
38 Xcell Journal First Quarter 2011
Wireless MIMO Sphere Detector Implemented in FPGA
XCELLENCE IN WIRELESS COMMUNICATIONS
by Juanjo NogueraSenior Research EngineerXilinx, Inc. [email protected]
Stephen NeuendorfferSenior Research EngineerXilinx, [email protected]
Kees VissersDistinguished EngineerXilinx, [email protected]
Chris DickDistinguished EngineerXilinx, [email protected]
High-level synthesis tools from
AutoESL made it possible to
build a complex receiver for
broadband wireless systems
in a Xilinx Virtex-5 device.
On Jan. 31, Xilinx announced it had acquired AutoESL.As such, you’ll be hearing more about this exciting new technology in future issues of Xcell Journal.

First Quarter 2011 Xcell Journal 39
S patial-division multiplexingMIMO processing significantlyincreases the spectral efficien-
cy, and hence capacity, of a wirelesscommunication system. For that rea-son, it is a core component of next-generation WiMAX and other OFDM-based wireless communications. Thisis a computationally intensive applica-tion that implements highly demand-ing signal-processing algorithms.
A specific example of spatial multi-plexing in MIMO systems is spheredecoding, an efficient method of solv-ing the MIMO detection problemwhile maintaining a bit-error rate(BER) performance comparable tothe optimal maximum-likelihooddetection algorithm. However, DSPprocessors don’t have enough com-pute power to cope with the require-ments of sphere decoding in real time.
Field-programmable gate arrays arean attractive target platform for theimplementation of complex DSP-inten-sive algorithms like the sphere decoder.Modern FPGAs are high-performanceparallel-computing platforms that pro-vide the dedicated hardware needed,while retaining the flexibility of pro-grammable DSP processors. There areseveral studies showing that FPGAscould achieve 100x higher performanceand 30x better cost/performance thantraditional DSP processors in a numberof signal-processing applications. [1]
Despite this tremendous perform-ance advantage, FPGAs are not gener-ally used in wireless signal processing,largely because traditional DSP pro-grammers believe they are hard tohandle. Indeed, the key barrier towidespread adoption of FPGAs inwireless applications is the traditionalhardware-centric design flow andtools. Currently, the use of FPGAsrequires significant hardware designexperience, including familiarity withhardware description languages likeVHDL and Verilog.
Recently, new high-level synthesistools [2] have become available asdesign aids for FPGAs. These design
tools take a high-level algorithmdescription as input, and generate anRTL that can be used with standardFPGA implementation tools (forexample, the Xilinx® ISE® design suiteand Embedded Development Kit). Thetools increase design productivity andreduce development time, while pro-ducing good quality of results. [3] Weused such tools to design an FPGAimplementation of a complex wirelessalgorithm—namely, a sphere detectorfor spatial-multiplexing MIMO in802.16e systems. Specifically, wechose AutoESL’s AutoPilot high-levelsynthesis tool to target a XilinxVirtex®-5 running at 225 MHz.
SPHERE DECODINGSphere detection, a part of the decod-ing process, is a prominent method ofsimplifying the detection complexity inspatial-multiplexing systems whilemaintaining BER performance compa-rable to that of optimum maximum-likelihood (ML) detection, a more com-plex algorithm.
In the block diagram of the MIMO802.16e wireless receiver shown inFigure 1, it is assumed that the channelmatrix is perfectly known to thereceiver, which can be accomplishedby classical means of channel estima-tion. The implementation consists of apipeline with three building blocks:channel reordering, QR decompositionand sphere detector (SD). In prepara-tion for engaging a soft-input-soft-out-put channel decoder (for example, aturbo decoder), we produced soft out-
puts by computing the log-likelihoodratio of the detected bits. [4]
CHANNEL MATRIX REORDERINGThe order in which the sphere detectorprocesses the antennas has a profoundimpact on the BER performance.Channel reordering comes first, priorto sphere detection. By utilizing a chan-nel matrix preprocessor that realizes atype of successive-interference cancel-lation similar in concept to thatemployed in BLAST (Bell Labs LayeredSpace Time) processing, the detectorachieves close-to-ML performance.
The method implemented by thechannel-reordering process determinesthe optimum detection order ofcolumns of the complex channel matrixover several iterations. The algorithmselects the row with the maximum orminimum norm depending on the itera-tion count. The row with the minimumEuclidean norm represents the influ-ence of the strongest antenna while therow with the maximum Euclidean normrepresents the influence of the weakest
antenna. This novel approach firstprocesses the weakest stream. All sub-sequent iterations process the streamsfrom highest to lowest power.
To meet the application’s high-data-rate requirements, we realized thechannel-ordering block using thepipelined architecture shown in Figure2, which processes five channels in atime-division multiplexing (TDM)approach. This scheme provided moreprocessing time between the matrixelements of the same channel while
ChannelEstimation
V-BLASTChannel
Reordering
ModifiedReal-Valued
QRD
SphereDetector
Soft-OutputGeneration
H
H sorted
Figure 1 – Block diagram for sphere decoder

sustaining high data throughput. Thecalculation of the G matrix is the mostdemanding component in Figure 2.The heart of the process is matrixinversion, which we realized usingQR decomposition (QRD). A commonmethod for realizing QRD is based onGivens rotations. The proposedimplementation performs the com-plex rotations in the diagonal and off-diagonal cells, which are the funda-mental computation units in the sys-tolic array we are using.
MODIFIED REAL-VALUED QRDAfter obtaining the optimal orderingof the channel matrix columns, thenext step is to apply QR decomposi-tion on the real-valued matrix coeffi-cients. The functional unit used forthis QRD processing is similar to theQRD engine designed to compute theinverse matrix, but with some modifi-cations. The input data in this casehas real values, and the systolic arraystructure has correspondingly higherdimensions (i.e., 8x8 real-valuedinstead of 4x4 complex-valued).
To meet the desired timing con-straints, the input data consumptionrate had to be one input sample perclock cycle. This requirement intro-duced challenges around processing-latency problems that we couldn’taddress with a five-channel TDMstructure. Therefore, we increasedthe number of channels in a TDMgroup to 15 to provide more timebetween the successive elements ofthe same channel matrix.
SPHERE DETECTOR DESIGNYou can view the iterative spheredetection algorithm as a tree travers-al, with each level of the tree i corre-sponding to processing symbols fromthe ith antenna. The tree traversal canbe performed using several differentmethods. The one we selected was abreadth-first search due to the attrac-tive, hardware-friendly nature of theapproach. At each level only the Knodes with the smallest partial-Euclidean distance (Ti) are chosen forexpansion. This type of detector iscalled a K-best detector.
The norm computation is done inthe partial Euclidean distance (PED)blocks of the sphere detector.Depending on the level of the tree,three different PED blocks are used.The root-node PED block calculatesall possible PEDs (tree-level index isi = M = 8). The second-level PEDblock computes eight possible PEDsfor each of the eight survivor pathsgenerated in the previous level. Thiswill give us 64 generated PEDs forthe tree-level index i = 7. The thirdtype of PED block is used for allother tree levels that compute theclosest-node PED for all PEDs com-puted on the previous level. This willfix the number of branches on eachlevel to K = 64, thus propagating tothe last level i = 1 and producing 64final PEDs along with their detectedsymbol sequences.
The pipeline architecture of theSD allows data processing on everyclock cycle. Thus, only one PEDblock is necessary at every tree level.The total number of PED units isequal to the number of tree levels,which for 4x4 64-QAM modulation iseight. Figure 3 illustrates the blockdiagram of the SD.
FPGA PERFORMANCEIMPLEMENTATION TARGETS The target FPGA device is a XilinxVirtex-5, with a target clock frequen-cy of 225 MHz. The channel matrix isestimated for every data subcarrier,which limits the available processingtime for every channel matrix. Forthe selected clock frequency and acommunication bandwidth of 5 MHz(corresponding to 360 data subcarri-ers in a WiMAX system), we calculat-ed the available number of process-ing clock cycles per channel matrixinterval as follows:
As mentioned earlier, we designedthe most computationally demandingconfiguration with 4x4 antennas and a
40 Xcell Journal First Quarter 2011
X C E L L E N C E I N W I R E L E S S C O M M U N I C A T I O N S
360*32x18b
360*32x18b
G matrixcalc
Normsearch
UpdateHsorted
360*32x18b
360*32x18b
G matrixcalc
Normsearch
UpdateHsorted
360*32x18b
360*32x18b
G matrixcalc
Normsearch
UpdateHsorted
Figure 2 – Iterative channel matrix reordering algorithm

64-QAM modulation scheme. Theachievable raw data rate in this case is83.965 Mbits per second.
HIGH-LEVEL SYNTHESIS FOR FPGASHigh-level synthesis tools take as theirinput a high-level description of thespecific algorithm to implement andgenerate an RTL description for FPGAimplementation, as shown in Figure 4.This RTL description can be integratedwith a reference design, IP core orexisting RTL code to create a com-plete FPGA implementation using tra-ditional Xilinx ISE/EDK tools.
Modern high-level synthesis toolsaccept untimed C/C++ descriptions asinput specifications. These tools givetwo interpretations to the same C/C++code: sequential semantics forinput/output behavior, and architec-ture specification based on C/C++code and compiler directives. Basedon the C/C++ code, compiler direc-tives and target throughput require-ments, these high-level synthesis toolsgenerate high-performance pipelinedarchitectures. Among other features,high-level synthesis tools enable auto-matic insertion of pipeline stages andresource sharing to reduce FPGAresource utilization. Essentially, high-level synthesis tools raise the level ofabstraction for FPGA design, andmake transparent the time-consumingand error-prone RTL design tasks.
We have focused on using C++descriptions, with the goal of leverag-ing C++ template classes to representarbitrary precision integer types and
template functions to represent para-meterized blocks in the architecture.
The overall design approach is seenin Figure 5, where the starting point isa reference C/C++ code that couldhave been derived from a MATLAB®
functional description. As the figureshows, the first step in implementingan application on any hardware targetis often to restructure the referenceC/C++ code. By “restructuring,” wemean rewriting the initial C/C++ code(which is typically coded for clarityand ease of conceptual understandingrather than for optimized perform-ance) into a format more suitable forthe target processing engine. Forexample, on a DSP processor it may benecessary to rearrange an applica-tion’s code so that the algorithmmakes efficient use of the cache mem-ories. When targeting FPGAs, thisrestructuring might involve, for exam-ple, rewriting the code so it representsan architecture specification that canachieve the desired throughput, orrewriting the code to make efficientuse of the specific FPGA features, likeembedded DSP macros.
We achieved the functional verifica-tion of this implementation C/C++ codeusing traditional C/C++ compilers (forexample, gcc) and reusing C/C++ leveltestbenches developed for the verifica-tion of the reference C/C++ code. Theimplementation C/C++ code is the maininput to the high-level synthesis tools.However, there are additional inputsthat significantly influence the generat-ed hardware, its performance and thenumber of FPGA resources used. Two
essential constraints are the targetFPGA family and target clock frequen-cy, both of which affect the number ofpipeline stages in the generated archi-tecture. Additionally, high-level synthe-sis tools accept compiler directives(e.g., pragmas inserted in the C/C++code). The designer can apply differenttypes of directives to different sectionsof the C/C++ code. For example, thereare directives that are applied to loops(e.g., loop unrolling), and others toarrays (for example, to specify whichFPGA resource must be used to theimplementation of the array).
Based on all these inputs, the high-level synthesis tools generate an outputarchitecture (RTL) and report itsthroughput. Depending on this through-put, the designer can then modify thedirectives, the implementation C/C++code or both. If the generated architec-ture meets the required throughput,then the output RTL is used as the inputto the FPGA implementation tools(ISE/EDK). The final achievable clockfrequency and number of FPGAresources used are reported only afterrunning logic synthesis and place-and-route. If the design does not meet tim-ing or the FPGA resources are not theexpected ones, the designer shouldmodify the implementation C/C++ codeor the compiler directives.
HIGH-LEVEL SYNTHESISIMPLEMENTATION OF SD We have implemented the three keybuilding blocks of the WiMAX spheredecoder shown in Figure 1 using theAutoPilot 2010.07.ft tool from AutoESL.It is important to emphasize that thealgorithm is exactly the algorithmdescribed in a recent SDR Conferencepaper, [4] and hence has exactly thesame BER. In this section we give spe-cific examples of code rewriting andcompiler directives that we used forthis particular implementation.
The original reference C code,derived from a MATLAB functionaldescription, contained approximately2,000 lines of code, including synthe-
First Quarter 2011 Xcell Journal 41
X C E L L E N C E I N W I R E L E S S C O M M U N I C A T I O N S
RootPED
8 PED metrics carried on TDM bus
8 PED metrics carried on TDM bus
PEDSortFreePED
SortFreePED
MinSearch
Figure 3 – Sphere detector processing pipeline

sizable and verification C code. It con-tains only fixed-point arithmetic usingC built-in data types. An FPGA-friend-ly implementation approximated allthe required floating-point operations(for example, sqrt).
In addition to the reference C codedescribing the functions to synthesizein the FPGA, there is a complete C-level verification testbench. We gener-ated the input test vectors as well asthe golden output reference files from
the MATLAB description. The originalC/C++ reference code is bit-accuratewith the MATLAB specification, andpasses the entire regression suite con-sisting of multiple data sets.
This reference C/C++ code has gonethrough different types of code restruc-turing. As examples, Figure 5 showsthree instances of code restructuringthat we have implemented. We reusedthe C-level verification infrastructure toverify any change to the implementa-
tion C/C++ code. Moreover, we carriedout all verification at the C level, not atthe register-transfer level, avoidingtime-consuming RTL simulations andhence, contributing to the reduction inthe overall development time.
MACROARCHITECTURESPECIFICATION Probably the most important part ofcode refactoring is to rewrite the C/C++code to describe a macroarchitecturethat would efficiently implement a spe-cific functionality. In other words, thedesigner is accountable for themacroarchitecture specification, whilethe high-level synthesis tools are incharge of the microarchitecture genera-tion. This type of code restructuring hasa major impact on the obtainedthroughput and quality of results.
In the case of our sphere decoder,there are several instances of this typeof code restructuring. For example, tomeet the high throughput of the chan-nel-ordering block, the designer shoulddescribe in C/C++ the macroarchitec-ture shown in Figure 2. Such C/C++code would consist of several functioncalls communicating using arrays. Thehigh-level synthesis tools might auto-matically translate these arrays in ping-pong buffers to allow parallel execu-tion of the several matrix calculationblocks in the pipeline.
Another example of code restruc-turing at this level would be to decidehow many channels to employ in theTDM structure of a specific block(e.g., five channels in the channelmatrix reordering block, or 15 chan-nels in the modified real-valued QRdecomposition block).
Figure 6 is one example of macroar-chitecture specification. This snippetof C++ code describes the spheredetector block diagram shown inFigure 3. We can observe a pipeline ofnine function calls, each one repre-senting a block as shown in Figure 3.The communication between func-tions takes place through arrays,which are mapped to streaming inter-
42 Xcell Journal First Quarter 2011
X C E L L E N C E I N W I R E L E S S C O M M U N I C A T I O N S
RTL
IP
ReferenceDesigns
High-LevelSynthesis
Tool
RTL System Design
C/C++ Agorithm
XilinxISE/EDK
Tools
Bitstream/Netlist
DirectivesHigh-LevelSynthesis
Tool
RTL Design
Implementation C/C++
Code Restructuring
Reference C/C++
C/C
++
Ver
ifica
tion
(C/C
++
Com
pile
r, M
atla
b)
Figure 4 – High-level synthesis for FPGAs
Figure 5 -- Iterative C/C++ refinement design approach

faces (not embedded BRAM memoriesin the FPGA) by using the appropriatedirectives (pragmas) in lines 5 and 7.
IMPORTANCE OFPARAMETERIZATION Parameterization is another key exam-ple of code rewriting. We have exten-sively leveraged C++ template func-tions to represent parameterized mod-ules in the architecture.
In the implementation of the spheredecoder, there are several cases of thistype of code rewriting. A specificexample would be the different matrixoperations used in the channel-reordering block. The matrix calcula-tions blocks (4x4, 3x3 and 2x2) shownin Figure 2 use different types ofmatrix operations, such as MatrixInverse or Matrix Multiply. Theseblocks are coded as C++ templatefunctions with the dimensions of thematrix as template parameters.
Figure 7 shows the C++ templatefunction for Matrix Multiply. In additionto the matrix dimension, this templatefunction has a third parameter, MM_II(Initiation Interval for Matrix Multiply),which is used to specify the number ofclock cycles between two consecutiveloop iterations. The directive (pragma)in line 9 is used to parameterize therequired throughput for a specificinstance. This is a really important fea-ture, since it has a major impact on thegenerated microarchitecture—that is,the ability of the high-level synthesistools to exploit resource sharing, andhence, to reduce the FPGA resourcesthe implementation will use. For exam-ple, just by modifying this InitiationInterval parameter and using exactlythe same C++ code, the high-level syn-thesis tools automatically achieve dif-ferent levels of resource sharing in theimplementation of the different MatrixInverse (4x4, 3x3, 2x2) blocks.
FPGA OPTIMIZATIONSFPGA optimization is the last exam-ple of code rewriting. The designercan rewrite the C/C++ code to more
First Quarter 2011 Xcell Journal 43
X C E L L E N C E I N W I R E L E S S C O M M U N I C A T I O N S
Figure 6 – Sphere detector macroarchitecture description
Figure 7 – Example of code parameterization
Figure 8 – FPGA optimization for DSP48 utilization
efficiently utilize specific FPGAresources, and hence, improve tim-ing and reduce area. Two very specif-ic examples of this type of optimiza-tion are bit-widths optimizations andefficient use of embedded DSPblocks (DSP48s). Efficient use ofDSP48s improves timing and FPGAresource utilization.
We wrote our reference C/C++code using built-in C/C++ data types(e.g., short, int), while the design uses18-bit fixed-point data types to repre-sent the matrix elements. We have
leveraged C++ template classes torepresent arbitrary precision fixed-point data types, hence reducingFPGA resources and minimizing theimpact on timing.
Figure 8 is a C++ template functionthat implements a multiplication fol-lowed by a subtraction, where thewidth of the input operands is parame-terized. You can map these two arith-metic operations into a single embed-ded DSP48 block. In Figure 8, we canalso observe two directives thatinstruct the high-level synthesis tool to
use a maximum of two cycles toschedule these operations and use aregister for the output return value.
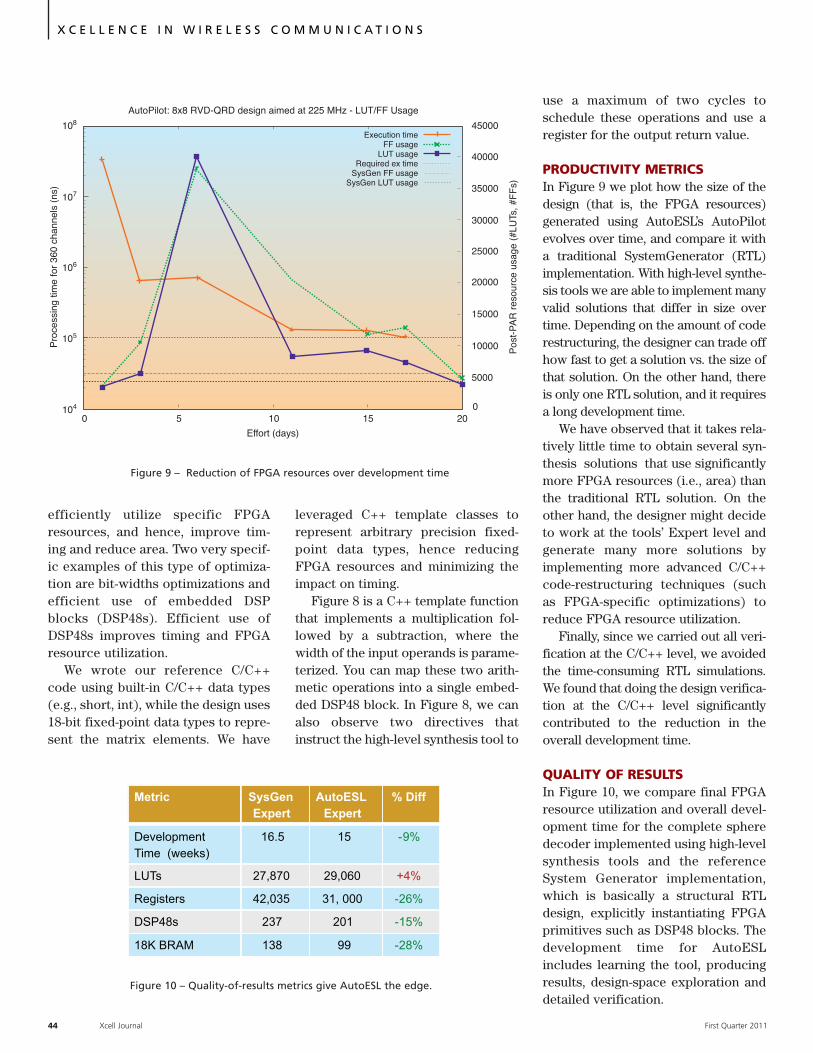
PRODUCTIVITY METRICSIn Figure 9 we plot how the size of thedesign (that is, the FPGA resources)generated using AutoESL’s AutoPilotevolves over time, and compare it witha traditional SystemGenerator (RTL)implementation. With high-level synthe-sis tools we are able to implement manyvalid solutions that differ in size overtime. Depending on the amount of coderestructuring, the designer can trade offhow fast to get a solution vs. the size ofthat solution. On the other hand, thereis only one RTL solution, and it requiresa long development time.
We have observed that it takes rela-tively little time to obtain several syn-thesis solutions that use significantlymore FPGA resources (i.e., area) thanthe traditional RTL solution. On theother hand, the designer might decideto work at the tools’ Expert level andgenerate many more solutions byimplementing more advanced C/C++code-restructuring techniques (suchas FPGA-specific optimizations) toreduce FPGA resource utilization.
Finally, since we carried out all veri-fication at the C/C++ level, we avoidedthe time-consuming RTL simulations.We found that doing the design verifica-tion at the C/C++ level significantlycontributed to the reduction in theoverall development time.
QUALITY OF RESULTS In Figure 10, we compare final FPGAresource utilization and overall devel-opment time for the complete spheredecoder implemented using high-levelsynthesis tools and the referenceSystem Generator implementation,which is basically a structural RTLdesign, explicitly instantiating FPGAprimitives such as DSP48 blocks. Thedevelopment time for AutoESLincludes learning the tool, producingresults, design-space exploration anddetailed verification.
44 Xcell Journal First Quarter 2011
X C E L L E N C E I N W I R E L E S S C O M M U N I C A T I O N S
AutoPilot: 8x8 RVD-QRD design aimed at 225 MHz - LUT/FF Usage
108
107
106
105
104
0 5 10 15 200
5000
10000
15000
20000
25000
30000
35000
40000
45000
Effort (days)
Pro
cess
ing
time
for
360
chan
nels
(ns
)
Pos
t-P
AR
res
ourc
e us
age
(#LU
Ts, #
FF
s)
Execution timeFF usage
LUT usageRequired ex time
SysGen FF usageSysGen LUT usage
Metric SysGenExpert
AutoESLExpert
% Diff
DevelopmentTime (weeks)
16.5 15 -9%
LUTs 27,870 29,060 +4%
Registers 42,035 31, 000 -26%
DSP48s 237 201 -15%
18K BRAM 138 99 -28%
Figure 9 – Reduction of FPGA resources over development time
Figure 10 – Quality-of-results metrics give AutoESL the edge.

To have accurate comparisons, wehave reimplemented the referenceRTL design using the latest Xilinx ISE12.1 tools targeting a Virtex-5 FPGA.Likewise, we implemented the RTLgenerated by AutoESL’s AutoPilotusing ISE 12.1 targeting the sameFPGA. Figure 10 shows thatAutoESL’s AutoPilot achieves signifi-cant savings in FPGA resources,mainly through resource sharing inthe implementation of the matrixinverse blocks. We can also observe asignificant reduction in the number ofregisters and a slightly higher utiliza-tion of lookup tables (LUTs). Thisresult is partially due to the fact thatdelay lines are mapped onto SRL16s(i.e., LUTs) in the AutoESL implemen-tation, while the SystemGeneratorversion implements them using regis-
ters. In other modules we traded offBRAMs for LUTRAM, resulting inlower BRAM usage in the channelpreprocessor.
AutoESL’s AutoPilot achieves sig-nificant abstractions from low-levelFPGA implementation details (e.g.,timing and pipeline design), while pro-ducing a quality of results highly com-petitive with those obtained using atraditional RTL design approach.C/C++ level verification contributes tothe reduction in the overall develop-ment time by avoiding time-consum-ing RTL simulations. However, obtain-ing excellent results for complex andchallenging designs requires goodmacroarchitecture definition and asolid knowledge of FPGA design tools,including the ability to understand andinterpret FPGA tool reports.
REFERENCES
[1] Berkeley Design Technology Inc.,
“FPGAs for DSP,” white paper, 2007.
[2] Grant Martin, Gary Smith, “High-
Level Synthesis: Past, Present and
Future,” IEEE Design and Test ofComputers, July/August 2009.
[3] Berkeley Design Technology Inc.,
“High-Level Synthesis Tools for Xilinx
FPGAs,” white paper, 2010:
http://www.xilinx.com/technology/dsp/BDTI_techpaper.pdf.
[4] Chris Dick et al., “FPGA
Implementation of a Near-ML Sphere
Detector for 802.16E Broadband
Wireless Systems,” SDR Conference’09,
December 2009.
[5] K. Denolf, S. Neuendorffer, K.
Vissers, “Using C-to-Gates to Program
Streaming Image Processing Kernels
Efficiently on FPGAs,” FPL’09 confer-
ence, September 2009.
First Quarter 2011 Xcell Journal 45
X C E L L E N C E I N W I R E L E S S C O M M U N I C A T I O N S
Versatile FPGA Platform
www.techway.eu
The Versatile FPGA Platform provides a cost-effective
way of undertaking intensive calculations
and high speedcommunications in an
industrial environment.
PCI Express 4x Short CardXilinx Virtex FamiliesI/0 enabled through an FMC site (VITA 57)Development kit and drivers optimized for Windows and Linux
Optical-Mez
Recommended

















