• Quando tornamos um modelo econômico com mais de uma variável explanatória em um modelo estatístico correspondente, nós dizemos que ele é um modelo de regressão múltipla.
• Grande parte dos resultados desenvolvidos para o modelo de regressão simples pode ser estendido naturalmente para esse caso geral. Existem pequenas mudanças na interpretação dos parâmetros , os graus de liberdade para a distribuição t mudarão e nós necessitaremos modificar as hipóteses concernentes as características das variáveis explanatórias (x).
Capítulo 7
O Modelo de Regressão Linear Múltipla

7.1 Especificação do Modelo e os Dados
7.1.1 O Modelo Econômico
•Cada semana, o gerente de uma rede de lanchonetes deve decidir quanto gastar com propaganda e que promoções deveria oferecer.
•Como se altera a receita total à medida que o nível de gastos com propaganda muda? Um aumento nos gastos com propaganda elevaria a receita total? Se afirmativo, o aumento na receita total é suficiente para justificar uma elevação nos gastos com propaganda?
•O gerente também está interessado na estratégia de preços. Reduzir os preços aumentará ou diminuirá a receita total? Se uma redução de preço levar a uma diminuição da receita total, então a demanda é inelástica; se uma redução de preço levar a um aumento da receita total, então a demanda é elástica.

•Nós, inicialmente, assumimos que a receita total, RT, é linearmente relacionada com o preço (p) e com os gastos em propaganda (a). Assim, o modelo econômico é:
1 2 3RT p a (7.1.1)
RT = representa a receita total para determinada semana p = representa o preço naquela semana a = nível de gastos com propaganda durante aquela semana. Tanto RT como a são mensurados em termos de milhares de unidades monetárias.
• Vamos assumir que o gerente construiu uma única série de preços semanal, p, mensurada em unidades monetárias e que representa os preços gerais. • Os itens remanescentes em (7.1.1) são os parâmetros desconhecidos 1, 2 e 3, que descrevem a dependência da receita (RT) em relação aos preços (p) e à propaganda (a).

• No modelo de regressão múltipla, o parâmetro intercepto, 1, é o valor da variável dependente quando cada variável explanatória assume o valor zero. Em muitos casos, esse parâmetro não tem uma interpretação econômica clara, mas ele é quase sempre incluído no modelo de regressão. Ele ajuda a estimação global do modelo e na previsão.
• Os outros parâmetros no modelo mensuram a variação no valor da variável dependente dado a mudança de uma unidade em uma variável explanatória, todas as outras variáveis mantidas constantes.
Por exemplo, em:
2 = a mudança em RT ($ 1000) quando p é aumentado em uma unidade ($1) e a é mantido constante, ou
( mantido constante)a
RT RT
p p
2 =
1 2 3RT p a

• O sinal de 2 pode ser positivo ou negativo. Se um aumento nos preços levar a um aumento da receita, então 2 > 0, e a demanda para a rede de lanchonetes é inelástica. Inversamente, uma demanda elástica em relação ao preço ocorre se um aumento nos preços conduzir a uma queda na receita, que é o caso de 2 < 0.
• O parâmetro 3 descreve a resposta da receita a mudanças no nível de gastos com propaganda; isto é,
3 = a mudança em RT ($1000) quando a é aumentado em uma unidade ($1000), e p é mantido constante 3 =
( mantido constante)p
RT RT
a a
• Nós esperamos que o sinal de 3 seja positivo.
1 2 3RT p a
7.1.2 O Modelo Econométrico
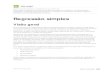
• O modelo econômico (7.1.1) descreve o comportamento esperado de muitas franquias individuais. Como tal, nós deveríamos escrever o modelo como , onde E(RT) é o “valor esperado” da receita total.
• Dados semanais para a receita total, preço e propaganda não seguirão uma relação linear exata. A equação 7.1.1 descreve, não uma reta como nos Capítulos 3-6, mas um plano.
• O plano intercepta o eixo vertical em 1. Os parâmetros 2 e 3 mensuram a inclinação do plano nas direções “eixo do preço” e “eixo da propaganda”, respectivamente.
1 2 3( )E RT p a

• Para permitir a diferenciação entre a receita total observada e o valor esperado da receita total, nós acrescentamos um termo de erro aleatório, • Esse erro aleatório representa todos os fatores que fazem a receita total semanal diferir do seu valor esperado. Esses fatores podem incluir o clima, o comportamento dos concorrentes, um relatório de uma agência importante sobre os efeitos mortais do consumo de gorduras, etc. • Denotando as t’s observações semanais pelo índice t, nós temos
( )e RT E RT
1 2 3( )t t t t t tRT E RT e p a e (7.1.2)
7.1.2a O Modelo Geral • No modelo de regressão múltipla geral, uma variável dependente yt é relacionada com um número de variáveis explanatórias através de uma equação linear que pode ser escrita como:
1 2 2 3 3t t t K tK ty x x x e (7.1.3)
• Os coeficientes 1, 2,…, K são parâmetros desconhecidos.

• O parâmetro mede o efeito de uma mudança na variável sobre o valor esperado de yt, E(yt), todas as outras variáveis mantidas constantes.
• O parâmetro 1 é o termo de intercepto. A “variável” xt1 = 1.
• A equação da receita total pode ser visualizada como um caso especial de (7.1.3) onde:
K = 3, yt = RTt, xt1 = 1, xt2 = pt e xt3 = at. Assim, nós podemos escrever (7.1.2) como:
ktkx
1 2 2 3 3t t t ty x x e (7.1.4)
7.1.2b As Hipóteses do Modelo
Para fazer o modelo estatístico em (7.1.4) completo, hipóteses sobre a distribuição do erro aleatório, et, precisam ser feitas.
1. E[et] = 0. Cada erro aleatório tem uma distribuição de probabilidade com média zero. Nós estamos assumindo que nosso modelo, em média, é correto.
2. var(et) = . A variância é um parâmetro des-conhecido e ele mede a incerteza do modelo estatístico. Ela é a mesma para cada observação. Erros com essa propriedade são chamados de homocedásticos.
3. cov(et, es) = 0. A covariância entre dois erros aleatórios correspondentes a duas observações diferentes é zero. Assim, qualquer par de erros não é correlacionada.
22

4. Em algumas ocasiões, nós assumiremos adicionalmente que os erros aleatórios et possuem distribuição de probabilidade normal; isto é, . 2~ 0,te N
As propriedades estatísticas de yt decorrem das do et.
1. Essa hipótese diz que o valor médio de yt muda para cada observação e é dado pela função de regressão .
1 2 2 3 3( )t t tE y x x
2. var(yt) = var(et) = . 2
3. cov(yt, ys) = cov(et, es) = 0.
4. é equivalente a assumir que
2
1 2 2 3 3~ ( ),t t ty N x x
2~ 0,te N
• Adicionalmente às hipóteses sobre o termo de erro (e conseqüentemente sobre a variável dependente), nós fazemos duas hipóteses sobre as variáveis explanatórias. • A primeira é que as variáveis explanatórias não são aleatórias. • A segunda hipótese é que nenhuma das variáveis explanatórias é uma função linear exata de qualquer uma das outras. Essa hipótese é equivalente a assumir que nenhuma variável é redundante. Como veremos, se essa hipótese é violada, uma condição chamada “multicolinearidade exata”, o procedimento de mínimos quadrados falha.

Hipóteses do Modelo de Regressão Múltipla
1 2 2 , 1, ,t t K tK ty x x e t T RM1.
1 2 2( ) ( ) 0t t K tK tE y x x E e RM2.
RM3. var(yt) = var(et) = . 2
RM4. cov(yt, ys) = cov(et, es) = 0
RM5. Os valores de xtk não são aleatórios e não são funções lineares exata de outras variáveis explanatórias.
RM6. 2 2
1 2 2~ ( ), ~ (0, )t t K tK ty N x x e N

7.2 Estimação dos Parâmetros do Modelo de Regressão Múltipla
Nós discutiremos estimação no contexto do modelo da equação 7.1.4, o qual é
1 2 2 3 3t t t ty x x e (7.2.1)
7.2.1 Procedimento de Estimação de Mínimos Quadrados
• Com o princípio de mínimos quadrados, nós minimizamos a soma de quadrados das diferenças entre os valores observados de yt e seu valor esperado:
1 2 2 3 3t t tE y x x • Matematicamente, nós minimizamos a soma de quadrados da função S(1, 2, 3), que é uma função dos parâmetros desconhecidos, dado os dados,
2
1 2 3
1
2
1 2 2 3 3
1
, ,T
t t
t
T
t t t
t
S y E y
y x x
(7.2.2)

• Dados as observações amostrais yt, minimizar a função da soma de quadrados é basicamente um exercício de cálculo. • Com o propósito de fornecer expressões para as estimativas de mínimos quadrados, é conveniente expressar cada uma das variáveis em termos de desvios em relação a suas médias; isto é, seja * * *
2 2 2 3 3 3, ,t t t t t ty y y x x x x x x • As estimativas de mínimos quadrados b1, b2 e b3 são:
1 2 2 3 3
* * *2 * * * *
2 3 3 2 3
2 2*2 *2 * *
2 3 2 3
* * *2 * * * *
3 2 2 3 2
3 2*2 *2 * *
2 3 2 3
t t t t t t t
t t t t
t t t t t t t
t t t t
b y b x b x
y x x y x x xb
x x x x
y x x y x x xb
x x x x
(7.2.3)
• Encaradas como uma maneira geral de utilizar dados amostrais, referimo-nos às fórmulas em (7.2.3) como regras ou procedimentos de estimação e são chamadas de estimadores de mínimos quadrados dos parâmetros desconhecidos. • Como seus valores não são conhecidos até os dados serem observados e as estimativas calculadas, os estimadores de mínimos quadrados são variáveis aleatórias.
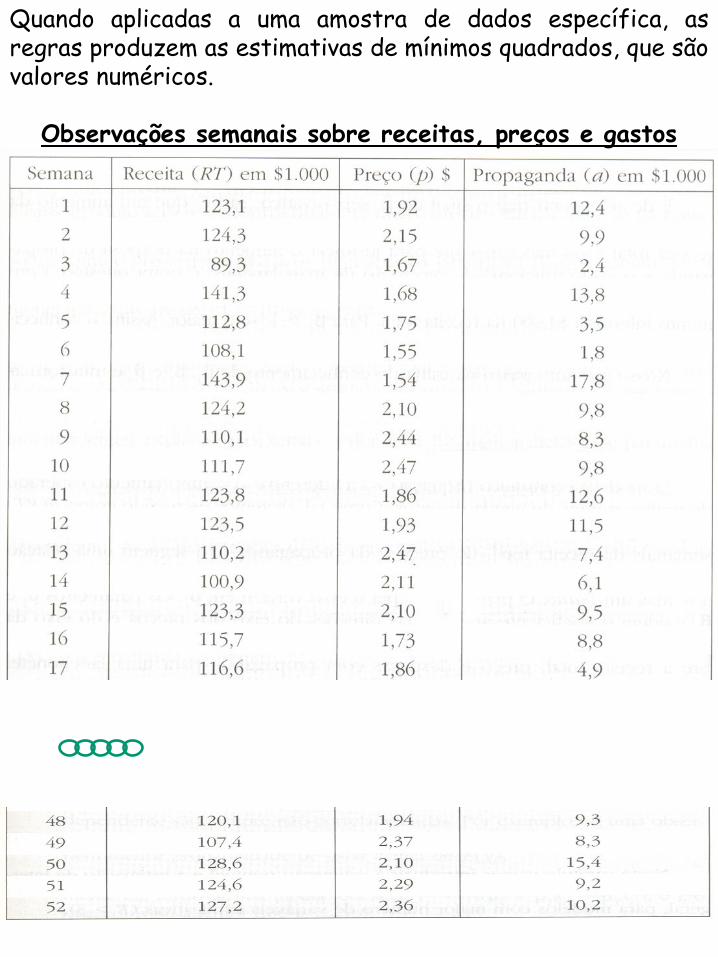
Quando aplicadas a uma amostra de dados específica, as regras produzem as estimativas de mínimos quadrados, que são valores numéricos.
Observações semanais sobre receitas, preços e gastos

7.2.2 Estimativas de Mínimos Quadrados Utilizando os Dados da Rede de Lanchonetes
Para os dados da Rede de Lanchonetes, nós obtemos as seguintes estimativas de mínimos quadrados:
1
2
3
104,79
6,642
2,984
b
b
b
(R7.1)
A função de regressão que nós estamos estimando é
1 2 2 3 3t t tE y x x (7.2.4)
A reta da regressão ajustada é
1 2 2 3 3
2 3
ˆ
104,79 6,642 2,984
t t t
t t
y b b x b x
x x
(R7.2)
Em termos das variáveis econômicas originais
ˆ 104,79 6,642 2,984t t tRT p a (R7.3)

Baseados nos resultados, o que nós podemos dizer?
1. O coeficiente negativo de pt sugere que a demanda é elástica em relação ao preço e nós estimamos que um aumento em $1 no preço levará a uma queda na receita semanal de $6.642. Ou, colocando positivamente, uma redução no preço de $1 levará a um aumento na receita de $6.642.
2. O coeficiente da propaganda é positivo e nós estimamos que um aumento no gasto com propaganda de $1.000 resultará em uma elevação da receita total de $2.984.
3. O intercepto estimado implica que se tanto o preço como o gasto com propaganda forem zero, a ganho de receita total seria de $104.790. Isso é obviamente incorreto. Nesse modelo, assim como em outros, o intercepto é incluído no modelo para melhorar a capacidade de previsão dele e dar uma especificação matemática mais completa .
• A equação estimada também pode ser utilizada para a previsão. Suponha que o gerente esteja interessado em prever a receita total para um preço de $2 e um gasto com propaganda de $10.000. A previsão é dada por
ˆ 104,785 6,6419 2 2,9843 10
121,34
tRT
(R7.4)
Assim, o valor previsto da receita total para os valores específicos de p e a é aproximadamente $121.340.

Observação O sinal negativo do preço implica que a redução desse aumentará a receita total. Se tomarmos isso literalmente, porque nós não deveríamos ir reduzindo o preço até zero? Obviamente que não conseguiríamos manter a elevação da receita total. Isso aponta para um importante ponto: modelos de regressão estimados descrevem a relação entre as variáveis econômicas para valores semelhantes dos encontrados na amostra de dados. A extrapolação dos resultados para valores extremos não é geralmente uma boa idéia. Em geral, predizer valores da variável dependente para valores das variáveis explanatórias distantes dos valores amostrais é um convite para o desastre

7.2.3 Estimação da Variância de Erro 2
• Os resíduos de mínimos quadrados para o modelo na equação 7.2.1 são:
1 2 2 3 3ˆ ˆt t t t t te y y y b x b x b (7.2.5)
Um estimador de , que é o que vamos utilizar, é 2
22 ˆˆ te
T K
(7.2.6)
onde K é o número de parâmetros sendo estimados no modelo de regressão múltipla.
• No exemplo da rede de lanchonetes, nós temos K = 3. A estimativa para nossa amostra de dados na Tabela 7.1 é
22 ˆ 1805,168ˆ 36,84
52 3
te
T K
(R7.5)

7.3 Propriedades Amostrais do Estimador de Mínimos Quadrados
• As propriedades amostrais do estimador de mínimos quadrados nos dizem como as estimativas variam de amostra para amostra.
O Teorema de Gauss-Markov: Para o modelo de regressão múltipla, se as hipóteses RM1-RM5 são mantidas, então os estimadores de mínimos quadrados são os melhores estimadores lineares não tendenciosos (BLUE – Best Linear Unbiased Estimators) dos parâmetros no modelo de regressão múltipla.
• Se nós formos capazes de assumir que os erros são normalmente distribuídos, então yt também será uma variável aleatória normalmente distribuída. • Os estimadores de mínimos quadrados também terão distribuição de probabilidade normal, já que eles são funções lineares de yt. • Se os erros não forem normalmente distribuídos, então os estimadores de mínimos quadrados serão aproximadamente normalmente distribuídos em grandes amostras, onde TK for maior que, talvez, 50.

7.3.1 As Variâncias e Covariâncias dos Estimadores de Mínimos Quadrados
• Como os estimadores de mínimos quadrados não são tendenciosos, quanto menor for a variância, maior será a probabilidade de eles produzirem estimativas “próximas” dos verdadeiros valores dos parâmetros. • Para K = 3, nós podemos expressar as variâncias e covariâncias em uma forma algébrica que seja proveitosa para elucidar o comportamento do estimador de mínimos quadrados. Por exemplo, nós podemos mostrar que:
2
2 2
2 2 23
var( )(1 )t
bx x r
(7.3.1)
onde r23 é o coeficiente de correlação simples entre os T valores de xt2 e xt3,
2 2 3 3
232 2
2 2 3 3
t t
t t
x x x xr
x x x x
(7.3.2)

Para outras variâncias e covariâncias existem fórmulas de natureza similar. É importante compreender os fatores que afetam a variância de b2:
1. Quanto maior for 2 , maior será a variância dos estimadores de mínimos quadrados. Isso é esperado já que 2 mede a incerteza global na especificação do modelo. Se 2 for grande, então os valores dos dados podem ser fortemente dispersos da função de regressão, existe uma menor quantidade de informação nos dados sobre os valores dos parâmetros.
1 2 2 3 3t t tE y x x
2. Quanto maior for o tamanho da amostra T , menor será a variância. A soma no denominador é
2
2 2
1
( )T
t
t
x x
Quanto maior for o tamanho da amostra T , maior será essa soma e, assim, menor será a variância.
Um maior número de observações produz uma estimação do parâmetro mais precisa.

3. Para estimar 2 de forma precisa, nós gostaríamos de possuir uma grande variação de xt2,
2
2 2
1
( )T
t
t
x x
A intuição aqui é que é mais fácil mensurar 2, a variação em y esperada dada uma mudança em x2, quando existe uma maior variação nos valores de x2 que nós observamos.
4. No denominador da var(b2) existe o termo , onde r23 é a correlação entre os valores amostrais de xt2 e xt3. Lembre-se que o coeficiente de correlação mensura a associação linear existente entre duas variáveis. Se os valores de xt2 e xt3 forem correlacionados, então o termo será menor do que 1. 2
231 r
2
231 r
• Quanto maior for a correlação entre xt2 e xt3, maior será a variância do estimador de mínimos quadrados b2. A razão para isso é que a variação em xt2 acrescenta uma maior precisão para a estimação quando ela não está associada à variação nas outras variáveis explanatórias.
• Idealmente, variáveis “independentes” apresentam uma variação que é “independente” da variação de outras variáveis explanatórias. Quando a variação em uma variável explanatória está associada à variação em outra variável explanatória, é difícil distinguir separadamente seus efeitos. No Capítulo 8, nós discutimos “multicolinearidade”, que é a situação onde as variáveis explanatórias estão correlacionadas entre si. A multicolinearidade conduz a um aumento das variâncias dos estimadores de mínimos quadrados.

• É comum apresentar as variâncias e covariâncias dos estimadores de mínimos quadrados numa matriz, com as variâncias na diagonal principal e as covariâncias fora da diagonal principal. Para um modelo com K=3, a matriz é
1 1 2 1 3
1 2 3 1 2 2 2 3
1 3 2 3 3
var cov , cov ,
cov , , cov , var cov ,
cov , cov , var
b b b b b
b b b b b b b b
b b b b b
(7.3.3)
Utilizando a estimativa = 36,84, as variâncias e covariâncias para b1, b2, b3 no exemplo da rede de lanchonetes são
2̂
1 2 3
42,026 19,863 0,16111
ˆcov , , 19,863 10,184 0,05402
0,16111 0,05402 0,02787
b b b
(7.3.4)
Assim, nós temos
1 1 2
2 1 3
3 2 3
ˆ ˆvar 42,026 cov , 19,863
ˆ ˆvar 10,184 cov , 0,16111
ˆ ˆvar 0,02787 cov , 0,05402
b b b
b b b
b b b

7.3.2 As Propriedades dos Estimadores de Mínimos Quadrados Admitindo Distribuição Normal dos Erros
Se nós acrescentarmos RM6 – que os erros aleatórios et têm distribuição de probabilidade normal –, então a variável dependente yt é normalmente distribuída,
2 2
1 2 2~ ( ), ~ (0, )t t K tK ty N x x e N
Como os estimadores de mínimos quadrados são funções lineares da variável dependente, segue que os estimadores de mínimos quadrados são normalmente distribuídos também,
~ , vark k kb N b (7.3.6)
• Nós podemos transformar a variável aleatória normal bk na variável normal padronizada z,
~ 0,1 , para 1, 2, ,
var
k k
k
bz N k K
b
(7.3.7)
• Quando nós substituímos 2 pelo seu estimador , nós obtemos a estimativa da var(bk), o qual nós denotamos como . Quando a var(bk) é substituída pela em (7.3.7), nós obtemos uma variável aleatória com distribuição t ao invés de uma variável normal; isto é,
2̂
ˆvar kb ˆvar kb
~
ˆvar
k k
T K
k
bt t
b
(7.3.8)

ˆep( ) var( )k kb b
• Nesse capítulo, existem K coeficientes desconhecidos no modelo geral e o número de graus de liberdade para a estatística t é (T-K)
• A raiz quadrada do estimador da variância é chamada de “erro padrão” de bk, o qual pode ser escrito como
ˆvar kb
(7.3.9)
Conseqüentemente, nós expressaremos usualmente a variável aleatória t como
~
ep( )
k k
T K
k
bt t
b
(7.3.10)

7.4 Estimação de Intervalos
• As estimativas de intervalos de parâmetros desconhecidos são baseadas numa sentença probabilística que é
1ep( )
k kc c
k
bP t t
b
(7.4.1)
Onde tc é o valor crítico para a distribuição t com (TK) graus de liberdade, tal que P(t tc) = /2.
• Rearranjando a equação 7.4.1, nós obtemos
ep( ) ep( ) 1k c k k k c kP b t b b t b (7.4.2)
• Os limites do intervalo definem um estimador de intervalo de 100(1-)% de confiança para k.
[ ep( ), ep( )]k c k k c kb t b b t b (7.4.3)
• Se esse estimador de intervalo é utilizado em muitas amostra extraídas da população, então 95% deles conterão o verdadeiro parâmetro k.

• Retornando à equação usada para descrever como a receita da rede de lanchonetes depende do preço e dos gastos com propaganda, nós temos
1 1 1
2 2 2
3 3 3
52 3
ˆ104,79 ep var 6,483
ˆ6,642 ep var 3,191
ˆ2,984 ep var 0,1669
T K
b b b
b b b
b b b
Nós usaremos essas informações para construir estimativas de intervalos para
2
3
a resposta da receita para uma mudança no preço
a resposta da receita para uma mudança no gasto da propaganda
• Os graus de liberdade são dados por (T-K) = (52-3) = 49.
• O valor crítico é tc = 2,01.
• Uma estimativa de intervalo de 95% para 2 é dado por
( 13,06, 0,23) (7.4.4)
• Essa estimativa de intervalos sugere que a diminuição de $1 no preço levará a um aumento da receita entre $230 e $13.060. • Esse é um amplo intervalo de confiança e não é muito informativo.

• Outro modo de descrever essa situação é afirmar que a estimativa pontual de b2 = 6,642 não é muito confiável.
• Um intervalo mais estreito só pode ser obtido pela redução da variância do estimador. Um modo é obter maiores quantidades de dados e dados mais precisos. Alternativamente, nós podemos introduzir algum tipo de informação não amostral nos coeficientes.
• Uma estimativa de intervalos de 95% para 3, a resposta da receita para os gastos com propaganda, é
(2,65, 3,32) (7.4.5)
• Esse intervalo é relativamente estreito e informativo. Nós estimamos que uma elevação nos gasto com propaganda de $1000 levará a um aumento na receita total de $2.650 à $3.320.

7.5 Teste de Hipótese para um Único Coeficiente
7.5.1 Teste da Significância de um Único Coeficiente
• Para saber se os dados contém alguma evidência de que y está relacionado com xk, nós testamos a hipótese nula
0 : 0kH contra a hipótese alternativa
1 : 0kH
• Para conduzir o teste, nós utilizamos a estatística do teste (7.3.10), o qual, se a hipótese nula for verdadeira, é
( )~
ep
kT K
k
bt t
b
• Para a hipótese alternativa de “desigualdade”, nós utilizamos um teste bicaudal e rejeitamos H0 se o valor t calculado for maior ou igual a tc, ou menor ou igual a tc.

• No exemplo da rede de lanchonetes nós testamos, seguindo nosso formato padrão de teste, se a receita está relacionado com o preço:
0 2: 0H
1 2: 0H
1.
2.
3. A estatística do teste, se a hipótese nula for verdadeira, é
2
( )
2
~ep
T K
bt t
b
4. Com 49 graus de liberdade e um nível de significância de 5%, os valores críticos que levam a ter uma probabilidade de 0,025 em cada calda da distribuição são tc = 2,01 e tc = 2,01. Assim, nós rejeitamos a hipótese nula se t 2,01 ou se t 2,01. Na notação em módulo, nós rejeitamos a hipótese nula se |t| 2,01.
5. O valor calculado da estatística t é
6,6422,08
3,191t
Como 2,08 < 2,01, nós rejeitamos a hipótese nula e aceitamos a alternativa.
• O valor-p é dado por P[|t(49)| > 2,08] = 2 0,021 = 0,042. Utilizando este procedimento nós rejeitamos H0 porque 0,042 < 0,05.

• Para testar se a receita está relacionada com os gastos com propaganda, nós temos
0 3: 0H
1 3: 0H
3. A estatística do teste, se a hipótese nula for verdadeira, é
1.
2.
3
( )
3
~ep
T K
bt t
b
4. Nós rejeitamos a hipótese nula se |t| 2,01.
5. O valor da estatística do teste é
2,98417,88
0,1669t
Como 17,88 > tc = 2,01, os dados admitem a conjuntura de que a receita está relacionada com os gastos em propaganda.

7.5.2 Teste de Hipótese Unicaudal para um Único Coeficiente
7.5.2a Teste para a Elasticidade da Demanda
•Em relação à elasticidade da demanda, nós desejamos saber se: •2 0: uma queda no preço leva a uma redução na receita total (a demanda é inelástica em relação ao preço) •2 < 0: uma queda no preço leva a um aumento na receita total (a demanda é elástica em relação ao preço)
0 2: 0 (demanda é unitária ou inelástica)H
1 2: 0 (demanda é elástica)H
3. Para construir uma estatística de teste, consideramos como hipótese nula a igualdade 2 = 0. Se a hipótese nula for verdadeira, então a estatística t é
~
ep( )
k
T K
k
bt t
b
1.
2.

5. O valor da estatística do teste é
2
2
6,6422,08
ep 3,191
bt
b
(R7.10)
Como t = 2,08 < tc = 1,68, nós rejeitamos H0: 2 0 e concluímos que H1: 2 < 0 (a demanda é elástica) é mais compatível com os dados. A evidência amostral dá base para a proposição de que uma redução no preço trará um aumento na receita total.
•O valor-p é dado por P[t(49) < 2,08] e rejeita-se H0 se o valor-p é menor do que 0,05. Utilizando um software, nós encontramos que P[t(49) < 2,08] = 0,021. Como 0,021 < 0,05, chega-se na mesma conclusão.
4. A região de rejeição consiste nos valores da distribuição t que são improváveis de ocorrer se a hipótese nula for verdadeira. Definindo “improvável” em termos de nível de significância de 5%, respondemos essa questão encontrando um valor crítico tc tal que P[t(T-K) tc ] = 0,05. Então, nós rejeitamos H0, se t tc . Dado uma amostra de T=52 observações, os graus de liberdade são T K = 49 e o valor crítico t é tc = 1,68.

• A outra hipótese de interesse é se um aumento nos gastos com propaganda trazem um aumento na receita total que é suficiente para cobrir os gastos feitos. Isso ocorrerá se 3 > 1. Elaborando o teste, nós temos:
0 3: 1 H
1 3: 1 H
1.
2.
3. Nós calculamos um valor para a estatística t como se a hipótese nula fosse 3 = 1. Utilizando (7.3.10) nós temos, se a hipótese nula for verdadeira,
3
3
1~
ep( )T K
bt t
b
4. Nesse caso, se o nível de significância for = 0,05, nós rejeitamos H0 se t tc = 1,68
5. O valor da estatística do teste é:
3 3
3
2,984 111,89
ep 0,1669
bt
b
Como 11,89 é muito maior do que 1,68, nós rejeitamos H0 e aceitamos a alternativa 3 > 1 como a mais compatível com os dados.
• Também, o valor-p nesse caso é essencialmente igual a zero (menor do que 1012). Assim, nós possuímos evidências estatísticas de que uma elevação nos gastos com propaganda serão justificados pelo aumento na receita.

7.6 Mensuração da Qualidade do Ajustamento
• O coeficiente de determinação é
2
2
2
2
2
ˆ
ˆ1 1
t
t
t
t
y ySQRR
SQT y y
eSQE
SQT y y
(7.6.1)
•Para o exemplo da rede de lanchonetes, a Tabela de Análise da Variância inclui as seguintes informações:
Tabela 7.4 Tabela Parcial ANOVA
Fonte GL Soma de Quadrados
Explicada 2 11776,18 Não Explicada 49 1805,168 Total 51 13581,35
Utilizando a soma de quadrados, nós temos
22
2
ˆ 1805,1681 1 0,867
13581,35
t
t
eR
y y
(R7.12)

•A interpretação de é que 86.7% da variação na receita total é explicada pela variação no preço e pela variação no nível de gastos com propaganda. •Uma dificuldade com o é que ele pode ser aumentado pela inclusão de novas variáveis, mesmo se as variáveis acrescentadas não apresentarem qualquer justificativa econômica. Algebricamente, isso é um fato de que à medida que se acrescenta mais variáveis, a SQE diminui (ela pode permanecer inalterada, mas isso é raro acontecer) e assim o sobe. Se o modelo contém T1 variáveis, o = 1. •Uma medida alternativa para mensurar a qualidade do ajustamento é chamada de ajustado, e tem, geralmente, como símbolo ; ele é usualmente apresentado pelos programas de regressão. Ele é calculado como
2R
2R
2R
2R
2R
2R
2 /( )1
/( 1)
SQE T KR
SQT T

• Para o exemplo da rede de lanchonetes, o valor da medida descritiva é .
• Essa medida nem sempre sobe quando uma variável é acrescentada.
• Enquanto é resolvido um problema, essa medida corrigida da qualidade do ajustamento infelizmente introduz outro. Ela perde sua interpretação; não significa mais a porcentagem da variação explicada.
• É importante uma nota final. O parâmetro de intercepto
é onde o “plano” da regressão cruza o eixo y, como mostrado na Figura 7.1. Se, por razões teóricas, você estiver certo que o plano da regressão passa pela origem, então e podemos omiti-lo do modelo.
2 0,8617R
2R
1
1 0
•Se o modelo não contém um parâmetro de intercepto, então a medida R2 dada em (7.6.1) não é mais apropriada. A razão para isso é que, sem um termo de intercepto no modelo,
2 2 2ˆ ˆ
t t ty y y y e
SQT SQR SQE
• Nessas condições não faz sentido falar da proporção da variação total que é explicada pela regressão.




Recommended