Embed Size (px)
Citation preview

About Me● 14 years Java Developer / Tech lead / ScrumMaster
● 3 years Data Engineer (Hadoop, Hive, Pig, Mahout)
skerrien

Meetup Outline● Purpose of Kafka
● Architecture
● Demo: Zookeeper
● More Kafka Internals
● Demos: writing Clients
● Discussions

If data is the lifeblood of high technology,
Apache Kafka is the circulatory system in use at LinkedIn.
-- Todd Palino
Source: https://engineering.linkedin.com/kafka/running-kafka-scale
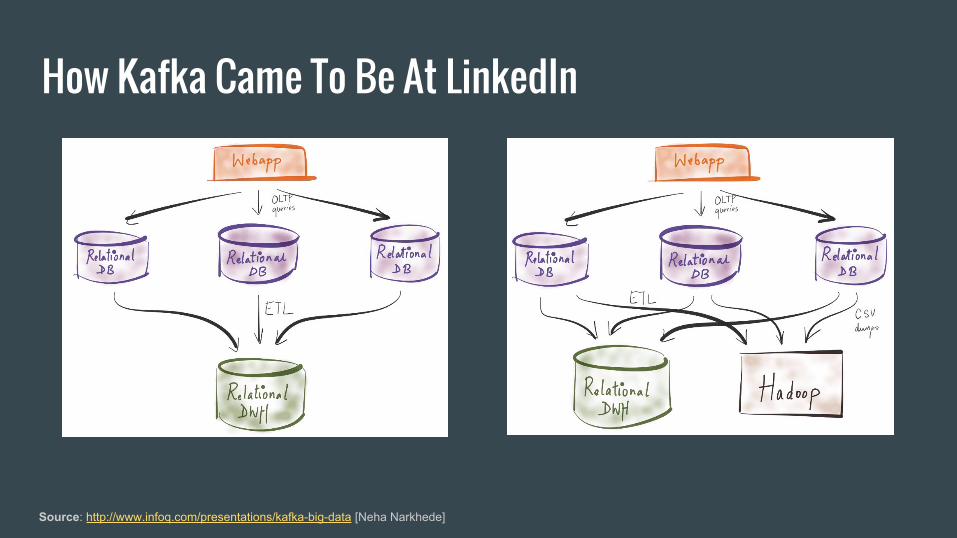
How Kafka Came To Be At LinkedIn
Source: http://www.infoq.com/presentations/kafka-big-data [Neha Narkhede]
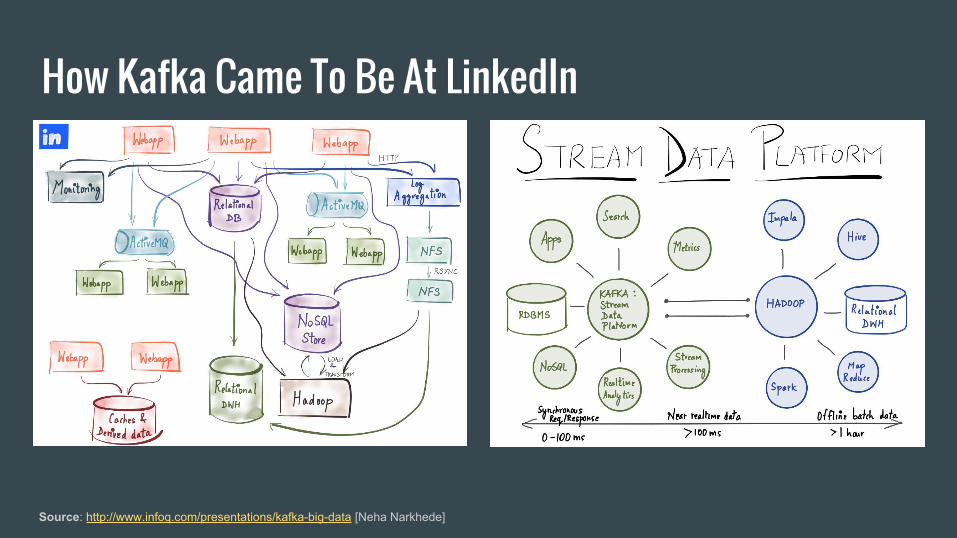
How Kafka Came To Be At LinkedIn
Source: http://www.infoq.com/presentations/kafka-big-data [Neha Narkhede]

A Week @ LinkedIn
630,516,047 msg/days (avg per broker)7,298 msg/sec (avg per broker)
Source: http://www.confluent.io/kafka-summit-2016-ops-some-kafkaesque-days-in-operations-at-linkedin-in-2015 [Joel Koshy]

Kafka Use CasesMessaging
Web Site Activity Tracking
Metrics
Log Aggregation
Stream Processing
Source: https://kafka.apache.org/08/uses.html
● Requirements
○ Low throughput
○ Low latency
○ Durability
● Replacement for JMS
● Decoupling producer/consumer
● Kafka
○ Better throughput
○ Partitioning
○ Replication
○ Fault tolerance

Kafka Use CasesMessaging
Web Site Activity Tracking
Metrics
Log Aggregation
Stream Processing
Source: https://kafka.apache.org/08/uses.html
● Requirements
○ Very high volume
● Track user activity
○ Page view
○ Searches
○ Actions
● Goals
○ Real time processing
○ Monitoring
○ Load into Hadoop
■ Reporting

Kafka Use CasesMessaging
Web Site Activity Tracking
Metrics
Log Aggregation
Stream Processing
Source: https://kafka.apache.org/08/uses.html
● Requirements
○ Very high volumes
● Feed of operational data
○ VMs
○ Apps

Kafka Use CasesMessaging
Web Site Activity Tracking
Metrics
Log Aggregation
Stream Processing
Source: https://kafka.apache.org/08/uses.html
● Log file collection on servers
● Similar to Scribe or Flume
○ Equally goof performance
○ Stronger durability
○ Lower end-to-end ltency

Kafka Use CasesMessaging
Web Site Activity Tracking
Metrics
Log Aggregation
Stream Processing
Source: https://kafka.apache.org/08/uses.html
● Stage of processing = topic
● Companion framework
○ Storm
○ Spark
○ ...

How Other Companies Use KafkaLinkedIn: activity streams, operational metrics
Yahoo: real time analytics (peak: 20Gbps compressed data), Kafka Manager
Twitter: storm stream processing
Netflix: real time monitoring, event processing pipelines
Spotify: log delivery system
Airbnb: event pipelines
. . .
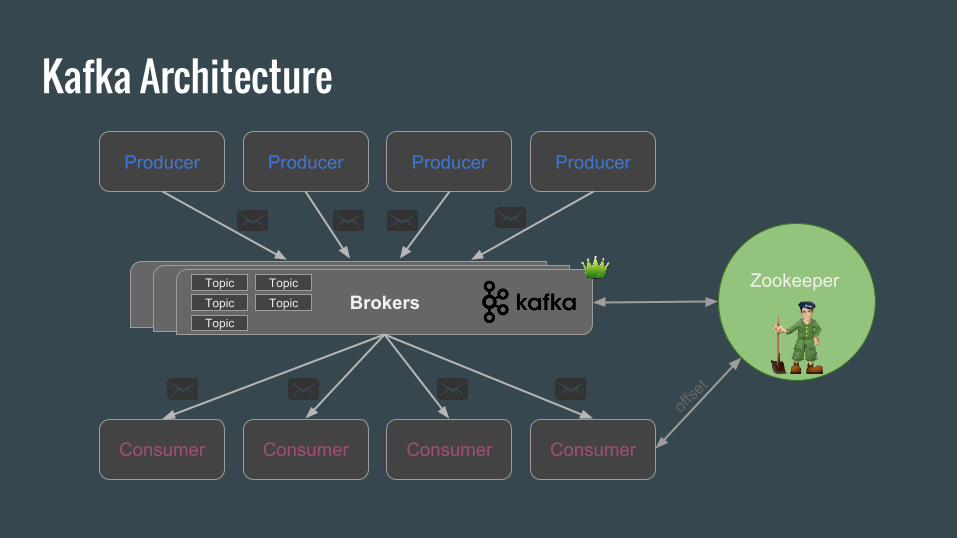
Kafka Architecture
Brokers
Producer
Consumer Consumer Consumer Consumer
Producer Producer Producer
Topic
Topic
Topic
Topic
Topic
Topic Zookeeper
offse
t

Kafka ControllerOne broker take the role of Controller which manages:
● Partition leaders
● State of partitions
● Partition reassignments
● Replicas
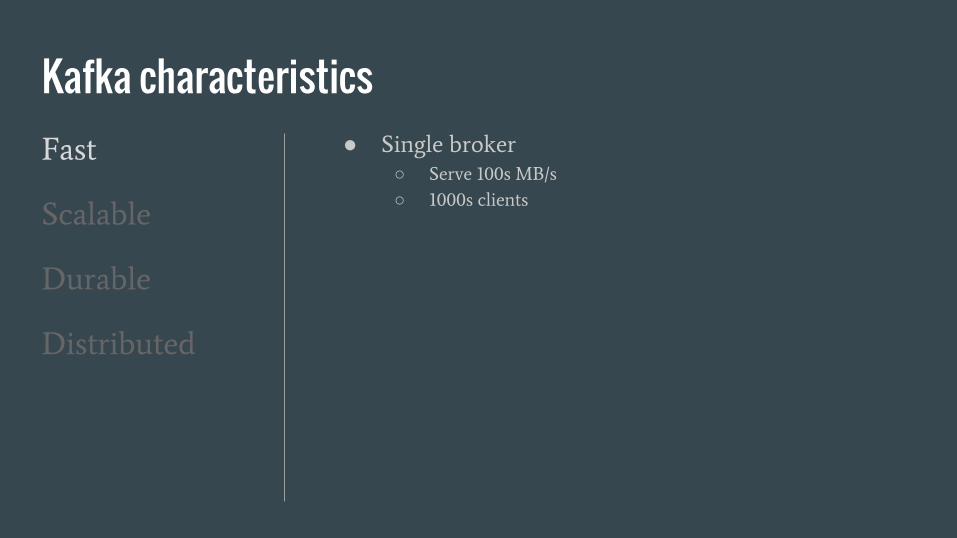
Kafka characteristicsFast
Scalable
Durable
Distributed
● Single broker
○ Serve 100s MB/s
○ 1000s clients

Kafka characteristicsFast
Scalable
Durable
Distributed
● Cluster as data backbone
● Expanded elastically

Kafka characteristicsFast
Scalable
Durable
Distributed
● Messages persisted on disk
● TB per broker with no performance impact
● Configurable retention

Kafka characteristicsFast
Scalable
Durable
Distributed
● Cluster can server larger streams than a single
machine can

Anatomy Of A Message
MagicCRC Key Length Key Msg Length MsgAttributes4 bytes 1 byte 1 byte 4 bytes K bytes 4 bytes M bytes
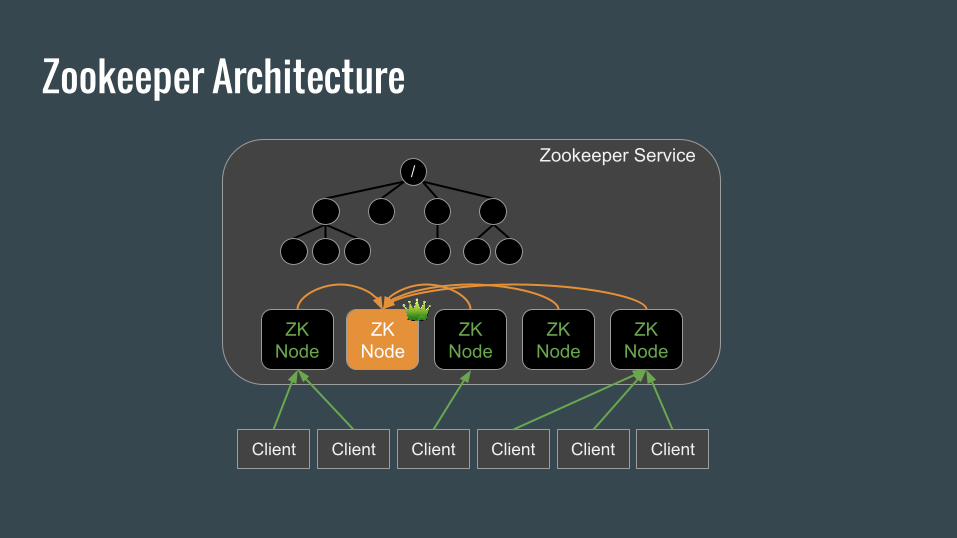
Zookeeper Architecture
ZK Node
ZK Node
ZK Node
ZK Node
ZK Node
Zookeeper Service
Client Client Client Client Client Client
/

How Kafka Uses Zookeeper (1/2)● Broker membership to a cluster
● Election of controller
● Topic configuration (#partitions, replica location, leader)
● Consumer offsets (alternative option since 0.8.2)
● Quotas (0.9.0)
● ACLs (0.9.0)

How Kafka Uses Zookeeper (2/2)Kafka zNodes Structure
● /brokers/ids/[0...N] --> host:port (ephemeral node)
● /brokers/topics/[topic]/[0...N] --> nPartions (ephemeral node)
● /consumers/[group_id]/ids/[consumer_id] --> {"topic1": #streams, ..., "topicN": #streams} (ephemeral node)
● /consumers/[group_id]/offsets/[topic]/[broker_id-partition_id] --> offset_counter_value (persistent node)
● /consumers/[group_id]/owners/[topic]/[broker_id-partition_id] --> consumer_node_id (ephemeral node)

Zookeeper Demo● List zNodes
● Create zNode
● Update zNode
● Delete zNode
● Ephemeral zNode
● Watches (data update & node deletion)

Kafka Demo 1● Install Kafka / Zookeeper (brew install kafka -> Kafka 0.8.2.1 + ZK 3.4.6 )
● Start a single broker cluster
○ Create a topic
○ Create a producer (Shell)
○ Create a consumer (Shell)
● Start a multi-broker cluster
○ Create a topic (partitioned & replicated)
○ Run producer & consumer
○ Kill a broker / check topic status (leader, ISR)
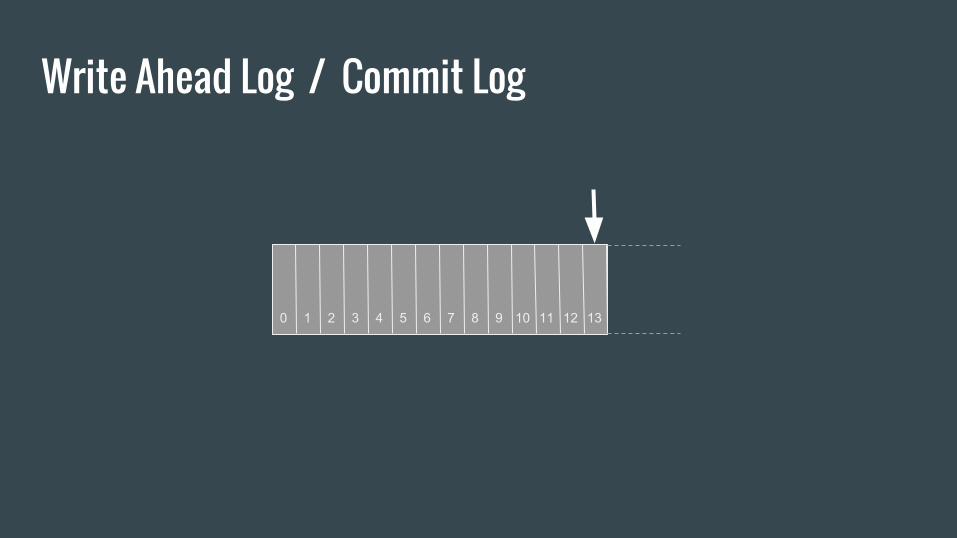
Write Ahead Log / Commit Log
0 1 2 3 4 5 6 7 8 9 10 11 12 13
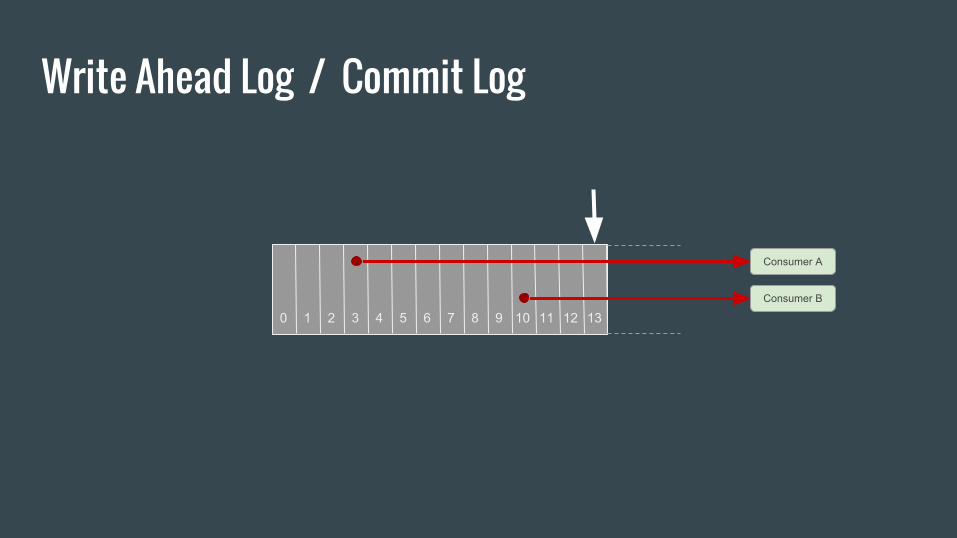
Write Ahead Log / Commit Log
0 1 2 3 4 5 6 7 8 9 10 11 12 13
Consumer A
Consumer B

Why Commit Log ?● Records what happened and when
● Databases
○ Record changes to data structures (physical or logical)
○ Used for replication
● Distributed Systems
○ Update ordering
○ State machine Replication principle
○ Last log timestamp defines its state
Source: https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
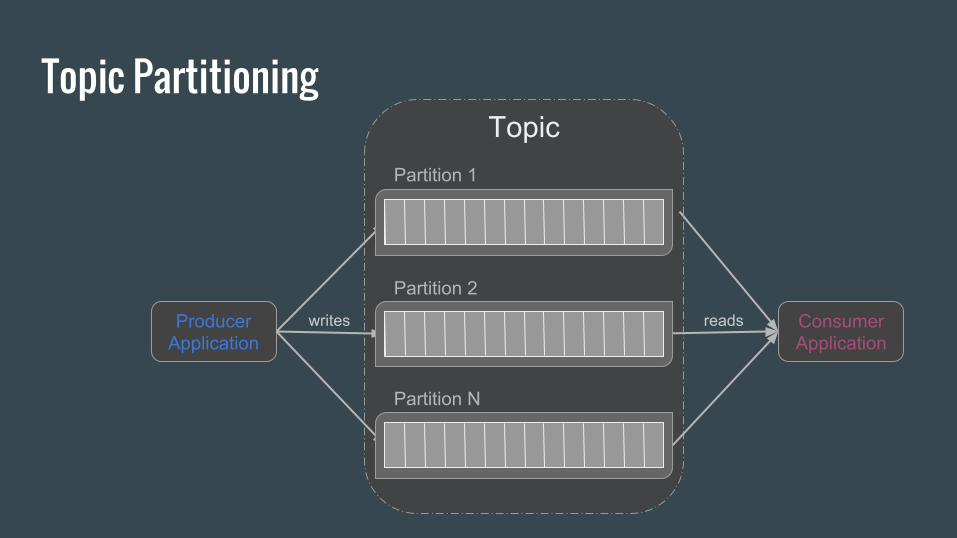
Topic Partitioning
ProducerApplication
ConsumerApplication
Partition 1
Topic
writes reads
Brokers
Brokers
Partition 2
Partition N
Brokers
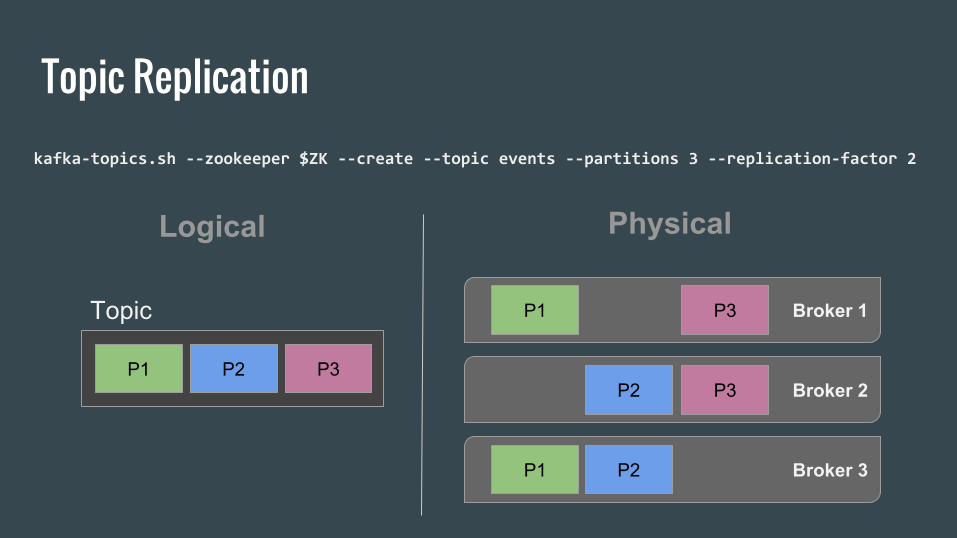
Topic Replicationkafka-topics.sh --zookeeper $ZK --create --topic events --partitions 3 --replication-factor 2
P1 P2 P3
Topic
Logical
Broker 1
Broker 2
Broker 3
P1
P1
P2 P3
P2
P3
Physical

Kafka Guaranties● Messages sent by a producer to a particular topic partition will be appended in the
order they are sent.
● A consumer instance sees messages in the order they are stored in the log.
● For a topic with replication factor N, Kafka will tolerate up to N-1 server failures
without losing any messages committed to a topic.

Durability GuaranteesProducer can configure acknowledgements:
● <= 0.8.2: request.required.acks● >= 0.9.0: acks
Value Impact Durability
0 Producer doesn’t wait for leader weak
1 (default)Producer waits for leader.Leader sends ack when message written to log. No wait for followers.
medium
all (0.9.0)-1 (0.8.2)
Producer waits for leader.Leader sends ack when all In-Sync-Replica have acknowledged.
strong

Consumer Offset Management● < 0.8.2: Zookeeper only
○ Zookeeper not meant for heavy write => scalability issues
● >= 0.8.2: Kafka Topic (__consumer_offset)
○ Configurable: offsets.storage=kafka
● Documentation show how to migrate offsets from Zookeeper to Kafka
http://kafka.apache.org/082/documentation.html#offsetmigration

Data Retention3 ways to configure it:
● Time based
● Size based
● Log compaction based
Broker Configurationlog.retention.bytes={ -1|...}log.retention.{ms,minutes,hours}=...log.retention.check.interval.ms=...log.cleanup.policy={delete|compact}log.cleaner.enable={ false|true}log.cleaner.threads=1log.cleaner.io.max.bytes.per.second=Double.MaxValuelog.cleaner.backoff.ms=15000log.cleaner.delete.retention.ms=1d
Topic Configurationcleanup.policy=...delete.retention.ms=......
Reconfiguring a Topic at Runtime
kafka-topics.sh --zookeeper localhost:2181 \ --alter --topic my-topic \ --config max.message.bytes=128000
kafka-topics.sh --zookeeper localhost:2181 \ --alter --topic my-topic \ --deleteConfig max.message.bytes
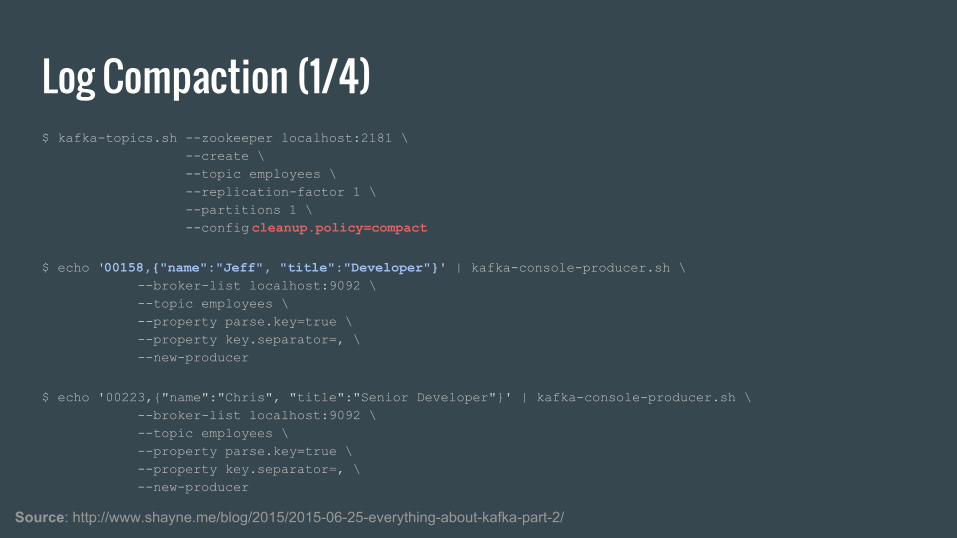
Log Compaction (1/4)$ kafka-topics.sh --zookeeper localhost:2181 \ --create \ --topic employees \ --replication-factor 1 \ --partitions 1 \ --config cleanup.policy=compact
$ echo '00158,{"name":"Jeff", "title":"Developer"}' | kafka-console-producer.sh \ --broker-list localhost:9092 \ --topic employees \ --property parse.key=true \ --property key.separator=, \ --new-producer
$ echo '00223,{"name":"Chris", "title":"Senior Developer"}' | kafka-console-producer.sh \ --broker-list localhost:9092 \ --topic employees \ --property parse.key=true \ --property key.separator=, \ --new-producer
Source: http://www.shayne.me/blog/2015/2015-06-25-everything-about-kafka-part-2/

Log Compaction (2/4)$ echo '00158,{"name":"Jeff", "title":"Senior Developer"}' | kafka-console-producer.sh \ --broker-list localhost:9092 \ --topic employees \ --property parse.key=true \ --property key.separator=, \ --new-producer
$ kafka-console-consumer.sh --zookeeper localhost:2181 \ --topic employees \ --from-beginning --property print.key=true \ --property key.separator=,
00158,{"name":"Jeff", "title":"Developer"}00223,{"name":"Chris", "title":"Senior Developer"}00158,{"name":"Jeff", "title":"Senior Developer"}
Source: http://www.shayne.me/blog/2015/2015-06-25-everything-about-kafka-part-2/

Log Compaction (3/4)$ kafka-topics.sh --zookeeper localhost:2181 \
--alter \
--topic employees \
--config segment.ms=30000
<... Wait 30 seconds ...>
$ kafka-console-consumer.sh --zookeeper localhost:2181 \
--topic employees \
--from-beginning \
--property print.key=true \
--property key.separator=,
00158,{"name":"Jeff", "title":"Developer"}
00223,{"name":"Chris", "title":"Senior Developer"}
00158,{"name":"Jeff", "title":"Senior Developer"}
Source: http://www.shayne.me/blog/2015/2015-06-25-everything-about-kafka-part-2/
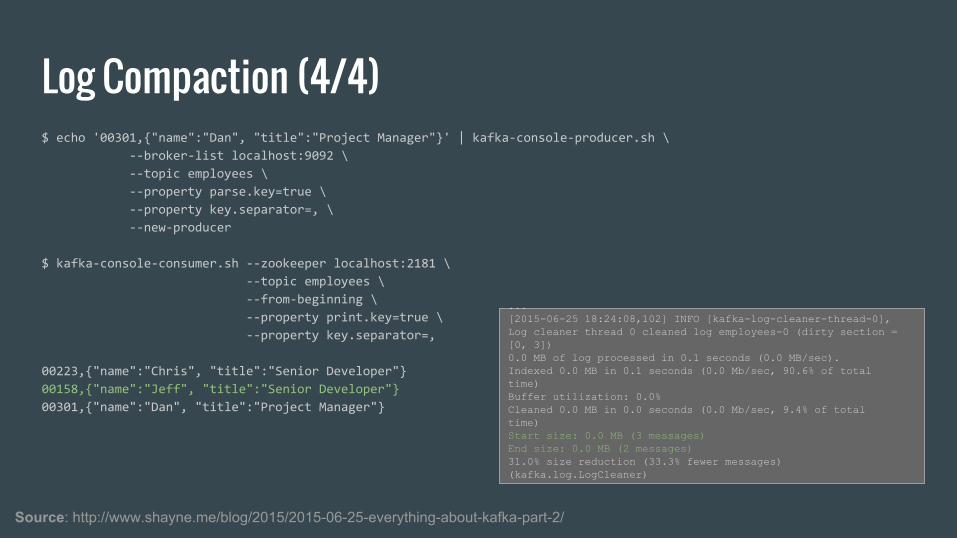
Log Compaction (4/4)$ echo '00301,{"name":"Dan", "title":"Project Manager"}' | kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic employees \
--property parse.key=true \
--property key.separator=, \
--new-producer
$ kafka-console-consumer.sh --zookeeper localhost:2181 \
--topic employees \
--from-beginning \
--property print.key=true \
--property key.separator=,
00223,{"name":"Chris", "title":"Senior Developer"}
00158,{"name":"Jeff", "title":"Senior Developer"}
00301,{"name":"Dan", "title":"Project Manager"}
Source: http://www.shayne.me/blog/2015/2015-06-25-everything-about-kafka-part-2/
...[2015-06-25 18:24:08,102] INFO [kafka-log-cleaner-thread-0],Log cleaner thread 0 cleaned log employees-0 (dirty section = [0, 3])0.0 MB of log processed in 0.1 seconds (0.0 MB/sec).Indexed 0.0 MB in 0.1 seconds (0.0 Mb/sec, 90.6% of total time)Buffer utilization: 0.0%Cleaned 0.0 MB in 0.0 seconds (0.0 Mb/sec, 9.4% of total time)Start size: 0.0 MB (3 messages)End size: 0.0 MB (2 messages)31.0% size reduction (33.3% fewer messages)(kafka.log.LogCleaner)

Kafka Performance - Theory● Efficient Storage
○ Fast sequential write and read
○ Leverages OS page cache (i.e. RAM)
○ Avoid storing data twice in JVM and in OS cache (better perf on startup)
○ Caches 28-30GB data in 32GB machine
○ Zero copy I/O using IBM’s sendfile API (https://www.ibm.com/developerworks/library/j-zerocopy/)
● Batching of messages + compression
● Broker doesn’t hold client state
● Dependent on persistence guaranties request.required.acks

Kafka Benchmark (1/5)● 0.8.1
● Setup
○ 6 Machines
■ Intel Xeon 2.5 GHz processor with six cores
■ Six 7200 RPM SATA drives (822 MB/sec of linear disk I/O)
■ 32GB of RAM
■ 1Gb Ethernet
○ 3 nodes for brokers + 3 for ZK and clients
Source: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines

Kafka Benchmark (2/5)
Source: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
Usecase Messages/sec Throughput (MB/sec)
1 producer thread, no replication6 partitions, 50M messages, payload: 100 bytes
821,557 78.3
1 producer thread, 3x asynchronous replication (ack=1) 786,980 75.1
1 producer thread, 3x synchronous replication (ack=all) 421,823 40.2
3 producers, 3x asynchronous replication 2,024,032 193.0
Producer throughput:
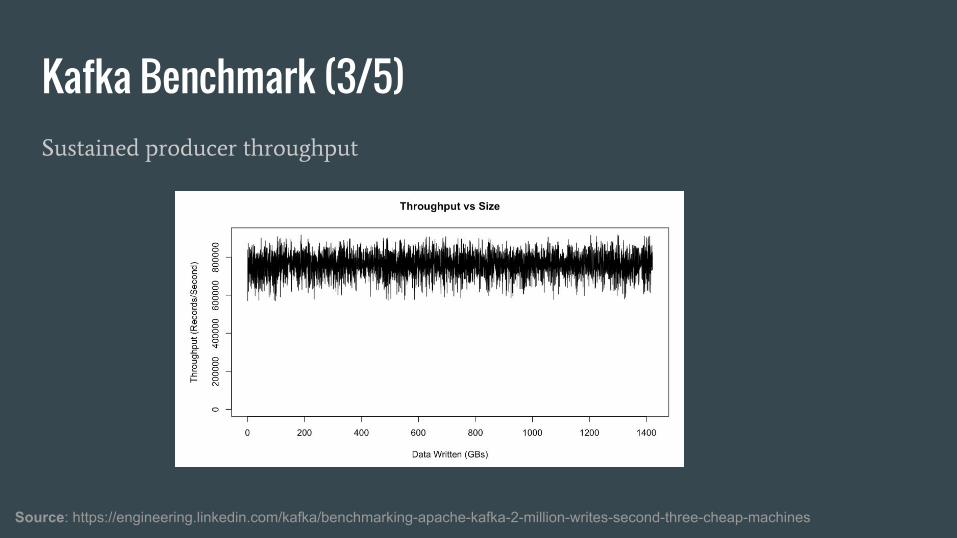
Kafka Benchmark (3/5)
Source: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
Sustained producer throughput

Kafka Benchmark (4/5)
Source: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
Usecase Messages/sec Throughput (MB/sec)
1 Consumer 940,521 89.7
3 Consumer (1 per machine) 2,615,968 249.5
Consumer throughput from 6 partitions, 3x replication:

Kafka Benchmark (5/5)
Source: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
End-to-end latency:
● 2ms (median)
● 3ms (99th percentile)
● 14ms (99.9th percentile)

Kafka Demo 2 - Java High Level API● Start a multi broker cluster + replicated topic
○ Write Java Partitioned Producer
○ Write Multi-Threaded Consumer
● Unit testing with Kafka

Kafka Versions0.8.2 (2014.12)
● New Producer API
● Delete topic
● Scalable offset writes
0.9.x (2015.10)
● Security
○ Encryption
○ Kerberos
○ ACLs
● Quotas (client rate control)
● Kafka Connect
0.10.x (2016.03)
● Kafka Streams
● Rack Awareness
● More SASL features
● Timestamp in messages
● API to better manage Connectors

Starting with Kafka: Jay Kreps’ Recommendations● Start with a single cluster
● Only a few non critical, limited usecases
● Pick a single data format for a given organisation
○ Avro
■ Good language support
■ One schema per topic (message validation, documentation...)
■ Supports schema evolution
■ Data embeds schema
■ Make Data Scientists job easier
■ Put some thoughts into field naming conventions
Source: http://www.confluent.io/blog/stream-data-platform-2/

Conclusions● Easy to start with for a PoC
● Maybe not so easy to build a production system from scratch
● Must have serious monitoring in place (see Yahoo, Confluent, DataDog)
● Vibrant community, fast pace technology
● Videos of Kafka Summit are online: http://kafka-summit.org/sessions/
https://github.com/samuel-kerrien/kafka-demo




![Evaluation of Apache Kafka in Real-Time Big Data Pipeline ... · Apache Kafka in the pipeline architecture. 3.1 Apache Kafka Architecture . Kafka [9] is an open source, distributed](https://img.pdfslide.net/doc/110x75/5ea885d2f35fca1745303e93/evaluation-of-apache-kafka-in-real-time-big-data-pipeline-apache-kafka-in-the.jpg)


























