Embed Size (px)
Citation preview

Using free Bluemix Analytics Exchange data with Big SQL 4.2
Cynthia M. Saracco, IBM Solution Architect
January 2017

Contents Page 1
Contents OVERVIEW 2ACQUIRING SAMPLE DATA FROM BLUEMIX ...................................................................................................................... 3TRANSFERRING THE DATA TO HDFS .................................................................................................................................. 8USING BIG SQL TO QUERY THE BLUEMIX SAMPLE DATA ............................................................................................... 9SUMMARY 12

2
Overview If you’re curious about how to use the free cloud-based data sets available through the Analytics Exchange on Bluemix with your Big Data exploratory projects, you might find this technical summary useful. It outlines how to:
• locate and download free sample data on Bluemix.
• copy the data to an HDFS subdirectory of an Apache Hadoop cluster running Big SQL 4.2. (I used IBM’s enterprise BigInsights for Apache Hadoop service on Bluemix, which is based on BigInsights 4.2. However, any supported environment for Big SQL 4.2 should suffice.)
• create external Big SQL tables for the data and query these tables.
Please note that the steps I describe here are intended to help you get started quickly. Production use may require a different approach. Feel free to experiment with other alternatives.
Before beginning, you will need access to a Hadoop cluster that has Big SQL and a query execution environment (e.g., JSqsh) running. You will also need prior knowledge of basic Big SQL operations – e.g., how to connect to Big SQL, how to create external Big SQL tables, how to query Big SQL tables, etc. If necessary, consult the Big SQL hands-on labs available on Hadoop Dev (such as https://developer.ibm.com/hadoop/docs/getting-started/tutorials/big-sql-hadoop-tutorial/) or the product documentation (http://www.ibm.com/support/knowledgecenter/en/SSPT3X_4.2.0/com.ibm.swg.im.infosphere.biginsights.welcome.doc/doc/welcome.html).
3
Acquiring sample data from Bluemix To get started, you’ll need some sample data from the Analytics Exchange on Bluemix. This section describes how you can access the various data sets freely available on Bluemix as of this writing and acquire the data set that I used on worldwide greenhouse gas emissions.
__1. If necessary, register for a free Bluemix account at http://bluemix.net.
__2. Log into Bluemix.
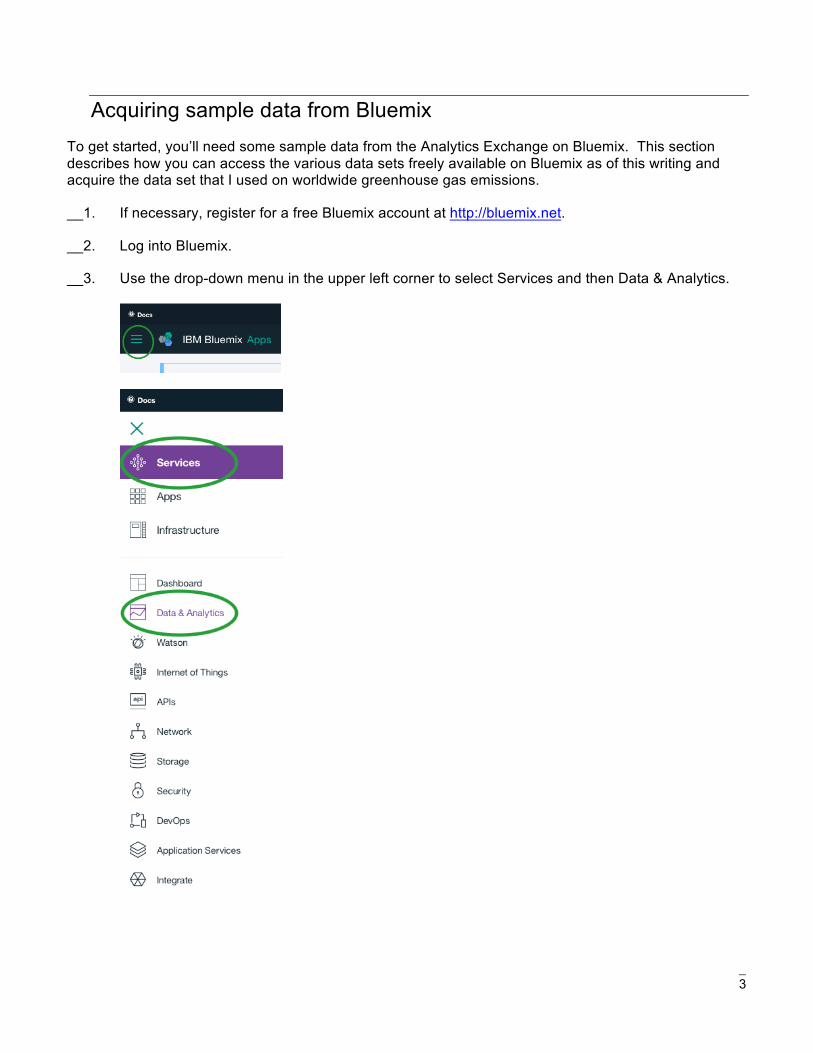
__3. Use the drop-down menu in the upper left corner to select Services and then Data & Analytics.
4
Alternately, access data services directly through https://console.ng.bluemix.net/data/services/.
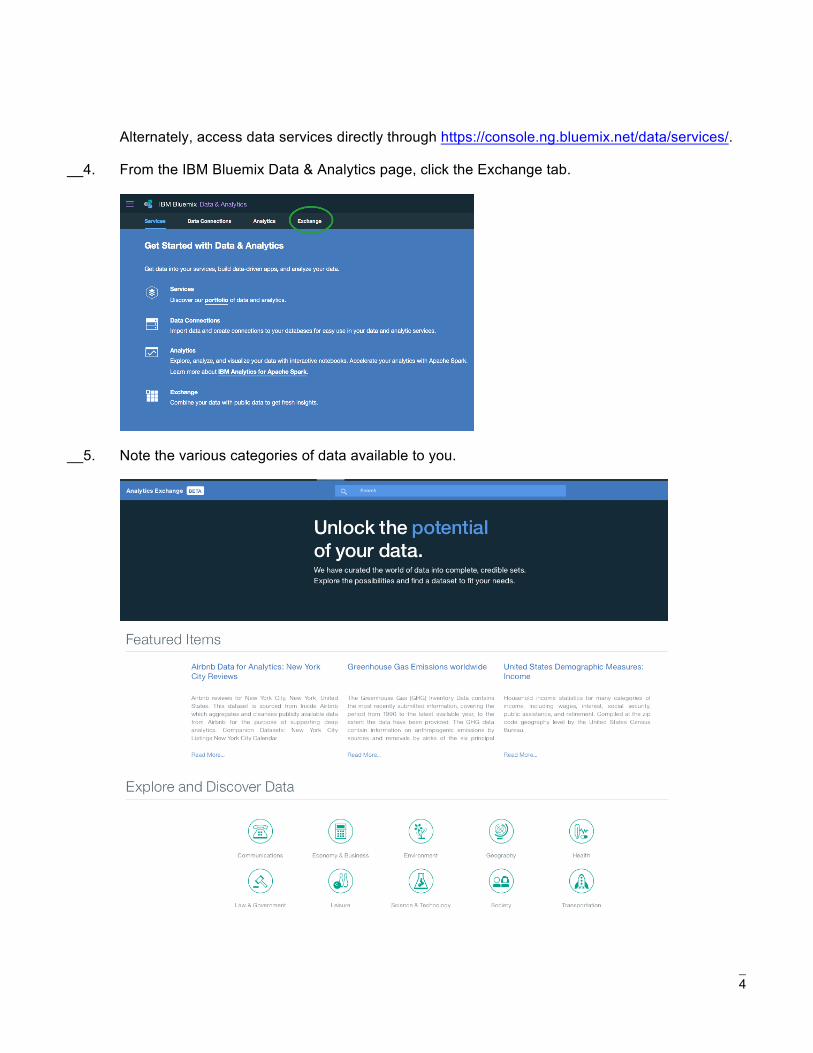
__4. From the IBM Bluemix Data & Analytics page, click the Exchange tab.
__5. Note the various categories of data available to you.

5
__6. Click the Environment category.
__7. Scroll through the various data sets to locate the Greenhouse Gas Emissions Worldwide data posted by IBM Cloud Data Services or enter “greenhouse gas” in the search bar to locate it. Click the data set title.
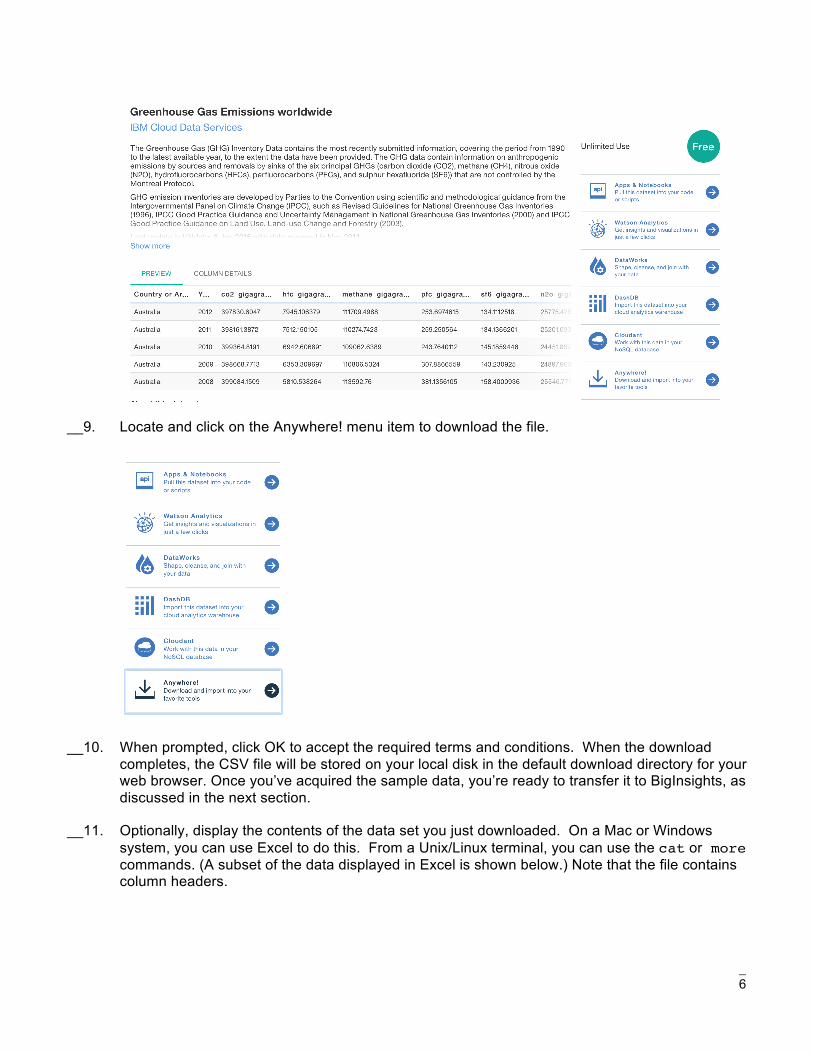
__8. Inspect the preview of this data set as well as the usage options shown at right.
6
__9. Locate and click on the Anywhere! menu item to download the file.
__10. When prompted, click OK to accept the required terms and conditions. When the download completes, the CSV file will be stored on your local disk in the default download directory for your web browser. Once you’ve acquired the sample data, you’re ready to transfer it to BigInsights, as discussed in the next section.
__11. Optionally, display the contents of the data set you just downloaded. On a Mac or Windows system, you can use Excel to do this. From a Unix/Linux terminal, you can use the cat or more commands. (A subset of the data displayed in Excel is shown below.) Note that the file contains column headers.

7
__12. Optionally, learn more about the data set you just downloaded by visiting its source site. Scroll through the data set’s Bluemix page to locate the “About this dataset” section. A source link is provided.

8
Transferring the data to HDFS Once you have the sample CSV file downloaded from Bluemix, you’ll need to upload it to your Hadoop cluster. This section summarizes the steps I took to do so. Note that my approach requires SSH access. If your environment does not support this, ask your administrator for the recommended approach for uploading files to HDFS.
__1. Use FTP or SFTP to transfer the CSV file to a local file system for your Hadoop cluster. (I typically use FileZilla.)
__2. Open a terminal window for your BigInsights cluster. (On Windows, I use PUTTY to establish a remote terminal session. On Mac, I open a local command window and issue an SSH command such as ssh [email protected].)
__3. Verify that the CSV file you transferred in the first step is available. Within your target directory, issue a command such as ls greenhouse.csv.
ls greenhouse.csv
__4. Issue an HDFS shell command to create a subdirectory within your user directory for testing. For example, here’s a command I issued (modify it to suit your environment):
hdfs dfs -mkdir /user/saracco/bluemix-data
__5. Copy the CSV file from your local directory to your new HDFS subdirectory. Adjust this command as needed for your environment:
hdfs dfs -copyFromLocal greenhouse.csv /user/saracco/bluemix-data
__6. Change permissions on your directory path and its contents. For example: hdfs dfs -chmod -R 777 /user/saracco
__7. List the contents of your HDFS subdirectories to validate your work.
hdfs dfs -ls /user
Found 40 items
. . .
drwxrwxrwx - saracco bihdfs 0 2016-10-10 20:34 /user/saracco
hdfs dfs -ls /user/saracco/bluemix-data Found 1 items -rwxrwxrwx 3 saracco bihdfs 78407 2016-10-10 20:34 /user/saracco/bluemix-data/greenhouse.csv

9
Using Big SQL to query the Bluemix sample data With the sample data now in HDFS, you’re ready to work with Big SQL to query it. First, however, you’ll need to create a table for this data. That’s not hard to do. In this section, you’ll create an externally managed Big SQL table, which effectively layers a SQL schema over the directory that contains your CSV file. Once that’s done, you can query the table.
__1. Launch your preferred Big SQL execution environment (e.g., JSqsh) and connect to your Big SQL database. If you don’t know how to do this, consult the resources mentioned earlier in the Overview section.
__2. Create a Big SQL external table (“greenhouse”) for the CSV file that you copied in to HDFS earlier. Adjust the statement below as needed to match your environment:
create external hadoop table if not exists greenhouse (area varchar(50), year varchar(4), co2 varchar(20), hfc varchar(20), methane varchar(20), pfc varchar(20), sf6 varchar(20), n2o varchar(20) ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' location '/user/saracco/bluemix-data'; Because the raw CSV file contains column headings in the first line (or row), all column types must support varying-length character strings even though the greenhouse gas measurements are decimals. Later, you’ll explore options for addressing this.
__3. Retrieve all columns from the table for the first 3 rows only. select * from greenhouse fetch first 3 rows only; […][saracco] 1> select * from greenhouse fetch first 3 rows only; +-----------------+------+---------------+---------------+-------------------+---------------+---------------+---------------+ | AREA | YEAR | CO2 | HFC | METHANE | PFC | SF6 | N2O | +-----------------+------+---------------+---------------+-------------------+---------------+---------------+---------------+ | Country or Area | Year | co2_gigagrams | hfc_gigagrams | methane_gigagrams | pfc_gigagrams | sf6_gigagrams | n2o_gigagrams | | Australia | 2012 | 397830.6047 | 7945.106379 | 111709.4988 | 253.6974615 | 134.1112518 | 25775.42951 | | Australia | 2011 | 398161.3872 | 7512.150105 | 110274.7423 | 259.250564 | 134.1366201 | 25201.09362 | +-----------------+------+---------------+---------------+-------------------+---------------+---------------+---------------+
__4. Query the table for information about methane and carbon dioxide (co2) emissions in 2012 for any area, fetching only the first 10 rows.
select area, methane, co2 from greenhouse where year = '2012' fetch first 10 rows only;

10
[…][saracco] 1> select area, methane, co2 from greenhouse where year = '2012' fetch first 10 rows only; +----------------+-------------+-------------+ | AREA | METHANE | CO2 | +----------------+-------------+-------------+ | Australia | 111709.4988 | 397830.6047 | | Austria | 5306.175712 | 67733.46873 | | Belarus | 15390.5419 | 57490.68938 | | Belgium | 6392.291172 | 100659.3803 | | Bulgaria | 7185.373932 | 48363.94947 | | Canada | 90563.313 | 550546.5937 | | Croatia | 3422.543649 | 19233.20131 | | Cyprus | 1303.681967 | 7082.826233 | | Czech Republic | 10255.769 | 111301.871 | | Denmark | 5522.202228 | 40798.82417 | +----------------+-------------+-------------+ 10 rows in results(first row: 0.23s; total: 0.23s)
__5. Retrieve carbon dioxide emissions (co2) data for Australia in decimal format. select cast(co2 as decimal(20,10)), year from greenhouse where area='Australia'; […][saracco] 1> select cast(co2 as decimal(20,10)), year from greenhouse where area='Australia'; +-------------------+------+ | 1 | YEAR | +-------------------+------+ | 397830.6047000000 | 2012 | | 398161.3872000000 | 2011 | | 399364.8191000000 | 2010 | | 398668.7713000000 | 2009 | | 399084.1509000000 | 2008 | | 393918.3205000000 | 2007 | | 385969.3355000000 | 2006 | | 380440.4543000000 | 2005 | | 376669.8639000000 | 2004 | | 364605.1036000000 | 2003 | | 358296.2618000000 | 2002 | | 354266.4988000000 | 2001 | | 346620.8507000000 | 2000 | | 340605.4425000000 | 1999 | | 331123.2263000000 | 1998 | | 317772.2529000000 | 1997 | | 309524.2626000000 | 1996 | | 302576.4261000000 | 1995 | | 291375.9340000000 | 1994 | | 286804.3815000000 | 1993 | | 282530.1556000000 | 1992 | | 277590.3048000000 | 1991 | | 276137.5504000000 | 1990 | +-------------------+------+
23 rows in results(first row: 0.30s; total: 0.30s)
At this point, you have a working Big SQL table with sample data downloaded from the Bluemix Analytics Exchange. But there’s certainly room for improvement. For example, you might want to get rid of the column headings stored in the first row of the table. In addition, you might want to represent the statistical data for greenhouse gas emissions in DECIMAL rather than VARCHAR(n) format. There are various ways that you can achieve such goals. Arguably, the best approach is to clean the data before creating a table over it. For example, you could have edited the CSV file to remove the column heading information before you copied it into HDFS.

11
However, if other applications depend on this data in its raw format, you can leave the file as is and create another “clean” Big SQL table based upon your existing external table.
__6. Experiment with using the CREATE TABLE AS . . . SELECT FROM . . . Big SQL statement to create a new, “clean” table, using CAST functions and an appropriate query predicate (WHERE clause). Here’s a partial example:
create hadoop table if not exists greenclean (area varchar(50), year int, co2 decimal(20,10)) as select area, cast(year as int), cast(co2 as decimal(20,10)) from greenhouse where year <> 'Year'; […][saracco] 1> create hadoop table if not exists greenclean (area varchar(50), year int, co2 decimal(20,10)) as select area, cast(year as int), cast(co2 as decimal(20,10)) from greenhouse where year <> 'Year'; 0 rows affected (total: 3.93s)
__7. Query the table you just created. select * from greenclean fetch first 3 rows only; […][saracco] 1> select * from greenclean fetch first 3 rows only; +-----------+------+-------------------+ | AREA | YEAR | CO2 | +-----------+------+-------------------+ | Australia | 2012 | 397830.6047000000 | | Australia | 2011 | 398161.3872000000 | | Australia | 2010 | 399364.8191000000 | +-----------+------+-------------------+
__8. Optionally, create a “clean” view of your original Big SQL greenhouse table and query this view. Note that this approach will require Big SQL to dynamically apply the CASTing and query filtering operations each time the view is queried. Doing so will result in runtime overhead, so you may prefer to simply create a “clean” table as shown in the previous step.
create view greenview (area, year, co2) as select area, cast(year as int), cast(co2 as decimal(20,10)) from greenhouse where year <> 'Year'; […][saracco] 1> create view greenview (area, year, co2) as select area, cast(year as int), cast(co2 as decimal(20,10)) from greenhouse where year <> 'Year'; 0 rows affected (total: 0.1s) select * from greenview fetch first 3 rows only; […][saracco] 1> select * from greenview fetch first 3 rows only; +-----------+------+-------------------+ | AREA | YEAR | CO2 | +-----------+------+-------------------+ | Australia | 2012 | 397830.6047000000 | | Australia | 2011 | 398161.3872000000 | | Australia | 2010 | 399364.8191000000 | +-----------+------+-------------------+ 3 rows in results(first row: 0.56s; total: 0.56s)

12
Summary The Analytics Exchange on Bluemix contains a variety of public data sets that are available in CSV format. Now you understand how you can use Big SQL to work with these data sets on a Hadoop cluster.
To expand your skills and learn more, enroll in free online courses offered by Big Data University (http://www.bigdatauniversity.com/) or work through free tutorials included in the BigInsights product documentation. The HadoopDev web site (https://developer.ibm.com/hadoop/) contains links to these and other resources.

13
© Copyright IBM Corporation 2016. Written by C. M. Saracco.
The information contained in these materials is provided for
informational purposes only, and is provided AS IS without warranty
of any kind, express or implied. IBM shall not be responsible for any
damages arising out of the use of, or otherwise related to, these
materials. Nothing contained in these materials is intended to, nor
shall have the effect of, creating any warranties or representations
from IBM or its suppliers or licensors, or altering the terms and
conditions of the applicable license agreement governing the use of
IBM software. References in these materials to IBM products,
programs, or services do not imply that they will be available in all
countries in which IBM operates. This information is based on
current IBM product plans and strategy, which are subject to change
by IBM without notice. Product release dates and/or capabilities
referenced in these materials may change at any time at IBM’s sole
discretion based on market opportunities or other factors, and are not
intended to be a commitment to future product or feature availability
in any way.
IBM, the IBM logo and ibm.com are trademarks of International
Business Machines Corp., registered in many jurisdictions
worldwide. Other product and service names might be trademarks of
IBM or other companies. A current list of IBM trademarks is
available on the Web at “Copyright and trademark information” at
www.ibm.com/legal/copytrade.shtml.




























![[Presentation] BIG DATA & ANALYTICS on IBM Bluemix](https://img.pdfslide.net/doc/110x75/55a62fa71a28ab796d8b47c4/presentation-big-data-analytics-on-ibm-bluemix.jpg)
