Embed Size (px)
Citation preview

New in ICUMarkus Scherer (Google)
Internationalization & Unicode Conference 40October 2016 — Santa Clara, CA
ICU (International Components for Unicode) is an open source development project sponsored, supported, and used by many organizations. It is dedicated to providing robust, full-featured, commercial quality, freely available Unicode-based technologies.
Comprehensive support for the Unicode Standard is the basis for multilingual, single-binary software. ICU uses the most current versions of the standard, and provides full support for supplementary characters.
As computing environments become more heterogeneous, software portability becomes more important. ICU lets you produce the same results across all the various platforms you support. It offers great flexibility to extend and customize the supplied system services.For more information, see the ICU website: http://site.icu-project.org/
Agenda:● Isn't Unicode enough?● Why ICU?
○ ICU features○ ICU works everywhere○ ICU is kept up to date
● Where is ICU?● What's new in ICU?● What's next for ICU?

● Encodes all modern world languages○ Lossless data exchange○ Additional symbols & historic characters continue to be
added● Efficient processing; single-binary global software● Unicode Locale Data (CLDR)● Unicode Collation Algorithm● IDNA, Security, regex, ...
Unicode Standard(s)
Unicode (and the parallel ISO 10646 standard) defines the character set necessary for efficiently processing text in any language and for maintaining text data integrity. In addition to global character coverage, the Unicode standard is unique among character set standards because it also defines data and algorithms for efficient and consistent text processing. This simplifies high-level processing and ensures that all conformant software produces the same results. The widespread adoption of Unicode over the last decade made text data truly portable and formed a cornerstone of the Internet.
Unicode enables lossless exchange of multilingual data between different types of computing systems, as well as single-binary installations of software which can handle text in all languages.
Beyond the character encoding and the character properties, several Unicode Technical Standards define important algorithms and processes, and the locale data project (CLDR) provides comprehensive, sophisticated data for localization to dozens of languages.

● Several large specs + Annexes● 128,172 characters in 9.0● > 80 character properties, many multi-valued● > 75 languages with comprehensive locale data● > 100 sort orders● Significant update every year● Formatting, line-break, regular expressions...
But...
As a result, these standards are complex and voluminous and not trivial to implement. ICU supports all Unicode characters and the Unicode CLDR data, is regularly updated to the latest Unicode version, and implements and provides most of the properties and algorithms.

● Requirements vary widely across languages & countries○ Sorting○ Text searching○ Bidirectional text processing and complex text layout○ Date/time/number/currency formatting○ Codepage conversion○ … and so on
● Performance is key○ It might be easy to do the right thing○ It is hard to do with high performance + small footprint
Internationalization,Localization & Locales
The design and architecture of software that can work with multiple languages and cultural specializations is called internationalization. It involves taking into account a variety of attributes for many areas of text handling and data input and output. The most common attributes are the written language and the country or region for which data is processed or presented. Standard codes for these attributes, and sometimes others, are often combined into “locale identifiers”. Depending on the context, the term “locale” refers either to such locale identifiers or to the relevant collection of associated data and behaviors. In addition to these familiar attributes, others are also important and cannot be reliably inferred. For example, currency codes and time zones need to be identified reliably for correct results.
Properly internationalized software can be compiled and installed once and handles text in all languages at the same time, as opposed to requiring recompilation or installation for each locale. Such software needs to use Unicode for text processing.
Localization provides internationalized software with locale-specific User Interface elements (text, images, layout) and sometimes functionality for regional business rules or similar.
It is often relatively easy to satisfy the requirements from one language or culture, or a small number of closely related ones. However, with the diversity of requirements from many languages and cultures on many processes, and the desire for high performance in many cases, the implementation of these processes can become rather complex. The ICU libraries provide “shrink-wrapped”, reusable, tested implementations that were designed with performance in mind.

● Unicode text handling● Charset conversions (200+)● Charset detection● Collation & Searching● Unicode Locale Data (CLDR)● Resource Bundles● Calendar & Time Zones● Unicode Regular
Expressions● ...
ICU Features
● Breaks: word, line, …● Formatting
○ Date & time○ Durations, intervals○ Messages○ Numbers, currencies○ Measurement units○ Plurals
● Transforms○ Normalization○ Casing○ Transliterations
In addition to basic Unicode standard conformance, both the ICU Java library (“ICU4J”) and the C/C++ libraries (“ICU4C”) also provide a full set of internationalization features listed above. New features and improvements are added with every release.
ICU C/C++ and Java APIs do differ slightly due to the differences of programming languages. Sometimes the feature development in ICU4C leapfrogs ICU4J or vice versa by 1-2 releases.
Since ICU is open source and closely tracks the Unicode Standard, ICU can support changes and additions to the Unicode Standard much more quickly than Java. Java support for Unicode is tied to major releases of the JDK, and can lag the Unicode Standard by a year or more.

● Mature, widely used set of C/C++ and Java libraries○ Basis for Java 1.1 internationalization, but goes far
beyond Java 1.1● Very portable – identical results on all platforms/programming
languages○ C/C++ (ICU4C): 30+ platforms/compilers○ Java (ICU4J): Oracle, IBM JRE, Android○ PyICU & other wrappers
● Customizable & Modular
● Open source (since 1999) – but non-restrictive○ Contributions from many parties (IBM, Google, Apple,
Microsoft, Yahoo, ...)
ICU Works Everywhere
International Components for Unicode (ICU) is a mature set of widely used C/C++ and Java libraries. They are portable to many environments and platforms.
There are 2 sub-projects of ICU: There is ICU4C, which is written in C and C++, and ICU4J which is written in Java.
Mature: Started in 1996, contributions to JDK 1.1 (1997), open source project since 1999.
ICU is distributed under the X license. The license allows ICU to be incorporated into a wide variety of software projects using the GPL license, while also allowing ICU to be incorporated into non-open source products.

● 2 ICU releases per year● Each ICU release supports the latest
○ Unicode version■ Properties, Unicode collation, IDNA, spoof
checker, line breaks, ...○ CLDR version○ Time zone database update
● TZ DB updates for past ICU versions
ICU Is Kept Up To Date
Every ICU release updates to the latest Unicode version (for characters & their properties) and CLDR version (locale data), including sorting/collation and line breaking/segmentation and other standards. ICU follows time zone database updates with every milestone and release, and updates are also available for download and updating.

Backwards Compatible
● C & Java binary compatible● C++ source compatible across ICU versions
○ Occasional changes (const) for subclasses● API rarely deprecated, kept functional if possible● Updated data & behavior; bug fixes
ABAS Software, Adobe, Amazon (Kindle), Amdocs, Android, Apache (Harmony, Lucene, Solr, PDFBox, Tika, Xlan, Xerces, ....), Appian, Apple, Argonne National Laboratory, Avaya, BAE Systems Geospatial eXploitation Products, BEA, BluePhoenix Solutions, BMC Software, Boost, BroadJump, Business Objects, caris, CERN, Debian Linux, Dell, Eclipse, eBay, EMC Corporation, ESRI, Free BSD, Gentoo Linux, Google, GroundWork Open Source, GTK+, Harman/Becker Automotive Systems GmbH, HP, Hyperion, IBM, Inktomi, Innodata Isogen, Informatica, Intel, Interlogics, IONA, IXOS, Jikes, Library of Congress, Mathworks, Microsoft, Mozilla, Netezza, Node.js, OpenOffice, Lawson Software, Leica Geosystems GIS & Mapping LLC, Mandrake Linux, OCLC, Progress Software, Python, QNX, Rogue Wave, SAP, SIL, SPSS, Software AG, Sun Microsystems (Solaris, Java), SuSE, Sybase, Symantec, Teradata (NCR), Trend Micro, Virage, webMethods, Wine, WMS Gaming, XyEnterprise, Yahoo!, ...
A Billion Devices
ICU is used in a large number of products and by a large number of organizations, several of which actively participate in improving ICU, in particular Apple, Google, and IBM (but we can always use more!).
ICU is also used by other full Unicode members including Adobe, SAP, and Yahoo, and by many other organizations including those listed here. Some uses may surprise you; ICU may be running in your automobile, via Harman/Becker automotive software used in a long list of car brands including Audi, BMW, Buick, etc.
See http://site.icu-project.org/

ICU in Apple/Google/IBM
Apple● Mac OS X, iOS (iPhone, iPad, ...), watchOS, tvOS,
Windows apps, Safari, iTunes, ...Google● Web Search, Google+, Chrome/Chrome OS, Android,
Adwords, Google Maps, Blogger, ...IBM● DB2, Lotus, WebSphere, Tivoli, Rational, AIX, IBM i,
z/OS, ...
2016: Microsoft joined the ICU project
ICU is used by Apple operating systems, and by most applications typically via ICU functionality exported by higher layers of the systems.It is also part of the common set of libraries used to support Apple applications for Windows.
ICU is part of the Android platform and used in the implementation of some of the SDK libraries. It is the basis of Chrome internationalization and used widely in cloud-based Google products.
ICU is used throughout IBM, in operating systems and across all 5 major brands.

ICU moved to Unicode
Thanks to IBM for open source stewardship 1999-2016! (And for continuing contributions.)
Now: ICU Technical Committee (ICU-TC) under Unicode
ICU 58 under Unicode license● Similar to ICU 1.8.1-57 license
http://blog.unicode.org/2016/05/icu-joins-unicode-consortium.html
http://www.unicode.org/consortium/consort.html
http://www.unicode.org/copyright.html#License

ICU4J in Android
Parts of ICU4J 56 public in SDK● Android 7.0 Nougat, API level 24
com.ibm.icu → android.icu● avoid conflicts with apps’ ICU4J
https://developer.android.com/guide/topics/resources/icu4j-framework.html

● Unicode 9.0 & draft Emoji 4.0● CLDR 29/30● New API, many bug fixes● Layout engine
What’s new in ICU 57 & 58
Within the last year, the ICU team has released two versions, each incorporating the corresponding CLDR locale data releases. The fall releases upgrade to the latest version of the Unicode Standard.
The layout engine code has been removed; the ParagraphLayout is not deprecated and remains (and must now be built on top of HarfBuzz). See http://userguide.icu-project.org/layoutengine
See http://site.icu-project.org/download
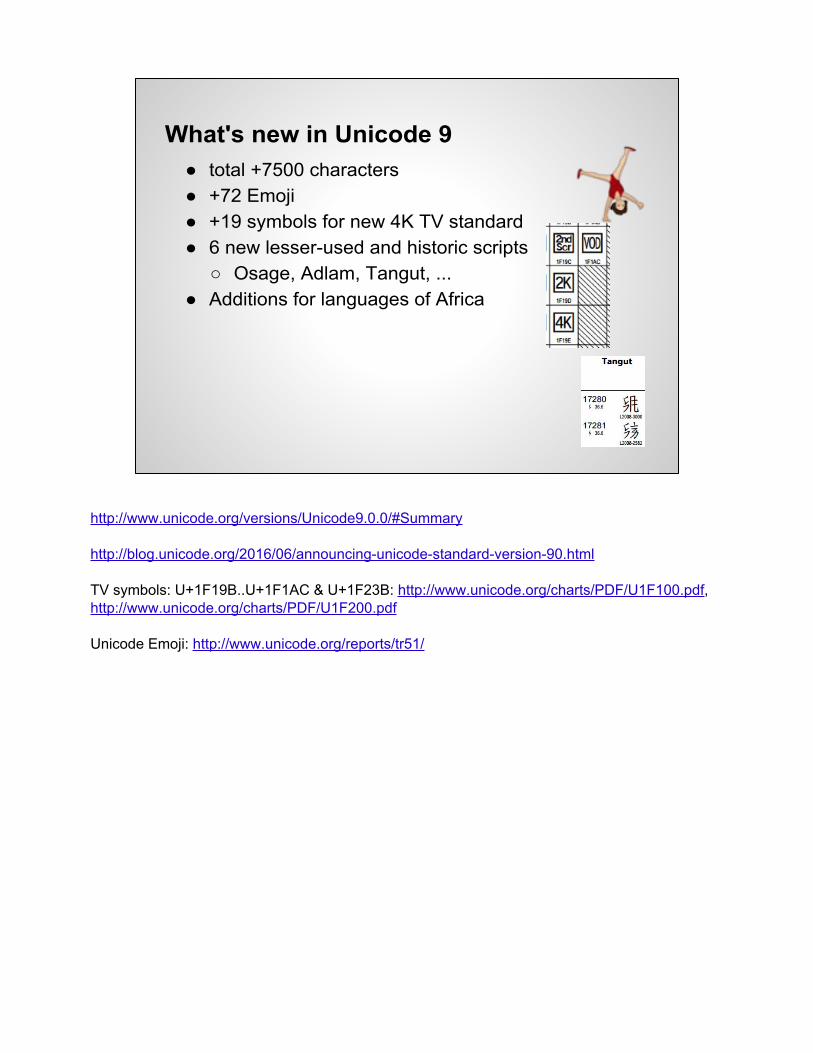
● total +7500 characters● +72 Emoji● +19 symbols for new 4K TV standard● 6 new lesser-used and historic scripts
○ Osage, Adlam, Tangut, ...● Additions for languages of Africa
What's new in Unicode 9
http://www.unicode.org/versions/Unicode9.0.0/#Summary
http://blog.unicode.org/2016/06/announcing-unicode-standard-version-90.html
TV symbols: U+1F19B..U+1F1AC & U+1F23B: http://www.unicode.org/charts/PDF/U1F100.pdf, http://www.unicode.org/charts/PDF/U1F200.pdf
Unicode Emoji: http://www.unicode.org/reports/tr51/

ICU support for emoji
Emoji properties API● draft emoji 4.0 data
Grapheme/word/line breaking for emoji sequences

● Unicode 9.0○ Also UCA & Unihan 9.0
● Display names for more languages● More likelySubtags, scripts for more languages● Cantonese locale added (+nds & ckb in ICU)● “3 Fridays ago”, “this hour”● Which units used in which country/region● Improved emoji annotations● Many more transforms; all have BCP 47 IDs● +9.2% data, 5.9% fixes
CLDR 29 & 30
A lot of work for ICU is done in and with other groups: Improving Unicode specs & data, improving CLDR capabilities, structure, and data, and then modifying ICU to support these improvements.
CLDR has added some more structure, defined more measurement units, and collected new data and improvements from more than 200 contributors.
New transforms:● Burmese Zawgyi → Unicode● Indic ↔ Urdu, Indic ↔ Arabic● Cherokee, Armenian, Sinhala, Burmese, Romansh, Amharic, Xhosa, Zulu, Kazakh (mostly
to/from IPA)
http://cldr.unicode.org/index/downloads/cldr-29http://blog.unicode.org/2016/03/cldr-version-29-released.html
http://cldr.unicode.org/index/downloads/cldr-30http://blog.unicode.org/2016/10/cldr-version-30-released.html
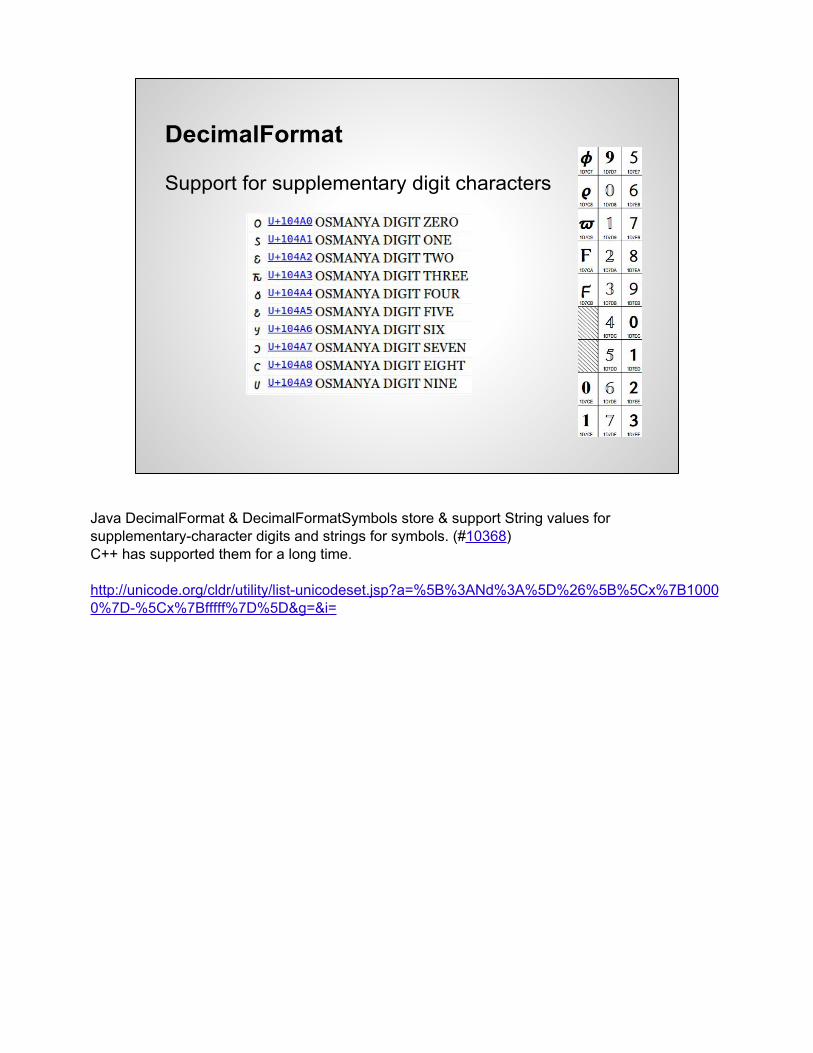
DecimalFormat
Support for supplementary digit characters
Java DecimalFormat & DecimalFormatSymbols store & support String values for supplementary-character digits and strings for symbols. (#10368)C++ has supported them for a long time.
http://unicode.org/cldr/utility/list-unicodeset.jsp?a=%5B%3ANd%3A%5D%26%5B%5Cx%7B10000%7D-%5Cx%7Bfffff%7D%5D&g=&i=

Date formatting & parsing
RelativeDateTimeFormatter“last week”, “in 5 days”
● easier-to-use C++ & Java API● new: C API
Day periods “noon”, “3:15 in the afternoon”
RelativeDateTimeFormatter: http://bugs.icu-project.org/trac/ticket/12072 http://www.icu-project.org/apiref/icu4j/com/ibm/icu/text/RelativeDateTimeFormatter.html
New in DateFormat: Colloquial day periods, especially for cultures where am/pm is not a customary way of expressing time. Pattern characters b & B, and DateTimePatternGenerator support of C for selecting the customary form.Formatting of “0:00 midnight” has been disabled because it is confusing except for at the end of an interval.
ICU implements the new narrow AM/PM markers (date pattern field “aaaaa”).
New convenience DateFormat::createInstanceForSkeleton() takes a skeleton – a specification of which fields to format. The C++ code also caches DateFormat patterns by locale and skeleton.
DateIntervalFormat: http://bugs.icu-project.org/trac/ticket/11706 http://bugs.icu-project.org/trac/ticket/11726

SpoofChecker● Visual confusability
“desordenado” vs. “ԁеѕогԁепаԁо”● Possible spoof/phishing attacks
“pаypаl.com” (Cyrillic 'а' characters)
● UTS #39 v9.0○ Data update○ Fewer false positives: “whole-script confusables” test
● More robust C API● Improved performance
SpoofChecker: Handling of "whole-script confusables" has been removed from ICU, in accordance with its deprecation in UTS #39 Version 9.0.0 and the removal of the corresponding Unicode data file.
Data file reduced from 74kB to 44kB.

Greek uppercasing
Πατάτα → ΠΑΤΑΤΑ
άυλος → ΑΫΛΟΣ
Το ένα ή το άλλο → ΤΟ ΕΝΑ Η ΤΟ ΑΛΛΟ
Greek uppercasing ("el" locale ID) removes most diacritics: http://bugs.icu-project.org/trac/ticket/5456
[potato, intangible, “the one or the other”]

SimpleFormatter
Fast & simple for simple patterns as in CLDR
SimpleFormatter fmt = SimpleFormatter.compile(
"{1} '{born}' in {0}");
System.out.println(fmt.format("england", "paul"));
// Output: "paul {born} in england"
http://icu-project.org/apiref/icu4j/com/ibm/icu/text/SimpleFormatter.html
Formats simple patterns like "{1} was born in {0}". Minimal subset of MessageFormat; fast, simple, minimal dependencies. Supports only numbered arguments with no type nor style parameters, and formats only string values.
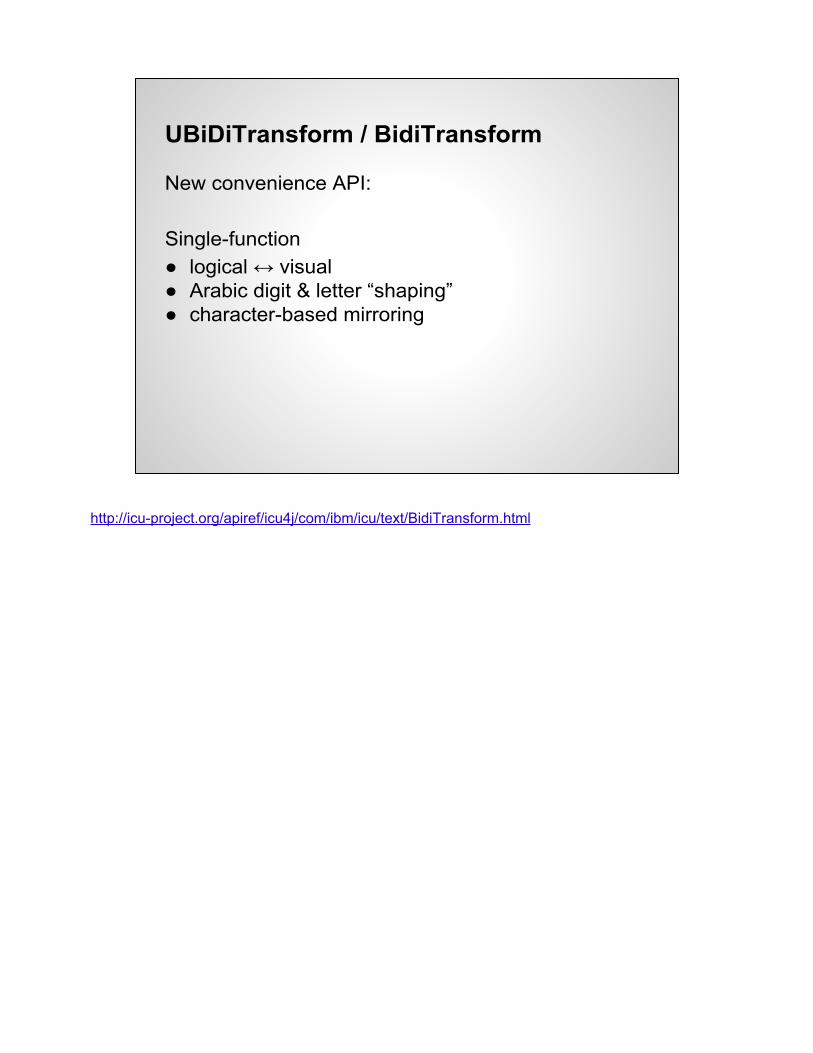
UBiDiTransform / BidiTransform
New convenience API:
Single-function● logical ↔ visual● Arabic digit & letter “shaping”● character-based mirroring
http://icu-project.org/apiref/icu4j/com/ibm/icu/text/BidiTransform.html

Under the hood
● More robust data loading● Bug fixes: ErrorProne, FindBugs, Coverity● @deprecated COUNT & LIMIT constants● Java 6● Unit tests now based on JUnit 4● Visual Studio 2015● Clang annotations for intended switch case
fallthroughs: -Wimplicit-fallthrough● Internal header files can be compiled by
themselves: simpler alternative build scripts
Data loading has been rewritten to be more robust for all services that load CLDR locale data and deal with its several levels of data fallback.
Most COUNT and LIMIT enum constants have been deprecated: http://bugs.icu-project.org/trac/ticket/12420
ICU4J 57 requires Java 6
ICU4C 58 supports & requires Visual Studio 2015

Upcoming
ICU 59 (2017q2)● CLDR 31● C++11 Unicode string types & literals● C++ source files in UTF-8?● Java 7?● API for more CLDR additions● Smaller segmentation data files
ICU 60 (2017q4)● Unicode 10.0● CLDR 32

http://site.icu-project.org/● Download ICU Releases● User Guide● Demonstrations● Technical FAQ● Bug Report● Mailing Lists (design & support)
This presentation: https://goo.gl/KkYxC9
References
Internationalization & Unicode Conference 40October 2016 — Santa Clara, CA
If you would like more information about ICU, you can go to our main site on http://site.icu-project.org There you will find links to download ICU, the ICU User Guide, the technical FAQ, where to get support, demonstrations of how ICU works, and many other topics related to ICU. You can also find more information about Unicode at the unicode.org site.

















![transliteration in icu[1] - DKUUG standardizingstd.dkuug.dk/jtc1/sc22/wg20/docs/n915-transliteration... · · 2002-03-2519th International Unicode Conference 1 San Jose, California,](https://img.pdfslide.net/doc/110x75/5aefff517f8b9aa9168d5703/transliteration-in-icu1-dkuug-international-unicode-conference-1-san-jose-california.jpg)











