Embed Size (px)
Citation preview

Redis 운영관리강대명 ([email protected])

WHO AM I?
Redis Contributor
Udemy Data Engineer
Kakao Story-Senior Backend Engineer
Naver Mail-Senior Backend Engineer

주제
Redis 운영 사례
Redis 장애 사례

Redis Performance #1
Redis는 Single Threaded
Connection이 안정적인 상황에서
Xeon 에서 150,000 TPS 도 가능
Connection이 불안정하면
극도로 느려질 수 있음.
사례 – 1~2만에서 ~ 15만까지…
Get/set 만 이용

Redis Performance #2
한번에많은 개수의 데이터를 순회해야 하는 명령을 피해야함 – 인재(人災)
메모리 관리를잘 해야함. 스왑을 쓰기 시작하면 프로세스를 종료하기 전까지는, 스왑을 안 쓸 방도가없음.

Redis Performance #3
메모리를 적게 사용하도록 설정이 필요.
Set/Sorted Set/Hash를많이사용하는데, 그 데이터 양이 적을 때는강제로 ziplist 형태를사용하도록설정을 수정, 한 collection에 들어가는아이템의개수가 적어야 한다.
Ziplist를 쓰면 메모리 사용량이 20% 이상줄어듬.

Redis Sorted Set #1
SkipList - O(log(N))
링크드 리스트에 급행 열차 처럼, 몇단계 뒤를 가르키는 노드 레벨이 존재 – 해당 방식으로 쉽게 데이터를찾을 수 있다.

Redis Sorted Set #2

Redis Sorted Set #3

Redis Sorted Set #4

Redis Sorted Set #5

Redis Sorted Set #6
Sorted Set 같은 경우에는 Value로의 접근을 위해서HashTable 도 유지를 하게 됨.
SkipList + HashTable을 유지하므로 메모리 사용량이많음.
Collection의 개수가 적고 사이즈가 적으면 ziplist 가유리함.
Ziplist 는 선형 검색이므로 개수가 많아질수록 느려짐

Redis Monitoring #1
하나의 Redis 서버의 정보를 자세히 보여주는 것보다, 같은 그룹의 여러대의 서버를 동시에 보여주는것이 훨씬 유용함.
Memory 보다 RSS 의 사용량이 더 중요함.
Telegraf, Grafana 등으로 쉽게 구축 가능

Redis Monitoring #2Used_memory RSS

Redis Monitoring Metrics항목 내용
RSS 실제 사용 메모리, 물리메모리 70% 정도면 이전 고려 필요.
KEY 개수
Client 수 클라이언트 수가 흔들리면, 문제발생
초당 커맨드 처리량
Hit Ratio
Eviction

기본 캐시 쓰임새…
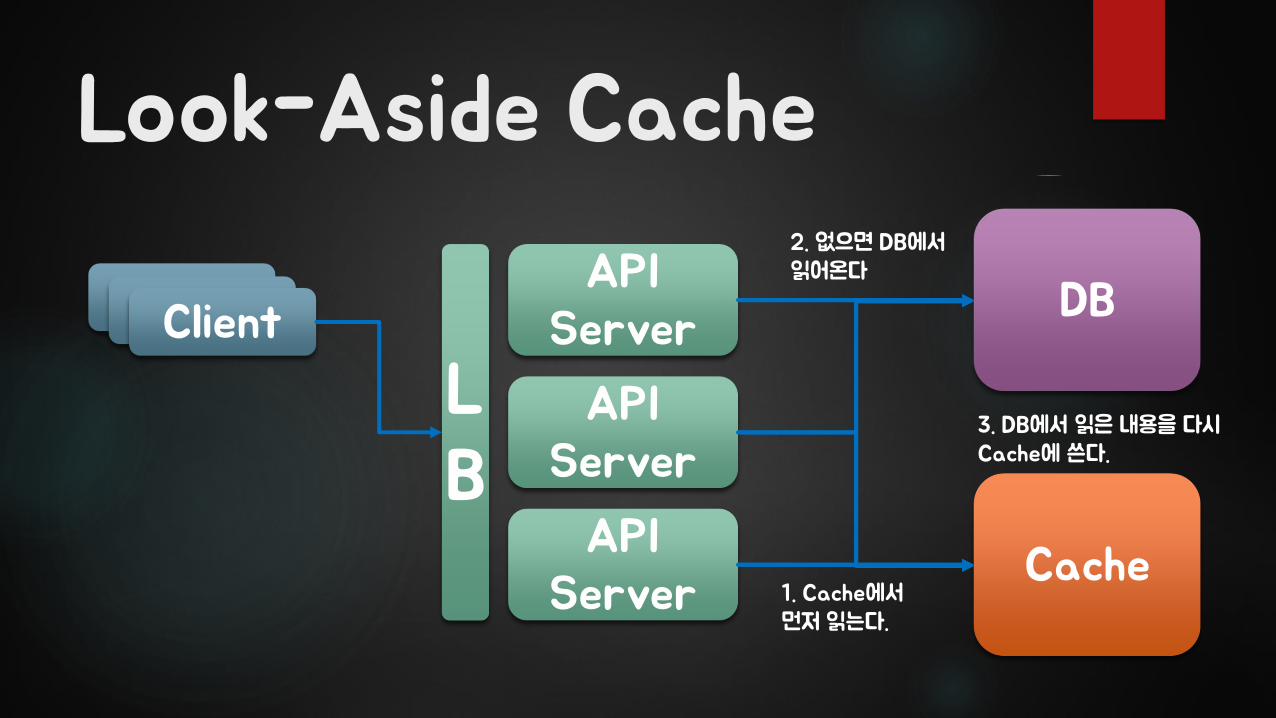
Look-Aside Cache
ClientClientClientAPI
Server
API Server
API Server
LB
DB
Cache1. Cache에서먼저 읽는다.
2. 없으면 DB에서읽어온다
3. DB에서 읽은 내용을 다시Cache에 쓴다.
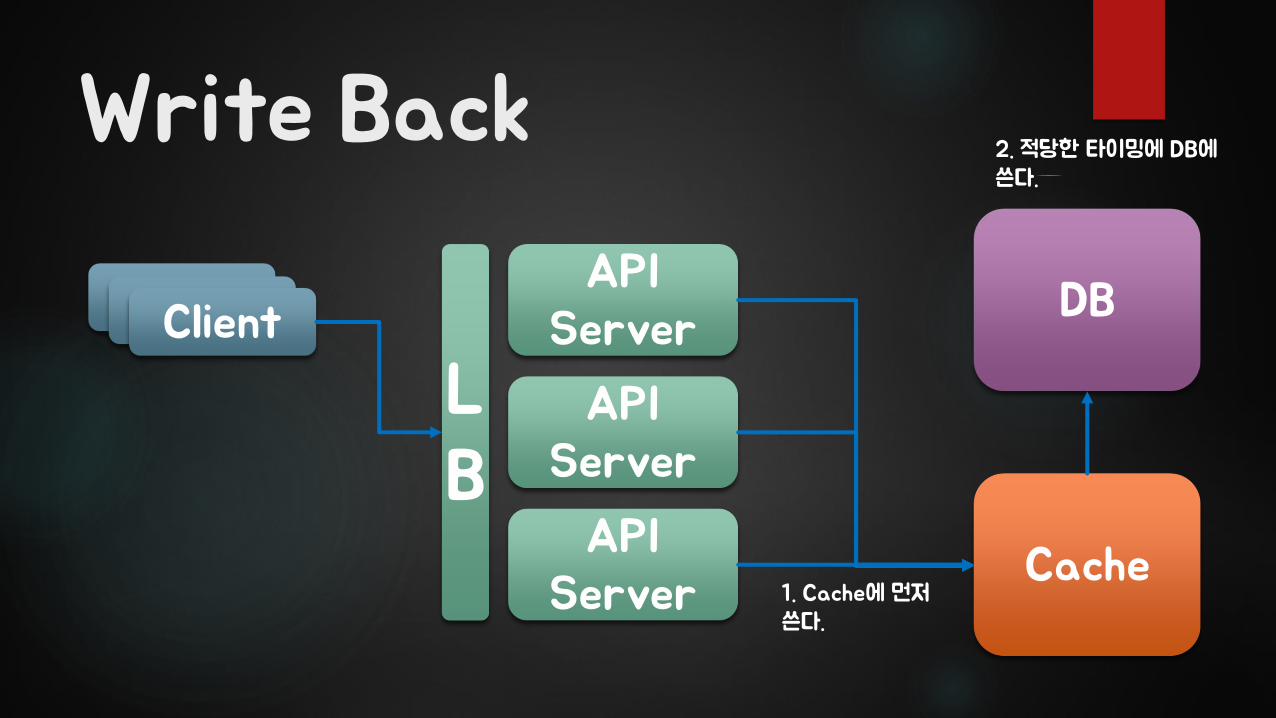
Write Back
ClientClientClientAPI
Server
API Server
API Server
LB
DB
Cache1. Cache에 먼저쓴다.
2. 적당한 타이밍에 DB에쓴다.
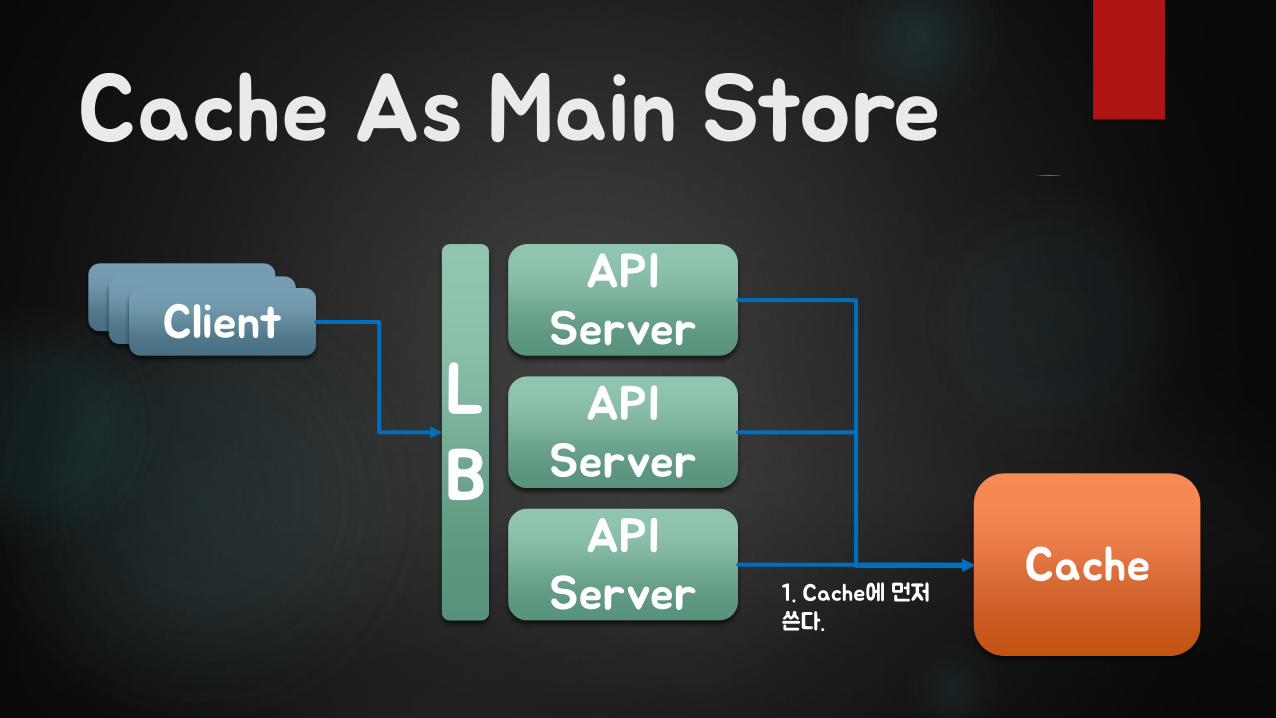
Cache As Main Store
ClientClientClientAPI
Server
API Server
API Server
LB
Cache1. Cache에 먼저쓴다.

다음 중 Failover가중요한 경우는?

1,2,3 번모두 중요할수도…모두 안중요할수도…

데이터의 성격!

Redis Failover
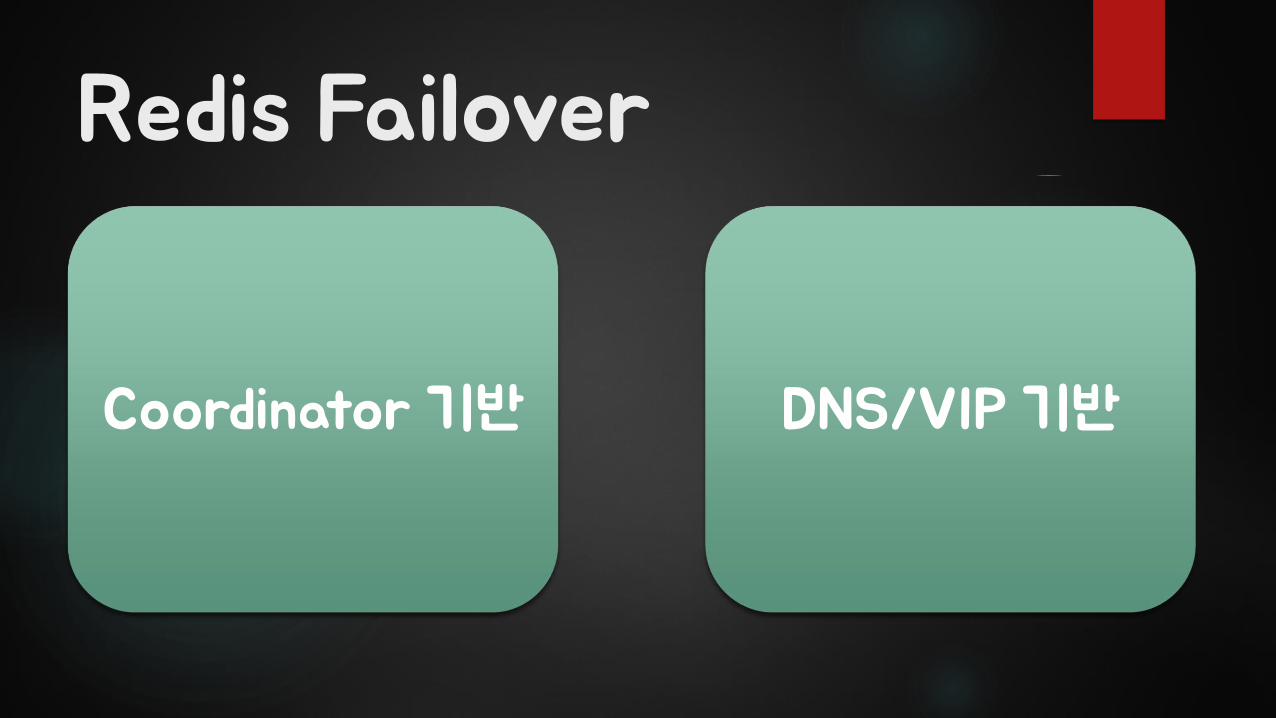
Redis Failover
Coordinator 기반 DNS/VIP 기반
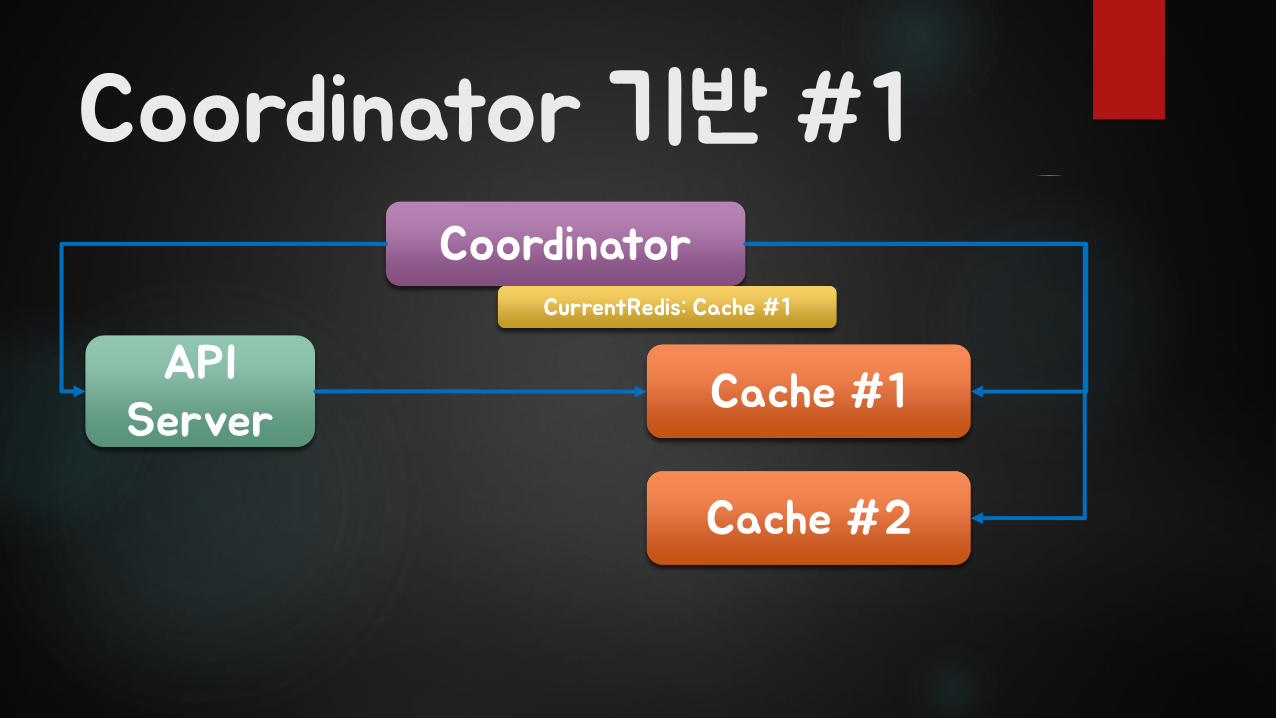
Coordinator 기반 #1
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #1
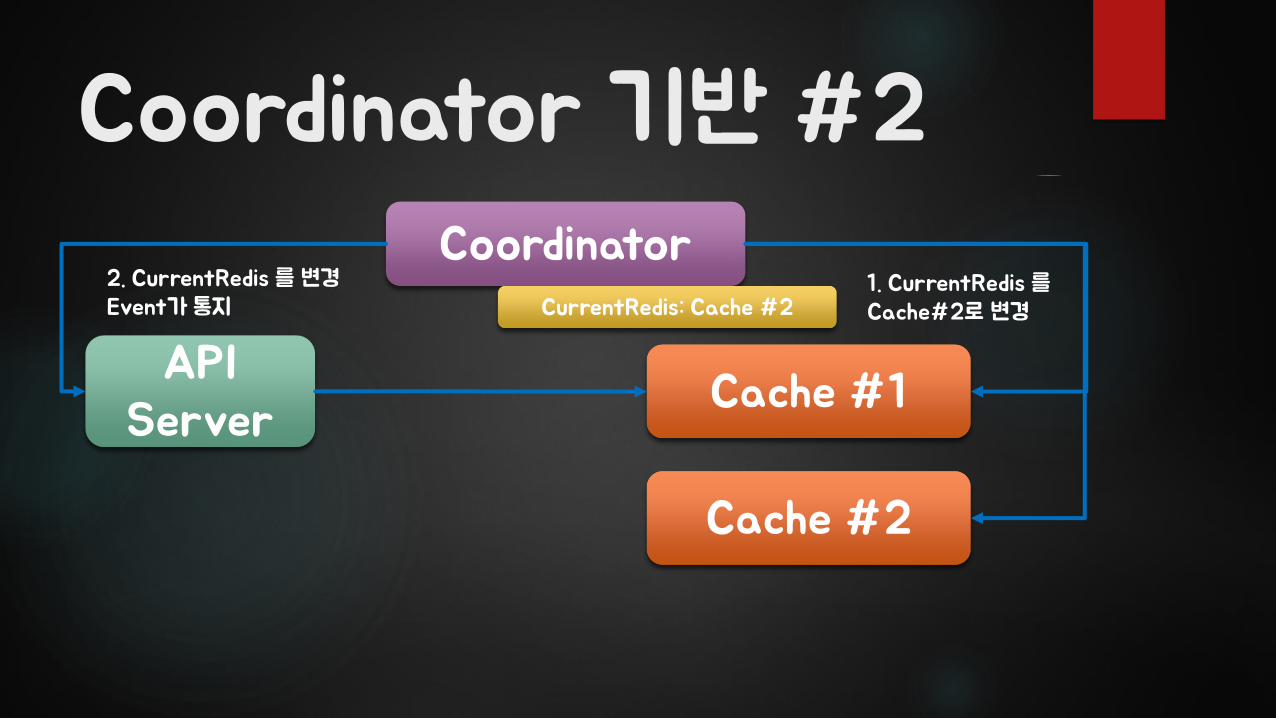
Coordinator 기반 #2
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #21. CurrentRedis 를Cache#2로 변경
2. CurrentRedis 를 변경Event가 통지
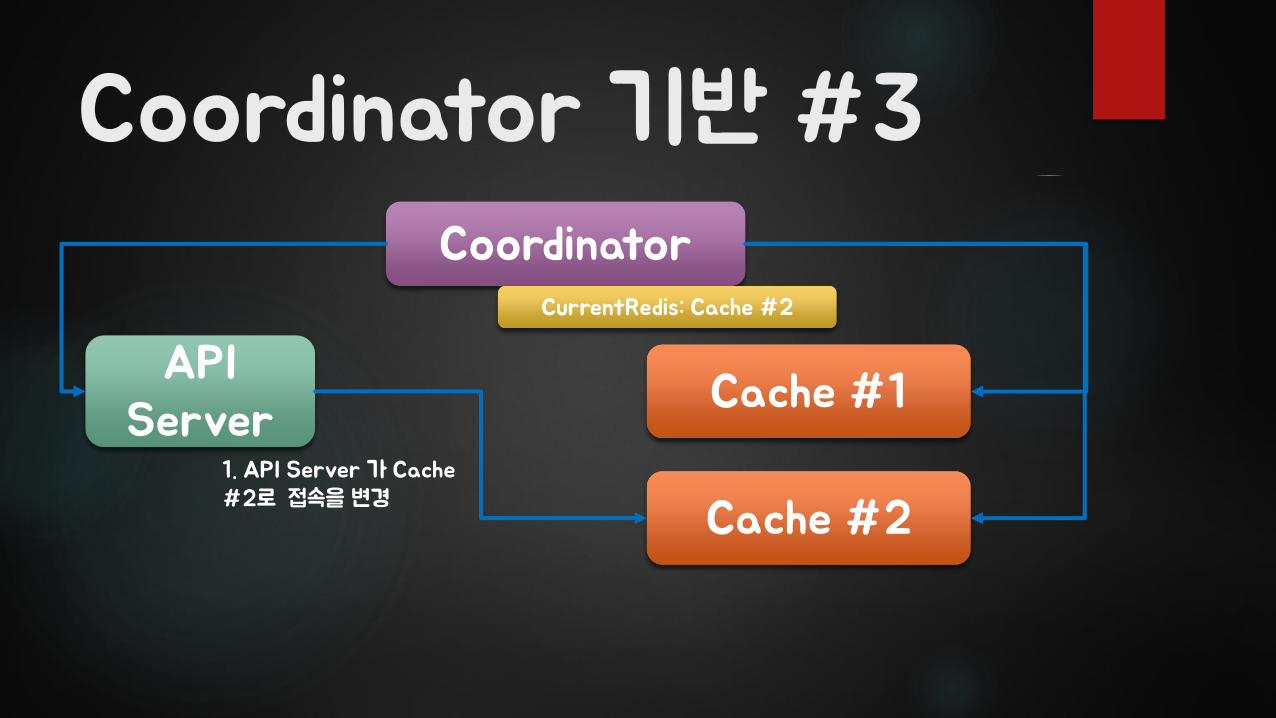
Coordinator 기반 #3
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #2
1. API Server 가 Cache #2로 접속을 변경

Coordinator Failover
Zookeeper/Consul/Etcd 같은 종류를 사용할수 있음(Eureka 라든지…)
코드가 Coordinator의 이벤트를 처리할 수 있도록 개발이 되어야함.
어차피 동적으로 설정 변경을 한다고 하면, 이런 방식을 도입을 해야함.

VIP 기반 #1
API Server
Cache #1192.168.0.101
VIP 192.168.0.100: Cache #1
Cache #2192.168.0.102

VIP 기반 #2
API Server
Cache #1192.168.0.101
VIP 192.168.0.100: Cache #2
Cache #2192.168.0.102
1. VIP 192.168.0.100 을192.168.0.102.와연결 2. Cache #1의 모든 연결을 끊음
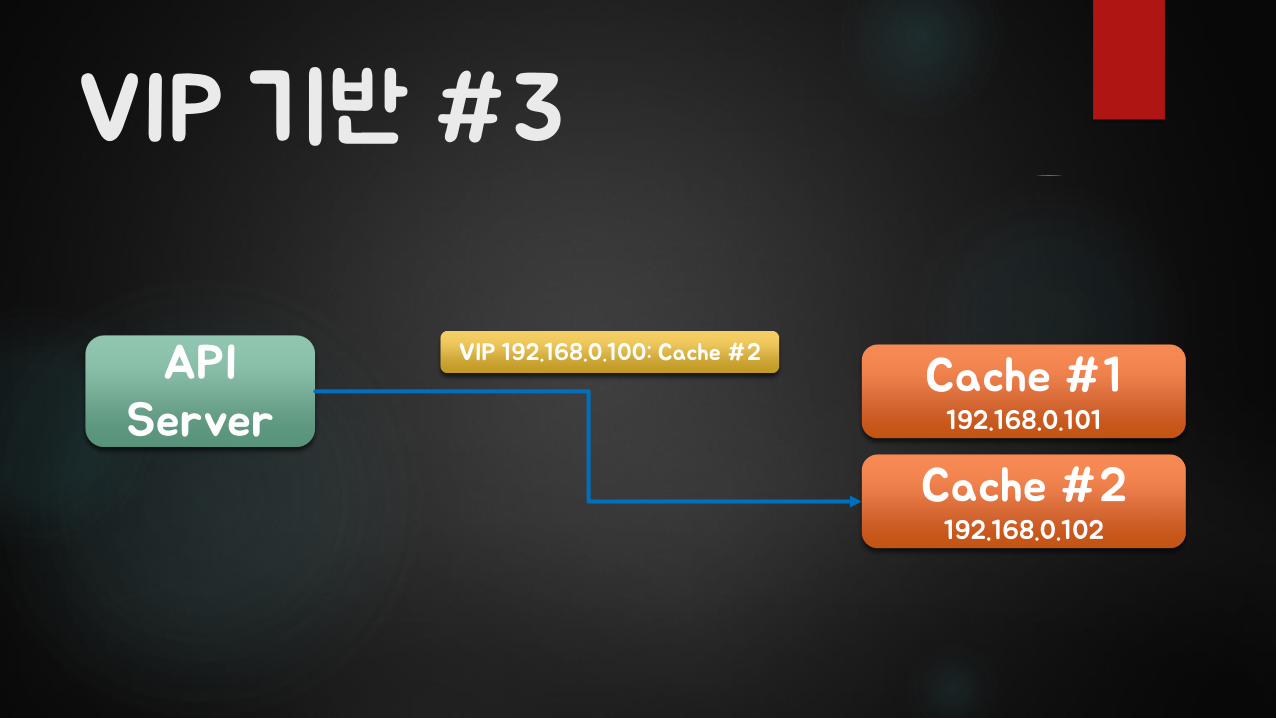
VIP 기반 #3
API Server
Cache #1192.168.0.101
VIP 192.168.0.100: Cache #2
Cache #2192.168.0.102

DNS 기반 #1
API Server
Cache #1192.168.0.101
.zsearch-cache001.suki.io: Cache #1
Cache #2192.168.0.102
DNS TTL을 0로 설정

DNS 기반 #2
API Server
Cache #1192.168.0.101
Cache #2192.168.0.102
1. DNS search-cache001.suki.io 의주소를 Cache #2로 변경 2. Cache #1의 모든 연결을 끊음
.zsearch-cache001.suki.io: Cache #1
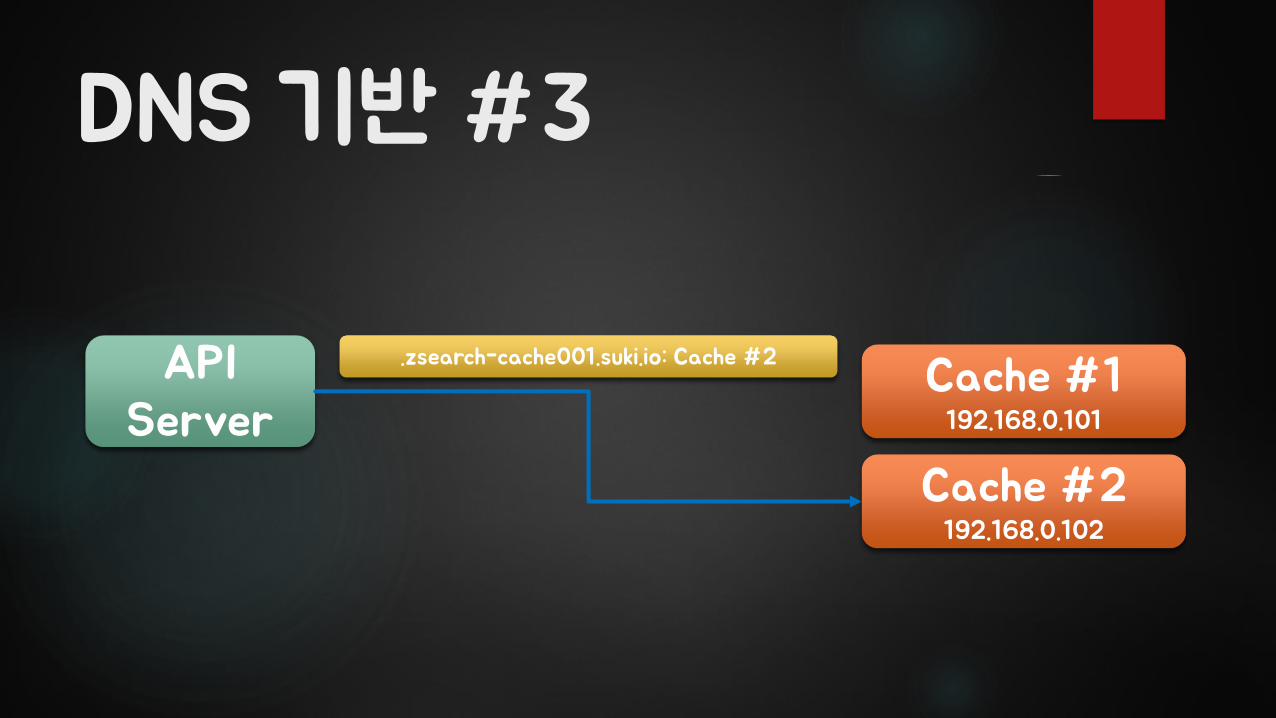
DNS 기반 #3
API Server
Cache #1192.168.0.101
Cache #2192.168.0.102
.zsearch-cache001.suki.io: Cache #2

DNS/VIP Failover기존 코드의 변경 없이 적용 가능.
VIP 방식은 어디서나(PasS 등으로 제공할때), DNS 방식은 서비스 내부에서만 적용가능실제로 RackSpace 는 PaaS 형태의 서비스를 제공하므로
VIP로 Failover 제공
K모사는 DNS 방식을 이용.
DNS방식은 언어, 프레임워크마다 고려할사항이있음Ex) JVM DNS Caching 이슈.
DNS TTL을 0으로 설정, Pool 구조로 접근해야 함.

Failover 시 주의사항
Failover 시, coordinator를 이용하든 dns/vip 방식을 이용하든, 위의 failover 절차가 끝난 다음에 변경 이벤트를 트리거해야한다.

Redis Migration

Redis Migration #1
새 버전의 Redis로 업그레이드 하거나 메모리가 부족한 Redis 서버를 새 서버로 이전하기 위해서 많이 사용함.
해당과정을 자동화함으로써, 유지보수에 이용
다만 Redis Replication 과정 자체에서 master에 부담을많이주므로 반대로 Master 장애를 유발할 수도 있다.

Redis Migration #2
B를 A의 slave 로 설정
기존 Redis 서버는 A새로운 Redis 서버는 B
B에 Read only 설정을 끔
클라이언트의 설정을 B로 변경
Sync가완료되었는지 확인
A와 B 의 관계를 끊음

Redis Migration #3
slaveof A:IP A:PORT(in B)
기존 Redis 서버는 A새로운 Redis 서버는 B
config set slave-read-only no
클라이언트의 설정을 B로 변경
Check master_link_statusis up
slaveof no one

Redis Sharding

Redis Sharding #1
Memory 분배가 더 적절히 일어나는 방향으로
Operation 수가 적절히 분배되는 방향으로
ID Range, ID Modular, Consistent Hashing

Redis Sharding #2
Cache 형태의 Data
Look-Aside Cache 형태
보통 Consitent Hashing을 많이 이용
버려도되거나, 새로 쉽게만들 수 있는데이터
캐시가 모자라면 그냥 장비 추가
일부데이터 유실

Redis Sharding #3
스토리지 형태의 Data
Write Back 또는 스토리지로 사용할 경우
중요한 데이터는 M/S로 사용
Range or Modular 형태로 구분미리 큰 그룹을 구성해 둠.
데이터가꽉차면해당장비만 Migration으로 더 큰 사이즈를할당하는방법으로처리

권장 설정Configuration

권장설정 - 공통
RDB off
maxclient 설정 50000
Protected-mode no
메모리 사용량을줄이기 위해서 해당값 조절
*-max-ziplist-entries
*-max-ziplist-value
특정 command disable

권장설정 - Cache
권장 설정 공통 이용

권장설정 - Storage
AOF on
Master-Slave
부하가 큰 경우에는 Master에만 AOF on
auto-aof-rewrite-percentage 0

Redis 운영 #1
물리 서버 하나에 Redis 서버 한대를 올리는 것 보다는 메모리를적게 사용하도록 n개의 instance를 실행하는게 좋음
메모리 모니터링이 필수

CPU 4 core, 32G Memory
Mem: 24G
Mem: 8G
Mem: 8G
Mem: 8G
more reliable

Redis 운영 #2
그룹별로 중요한 정보만 보여주는 대시보드를 만든다.
메모리 사용량이 얼마 이상이 되면, 메신저등을 통해서 알람을 받는다.
마이그레이션 과정은 자동화된 스크립트를 통해서 처리한다.
Ex) redis_migration_tool [src] [target]

Redis 운영 #3
M/S로 구성된 서비스의 경우는 장애시 자동으로 Failover를수행한다.
Redis 서버의 업그레이드나 설정 변경등은 ansible, chef, Capistrano 등의 tool을 이용
200대 Redis 설치나 업그레이드에 시간이 얼마나 걸릴까요?(설치는 금방, 업그레이드는 순차적으로…)
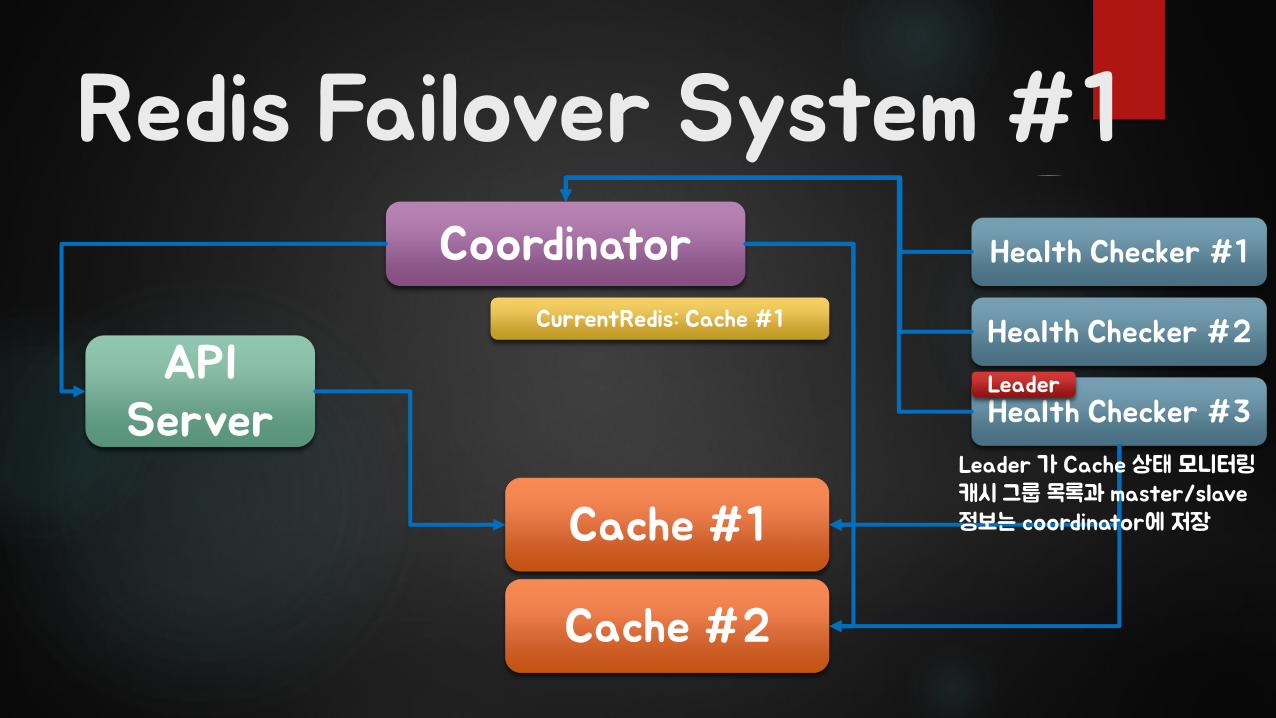
Redis Failover System #1
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #1
Health Checker #1
Health Checker #2
Health Checker #3Leader
Leader 가 Cache 상태 모니터링캐시 그룹 목록과 master/slave 정보는 coordinator에 저장
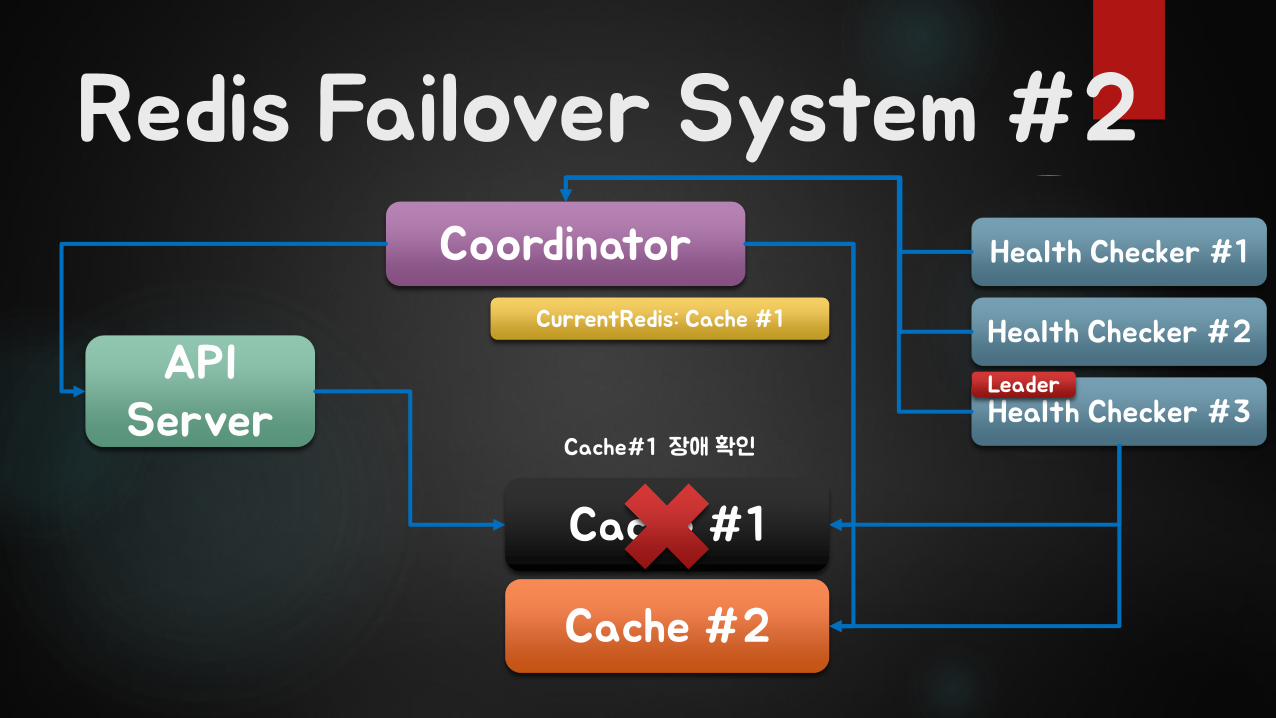
Redis Failover System #2
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #1
Health Checker #1
Health Checker #2
Health Checker #3Leader
Cache#1 장애확인
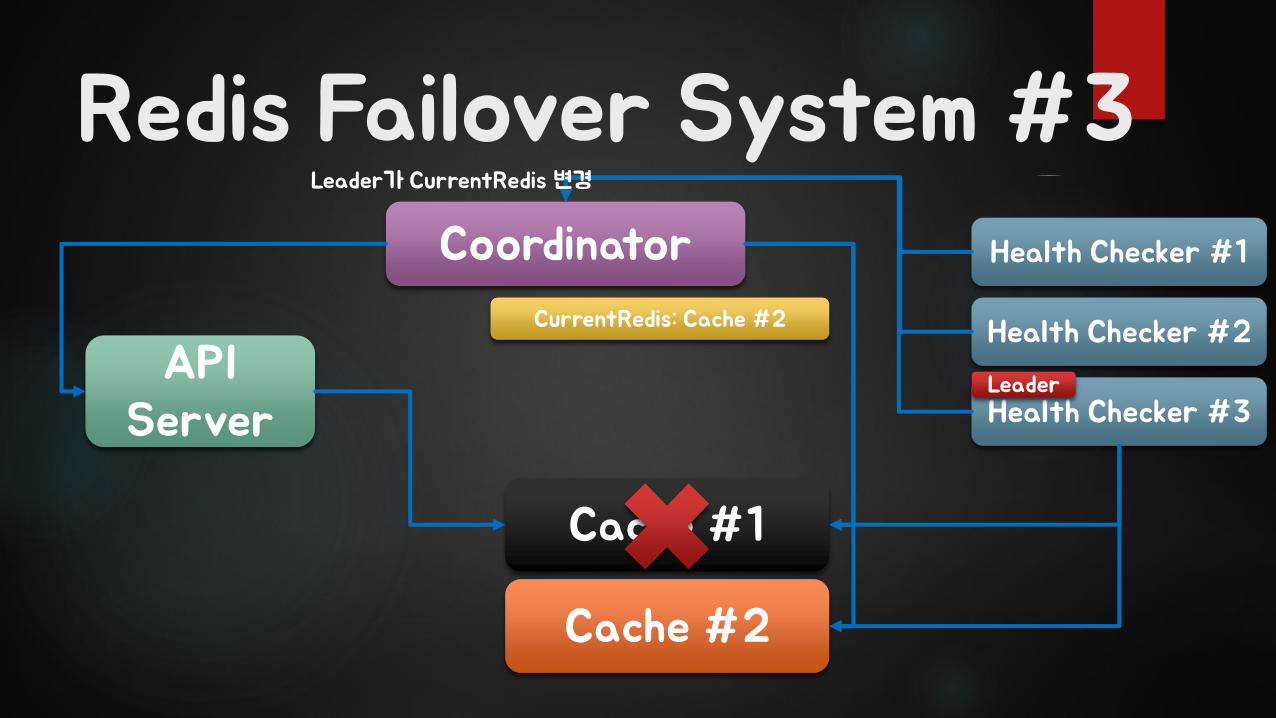
Redis Failover System #3
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #2
Health Checker #1
Health Checker #2
Health Checker #3Leader
Leader가 CurrentRedis 변경
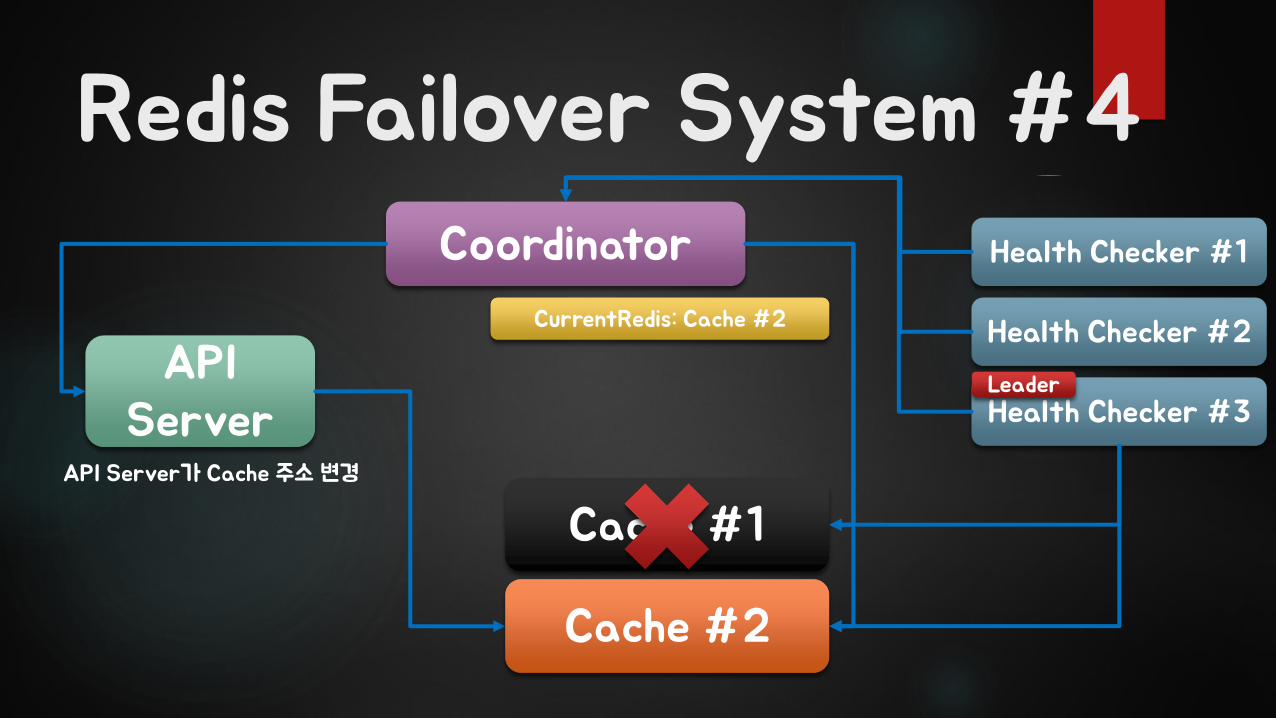
Redis Failover System #4
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #2
Health Checker #1
Health Checker #2
Health Checker #3Leader
API Server가 Cache 주소 변경
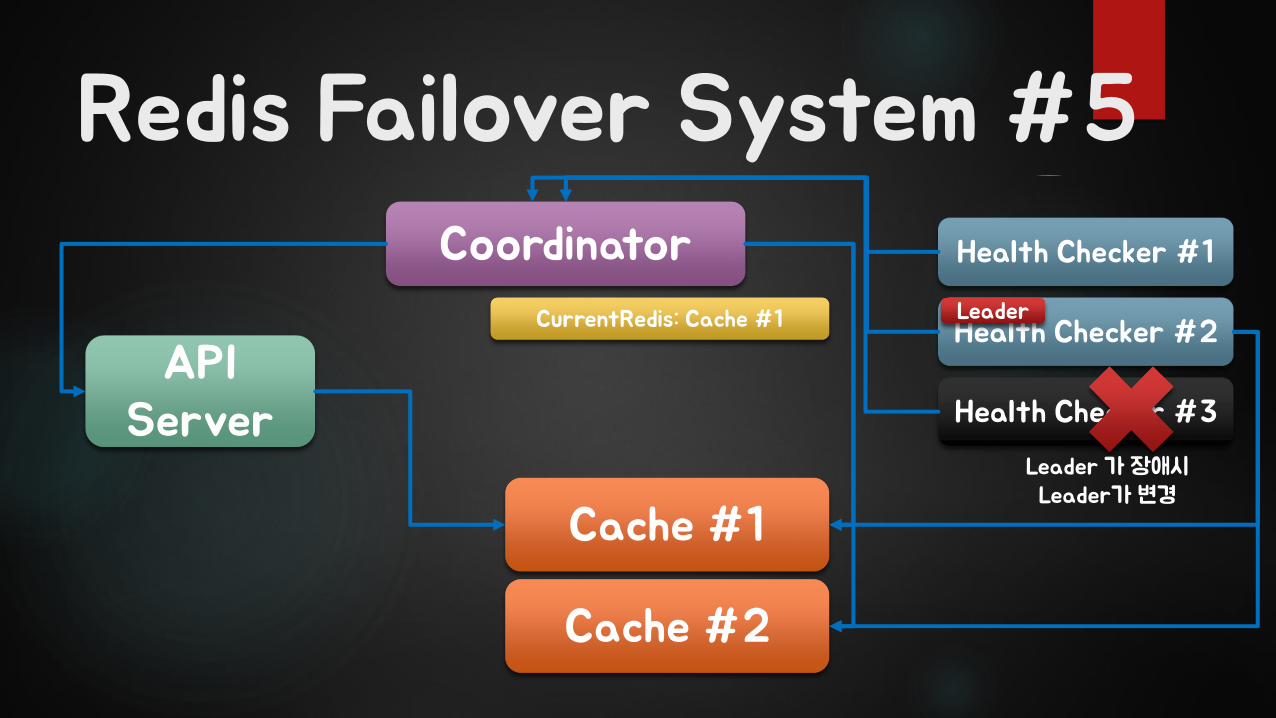
Redis Failover System #5
API Server
Coordinator
Cache #1
Cache #2
CurrentRedis: Cache #1
Health Checker #1
Health Checker #2
Health Checker #3
Leader
Leader 가 장애시Leader가변경

장애사례

기본 설정을 사용
Redis 의 기본 설정은 서비스 운영과맞지 않음RDB 관련 설정을 끄고
Maxclient 설정을 올려야함.(커널 설정도확인)

느린 명령의 실행
느린 명령의 실행은 대표적으로할 수 있는 실수
Keys 의 사용
해당 명령을 disable
큰 collection 의 삭제
Redis 4.0 부터는 lazy deletion이 가능(config)
Lazyfree-lazy-eviction
Lazyfree-lazy-expire
Lazyfree-lazy-server-del

AOF Rewrite는 수동으로
기본적으로 AOF Rewrite가 발생.
여러 대의 노드에서 동시에 AOF Rewrite가 발생하면 메모리/IO 사용량이 급증
해당 작업이 필요할 때 시간을 정해서 개별적으로AOF Rewrite 작업을 수행

결론
Redis 의 특성을 파악해야 한다.
다른 컴포넌트와 마찬가지로 해당 장애에 대한 자동화된Failover 와 Migration 에 대한 고려가 필요.
사람이 살아야 서비스가 산다.

Thank you.





























