Embed Size (px)
Citation preview

1 ©HortonworksInc.2011– 2016.AllRightsReserved
Integrate SparkR with existing R packagesto accelerate data science workflows
Feb 2017
Yanbo LiangSoftware engineer @ HortonworksApache Spark committer

2 ©HortonworksInc.2011– 2016.AllRightsReserved
Outline
à Introduction toRand SparkR.
à Typical data science workflow.
à SparkR + R for typical data science problem.– Big data, small learning.– Partition aggregate.– Large scale machine learning.
à Future directions.

3 ©HortonworksInc.2011– 2016.AllRightsReserved
R for data scientist
à Pros– Open source.– Rich ecosystem of packages.– Powerful visualization infrastructure.– Data frames make data manipulation convenient.– Taught by many schools to statistics and computer science students.
à Cons– Single threaded– Everything has to fit in single machine memory

4 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkR = Spark + R
à AnRfrontendforApacheSpark,awidely deployed cluster computing engine.
à Wrappers over DataFrames and DataFrame-based APIs (MLlib).– Complete DataFrame API to behave just like R data.frame.– ML APIs mimic to the methods implemented in R or R packages, rather than Scala/Python APIs.
à Data frame concept is the corner stone of both Spark and R.
à Convenient interoperability between R and Spark DataFrames.
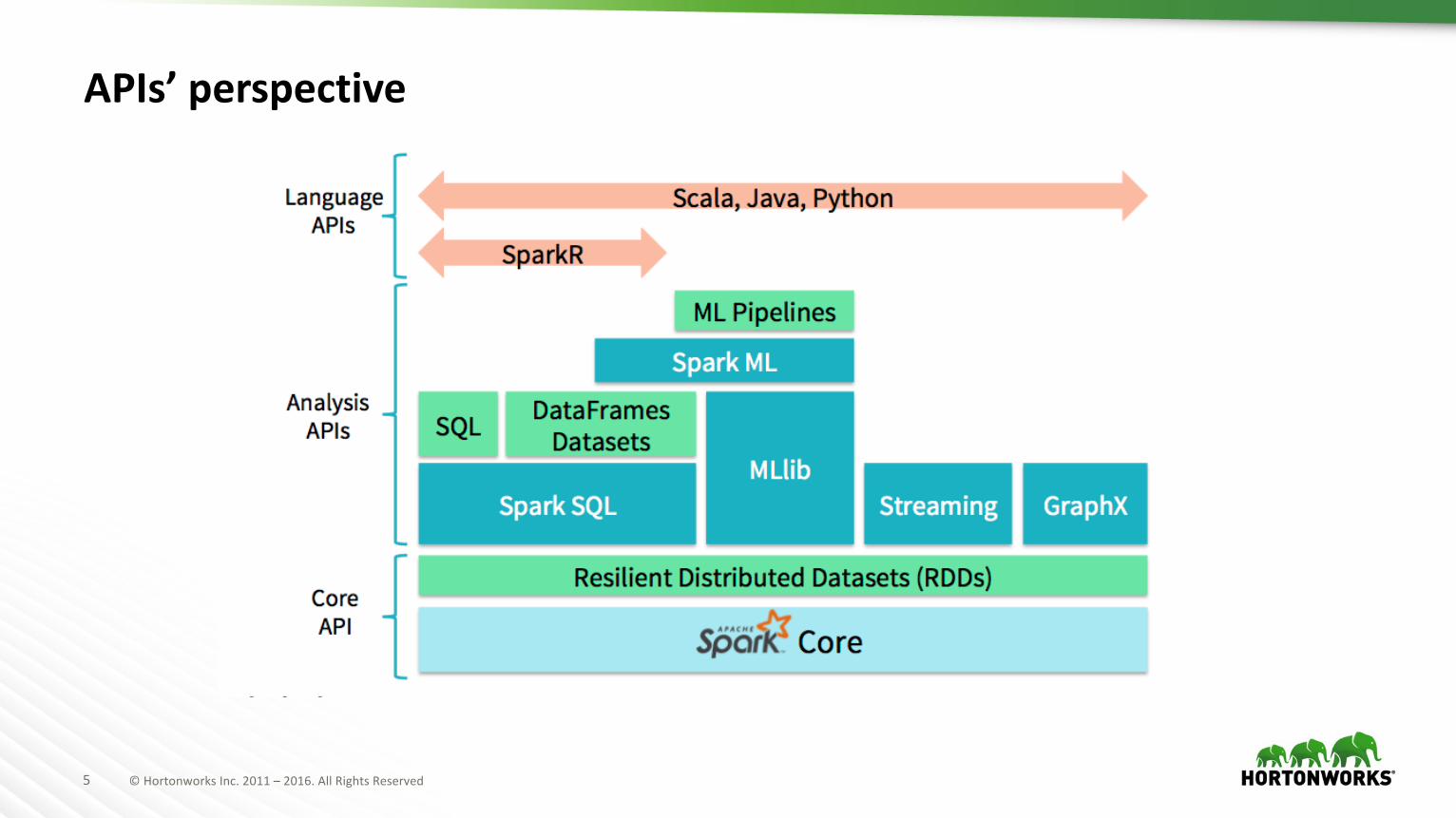
5 ©HortonworksInc.2011– 2016.AllRightsReserved
APIs’ perspective
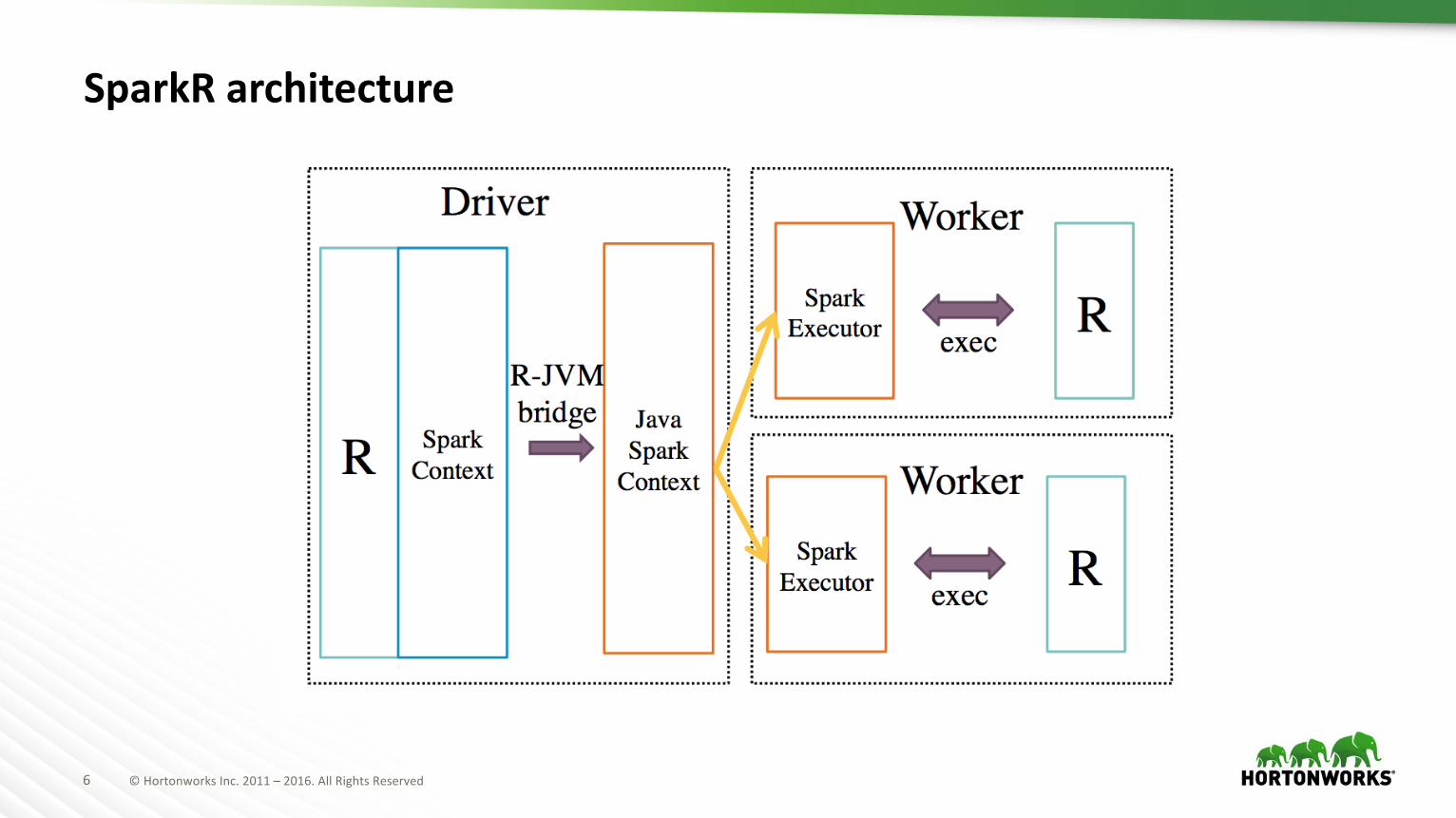
6 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkR architecture
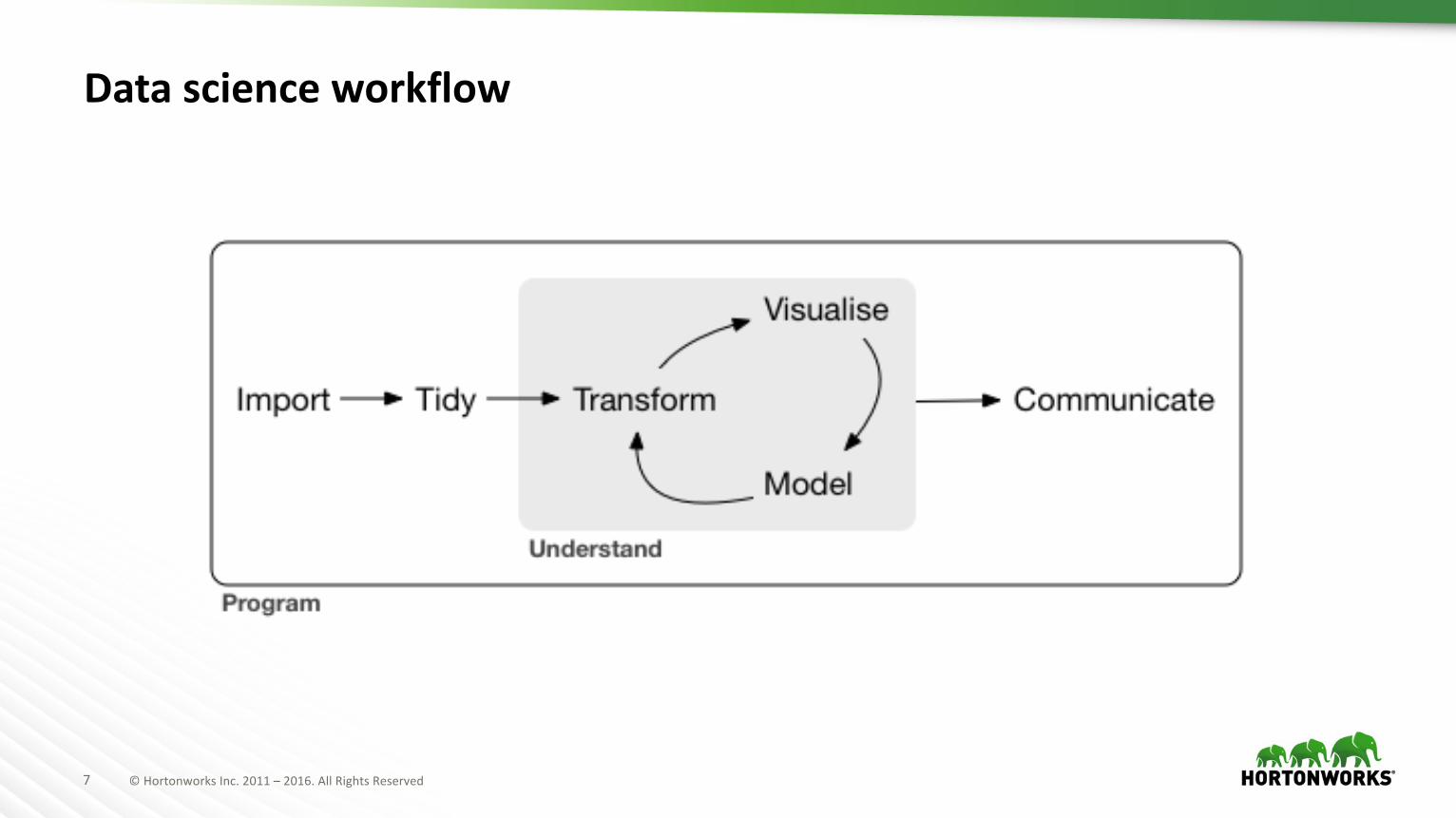
7 ©HortonworksInc.2011– 2016.AllRightsReserved
Data science workflow

8 ©HortonworksInc.2011– 2016.AllRightsReserved
Why SparkR + R
à There are thousands of community packages on CRAN.– It is impossible for SparkR to match all existing features.
à Not every dataset is large.– Many people work with small/medium datasets.

9 ©HortonworksInc.2011– 2016.AllRightsReserved
SparkR + R for typical data science application
à Big data, small learning
à Partition aggregate
à Large scale machine learning
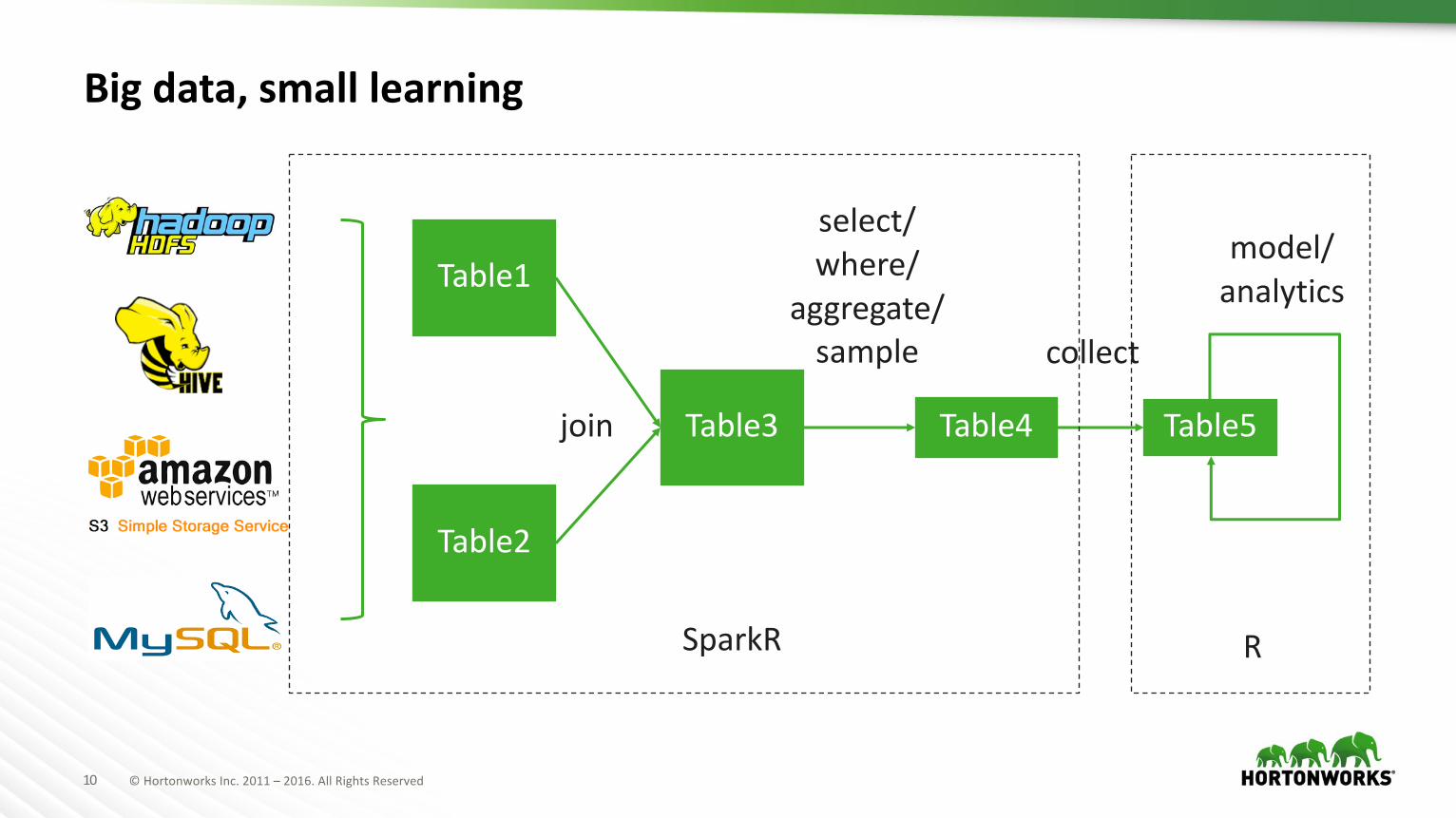
10 ©HortonworksInc.2011– 2016.AllRightsReserved
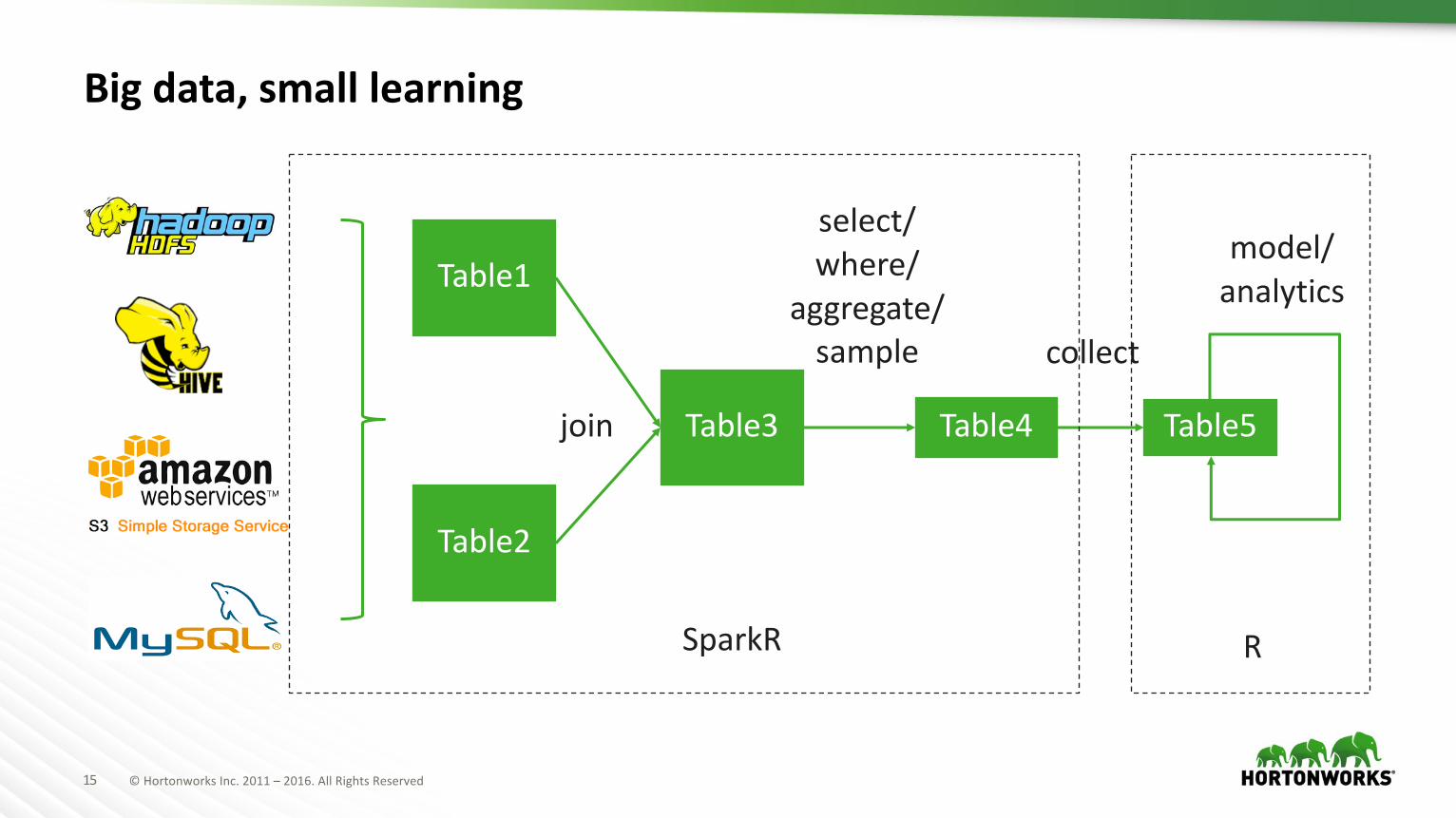
Big data, small learning
Table1
Table2
Table3 Table4 Table5join
select/where/
aggregate/sample collect
model/analytics
SparkR R
11 ©HortonworksInc.2011– 2016.AllRightsReserved
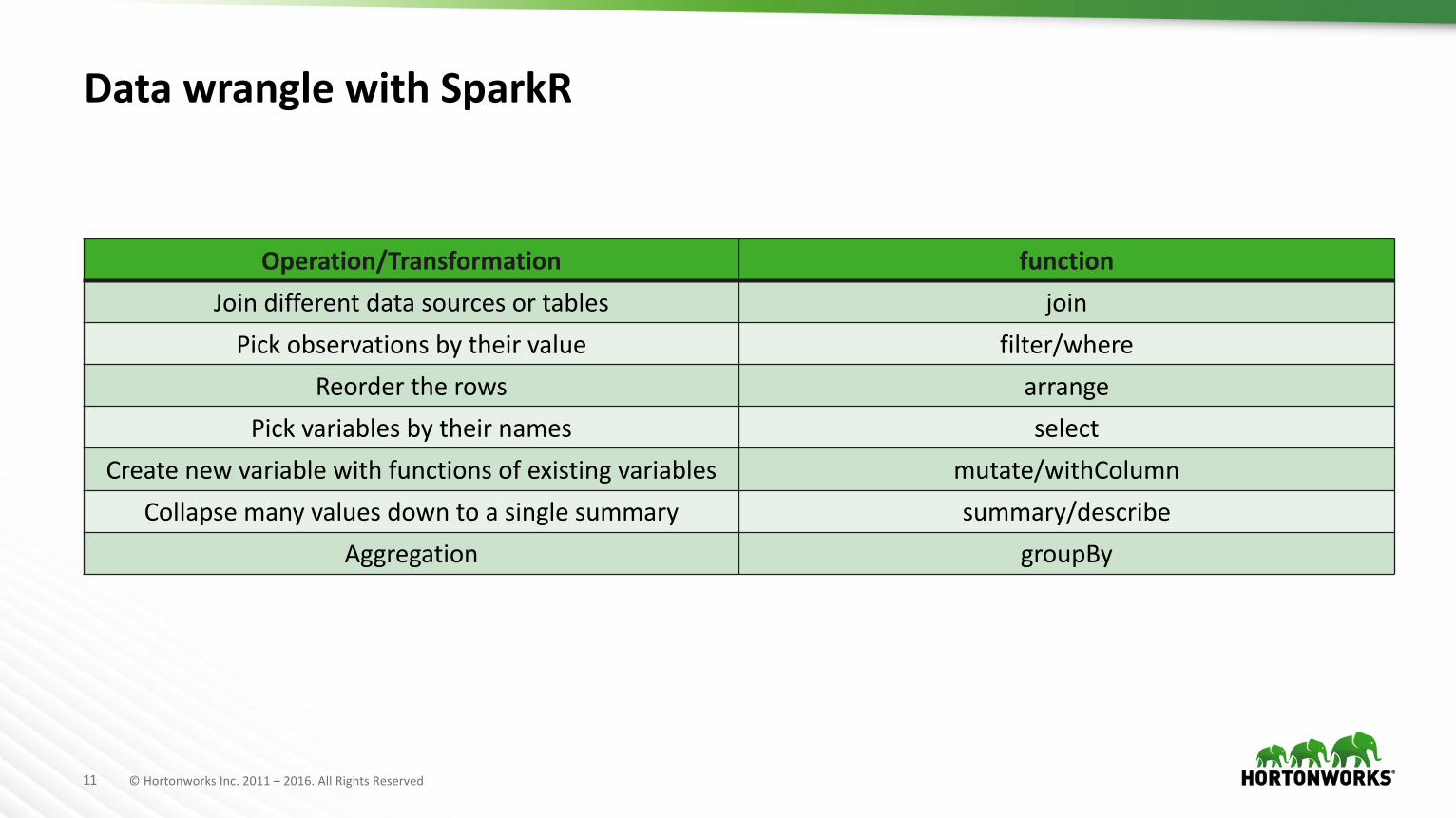
Data wrangle with SparkR
Operation/Transformation functionJoin different data sources or tables joinPick observations by their value filter/where
Reorder the rows arrangePick variables by their names select
Create new variable with functions of existing variables mutate/withColumnCollapse many values down to a single summary summary/describe
Aggregation groupBy

12 ©HortonworksInc.2011– 2016.AllRightsReserved
Data wrangle
airlines <- read.df(path="/data/2008.csv", source="csv", header="true", inferSchema="true")
planes <- read.df(path="/data/plane-data.csv", source="csv", header="true", inferSchema="true")
joined <- join(airlines, planes, airlines$TailNum == planes$tailnum)
df1 <- select(joined, “aircraft_type”, “Distance”, “ArrDelay”, “DepDelay”)
df2 <- dropna(df1)
13 ©HortonworksInc.2011– 2016.AllRightsReserved
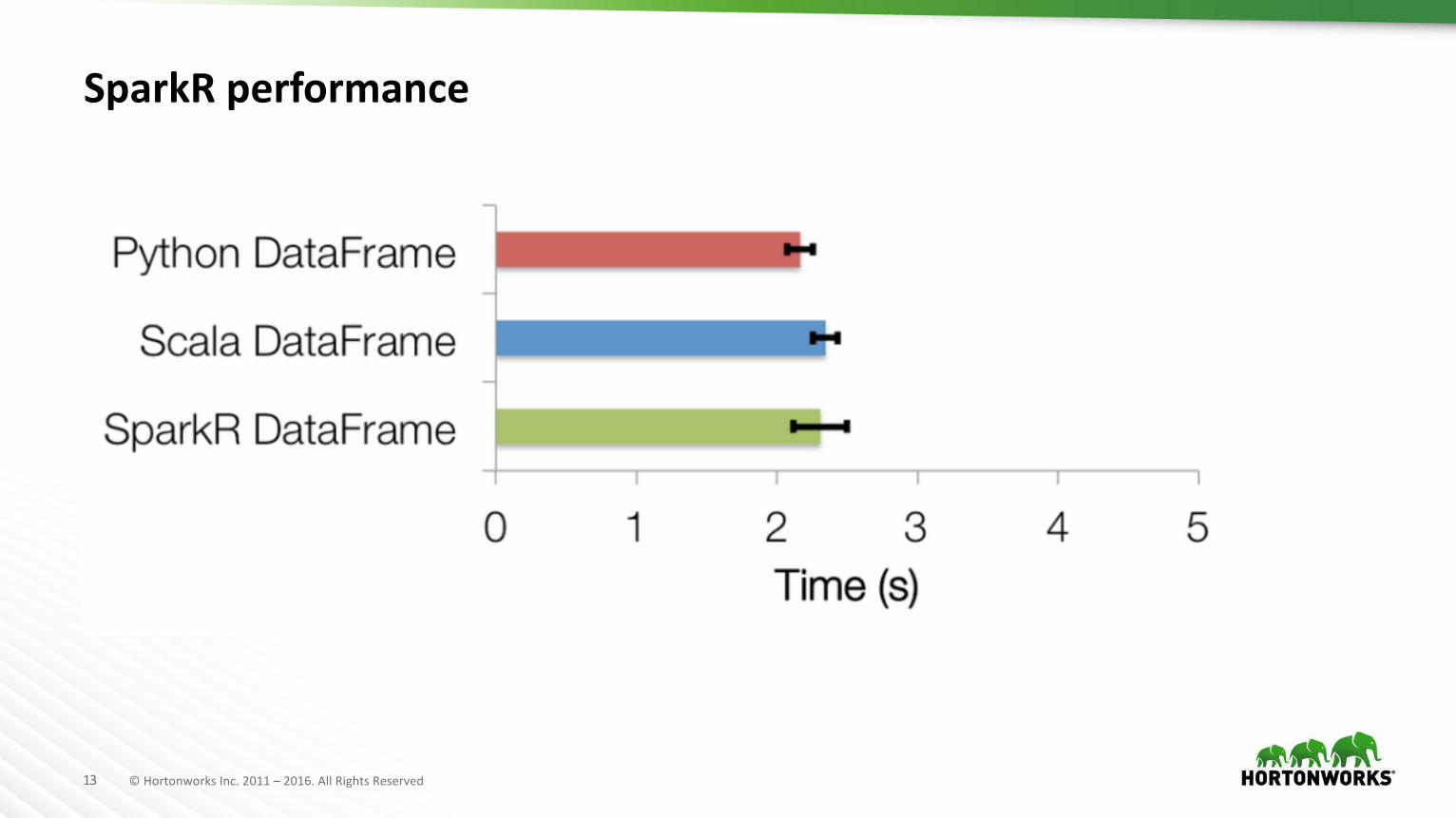
SparkR performance

14 ©HortonworksInc.2011– 2016.AllRightsReserved
Sampling Algorithms
à Bernoulli sampling (without replacement)– df3 <- sample(df2,FALSE,0.1)
à Poisson sampling (with replacement)– df3 <- sample(df2, TRUE, 0.1)
à stratified sampling– df3 <- sampleBy(df2,"aircraft_type",list("FixedWingMulti-Engine"=0.1,"FixedWingSingle-
Engine"=0.2,"Rotorcraft"=0.3),0)
15 ©HortonworksInc.2011– 2016.AllRightsReserved
Big data, small learning
Table1
Table2
Table3 Table4 Table5join
select/where/
aggregate/sample collect
model/analytics
SparkR R
16 ©HortonworksInc.2011– 2016.AllRightsReserved
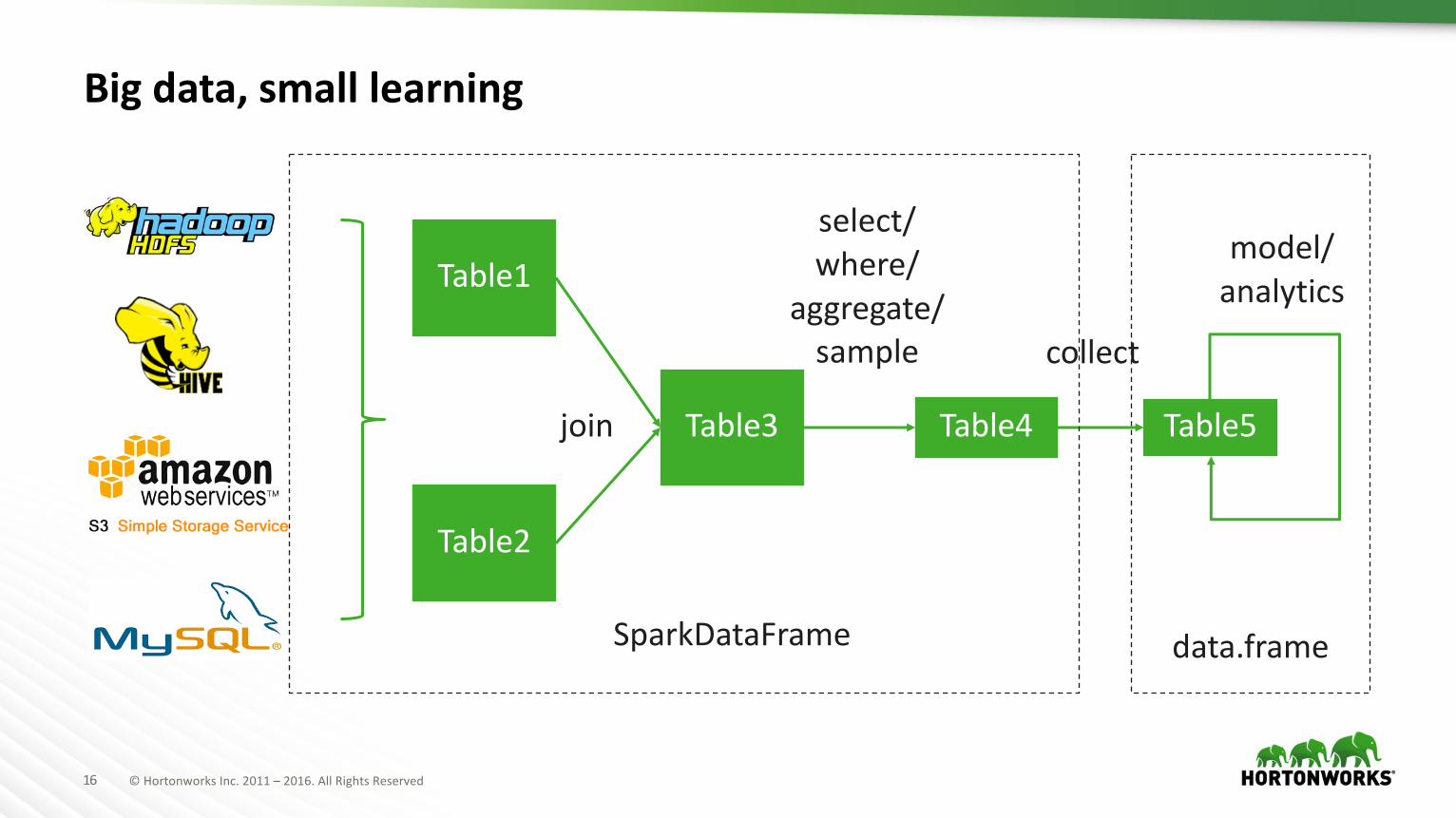
Big data, small learning
Table1
Table2
Table3 Table4 Table5join
select/where/
aggregate/sample collect
model/analytics
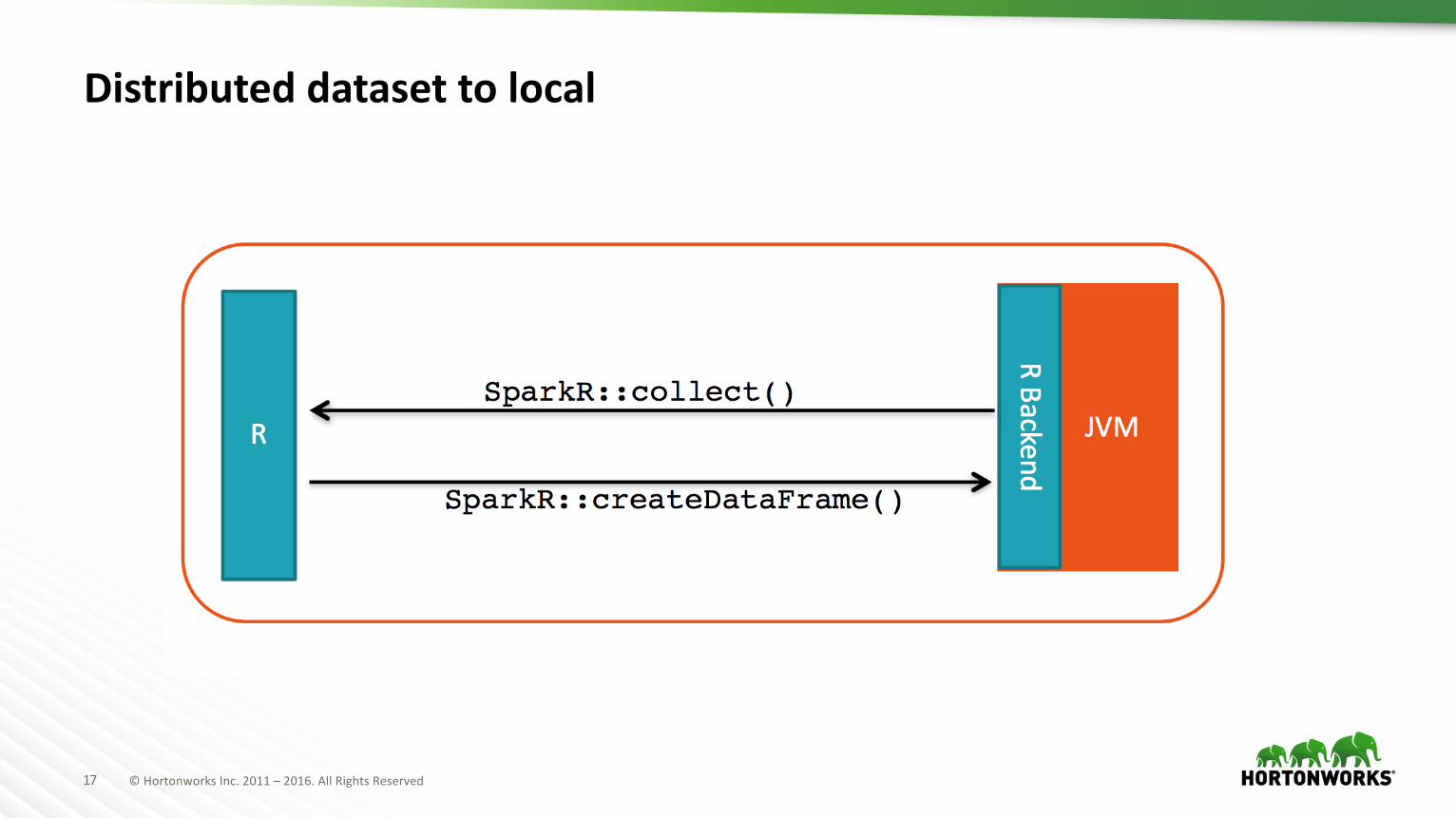
SparkDataFrame data.frame
17 ©HortonworksInc.2011– 2016.AllRightsReserved
Distributed dataset to local

18 ©HortonworksInc.2011– 2016.AllRightsReserved
Partition aggregate
à User Defined Functions (UDFs).– dapply– gapply
à Parallel execution of function.– spark.lapply

19 ©HortonworksInc.2011– 2016.AllRightsReserved
User Defined Functions (UDFs)
à dapply
à gapply
20 ©HortonworksInc.2011– 2016.AllRightsReserved
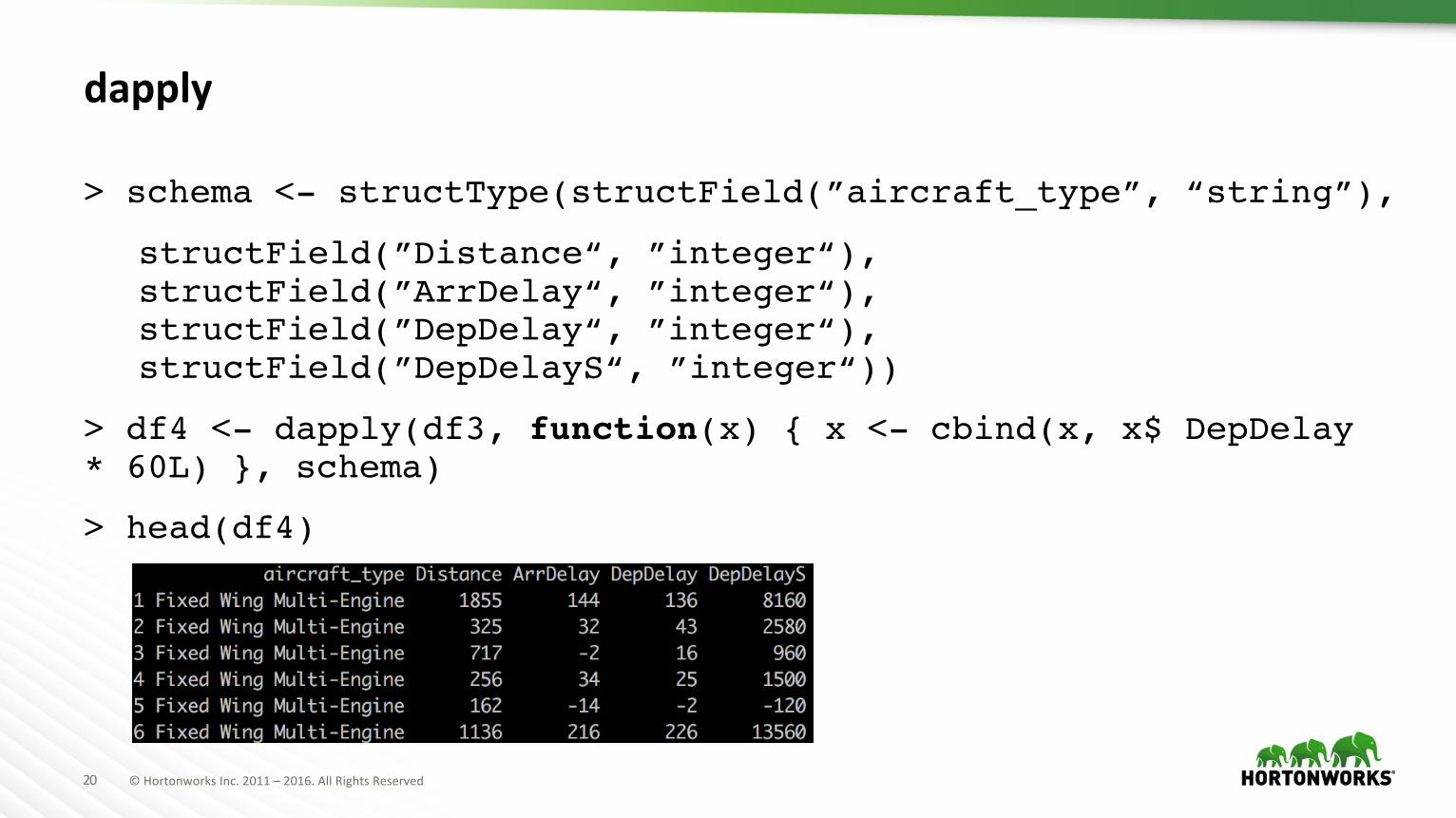
dapply
> schema <- structType(structField(”aircraft_type”, “string”),
structField(”Distance“, ”integer“),structField(”ArrDelay“, ”integer“),structField(”DepDelay“, ”integer“), structField(”DepDelayS“, ”integer“))
> df4 <- dapply(df3, function(x) { x <- cbind(x, x$ DepDelay* 60L) }, schema)
> head(df4)

21 ©HortonworksInc.2011– 2016.AllRightsReserved
gapply
> schema <- structType(structField(”Distance“, ”integer“),structField(”MaxActualDelay“, ”integer“))
> df5 <- gapply(df3, “Distance”, function(key, x) { y <-data.frame(key, max(x$ArrDelay-x$DepDelay)) }, schema)
> head(df5)

22 ©HortonworksInc.2011– 2016.AllRightsReserved
spark.lapply
à Ideal way for distributing existing R functionality and packages

23 ©HortonworksInc.2011– 2016.AllRightsReserved
spark.lapply
for (lambda in c(0.5, 1.5)) {
for (alpha in c(0.1, 0.5, 1.0)) {
model <- glmnet(A, b, lambda=lambda, alpha=alpha)
c <- predit(model, A)
c(coef(model), auc(c, b))
}}

24 ©HortonworksInc.2011– 2016.AllRightsReserved
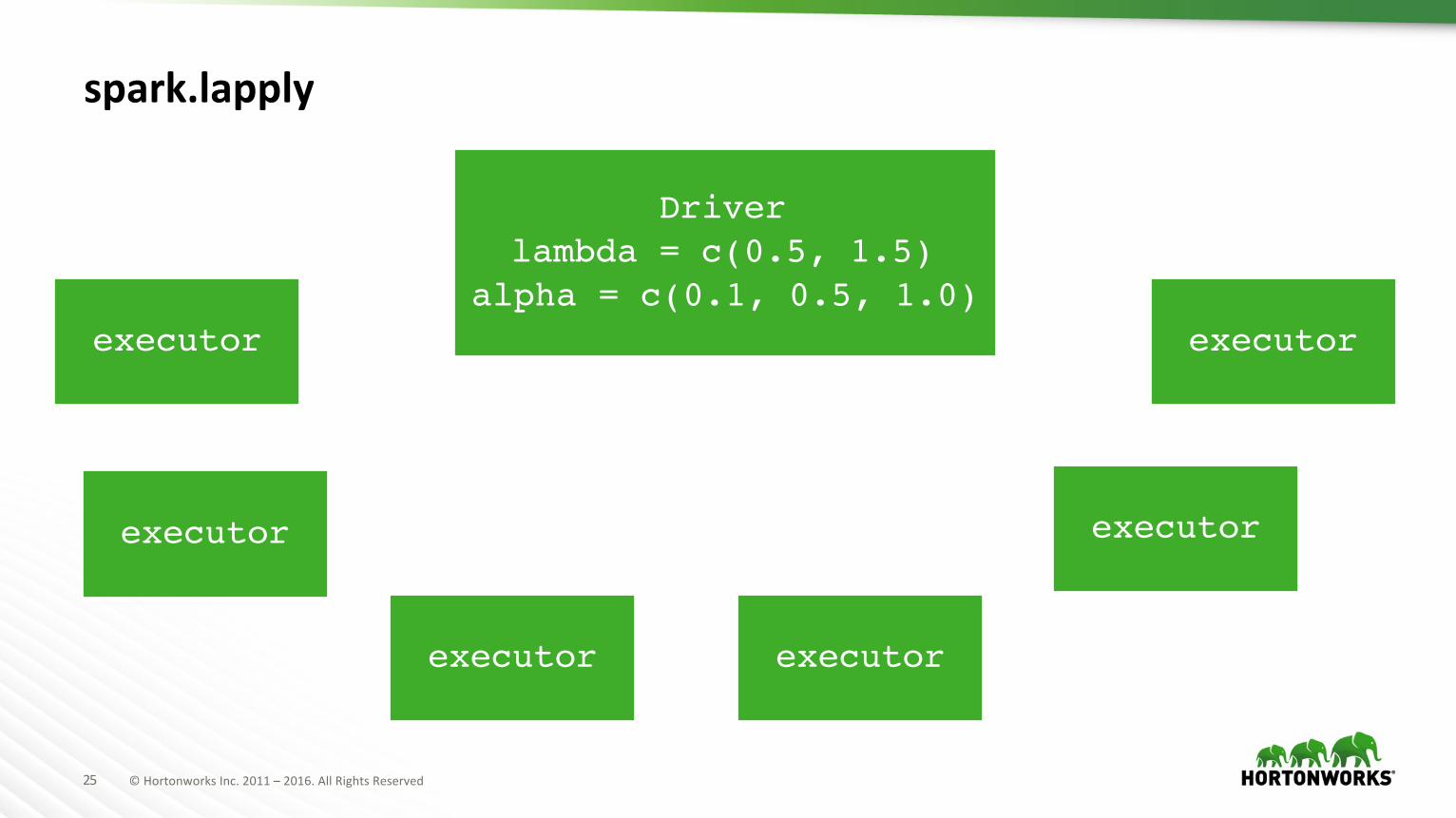
spark.lapply
values <- c(c(0.5, 0.1), c(0.5, 0.5), c(0.5, 1.0), c(1.5,0.1), c(1.5, 0.5), c(1.5, 1.0))
train <- function(value) {
lambda <- value[1]
alpha <- value[2]
model <- glmnet(A, b, lambda=lambda, alpha=alpha)
c(coef(model), auc(c, b))
}
models <- spark.lapply(values, train)
25 ©HortonworksInc.2011– 2016.AllRightsReserved
spark.lapply
executor
executor
executor
executor
executor
Driverlambda = c(0.5, 1.5)
alpha = c(0.1, 0.5, 1.0)
executor
26 ©HortonworksInc.2011– 2016.AllRightsReserved
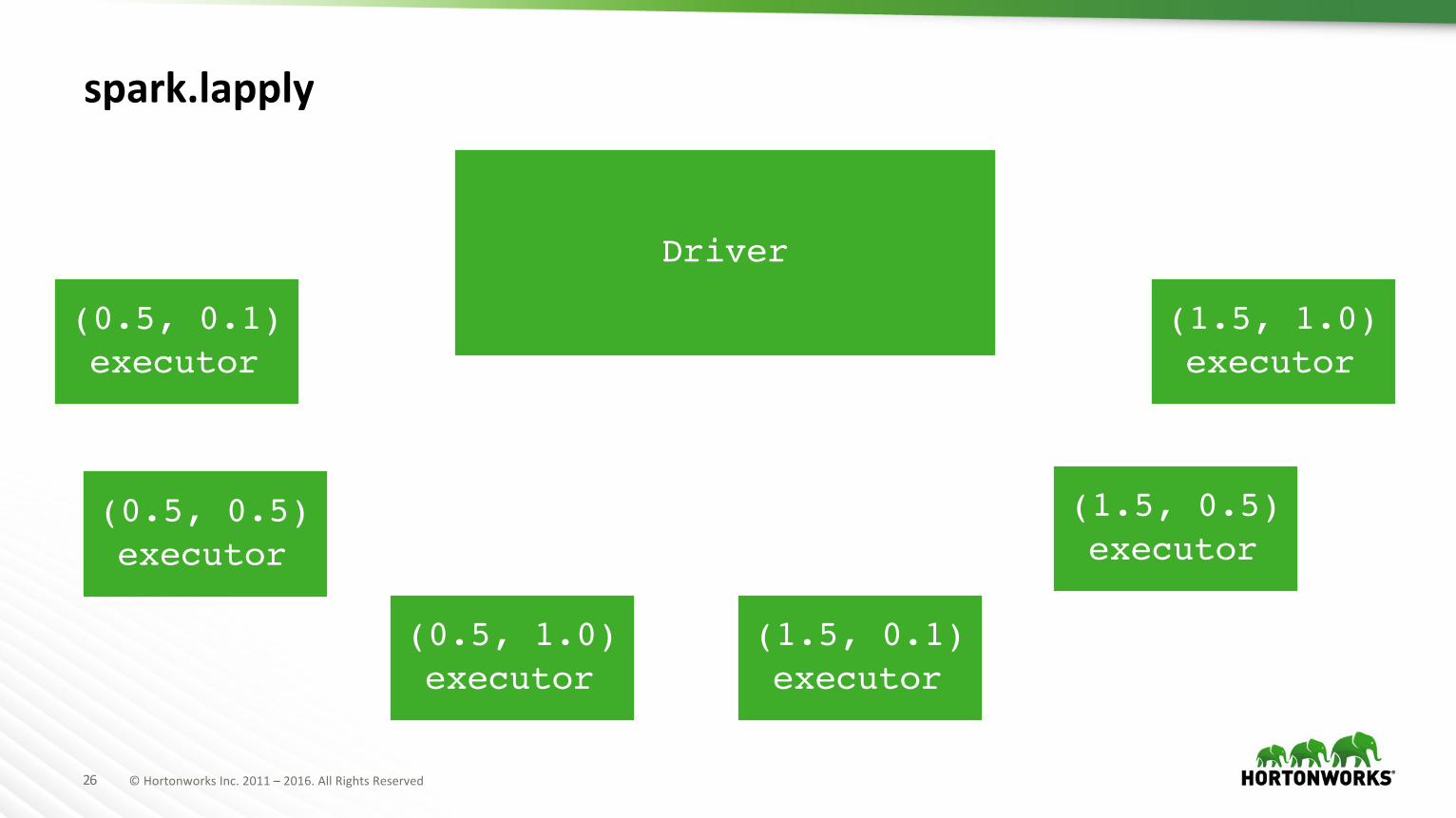
spark.lapply
(0.5, 0.1)executor
(1.5, 0.1)executor
(0.5, 0.5)executor
(0.5, 1.0)executor
(1.5, 1.0)executor
Driver
(1.5, 0.5)executor
27 ©HortonworksInc.2011– 2016.AllRightsReserved
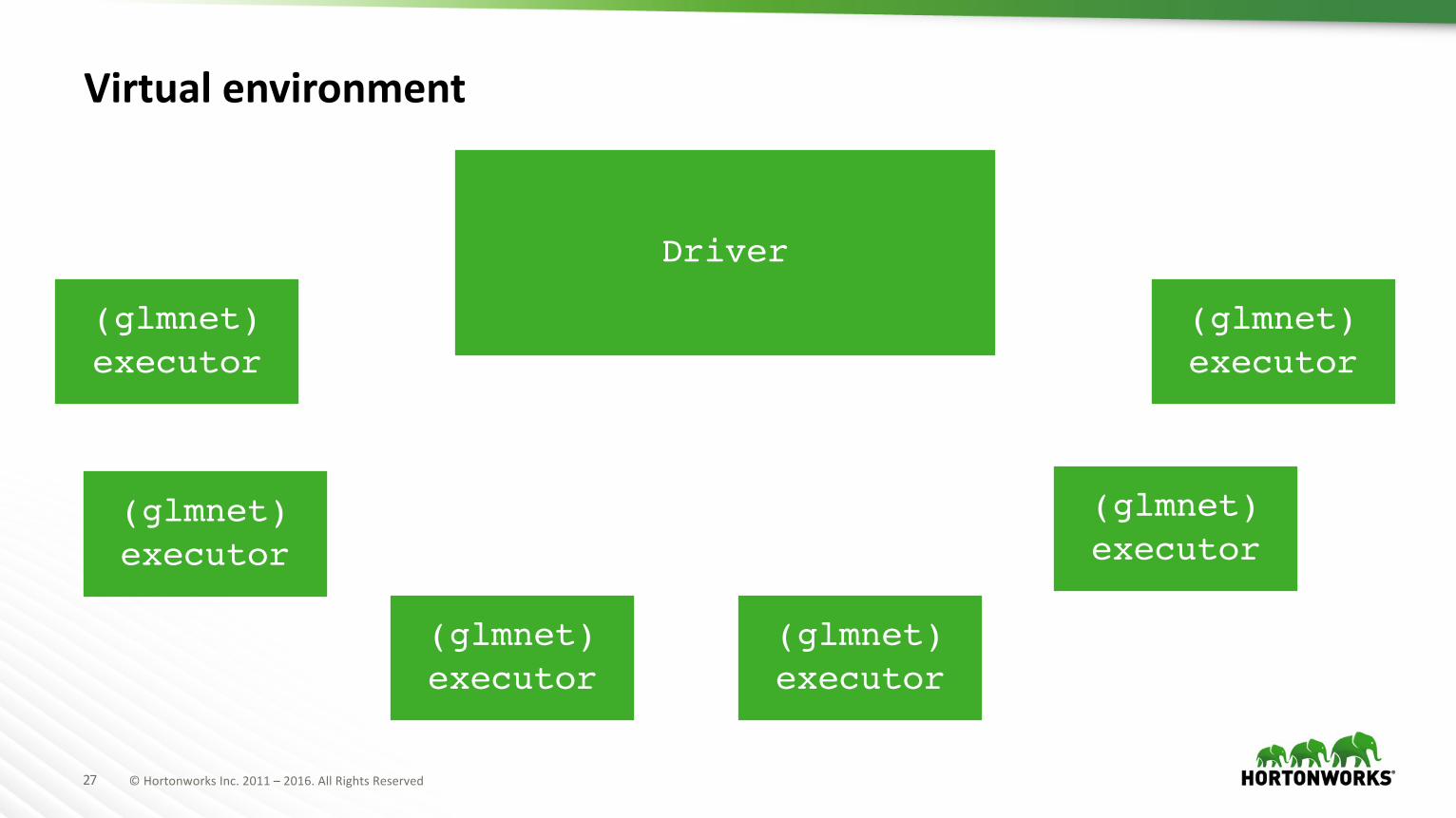
Virtual environment
(glmnet)executor
(glmnet)executor
(glmnet)executor
(glmnet)executor
(glmnet)executor
Driver
(glmnet)executor

28 ©HortonworksInc.2011– 2016.AllRightsReserved
Virtual environment
download.packages(”glmnet", packagesDir, repos = "https://cran.r-project.org")
filename <- list.files(packagesDir, "^glmnet")
packagesPath <- file.path(packagesDir, filename)
spark.addFile(packagesPath)

29 ©HortonworksInc.2011– 2016.AllRightsReserved
Virtual environmentpath <- spark.getSparkFiles(filename)
values <- c(c(0.5, 0.1), c(0.5, 0.5), c(0.5, 1.0), c(1.5, 0.1), c(1.5,0.5), c(1.5, 1.0))
train <- function(value) {
install.packages(path, repos = NULL, type = "source")
library(glmnet)
lambda <- value[1]
alpha <- value[2]
model <- glmnet(A, b, lambda=lambda, alpha=alpha)
c(coef(model), auc(c, b))
}
models <- spark.lapply(values, train)

30 ©HortonworksInc.2011– 2016.AllRightsReserved
Large scale machine learning

31 ©HortonworksInc.2011– 2016.AllRightsReserved
Large scale machine learning
32 ©HortonworksInc.2011– 2016.AllRightsReserved
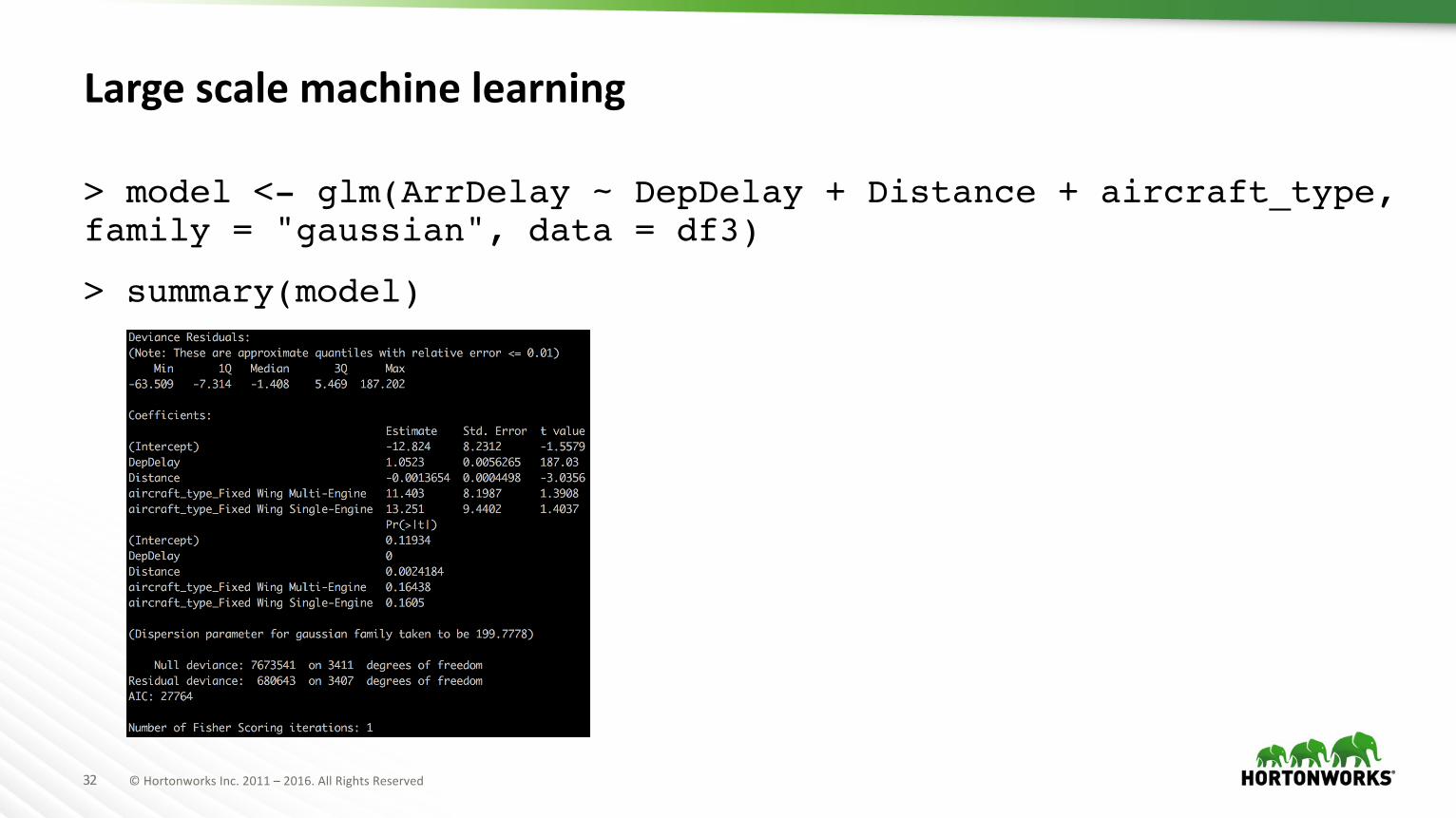
Large scale machine learning
> model <- glm(ArrDelay ~ DepDelay + Distance + aircraft_type, family = "gaussian", data = df3)
> summary(model)

33 ©HortonworksInc.2011– 2016.AllRightsReserved
Future directions
à Improve collect/createDataFrame performance in SparkR (SPARK-18924).
à More scalable machine learning algorithms from MLlib.
à Better R formula support.
à Improve UDF performance.

34 ©HortonworksInc.2011– 2016.AllRightsReserved
Reference
à SparkR:ScalingRProgramswithSpark (SIGMOD 2016)
à http://www.slideshare.net/databricks/recent-developments-in-sparkr-for-advanced-analytics
à https://databricks.com/blog/2015/10/05/generalized-linear-models-in-sparkr-and-r-formula-support-in-mllib.html
à https://databricks.com/blog/2016/12/28/10-things-i-wish-i-knew-before-using-apache-sparkr.html
à http://www.kdnuggets.com/2015/06/top-20-r-machine-learning-packages.html
à R for Data Science (http://r4ds.had.co.nz/)

35 ©HortonworksInc.2011– 2016.AllRightsReserved
Integrate SparkR with existing R packagesto accelerate data science workflows
Feb 2017
Yanbo LiangSoftware engineer @ HortonworksApache Spark committer





























