Embed Size (px)
Citation preview

Barbara Rychalska, Katarzyna Pakulska, Krystyna Chodorowska, Wojciech Walczak, Piotr Andruszkiewicz
Paraphrase Detection Ensemble SemEval 2016 winner
1st place in the English Semantic Textual Similarity (STS) Task

Agenda
1. What is SemEval?2. Neural networks – what are they?3. Vector word representations – what are they?4. Our solution in SemEval2016
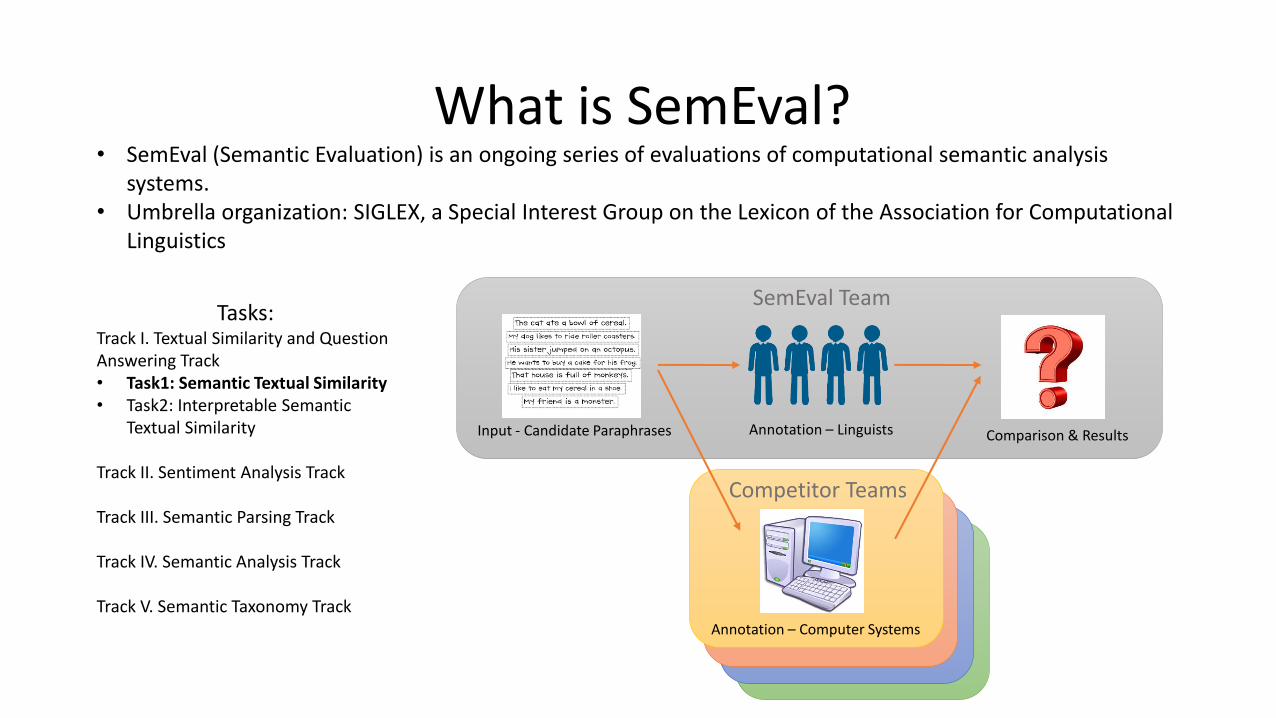
What is SemEval?• SemEval (Semantic Evaluation) is an ongoing series of evaluations of computational semantic analysis
systems.• Umbrella organization: SIGLEX, a Special Interest Group on the Lexicon of the Association for Computational
Linguistics
Tasks:Track I. Textual Similarity and Question Answering Track• Task1: Semantic Textual Similarity• Task2: Interpretable Semantic
Textual Similarity
Track II. Sentiment Analysis Track
Track III. Semantic Parsing Track
Track IV. Semantic Analysis Track
Track V. Semantic Taxonomy Track
Input - Candidate Paraphrases Comparison & ResultsAnnotation – Linguists
Annotation – Computer Systems
SemEval Team
Competitor Teams
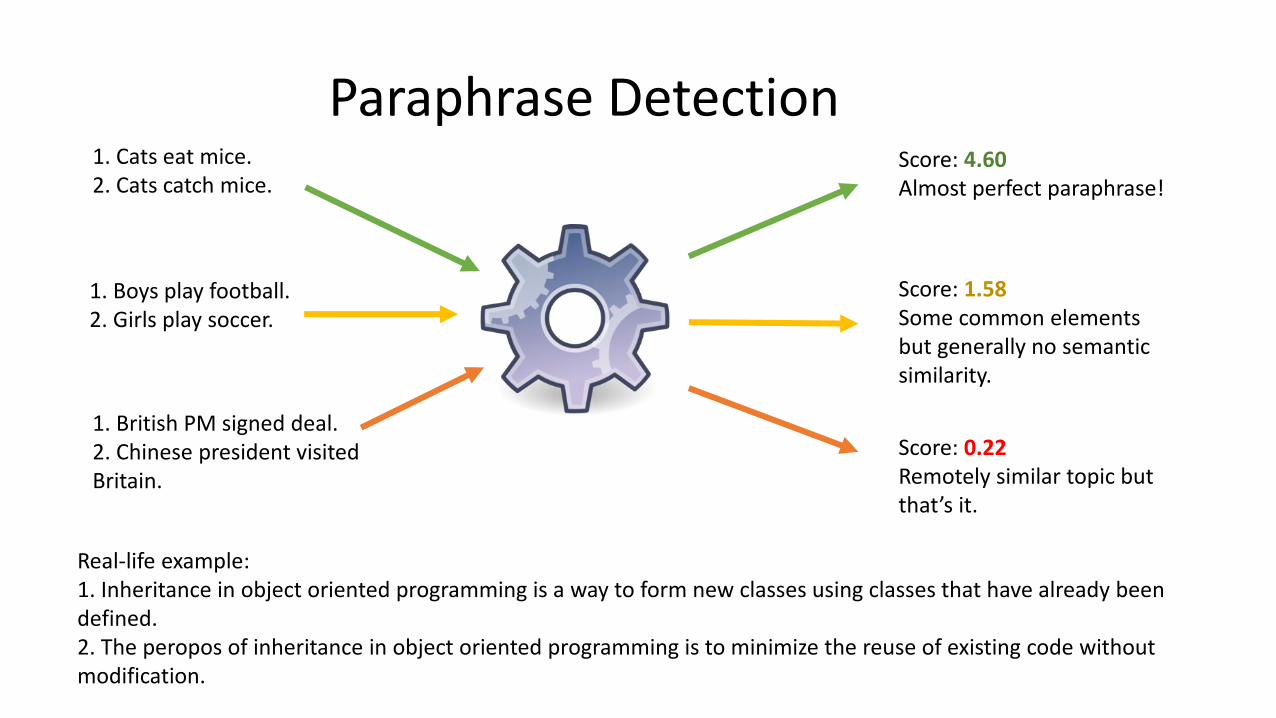
Paraphrase Detection1. Cats eat mice.2. Cats catch mice.
1. Boys play football.2. Girls play soccer.
1. British PM signed deal.2. Chinese president visited Britain.
Score: 4.60Almost perfect paraphrase!
Score: 0.22Remotely similar topic but that’s it.
Score: 1.58Some common elements but generally no semantic similarity.
Real-life example: 1. Inheritance in object oriented programming is a way to form new classes using classes that have already been defined.2. The peropos of inheritance in object oriented programming is to minimize the reuse of existing code without modification.
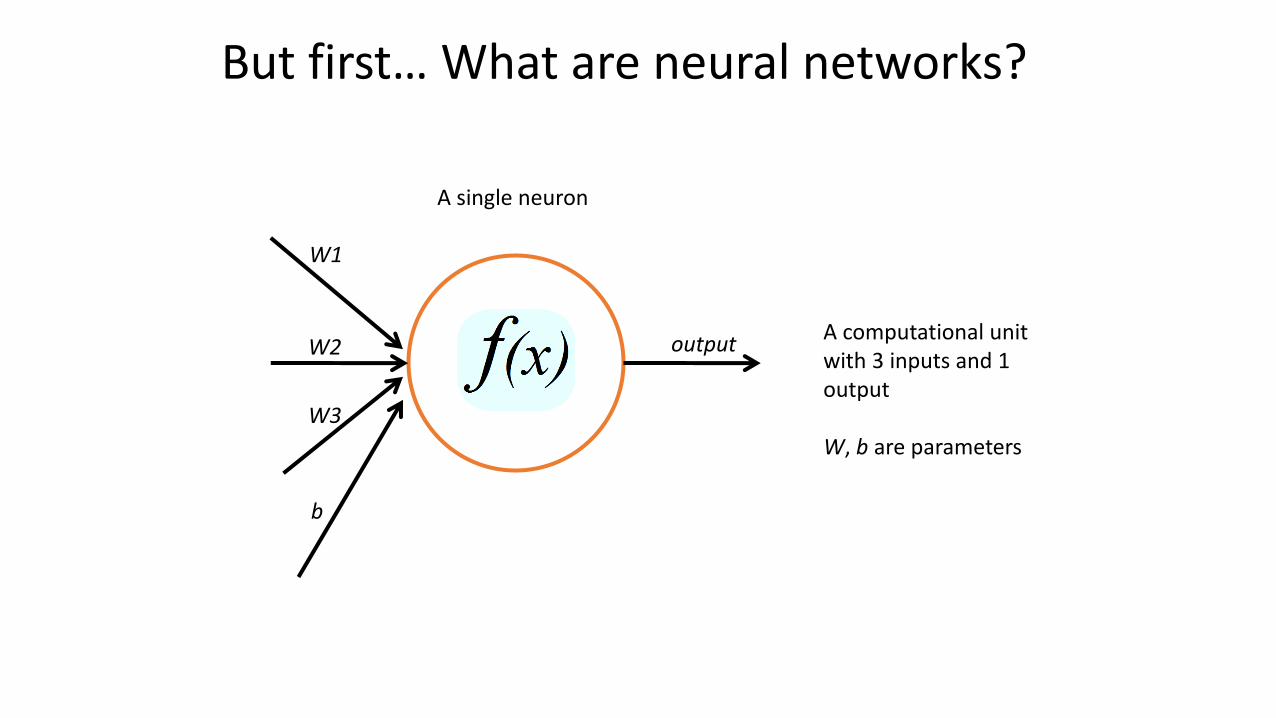
But first… What are neural networks?
A single neuron
A computational unit with 3 inputs and 1 output
W, b are parameters
W1
W2
W3
b
output
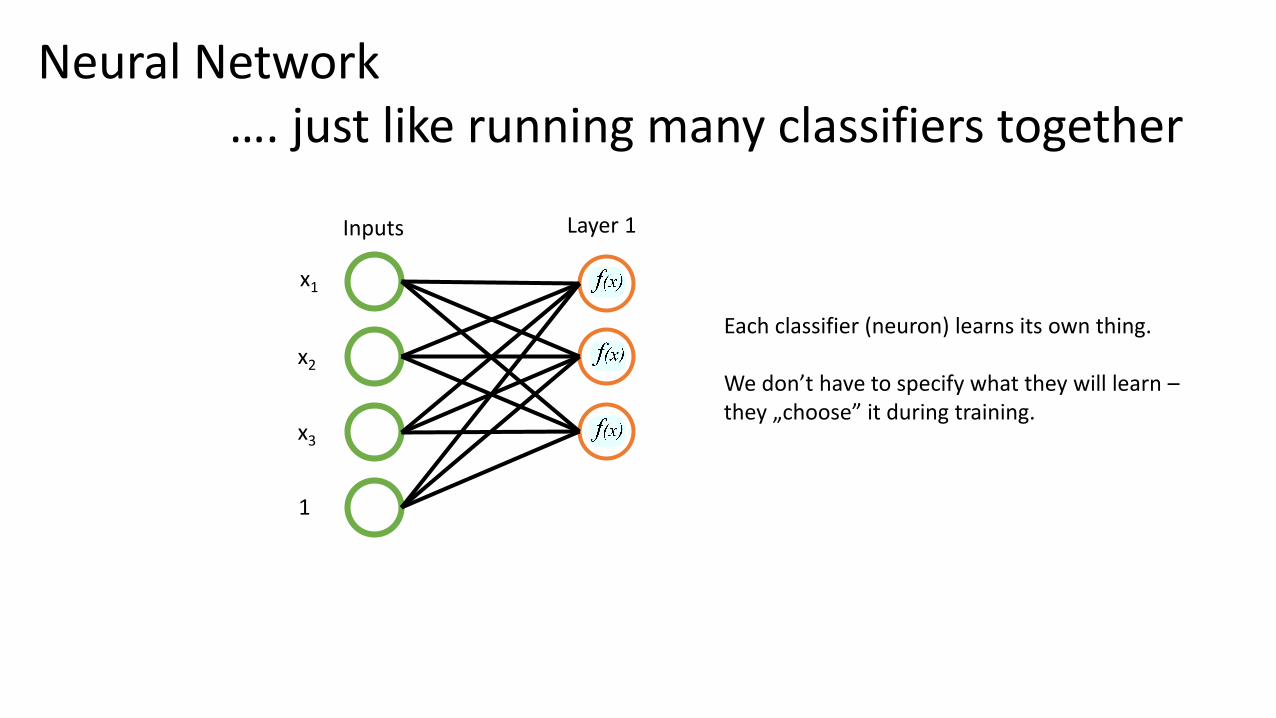
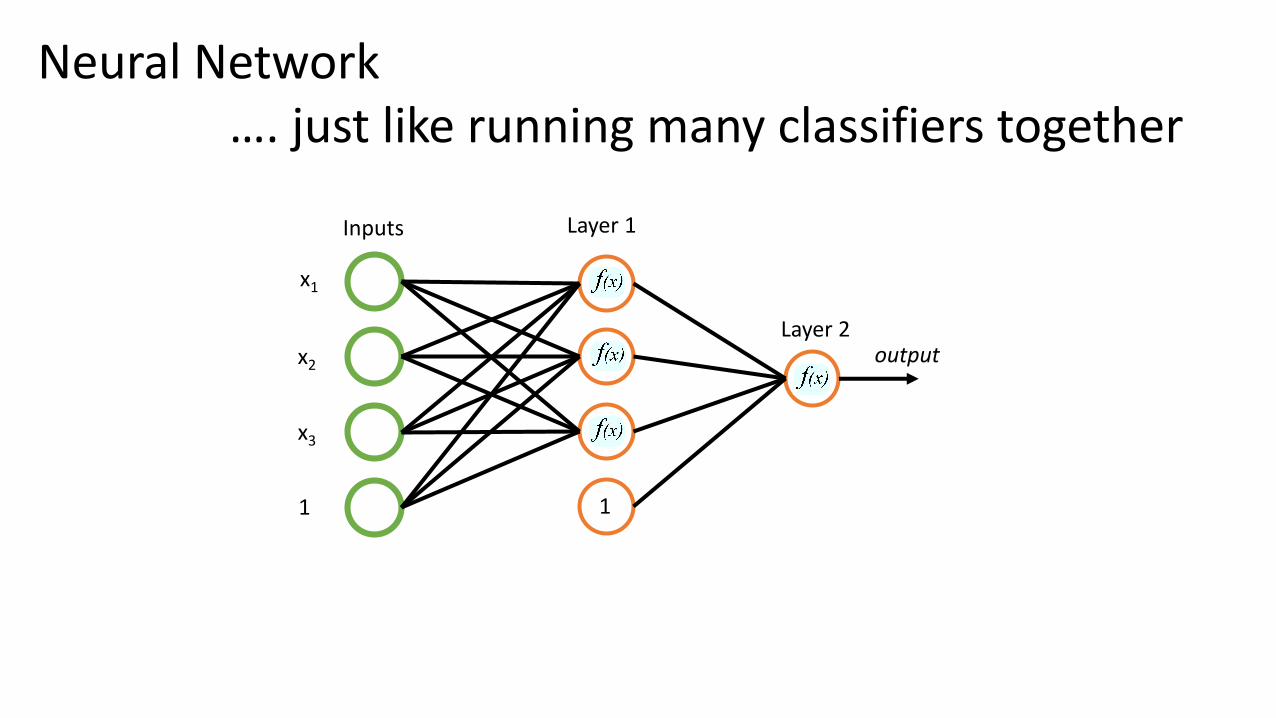
Neural Network…. just like running many classifiers together
x1
x2
x3
1
Inputs
Each classifier (neuron) learns its own thing.
We don’t have to specify what they will learn –they „choose” it during training.
Layer 1
Neural Network…. just like running many classifiers together
x1
x2
x3
1
Layer 2
Inputs
1
Layer 1
output
x1
x2
x3
1
Layer 2
Inputs
1
Layer 1
Neural Network…. just like running many classifiers together

And second… What are word vecor representations?
Traditional approach: words as atomic symbols.
In vector space it a word looks like this:
length equal to the size of full dictionary
[ 0 0 0 0 0 0 1 0 0 0 0 ]a sparse vector (many zeros, one 1).
The problems:• Dimensionality: up to a few dozen million words (vectors) – we face millions of zeros with a single 1.• No semantic similarity is represented.Motel: [ 0 0 0 0 0 1 0 ]Hotel: [ 1 0 0 0 0 0 0 ]
„Motel” AND „Hotel” = 0

How to make it better? An idea
Similar words appear in similar neighborhoods.
Represent words with respect to their neighbor.s
„You shall know a word by the company it keeps.” J.R.Firth 1957
window of length 5 window of length 5

The word representation vector
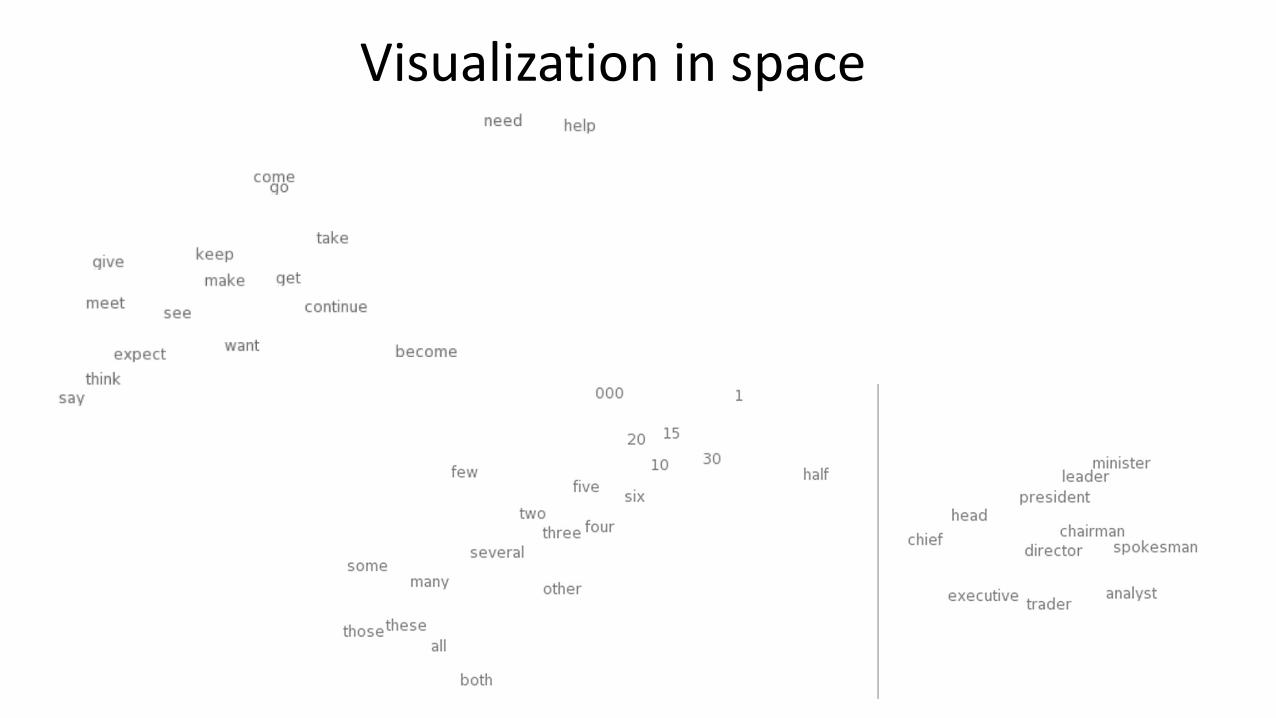
Visualization in space
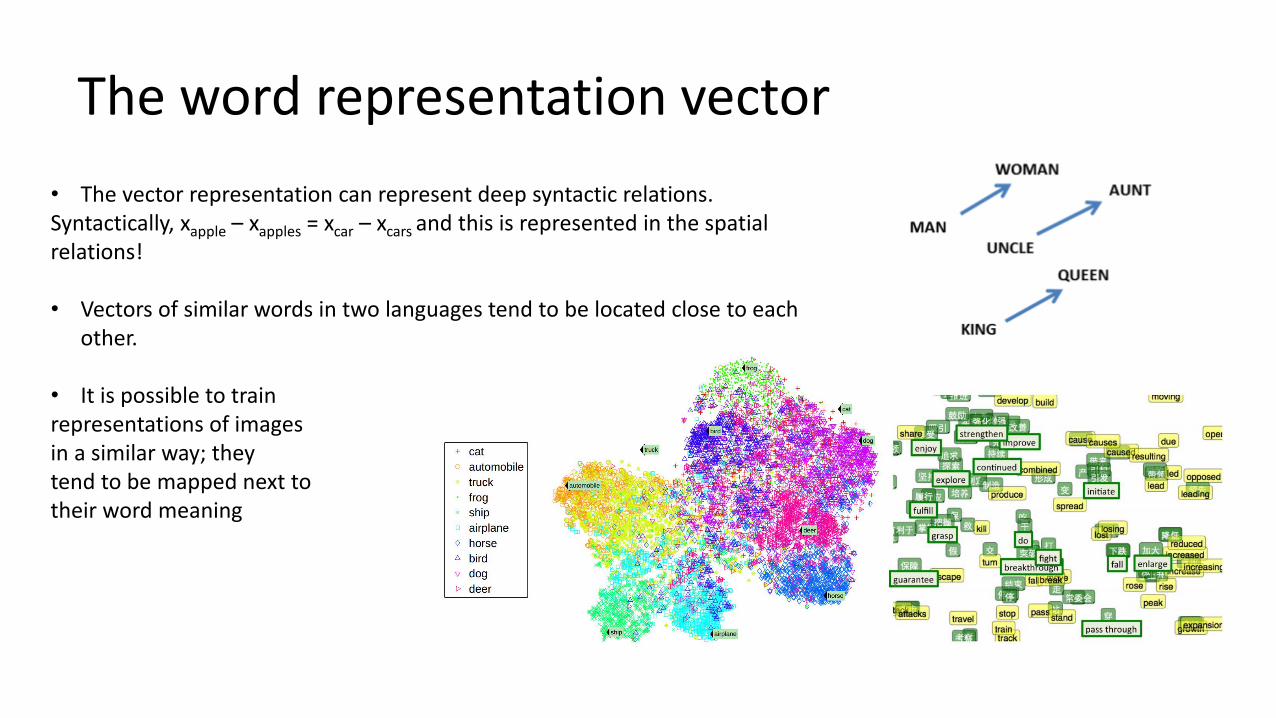
The word representation vector
• The vector representation can represent deep syntactic relations.Syntactically, xapple – xapples = xcar – xcars and this is represented in the spatial relations!
• Vectors of similar words in two languages tend to be located close to each other.
• It is possible to trainrepresentations of images in a similar way; they tend to be mapped next to their word meaning
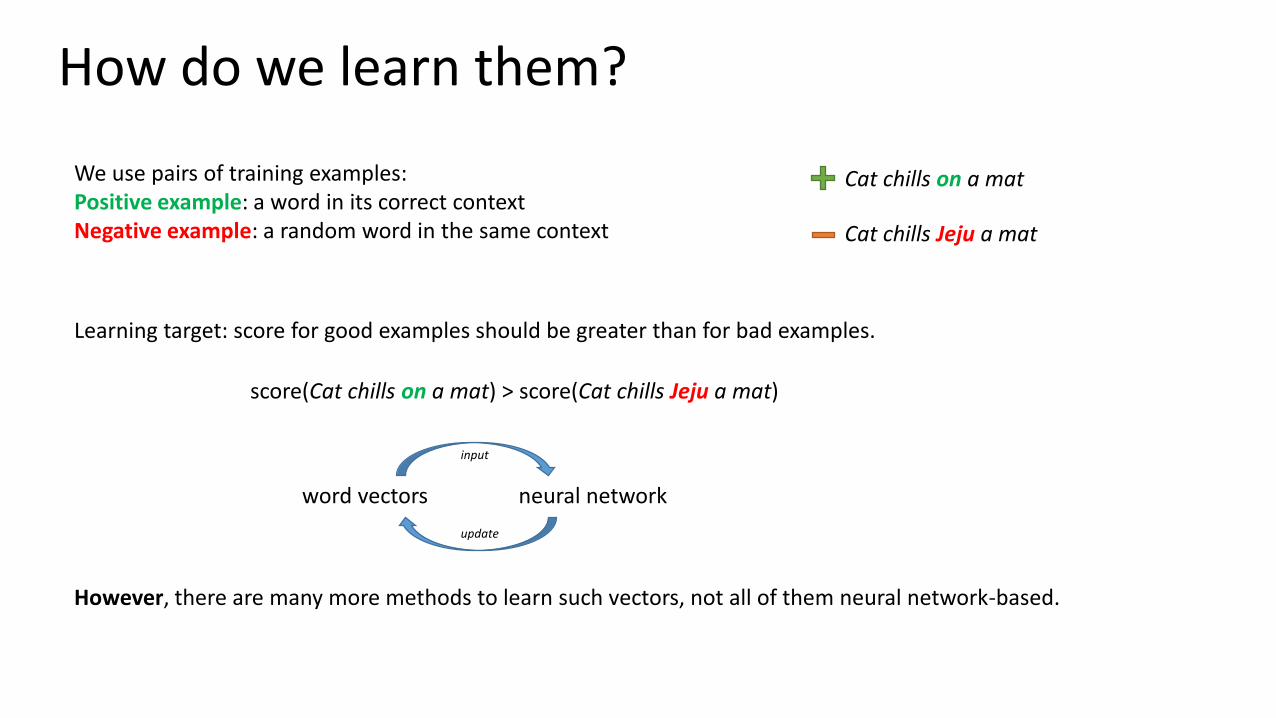
How do we learn them?
We use pairs of training examples:Positive example: a word in its correct contextNegative example: a random word in the same context
Cat chills on a mat
Cat chills Jeju a mat
Learning target: score for good examples should be greater than for bad examples.
score(Cat chills on a mat) > score(Cat chills Jeju a mat)
However, there are many more methods to learn such vectors, not all of them neural network-based.
word vectors neural network
input
update
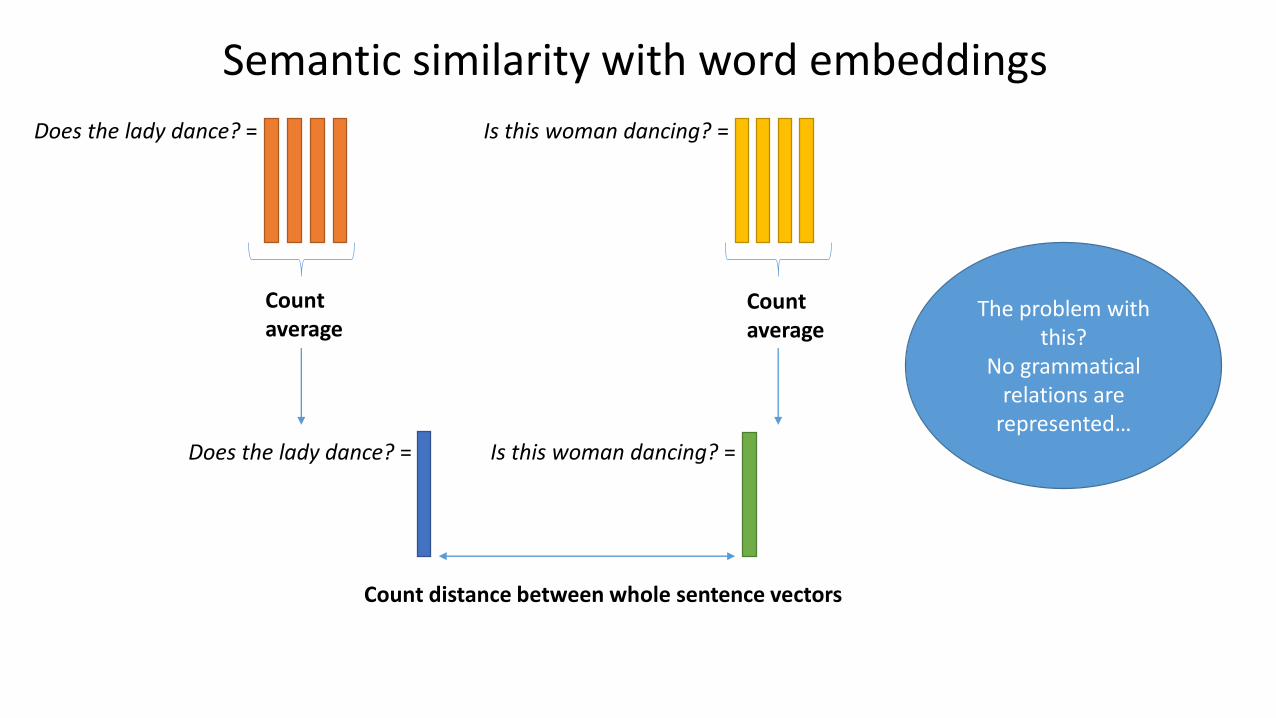
Semantic similarity with word embeddings
Does the lady dance? = Is this woman dancing? =
Count average
Count average
Does the lady dance? = Is this woman dancing? =
Count distance between whole sentence vectors
The problem with this?
No grammatical relations are
represented…
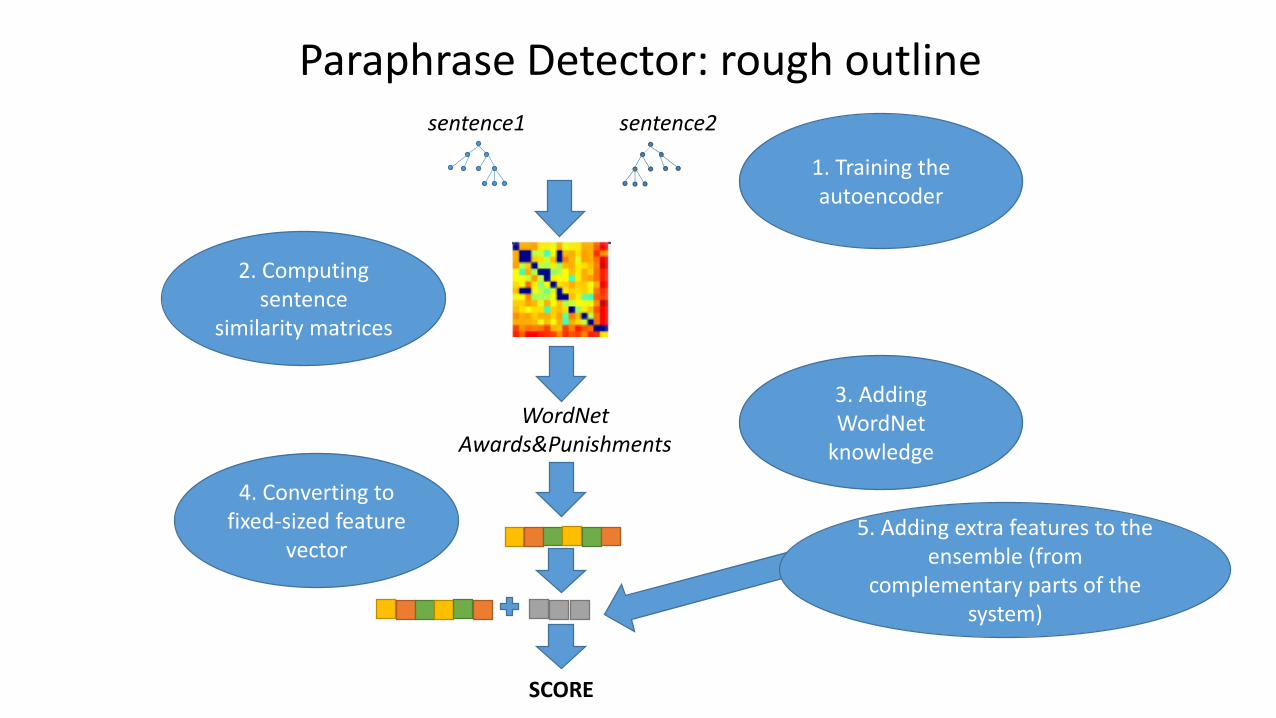
Paraphrase Detector: rough outlinesentence1 sentence2
1. Training the autoencoder
3. Adding WordNet
knowledge
WordNet Awards&Punishments
2. Computing sentence
similarity matrices
4. Converting to fixed-sized feature
vector5. Adding extra features to the
ensemble (from complementary parts of the
system)
SCORE

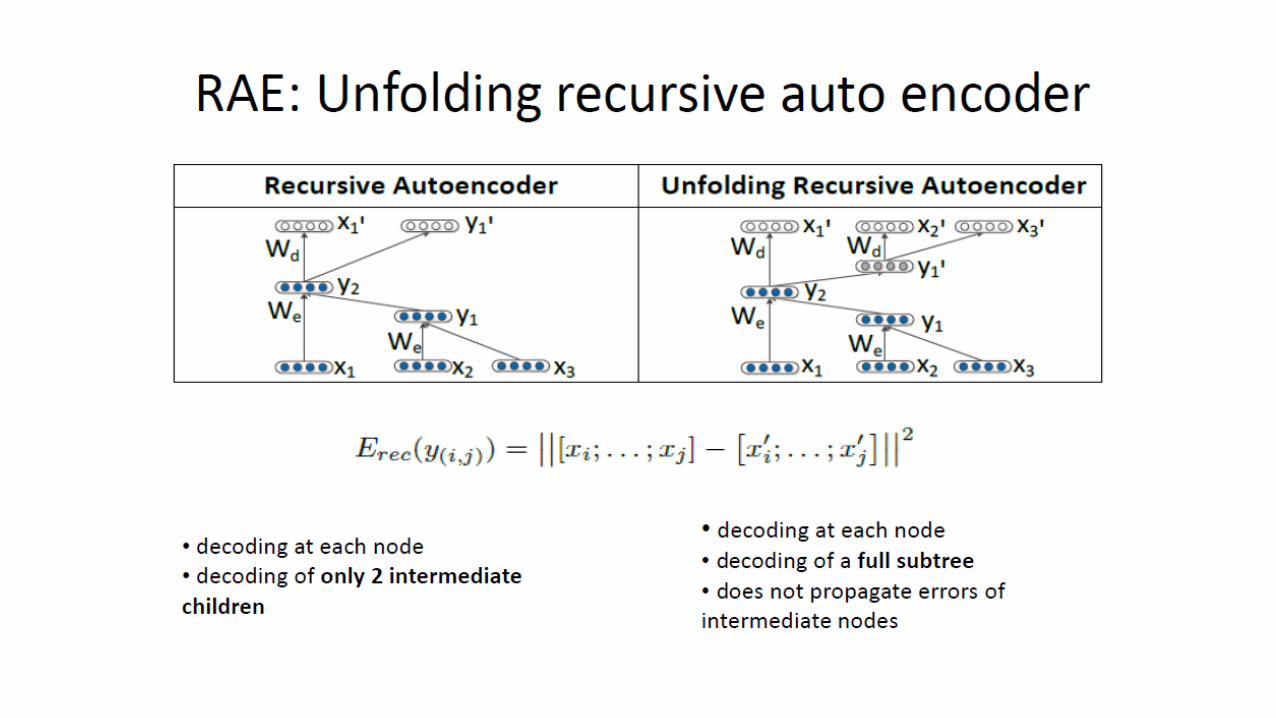

The
womenThe women swimming
in the morningswimming
in
the morning
Sentence: The women swimming in the morning
Natural parse tree
Artificially binarized parse tree(a possibility – not an actual tree)
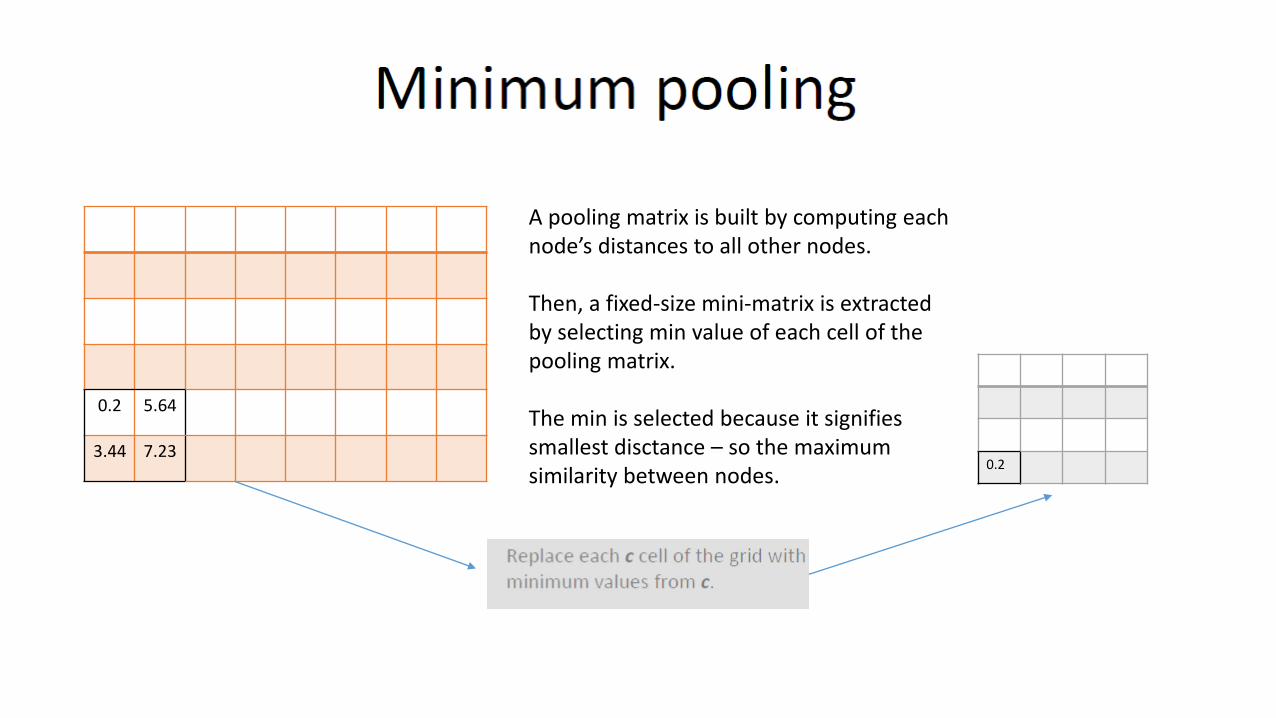
0.2 5.64
3.44 7.230.2
A pooling matrix is built by computing each node’s distances to all other nodes.
Then, a fixed-size mini-matrix is extracted by selecting min value of each cell of the pooling matrix.
The min is selected because it signifies smallest disctance – so the maximum similarity between nodes.
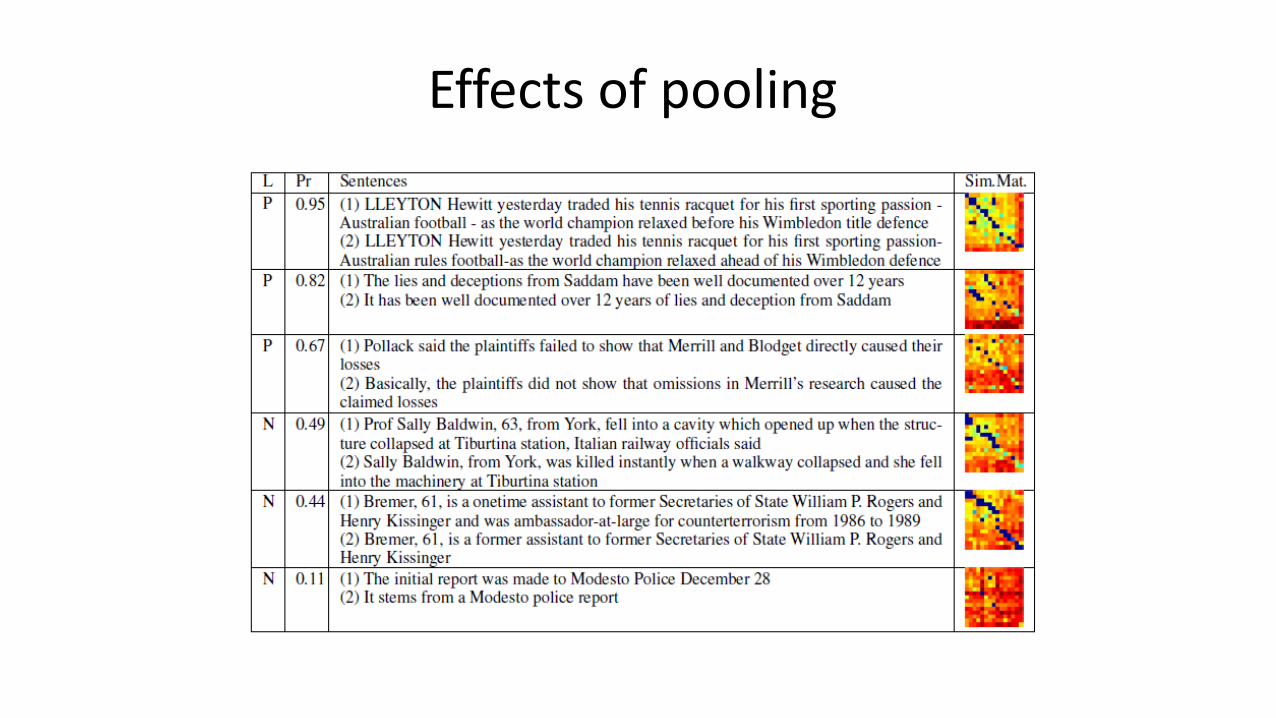
Effects of pooling
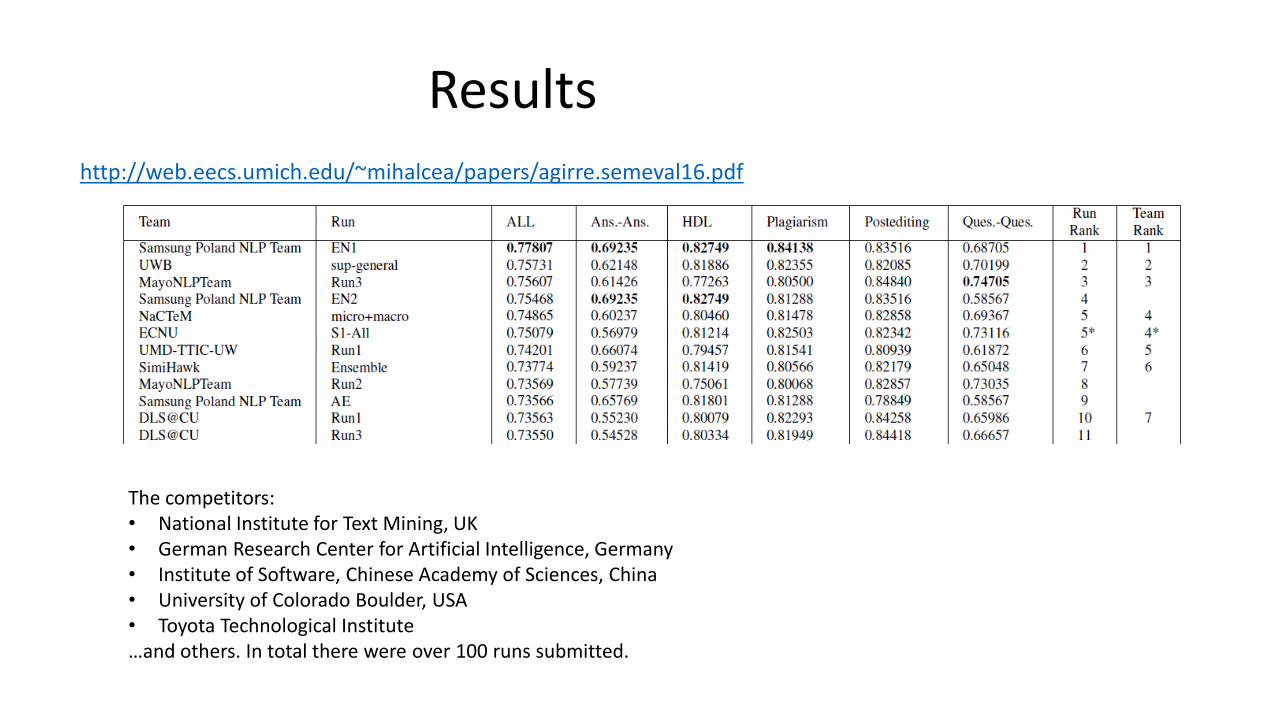
http://web.eecs.umich.edu/~mihalcea/papers/agirre.semeval16.pdf
Results
The competitors:• National Institute for Text Mining, UK• German Research Center for Artificial Intelligence, Germany• Institute of Software, Chinese Academy of Sciences, China• University of Colorado Boulder, USA• Toyota Technological Institute…and others. In total there were over 100 runs submitted.

Bibliography
• Barbara Rychalska, Katarzyna Pakulska, Krystyna Chodorowska, Wojciech Walczak and Piotr Andruszkiewicz; Samsung Poland NLP Team at SemEval-2016 Task 1: Necessity for diversity; combining recursive autoencoders, WordNet and ensemble methods to measure semantic similarity.
• Our presentation at IPI PAN: http://zil.ipipan.waw.pl/seminarium-archiwum?action=AttachFile&do=view&target=2016-10-10.pdf
• Some ideas and images in ths presentation: http://www.socher.org/index.php/DeepLearningTutorial/DeepLearningTutorial
• http://colah.github.io/posts/2014-07-NLP-RNNs-Representations/





























