Embed Size (px)
Citation preview

Big Data Ready Enterprise (BDRE) | Open Source Product 1
An Open Source Product
Big Data Ready Enterprise (BDRE)
Big Data Ready Enterprise (BDRE) | Open Source Product 2
Speakers
Arijit Banerjee • BDRE Product Architect
- Wipro Technologies Rahul Sarda • Big Data Practice Head
- Wipro Technologies
Big Data Ready Enterprise (BDRE) | Open Source Product 3
Agenda
How BDRE addresses the needs across the lifecycle
Fast track implementations using BDRE
Demo
BDRE In Action: Implementations Underway
Typical enterprise deployment view with BDRE
2
3
4
5
6
BDRE Roadmap 7
1 Typical Big Data use cases and common challenges
Big Data Ready Enterprise (BDRE) | Open Source Product 4
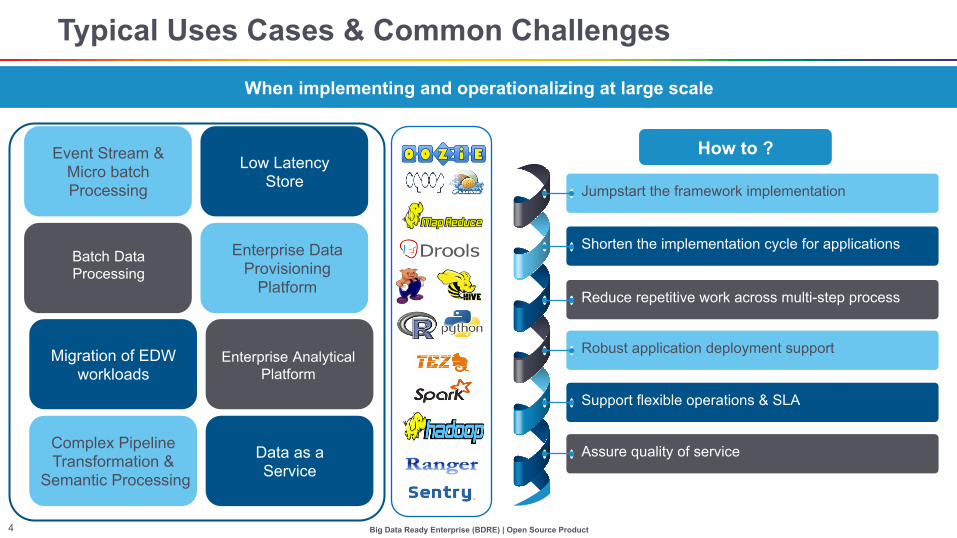
Typical Uses Cases & Common Challenges
When implementing and operationalizing at large scale
Jumpstart the framework implementation
Shorten the implementation cycle for applications
Reduce repetitive work across multi-step process
Robust application deployment support
Support flexible operations & SLA
Assure quality of service
Batch Data Processing
Enterprise Data Provisioning
Platform
Complex Pipeline Transformation &
Semantic Processing
Data as a Service
Event Stream & Micro batch Processing
Low Latency Store
Migration of EDW workloads
Enterprise Analytical Platform
How to ?
Big Data Ready Enterprise (BDRE) | Open Source Product 5
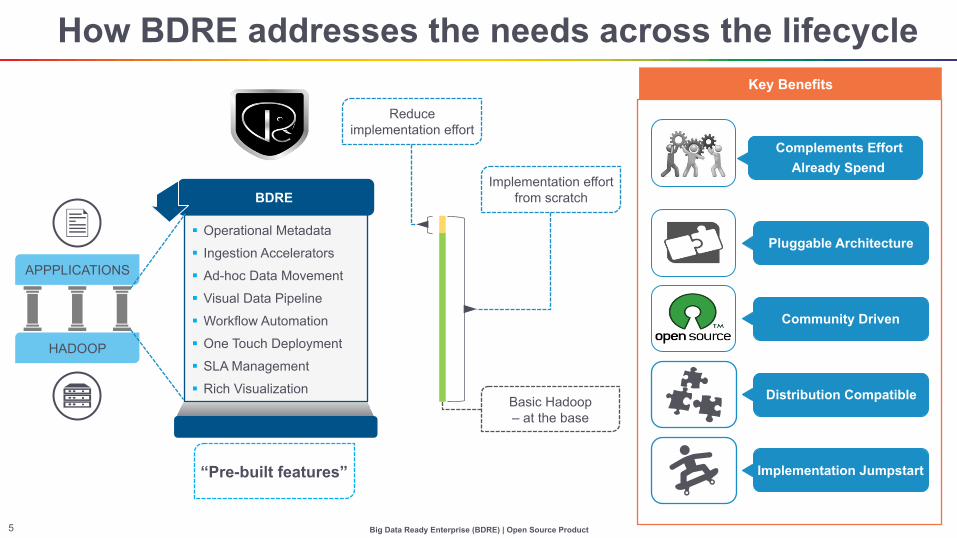
How BDRE addresses the needs across the lifecycle
Pluggable Architecture
Community Driven
Distribution Compatible
Implementation Jumpstart
Key Benefits
Basic Hadoop – at the base
“Pre-built features”
BDRE
§ Operational Metadata
§ Ingestion Accelerators
§ Ad-hoc Data Movement
§ Visual Data Pipeline
§ Workflow Automation
§ One Touch Deployment
§ SLA Management
§ Rich Visualization
Implementation effort from scratch
APPPLICATIONS
HADOOP
Reduce implementation effort
Complements Effort Already Spend
Big Data Ready Enterprise (BDRE) | Open Source Product 6
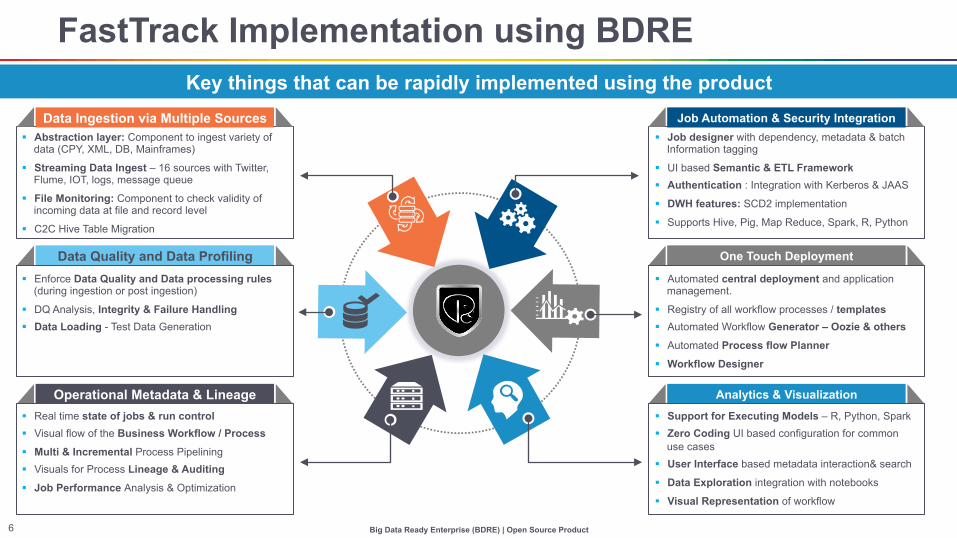
Data Quality and Data Profiling
Operational Metadata & Lineage
Data Ingestion via Multiple Sources
One Touch Deployment
Analytics & Visualization
Job Automation & Security Integration
FastTrack Implementation using BDRE Key things that can be rapidly implemented using the product
§ Job designer with dependency, metadata & batch Information tagging
§ UI based Semantic & ETL Framework § Authentication : Integration with Kerberos & JAAS
§ DWH features: SCD2 implementation
§ Supports Hive, Pig, Map Reduce, Spark, R, Python
§ Automated central deployment and application management.
§ Registry of all workflow processes / templates § Automated Workflow Generator – Oozie & others
§ Automated Process flow Planner
§ Workflow Designer
§ Support for Executing Models – R, Python, Spark § Zero Coding UI based configuration for common
use cases § User Interface based metadata interaction& search
§ Data Exploration integration with notebooks
§ Visual Representation of workflow
§ Abstraction layer: Component to ingest variety of data (CPY, XML, DB, Mainframes)
§ Streaming Data Ingest – 16 sources with Twitter, Flume, IOT, logs, message queue
§ File Monitoring: Component to check validity of incoming data at file and record level
§ C2C Hive Table Migration
§ Enforce Data Quality and Data processing rules (during ingestion or post ingestion)
§ DQ Analysis, Integrity & Failure Handling § Data Loading - Test Data Generation
§ Real time state of jobs & run control § Visual flow of the Business Workflow / Process
§ Multi & Incremental Process Pipelining § Visuals for Process Lineage & Auditing
§ Job Performance Analysis & Optimization

Big Data Ready Enterprise (BDRE) | Open Source Product 7
Demo
Big Data Ready Enterprise (BDRE) | Open Source Product 8
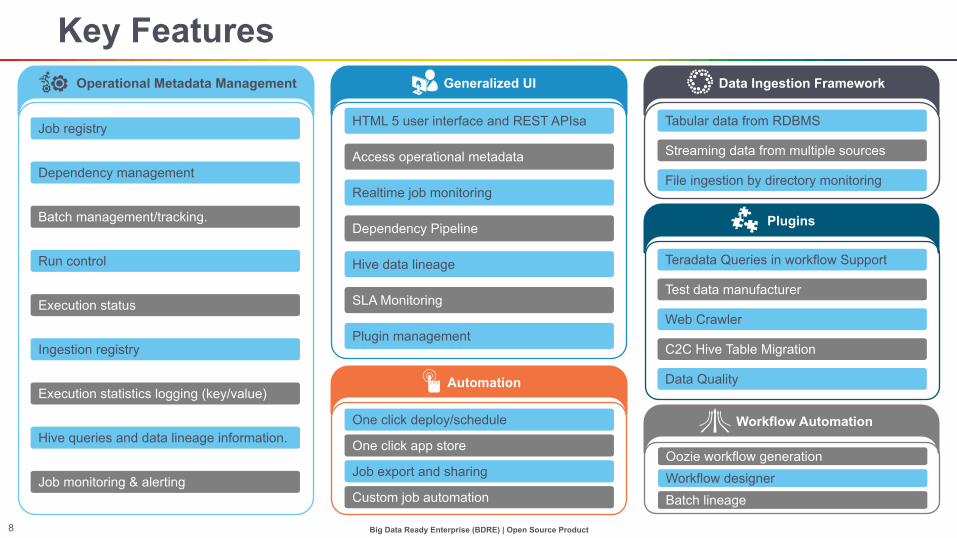
Key Features
Job registry
Dependency management
Batch management/tracking.
Run control
Execution status
Ingestion registry
Execution statistics logging (key/value)
Hive queries and data lineage information.
Job monitoring & alerting
HTML 5 user interface and REST APIsa
Access operational metadata
Realtime job monitoring
Dependency Pipeline
Hive data lineage
SLA Monitoring
Plugin management
Operational Metadata Management
Plugins
Teradata Queries in workflow Support
Test data manufacturer
Web Crawler
C2C Hive Table Migration
Data Quality
Tabular data from RDBMS
Streaming data from multiple sources
File ingestion by directory monitoring
Automation
One click deploy/schedule
One click app store
Job export and sharing
Custom job automation
Oozie workflow generation Workflow designer Batch lineage
Generalized UI Data Ingestion Framework
Workflow Automation
Big Data Ready Enterprise (BDRE) | Open Source Product 9
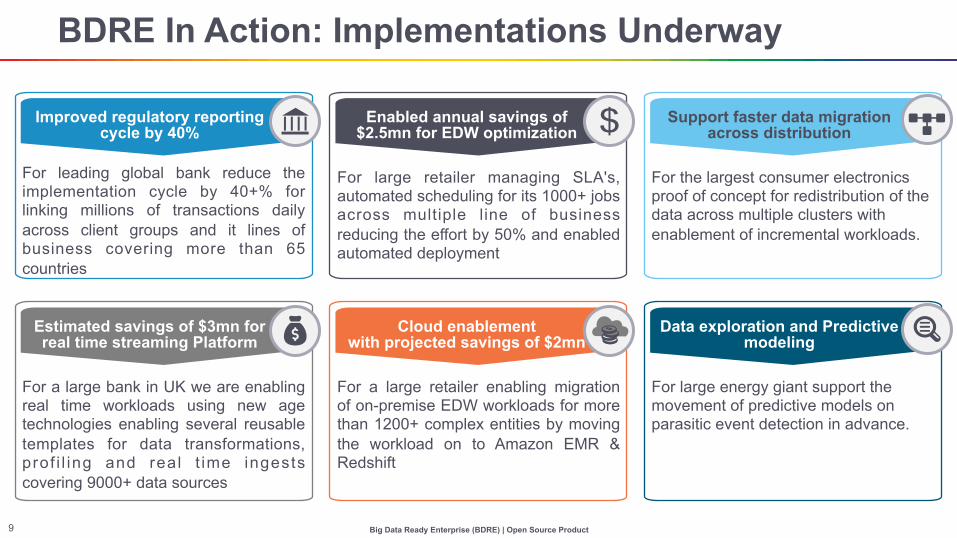
BDRE In Action: Implementations Underway
For leading global bank reduce the implementation cycle by 40+% for linking millions of transactions daily across client groups and it lines of business covering more than 65 countries
For the largest consumer electronics proof of concept for redistribution of the data across multiple clusters with enablement of incremental workloads.
For large retailer managing SLA's, automated scheduling for its 1000+ jobs across multiple line of business reducing the effort by 50% and enabled automated deployment
Improved regulatory reporting cycle by 40%
Enabled annual savings of$2.5mn for EDW optimization
Support faster data migration across distribution
For a large bank in UK we are enabling real time workloads using new age technologies enabling several reusable templates for data transformations, prof i l ing and real t ime ingests covering 9000+ data sources
For large energy giant support the movement of predictive models on parasitic event detection in advance.
For a large retailer enabling migration of on-premise EDW workloads for more than 1200+ complex entities by moving the workload on to Amazon EMR & Redshift
Estimated savings of $3mn for real time streaming Platform
Cloud enablement with projected savings of $2mn
Data exploration and Predictive modeling
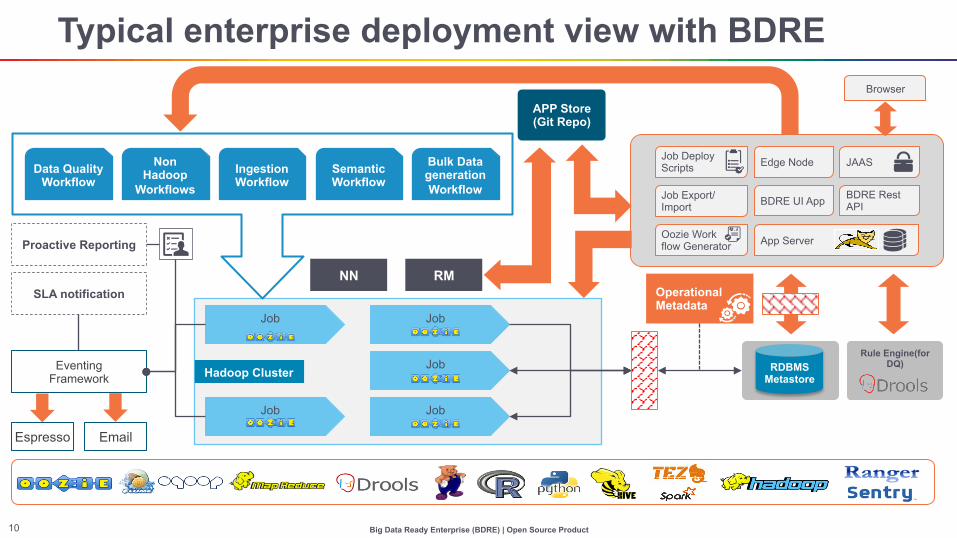
Big Data Ready Enterprise (BDRE) | Open Source Product 10
Typical enterprise deployment view with BDRE
Eventing Framework
Espresso Email
SLA notification
Proactive Reporting
Job
Job
Job
Job
Job
Hadoop Cluster
Data Quality Workflow
Non Hadoop
Workflows Ingestion Workflow
Semantic Workflow
Bulk Data generation Workflow
APP Store (Git Repo)
NN RM
Oozie Work flow Generator
Job Deploy Scripts
Job Export/Import
Edge Node
BDRE UI App
App Server
JAAS
BDRE Rest API
Browser
Operational Metadata
RDBMS Metastore
Rule Engine(for DQ)
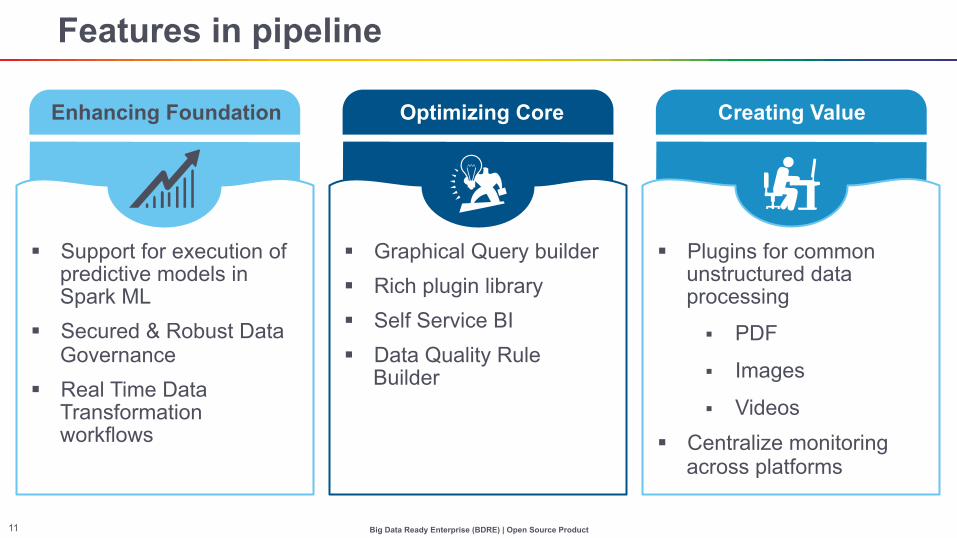
Big Data Ready Enterprise (BDRE) | Open Source Product 11
Features in pipeline
Enhancing Foundation Optimizing Core Creating Value
§ Support for execution of predictive models in Spark ML
§ Secured & Robust Data Governance
§ Real Time Data Transformation workflows
§ Graphical Query builder § Rich plugin library § Self Service BI § Data Quality Rule
Builder
§ Plugins for common unstructured data processing
§ Images
§ Videos § Centralize monitoring
across platforms
Big Data Ready Enterprise (BDRE) | Open Source Product 12
Get Involved
Project Site § http://wiproopensourcepractice.github.io/openbdre/
Source Code § https://github.com/wiproopensourcepractice/openbdre
Community Dashboard § https://github.com/wiproopensourcepractice/openbdre

BDRE Core Team Arijit Banerjee Sri Harsha Boda Kapil Paliwal Mishi Vidya Sinku Sudam Madhav Prem Kumar Rahul Sarda
THANK YOU

Big Data Ready Enterprise (BDRE) | Open Source Product 14
Additional Slides

Big Data Ready Enterprise (BDRE) | Open Source Product 15
BDRE Screenshots
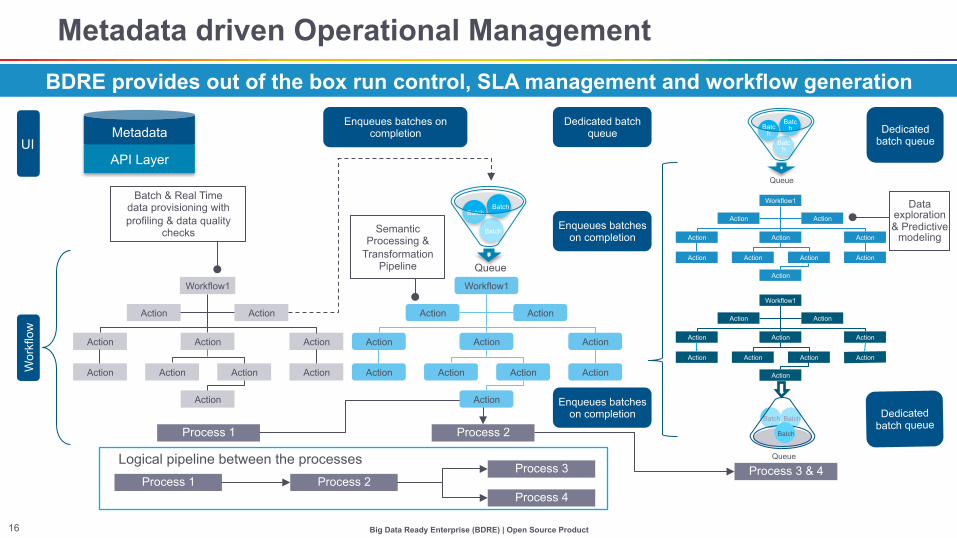
Big Data Ready Enterprise (BDRE) | Open Source Product 16
Batch Batch
Metadata driven Operational Management BDRE provides out of the box run control, SLA management and workflow generation
UI Metadata
API Layer
Batch & Real Time data provisioning with profiling & data quality
checks
Wor
kflo
w
Workflow1
Action Action
Action Action Action
Action Action Action Action
Action
Workflow1
Action Action
Action Action Action
Action Action Action Action
Action
Workflow1
Action Action
Action Action Action
Action Action Action Action
Action
Semantic Processing &
Transformation Pipeline
Enqueues batches on completion
Queue
Batch
Batch Batch
Dedicated batch queue
Enqueues batches on completion
Enqueues batches on completion
Workflow1
Action Action
Action Action Action
Action Action Action Action
Dedicated batch queue
Data exploration & Predictive
modeling
Dedicated batch queue
Queue
Batch
Batch
Batch
Queue
Process 1 Process 2
Process 3 & 4 Process 1 Process 2
Process 3
Process 4
Logical pipeline between the processes
Batch
Action
Big Data Ready Enterprise (BDRE) | Open Source Product 17
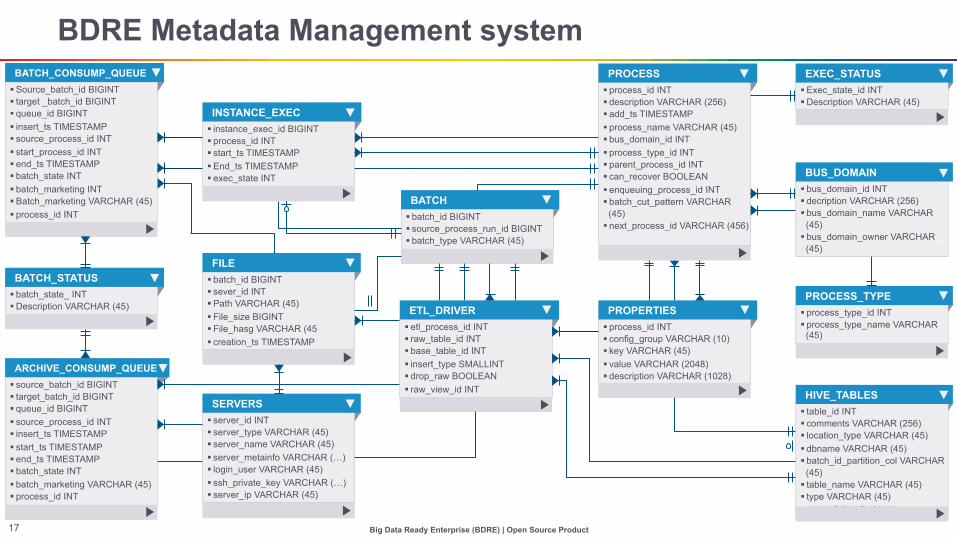
BDRE Metadata Management system
§ Source_batch_id BIGINT § target _batch_id BIGINT § queue_id BIGINT § insert_ts TIMESTAMP § source_process_id INT § start_process_id INT § end_ts TIMESTAMP § batch_state INT § batch_marketing INT § Batch_marketing VARCHAR (45) § process_id INT
BATCH_CONSUMP_QUEUE
§ batch_state_ INT § Description VARCHAR (45)
BATCH_STATUS
§ source_batch_id BIGINT § target_batch_id BIGINT § queue_id BIGINT § source_process_id INT § insert_ts TIMESTAMP § start_ts TIMESTAMP § end_ts TIMESTAMP § batch_state INT § batch_marketing VARCHAR (45) § process_id INT
ARCHIVE_CONSUMP_QUEUE
§ instance_exec_id BIGINT § process_id INT § start_ts TIMESTAMP § End_ts TIMESTAMP § exec_state INT
INSTANCE_EXEC
§ batch_id BIGINT § sever_id INT § Path VARCHAR (45) § File_size BIGINT § File_hasg VARCHAR (45 § creation_ts TIMESTAMP
FILE
§ server_id INT § server_type VARCHAR (45) § server_name VARCHAR (45) § server_metainfo VARCHAR (…) § login_user VARCHAR (45) § ssh_private_key VARCHAR (…) § server_ip VARCHAR (45)
SERVERS
§ etl_process_id INT § raw_table_id INT § base_table_id INT § insert_type SMALLINT § drop_raw BOOLEAN § raw_view_id INT
ETL_DRIVER
§ batch_id BIGINT § source_process_run_id BIGINT § batch_type VARCHAR (45)
BATCH
§ process_id INT § config_group VARCHAR (10) § key VARCHAR (45) § value VARCHAR (2048) § description VARCHAR (1028)
PROPERTIES
§ process_id INT § description VARCHAR (256) § add_ts TIMESTAMP § process_name VARCHAR (45) § bus_domain_id INT § process_type_id INT § parent_process_id INT § can_recover BOOLEAN § enqueuing_process_id INT § batch_cut_pattern VARCHAR
(45) § next_process_id VARCHAR (456)
PROCESS
§ bus_domain_id INT § decription VARCHAR (256) § bus_domain_name VARCHAR
(45) § bus_domain_owner VARCHAR
(45)
BUS_DOMAIN
§ Exec_state_id INT § Description VARCHAR (45)
EXEC_STATUS
§ process_type_id INT § process_type_name VARCHAR
(45)
PROCESS_TYPE
§ table_id INT § comments VARCHAR (256) § location_type VARCHAR (45) § dbname VARCHAR (45) § batch_id_partition_col VARCHAR
(45) § table_name VARCHAR (45) § type VARCHAR (45) § ddl VARCHAR (2048)
HIVE_TABLES

Big Data Ready Enterprise (BDRE) | Open Source Product 18
Automated Oozie Workflow Generation Process id Parent id Next Steps Enqueuer Id
100 null 101,102 null
101 100 103 null
102 100 103 Null
103 100 100 null
Fork
InitJob 100
103
HaltStep 101
HaltStep 102
InitStep 103
HaltStep 103
HaltJob 100
Join
101 102
InitStep 101 InitStep 101
Big Data Ready Enterprise (BDRE) | Open Source Product 19
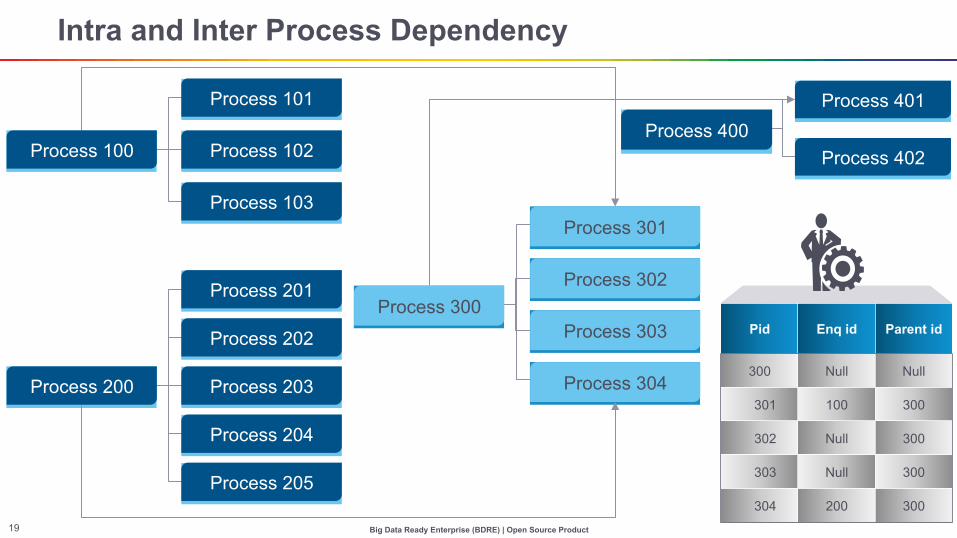
Intra and Inter Process Dependency
Process 401
Process 402 Process 400
Process 101
Process 102
Process 103
Process 203
Process 204
Process 205
Process 202
Process 201
Process 100
Process 200
Process 301
Process 302
Process 303
Process 304
Process 300 Pid Enq id Parent id
300 Null Null
301 100 300
302 Null 300
303 Null 300
304 200 300
Big Data Ready Enterprise (BDRE) | Open Source Product 20
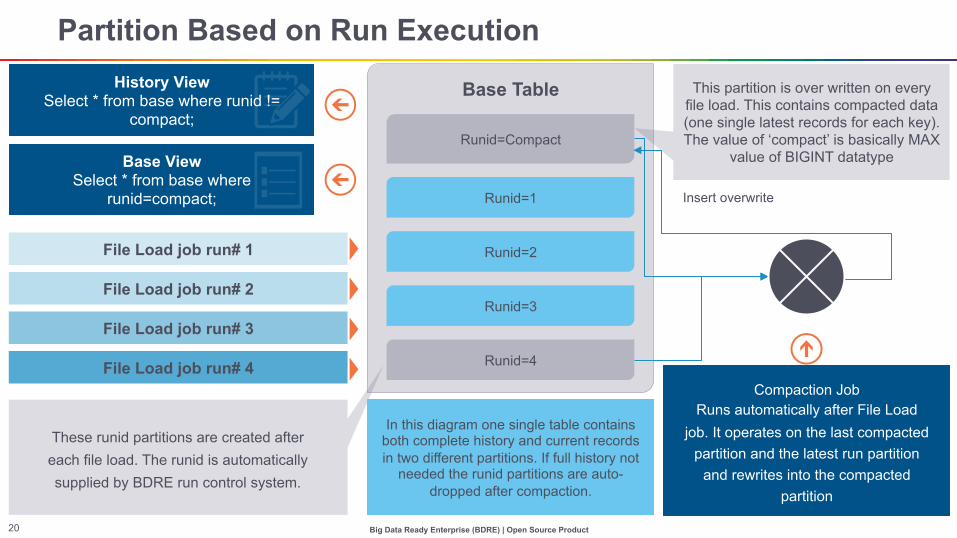
Partition Based on Run Execution
Insert overwrite
Base View Select * from base where
runid=compact;
File Load job run# 4
File Load job run# 3
File Load job run# 2
File Load job run# 1
History View Select * from base where runid !=
compact;
This partition is over written on every file load. This contains compacted data (one single latest records for each key). The value of ‘compact’ is basically MAX
value of BIGINT datatype
In this diagram one single table contains both complete history and current records in two different partitions. If full history not
needed the runid partitions are auto-dropped after compaction.
Base Table
Runid=1
Runid=2
Runid=3
Runid=4
Runid=Compact
These runid partitions are created after each file load. The runid is automatically supplied by BDRE run control system.
Compaction Job Runs automatically after File Load
job. It operates on the last compacted partition and the latest run partition
and rewrites into the compacted partition
Big Data Ready Enterprise (BDRE) | Open Source Product 21
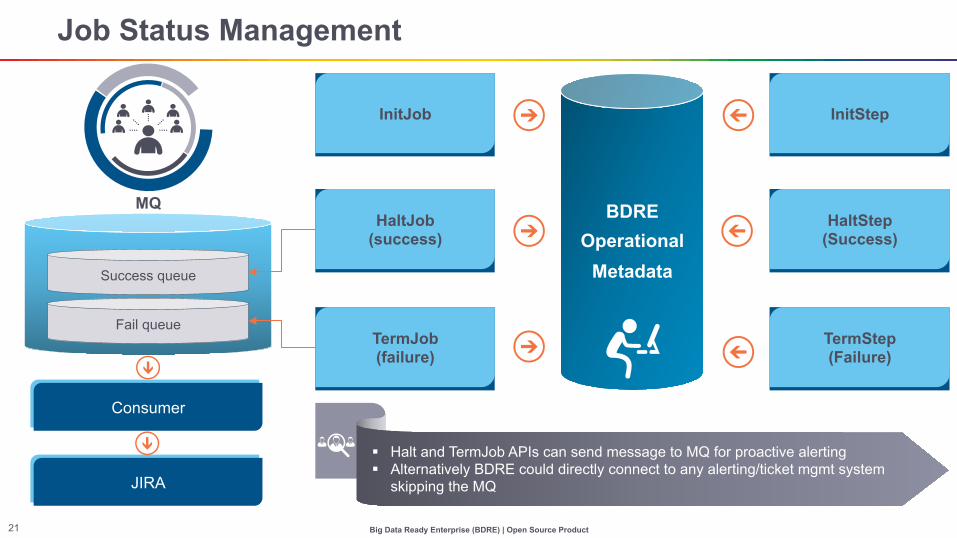
Job Status Management
InitJob
HaltJob (success)
TermJob (failure)
InitStep
HaltStep (Success)
TermStep (Failure)
BDRE Operational
Metadata
Fail queue
Success queue
Consumer
JIRA
MQ
§ Halt and TermJob APIs can send message to MQ for proactive alerting § Alternatively BDRE could directly connect to any alerting/ticket mgmt system
skipping the MQ
Big Data Ready Enterprise (BDRE) | Open Source Product 22
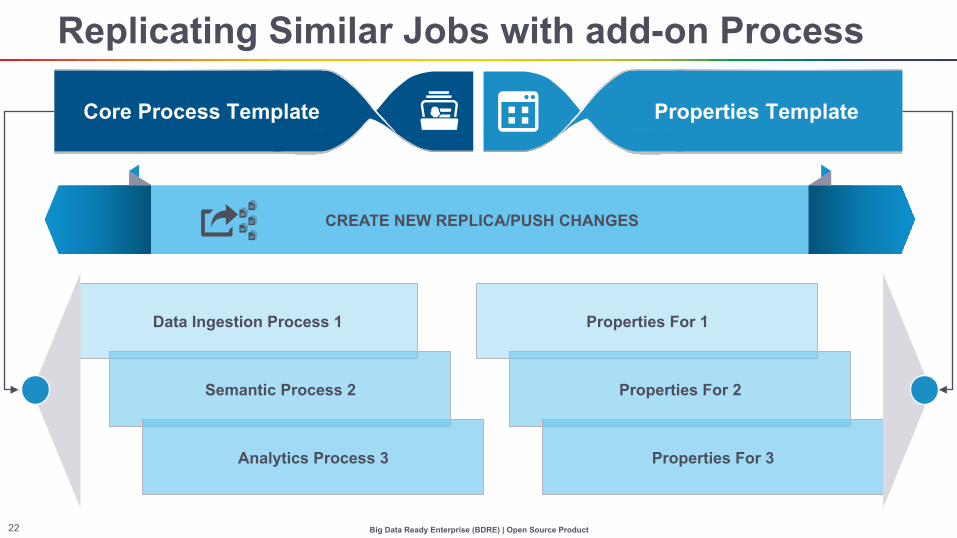
Replicating Similar Jobs with add-on Process
Data Ingestion Process 1
Semantic Process 2
Analytics Process 3
Properties For 1
Properties For 2
Properties For 3
Properties Template Core Process Template
CREATE NEW REPLICA/PUSH CHANGES
Big Data Ready Enterprise (BDRE) | Open Source Product 23
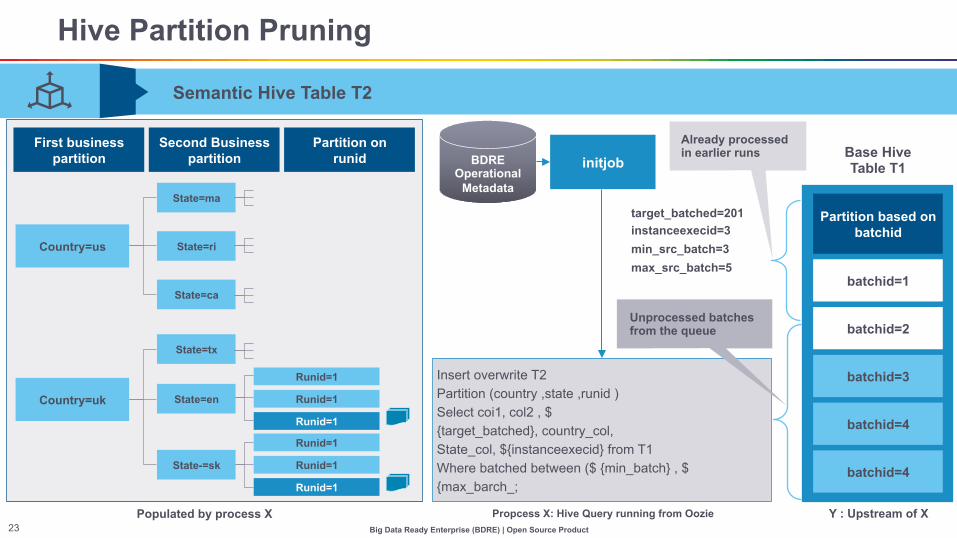
Hive Partition Pruning
Populated by process X
Insert overwrite T2 Partition (country ,state ,runid ) Select coi1, col2 , $ {target_batched}, country_col, State_col, ${instanceexecid} from T1 Where batched between ($ {min_batch} , $ {max_barch_;
Propcess X: Hive Query running from Oozie
BDRE Operational
Metadata
initjob
target_batched=201 instanceexecid=3 min_src_batch=3 max_src_batch=5
Partition based on batchid
batchid=1
batchid=2
batchid=3
batchid=4
batchid=4
Base Hive Table T1
Y : Upstream of X
First business partition
Second Business partition
Partition on runid
Country=us
State=ma
State=ri
State=ca
State=tx
Country=uk State=en
Runid=1
Runid=1
Runid=1
State-=sk
Runid=1
Runid=1
Runid=1
Semantic Hive Table T2
Already processed in earlier runs
Unprocessed batches from the queue
Big Data Ready Enterprise (BDRE) | Open Source Product 24
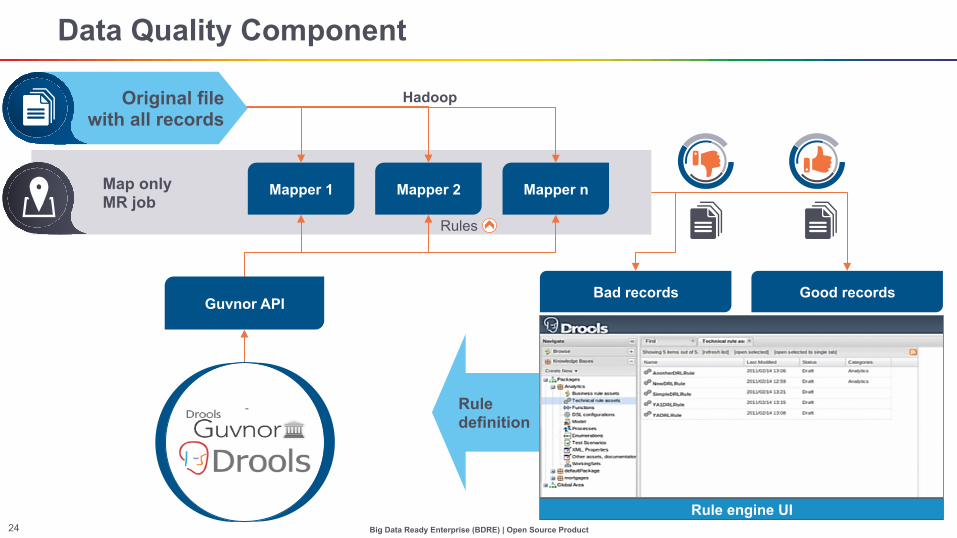
Rule definition
Rule engine UI
Data Quality Component
Map only MR job
Mapper 1 Mapper 2 Mapper n
Rules
Bad records Good records
Hadoop Original file with all records
Guvnor API
Big Data Ready Enterprise (BDRE) | Open Source Product 25
300 301
302 303
304
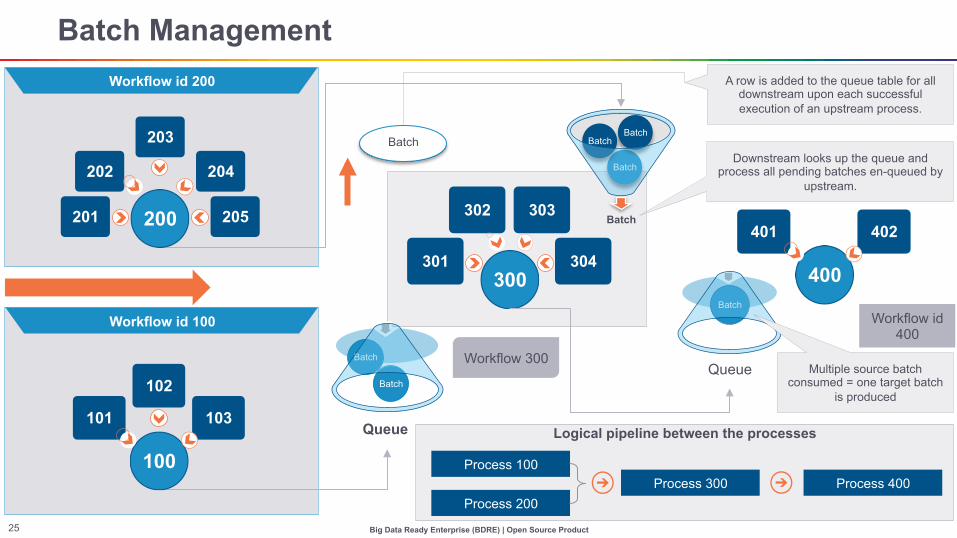
Batch Management
101
102
103
201
202
203
204
205
400
401 402 Batch
Batch
Batch Batch
Queue
Batch
Batch Queue
Batch
Logical pipeline between the processes
Process 200 Process 300
Process 100 Process 400
Workflow id 400
Batch
A row is added to the queue table for all downstream upon each successful execution of an upstream process.
Downstream looks up the queue and process all pending batches en-queued by
upstream.
Multiple source batch consumed = one target batch
is produced
Workflow 300
100
200
Workflow id 200
Workflow id 100