Embed Size (px)
Citation preview

OPENSTACK AT 99.999% AVAILABILITYWITH CEPH
Danny Al-Gaaf (Deutsche Telekom)Deutsche OpenStack Tage 2016 - Cologne

● Motivation● Availability and SLA's● Data centers
○ Setup and failure scenarios● OpenStack and Ceph
○ Architecture and Critical Components○ HA setup○ Quorum?
● OpenStack and Ceph == HA?○ Failure scenarios○ Mitigation
● Conclusions
Overview
2
Motivation
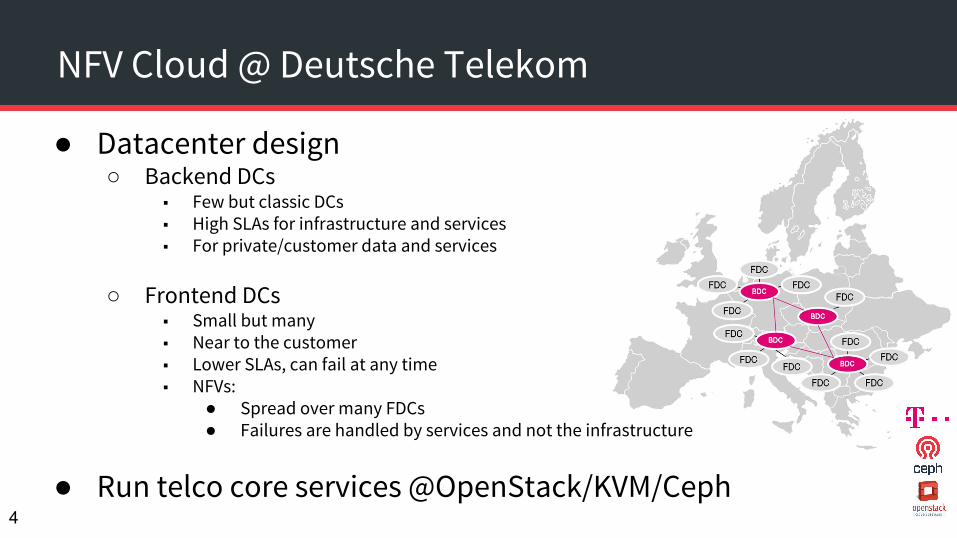
NFV Cloud @ Deutsche Telekom
● Datacenter design○ Backend DCs
■ Few but classic DCs ■ High SLAs for infrastructure and services■ For private/customer data and services
○ Frontend DCs■ Small but many■ Near to the customer■ Lower SLAs, can fail at any time■ NFVs:
● Spread over many FDCs● Failures are handled by services and not the infrastructure
● Run telco core services @OpenStack/KVM/Ceph4

Availability

High Availability
● Continuous system availability in case of component failures
● Which availability?○ Server ○ Network○ Datacenter○ Cloud○ Application/Service
● End-to-End availability most interesting6
availability downtime/year classification
99.9% 8.76 hours high availability
99.99% 52.6 minutes very high availability
99.999% 5.26 minutes highest availability
99.9999% 0.526 minutes disaster tolerant

High Availability
● Calculation○ Each component contributes to the service availability
■ Infrastructure■ Hardware■ Software■ Processes
○ Likelihood of disaster and failure scenarios○ Model can get very complex○ Hard to get all numbers required
● SLA’s○ ITIL (IT Infrastructure Library)○ Planned maintenance depending on SLA may be excluded
7

Data centers

Failure scenarios
● Power outage○ External○ Internal ○ Backup UPS/Generator
● Network outage ○ External connectivity○ Internal
■ Cables■ Switches, router
● Failure of:○ Cooling ○ server or component○ software services
9

Failure scenarios
● Human error○ Misconfiguration○ Accidents○ Emergency power-off○ Often leading cause of outage
● Disaster○ Fire○ Flood○ Earthquake○ Plane crash○ Nuclear accident
10
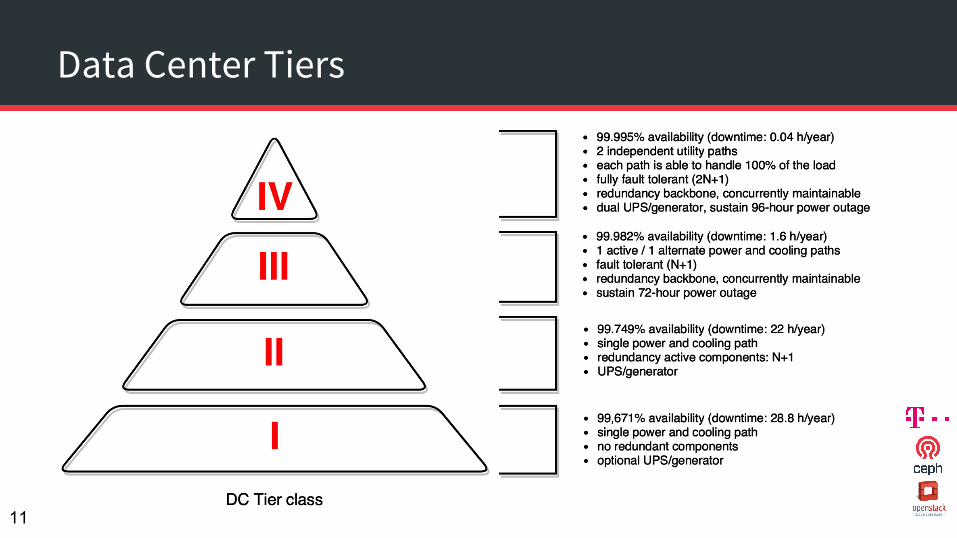
Data Center Tiers
11

Mitigation
● Identify potential SPoF● Use redundant components● Careful planning
○ Network design (external / internal)○ Power management (external / internal)○ Fire suppression○ Disaster management○ Monitoring
● 5-nines on DC/HW level hard to achieve ○ Tier IV often too expensive (compared with Tier III or III+)○ Even Tier IV does not provide 5-nines○ Requires HA concept on cloud and application level
12
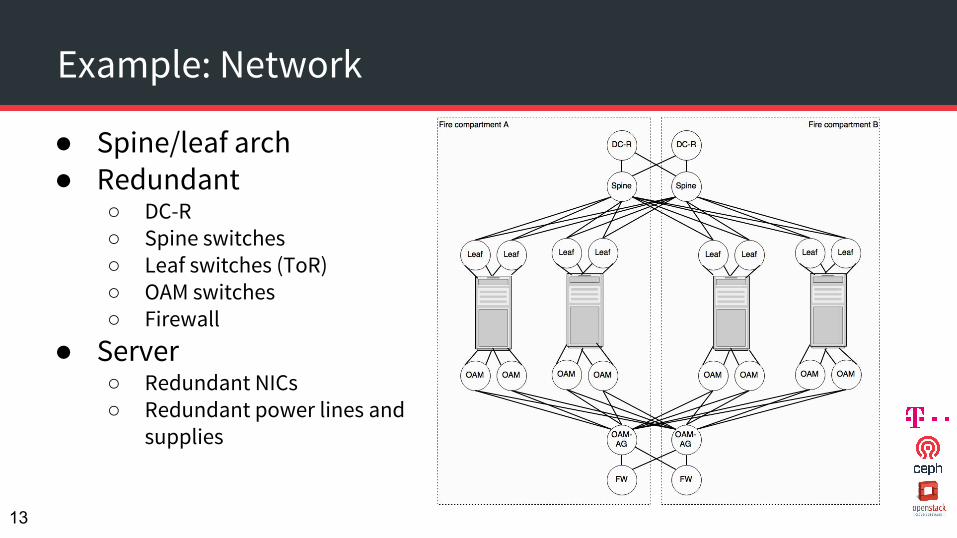
Example: Network
● Spine/leaf arch● Redundant
○ DC-R○ Spine switches○ Leaf switches (ToR)○ OAM switches○ Firewall
● Server○ Redundant NICs○ Redundant power lines and
supplies
13

Ceph and OpenStack
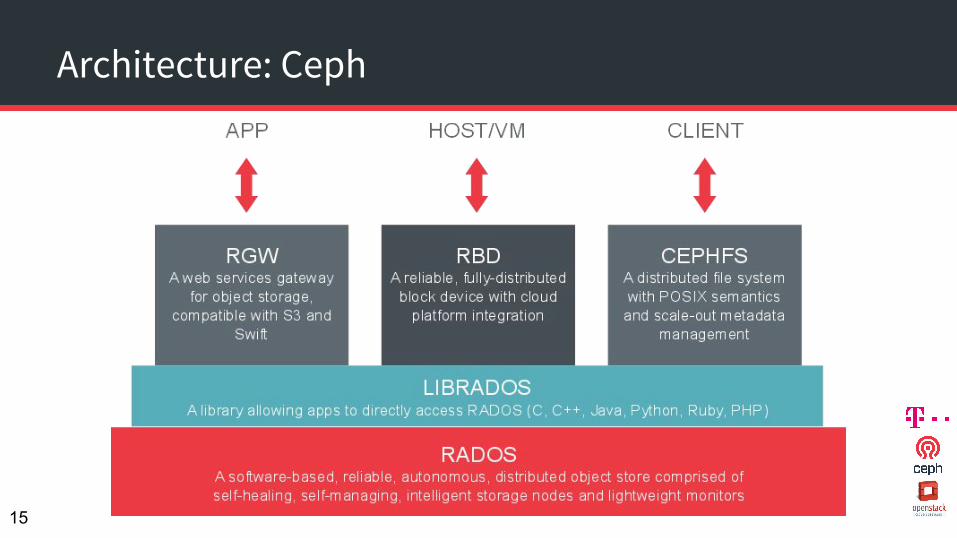
Architecture: Ceph
15

Architecture: Ceph Components
● OSDs○ 10s - 1000s per cluster○ One per device (HDD/SSD/RAID Group, SAN …)○ Store objects○ Handle replication and recovery
● MONs:○ Maintain cluster membership and states○ Use PAXOS protocol to establish quorum consensus○ Small, lightweight○ Odd number
16
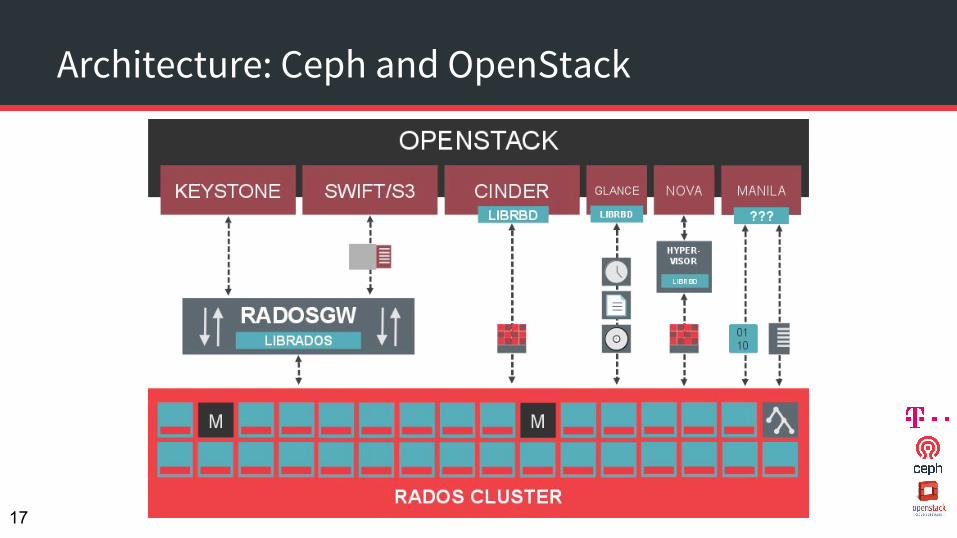
Architecture: Ceph and OpenStack
17

HA - Critical Components
Which services need to be HA? ● Control plane
○ Provisioning, management○ API endpoints and services ○ Admin nodes○ Control nodes
● Data plane○ Steady states○ Storage○ Network
18

HA Setup
● Stateless services○ No dependency between requests ○ After reply no further attention required○ API endpoints (e.g. nova-api, glance-api,...) or nova-scheduler
● Stateful service ○ Action typically comprises out of multiple requests○ Subsequent requests depend on the results of a former request○ Databases, RabbitMQ
19
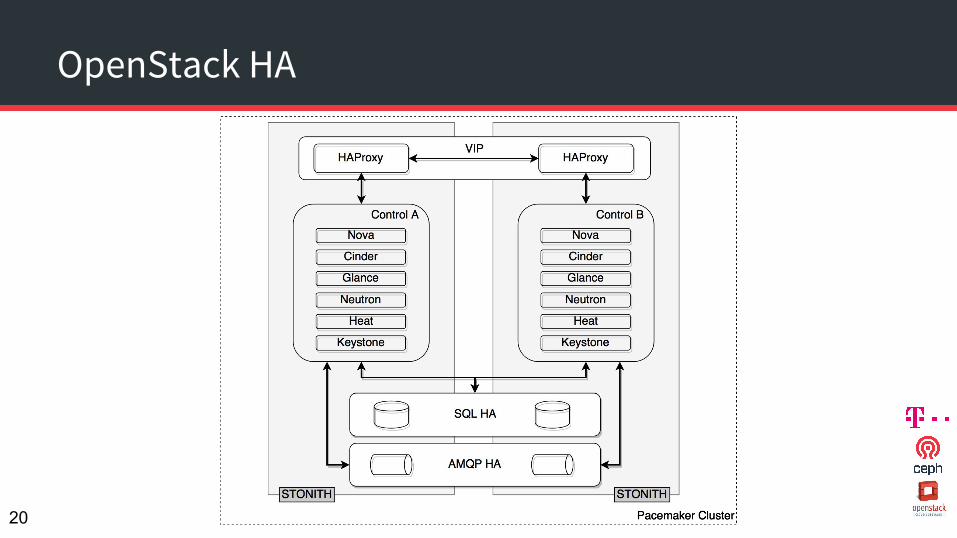
OpenStack HA
20

Quorum?
● Required to decide which cluster partition/member is primary to prevent data/service corruption
● Examples:○ Databases
■ MariaDB / Galera, MongoDB, CassandraDB○ Pacemaker/corosync○ Ceph Monitors
■ Paxos■ Odd number of MONs required■ At least 3 MONs for HA, simple majority (2:3, 3:5, 4:7, …)■ Without quorum:
● no changes of cluster membership (e.g. add new MONs/OSDs)● Clients can’t connect to cluster
21

OpenStack and Ceph == HA ?

SPoF
● OpenStack HA○ No SPoF assumed
● Ceph○ No SPoF assumed○ Availability of RBDs is critical to VMs○ Availability of RadosGW can be easily managed via HAProxy
● What in case of failures on higher level?○ Data center cores or fire compartments○ Network
■ Physical■ Misconfiguration
○ Power23
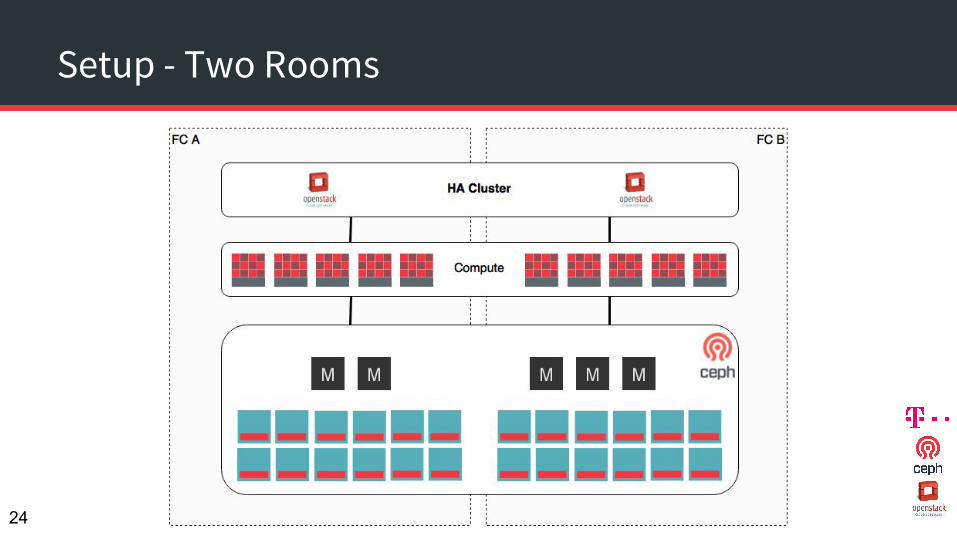
Setup - Two Rooms
24
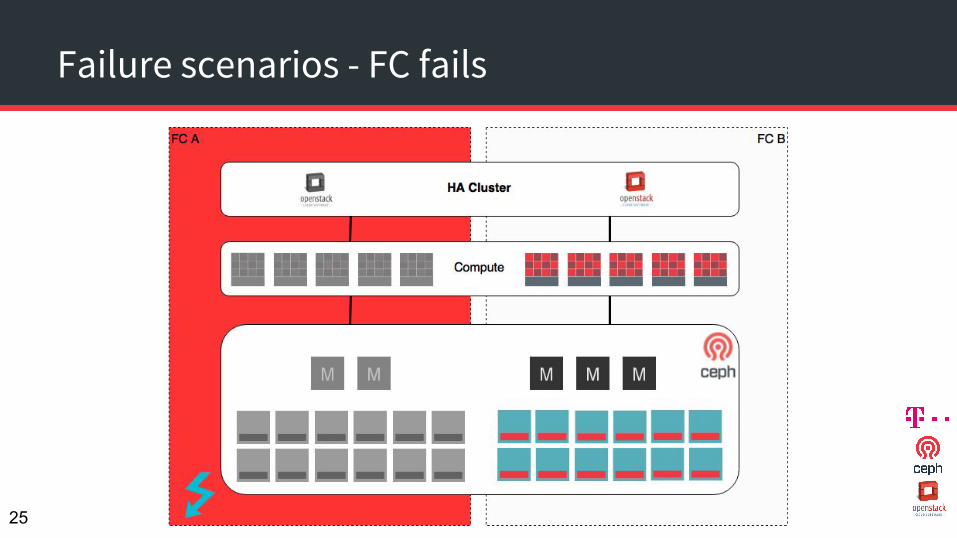
Failure scenarios - FC fails
25
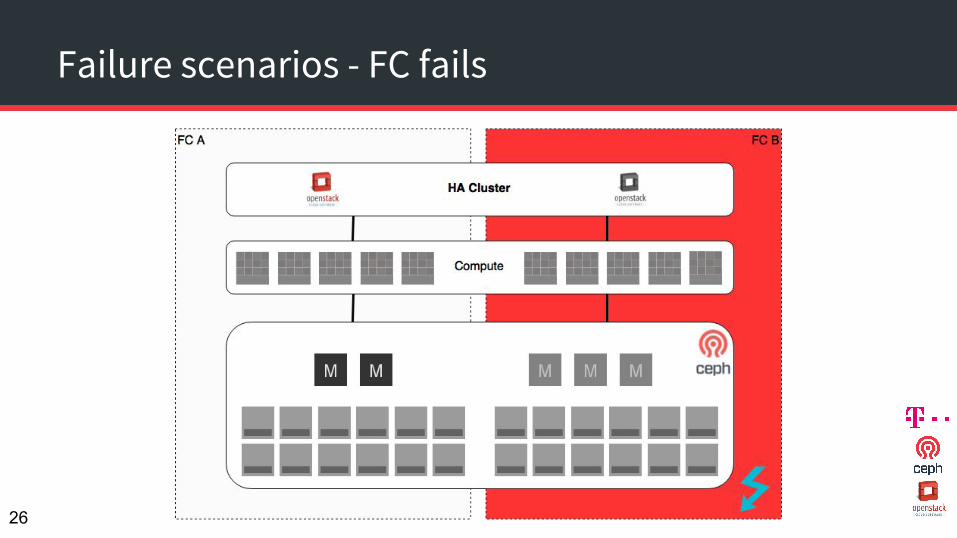
Failure scenarios - FC fails
26
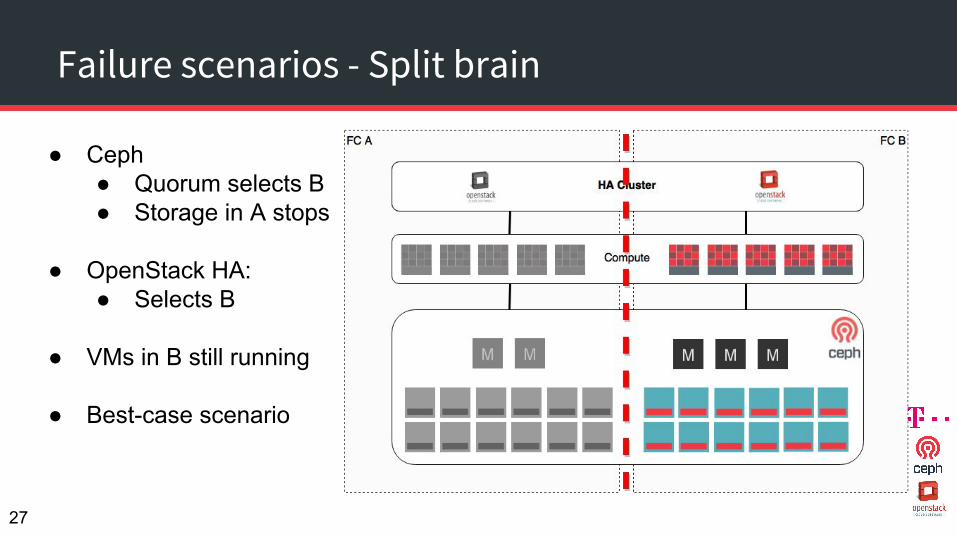
Failure scenarios - Split brain
27
● Ceph● Quorum selects B● Storage in A stops
● OpenStack HA:● Selects B
● VMs in B still running
● Best-case scenario
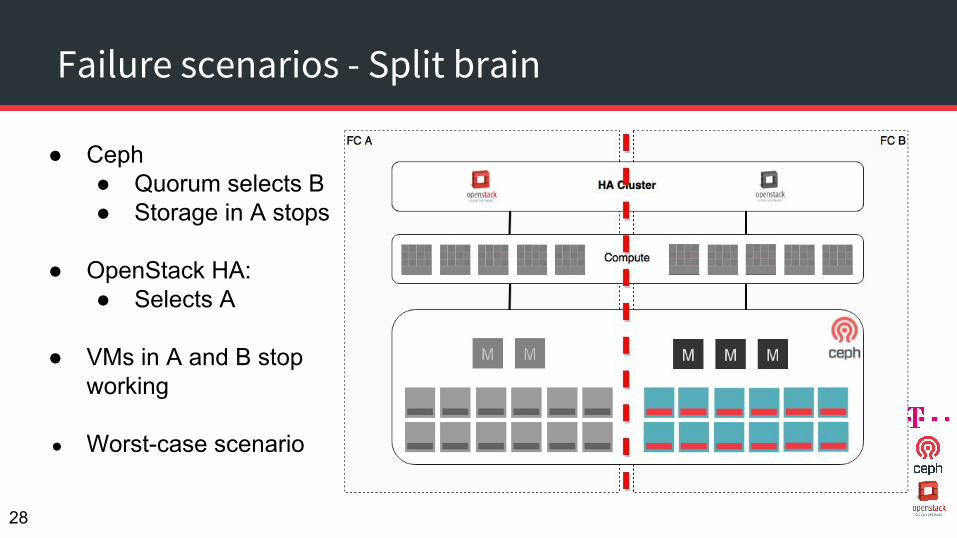
Failure scenarios - Split brain
28
● Ceph● Quorum selects B● Storage in A stops
● OpenStack HA:● Selects A
● VMs in A and B stop working
● Worst-case scenario

Other issues
● Replica distribution○ Two room setup:
■ 2 or 3 replica contain risk of having only one replica left■ Would require 4 replica (2:2)
● Reduced performance● Increased traffic and costs
○ Alternative: erasure coding ■ Reduced performance, less space required
● Spare capacity○ Remaining room requires spare capacity to restore○ Depends on
■ Failure/restore scenario■ Replication vs erasure code
○ Costs29
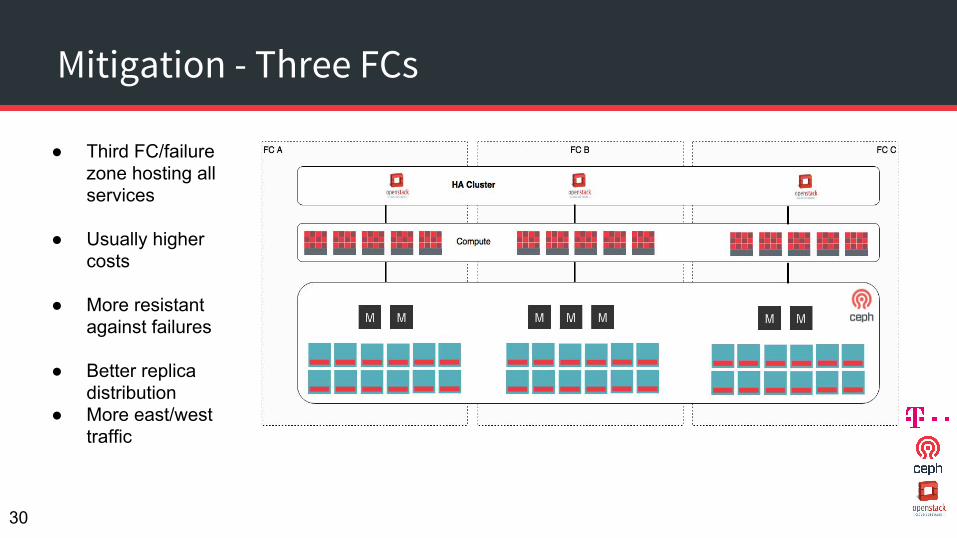
Mitigation - Three FCs
30
● Third FC/failure zone hosting all services
● Usually higher costs
● More resistant against failures
● Better replica distribution
● More east/west traffic
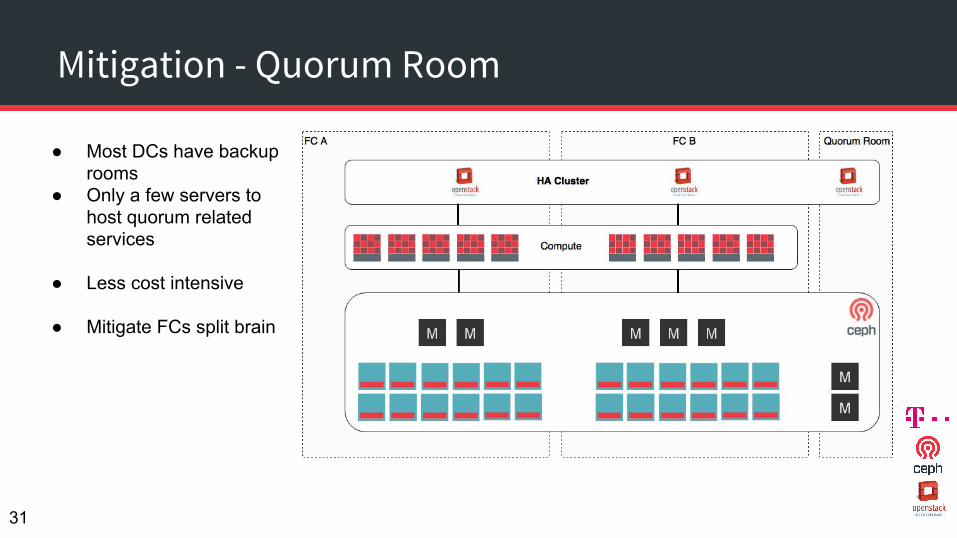
Mitigation - Quorum Room
31
● Most DCs have backup rooms
● Only a few servers to host quorum related services
● Less cost intensive
● Mitigate FCs split brain

Mitigation - Applications: First Rule
32

Mitigation - Applications: Third Rule
33

Mitigation - Applications: Third Rule
34

Mitigation - Applications: Pets vs Cattle
35
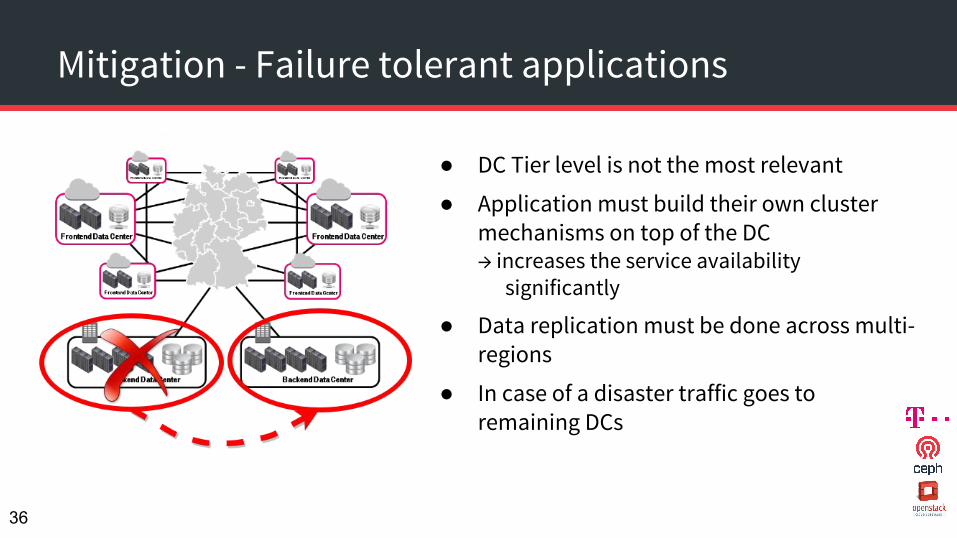
Mitigation - Failure tolerant applications
36
● DC Tier level is not the most relevant
● Application must build their own cluster mechanisms on top of the DC→ increases the service availability significantly
● Data replication must be done across multi-regions
● In case of a disaster traffic goes to remaining DCs
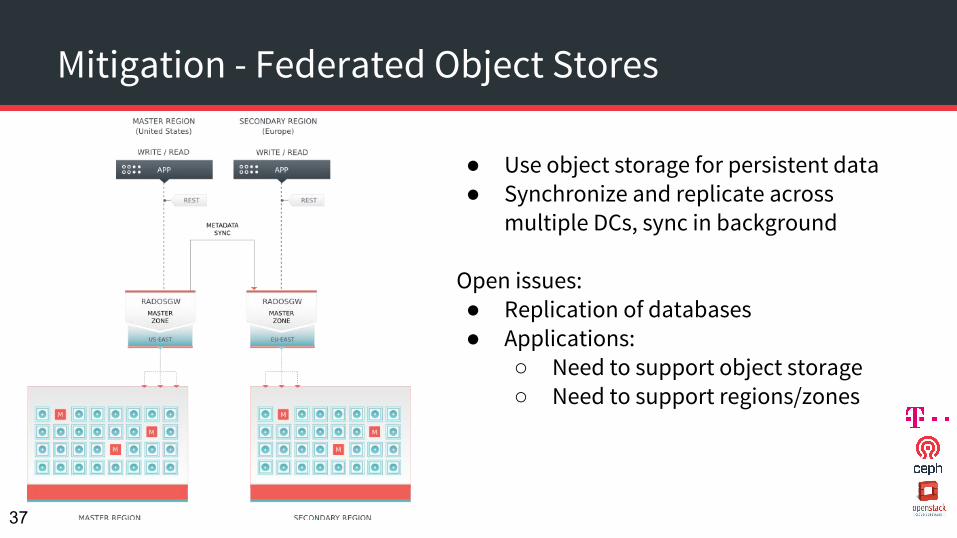
Mitigation - Federated Object Stores
37
● Use object storage for persistent data● Synchronize and replicate across
multiple DCs, sync in background
Open issues: ● Replication of databases● Applications:
○ Need to support object storage○ Need to support regions/zones

Mitigation - Outlook
● “Compute follows Storage” ○ Use RBDs as fencing devices in OpenStack HA setup○ Extend Ceph MONs
■ Include information about physical placement similar to CRUSH map■ Enable HA setup to monitor/query quorum decisions and map to physical layout
● Passive standby Ceph MONs to ease deployment of MONs if quorum fails○ http://tracker.ceph.com/projects/ceph/wiki/Passive_monitors
● Generic quorum service/library ?38

Conclusions

Conclusions
● OpenStack and Ceph provide HA if carefully planed○ Be aware of potential failure scenarios!○ All Quorum decisions must be in sync○ Third room must be used○ Replica distribution and spare capacity must be considered○ Ceph need more extended quorum information
● Target for five 9’s is E2E○ Five 9’s on data center level very expensive○ NO PETS, NO PETS, NO PETS !!!○ Distribute applications or services over multiple DCs
40

Get involved !
● Ceph○ https://ceph.com/community/contribute/ ○ [email protected]○ IRC: OFTC
■ #ceph, ■ #ceph-devel
● OpenStack○ Cinder, Glance, Manila, ...
41

dalgaaf
blog.bisect.de
@dannnyalgaaf
linkedin.com/in/dalgaaf
xing.com/profile/Danny_AlGaaf
Danny Al-Gaaf Senior Cloud Technologist
Q&A - THANK YOU!





























