Embed Size (px)
Citation preview

Cormac Hogan - @CormacJHoganDuncan Epping - @DuncanYB
STO1264BU
#VMworld #STO1264BU
Top 10 things to know about VMware vSAN

• This presentation may contain product features that are currently under development.
• This overview of new technology represents no commitment from VMware to deliver these features in any generally available product.
• Features are subject to change, and must not be included in contracts, purchase orders, or sales agreements of any kind.
• Technical feasibility and market demand will affect final delivery.
• Pricing and packaging for any new technologies or features discussed or presented have not been determined.
Disclaimer
2

Agenda
1. vSAN is Object Storage (Duncan)
2. How vSAN survives Device, Host, Rack and Site Failures (Cormac)
3. Which features are not policy driven (Duncan)
4. The impact of changing a policy on the fly (Cormac)
5. Things you may not know about the Health Check (Duncan)
6. Troubleshooting options you may not know about (Cormac)
7. Things to know about dealing with disk replacements (Duncan)
8. The impact of unicast on vSAN network topologies (Cormac)
9. Getting the most out of Monitoring and Logging (Duncan)
10. Understanding congestion and how to avoid it (Cormac)

#10vSAN is Object Based Storage
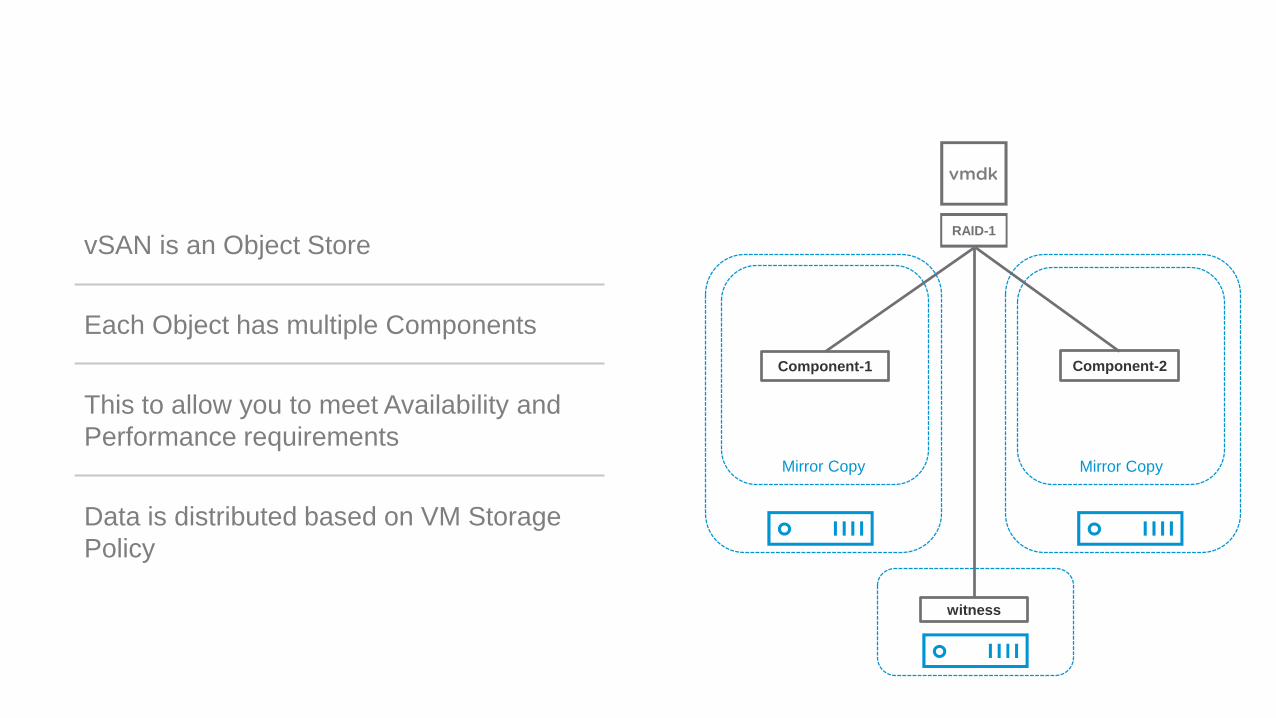
Component-2
Mirror Copy
Component-1
witness
Mirror Copy
RAID-1
vSAN is an Object Store
Each Object has multiple Components
This to allow you to meet Availability and
Performance requirements
Data is distributed based on VM Storage
Policy
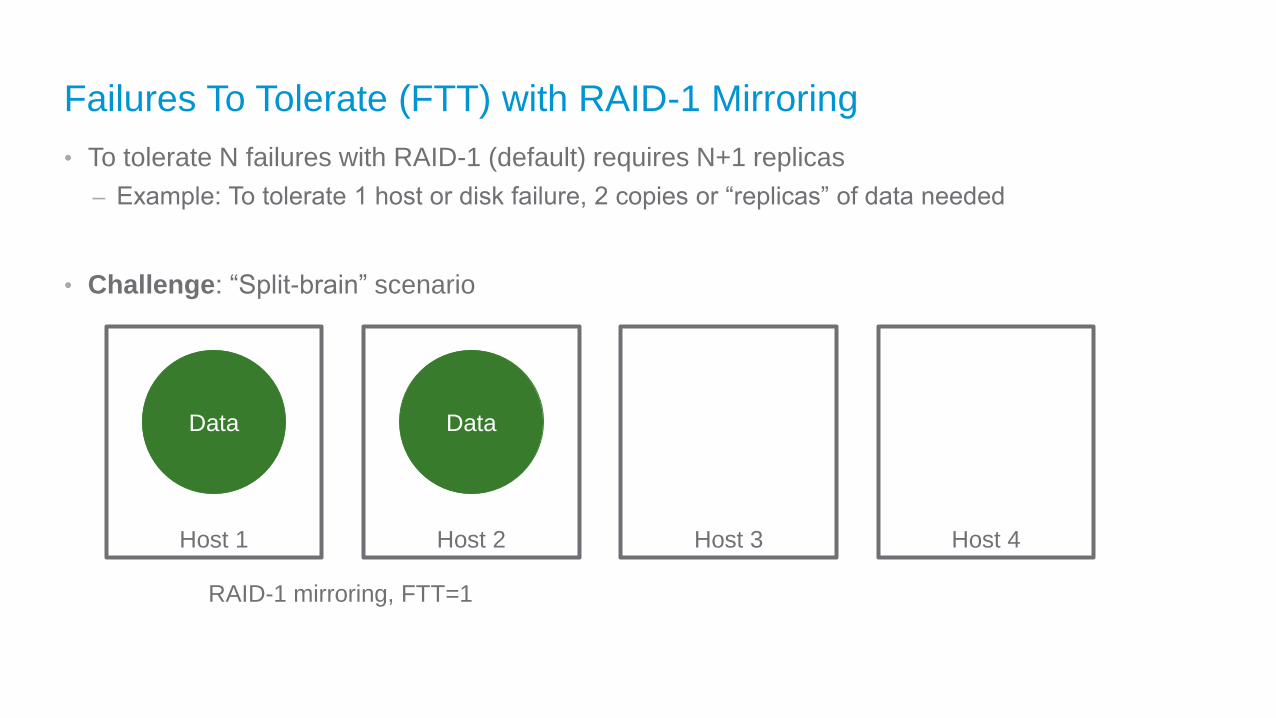
Failures To Tolerate (FTT) with RAID-1 Mirroring
• To tolerate N failures with RAID-1 (default) requires N+1 replicas
– Example: To tolerate 1 host or disk failure, 2 copies or “replicas” of data needed
• Challenge: “Split-brain” scenario
DataData
Host 1 Host 2 Host 3 Host 4
RAID-1 mirroring, FTT=1

Failures To Tolerate (FTT) with RAID-1 Mirroring - Witness
• To tolerate N failures requires N+1 replicas and 2N+1 hosts in the cluster
• For an object to remain active, requires >50% of components votes.
• If 2N+1 is not satisfied by components, witness added – serves as “tie-breaker”
• Witness component provides quorum.
WitnessDataData
Host 1 Host 2 Host 3 Host 4
RAID-1 mirroring, FTT=1

Querying votes with esxcli vsan debug object list
[root@esx-01a:~] esxcli vsan debug object list
Object UUID: 51914759-1dfc-6147-4065-00505601dfda
Version: 5
Health: healthy
Owner: esx-01a.corp.local
<snip>
RAID_1
Component: 51914759-9ad9-b54a-9297-00505601dfda
Component State: ACTIVE, Address Space(B): 273804165120 (255.00GB), Disk UUID: 52b339dd-
75d2-f31f-b4e9-8ecaaf9c57b9, Disk Name: mpx.vmhba3:C0:T0:L0:2 Votes: 1, Capacity Used(B): 402653184
(0.38GB), Physical Capacity Used(B): 398458880 (0.37GB), Host Name: esx-02a.corp.local
Component: 51914759-0b3f-b94a-6bfa-00505601dfda
Component State: ACTIVE, Address Space(B): 273804165120 (255.00GB), Disk UUID: 529f5f2c-
d289-7424-906c-b7ff0d2a1542, Disk Name: mpx.vmhba4:C0:T0:L0:2 Votes: 1, Capacity Used(B): 406847488
(0.38GB), Physical Capacity Used(B): 402653184 (0.38GB), Host Name: esx-01a.corp.local
Witness: 51914759-fb72-bb4a-51c8-00505601dfda
Component State: ACTIVE, Address Space(B): 0 (0.00GB), Disk UUID: 5270e262-b795-cc58-f8a3-
6011e81b4faa, Disk Name: mpx.vmhba3:C0:T0:L0:2 Votes: 1, Capacity Used(B): 12582912
(0.01GB), Physical Capacity Used(B): 4194304 (0.00GB), Host Name: esx-03a.corp.local
New in vSAN 6.6
Stripe Width vs Chunking due to Component Size
• Number of Disk Stripes per Object has a dependency on the number of available capacity devices per cluster
– Number of Disk Stripes per Object cannot be greater than number of capacity devices
– Striped components from same object cannot reside on the same physical disks
– Components are RAID-0 stripes
• vSAN ‘chunks’ components that are greater than 255GB into multiple smaller components
– Resulting components may reside on the same capacity device
– Components may be considered as RAID-0 concatenation
• vSAN also ‘chunks’ components when the capacity disk size is smaller than the requested VMDK size, e.g. 250GB VMDK, but 200GB physical drive.

#09vSAN can incur
Device, Host, Rack and Site Failures
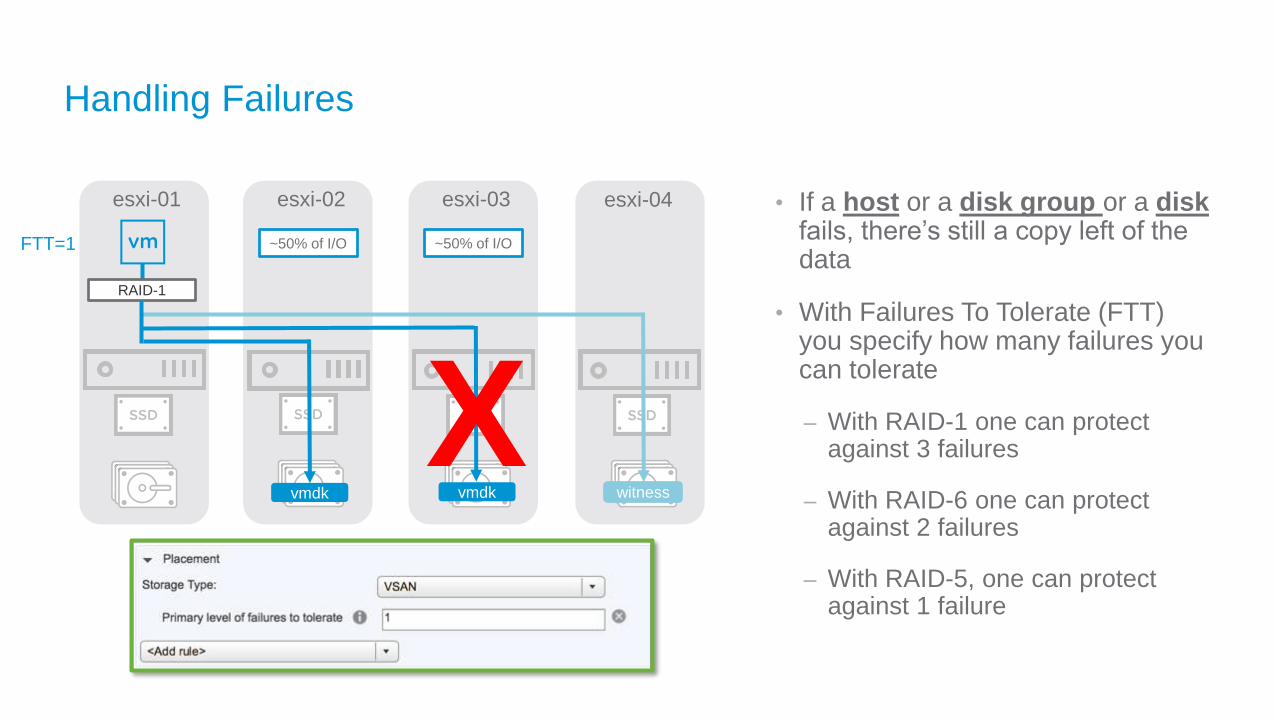
Handling Failures
esxi-01 esxi-02 esxi-03
vmdk
RAID-1
FTT=1
esxi-04
witnessvmdk
~50% of I/O ~50% of I/O
X
• If a host or a disk group or a diskfails, there’s still a copy left of the data
• With Failures To Tolerate (FTT) you specify how many failures you can tolerate
– With RAID-1 one can protect against 3 failures
– With RAID-6 one can protect against 2 failures
– With RAID-5, one can protect against 1 failure
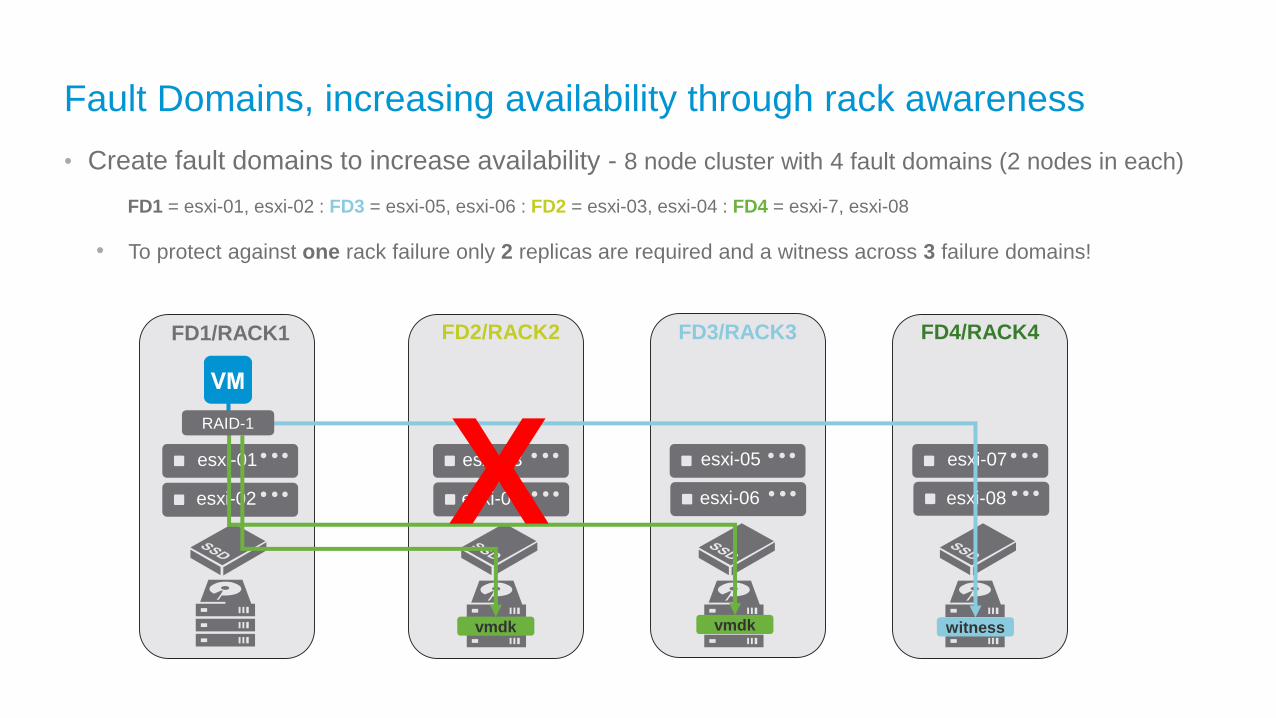
FD2/RACK2
esxi-03
esxi-04
Fault Domains, increasing availability through rack awareness
• Create fault domains to increase availability - 8 node cluster with 4 fault domains (2 nodes in each)
FD1 = esxi-01, esxi-02 : FD3 = esxi-05, esxi-06 : FD2 = esxi-03, esxi-04 : FD4 = esxi-7, esxi-08
• To protect against one rack failure only 2 replicas are required and a witness across 3 failure domains!
14
FD3/RACK3
esxi-05
esxi-06
FD4/RACK4
esxi-07
esxi-08
esxi-01
esxi-02
FD1/RACK1
vmdk vmdk witness
RAID-1
X
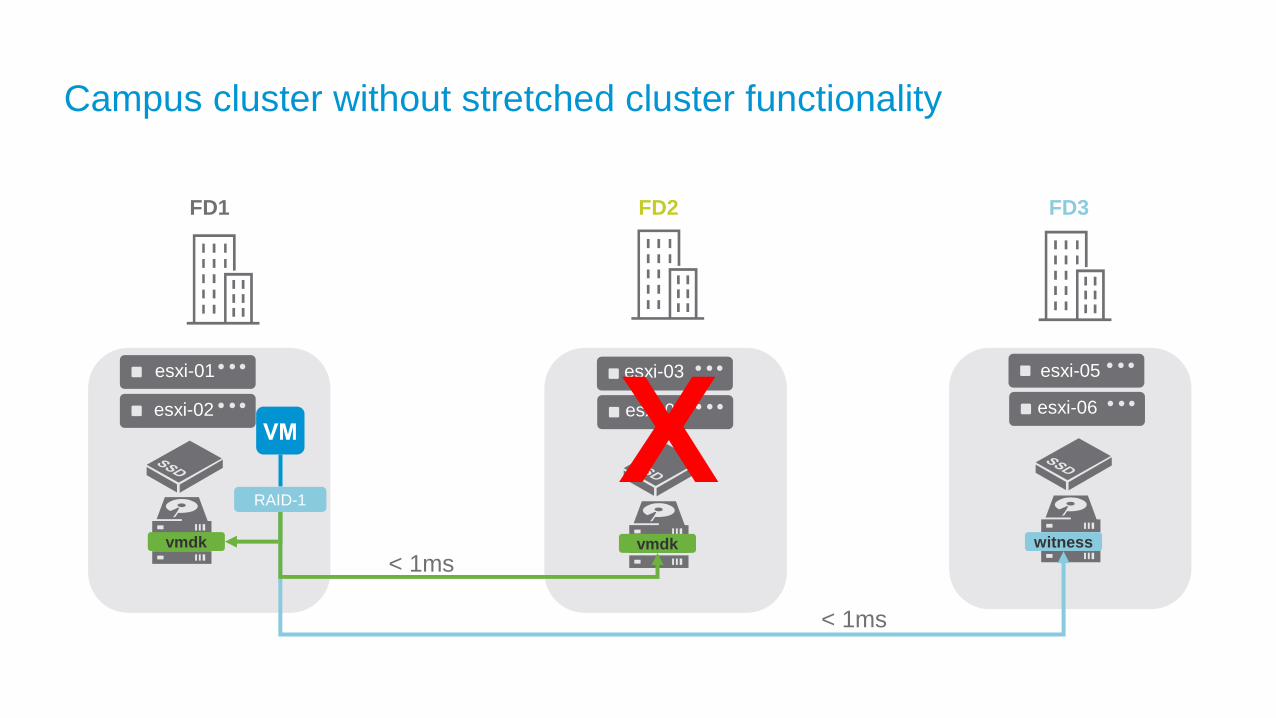
Campus cluster without stretched cluster functionality
FD2 FD3
esxi-01
esxi-02
esxi-03
esxi-04
FD1
vmdk witness
RAID-1
vmdk
Xesxi-05
esxi-06
< 1ms
< 1ms
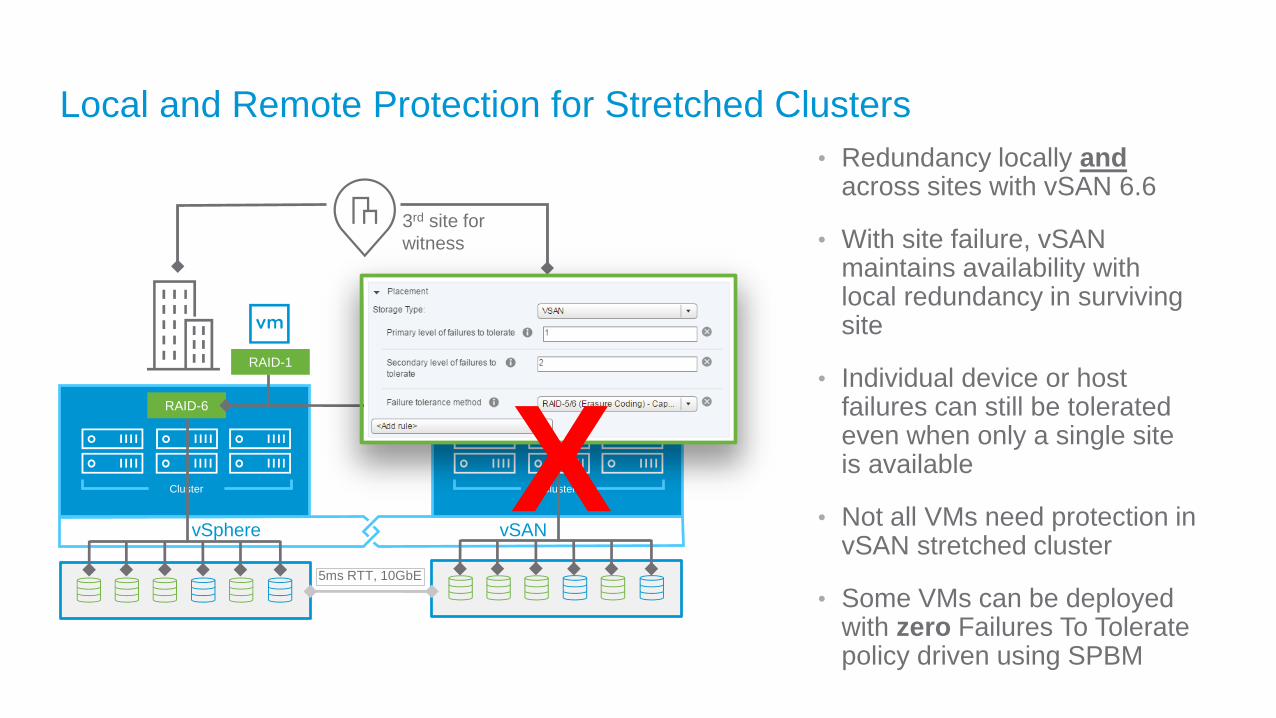
Local and Remote Protection for Stretched Clusters
vSphere vSAN
ClusterCluster
5ms RTT, 10GbE
• Redundancy locally andacross sites with vSAN 6.6
• With site failure, vSAN maintains availability with local redundancy in surviving site
• Individual device or host failures can still be tolerated even when only a single site is available
• Not all VMs need protection in vSAN stretched cluster
• Some VMs can be deployed with zero Failures To Tolerate policy driven using SPBM
RAID-6
3rd site for
witness
RAID-6
RAID-1
X
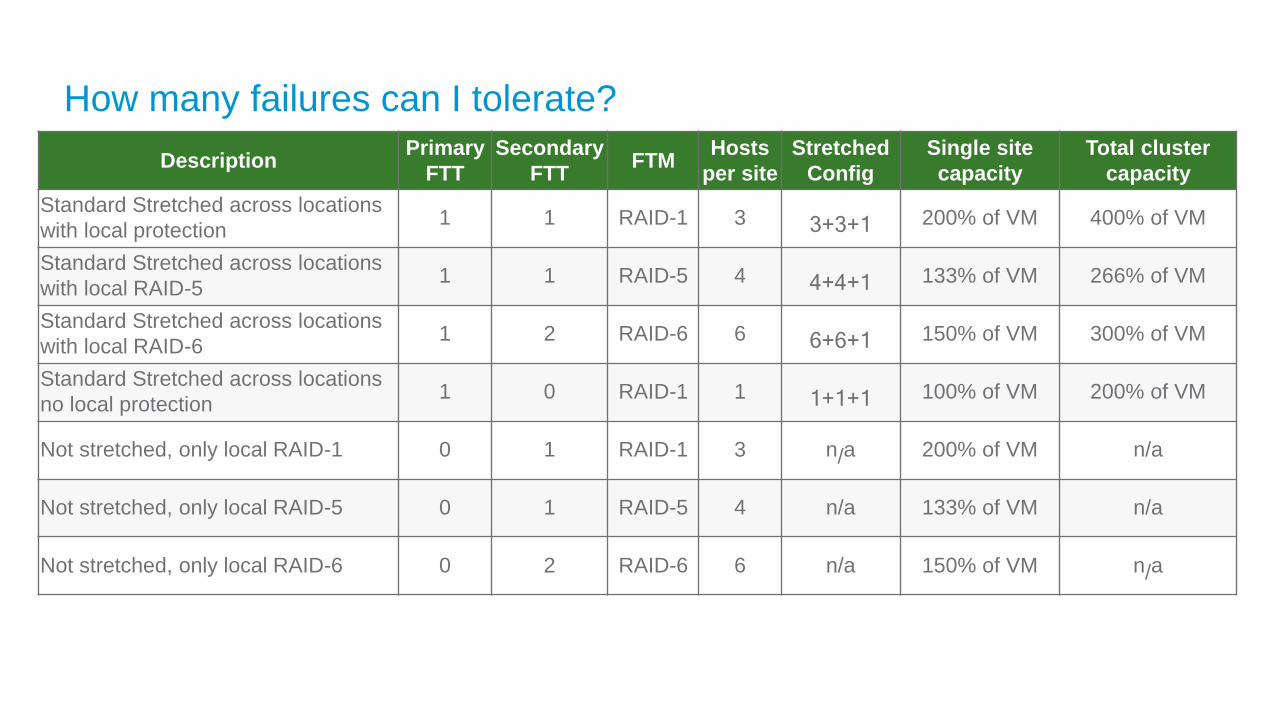
How many failures can I tolerate?
DescriptionPrimary
FTT
Secondary
FTTFTM
Hosts
per site
Stretched
Config
Single site
capacity
Total cluster
capacity
Standard Stretched across locations
with local protection1 1 RAID-1 3 3+3+1 200% of VM 400% of VM
Standard Stretched across locations
with local RAID-51 1 RAID-5 4 4+4+1 133% of VM 266% of VM
Standard Stretched across locations
with local RAID-61 2 RAID-6 6 6+6+1 150% of VM 300% of VM
Standard Stretched across locations
no local protection1 0 RAID-1 1 1+1+1 100% of VM 200% of VM
Not stretched, only local RAID-1 0 1 RAID-1 3 n/a 200% of VM n/a
Not stretched, only local RAID-5 0 1 RAID-5 4 n/a 133% of VM n/a
Not stretched, only local RAID-6 0 2 RAID-6 6 n/a 150% of VM n/a

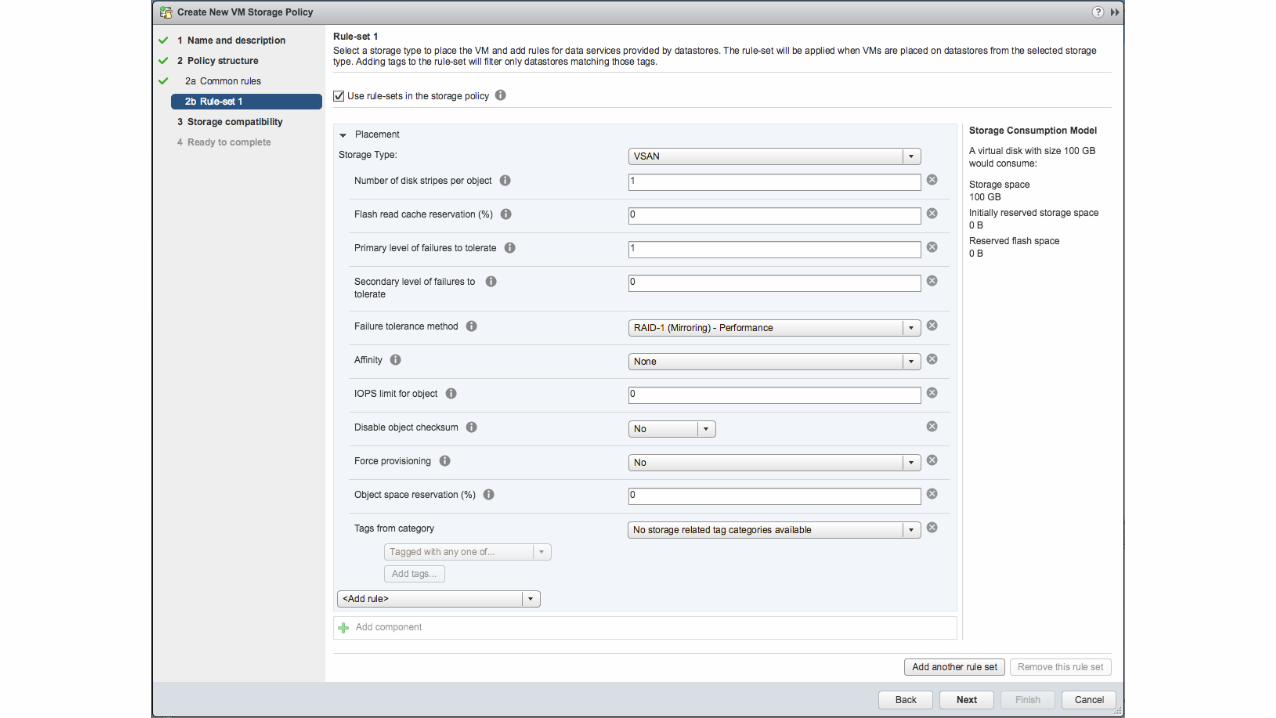
#08Which features are not policy driven?
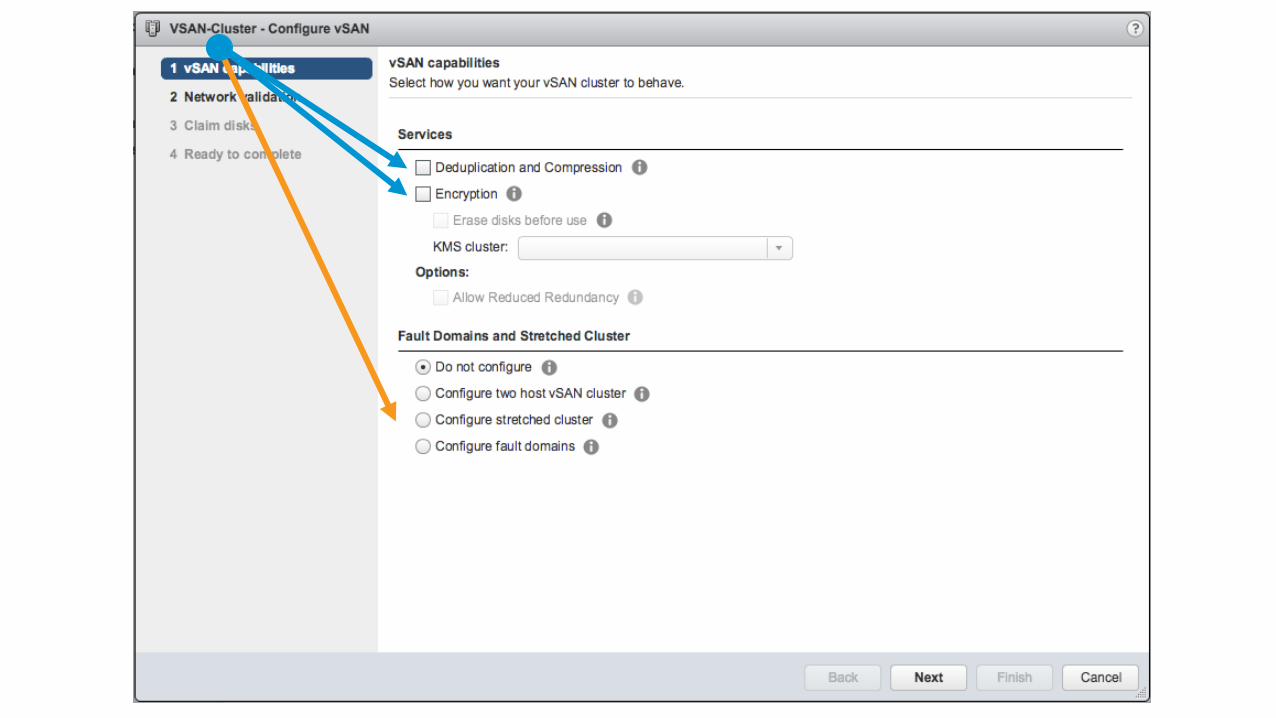

• Nearline deduplication and compression per disk group level
– Enabled on a cluster level
– Deduplicated when de-staging from cache tier to capacity tier
– Fixed block length deduplication (4KB Blocks)
• Compression after deduplication
– If block is compressed <= 2KB
– Otherwise full 4KB block is stored
Beta
Deduplication and Compression for Space Efficiency
SSD
SSD
1. VM issues write
2. Write acknowledged by cache
3. Cold data to memory
4. Deduplication5. Compression
6. Data written to capacity
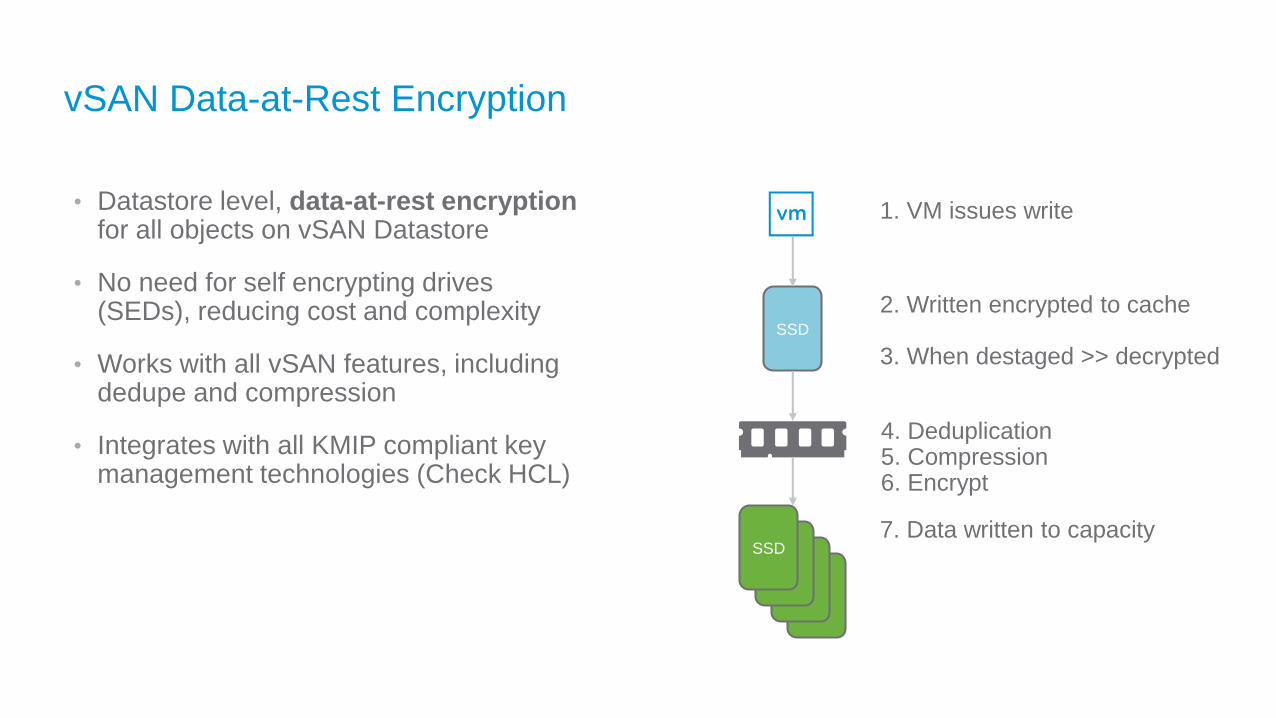
vSAN Data-at-Rest Encryption
• Datastore level, data-at-rest encryption for all objects on vSAN Datastore
• No need for self encrypting drives (SEDs), reducing cost and complexity
• Works with all vSAN features, including dedupe and compression
• Integrates with all KMIP compliant key management technologies (Check HCL)
SSD
SSD
1. VM issues write
2. Written encrypted to cache
3. When destaged >> decrypted
4. Deduplication5. Compression6. Encrypt
7. Data written to capacity
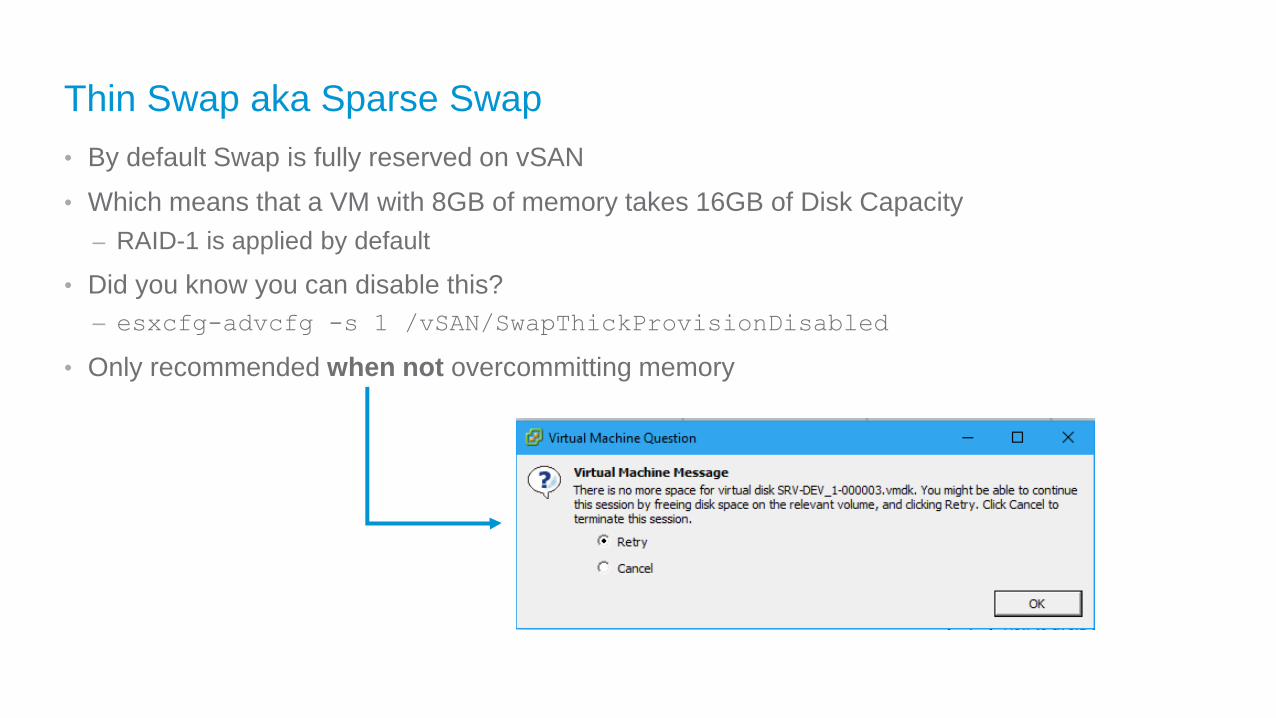
Thin Swap aka Sparse Swap
• By default Swap is fully reserved on vSAN
• Which means that a VM with 8GB of memory takes 16GB of Disk Capacity
– RAID-1 is applied by default
• Did you know you can disable this?
– esxcfg-advcfg -s 1 /vSAN/SwapThickProvisionDisabled
• Only recommended when not overcommitting memory

#07Impact of changing
policy / applying policy changes
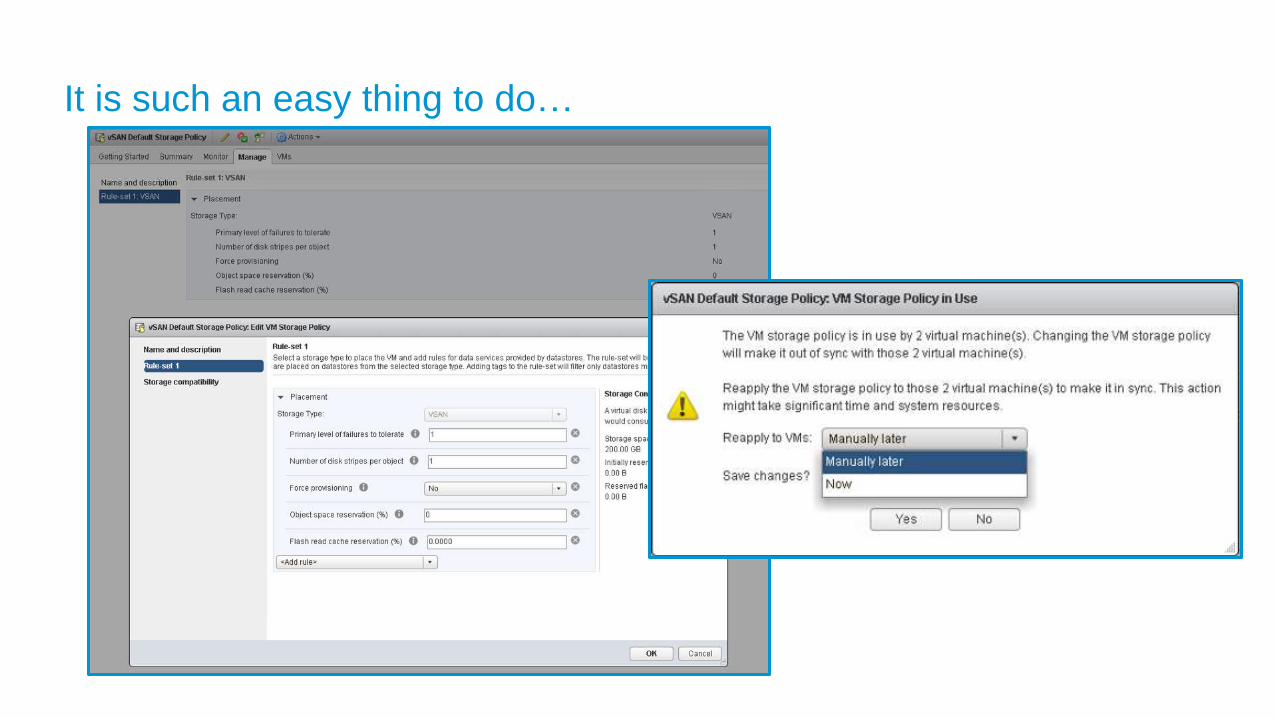
It is such an easy thing to do…
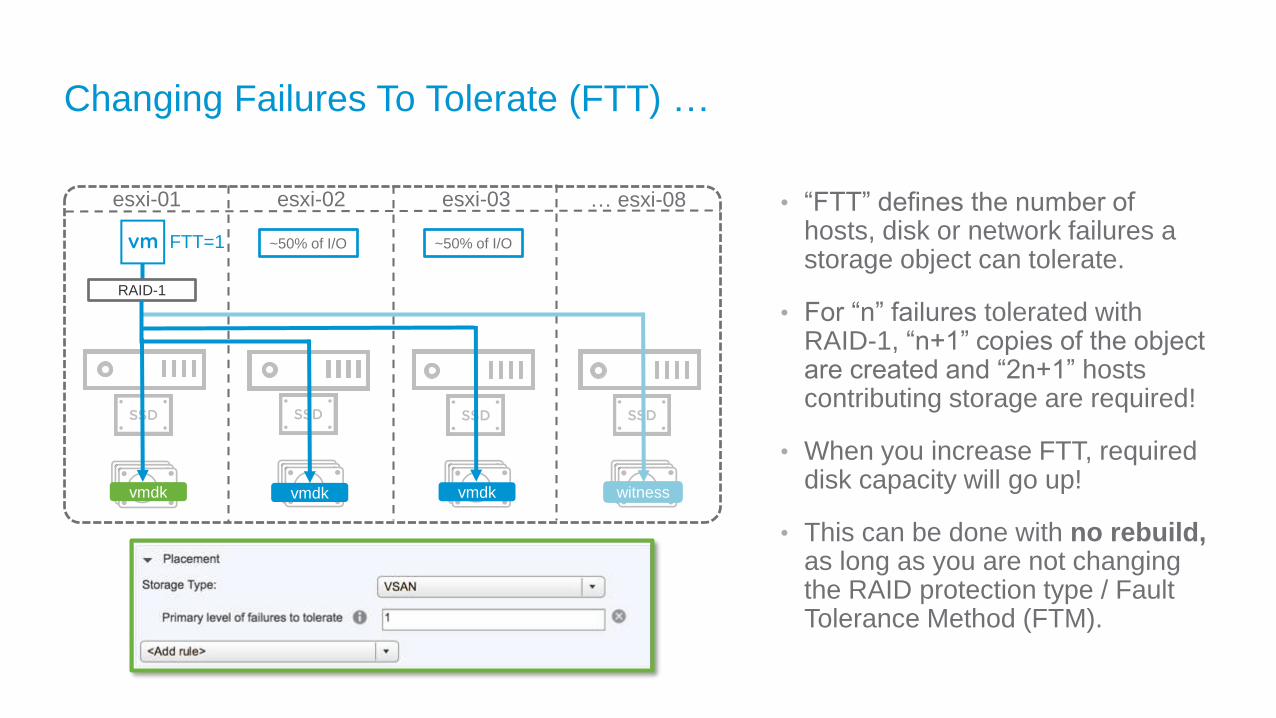
Changing Failures To Tolerate (FTT) …
• “FTT” defines the number of hosts, disk or network failures a storage object can tolerate.
• For “n” failures tolerated with RAID-1, “n+1” copies of the object are created and “2n+1” hosts contributing storage are required!
• When you increase FTT, required disk capacity will go up!
• This can be done with no rebuild, as long as you are not changing the RAID protection type / Fault Tolerance Method (FTM).
esxi-01 esxi-02 esxi-03
vmdk
RAID-1
FTT=1
… esxi-08
witnessvmdk
~50% of I/O ~50% of I/O
vmdk
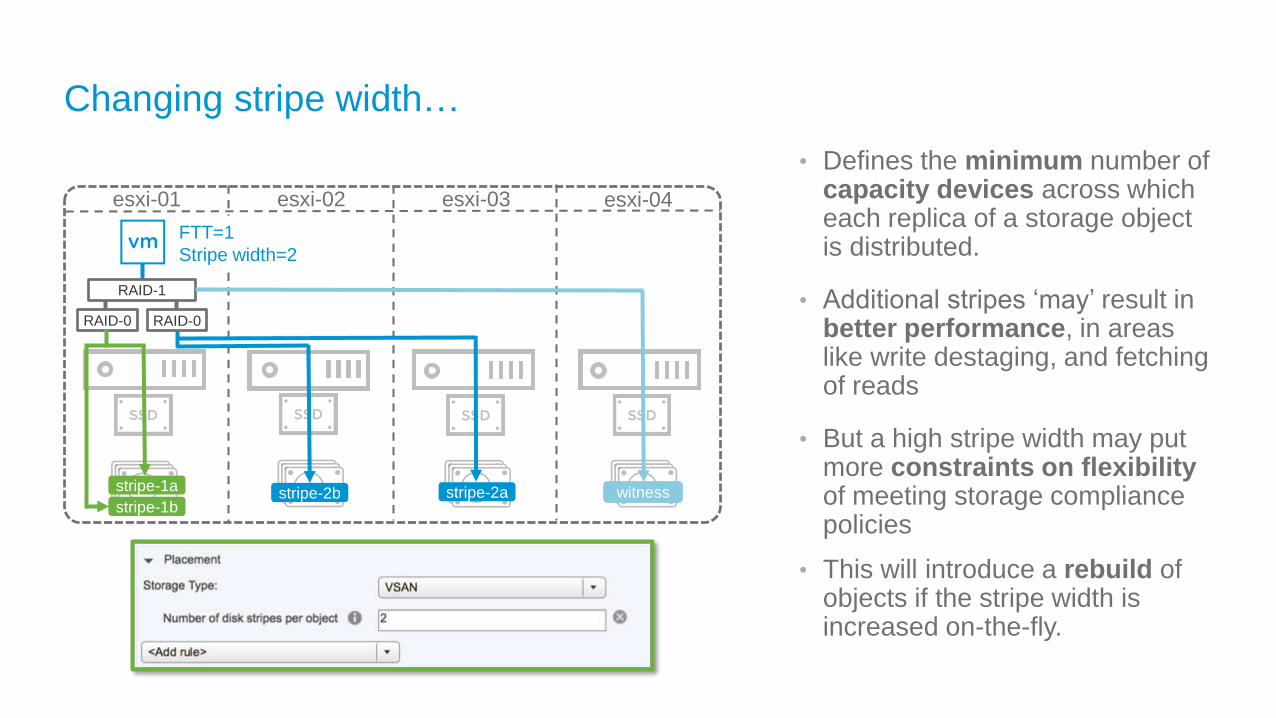
Changing stripe width…
• Defines the minimum number of capacity devices across which each replica of a storage object is distributed.
• Additional stripes ‘may’ result in better performance, in areas like write destaging, and fetching of reads
• But a high stripe width may put more constraints on flexibility of meeting storage compliance policies
• This will introduce a rebuild of objects if the stripe width is increased on-the-fly.
esxi-01 esxi-02 esxi-03
stripe-2a
RAID-1
esxi-04
witnessstripe-2b
RAID-0 RAID-0
stripe-1a
stripe-1b
FTT=1
Stripe width=2
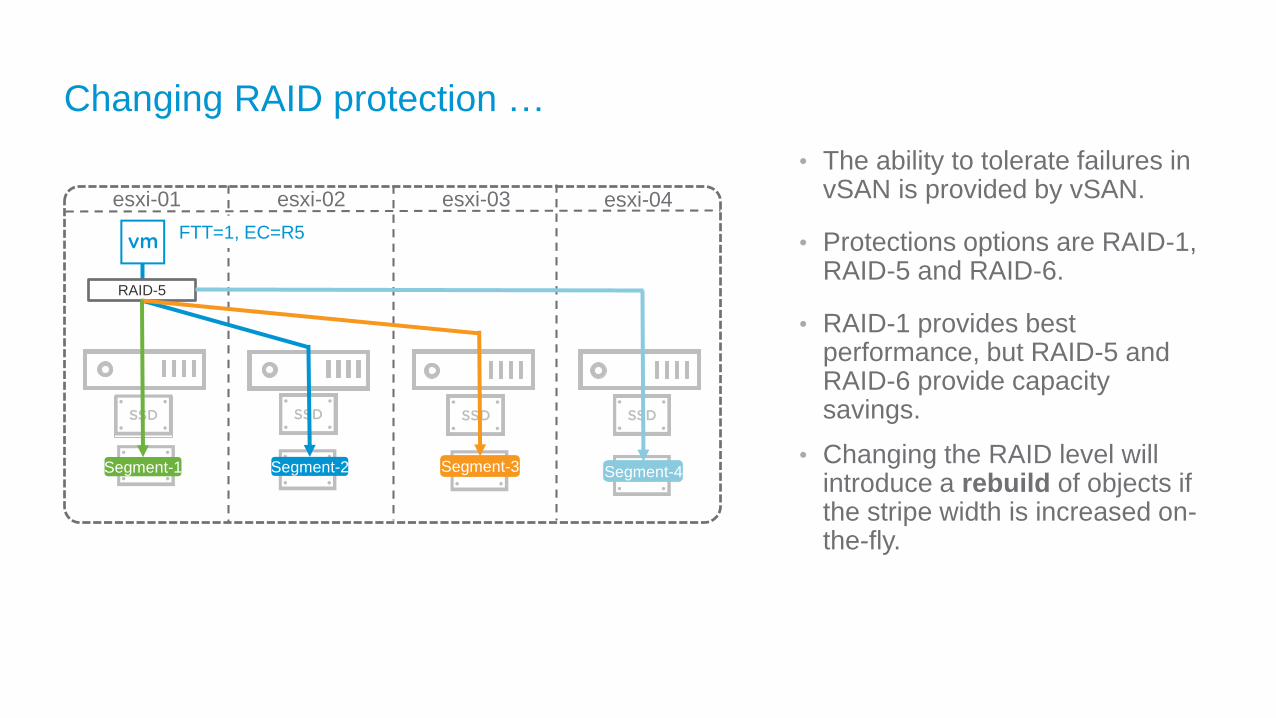
Changing RAID protection …
• The ability to tolerate failures in vSAN is provided by vSAN.
• Protections options are RAID-1, RAID-5 and RAID-6.
• RAID-1 provides best performance, but RAID-5 and RAID-6 provide capacity savings.
• Changing the RAID level will introduce a rebuild of objects if the stripe width is increased on-the-fly.
esxi-01 esxi-02 esxi-03
Segment-3
RAID-5
esxi-04
Segment-4Segment-2Segment-1
FTT=1, EC=R5
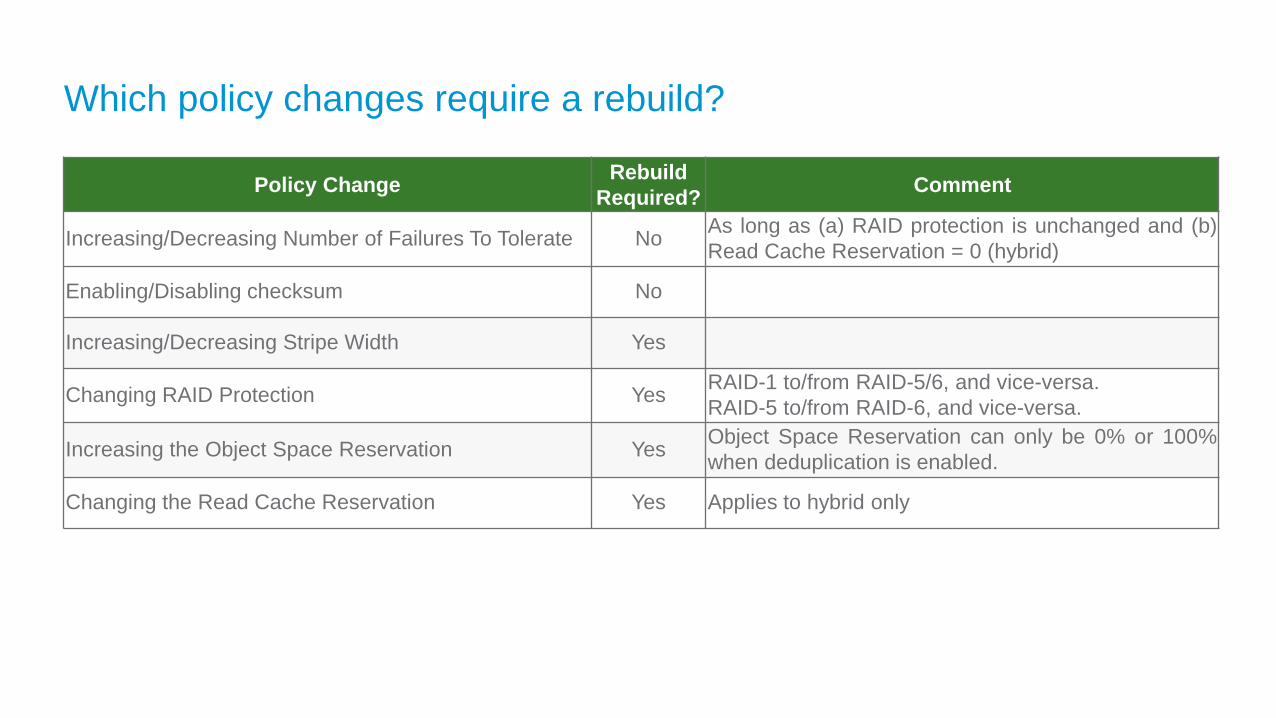
Which policy changes require a rebuild?
Policy ChangeRebuild
Required?Comment
Increasing/Decreasing Number of Failures To Tolerate NoAs long as (a) RAID protection is unchanged and (b)
Read Cache Reservation = 0 (hybrid)
Enabling/Disabling checksum No
Increasing/Decreasing Stripe Width Yes
Changing RAID Protection YesRAID-1 to/from RAID-5/6, and vice-versa.
RAID-5 to/from RAID-6, and vice-versa.
Increasing the Object Space Reservation YesObject Space Reservation can only be 0% or 100%
when deduplication is enabled.
Changing the Read Cache Reservation Yes Applies to hybrid only

#06Things you may not
know about the Health Check and
…
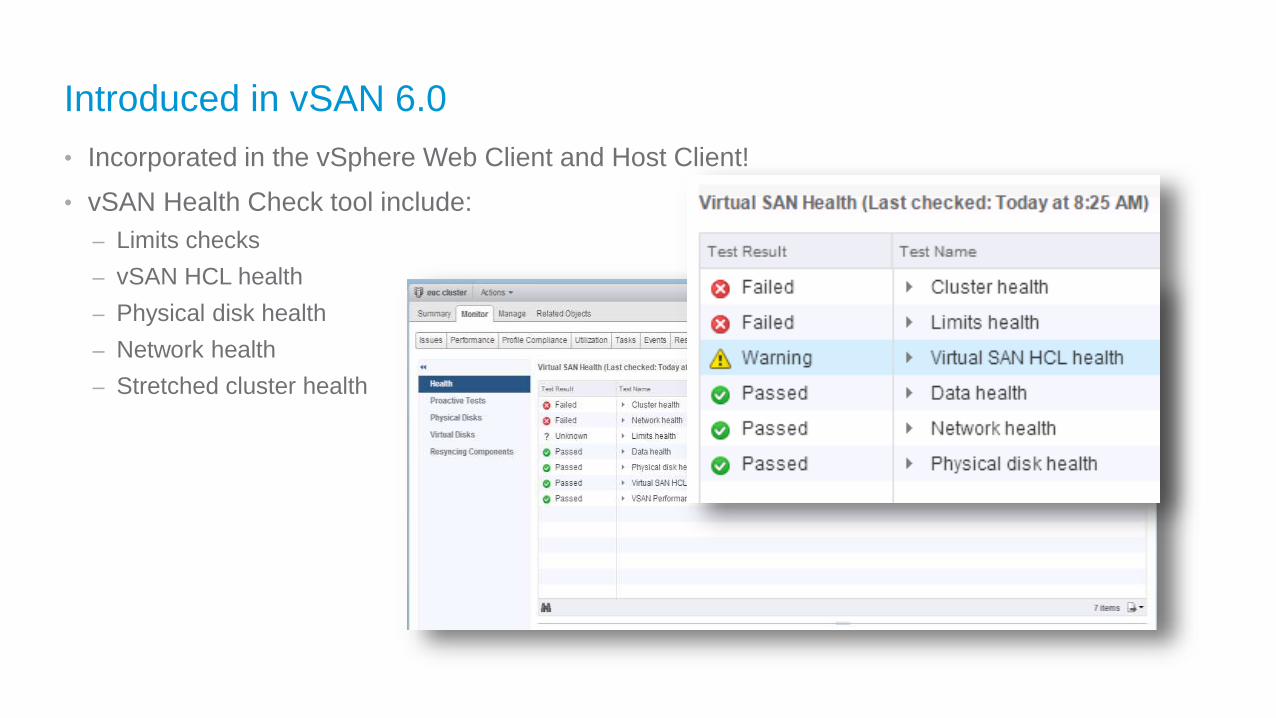
Introduced in vSAN 6.0
• Incorporated in the vSphere Web Client and Host Client!
• vSAN Health Check tool include:
– Limits checks
– vSAN HCL health
– Physical disk health
– Network health
– Stretched cluster health
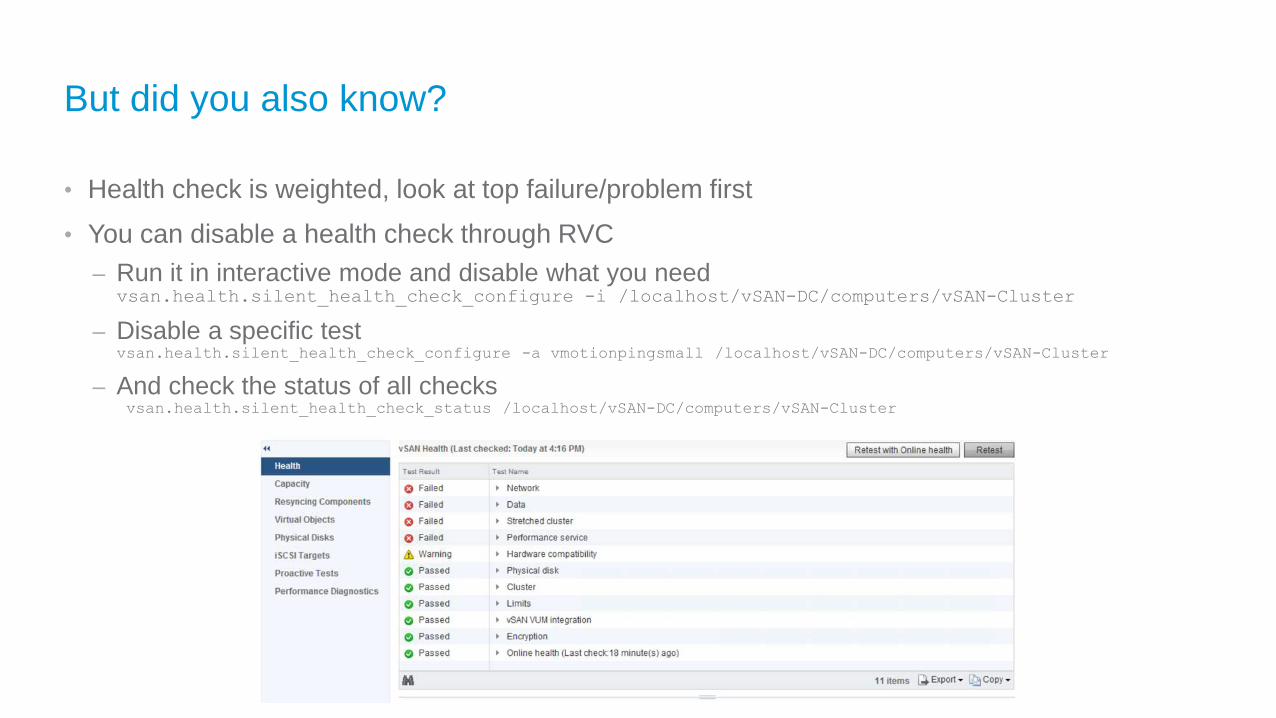
But did you also know?
• Health check is weighted, look at top failure/problem first
• You can disable a health check through RVC
– Run it in interactive mode and disable what you needvsan.health.silent_health_check_configure -i /localhost/vSAN-DC/computers/vSAN-Cluster
– Disable a specific testvsan.health.silent_health_check_configure -a vmotionpingsmall /localhost/vSAN-DC/computers/vSAN-Cluster
– And check the status of all checksvsan.health.silent_health_check_status /localhost/vSAN-DC/computers/vSAN-Cluster
.
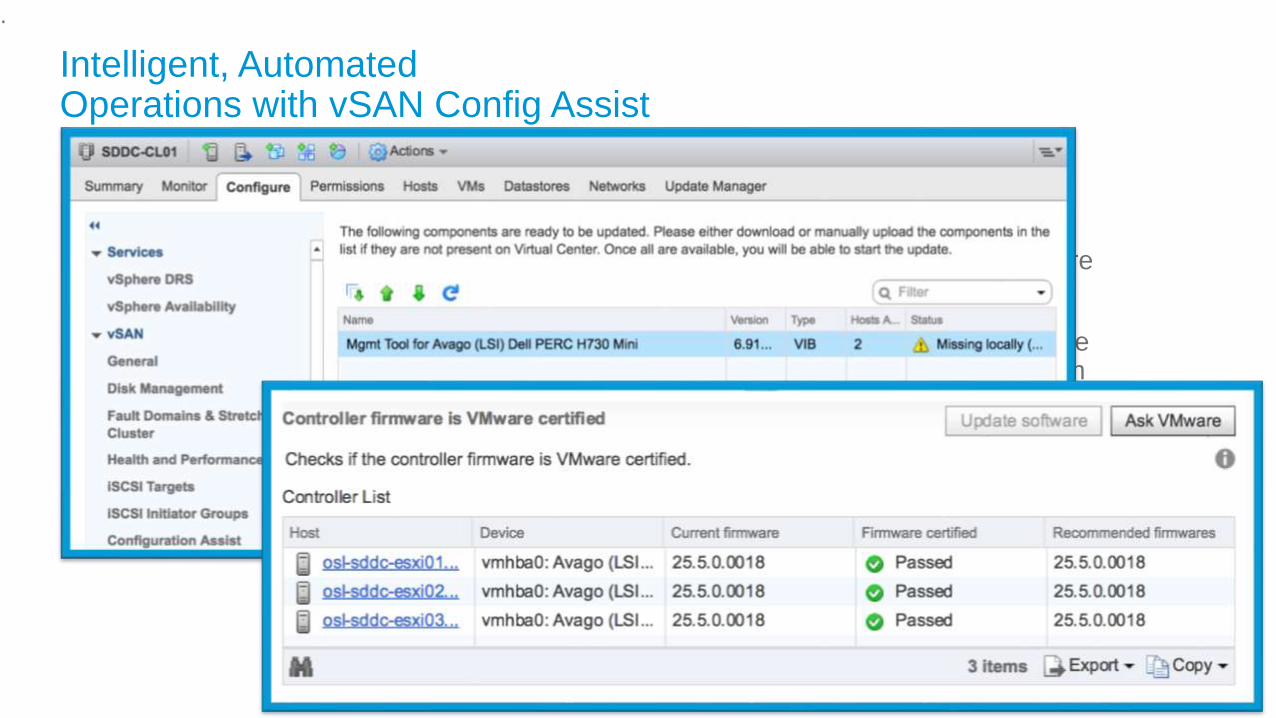
Intelligent, AutomatedOperations with vSAN Config Assist
• Simplify HCI Management with prescriptive one-click controller firmware and driver upgrades
• HCL aware. Pulls correct OEM firmware and drivers for selected controllers from participating vendors including Dell, Lenovo, Fujitsu, and SuperMicro
• Validate and remediate software configuration settings for vSAN
• Configuration wizards validate vSAN settings and ensure best practice compliance
vSphere vSAN
vSAN Datastore
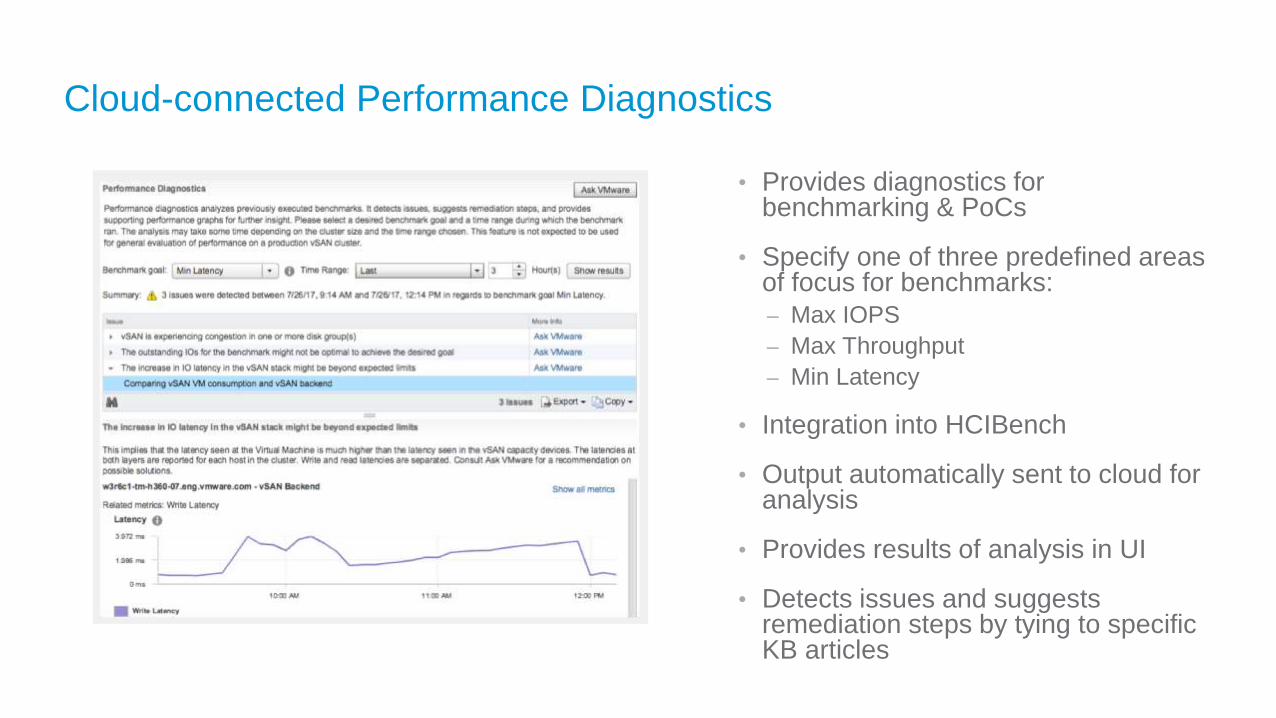
Cloud-connected Performance Diagnostics
• Provides diagnostics for benchmarking & PoCs
• Specify one of three predefined areas of focus for benchmarks:
– Max IOPS
– Max Throughput
– Min Latency
• Integration into HCIBench
• Output automatically sent to cloud for analysis
• Provides results of analysis in UI
• Detects issues and suggests remediation steps by tying to specific KB articles
vSphere vSAN
HCIBench
Analysis
Detect issues
Visible to GSS
Feedback
Site results
Links to KBs
vSAN Cloud Analytics
VMware Customer Experience Improvement Program

#05Troubleshooting
options you may not know about

Host reboots are not troubleshooting steps!!!
You also don’t try to rip off your wheels while you driving?

CLI tools
• esxcli
• RVC – Ruby vSphere Console (available in your vCenter Server)
• PowerCLI
• cmmds-tool
• python /usr/lib/vmware/vsan/bin/vsan-health-status.pyc
36
This one is useful as it decodes a lot of the
UUIDs
• RVC will eventually be deprecated, and cmmds-tool and vsan-health-status.pyc are primarily support tools
• VMware has enhanced esxcli to provide further troubleshooting features

• [root@esxi-dell-b:/usr] esxcli vsanUsage: esxcli vsan {cmd} [cmd options]
Available Namespaces:cluster Commands for vSAN host cluster configurationdatastore Commands for vSAN datastore configurationdebug Commands for vSAN debugginghealth Commands for vSAN Healthiscsi Commands for vSAN iSCSI target configurationnetwork Commands for vSAN host network configurationresync Commands for vSAN resync configurationstorage Commands for vSAN physical storage configurationfaultdomain Commands for vSAN fault domain configurationmaintenancemode Commands for vSAN maintenance mode operationpolicy Commands for vSAN storage policy configurationtrace Commands for vSAN trace configuration
esxcli commands (as of vSAN 6.6)

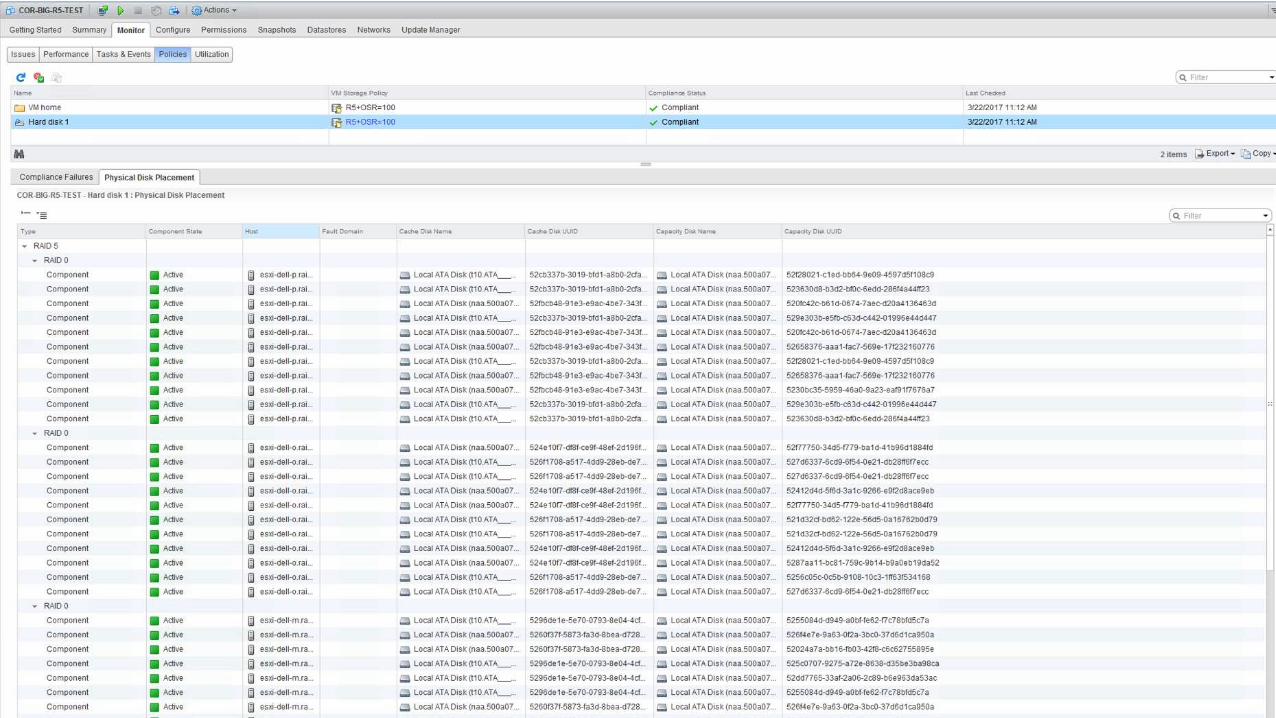
Get limits info via esxcli vsan debug
[root@esxi-dell-e:~] esxcli vsan debug limit get
Component Limit Health: green
Max Components: 9000
Free Components: 8990
Disk Free Space Health: green
Lowest Free Disk Space: 83 %
Used Disk Space: 192329932062 bytes
Used Disk Space (GB): 179.12 GB
Total Disk Space: 1515653332992 bytes
Total Disk Space (GB): 1411.56 GB
Read Cache Free Reservation Health: green
Reserved Read Cache Size: 0 bytes
Reserved Read Cache Size (GB): 0.00 GB
Total Read Cache Size: 0 bytes
Total Read Cache Size (GB): 0.00 GB
Read Cache is only relevant to hybrid vSAN. For AF-vSAN, this is the
expected output

Get controller info via esxcli vsan debug
[root@esxi-dell-e:~] esxcli vsan debug controller list
Device Name: vmhba1
Device Display Name: Intel Corporation Wellsburg AHCI Controller
Used By vSAN: false
PCI ID: 8086/8d62/1028/0601
Driver Name: vmw_ahci
Driver Version: 1.0.0-39vmw.650.1.26.5969303
Max Supported Queue Depth: 31
Device Name: vmhba0
Device Display Name: Avago (LSI) Dell PERC H730 Mini
Used By vSAN: true
PCI ID: 1000/005d/1028/1f49
Driver Name: lsi_mr3
Driver Version: 6.910.18.00-1vmw.650.0.0.4564106
Max Supported Queue Depth: 891
39
Information pertinent to vSAN

#04Dealing with disk
replacement

Did you know there are two different component states?Absent vs. Degraded
• Component marked Degraded when it is unlikely component will return
– Failed drive (PDL)
– Rebuild starts immediately!
• Component marked Absent when component may return
• Host rebooted
• Drive is pulled
• Network partition / isolation
– Rebuild starts after 60 minutes
• Avoids unnecessary rebuilds
– Or simply click “repair object immediately
– Advanced setting: vSAN.ClomRepairDelay

Disk Failure, what happens?
• Deduplication and compression disabled
– If capacity device fails, then drive is unmounted, disk group stays online
• Exception: Only one capacity device, then DG cannot remain available
– If cache device fails, then entire disk group is unmounted
• Deduplication and compression enabled
– Any device in disk group fails, then disk group is unmounted

Did you know we detect devices degrading?
Degraded Device Handling
• Smarter intelligence in detecting impending drive failures
• If replica exists, components on suspect device marked as “absent” with standard repair process
• If last replica, proactive evacuation of components occurs on suspect device
• Any evacuation failures will be shown in UI
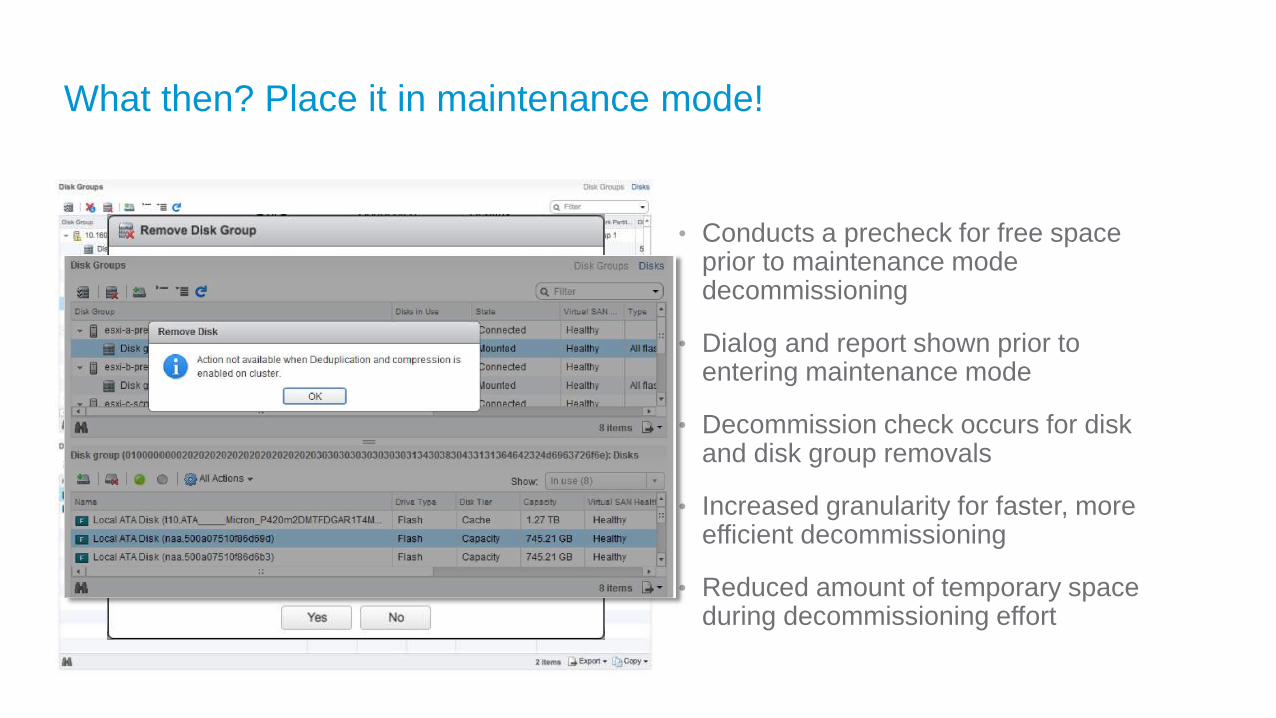
What then? Place it in maintenance mode!
• Conducts a precheck for free space prior to maintenance mode decommissioning
• Dialog and report shown prior to entering maintenance mode
• Decommission check occurs for disk and disk group removals
• Increased granularity for faster, more efficient decommissioning
• Reduced amount of temporary space during decommissioning effort

#03The impact of
unicast on vSAN network topologies

Multicast introduces complexity
• Multicast needs to be enabled on the switch/routers of the
physical network.
• Internet Group Management Protocol (IGMP) used
within an L2 domain for group membership (follow
switch vendor recommendations)
• Protocol Independent Multicast (PIM) used for
routing multicast traffic to a different L3 domain
• VMware received a lot of feedback from our customers on
how they would like to see multicast removed as a
requirement from vSAN.
• In vSAN 6.6, all multicast traffic was moved to unicast.
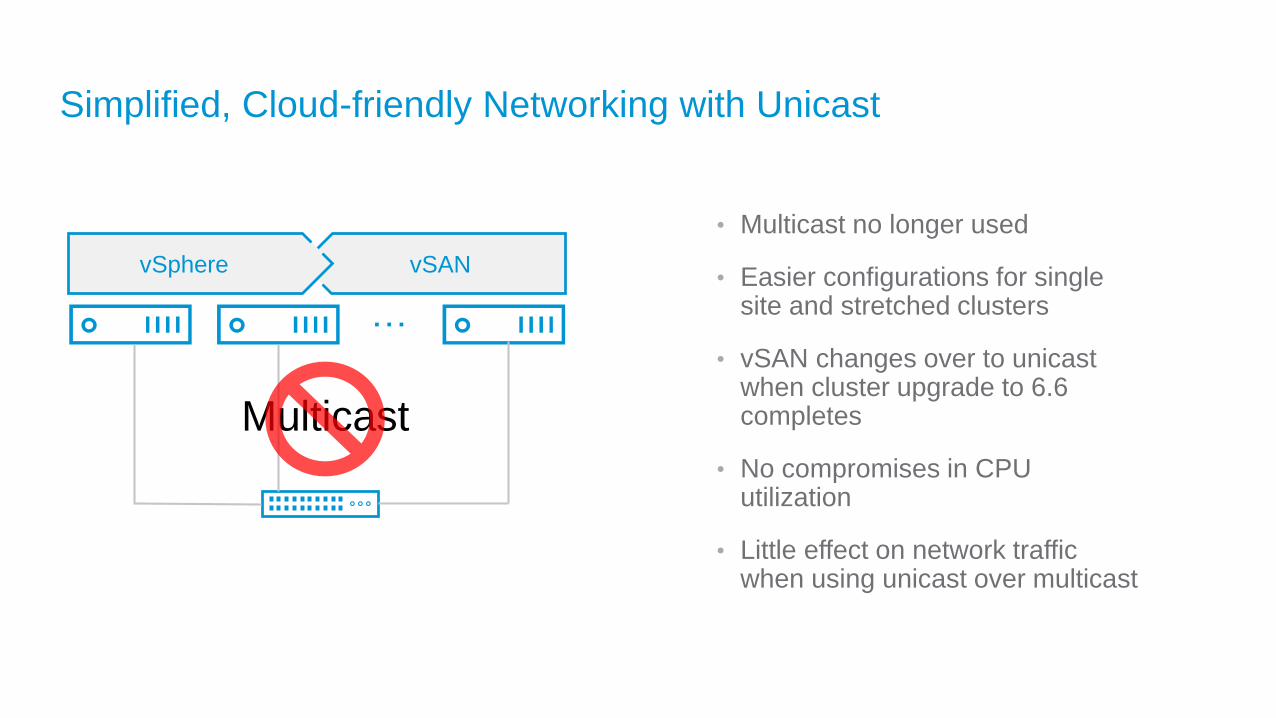
Simplified, Cloud-friendly Networking with Unicast
• Multicast no longer used
• Easier configurations for single site and stretched clusters
• vSAN changes over to unicast when cluster upgrade to 6.6 completes
• No compromises in CPU utilization
• Little effect on network traffic when using unicast over multicast
vSphere vSAN
Multicast
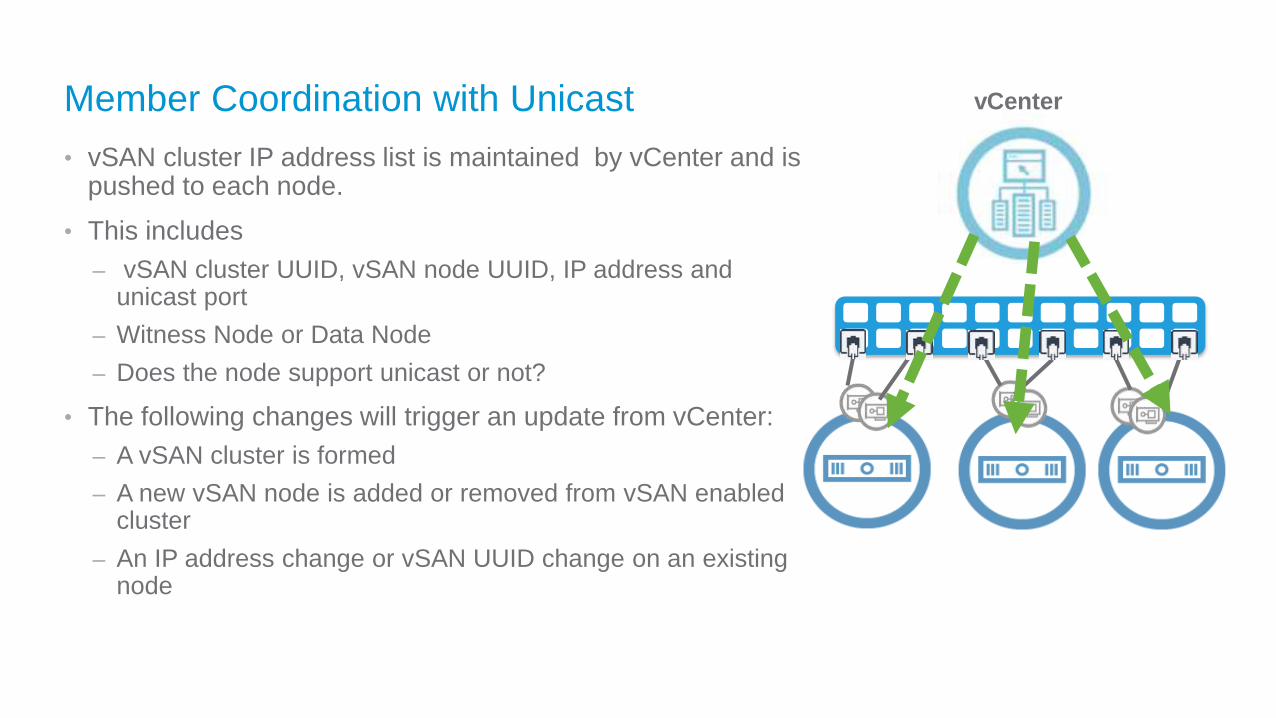
Member Coordination with Unicast
• vSAN cluster IP address list is maintained by vCenter and is pushed to each node.
• This includes
– vSAN cluster UUID, vSAN node UUID, IP address and unicast port
– Witness Node or Data Node
– Does the node support unicast or not?
• The following changes will trigger an update from vCenter:
– A vSAN cluster is formed
– A new vSAN node is added or removed from vSAN enabled cluster
– An IP address change or vSAN UUID change on an existing node
vCenter

Upgrade / Mixed Cluster Considerations with unicast
vSAN Cluster
Software
Configuration
Disk Format
Version(s)
CMMDS Mode Comments
6.6 Only Nodes* Version 5 UnicastPermanently operates in unicast.
Cannot switch to multicast.
6.6 Only Nodes*Version 3 or
belowUnicast
6.6 nodes operate in unicast mode.
Switches to multicast when < vSAN 6.6 node added.
Mixed 6.6 and
vSAN pre-6.6
Nodes
Version 5
(Version 3 or
below)
Unicast
6.6 nodes with v5 disks operate in unicast mode. Pre-
6.6 nodes with v3 disks will operate in multicast mode.
This will cause a cluster partition!
Mixed 6.6 and
vSAN pre-6.6
Nodes
Version 3 or
BelowMulticast
Cluster operates in multicast mode. All vSAN nodes
must be upgraded to 6.6 to switch to unicast mode. Disk
format upgrade to v5 will make unicast mode
permanent.
Mixed 6.6 and
vSAN 5.X NodesVersion 1 Multicast
Operates in multicast mode. All vSAN nodes must be
upgraded to 6.6 to switch to unicast mode. Disk format
upgrade to v5 will make unicast mode permanent.
Mixed 6.6 and
vSAN 5.X Nodes
Version 5
(Version 1)Unicast
6.6 nodes operate in unicast mode.
5.x nodes with v1 disks operate in multicast mode. This
will cause a cluster partition!

vSAN 6.6 only nodes – additional considerations with unicast
• A uniform vSAN 6.6+ cluster will communicate using unicast, even when disk-groups that arenot formatted with version 5 are present
• If no host has on-disk format version 5, vSAN will revert from unicast to multicast mode if a non-vSAN 6.6 node is added to the cluster.
• If a vSAN 6.6+ clusters has at least one node has a v5.0 on-disk format, it will only evercommunicate in unicast.
• This means that if a non-vSAN 6.6 node added to this cluster will not be able to communicatewith the vSAN 6.6 nodes
– this non-vSAN 6.6 node will be partitioned

#02Getting the most out of Monitoring and Logging

Health Check is awesome, but provides you
with current info. What about historic data
and trends?
Monitor your environment closely with:
• Web Client
• vCenter VOBs
• VROps
• LogInsight
• Sexigraf (http://www.sexigraf.fr/)
• Or anything else that you want to use
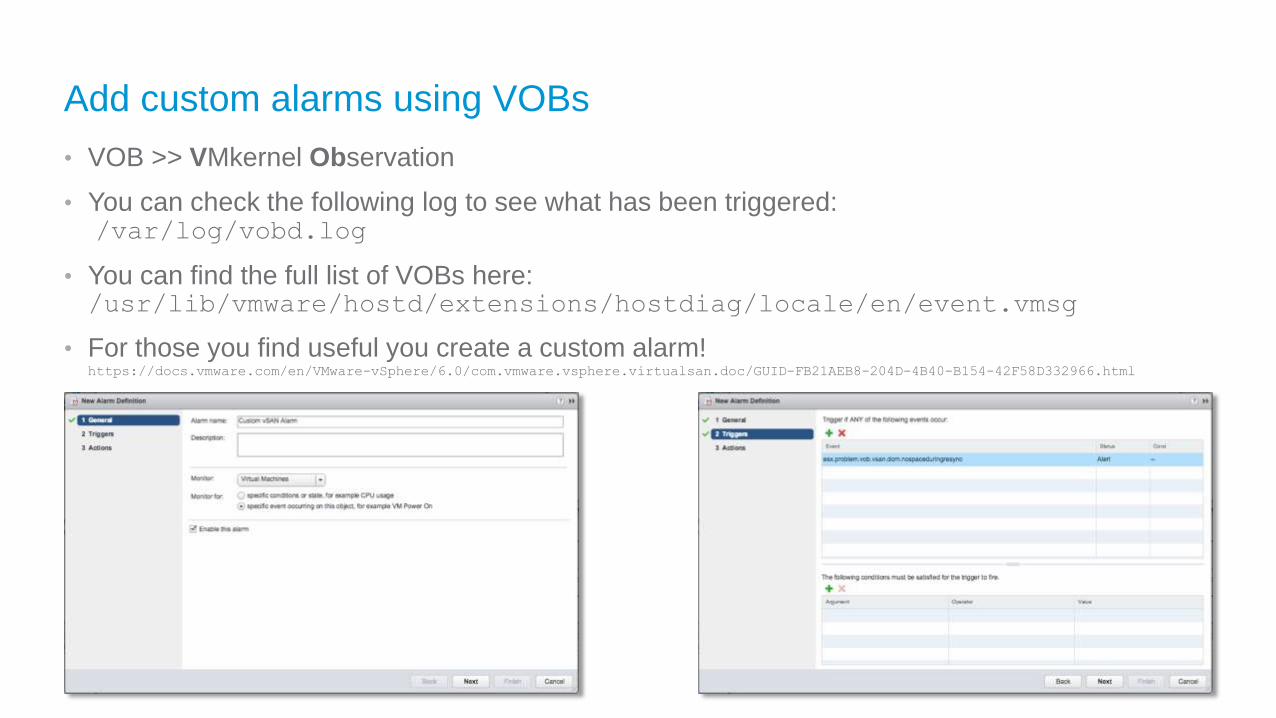
Add custom alarms using VOBs
• VOB >> VMkernel Observation
• You can check the following log to see what has been triggered:/var/log/vobd.log
• You can find the full list of VOBs here: /usr/lib/vmware/hostd/extensions/hostdiag/locale/en/event.vmsg
• For those you find useful you create a custom alarm!https://docs.vmware.com/en/VMware-vSphere/6.0/com.vmware.vsphere.virtualsan.doc/GUID-FB21AEB8-204D-4B40-B154-42F58D332966.html
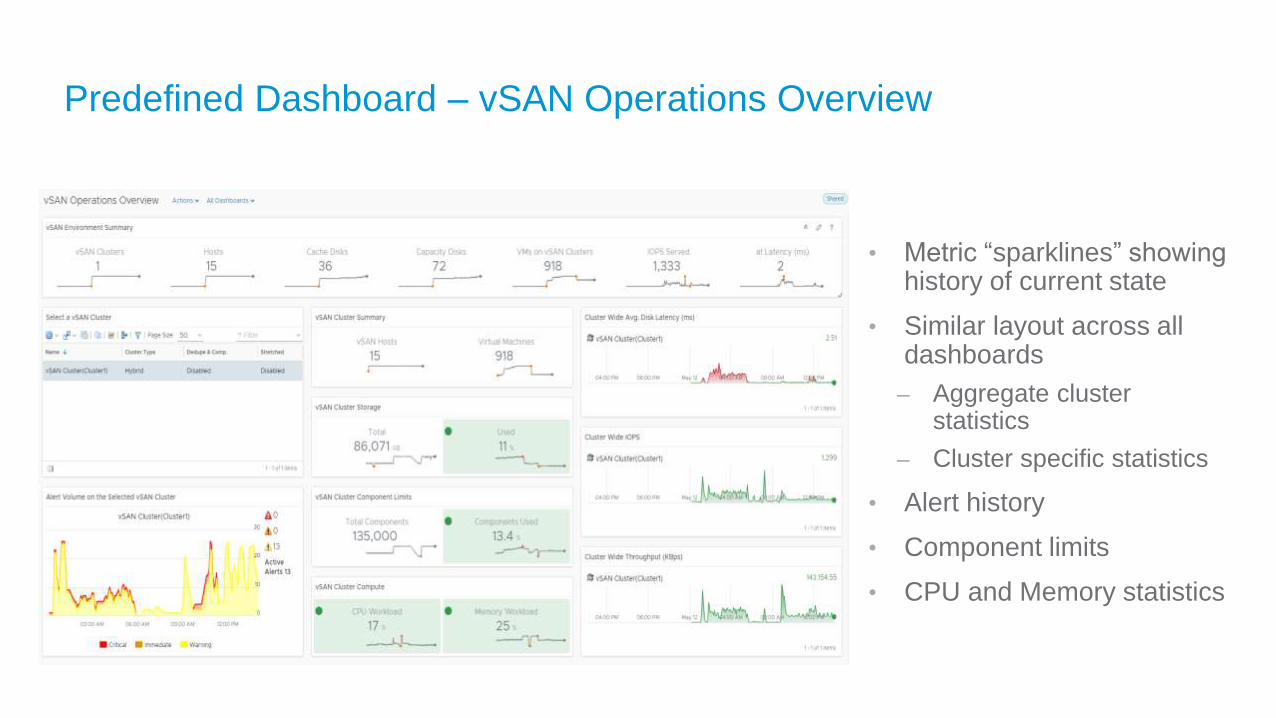
Predefined Dashboard – vSAN Operations Overview
• Metric “sparklines” showing history of current state
• Similar layout across all dashboards
– Aggregate cluster statistics
– Cluster specific statistics
• Alert history
• Component limits
• CPU and Memory statistics

Log Insight Content Pack for vSAN
• Provides collection of dashboards and widgets for immediate analysis of vSAN activities
• Exposes non-error events to provide context
• Content pack collects vSAN urgent traces
• vSAN traces high volume, binary and compressed
• Urgent traces automatically decompressed, converted from binary to human readable format. (vSAN 6.2 and newer)
• [root@esx01:~] esxcli vsan trace
get
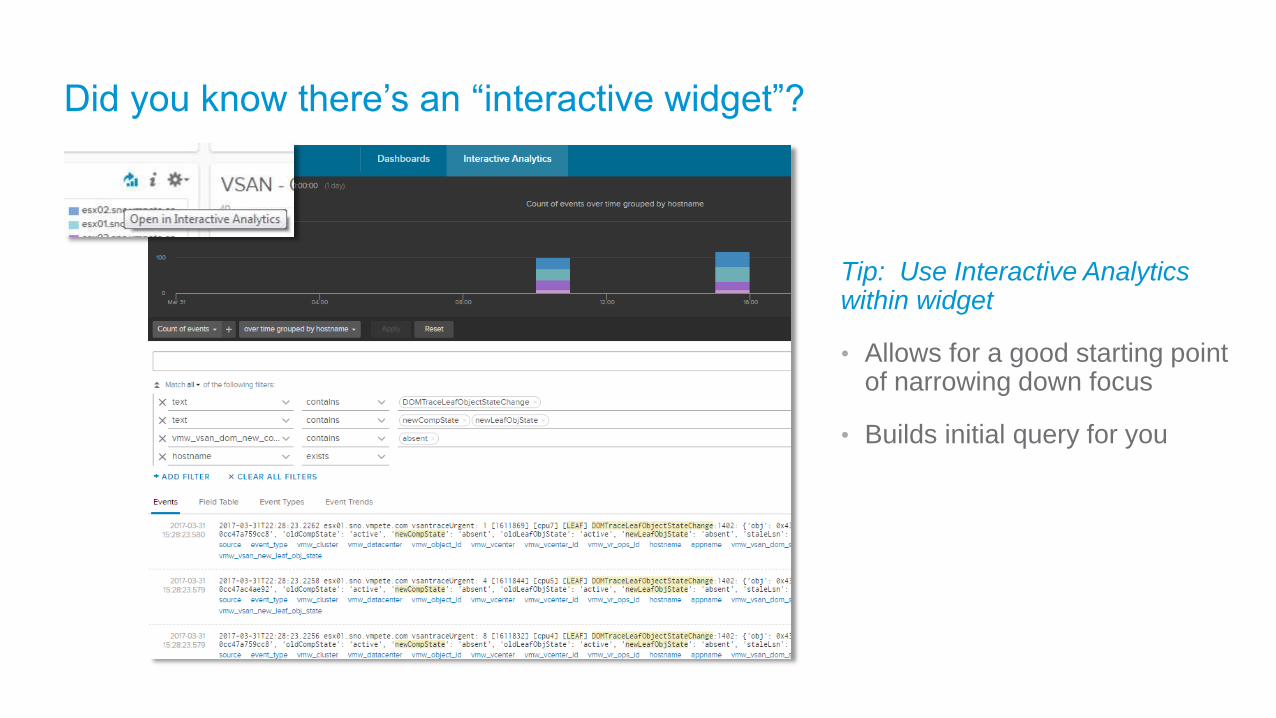
Did you know there’s an “interactive widget”?
Tip: Use Interactive Analytics within widget
• Allows for a good starting point of narrowing down focus
• Builds initial query for you

#01What is
Congestion?
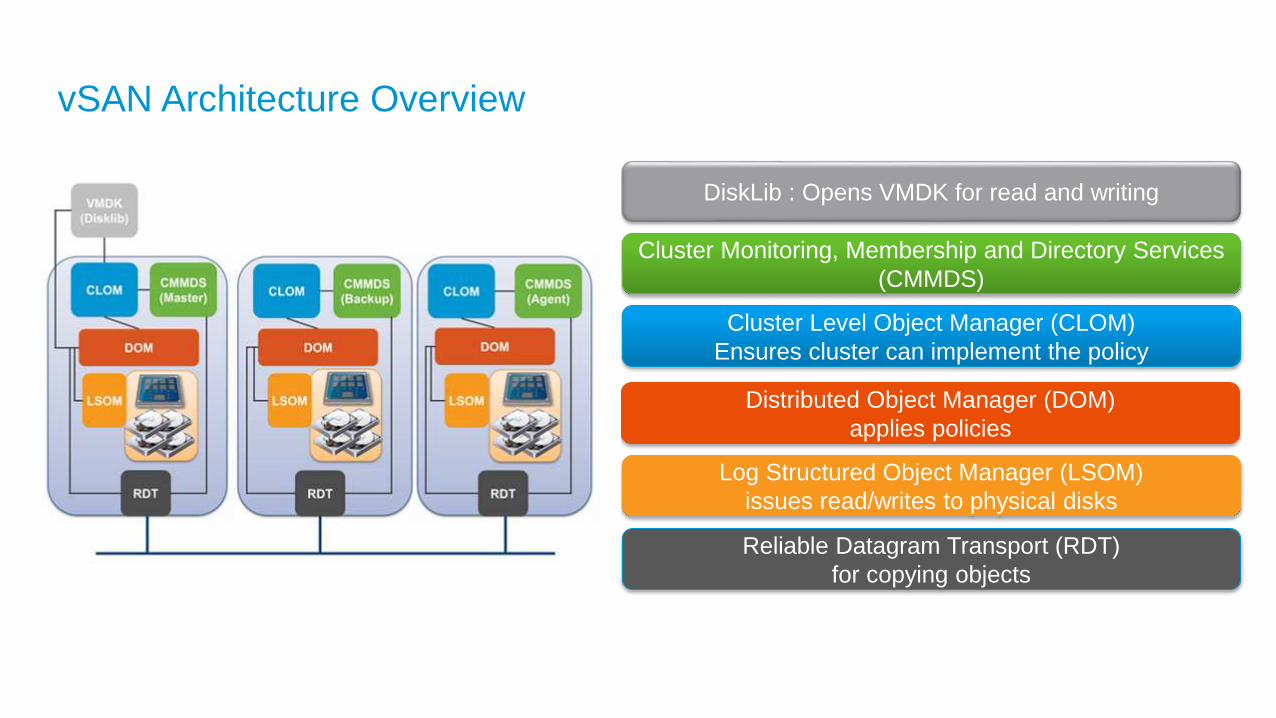
vSAN Architecture Overview
DiskLib : Opens VMDK for read and writing
Cluster Level Object Manager (CLOM)
Ensures cluster can implement the policy
Cluster Monitoring, Membership and Directory Services
(CMMDS)
Log Structured Object Manager (LSOM)
issues read/writes to physical disks
Distributed Object Manager (DOM)
applies policies
Reliable Datagram Transport (RDT)
for copying objects
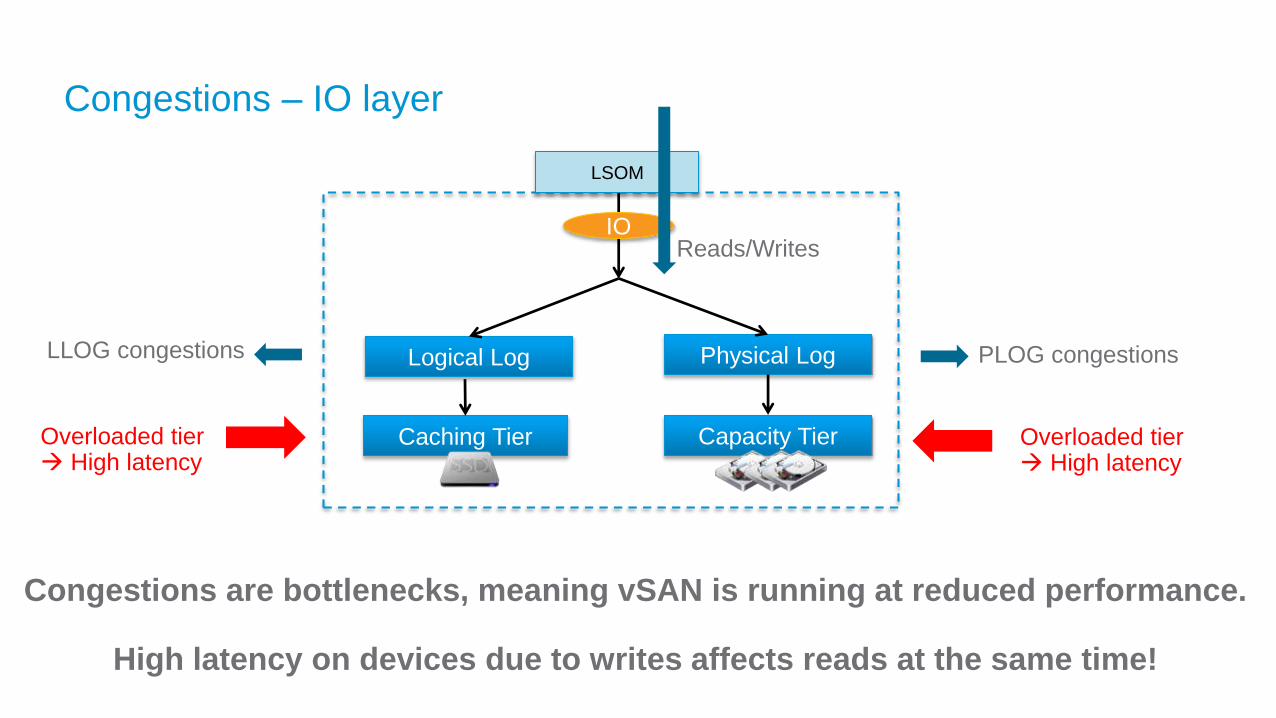
Congestions – IO layer
Logical Log Physical Log
Caching Tier Capacity Tier
IO
LSOM
LLOG congestions PLOG congestions
Congestions are bottlenecks, meaning vSAN is running at reduced performance.
High latency on devices due to writes affects reads at the same time!
Reads/Writes
Overloaded tier High latency
Overloaded tier High latency

– SSD LLOG/PLOG congestions
• Overload on either the LLOG (caching tier) or the PLOG (capacity tier)
• Insufficient resources on the physical/hardware layer for the workload that is being tested/run
– High network errors (Observable via vSAN observer or new in vSAN 6.6 with vCenter)
• High errors indicates a low traffic flow or overload on the physical NICs
• Network over utilized, often seen on re-sync, or when vSAN network is shared with other aggressive network traffic types, e.g. vMotion
– vSAN Software Layer
• De-staging from caching tier to capacity tier (with Deduplication/Compression)
• Checksum (< 6.0P04 or < 6.5ep02)
– CPU contention
• CPU contention in the ESXi scheduler, seen when wrong setup in BIOS (KB)
Possible causes of Congestions


Cormac Hogan@CormacJHogan
Duncan Epping@DuncanYB








![Oracle VM Server for SPARC 3.3 Reference Manual · ldm set-vhba timeout=seconds vHBA-name domain-name ldm add-vsan [-q] iport-path vSAN-name domain-name ldm remove-vsan vSAN-name](https://img.pdfslide.net/doc/110x75/5f98fbe69e2b5815e22b3dd2/oracle-vm-server-for-sparc-33-reference-manual-ldm-set-vhba-timeoutseconds-vhba-name.jpg)




















