Embed Size (px)
Citation preview

APACHE SAMOA: MINING BIG DATA STREAMS
WITH APACHE FLINK
Albert Bifet @abifet
12 October 2015

APACHE SAMOA 0.3.0
• Released July 2015
real time computation: streaming computation
MapReduce Limitations
ExampleHow compute in real time (latency less than 1 second):
1 predictions2 frequent items as Twitter hashtags3 sentiment analysis
14

Streaming Predictive Analytics onApache Flink
Author:Foteini Beligianni
Examiner:Vladimir Vlassov
Supervisors:Seif HaridiParis Carbone
A thesis submitted for the degree of Master of Science inDistributed Systems and Services
Stockholm, 15.07.2015

MOTIVATION

REAL TIME ANALYTICSreal time analytics
2

REAL TIME ANALYTICSreal time analytics
3

APACHE SAMOA VISION• Distributed stream mining platform
• Library of state-of-the-art algorithmsfor practitioners
• Development and collaboration frameworkfor researchers
• Algorithms & Systems
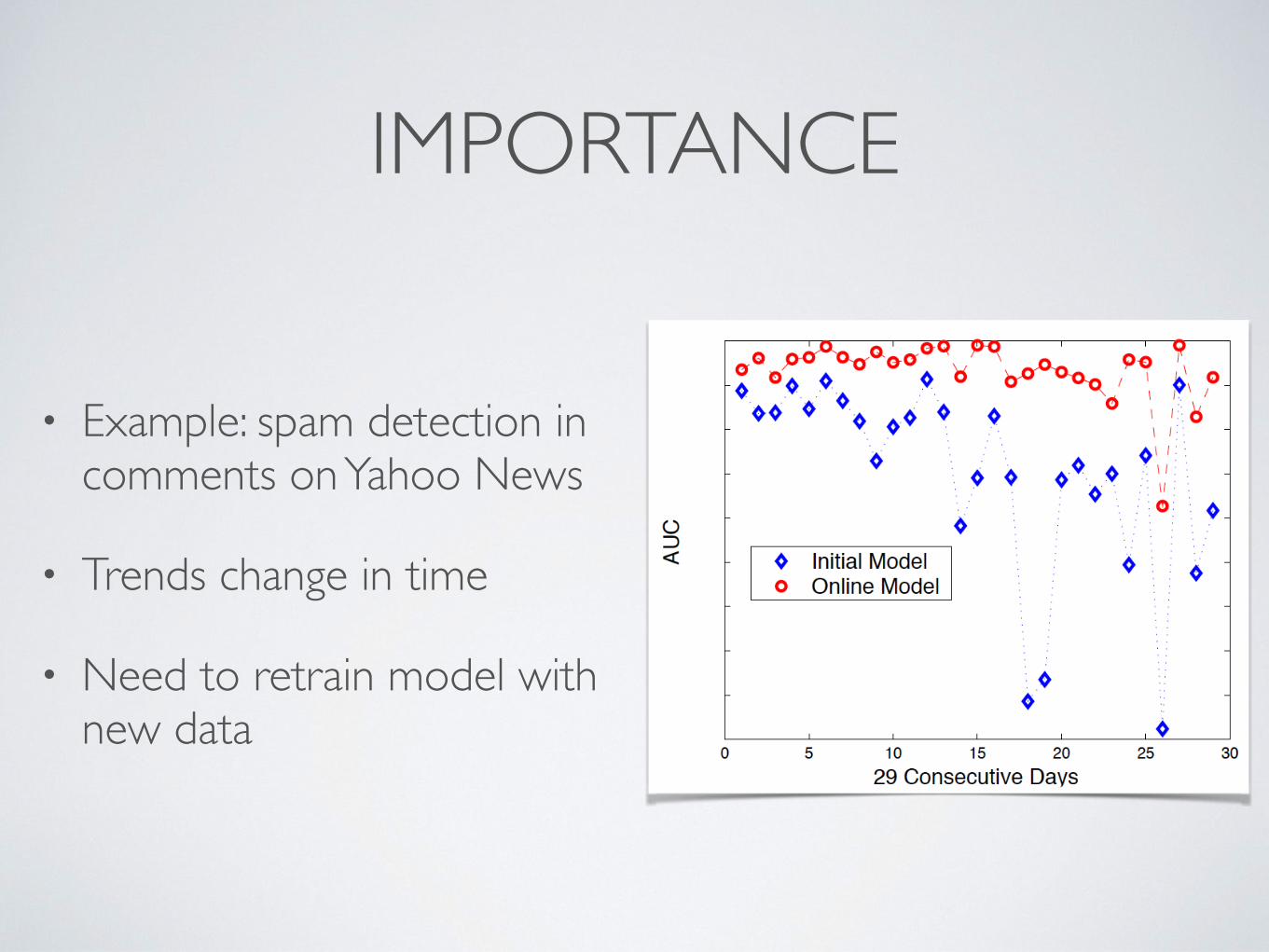
IMPORTANCE
• Example: spam detection in comments on Yahoo News
• Trends change in time
• Need to retrain model with new data
Importance$of$Online$Learning$$
• As$spam$trends$change,$it$is$important$to$retrain$the$model$with$newly$judged$data$
• Previously$tested$using$news$comment$in$Y!Inc$
• Over$29$days$period,$you$can$see$degrada)on$in$performance$of$base$model$(w/o$ac)ve$learning)$VS$Online$model$(AUC$stands$for$Area$Under$Curve)$
• Original$paper$$
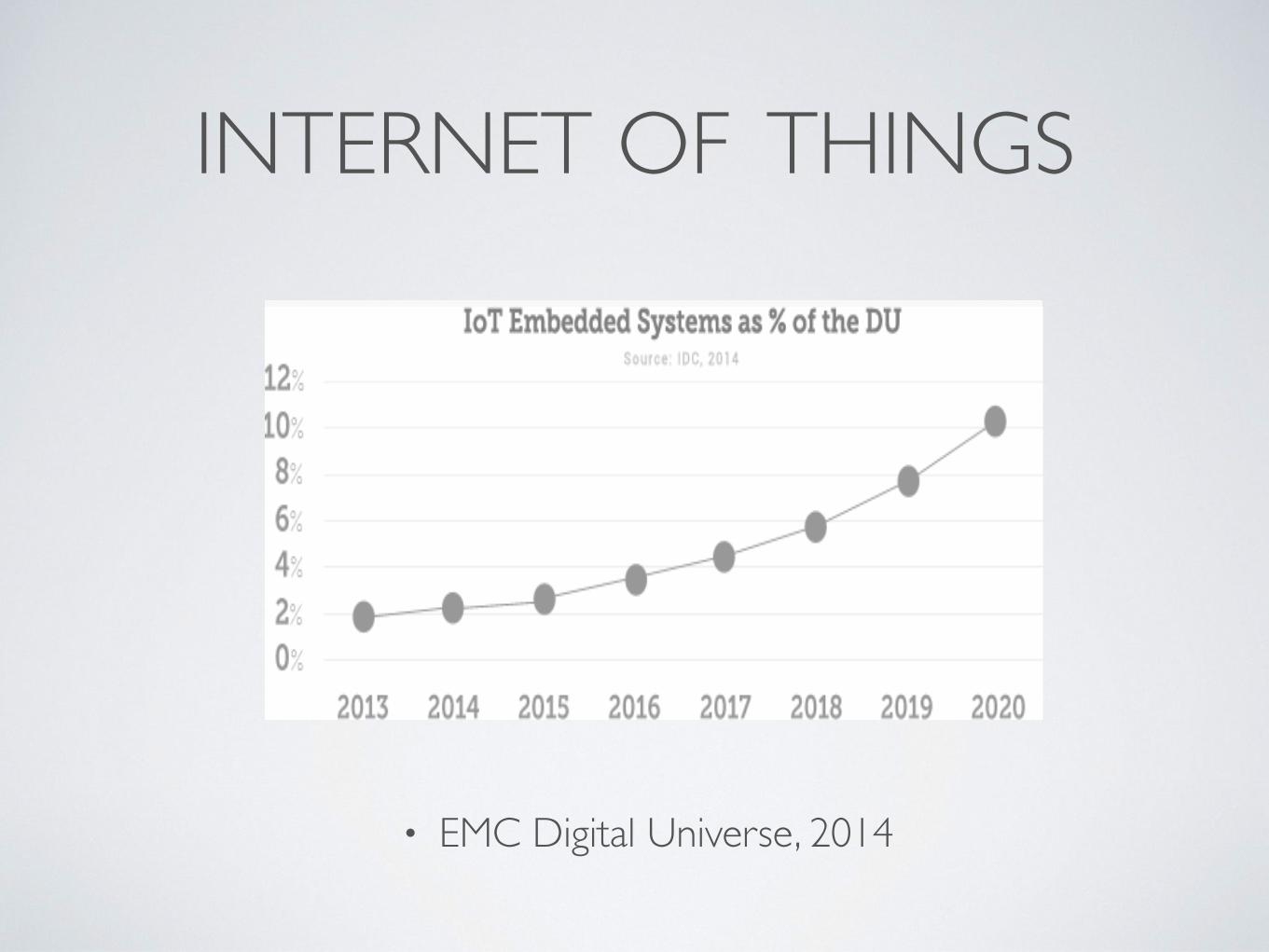
INTERNET OF THINGS
• EMC Digital Universe, 2014
digital universe
Figure 3: EMC Digital Universe, 2014
7

BIG DATA STREAM• Volume + Velocity (+ Variety)
• Too large for single commodity server main memory
• Too fast for single commodity server CPU
• A solution should be:
• Distributed
• Scalable

BIG DATA PROCESSING ENGINES
• Low latency
• High Latency (Not real time)
apache storm
Storm characteristics for real-time data processing workloads:
1 Fast2 Scalable3 Fault-tolerant4 Reliable5 Easy to operate
8
apache samza from linkedin
Storm and Samza are fairly similar. Both systems provide:
1 a partitioned stream model,2 a distributed execution environment,3 an API for stream processing,4 fault tolerance,5 Kafka integration
10
real time computation: streaming computation
MapReduce Limitations
ExampleHow compute in real time (latency less than 1 second):
1 predictions2 frequent items as Twitter hashtags3 sentiment analysis
14
apache spark streaming
Spark Streaming is an extension of Spark that allowsprocessing data stream using micro-batches of data.
11

DATA SCIENCEdata scientist
Figure 1:
2

MACHINE LEARNING
• Classification
• Regression
• Clustering
• Frequent Pattern Mining

WHAT IS APACHE SAMOA?

STREAMING MODEL• Sequence is potentially infinite
• High amount of data, high speed of arrival
• Change over time (concept drift)
• Approximation algorithms(small error with high probability)
• Single pass, one data item at a time
• Sub-linear space and time per data item
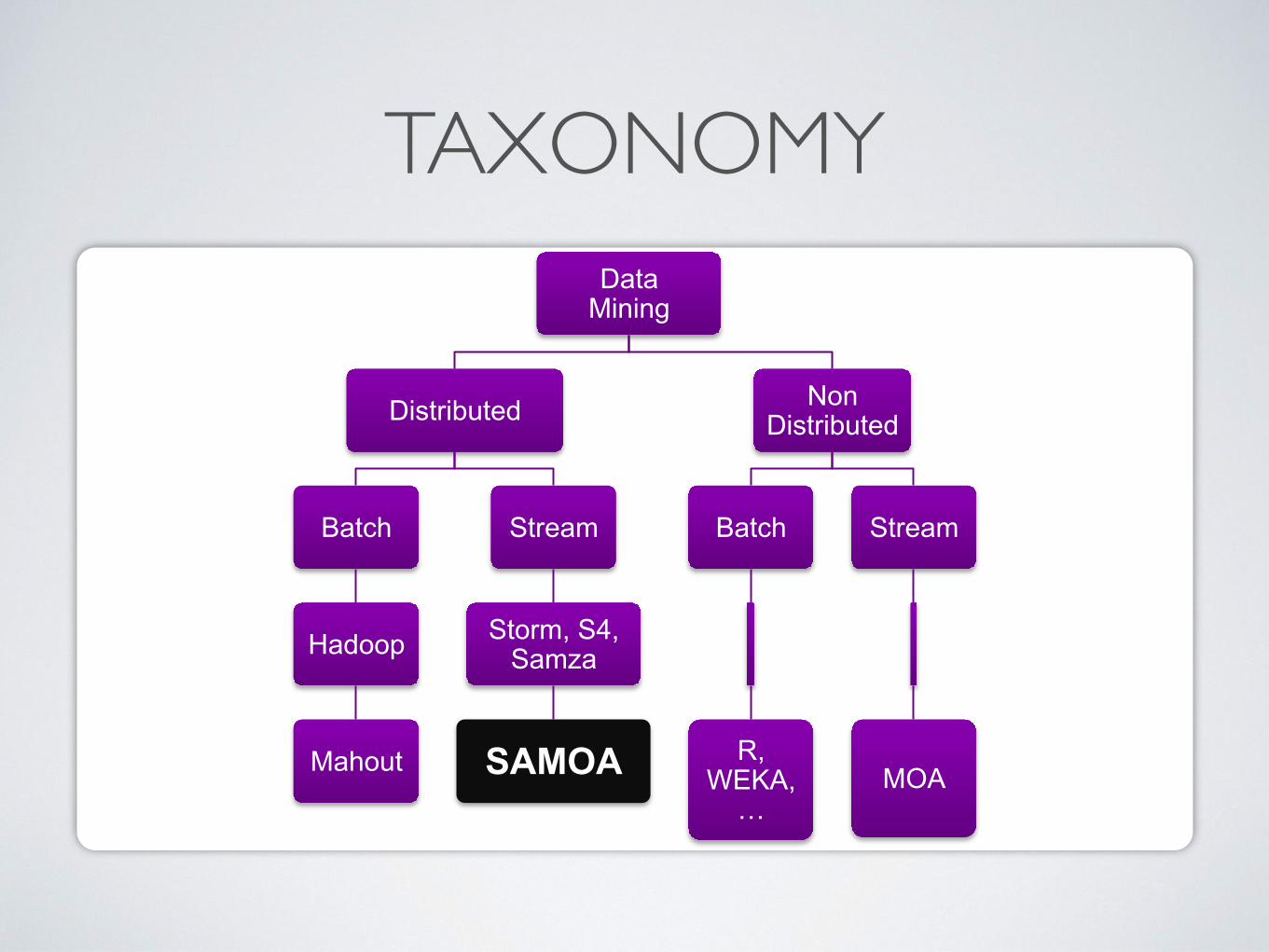
TAXONOMYData
Mining
Distributed
Batch
Hadoop
Mahout
Stream
Storm, S4, Samza
SAMOA
Non Distributed
Batch
R, WEKA,…
Stream
MOA
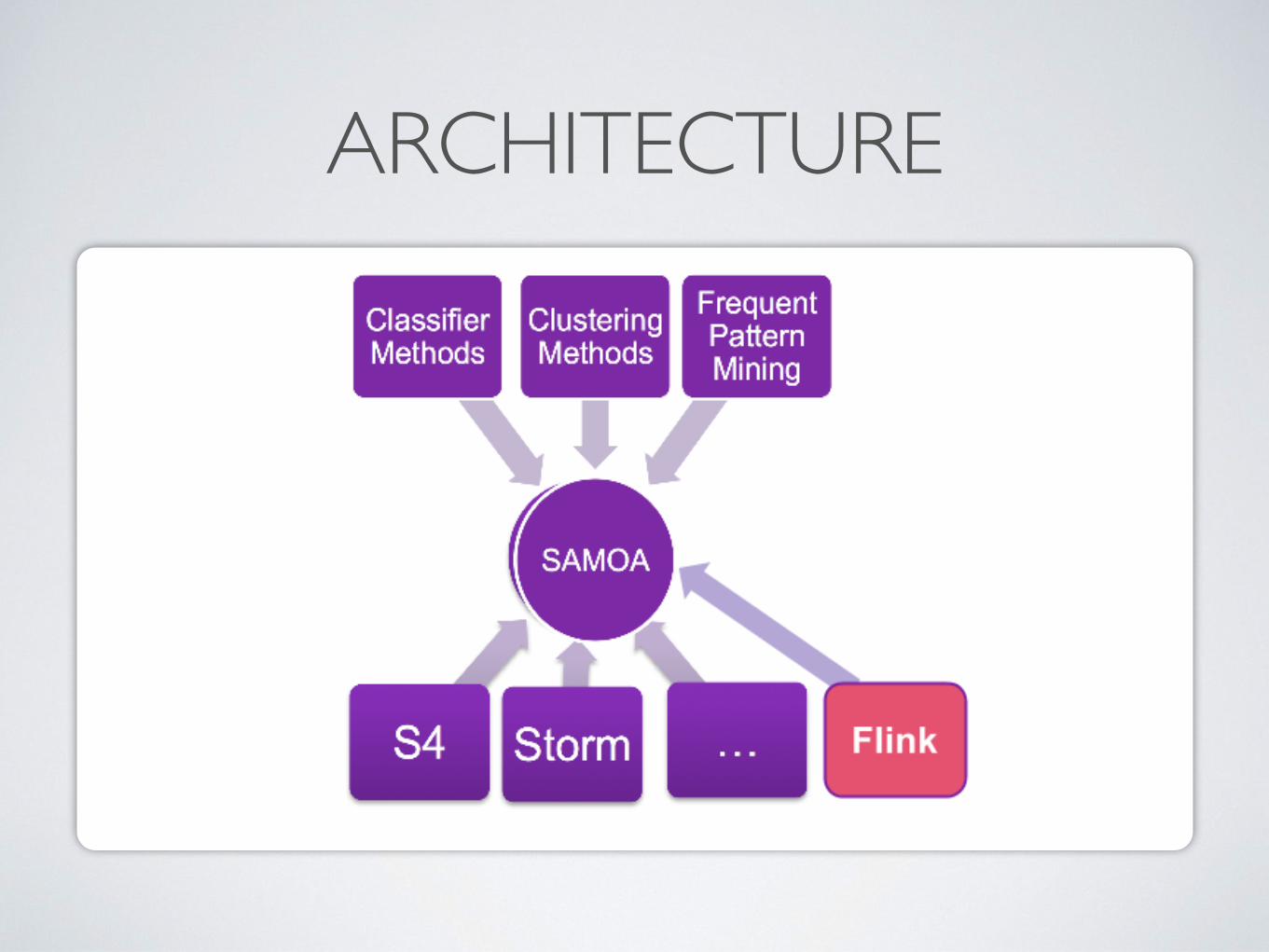
ARCHITECTURE
5 CREATING A FLINK ADAPTER ON APACHE SAMOA
5 Creating a Flink Adapter on Apache SAMOA
Apache Scalable Advanced Massive Online Analysis (SAMOA) is a platform formining data streams with the use of distributed streaming Machine Learning al-gorithms, which can run on top of different Data Stream Processing Engines(DSPE)s.
As depicted in Figure 20, Apache SAMOA offers the abstractions and APIs fordeveloping new distributed ML algorithms to enrich the existing library of state-of-the-art algorithms [27, 28]. Moreover, SAMOA provides the possibility of inte-grating new DSPEs, allowing in that way the ML programmers to implement analgorithm once and run it in different DSPEs [28].
An adapter for integrating Apache Flink into Apache SAMOA was implementedin scope of this master thesis, with the main parts of its implementation beingaddressed in this section. With the use of our adapter, ML algorithms can beexecuted on top of Apache Flink. The implemented adapter will be used for theevaluation of the ML pipelines and HT algorithm variations.
Figure 20: Apache SAMOA’s high level architecture.
5.1 Apache SAMOA Abstractions
Apache SAMOA offers a number of abstractions which allow users to implementany distributed streaming ML algorithms in a platform independent way. The mostimportant abstractions of Apache SAMOA are presented below [27, 28].
40

STATUSSTATUS• Parallel algorithms
• Classification (Vertical Hoeffding Tree)
• Clustering (CluStream)
• Regression (Adaptive Model Rules)
• Execution engines

IS SAMOA USEFUL FOR YOU?• Only if you need to deal with:
• Large fast data
• Evolving process (model updates)
• What is happening now?
• Use feedback in real-time
• Adapt to changes faster
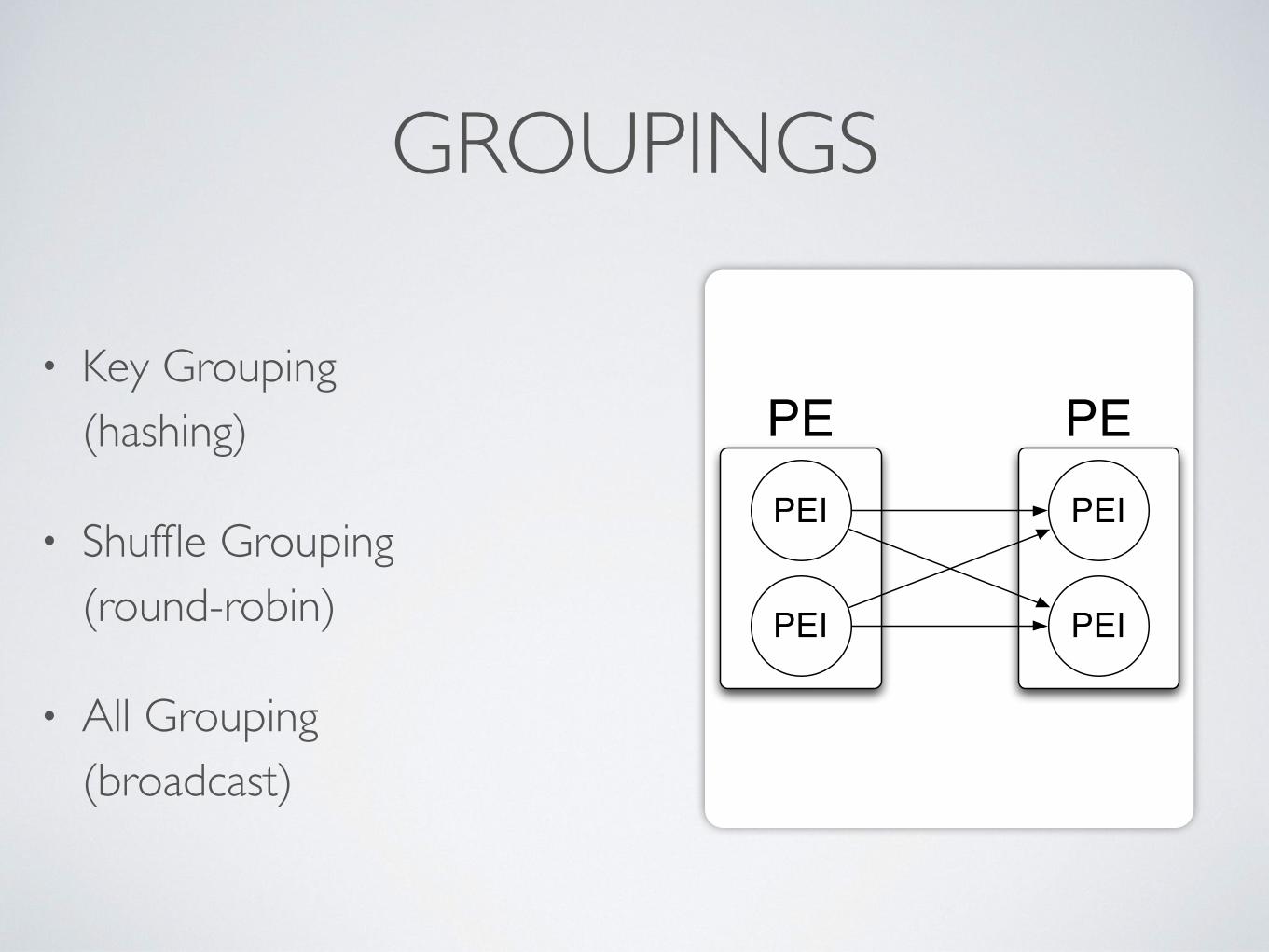
GROUPINGS
• Key Grouping (hashing)
• Shuffle Grouping(round-robin)
• All Grouping(broadcast)
PE PEPEI
PEI
PEI
PEI
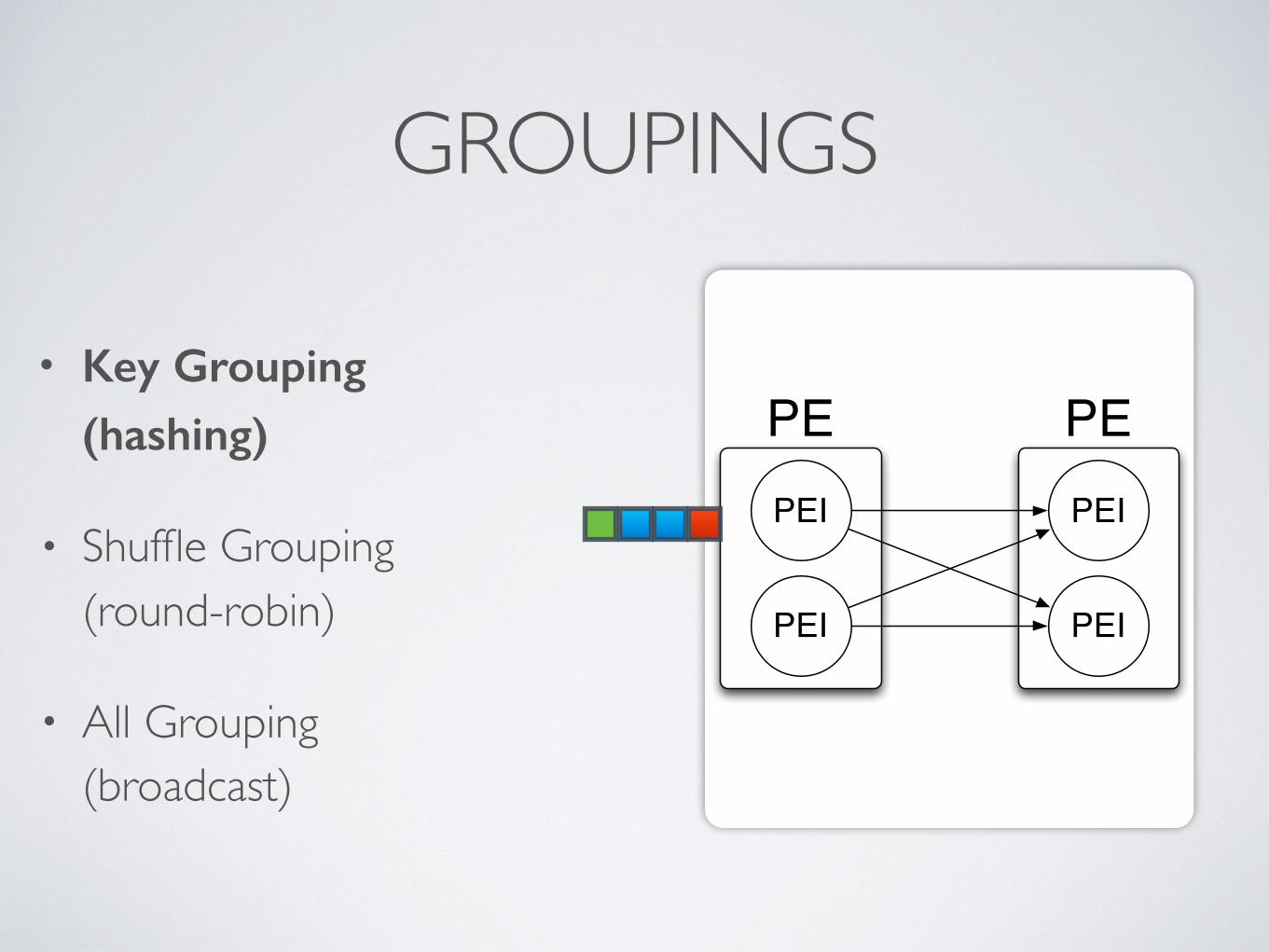
PE PEPEI
PEI
PEI
PEI
GROUPINGS
• Key Grouping (hashing)
• Shuffle Grouping(round-robin)
• All Grouping(broadcast)
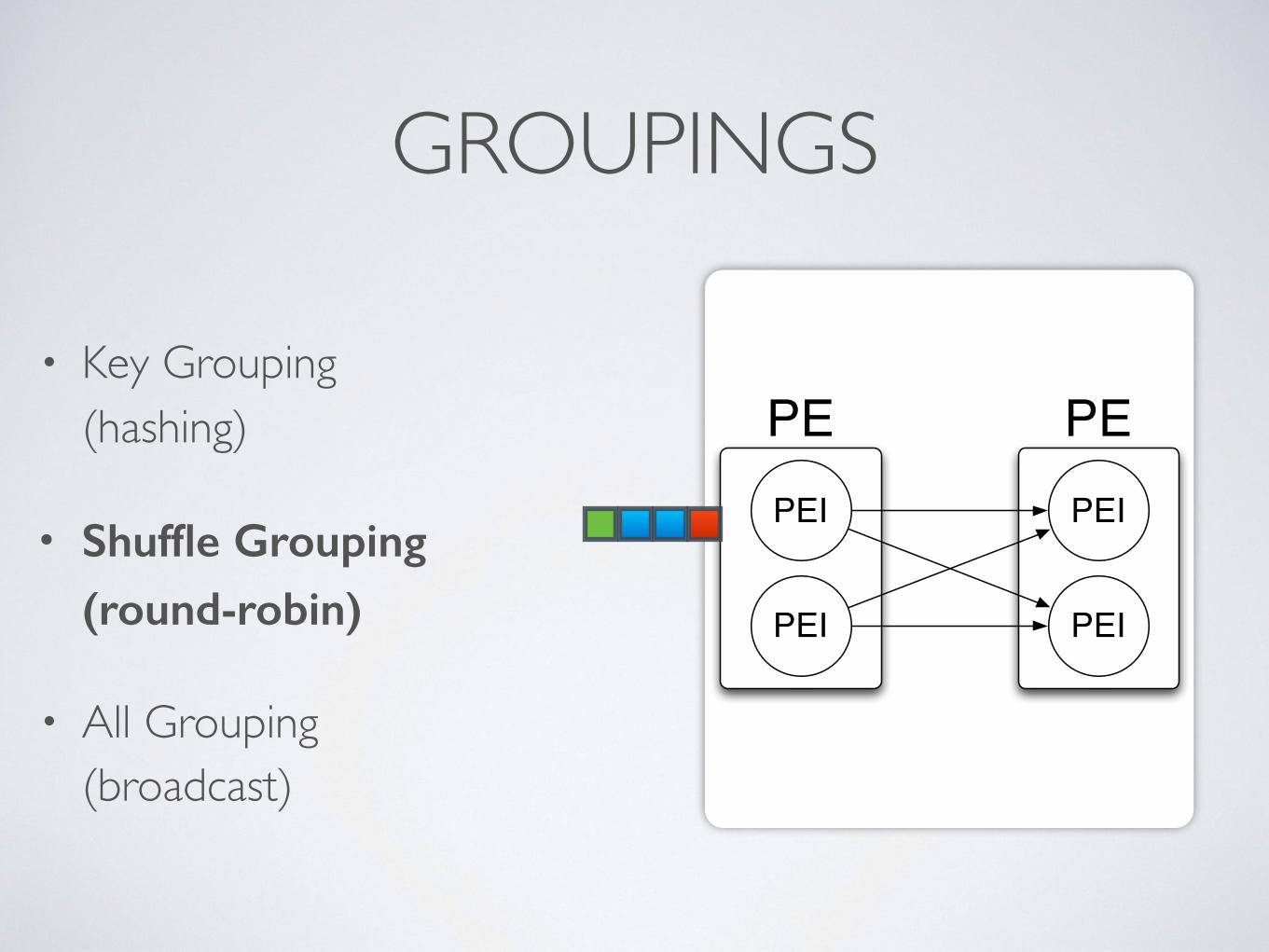
PE PEPEI
PEI
PEI
PEI
GROUPINGS
• Key Grouping (hashing)
• Shuffle Grouping (round-robin)
• All Grouping(broadcast)
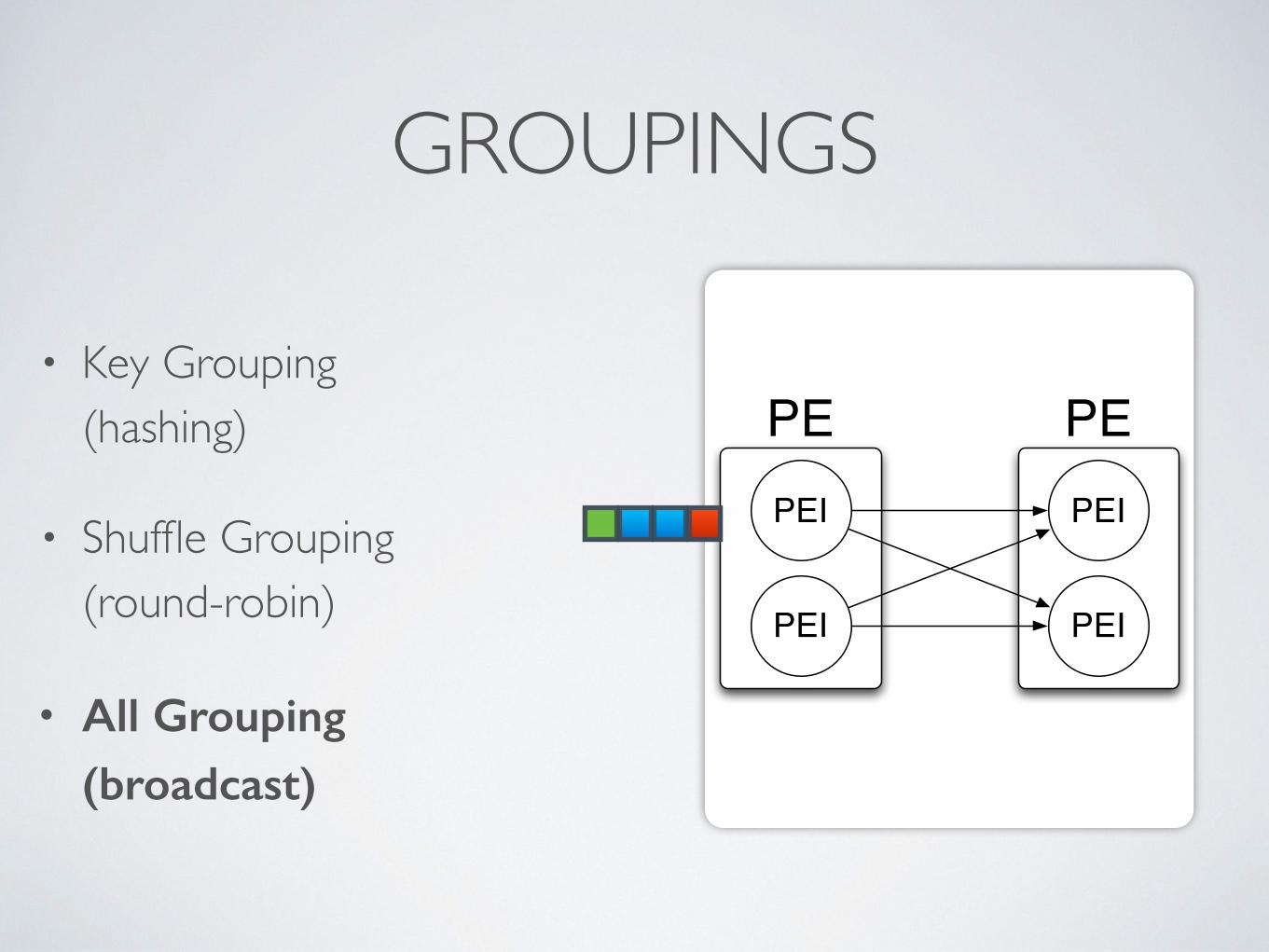
PE PEPEI
PEI
PEI
PEI
GROUPINGS
• Key Grouping (hashing)
• Shuffle Grouping(round-robin)
• All Grouping (broadcast)
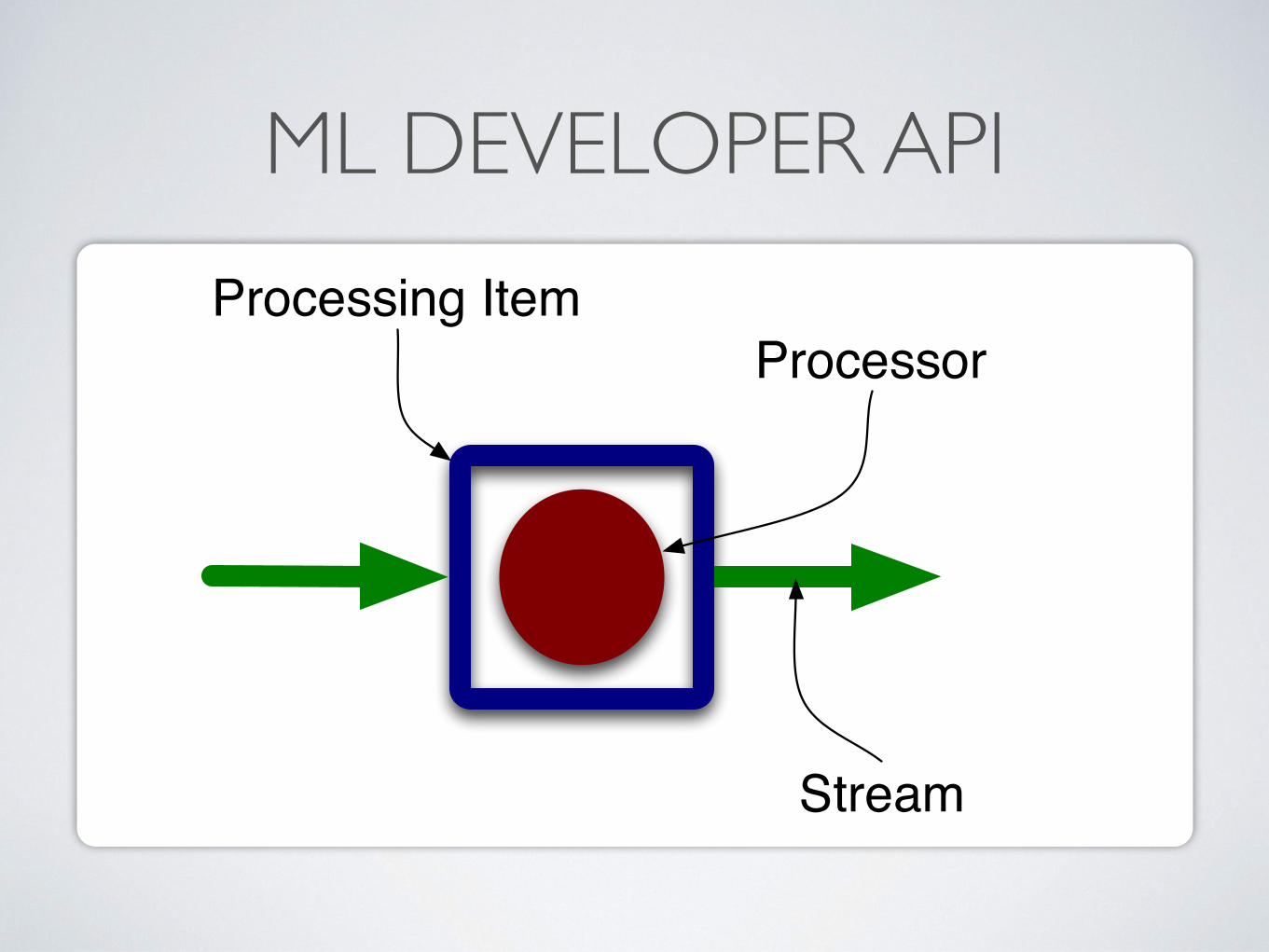
ML DEVELOPER APIProcessing Item
Processor
Stream

ML DEVELOPER API TopologyBuilder builder ;Processor sourceOne = new SourceProcessor();builder.addProcessor(sourceOne);Stream streamOne = builder.createStream(sourceOne);
Processor sourceTwo = new SourceProcessor();builder.addProcessor(sourceTwo);Stream streamTwo = builder.createStream(sourceTwo);
Processor join = new JoinProcessor());builder.addProcessor(join)
.connectInputShuffle(streamOne)
.connectInputKey(streamTwo);

VERTICAL HOEFFDING TREE
(VHT)
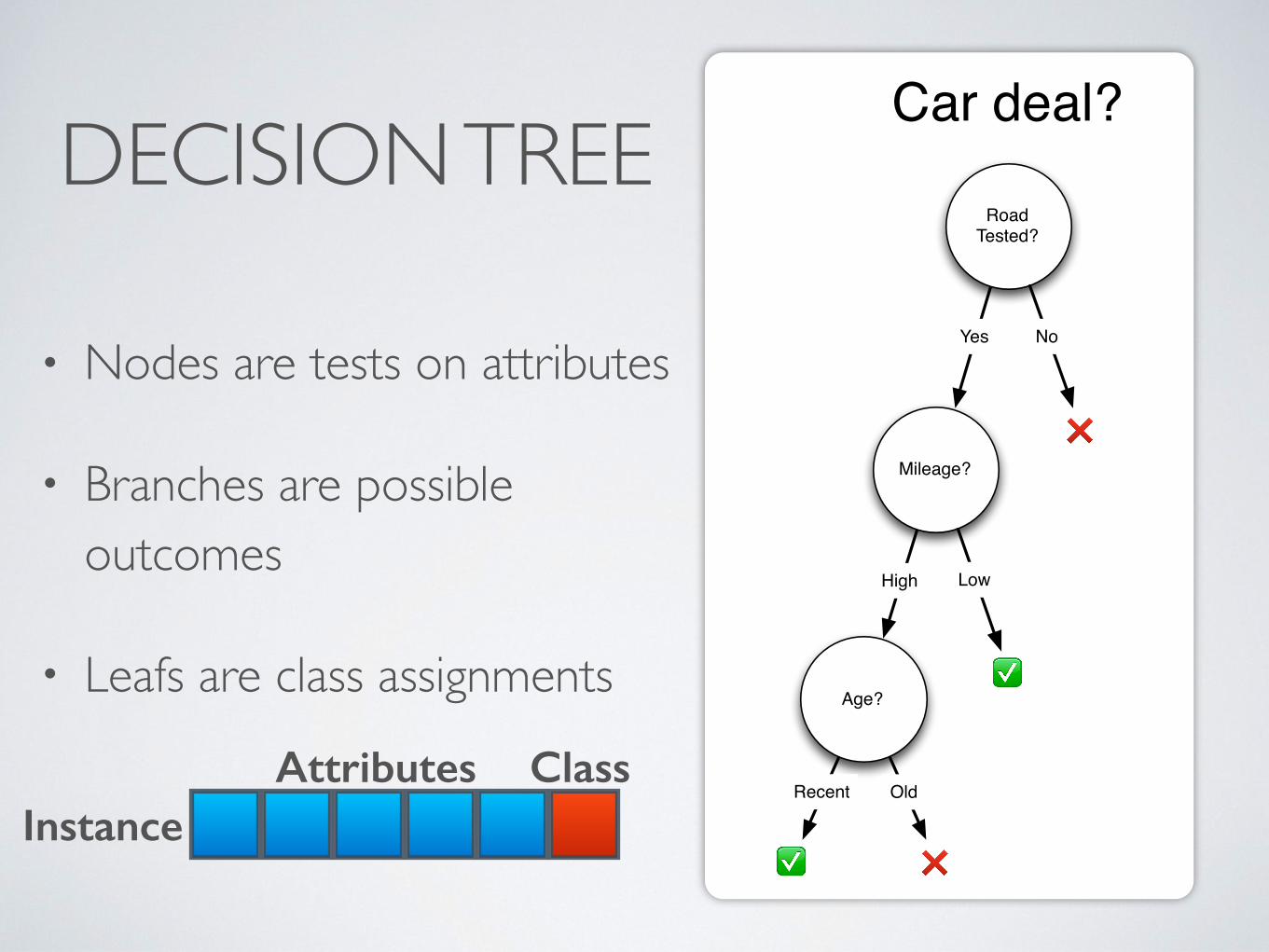
DECISION TREE
• Nodes are tests on attributes
• Branches are possible outcomes
• Leafs are class assignments Class
InstanceAttributes
RoadTested?
Mileage?
Age?
NoYes
High
✅
❌
Low
OldRecent
✅ ❌
Car deal?

HOEFFDING TREE• Sample of stream enough for near optimal decision
• Estimate merit of alternatives from prefix of stream
• Choose sample size based on statistical principles
• When to expand a leaf?
• Let x1 be the most informative attribute,x2 the second most informative one
• Hoeffding bound: split if �G(x1, x2) > ✏ =
rR
2 ln(1/�)
2n
P. Domingos and G. Hulten, “Mining High-Speed Data Streams,” KDD ’00
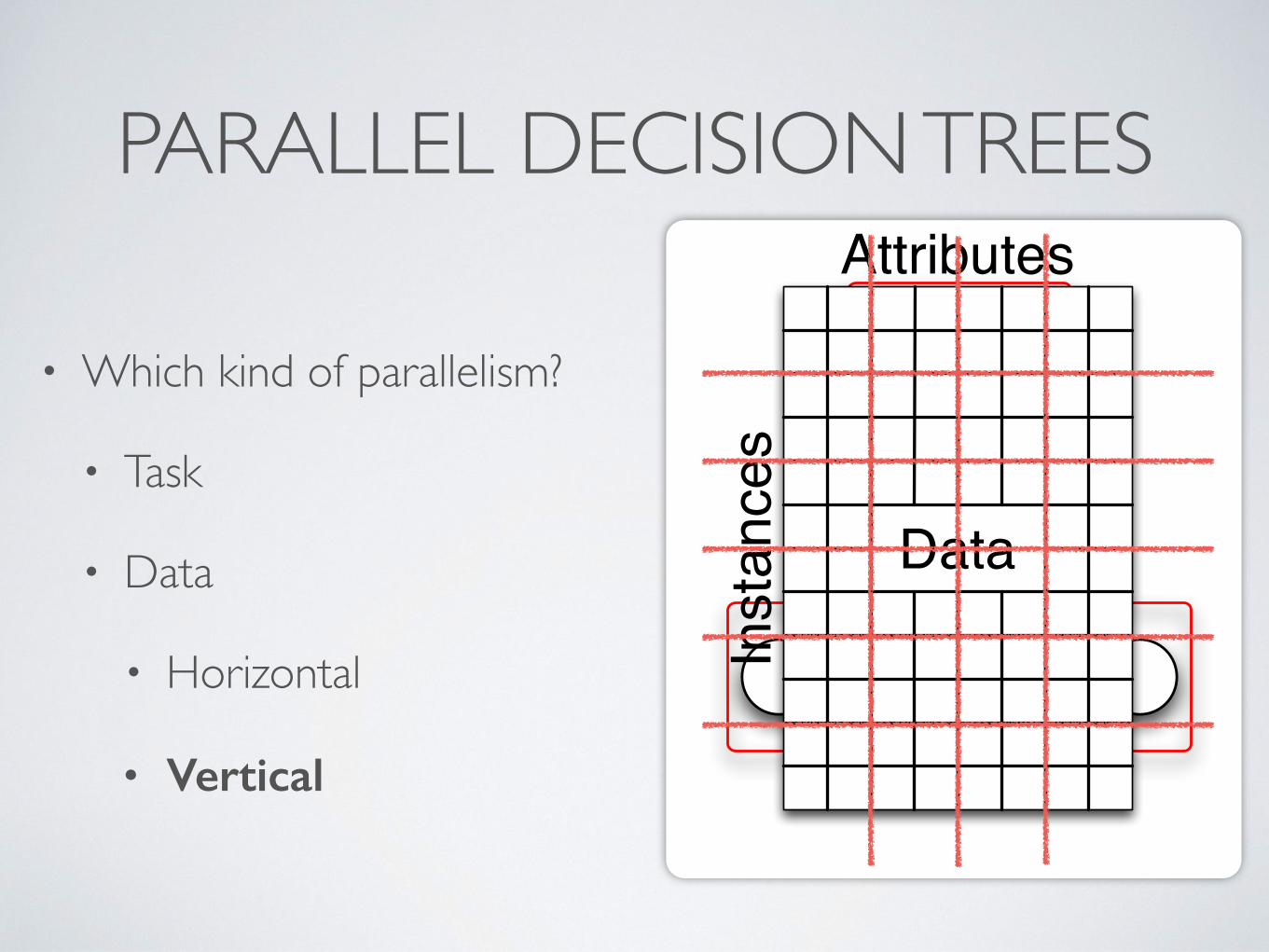
PARALLEL DECISION TREES
• Which kind of parallelism?
• Task
• Data
• Horizontal
• Vertical
Data
Attributes
Instances
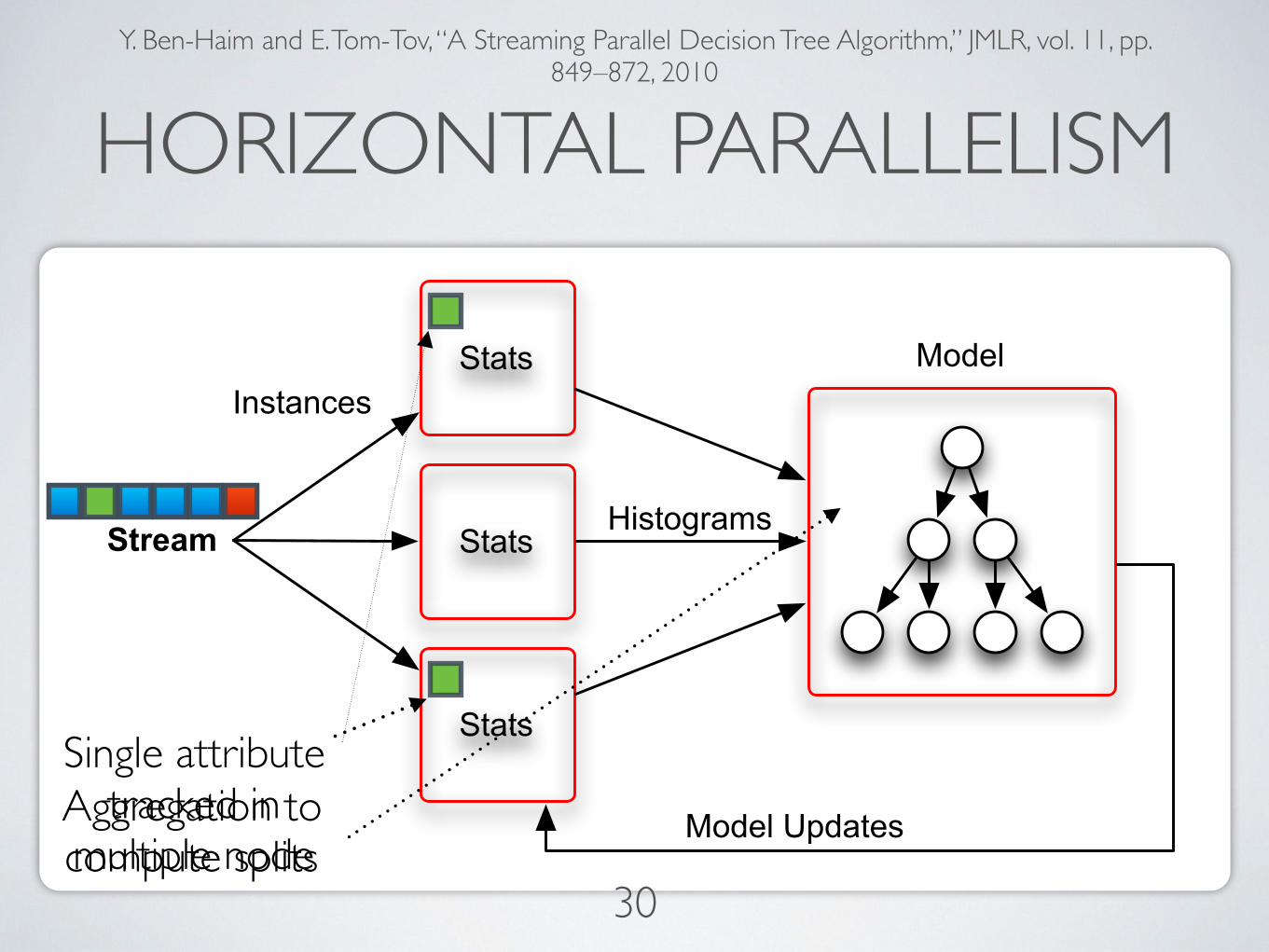
HORIZONTAL PARALLELISMY. Ben-Haim and E. Tom-Tov, “A Streaming Parallel Decision Tree Algorithm,” JMLR, vol. 11, pp.
849–872, 2010
Stats
Stats
Stats
Stream Histograms
ModelInstances
Model UpdatesAggregation to compute splits
Single attribute tracked in
multiple node30

HOEFFDING TREE PROFILING
Other6 %Split
24 %
Learn70 %
CPU time for training100 nominal and 100
numeric attributes
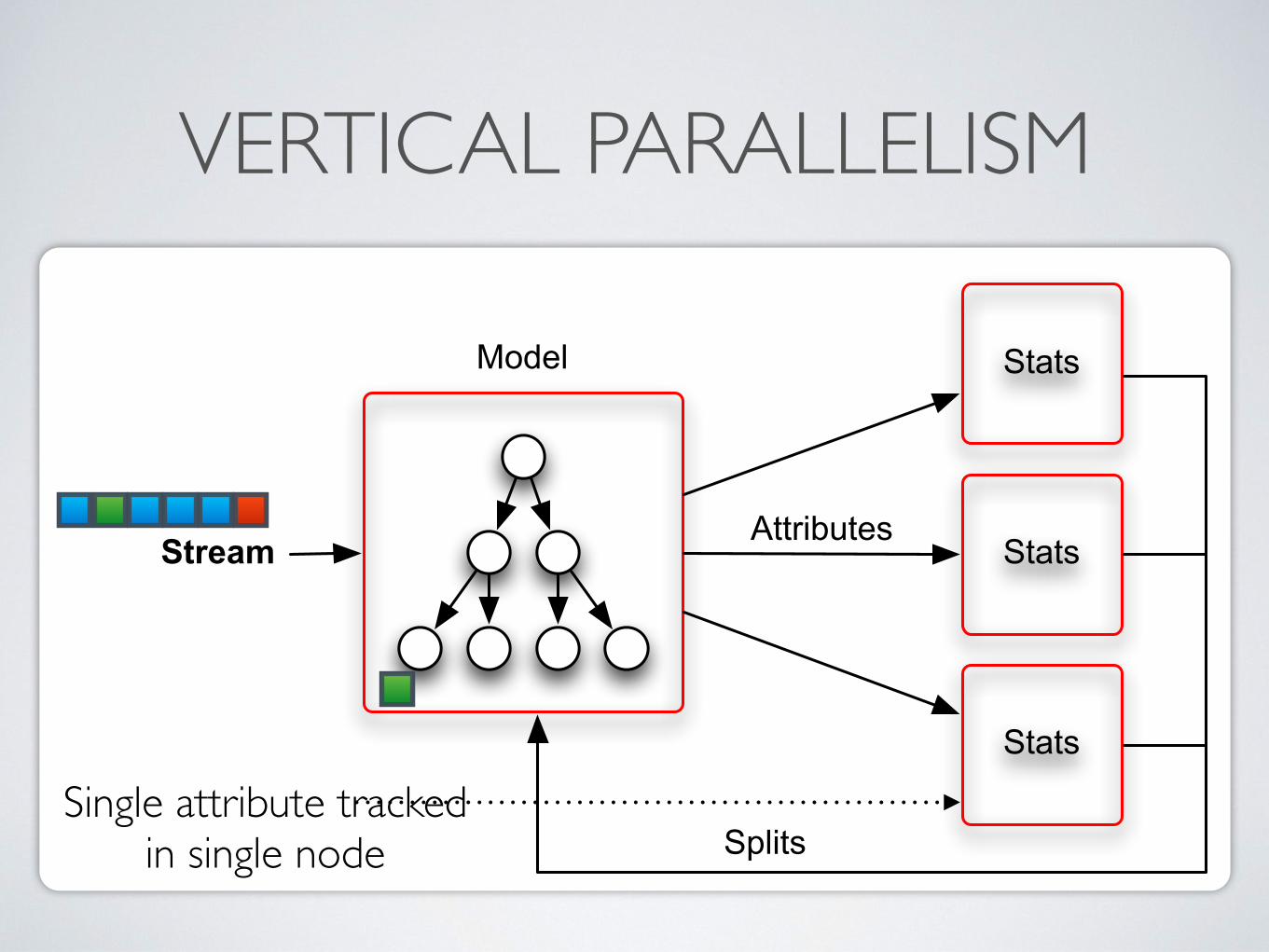
VERTICAL PARALLELISM
Single attribute tracked in single node
Stats
Stats
Stats
Stream
Model
Attributes
Splits

ADVANTAGES OF VERTICAL• High number of attributes => high level of parallelism
(e.g., documents)
• Vs task parallelism
• Parallelism observed immediately
• Vs horizontal parallelism
• Reduced memory usage (no model replication)
• Parallelized split computation
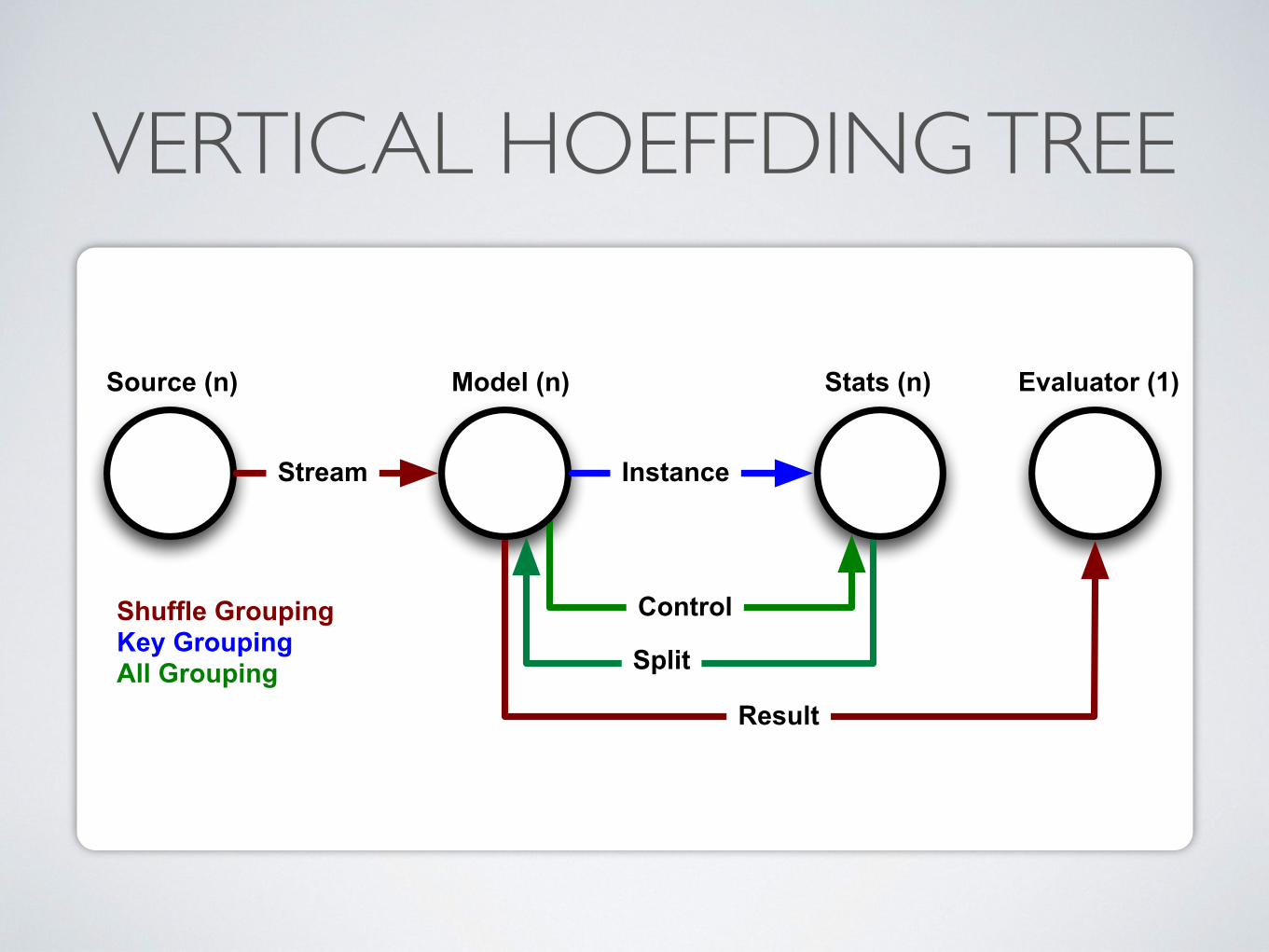
VERTICAL HOEFFDING TREE
Control
Split
Result
Source (n) Model (n) Stats (n) Evaluator (1)
InstanceStream
Shuffle GroupingKey GroupingAll Grouping
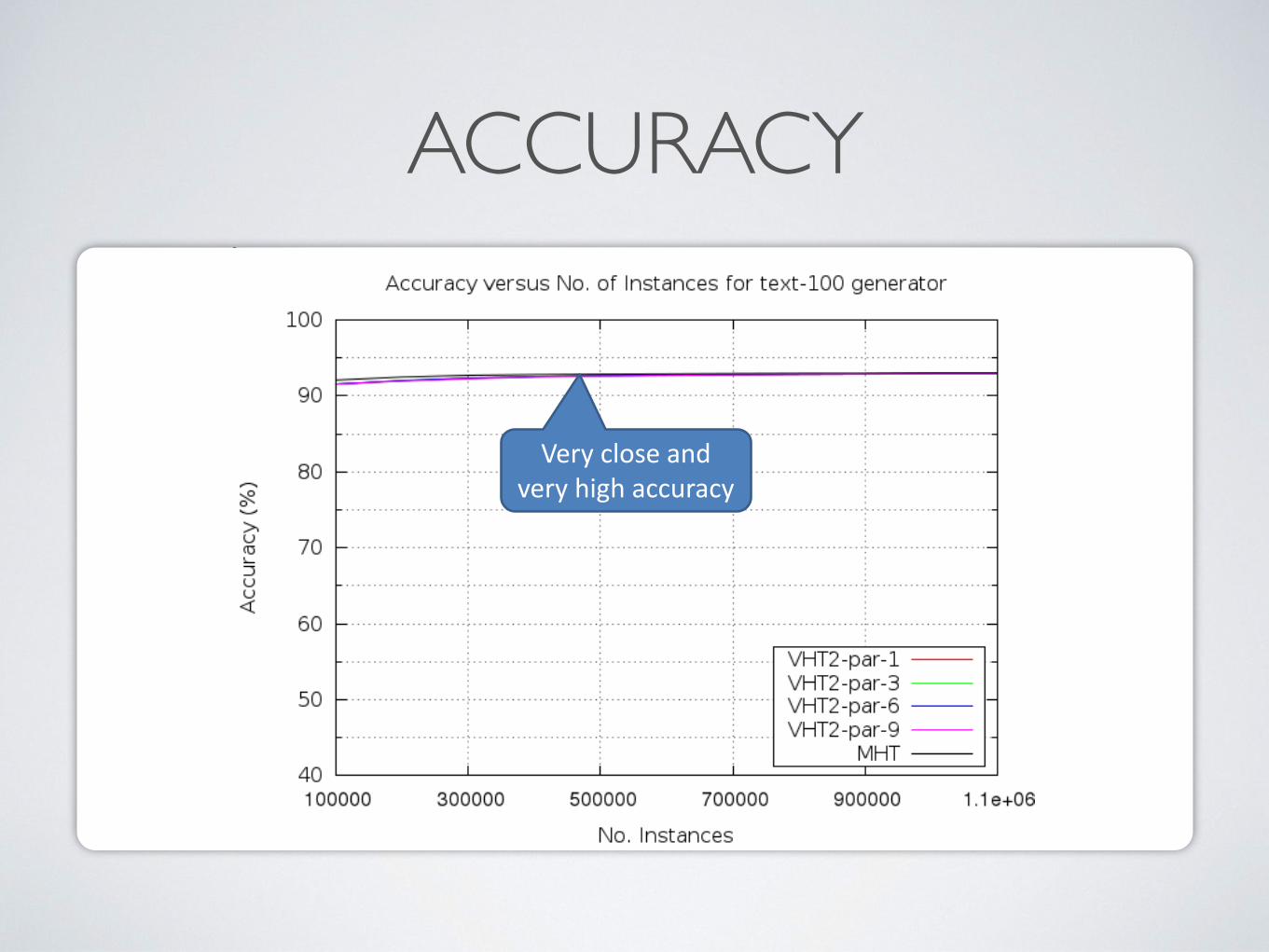
ACCURACYNo. Leaf Nodes VHT2 – tree-100
30
Very close and very high accuracy
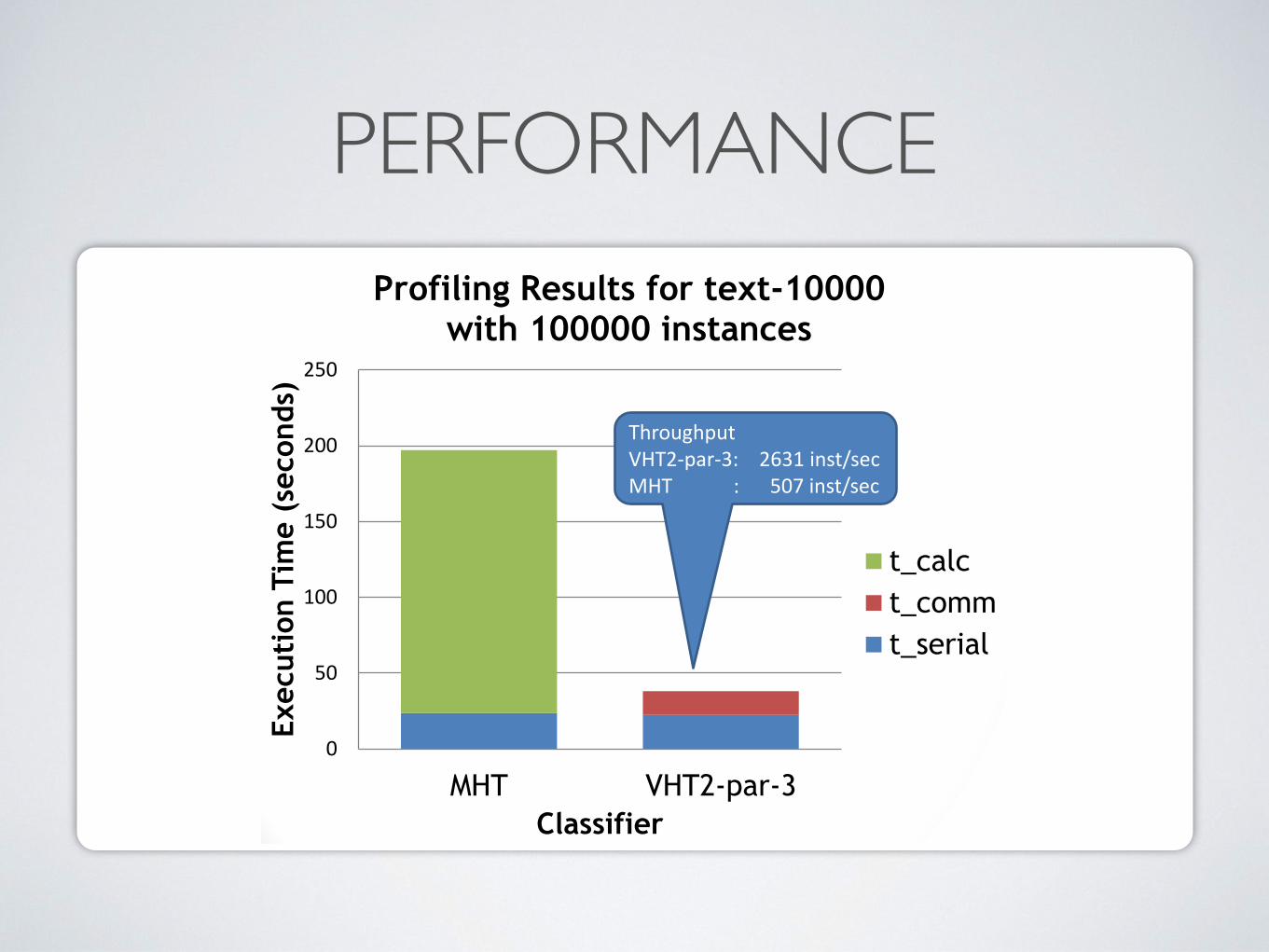
PERFORMANCE
35
0
50
100
150
200
250
MHT VHT2-par-3
Exec
utio
n Ti
me
(sec
onds
)
Classifier
Profiling Results for text-10000 with 100000 instances
t_calct_commt_serial
Throughput VHT2-par-3: 2631 inst/sec MHT : 507 inst/sec

Streaming Predictive Analytics onApache Flink
Author:Foteini Beligianni
Examiner:Vladimir Vlassov
Supervisors:Seif HaridiParis Carbone
A thesis submitted for the degree of Master of Science inDistributed Systems and Services
Stockholm, 15.07.2015
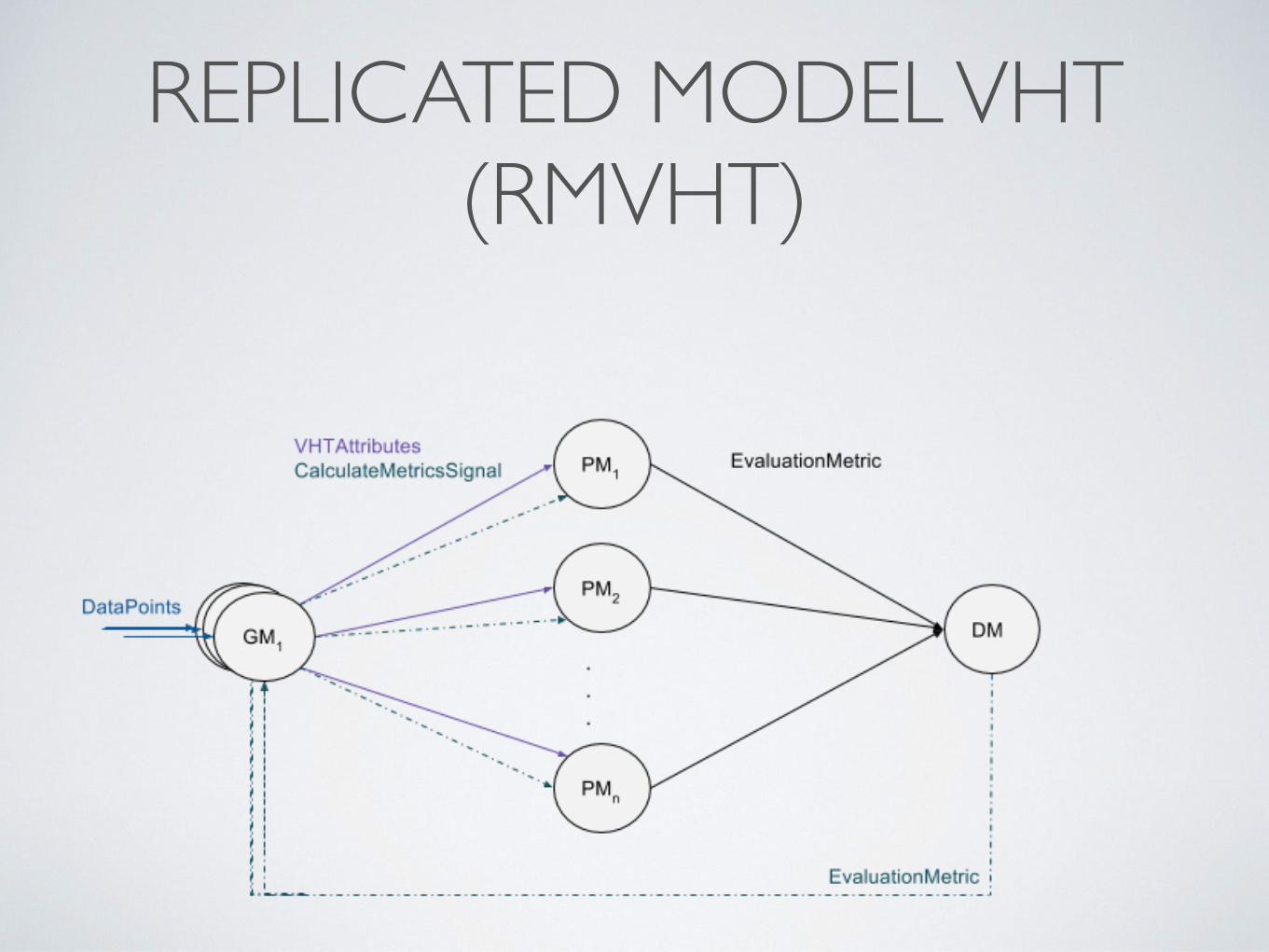
REPLICATED MODEL VHT (RMVHT)4 ALGORITHM IMPLEMENTATION
4.1.2 Replicated Model of VHT Algorithm (RmVHT)
Figure 17: Data flow of Replicated model VHT implementation on Apache Flink
The Replicated Model variation of the HT presented in this section has two maindifferences from the VHT :
1. Addition of DecisionMaker operator between the PartialVHTMetricsMapperand the GlobalModelMapper.
2. Replication of the Global Model Parallelism, by increasing the parallelizationof the GlobalModelMapper operator.
In data streaming machine learning context the speed of the input elements fromthe source to the Learner is often too high. A parallelization of the GlobalMod-elMapper operator can achieve a higher throughput of the algorithm which willresult in processing much more input DataPoint instances per second from thesource.
In order to keep the cohesion between the parallel models learned in each of theGlobalModelMapper operators, the decision about the best attribute to split eachnode is done on a new operator called DecisionMaker. Even though we still have
32
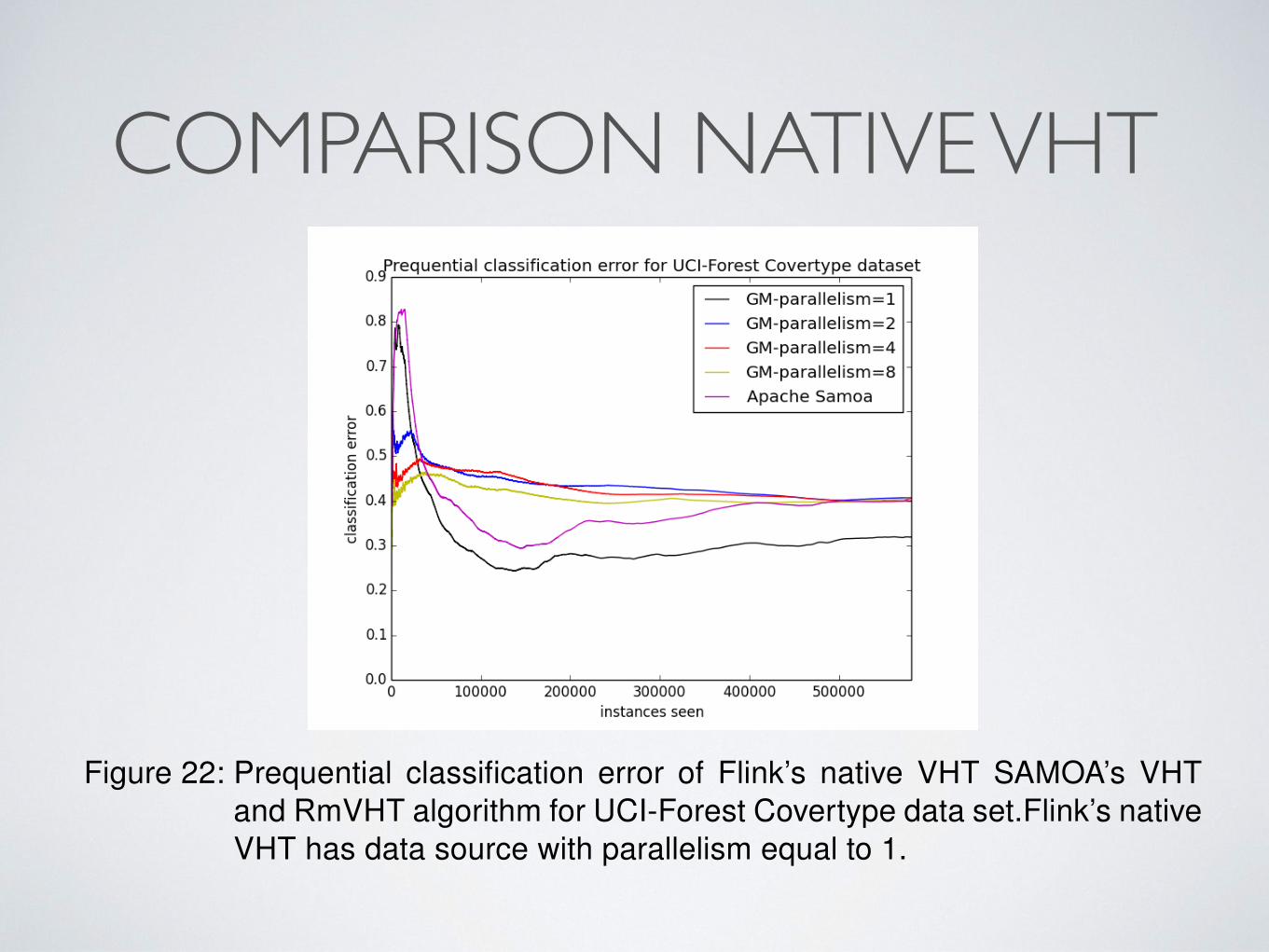
COMPARISON NATIVE VHT6 EXPERIMENTAL EVALUATION
Figure 22: Prequential classification error of Flink’s native VHT SAMOA’s VHTand RmVHT algorithm for UCI-Forest Covertype data set.Flink’s nativeVHT has data source with parallelism equal to 1.
As we see, Flink’s native VHT outperforms SAMOA’s VHT implementation withthe error of Flink’s native VHT implementation to be around 9% lower at the endof the training.
Moreover, in Figure 23 we see that the average delay between node splits isby 3 seconds lower in Flink’s native VHT than SAMOA’s VHT. Furthermore, inFigure 24 we observe that the average number of instances seen in each leafbefore a split in native VHT of Flink, is approximately 3 times the instances seenin SAMOA’s VHT.
Figure 23: Average delay in seconds between node splits of VHT classifier, forUCI-Forest Covertype data set on Apache Flink and Apache SAMOA.
46
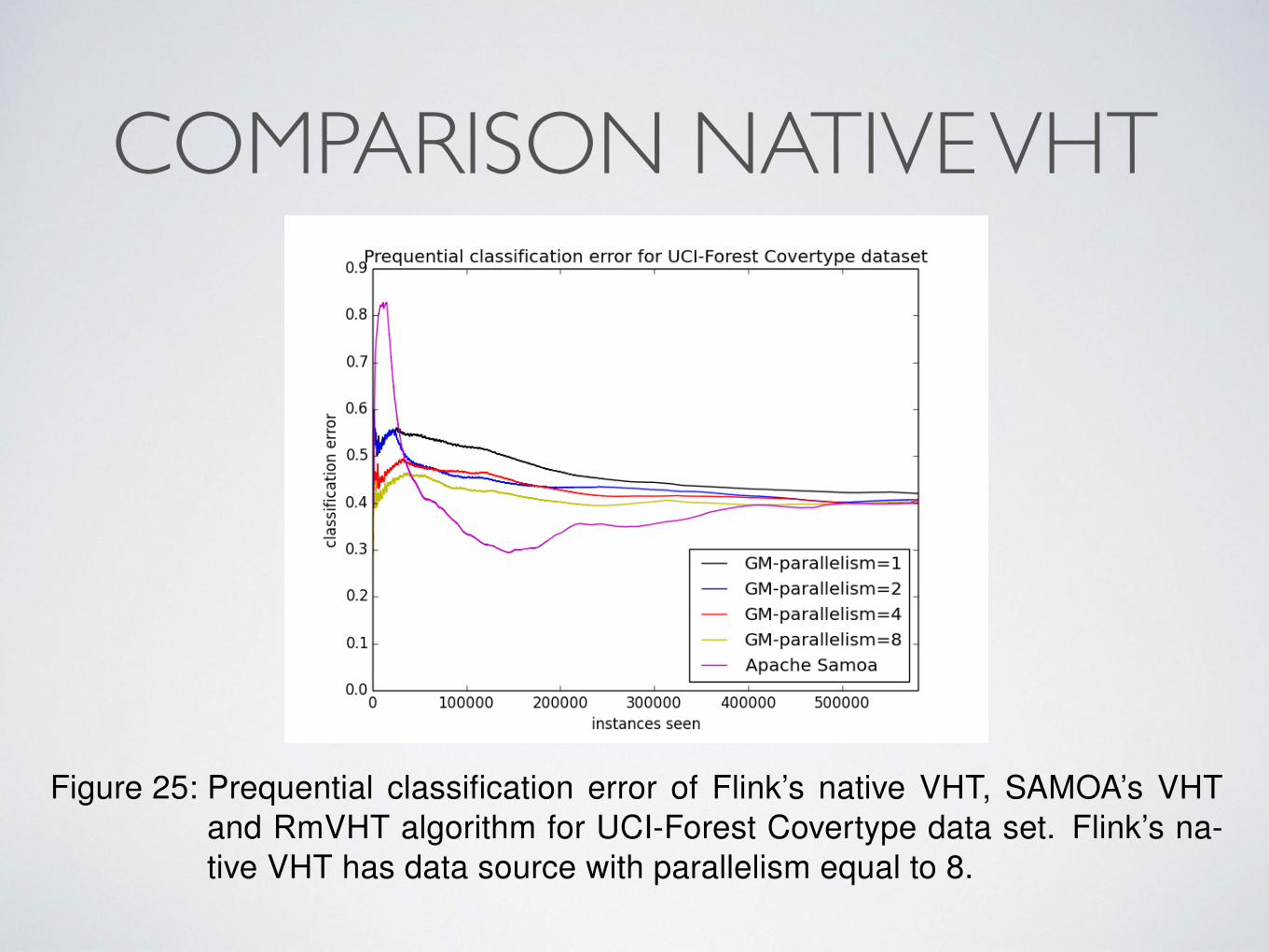
COMPARISON NATIVE VHT6 EXPERIMENTAL EVALUATION
Figure 25: Prequential classification error of Flink’s native VHT, SAMOA’s VHTand RmVHT algorithm for UCI-Forest Covertype data set. Flink’s na-tive VHT has data source with parallelism equal to 8.
Regarding RmVHT, in Figure 22 we observe that the final prequential error of theRmVHT implementation is almost equal to SAMOA’s VHT prequential error andworser than Flink’s native VHT algorithm. Moreover, we see that in total RmVHThas a higher prequential classification error than the error of the centralized VHTalgorithm. This is caused mainly due to the increased throughput of the RmVHTvariation, where more instances are classified with a DT model which is not up-dated, thus more instances are misclassified. Another reason for the increasederror of the RmVHT model is the incoming order of the data points, as it is knownthat in classification algorithms, the incoming order plays a significant role.
In order to understand why the RmVHT has higher error than the VHT algorithmwe compared the average number of instances seen in each Global Model oper-ator in RmVHT variation, presented in Figure 26. Combining those results withthe prequential classification error of Figure 22, we understand that when the par-allelism of the model increases, the throughput of the algorithm increases, whichresults in more instances "spent" in each of the leaves before they split, thus moreinstances are classified with an "expired" DT model.
48
COMPARISON NATIVE VHT
6 EXPERIMENTAL EVALUATION
Figure 26: Average number of instances seen in each leaf before it splits onApache Flink VHT for different model parallelism.
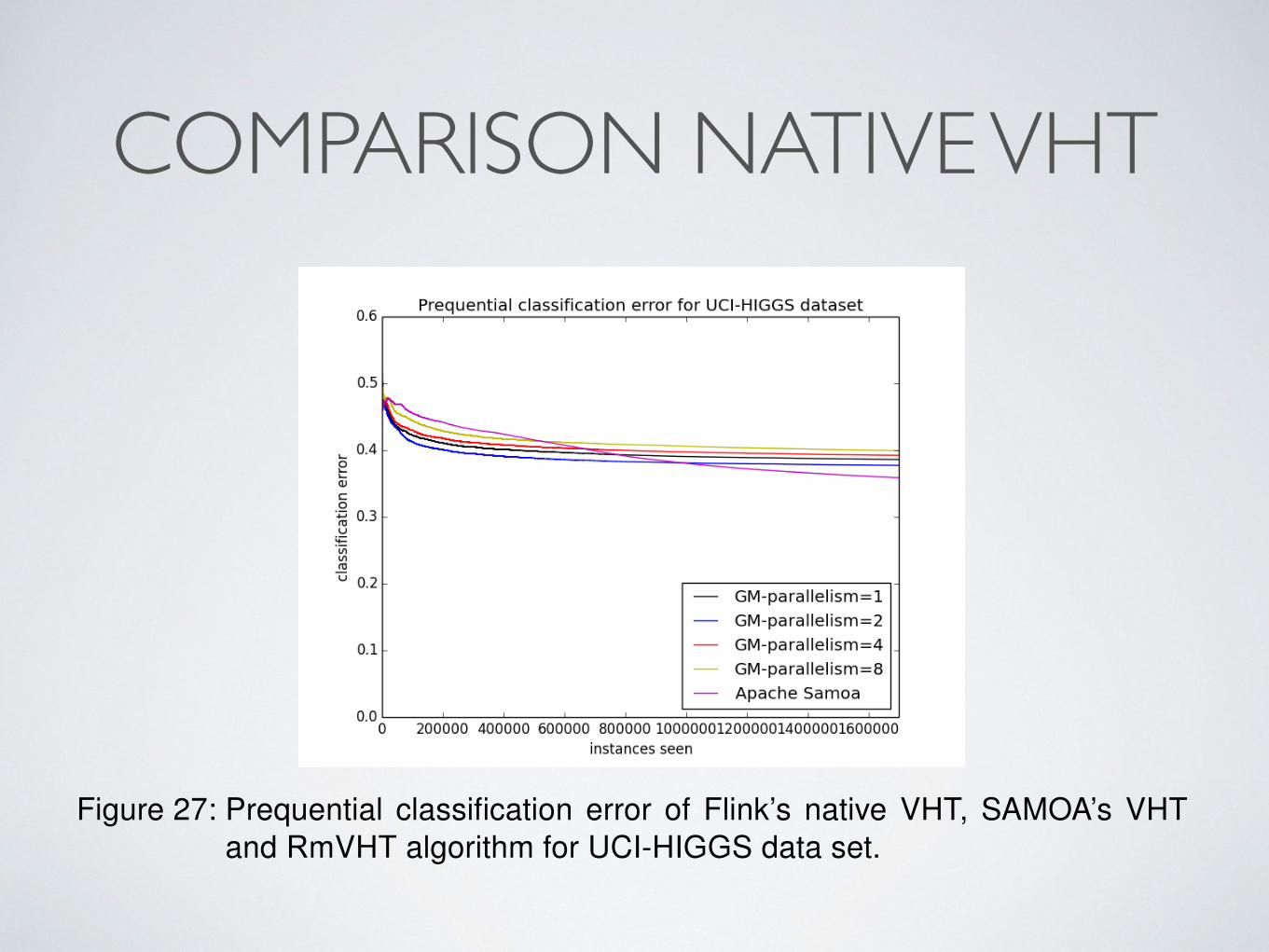
6.3.2 HIGGS data set
The Higgs data set is a synthetic data set, a detailed description of which ispresented in Appendix Section A.2.1. In general we observe that Higgs is notsuch a good data set to be used for classification with a DT classifier. As we seein Figure 27, SAMOA’s VHT learns slower than Flink’s native VHT but achieveslower prequential classification error at the end. On the other hand Flink’s VHTseems to learn faster at the beginning, but then its prequential classification errorremains stable and slightly greater than SAMOA’s.
Figure 27: Prequential classification error of Flink’s native VHT, SAMOA’s VHTand RmVHT algorithm for UCI-HIGGS data set.
49
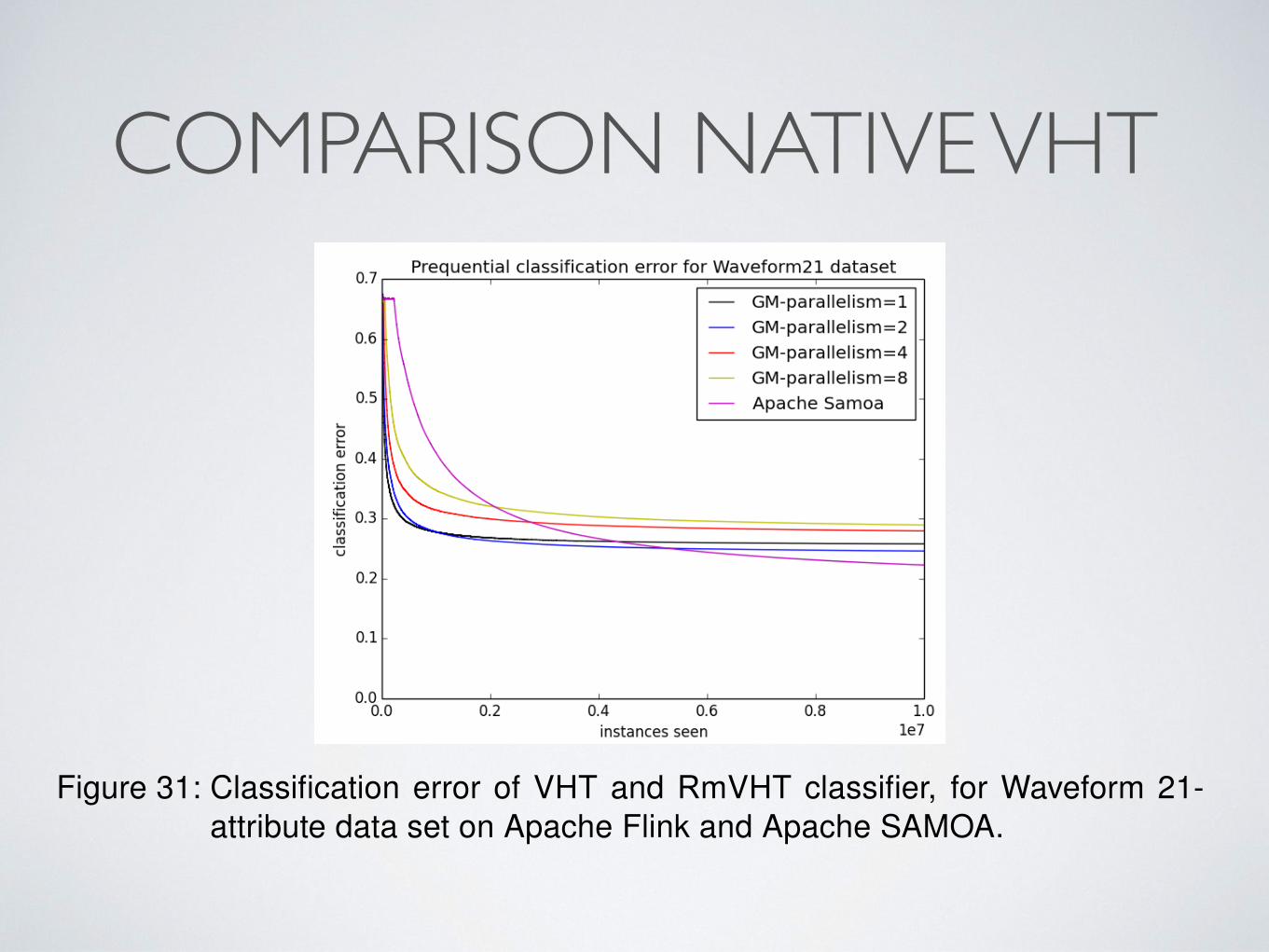
COMPARISON NATIVE VHT
6 EXPERIMENTAL EVALUATION
As we observe in Figure 31, for the Waveform21 data set SAMOA’s VHT outper-forms Flink’s native VHT implementation. Moreover, we see that SAMOA’s VHT islearning slower, but achieves lower classification error at the end, whereas Flink’snative VHT learns faster, as it decreases very fast the classification error, but thenits error remains stable.
Figure 31: Classification error of VHT and RmVHT classifier, for Waveform 21-attribute data set on Apache Flink and Apache SAMOA.
In Figure 32, we observe that for the Led data set Flink’s native VHT outper-forms SAMOA’s VHT implementation but also that SAMOA’s implementation hasa higher classification error than Flink’s RmVHT algorithm.
Figure 32: Classification error of VHT and RmVHT classifier, for Led data set onApache Flink and Apache SAMOA.
52

COMPARISON NATIVE VHT
• Native VHT is faster than SAMOA VHT
• Native VHT is more accurate than SAMOA VHT in real datasets
• Future work for native VHT: stress test with nominal attributes, and use Gini Impurity

CONCLUSIONS• Streaming is the future and is happening now
• Mining big data streams is an open field
• SAMOA: A Platform for Mining Big Data Streams
• Available and open-source (incubating @ASF)http://samoa.incubator.apache.org
• A platform for collaboration and research on distributed stream mining

OPEN CHALLENGES• Distributed stream mining algorithms
• Active & semi-supervised learning + crowdsourcing
• Millions of classes (e.g., Wikipedia pages)
• Multi-target learning
• System issues (load balancing, communication)
• Programming paradigms and abstractions

THE TEAM
AlbertBifet
MatthieuMorel
GianmarcoDe Francisci Morales
ArintoMurdopo
NicolasKourtellis
OlivierVan Laere

SUPPORTING ORGANISATIONS






























