Embed Size (px)
Citation preview

Spark @ Couchbase Connect John Tripier, [email protected] Michael Nitschinger, Couchbase June, 2015

What is Apache Spark?
Fast and general engine for big data processing with libraries for advanced analytics Most active open source project in big data

Founded by the creators of Spark in 2013 Most active organization contributing to Spark
– 3/4 of the code in 2014
Created Databricks Cloud, a cloud-based big data platform on top of Spark to make big data simple
About Databricks

2014: an Amazing Year for Spark
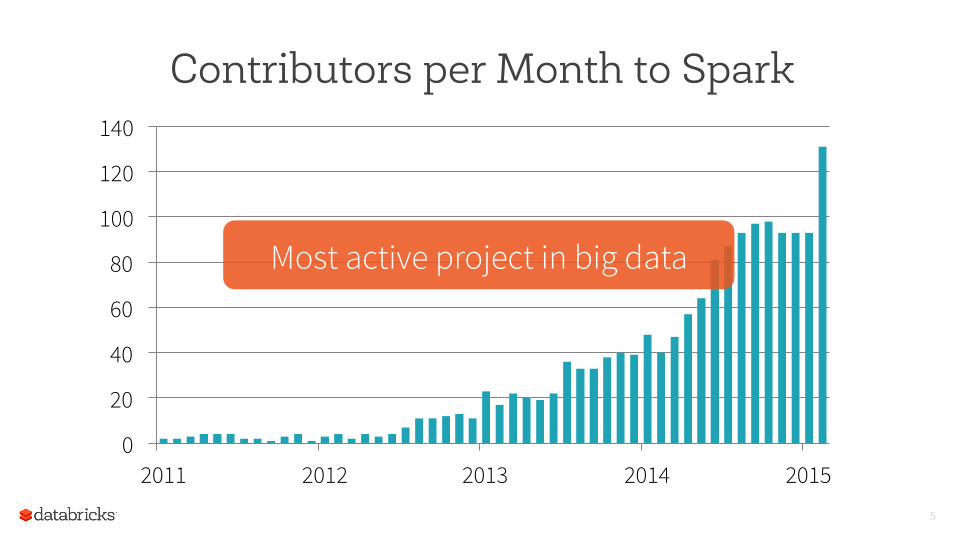
Total contributors: 150 => 500
Lines of code: 190K => 370K
500+ active production deployments
4
0
20
40
60
80
100
120
140
2011 2012 2013 2014 2015
Contributors per Month to Spark
Most active project in big data
5

6
On-Disk Sort Record: Time to sort 100TB
Source: Daytona GraySort benchmark, sortbenchmark.org
2100 machines 2013 Record: Hadoop
72 minutes
2014 Record: Spark
207 machines
23 minutes
2015 Project Tungsten: memory and CPU for Spark applications
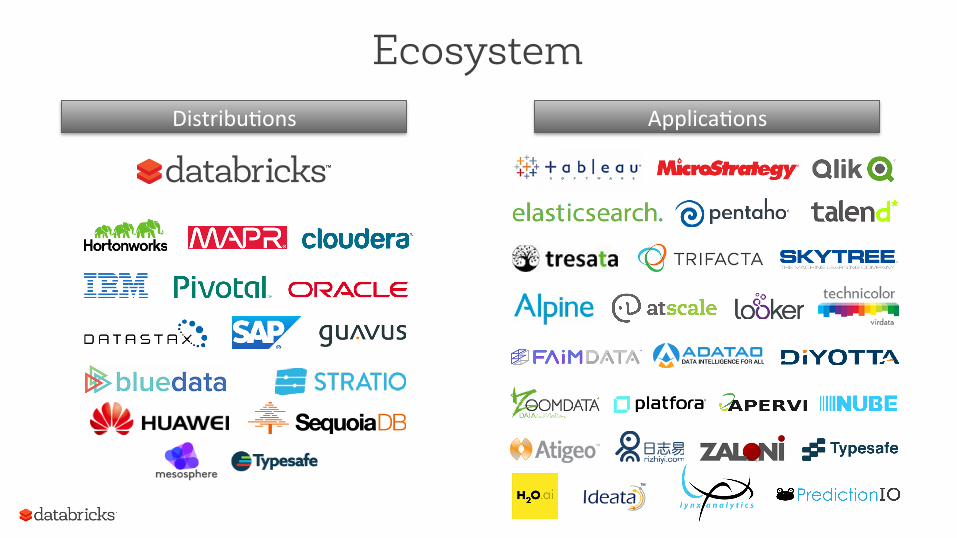
Ecosystem Distribu(ons Applica(ons
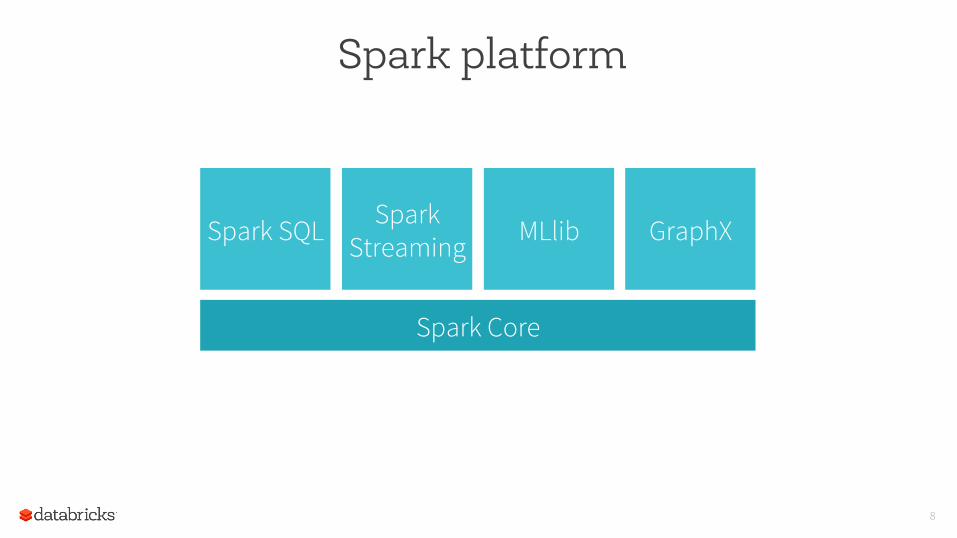
8
Spark Core
Spark Streaming
Spark SQL MLlib GraphX
Spark platform

9
New Directions in 2015
Data Science High-level interfaces similar
to single-machine tools
Platform Interfaces Plug in data sources
and algorithms

10
DataFrames Similar API to data frames in R and Pandas
Automatically optimized via Spark SQL
0
5
10
Python Scala DataFrame Ru
nnin
g Ti
me
A distributed collection of data grouped into named columns Faster and easier for Spark developers to work with structured data by providing simplified methods for filtering, aggregating, and projecting over large datasets
11
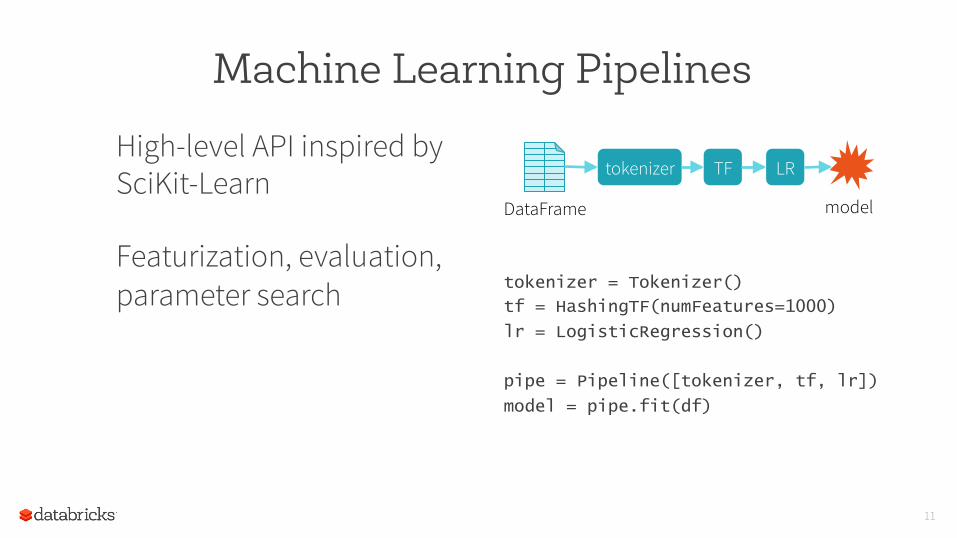
Machine Learning Pipelines
High-level API inspired by SciKit-Learn
Featurization, evaluation, parameter search tokenizer = Tokenizer()
tf = HashingTF(numFeatures=1000)
lr = LogisticRegression()
pipe = Pipeline([tokenizer, tf, lr])
model = pipe.fit(df)
tokenizer TF LR
model DataFrame

12
R Interface (SparkR)
Targeting Spark 1.4 (June)
Exposes DataFrames, RDDs, and ML library in R
df = jsonFile(“tweets.json”)
summarize(
group_by(
df[df$user == “matei”,],
“date”),
sum(“retweets”))

13
New Directions in 2015
Data Science High-level interfaces similar
to single-machine tools
Platform Interfaces Plug in data sources
and algorithms
14
External Data Sources
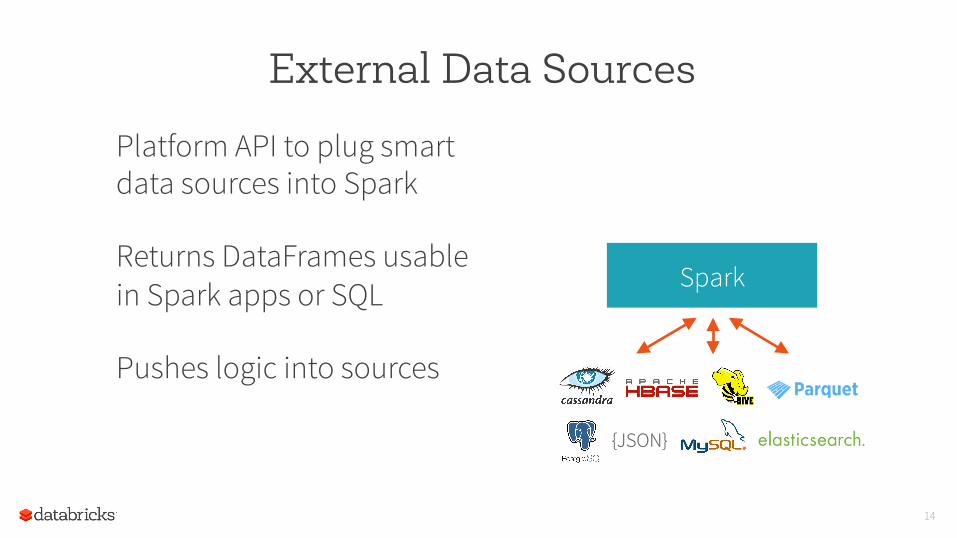
Platform API to plug smart data sources into Spark
Returns DataFrames usable in Spark apps or SQL
Pushes logic into sources
Spark
{JSON}
15
External Data Sources
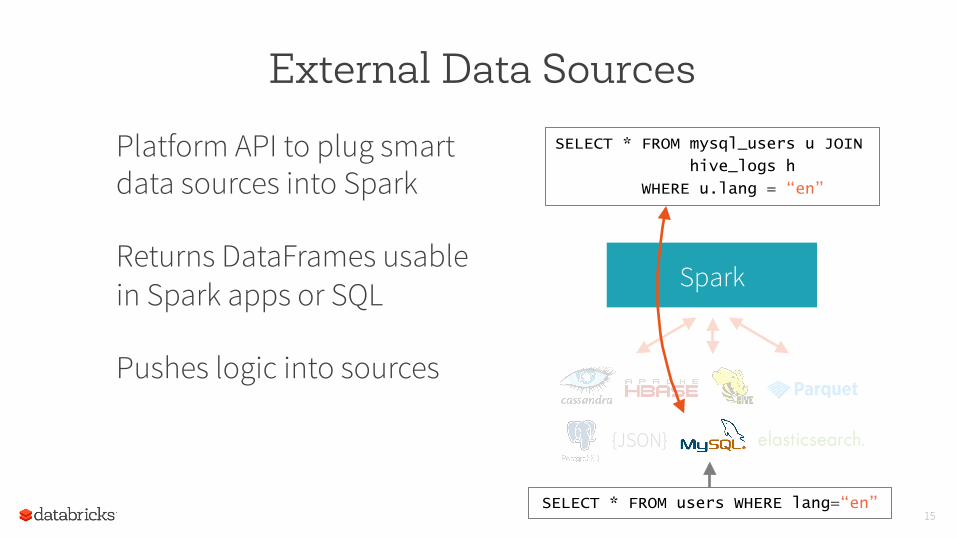
Platform API to plug smart data sources into Spark
Returns DataFrames usable in Spark apps or SQL
Pushes logic into sources
SELECT * FROM mysql_users u JOIN
hive_logs h
WHERE u.lang = “en”
Spark
{JSON}
SELECT * FROM users WHERE lang=“en”
16
{JSON}
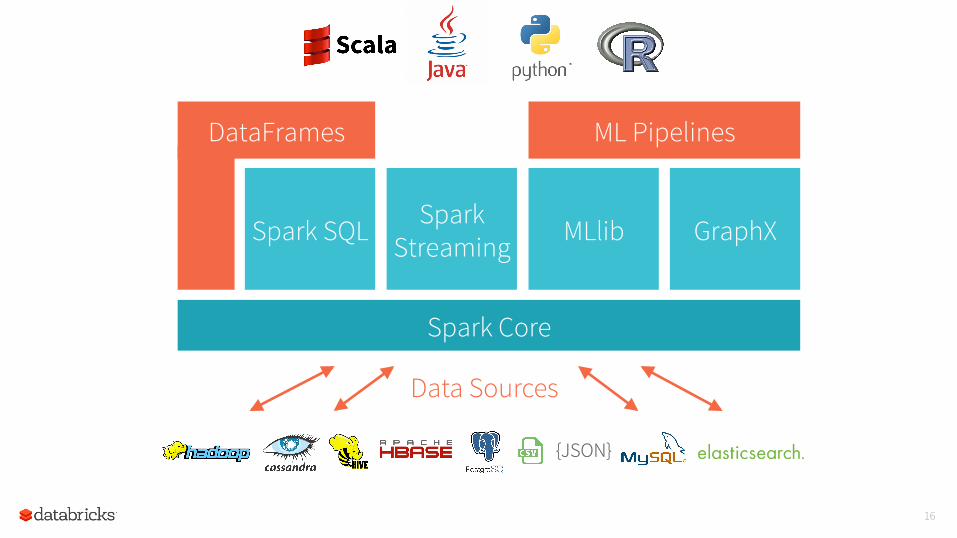
Data Sources
Spark Core
DataFrames ML Pipelines
Spark Streaming
Spark SQL MLlib GraphX
17
{JSON}
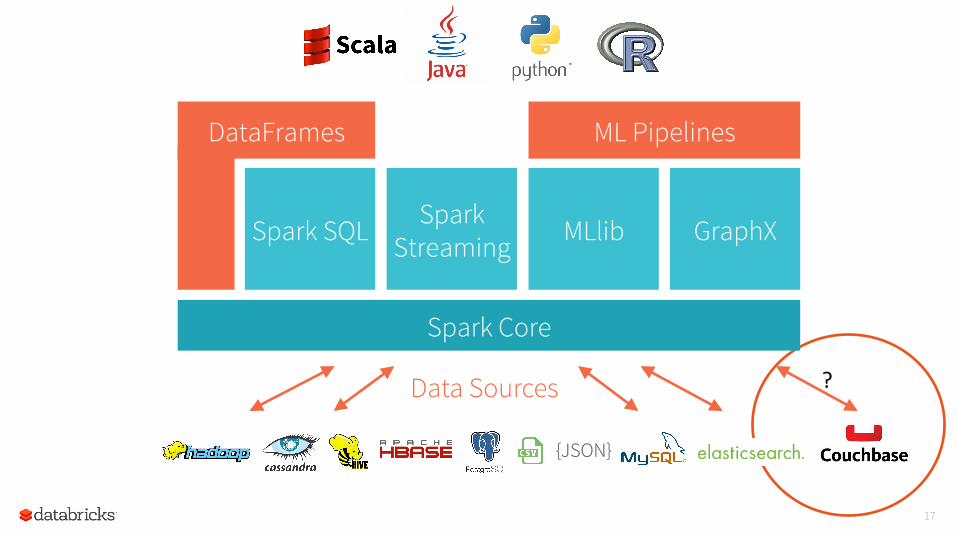
Data Sources
Spark Core
DataFrames ML Pipelines
Spark Streaming
Spark SQL MLlib GraphX
?

18
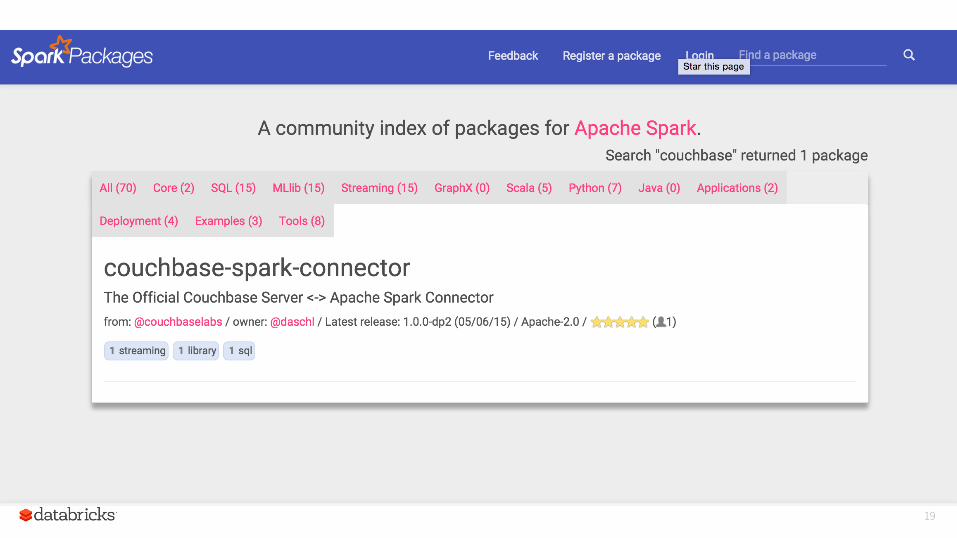
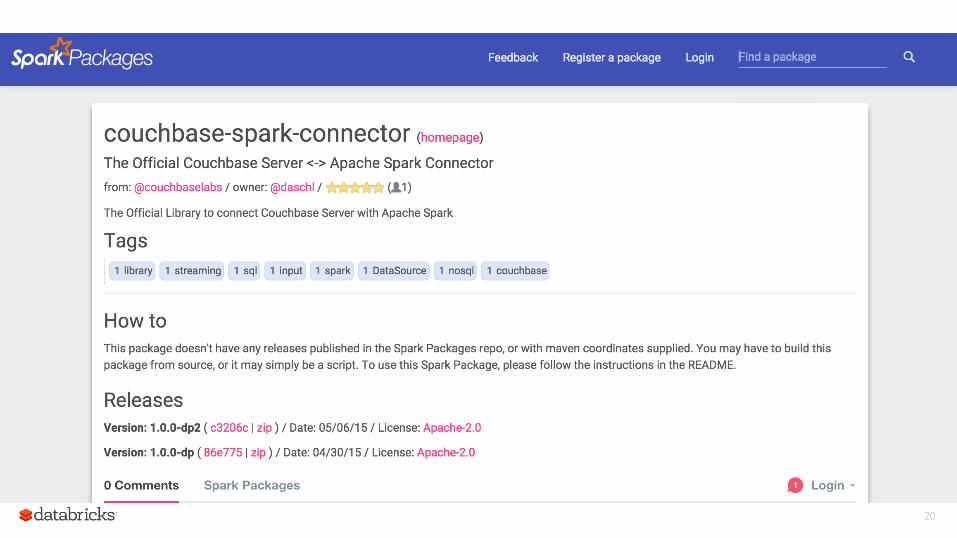
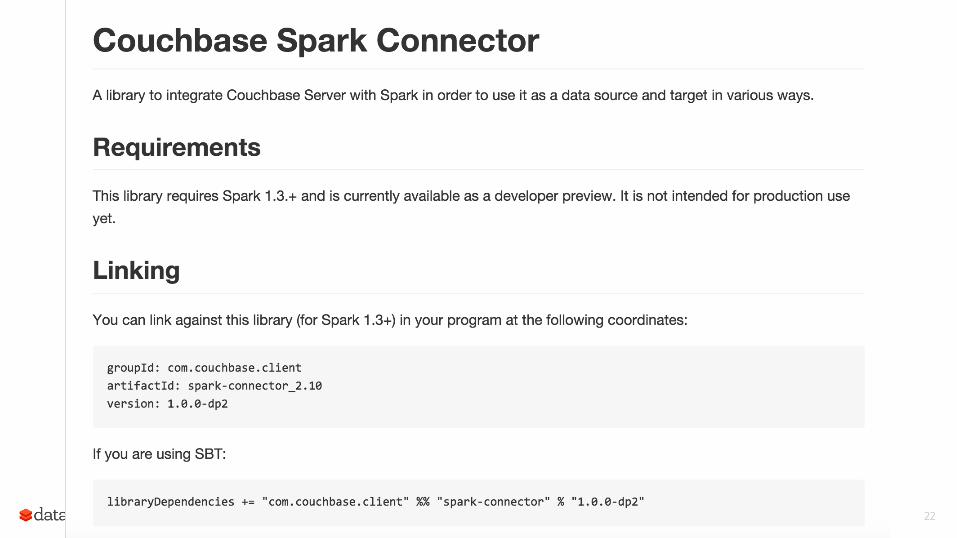
Spark Packages
Community index of third party packages bin/spark-shell --packages databricks/spark-csv:0.2 spark-packages.org
19
20
21
22
23

Demo
24
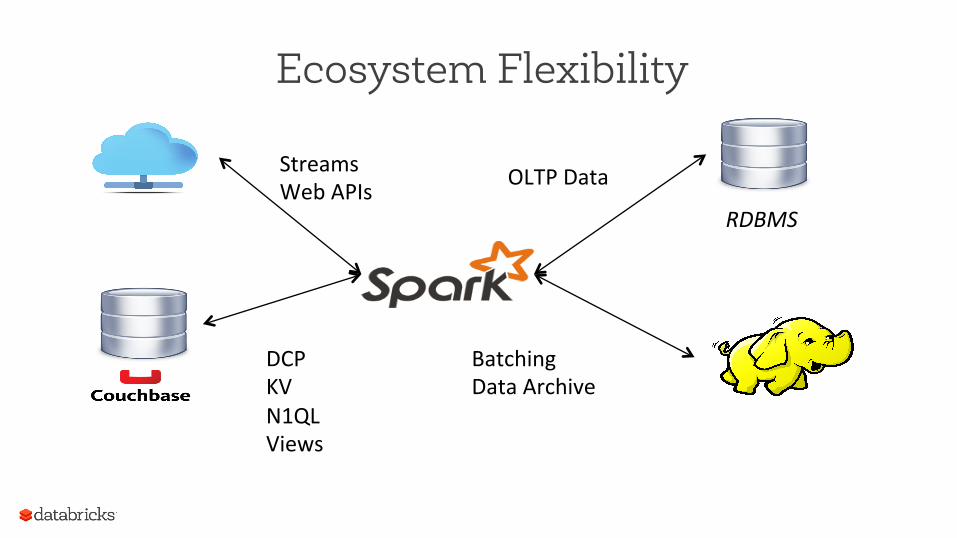
Ecosystem Flexibility
RDBMS
Streams Web APIs
DCP KV N1QL Views
Batching Data Archive
OLTP Data
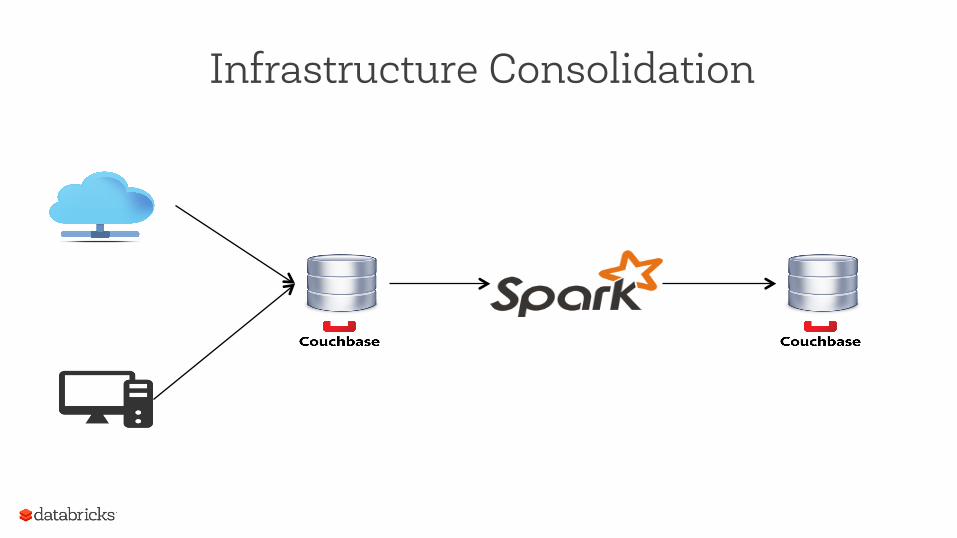
Infrastructure Consolidation

To Learn More
Two free massive online courses (MOOCs) on Big Data and Spark: http://databricks.com/moocs
Couchbase Spark Package: http://spark-packages.org/?q=couchbase
Try Databricks Cloud: databricks.com Email me at [email protected]
27

Thank you
28





























