Embed Size (px)
Citation preview

World Wide WebPresented By
Bharath
Praveen
Swathi

World Wide Web
The World Wide Web was created in 1989 by Tim Berners-Lee, working at the European Organization for Nuclear Research (CERN) in Geneva, Switzerland and released in 1992
Web - Accessing information over internet
It is not Internet – Network of networksEmail (SMTP), File sharing (FTP)
System of interlinked documents
Browser / Web Browser
The first Web browser, written by Tim Berners Lee and introduced in early 1991 ran on NeXT
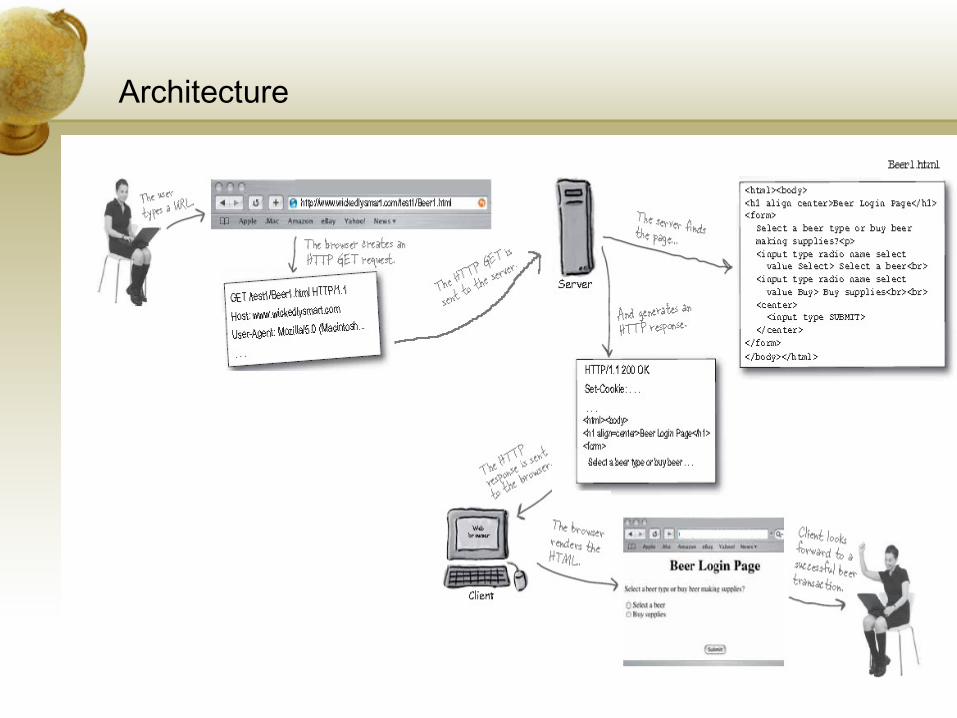
Architecture
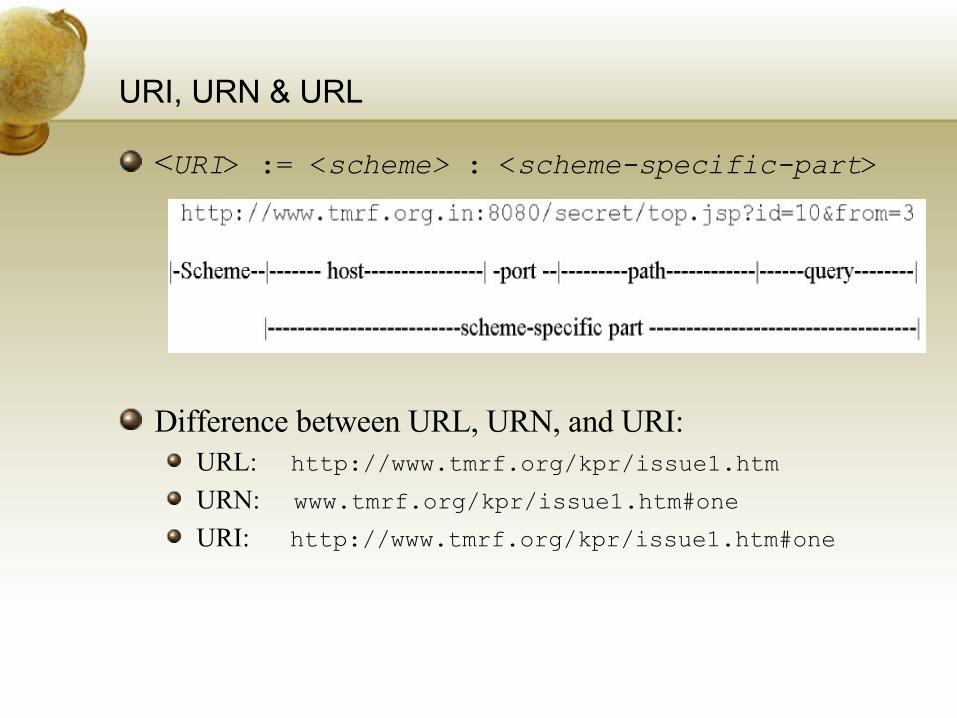
URI, URN & URL
<URI> := <scheme> : <scheme-specific-part>
Difference between URL, URN, and URI: URL: http://www.tmrf.org/kpr/issue1.htm
URN: www.tmrf.org/kpr/issue1.htm#one
URI: http://www.tmrf.org/kpr/issue1.htm#one

Web Protocols
ARP: Address Resolution ProtocolDHCP: Dynamic Host Configuration ProtocolDNS: Domain Name ServiceDSN: Data Source NameFTP: File Transfer ProtocolHTTP: Hypertext Transfer ProtocolIMAP: Internet Message Access ProtocolICMP: Internet Control Message ProtocolIDRP: ICMP Router-Discovery ProtocolIP: Internet ProtocolIRC: Internet Relay Chat ProtocolPOP3: Post Office Protocol version 3PAR: Positive Acknowledgment and RetransmissionRLOGIN: Remote LoginSMTP: Simple Mail Transfer ProtocolSSL: Secure Sockets LayerSSH: Secure ShellTCP: Transmission Control ProtocolTELNET: TCP/IP Terminal Emulation ProtocolUPD: User Datagram ProtocolUPS: Uninterruptible Power Supply

HTTP Hyper Text Transfer Protocol
HTTP 1.1 Persistent connections
Pipelining
Cache validation commands
Request Types: GET, POST, PUT, HEAD, DELETE, TRACE, OPTIONS, CONNECT

Request & Response
RequestGET
POST

Languages used
Client SideHTML, CSS, Javascript, AJAX, Flex3
Server Side.NET (Asp.net, VB.net, c#.net)Java (JSP, Servlets, Plain java class) CGI Perl / PHP
Other LanguagesAda 95, Applescript, BEF & Dylan (similar to PASCAL), CCI (Common Client Interface) , CMM, Guile, Hypertalk, Icon, KQML (Knowledge Query and Manipulation language), Linda, Lingo, Lisp, ML, Modula 3, Obliq, Phantom, Python, ReXX, ScriptX, SDI (Software Development Interface),VRML

Web 2.0
AJAXReverse AJAX
Democracy (Wiki, reddit, digg, youtube)
RIASOAMashupsWidgetsFeeds, RSS, Web servicesBloggingTagging
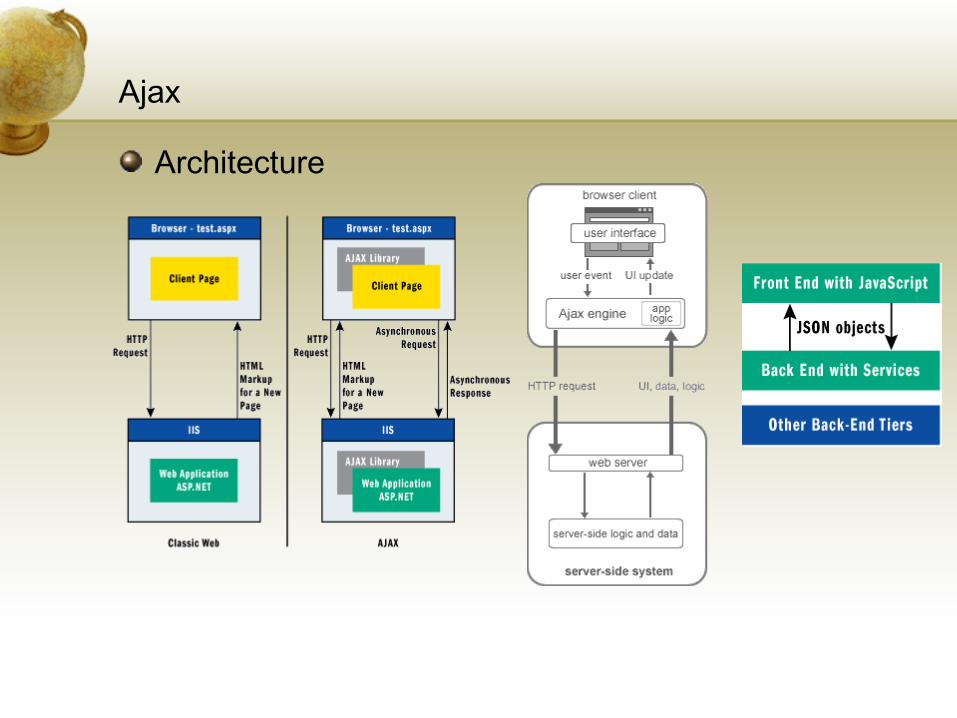
Ajax
Architecture

Ajax
Technologies AssociatedXHTML & CSS for presentationDOM to interact with dataXML & XSLT for interchange and manipulation of dataXMLHttpRequest object for asynchronous communicationJavascript to integrate all the above technologies
AdvantagesFast, No reload, updates the section of a page
• Disadvantages• Actions are not registered with browser’s history• Need an alternate way to be indexed• JavaScript must be enabled on the browser• Server load
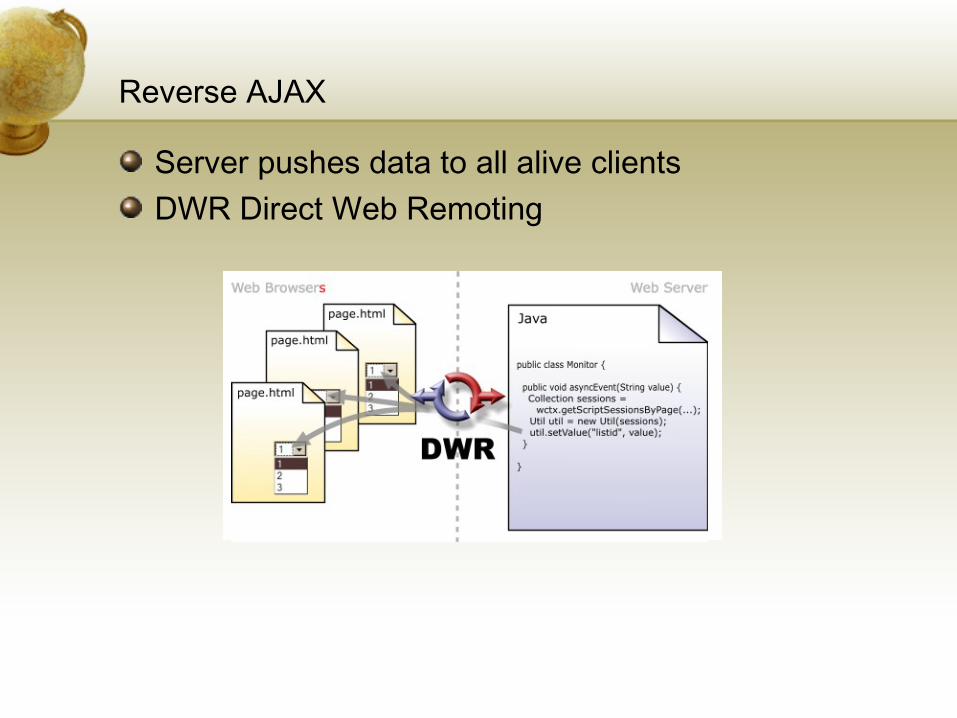
Reverse AJAX
Server pushes data to all alive clientsDWR Direct Web Remoting

Mashups
Mixing multiple service together to produce newTypes: Data & Enterprise mashupsTools: Microsoft Popfly, Yahoo Pipes, Google Mashup editor

Widgets
UWA Universal Widget API from NetVibes

Feeds – RSS, JSON, Atom

Web 3.0
The Data Web making data as openly accessible and linkable as Web pages
Querying for data across distributed RDF databases
Semantic web
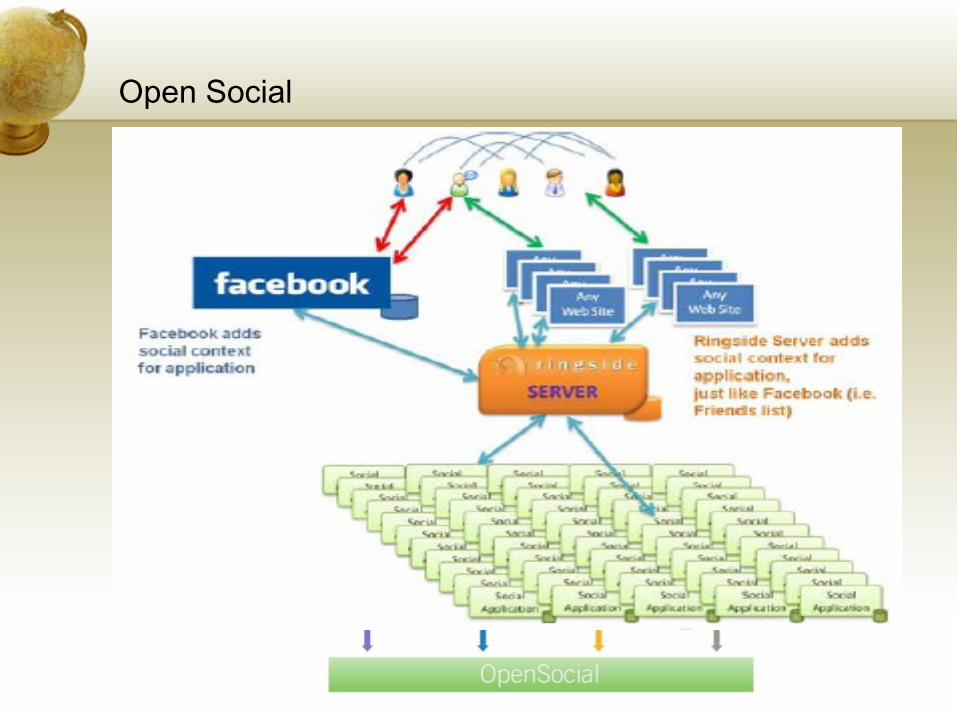
Open Social
A common API for social applications across multiple websitesSupports interoperability with other social networks that support themCore Services: People & Friends, Activities, PersistencePlatforms: google, hi5, myspace, ImeemHTML, JavaScript, REST, OAUTH
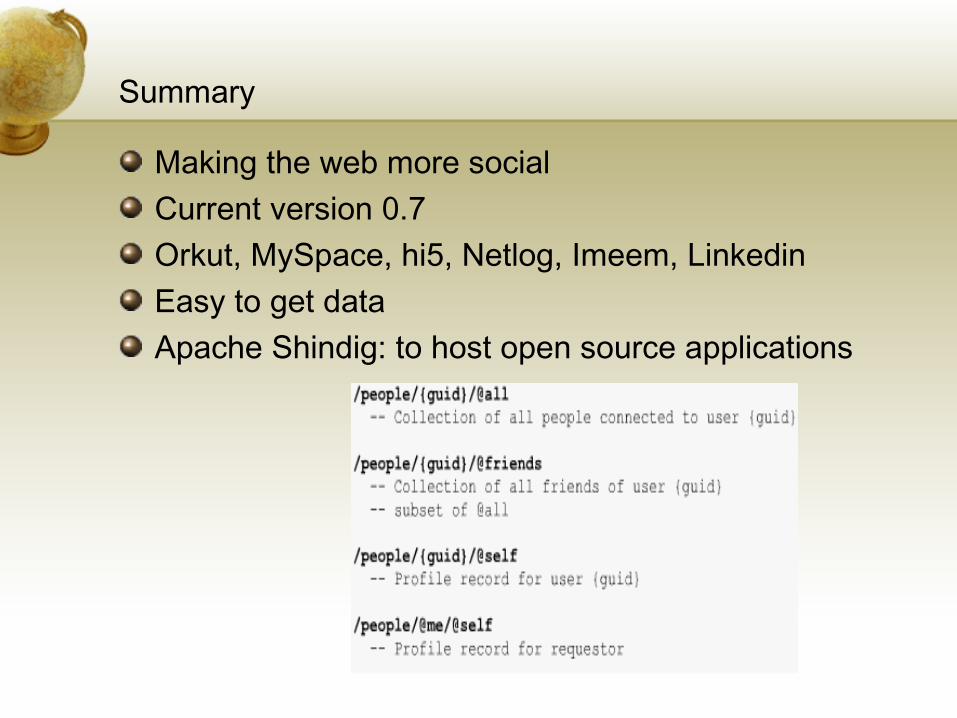
Summary
Making the web more socialCurrent version 0.7Orkut, MySpace, hi5, Netlog, Imeem, LinkedinEasy to get dataApache Shindig: to host open source applications

Semantic Web
IntroductionHistoryArchitectureChallengesFutureConclusion
Logo of Semantic Web

What is Semantic Web ?
Meaningful representation of data on World Wide Web
Processed by humans as well as machines in global scale

Why do we need Semantic Web ?
Enhanced Search and Discovery
Enhanced System and Data Interoperability
Knowledge Management
Semantic Web Service
Electronic Commerce

History
1989 – Vision of Tim-Berners Lee
1994 – Presented at first WWW conference
2002 – Architecture
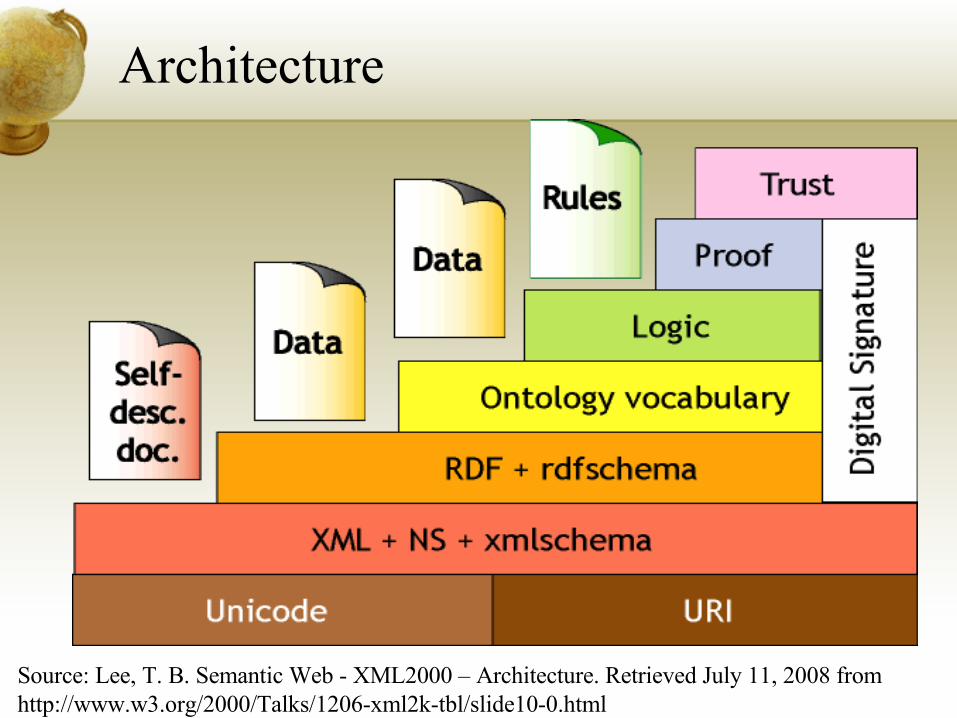
Architecture
Source: Lee, T. B. Semantic Web - XML2000 – Architecture. Retrieved July 11, 2008 from http://www.w3.org/2000/Talks/1206-xml2k-tbl/slide10-0.html

Unicode and URI
Unicode – International standard for encoding textEx: UTF-8, UTF-16
URI – Universal Resource IdentifierUniform Resource Locator (URL)
Identify resources via a representation of their primary access mechanism
Ex: http://seal.ifi.unizh.ch
Universal Resource Name (URN)Globally unique and persistent even when the resource ceases to exist or becomes unavailable.
Ex: urn:ISBN:0-395-36341-1

XML and Namespace
eXtensible Markup LanguageStores data in related entitiesProvides standard for storage layout and logical structureSupports syntactic interoperability
NamespaceElements and attributes have expanded namesExpanded name = Namespace name + Local nameNamespace name – name holding URI
XML Schema

RDF – Resource Description Framework
Language for representing metadata of web resources
Framework for exchange of information between applications without loss of meaning

RDF Model
Resource - Thing being described by RDF expressionProperty - Specific aspect, characteristic, attribute, or relation used to describe a resource. Statement - A specific resource + a named property + the value of that property for that resource
Represented as 3-tuple – Subject, Predicate and ObjectEx: http://www.example.org/index.html has a creator called John Smith
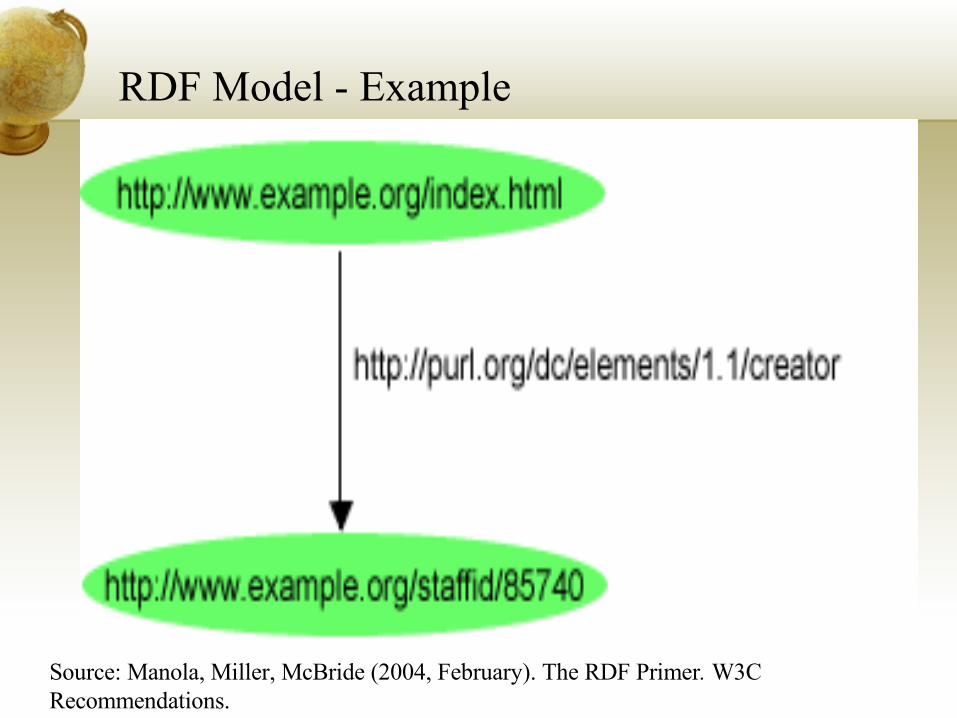
RDF Model - Example
Source: Manola, Miller, McBride (2004, February). The RDF Primer. W3C Recommendations.
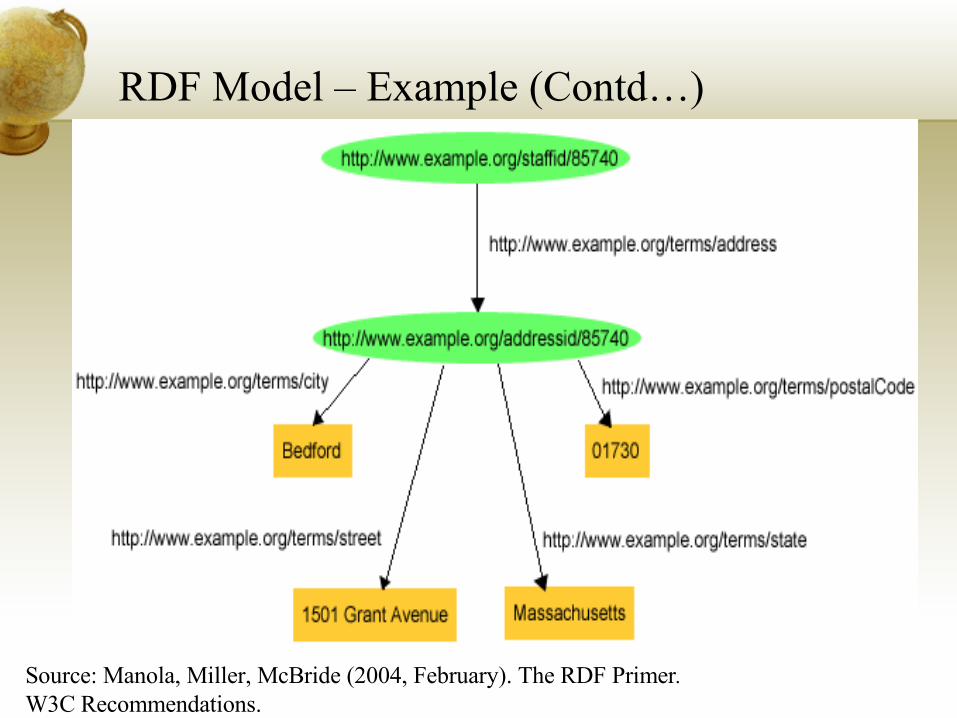
RDF Model – Example (Contd…)
Source: Manola, Miller, McBride (2004, February). The RDF Primer. W3C Recommendations.

Why RDF and not just XML ?
Many XML trees for single 3-tuple
XML parser cannot distinguish subject, object and property
RDF model – direct, unambiguous and decentralized

Why RDF and not just XML ? (Contd…)
Example3-tuple (index.html, John Smith, author)
Relationship: Index.html has author John Smith<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf- syntax-ns#" xmlns:exterms="http://www.example.org/terms/">
<rdf:Description rdf:about="http://www.example.org/index.html"> <exterms:creator>John Smith</exterms:creator> </rdf:Description>
</rdf:RDF>

Why RDF and not just XML ? (Contd…)
Possible XML trees<author>
<uri> Index.html </uri> <name>John Smith</name> </author>
<document href=" Index.html "> <author> John Smith </author> </document>
<document> <details> <uri>href=" Index.html "</uri> <author> <name> John Smith </name> </author> </details> </document> or maybe
<document> <author> <uri>href=" Index.html "</uri> <details> <name> John Smith </name> </details> </author> </document>

RDF Schema (RDFS)
Collection of classes authored for specific purpose or domain
Classes organized in hierarchy
Describes inheritance hierarchies, class schemas, properties, domain and range and restriction for properties
Supports extensibility and reusability
Multiple views of same metadata

RDFS - Example
<Class ID=“Animal”>
<Class ID="Male"> <subclass Ofresource="#Animal"/> </Class> <Class ID="Female"> <subclass Ofresource="#Animal"/> <disjointFrom resource="#Male"/> </Class>

Web Ontology Language (OWL)
Extends from RDFS
Specifies axioms based on the classes of entities, their properties and relationships
Draw inference based on axioms
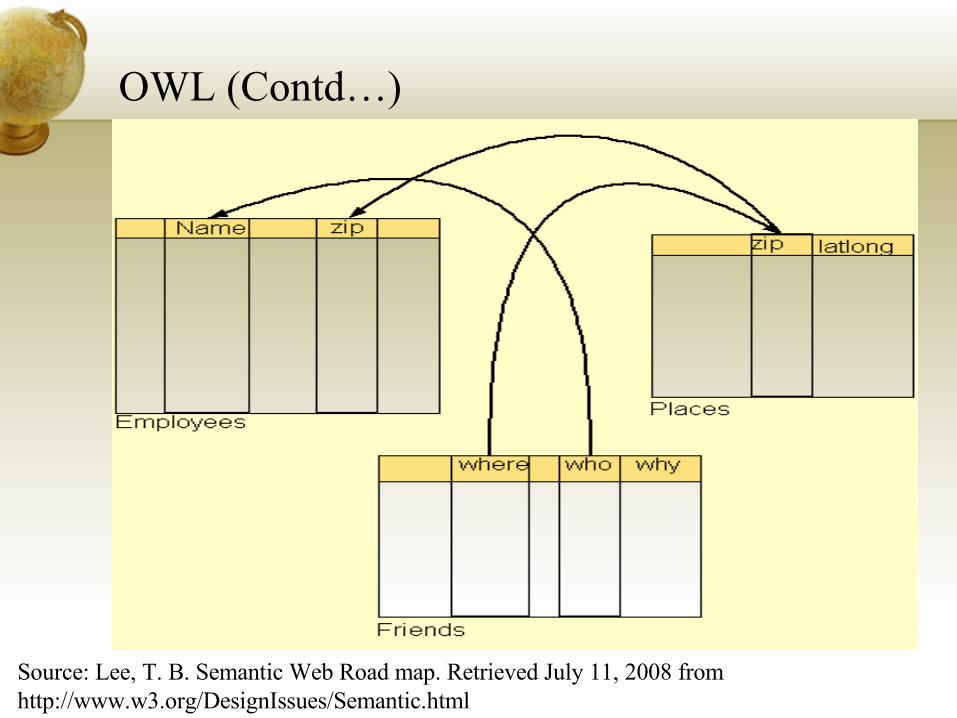
OWL (Contd…)
Source: Lee, T. B. Semantic Web Road map. Retrieved July 11, 2008 from http://www.w3.org/DesignIssues/Semantic.html

Challenges
Standardizing Semantic Web Stack
Developing Ontologies
Converting existing WWW into Semantic Web
Capturing Cultural Semantics
Interoperability Issues

Some News…
SPARQL Protocol
Semantic Search Engines – Google, Yahoo, Intelliseek
Jena Semantic Web Toolkit – HP
Joseki Web API – HP
Wilbur – Nokia
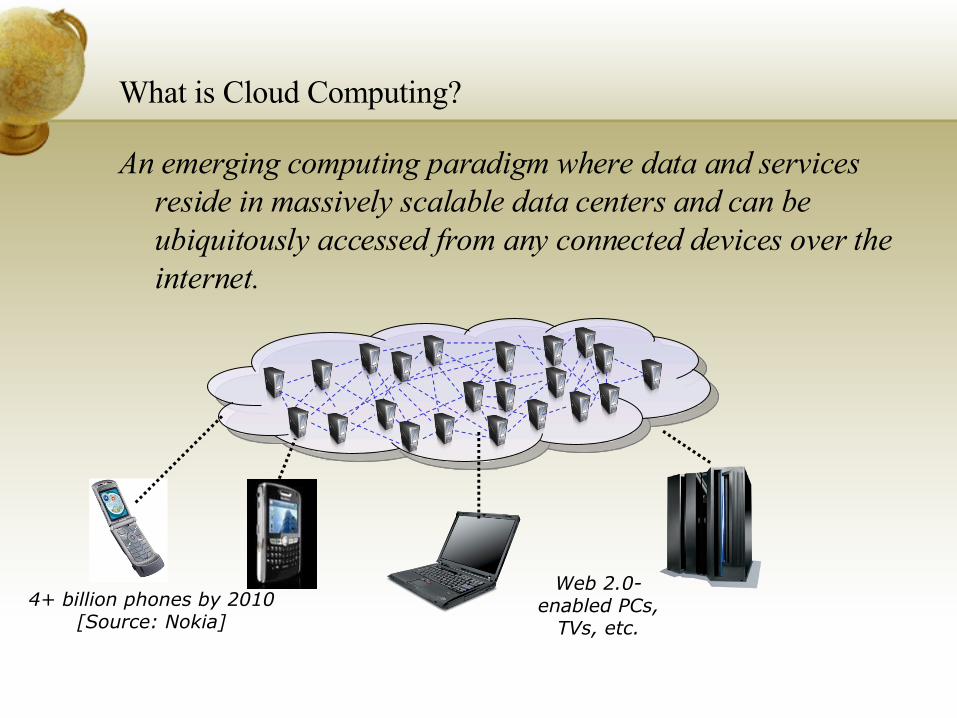
What is Cloud Computing?
An emerging computing paradigm where data and services reside in massively scalable data centers and can be ubiquitously accessed from any connected devices over the internet.
4+ billion phones by 2010 [Source: Nokia]
Web 2.0-enabled PCs,
TVs, etc.

Characteristics of Cloud Computing
Virtual – Physical location and underlying infrastructure details are transparent to users
Scalable – Able to break complex workloads into pieces to be served across an incrementally expandable infrastructure
Efficient – Services Oriented Architecture for dynamic provisioning of shared compute resources
Flexible – Can serve a variety of workload types – both consumer and commercial

Cloud Computing Building Blocks A massively scalable and flexible computing platform of the future,
built on IBM and open source software, for hosting Web 2.0 and SOA applications.
Business Benefits
• Cost efficient model for creating
and acquiring information services• Removes or reduces IT management
complexity• Increases business responsiveness
with real-time capacity reallocation• Powers rich internet applications
Enabling TechnologiesOpen source Linux platform
Xen open source systems virtualization
Automated provisioning of computing resources by Tivoli Provisioning Manager
Systems management and monitoring by IBM Tivoli Monitoring
Parallel computing clusters using Apache Hadoop
Open source Eclipse-based development tools for parallel applications
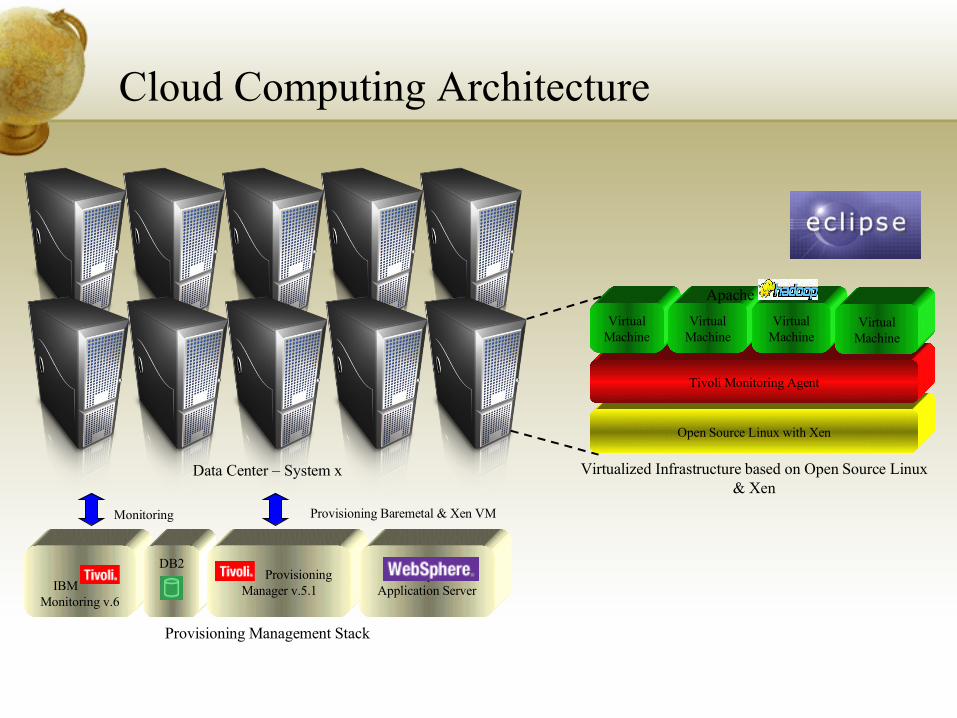
Cloud Computing Architecture
IBM Monitoring v.6
DB2
Provisioning Management Stack
Provisioning Manager v.5.1
WebSphere Application Server
Monitoring Provisioning Baremetal & Xen VM
Open Source Linux with Xen
Tivoli Monitoring Agent
Virtualized Infrastructure based on Open Source Linux & Xen
VirtualMachine
VirtualMachine
VirtualMachine
VirtualMachine
Data Center – System x
Apache

Examples of Cloud Computing Workloads
Web 2.0 applications
Software to scan voluminous Wikipedia edits to identify spam
Organize global news articles by geographic location
Data-intensive workloads based on scalable architectures.
Next generation rich media, such as virtual worlds, streaming videos, etc.
New services can be created and published via a completely integrated Eclipse-based environment
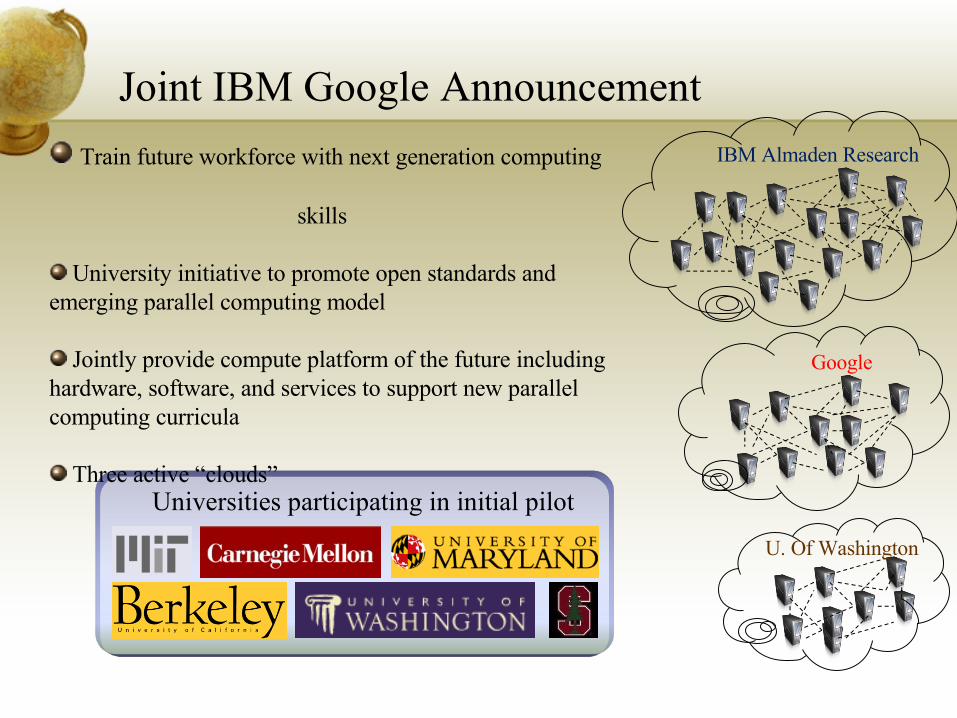
Joint IBM Google Announcement
IBM Almaden Research
Universities participating in initial pilot
Train future workforce with next generation computing skills
University initiative to promote open standards and emerging parallel computing model
Jointly provide compute platform of the future including hardware, software, and services to support new parallel computing curricula
Three active “clouds”
U. Of Washington

Web Mining
Web mining is the use of data mining techniques to automatically discover and extract information from Web documents/services

Why is Web Information Retrieval Important?
Research
Health/Medicine
Travel
Business
Entertainment
Arts

Why is Web Information Retrieval Difficult?
The Abundance Problem
Hundreds of irrelevant documents returned in response to a search
query.
Limited Coverage of the Web
Largest crawlers cover less than 18% of Web pages
The Web is extremely dynamic
Lots of pages added, removed and changed every day
Very high dimensionality (thousands of dimensions)
Limited query interface based on keyword-oriented search
Limited customization to individual users
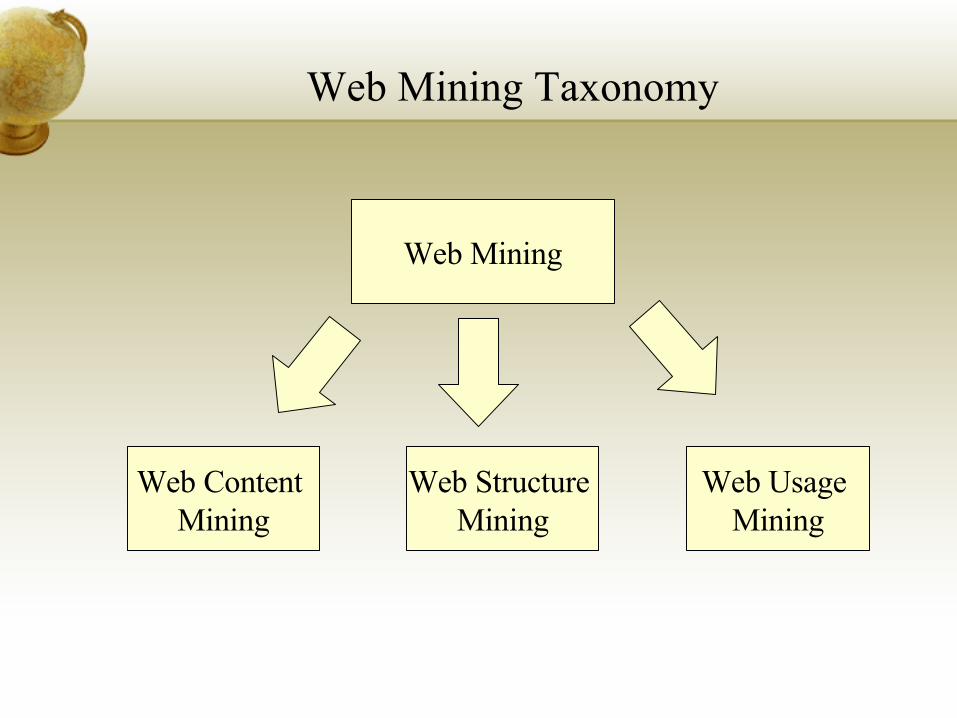
Web Mining Taxonomy
Web Mining
Web Usage Mining
Web Structure Mining
Web Content Mining

Web Mining Taxonomy
Web content mining: focuses on techniques for assisting a user in finding documents that meet a certain criterion (text mining)
Web structure mining: aims at developing techniques to take advantage of the collective judgment of web page quality which is available in the form of hyperlinks
Web usage mining: focuses on techniques to study the user behavior when navigating the web (also known as Web log mining and clickstream analysis)

Web Content Mining
Can be thought of as extending the work performed by basic search engines.
Search engines have crawlers to search the web and gather information, indexing techniques to store the information, and query processing support to provide information to the users
Web Content Mining is: the process of extracting knowledge from web contents

Semi-Structured Data
Content is, in general, semi-structured
Example:
Title
Author Publication_Date Structured attribute/value pairs
Length
Category
Abstract Unstructured
Content

Text Mining
Document classification
Document clustering
Key-word based association rules

Web Structure Mining
Early days: keyword based searches
Keywords: “web mining”
Retrieves documents with “web” and mining”
Later on: cope with
Synonymy problem
Polysemy problem
stop words
Modern search engines use link structure as
important source of information

Central Question:
Which useful information can be derived
from the link structure of the web?

Some Answers
1. Structure of Internet
2. Google
3. HITS: Hubs and Authorities
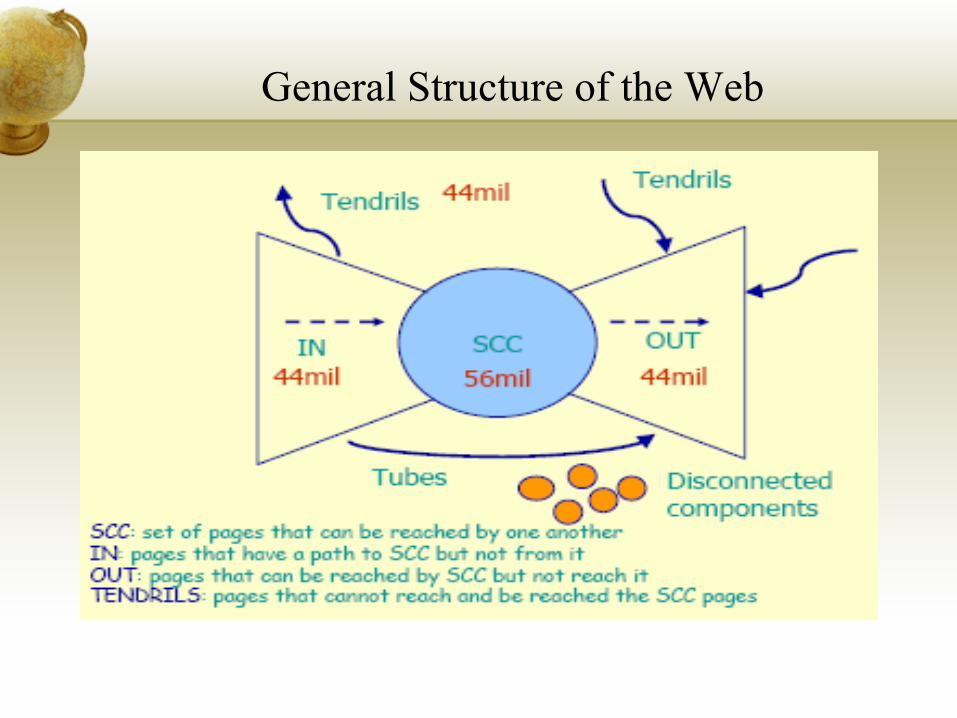
General Structure of the Web

Search engine that uses link structure to calculate a quality ranking (PageRank) for each page
Intuition: PageRank can be seen as the probability that a “random surfer” visits a page
Keywords CMPE272 entered by user
Select pages containing CMPE272 and pages which have in-links with caption CMPE272.
Font sizes of words in text: Words in larger or bolder font are assigned higher weights.

HITS (hyperlink-Induced Topic Search)
HITS uses hyperlink structure to identify authoritative Web sources for broad-topic information discovery
Premise: Sufficiently broad topics contain communities consisting of two types of hyperlinked pages:
Authorities: highly-referenced pages on a topic
Hubs: pages that “point” to authorities
A good authority is pointed to by many good hubs; a good hub points to many good authorities
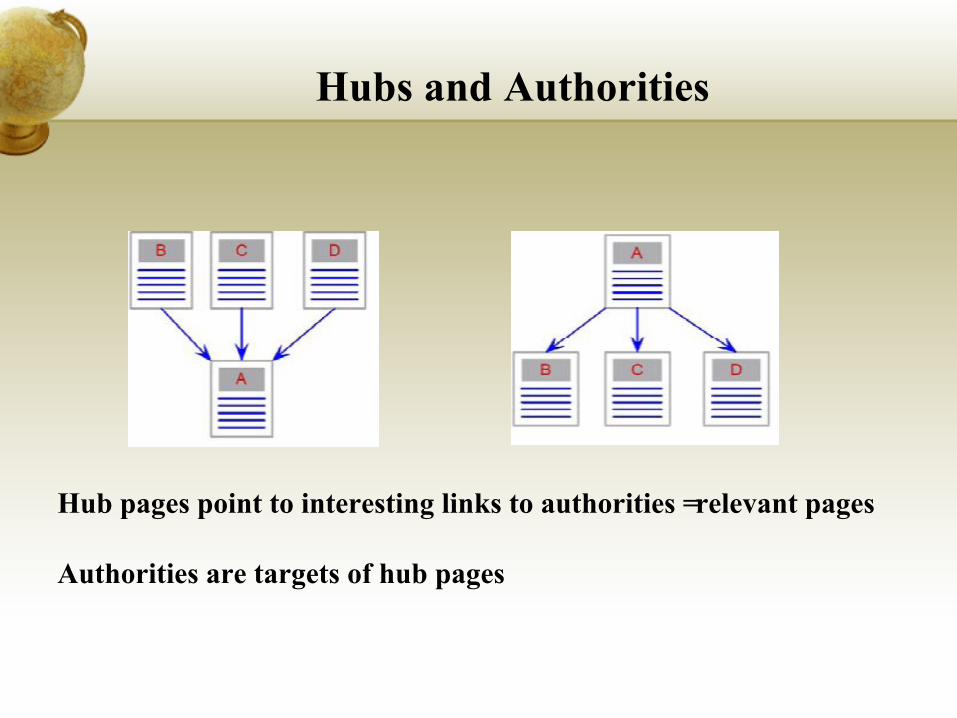
Hubs and Authorities
Hub pages point to interesting links to authorities = relevant pages
Authorities are targets of hub pages

Web Usage Mining
Pages contain information
Links are “roads”
How do people navigate over the Internet?
⇒Web usage mining (Clickstream Analysis)
Information on navigation paths are logged.

Web Usage Analysis
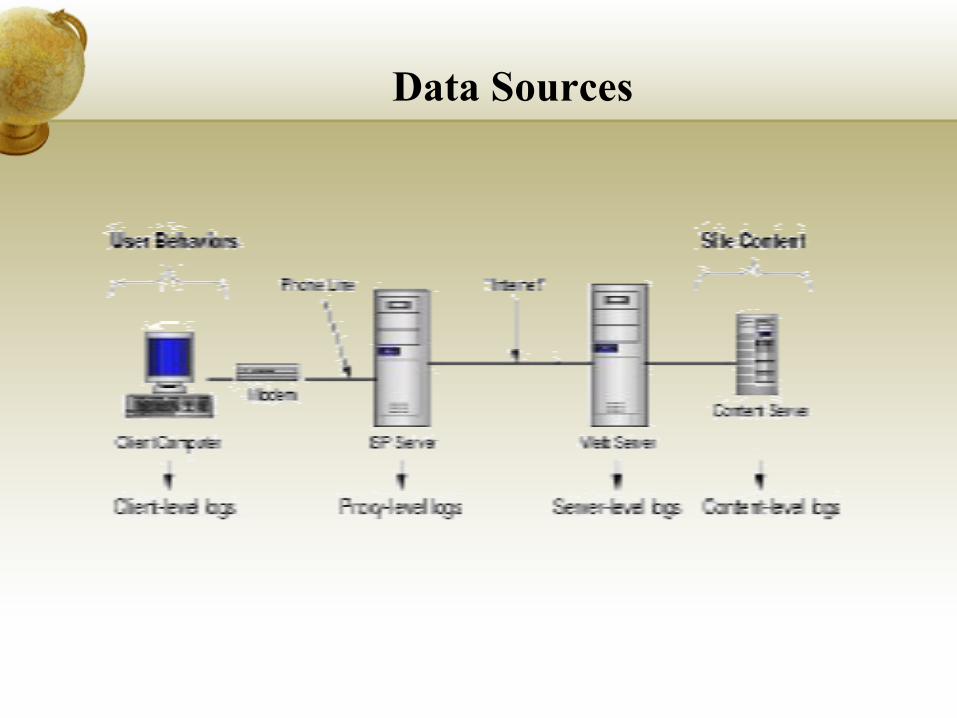
Data Sources
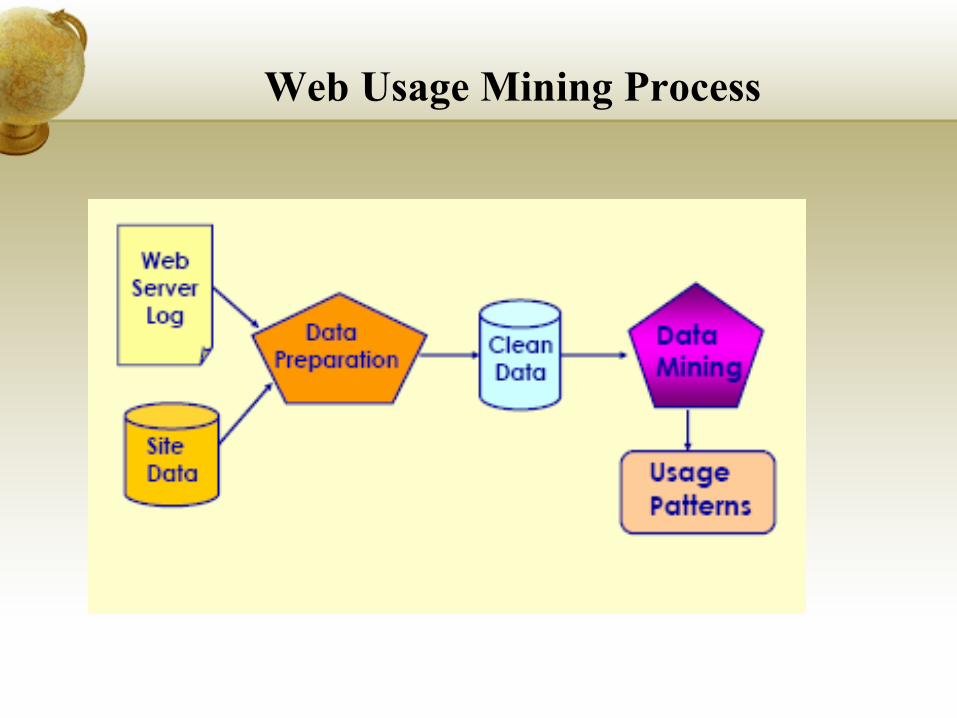
Web Usage Mining Process

Data Preparation
Data cleaning
By checking the suffix of the URL name, for example, all log
entries with filename suffixes such as, gif, jpeg, etc
User identification
If a page is requested that is not directly linked to the
previous pages, multiple users are assumed to exist on the
same machine
Other heuristics involve using a combination of IP address,
machine name, browser agent, and temporal information to
identify users
Transaction identification
All of the page references made by a user during a single visit
to a site
Size of a transaction can range from a single page reference to
all of the page references

References - Web
Bryan Basham, Kathy Sierra, & Bert Bates. (2008). Head first servlets and JSP Oreilly & Associates Inc.
Dan Harkey, Robert Orfali, & Jeri Edwards. Client/Server survival guide (Third ed.) Wiley.
Open social. (2008). http://www.opensocial.org/
Praveen, A. (2008). Job quest mashup.http://praveen.987mb.com/Projects/JobDashBoard/HTML/JobQuest.html
Wikipedia. (2008). http://en.wikipedia.org/wiki/Main_Page

References – Semantic Web
Lee, T. B. (1998, September). Semantic Web Road map. Retrieved July 11, 2008 from http://www.w3.org/DesignIssues/Semantic.htmlLee, T. B. Semantic Web - XML2000. Retrieved July 11, 2008 from http://www.w3.org/2000/Talks/1206-xml2k-tbl/Overview.htmlManola, Miller, McBride (2004, February). The RDF Primer. W3C Recommendations.Lee, T. B. (1998, September). Why RDF model is different from the XML model. Retrieved July 11, 2008 from http://www.w3.org/DesignIssues/RDF-XML.htmlW3C. (1999, January). Resource Description Framework(RDF) Model and Syntax Specification. Retrieved July 11, 2008 from http://www.w3.org/TR/PR-rdf-syntax/Palmer, S., B. (1999, September). The Semantic Web: An introduction. Retrieved July 11, 2008 from http://infomesh.net/2001/swintro/#itWorks

References
www.umass.edu/research/rld/iln/uploads/Cloud%20Computing%20Oct%2003%20Ext.ppt
en.wikipedia.org/wiki/Cloud_computing
infolab.stanford.edu/~ullman/mining/2006/lectureslides/web%20mining%20overview.pdf
www.cs.uic.edu/~liub/WebContentMining.html
en.wikipedia.org/wiki/Web_mining





























