate and Scale the sheared volume into canonical view volume:
Tpar = T( -(umax+umin)/2, -(vmax+vmin)/2, -F)
Spar = S( 2/(umax-umin), 2/(vmax-vmin), 1/(F-B))
where F and B are the front and back distances for the view volume.
So, finally we have the following procedure for computing Npar:
Npar = Spar * TPar * SHpar * R * T(-VRP)
For Nper the steps involved are:
1. Translate VRP to the origin
2. Rotate VRC so n-axis (VPN) is z-axis, u-axis is x-axis, and v-axis is y-axis
3. Translate so that the center of projection(PRP) is at the origin
4. Shear so the center line of the view volume is the z-axis
5. Scale into canonical view volume
Step 2.1 Translate VRP to the origin is the same as step 2.1 for Npar: T(-VRP)
Step 2.2 Rotate VRC so n-axis (VPN) is z-axis, u-axis is x-axis, and v-axis is y-axis is the same
as step 2.2 for Npar:
Step 2.3 Translate PRP to the origin which is T(-PRP)
Step 2.4 is the same as step 2.3 for Npar. The PRP is now at the origin but the CW may not be
on the Z axis. If it isn't then we need to shear to put the CW onto the Z axis.
Step 2.5 scales into the canonical view volume
up until step 2.3, the VRP was at the origin, afterwards it may not be. The new location of the
VRP is:
_ _ | 0 | VRP' = SHpar * T(-PRP) * | 0 | | 0 |

| 1 | - -
so
Sper = ( 2VRP'z / [(umax-umin)(VRP'z+B)] , 2VRP'z / [(vmax-vmin)(VRP'z+B)], -1 /
(VRP'z+B))
So, finally we have the following procedure for computing Nper:
Nper = Sper * SHpar * T(-PRP) * R * T(-VRP)
You should note that in both these cases, with Npar and Nper, the matrix depends only on the
camera parameters, so if the camera parameters do not change, these matrices do not need to be
recomputed. Conversely if there is constant change in the camera, these matrices will need to be
constantly recreated.
The Remaining Steps Differ for the Two Methods
Now, here is where the 2 methods diverge with method one going back to 3D coordinates to clip
while method 2 remains in homogeneous coordinates.
The choice is based on whether W is ensured to be > 0. If so method 1 can be used, otherwise
method 2 must be used. With what we have discussed in this class so far W will be > 0, and W
should remain 1 thorought the normaliztion step. You get W < 0 when you do fancy stuff like b-
splines. Method 2 also has the advantage of treating parallel and perspective cases with the same
clipping algorithms, and is generally supported in modern hardware.
We will deal with Method 1 first.
3. Divide by W to go back to 3D coordinates
This is easy we just take (x, y, z, W) and divide all the terms by W to get (x/W, y/W, z/W, 1) and
then we ignore the 1 to go back to 3D coordinates. We probably do not even need to divide by W
as it should still be 1.
4. Clip in 3D against the appropriate view volume
At this point we want to keep everything that is inside the canonical view volume, and clip away
everything that is outside the canonical view volume.
We can take the Cohen-Sutherland algorithm we used in 2D and extend it to 3D, except now
there are 6 bits instead of four.
For the parallel case the 6 bits are:
point is above view volume: y > 1

point is below view volume: y < -1
point is right of view volume: x > 1
point is left view volume: x < -1
point is behind view volume: Z < -1
point is in front of view volume: z > 0
For the perspective case the 6 bits are:
point is above view volume: y > -z
point is below view volume: y < z
point is right of view volume: x > -z
point is left view volume: x < z
point is behind view volume: z < -1
point is in front of view volume: z > zmin
P273 in the white book shows the appropriate equations for doing this.
5. Back to homogeneous coordinates again
This is easy we just take (x, y, z) and add a W=1 (x, y, z, 1)
6.Perform Projection - Collapse 3D onto 2D
For the parallel case the projection plane is normal to the z-axis at z=0. For the perspective case
the projection plane is normal to the z axis at z=d. In this case we set z = -1.
In the parallel case, since there is no forced perspective, Xp = X and Yp = Y and Z is set to 0 to
do the projection onto the projection plane. Points that are further away in Z still retain the same
X and Y values - those values do not change with distance.
For the parallel case, Mort is:
_ _ | 1 0 0 0 | | 0 1 0 0 | | 0 0 0 0 | | 0 0 0 1 | - -
Multiplying the Mper matrix and the vector (X, Y, Z, 1) holding a given point, gives the
resulting vector (X, Y, 0, 1).
In the perspective case where there is forced perspective, the projected X and Y values do
depend on the Z value. Objects that are further away should appear smaller than similar objects
that are closer.

For the perspective case, Mper is:
_ _ | 1 0 0 0 | | 0 1 0 0 | | 0 0 1 0 | | 0 0 -1 0 | - -
Multiplying the Mper matrix and the vector (X, Y, Z, 1) holding a given point, gives the
resulting vector (X, Y, Z, -Z).
7. Translate and Scale into device coordinates
All of the points that were in the original view volume are still within the following range:
-1 <= X <= 1
-1 <= Y <= 1
-1 <= Z <= 0
In the parallel case all of the points are at their correct X and Y locations on the Z=0 plane. In the
perspective case the points are scattered in the space, but each has a W value of -Z which will
map each (X, Y, Z) point to the appropriate (X', Y') place on the projection plane.
Now we will map these points into the viewport by moving to device coordinates.
This involves the following steps:
1. translate view volume so its corner (-1, -1, -1) is at the origin
2. scale to match the size of the 3D viewport (which keeps the corner at the origin)
3. translate the origin to the lower left hand corner of the viewport
Mvv3dv = T(Xviewmin, Yviewmin, Zviewmin) * Svv3dv * T(1, 1, 1)
where
Svv3dv = S( (Xviewmax-Xviewmin)/2, (Yviewmax-Yviewmin)/2, (Zviewmax-Zviewmin)/1 )
You should note here that these parameters will only depend on the size and shape of the
viewport - they are independant of the camera settings, so if the viewport is not resized, these
matrices will remain constant and reusable.
*** note that the red book has another misprint in this section. The discussion of the translation
matrix before equation 6.44 has a spurious not equal to sign.

8. Divide by W to go from homogeneous to 2D coordinates
Again we just take (x, y, z, W) and divide all the terms by W to get (x/W, y/W, z/W, 1) and then
we ignore the 1 to go back to 3D coordinates.
In the parallel case dropping the W takes us back to 3D coordinates with Z=0, which really
means we now have 2D coordinates on the projection plane.
In the perspective projection case, dividing by W will affect the transformation of the points.
Dividing by W (which is -Z) takes us back to the 3D coordinates of (-X/Z, -Y/Z, -1, 1). Dropping
the W takes us to the 3D coordinates of (-X/Z, -Y/Z, -1) which positions all of the points onto the
Z=-1 projection plane which is what we wanted. Dropping the Z coordinate gives us the 2D
location on the Z=-1 plane.
The Second Method
BUT ... there is still the second method where we clip in homogeneous coordinates to be more
general
The normalization step (step 2) is slighly different here, as both the parallel and perspective
projections need to be normalized into the canonical parallel perspective view volume.
Npar above does this for the parallel case.
Nper' for the perspective case is M * Nper. Nper is the normalization given in step 2. This is the
same normalization that needed to be done in step 8 of method one before we could convert to
2D coordinates.
M =
1 0 0 0
0 1 0 0
0 0 1/(1+Zmin) z/(1+Zmin)
0 0 -1 0
Now in both the parallel and perspective cases the clipping routine is the same.
Again we have 6 planes to clip against:
X = -W
X = W
Y = -W

Y = W
Z = -W
Z = 0
but since W can be positive or negative the region defined by those planes is different depending
on W.
2nd method step 4: Then we know all of the points that were in the original view volume are
now within the following range:
-1 <= X <= 1
-1 <= Y <= 1
-1 <= Z <= 0
Now we need to map these points into the viewport by moving to the device coordinates.
This involves the following steps:
1. translate view volume so its corner (-1, -1, -1) is at the origin
2. scale to match the size of the 3D viewport (which keeps the corner at the origin)
3. translate the origin to the lower left hand corner of the viewport
Mvv3dv = T(Xviewmin, Yviewmin, Zviewmin) * Svv3dv * T(1, 1, 1)
where
Svv3dv = S( (Xviewmax-Xviewmin)/2, (Yviewmax-Yviewmin)/2, (Zviewmax-Zview.min)/1 )
The new x and new y give us the information we need for the 2D version, but we will also find
the new z to be useful for determining occlusion - which we will discuss in a few weeks as z-
buffer techniques.
2nd method step 5: Then we divide by W to go from homogeneous to 2D coordinates. In the
perspective projection case, dividing by W will affect the transformation of the points.

Lighting and Shading
What the human eye ( or virtual camera ) sees is a result of light coming off of an object or other
light source and striking receptors in the eye. In order to understand and model this process, it is
necessary to understand different light sources and the ways that different materials reflect those
light sources.
Trying to recreate reality is difficult.
Lighting calculations can take a VERY long time.
The techniques described here are heuristics which produce appropriate results, but they do not
work in the same way reality works - because that would take too long to compute, at least for
interactive graphics.
Instead of just specifying a single colour for a ploygon we will instead specify the properties of
the material that the polygon is supposed to be made out of, ( i.e. how the material responds to
different kinds of light ), and the properties of the light or lights shining onto that material.
Illumination Models
No Lighting ( Emissive Lighting )
There are no lights in the scene
Each polygon is self-luminous (it lights itself, but does not give off light)
o This is also known as "emissive" lighting in some systems.
o ( Truly "no" lighting would be a totally black screen and not very interesting. )
o Emissive lighting can have some interesting effects, such as car headlights or
neon signs.
Each polygon has its own colour which is constant over its surface
That colour is not affected by anything else in the world
That colour is not affected by the position or orientation of the polygon in the world
This is very fast, but not very realistic
position of viewer is not important
No 3-D information provided.
o Generally used as a special effect in combination with other lighting, or for very
simple graphics.
I = Ki
I: intensity
Ki: object's intrinsic intensity, 0.0 - 1.0 for each of R, G, and B

This scene from battalion has no lighting ( ? )
Ambient
Non-directional light source
Simulates light that has been reflected so many times from so many surfaces it appears to
come equally from all directions
intensity is constant over polygon's surface
intensity is not affected by anything else in the world
intensity is not affected by the position or orientation of the polygon in the world
position of viewer is not important
No 3-D information provided.
o Generally used as a base lighting in combination with other lights.
I = IaKa
I: intensity
Ia: intensity of Ambient light
Ka: object's ambient reflection coefficient, 0.0 - 1.0 for each of R, G, and B
Types of Light Sources Which Can be Used to Light a Scene
Directional light - produced by a light source an infinite distance from the scene., All of
the light rays emanating from the light strike the polygons in the scene from a single
parallel direction, and with equal intensity everywhere.
o Sunlight is for all intents and purposes a directional light.
o Characterized by color, intensity, and direction.
Point light - a light that gives off equal amounts of light in all directions. Polygons, and
parts of polygons which are closer to the light appear brighter than those that are further
away. The angle at which light from a point light source hits an object is a function of the
positions of both the object and the light source. The intensity of the light source hitting
the object is a function of the distance between them. Different graphics programs may (
or may not ) allow the programmer to adjust the falloff function in different ways.
o A bare bulb hanging from a cord is essentially a point light.
o Characterized by color, intensity, location, and falloff function.
Spotlight - light that radiates light in a cone with more light in the center of the cone,
gradually tapering off towards the sides of the cone. The simplest spotlight would just be

a point light that is restricted to a certain angle around its primary axis of direction -
Think of something like a flashlight or car headlight as opposed to a bare bulb hanging on
a wire. More advanced spotlights have a falloff function making the light more intense at
the center of the cone and softer at the edges.
o Characterized as a point light, an axis of direction, a radius about that axis, and
possibly a radial falloff function.
Here is the same object (Christina Vasilakis' SoftImage Owl) under different lighting conditions:
bounding boxes of the components of the owl

self-luminous owl
directional light from the front of the owl

point light slightly in front of the owl
spotlight slightly in front of the owl aimed at the owl
Diffuse Reflection (Lambertian Reflection)

Using a point light:
comes from a specific direction
reflects off of dull surfaces
light reflected with equal intensity in all directions
brightness depends on theta - angle between surface normal (N) and the direction to the
light source (L)
position of viewer is not important
I = Ip Kd cos(theta) or I = Ip Kd(N' * L')
I: intensity
Ip: intensity of point light
Kd: object's diffuse reflection reflection coefficient, 0.0 - 1.0 for each of R, G, and B
N': normalized surface normal
L': normalized direction to light source
*: represents the dot product of the two vectors
Using a directional light:
theta is constant
L' is constant
Directional lights are faster than point lights because L' does not need to be recomputed for each
polygon.
It is rare that we have an object in the real world illuminated only by a single light. Even on a
dark night there is a some ambient light. To make sure all sides of an object get at least a little
light we add some ambient light to the point or directional light:
I = Ia Ka + Ip Kd(N' * L')
Currently there is no distinction made between an object close to a point light and an object far
away from that light. Only the angle has been used so far. It helps to introduce a term based on
distance from the light. So we add in a light source attenuation factor: Fatt.
I = Ia Ka + Fatt Ip Kd(N' * L')
Coming up with an appropriate value for Fatt is rather tricky.
It can take a fair amount of time to balance all the various types of lights in a scene to give the
desired effect (just as it takes a fair amount of time in real life to set up proper lighting)
Specular Reflection
reflection off of shiny surfaces - you see a highlight

shiny metal or plastic has high specular component
chalk or carpet has very low specular component
position of the viewer IS important in specular reflection
I = Ip cos^n(a) W(theta)
I: intensity
Ip: intensity of point light
n: specular-reflection exponent (higher is sharper falloff)
W: gives specular component of non-specular materials
So if we put all the lighting models depending on light together we add up their various
components to get:
I = Ia Ka + Ip Kd(N' * L') + Ip cos^n(a) W(theta)
As shown in the following figures:
+ +
=
Ambient + Diffuse + Specular = Result
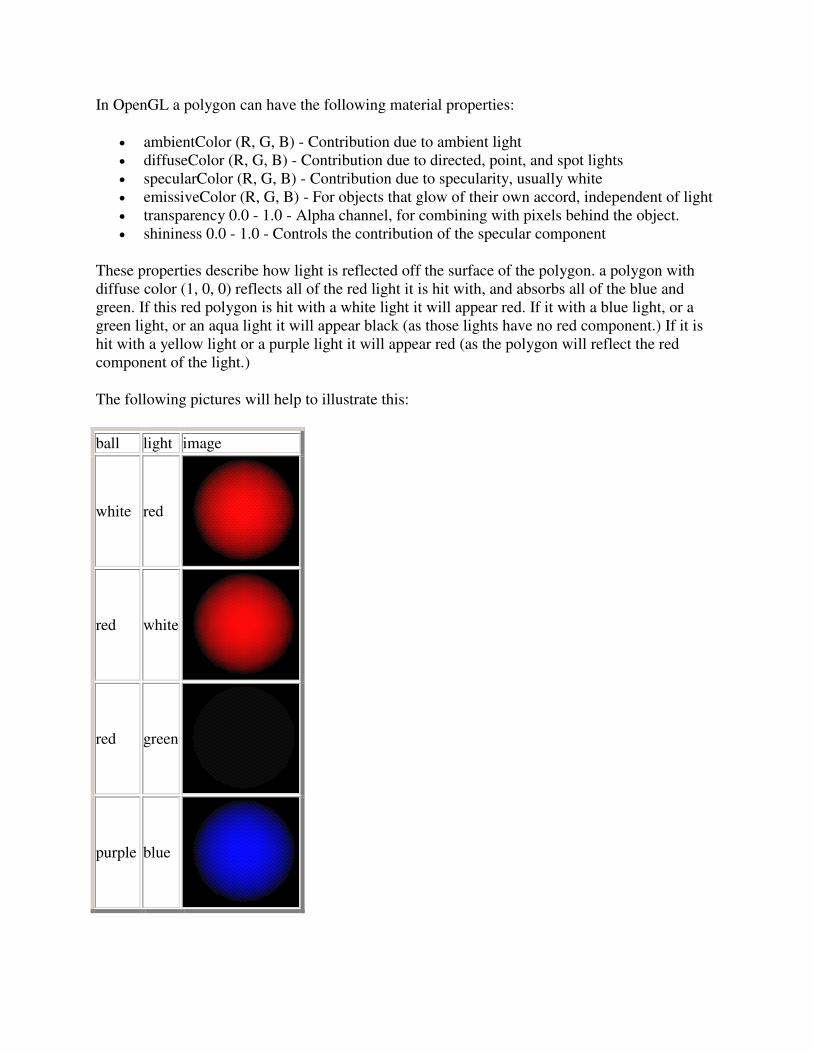
In OpenGL a polygon can have the following material properties:
ambientColor (R, G, B) - Contribution due to ambient light
diffuseColor (R, G, B) - Contribution due to directed, point, and spot lights
specularColor (R, G, B) - Contribution due to specularity, usually white
emissiveColor (R, G, B) - For objects that glow of their own accord, independent of light
transparency 0.0 - 1.0 - Alpha channel, for combining with pixels behind the object.
shininess 0.0 - 1.0 - Controls the contribution of the specular component
These properties describe how light is reflected off the surface of the polygon. a polygon with
diffuse color (1, 0, 0) reflects all of the red light it is hit with, and absorbs all of the blue and
green. If this red polygon is hit with a white light it will appear red. If it with a blue light, or a
green light, or an aqua light it will appear black (as those lights have no red component.) If it is
hit with a yellow light or a purple light it will appear red (as the polygon will reflect the red
component of the light.)
The following pictures will help to illustrate this:
ball light image
white red
red white
red green
purple blue

yellow aqua
One important thing to note about all of the above equations is that each object is dealt with
separately. That is, one object does not block light from reaching another object. The creation of
realistic shadows is quite expensive if done right, and is a currently active area of research in
computer graphics. ( Consider, for example, a plant with many leaves, each of which could cast
shadows on other leaves or on the other nearby objects, and then further consider the leaves
fluttering in the breeze and lit by diffuse or unusual light sources. )
Multiple Lights
With multiple lights the affect of all the lights are additive.
Shading Models
We often use polygons to simulate curved surfaces. If these cases we want the colours of the
polygons to flow smoothly into each other.
flat shading
goraud shading ( color interpolation shading )
phong shading ( normal interpolation shading )
Flat Shading
each entire polygon is drawn with the same colour
need to know one normal for the entire polygon
fast
lighting equation used once per polygon
Given a single normal to the plane the lighting equations and the material properties are used to
generate a single colour. The polygon is filled with that colour.
Here is another of the OpenGL samples with a flat shaded scene:

Goraud Shading
colours are interpolated across the polygon
need to know a normal for each vertex of the polygon
slower than flat shading
lighting equation used at each vertex
Given a normal at each vertex of the polygon, the colour at each vertex is determined from the
lighting equations and the material properties. Linear interpolation of the colour values at each
vertex are used to generate colour values for each pixel on the edges. Linear interpolation across
each scan line is used to then fill in the colour of the polygon.
Here is another of the OpenGL samples with a smooth shaded scene:
Phong Shading
normals are interpolated across the polygon
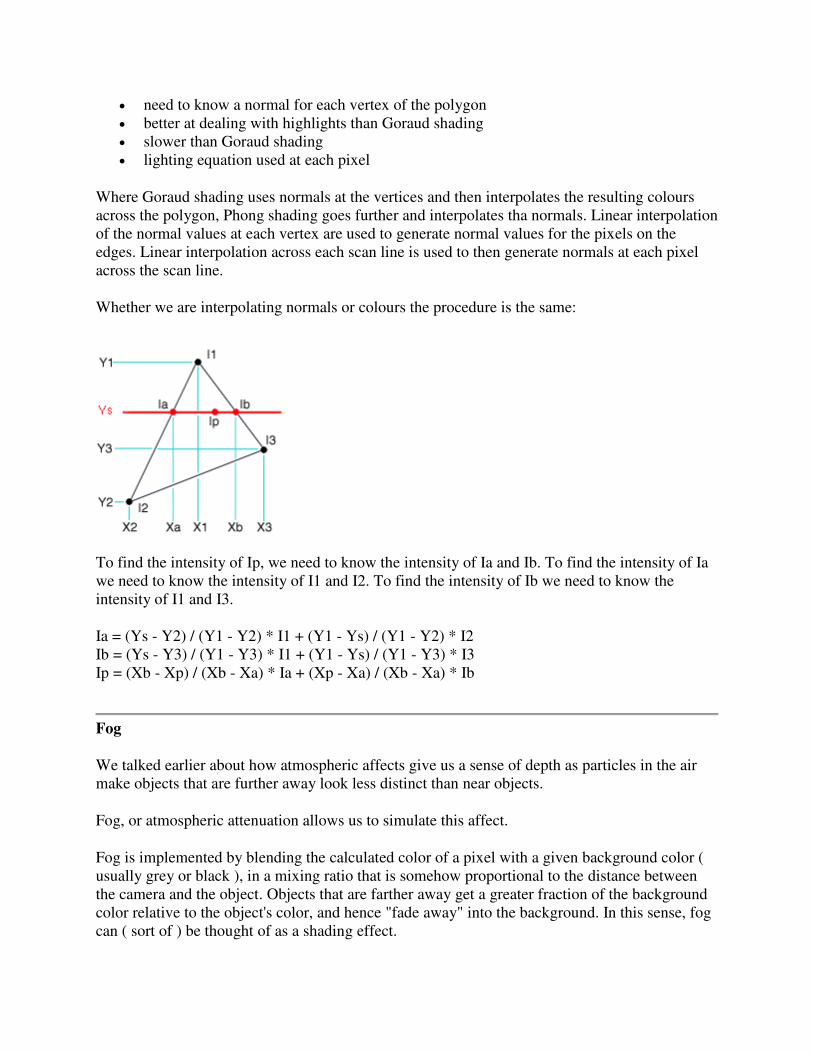
need to know a normal for each vertex of the polygon
better at dealing with highlights than Goraud shading
slower than Goraud shading
lighting equation used at each pixel
Where Goraud shading uses normals at the vertices and then interpolates the resulting colours
across the polygon, Phong shading goes further and interpolates tha normals. Linear interpolation
of the normal values at each vertex are used to generate normal values for the pixels on the
edges. Linear interpolation across each scan line is used to then generate normals at each pixel
across the scan line.
Whether we are interpolating normals or colours the procedure is the same:
To find the intensity of Ip, we need to know the intensity of Ia and Ib. To find the intensity of Ia
we need to know the intensity of I1 and I2. To find the intensity of Ib we need to know the
intensity of I1 and I3.
Ia = (Ys - Y2) / (Y1 - Y2) * I1 + (Y1 - Ys) / (Y1 - Y2) * I2
Ib = (Ys - Y3) / (Y1 - Y3) * I1 + (Y1 - Ys) / (Y1 - Y3) * I3
Ip = (Xb - Xp) / (Xb - Xa) * Ia + (Xp - Xa) / (Xb - Xa) * Ib
Fog
We talked earlier about how atmospheric affects give us a sense of depth as particles in the air
make objects that are further away look less distinct than near objects.
Fog, or atmospheric attenuation allows us to simulate this affect.
Fog is implemented by blending the calculated color of a pixel with a given background color (
usually grey or black ), in a mixing ratio that is somehow proportional to the distance between
the camera and the object. Objects that are farther away get a greater fraction of the background
color relative to the object's color, and hence "fade away" into the background. In this sense, fog
can ( sort of ) be thought of as a shading effect.

Fog is typically given a starting distance, an ending distance, and a colour. The fog begins at the
starting distance and all the colours slowly transition to the fog colour towards the ending
distance. At the ending distance all colours are the fog colour.
Here are those o-so-everpresent computer graphics teapots from the OpenGL samples:
To use fog in OpenGL you need to tell the computer a few things:
color of the fog as R, G, and B values
function for how to map the intermediate distances (linear, exponential, exponential
squared
where the fog begins and where the fog ends if using linear mapping
density of the fog if using one of the two exponentials mappings
Here is a scene from battalion without fog. The monster sees a very sharp edge to the world
Here is the same scene with fog. The monster sees a much softer horizon as objects further away
tend towards the black colour of the sky

AntiAliasing
Lines and the edges of polygons still look jagged at this point. This is especially noticable when
moving through a static scene looking at sharp edges.
This is known as aliasing, and is caused by the conversion from the mathematical edge to a
discrete set of pixels. We saw near the beginning of the course how to scan convert a line into the
frame buffer, but at that point we only dealth with placing the pixel or not placing the pixel. Now
we will deal with coverage.
The mathematical line will likely not exactly cover pixel boundaries - some pixels will be mostly
covered by the line (or edge), and others only slightly. Instead of making a yes/no decision we
can assign a value to this coverage (from say 0 to 1) for each pixel and then use these values to
blend the colour of the line (or edge) with the existing contents of the frame buffer.
In OpenGL you give hints setting the hints for GL_POINT_SMOOTH_HINT,
GL_LINE_SMOOTH_HINT, GL_POLYGON_SMOOTH_HINT to tell OpenGL to be
GL_FASTEST or GL_NICEST to try and smooth things out using the alpha (transparency)
values.
You also need to enable or disable that smoothing
glEnable(GL_POINT_SMOOTH);
glEnable(GL_LINE_SMOOTH);
glEnable(GL_POLYGON_SMOOTH);
In the beginning of the semester we dealt with simple wireframe drawings of the models. The
main reason for this is so that we did not have to deal with hidden surface removal. Now we
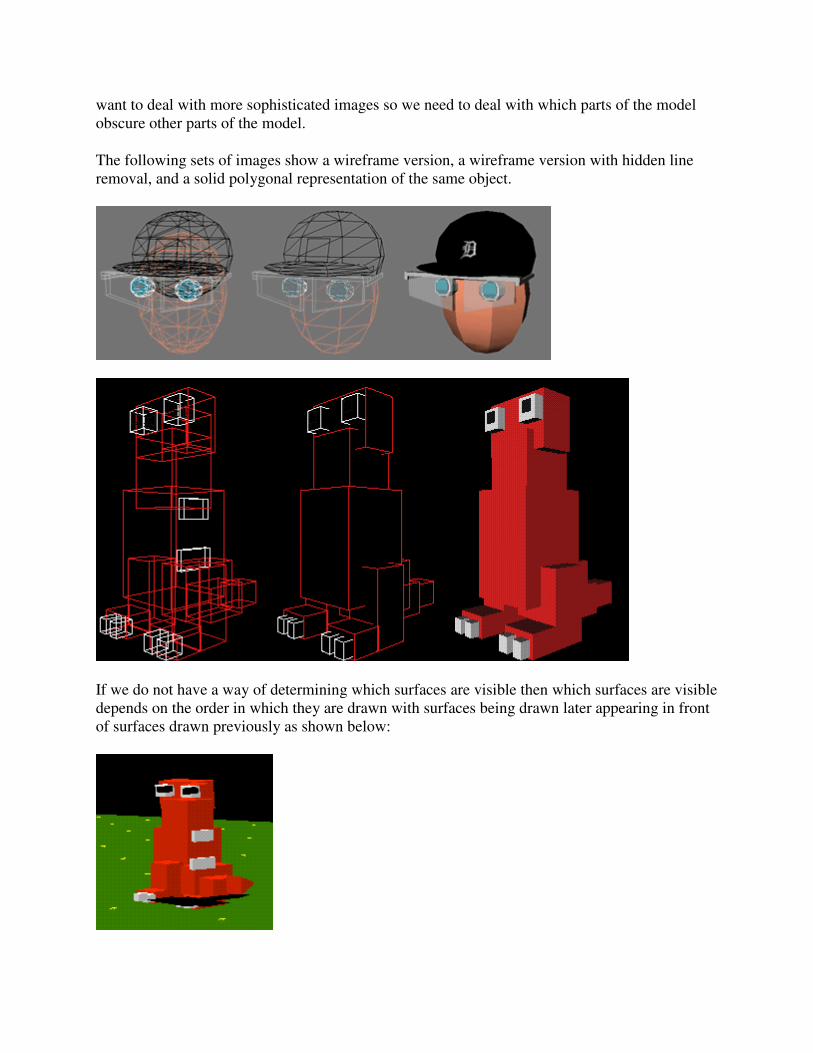
want to deal with more sophisticated images so we need to deal with which parts of the model
obscure other parts of the model.
The following sets of images show a wireframe version, a wireframe version with hidden line
removal, and a solid polygonal representation of the same object.
If we do not have a way of determining which surfaces are visible then which surfaces are visible
depends on the order in which they are drawn with surfaces being drawn later appearing in front
of surfaces drawn previously as shown below:

Here the fins on the back are visible because they are drawn after the body, the shadow is drawn
on top of the monster because it is drawn last. Both legs are visible and the eyes just look really
weird.
General Principles
We do not want to draw surfaces that are hidden. If we can quickly compute which surfaces are
hidden, we can bypass them and draw only the surfaces that are visible.
For example, if we have a solid 6 sided cube, at most 3 of the 6 sides are visible at any
one time, so at least 3 of the sides do not even need to be drawn because they are the back
sides.
We also want to avoid having to draw the polygons in a particular order. We would like to tell
the graphics routines to draw all the polygons in whatever order we choose and let the graphics
routines determine which polygons are in front of which other polygons.
With the same cube as above we do not want to have to compute for ourselves which
order to draw the visible faces, and then tell the graphics routines to draw them in that
order.
The idea is to speed up the drawing, and give the programmer an easier time, by doing some
computation before drawing.
Unfortunately these computations can take a lot of time, so special purpose hardware is often
used to speed up the process.
Techniques
Two types of approaches:
object space (object precision in our text)
image space (image precision in our text)
object space algorithms do their work on the objects themselves before they are converted to
pixels in the frame buffer. The resolution of the display device is irrelevant here as this
calculation is done at the mathematical level of the objects
for each object a in the scene determine which parts of object a are visible (involves comparing the polyons in object a to other polygons in a and to polygons in every other object in the scene)

image space algorithms do their work as the objects are being converted to pixels in the frame
buffer. The resolution of the display device is important here as this is done on a pixel by pixel
basis.
for each pixel in the frame buffer determine which polygon is closest to the viewer at that pixel location colour the pixel with the colour of that polygon at that location
As in our discussion of vector vs raster graphics earlier in the term the mathematical (object
space) algorithms tended to be used with the vector hardware whereas the pixel based (image
space) algorithms tended to be used with the raster hardware.
When we talked about 3D transformations we reached a point near the end when we converted
the 3D (or 4D with homogeneous coordinates) to 2D by ignoring the Z values. Now we will use
those Z values to determine which parts of which polygons (or lines) are in front of which parts
of other polygons.
There are different levels of checking that can be done.
Object
Polygon
part of a Polygon
There are also times when we may not want to cull out polygons that are behind other polygons.
If the frontmost polygon is transparent then we want to be able to 'see through' it to the polygons
that are behind it as shown below:

Which objects are transparent in the above scene?
Coherence
We used the idea of coherence before in our line drawing algorithm. We want to exploit 'local
similarity' to reduce the amount of computation needed (this is how compression algorithms
work.)
Face - properties (such as colour, lighting) vary smoothly across a face (or polygon)
Depth - adjacent areas on a surface have similar depths
Frame - images at successive time intervals tend to be similar
Scan Line - adjacent scan lines tend to have similar spans of objects
Area - adjacent pixels tend to be covered by the same face
Object - if objects are separate from each other (ie they do not overlap) then we only need
to compare polygons of the same object, and not one object to another
Edge - edges only disappear when they go behind another edge or face
Implied Edge - line of intersection of 2 faces can be determined by the endpoints of the
intersection
Extents

Rather than dealing with a complex object, it is often easier to deal with a simpler version of the
object.
in 2: a bounding box
in 3d: a bounding volume (though we still call it a bounding box)
We convert a complex object into a simpler outline, generally in the shape of a box and then we
can work with the boxes. Every part of the object is guaranteed to fall within the bounding box.
Checks can then be made on the bounding box to make quick decisions (ie does a ray pass
through the box.) For more detail, checks would then be made on the object in the box.
There are many ways to define the bounding box. The simplest way is to take the minimum and
maximum X, Y, and Z values to create a box. You can also have bounding boxes that rotate with
the object, bounding spheres, bounding cylinders, etc.
Back-Face Culling
Back-face culling (an object space algorithm) works on 'solid' objects which you are looking at
from the outside. That is, the polygons of the surface of the object completely enclose the object.
Every planar polygon has a surface normal, that is, a vector that is normal to the surface of the
polygon. Actually every planar polygon has two normals.
Given that this polygon is part of a 'solid' object we are interested in the normal that points OUT,
rather than the normal that points in.

OpenGL specifies that all polygons be drawn such that the vertices are given in counterclockwise
order as you look at the visible side of polygon in order to generate the 'correct' normal.
Any polygons whose normal points away from the viewer is a 'back-facing' polygon and does not
need to be further investigated.
To find back facing polygons the dot product of the surface normal of each polygon is taken with
a vector from the center of projection to any point on the polygon.
The dot product is then used to determine what direction the polygon is facing:
greater than 0 : back facing
equal to 0 : polygon viewed on edge
less than 0 : front facing
Back-face culling can very quickly remove unnecessary polygons. Unfortunately there are often
times when back-face culling can not be used. For example if you wish to make an open-topped
box - the inside and the ouside of the box both need to be visible, so either two sets of polygons
must be generated, one set facing out and another facing in, or back-face culling must be turned
off to draw that object.
in OpenGL back-face culling is turned on using:
glCullFace(GL_BACK); glEnable(GL_CULL_FACE);
Depth Buffer
Early on we talked about the frame buffer which holds the colour for each pixel to be displayed.
This buffer could contain a variable number of bytes for each pixel depending on whether it was
a greyscale, RGB, or colour-indexed frame buffer. All of the elements of the frame buffer are
initially set to be the background colour. As lines and polygons are drawn the colour is set to be
the colour of the line or polygon at that point. T
We now introduce another buffer which is the same size as the frame buffer but contains depth
information instead of colour information.
z-buffering (an image-space algorithm) is another buffer which maintains the depth for each
pixel. All of the elements of the z-buffer are initially set to be 'very far away.' Whenever a pixel
colour is to be changed the depth of this new colour is compared to the current depth in the z-
buffer. If this colour is 'closer' than the previous colour the pixel is given the new colour, and the
z-buffer entry for that pixrl is updated as well. Otherwise the pixel retains the old colour, and the
z-buffer retains its old value.
Here is a pseudo-code algorithm

for each polygon for each pixel p in the polygon's projection { pz = polygon's normalized z-value at (x, y); //z ranges from -1 to 0 if (pz > zBuffer[x, y]) // closer to the camera { zBuffer[x, y] = pz; framebuffer[x, y] = colour of pixel p } }
This is very nice since the order of drawing polygons does not matter, the algorithm will always
display the colour of the closest point.
The biggest problem with the z-buffer is its finite precision, which is why it is important to set
the near and far clipping planes to be as close together as possible to increase the resolution of
the z-buffer within that range. Otherwise even though one polygon may mathematically be 'in
front' of another that difference may disappear due to roundoff error.
These days with memory getting cheaper it is easy to implement a software z-buffer and
hardware z-buffering is becoming more common.
In OpenGL the z-buffer and frame buffer are cleared using:
glClear(GL_DEPTH_BUFFER_BIT | GL_COLOR_BUFFER_BIT);
In OpenGL z-buffering is turned on using:
glEnable(GL_DEPTH_TEST);
The depth-buffer is especially useful when it is difficult to order the polygons in the scene based
on their depth, such as in the case shown below:
Warnock's Algorithm

Warnock's algorithm is a recursive area-subdivision algorithm. Warnock's algorithm looks at an
area of the image. If is is easy to determine which polygons are visible in the area they are
drawn, else the area is subdivided into smaller parts and the algorithm recurses. Eventually an
area will be represented by a single non-intersecting polygon.
At each iteration the area of interest is subdivided into four equal areas. Each polygon is
compared to each area and is put into one of four bins:
Disjoint polygons are completely outside the area
Intersecting polygons intersect the area
Surrounding polygons completely contain the area
Contained polygons are completely contained in the area
For a given area:
1. If all polygons are disjoint then the background colour fills the area
2. If there is a single contained polygon or intersecting polygon then the background colour is
used to fill the area, then the part of the polygon contained in the area is filled with the colour of
that polygon
3. If there is a single surrounding polygon and no intersecting or contained polygons then the
area is filled with the colour of the surrounding polygon
4. If there is a surrounding polygon in front of any other surrounding, intersecting, or contained
polygons then the area is filled with the colour of the front surrounding polygon
Otherwise break the area into 4 equal parts and recurse.
At worst log base 2 of the max(screen width, screen height) recursive steps will be needed. At
that point the area being looked at is only a single pixel which can't be divided further. At that
point the distance to each polygon intersecting,contained in, or surrounding the area is computed
at the center of the polygon to determine the closest polygon and its colour,

Below is an example scanned out of the text, where the numbers refer to the numbered steps
listed above:
Here is a place where the use of bounding boxes can speed up the process. Given that the
bounding box is always at least as large as the polygon, or object checks for contained and
disjoint polygons can be made using the bounding boxes, while checks for interstecting and
surrounding can not.
Depth Sort Algorithm, a.k.a. The Painter's Algorithm
The idea here is to go back to front drawing all the objects into the frame buffer with nearer
objects being drawn over top of objects that are further away.
Simple algorithm:
1. Sort all polygons based on their farthest z coordinate
2. Resolve ambiguities
3. draw the polygons in order from back to front
This algorithm would be very simple if the z coordinates of the polygons were guaranteed never
to overlap. Unfortunately that is usually not the case, which means that step 2 can be somewhat
complex.
Any polygons whose z extents overlap must be tested against each other.
We start with the furthest polygon and call it P. Polygon P must be compared with every polygon
Q whose z extent overlaps P's z extent. 5 comparisons are made. If any comparison is true then P

can be written before Q. If at least one comparison is true for each of the Qs then P is drawn and
the next polygon from the back is chosen as the new P.
1. do P and Q's x-extents not overlap.
2. do P and Q's y-extents not overlap.
3. is P entirely on the opposite side of Q's plane from the viewport.
4. is Q entirely on the same side of P's plane as the viewport.
5. do the projections of P and Q onto the (x,y) plane not overlap.
If all 5 tests fail we quickly check to see if switching P and Q will work. Tests 1, 2, and 5 do not
differentiate between P and Q but 3 and 4 do. So we rewrite 3 and 4
3 - is Q entirely on the opposite side of P's plane from the viewport.
4 - is P entirely on the same side of Q's plane as the viewport.
If either of these two tests succeed then Q and P are swapped and the new P (formerly Q) is
tested against all the polygons whose z extent overlaps it's z extent.
If these two tests still do not work then either P or Q is split into 2 polygons using the plane of
the other. These 2 smaller polygons are then put into their proper places in the sorted list and the
algorithm continues.
beware of the dreaded infinite loop.
BSP Trees
Another popular way of dealing with these problems (especially in games) are Binary Space
Partition trees. It is a depth sort algorithm with a large amount of preprocessing to create a data
structure to hold the polygons.
First generate a 3D BSP tree for all of the polygons in the scene
Then display the polygons according to their order in the scene
1. polygons behind the current node
2. the current node
3. polygons in front of the current node
Each node in the tree is a polygon. Extending that polygon generates a plane. That plane cuts
space into 2 parts. We use the front-facing normal of the polygon to define the half of the space
that is 'in front' of the polygon. Each node has two children: the front children (the polygons in
front of this node) and the back children (the polgons behind this noce)
In doing this we may need to split some polygons into two.

Then when we are drawing the polygons we first see if the viewpoint is in front of or behind the
root node. Based on this we know which child to deal with first - we first draw the subtree that is
further from the viewpoint, then the root node, then the subtree that is in front of the root node,
recursively, until we have drawn all the polygons.
Compared to depth sort it takes more time to setup but less time to iterate through since there are
no special cases.
If the position or orientation of the polygons change then parts of the tree will need to be
recomputed.
here is an example originally by Nicolas Holzschuch showing the construction and use of a BSP
tree for 6 polygons.

Scan Line Algorithm
This is an extension of the algorithm we dealt with earlier to fill polygons one scan line at a time.
This time there will be multiple polygons being drawn simultaneously.
Again we create a global edge table for all non-horizontal edges sorted based on the edges
smaller y coordinate.
Each entry in the table contains:
x coordinate corresponding to the smallest y coordinate
y coordinate of the other end of the edge
deltaX = 1/m
and a new entry
a way to identify which polygon this edge belongs to
In the scan line algorithm we had a simple 0/1 variable to deal with being in or out of the
polygon. Since there are multiple polygons here we have a Polygon Table.
The Polygon Table contains:
coefficients of the equation of the plane of the polygon
shading / colour information on this polygon
in / out flag initialized to false
Again the edges are moved from the global edge table to the active edge table when the scan line
corresponding to the bottom of the edge is reached.
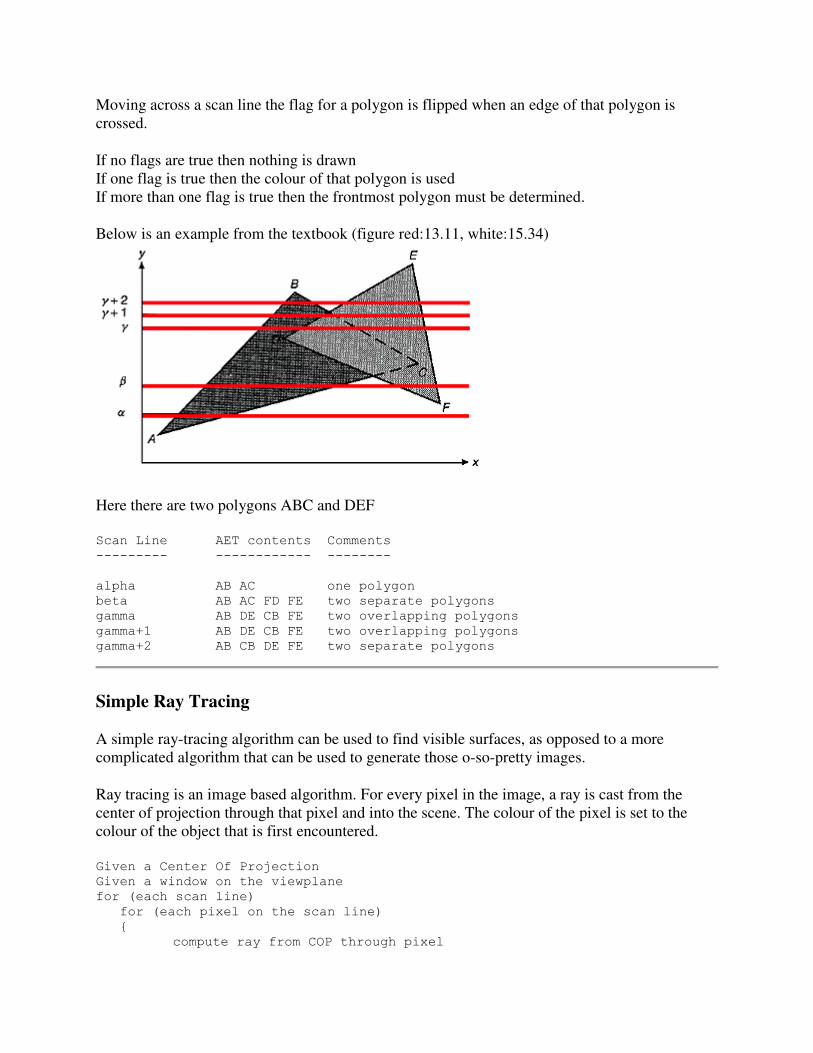
Moving across a scan line the flag for a polygon is flipped when an edge of that polygon is
crossed.
If no flags are true then nothing is drawn
If one flag is true then the colour of that polygon is used
If more than one flag is true then the frontmost polygon must be determined.
Below is an example from the textbook (figure red:13.11, white:15.34)
Here there are two polygons ABC and DEF
Scan Line AET contents Comments --------- ------------ -------- alpha AB AC one polygon beta AB AC FD FE two separate polygons gamma AB DE CB FE two overlapping polygons gamma+1 AB DE CB FE two overlapping polygons gamma+2 AB CB DE FE two separate polygons
Simple Ray Tracing
A simple ray-tracing algorithm can be used to find visible surfaces, as opposed to a more
complicated algorithm that can be used to generate those o-so-pretty images.
Ray tracing is an image based algorithm. For every pixel in the image, a ray is cast from the
center of projection through that pixel and into the scene. The colour of the pixel is set to the
colour of the object that is first encountered.
Given a Center Of Projection Given a window on the viewplane for (each scan line) for (each pixel on the scan line) { compute ray from COP through pixel

for (each object in scene) if (object is intersected by ray && object is closer than previous intersection) record (intersection point, object) set pixel's colour to the colour of object at intersection point }
So, given a ray (vector) and an object the key idea is computing if and if so where does the ray
intersect the object.
the ray is represented by the vector from (Xo, Yo, Zo) at the COP, to (X1, Y1, Z1) at the center
of the pixel. We can parameterize this vector by introducing t:
X = Xo + t(X1 - Xo)
Y = Yo + t(Y1 - Yo)
Z = Zo + t(Z1 - Zo)
or
X = Xo + t(deltaX)
Y = Yo + t(deltaY)
Z = Zo + t(deltaZ)
t equal to 0 represents the COP, t equal to 1 represents the pixel
t < 0 represents points behind the COP
t > 1 represents points on the other side of the view plane from the COP
We want to find out what the value of t is where the ray intersects the object. This way we can
take the smallest value of t that is in front of the COP as defining the location of the nearest
object along that vector.
The problem is that this can take a lot of time, especially if there are lots of pixels and lots of
objects.
The raytraced images in 'Toy Story' for example took at minimum 45 minutes and at most 20
hours for a single frame.
So minimizing the number of comparisons is critical.
- Bounding boxes can be used to perform initial checks on complicated objects
- hierarchies of bounding boxes can be used where a successful intersection with a
bounding box then leads to tests with several smaller bounding boxes within the larger
bounding box.
- The space of the scene can be partitioned. These partitions are then treated like buckets
in a hash table, and objects within each partition are assigned to that partition. Checks can
then be made against this constant number of partitions first before going on to checking

the objects themselves. These partitions could be equal sized volumes, or contain equal
numbers of polygons.
Full blown ray tracing takes this one step further by reflecting rays off of shiny objects, to see
what the ray hits next, and then reflecting the ray off of that, and so on, until a limiting number
of reflections have been encountered. For transparent or semi-transparent objects, rays are passed
through the object, taking into account any deflection or filtering that may take place ( e.g.
through a colored glass bottle or chess piece ), again proceeding until some limit is met. Then the
contributions of all the reflections and transmissions are added together to determine the final
color value for each pixel. The resulting images can be incredibly beautiful and realistic, and
usually take a LONG time to compute.
Comparison
From table 13.1 in the red book (15.3 in the white book) the relative performance of the various
algorithms where smaller is better and the depth sort of a hundred polygons is set to be 1.
# of polygonal faces in the scene Algorithm 100 250 60000 -------------------------------------------------- Depth Sort 1 10 507 z-buffer 54 54 54 scan line 5 21 100 Warnock 11 64 307
This table is somewhat bogus as z-buffer performance degrades as the number of polygonal faces
increases.
To get a better sense of this, here are the number of polygons in the following models:
250 triangular polygons:

550 triangular polygons:
6,000 triangular polygons:
(parrot by Christina Vasilakis)
8,000 triangular polygons:
10,000 triangular polygons:
(ARPA Integration testbed space by Jason Leigh, Andrew Johnson, Mike Kelley)

MultiMedia
Introduction Multimedia has become an inevitable part of any presentation. It has found a variety of
applications right from entertainment to education. The evolution of internet has also increased
the demand for multimedia content.
Definition Multimedia is the media that uses multiple forms of information content and information
processing (e.g. text, audio, graphics, animation, video, interactivity) to inform or entertain the
user. Multimedia also refers to the use of electronic media to store and experience multimedia
content. Multimedia is similar to traditional mixed media in fine art, but with a broader scope.
The term "rich media" is synonymous for interactive multimedia.
Elements of Multimedia System Multimedia means that computer information can be represented through audio, graphics, image,
video and animation in addition to traditional media(text and graphics). Hypermedia can be
considered as one type of particular multimedia application.
Features of Multimedia Multimedia presentations may be viewed in person on stage, projected, transmitted, or played
locally with a media player. A broadcast may be a live or recorded multimedia presentation.
Broadcasts and recordings can be either analog or digital electronic media technology. Digital
online multimedia may be downloaded or streamed. Streaming multimedia may be live or on-
demand.
Multimedia games and simulations may be used in a physical environment with special effects,
with multiple users in an online network, or locally with an offline computer, game system, or
simulator.
Applications of Multimedia Multimedia finds its application in various areas including, but not limited to, advertisements,
art, education, entertainment, engineering, medicine, mathematics, business, scientific research
and spatial, temporal applications.
A few application areas of multimedia are listed below:
Creative industries
Creative industries use multimedia for a variety of purposes ranging from fine arts, to
entertainment, to commercial art, to journalism, to media and software services provided for any
of the industries listed below. An individual multimedia designer may cover the spectrum
throughout their career. Request for their skills range from technical, to analytical and to
creative.
Commercial
Much of the electronic old and new media utilized by commercial artists is multimedia. Exciting
presentations are used to grab and keep attention in advertising. Industrial, business to business,
and interoffice communications are often developed by creative services firms for advanced
multimedia presentations beyond simple slide shows to sell ideas or liven-up training.
Commercial multimedia developers may be hired to design for governmental services and
nonprofit services applications as well.

Entertainment and Fine Arts
In addition, multimedia is heavily used in the entertainment industry, especially to develop
special effects in movies and animations. Multimedia games are a popular pastime and are
software programs available either as CD-ROMs or online. Some video games also use
multimedia features. Multimedia applications that allow users to actively participate instead of
just sitting by as passive recipients of information are called Interactive Multimedia.
Education
In Education, multimedia is used to produce computer-based training courses (popularly called
CBTs) and reference books like encyclopaedia and almanacs. A CBT lets the user go through a
series of presentations, text about a particular topic, and associated illustrations in various
information formats. Edutainment is an informal term used to describe combining education with
entertainment, especially multimedia entertainment.
Engineering
Software engineers may use multimedia in Computer Simulations for anything from
entertainment to training such as military or industrial training. Multimedia for software
interfaces are often done as collaboration between creative professionals and software engineers.
Industry
In the Industrial sector, multimedia is used as a way to help present information to shareholders,
superiors and coworkers. Multimedia is also helpful for providing employee training, advertising
and selling products all over the world via virtually unlimited web-based technologies.
Multimedia Building Blocks Any multimedia application consists any or all of the following components :
Text : Text and symbols are very important for communication in any medium. With the recent
explosion of the Internet and World Wide Web, text has become more the important than ever.
Web is HTML (Hyper text Markup language) originally designed to display simple text
documents on computer screens, with occasional graphic images thrown in as illustrations.
Audio : Sound is perhaps the most element of multimedia. It can provide the listening pleasure
of music, the startling accent of special effects or the ambience of a mood-setting background.
3. Images : Images whether represented analog or digital plays a vital role in a multimedia. It is
expressed in the form of still picture, painting or a photograph taken through a digital camera.
4. Animation : Animation is the rapid display of a sequence of images of 2-D artwork or model
positions in order to create an illusion of movement. It is an optical illusion of motion due to the
phenomenon of persistence of vision, and can be created and demonstrated in a number of ways.
5. Video : Digital video has supplanted analog video as the method of choice for making video
for multimedia use. Video in multimedia are used to portray real time moving pictures in a
multimedia project.
Text in Multimedia Words and symbols in any form, spoken or written, are the most common system of
communication. They deliver the most widely understood meaning to the greatest number of
people.
Most academic related text such as journals, e-magazines are available in the Web Browser
readable form.
Multimedia Sound Systems The multimedia application user can use sound right off the bat on both the Macintosh and on a
multimedia PC running Windows because beeps and warning sounds are available as soon as the

operating system is installed. On the Macintosh you can choose one of the several sounds for the
system alert. In Windows system sounds are WAV files and they reside in the windows\Media
subdirectory.
There are still more choices of audio if Microsoft Office is installed. Windows makes use of
WAV files as the default file format for audio and Macintosh systems use SND as default file
format for audio.
Digital Audio Digital audio is created when a sound wave is converted into numbers – a process referred to as
digitizing. It is possible to digitize sound from a microphone, a synthesizer, existing tape
recordings, live radio and television broadcasts, and popular CDs. You can digitize sounds from
a natural source or prerecorded.
Making MIDI Audio MIDI (Musical Instrument Digital Interface) is a communication standard developed for
electronic musical instruments and computers. MIDI files allow music and sound synthesizers
from different manufacturers to communicate with each other by sending messages along cables
connected to the devices.
Audio File Formats A file format determines the application that is to be used for opening a file. Following is the list
of different file formats and the software that can be used for opening a specific file.
1. *.AIF, *.SDII in Macintosh Systems
2. *.SND for Macintosh Systems
3. *.WAV for Windows Systems
4. MIDI files – used by north Macintosh and Windows
5. *.WMA –windows media player
6. *.MP3 – MP3 audio
7. *.RA – Real Player
8. *.VOC – VOC Sound
9. AIFF sound format for Macintosh sound files
10. *.OGG – Ogg Vorbis
Software used for Audio Software such as Toast and CD-Creator from Adaptec can translate the digital files of red book
Audio format on consumer compact discs directly into a digital sound editing file, or decompress
MP3 files into CD-Audio. There are several tools available for recording audio. Following is the
list of different software that can be used for recording and editing audio ;
Soundrecorder fromMicrosoft
Apple’s QuickTime Player pro
Sonic Foundry’s SoundForge for Windows
Soundedit16
Digital Image A digital image is represented by a matrix of numeric values each representing a quantized
intensity value. When I is a two-dimensional matrix, then I(r,c) is the intensity value at the
position corresponding to row r and column c of the matrix.
The points at which an image is sampled are known as picture elements, commonly abbreviated
as pixels. The pixel values of intensity images are called gray scale levels (we encode here the

“color” of the image). The intensity at each pixel is represented by an integer and is determined from the continuous image by averaging over a small neighborhood around the pixel location. If
there are just two intensity values, for example, black, and white, they are represented by the
numbers 0 and 1; such images are called binary-valued images. If 8-bit integers are used to store
each pixel value, the gray levels range from 0 (black) to 255 (white).
Bitmaps A bitmap is a simple information matrix describing the individual dots that are the smallest
elements of resolution on a computer screen or other display or printing device. A one-
dimensional matrix is required for monochrome (black and white); greater depth (more bits of
information) is required to describe more than 16 million colors the picture elements may have,
as illustrated in following figure. The state of all the pixels on a computer screen make up the
image seen by the viewer, whether in combinations of black and white or colored pixels in a line
of text, a photograph-like picture, or a simple background pattern.
Clip Art
A clip art collection may contain a random assortment of images, or it may contain a series of
graphics, photographs, sound, and video related to a single topic. For example, Corel,
Micrografx, and Fractal Design bundle extensive clip art collection with their image-editing
software.
Image File Formats There are many file formats used to store bitmaps and vectored drawing. Following is a
list of few image file formats.
Format Extension
Microsoft Windows DIB .bmp .dib .rle
Microsoft Palette .pal
Autocad format 2D .dxf
JPEG .jpg
Windows Meta file .wmf
Portable network graphic png
Compuserve gif .gif
Apple Macintosh .pict .pic .pct
Principles of Animation Animation is the rapid display of a sequence of images of 2-D artwork or model positions in
order to create an illusion of movement. It is an optical illusion of motion due to the phenomenon
of persistence of vision, and can be created and demonstrated in a number of ways. The most
common method of presenting animation is as a motion picture or video program, although
several other forms of presenting animation also exist.
Animation is possible because of a biological phenomenon known as persistence of vision and a
psychological phenomenon called phi. An object seen by the human eye remains chemically
mapped on the eye’s retina for a brief time after viewing. Combined with the human mind’s need to conceptually complete a perceived action, this makes it possible for a series of images that are
changed very slightly and very rapidly, one after the other, to seemingly blend together into a
visual illusion of movement. The following shows a few cells or frames of a rotating logo. When
the images are progressively and rapidly changed, the arrow of the compass is perceived to be
spinning. Television video builds entire frames or pictures every second; the speed with which
each frame is replaced by the next one makes the images appear to blend smoothly into

movement. To make an object travel across the screen while it changes its shape, just change the
shape and also move or translate it a few pixels for each frame.
Animation File Formats Some file formats are designed specifically to contain animations and the can be ported among
application and platforms with the proper translators.
Director *.dir, *.dcr
AnimationPro *.fli, *.flc
3D Studio Max *.max
SuperCard and Director *.pics
CompuServe *.gif
Flash *.fla, *.swf
Following is the list of few Software used for computerized animation:
3D Studio Max
Flash
AnimationPro
Video Analog versus Digital
Digital video has supplanted analog video as the method of choice for making video for
multimedia use. While broadcast stations and professional production and postproduction houses
remain greatly invested in analog video hardware (according to Sony, there are more than
350,000 Betacam SP devices in use today), digital video gear produces excellent finished
products at a fraction of the cost of analog. A digital camcorder directly connected to a computer
workstation eliminates the image-degrading analog-to-digital conversion step typically
performed by expensive video capture cards, and brings the power of nonlinear video editing and
production to everyday users.
Multimedia Authoring Tools Multimedia authoring tools provide the important framework you need for organizing and
editing the elements of multimedia like graphics, sounds, animations and video clips. Authoring
tools are used for designing interactivity and the user interface, for presentation your project on
screen and assembling multimedia elements into a single cohesive project.
Features of Authoring Tools
Features of multimedia authoring tools are as mention below:
1. Editing features:- The elements of multimedia – image, animation, text, digital
audio and MIDI music and video clips – need to be created, edited and converted
to standard file formats and the specialized applications provide these capabilities.
Editing tools for these elements, particularly text and still images are often
included in your authoring system.
2. Organizing features:- The organization, design and production process for
multimedia involves storyboarding and flowcharting. Some authoring tools
provide a visual flowcharting system or overview facility for illustrating your

project’s structure at a macro level. Storyboards or navigation diagrams too can help organize a project. Because designing the interactivity and navigation flow of
you project often requires a great deal of planning and programming effort, your
story board should describe not just graphics of each screen but the interactive
elements as well. Features that help organize your material, such as those
provided by Super Edit, Authorware, IconAuthor and other authoring systems, are
a plus.
3. Programming features:- Authoring tools that offer a very high level language or
interpreted scripting environment for navigation control and for enabling user
inputs – such as Macromedia Director, Macromedia Flash, HyperCard, MetaCard
and ToolBook are more powerful. The more commands and functions provided in
the scripting language, the more powerful the authoring system. As with
traditional programming tools looks for an authoring package with good
debugging facilities, robust text editing and online syntax reference. Other
scripting augmentation facilities are advantages as well. In complex projects you
may need to program custom extensions of the scripting language for direct
access to the computer’s operating system. Some authoring tools offer direct importing of preformatted text, including facilities, complex text search
mechanisms and hyper linkage tools. These authoring systems are useful for
development of CD-ROM information products online documentation products,
online documentation and help systems and sophisticated multimedia enhanced
publications. With script you can perform computational tasks; sense and respond
to user input; create character, icon and motion animation; launch other
application; and control external multimedia devices.
4. Interactivity features:- Interactivity empowers the end users of your project by
letting them control the content and flow of information. Authoring tools should
provide one or more levels of interactivity: Simple branching, which offers the
ability to go to another section of the multimedia production. Conditional
branching, which supports a go-to based on the result of IF-THEN decision or
events. A structured language that supports complex programming logic, such as
nested IF-THENs, subroutines, event tracking and message passing among
objects and elements.
5. Performance tuning features:- Complex multimedia projects require extra
synchronization of events. Accomplishing synchronization is difficult because
performance varies widely among the different computers used for multimedia
development and delivery. Some authoring tools allow you to lock a production’s playback speed to specified computer platform, but other provides no ability what
so ever to control performance on various systems.
6. Playback features:- When you are developing multimedia project, your will
continually assembling elements and testing to see how the assembly looks and
performs. Your authoring system should let you build a segment or part of your
project and then quickly test it as if the user were actually using it.
7. Delivery features:- Delivering your project may require building a run-time
version of the project using the multimedia authoring software. A run-time
version allows your project to play back with out requiring the full authoring
software and all its tools and editors. Many times the run time version does not

allow user to access or change the content, structure and programming of the
project. If you are going to distribute your project widely, you should distribute it
in the run-time version.
8. Cross-Platform features:- It is also increasingly important to use tools that make
transfer across platforms easy. For many developers, the Macintosh remains the
multimedia authoring platform of choice, but 80% of that developer’s target market may be Windows platforms. If you develop on a Macintosh, look for tools
that provide a compatible authoring system for Windows or offer a run-time
player for the other platform.
9. Internet Playability:- Due to the Web has become a significant delivery medium
for multimedia, authoring systems typically provide a means to convert their
output so that it can be delivered within the context of HTML or DHTML, either
with special plug-in or embedding Java, JavaScript or other code structures in the
HTML document.
JPEG(Joint Photographic Expert Group) JPEG baseline compression algorithm using the image on the right as an example. (JPEG is an
acronym for "Joint Photographic Experts Group.") Some compression algorithms are lossless for
they preserve all the original information. Others, such as the JPEG baseline algorithm, are lossy-
-some of the information is lost, but only information that is judged to be insignificant. Home
pages for the JPEG committee and JPEG 2000 committee
The JPEG compression algorithm
First, the image is divided into 8 by 8 blocks of pixels.

Since each block is processed without reference to the others, we'll concentrate on a single block.
In particular, we'll focus on the block highlighted below.
Here is the same block blown up so that the individual pixels are more apparent. Notice that
there is not tremendous variation over the 8 by 8 block (though other blocks may have more).
Remember that the goal of data compression is to represent the data in a way that reveals some
redundancy. We may think of the color of each pixel as represented by a three-dimensional
vector (R,G,B) consisting of its red, green, and blue components. In a typical image, there is a
significant amount of correlation between these components. For this reason, we will use a color

space transform to produce a new vector whose components represent luminance, Y, and blue
and red chrominance, Cb and Cr.
The luminance describes the brightness of the pixel while the chrominance carries information
about its hue. These three quantities are typically less correlated than the (R, G, B) components.
Furthermore, psychovisual experiments demonstrate that the human eye is more sensitive to
luminance than chrominance, which means that we may neglect larger changes in the
chrominance without affecting our perception of the image.
Since this transformation is invertible, we will be able to recover the (R,G,B) vector from the (Y,
Cb, Cr) vector. This is important when we wish to reconstruct the image. (To be precise, we
usually add 128 to the chrominance components so that they are represented as numbers between
0 and 255.)
When we apply this transformation to each pixel in our block
we obtain three new blocks, one corresponding to each component. These are shown below
where brighter pixels correspond to larger values.
Y Cb Cr

As is typical, the luminance shows more variation than the the chrominance. For this reason,
greater compression ratios are sometimes achieved by assuming the chrominance values are
constant on 2 by 2 blocks, thereby recording fewer of these values. For instance, the image
editing software Gimp provides the following menu when saving an image as a JPEG file:
The Discrete Cosine Transform
Now we come to the heart of the compression algorithm. Our expectation is that, over an 8 by 8
block, the changes in the components of the (Y, Cb, Cr) vector are rather mild, as demonstrated
by the example above. Instead of recording the individual values of the components, we could
record, say, the average values and how much each pixel differs from this average value. In
many cases, we would expect the differences from the average to be rather small and hence
safely ignored. This is the essence of the Discrete Cosine Transform (DCT), which will now be
explained.
We will first focus on one of the three components in one row in our block and imagine that the
eight values are represented by f0, f1, ..., f7. We would like to represent these values in a way so
that the variations become more apparent. For this reason, we will think of the values as given by
a function fx, where x runs from 0 to 7, and write this function as a linear combination of cosine
functions:
Don't worry about the factor of 1/2 in front or the constants Cw (Cw = 1 for all w except C0 =
). What is important in this expression is that the function fx is being represented as a
linear combination of cosine functions of varying frequencies with coefficients Fw. Shown below
are the graphs of four of the cosine functions with corresponding frequencies w.
w = 0 w = 1
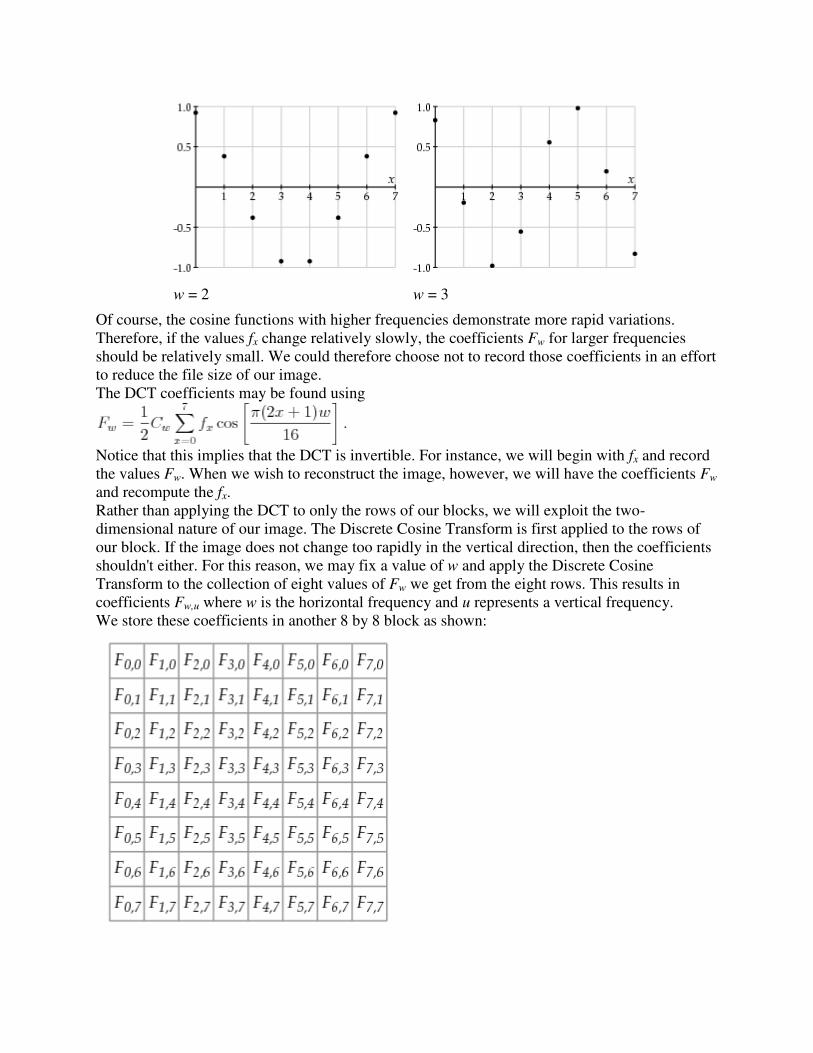
w = 2 w = 3
Of course, the cosine functions with higher frequencies demonstrate more rapid variations.
Therefore, if the values fx change relatively slowly, the coefficients Fw for larger frequencies
should be relatively small. We could therefore choose not to record those coefficients in an effort
to reduce the file size of our image.
The DCT coefficients may be found using
Notice that this implies that the DCT is invertible. For instance, we will begin with fx and record
the values Fw. When we wish to reconstruct the image, however, we will have the coefficients Fw
and recompute the fx.
Rather than applying the DCT to only the rows of our blocks, we will exploit the two-
dimensional nature of our image. The Discrete Cosine Transform is first applied to the rows of
our block. If the image does not change too rapidly in the vertical direction, then the coefficients
shouldn't either. For this reason, we may fix a value of w and apply the Discrete Cosine
Transform to the collection of eight values of Fw we get from the eight rows. This results in
coefficients Fw,u where w is the horizontal frequency and u represents a vertical frequency.
We store these coefficients in another 8 by 8 block as shown:
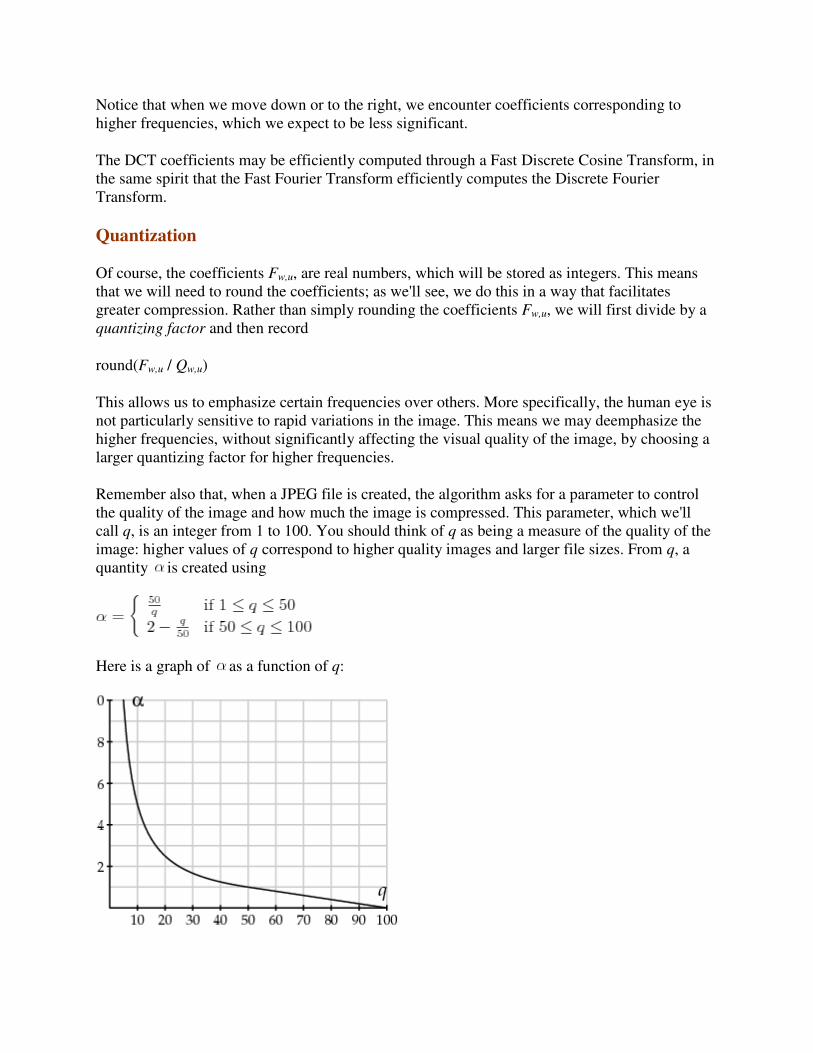
Notice that when we move down or to the right, we encounter coefficients corresponding to
higher frequencies, which we expect to be less significant.
The DCT coefficients may be efficiently computed through a Fast Discrete Cosine Transform, in
the same spirit that the Fast Fourier Transform efficiently computes the Discrete Fourier
Transform.
Quantization
Of course, the coefficients Fw,u, are real numbers, which will be stored as integers. This means
that we will need to round the coefficients; as we'll see, we do this in a way that facilitates
greater compression. Rather than simply rounding the coefficients Fw,u, we will first divide by a
quantizing factor and then record
round(Fw,u / Qw,u)
This allows us to emphasize certain frequencies over others. More specifically, the human eye is
not particularly sensitive to rapid variations in the image. This means we may deemphasize the
higher frequencies, without significantly affecting the visual quality of the image, by choosing a
larger quantizing factor for higher frequencies.
Remember also that, when a JPEG file is created, the algorithm asks for a parameter to control
the quality of the image and how much the image is compressed. This parameter, which we'll
call q, is an integer from 1 to 100. You should think of q as being a measure of the quality of the
image: higher values of q correspond to higher quality images and larger file sizes. From q, a
quantity is created using
Here is a graph of as a function of q:

Notice that higher values of q give lower values of . We then round the weights as
round(Fw,u / Qw,u)
Naturally, information will be lost through this rounding process. When either or Qw,u is
increased (remember that large values of correspond to smaller values of the quality parameter
q), more information is lost, and the file size decreases.
Here are typical values for Qw,u recommended by the JPEG standard. First, for the luminance
coefficients:
and for the chrominance coefficients:
These values are chosen to emphasize the lower frequencies. Let's see how this works in our
example. Remember that we have the following blocks of values:
Y Cb Cr

Quantizing with q = 50 gives the following blocks:
Y Cb Cr
The entry in the upper left corner essentially represents the average over the block. Moving to
the right increases the horizontal frequency while moving down increases the vertical frequency.
What is important here is that there are lots of zeroes. We now order the coefficients as shown
below so that the lower frequencies appear first.
In particular, for the luminance coefficients we record
20 -7 1 -1 0 -1 1 0 0 0 0 0 0 0 -2 1 1 0 0 0 0 ... 0
Instead of recording all the zeroes, we can simply say how many appear (notice that there are
even more zeroes in the chrominance weights). In this way, the sequences of DCT coefficients
are greatly shortened, which is the goal of the compression algorithm. In fact, the JPEG
algorithm uses extremely efficient means to encode sequences like this.
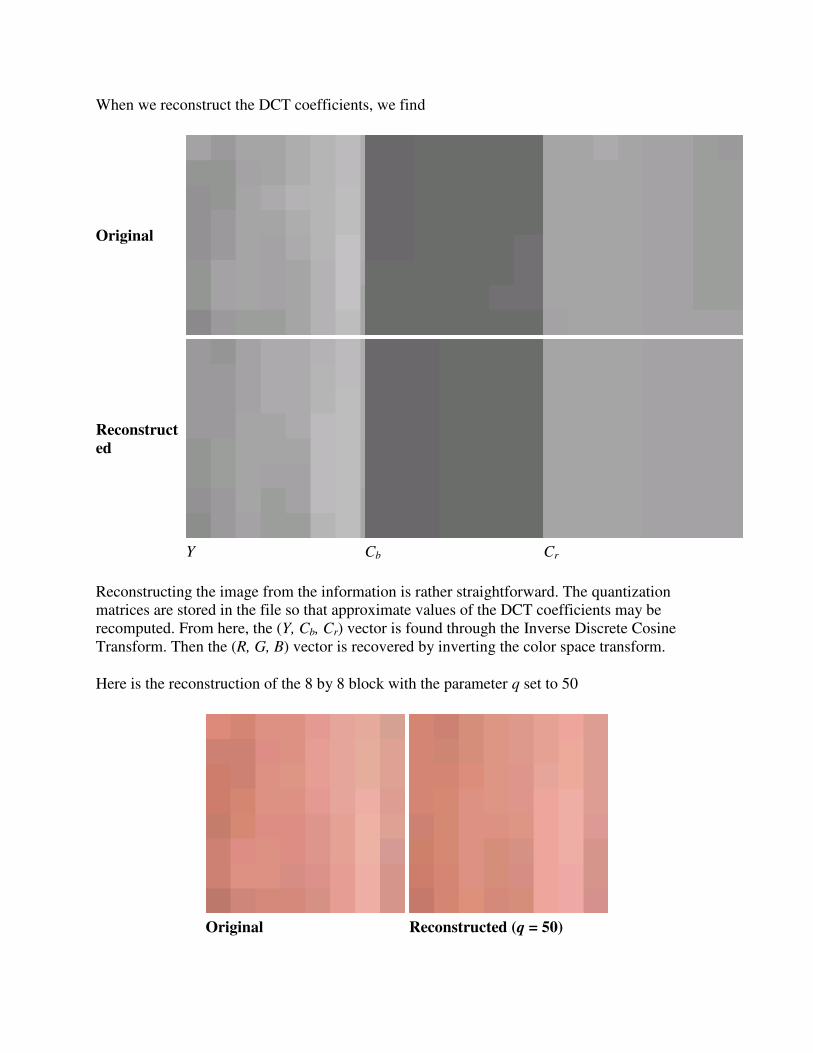
When we reconstruct the DCT coefficients, we find
Original
Reconstruct
ed
Y Cb Cr
Reconstructing the image from the information is rather straightforward. The quantization
matrices are stored in the file so that approximate values of the DCT coefficients may be
recomputed. From here, the (Y, Cb, Cr) vector is found through the Inverse Discrete Cosine
Transform. Then the (R, G, B) vector is recovered by inverting the color space transform.
Here is the reconstruction of the 8 by 8 block with the parameter q set to 50
Original Reconstructed (q = 50)
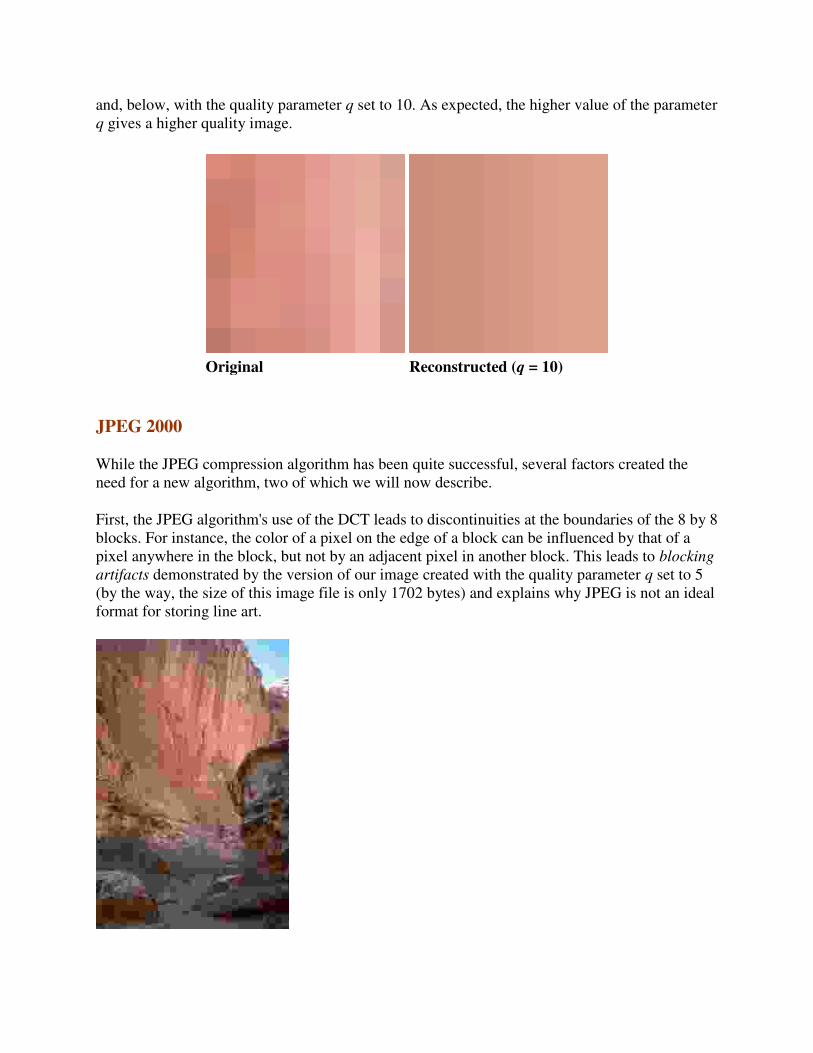
and, below, with the quality parameter q set to 10. As expected, the higher value of the parameter
q gives a higher quality image.
Original Reconstructed (q = 10)
JPEG 2000
While the JPEG compression algorithm has been quite successful, several factors created the
need for a new algorithm, two of which we will now describe.
First, the JPEG algorithm's use of the DCT leads to discontinuities at the boundaries of the 8 by 8
blocks. For instance, the color of a pixel on the edge of a block can be influenced by that of a
pixel anywhere in the block, but not by an adjacent pixel in another block. This leads to blocking
artifacts demonstrated by the version of our image created with the quality parameter q set to 5
(by the way, the size of this image file is only 1702 bytes) and explains why JPEG is not an ideal
format for storing line art.

In addition, the JPEG algorithm allows us to recover the image at only one resolution. In some
instances, it is desirable to also recover the image at lower resolutions, allowing, for instance, the
image to be displayed at progressively higher resolutions while the full image is being
downloaded.
To address these demands, among others, the JPEG 2000 standard was introduced in December
2000. While there are several differences between the two algorithms, we'll concentrate on the
fact that JPEG 2000 uses a wavelet transform in place of the DCT.
Before we explain the wavelet transform used in JPEG 2000, we'll consider a simpler example of
a wavelet transform. As before, we'll imagine that we are working with luminance-chrominance
values for each pixel. The DCT worked by applying the transform to one row at a time, then
transforming the columns. The wavelet transform will work in a similar way.
To this end, we imagine that we have a sequence f0, f1, ..., fn describing the values of one of the
three components in a row of pixels. As before, we wish to separate rapid changes in the
sequence from slower changes. To this end, we create a sequence of wavelet coefficients:
Notice that the even coefficients record the average of two successive values--we call this the
low pass band since information about high frequency changes is lost--while the odd coefficients
record the difference in two successive values--we call this the high pass band as high frequency
information is passed on. The number of low pass coefficients is half the number of values in the
original sequence (as is the number of high pass coefficients).
It is important to note that we may recover the original f values from the wavelet coefficients, as
we'll need to do when reconstructing the image:
We reorder the wavelet coefficients by listing the low pass coefficients first followed by the high
pass coefficients. Just as with the 2-dimensional DCT, we may now apply the same operation to
transform the wavelet coefficients vertically. This results in a 2-dimensional grid of wavelet
coefficients divided into four blocks by the low and high pass bands:

As before, we use the fact that the human eye is less sensitive to rapid variations to deemphasize
the rapid changes seen with the high pass coefficients through a quantization process analagous
to that seen in the JPEG algorithm. Notice that the LL region is obtained by averaging the values
in a 2 by 2 block and so represents a lower resolution version of the image.
In practice, our image is broken into tiles, usually of size 64 by 64. The reason for choosing a
power of 2 will be apparent soon. We'll demonstrate using our image with the tile indicated.
(This tile is 128 by 128 so that it may be more easily seen on this page.)
Notice that, if we transmit the coefficients in the LL region first, we could reconstruct the image
at a lower resolution before all the coefficients had arrived, one of aims of the JPEG 2000
algorithm.
We may now perform the same operation on the lower resolution image in the LL region thereby
obtaining images of lower and lower resolution.

The wavelet coefficients may be computed through a lifting process like this:
The advantage is that the coefficients may be computed without using additional computer
memory--a0 first replaces f0 and then a1 replaces f1. Also, in the wavelet transforms that are used
in the JPEG 2000 algorithm, the lifting process enables faster computation of the coefficients.
MPEG The most common form of the video signal in use today is still analog. This signal is obtained through a
process known as scanning. In this section the analog representation of the video signal and its
disadvantages are discussed.This part also describes the need towards digital representation of video
signal. After describing the need for compression of video signal, this paper describes the MPEG
compression technique for video signals.
Analog Video Signal
Analog signal is obtained through a process known as scanning. This is shown in Figure 2. Scanning
records the intensity values of the spatio-temporal signal only in the h direction. This signal is coupled
with the horizontal and vertical synchronization pulses to yield the complete video signal. Scanning can
be either progressive or interlaced. Progressive scanning scans all the horozontal lines to form the
complete frame. In the interlaced scanning, the even and the odd horizontal lines of a picture are
scanned seperately yielding the two fields of a picture. There are three main analog video standards.
Composite.
Component.
S-Video.
In the composit standard, the luminance and the two chrominance components are encoded together
as a single signal. This is in contrast to the component standard, where the three components are coded
as three distinct signals. The S-Video consists of seperate Y and C analog video signals.
Today, the technology is attempting to integrate the video, computer and telecommunication
industry together on a single mutimedia platform. The video signal is required to be scalable,
platform independent, able to provide interactivity, and be robust. The analog unfortunately fails

to address these requirements. Moving to digital not only eliminates most of the above
mentioned problems but also opens door to a whole range of digital video processing techniques
which can make the picture sharper.
Digital Video Signal
To digitize the spatio-temporal signal x(h,v,t), usually, the component form of the analog signal is
sampled in all three directions. Each sample point in a frame is called a pixel. Sampling in the horizontal
direction yields the pixels per line, which defines the horizontal resolution of the picture. Vertical
resolution is controlled by sampling vertically. Temporal sampling determines the frame rate.
Digital video too has its share of bottlenecks. The most important one is the huge bandwidth
requirement. Inspite of being digital, it thus still need to stored. The logical solution to this
problem is digital video compression.
MPEG Compression Standard
Compression aims at lowering the total number of parameters required to represent the signal, while
maintaining good quality. These parameters are then coded for transmission or storage. A result of
compressing digital video is that it becomes available as computer data, ready to transmitted over
existing communication networks.
There are many different redandancies present in the video signal data.
spatial.
Temporal.
Psychovisual.
Coding.
Spatial redandancy occurs because neighboring pixels in each individual frame of a video signal
are related. The pixels in consecitive frames of signal are also related, leading to temporal
redundancy. The human visual system does not treat all the visual information with equal
sensitivity, leading to psychovisual redundancy. Finally, not all parameters occur with the same
probability in an image. As a result, they would not require equal number of bits to code them
(Huffman coding).
There are several different compression standards around today (CCITT recomandation H. 261).
MPEG, which stands for moving pictures experts groups, is a joint coommitte of the OSI and
IEC. It has been responsible for the MPEG-1(ISO/IEC 11172) and MPEG-2(ISO/IEC 13818)
standards in the past and is currently developing the MPEG-4 standard. MPEG standards are
generic and universal. There are three main parts in the MPEG-1 and MPEG-2 specifications,
namely, Systems, Video and Audio. The Video part defines the syntax and semantics of the
compressed video bitstream. The Audio part defines the same for audio bitstream, while the
System part specifies the combination of one or more elementary streams of video and audio, as
well as other data, into a single or multiple streams which are suitable for storage or transmision.
The MPEG-2 standard consists of a fourth part called DSMCC, which defines a set of protocols
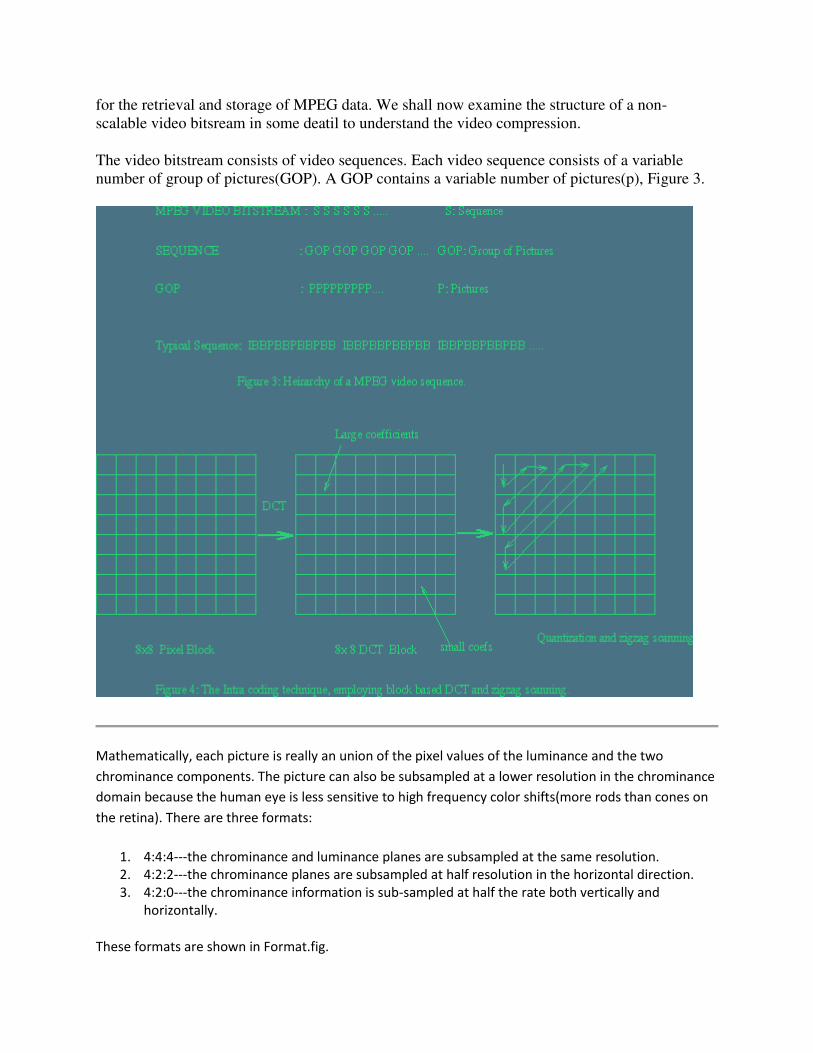
for the retrieval and storage of MPEG data. We shall now examine the structure of a non-
scalable video bitsream in some deatil to understand the video compression.
The video bitstream consists of video sequences. Each video sequence consists of a variable
number of group of pictures(GOP). A GOP contains a variable number of pictures(p), Figure 3.
Mathematically, each picture is really an union of the pixel values of the luminance and the two
chrominance components. The picture can also be subsampled at a lower resolution in the chrominance
domain because the human eye is less sensitive to high frequency color shifts(more rods than cones on
the retina). There are three formats:
1. 4:4:4---the chrominance and luminance planes are subsampled at the same resolution.
2. 4:2:2---the chrominance planes are subsampled at half resolution in the horizontal direction.
3. 4:2:0---the chrominance information is sub-sampled at half the rate both vertically and
horizontally.
These formats are shown in Format.fig.

Pictures can be devided into three main types based on their compression schemes.
I or Intra pictures.
P or Predicted pictures.
B or Bidirectional pictures.
The frames that can be predicted from previous frames are called P-frames. But what happens if
transmission errors occur in a sequnce of P-frames?. To avoid the propagation of transmission errors
and to allow periodic resynchronization, a complete frame which does not rely on information from
other frames is transmitted approximately once every 12 frames. These stand-alone frames are "intra
coded" and are called I-frames. The coding technique for I pictures falls in the category of transform
coding. Each picture is divided into 8x8 non-overlapping pixels blocks. Four of these blocks are
additionally arranged into a bigger block of size 16x16, called macroblock. The DCT is applied to each 8x8
block individually, Figure 4. This transform converts the data into series of coefficients which represent
the magnitudes of the cosine functions at increasing freqncies. The quantization process allows the high
energy, low frequency coefficients to be coded with greater number of bits, while using fewer or zero
bits for the high freuency coefficients. Retaining only a subset of the coeffients reduces the total number
of parameters needed for representation by a substantial amount. The quantization process also helps
in allowing the encoder to output bitstreams at specified bitrate.
The DCT oefficients are coded using a combination of two special coding schemes- Run length
and Huffman. The coefficients are scaned in a zigzag pattern to create a 1-D sequence. MPEG-2
provides an alternative scanning method. The resulting 1-D sequence usually contains a large
number of zeros due to DCT and the quantization process. Each non-zero coefficients is

assosiated with a pair of pointers. First, its position in the block which is indicated by the number
of zeros between itself and the prevoius non-zero coefficient. Second, its coefficient value. Based
on these two pointers, it is given a variable length code from a lookup table. This is done in a
manner so that a highly probable combination gets a code with fewer bits, while the unlikely
ones get longer codes. However, since spatial redundandancy is limitted, the I Pictures provide
only moderate compression.
The P and B pictures are where MPEG derives its maximum compression efficiency. It is done
by a technique called motion compensation(MC) based prediction, which exploits the temporal
redundancy. Since frames are closely related, it is assumed that a current picture can be modelled
as a translation of the picture at the previous time. It is possible then to accurately "predict" the
data of one frame based on the data of a previous frame. In P pictures, each 16x16 sized
macroblocks is predicted from macroblock of previously encoded I picture. Since, frames are
snapshots in time of a moving object, the macroblocks in the two frames may not correspond to
the same spatial location. The encoder searches the previous frame(for P-frames, or the frames
before and after for B-frames) in half pixel increments for other macroblock locations that are a
close match to the information that is contained in the current macroblock. The displacements in
the horizontal and vertical directions of the best match macroblocks from the cosited macroblock
are called Motion vectors, Figure 5.
If no matching macroblocks are found in the neighboring region, the macroblock is intra coded
and the DCT coefficients are encoded. if a matching block is found in the search region the
coefficients are not transmitted, but a motion vector is used instead.

The motion vectors can also be used for motion prediction in case of corrupted data, and sophisticated
decoder algorithms can use these vectors for error concealment( refer to article1).
For B pictures, MC prediction and interpolation is performed using reference frames present on
either side of it.

Compared to I and P, B pictures provides the maximum compression. There are other advantages of B
pictures.
Reduction of noise due to the averaging process.
Use of future pictures for coding.
B pictures themselves never used for predictions and hence do not propagate errors. MPEG-2 allows for
both frame and field based MC. Field based MC is spatially useful when the video signal includes fast
motion.

![arXiv:1002.4301v2 [astro-ph.SR] 2 Feb 2011At ESO, a Loral/Lesser CCD camera #38, of 2688×512 pixels with pixel size of 15 µm and a grating of 600 l/mm were used, allowing a spectral](https://img.pdfslide.net/doc/110x75/5e80ffd835ee82242558f4a5/arxiv10024301v2-astro-phsr-2-feb-2011-at-eso-a-lorallesser-ccd-camera-38.jpg)
