Embed Size (px)
Citation preview

text data
analyticscusto
mer unstructured
Biguse
characteristicsScorecard
extraction
words
Data
predic
tivebehavior
techno
logy
unders
tand
decisio
ns
structured
interactions
result
s
predictors
extrac
tedtag
ged
LDA
change
analy
zing
statis
tical
based
docum
entnew
operat
ional
Textrange
strong
addition historical
insights
right sales
ability
predict
distributed
need
process
meaning
automated
NEE
multiple
businessbetter
Semantic
availab
lesource
s
changi
ng
source
value
perfor
mance
improve
example
mode
ls time
entities
processing
techn
iques
segme
ntation
topics
discover
meaningful
algori
thms analysis
intel
ligen
ce
numerical
major
» insights
Extracting Value from Unstructured DataText analytics discover new predictive customer insights in a major source of untapped data
Even the most customer-centric businesses today are making decisions about their customers based
on only about 20% of available data. Much of the untapped 80%—data that is unstructured—could
be yielding not only more insights but different and complementary insights. This new intelligence
improves the ability to predict customer behavior, as well as understand and respond to the needs
and motivations behind it.
Text analytics helps to deliver this fresh intelligence by mining a major category of unstructured
data—one many organizations currently have on hand. Customer-related text may be abundant
and available, but most organizations don’t know how to efficiently extract predictive elements from
it. They don’t know how to reap the value of these insights by using them to boost the performance
of predictive analytics and make better operational customer decisions.
This white paper discusses how text analytics can help bring Big Data benefits to your organization’s
bottom line. It covers:
• Understanding what text analytics is and how it can help you.
• Boosting the performance of existing models with text-derived insights.
• Using text-derived insights to improve segmentation,
decisions strategies and customer interactions.
• Exploring how text analytics reveal behavioral context, and
can provide clues to what customers are thinking and feeling.
• Choosing the right text analytic techniques for your objectives.
Number 71—October 2013
Done right, extracting valuable predictive insights from huge quantities of text takes just seconds.
www.fico.com Make every decision countTM

www.fico.com page 2
Extracting Value from Unstructured Data
» insights
As organizations strive to become more customer-centric and deliver ever-better service, they
need additional sources of data-driven insights. Text is a major untapped potential source of
these insights—if structured in ways that make it usable by traditional analytic models. There are
also opportunities to use insights from text independently and with insights from other types of
unstructured data.
The time to unlock this value is now. For many organizations, text currently accounts for
the largest percentage of unstructured data that is on hand or easily accessible. New sources
of text—for instance, from blogs, Twitter feeds and other social media—are proliferating.
And text analytics, which provides the means to do the unlocking, has reached a level of
developmental maturity suitable for widespread use. In its Hype Cycle for Big Data, 2013
(July 2013), Gartner positions text analytics as having high benefit and projects mainstream
adoption within two to five years.
What has brought text analytics to this point of readiness? Recent technological advances are
solving many of the problems that posed obstacles in the past:
• Transforming for machine insights. Text in email messages, call center logs, new business
applications and collections agent notes is readily understood by us, but it’s meaningless
to traditional predictive models. A variety of machine learning methods, however, can
determine what texts are about and classify them for further analysis. They can discover
customer characteristics and transform them into structured numerical inputs that are
comprehensible to predictive models and other types of traditional analytic algorithms.
• Handling complexity. Unstructured and semi-structured text (e.g., XML files, Excel
spreadsheets, weblogs) is inherently complex since it may contain a wide range of content
on a wide range of topics. Moreover, the potential value of text analysis is often increased by
combining text of different types from multiple sources. Such a comprehensive approach
may reveal complex, subtle customer behavior patterns not evident in smaller, more
homogeneous document sets. But the task of collating, regularizing and organizing diverse
data would be impossible without today’s advanced technologies. We now have the analytic
techniques and data infrastructures to essentially merge disparate varieties of text into one
“document” for analysis.
• Facilitating engineering, deployment, management and regulatory compliance.
While text and the process of analyzing it can be quite complex, the results need to be simple
to understand and use. Today we can bring new insights from text analysis into predictive
scorecards, for example, maintaining all the advantages they provide. The resulting scorecard
has higher predictive power, but can still be engineered to meet specific business needs
and regulatory requirements. It’s easily deployed into rules-driven decision processes and
operational workflows. It’s easy to manage, including tracking performance, automating
updates and measuring the impact of change. The contribution of text analysis is transparent,
explainable to regulators, and documentable through automated audit trails and regular
validation and compliance reporting.
» Why Text Analytics Now

www.fico.com page 3
Extracting Value from Unstructured Data
» insights » insights
• Scalable processing. While in many cases text analysis can be performed on a stand-
alone PC, there are situations where the quantity of text and number of potential customer
characteristics it contains are immense. Today’s Big Data infrastructures can perform analysis
at this scale with extreme efficiency and speed. Open source implementations of the
MapReduce programming model and Hadoop distributed file system, for instance, process
very large data sets in parallel across processor grids of enormous size. Storm, another open
source distributed computation system, provides near-real-time distributed processing.
All of these developments have come together to make now the time for getting started with
text analytics. In addition, the full range of capabilities—including advanced algorithms and
Big Data infrastructures—are becoming available through cloud-based services. Without deep-
pocket investment, organizations of all types and sizes can tap into these powerful technologies
to better serve their customers or constituents.
Text analytics is not a single technology. It’s a convergence of many disciplines and technologies
around the problem of extracting meaningful signals from text, as shown in Figure 1. Some of
these contributors have been around for a long time, and some are newer and rapidly advancing.
At the end of this paper, you’ll find guidance for determining the right one for your application.
» How to Use Text Analytics
FIGURE 1 HERE
Text Mining
Text Analytics
WebMining
InformationRetrieval
NaturalLanguageProcessing
ConceptExtraction
Clustering
InformationExtraction
Statistics
Computer Science Other Disciplines
Machine Learning
Management Science
Inverted IndexDocument MatchingSearch Optimization
Co-ReferenceRelationship Extraction
Entity Extraction
ColocationsWord Association
Sentiment Analysis
TokenizationPart-of-Speech
TaggingLemmatization
Document SimilarityDocument Clustering
Document RankingDocument
Categorization
Alert Detection
Web AnalyticsWeb Content Mining
Web Structure Analysis
Classification
Artificial Intelligence
Figure 1: Text analytics comprises many rapidly advancing technologies
Source: Miner, Gary, et al. Practical Text Mining and Statistical Analysis for Non-structured Text Data Applications: 2012. Print.

www.fico.com page 4
Extracting Value from Unstructured Data
» insights
The best place to start, however, is not with technology but with how you want to use
text-extracted insights:
• Is your objective to improve an analytic model’s ability to predict a particular
customer behavior? Are you looking for additional insights into the likelihood that a
customer will, say, purchase a certain product, become 60-days delinquent or attrite?
• Is your objective to more generally increase analytic insights for better
segmentation, decision strategies and interactions? Are you trying, for example, to
better understand why you’re losing some of your best customers to attrition or how to
improve your collections results with certain types of customers?
As depicted in Figure 2, text-derived customer characteristics can be used for both
types of objectives.
On the left branch, the graphic shows that once transformed into structured numerical
inputs, text-derived characteristics can be used with traditional supervised analytic
techniques. These use historical data tagged with observed outcomes (e.g., fraud/no
fraud, purchase within six weeks, delinquent account paid/rolled over) to train models
to predict a targeted customer behavior.
A text-derived characteristic could potentially
be used in multiple models, where its
information value depends on the degree
to which it correlates with the targeted
customer behavior.
The right branch incorporates text-derived
characteristics into unsupervised analytic
techniques that do not require tagged
historical data. These include analytic
methods for improving segmentation,
deepening understanding of individual
customers, adapting decision strategies to
customer needs and behavior context, and
even triggering timely actions in response to
changing customer behavior and attitudes.
Let’s look in more detail at how text-derived
insights can improve results in both supervised
and unsupervised analytics.
Using text-derived characteristics in supervised analytic techniques
Organizations that already have predictive models built with structured data can boost the
performance of these models by analyzing text they already have or routinely generate. Hidden
in this text may be numerous customer characteristics that could have predictive value when
used with characteristics from structured data.
Text Mining Objective
Use text-derived customer characteristics for:
Increasing insights forsegmentation & decisions
Unsupervised analyticse.g., classification, segmentation,
self-calibrating outlier models, Latent Dirichlet Allocation
Improving performance of a predictive model
Supervised analyticse.g., scorecards, attrition models, response models
Figure 2: Text-derived customer characteristics can be used in both supervised and unsupervised analytics
» Boost the Performance of Existing Models
www.fico.com page 5
Extracting Value from Unstructured Data
» insights
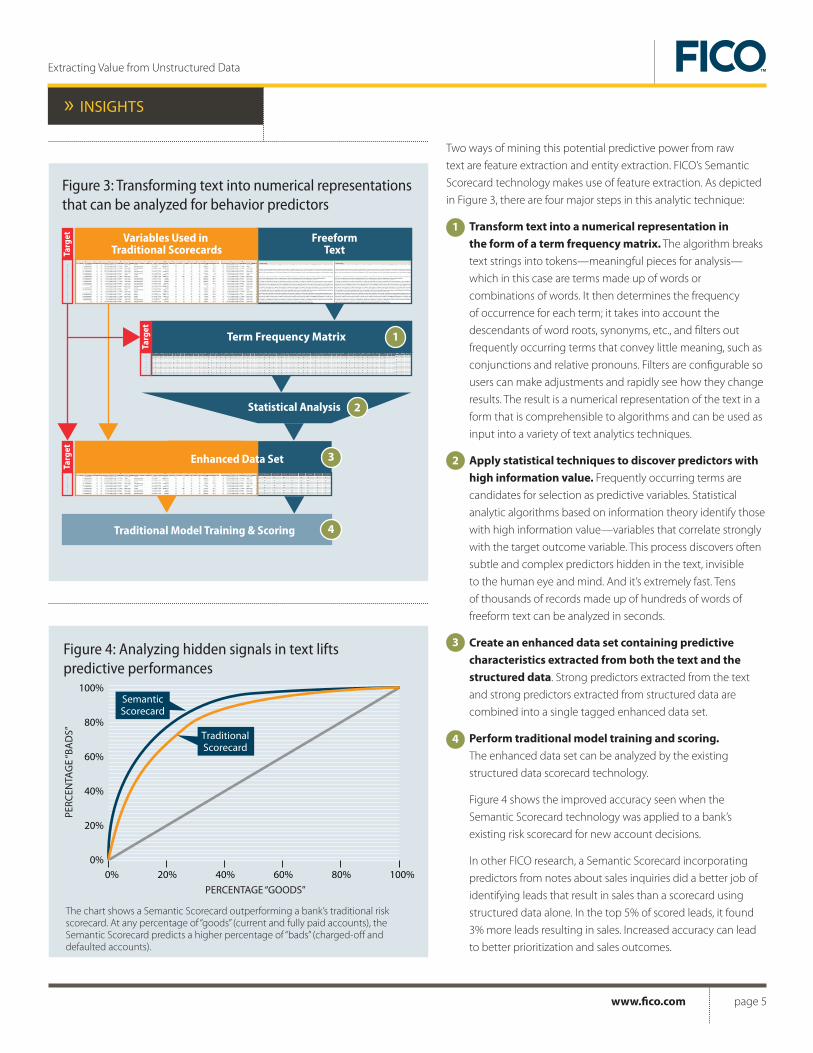
Two ways of mining this potential predictive power from raw
text are feature extraction and entity extraction. FICO’s Semantic
Scorecard technology makes use of feature extraction. As depicted
in Figure 3, there are four major steps in this analytic technique:
Transform text into a numerical representation in
the form of a term frequency matrix. The algorithm breaks
text strings into tokens—meaningful pieces for analysis—
which in this case are terms made up of words or
combinations of words. It then determines the frequency
of occurrence for each term; it takes into account the
descendants of word roots, synonyms, etc., and filters out
frequently occurring terms that convey little meaning, such as
conjunctions and relative pronouns. Filters are configurable so
users can make adjustments and rapidly see how they change
results. The result is a numerical representation of the text in a
form that is comprehensible to algorithms and can be used as
input into a variety of text analytics techniques.
Apply statistical techniques to discover predictors with
high information value. Frequently occurring terms are
candidates for selection as predictive variables. Statistical
analytic algorithms based on information theory identify those
with high information value—variables that correlate strongly
with the target outcome variable. This process discovers often
subtle and complex predictors hidden in the text, invisible
to the human eye and mind. And it’s extremely fast. Tens
of thousands of records made up of hundreds of words of
freeform text can be analyzed in seconds.
Create an enhanced data set containing predictive
characteristics extracted from both the text and the
structured data. Strong predictors extracted from the text
and strong predictors extracted from structured data are
combined into a single tagged enhanced data set.
Perform traditional model training and scoring.
The enhanced data set can be analyzed by the existing
structured data scorecard technology.
Figure 4 shows the improved accuracy seen when the
Semantic Scorecard technology was applied to a bank’s
existing risk scorecard for new account decisions.
In other FICO research, a Semantic Scorecard incorporating
predictors from notes about sales inquiries did a better job of
identifying leads that result in sales than a scorecard using
structured data alone. In the top 5% of scored leads, it found
3% more leads resulting in sales. Increased accuracy can lead
to better prioritization and sales outcomes.
Figure 3: Transforming text into numerical representations that can be analyzed for behavior predictors
Term Frequency Matrix
Traditional Model Training & Scoring
Statistical Analysis
1
2
3
4
FreeformText
Variables Used in Traditional Scorecards
01100100011010111001101
Targ
et
0
1
1
1
0
0
1
Targ
et
0111001101
Targ
et
Enhanced Data Set
Figure 4: Analyzing hidden signals in text lifts predictive performances
0%
20%
40%
60%
80%
100%
0% 20% 40% 60% 80% 100%
PERC
ENTA
GE
“BA
DS”
PERCENTAGE “GOODS”
TraditionalScorecard
SemanticScorecard
The chart shows a Semantic Scorecard outperforming a bank’s traditional risk scorecard. At any percentage of “goods” (current and fully paid accounts), the Semantic Scorecard predicts a higher percentage of “bads” (charged-off and defaulted accounts).
1
2
3
4

www.fico.com page 6
Extracting Value from Unstructured Data
» insights
For the same project, we also employed named entity extraction (NEE) as a complementary
technique. NEE is based on natural language processing, which draws on the disciplines of
computer science, artificial intelligence and linguistics. By analyzing the structure of the text, NEE
determines which parts of it are likely to represent entities such as people, locations, organizations,
job titles, money, percentages, dates and times.
One reason NEE is compatible with scorecards is that both techniques enable strategy engineering.
For every entity identified, the NEE algorithm generates a score indicating the probability that the
identification is correct. Engineers can set thresholds—accepting only those entities with a score
above 80%, for example.
In this project, we used extracted entities with a similarity-based matching algorithm to join
records from different kinds of files having no direct links (e.g., a structured file containing customer
information and unstructured texts about interactions with the customer). In addition, by combining
extracted entities, we were able to impute an individual’s authority to make a purchase decision—a
strong predictor for improving intelligent automated lead generation that is not directly available in
the dataset.
This customer characteristic and others that prove to have high information value (i.e., to correlate
strongly with the targeted customer behavior) can be incorporated into the Semantic Scorecard or
another type of supervised model. They can also be used in unsupervised analytics, which we’ll look
at next.
Using text-derived characteristics in unsupervised analytic techniques
Text-derived characteristics provide insights for improving population segmentation, as well as
individualized customer decisions and interactions. They can also be used for models that do not
require training with historical data.
Consider the named entity extraction we described in the previous section. Such entities could be
used to refine peer group definitions for self-calibrating outlier models that detect changes in
customer behavior. These models can incorporate new customer characteristics without training
on tagged historical data. In production, they determine on the fly, from ongoing customer
activity, what the current normal ranges of values are for these characteristics. Out-of-range values
can trigger alerts. This patented FICO technology is critical to streaming analytic problems where
the algorithms must continuously update, in real time, estimates of feature distributions so that
detection of outliers is always based on the current distributions.
Another analytic technique effective for segmentation, as well as for detecting changing customer
behavior, is Latent Dirichlet Allocation (LDA) and related methods for finding similarities in data that
enable classification and grouping. LDA is an unsupervised statistical method of extracting topics,
concepts and other types of meaning from unstructured data. It doesn’t understand syntax or any
other aspect of human language. It’s looking for patterns, and it does that equally well no matter
what language text is in, or even if it consists of just symbols rather than characters.
LDA could be used to examine a blog with a 100,000 posts, for example, to determine what the
blog is about overall. The algorithm could identify four or five predominant topics or “archetypes” of
content. It could also be applied to a heterogeneous mix of text. In fact, any type of unstructured,
semi-structured and structured data from any number of sources can be combined into a single
“document” for LDA to find patterns across them.
» Understanding Customers and Their Changing Behavior

www.fico.com page 7
Extracting Value from Unstructured Data
» insights
This very flexible technique is commonly used in marketing to generate archetypes for customers
with similar behaviors. FICO is also using this approach to analyze a bank’s call center data. The
goal is to identify meaningful reasons why customers are calling, and use these insights to better
understand and predict attrition risk.
Among the useful discoveries so far: Customers mapping strongly to a frequent traveler archetype
are among the least likely to attrite. Moreover, if these customers interact with a call center
representative regarding a payment missed due to traveling—resulting in waiver of the late fee—
attrition becomes even less likely. This insight could help focus the budget for late fee waivers
where it will have a strong impact on improving attrition rates.
In another area of application, fraud detection, FICO has developed Collaborative Profiles, a patent-
pending streaming version of LDA. As shown in Figure 6, by analyzing card transactions, Collaborative
Profiles represent a real customer as a distribution across multiple archetypes—and updates the
distribution continuously, with each transaction.
Figure 5: Using LDA to generate archetypes from text“Bag of words”—collection of words from call transcripts (size indicates frequency of occurrence)
20.1% 11.3% 22% 38.5% 8.1%
Generation of call center content archetypes—determining customer topics
Call center text
Mapping of customer interactions to archetypes by % of match
Karen’s calls
notice. I missed only one paymente I was out of town and now I’veh hit by a late fee that I don’t feelI’d have to pay. I want to make my account is not reported toto bureaus as delinquint. I’ve beenformer more than five years andally pay my bills on time. Why cabank know me well enough to understand that I have to travelequently for my work thereforealways meet their imposed deadlines. If you want to keep my business you need to show me more
notice. I missed only one paymente I was out of town and now I’veh hit by a late fee that I don’t feelI’d have to pay. I want to make my account is not reported toto bureaus as delinquint. I’ve beenformer more than five years andally pay my bills on time. Why cabank know me well enough to understand that I have to travelequently for my work thereforealways meet their imposed deadlines. If you want to keep my business you need to show me more
notice. I missed only one paymente I was out of town and now I’veh hit by a late fee that I don’t feelI’d have to pay. I want to make my account is not reported toto bureaus as delinquint. I’ve beenformer more than five years andally pay my bills on time. Why cabank know me well enough to understand that I have to travelequently for my work thereforealways meet their imposed deadlines. If you want to keep my business you need to show me more
notice. I missed only one paymente I was out of town and now I’veh hit by a late fee that I don’t feelI’d have to pay. I want to make my account is not reported toto bureaus as delinquent. I’ve beenformer more than five years andally pay my bills on time. Why cabank know me well enough to understand that I have to travelequently for my work thereforealways meet their imposed deadlines. If you want to keep my business you need to show me more
Real-time updates fromtransaction streams
Actual customer Casey Dynamic mapping of Casey’s behavior to multiplearchetypes by % of match
32.8% 2.6% 49.3% 0.5% 14.8%
35.2% 2.4% 50.5% 0.1% 11.8%
39.2% 1.3% 52.1% 0.3% 7.1%
Figure 6: Using Collaborative Profiles to update customer archetype distributions in real time

www.fico.com page 8
Extracting Value from Unstructured Data
» insights
An advantage of this streaming technique is that, based on the delta between the current
distribution and the updated one, Collaborative Profiles can trigger an alert that a significant
change in customer behavior is underway. For example, by analyzing collectors’ notes over the
course of several interactions regarding a delinquent bill, Collaborative Profiles could detect
that the customer is becoming frustrated, angry or losing confidence in his eventual ability to
repay the debt. Perhaps a new factor has entered the equation, such as a family member falling
ill, which may require an adjustment in collections strategy. This type of analysis could even
signal a change in intent—identifying the moment when a customer who originally intended
to pay consciously or unconsciously gives himself permission not to.
Digging deeper for insights into not only how customers are likely to behave, but also what
they’re thinking and feeling is an area of text analytics generally referred to as sentiment
analysis. The analytic techniques used are often based on natural language processing (NLP),
but they may also be statistical or a hybrid of these.
Traditionally, supervised methods have been
used to analyze the “polarity” of a document
or phrase: Is it positive, negative or neutral? At
the most basic level, this classification is done
by simple statistical methods like key word
indexing. More sophisticated NLP approaches
try to understand the semantic context in
which key words appear to determine degree
of positive or negative sentiment. Some
are able to track and compare changes in
sentiment over time.
Unsupervised techniques that, like LDA, can
extract topics from text are also being used to
identify a wider range of customer issues and
attitudes. Among them are latent semantic
analysis (LSA) and latent semantic indexing (LSI).
These are attractive not only because they can
be applied to unclassified text, but also because
they can discover unknown and emerging
customer sentiments. They can also be used at
a macro level to identify attitudinal shifts and
developing trends within a market.
Some of the most promising and challenging
areas of development seek to use natural
language processing to understand what
customers really mean when they use a set of words. For example, is the phrase “That’s great”
always positive? What does it mean when the client says “Yeah, sure, sure”? Often we humans
express ourselves in ambiguous ways or employ sarcasm. As more and more customer
interactions take place through email, chat and text messaging rather than phone calls, we lose
the crucial clues to meaning that come from voice tonality and emphasis. The cutting edge of
sentiment analysis seeks to pick up these subtleties through other automated means.
» How Deep Can We Go?
to learn more about text analytics and FiCO’s semantic scorecard technology,
read the FICO ebook (registration required).

www.fico.com page 9
Extracting Value from Unstructured Data
» insights
» Choosing the Right Text Analytic Technique
This overview of several text analytics applications demonstrates the wide range of methods that
can be employed to extract value. Once you have the answer to the fundamental question of how
you want to use text-extracted insights, there are other questions that can help you select the right
techniques for your purpose. The simplified decision tree in Figure 7 is provided as one possible
example of how to think through some of the possibilities.
Figure 7: Example of sorting through text analytics possibilities to select the right approach for your purpose
WordsDocuments
Text Mining Application
Structure Meaning
Concept ExtractionNatural Language Processing
Specific facts Understanding
Is your focus on the meaning of the text or on the structure?
Information Extraction
Do you want to automatically identify specific facts or gain overall understanding?
Independent Connected
Web MiningDocument Classification
No categories Have categories
Are your documents independent or connected via hyperlinks?
Clustering
Search Sort
Do you have categories already? Information Retrieval
Do you want to sort documents into groups or search for specific documents?
OR Individual words and phrases?Sentences, paragraphs, document analysis?
the latest release of FICO® Model Builder, our complete analytic
development environment, includes extensive capabilities for
Big Data text analytics. these include FiCO’s proprietary semantic
scorecard technology for combining predictors discovered in
both text and structured data into a single, easy to deploy and
manage scorecard. Model Builder also provides access to scalable
data processing via hadoop and to the huge library of algorithms
(including for entity extraction, topic modeling and sentiment
analysis) from R, the open source statistical programming
language. in addition, Model Builder ships with the tika and
Lucene libraries for text extraction and indexing.
FICO® Decision Management Platform, accessible soon
via cloud-based services, provides everything you need to
quickly and efficiently bring text-extracted insights to bear on
operational decisions. it includes Big Data infrastructure, rapid
application development (RAD) tools and decision applications.
FICO® Model Central™ Solution provides the means to deploy,
track, validate, monitor and manage a wide range of analytics
to improve bottom-line impact and regulatory compliance. this
kind of centralized control is increasingly crucial today as analytics
become part of almost every customer operational decision, and
the number and variety of models in use expands dramatically.
Among the specific benefits for text analytics is the ability
to assess change by tracking volatility in the prevalence and
importance of topics, entities and other text-extracted insights.
FICO Text Analytics Solutions

Extracting Value from Unstructured Data
» insights
The Insights white paper series
provides briefings on research
findings and product development
directions from FICO. To subscribe,
go to www.fico.com/insights.
FICO, Model Central and “Make every decision count” are trademarks or registered trademarks of Fair Isaac Corporation in the United States and in other countries. Other product and company names herein may be trademarks of their respective owners. © 2013 Fair Isaac Corporation. All rights reserved.3017WP 10/13 PDF
For more information North America toll-free International email web +1 888 342 6336 +44 (0) 207 940 8718 [email protected] www.fico.com
» Conclusion—Make Decisions Based on All the Data
The obstacles that once forced organizations to make operational decisions based on a partial
representation of customer data are now falling away. Leaders in all industries and sectors are
beginning to make decisions on an increasingly wide range of Big Data—including vast stores
of text they already have. Text analytics are delivering abundant, fresh customer insights to fuel
higher levels of customer service and business performance.
To learn more about advances in Big Data analytics and related technologies, visit the
FICO Labs Blog or read these Insights papers:
• When Is Big Data the Way to Customer Centricity?
• Is It Fraud? Or New Behavior?
• From Big Data to Big Marketing: Seven Essentials

![[poster] Structured and Unstructured: Extracting Information from Classics Scholarly Texts](https://img.pdfslide.net/doc/110x75/558dfd241a28abb50d8b45de/poster-structured-and-unstructured-extracting-information-from-classics-scholarly-texts.jpg)



























