Embed Size (px)
Citation preview

Page 1 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive on Spark is Blazing Fast… Or Is It?
Carter Shanklin and Mostafa Mokhtar

Page 2 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Why SQL on Hadoop? Solving for Scale.
Hadoop is great forcost, but MapReduce istoo difficult.
SQL on Hadoop makesHadoop real and givesme scale that traditionalSQL can’t offer.
I’m deleting importantdata because it’s tooexpensive to store it.
$

Page 3 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
SQL at Facebook: Emergence of Apache Hive
Developed Hive to address traditional RDBMS limitations.300+ PB of data under management(1).600+ TB of data loaded daily.60,000+ Hive queries per day(2).More than 1,000 users per day.Initial Apache release in April 2009.

Page 4 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive Classic: Strengths and Challenges
Familiar SQL Interface+
Economical Processing of Petabytes+
Hive Classic tied to MapReduce, leading to latency
Traditional SQL Workloads Needed Higher Performance!

Page 5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Need for Speed: The Stinger Initiative
Stinger: An Open Roadmap to improve Apache Hive’s performance 100x.
Launched: February 2013; Delivered: April 2014.
Delivered in 100% Apache Open Source.
SQL Engine
VectorizedSQL Engine
ColumnarStorage
ORCFile
= 100X+ +
Distributed Execution
Apache Tez
Page 6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
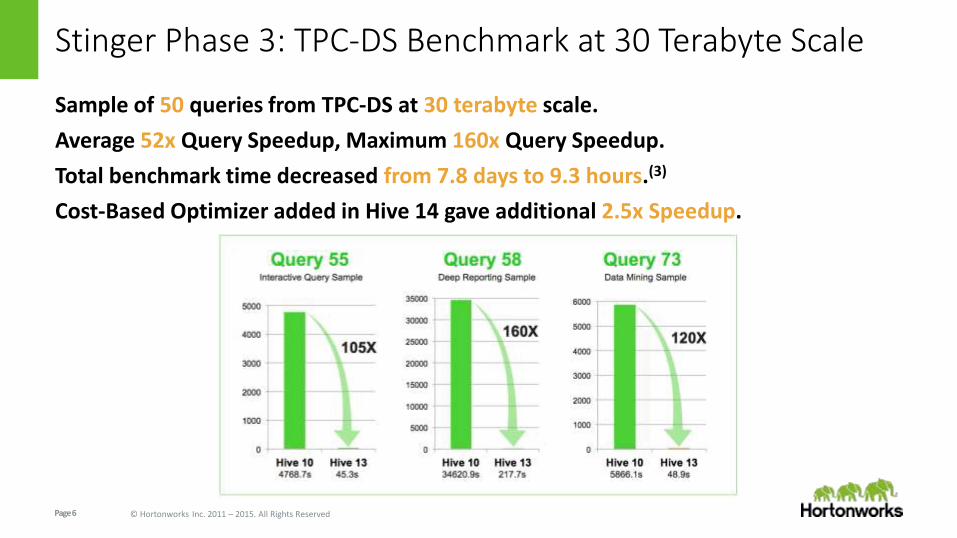
Stinger Phase 3: TPC-DS Benchmark at 30 Terabyte Scale
Sample of 50 queries from TPC-DS at 30 terabyte scale.
Average 52x Query Speedup, Maximum 160x Query Speedup.
Total benchmark time decreased from 7.8 days to 9.3 hours.(3)
Cost-Based Optimizer added in Hive 14 gave additional 2.5x Speedup.
Page 7 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
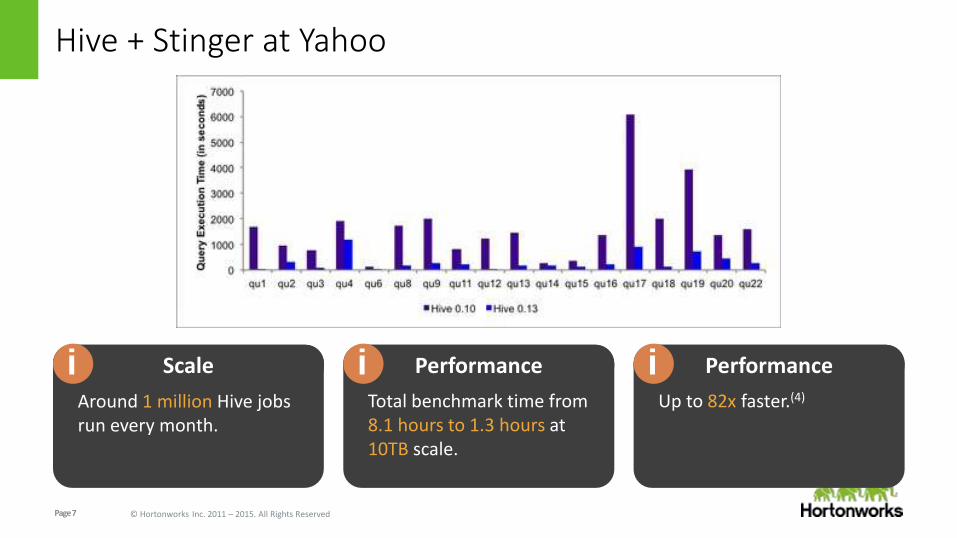
Hive + Stinger at Yahoo
Around 1 million Hive jobs run every month.
ScaleiTotal benchmark time from 8.1 hours to 1.3 hours at 10TB scale.
PerformanceiUp to 82x faster.(4)
Performancei

Page 8 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Stinger at Spotify
Query 25 TB of compressed data in 10 Minutes across 690 nodes (MapReduce too slow to complete.)
Speedi16x less HDFS read when using ORCFile versus Avro.(5)
Efficiencyi

Page 9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
ORCFile at Facebook
Saved more than 1,400 servers worth of storage.
CompressioniCompression ratio increased from 5x to 8xglobally.
Compressioni

Page 10 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Hive on Tez: Conclusion
Hive on Tez delivers fast batch and interactive SQL today.
But users need more speed!
Proven at petabyte scale.
ScaleiThe most comprehensive open-source SQL on Hadoop.
SQLiMore than 90 Hortonworks customers use Hive-on-Tez today for fast SQL.
Speedi
Hortonworks Customer Support metrics as of Feb/2015
Page 11 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
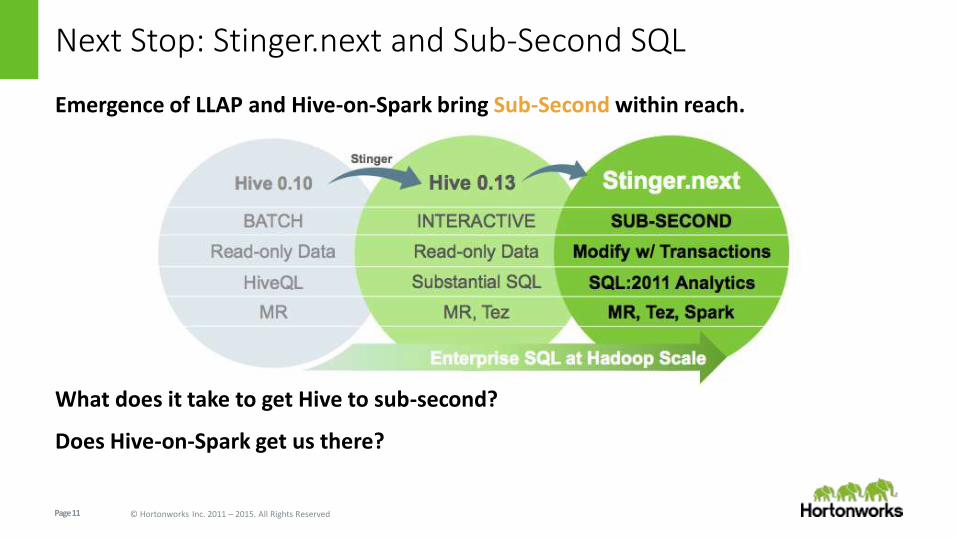
Next Stop: Stinger.next and Sub-Second SQL
Emergence of LLAP and Hive-on-Spark bring Sub-Second within reach.
What does it take to get Hive to sub-second?
Does Hive-on-Spark get us there?

Page 12 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Performance Today and the Sub-Second FutureHive on Tez, Hive on Spark, Hive on Mapreduce & Spark-SQL
Page 13 © Hortonworks Inc. 2014
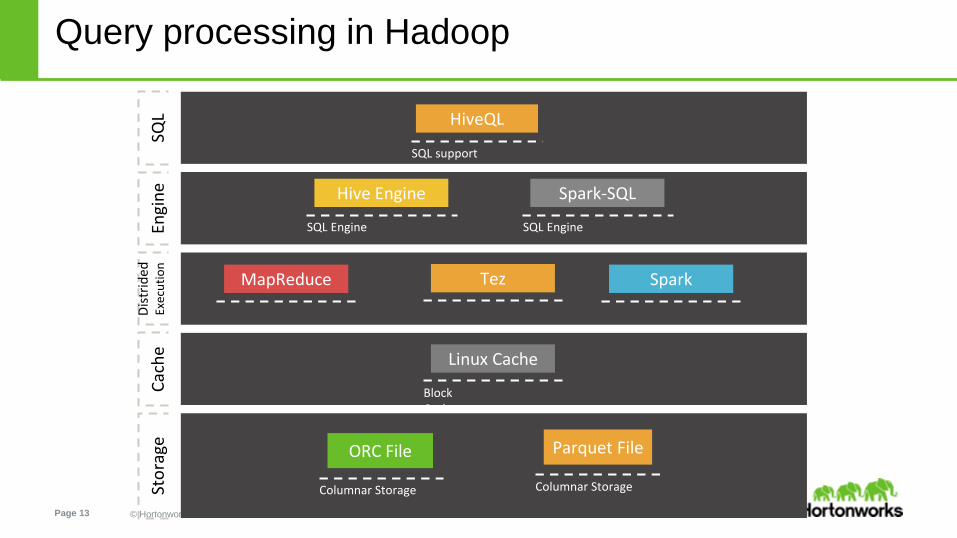
Query processing in Hadoop
Cac
he
Block Cache
Linux Cache
Sto
rage
Columnar Storage
Parquet File
Dis
trid
edEx
ecu
tio
nEn
gin
e
SQL Engine
Hive Engine
SQL
SQL support
HiveQL
Tez
Columnar Storage
ORC File
MapReduce Spark
Spark-SQL
SQL Engine
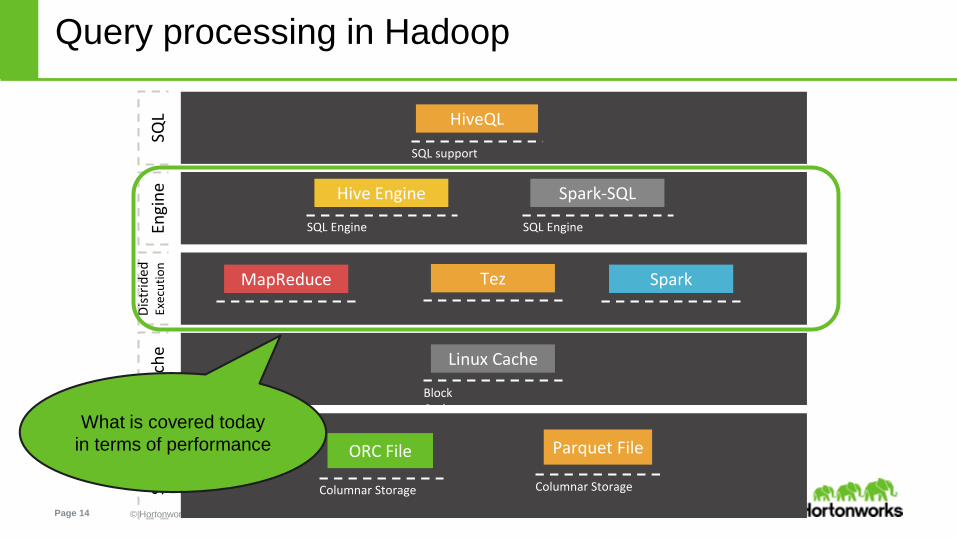
Page 14 © Hortonworks Inc. 2014
Query processing in Hadoop
Cac
he
Block Cache
Linux Cache
Sto
rage
Columnar Storage
Parquet File
Dis
trid
edEx
ecu
tio
nEn
gin
e
SQL Engine
Hive Engine
SQL
SQL support
HiveQL
Tez
Columnar Storage
ORC File
MapReduce Spark
Spark-SQL
SQL Engine
What is covered today
in terms of performance

Page 15 © Hortonworks Inc. 2014
Performance comparison : Test bed
Component Version
Hive 1.2.0
Tez 0.5.2
Spark 1.2.0
Hadoop 2.6.0
Software :
Hardware
20 physical nodes, each with:
● 2x Intel(R) Xeon(R) CPU E5-2640 v2 @ 2.00GHz for total of 16 CPU cores/machine
● Hyper-threading enabled
● 256GB RAM per node
● 6x 4TB WDC WD4000FYYZ-0 drives per node
● 10 Gigabit interconnect between the nodes
Note: Based on the YARN Node Manager’s Memory Resource setting used below, only 128 GB of RAM per node
was dedicated to query processing.
Execution
Engine
Primitives on 30TB
Scale factor
TPC-DS queries on
30TB Scale factor
TPC-DS queries on 200GB
Scale factor
Spark X X X
Tez X X X
Map Reduce X
Spark-SQL X X X
Performance benchmarks :
Page 16 © Hortonworks Inc. 2014
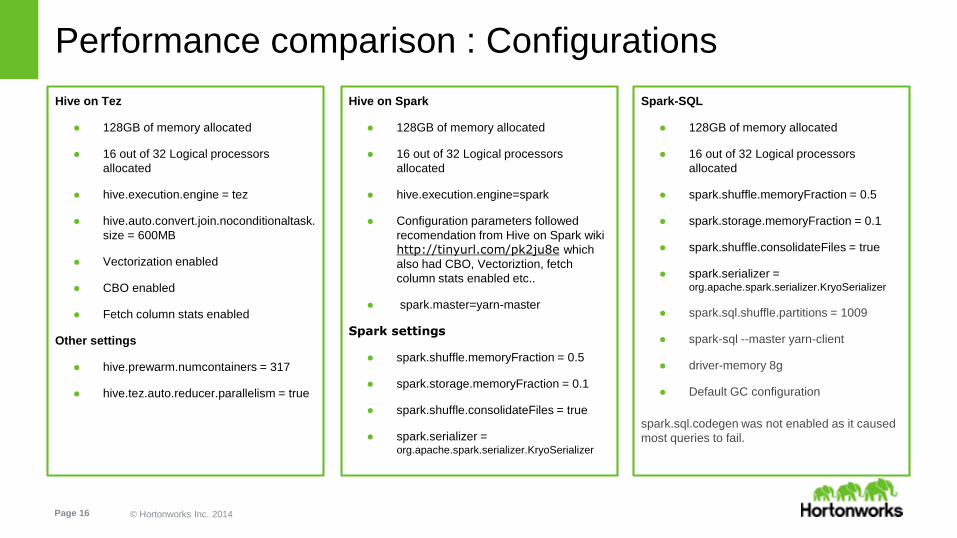
Performance comparison : Configurations
Hive on Tez
● 128GB of memory allocated
● 16 out of 32 Logical processors
allocated
● hive.execution.engine = tez
● hive.auto.convert.join.noconditionaltask.
size = 600MB
● Vectorization enabled
● CBO enabled
● Fetch column stats enabled
Other settings
● hive.prewarm.numcontainers = 317
● hive.tez.auto.reducer.parallelism = true
Hive on Spark
● 128GB of memory allocated
● 16 out of 32 Logical processors
allocated
● hive.execution.engine=spark
● Configuration parameters followed
recomendation from Hive on Spark wiki
http://tinyurl.com/pk2ju8e which
also had CBO, Vectoriztion, fetch
column stats enabled etc..
● spark.master=yarn-master
Spark settings
● spark.shuffle.memoryFraction = 0.5
● spark.storage.memoryFraction = 0.1
● spark.shuffle.consolidateFiles = true
● spark.serializer = org.apache.spark.serializer.KryoSerializer
Spark-SQL
● 128GB of memory allocated
● 16 out of 32 Logical processors
allocated
● spark.shuffle.memoryFraction = 0.5
● spark.storage.memoryFraction = 0.1
● spark.shuffle.consolidateFiles = true
● spark.serializer = org.apache.spark.serializer.KryoSerializer
● spark.sql.shuffle.partitions = 1009
● spark-sql --master yarn-client
● driver-memory 8g
● Default GC configuration
spark.sql.codegen was not enabled as it caused
most queries to fail.
Page 17 © Hortonworks Inc. 2014
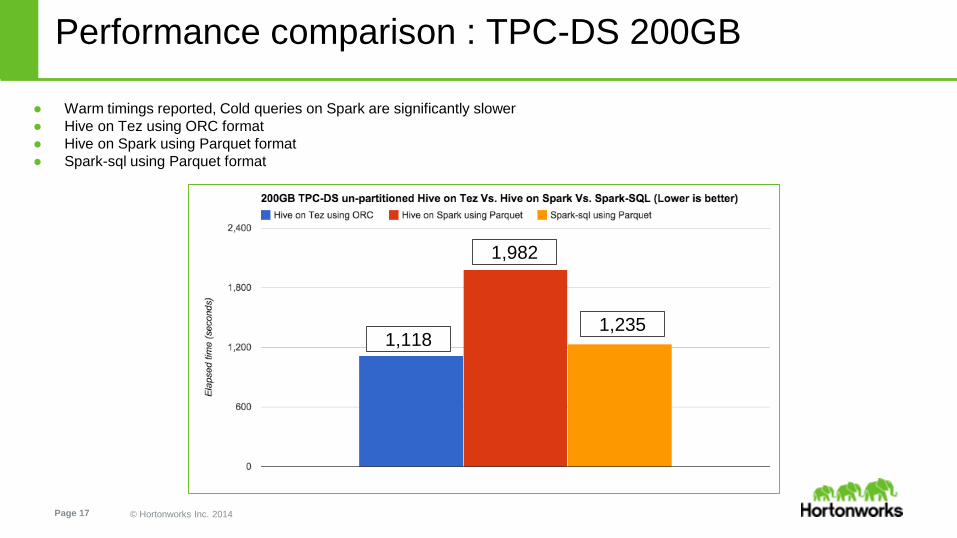
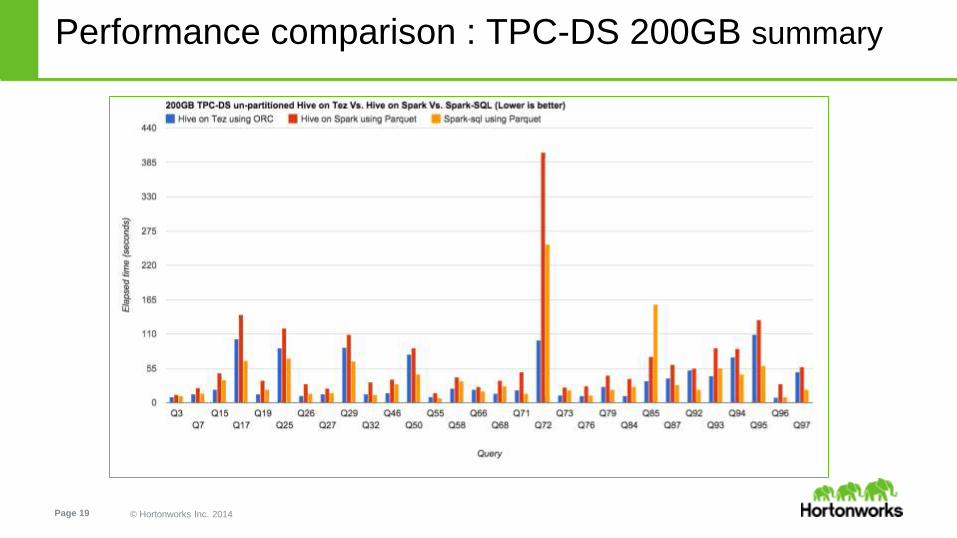
Performance comparison : TPC-DS 200GB
● Warm timings reported, Cold queries on Spark are significantly slower
● Hive on Tez using ORC format
● Hive on Spark using Parquet format
● Spark-sql using Parquet format
1,118
1,982
1,235
Page 18 © Hortonworks Inc. 2014
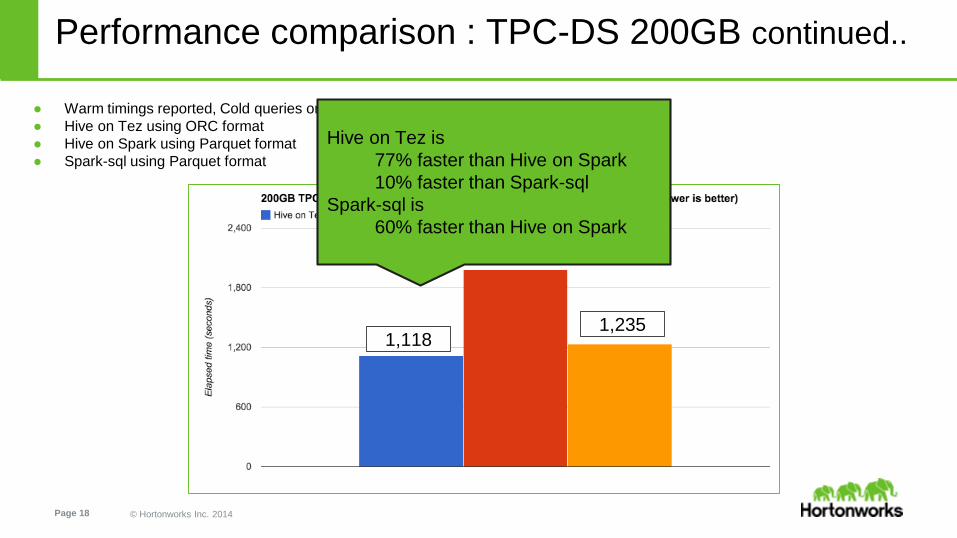
Performance comparison : TPC-DS 200GB continued..
● Warm timings reported, Cold queries on Spark are significantly slower
● Hive on Tez using ORC format
● Hive on Spark using Parquet format
● Spark-sql using Parquet format
1,118
1,982
1,235
Hive on Tez is
77% faster than Hive on Spark
10% faster than Spark-sql
Spark-sql is
60% faster than Hive on Spark
Page 19 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 200GB summary
Page 20 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 200GB summary
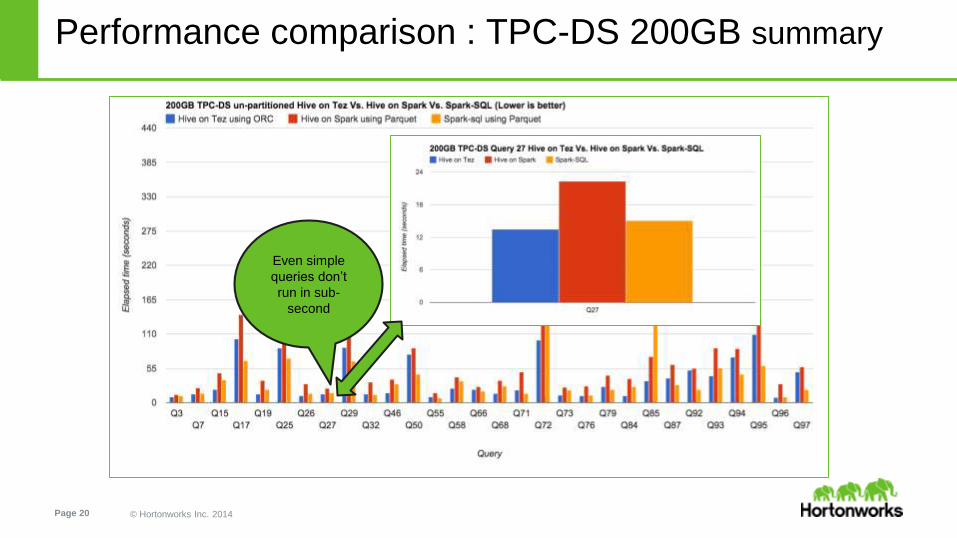
Even simple
queries don’t
run in sub-
second
Page 21 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 200GB summary
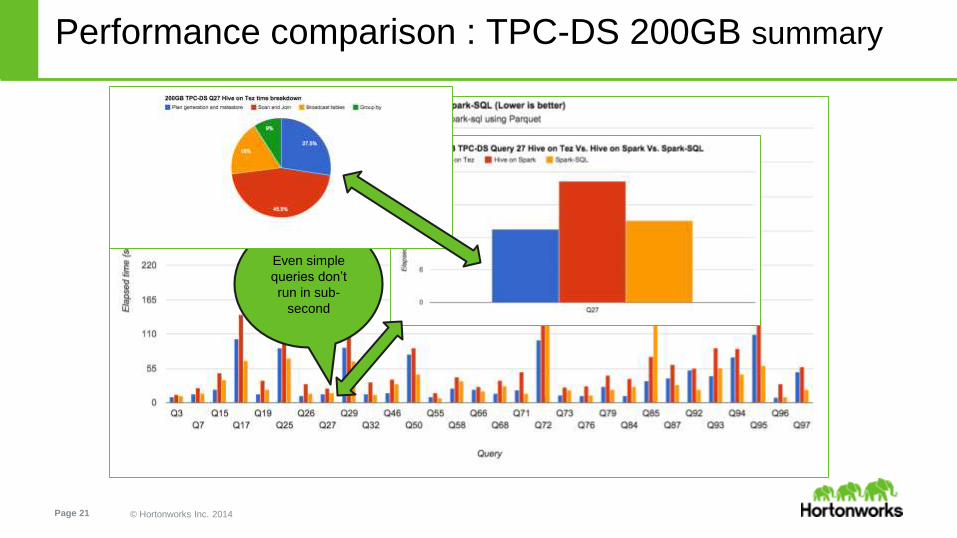
Even simple
queries don’t
run in sub-
second
Page 22 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 200GB
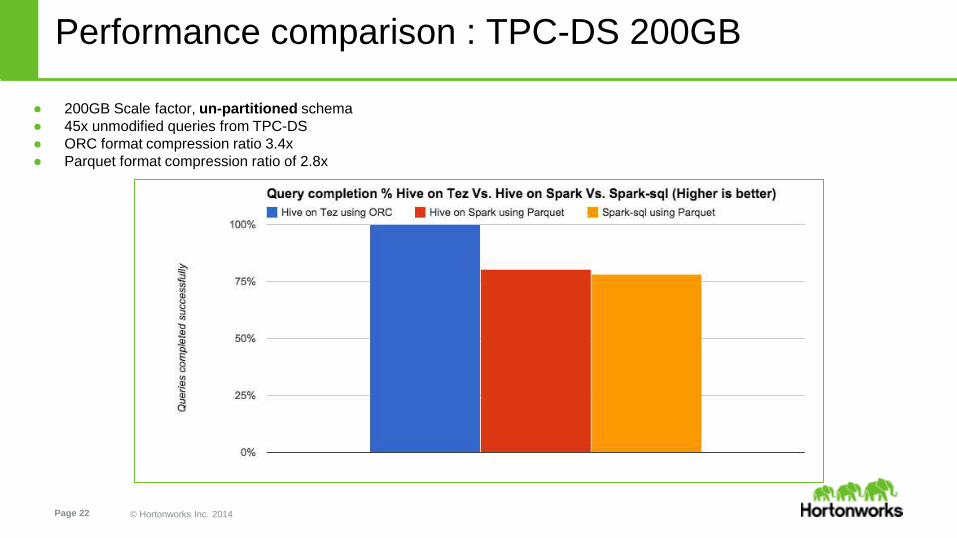
● 200GB Scale factor, un-partitioned schema
● 45x unmodified queries from TPC-DS
● ORC format compression ratio 3.4x
● Parquet format compression ratio of 2.8x

Page 23 © Hortonworks Inc. 2014
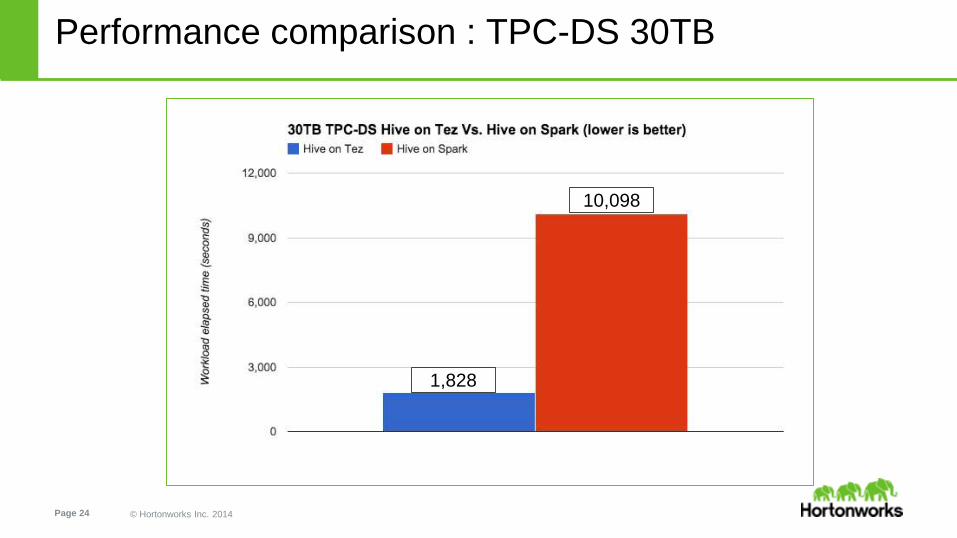
Performance comparison : TPC-DS 30TB
● 30 TB Scale factor
● ORC Table format
● Fact tables partitioned on *_date_sk
● Explicit partition filters where used for Hive on Spark and Spark-SQL (but not for Hive-on-Tez)
● 20 out of the previously used queries where used, warm query timings reported
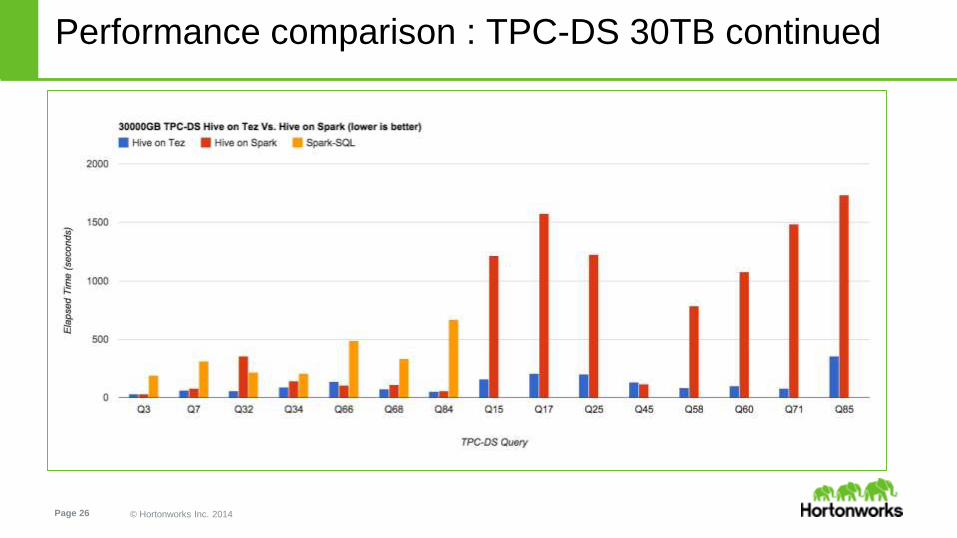
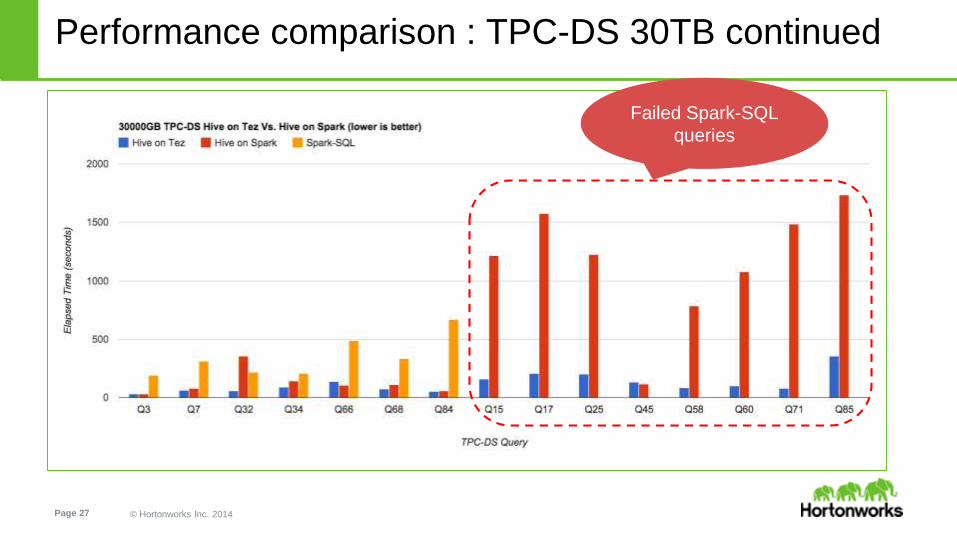
● Hive on Tez outperforms Hive on Spark and Spark-SQL by up to 18x
● Hive on Spark completed 15 out of the 20, the remaining 5 queries errored out or where stuck in GC and got cancelled
● Spark-SQL completed 7 out of the 20, the remaining 13 queries either failed within a couple of minutes or errored out after running
for hours
● Spark-SQL performance is negatively affected by in-efficient query plans as it lacks a query optimizer
Workload config
Highlights from 30TB TPC-DS test
Page 24 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 30TB
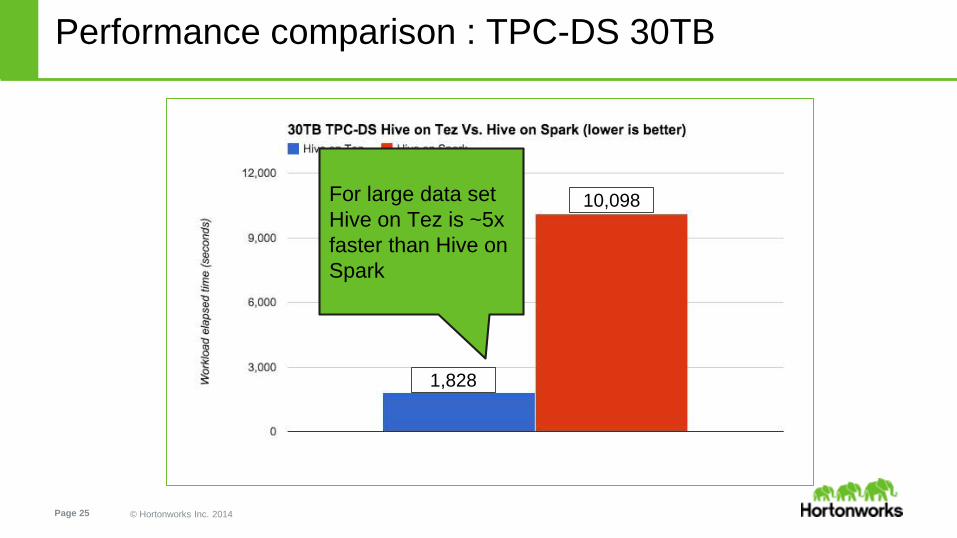
1,828
10,098
Page 25 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 30TB
1,828
10,098For large data set
Hive on Tez is ~5x
faster than Hive on
Spark
Page 26 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 30TB continued
Page 27 © Hortonworks Inc. 2014
Performance comparison : TPC-DS 30TB continued
Failed Spark-SQL
queries
Page 28 © Hortonworks Inc. 2014
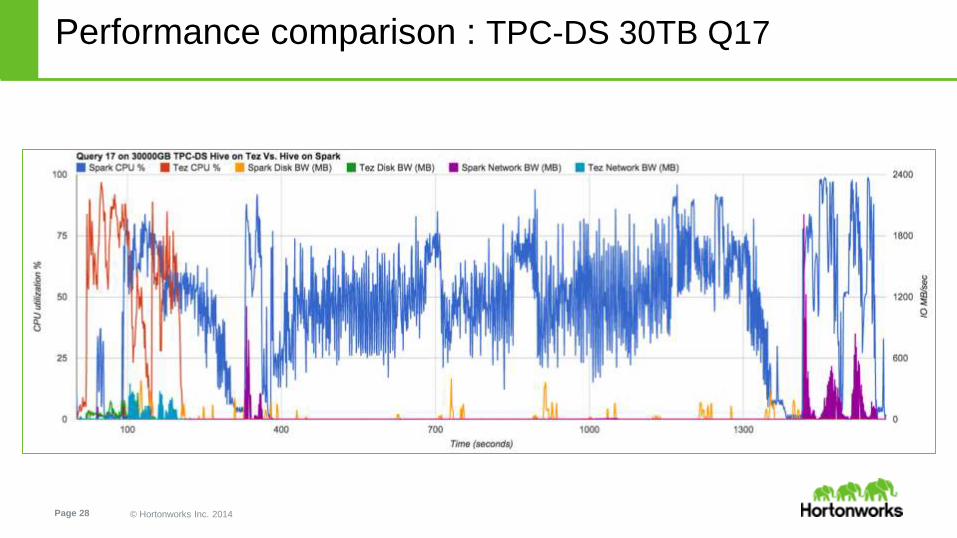
Performance comparison : TPC-DS 30TB Q17
Page 29 © Hortonworks Inc. 2014
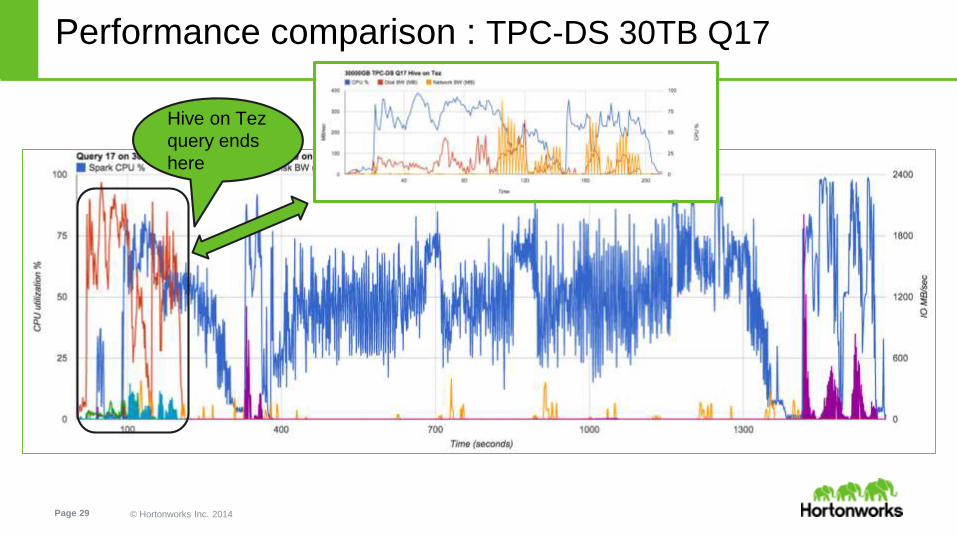
Performance comparison : TPC-DS 30TB Q17
Hive on Tez
query ends
here
Page 30 © Hortonworks Inc. 2014
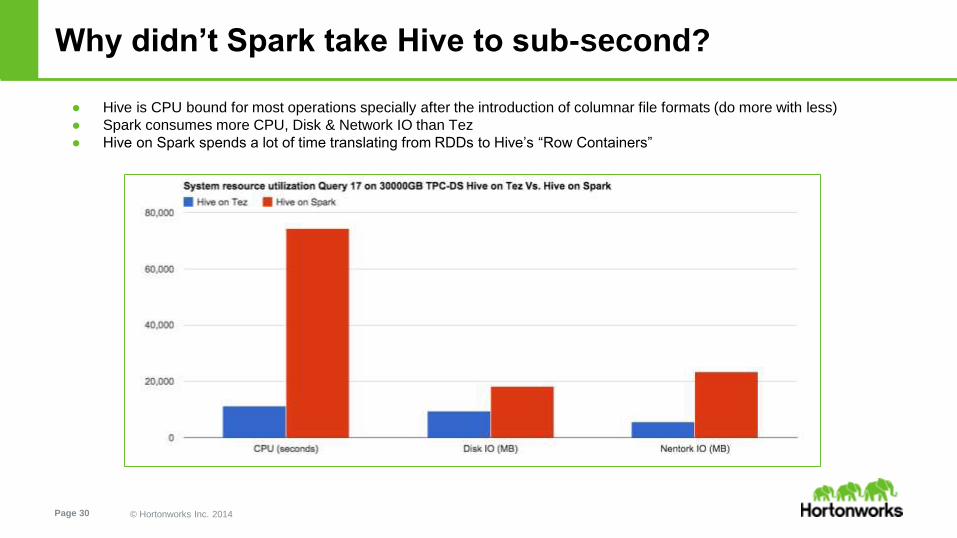
Why didn’t Spark take Hive to sub-second?
● Hive is CPU bound for most operations specially after the introduction of columnar file formats (do more with less)
● Spark consumes more CPU, Disk & Network IO than Tez
● Hive on Spark spends a lot of time translating from RDDs to Hive’s “Row Containers”
Page 31 © Hortonworks Inc. 2014
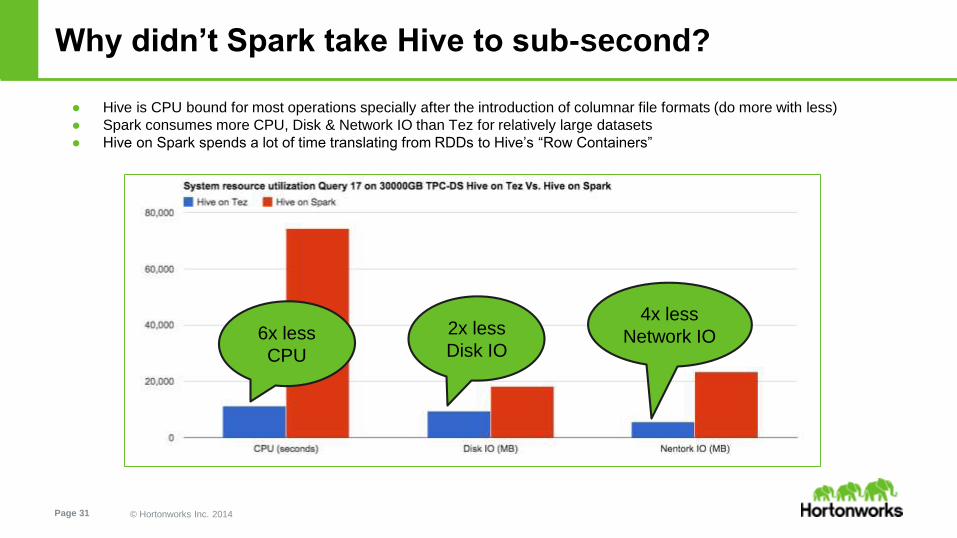
Why didn’t Spark take Hive to sub-second?
● Hive is CPU bound for most operations specially after the introduction of columnar file formats (do more with less)
● Spark consumes more CPU, Disk & Network IO than Tez for relatively large datasets
● Hive on Spark spends a lot of time translating from RDDs to Hive’s “Row Containers”
2x less
Disk IO
4x less
Network IO6x less
CPU

Page 32 © Hortonworks Inc. 2014
I don’t believe what you just said!!!
Show me some queries I can understand...
Simple queries to understand complex systems
Execution engine Primitives
Page 33 © Hortonworks Inc. 2014
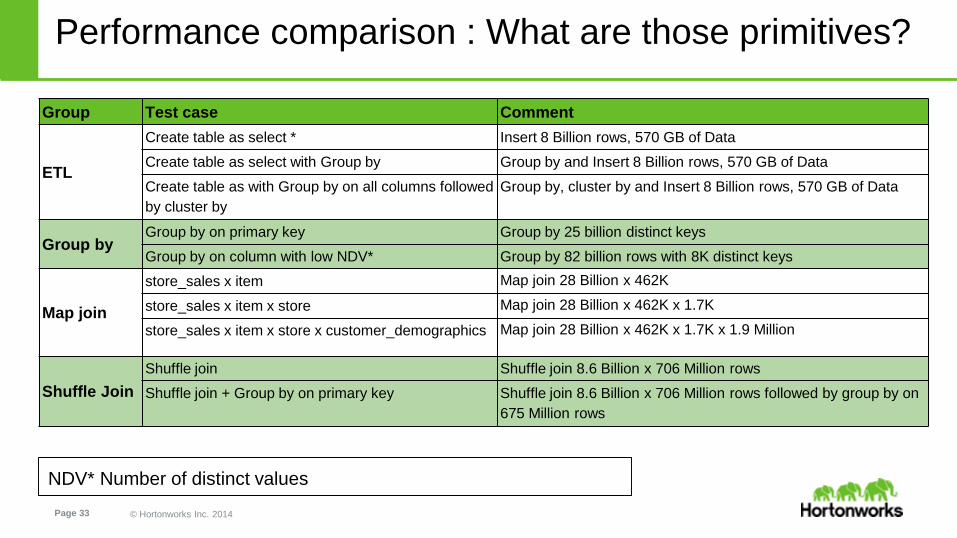
Performance comparison : What are those primitives?
Group Test case Comment
ETL
Create table as select * Insert 8 Billion rows, 570 GB of Data
Create table as select with Group by Group by and Insert 8 Billion rows, 570 GB of Data
Create table as with Group by on all columns followed
by cluster by
Group by, cluster by and Insert 8 Billion rows, 570 GB of Data
Group byGroup by on primary key Group by 25 billion distinct keys
Group by on column with low NDV* Group by 82 billion rows with 8K distinct keys
Map join
store_sales x item Map join 28 Billion x 462K
store_sales x item x store Map join 28 Billion x 462K x 1.7K
store_sales x item x store x customer_demographics Map join 28 Billion x 462K x 1.7K x 1.9 Million
Shuffle Join
Shuffle join Shuffle join 8.6 Billion x 706 Million rows
Shuffle join + Group by on primary key Shuffle join 8.6 Billion x 706 Million rows followed by group by on
675 Million rows
NDV* Number of distinct values
Page 34 © Hortonworks Inc. 2014
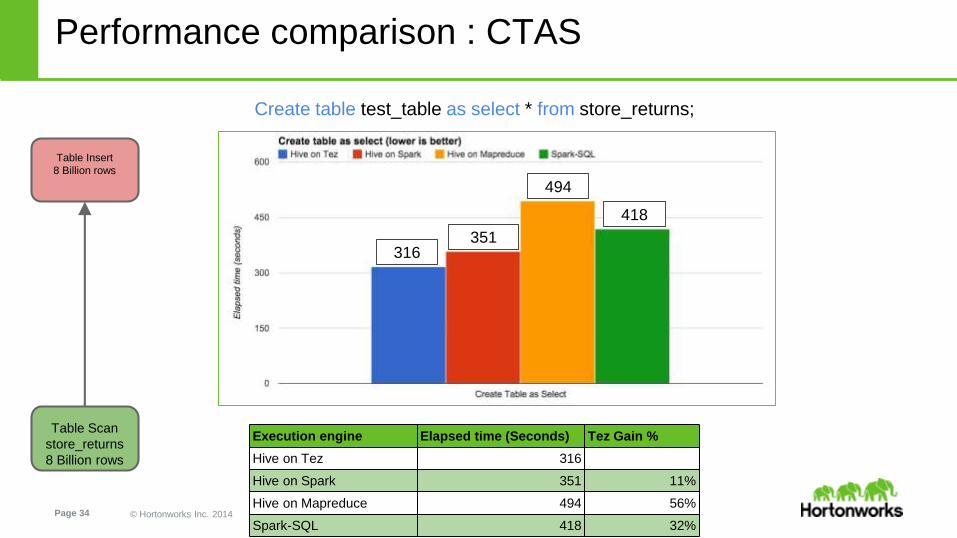
Performance comparison : CTAS
Create table test_table as select * from store_returns;
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 316
Hive on Spark 351 11%
Hive on Mapreduce 494 56%
Spark-SQL 418 32%
Table Scan
store_returns
8 Billion rows
Table Insert
8 Billion rows
316351
494
418
Page 35 © Hortonworks Inc. 2014
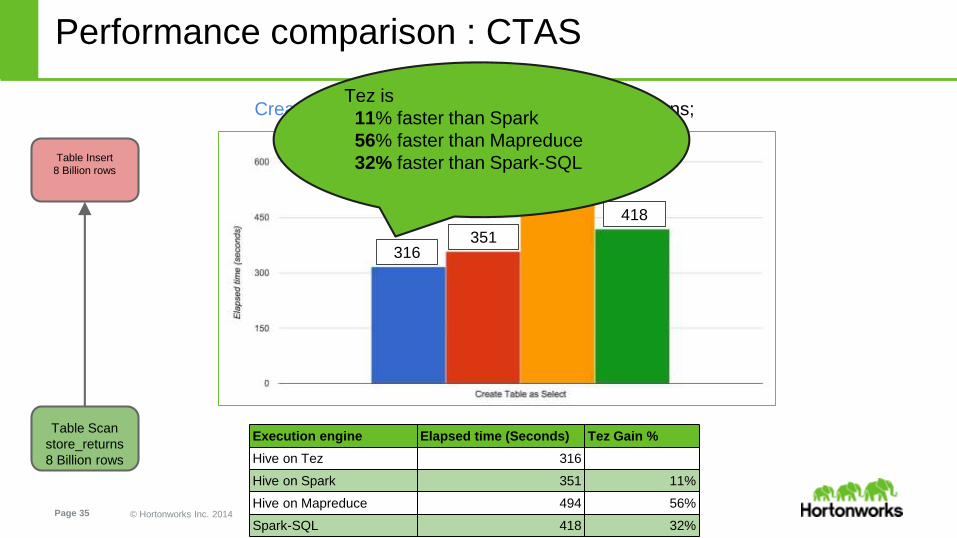
Performance comparison : CTAS
Create table test_table as select * from store_returns;
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 316
Hive on Spark 351 11%
Hive on Mapreduce 494 56%
Spark-SQL 418 32%
Table Scan
store_returns
8 Billion rows
Table Insert
8 Billion rows
316351
494
418
Tez is
11% faster than Spark
56% faster than Mapreduce
32% faster than Spark-SQL
Page 36 © Hortonworks Inc. 2014
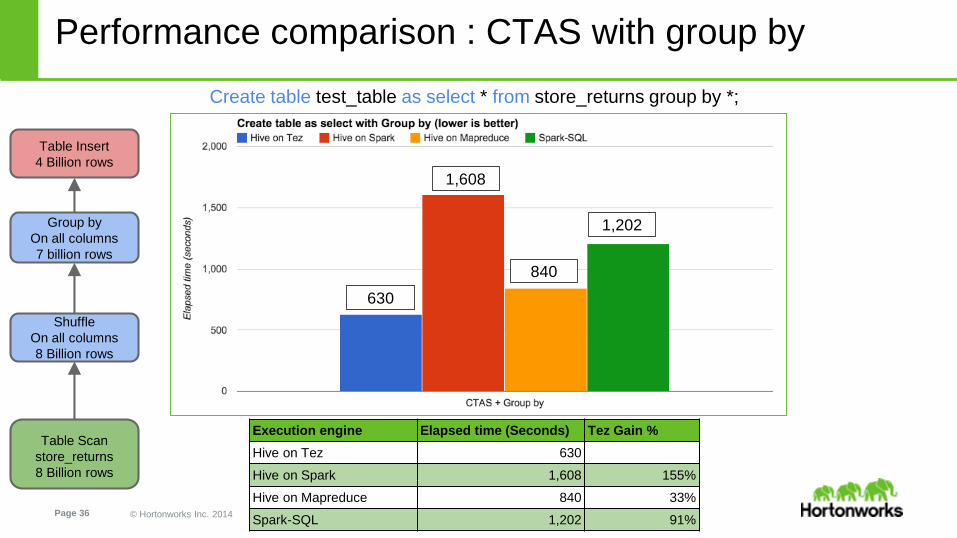
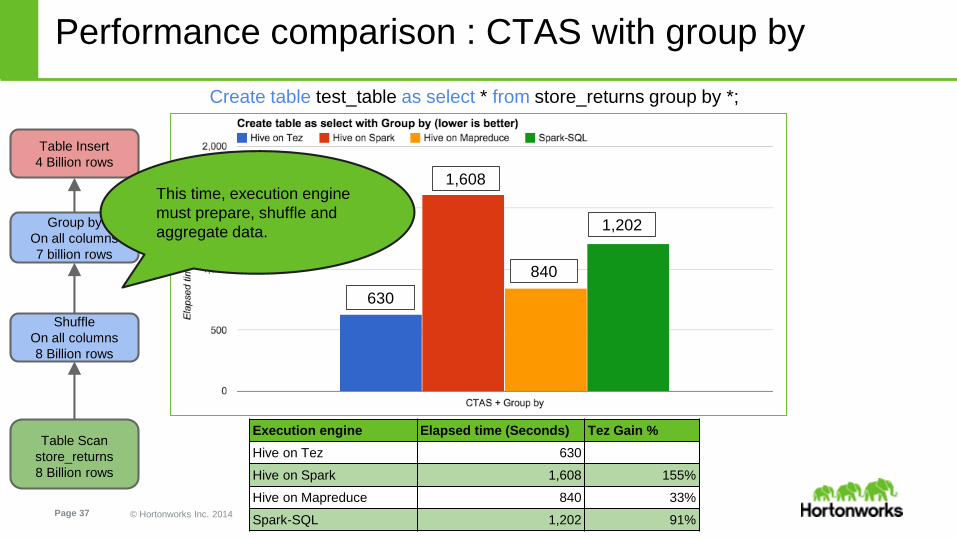
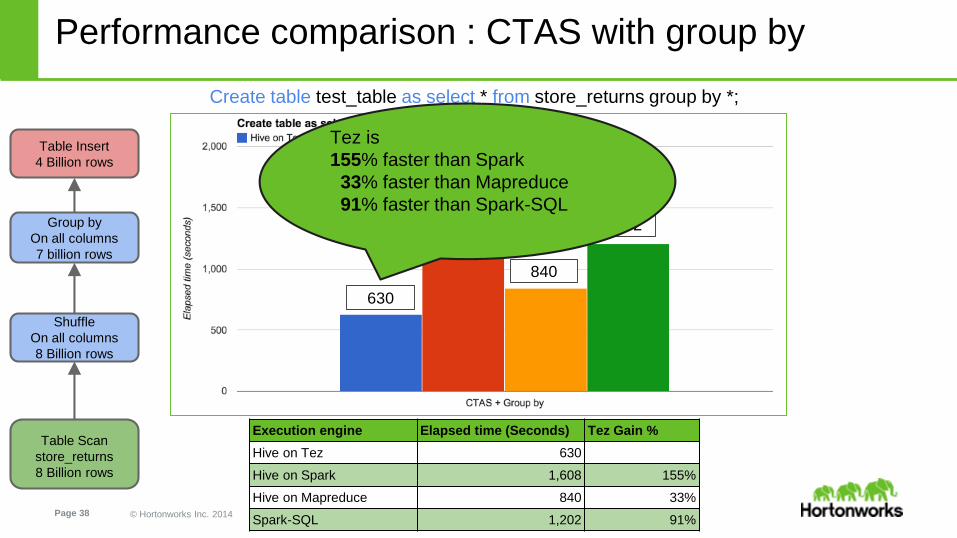
Performance comparison : CTAS with group by
Create table test_table as select * from store_returns group by *;
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 630
Hive on Spark 1,608 155%
Hive on Mapreduce 840 33%
Spark-SQL 1,202 91%
Table Insert
4 Billion rows
Shuffle
On all columns
8 Billion rows
Group by
On all columns
7 billion rows
Table Scan
store_returns
8 Billion rows
630
1,608
840
1,202
Page 37 © Hortonworks Inc. 2014
Performance comparison : CTAS with group by
Create table test_table as select * from store_returns group by *;
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 630
Hive on Spark 1,608 155%
Hive on Mapreduce 840 33%
Spark-SQL 1,202 91%
Table Insert
4 Billion rows
Shuffle
On all columns
8 Billion rows
Group by
On all columns
7 billion rows
Table Scan
store_returns
8 Billion rows
630
1,608
840
1,202
This time, execution engine
must prepare, shuffle and
aggregate data.
Page 38 © Hortonworks Inc. 2014
Performance comparison : CTAS with group by
Create table test_table as select * from store_returns group by *;
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 630
Hive on Spark 1,608 155%
Hive on Mapreduce 840 33%
Spark-SQL 1,202 91%
Table Insert
4 Billion rows
Shuffle
On all columns
8 Billion rows
Group by
On all columns
7 billion rows
Table Scan
store_returns
8 Billion rows
630
1,608
840
1,202
Tez is
155% faster than Spark
33% faster than Mapreduce
91% faster than Spark-SQL
Page 39 © Hortonworks Inc. 2014
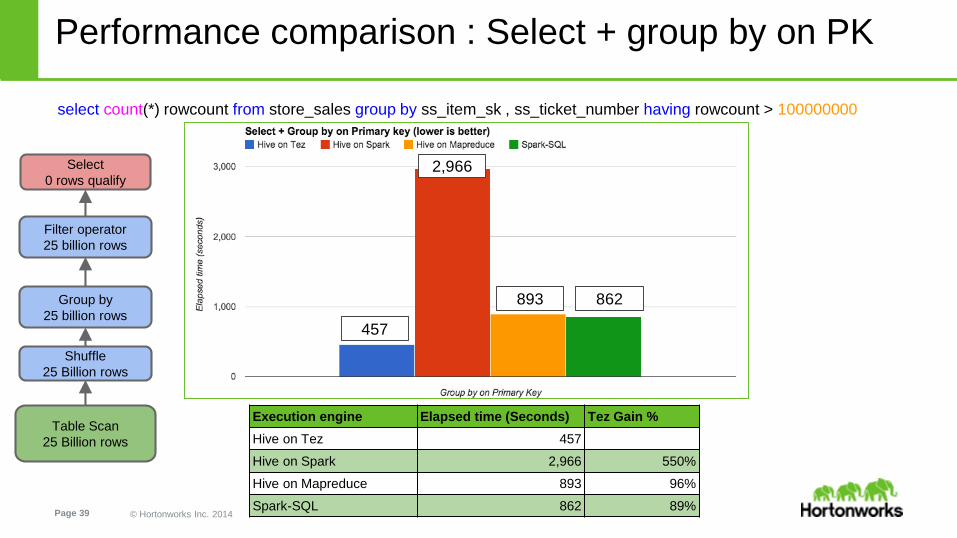
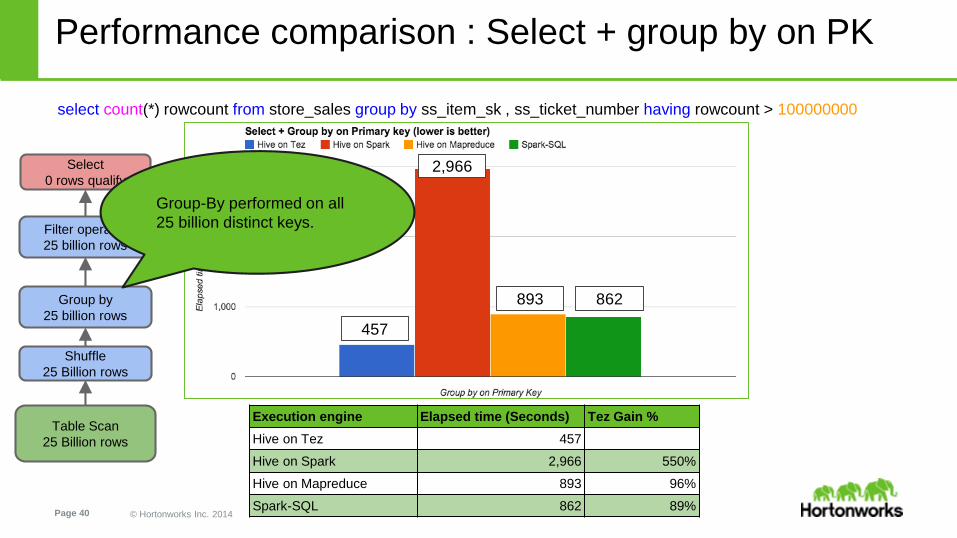
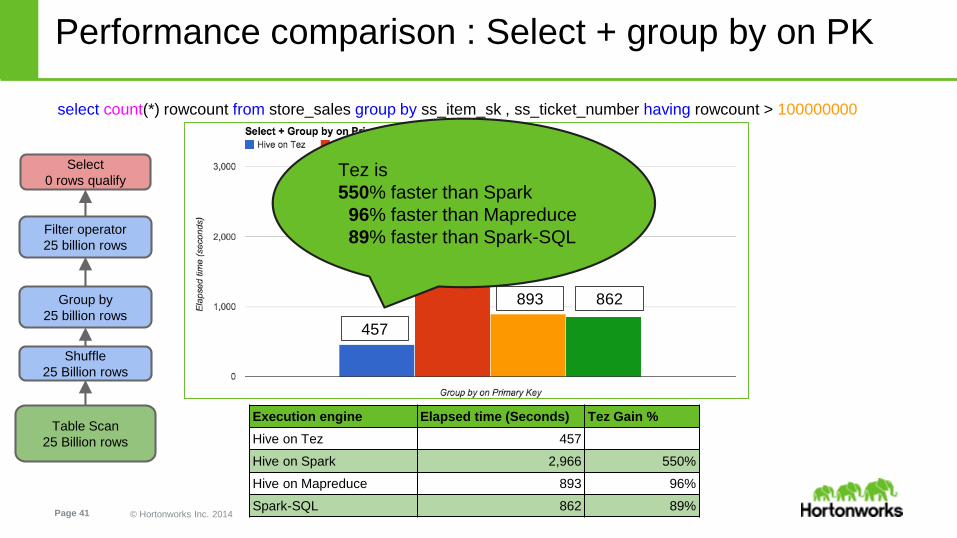
Performance comparison : Select + group by on PK
select count(*) rowcount from store_sales group by ss_item_sk , ss_ticket_number having rowcount > 100000000
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 457
Hive on Spark 2,966 550%
Hive on Mapreduce 893 96%
Spark-SQL 862 89%
Select
0 rows qualify
Shuffle
25 Billion rows
Group by
25 billion rows
Table Scan
25 Billion rows
Filter operator
25 billion rows
457
2,966
893 862
Page 40 © Hortonworks Inc. 2014
Performance comparison : Select + group by on PK
select count(*) rowcount from store_sales group by ss_item_sk , ss_ticket_number having rowcount > 100000000
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 457
Hive on Spark 2,966 550%
Hive on Mapreduce 893 96%
Spark-SQL 862 89%
Select
0 rows qualify
Shuffle
25 Billion rows
Group by
25 billion rows
Table Scan
25 Billion rows
Filter operator
25 billion rows
457
2,966
893 862
Group-By performed on all
25 billion distinct keys.
Page 41 © Hortonworks Inc. 2014
Performance comparison : Select + group by on PK
select count(*) rowcount from store_sales group by ss_item_sk , ss_ticket_number having rowcount > 100000000
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 457
Hive on Spark 2,966 550%
Hive on Mapreduce 893 96%
Spark-SQL 862 89%
Select
0 rows qualify
Shuffle
25 Billion rows
Group by
25 billion rows
Table Scan
25 Billion rows
Filter operator
25 billion rows
457
2,966
893 862
Tez is
550% faster than Spark
96% faster than Mapreduce
89% faster than Spark-SQL
Page 42 © Hortonworks Inc. 2014
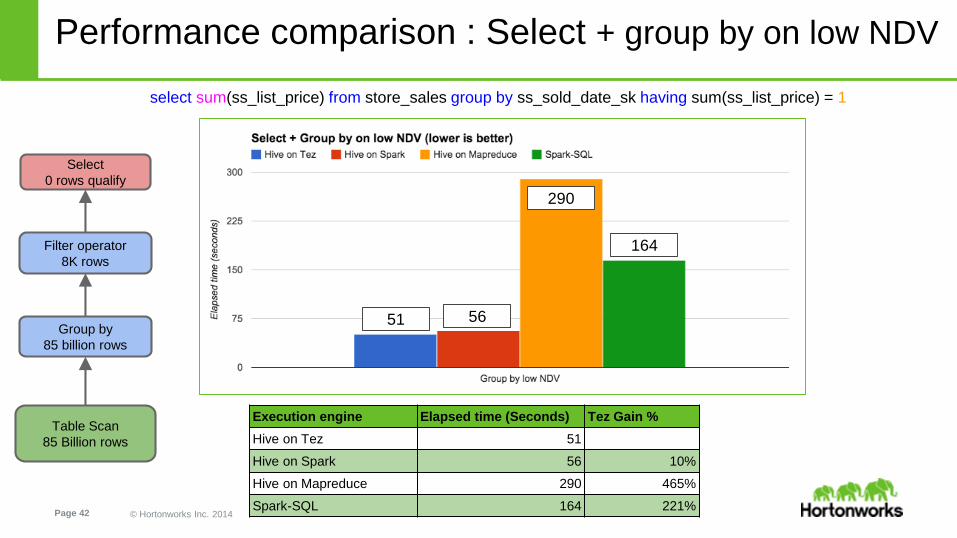
Performance comparison : Select + group by on low NDV
select sum(ss_list_price) from store_sales group by ss_sold_date_sk having sum(ss_list_price) = 1
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 51
Hive on Spark 56 10%
Hive on Mapreduce 290 465%
Spark-SQL 164 221%
Select
0 rows qualify
Group by
85 billion rows
Table Scan
85 Billion rows
Filter operator
8K rows
51
290
56
164
Page 43 © Hortonworks Inc. 2014
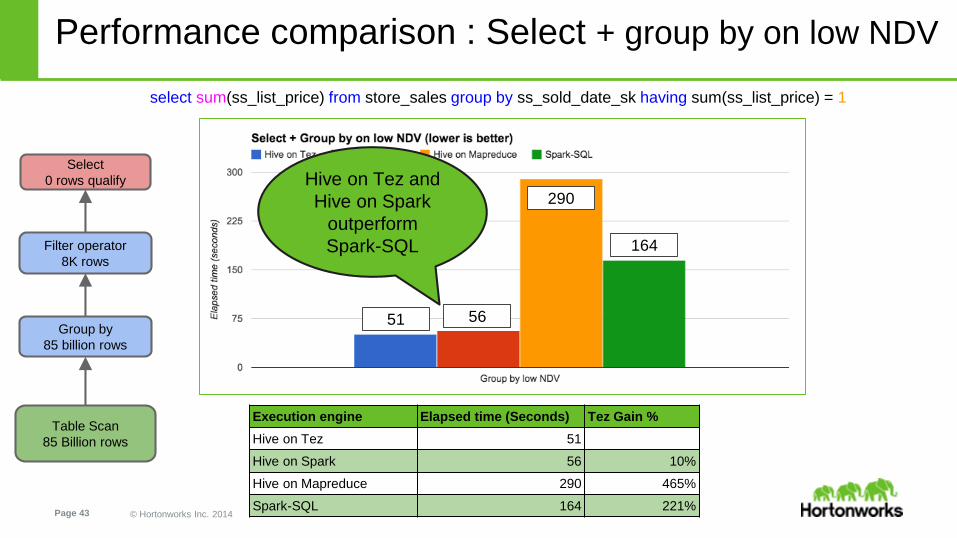
Performance comparison : Select + group by on low NDV
select sum(ss_list_price) from store_sales group by ss_sold_date_sk having sum(ss_list_price) = 1
Execution engine Elapsed time (Seconds) Tez Gain %
Hive on Tez 51
Hive on Spark 56 10%
Hive on Mapreduce 290 465%
Spark-SQL 164 221%
Select
0 rows qualify
Group by
85 billion rows
Table Scan
85 Billion rows
Filter operator
8K rows
51
290
56
164
Hive on Tez and
Hive on Spark
outperform
Spark-SQL
Page 44 © Hortonworks Inc. 2014
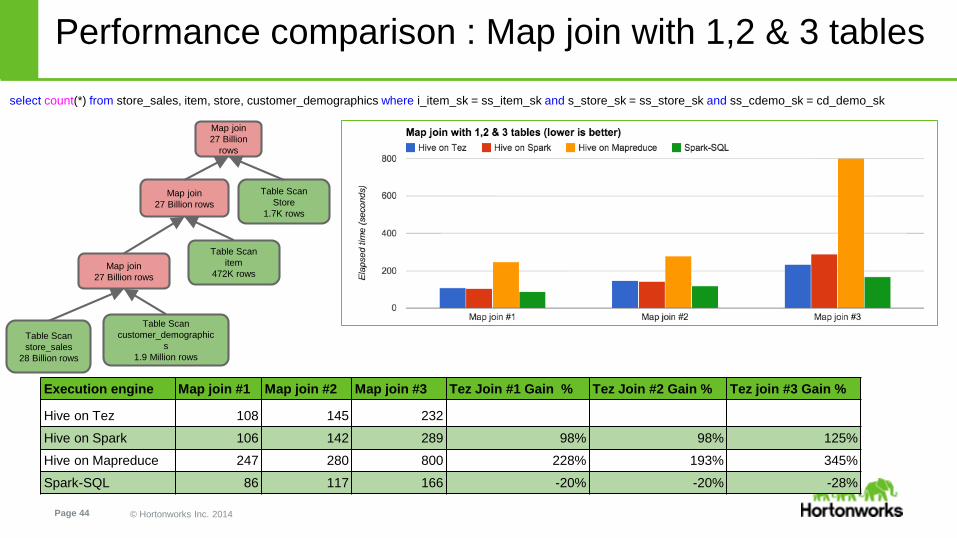
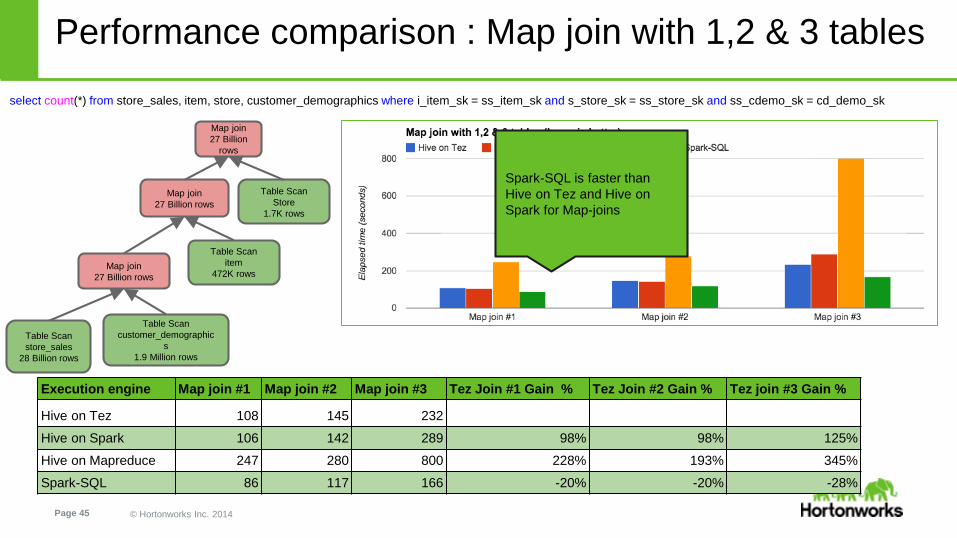
select count(*) from store_sales, item, store, customer_demographics where i_item_sk = ss_item_sk and s_store_sk = ss_store_sk and ss_cdemo_sk = cd_demo_sk
Performance comparison : Map join with 1,2 & 3 tables
Map join
27 Billion
rows
Map join
27 Billion rows
Map join
27 Billion rows
Table Scan
store_sales
28 Billion rows
Table Scan
customer_demographic
s
1.9 Million rows
Table Scan
item
472K rows
Table Scan
Store
1.7K rows
Execution engine Map join #1 Map join #2 Map join #3 Tez Join #1 Gain % Tez Join #2 Gain % Tez join #3 Gain %
Hive on Tez 108 145 232
Hive on Spark 106 142 289 98% 98% 125%
Hive on Mapreduce 247 280 800 228% 193% 345%
Spark-SQL 86 117 166 -20% -20% -28%
Page 45 © Hortonworks Inc. 2014
select count(*) from store_sales, item, store, customer_demographics where i_item_sk = ss_item_sk and s_store_sk = ss_store_sk and ss_cdemo_sk = cd_demo_sk
Performance comparison : Map join with 1,2 & 3 tables
Map join
27 Billion
rows
Map join
27 Billion rows
Map join
27 Billion rows
Table Scan
store_sales
28 Billion rows
Table Scan
customer_demographic
s
1.9 Million rows
Table Scan
item
472K rows
Table Scan
Store
1.7K rows
Execution engine Map join #1 Map join #2 Map join #3 Tez Join #1 Gain % Tez Join #2 Gain % Tez join #3 Gain %
Hive on Tez 108 145 232
Hive on Spark 106 142 289 98% 98% 125%
Hive on Mapreduce 247 280 800 228% 193% 345%
Spark-SQL 86 117 166 -20% -20% -28%
Spark-SQL is faster than
Hive on Tez and Hive on
Spark for Map-joins
Page 46 © Hortonworks Inc. 2014
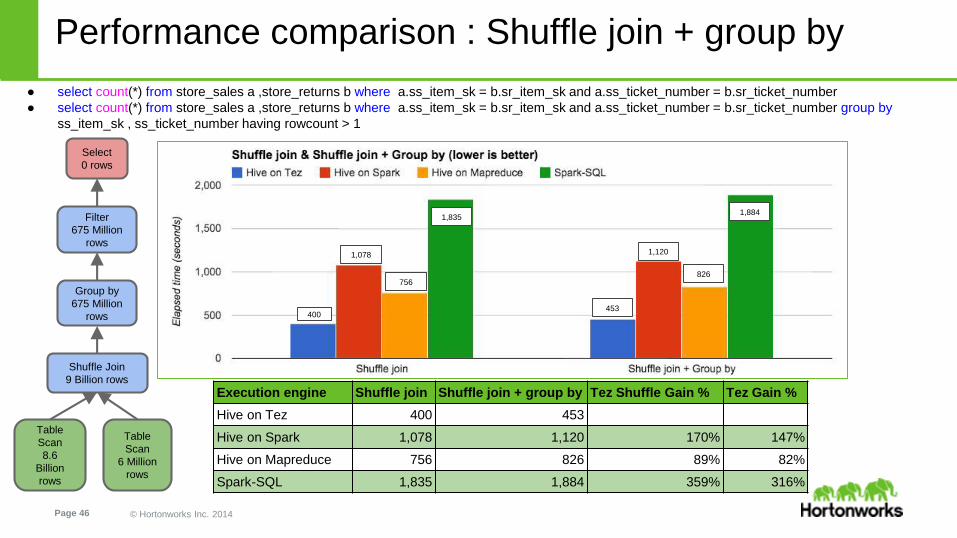
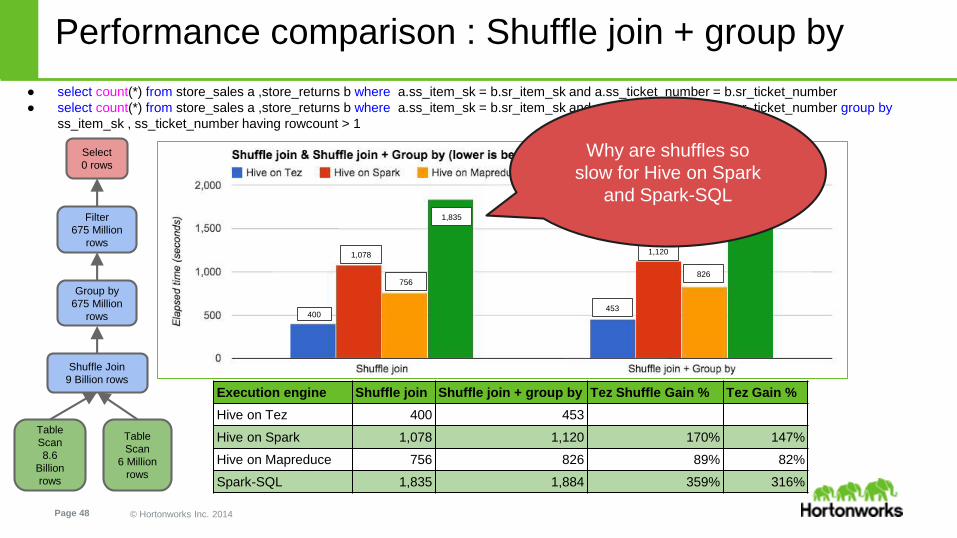
Performance comparison : Shuffle join + group by
● select count(*) from store_sales a ,store_returns b where a.ss_item_sk = b.sr_item_sk and a.ss_ticket_number = b.sr_ticket_number
● select count(*) from store_sales a ,store_returns b where a.ss_item_sk = b.sr_item_sk and a.ss_ticket_number = b.sr_ticket_number group by
ss_item_sk , ss_ticket_number having rowcount > 1
Execution engine Shuffle join Shuffle join + group by Tez Shuffle Gain % Tez Gain %
Hive on Tez 400 453
Hive on Spark 1,078 1,120 170% 147%
Hive on Mapreduce 756 826 89% 82%
Spark-SQL 1,835 1,884 359% 316%
Shuffle Join
9 Billion rows
Group by
675 Million
rows
Table
Scan
8.6
Billion
rows
Table
Scan
6 Million
rows
Select
0 rows
Filter
675 Million
rows
400
1,078 1,120
826
453
756
1,8841,835

Page 47 © Hortonworks Inc. 2014
Performance comparison : Shuffle join + group by
● select count(*) from store_sales a ,store_returns b where a.ss_item_sk = b.sr_item_sk and a.ss_ticket_number = b.sr_ticket_number
● select count(*) from store_sales a ,store_returns b where a.ss_item_sk = b.sr_item_sk and a.ss_ticket_number = b.sr_ticket_number group by
ss_item_sk , ss_ticket_number having rowcount > 1
Shuffle Join
9 Billion rows
Group by
675 Million
rows
Table
Scan
8.6
Billion
rows
Table
Scan
6 Million
rows
Select
0 rows
Filter
675 Million
rows
400
1,078 1,120
826
453
756
1,8841,835
Tez is
170% faster than Spark
89% faster than Mapreduce
359% faster than Spark-SQL
Tez is
147% faster than Spark
82% faster than Mapreduce
316% faster than Spark-SQL
Execution engine Shuffle join Shuffle join + group by Tez Shuffle Gain % Tez Gain %
Hive on Tez 400 453
Hive on Spark 1,078 1,120 170% 147%
Hive on Mapreduce 756 826 89% 82%
Spark-SQL 1,835 1,884 359% 316%
Page 48 © Hortonworks Inc. 2014
Performance comparison : Shuffle join + group by
● select count(*) from store_sales a ,store_returns b where a.ss_item_sk = b.sr_item_sk and a.ss_ticket_number = b.sr_ticket_number
● select count(*) from store_sales a ,store_returns b where a.ss_item_sk = b.sr_item_sk and a.ss_ticket_number = b.sr_ticket_number group by
ss_item_sk , ss_ticket_number having rowcount > 1
Shuffle Join
9 Billion rows
Group by
675 Million
rows
Table
Scan
8.6
Billion
rows
Table
Scan
6 Million
rows
Select
0 rows
Filter
675 Million
rows
400
1,078 1,120
826
453
756
1,8841,835
Why are shuffles so
slow for Hive on Spark
and Spark-SQL
Execution engine Shuffle join Shuffle join + group by Tez Shuffle Gain % Tez Gain %
Hive on Tez 400 453
Hive on Spark 1,078 1,120 170% 147%
Hive on Mapreduce 756 826 89% 82%
Spark-SQL 1,835 1,884 359% 316%
Page 49 © Hortonworks Inc. 2014
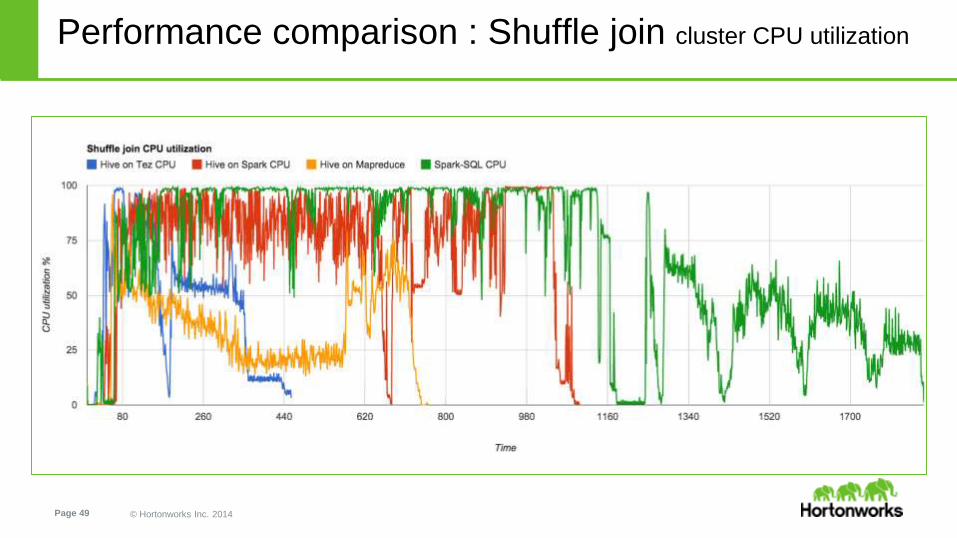
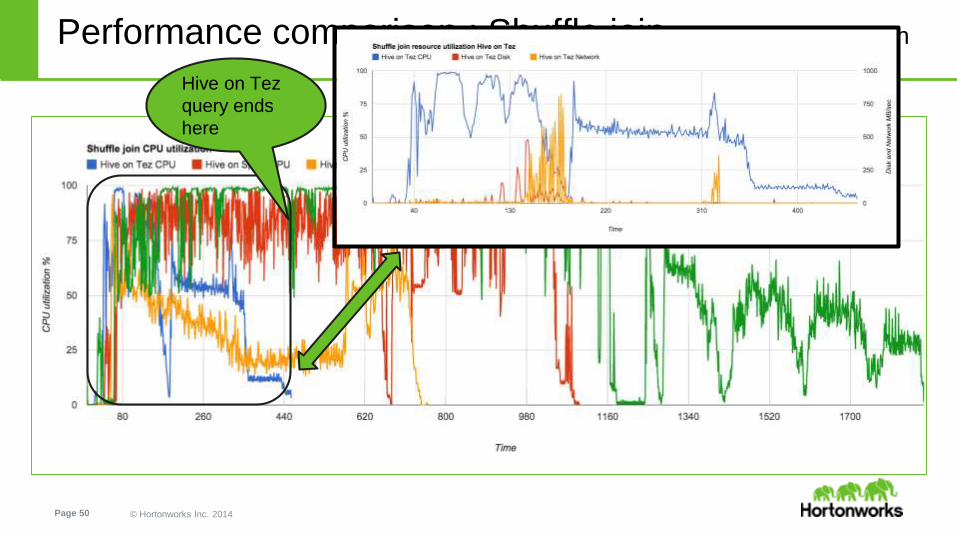
Performance comparison : Shuffle join cluster CPU utilization
Page 50 © Hortonworks Inc. 2014
Performance comparison : Shuffle join cluster CPU utilization
Hive on Tez
query ends
here
Page 51 © Hortonworks Inc. 2014
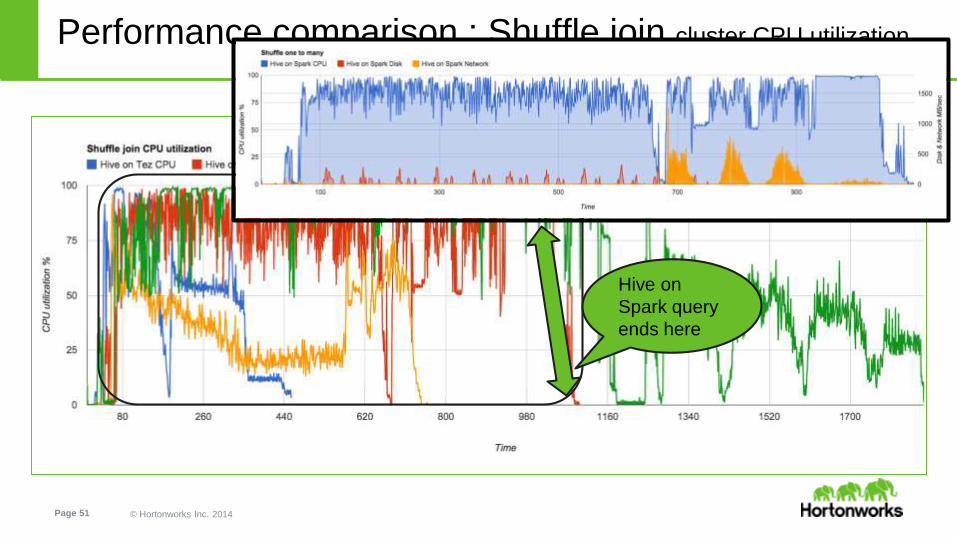
Performance comparison : Shuffle join cluster CPU utilization
Hive on
Spark query
ends here
Page 52 © Hortonworks Inc. 2014
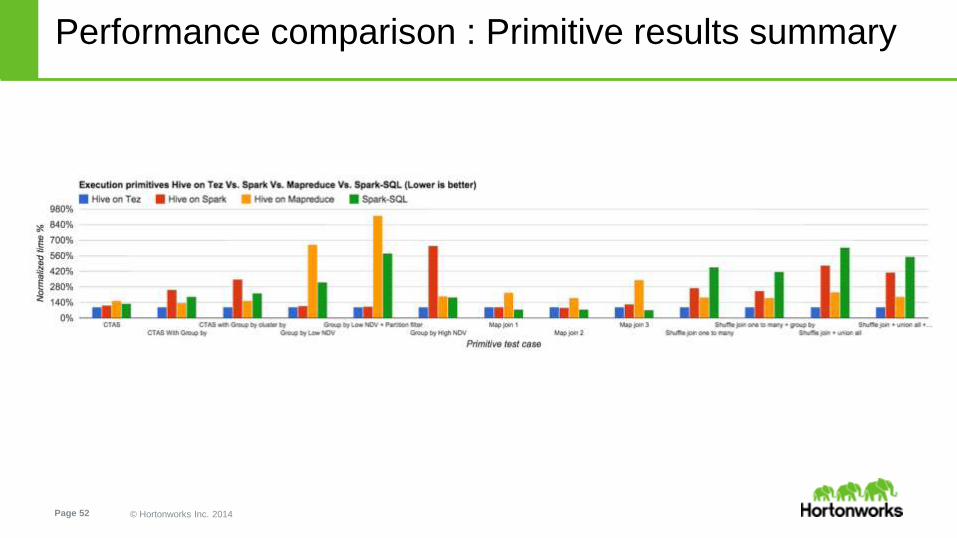
Performance comparison : Primitive results summary

Page 53 © Hortonworks Inc. 2014
Performance comparison : Performance summary
Short running query+
ETL+
Large joins and aggregates+
Slower than Spark-SQL in Map joins
High GC
Instability
SQL support limited compared to Hive
Lack of sophisticated query optimizer
Efficient resource utilization+
Map join performance+
Large Joins
Outperforms Spark-SQL in large join+
Slower than Tez for large joins and aggregates
High GC
Hive Tez
Spark-SQL
Hive on Spark
MapReduce
Promising initial release+

Page 54 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Solving Hive’s Top Performance Challenges
Page 55 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
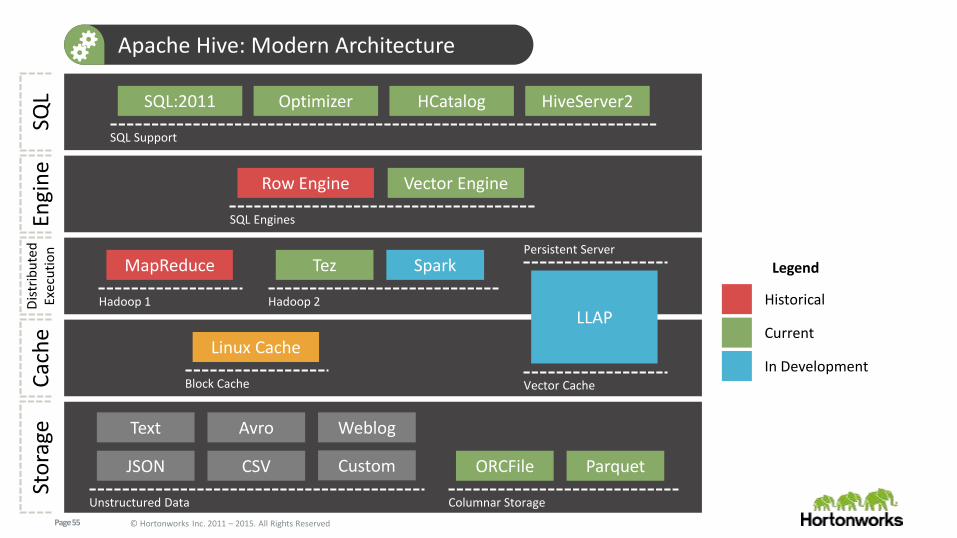
Apache Hive: Modern ArchitectureSt
ora
ge
Columnar Storage
ORCFile Parquet
Unstructured Data
JSON CSV
Text Avro
Custom
Weblog
Engi
ne
SQL Engines
Row Engine Vector Engine
SQL
SQL Support
SQL:2011 Optimizer HCatalog HiveServer2
Cac
he
Block Cache
Linux Cache
Dis
trib
ute
dEx
ecu
tio
n
Hadoop 1
MapReduce
Hadoop 2
Tez Spark
Vector Cache
LLAP
Persistent Server
Historical
Current
In Development
Legend
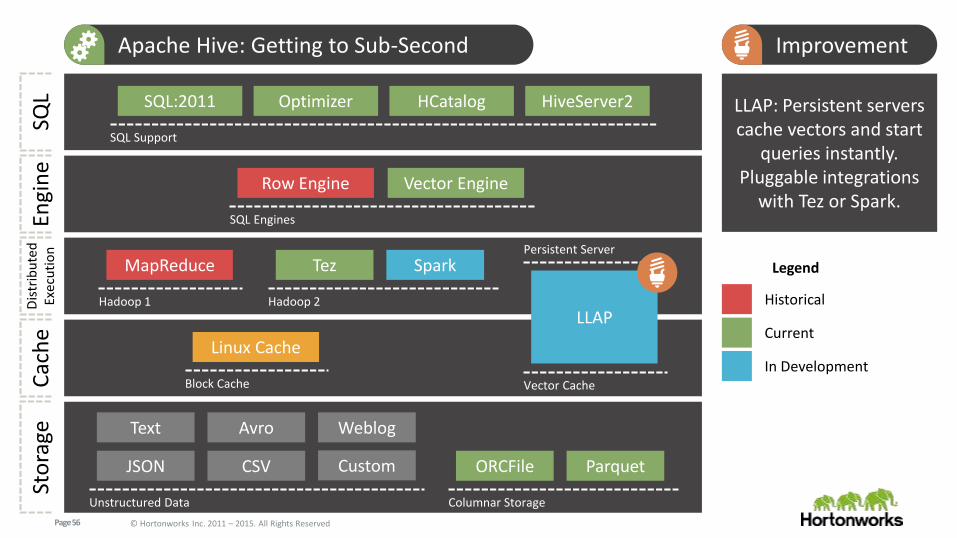
Page 56 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Sto
rage
Columnar Storage
ORCFile Parquet
Unstructured Data
JSON CSV
Text Avro
Custom
Weblog
Engi
ne
SQL Engines
Row Engine Vector Engine
SQL
SQL Support
SQL:2011 Optimizer HCatalog HiveServer2
Apache Hive: Getting to Sub-Second Improvement
LLAP: Persistent servers cache vectors and start
queries instantly. Pluggable integrations
with Tez or Spark.
Cac
he
Block Cache
Linux Cache
Dis
trib
ute
dEx
ecu
tio
n
Hadoop 1
MapReduce
Hadoop 2
Tez Spark
Historical
Current
In Development
Legend
Vector Cache
LLAP
Persistent Server
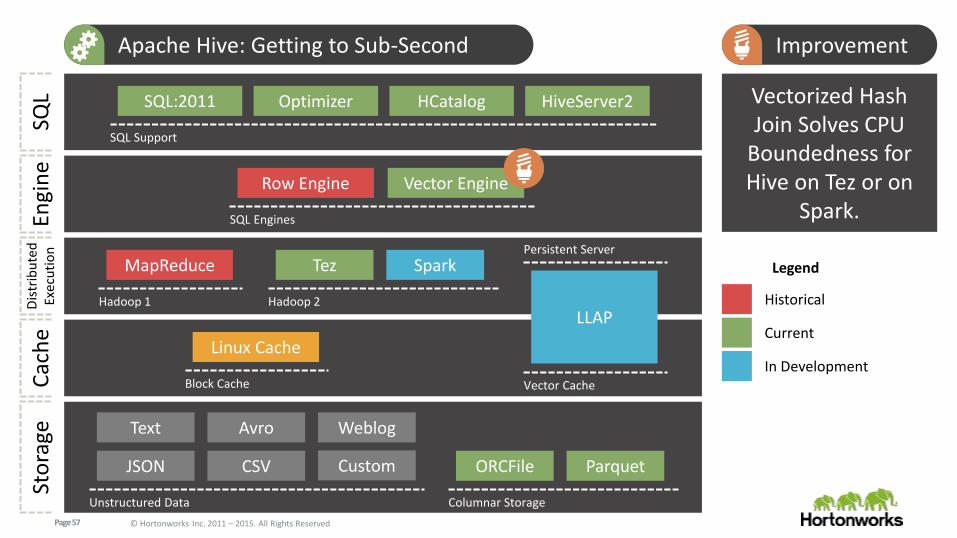
Page 57 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Sto
rage
Columnar Storage
ORCFile Parquet
Unstructured Data
JSON CSV
Text Avro
Custom
Weblog
Engi
ne
SQL Engines
Row Engine Vector Engine
SQL
SQL Support
SQL:2011 Optimizer HCatalog HiveServer2 Vectorized Hash Join Solves CPU
Boundedness for Hive on Tez or on
Spark.
Cac
he
Block Cache
Linux Cache
Dis
trib
ute
dEx
ecu
tio
n
Hadoop 1
MapReduce
Hadoop 2
Tez Spark
Historical
Current
In Development
Legend
Apache Hive: Getting to Sub-Second Improvement
Vector Cache
LLAP
Persistent Server
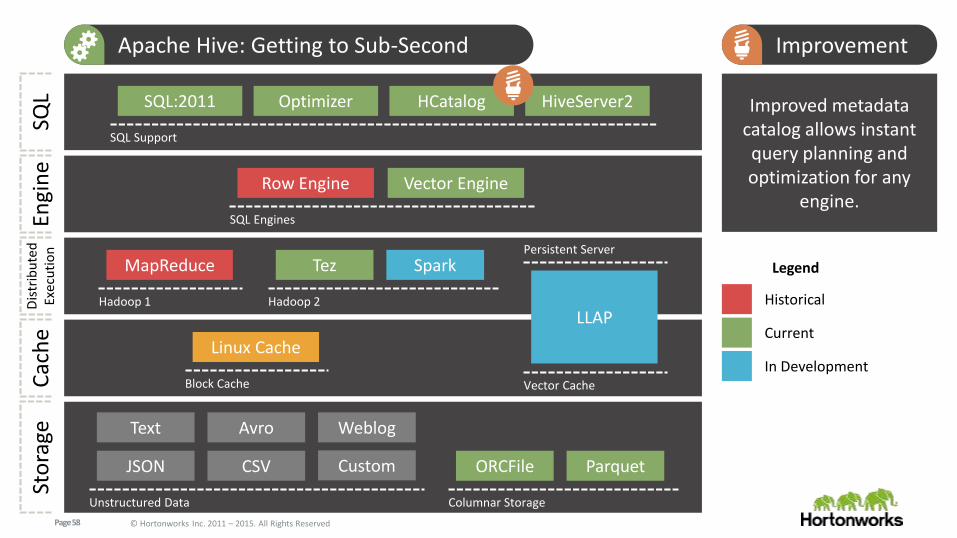
Page 58 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Sto
rage
Columnar Storage
ORCFile Parquet
Unstructured Data
JSON CSV
Text Avro
Custom
Weblog
Engi
ne
SQL Engines
Row Engine Vector Engine
SQL
SQL Support
SQL:2011 Optimizer HCatalog HiveServer2 Improved metadata catalog allows instant query planning and optimization for any
engine.
Cac
he
Block Cache
Linux Cache
Dis
trib
ute
dEx
ecu
tio
n
Hadoop 1
MapReduce
Hadoop 2
Tez Spark
Historical
Current
In Development
Legend
Apache Hive: Getting to Sub-Second Improvement
Vector Cache
LLAP
Persistent Server
Page 59 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
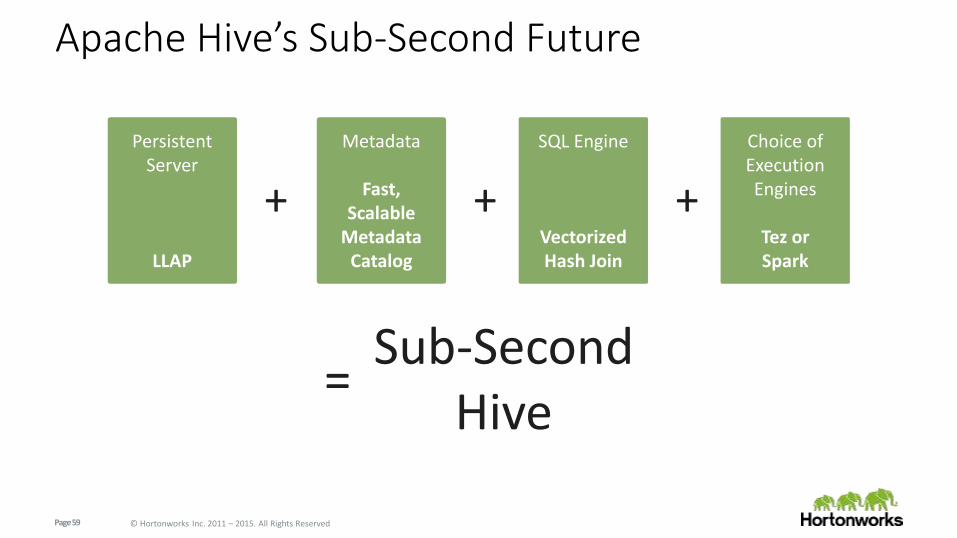
Apache Hive’s Sub-Second Future
=Sub-Second
Hive
Metadata
Fast, Scalable
Metadata Catalog
Persistent Server
LLAP
+ +
SQL Engine
VectorizedHash Join
Choice of Execution Engines
Tez orSpark
+

Page 60 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Questions?
?Interested? Stop by the Hortonworks booth to learn more

Page 61 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Endnotes
(1) https://code.facebook.com/posts/229861827208629/scaling-the-facebook-data-warehouse-to-300-pb/
(2) https://www.facebook.com/notes/facebook-engineering/under-the-hood-scheduling-mapreduce-jobs-more-efficiently-with-corona/10151142560538920
(3) http://hortonworks.com/blog/benchmarking-apache-hive-13-enterprise-hadoop/
(4) http://yahoodevelopers.tumblr.com/post/85930551108/yahoo-betting-on-apache-hive-tez-and-yarn
(5) http://www.slideshare.net/AdamKawa/a-perfect-hive-query-for-a-perfect-meeting-hadoop-summit-2014





























