Embed Size (px)
Citation preview

Stream processing by default
Modern processing for Big Data, as offered by Google Cloud Dataflow and Flink
William VambenepeLead Product Manager for Data ProcessingGoogle Cloud Platform@vambenepe / [email protected]
Goals:
Write interesting computations
Run in both batch & streaming
Use custom timestamps
Handle late data

Data Shapes
Google’s Data Processing Story
The Dataflow Model
Agenda
Google Cloud Dataflow service
1
2
3
4

Data Shapes1

Data...
...can be big...
...really, really big...
TuesdayWednesday
Thursday
...maybe even infinitely big...
9:008:00 14:0013:0012:0011:0010:002:001:00 7:006:005:004:003:00

… with unknown delays.
9:008:00 14:0013:0012:0011:0010:00
8:00
8:008:00
8:00

1 + 1 = 2Completeness Latency Cost
$$$
Data Processing Tradeoffs
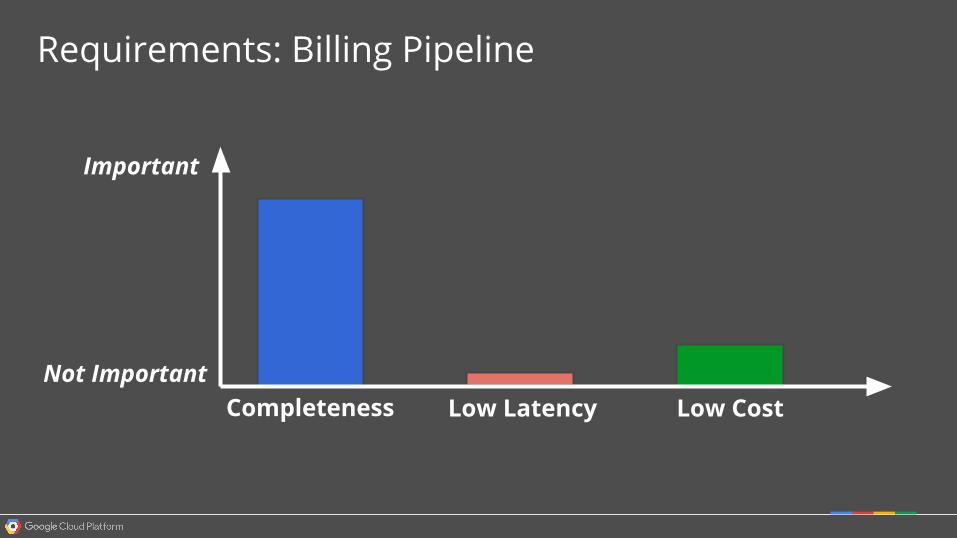
Requirements: Billing Pipeline
Completeness Low Latency Low Cost
Important
Not Important
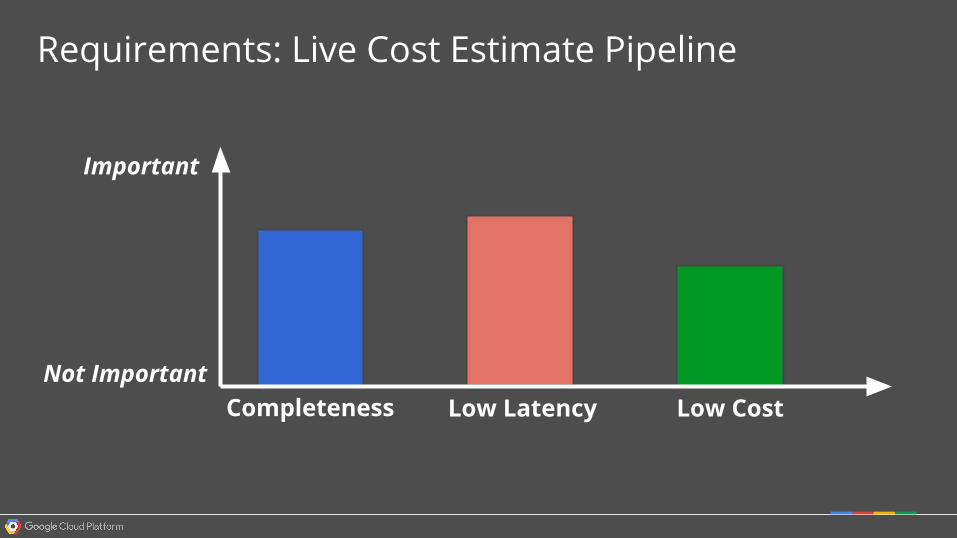
Requirements: Live Cost Estimate Pipeline
Completeness Low Latency Low Cost
Important
Not Important
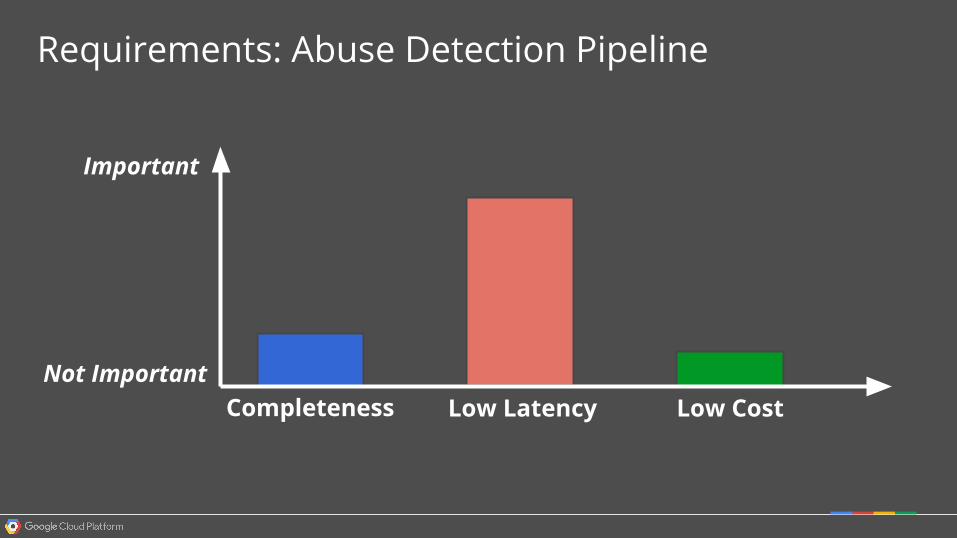
Requirements: Abuse Detection Pipeline
Completeness Low Latency Low Cost
Important
Not Important
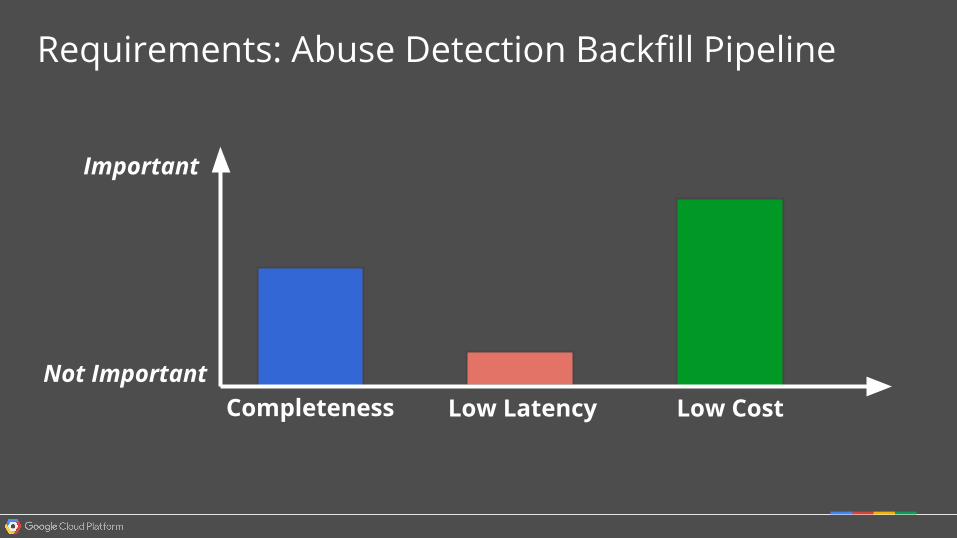
Requirements: Abuse Detection Backfill Pipeline
Completeness Low Latency Low Cost
Important
Not Important

Google’s Data Processing Story2

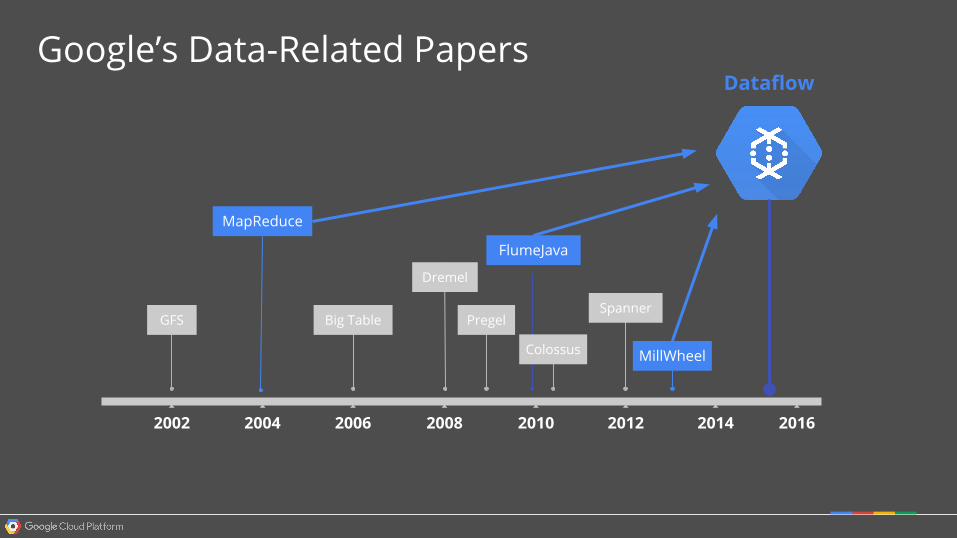
20122002 2004 2006 2008 2010
MapReduce
GFS Big Table
Dremel
Pregel
FlumeJava
Colossus
Spanner
2014
MillWheel
Dataflow
2016
Google’s Data-Related Papers
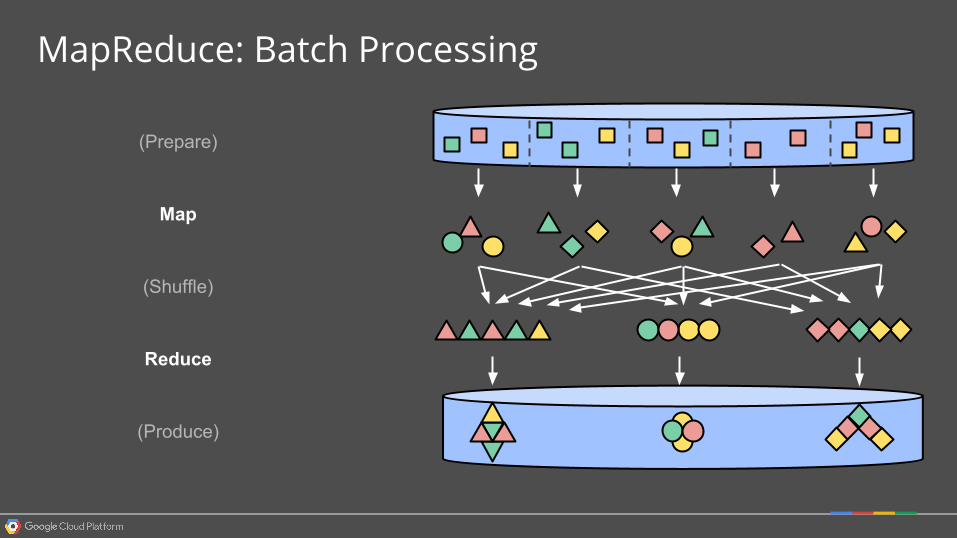
(Produce)
MapReduce: Batch Processing
(Prepare)
(Shuffle)
Map
Reduce
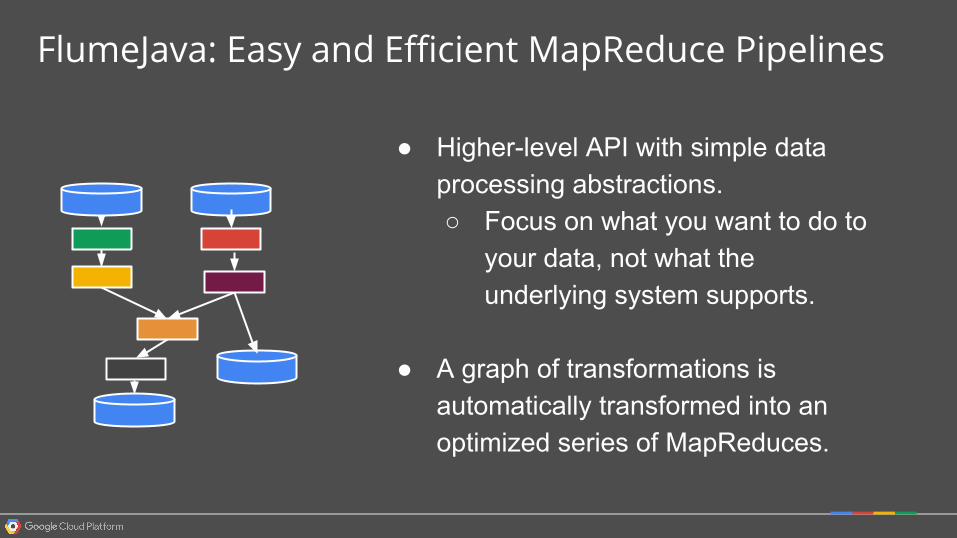
FlumeJava: Easy and Efficient MapReduce Pipelines
● Higher-level API with simple data processing abstractions.○ Focus on what you want to do to
your data, not what the underlying system supports.
● A graph of transformations is automatically transformed into an optimized series of MapReduces.
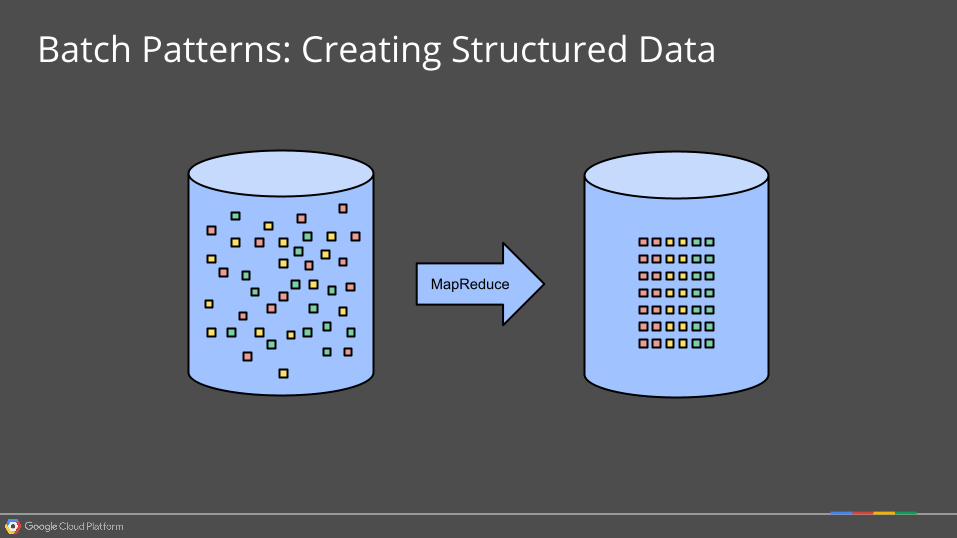
MapReduce
Batch Patterns: Creating Structured Data
MapReduce
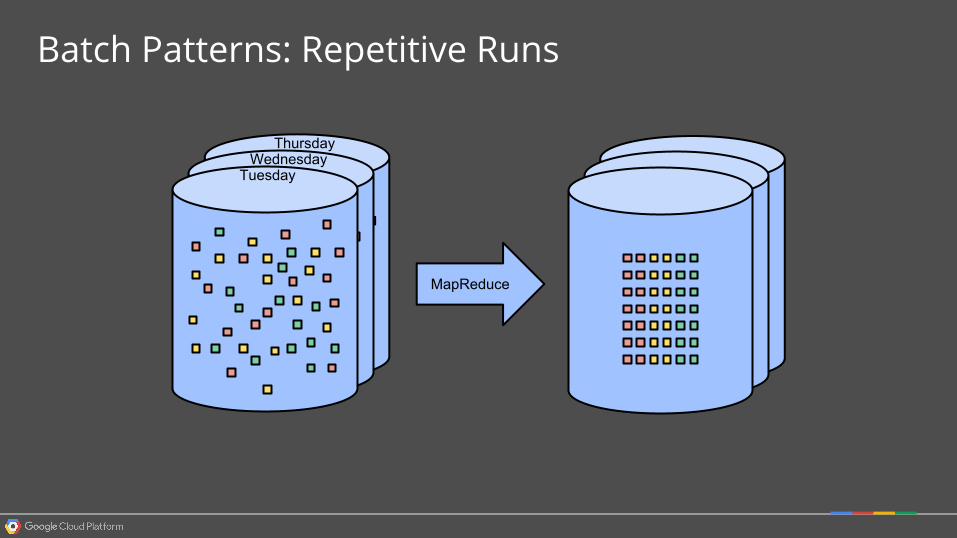
Batch Patterns: Repetitive Runs
TuesdayWednesday
Thursday
MapReduce
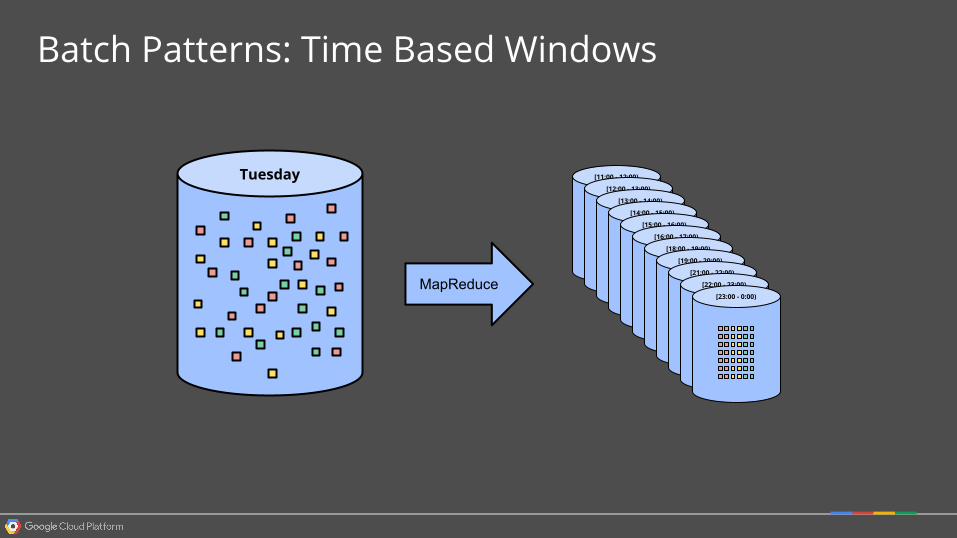
Tuesday [11:00 - 12:00)
[12:00 - 13:00)
[13:00 - 14:00)
[14:00 - 15:00)
[15:00 - 16:00)
[16:00 - 17:00)
[18:00 - 19:00)
[19:00 - 20:00)
[21:00 - 22:00)
[22:00 - 23:00)
[23:00 - 0:00)
Batch Patterns: Time Based Windows
MapReduce
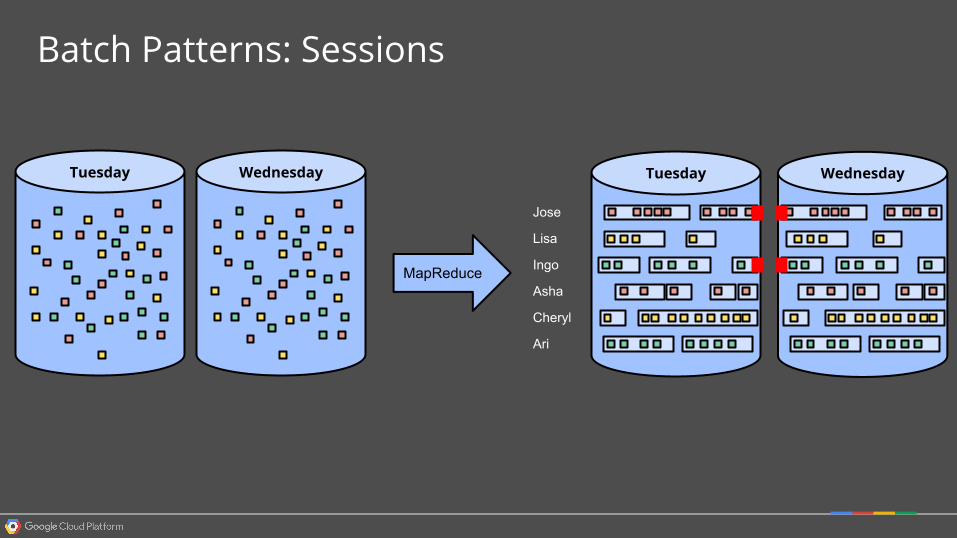
TuesdayWednesday
Batch Patterns: Sessions
Jose
Lisa
Ingo
Asha
Cheryl
Ari
WednesdayTuesday
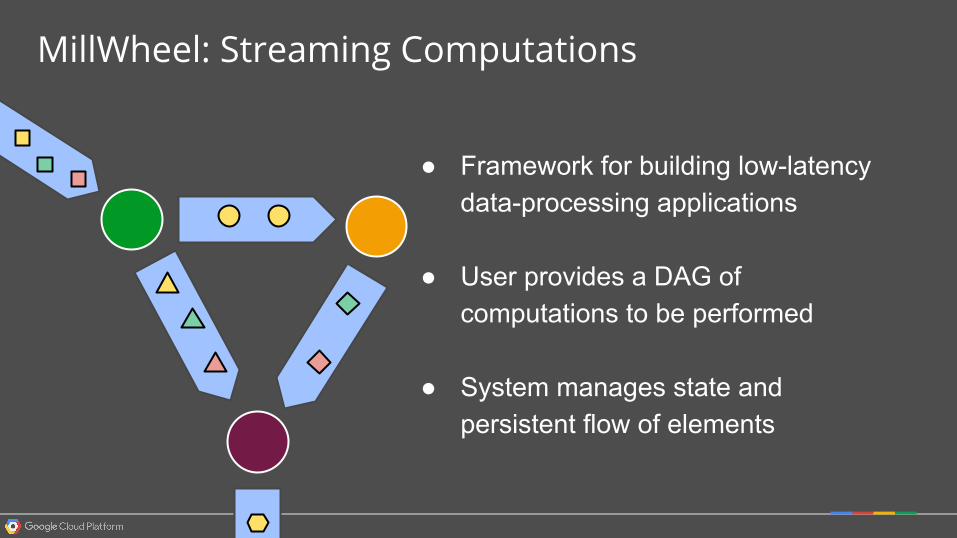
MillWheel: Streaming Computations
● Framework for building low-latency data-processing applications
● User provides a DAG of computations to be performed
● System manages state and persistent flow of elements
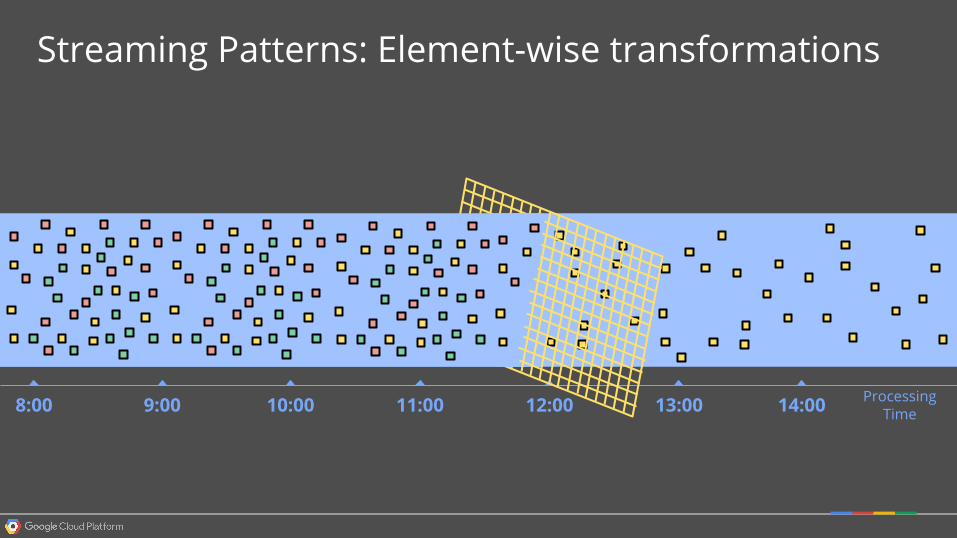
Streaming Patterns: Element-wise transformations
13:00 14:008:00 9:00 10:00 11:00 12:00 Processing Time
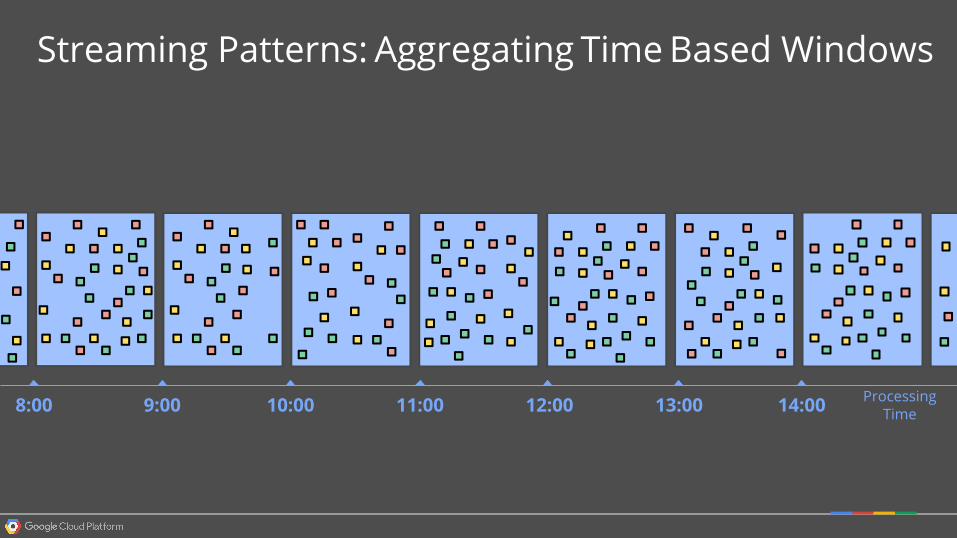
Streaming Patterns: Aggregating Time Based Windows
13:00 14:008:00 9:00 10:00 11:00 12:00 Processing Time
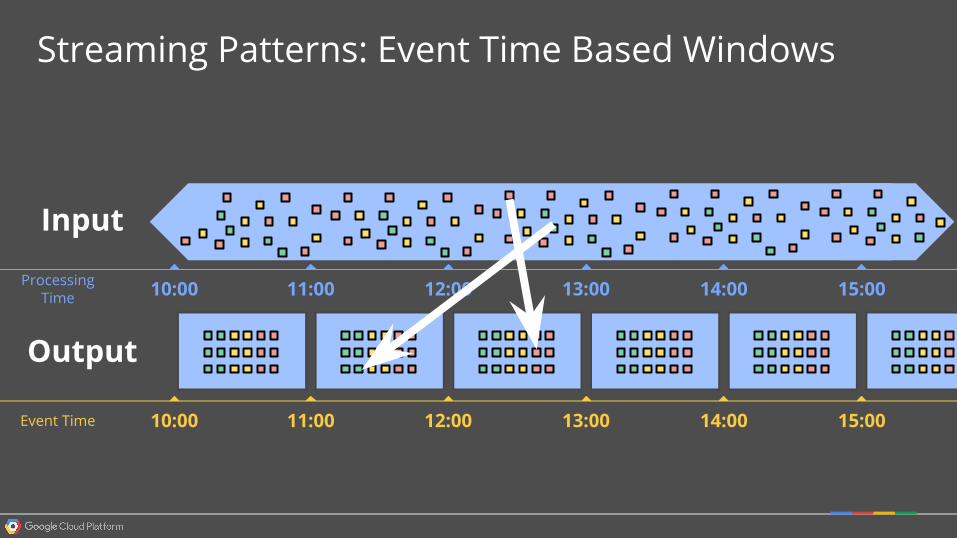
11:0010:00 15:0014:0013:0012:00Event Time
11:0010:00 15:0014:0013:0012:00Processing Time
Input
Output
Streaming Patterns: Event Time Based Windows
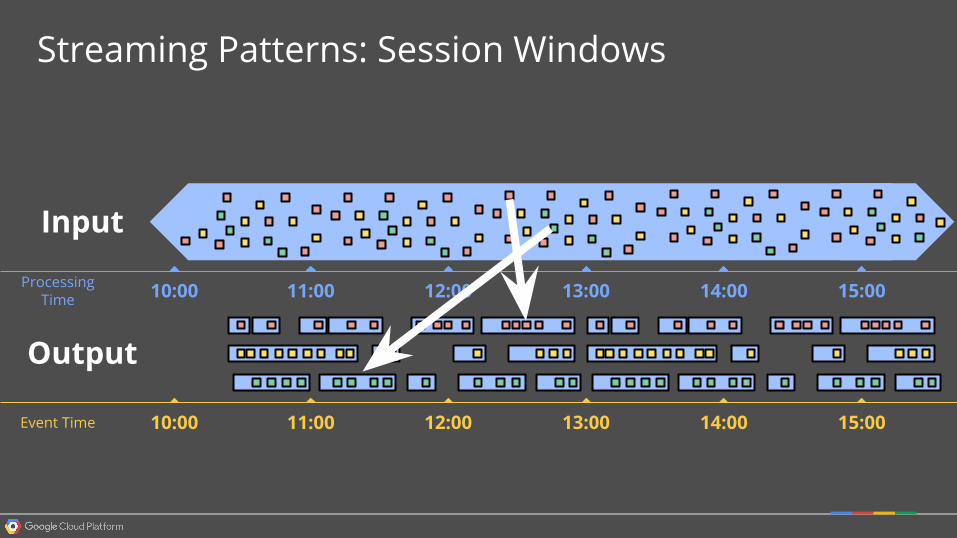
Streaming Patterns: Session Windows
Event Time
Processing Time 11:0010:00 15:0014:0013:0012:00
11:0010:00 15:0014:0013:0012:00
Input
Output
Proc
essi
ng T
ime
Event Time
Skew
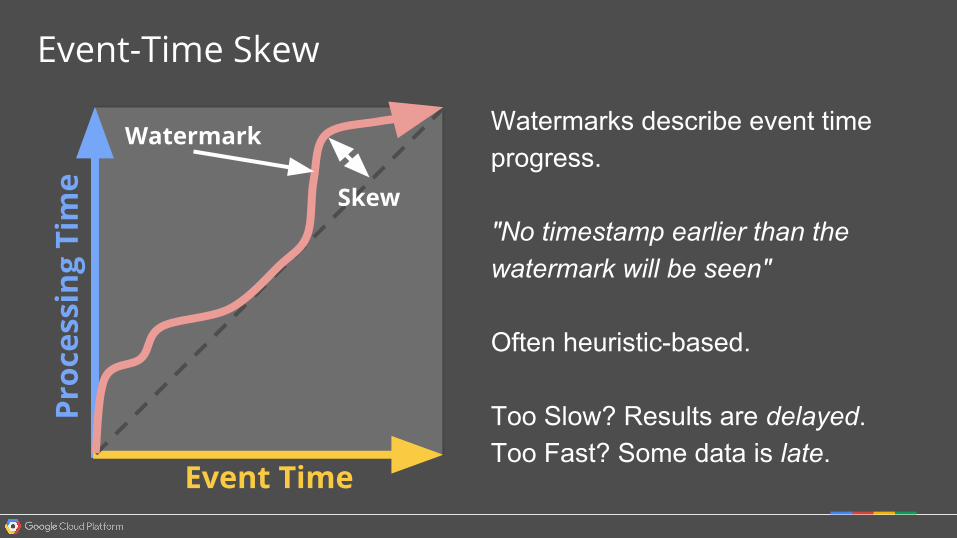
Event-Time Skew
Watermark Watermarks describe event time progress.
"No timestamp earlier than the watermark will be seen"
Often heuristic-based.
Too Slow? Results are delayed.Too Fast? Some data is late.

The Dataflow Model3

What are you computing?
Where in event time?
When in processing time?
How do refinements relate?
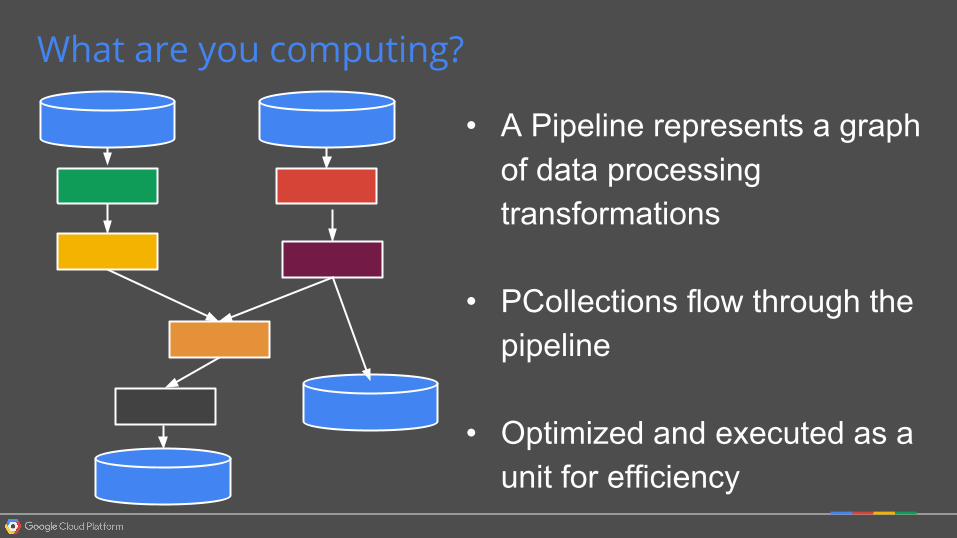
What are you computing?
• A Pipeline represents a graph of data processing transformations
• PCollections flow through the pipeline
• Optimized and executed as a unit for efficiency
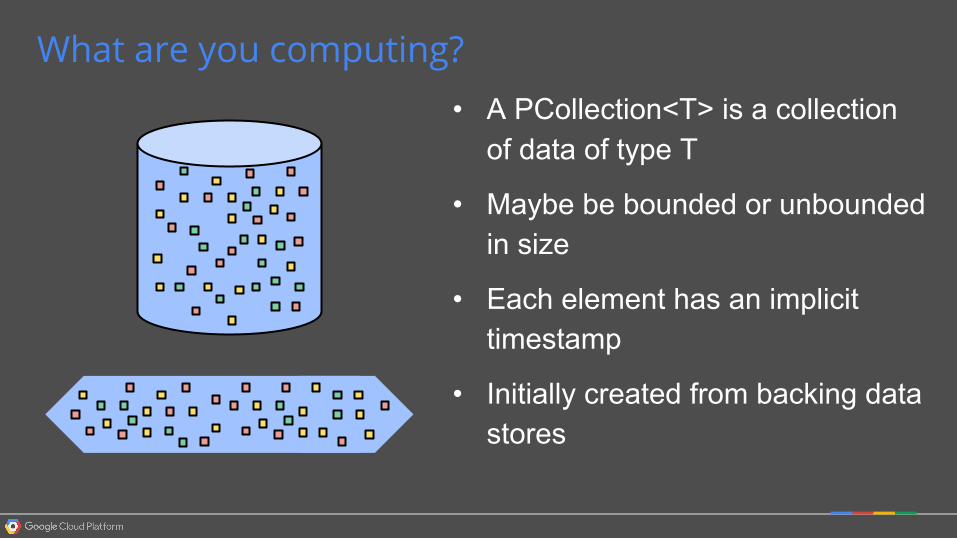
What are you computing? • A PCollection<T> is a collection
of data of type T
• Maybe be bounded or unbounded in size
• Each element has an implicit timestamp
• Initially created from backing data stores
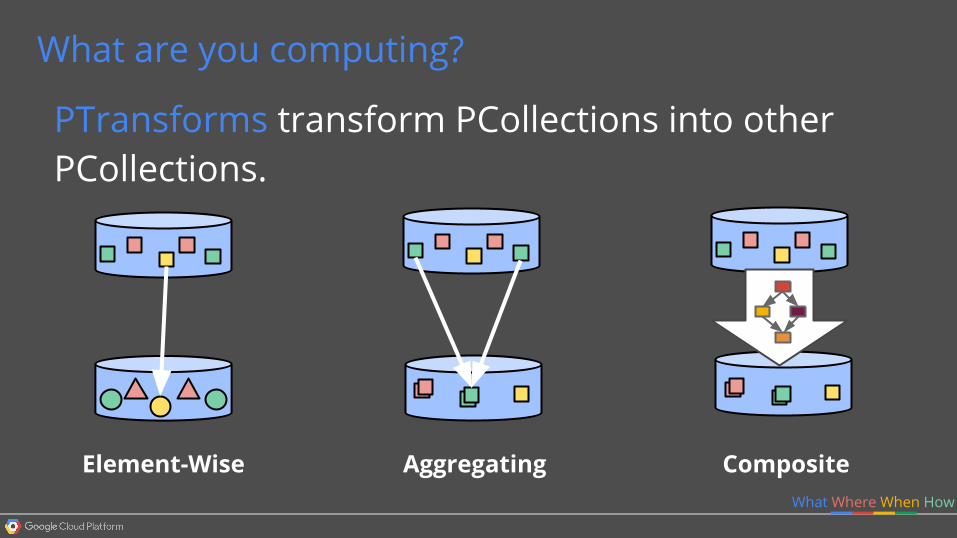
What are you computing?
PTransforms transform PCollections into other PCollections.
What Where When How
Element-Wise Aggregating Composite
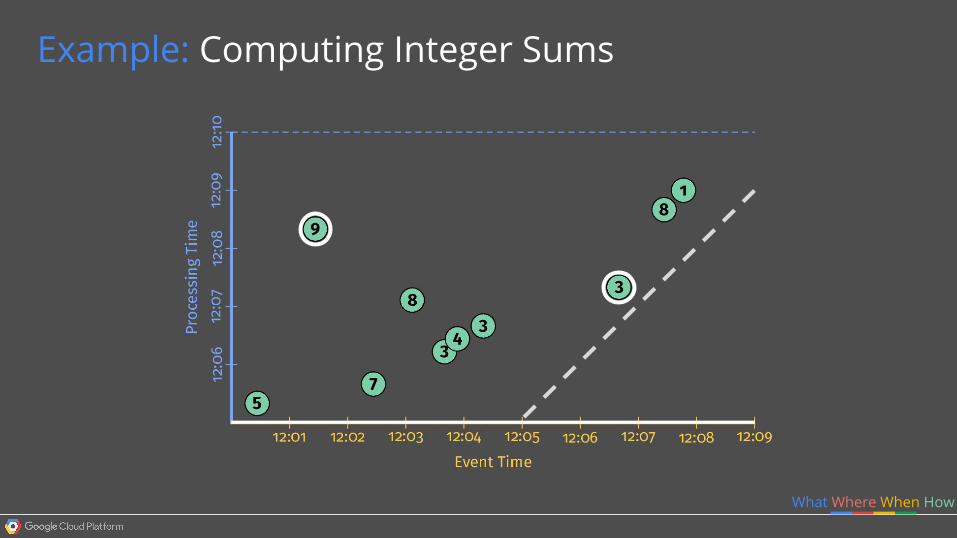
Example: Computing Integer Sums
What Where When How
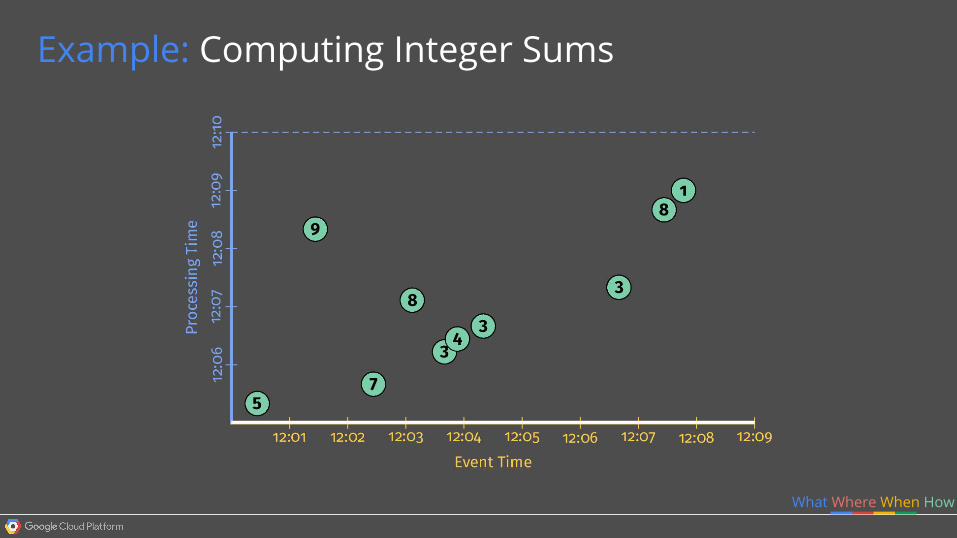
What Where When How
Example: Computing Integer Sums
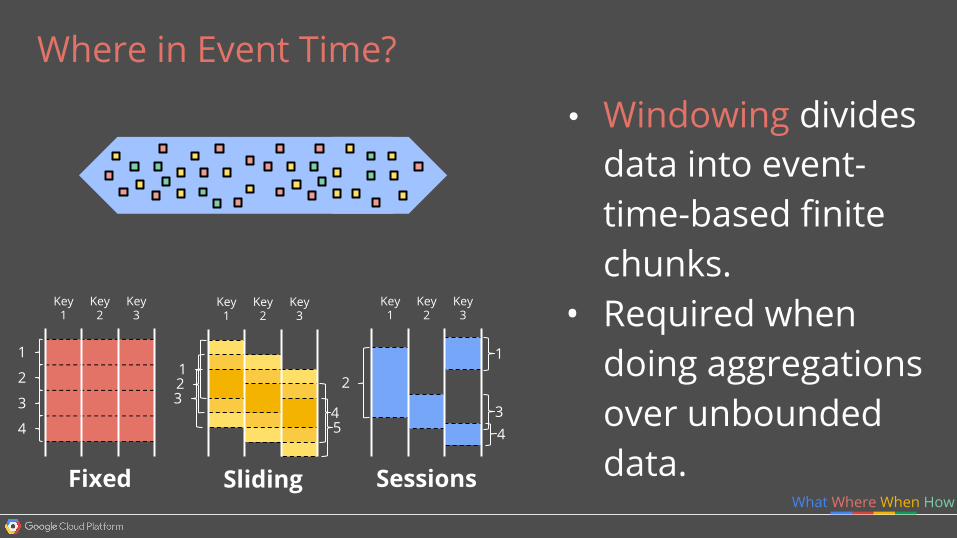
Key 2
Key 1
Key 3
1
Fixed
2
3
4
Key 2
Key 1
Key 3
Sliding
123
54
Key 2
Key 1
Key 3
Sessions
2
43
1
Where in Event Time?
• Windowing divides data into event-time-based finite chunks.
• Required when doing aggregations over unbounded data.
What Where When How
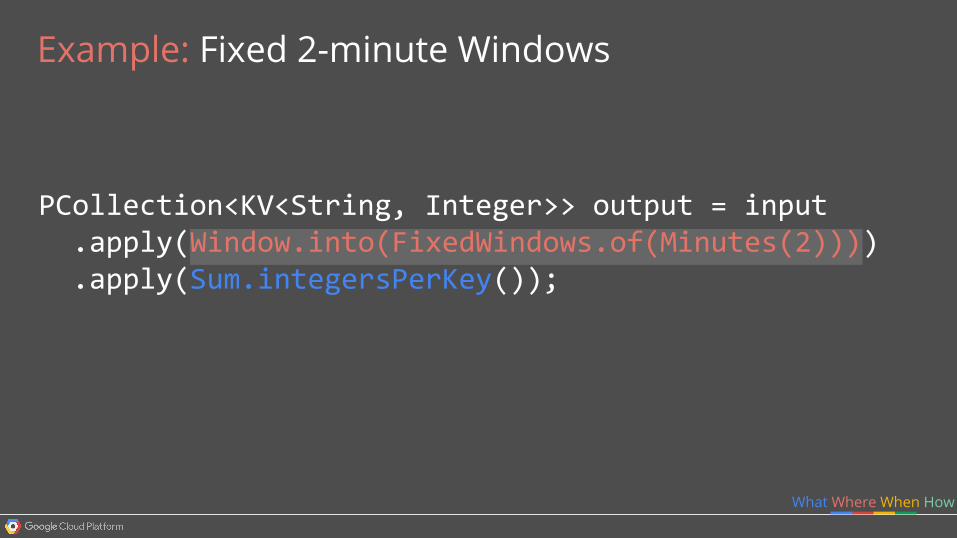
PCollection<KV<String, Integer>> output = input .apply(Window.into(FixedWindows.of(Minutes(2)))) .apply(Sum.integersPerKey());
What Where When How
Example: Fixed 2-minute Windows
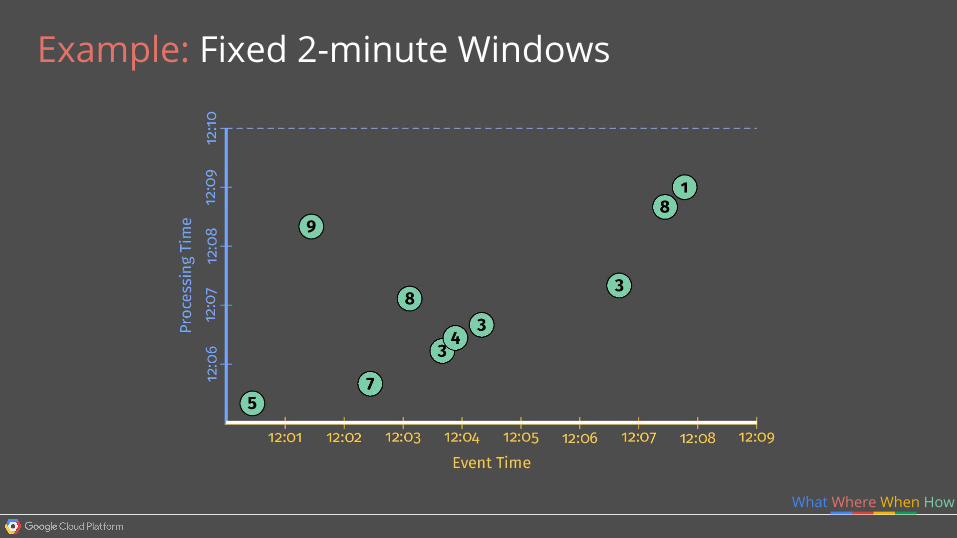
What Where When How
Example: Fixed 2-minute Windows
What Where When How
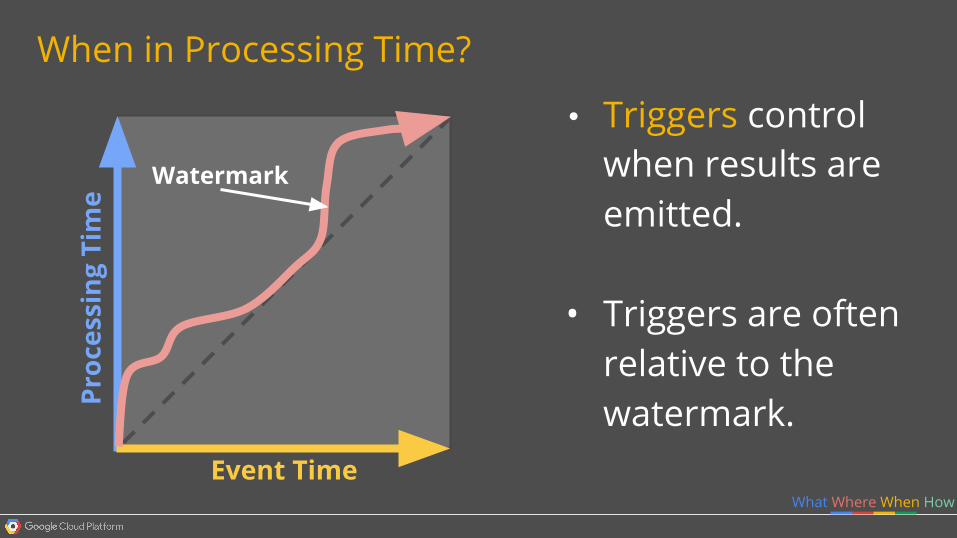
When in Processing Time?
• Triggers control when results are emitted.
• Triggers are often relative to the watermark.Pr
oces
sing
Tim
e
Event Time
Watermark

PCollection<KV<String, Integer>> output = input .apply(Window.into(FixedWindows.of(Minutes(2))) .trigger(AtWatermark()) .apply(Sum.integersPerKey());
What Where When How
Example: Triggering at the Watermark
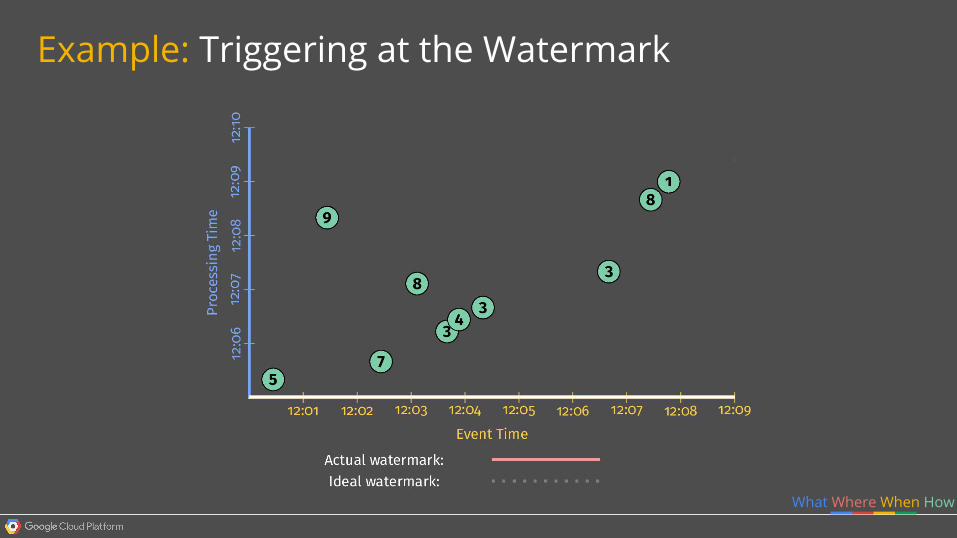
What Where When How
Example: Triggering at the Watermark

What Where When How
Example: Triggering for Speculative & Late Data
PCollection<KV<String, Integer>> output = input .apply(Window.into(FixedWindows.of(Minutes(2))) .trigger(AtWatermark() .withEarlyFirings(AtPeriod(Minutes(1))) .withLateFirings(AtCount(1)))) .apply(Sum.integersPerKey());
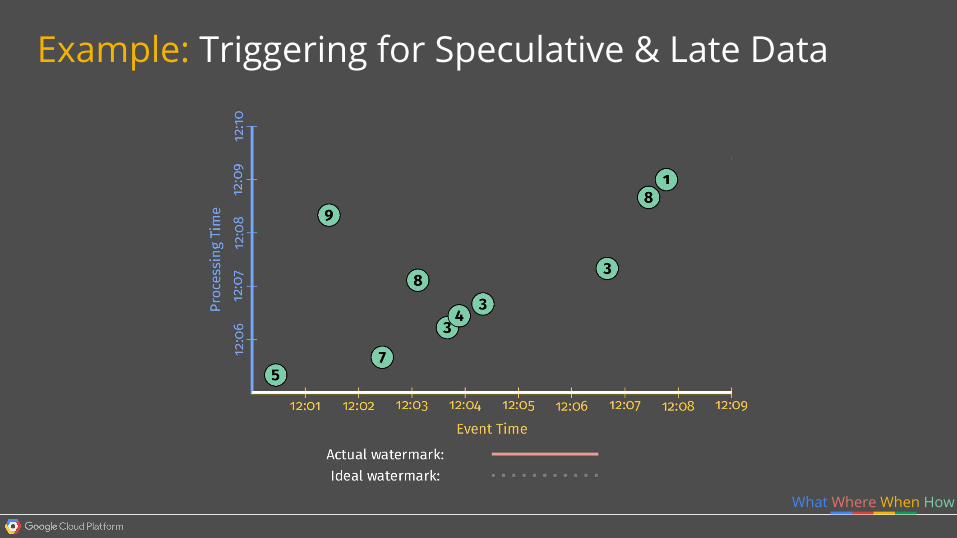
What Where When How
Example: Triggering for Speculative & Late Data
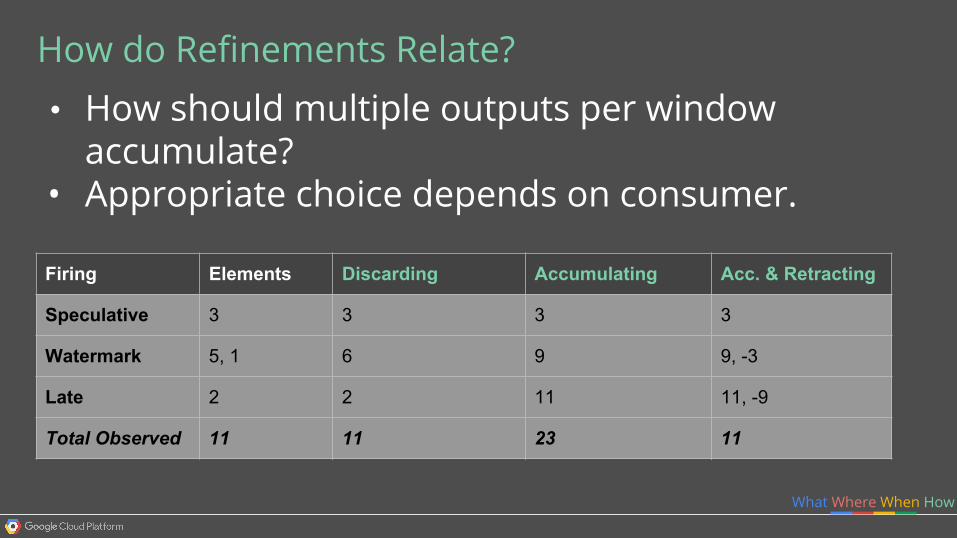
What Where When How
How do Refinements Relate?• How should multiple outputs per window
accumulate?• Appropriate choice depends on consumer.
Firing Elements
Speculative 3
Watermark 5, 1
Late 2
Total Observed 11
Discarding
3
6
2
11
Accumulating
3
9
11
23
Acc. & Retracting
3
9, -3
11, -9
11

PCollection<KV<String, Integer>> output = input .apply(Window.into(Sessions.withGapDuration(Minutes(1))) .trigger(AtWatermark() .withEarlyFirings(AtPeriod(Minutes(1))) .withLateFirings(AtCount(1))) .accumulatingAndRetracting()) .apply(new Sum());
What Where When How
Example: Add Newest, Remove Previous
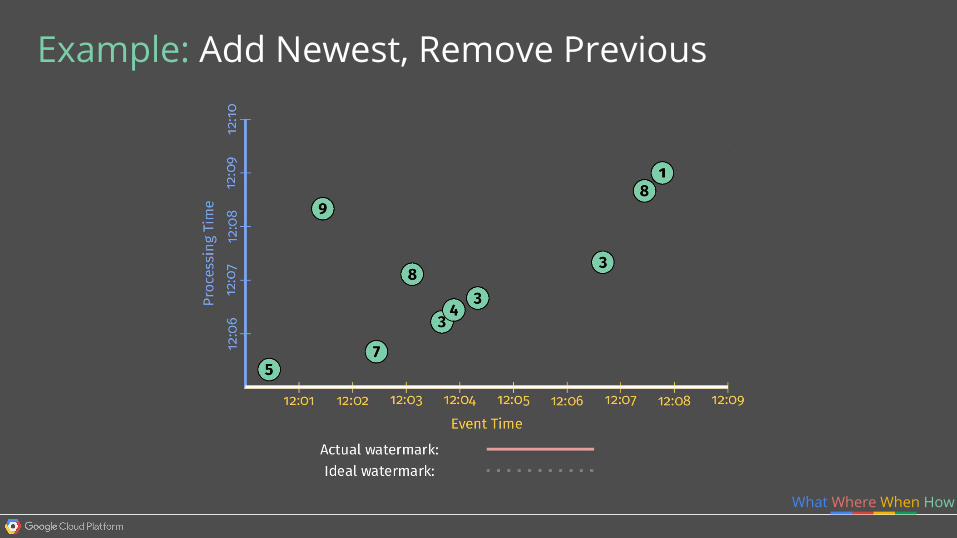
What Where When How
Example: Add Newest, Remove Previous
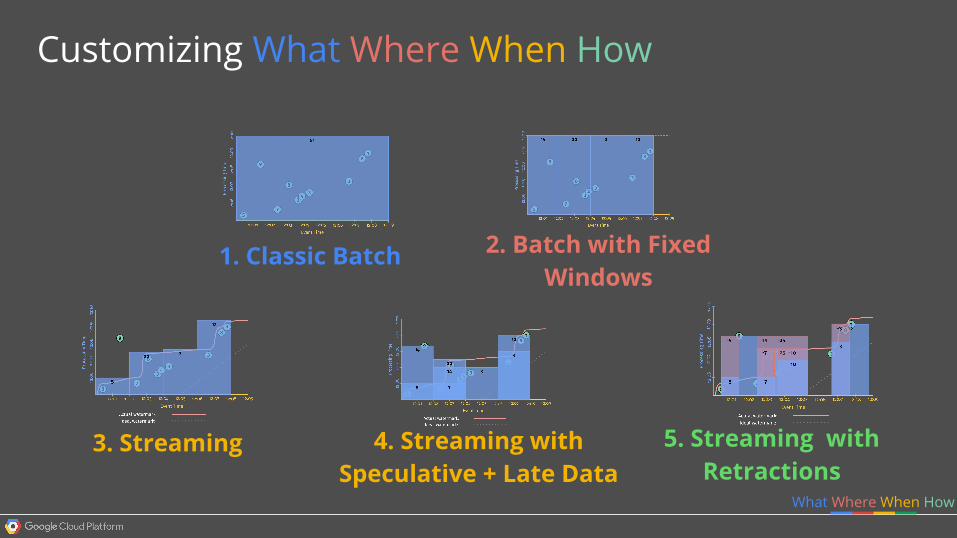
1. Classic Batch 2. Batch with Fixed Windows
3. Streaming 5. Streaming with Retractions
4. Streaming with Speculative + Late Data
Customizing What Where When How
What Where When How

Dataflow improvements over Lambda architecture
Low-latency, approximate results
Complete, correct results as soon as possible
One system: less to manage, fewer resources, one set of bugs
Tools for explicit reasoning about time= Power + Flexibility + Clarity
Never re-architect a working pipeline for operational reasons
Open Source SDKs
● Used to construct a Dataflow pipeline.
● Java available now. Python in the works.
● Pipelines can run…○ On your development machine○ On the Dataflow Service on Google Cloud Platform ○ On third party environments like Spark (batch only) or
Flink (streaming coming soon)

Google Cloud Dataflow service4

Fully Managed Dataflow Service
Runs the pipeline on Google Cloud Platform. Includes:
● Graph optimization: Modular code, efficient execution● Smart Workers: Lifecycle management, Autoscaling, and
Smart task rebalancing ● Easy Monitoring: Dataflow UI, Restful API and CLI,
Integration with Cloud Logging, etc.
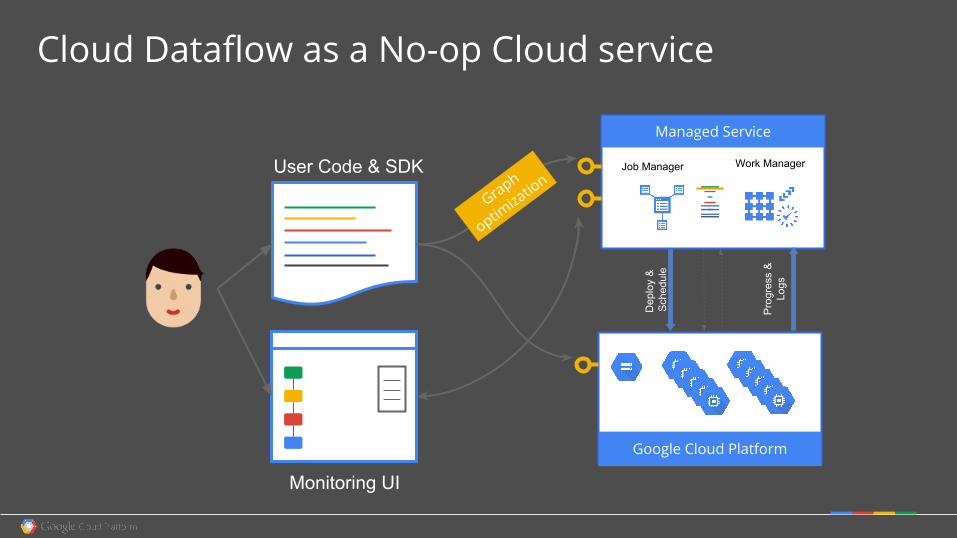
Cloud Dataflow as a No-op Cloud service
Google Cloud Platform
Managed Service
User Code & SDK Work Manager
Dep
loy
& S
ched
ule
Pro
gres
s &
Lo
gs
Monitoring UI
Job Manager
Graph
optimiza
tion
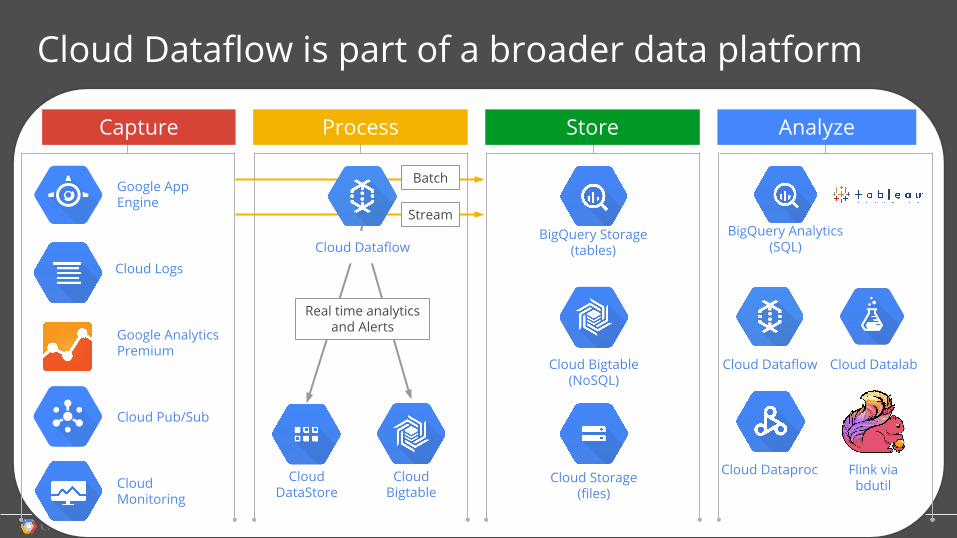
Cloud Dataflow is part of a broader data platform
Cloud Logs
Google App Engine
Google Analytics Premium
Cloud Pub/Sub
BigQuery Storage(tables)
Cloud Bigtable(NoSQL)
Cloud Storage(files)
Cloud Dataflow
BigQuery Analytics(SQL)
Capture Store Analyze
Batch
Cloud DataStore
Process
Stream
Cloud Monitoring
Cloud Bigtable
Real time analytics and Alerts
Cloud Dataflow
Cloud Dataproc
Cloud Datalab
Flink viabdutil
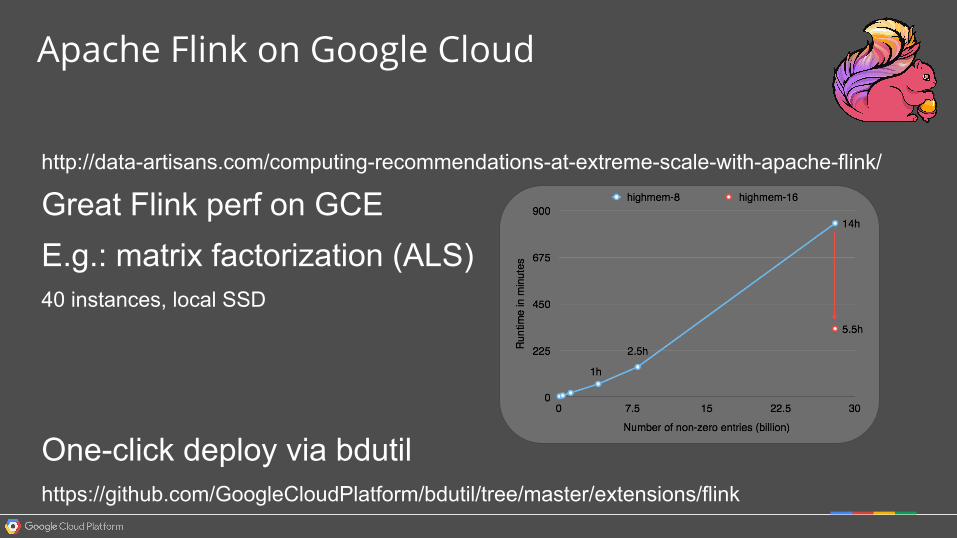
http://data-artisans.com/computing-recommendations-at-extreme-scale-with-apache-flink/
Great Flink perf on GCEE.g.: matrix factorization (ALS)40 instances, local SSD
One-click deploy via bdutilhttps://github.com/GoogleCloudPlatform/bdutil/tree/master/extensions/flink
Apache Flink on Google Cloud
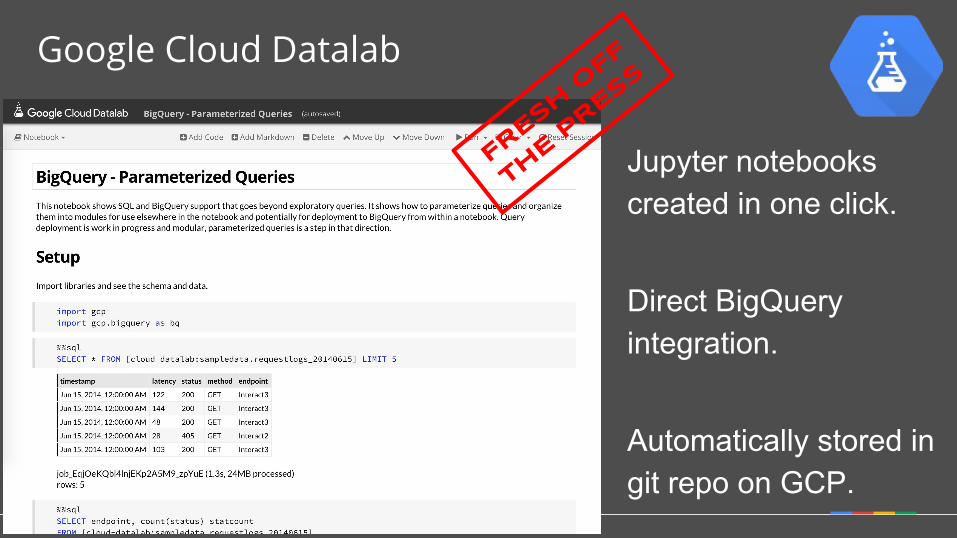
Google Cloud Datalab
Jupyter notebooks created in one click.
Direct BigQuery integration.
Automatically stored in git repo on GCP.
FRESH O
FF
THE P
RESS

Learn More
● The Dataflow Model @VLDB 2015 http://www.vldb.org/pvldb/vol8/p1792-Akidau.pdf
● Dataflow SDK for Javahttps://github.com/GoogleCloudPlatform/DataflowJavaSDK
● Google Cloud Dataflow on Google Cloud Platformhttp://cloud.google.com/dataflow (Free Trial!)
● Contact me: [email protected] or on Twitter @vambenepe





![StreamBox-HBM: Stream Analytics on High Bandwidth Hybrid ...pekhimenko/Papers/StreamBox-ASPLOS_19.pdf · as Flink [12], Spark Streaming [71], and Google Cloud Dataflow [5]. These](https://img.pdfslide.net/doc/110x75/5fc263a4d5e0fe745b3b5c92/streambox-hbm-stream-analytics-on-high-bandwidth-hybrid-pekhimenkopapersstreambox-asplos19pdf.jpg)























