Embed Size (px)
Citation preview

1
Big DataとContainerとStream- AWSでのクラスタ構成とストリーム処理 -
JAWS DAYS 2016, Mar 12
Ryosuke Iwanaga
Solutions Architect, Amazon Web Services Japan

2
Agenda
• Stream processing
• What is Amazon Kinesis?
• Amazon Kinesis Architecture with Containers

3
Key takeaways
• ストリーム処理の基礎
• Amazon Kinesisの概要
• Amazon Kinesisと他サービスの組み合わせ方

4
Stream processing

5
Stream
• Sequence of events/records/data
• Features– High throughput/volume
– Continuous ingestion
• Use cases– Log/event collection
– IoT (sensor data, image, etc.)
Ex. 1 KB * 10K record/s * 365 days= 300 TB / year
Stream => Big Data

6
Stream processing
• Event processing– Process each event one by one
• Graph for distributed event processing
– Ex. Apache Storm
• Micro-batch processing– Process a small amount of events in a batch
• Just like a sequence of batch processing
– Ex. Spark Streaming
7
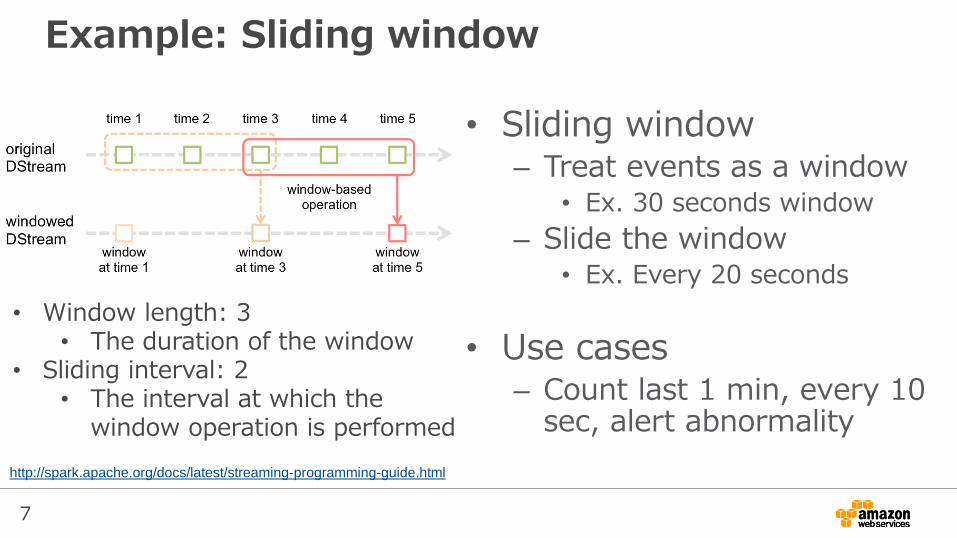
Example: Sliding window
• Sliding window– Treat events as a window
• Ex. 30 seconds window
– Slide the window• Ex. Every 20 seconds
• Use cases– Count last 1 min, every 10
sec, alert abnormality
http://spark.apache.org/docs/latest/streaming-programming-guide.html
• Window length: 3• The duration of the window
• Sliding interval: 2• The interval at which the
window operation is performed
8
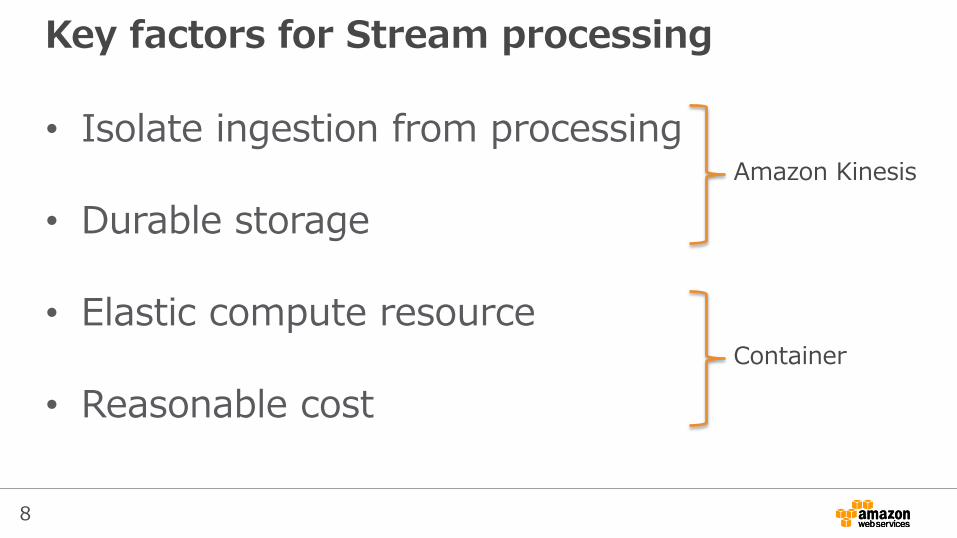
Key factors for Stream processing
• Isolate ingestion from processing
• Durable storage
• Elastic compute resource
• Reasonable cost
Amazon Kinesis
Container

9
What is Amazon Kinesis?

Amazon Kinesis Streams
カスタムアプリを自身で構築して
ストリーミングデータを処理・分析する
Amazon Kinesis Firehose
簡単に大規模の
ストリーミングデータをAmazon S3と
Redshiftにロードする
Amazon Kinesis Analytics
SQLクエリを使って
簡単にストリーミングデータを分析する
Amazon Kinesis: ストリーミングデータを簡単に扱うストリームを捕まえ、転送し、処理することを簡単にするAWSサービス
2013/12 2015/10 2015/10Pre-announce

Amazon Kinesis Streams自身でストリーミングアプリケーションを構築できる
簡単な管理: 新しいストリームを作り、あなたのデータスループットと規模に合った必要なキャパシティとパーティションを設定するだけ
リアルタイムアプリを構築: Kinesis Client Libray, Apache Spark/Storm, AWS Lambda等々を使って、ストリーミングデータ上のレコードをカスタム処理する
低コスト: どんな規模のワークロードでもコスト効率が良い
クリックストリームデータをKinesis Streamsに送信
Kinesis Streamsがクリックストリームデータを保存し、
処理のために提供
Kinesis Client Libraryベースのカスタムアプリケーションによって、
リアルタイムのコンテンツレコメンド作成
読者はパーソナライズされたコンテンツの推薦を受けられる
12
Amazon Kinesis Streams: Architecture
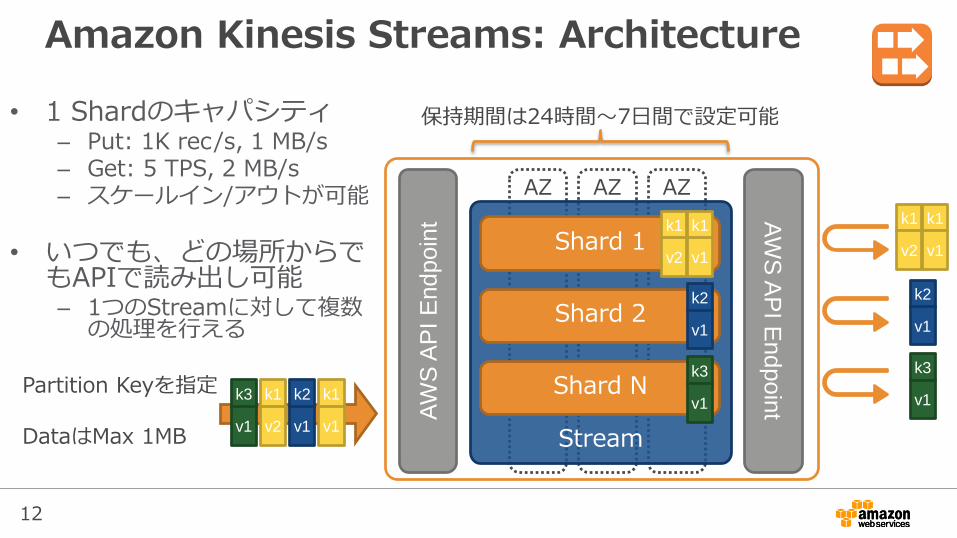
• 1 Shardのキャパシティ– Put: 1K rec/s, 1 MB/s– Get: 5 TPS, 2 MB/s– スケールイン/アウトが可能
• いつでも、どの場所からでもAPIで読み出し可能– 1つのStreamに対して複数の処理を行える
k1
v1
k1
v2
k2
v1
k3
v1
AZ AZ AZ
StreamA
WS
AP
I E
ndpoin
t
Shard 1
Shard 2
Shard N
k1
v1
k1
v2
k2
v1
k3
v1
AW
S A
PI E
ndpoin
t
保持期間は24時間〜7日間で設定可能
k1
v1
k1
v2
k2
v1
k3
v1Partition Keyを指定
DataはMax 1MB
13
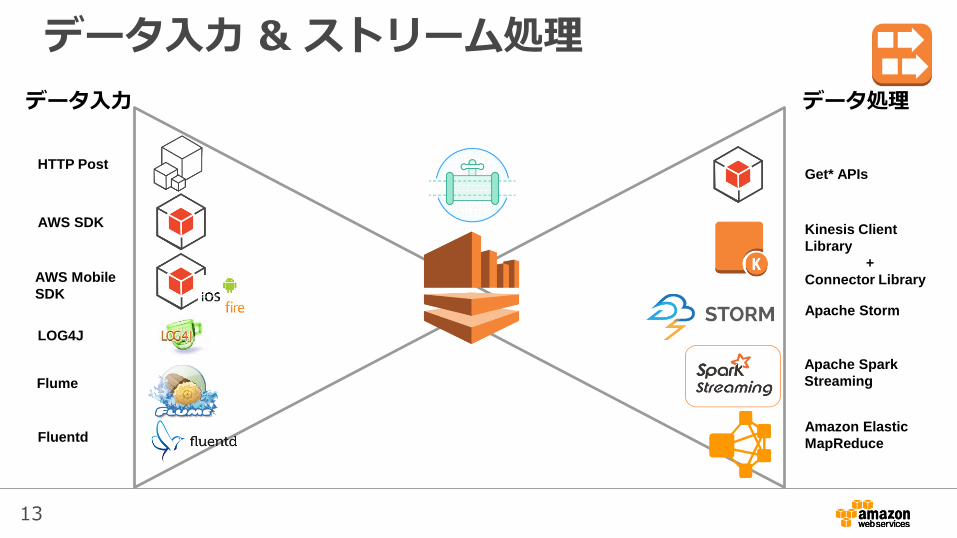
データ入力 & ストリーム処理
HTTP Post
AWS SDK
LOG4J
Flume
Fluentd
Get* APIs
Kinesis Client
Library
+
Connector Library
Apache Storm
Amazon Elastic
MapReduce
データ入力 データ処理
AWS Mobile
SDK
Apache Spark
Streaming
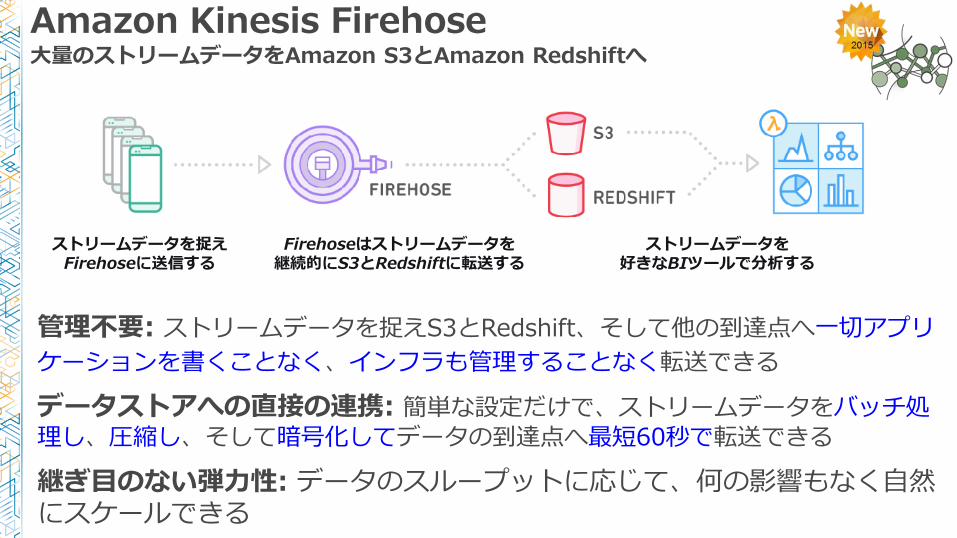
Amazon Kinesis Firehose大量のストリームデータをAmazon S3とAmazon Redshiftへ
管理不要: ストリームデータを捉えS3とRedshift、そして他の到達点へ一切アプリ
ケーションを書くことなく、インフラも管理することなく転送できる
データストアへの直接の連携: 簡単な設定だけで、ストリームデータをバッチ処理し、圧縮し、そして暗号化してデータの到達点へ最短60秒で転送できる
継ぎ目のない弾力性: データのスループットに応じて、何の影響もなく自然にスケールできる
ストリームデータを捉えFirehoseに送信する
Firehoseはストリームデータを継続的にS3とRedshiftに転送する
ストリームデータを好きなBIツールで分析する
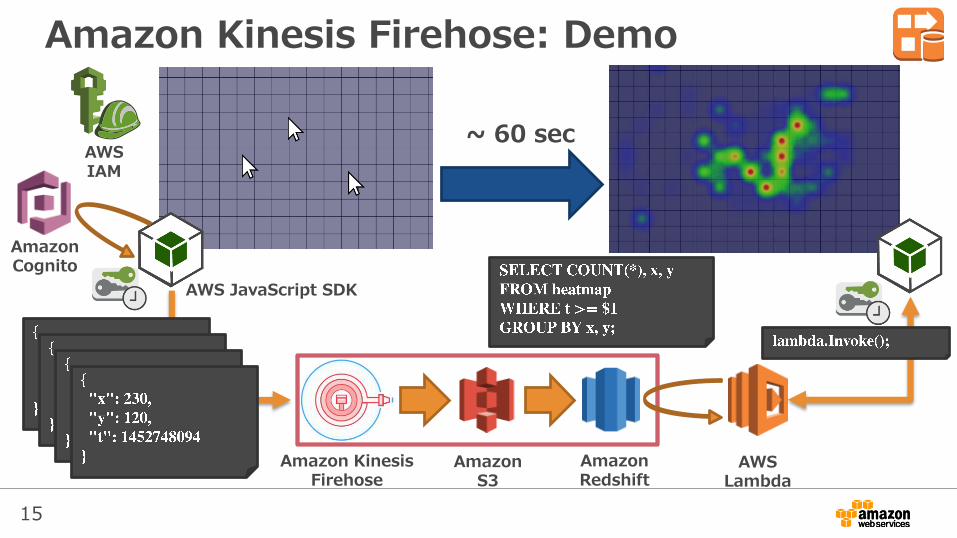
15
Amazon Kinesis Firehose: Demo
~ 60 sec
AWS JavaScript SDK
Amazon Cognito
AWS IAM
Amazon KinesisFirehose
Amazon S3
Amazon Redshift
AWS Lambda

16
Fluent plugin for Amazon Kinesis
• v1.0.0開発中(今RC)
• 3つのoutputサポート
– Kinesis Streams用
• kinesis_streams
• kinesis_producer
– Kinesis Firehose用
• kinesis_firehose
• GitHub/rubygemsで提供
– Maintainerは@riywo
• リリースに向けて、絶賛フィードバック募集中!
– Issue下さい!
https://github.com/awslabs/aws-fluent-plugin-kinesis
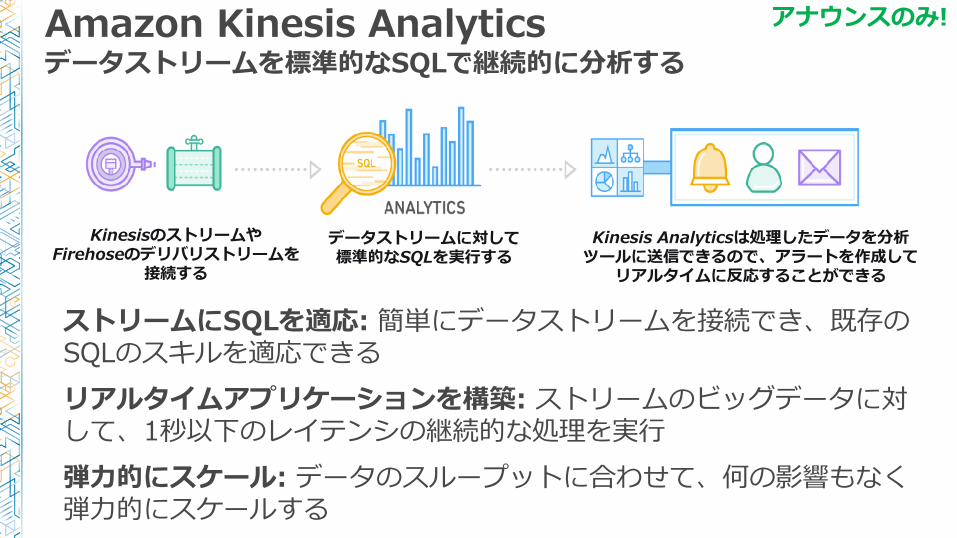
Amazon Kinesis Analyticsデータストリームを標準的なSQLで継続的に分析する
ストリームにSQLを適応: 簡単にデータストリームを接続でき、既存のSQLのスキルを適応できる
リアルタイムアプリケーションを構築: ストリームのビッグデータに対して、1秒以下のレイテンシの継続的な処理を実行
弾力的にスケール: データのスループットに合わせて、何の影響もなく弾力的にスケールする
アナウンスのみ!
KinesisのストリームやFirehoseのデリバリストリームを
接続する
データストリームに対して標準的なSQLを実行する
Kinesis Analyticsは処理したデータを分析ツールに送信できるので、アラートを作成して
リアルタイムに反応することができる

18
Amazon Kinesis Architecture w/Containers

19
What is "Container"?
• OS-level isolation
• Portability
• Major container engine on AWS– Docker Engine
– JVM
– AWS Lambda (Node.js/Java/Python)

20
Why is "Container" important for Big Data?
• Scalability– Easy to scale in/out
• Cost efficiency– High utilization by multi-tenancy
• Speed of innovation– Fine-grained architecture / Good abstraction
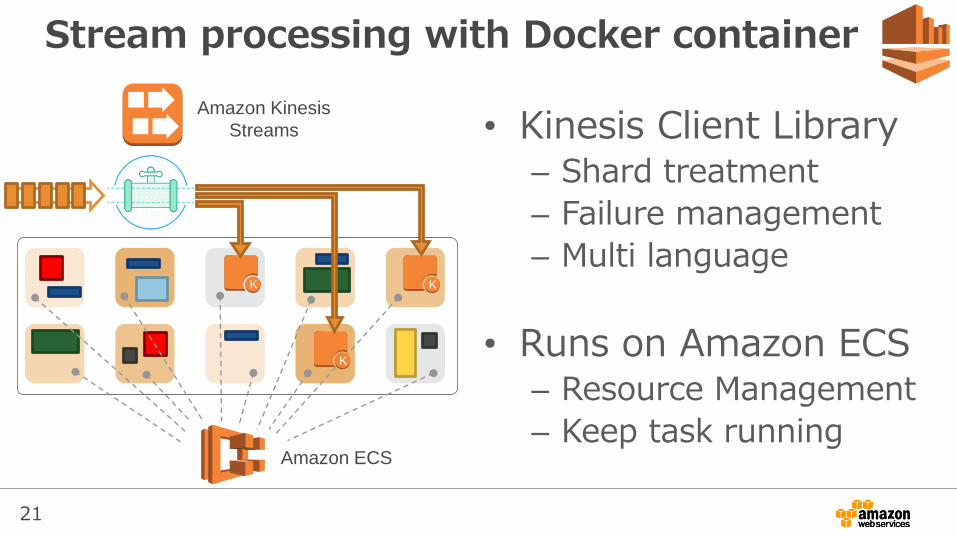
21
Stream processing with Docker container
• Kinesis Client Library– Shard treatment
– Failure management
– Multi language
• Runs on Amazon ECS– Resource Management
– Keep task runningAmazon ECS
Amazon Kinesis
Streams
22
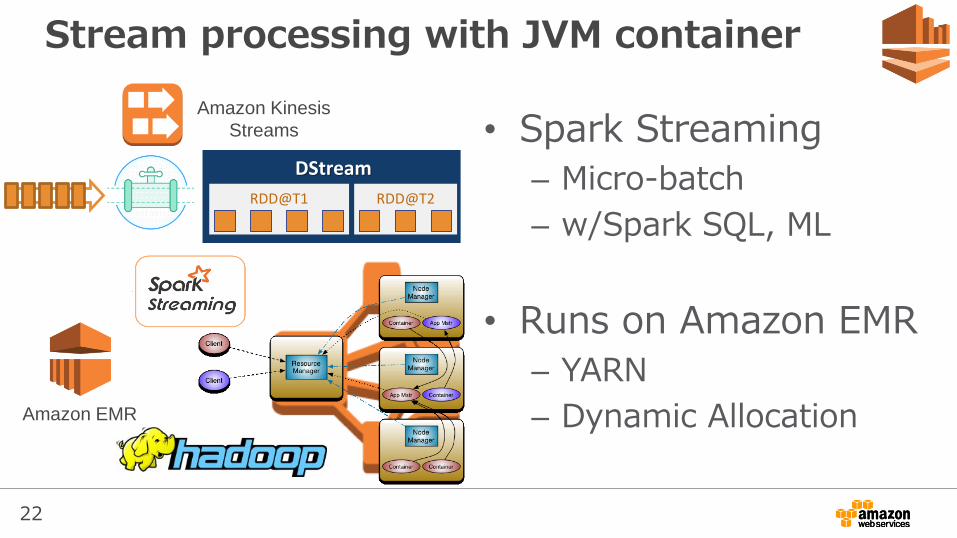
Stream processing with JVM container
• Spark Streaming
– Micro-batch
– w/Spark SQL, ML
• Runs on Amazon EMR
– YARN
– Dynamic Allocation
DStream
RDD@T1 RDD@T2
Amazon Kinesis
Streams
Amazon EMR
23
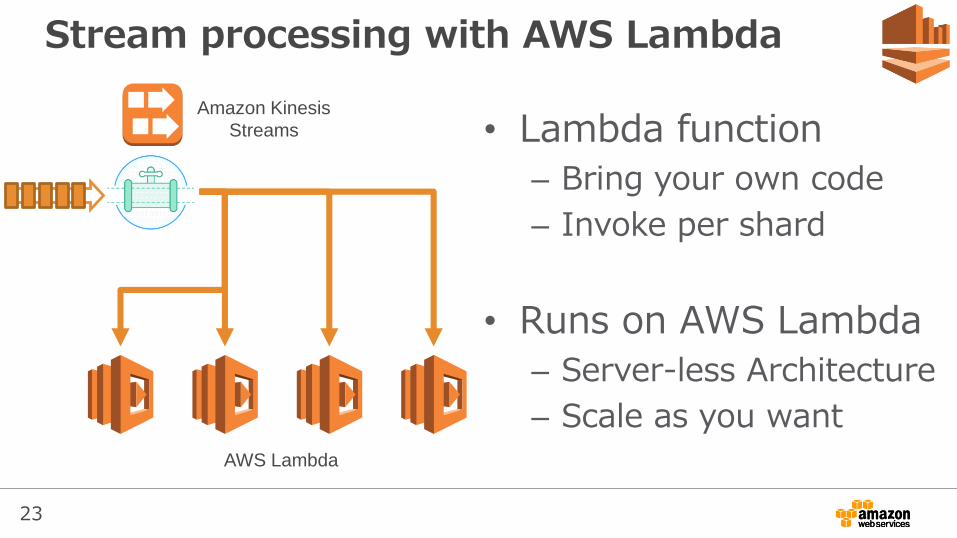
Stream processing with AWS Lambda
• Lambda function
– Bring your own code
– Invoke per shard
• Runs on AWS Lambda
– Server-less Architecture
– Scale as you want
Amazon Kinesis
Streams
AWS Lambda
24
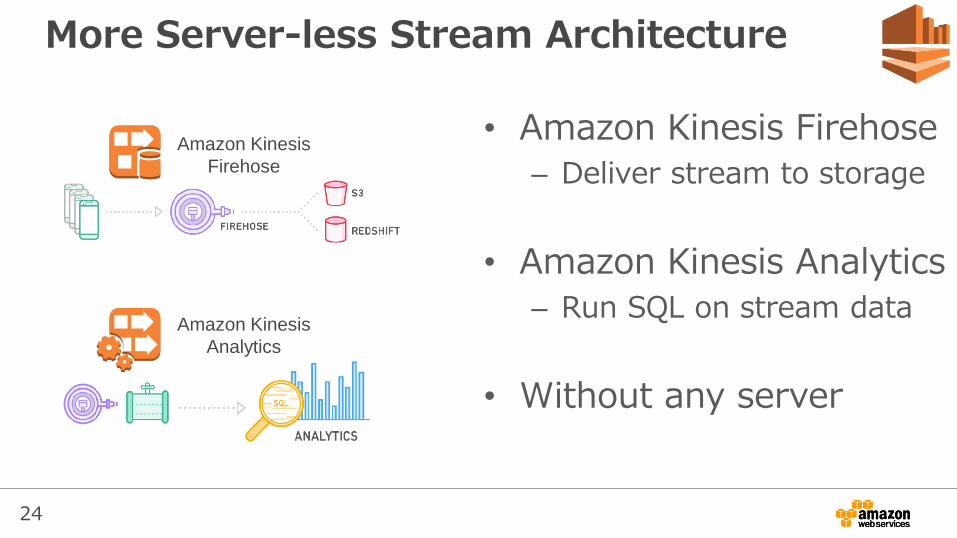
More Server-less Stream Architecture
• Amazon Kinesis Firehose
– Deliver stream to storage
• Amazon Kinesis Analytics
– Run SQL on stream data
• Without any server
Amazon Kinesis
Analytics
Amazon Kinesis
Firehose

25
Summary
• Amazon Kinesisで安心できるストリーム処理を– Amazon Kinesis Streamsと、Amazon ECS, Amazon EMR,
AWS Lambda等のコンテナ技術で、自由なストリーム処理
– Amazon Kinesis Firehose, Amazon Kinesis Analyticsで、よくあるユースケースをサーバレスに実現
• 使い分けは場合によりけり– 迷ったら、ぜひAWS JapanのSAまでご相談を!
– → 今日もMeet the SAと称して、終日ブース待機してます!

26

![Hadoop クラスタの管理 · ステップ3 [インスタントHadoopクラスタ(InstantHadoopCluster)]をクリックします。 ステップ4 [インスタントHadoopクラスタの作成]画面で、次のフィールドに値を入力します。](https://img.pdfslide.net/doc/110x75/605a7419107dd869ed3434e3/hadoop-fcc-ffff3-fffhadoopfiinstanthadoopclusterifff.jpg)



























