Embed Size (px)
Citation preview

Kumar Palaniappan Enterprise Architect, NetApp
Architecting business critical enterprise application: Automated Support

Agenda
¡ NetApp’s Business Challenge
¡ Solution Architecture
¡ Best Practices
¡ Performance Benchmarks
¡ Questions
2
The AutoSupport Family The Foundation of NetApp Support Strategies
¡ Catch issues before they become critical
¡ Secure automated “call-home” service
¡ System monitoring and nonintrusive alerting
¡ RMA requests without customer action
¡ Enables faster incident management
3
“My AutoSupport Upgrade Advisor tool does all the hard work for me, saving me 4 to 5 hours of work per storage system and providing an upgrade plan that’s complete and easy to follow.”
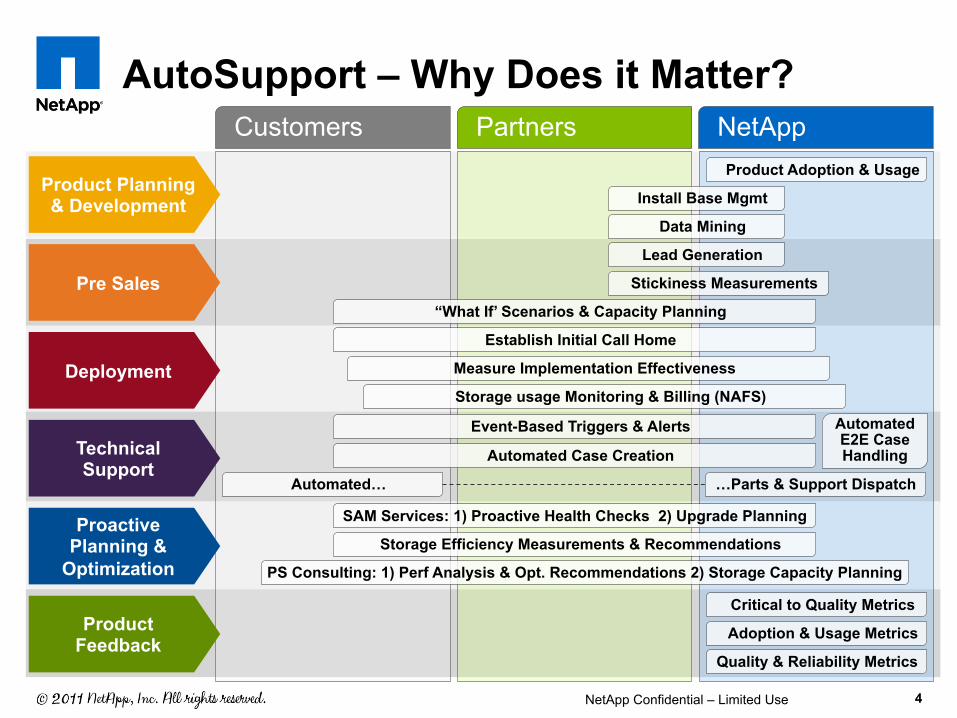
AutoSupport – Why Does it Matter?
NetApp Confidential – Limited Use
Product Planning & Development
Pre Sales
Deployment
Technical Support
Proactive Planning &
Optimization
Product Feedback
Critical to Quality Metrics
Adoption & Usage Metrics
Quality & Reliability Metrics
SAM Services: 1) Proactive Health Checks 2) Upgrade Planning
Storage Efficiency Measurements & Recommendations
Event-Based Triggers & Alerts
Automated Case Creation
Automated E2E Case Handling
Establish Initial Call Home
Measure Implementation Effectiveness
Storage usage Monitoring & Billing (NAFS)
Product Adoption & Usage
Automated…
PS Consulting: 1) Perf Analysis & Opt. Recommendations 2) Storage Capacity Planning
Install Base Mgmt
Data Mining
Lead Generation
Stickiness Measurements
“What If’ Scenarios & Capacity Planning
…Parts & Support Dispatch
Customers Partners NetApp
4
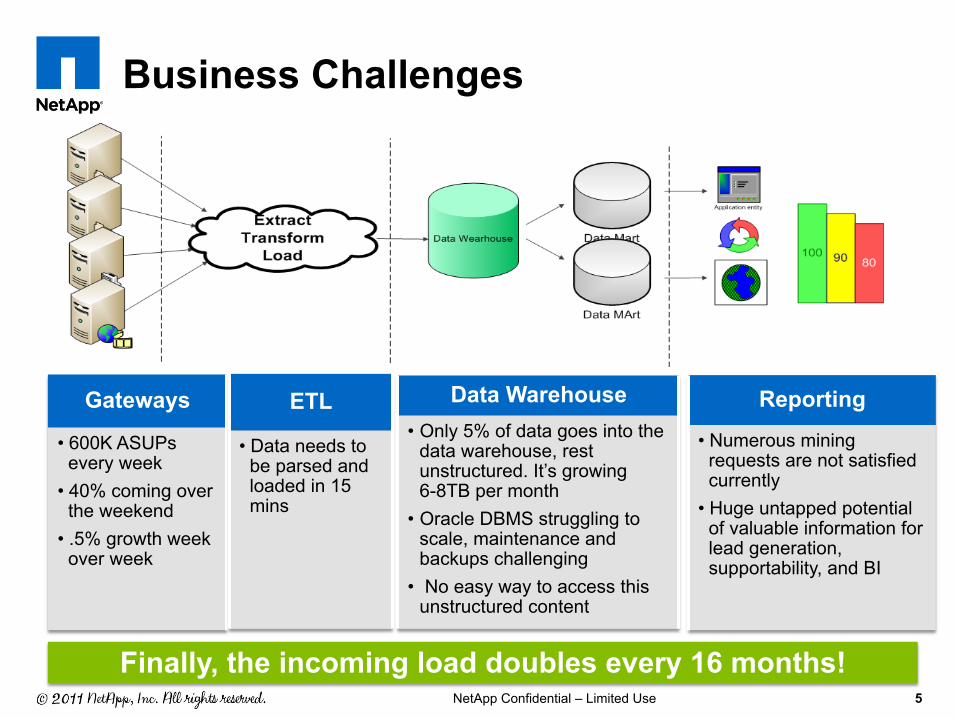
Business Challenges
5 NetApp Confidential – Limited Use
Gateways
• 600K ASUPs every week
• 40% coming over the weekend
• .5% growth week over week
ETL
• Data needs to be parsed and loaded in 15 mins
Data Warehouse • Only 5% of data goes into the
data warehouse, rest unstructured. It’s growing 6-8TB per month
• Oracle DBMS struggling to scale, maintenance and backups challenging
• No easy way to access this unstructured content
Reporting
• Numerous mining requests are not satisfied currently
• Huge untapped potential of valuable information for lead generation, supportability, and BI
Finally, the incoming load doubles every 16 months!
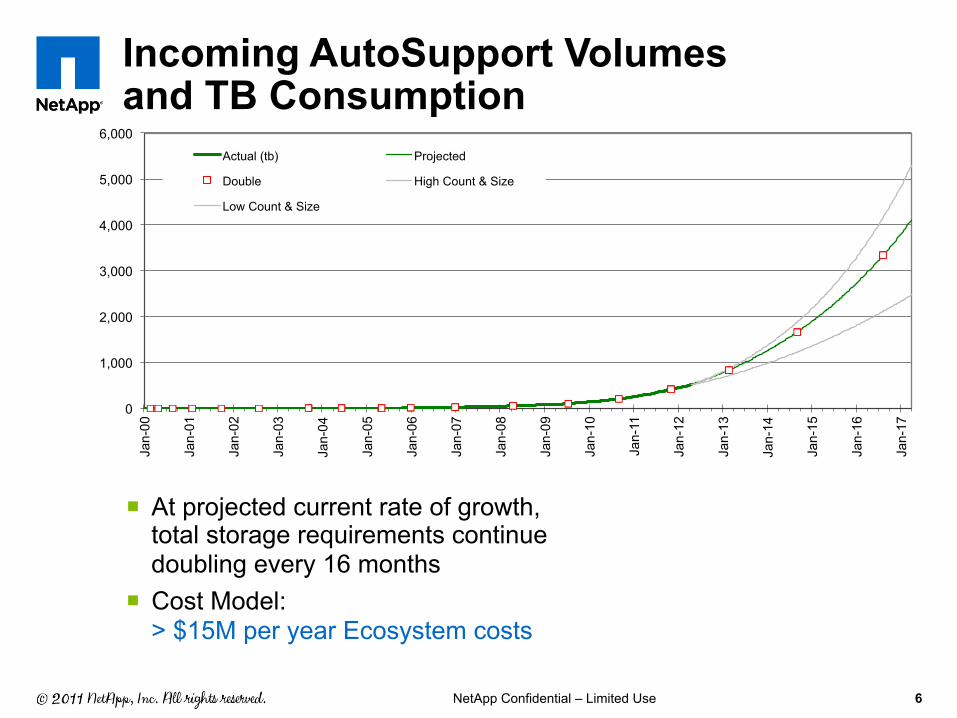
Incoming AutoSupport Volumes and TB Consumption
6 NetApp Confidential – Limited Use
¡ At projected current rate of growth, total storage requirements continue doubling every 16 months
¡ Cost Model: > $15M per year Ecosystem costs
0
1,000
2,000
3,000
4,000
5,000
6,000 Ja
n-00
Jan-
01
Jan-
02
Jan-
03
Jan-
04
Jan-
05
Jan-
06
Jan-
07
Jan-
08
Jan-
09
Jan-
10
Jan-
11
Jan-
12
Jan-
13
Jan-
14
Jan-
15
Jan-
16
Jan-
17
Actual (tb) Projected
Double High Count & Size
Low Count & Size
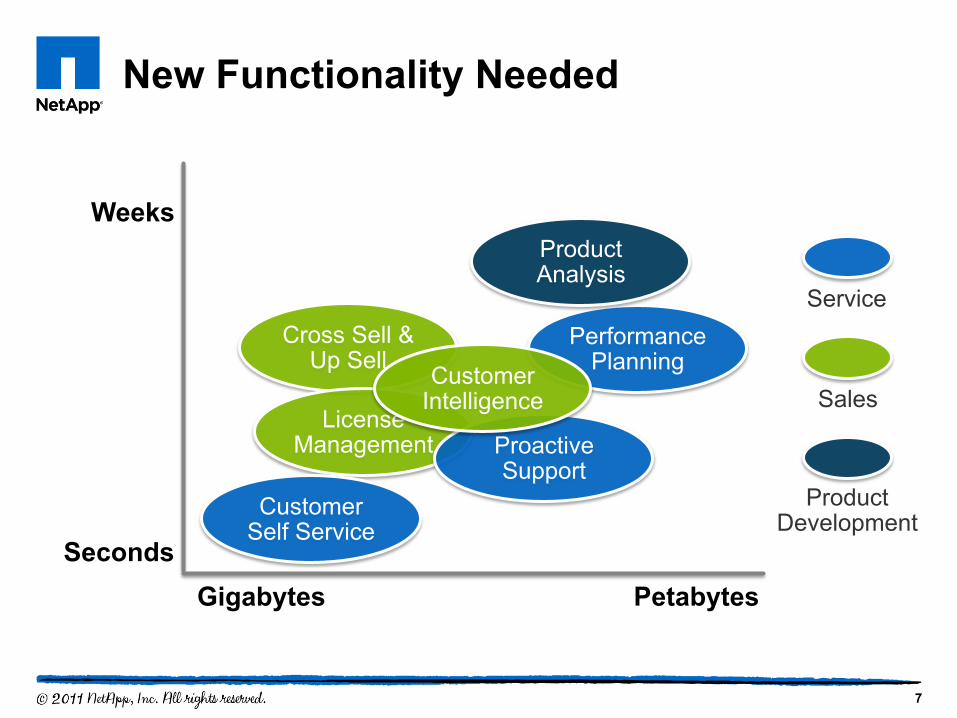
New Functionality Needed
7
Service
Sales
Product Development
Cross Sell & Up Sell
License Management
Petabytes
Customer Self Service
Weeks
Seconds
Performance Planning
Product Analysis
Gigabytes
Proactive Support
Customer Intelligence
Solution Architecture
8
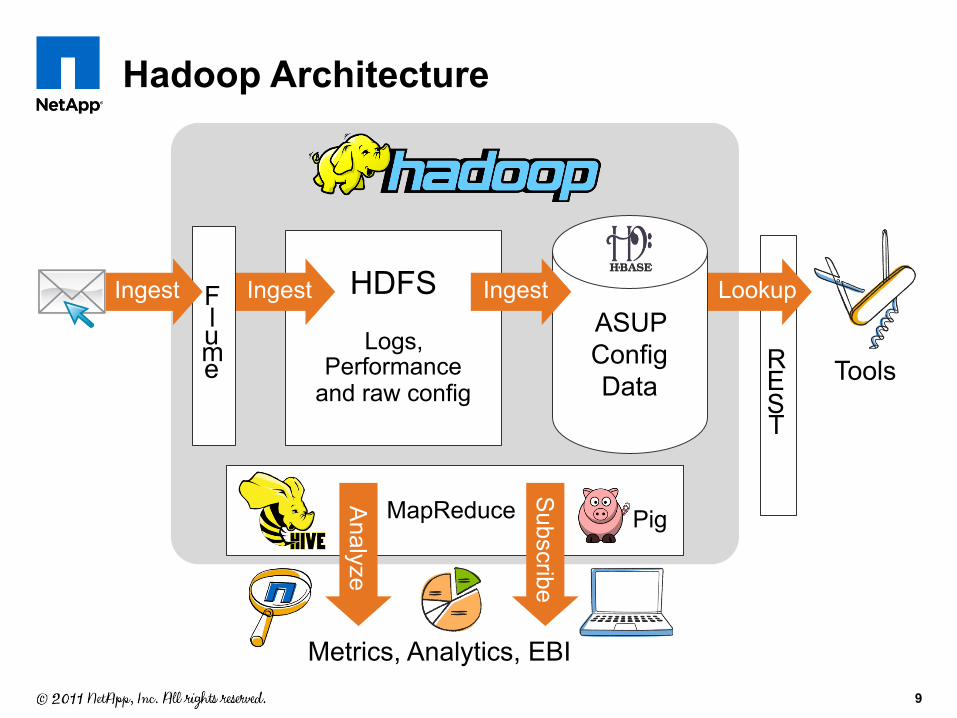
Hadoop Architecture
REST
Lookup ASUP Config Data
HDFS
Logs, Performance
and raw config Tools
Ingest Flume
Ingest Ingest
Pig MapReduce
Metrics, Analytics, EBI
Analyze
Subscribe
9
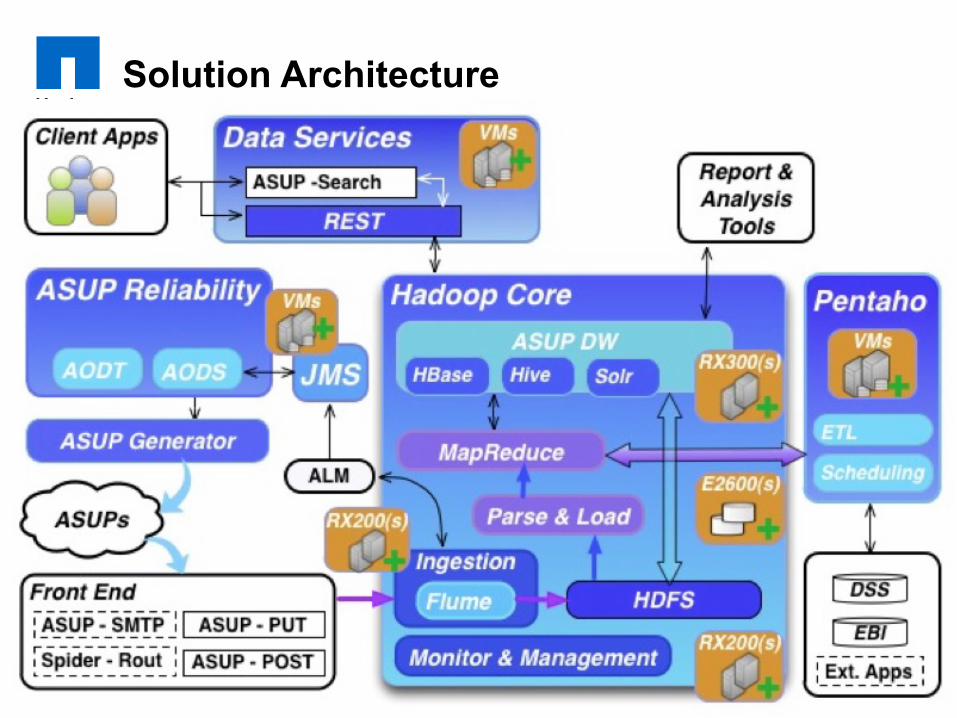
Solution Architecture
10

¡ Use of Flume (v1) to consume large XML objects up to 20 MB compressed ea.
¡ 4 agents feed 2 collectors in production ¡ Basic Process Control using supervisord (ZK in R2?) ¡ Reliability Mode: Disk Failover (Store on Failure) ¡ Separate sinks for Text and Binary sections ¡ Arrival time bucketing by minute ¡ Snappy Sequence Files with JSON values ¡ Evaluating Flume NG ¡ Ingesting 4.5 TB uncompressed/week 80% in an 8
hour window
Data Ingestion

¡ Ingested data processed every 1 min. (w/ 5 min. lag) – Relies on Fair Scheduler to meet SLA – Oozie (R0) -> Pentaho PDI (R1) for scheduling
¡ Configuration data written to HBase using Avro ¡ Duplicate data written to HDFS as Hive / JSON for ad
hoc queries ¡ User scans of HBase for ad hoc queries avoided to
meet SLA ¡ Also simplifies data access
– query tools don’t yet have support for Avro serialization in HBase
– they all assume String keys and values (evolving to support Avro)
Data Transformation

¡ High performance REST lookups ¡ Data stored as Avro serialized objects for
performance and versioning ¡ Solr used to search for objects (one core per region) ¡ Then details pulled from HBase ¡ Large objects (logs) indexed and pulled from HDFS ¡ ~100 HBase regions (500 GB ea.)
– no splitting – Snappy compressed tables
¡ Future: HBase coprocessors to keep Solr indexes up to date
Low Latency Application Data Access
¡ Pentaho pulls data from HBase and HDFS ¡ Pushes into Oracle star schema ¡ Daily export
– 530 million rows and 350 GB on peak days ¡ Runs on 2 VMs
– 64 GB RAM, 12 cores ¡ Enables existing BI tools (OBIE) to query DSS
database
Export to Oracle DSS

¡ DR cluster with 75% of production capacity – in Release 2
¡ Active/active from Flume back – Primary cluster the one HTTP/SMTP responder
¡ SLA: cannot lose >1 hour of data – can be lost in front-end switchover
¡ HBase incremental backups ¡ Staging used frequently for engineering test,
operationally expensive so not used for DR
Disaster Recovery
NetApp Open Solution for Hadoop (NOSH)
16

HDFS Storage: Key Needs
17
Attribute Key Drivers Requirement
Performance • Fast response time for search, ad-hoc, and real-time queries
• High replication counts impact throughput
• Minimize Network bottlenecks • Optimize server workload • Leverage storage HW to
increase cluster performance
Opex • Lower operational costs for managing huge amounts of data
• Controlling staff costs and cluster management costs as clusters scale
• Optimize usable storage capacity
• Decouple storage from compute nodes to decrease the need to add more compute nodes
Enterprise Robustness
• Protect SPOF at the Hadoop name node
• Minimize cluster rebuild
• Protect cluster metadata from SPOF
• Minimize risks where equipment tends to fail
NetApp Confidential – Limited Use
18
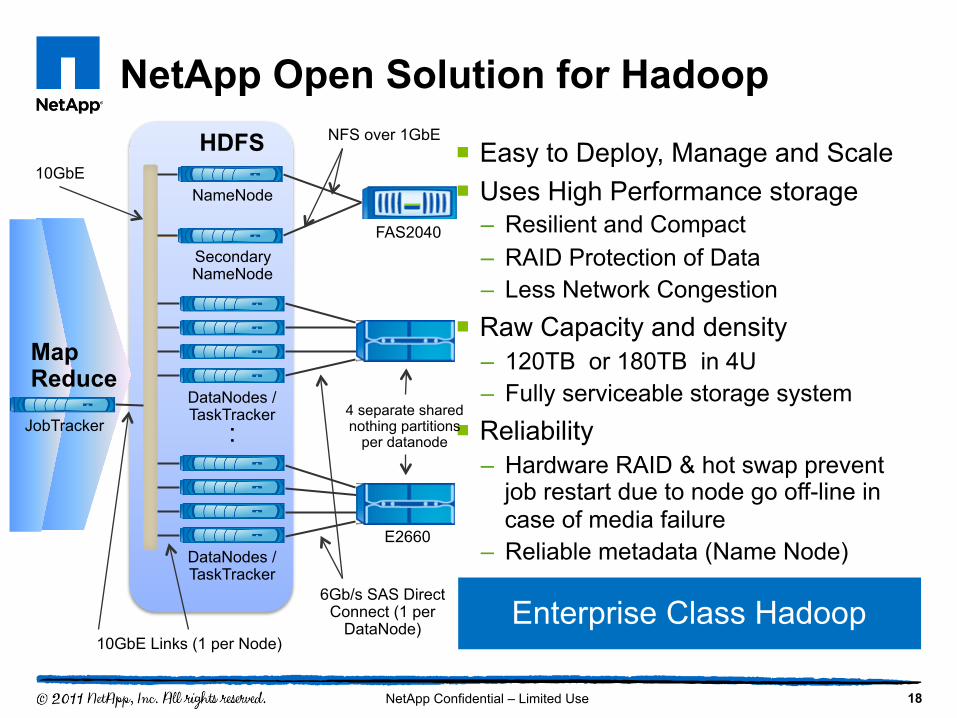
NetApp Open Solution for Hadoop ¡ Easy to Deploy, Manage and Scale ¡ Uses High Performance storage
– Resilient and Compact – RAID Protection of Data – Less Network Congestion
¡ Raw Capacity and density – 120TB or 180TB in 4U – Fully serviceable storage system
¡ Reliability – Hardware RAID & hot swap prevent
job restart due to node go off-line in case of media failure
– Reliable metadata (Name Node)
Enterprise Class Hadoop
NetApp Confidential – Limited Use
Map Reduce
NameNode
DataNodes / TaskTracker
DataNodes / TaskTracker
:
HDFS
Secondary NameNode
4 separate shared nothing partitions
per datanode JobTracker
FAS2040
E2660
10GbE
10GbE Links (1 per Node)
6Gb/s SAS Direct Connect (1 per
DataNode)
NFS over 1GbE
Performance and Scaling
19
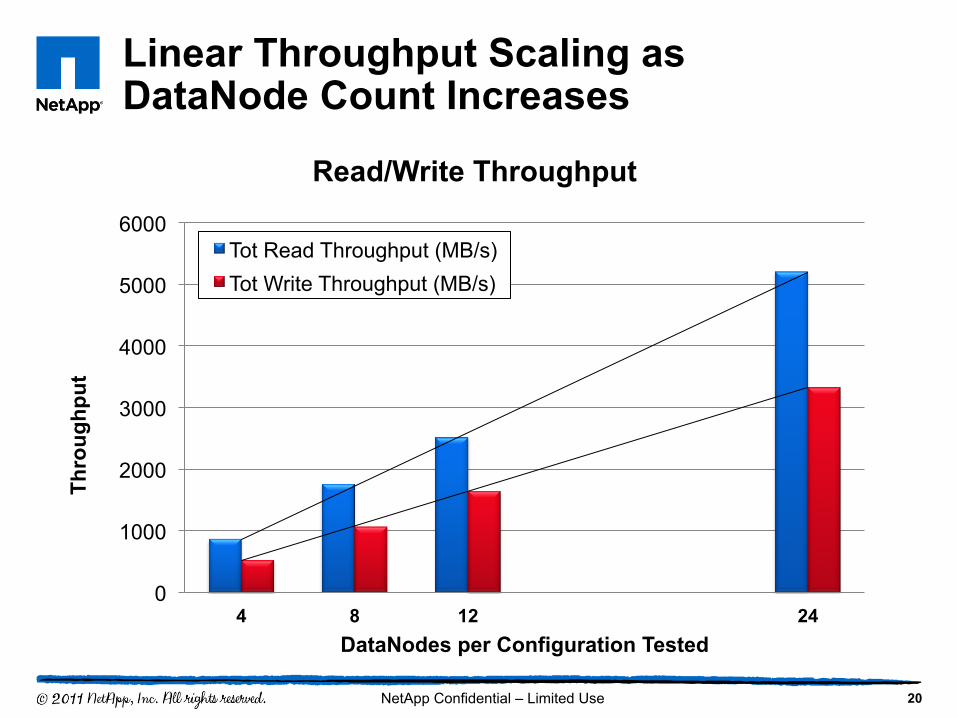
0
1000
2000
3000
4000
5000
6000
4 8 12 24
Thro
ughp
ut
DataNodes per Configuration Tested
Read/Write Throughput
Tot Read Throughput (MB/s) Tot Write Throughput (MB/s)
Linear Throughput Scaling as DataNode Count Increases
20 NetApp Confidential – Limited Use
Summary
21
Takeaways ¡ Hadoop-based Big Data architecture
enables
– Cost effective scaling
– Low latency access to data
– Ad hoc issues & pattern detection
– Predictive modeling in future
¡ Using our own innovative Hadoop storage technology NOSH
¡ An enterprise transformation
22

© 2011 NetApp, Inc. All rights reserved. No portions of this document may be reproduced without prior written consent of NetApp, Inc. Specifications are subject to change without notice. NetApp, the NetApp logo, and Go further, faster, are trademarks or registered trademarks of NetApp, Inc. in the United States and/or other countries. All other brands or products are trademarks or registered trademarks of their respective holders and should be treated as such.
¡ Kumar Palaniappan @megamda





























