Embed Size (px)
Citation preview

Deep Speech Scaling up end-‐to-‐end deep learning for speech
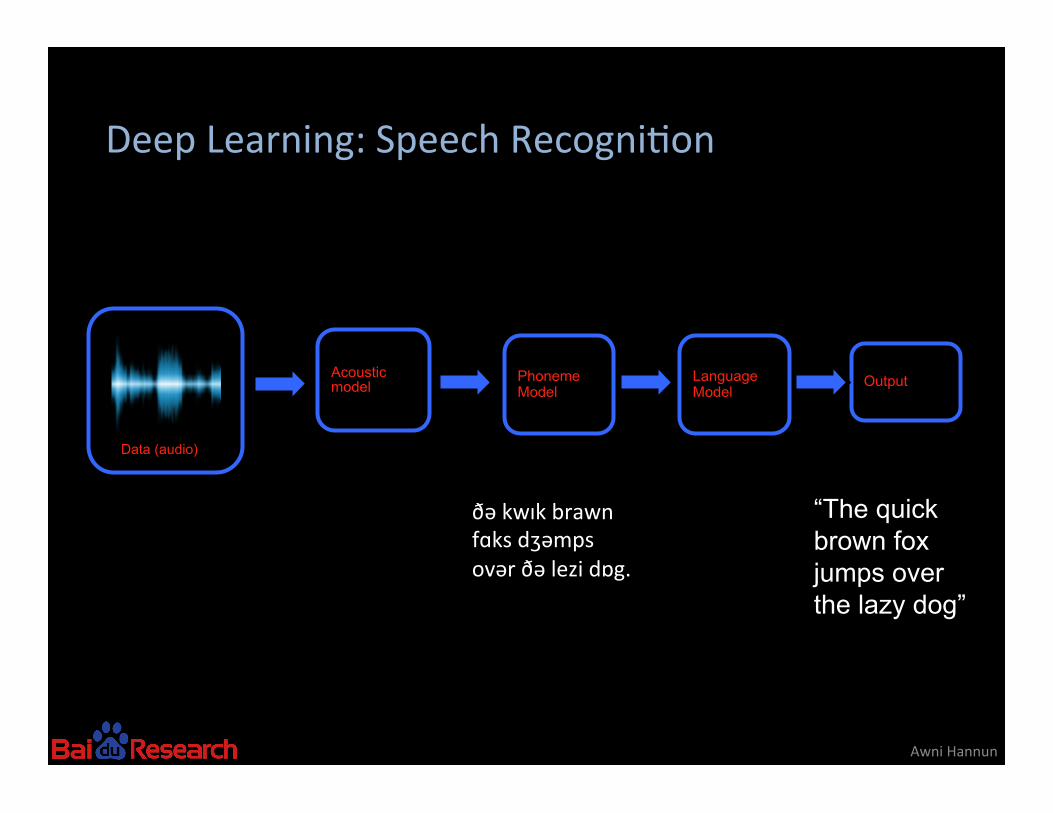
Deep Learning: Speech Recogni8on
Awni Hannun
Data (audio)
Output
Phoneme Model
Language Model
Acoustic model
“The quick brown fox jumps over the lazy dog”
ðə kwɪk brawn fɑks dʒəmps ovər ðə lezi dɒg.
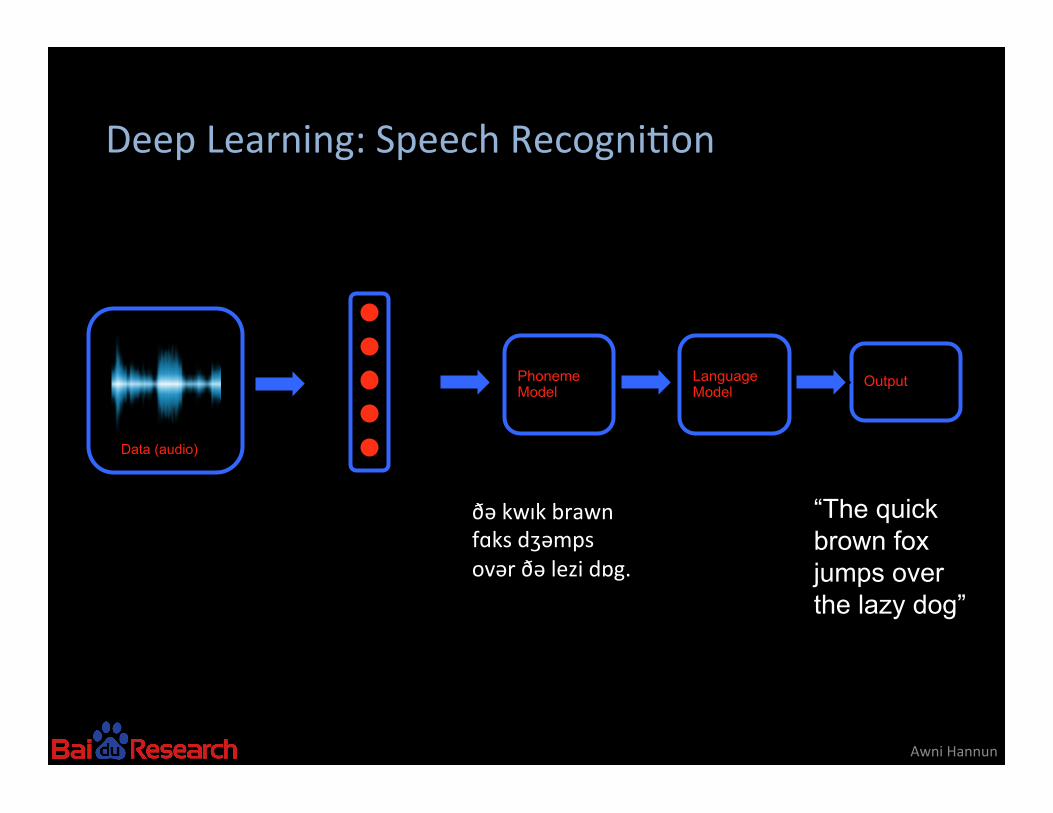
Deep Learning: Speech Recogni8on
Awni Hannun
Data (audio)
Output
Phoneme Model
Language Model
“The quick brown fox jumps over the lazy dog”
ðə kwɪk brawn fɑks dʒəmps ovər ðə lezi dɒg.
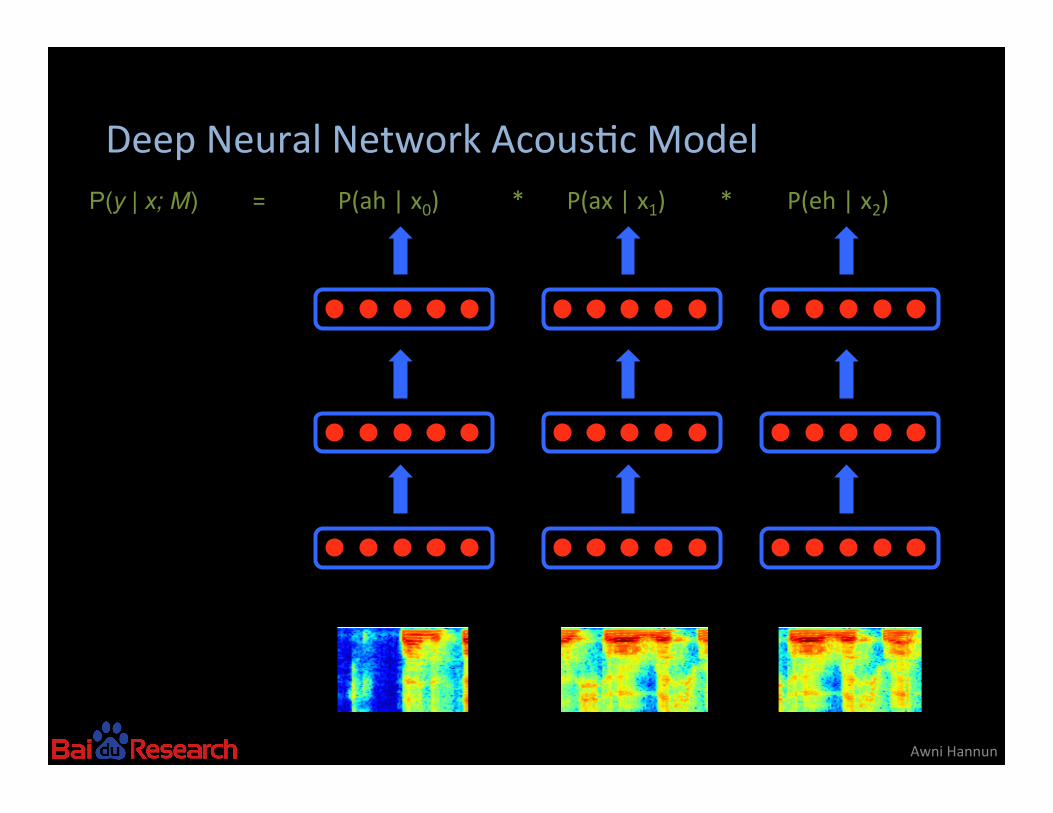
Deep Neural Network Acous8c Model
Awni Hannun
P(y | x; M) = P(ah | x0) * P(ax | x1) * P(eh | x2)
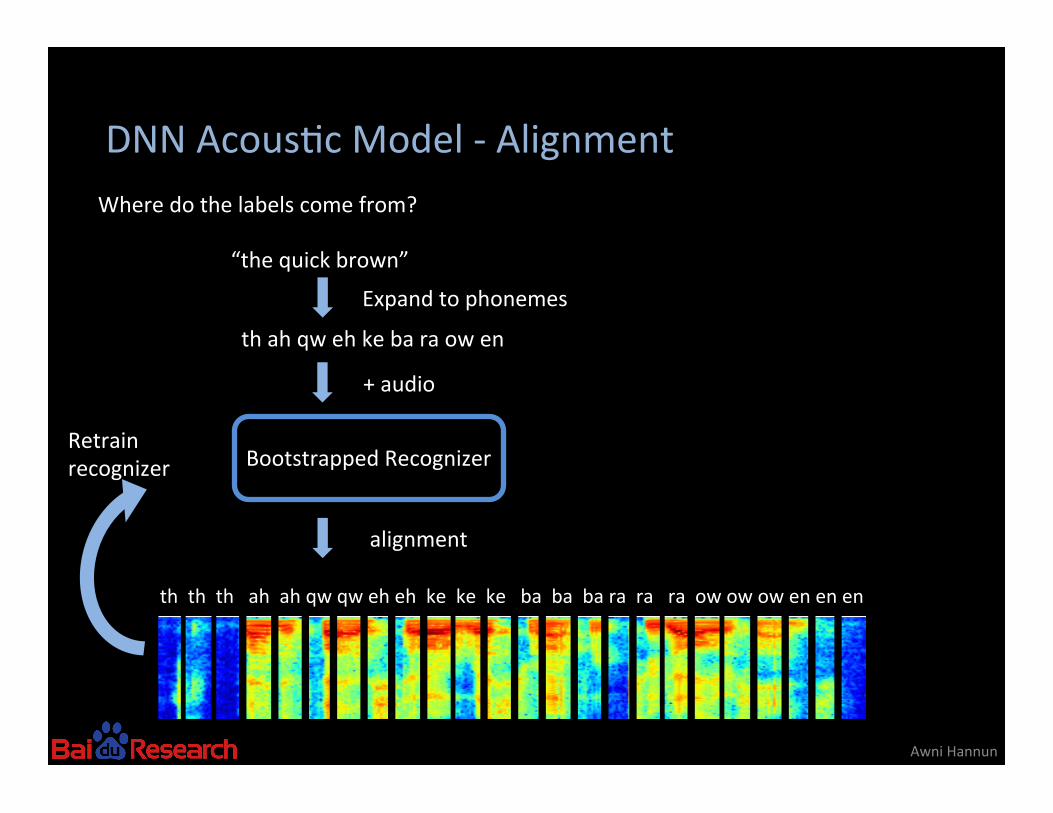
DNN Acous8c Model -‐ Alignment
Awni Hannun
“the quick brown”
Where do the labels come from?
th ah qw eh ke ba ra ow en
Expand to phonemes
Bootstrapped Recognizer
+ audio
th th th ah ah qw qw eh eh ke ke ke ba ba ba ra ra ra ow ow ow en en en
alignment
Retrain recognizer
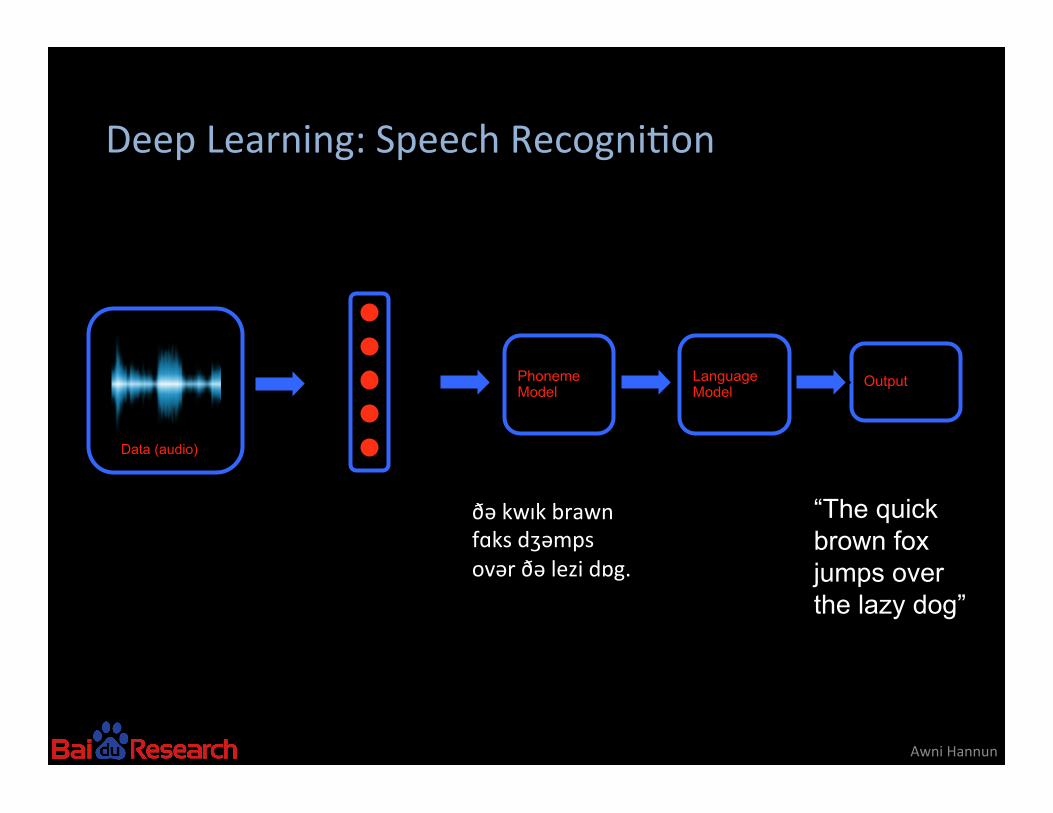
Deep Learning: Speech Recogni8on
Awni Hannun
Data (audio)
Output
Phoneme Model
Language Model
“The quick brown fox jumps over the lazy dog”
ðə kwɪk brawn fɑks dʒəmps ovər ðə lezi dɒg.
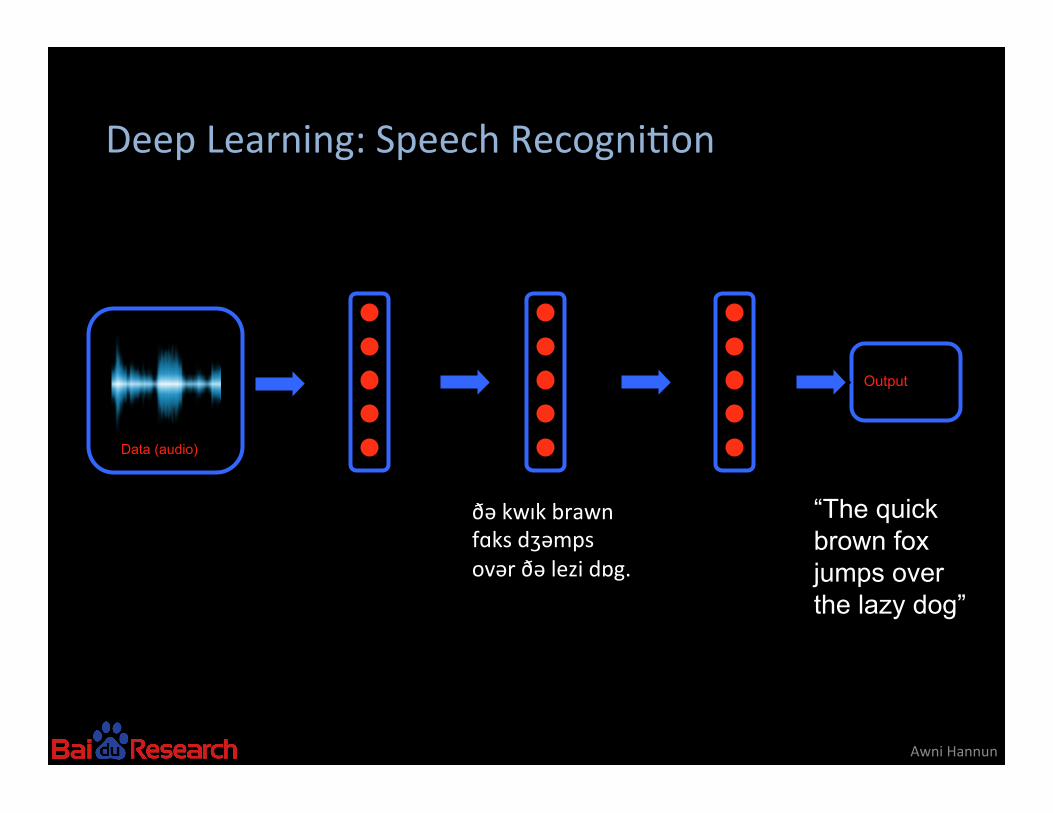
Deep Learning: Speech Recogni8on
Awni Hannun
Data (audio)
Output
“The quick brown fox jumps over the lazy dog”
ðə kwɪk brawn fɑks dʒəmps ovər ðə lezi dɒg.

Deep Speech – Key ingredients
Awni Hannun
• Model • No alignment needed, using objective from [Graves,
Fernandez, Gomez and Schmidhuber, 2006]
• Data
• Computation (GPUs)

Two hard modeling problems
Awni Hannun
y = “the quick brown …”
1. Loss function – compute P(y | x; M)
2. Inference - Find y* = argmaxy P(y | x; M)
Must handle variable length input and output
x =
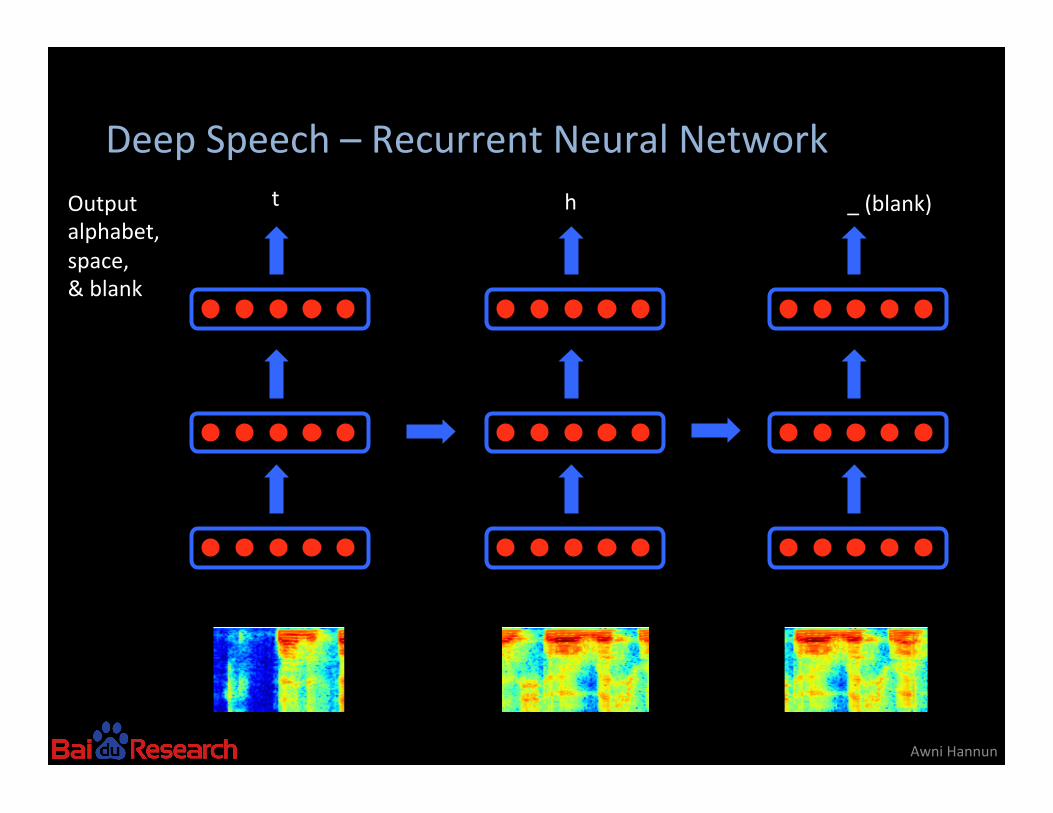
Deep Speech – Recurrent Neural Network
Awni Hannun
t h _ (blank) Output alphabet, space, & blank
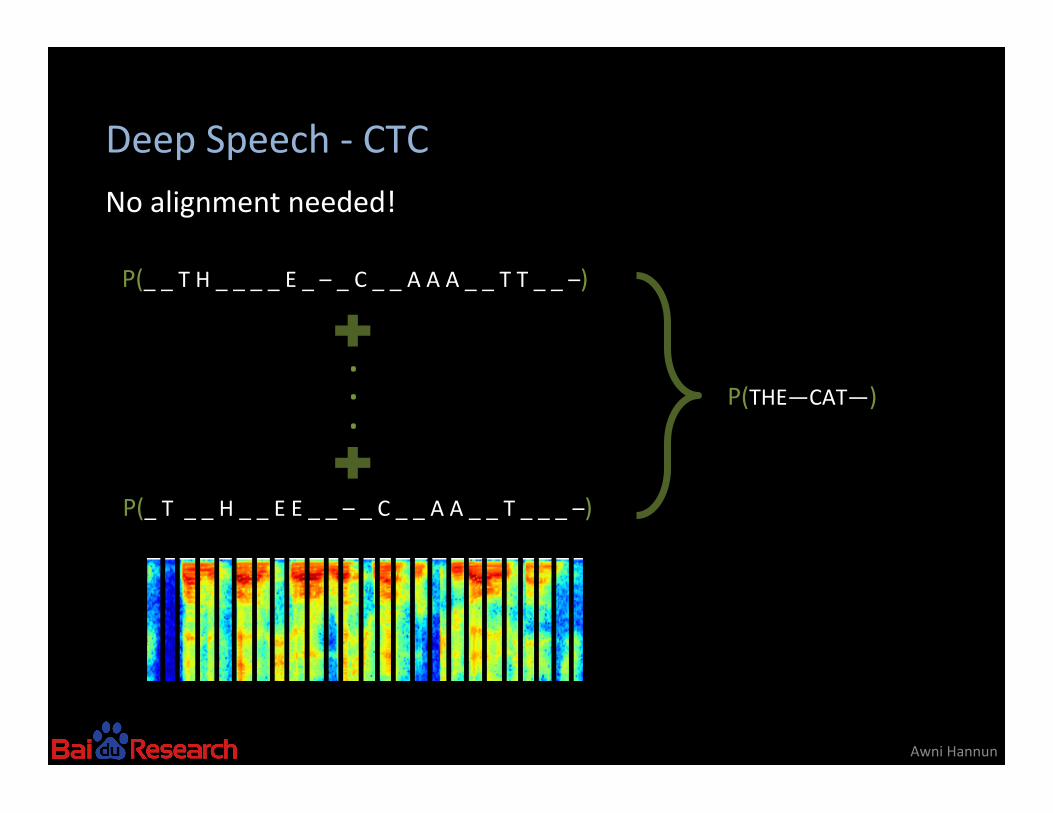
Deep Speech -‐ CTC
Awni Hannun
No alignment needed!
P(_ _ T H _ _ _ _ E _ – _ C _ _ A A A _ _ T T _ _ –)
P(_ T _ _ H _ _ E E _ _ – _ C _ _ A A _ _ T _ _ _ –)
P(THE—CAT—)
. . .

Deep Speech -‐ Data
Awni Hannun
House
Translated House Reflected House Rotated house
Data – Synthe8c

Deep Speech -‐ Data
Awni Hannun
Speech
Noise
Noisy Speech
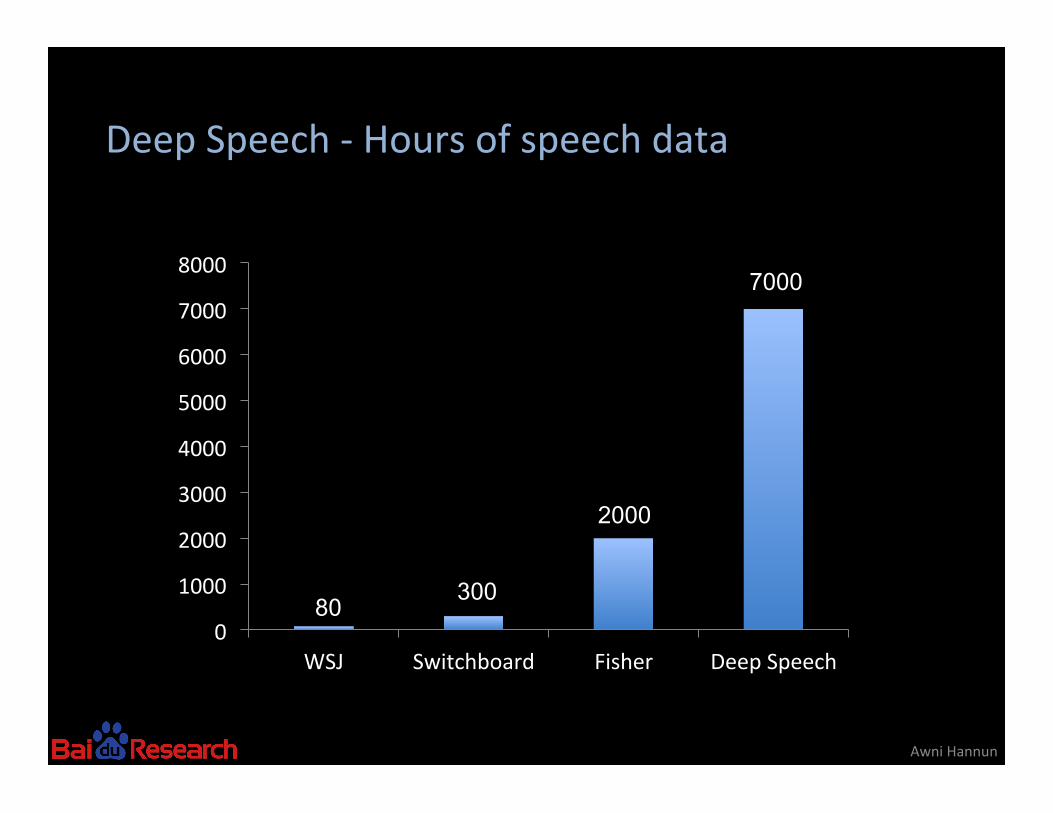
Deep Speech -‐ Hours of speech data
0
1000
2000
3000
4000
5000
6000
7000
8000
WSJ Switchboard Fisher Deep Speech
Series 1
80 300
2000
7000
Awni Hannun
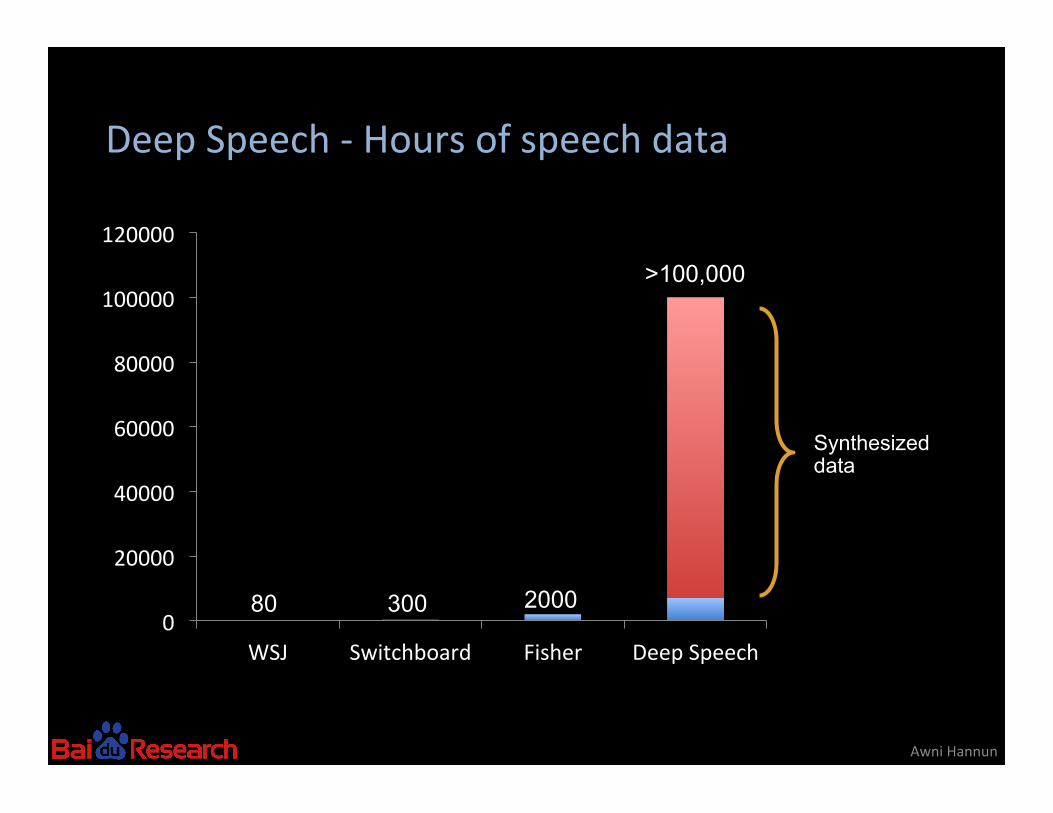
Deep Speech -‐ Hours of speech data
0
20000
40000
60000
80000
100000
120000
WSJ Switchboard Fisher Deep Speech
80 300 2000
>100,000
Synthesized data
Awni Hannun

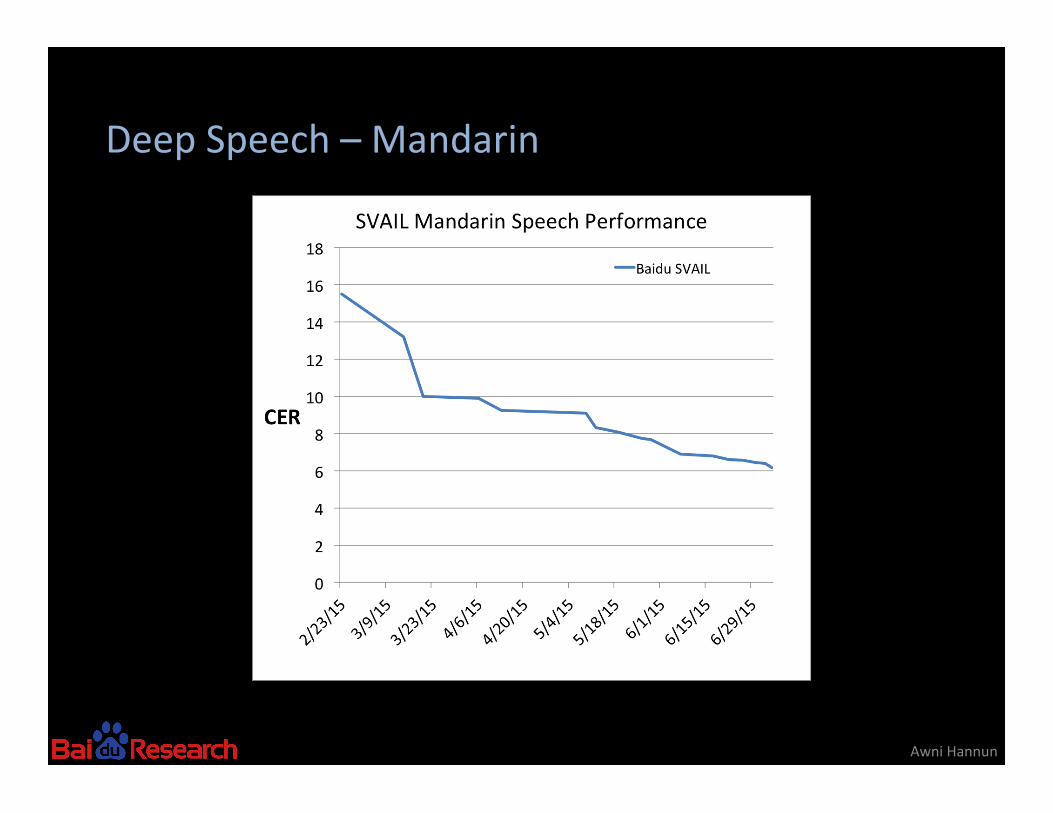
Deep Speech – Mandarin
Awni Hannun
Mandarin is a tonal language
Hz
Time
Model can learn pitch from Spectrogram

Deep Speech – Mandarin
Awni Hannun
Thousands of characters! > 80K
Pinyin?
Deep Speech – Mandarin
Awni Hannun








![Deep learning for end-to-end speech recognitionttic.uchicago.edu/~llu/pdf/liang_ttic_slides.pdf · + 2nd pass with various features p 19.9 CTC [Graves 2013] ... Vocabulary End-to-End](https://img.pdfslide.net/doc/110x75/5ec67ae718bbe609472157ca/deep-learning-for-end-to-end-speech-llupdfliangtticslidespdf-2nd-pass-with.jpg)




















