Embed Size (px)
Citation preview

1 Introduction
Whole-body modellingof people from multiviewimages to populate virtualworlds
Adrian Hilton, Daniel Beresford,Thomas Gentils, Raymond Smith,Wei Sun, John Illingworth
Centre for Vision, Speech and Signal Processing,University of Surrey, Guildford GU25XH,United Kingdome-mail: [email protected],http://www.ee.surrey.ac.uk/Research/VSSP/3DVision/VirtualPeople
In this paper a new technique is intro-duced for automatically building recognis-able, moving 3D models of individual peo-ple. A set of multiview colour images ofa person is captured from the front, sides andback by one or more cameras. Model-basedreconstruction of shape from silhouettes isused to transform a standard 3D generic hu-manoid model to approximate a person’sshape and anatomical structure. Realistic ap-pearance is achieved by colour texture map-ping from the multiview images. The resultsshow the reconstruction of a realistic 3D fac-simile of the person suitable for animationin a virtual world. The system is inexpensiveand is reliable for large variations in shape,size and clothing. This is the first approachto achieve realistic model capture for clothedpeople and automatic reconstruction of ani-mated models. A commercial system basedon this approach has recently been used tocapture thousands of models of the generalpublic.
Key words: Avatar – Virtual human – Whole-body modelling – 3D vision – VRML
Correspondence to: A. Hilton
There is increasing demand for a low-cost systemto capture both human shape and appearance. Po-tential applications for such a system include thepopulation of virtual environments, communication,multimedia games and clothing. This paper presentsa technique for capturing recognisable models of in-dividual people for use in VR applications. For in-stance, each participant in a multiuser virtual envi-ronment could be represented to others as an ‘avatar’,which is a realistic facsimile of the person’s shape,size and appearance. The key requirements for build-ing models of individuals for use in virtual worldsare:
• Realistic models
• Animatable movements
• Low-cost (automatic) acquisition
These requirements contrast with previous objec-tives of whole-body measurement systems, whichwere principally designed to obtain accurate metricinformation of human shape. Such systems typicallycapture low-resolution colour and have restrictionson surface properties that result in no measurementsfor areas of dark colours and hair. Current whole-body measurement systems are very expensive andrequire expert knowledge to interpret the data andbuild animated models (Paquette 1996). These sys-tems are suitable for capturing measurements ofindividual people for clothing applications, but arenot capable of capturing recognisable models forVR or photorealistic models for computer anima-tion. Recent research has addressed reconstructingrealistic animated face models (Akimoto et al. 1993;Escher and Magnenat-Thalmann 1997; Fua and Mic-cio 2000; Lee and Magnenat-Thalmann 1998) andwhole-body models of kinematic structure (Plankerset al. 1999; Kakadiaris and Metaxas 1998a) fromcaptured images. The objective of this research isto extend this work to address the reconstruction ofwhole-body models of shape and appearance fromcaptured images.In this paper we introduce a technique for build-ing models of individual people from a set of fourorthogonal view images using standard camera tech-nology. The reconstruction from multiple orthog-onal view images is analogous to previous workon facial modelling (Akimoto et al. 1993; Lee andMagnenat-Thalmann 1998; Mortlock et al. 1997).A major feature of our approach is that we can recon-struct recognisable colour models of people who are
The Visual Computer (2000) 16:411–436c© Springer-Verlag 2000

412 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
fully clothed. The aim is to capture accurate appear-ance together with approximate shape information;not to accurately measure the underlying body di-mensions. The reconstruction algorithm modifiesa generic humanoid model to fit the silhouette shapeof a particular individual from multiple-view im-ages. This approach follows the ‘functional mod-elling’ paradigm (Terzopoulos 1994) of modifyingthe shape and appearance of a generic model con-taining the kinematic structure to generate a modelthat can be animated. This research uses a genericmodel based on the VRML Humanoid AnimationH-Anim (Roehl 1997) standard. The resulting modelof a specific person is in a standard format thatcan be viewed in any VRML97-compliant inter-net browser to obtain a recognisable moving virtualmodel (avatar) of a particular individual. It is envis-aged that the commercial availability of low-cost,whole-body capture will open up a mass marketfor personalised plug-ins to multimedia and gamespackages with individuals having a personal set ofmodels.
2 Previous work
Capturing human shape and appearance has receivedconsiderable interest throughout history. This sec-tion attempts to summarise the principal achieve-ments of recent related research in reconstructingrealistic models of people with active 3D surfacemeasurements systems and passive 2D images. Mod-elling facial appearance and expression has beenextensively addressed, as this is the most impor-tant attribute for person-to-person communication.Whole-body capture initially addressed measure-ment systems for apparel design and ergonomics.Only recently have whole-body capture systems be-gun to address modelling of an individual’s appear-ance and characteristic gestures.
2.1 Object modelling
Our approach integrates two areas of computer vi-sion research: ‘model-based fitting’ and ‘silhouette-based shape reconstruction’ to produce a powerfulnew method of ‘model-based 3D shape reconstruc-tion’. This enables reconstruction of the approximate3D shape of a specific person from a set of two ormore orthogonal view silhouette images.
Silhouette-based reconstruction of 3D shape hasreceived considerable interest for capturing objectmodels (Szeliski 1990; Niem and Wingebermuhle1997; Fitzgibbon et al. 1998). Recent research hasresulted in the reconstruction of 3D volumetric mod-els of moving objects from sequences of silhouetteimages captured by multiple cameras from vari-ous views (Kanade and Rander 1997; Moezzi et al.1997). Niem and Wingebermuhle (1997) show thatvery realistic object models can be captured by tak-ing a large number of images from various views ofan object against a uniform blue background. Thecamera viewpoint and intrinsic parameters are com-puted for each image based on a static calibrationpattern within the scene. Fitzgibbon et al. (1998)describe silhouette-based reconstruction using auto-calibration techniques based on tracking points onthe object surface without the need for a static cali-bration pattern. Combining the extracted silhouetteimages into a 3D volumetric framework with pro-jective geometry enables a coarse approximation ofthe object-surface shape. Colour texture mapping ofthe approximate shape model achieves very realisticobject models suitable for immersive virtual envi-ronments. An inherent limitation of silhouette-basedapproaches is that concave surface shapes cannot bereconstructed. The passive approach to 3D shape re-construction does not achieve the metric accuracy ofactive measurement systems. However, the passiveapproach achieves a greater level of photorealism inreconstructing fine surface detail.In this paper, we combine silhouette-based 3D shapereconstruction with model-based fitting techniquesto obtain an approximation of the shape of an indi-vidual person. The use of a model-based approachallows reconstruction from a minimal set of two or-thogonal images and enables approximation of con-cave surface shapes. Terzopoulos et al. (1988) intro-duced fitting of deformable models to image silhou-ettes to recover shape and nonrigid motion. Model-based techniques have been widely used for fitting3D measurements of surface shape using deformablemeshes (Hilton and Goncalves 1995), parametric de-formable models (McInerney and Terzopoulos 1996)and super-quadrics (Lejeune and Ferrie 1996). How-ever, model-based shape fitting fails to accuratelymodel fine surface detail and is limited to the recon-struction of objects with smooth surfaces. No resultshave been given for the accurate reconstruction ofvery complex objects with large shape variations,such as the human body.

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 413
2.2 Head modelling
There is a considerable body of literature addressingthe goal of realistic modelling of the head and face ofthe individual person. In modelling a particular per-son, the face is the most important component thatmust be modelled realistically to achieve an accept-able representation. Fully automatic acquisition ofrealistically animated, ‘talking-head’ models of indi-vidual people remains an open problem. The princi-pal difficulty in fully automated model acquisition isthe considerable variability in individual shape andhair. Recent research has begun to address the prob-lem of realistic modelling of facial expression.The techniques presented (Akimoto et al. 1993;Fua and Miccio 2000; Kurihara and Kiyoshi 1990;Lee and Magnenat-Thalmann 1998; Mortlock et al.1997; Sannier and Magnenat-Thalmann 1997) usecaptured 2D images to modify the shape of a 3Dgeneric face model to approximate a particular in-dividual. Photogrammetric techniques are used toestimate the 3D displacement of points on the sur-face of a generic model from multiple camera im-ages. Texture mapping of the captured images isthen used to achieve a recognisable 3D face model.Facial features from the captured images are usedto register them with corresponding 3D points onthe generic model. The correct registration of fea-ture points is required to ensure proper animationof the resulting model. Initial work (Kurihara andKiyoshi 1990) manually labelled feature points onseveral view images. Automatic feature labellingwith limited manual intervention to correct mis-takes has been achieved in recent work (Lee andMagnenat-Thalmann 1998; Mortlock et al. 1997).This approach has also been extended to model indi-vidual facial expressions (Guenter et al. 1998; Pighinet al. 1998). Reconstruction of facial shape from twoorthogonal view images uses silhouette template fit-ting (Akimoto et al. 1993) and feature-point labelling(Lee and Magnenat-Thalmann 1998; Mortlock et al.1997). The use of orthogonal view images is analo-gous to the approach to whole-body reconstructionpresented in this paper.Animated face models for individual people fromdense 3D surface measurements have been recon-structed (Escher and Magnenat-Thalmann 1997; Leeet al. 1995; Terzopoulos 1994) with data from active3D range sensors. A generic face model is adapted tothe 3D measurement points to accurately model theface shape for animation. Colour information avail-
able from the range sensor is mapped onto the face.This approach achieves very accurate modelling ofthe face shape, but the quality of the visual appear-ance is not as good as that of image-based tech-niques. In more recent research, Fua and Miccio(2000) and Fua (1998) reconstruct dense 3D mea-surements from stereo images and video sequencesof the face. A least-squares surface-fitting approachis then used to fit a generic face model to the densedepth map with constraints for feature-point loca-tion and silhouette shape. Currently, feature pointsare specified manually. This image-based approachachieves very realistic face models suitable for ani-mation. DeCarlo and Metaxas (1996, 1999) use op-tical flow to fit constrained deformable models tovideo sequences for estimation of both shape andmovement of the face. Anthropometric constraintshave been introduced to model the variation in headshape for generating synthetic face models (DeCarloet al. 1998). Blanz and Vetter (1999) reconstructfaces photo-realistically on the basis of a statisticalmodel of the variation in face shape and appearancederived from a database of captured 3D colour headmodels.Face modelling techniques using multiple view im-ages are similar to the approach presented in thispaper for whole-body modelling. A difference in ourapproach is the use of silhouette data to register theimages with a generic model and to estimate the3D shape. Silhouette shape reliably locates featurepoints on images of clothed persons with large vari-ations in size, shape and appearance. A current limi-tation of the automatic whole-body modelling usingsilhouette shape is the reliability of the facial re-construction. Techniques for facial modelling (Blanzand Vetter 1999; Fua and Miccio 2000; Lee andMagnenat-Thalmann 1998; Mortlock et al. 1997)could be used in conjunction with whole-body re-construction to improve facial modelling. However,current image-based techniques for face modellingrequire a full resolution image to enable automaticfeature labelling. In addition, current face modellingtechniques may fail to reliably reconstruct face shapeautomatically for large variations in shape and ap-pearance due to hair, glasses and beards.
2.3 Whole-body modelling
There is considerable interest in capturing models ofindividual people for anthropometric studies, cloth-ing design, human factors analysis, teleconferencing

414 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
and virtual reality. A number of systems have beendeveloped for measuring the human shape by activeprojection of a light stripe or pattern onto the subjectand triangulation of the image to obtain dense 3Dsurface measurements. Several ‘whole body’ mea-surement systems, now commercially available, arebased on laser-stripe triangulation, including Cyber-ware, Hamamatsu and Vitronic. For a recent reviewsee Paquette (1996). The systems are capable of cap-turing dense 3D surface measurements with an ac-curacy of approximately 2–3 mm and capture timesof 10 to 20 s. However, such devices are very expen-sive, and therefore they are only available for special-ist anthropometric studies such as military clothingor large-scale surveys. Identification of anatomicallandmarks from surface measurement data is a pri-mary goal of current research (Dekker et al. 1998;Geisen et al. 1997). The authors are not aware of anyreported technique for automatically generating an-imated whole-body models from 3D scanned data.A principal limitation of current whole-body mea-surement systems for capturing realistic models ofindividual people is the quality of the captured colourinformation. Current systems are designed primarilyfor accurate measurement of surface shape and donot provide photo-realistic colour.The model-based reconstruction algorithm presentedin this work addresses modelling people from a setof colour images. Previous research has achieved re-construction of the 3D shape, appearance and move-ment of a person from multiview video sequences; a40-camera stereo set-up (Kanade and Rander 1997)and an 8-camera silhouette system (Moezzi et al.1997) are used for this purpose. These systems ad-dress the long-term aim of noninvasive capture of3D video. However, current systems require expen-sive hardware and do not address the reconstructionof a model of a particular person. Gu et al. (1998)present a 12-camera, multiview system for whole-body measurement, which enables capture of theshape of a particular person in a single pose. Theshape is reconstructed without the use of a generichumanoid model by fitting parametric superquadricmodels to the silhouette image for each view. Thissystem results in a model of the 3D shape of a partic-ular individual that is sufficiently accurate to providedimensional measurements for clothing design.Modelling of human shape and kinematic structurehas been addressed for captured images sequences(Hilton et al. 1999; Kakadiaris and Metaxas 1998a;Plankers et al. 1999; Wingbermuhle and Weik 1997).
Kakadiaris and Metaxas (1998a) introduce a mul-tiple pose approach for spatio-temporally analysinga captured human silhouette sequence to determinethe joint positions and the 3D shape of body parts.Kakadiaris and Metaxas (1998b) use multiview im-age sequences to animate a customised virtual hu-man model. The results show the segmentation ofthe body into parts from a side view of the personperforming a predefined sequence of arm and legmovements. Plankers et al. (1999) reconstruct mod-els of body parts using a stereo video to estimate the3D surface shape. A least-squares approach is usedto simultaneously estimate the shape and kinematicstructure. Initial results show the estimation of shapeand kinematic structure of the arm from a frontalimage sequence. Wingbermuhle and Weik (1997)reconstruct the upper-body shape from video se-quences by fitting a simple generic humanoid modelto the silhouette of a particular person in each imageframe.Unlike previous whole-body modelling techniques,the approach presented in this paper aims to recon-struct a recognisable model of a person’s shape andappearance. The captured silhouette images of a per-son in a single pose are used to modify the shape ofa generic humanoid model to approximate the shapeof a particular individual and estimate the kinematicstructure. Techniques for estimating kinematic struc-ture from image sequences (Kakadiaris and Metaxas1998a; Plankers et al. 1999) could be combined withthe current approach to accurately estimate joint po-sitions in images of a person in multiple poses. Thiswould significantly improve the accuracy of the re-constructed kinematic structure for large variationsin shape, size and clothing.
3 Overview
An overview of the model-based, 3D, human shape,reconstruction algorithm is illustrated in Fig. 1.A generic 3D humanoid model is used as the basisfor reconstruction as shown in Fig. 1a. Four syntheticimages are generated for orthogonal views (front,left, right, back) of the model by projection of thegeneric model as illustrated in Fig. 1b. To reconstructa model of a person, four orthogonal view imagesare captured with the subject in approximately thesame posture as that of the generic model. This is il-lustrated in Fig. 1c. We refer to captured images of
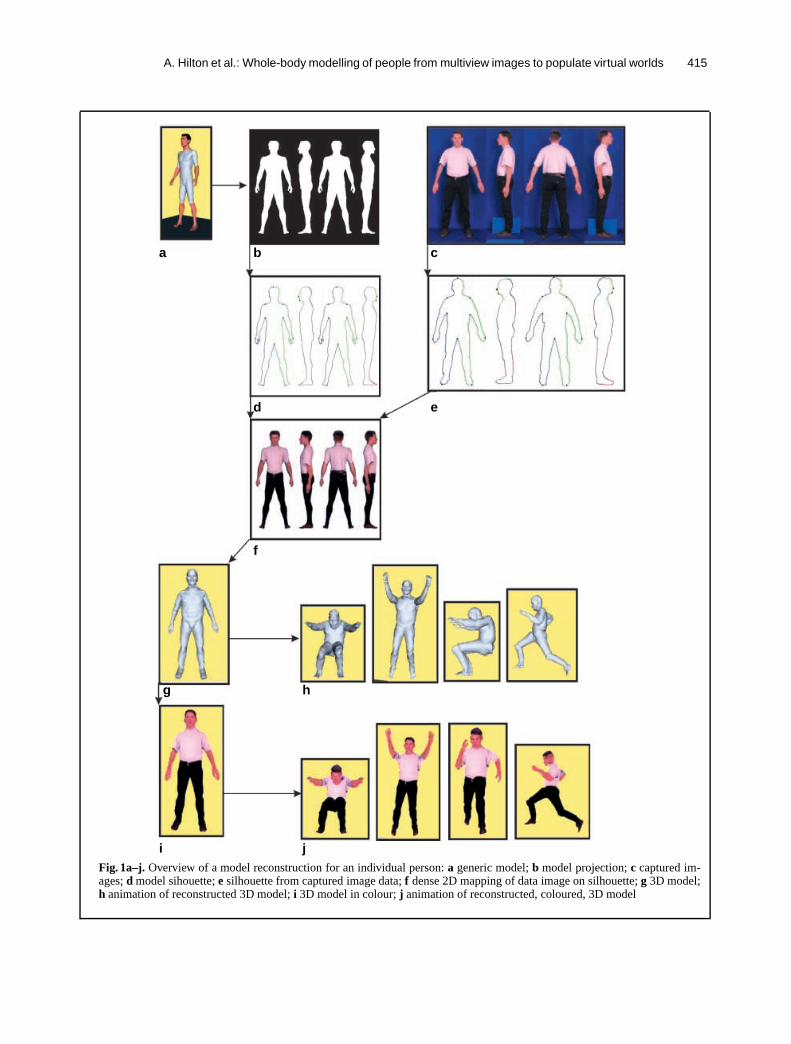
A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 415
a b c
d e
f
g h
i jFig. 1a–j. Overview of a model reconstruction for an individual person:a generic model;b model projection;c captured im-ages;d model sihouette;e silhouette from captured image data;f dense 2D mapping of data image on silhouette;g 3D model;h animation of reconstructed 3D model;i 3D model in colour;j animation of reconstructed, coloured, 3D model

416 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
a particular person as the ‘data images’ and to imagesof the generic 3D model as the ‘model images’.The silhouette is extracted from the model and dataimages, and a small set of key feature points are ex-tracted, as illustrated in Fig. 1d,e. Initial alignmentof the feature points between the model and the dataensures that separate functional body parts of thegeneric model (arms, legs and head) are correctlymapped to corresponding parts of the captured im-age silhouettes. The correct correspondence of bodyparts is required to achieve correct animation of thereconstructed 3D model of a particular person. A 2D-to-2D linear affine mapping between the model anddata image silhouettes establishes a dense correspon-dence for any point inside the silhouette. This corre-spondencecan be used to map the colour informationfrom the data image onto the model image, as illus-trated in Fig. 1f.The dense 2D-to-2D mapping for a single image isused to define the shape deformation of the 3D modelin a plane orthogonal to the view direction. Applyingthis deformation to the 3D generic model achievesa 2D-to-3D linear mapping of the image silhouetteshape onto the shape of the 3D model. This model-based 2D-to-3D mapping is the core of the techniquefor reconstructing 3D models of people. Integratingshape-deformation information from two or more or-thogonal views gives three orthogonal componentsof shape deformation. Applying this deformation tothe generic model, we can approximate the shape ofa particular individual, as illustrated in Fig. 1g. Com-bining the 3D shape with the 2D-to-2D mappingof the colour information, we can obtain a colourtexture-mapped 3D model, as illustrated in Fig. 1i.The resulting reconstructed 3D model provides a re-alistic representation of a particular individual. Thearticulated joint structure of the generic functionalmodel can then be used to generate movement se-quences for a particular individual in a virtual world.Walking and jumping animations derived from mo-tion capture data are illustrated in Fig. 1h and j.
4 Model-based avatar reconstruction
This section introduces in detail each stage in thereconstruction of an articulated model of a spe-cific person from multiview images. The algo-rithm automatically reconstructs a model of theshape and appearance of a particular individualwithout any user intervention. This approach ad-
dresses whole-body modelling and uses the samealgorithm for all body parts. This could be com-bined with specific algorithms for reconstructingthe face (Lee and Magnenat-Thalmann 1998; Mort-lock et al. 1997) to obtain realistic animated facemodels.
4.1 Generic human model specification
The definition of a standard 3D humanoid model hasrecently received considerable interest for both effi-cient coding (Koenen 1996) and animation in virtualworlds (Roehl 1997). In this work, we have adoptedthe draft specification of the VRML Humanoid An-imation Working Group (H-Anim), which definesa humanoid model structure that can be viewed withany VRML97-compliant browser. A set of 3D hu-manoid models based on the draft standard are pub-licly available from the humanoid animation Website (Roehl 1997). The generic humanoid model usedin this work is shown in Fig. 2. The H-Anim draftstandard defines a hierarchical articulated joint struc-ture to represent the degrees of freedom of a hu-manoid. The humanoid shape is modelled by at-taching either a 3D polygonal mesh segment to thejoint for each body part or a single seamless polyg-onal mesh surface for the whole body. For exam-ple, the articulated structure of an arm can be rep-resented by three joints (shoulder, elbow and wrist)and the shape by segments attached to each joint ofthe upper arm, forearm and hand. The shape seg-ments can be specified with multiple levels of detailto achieve both efficient and realistic humanoid an-imation. Material properties and texture maps canbe attached to each body segment for rendering themodel.The model-based reconstruction algorithm intro-duced in this paper can use any reasonable generichumanoid body, as the initial model that is modifiedto approximate the shape and texture of a particularperson. The reconstruction algorithm can also han-dle models with multiple levels of detail for eachbody part. All reconstruction results presented in thispaper are based on a publicly available humanoidmodel that is compliant with the draft standard andgives a reasonable compromise between representa-tion quality and animation efficiency. The joint struc-ture for the generic humanoid model consists of 15joints as illustrated in Fig. 2a. The model shape con-sists of 15 body segments with a total of 10 K meshvertices and 20 K triangular polygons. The rendered

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 417
a b c d
Fig. 2a–d. Generic humanoid model based on the VRML draft specification:a joints;b surface;c running;d jumping
surface model is shown in Fig. 2b. The VRML97specification allows movement animations based onthe interpolation of joint angles to be specified in-dependently of the humanoid geometry. Figure 2cand d show snap-shots of running and jumping ani-mations.The following nomenclature is used in later sectionsto refer to the polygonal model and the associatedtexture map. Throughout this work, the notationx =(x, y, z) refers to a 3D vector such as a mesh vertex.For each body part, the polygonal mesh is specifiedas a list ofNv 3D vertices,{vi = (xi, yi, zi)}Nv
i=1, anda list of Nt polygons,{tr = (vi,v j ,vk)}Nt
i=1. An im-age or texture map 2D coordinate is defined asu =(u, v), whereu is the vertical coordinate andv isthe horizontal coordinate withu, v ∈ [0, 1], and theorigin is at the top left-hand corner of the image. Tex-ture mapping of an image onto a polygonal mesh isspecified by a 2D texture coordinate for each meshvertex,{ui = (ui, vi)}Nv
i=1.
4.2 Image capture, silhouetteand feature extraction
4.2.1 Image capture
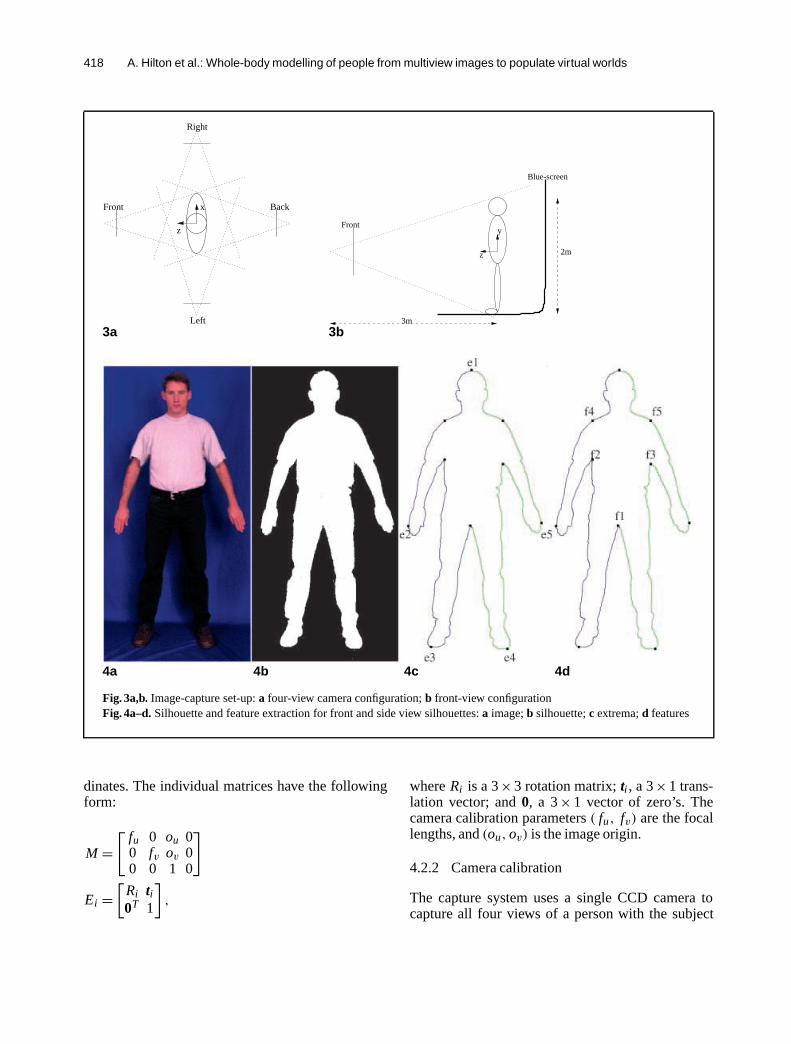
An experimental system has been set up to cap-ture whole body images of an individual from fourorthogonal views (front, left, back, right). The four-view camera configuration is illustrated in Fig. 3a.Colour images are captured with a Sony DXC-930P 3CCD camera with 756× 582 picture ele-ments. This gives a resolution of approximately40× 40 pixels for the subject’s face. Images are
taken against a photo-reflective, blue screen back-drop called ‘Truematte’ (Popkin 1997), which allowsreliable foreground/background separation with ar-bitrary foreground lighting and clothing colours in-cluding most shades of blue. The subject stands ina standard pose similar to the generic model pose asshown in Fig. 4a. Currently, each view is taken witha single camera with the subject rotating to presentthe required view to the camera. The use of a singlecamera may result in small changes of pose betweenviews, but has the advantage of identical intrinsiccamera projection parameters for each view. Thecapture process results in a set of four data images,I Di , i = 1 . . . 4, for orthogonal views of a specific
person. Only two orthogonal views are required toapproximate the 3D shape of a particular person. Theuse of four views gives additional high-quality tex-ture information for the front, back and sides of thebody.To model the image capture process, we assumea pin-hole camera without lens distortion. The cam-era 3D to 2D projection can be expressed in homoge-neous coordinates as:
u′i = Pix′ = MEi x′, (1)
whereu′i = (u, v,w) is a 2D pointui = (u/w,v/w)
in the camera image plane andx′ = (x, y, z, 1) isa 3D point x = (x, y, z) in world coordinates ex-pressed in homogeneous form.P is the 4×3 cam-era projection matrix that can be decomposed intoa 3×4 camera calibration matrixM (intrinsic pa-rameters) and a euclidean rigid body transform in3D spaceEi (extrinsic parameters) representing theview transform for theith camera in world coor-
418 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
x
z
Front Back
Left
Right
Front
Blue-screen
y
z
3m
2m
3a 3b
4a 4b 4c 4d
Fig. 3a,b. Image-capture set-up:a four-view camera configuration;b front-view configurationFig. 4a–d. Silhouette and feature extraction for front and side view silhouettes:a image;b silhouette;c extrema;d features
dinates. The individual matrices have the followingform:
M =[
fu 0 ou 00 fv ov 00 0 1 0
]
Ei =[
Ri ti0T 1
],
whereRi is a 3×3 rotation matrix;ti , a 3×1 trans-lation vector; and0, a 3× 1 vector of zero’s. Thecamera calibration parameters( fu, fv) are the focallengths, and(ou, ov) is the image origin.
4.2.2 Camera calibration
The capture system uses a single CCD camera tocapture all four views of a person with the subject

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 419
turning between views. Figure 3b illustrates the cam-era projection process for a single view. The use ofa single camera avoids the requirement for accuratemulticamera calibration to register images from dif-ferent views.Intrinsic camera calibration is based on the estima-tion of the camera parameters from direct measure-ment of the field of view for a plane orthogonal tothe view direction. From the size of the horizontaland vertical field of view at a distance of 3 m fromthe camera, we estimate the camera focal lengths inimage pixels as:
fu = verticalpixels× distance-to-camera
vertical-height
≈ 7563
2= 1134
and
fv = horizontalpixels× distance-to-camera
horizontal-height
≈ 5823
1.5= 1164.
This gives an approximate estimate of the camerafocal length. As all views of a person are takenwith the same camera, this estimate is sufficientfor view integration and accurate camera calibrationis not necessary. The image origin is taken as thecentre of the image, which in pixel coordinates is(ou, ov) = (378, 291).There is no calibration for extrinsic camera parame-ters. The person is assumed to rotate approximately90◦ between the front, left, back and right views. Ex-trinsic parametersEi are taken as orthogonal rigid-body transforms of the camera centre at a distance of3 m from the origin of the world coordinate system asillustrated in Fig. 3a.The approximate calibrated camera modelPi = MEiis used to generate a set of four synthetic images ofthe generic humanoid model,I M
i , i = 1 . . . 4. This isachieved by projecting each vertexvi on the genericmodel to its corresponding image coordinatesuiwith (1).A four-camera capture system could be used to cap-ture all views simultaneously. This would have theadvantage of avoiding movement of the person be-tween views. A multicamera system would requireaccurate camera calibration to enable view integra-tion and considerably more space to set up.
4.2.3 Silhouette extraction
Silhouette extraction aims to construct the chain ofimage pixels that lie on the boundary between theimage of the person and the background. A standardchroma-key technique is used to identify backgroundpixels on the basis of percentage of blue in eachpixel. Given an image pixel with red, green and bluecolour components(r, g, b), the percentage of blue ispb = 100× (b/(r + g +b)). A constant chroma-keythreshold (50%) is used, together with an intensitythreshold (|b| > 150), to reliably generate a binaryimage with each pixel labelled as either foregroundor background. An example of an extracted binarysilhouette image is shown in Fig. 4b.The silhouette curveC D
i for each captured im-age I D
i is extracted by following an 8-connectedchain of pixels on the border of the foregroundimage of a person. We denote the silhouette bythe chain ofNp 8-connected adjacent pixel coordi-natesC D
i = {u j}NPj=1, which is specified in counter
clockwise order with respect to the image view di-rection. An example of an extracted silhouette chainis shown in Fig. 4c. A similar process on the syn-thetic imagesI M
i of the generic model uses a bi-nary threshold to obtain a set of model silhouettecurvesC M
i .
4.2.4 Feature extraction
The objective of feature extraction is to establish thecorrect correspondence between the captured dataand synthetic model images for body parts such asthe arms, legs, head and torso. Correct correspon-dence is essential for realistic animation of the recon-structed model of a person based on the articulatedjoint structure of the generic model. We thereforerequire robust extraction of a set of feature pointsfor a wide range of changes in body shape, size andclothing. To achieve this, we constrain the person tostand approximately in a prespecified pose and wearclothing that allows both the arm pits and the crotchto be visible; clothing such as a shirt and trousers.Given these assumptions, an algorithm has been de-veloped for reliable extraction and localisation ofa set of features based on our knowledge of the sil-houette contour structure.The algorithm for extracting feature points is pre-sented at the end of Sect. 4.2.4. Initially, the algo-rithm traverses the silhouette contourCi to locatefive extremum points,ue1−e5, on the contour. These

420 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
correspond to the head, hands and feet, as illus-trated in Fig. 4c. The extrema points can be reli-ably extracted for all silhouettes, but their locationvaries significantly due to variation in shape andpose. Therefore, the extrema are used to identify fivekey feature pointsu f 1− f 5, which can be accuratelylocated even with large changes in shape and pose.The feature points correspond to the crotch, armpitsand shoulders as shown in Fig. 4d.This procedure gives reliable extraction of a set ofkey feature points for a wide range of people shape,size, clothing and hair styles. It has been found thatother potential feature points such as the neck can-not be reliably localised, as small changes in shapecan result in a large variation in position, resulting inpoor quality of correspondence between the capturedand generic model images. The set of extracted fea-tures are sufficient to accurately align the major bodyparts for a captured image silhouette (head, torso,arms, legs) with those of the generic model image.A similar procedure is applied for the side views toidentify the tip of the nose as the left or right ex-tremum on the head. Other body parts, such as thefingers, cannot reliably be identified with the imageresolution used, as each finger is less than three pix-els across. Higher resolution images may permit cor-respondences to be established between additionalbody parts.An algorithm for extracting features from a silhou-ette contourCi for front and back views is given here.
1. Find the extremum pointsue1−e5:(a) Find the extremum point on the top of thehead,ue1, as the contour point with minimum ver-tical coordinate,u:
ue1 = min({u j}NPj=1) and ve1 = v j
(b) Find the extremum point on the left hand,ue2, and right hand,ue5, hands as the contourpoints with minimum and maximum horizontalcoordinate,v:
ue2 = min({v j}NPj=1) and ue2 = u j
ue5 = max({v j}NPj=1) and ue5 = u j
(c) Evaluate the centroid of the silhouette con-tour:
uC = 1
NP
NP∑j=1
u j .
(d) Find the extremum points on the left,ue3, andright, ue4, feet as the contour points with maxi-mum vertical coordinate,u, either side of the cen-troids horizontal coordinate,vC :
ue3 = max({u j}NPj=1) and ve3 = v j ≤ vC
ue4 = max({u j}NPj=1) and ve4 = v j ≥ vC
2. Find the feature pointsuf 1− f 5:(a) Locate the key feature points correspondingto the crotch,u f 1, and the left armpit,u f 2, and theright armpit,u f 3, as the contour points with mini-mum vertical coordinateu, which are between thecorresponding hand and foot extremum points:
crotch uf 1 = min({u j}e4j=e3) and v f 1 = v j
left armpit uf 2 = min({u j}e3j=e2) and v f 2 = v j
right armpit uf 3 = min({u j}e5j=e4) and v f 2 = v j
(b) Locate feature points on the left shoulder,u f 4, and the right shoulder,u f 5, with the samehorizontal coordinate,v, as the armpit featuresuf 2 anduf 3:
left shoulderuf 4 = min({u j}e2j=e1)
and v f 4 = v f 2
right shoulderuf 5 = min({u j}e1j=e5)
and v f 5 = v f 3
4.2.5 Pose estimation
Pose estimation identifies the angle of the arms andlegs for a set of captured images of a specific per-son. This information is used to adjust the pose ofthe generic model to that of a particular individual.The pose of the arms, legs and head is estimated bycomputing the principal axis for the contour pointscorresponding to each of these components. If theset of contour points for a particular body part isCi = {u j}s
j=r, then the principal axis is given by:
uaxis= 1
(s −r +1)
s∑j=r
u2j − 1
(s −r +1)
s∑j=r
ui
2
.
(2)
The angle of the principal axis with the vertical givesthe approximate pose of the body parallel to the im-age plane. The body-part pose is used in the mapping

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 421
to correct for small variations between the genericmodel and the captured image set for a particular in-dividual.
4.3 2D-to-2D silhouette mapping
The objective of mapping between the generic hu-manoid model and the captured images is to establisha dense correspondence for mapping each modelpart. Dense correspondence establishes a uniqueone-to-one mapping between any pointuM insidethe generic model silhouette and a point on the samebody partuD inside the captured image silhouette.This correspondence is used to modify the shapeof the generic humanoid model to approximate theshape of a particular individual. For example, toachieve realistic arm movement for the reconstructedmodel of an individual, it is necessary to map the pro-jection of the arm on the generic model image to thecorresponding arm on the captured image.The feature pointsuf 1− f 5 on the silhouette con-tours of the generic model and the captured data im-ages are used to establish body-part correspondence.These features can be used to establish a correct cor-respondence for each part of the human body. Basedon the five key points, the human model is separatedinto seven functional parts as illustrated in Fig. 5a:head (1); shoulders (2); left arm (3); right arm (4);torso (5); left leg (6); right leg (7). Separating the sil-houette images into body parts allows a dense map-ping to be established independently for points in-side each body-part silhouette.A unique one-to-one correspondence between pointsinside the model and data sets for a particular bodypart is established by a 2D linear mapping basedon the relative dimensions of the silhouette. Thisis equivalent to a 2D affine transform in the im-age plane (rotation, scale, shear and translation). Themapping between corresponding points inside thesilhouette for a particular body part is given as fol-lows in homogeneous coordinates:
u′D = Su′M (3)
S =[
su suv tusvu sv tv0 0 1
].
The componentss represent the rotation, shear andscale between the parts, andt the translation be-tween body parts. If the principal axis of the body
a
b
Fig. 5a,b. 2D-to-2D mapping between the model and thedata silhouette:a vertical mapping;b horizontal mapping
parts are aligned,suv = svu = 0 andsu, sv representthe horizontal and vertical scale factors, respectively.The vertical scale factorsu and translationtu fora particular body part can be computed from thevertical limits [umin, umax]. Similarly, the horizon-tal scale factorsv and translationtv are given by thehorizontal limits [vmin, vmax] for a horizontal slice(u = const) through the silhouette contour. The ver-tical and horizontal scale factors and translations aregiven by:
su = u Dmax−u D
min
u Mmax−u M
min
tu = −suu Mmin+u D
min
sv(u) = vDmax(u)−vD
min(u)
vMmax(u)−vM
min(u)
tv(u) = −sv(u)vMmin(u)+vD
min(u).

422 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
This mapping enables us to evaluate a unique one-to-one correspondence of points inside the data sil-houetteuD for any point inside the model silhou-ette uM. This allows 2D information such as thecolour from the captured model, to be mapped tothe silhouette of the generic model, as illustratedin Fig. 1f. The mapping achieves an exact corre-spondence at the feature points and a continuousmapping elsewhere including across boundaries be-tween the various body parts. The change in posi-tion ∆u between the model and the data silhouette isgiven by:
uD = uM +∆u. (4)
This 2D change in position in the image plane fora particular view can be used to estimate the changein position of a 3D point orthogonal to the viewdirection.
4.4 2D-to-3D shape mapping fromorthogonal views
The objective of the 2D-to-3D mapping is to com-bine the dense 2D-to-2D mapping information∆uifrom multiple viewsi = 1, . . . , 4 to estimate the 3Ddisplacement∆x of a pointx on the surface of the 3Dmodel. We first outline the theory for 2D-to-3D in-verse projection and then present the application ofthis to our model-based reconstruction.
4.4.1 2D-to-3D inverse projection
A point in the 2D camera-image plane correspondsto an infinite ray in 3D space. Therefore, invert-ing the camera projection (1) gives the equation ofa line in 3D space. From (1), the inverse projectionin homogeneous coordinates for theith view direc-tion is:
x′D = x′M +∆xi = λi(xD)P−1i (u′M
i + δu′i) (5)
= λi(xD)E−1i M−1(u′M
i +∆u′i),
where λi is a scale factor equal to the orthog-onal distance of the 3D point from the camera:λi(xD) = ||Ri xD + ti ||. The estimated 3D displace-ment component∆xi is orthogonal to the cameraview directionni. The inverse camera calibration andtransform matrices are given by:
M−1 =
1fu
0 − oufu
0 1fv
− ov
fv0 0 10 0 0
E−1i =
[R−1
i − R−1i ti
0T 1
].
Thus, the 3D point on the model in real coordinatesxD is on the 3D line represented by:
xD = xM +∆xi (6)
= λi(xD)R−1i M−1(uM
i +∆ui)− R−1i ti .
Equation (6) defines the relationship between a linethrough the real 3D pointxD and the estimated 2Ddisplacement for the∆u in the image plane for thecorresponding point on the generic modelxM. Asthe real 3D pointxD is unknown we must estimatethe scale factorλi(xD) in order to estimate the 3Ddisplacement∆x orthogonal to the camera view di-rection.
4.4.2 3D displacement of a single view
The 2D-to-2D mapping for theith view gives anestimate of the displacement of a 3D pointx be-tween the projection of the generic modeluM
i and theprojection of the surface of a real personuD
i . This2D image-plane displacement∆ui defined by (4),can be used to estimate the 3D displacement com-ponent∆xi = (∆xi,∆yi,∆zi), of the projected 3Dpoint x on the generic model orthogonal to theithimage view direction. This is achieved by estimatingthe inverse projection of the displacement of the 2Dpoint ∆ui in the camera image. The inverse projec-tion can be estimated uniquely from our knowledgeof the distance to the corresponding 3D pointxM onthe generic model. This approximates the unknowndistance to the corresponding 3D pointxD on thecaptured image of the person we want to estimate.From (6), we obtain the approximate 3D displace-ment as:
∆xi ≈ λi(xM)R−1i M−1(uM
i +∆ui)− R−1i ti − xM,
(7)
where we have approximated the distance along theray by the distance to the corresponding point on thegeneric model: λi(xD) ≈ λi(xM) = ||Ri xD + ti ||.

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 423
���
���
����
�������������������������
�������������������������
Front
y
zx
u
v
(x,y,z)(dx,dy,0)
(du,dv)
������
������
��������
��������
Front Left
(x,y,z)+(dx,dy,dz)
(du,dv)(du,dv)
v
u
v
u
(x,y,z)
z x
y
a
b
Fig. 6a,b. 3D displacement estimation from multipleview 2D image displacements;a single view ∆x0 =(∆x0,∆y0, 0); b multiview ∆x = (∆x0,
∆y0+∆y12 , ∆z1)
The distance to the generic model is a reasonable ap-proximation, as the distance between the camera andperson,(≈ 3 m), is large relative to the difference in3D surface position,(≈ 0.1 m), between the modeland the person. Section 6.2 presents an analysis ofthe errors in the reconstructed model based on thisassumption.Estimation of the 3D displacement component or-thogonal to the view direction is illustrated in Fig. 6a.A single view imageI D
i gives an approximation ofthe component of 3D displacement∆xi of a known3D point xM on the generic model orthogonalto the ith view direction ni = (nx, ny, nz), suchthat ni •∆xi = 0. For example, for the front im-age, the view directionn0 = (0, 0, 1) is alignedwith the z axis of the world-coordinate system,
consequently the displacement of an image point∆u0 = (∆u0,∆v0) gives an approximation of the3D displacement orthogonal to the view direction∆x0 = (∆x0,∆y0, 0). Similarly, a left side viewwith the view directionn1 = (1, 0, 0) gives an esti-mate of the 3D displacement∆x1 = (0,∆y1,∆z1).Applying the estimated displacement component toeach vertex on the 3D generic model results in anaffine transform of the 3D model orthogonal to theview direction. Application of the 2D-to-3D map-ping for a single view is illustrated in Fig. 7a. Repro-jecting the modified model results in a silhouette thatapproximates the captured silhouette shape. The sur-face shape for 3D points whose projection is insidethe silhouette is a 2D affine transform of the shape ofthe generic model.
4.4.3 3D displacement of multi-views
Combining the estimated displacement componentsfrom two or more orthogonal views of a pointx, weobtain an estimate of the 3D displacement∆x, as il-lustrated in Fig. 6b. Only two orthogonal views arerequired to estimate all three components of the dis-placement, if each view gives estimates of two ofthe three components. To obtain an estimate of the3D displacement from two or more views, we caneither take estimates of each displacement compo-nent from a single view or combine the estimates.Displacement components from multiple views canbe combined by averaging to estimate the 3D dis-placement:
∆x =
1Nx
∑Nxi=0 ∆xi
1Ny
∑Nyi=0 ∆yi
1Nz
∑Nzi=0 ∆zi
, (8)
where Nx, Ny and Nz are the number of displace-ment estimates in a particular direction. Combiningdisplacement components from multiple views av-erages out any misalignment or change in shape ofthe 2D silhouettes for different views. This gives anestimate of the 3D displacement∆x of a point onthe generic modelxM. The estimated displacement isused to approximate the 3D shape of a specific per-son:
xD = xM +∆x. (9)
The generic model shape is modified by estimatingthe 3D displacement∆x(v j) for each vertexv j . Themodel vertex positionv j is projected to the 2D im-age plane with the camera model (1) to obtain the

424 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
a
b
Fig. 7a,b. 2D-to-3D mapping between the model and the data silhouette for orthogonal views:a mapping for a single view;b mapping from two orthogonal views for a horizontal slice
2D coordinatesuMi (v j). This point is then mapped
to a corresponding point on the captured data imageuD
i (v j ) with (3). The 2D displacement∆ui(v j) isthen used to estimate the corresponding 3D displace-ment component orthogonal to the view direction∆xi(v j) from (5). The 3D displacement componentsfrom each view are then combined with (8) to esti-mate the 3D displacement∆x(v j) for a vertex on themodel.Applying the estimated vertex displacement to allvertices on the generic model results in a modifiedmodel that approximates the shape of a specific per-son. The 2D-to-3D shape mapping for two orthogo-nal views is illustrated in Fig. 7b. The modified 3Dmodel for a particular individual will produce sil-houette images with approximately the same shapeas the captured image silhouettes for each view di-rection. Points that do not project to the silhouette
boundary are subject to a linear transform based onthe position of the corresponding point on the 3Dmodel. For example, concavities on the generic hu-manoid model are scaled according to the 2D affinemapping to produce concavities in the final model.The resulting modified 3D model shape is a first-order linear approximation of the shape of a particu-lar person based on the local surface shape informa-tion represented in the 3D generic humanoid model.The same process is applied to estimate the 3D jointpositions of a particular individual from the joint po-sitions in the generic model.
4.5 Colour texture mapping
The 2D-to-2D mapping for a single view enablesthe colour texture of the captured data image to bemapped onto the projected model image as illus-
A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 425
θ
Cylindrical Texture Map
3D Horizontal Slice
Left Image
Front Image
y
z
x
θ
h
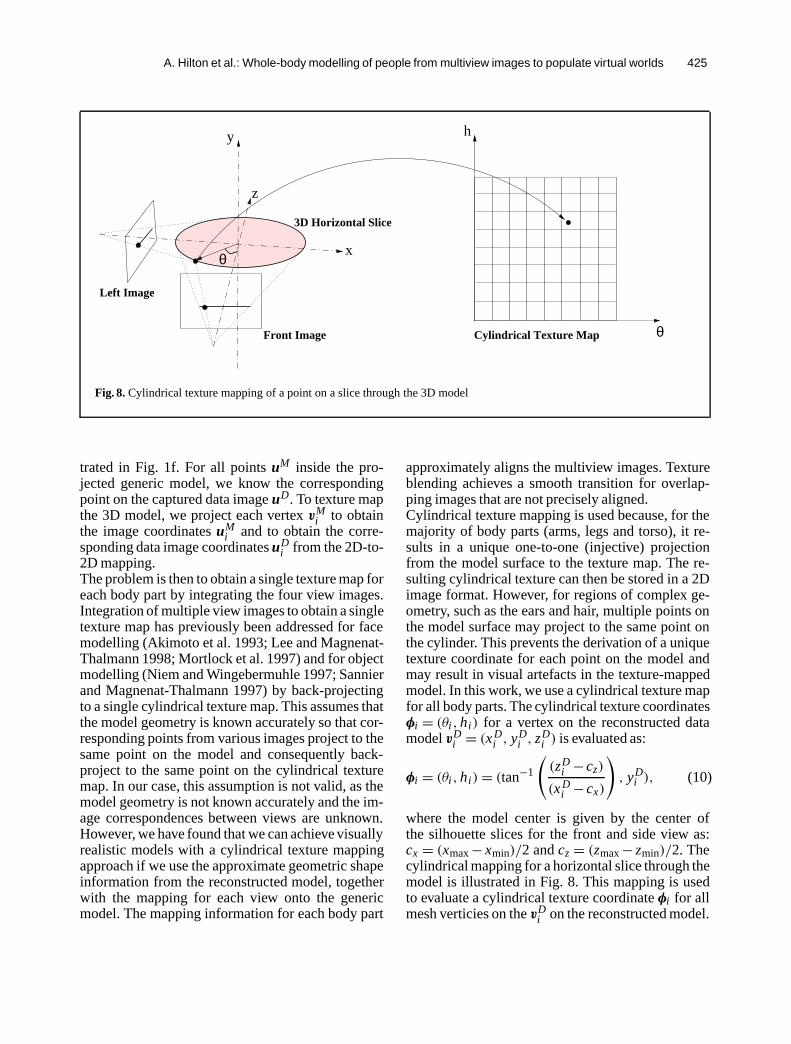
Fig. 8. Cylindrical texture mapping of a point on a slice through the 3D model
trated in Fig. 1f. For all pointsuM inside the pro-jected generic model, we know the correspondingpoint on the captured data imageuD. To texture mapthe 3D model, we project each vertexvM
i to obtainthe image coordinatesuM
i and to obtain the corre-sponding data image coordinatesuD
i from the 2D-to-2D mapping.The problem is then to obtain a single texture map foreach body part by integrating the four view images.Integration of multiple view images to obtain a singletexture map has previously been addressed for facemodelling (Akimoto et al. 1993; Lee and Magnenat-Thalmann 1998; Mortlock et al. 1997) and for objectmodelling (Niem and Wingebermuhle 1997; Sannierand Magnenat-Thalmann 1997) by back-projectingto a single cylindrical texture map. This assumes thatthe model geometry is known accurately so that cor-responding points from various images project to thesame point on the model and consequently back-project to the same point on the cylindrical texturemap. In our case, this assumption is not valid, as themodel geometry is not known accurately and the im-age correspondences between views are unknown.However, we have found that we can achieve visuallyrealistic models with a cylindrical texture mappingapproach if we use the approximate geometric shapeinformation from the reconstructed model, togetherwith the mapping for each view onto the genericmodel. The mapping information for each body part
approximately aligns the multiview images. Textureblending achieves a smooth transition for overlap-ping images that are not precisely aligned.Cylindrical texture mapping is used because, for themajority of body parts (arms, legs and torso), it re-sults in a unique one-to-one (injective) projectionfrom the model surface to the texture map. The re-sulting cylindrical texture can then be stored in a 2Dimage format. However, for regions of complex ge-ometry, such as the ears and hair, multiple points onthe model surface may project to the same point onthe cylinder. This prevents the derivation of a uniquetexture coordinate for each point on the model andmay result in visual artefacts in the texture-mappedmodel. In this work, we use a cylindrical texture mapfor all body parts. The cylindrical texture coordinatesφi = (θi, hi) for a vertex on the reconstructed datamodelvD
i = (x Di , yD
i , zDi ) is evaluated as:
φi = (θi, hi) = (tan−1
((zD
i − cz)
(x Di − cx)
), yD
i ), (10)
where the model center is given by the center ofthe silhouette slices for the front and side view as:cx = (xmax− xmin)/2 andcz = (zmax− zmin)/2. Thecylindrical mapping for a horizontal slice through themodel is illustrated in Fig. 8. This mapping is usedto evaluate a cylindrical texture coordinateφi for allmesh verticies on thevD
i on the reconstructed model.
426 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
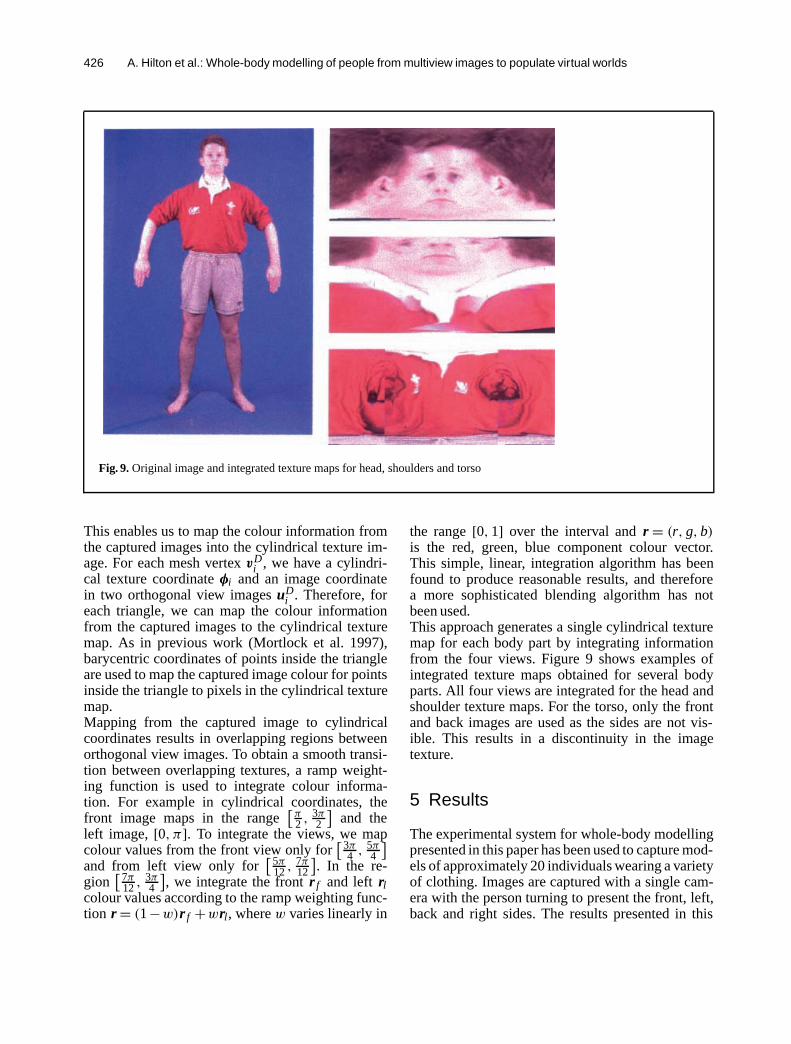
Fig. 9. Original image and integrated texture maps for head, shoulders and torso
This enables us to map the colour information fromthe captured images into the cylindrical texture im-age. For each mesh vertexvD
i , we have a cylindri-cal texture coordinateφi and an image coordinatein two orthogonal view imagesuD
i . Therefore, foreach triangle, we can map the colour informationfrom the captured images to the cylindrical texturemap. As in previous work (Mortlock et al. 1997),barycentric coordinates of points inside the triangleare used to map the captured image colour for pointsinside the triangle to pixels in the cylindrical texturemap.Mapping from the captured image to cylindricalcoordinates results in overlapping regions betweenorthogonal view images. To obtain a smooth transi-tion between overlapping textures, a ramp weight-ing function is used to integrate colour informa-tion. For example in cylindrical coordinates, thefront image maps in the range
[π2 , 3π
2
]and the
left image,[0, π]. To integrate the views, we mapcolour values from the front view only for
[3π4 , 5π
4
]and from left view only for
[5π12, 7π
12
]. In the re-
gion[7π
12, 3π4
], we integrate the frontr f and left rl
colour values according to the ramp weighting func-tion r = (1−w)r f +wrl, wherew varies linearly in
the range[0, 1] over the interval andr = (r, g, b)is the red, green, blue component colour vector.This simple, linear, integration algorithm has beenfound to produce reasonable results, and thereforea more sophisticated blending algorithm has notbeen used.This approach generates a single cylindrical texturemap for each body part by integrating informationfrom the four views. Figure 9 shows examples ofintegrated texture maps obtained for several bodyparts. All four views are integrated for the head andshoulder texture maps. For the torso, only the frontand back images are used as the sides are not vis-ible. This results in a discontinuity in the imagetexture.
5 Results
The experimental system for whole-body modellingpresented in this paper has been used to capture mod-els of approximately 20 individuals wearing a varietyof clothing. Images are captured with a single cam-era with the person turning to present the front, left,back and right sides. The results presented in this

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 427
section show models generated automatically fromthe captured images without any manual interven-tion. The approach introduced in Sect. 4 producedthese results.
5.1 Whole-body modelling
The model-based reconstruction algorithm has beenused to capture models of approximately 20 indi-viduals wearing a variety of clothing. Each subjectwas constrained to wear clothing such as a pair oftrousers and a shirt that allow the location of thearmpits and crotch to be visible in the front view.The silhouette extraction and feature-point identi-fication algorithms presented in Sect. 4 were ap-plied to automatically identify the five key points.The feature-point extraction algorithm was foundto give valid feature-point labelling for all capturedimages. This includes people with a wide varietyof clothing including baggy shirts and skirts thatobscure the physical location of the crotches andarmpits. The feature points facilitate segmentingthe body into seven parts. The model-based recon-struction from silhouettes is applied to all bodyparts except the hands and feet. Hands and feetare modelled by scaling the corresponding part ofthe generic model as there is insufficient informa-tion on the silhouette images to identify featurepoints.Reconstructed 3D models for three individuals areshown in Fig. 10a. The left-hand column shows theoriginal front and left side colour photos. The sec-ond column shows the estimated joint positions andreconstructed model front view silhouette. The re-maining columns show the 3D model with and with-out texture and a single frame from a running an-imation. These results show that the automatic re-construction generates a recognisable 3D facsimileof the real person. The reprojected silhouette shapeof the person for the four views matches the silhou-ette shape of the captured image. It should be notedthat the silhouette shapes for the hands and feet donot match, as these are only scaled versions of thegeneric model hands and feet.The reconstructed 3D whole-body shape based onthe silhouette data gives a good approximation ofthe shape for a particular individual. Some artefactscan be seen in the shape between the arm and handand the leg and foot. This is due to poor segmenta-tion of the feet from the legs and of the arms fromthe hands, as no feature points are available. The
3D shape approximation is of sufficient accuracy togive a recognisable model when it is texture mappedwith the image colour information. The joint posi-tions estimated from the silhouette shape give anapproximation of the anatomical structure of a per-son. Provide the clothing does not obscure the truecrotch and armpit locations, the estimated joint po-sitions are sufficiently accurate to enable realisticanimation.Further examples of reconstructed models for maleand female subjects are presented in Fig. 10b. Notethat one of the subjects is wearing a long skirt thatviolates the assumption that the crotch point is vis-ible. In this situation, a good model of the per-son’s shape and appearance is generated. However,the joint positions are incorrect and result in an in-valid animation because the body-part correspon-dence between the generic model and the person isnot correct. Anatomical constraints could be used togive improved estimates of the joint position in thissituation. Figure 10c shows reconstructions for thesame person wearing different clothing. This exam-ple shows that the approach can be used to generatea set of models for a particular individual suitable formultiple virtual world applications (business, sports,leisure).These results show the feasibility of obtaining realis-tic whole-body models from sets of captured images.The quality of the final texture-mapped 3D models islimited by the resolution of the captured images. Thecurrent resolution is sufficient for a realistic approx-imation when the whole body is viewed, but not forclose-ups of individual parts such as the face. High-resolution images of individual body parts would al-low reconstruction of realistic models for close-upviews.Currently, the principal limitation of the reconstruc-tion from silhouettes is the quality of the face modelsgenerated. Due to the absence of feature-point la-belling on the face, the alignment with the genericmodel is inaccurate. This may result in bumps inthe face shape and distortion of the face shapein the presence of long hair, which obscures thesides of the face. Previous feature-based approachesto face modelling (Lee and Magnenat-Thalmann1998; Mortlock et al. 1997) could be used to im-prove face modelling if full resolution face im-ages were captured. However, current techniquesfor face modelling may also fail to automaticallyreconstruct face shape in the presence of hair andglasses.

428 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
a
b
c
Fig. 10a–c. Reconstructed 3D texture mapped models for individual people with animated movements:a reconstructed modelsshowing photos, joints, 3D model, colour 3D model, running animation;b examples of virtual men and women;c models of the sameperson with different clothing

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 429
a
b
Fig. 11a,b. Virtual people in a virtual catwalk scene animation:a a simple catwalk scene with four models;b front and side views ofthe walking animation
5.2 Animation
Animation of the reconstructed 3D models for par-ticular individuals moving in a standard way isillustrated in Fig. 11. In this work, avatars havebeen animated using simple animation sequencesfor walking, running and jumping, these animations
are predefined from captured motion data. The an-imation sequence in the form of joint angle/axisrotations are applied directly to the virtual modelfor a particular individual. Multiple virtual peoplemodels can be run in real time with reasonablysmooth movement on a 400 MHz Intel Pentiumplatform.

430 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
Figure 11a shows a simple virtual catwalk scene withseveral animated virtual people. We modify the ar-ticulated structure of the generic humanoid modelfor a particular individual by mapping the 3D jointpositions with the 2D-to-3D mapping algorithm pre-sented in the previous section. The animation pa-rameters based on joint angle interpolation are thesame as those for the generic model. Using a com-mon set of parameters to animate movements such aswalking, running and jumping results in reasonablemovements of a particular individual for VR applica-tions. However, the animation is based on a rigid 3Dmodel that does not incorporate changes in the bodyor clothing shape during movement. This results invisible artefacts in the humanoid animation.Figure 11b shows a sequence from the walking an-imation for a particular individual. As the clothingtexture is rigidly fixed to the segments of the genericmodel, the clothing moves rigidly with the bodyparts. This results in visual artefacts as regions of thetexture appear and disappear. This can be seen in thepelvis region for the front views of Fig. 11b. A sec-ond visual artefact in the animation occurs becauseof the segment-based structure of the generic model.The reconstruction algorithm modifies each segmentin the body to approximate the silhouette shape fora particular person. When the model is animated, thedeformed segments may no longer form a smoothsurface, which causes visible gaps near the joints.This can be seen for the knee from the side view ofthe animation sequence of Fig. 11b.The reconstructed joint structure and colour 3Dmodels achieve realistic animation of a person’smovement. However, the generic model structureand the simplicity of the animation cause visual arte-facts. Greater realism could be achieved with a moresophisticated humanoid model based on a seam-less mesh that can be deformed in real time (Kalraand Magnenat-Thalmann 1998). Physically-basedmodels could also be used to achieve realistic defor-mation of the skin and clothing. However, this maybe prohibitively expensive for real-time applications.
5.3 Avatar booth
A commercial booth system developed with our ap-proach is illustrated in Fig. 12. The booth uses a sin-gle camera capture system with the person turning topresent the four front, back and side views. Manualinteraction is used to identify key feature points onthe face. The use of manually identified face feature
Fig. 12. Prototype avatar booth to populate virtual worlds (cour-tesy AvatarMe, www.avatarme.com)
points ensures that faces are correctly reconstructedwhen the silhouette is obscured by the person’shair. Whole-body models are then generated auto-matically using our approach. A generic humanoidmodel with a seamless mesh surface is used to givesmooth animation of the reconstructed virtual per-son’s shape.The prototype booth system was launched atSIGGRAPH ’99 and has recently been used ina location-based entertainment application to gen-erate tens of thousands of models of members ofthe general public of all ages, sizes, shapes and ap-pearance. The results of this mass-user generationof models of people show that the whole-body mod-elling technique is reliable and robust to changesin shape, size and clothing. The approach success-fully captures models that are recognisable and canbe realistically animated for a wide variety of peo-ple. The generated virtual people are immediatelyshown in various animation sequences such as danc-ing, skate boarding, and playing basketball. Modelsare then securely uploaded onto the internet for per-sonal use in various VR, entertainment and gamesapplications.
6 Discussion
6.1 Assumptions
The model-based whole-body reconstruction fromsilhouettes introduced in this paper makes a numberof underlying assumptions:

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 431
1. The person is standing in an approximatelyknown pose.
2. The person is wearing clothing that allows thearmpits and crotch to be identified.
3. The person’s shape can be approximated by anaffine transform of the generic humanoid fromtwo or more orthogonal views.
4. The anatomical joint structure of a person can beapproximated by an affine transform of the jointstructure for the generic model.
5. The estimated shape information is sufficientlyaccurate to enable integration of the captured im-ages into a single texture map.
The first two assumptions are satisfied by constrain-ing the clothing and pose of the person in the imagecaptured. These assumptions are satisfied for a widerange of people size, shape and clothing. The re-sults show that the reconstruction is insensitive toa wide variation in the initial pose. If the constraintson clothing are not satisfied, the person’s shape iscorrectly reconstructed but the estimated joint posi-tions may be incorrect.The results show that the approximation of the bodyshape from the orthogonal view silhouettes givesa reasonable model of the body surface. This isthe case for all body parts except the head, handsand feet. For other body parts, nonuniform scal-ing of the generic model shape gives a good ap-proximation of the shape of a particular individualdue to their inherent symmetry. Similarly, nonuni-form scaling of the joint structure gives a reason-able approximation of the joint positions. The resultsshow that the approximate shape is sufficiently accu-rate to enable blending of overlapping images frommultiple views to obtain a single texture map. Tex-ture mapping a model with approximately the sameshape as a particular person gives a realistic virtualmodel.An additional assumption made in the single cameracapture system used in this work is that the approx-imate intrinsic and extrinsic camera calibration en-able satisfactory reconstruction. The shape approxi-mation error resulting from the intrinsic calibrationis discussed in Sect. 6.2. The extrinsic calibration isdetermined by the person turning 90◦ to present eachview. The reconstruction has been found to be in-sensitive to errors in both the intrinsic and extrinsiccalibration. No reduction in the visual quality of thereconstructed model has been observed because oferrors in the calibration.
6.2 Shape-approximation error
The model-based reconstruction of 3D shape fromsilhouettes presented in Sect. 4.4 is based on the as-sumption that the distance to a point on a particularindividual zD is approximately equal to the distanceto the corresponding point on the generic modelzM.This assumption is used to evaluate the inverse pro-jection given by (5). In practice, the error in this dis-tance is the principal factor contributing to the errorin the estimation of the 3D silhouette shape for a par-ticular person.Given an estimate of the maximum error in thedistance between the camera and the person, wecan estimate the error in the 3D silhouette shape.This is illustrated in Fig. 13a. For a pin-hole cam-era aligned with the world coordinate system wehave the relationships:fu = x M/zM = x D/zD andfv = yM/zM = yD/zD. Now if we know thatzD =zM ± εz, then we can derive the following relation-ship:
εx = εz
zMx M; εy = εy
zMyM. (11)
For the current experimental set-up, as illustratedin Fig. 3, the distance between the camera and theperson is approximatelyzM = 3 m, and the maxi-mum error in a person’s position isεz = ±0.1 m.From (11), the resulting maximum percentage er-ror in the estimated 3D silhouette width or height isapproximately 3%. For a typical person’s width of0.6 m the corresponding error in the estimated pointon the 3D silhouette isεx = ±0.01 m and the re-sulting error in the estimated width of the person is±0.02 m.This level of accuracy is adequate for the proposedapplication of capturing human models to representpeople in virtual worlds and games. However, thisaccuracy is not sufficient for clothing applicationsor anthropometric measurement where a maximumerror of less than 1% (0.01 m) is required. Currentlaser-based whole-body measurement systems aremore appropriate for this application domain.This analysis gives an approximate maximum errorfor points on the 3D model silhouette. The recon-structed surface shape approximation of a particularindividual is based on the shape of the generic hu-manoid model. The shape of the generic humanoidmodel is scaled according to a linear affine transformto fit the 3D silhouette shape of a particular indi-vidual as discussed in Sect. 4. A particular individ-ual with clothing may exhibit large shape variations

432 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
������
������
xe
exz
z zM D
M
Camera
ModelData
������
������
���
���
������
������
������
������
����
��������
������
������
������
������
��������
��������
������������
����������
����������
��������
ReconstructedModel
Error Bounds
Smooth Data 3D Silhouette Point
3D Silhouette PointsSide Estimated
Front Estimated
��������
������
������
��������
������
������
������
������
������
������
����
����
�����
�����
������
������
�����
�����
������
������
Reconstructed
3D Silhouette Points
3D Silhouette Points
ComplexData
Model Smooth
Front Estimated
Side Estimated
a
b
c
Fig. 13. Errors in 3D silhouette estimation and model-based sur-face reconstruction:a errors in 3D silhouette due to error indistance to person;b smooth surface data;c complex surfacedata
that are not captured in the orthogonal view 3D sil-houettes. Therefore, errors larger than the maximumsilhouette error may occur, particularly for complexbody parts such as a head with long hair. For approx-imately smooth symmetrical body parts such as thearms, legs and torso, transforming the model to fitthe orthogonal view silhouettes will give an approx-imation error for the body surface that is similar tothe error in the estimated 3D silhouettes. Hence, forsmooth body parts, we can expect the maximum er-ror to be of the same order of magnitude as the errorin the silhouette approximation. The surface approx-imation error based on scaling the generic model isillustrated in Fig. 13b and c for a smooth surfaceshape and a complex shape.A limited quantitative evaluation of the accuracy ofthe 3D silhouette and model-based surface recon-struction has been performed. This evaluation wasperformed by direct comparisons of measurements
of the dimensions of a person with the correspondingdimensions on the reconstructed 3D model. Resultsof this analysis indicate that the error in the 3D sil-houette dimensions is of the order of±0.01 m formost of the body, excluding the face, hands and feet.Similarly, for smooth body parts such as the arms,legs and torso, the error in the estimated surface canbe estimated by taking cross-sections through thereconstructed mode. From this analysis it has beenfound that, in general, the error is less than±0.03 mof the real body shape for smooth body parts withapproximately the same shape as the original model.The sample of models taken for this evaluation islimited to those illustrated in this paper. The ac-curacy of the reconstruction process could be fullyevaluated by comparison of the reconstructed mod-els with whole-body laser measurements of the samesubject. This has not been done for lack of sucha device. However, as the focus of the proposed ap-

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 433
proach is not on measurement of whole-body shape,it is considered that this analysis is not essential tovalidate the current approach. Reconstructed modelsshould be evaluated qualitatively in terms of visualappearance.
6.3 Computational cost
The primary cost in the reconstruction algorithm isthe computation of displacements for mesh verticeson the generic model to approximate the silhouetteshape of the captured data images. This requires firstprojecting each mesh vertex on the generic modelto the 2D image plane with (1). The projection ma-trix can be precomputed; hence, this operation re-quires 14 multiplication and 12 addition operations.The next stage is to map the 2D vertex projectionfrom the model to the data silhouette. The 2D-to-2Dsilhouette mapping is precomputed as a look-up ta-ble, which maps each horizontal slice on the modelsilhouette to the corresponding slice on the data sil-houette. The look-up table contains the precomputedhorizontal and vertical scale factors for each hori-zontal slice. This look-up requires a single operationper vertex. Hence, the cost of 2D-to-2D mapping foreach vertex is determined by the cost of implement-ing (3), which requires two multiplications and twoaddition operations per vertex. Finally, the 2D datavertex position is reprojected into 3D space by (5).The inverse projection matrix is precomputed. Eval-uation of the inverse projection for a single viewdirection requires 16 multiplication and addition op-erations per vertex. This sequence of operations is re-peated for each vertex in each view direction. Hence,the computational complexity of the reconstructionalgorithm isO(Nv) whereNv is the number of meshvertices. The number total of operations per vertexfor reconstruction from four views is 128 floatingpoint multiplications and 120 additions.The experimental implementation on a 400 MHz In-tel PentiumII PC platform requires approximately3 min to perform the complete reconstruction fromimage capture to texture-mapped 3D model. This isfor a generic humanoid model containing a total of10 K mesh verticies. This process is completely au-tomatic and requires no user intervention. It is en-visaged that this computation time could be signifi-cantly reduced with further optimisation of the soft-ware. Commercial development of this approach hasreduced the reconstruction time to less than 15 s ona similar platform.
7 Conclusions
A model-based approach has been introduced for au-tomatic reconstruction of an articulated 3D colourmodel of a particular person from a set of colour im-ages. The results show that this approach achievesrecognisable models of individuals with a wide rangeof shape, size and clothing. The reconstructed modelrepresents the 3D shape, colour texture and articu-lation structure required for animating movements.This approach enables low-cost capture of models ofpeople in a VRML H-Anim avatar format suitablefor populating virtual worlds. The principal contribu-tions of this work are:• A novel method for model-based reconstruction
of shape from silhouettes• Whole-body reconstruction of shape and appear-
ance from multiview images• Capture of models for clothed people• Automatic reconstruction of full body animated
models.The results presented show the feasibility of model-based reconstruction of realistic representations ofindividual people from sets of images. However, sev-eral issues could be addressed in future work toachieve photorealistic animated models:• Facial feature-point labelling for accurate model-
ling and animation (Lee and Magnenat-Thalmann1998; Mortlock et al. 1997)
• Capture of a person in multiple poses for accuratereconstruction of kinematic structure (Kakadiarisand Metaxas 1998a; Plankers et al. 1999).
• Seamless deformable generic model for realisticanimation
• High-resolution image acquisition for improvedphotorealism
• Synchronous image acquisition from multipleviews to avoid movement
• Increased number of views to reduce occlusion• Multiple levels of detail to efficiently represent
shape.Further development of this system and integrationwith previous work on face and body modellingwill give incremental improvements in the quality ofthe reconstructed models. The silhouette-based ap-proach for mapping a generic humanoid model toa particular person could be used to generate an-imated models from 3D whole-body surface mea-surements acquired from passive stereo (Plankers etal. 1999) or commercial laser-stripe scanners.

434 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
The results presented in this paper show the po-tential of a low cost, whole-body system for cap-turing recognisable 3D models of individual peo-ple from sets of colour images. Current models ofpeople are suitable for representing an individual ina shared virtual environment, interactive games orgenerating animated image sequences from prede-fined motion.
Acknowledgements. This research was supported by the Engineering &Physical Sciences Research Council (EPSRC), UK Funding Councilon Advanced Fellowship AF/95/2531, held by Dr. Adrian Hilton andGrant No. GR/89518 ‘Functional models: building realistic models forvirtual reality and animation’.
References1. Akimoto T, Suenaga Y, Wallace R (1993) Automatic cre-
ation of 3D facial models. IEEE Comput Graph Appl13:16–22
2. Blanz V, Vetter T (1999) A morphable model for the syn-thesis of 3D faces. Proceedings of SIGGRAPH ’99, AnnualConference Series in Comput Graph, ACM SIGGRAPH,Addison-Wesley, pp 187–194
3. DeCarlo D, Metaxas D (1996) The integration of opticalflow and deformable models with applications to humanface shape and motion estimation. Conference on Com-puter Vision and Pattern Recognition, Puerto Rico, IEEECS Press, pp 231–238
4. DeCarlo D, Metaxas D (1999) Combining information us-ing hard constraints. Conference on Computer Vision andPattern Recognition, Colorado, IEEE CS Press, pp 132–138
5. DeCarlo D, Metaxas D, Stone M (1998) An anthropomet-ric face model using variational techniques. Proceedingsof SIGGRAPH ’98, Annual Conference Series in ComputGraph, ACM SIGGRAPH, Addison-Wesley, pp 67–74
6. Dekker L, Khan S, West E, Buxton B, Treleaven P (1998)Models for understanding the 3D human body form. Pro-ceedings of IEEE Workshop on Model-Based 3D ImageAnalysis, Bombay, India, IEEE CS Press, pp 65–74
7. Escher M, Magnenat-Thalmann N (1997) Automatic 3Dcloning and real-time animation of a human face. Proceed-ings of IEEE International Conference on Computer Ani-mation, Geneva, Switzerland, IEEE CS Press, pp 58–66
8. Fitzgibbon AW, Cross G, Zisserman A (1998) Auto-matic 3D model construction for turn-table sequences. In:Koch R, Van Gool L (eds) 3D Structure from multipleimages of large-scale environments (Lecture Notes in Com-puter Science, Vol 1506), Springer, Berlin Heidelberg NewYork, pp 155–170
9. Fua P (1998) Face models from uncalibrated video se-quences. In Magnenat-Thalmann N, Thalmann D (eds)Modelling and Motion Capture Techniques for Virtual En-vironments (Lecture Notes in Artificial Intelligence, Vol1537), Springer, Berlin Heidelberg New York, pp 214–228
10. Fua P, Miccio C (2000) Animated heads from ordinaryimages: a least squares approach. Comput Vision ImageUnderstanding (to appear)
11. Geisen G, Mason G, Houston V, Taylor C, Graham J(1997) Automatic detection, identification and registrationof anatomical landmarks. In: Proceedings of the 39th An-nual Meeting of the Human Factors and Ergonomics Soci-ety (2), pp 750–753
12. Gu J, Chang T, Mak I, Gopalsamy S, Shen H, Yuen M(1998) A 3D reconstruction system for human body mod-eling. In: Magnenat-Thalmann N, Thalmann D (eds) Pro-ceedings of Modelling and Motion Capture Techniques forVirtual Environments (Lecture Notes in Artificial Intelli-gence, Vol 1537), Springer Berlin Heidelberg New York, pp229–240
13. Guenter B, Grimm C, Wood D, Malvar H, Pighin F (1998)Making faces. Proceedings of SIGGRAPH ’98, AnnualConference Series in Comput Graph, ACM SIGGRAPH,Addison-Wesley, pp 55–66
14. Hilton A, Goncalves J (1995) 3D scene representation usinga deformable surface. In: IEEE Workshop on Physics BasedModelling, Boston, USA, IEEE CS Press, pp 24–30
15. Hilton A, Beresford D, Gentils T, Smith R, Sun W (1999)Virtual people: capturing human models to populate virtualworlds. In: IEEE International Conference on ComputerAnimation, Geneva, Switzerland, IEEE CS Press, pp 174–185
16. Kakadiaris I, Metaxas D (1998a) Three-dimensional humanbody model acquisition from multiple views. Int J ComputVision 30:191–218
17. Kakadiaris I, Metaxas D (1998b) Vision-based animation ofdigital humans. In: IEEE International Conference on Com-puter Animation, Philadelphia, USA, IEEE CS Press, pp144–152
18. Kalra N, Magnenat-Thalmann N (1998) Real-time anima-tion of virtual humans IEEE Comput Graph Appl 18:42–56
19. Kanade T, Rander P (1997) Virtualized reality: constructingvirtual worlds from real scenes. IEEE MultiMedia 4:34–47
20. Koenen RE (1996) Coding of moving pictures and audio.http://drogo.cselt.stet.it/mpeg/standards/mpeg-4.htm
21. Kurihara T, Kiyoshi A (1990) A transformation methodfor modeling and animation of the human face fromphotographs. In: State of the art in computer animation.Springer, Berlin Heidelberg New York, pp 45–57
22. Lee W-S, Magnenat-Thalmann N (1998) Head modelingfrom pictures and morphing in 3D with image metamorpho-sis based on triangulation. In Magnenat-Thalmann N, Thal-mann D (eds) Modelling and motion capture techniquesfor virtual environments (Lecture Notes in Artificial Intelli-gence Vol 1537), Springer Berlin Heidelberg New York, pp254–268
23. Lee Y, Terzoupoulos D, Walters K (1995) Realistic model-ing for facial animiation. Proceedings of SIGGRAPH ’95,Annual Conference Series in Comput Graph, ACM SIG-GRAPH, Addison-Wesley, pp 55–62
24. Lejeune A, Ferrie F (1996) Finding the parts of objectsin range images. Comput Vision Image Understanding64:230–247
25. McInerney T, Terzopoulos D (1996) Deformable models inmedical image processing. Med Image Anal 1:91–108
26. Moezzi S, Tai L-C, Gerard P (1997) Virtual view generationfor 3d digital video. IEEE MultiMedia 4:18–26
27. Mortlock A, Machin D, McConnell S, Sheppard P (1997)Virtual conferencing. BT Technol J 15:120–129

A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds 435
28. Niem W, Wingebermuhle J (1997) Automatic reconstruc-tion of 3D objects using a mobile monoscopic camera.Proceedings of IEEE International Conferences on RecentAdvances in 3D Digital Imaging and Modeling, Ottawa,Canada, IEEE CS Press, pp 173–180
29. Paquette S (1996) 3D Scanning in apparel design and hu-man engineering. IEEE Comput Graph Appl 16:11–15
30. Pighin F, Hecker J, Lischinski D, Szeliski R, Salesin D(1998) Syntehsizing realistic facial expressions from pho-tographs. Proceedings of SIGGRAPH ’98, Annual Confer-ence Series in Comput Graph, ACM SIGGRAPH, Addison-Wesley, pp 75–84
31. Plankers R, D’Apuzzo N, Fua P (1999) Automated bodymodeling from video sequences. In: Proceedings IEEE In-ternational Workshop on Modelling People. Corfu, Greece,IEEE CS Press, pp 45–53
32. Popkin D (1997) The real guide to virtual studios. BBC Re-sources, BBC Publications
33. Roehl B (1997) Draft specification for a standard VRMLhumanoid, version 1.0. http://ece.uwaterloo.ca/h-anim/
34. Sannier G, Magnenat-Thalmann N (1997) A user-friendlytexture-fitting methodology for virtual humans. Proceed-ings of Computer Graphics International Conference,Geneva, IEEE CS Press, pp 167–176
35. Szeliski R (1990) Rapid octree construction from image se-quences. CVGIP: Image Understanding 58:23–32
36. Terzopoulos D (1994) From physics-based representation tofunctional modeling of highly complex objects. NSF-ARPAWorkshop on Object Representation in Computer Vision.Springer, Berlin Heidelberg New York, pp 347–359
37. Terzopoulos D, Witkin A, Kass K (1988) Constraints ondeformable models: recovering 3D shape and nonrigid mo-tion. Artif Intell 36:91–123
38. Wingbermuhle J, Weik S (1997) Highly realistic model-ing of persons for 3D videoconferencing systems. In: IEEESignal Processing Society 1997 Workshop on MultimediaSignal Processing Berlin, IEEE CS Press
Photographs of the authors and their biographies are given onthe next page.

436 A. Hilton et al.: Whole-body modelling of people from multiview images to populate virtual worlds
ADRIAN HILTON receiveda BSc (Hons) in Mechanical En-gineering and a DPhil degreefrom the University of Sussexin 1988 and 1992, respectively.From 1992, at the Universityof Surrey, he worked on 3Dshape capture for realistic com-puter graphics and accurate in-spection, receiving Best Paperawards from Pattern Recogni-tion in 1996 andIEE Electronics
and Communications in 1999. Collaboration with 3D Scannersresulted in the first hand-held system for capturing 3D objectmodels. In 1999 he became lecturer in 3D Digital Media andBroadcast. His active research interests include model-based 3Dvision for capturing human movement and photorealistic 3Dmodels for computer animation.
DANIEL BERESFORDgrad-uated from the University ofReading in 1996 with a Bachelorof Engineering degree in Inte-grated Engineering. In 1997 hereceived a Master of Researchdegree from University CollegeLondon. Since May 1998 he hasbeen a PhD student in the Com-puter Vision Group at The Uni-versity of Surrey. His researcharea is that of human body mod-elling.
THOMAS GENTILS grad-uated from the University ofOrleans, France, in 1999 witha degree in Electronics and Sig-nals. He was a visitor to theCVSSP at the University of Sur-rey for a period of 5 months in1997, funded on the EU ERAS-MUS program as part of his pro-fessional training. During thisperiod he worked with AdrianHilton in initiating the researchon modelling people from digitalimages.
RAYMOND SMITH gradu-ated from the University of Sur-rey in 1998 with a Master of En-gineering degree in InformationSystems Engineering. Since Oc-tober 1998, he has been a PhDstudent in the Centre for Vision,Speech and Signal Processingat the University of Surrey, per-forming research into the au-tomatic creation of 3D modelssuitable for animation. He alsohas interests in VRML, humanmodeling and animation.
WEI SUN is a Research Fel-low in the 3D version group atthe University of Surrey. He re-ceived a BSc and an MSc inMathematics. His research areasare in computer animation andgraphics.
JOHN ILLINGWORTH isa Professor of Machine Vision atSurrey University. He has a doc-torate in physics, but has beenactive in research in computervision, image processing andpattern recognition for the last18 years. He has published over130 papers in refereed journalsand conferences. He is a Fellowof the Institution of ElectricalEngineers and editsIEE Pro-ceedings on Vision Image andSignal Processing.





























