Embed Size (px)
Citation preview

3 bash one-liners
[email protected]@gmail.com
onliners: sao codigos escritos todos em uma linha bash: eh um shell muito popular, provavelmente quando vc abre o seu terminal vc estah usando o bash
entao, vou contar 3 histórias.

1

To lá eu fazendo um dump de banco...
$ mongoexport -d sambatech -c portal | gzip > dump.json.gz
connected to: 127.0.0.1

Demorou mais de 10 segundos...
$ mongoexport -d sambatech -c portal | gzip > dump.json.gz
connected to: 127.0.0.1^C

Tá, preciso mostrar o progresso...
$ mongoexport -d sambatech -c portal | gzip | pv > dump.json.gz
connected to: 127.0.0.17.83MB 0:00:05 [1.75MB/s] [ <=> ]
vermelho: pv simples mostrando a taxa de transferencia

Hunnn... Ainda não sei quanto falta.
$ mongoexport -d sambatech -c portal | pv -c -N raw | gzip | pv -c -N gz > dump.json.gz connected to: 127.0.0.1 raw: 54.5MB 0:00:07 [8.28MB/s] [ <=> ] gz: 11.1MB 0:00:07 [1.72MB/s] [ <=> ]
vermelho: pv mostrando o ratio de compressao on-the-fly

Ah, eu sei quantas linhas são...
$ ( export H=localhost D=sambatech C=portal; export F="dump-$H-$D-$C-$(date +%Y%m%d_%H%M%S)"; mongoexport -h $H -d $D -c $C 2> $F.log | pv -c -N raw | pv -c -N rows -l -s "$( echo -e "use $D;\ndb.$C.find().count();" | mongo $H 2>> $F.log | grep "switched to db $D" -A1 | tail -1 | cut -c 2- )" | gzip | pv -c -N gz | tee $F.gz | md5sum > $F.md5 )
raw: 78.4MB 0:00:10 [7.97MB/s] [ <=> ] gz: 16.1MB 0:00:10 [1.69MB/s] [ <=> ] rows: 46.7k 0:00:10 [4.59k/s] [> ] 63% ETA 0:00:05
vermelho: novo pv contando porcentagem de linhas, calculadas por um count() do mongo azul: variaveis para nao repetir as informacoes
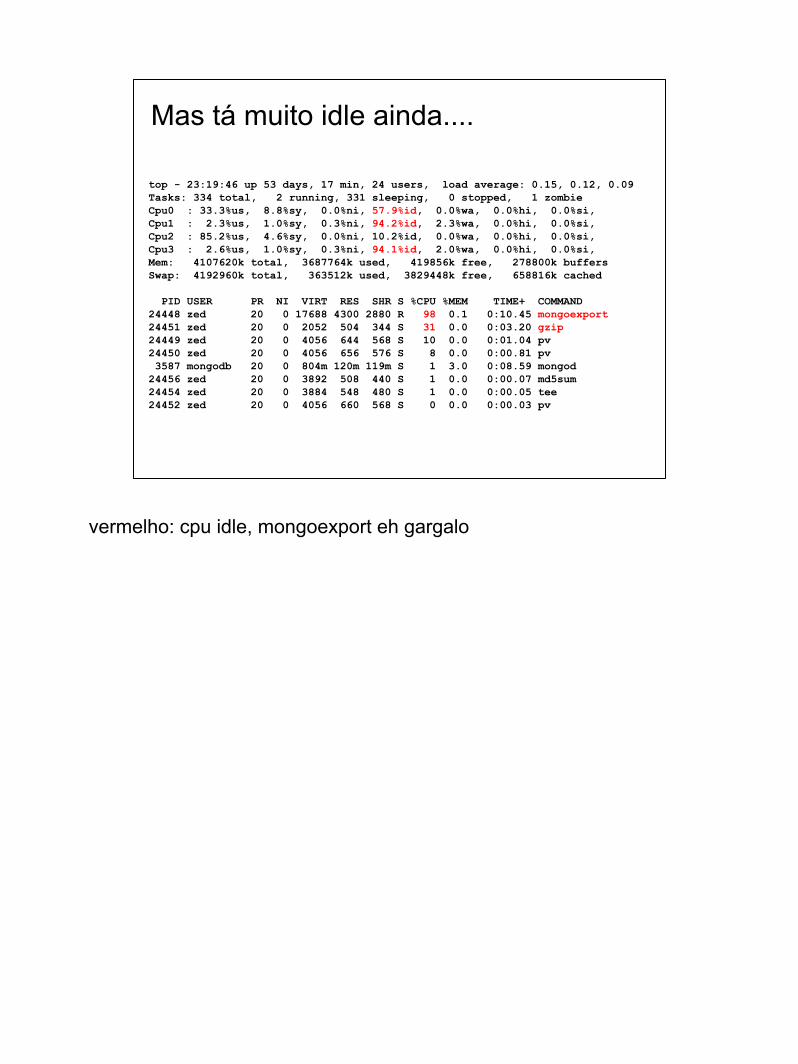
Mas tá muito idle ainda....
top - 23:19:46 up 53 days, 17 min, 24 users, load average: 0.15, 0.12, 0.09Tasks: 334 total, 2 running, 331 sleeping, 0 stopped, 1 zombieCpu0 : 33.3%us, 8.8%sy, 0.0%ni, 57.9%id, 0.0%wa, 0.0%hi, 0.0%si,Cpu1 : 2.3%us, 1.0%sy, 0.3%ni, 94.2%id, 2.3%wa, 0.0%hi, 0.0%si,Cpu2 : 85.2%us, 4.6%sy, 0.0%ni, 10.2%id, 0.0%wa, 0.0%hi, 0.0%si,Cpu3 : 2.6%us, 1.0%sy, 0.3%ni, 94.1%id, 2.0%wa, 0.0%hi, 0.0%si,Mem: 4107620k total, 3687764k used, 419856k free, 278800k buffersSwap: 4192960k total, 363512k used, 3829448k free, 658816k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24448 zed 20 0 17688 4300 2880 R 98 0.1 0:10.45 mongoexport 24451 zed 20 0 2052 504 344 S 31 0.0 0:03.20 gzip 24449 zed 20 0 4056 644 568 S 10 0.0 0:01.04 pv 24450 zed 20 0 4056 656 576 S 8 0.0 0:00.81 pv 3587 mongodb 20 0 804m 120m 119m S 1 3.0 0:08.59 mongod 24456 zed 20 0 3892 508 440 S 1 0.0 0:00.07 md5sum 24454 zed 20 0 3884 548 480 S 1 0.0 0:00.05 tee 24452 zed 20 0 4056 660 568 S 0 0.0 0:00.03 pv
vermelho: cpu idle, mongoexport eh gargalo

Vamos ver...
$ time --help--help: command not found
$ type timetime is a shell keyword
$ help timetime: time [-p] pipeline Report time consumed by pipeline's execution.
$ /usr/bin/time --helpUsage: /usr/bin/time [-apvV] [-f format] [-o file] [--append] [--verbose] [--portability] [--format=format] [--output=file] [--version] [--quiet] [--help] command [arg...]
tem dois times no sistema, cuidado com aliases e built-ins

Ei, espera aí, que tal usar xz?!
$ mongoexport -d sambatech -c portal | head -c 10000 | tee >( ( /usr/bin/time -f 'gz: %E real, %U user, %S sys' gzip -9 | wc -c | sed 's/^/gz: /' ) 1>&2) | /usr/bin/time -f 'xz: %E real, %U user, %S sys' xz -9 | wc -c | sed 's/^/xz: /'
connected to: 127.0.0.1gz: 0:00.24 real, 0.00 user, 0.00 sysgz: 2078xz: 0:00.31 real, 0.02 user, 0.04 sysxz: 2012
vemelho: limitei os bytes de entrada em um tamanho arbitrário, mas ele foi insuficiente para chegar a alguma conclusão.

Melhor limitar por tempo do que por bytes. Mas como parar?...$ { ( mongoexport -d sambatech -c portal | tee >(wc -c | sed 's/^/raw: /' 1>&2) | tee >( ( /usr/bin/time -f 'gz: %E real, %U user, %S sys' gzip -9 | wc -c | sed 's/^/gz: /' ) 1>&2) | /usr/bin/time -f 'xz: %E real, %U user, %S sys' xz -9 | wc -c | sed 's/^/xz: /' ) & } ; sleep 9 ; kill -INT %% [1] 12289connected to: 127.0.0.1$ raw: 14623779gz: 0:08.99 real, 0.75 user, 0.00 sysgz: 2706591Command terminated by signal 2xz: 0:09.02 real, 8.78 user, 0.17 sys
vermelho: os 3 wc(raw, gz, xz) e os seus respectivos resultados (note que falta um resultado) azul: a causa; tentei matar o pipe inteiro, mas o resultado ficou cortado.

Ahh, aí está o número perdido!
$ { ( mongoexport -d sambatech -c portal | tee >(wc -c | sed 's/^/raw: /' 1>&2) | tee >( ( /usr/bin/time -f 'gz: %E real, %U user, %S sys' gzip -9 | wc -c | sed 's/^/gz: /' ) 1>&2) | /usr/bin/time -f 'xz: %E real, %U user, %S sys' xz -9 | wc -c | sed 's/^/xz: /' ) & } ; sleep 9 ; kill -INT $(pstree -p $! | sed -n 's/.*mongoexport(\([0-9]*\)).*/\1/p') [1] 12724connected to: 127.0.0.1$ raw: 14497402gz: 0:09.10 real, 0.73 user, 0.01 sysgz: 2695783xz: 0:09.18 real, 8.73 user, 0.16 sysxz: 2021928
vermelho: o wc e sue resultado ,(que estava perdido)
azul: o que fiz pra resolver, matei o processo inicial do pipe e não o pipe todo
roxo: pid do ultimo processo que foi pra background

Mas deixa eu formatar isso melhor...
$ { ( { mongoexport -d sambatech -c portal 2>/dev/null | tee >(wc -c | sed 's/^/s_raw=/' 1>&2) | tee >( ( /usr/bin/time -f 't_gz=%U+%S' gzip -9 | wc -c | sed 's/^/s_gz=/') 1>&2) | /usr/bin/time -f 't_xz=%U+%S' xz -9 | wc -c | sed 's/^/s_xz=/' ; echo 'scale=2; print "\nxz is ", t_xz/t_gz; r_sz=s_gz/s_xz; r_gz=s_gz/s_raw; r_xz=s_xz/s_raw; scale=0; print " times slower and ", (r_sz-1)/.01,"% smaller\ncompression ratios: gz=",(1-r_gz)/.01,"%, xz=",(1-r_xz)/.01,"%\n"' ; } 2>&1 | bc ) & } ; sleep 9 ; kill -INT $(pstree -p $! | sed -n 's/.*mongoexport(\([0-9]*\)).*/\1/p') xz is 12.02 times slower and 33% smallercompression ratios: gz=82%, xz=87%
vermelho: contas em bc pra calcular as taxas
azul: variaveis usadas no bc fundo verde: bloco de shell script cujo output eh codigo para o bc

Ai... :/ será que tem algum outro nível de compressão que valha a pena?
$ { ( { { echo -n 'mongoexport -d sambatech -c portal 2>/dev/null | tee' ; for z in 0 1 ; do for l in $(seq 0 9); do test $z = 1 -a $l = 0 || echo -n " >(/usr/bin/time -f 't[$z$l]=%U+%S' $(test $z == 1 && echo gzip || echo xz) -$l | wc -c | sed 's/^/s[$z$l]=/' 1>&2)" ; done ; done ; echo -n ' | cat > /dev/null' ; } | bash 2>&1 ; echo 'scale=2; for(p=1;p<=13;p+=6) { for(x=0;x<=1;x++) { for(l=x;l<=9;l++) { i=x*10+l; s=s[i]/s[16]; t=t[i]/t[16]; print 1/s^p/t," (1/s^",p,"/t) "; if(x==1) print "gzip" else print "xz"; print" -",l," is ",t," time and ",s," size of gzip -6\n" } } }' ; } | bash <( echo -n 'bc | tee ' ; for p in $(seq 1 6 13) ; do echo -n " >(grep 's^$p/t' | sort -n | tail -1 | cut -d ' ' -f 2- 1>&2)" ; done ; echo -n ' > /dev/null' ) 2>&1 ) & } ; sleep 9 ; kill -INT $(pstree -p $! | sed -n 's/.*mongoexport(\([0-9]*\)).*/\1/p'); fg (1/s^1/t) gzip -2 is .62 time and 1.12 size of gzip -6(1/s^7/t) gzip -6 is 1.00 time and 1.00 size of gzip -6(1/s^13/t) xz -6 is 14.00 time and .76 size of gzip -6
enfase na metaprogramacao
vermelho: interpretadores, o bash do meio teve que receber o script como arquivo e nao como stdin pq o bc dentro dele precisava da stdin pra ele. azul: geracao dinamica dos scripts fundo vermelho: primeiro bash, que vai gerar um bash script que, finalmente, vai escrever as variaveis para o bc
fundo verde: codigo estatico para o bc
fundo azul: script shell que vai receber com stdin um codigo bc e vai parsear a saida do bc verde: o cat eh necessario pq os redirects se comportam diferentes do pipe, sem ele as variaveis viriam depois do codigo bc que usa elas branco com fundo vermelho: tem um race-condition na geracao paralela das variaveis do bc, tive que rodar varias vezes pra conseguir

o resultado completo

pstree dos comandos no slide anterior
bash─┬─bash───bash─┬─cat │ ├─mongoexport │ └─tee─┬─10*[bash─┬─sed] │ │ ├─time───xz] │ │ └─wc] │ └─9*[bash─┬─sed] │ ├─time───gzip] │ └─wc] └─bash─┬─bc └─tee───3*[bash─┬─cut] ├─grep] ├─sort] └─tail]
vermelho: os pontos chaves de processamento azul: o unico input que flui por toda essa arvore verde: tees que forkam os processos e pipes

código bash, resultado do primeiro trecho
mongoexport -d sambatech -c portal 2>/dev/null | tee >(/usr/bin/time -f 't[00]=%U+%S' xz -0 | wc -c | sed 's/^/s[00]=/' 1>&2) >(/usr/bin/time -f 't[01]=%U+%S' xz -1 | wc -c | sed 's/^/s[01]=/' 1>&2) >(/usr/bin/time -f 't[02]=%U+%S' xz -2 | wc -c | sed 's/^/s[02]=/' 1>&2) >(/usr/bin/time -f 't[03]=%U+%S' xz -3 | wc -c | sed 's/^/s[03]=/' 1>&2) >(/usr/bin/time -f 't[04]=%U+%S' xz -4 | wc -c | sed 's/^/s[04]=/' 1>&2) >(/usr/bin/time -f 't[05]=%U+%S' xz -5 | wc -c | sed 's/^/s[05]=/' 1>&2) >(/usr/bin/time -f 't[06]=%U+%S' xz -6 | wc -c | sed 's/^/s[06]=/' 1>&2) >(/usr/bin/time -f 't[07]=%U+%S' xz -7 | wc -c | sed 's/^/s[07]=/' 1>&2) >(/usr/bin/time -f 't[08]=%U+%S' xz -8 | wc -c | sed 's/^/s[08]=/' 1>&2) >(/usr/bin/time -f 't[09]=%U+%S' xz -9 | wc -c | sed 's/^/s[09]=/' 1>&2)
>(/usr/bin/time -f 't[11]=%U+%S' gzip -1 | wc -c | sed 's/^/s[11]=/' 1>&2) >(/usr/bin/time -f 't[12]=%U+%S' gzip -2 | wc -c | sed 's/^/s[12]=/' 1>&2) >(/usr/bin/time -f 't[13]=%U+%S' gzip -3 | wc -c | sed 's/^/s[13]=/' 1>&2) >(/usr/bin/time -f 't[14]=%U+%S' gzip -4 | wc -c | sed 's/^/s[14]=/' 1>&2) >(/usr/bin/time -f 't[15]=%U+%S' gzip -5 | wc -c | sed 's/^/s[15]=/' 1>&2) >(/usr/bin/time -f 't[16]=%U+%S' gzip -6 | wc -c | sed 's/^/s[16]=/' 1>&2) >(/usr/bin/time -f 't[17]=%U+%S' gzip -7 | wc -c | sed 's/^/s[17]=/' 1>&2) >(/usr/bin/time -f 't[18]=%U+%S' gzip -8 | wc -c | sed 's/^/s[18]=/' 1>&2)
>(/usr/bin/time -f 't[19]=%U+%S' gzip -9 | wc -c | sed 's/^/s[19]=/' 1>&2) | cat > /dev/null
fundo vermelho: codigo de bash que vai gerar codigo de bc

t[09]=2.17+0.09s[09]=500800t[08]=2.21+0.07s[08]=500800t[07]=2.12+0.06s[07]=500800t[06]=2.12+0.04s[06]=500800t[05]=1.60+0.03s[05]=518820t[04]=1.56+0.01s[04]=520052t[03]=1.44+0.02s[03]=524920t[02]=0.50+0.02s[02]=603160t[01]=0.35+0.01s[01]=634096t[00]=0.32+0.02s[00]=671448
scale=2;for(p=1;p<=13;p+=6) { for(x=0;x<=1;x++) { for(l=x;l<=9;l++) { i=x*10+l; s=s[16]/s[i]; t=t[i]/t[16]; print s^p/t," (s^",p,"/t) "; if(x==1) print "gzip" else print "xz"; print" -",l," is ",t," slower and ",s," smaller than gzip -6\n"} } }
t[19]=0.20+0.00s[19]=639917t[18]=0.20+0.00s[18]=640335t[17]=0.16+0.00s[17]=649143t[16]=0.14+0.00s[16]=652085t[15]=0.13+0.01s[15]=663714t[14]=0.12+0.01s[14]=690369t[13]=0.09+0.01t[12]=0.08+0.00s[13]=722305s[12]=734534t[11]=0.09+0.00s[11]=752727
código bc, resultado do primeiro e segundo trechos
fundo vermelho: codigo de bc gerado pelo primeiro trecho
fundo verde: codigo de bc que vai processar as variaveis mostradas no fundo vermelho

código bash, resultado do terceiro trecho
bc | tee >(grep 's^1/t' | sort -n | tail -1 | cut -d ' ' -f 2- 1>&2) >(grep 's^7/t' | sort -n | tail -1 | cut -d ' ' -f 2- 1>&2)
>(grep 's^13/t' | sort -n | tail -1 | cut -d ' ' -f 2- 1>&2) > /dev/null
fundo azul: ultimo script bash que recebe o stdin com o bc e faz o pos-processamento do seu output

Como tirar o race-condition?
$ while true ; do { { { for d in {1,2}{0,1}{0..9} ; do echo -n " { { echo -n "$d: " ; ls /dev/fd/ ; } 1>&2 ; " ; done ; echo -n 'seq 2000 2>/dev/null | tee' ; for z in 0 1 ; do for l in $(seq 0 9); do test $z = 1 -a $l = 0 || echo -n " >(/usr/bin/time -f 't[$z$l]=%U+%S' 2>&2$z$l $(test $z == 1 && echo gzip || echo xz) -$l | wc -c | sed 's/^/s[$z$l]=/' 1>&1$z$l)" ; done ; done ; echo -n ' >/dev/null' ; for d in {1,2}{0,1}{0..9} ; do echo -n " ; } $d>&1 | grep '' " ; done ; } | tee /dev/fd/2 | bash ; echo 123 ; } | sed 's/^/b:/' | grep =.*= ; } 2>/dev/null ; done
vermelho: grep "" line buffered dos varios file descriptors; o ultimo grep testa por linhas encavaladas
azul: debug supimido pelo 2>/dev/null no final
mas isso eh uma outra história...

Mais consistência no teste dos parâmetros de compressão
$ { { { { { for d in {1,2}{0,1}{0..9} ; do echo -n " { " ; done ; echo -n 'mongoexport -d sambatech -c portal 2>/dev/null | tee' ; for z in 0 1 ; do for l in $(seq 0 9); do test $z = 1 -a $l = 0 || echo -n " >(/usr/bin/time -f 't[$z$l]=%U+%S' 2>&2$z$l $(test $z == 1 && echo gzip || echo xz) -$l | wc -c | sed 's/^/s[$z$l]=/' 1>&1$z$l)" ; done ; done ; echo -n ' > /dev/null' ; for d in {1,2}{0,1}{0..9} ; do echo -n " ; } $d>&1 | sed '' " ; done ; } | bash ; echo 'scale=2; for(p=1;p<=13;p+=6) { for(x=0;x<=1;x++) { for(l=x;l<=9;l++) { i=x*10+l; s=s[i]/s[16]; t=t[i]/t[16]; print 1/s^p/t," (1/s^",p,"/t) "; if(x==1) print "gzip" else print "xz"; print" -",l," is ",t," time and ",s," size than gzip -6\n" } } }' ; } | bash <( echo -n 'bc | { tee ' ; for p in $(seq 1 6 13) ; do echo -n " >(grep 's^$p/t' | sort -n | tail -1 | cut -d ' ' -f 2- 1>&2)" ; done ; echo -n ' >/dev/null ; } 2>&1 | grep "" ' ) ; } & } ; A=$! ; { { sleep 9 ; kill -INT $(pstree -laAp $A | sed -n 's/^[^,]*\<mongoexport,\([0-9][0-9]*\)\>.*/\1/p') ; } & } ; B=$! ; fg %- || { echo "finishing..." ; kill -INT $( { pstree -laAp $A ; pstree -laAp $B ; } | sed -n 's/^[^,]*,\([0-9][0-9]*\)\>.*/\1/p') ; } ; } #xz-vs-gz
vermelho: separacao dos streams em multiplos file descriptors
azul: limpando rodadas incompletas
cinza: tag

Bom, mas voltando ao dump do banco, com xv fica assim:$ ( export H=localhost D=sambatech C=portal; export F="dump-$H-$D-$C-$(date +%Y%m%d_%H%M%S)"; mongoexport -h $H -d $D -c $C 2> $F.log | pv -c -N raw | pv -c -N rows -l -s "$( echo -e "use $D;\ndb.$C.find().count();" | mongo $H 2>> $F.log | grep "switched to db $D" -A1 | tail -1 | cut -c 2- )" | xz | pv -c -N xz | tee $F.xz | md5sum > $F.md5 )
raw: 54.7MB 0:00:38 [ 1.4MB/s] [ <=> ] xz: 7.85MB 0:00:38 [ 176kB/s] [ <=> ] rows: 32.7k 0:00:38 [ 818/s ] [=> ] 44% ETA 0:00:47
vermelho: o xz na linha do dump de bando

Como está idle e o xv é o gargalo, o negócio é paralelizar de algum jeitotop - 12:15:16 up 53 days, 13:13, 27 users, load average: 0.69, 0.24, 0.29Tasks: 338 total, 3 running, 334 sleeping, 0 stopped, 1 zombieCpu0 : 99.7%us, 0.3%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.0%si,Cpu1 : 2.3%us, 1.3%sy, 0.0%ni, 96.4%id, 0.0%wa, 0.0%hi, 0.0%si,Cpu2 : 18.3%us, 1.7%sy, 0.0%ni, 79.4%id, 0.7%wa, 0.0%hi, 0.0%si,Cpu3 : 2.0%us, 1.3%sy, 0.0%ni, 96.7%id, 0.0%wa, 0.0%hi, 0.0%si,Mem: 4107620k total, 1334364k used, 2773256k free, 24868k buffersSwap: 4192960k total, 2373236k used, 1819724k free, 259280k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND20507 zed 20 0 99420 93m 736 R 100 2.3 1:06.74 xz 20504 zed 20 0 17688 4304 2880 S 17 0.1 0:11.88 mongoexport 20506 zed 20 0 4056 780 576 S 2 0.0 0:01.45 pv 20505 zed 20 0 4056 732 576 S 0 0.0 0:00.25 pv
vermelho: xv como gargalo, no lugar do mongoexport; processos single thread

pixz ou parallel?
$ git clone https://github.com/vasi/pixz.git$ cd pixz/$ makepixz.h:1: fatal error: lzma.h: No such file or directory $ sudo apt-get install lzma-dev Setting up lzma-dev (4.43-14ubuntu2) ... $ makepixz.h:1: fatal error: lzma.h: No such file or directory $ grep lzma README * liblzma 4.999.9-beta-212 or later (from the xz distribution)
vermelho: muitos poblemas para instalar um xz paralelo

parallel? não?..
$ parallelThe program 'parallel' is currently not installed. You can install it by typing: sudo apt-get install moreutils $ apt-get install moreutils... $ parallel --helpparallel: invalid option -- '-'parallel [OPTIONS] command -- arguments
for each argument, run command with argument, in parallelparallel [OPTIONS] -- commands
run specified commands in parallel
vermelho: o parallel do ubuntu parece muito velho

Bem vindo ao mundo real...
$ wget http://ftp.gnu.org/gnu/parallel/parallel-20110822.tar.bz2$ tar xvf parallel-20110822.tar.bz2$ cd parallel-20110822 $ ./configure && make -j 4$ ./src/parallel --helpUsage:parallel [options] [command [arguments]] < list_of_argumentsparallel [options] [command [arguments]] (::: arguments|:::: argfile(s))...cat ... | parallel --pipe [options] [command [arguments]]
-j n Run n jobs in parallel-k Keep same order
vermelho: parallel sendo buildado em paralelo :)

Quantos jobs pra compressão?...
$ uptime ; for j in $(seq $(( $(grep -c ^bogomips /proc/cpuinfo) * 4 )) ) ; do echo "$j: $( ( time ( mongoexport -d sambatech -c portal 2>/dev/null | head -20000 | parallel -j $j --pipe nice xz | xz -t ) ) 2>&1 | tr "\n" "\t" )" ; done ; uptime
14:46:08 up 53 days, ... load average: 0.07, 1.29, 2.23 1: real 0m18.759s user 0m26.602s sys 0m2.448s2: real 0m11.673s user 0m24.746s sys 0m1.916s3: real 0m9.033s user 0m23.553s sys 0m1.460s4: real 0m8.561s user 0m23.093s sys 0m1.468s...8: real 0m7.645s user 0m23.173s sys 0m1.356s...16: real 0m7.087s user 0m22.153s sys 0m1.260s14:48:27 up 53 days, ... load average: 6.49, 2.88, 2.66
vermelho: parallel configurado para fazer split de um pipe para varios xz
azul: numero de jogs testados: de 1 ateh 4 vezes o numero de cores
verde: o nice eh importante senao o mongoexport nao tem cpu o suficiente para alimentar todos os xz laranja: note que usei o time built-in, porque estou fazendo time de um parenteses (sub-shell)

Achievement Unlocked
$ ( export H=localhost D=sambatech C=portal; export F="dump-$H-$D-$C-$(date +%Y%m%d_%H%M%S)"; mongoexport -h $H -d $D -c $C 2> $F.log | pv -c -N raw | pv -c -N rows -l -s "$( echo -e "use $D;\ndb.$C.find().count();" | mongo $H 2>> $F.log | grep "switched to db $D" -A1 | tail -1 | cut -c 2- )" | parallel --pipe nice xz | pv -c -N xz | tee $F.xz | md5sum > $F.md5 ) #dump-mongo-collection
raw: 48.9MB 0:00:10 [5.64MB/s] [ <=> ] xz: 6.38MB 0:00:10 [ 678kB/s] [ <=> ] rows: 29.6k 0:00:10 [3.27k/s] [==> ] 40% ETA 0:00:14
vermelho: o parallel na linha de dump do banco; o default do parallel eh um para cada core
cinza: tag, pra lembrar do oneliner

2

E se eu quiser mandar pra net?
$ scp dump.xz example.com:
dump.xz 100% 97MB 32.3MB/s 00:03

Putz, mas e a integridade?
$ ssh example.com "xz -vd > dump" < dump-*.xz
(stdin): 96.9 MiB / 228.5 MiB = 0.424, 22 MiB/s, 0:10
vermelho: descomprime do lado remoto para verificar integridade
azul: arquivo armazenado estah descomprimido fundo amarelo: roda remoto

Mas não queria descomprimir lá...
$ F="dump.xz"; ssh example.com "tee >(xz -tv) > '$F' " < "$F"
vermelho: tee para testar apenas
azul: armazena o arquivo comprimido
fundo amarelo: roda remoto

Ueh?.. kd o output?
$ F="dump.xz"; ssh example.com "tee >(xz -tv) > '$F' " < "$F"$
vermelho: xz -tv normalmente imprime na stderr fundo amarelo: roda remoto

Aff, a stderr nao passou pelo ssh, claro... mas tudo bem.$ time ( F="dump.xz"; ssh example.com "{ tee >(xz -vt) > '$F' ; } 2>&1" < "$F" )
(stdin): 96.9 MiB / 228.5 MiB = 0.424, 22 MiB/s, 0:10
real 0m10.580suser 0m2.963ssys 0m0.243s
vermelho: redirecionando a stderr para stdout antes de sair do ssh azul: xz e seu output verde: stdout dentro das chaves precisa ser preservada para o arquivo
laranja: tempo total do processo fundo amarelo: roda remoto note que ssh -t nao funciona: Pseudo-terminal will not be allocated because stdin is not a terminal.

Soh que descomprimir o xz pra validar eh overkill... que tal usar o md5sum?$ F=dump.xz; pv "$F" | tee >(printf 'size:%-10d\n' $(wc -c) ) >(echo "md5:$(md5sum)") | ssh example.com 'FIFO=$(mktemp -d); mkfifo $FIFO/{a,b}; trap "rm $FIFO\/[ab]; rmdir $FIFO" 0; tee >(tail -c 56 | tee >( sed -n "s/size:\(.*\)/\1/p" >$FIFO/a ) | sed -n "s/md5:\(.*\)/\1/p" >$FIFO/b ) | head -c $(cat <$FIFO/a) | tee '"$F"' | md5sum -c $FIFO/b | cut -c 4-'
vermelho: multiplexa arquivo, seu md5 e tamanho
azul: demultiplexa do outro lado verde: fifo a carrega o tamanho do arquivo e o fifo b o md5
roxo: trap para apagar os fifos quando sair, mesmo se cancelado fundo amarelo: roda remoto

Droga, deadlock! E agora?...
$ F=dump.xz; pv "$F" | tee >(printf 'size:%-10d\n' $(wc -c) ) >(echo "md5:$(md5sum)") | ssh example.com 'FIFO=$(mktemp -d); mkfifo $FIFO/{a,b}; trap "rm $FIFO\/[ab]; rmdir $FIFO" 0; tee >(tail -c 56 | tee >( sed -n "s/size:\(.*\)/\1/p" >$FIFO/a ) | sed -n "s/md5:\(.*\)/\1/p" >$FIFO/b ) | head -c $(cat <$FIFO/a) | tee '"$F"' | md5sum -c $FIFO/b | cut -c 4-'^C
vermelho: multiplexa arquivo, seu md5 e tamanho
azul: demultiplexa do outro lado verde: fifo a carrega o tamanho do arquivo e o fifo b o md5
roxo: trap para apagar os fifos quando sair, mesmo se cancelado fundo amarelo: roda remoto o deadlock causado por arquivos maiores que o buffer do pipe porque os metadados estao no final (nao tem como saber o md5 no inicio), mas para comecar a gravar o arquivo no disco, e permitir que o pipe avance, preciso do size e do md5 nos fifos

kkkk, tem um jeito bem mais simples!
$ time ( F=dump.xz; pv "$F" | { tee >(md5sum 1>&2) | ssh example.com 'tee '"$F"' | md5sum' ; } 2>&1 | sort -u | wc -l | grep -qx 1 && echo OK || echo ERR )
96.9MB 0:00:03 [28.7MB/s] [===========>] 100%OK
real 0m3.212suser 0m2.373ssys 0m0.307s
$ ### time ssh + xz:$ #real 0m10.580s$ #user 0m2.963s$ #sys 0m0.243s
vermelho: o md5 eh rodado local (para stderr) e remoto (stdout)
azul: no final verificamos se tem apenas uma variedade de arquivo
laranja: o md5sum eh bem mais rapido que o xz -t
fundo amarelo: roda remoto

Jah tah bem mais leve;que tal tirar o ssh tb?$ { F="dump.xz" ; H="example.com" ; P=9999 ; pv "$F" | tee >(md5sum 1>&2) >(wc -c 1>&2) >( sed -n '' | ssh "$H" "{ netcat \$(set | grep [S]SH_CLIENT | sed \"s/.*'\([^ ]*\) .*/\1/\") $P | tee '$F' >(wc -c 1>&2) | md5sum ; } 2>&1" 1>&2 ) >(netcat -l $P) >/dev/null ; } 2>&1 | tee >( sort -u | wc -l | grep -qx 2 && echo OK || echo ERR ) 19405636a84a3cd315f4ee235c5e15d82872ab5d -1933516885d99c783b541885b05ef263c1f35cdc -ERR
azul: todo o fluxo foi controlado por um unico pipe, mas o ssh que nao deveria receber os dados teve seu input editado vermelho: deu erro na transmissao porque o pipe produtor fechou antes do netcat receptor terminar; esse erro eh intermitente
verde: note que a seguranca eh fraca, se alguem estiver tentando pegar o arquivo dessa porta vai conseguir, isso nao eh pra redes desprotegidas
fundo amarelo: roda remoto

Morreu antes de terminar o envio,o receptor vai ter que autorizar o fim$ { F="dump.xz" ; H="example.com" ; P=$(printf "39%03d" $RANDOM | cut -c 1-5) ; { ssh "$H" "{ netcat \$(set | grep [S]SH_CLIENT | sed \"s/.*'\([^ ]*\) .*/\1/\") $P | tee '$F' >(wc -c 1>&2) | md5sum ; } 2>&1" 1>&2 ; } | { < "$F" tee >(md5sum 1>&2) >(wc -c 1>&2) >(netcat -l $P) >/dev/null ; } ; } 2>&1 | tee >( sort -u | wc -l | grep -qx 2 && echo OK || echo ERR ) 19405636a84a3cd315f4ee235c5e15d82872ab5d -19405636a84a3cd315f4ee235c5e15d82872ab5d -OK
vermelho: o ssh estah dominando o pipe azul: o pipe soh morre quando o ssh morrer
roxo: o produtor vem depois
verde: um pouco mais de segurança por obscuridade
fundo amarelo: roda remoto
isso funcionou no ubuntu 10.10, mas nao funcionou no archlinux 2011-09

Cuidados com o netcat
$ { F="dump.xz" ; H=example.com ; P=$(printf "39%03d" $RANDOM | cut -c 1-5) ; S=$(stat -c %s "$F") ; { { pv "$F" | { tee >(md5sum 1>&2) | { netcat -l -p $P 2>/dev/null || netcat -l $P ; } ; } 2>&1 ; } & } ; A=$! ; ssh $H "{ H=\$(set | grep [S]SH_CLIENT | sed \"s/.*'\([^ ]*\) .*/\1/\") ; { netcat -w 5 -c \$H $P 2>/dev/null || netcat -w 5 \$H $P ; } | tee '$F' >(md5sum 1>&2) | pv -n -s $S 2>&1 >/dev/null | while read X ; do test \"\$X\" -ge 100 && kill -INT \$(pstree -laAp \$\$ | sed -n 's/^[^,]*\<netcat,\([0-9][0-9]*\)\>.*/\1/p') &>/dev/null ; done ; } 2>&1" ; kill -INT $(pstree -laAp $A | sed -n 's/^[^,]*\<netcat,\([0-9][0-9]*\)\>.*/\1/p') &>/dev/null ; } | uniq | wc -l | grep -qx 1 && echo OK || echo ERR #netcat-send 537MB 0:00:04 [ 110MB/s] [=================>] 100%OK
vermelho: por causa das inconsistencias de terminacao do netcat, tive que monitorar o progresso da transmissao e matar explicitamente o netcat
azul: alternativas de parametros do netcat em sistemas diferentes
verde: melhoria de tempo
a inversao do consumidor com o produtor acrescentou um race-condition, o ssh podia tentar conectar no netcat local antes dele existir (teoricamente)
e pior, em alguns sistemas o netcat precisa de um "-p" alem do "-l" e, pior, algumas versões não fecham, sem o "-c", quando o pipe fecha, o que faz o script anterior travar. nesse ultimo caso o ideal é usar a mesma técnica do mongoexport; por em background e matar com pstree requisitos:1) netcat escutando tem que ser criado primeiro;2) logo o netcat do ssh tem que conectar depois,

3) ateh porque ele que tem a autoridade de terminar pq o receptor terminar depois.4) foi preciso fazer fallback entre os dois estilos de netcat;5) soh o netcat que conecta fecha consistentemente com o pipe, mas, como o ssh precisa conectar ./ fechar e ele nao tem o arquivo, foi preciso monitorar a transmissao com pv e matar explicitamente o netcat
melhor ter um netcat confiavel, mas se nao foi possivel o slide apresenta um contorno para o problema

Mas serah que houve vantagem?
$ time !?#netcat-send 537MB 0:00:04 [ 110MB/s] [============>] 100% real 0m5.298suser 0m0.063ssys 0m0.003sOK
$ time !?scp dump.xz 100% 537MB 35.8MB/s 00:15
real 0m14.658suser 0m11.123ssys 0m1.130s
vermelho: tempos do netcat e do ssh

3

E se forem vários arquivos?
$ find dumps/ -type f -printf "%10s %p\n" 101632892 dumps/b/dump.xz.2 65536 dumps/b/a/dump.xz.1 0 dumps/a/3688 0 dumps/a/8958 (... total de 10000 arquivos no dumps/a/) 0 dumps/a/4308 0 dumps/a/3338
$ scp -r dumps/* example.com:dump-backup/(...)3338 100% 0 0.0KB/s 00:00dump.xz.2 100% 97MB 48.5MB/s 00:02dump.xz.1 100% 64KB 64.0KB/s 00:00
vermelho: scp recursivo

Mas quero selecionar melhor
$ tar c -C dumps/ --exclude=./a . | ssh example.com "tar xv -C dump-backup/" ././b/./b/dump.xz.2./b/a/./b/a/dump.xz.1
vermelho: tarpipe
azul: um lista menor foi selecionada

Progresso...
$ TAR="tar c -C dumps/ --exclude=./a ." ; $TAR | pv -s $($TAR | wc -c) | ssh example.com "tar x -C dump-backup/" 97MB 0:00:02 [32.8MB/s] [================>] 100%
vermelho: pv mostrando o progresso a partir de uma rodada previa do mesmo tar

Não rola fazer o tar duas vezes...
$ S="dumps" ; D="dump-backup" ; X="--exclude=a" ; H=example.com ; tar c -C "$S" $X . | pv -s $(cd "$S" && du --apparent-size --block-size=1 $X -s . | cut -f 1) | ssh $H "tar x -C '$D' " 96.9MB 0:00:02 [33.5MB/s] [==============>] 100%
$ S="dumps" ; D="dump-backup" ; X="" ; H=example.com ; tar c -C "$S" $X . | pv -s $(cd "$S" && du --apparent-size --block-size=1 $X -s . | cut -f 1) | ssh $H "tar x -C '$D' " 102MB 0:00:03 [33.7MB/s] [================] 104%
vermelho: du do tamanho dos arquivos, isso eh impreciso quando tem arquivos pequenos no meio
azul: filtros para um arquivo grande e um arquivo grande com muitos pequenos, respectivamente

Mas assim tem muita imprecisão... :/
$ S="dumps" ; D="dump-backup" ; X="--exclude=./a --exclude=./b/d*" ; H=example.com ; tar c -C "$S" $X . | pv -s $(cd "$S" && du --apparent-size --block-size=1 $X -s . | cut -f 1) | ssh $H "tar x -C '$D' " 70kB 0:00:00 [ 544kB/s] [====> ] 29%
$ S="dumps" ; D="dump-backup" ; X="--exclude=./b/d*" ; H=example.com ; tar c -C "$S" $X . | pv -s $(cd "$S" && du --apparent-size --block-size=1 $X -s . | cut -f 1) | ssh $H "tar x -C '$D' " 4.95MB 0:00:00 [7.77MB/s] [================] 1267%
vermelho: du do tamanho dos arquivos, isso eh impreciso especialmente se tiverem varios arquivos pequenos, por causa do overhead do tar, mas quebra um galho.
azul: filtros para um arquivo muito pequeno e muitos arquivos pequenos, respectivamente

Vou tentar incorporar o overhead do tar na conta do tamanho total$ for X in "('./a/*' './b/a/*')" "()" "('./a/*' './b/d*')" "('./b/d*')" ; do eval "X=$X" ; E=""; N=""; for x in "${X[@]}" ; do test -n "$N" && N="$N -and" ; N="$N -not -path '$x'" ; E="$E --exclude='$x'" ; done ; echo "${X[@]} => $E => $N"; S="dumps" ; D="dump-backup" ; H=example.com ; eval "tar c -C '$S' $E ." | pv -s $(cd "$S" && eval "find . $N -printf '%y %s %p\n'" | awk 'BEGIN { sum=0 } { s=length($0)-length($2)-1+($1 ~ /f/ ? $2 : 0) ; c=512; r=s%c; s=s+(r?c-r:0) ; sum+=s } END { chunk=10240; remain=sum%chunk; print sum+(remain?chunk-remain:0) }') | ssh $H "tar x -C '$D' " ; done #tar-pipe-ssh 96.9MB 0:00:02 [34.7MB/s] [====================>] 100% 102MB 0:00:02 [41.5MB/s] [====================>] 100% 70kB 0:00:00 [ 835kB/s] [====================>] 100%4.95MB 0:00:00 [21.2MB/s] [====================>] 100%
vermelho: find + awk calculando, respectivamente os arquivos da mesma maneira que o tar vai fazer
azul: todas as configurações de exceção mostradas antes
passo pelos arquivos duas vezes, mas isso tem uma certa vantagem, que a primeira eh soh pela listagem de diretorios (curta e que deve ficar cacheada depois dessa passada) e a segunda pelo conteudo dos arquivos.. que ficam em lugares bem diferentes do disco, entao possivelmente fazendo isso estou evitando muito io-wait em seek

0

Não tentem isso em casa
Nesse fantástico mundo dos one-liners se pode usar o history como repositório de comandos; basta comentá-los com tags memoráveis e deixar o history bem, bem grande:
$ export HISTSIZE=999999999 HISTFILESIZE=999999999$ echo !! >> $(ls -S ~/.{,bash}{rc,{,_}profile} 2>/dev/null | head -1) $ ls -ltr #lista-recentes...
$ !?#lista-rels -ltr #lista-recentes...

Referência
GNU bash, version 4.1.5(1)-release (i686-pc-linux-gnu)Copyright (C) 2009 Free Software Foundation, Inc. (*) GNU bash, version 4.2.10(2)-release (i686-pc-linux-gnu)Copyright (C) 2011 Free Software Foundation, Inc. (+) License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software; you are free to change and redistribute it.There is NO WARRANTY, to the extent permitted by law.
(*) Ubuntu 10.10(+) Arch Linux 2011-09

Obrigado

Obrigado
( export H=localhost D=sambatech C=portal; export F="dump-$H-$D-$C-$(date +%Y%m%d_%H%M%S)"; mongoexport -h $H -d $D -c $C 2> $F.log | pv -c -N raw | pv -c -N rows -l -s "$( echo -e "use $D;
\ndb.$C.find().count();" | mongo $H 2>> $F.log | grep "switched to db $D" -A1 | tail -1 | cut -c 2- )" | parallel --pipe nice xz | pv -c -N xz | tee $F.xz | md5sum > $F.md5 ) +++++++++ { F="dump.xz" ; H=example.com ; P=$(printf "39%03d" $RANDOM | cut -c 1-5) ; S=$(stat -c %s "$F") ; { { pv "$F" | { tee >(md5sum 1>&2) |
{ netcat -l -p $P 2>/dev/null || netcat -l $P ; } ; } 2>&1 ; } & } ; A=$! ; ssh $H "{ H=\$(set | grep [S]SH_CLIENT | sed \"s/.*'\([^ ]*\) .*/\1/\") ; { netcat -w 5 -c \$H $P 2>/dev/null || netcat -w 5 \$H $P ; } | tee '$F' >(md5sum 1>&2) | pv -n -s $S 2>&1 >/dev/null | while read X ; do test \"\$X\" -ge 100 && kill -INT
\$(pstree -laAp \$\$ | sed -n 's/^[^,]*\<netcat,\([0-9][0-9]*\)\>.*/\1/p') &>/dev/null ; done ; } 2>&1" ; kill -INT $(pstree -laAp $A | sed -n 's/^[^,]*\<netcat,\([0-9][0-9]*\)\>.*/\1/p') &>/dev/null ; } | uniq | wc -l | grep -qx 1
&& echo OK || echo ERR +++++++++ for X in "('./a/*' './b/a/*')" "()" "('./a/*' './b/d*')" "('./b/d*')" ; do eval "X=$X" ; E=""; N=""; for x in "${X[@]}" ; do test -n "$N" && N="$N -and" ; N="$N -not -path '$x'" ; E="$E --
exclude='$x'" ; done ; echo "${X[@]} => $E => $N"; S="dumps" ; D="dump-backup" ; H=example.com ; eval "tar c -C '$S' $E ." | pv -s $(cd "$S" && eval "find . $N -printf '%y %s %p\n'" | awk 'BEGIN { sum=0 } {
s=length($0)-length($2)-1+($1 ~ /f/ ? $2 : 0) ; c=512; r=s%c; s=s+(r?c-r:0) ; sum+=s } END { chunk=10240; remain=sum%chunk; print sum+(remain?chunk-remain:0) }') | ssh $H "tar x -C '$D' " ; done
http://bash.org/http://tldp.org/LDP/abs/
TODO linha que pega uma lista de arquivos do banco, seleciona quais não estão no destino e envia apenas esses por tar | netcat





























