Embed Size (px)
Citation preview

This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent
Server Side Optimization for SSD (SSOS)
G-Cube Inc.

2This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Agenda
• Introduction
• OS’s storage stack
• Storage stack optimization for next-generation SSD
• Ongoing works

3This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
• It’s time for low-latency I/O.-Very high I/O demand in computer systems. -Social network services, cloud platform ,and desktop users
• New technology - Storage Class Memory (SCM) -high-performance and robustness + the archival capabilities and low cost.
-Deployable as a disk drive replacement as well as a scalable main memory alternative.
- NAND Flash, Phase-change memory (PCM), MRAM, RRAM, …
Introduction

4This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
There is No Free Lunch !
Storage Class Memory
Storage Stack in Modern OS
What matters us !Application performance: response time, throughput, TPM…
What SCM vendors give to us.High-throughput and ultra-latency
Show Different Perfor-mance Number !

5This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
User Experience with New Computing Resources, New Service Framework, but Traditional System & Interfaces
User
System
Resource* Many-core CPU ( 64 cores ~) * No mechanical movement(~ microseconds)
Virtual Memory File systemBlock I/O & I/O schedulerDevice driverHW Interfaces
User Experience is poor
Poor
parallel
Unaware
fast
UX
Scalable
Resourceawarness
Performance
non-scalable
Parallism
Service Mobile apps, Cloud, Big data, HPC… I/O
pressure
Highly frequent & concurrent & randomized
Interfaces
Narrow and Limited Information
Device-aware
Scalable
Rich & Context-aware
Best

6This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
SSD Performance in Modern Operating System
I/O load(users, applications)
Performance
HDD
SSD (UX)
SSD vendor performance
SSD
최대
성능
향상
2~4 배
Storage Stack in Modern OS
Show Differ-ent Perfor-mance Num-ber !
Storage Class Memory
What SCM ven-dors give to us.High-throughput and ultra-latency
What matters us !Application perfor-mance: response time, throughput, TPM…

7This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Technical strategy
Server Side Optimization for SSD: Make fast & broad I/O path between user & SSD
I/O 부하량(users, applications)
성능 (1/average response time)
SSD (now)
SSD (hardware)
SSD 최
대 성
능SSD 최대 부하
SSD ( 제안 제품 )
Fast I/O path
Broad I/O path
• User latency, response time
• Throughput
“Exploting peek device throughput even from con-
current small random access workload”

8This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Storage Stack in Modern OS
Device driver
IO Scheduler
Filesystem
Apps
Hard disk drive
Block layerLong and complex to mitigateperformance gap between CPU, memory and hard disk drive.
Diskified

9This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Storage Stack Optimizations for NVM SSD
Device driver
IO Scheduler
Filesystem
Apps
NVM SSD
Block layer
De-diskify Employ SSD feature Remove diskified feature in
software storage stack Enlarge interfaces between
layers Make I/O path synchronous

10This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Performance Metrics
•Latency-IOPS (I/Os per second)-Small random workload
•Throughput-Bandwidth (MB/s)
-Large sequential workload
•Our goal -Exploit peak device throughput from small random access workload.

11This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Focusing on Latency…
•New Hardware Abstraction Layer.-Get rid of disk-based HAL overhead.
•Polling-based interfaces-Avoid interrupt handling overhead for NVM SSD with a few micro-second response time.

12This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Polling vs Interrupt
I/O command
I/O command IRQ SoftIRQ
ApplicationContext
ApplicationContext
sleep
Device response
time
Device response
time
Busy wait(polling)
Interrupt-based I/O event handling
Polling-based I/O event handling
Schedule delay
4~5us 8~15us
2~3us
4~5us
14~23us

13This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Performance Evaluation
Peak device throughput
polling
sequential read seq_write random read rand_write

14This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Device Throughput
•Temporal merge-Device-level scatter-gather I/O
•Multiple I/O path-Non-blocking write
15This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
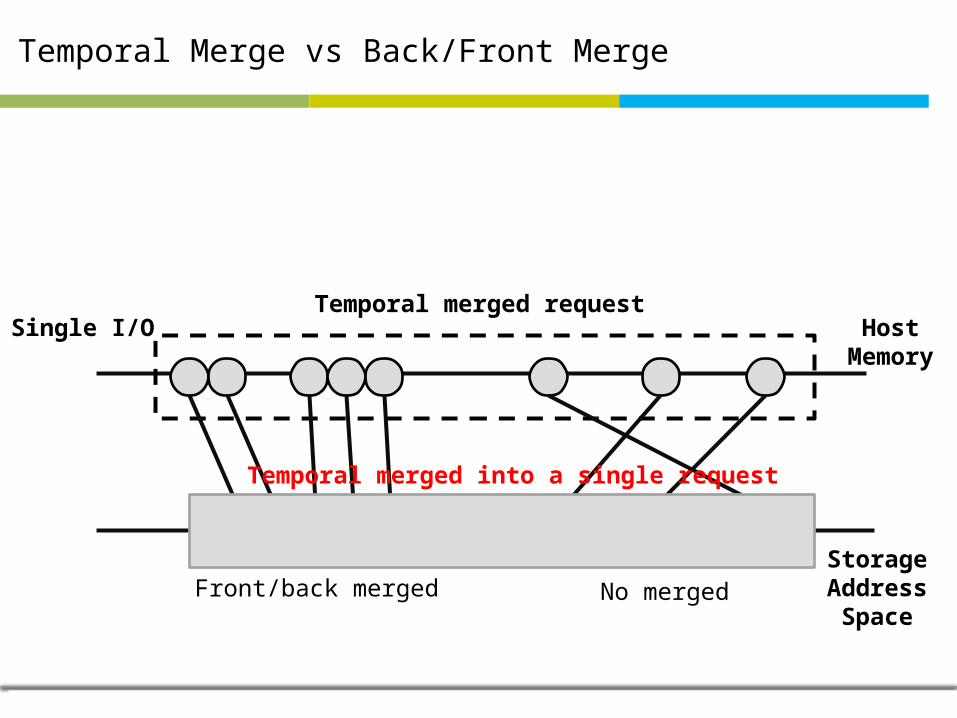
Temporal Merge vs Back/Front Merge
Temporal merged requestSingle I/O
StorageAddressSpace
HostMemory
Front/back merged No merged
Temporal merged into a single request

16This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Merge I/O requests from temporal locality
REQ 1
Temporal Merge
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
5
4
3
3
2
5
4
3
1 2
1
5
4
3
2
1 1 1 1 11
Read requests
2 22 2
REQ 2
REQ 3
REQ 4
Busy Wait
Perform I/O

17This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Performance Evaluation
Peak Device Throughput
Temporal Merge
sequential read seq_write random read rand_write
18This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
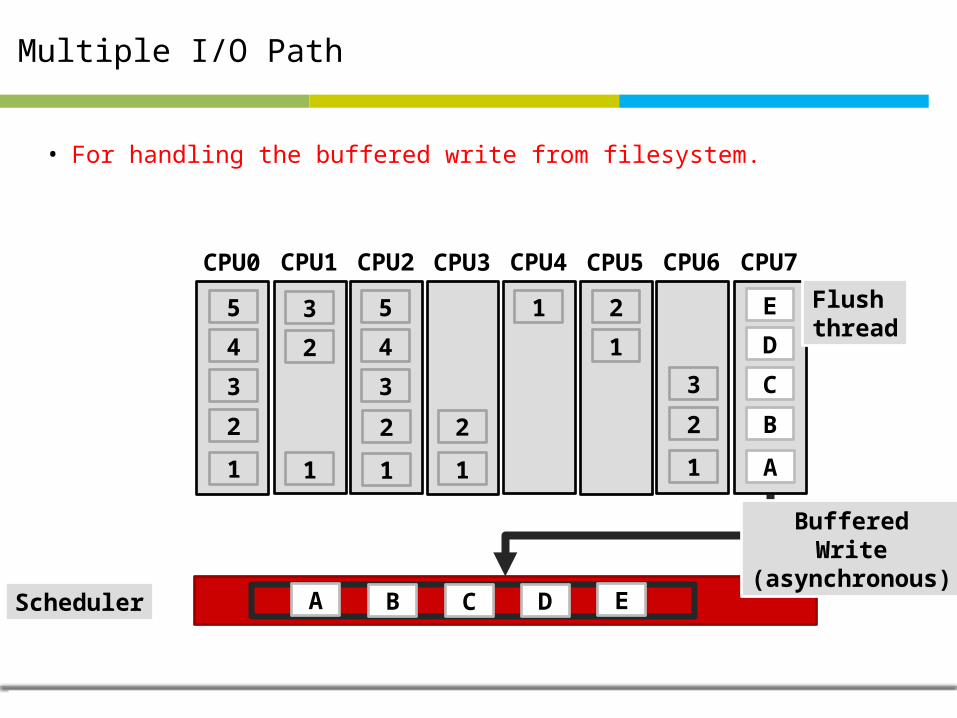
Multiple I/O Path
• For handling the buffered write from filesystem.
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7
5
4
3
3
2
5
4
3
1 2
1
3
2 22 2
1 1 1 11
E
D
C
B
A
Flush thread
Scheduler A B D EC
BufferedWrite
(asynchronous)

19This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Performance Evaluation
19
ideal max throughput
All done except for random read!!!
Misunderstood read-ahead contextin EXT2 filesys-tem
sequential read seq_write random read rand_write

20This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Latency Again…
• Pipelined post I/O processing-Post I/O processing: DMA unmap, notifying I/O comple-tion, free pages.
-More effective for small-size requests.
21This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
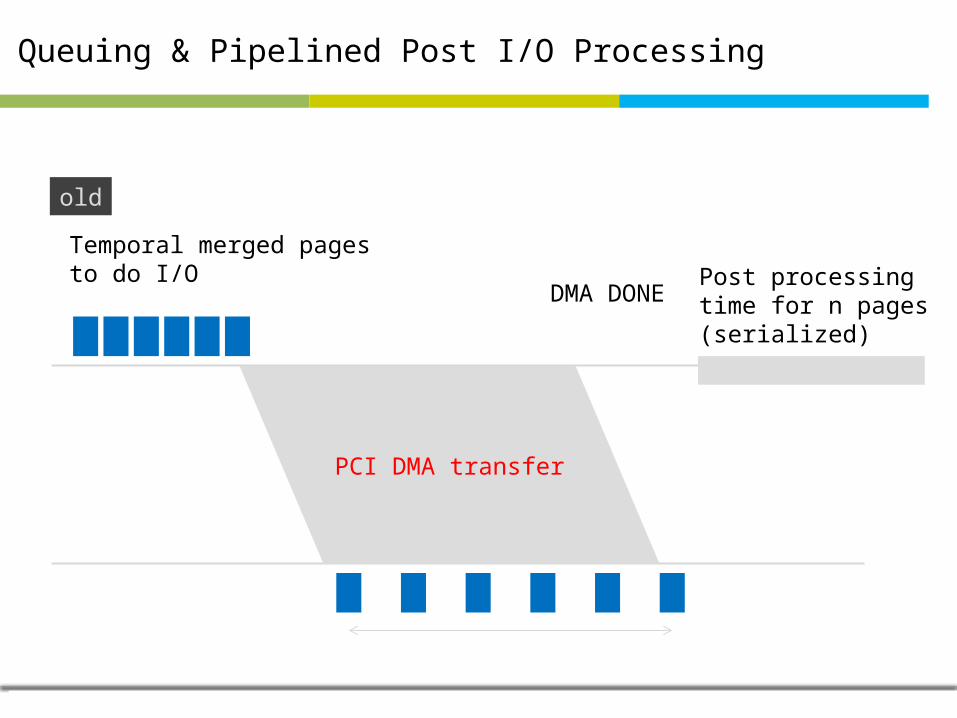
Queuing & Pipelined Post I/O Processing
old
Temporal merged pages to do I/O
PCI DMA transfer
DMA DONEPost processingtime for n pages(serialized)

22This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Pipelined Post I/O Processing
22
Pipelined Post I/O Processing
Temporal merged pages to do I/O
DMA DONE
Post processing time for a page (pipelined)
BLOCK I/O Done(new interfaces)
23This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
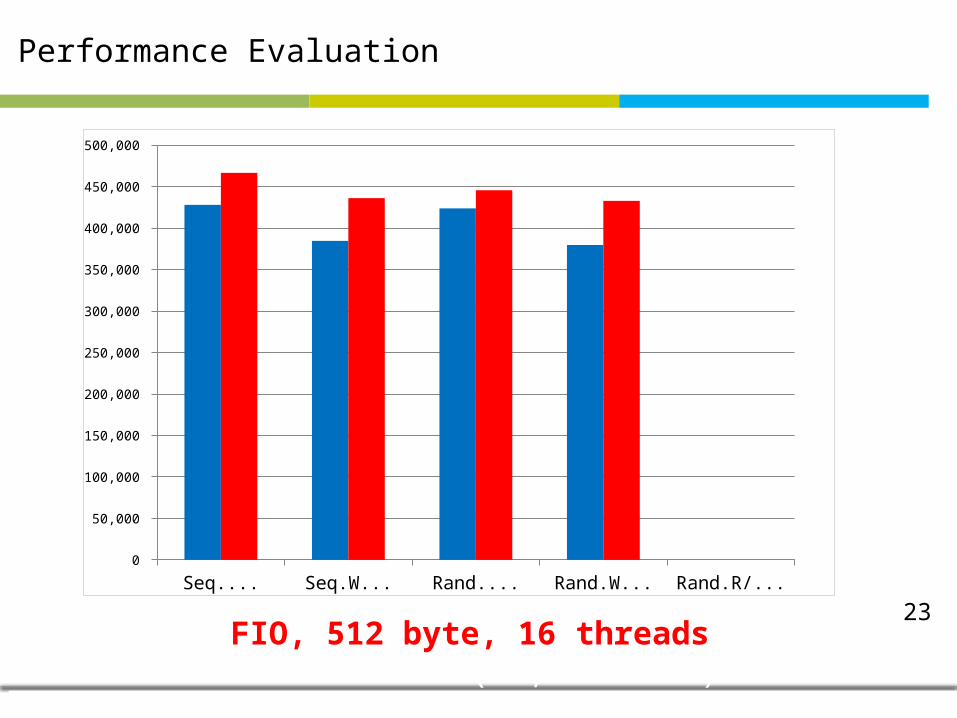
Performance Evaluation
23
Seq.Read Seq.Write Rand.Read Rand.Write Rand.R/W(7/3)0
50,000
100,000
150,000
200,000
250,000
300,000
350,000
400,000
450,000
500,000
FIO, 512 byte, 16 threadsincrease 14% (60,000 IOPS)

24This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Issue: Scalable I/O for Many-core Machine
Device driver
IO Scheduler
Virtual Memory(page cache tree)
Many-core CPU
NVM SSD
Block layer
1 2 4 8 16 320
2000400060008000
10000120001400016000
initail writers
rewriters
readers
re-readers
random readers
random writers
# of threads
Thro
ughp
ut (M
B/se
c)
Ramdisk buffered read
1 2 4 8 16 320
5000
10000
15000
20000
25000
30000
initail writersrewritersreadersre-readersrandom readersrandom writers
# of threads
Thro
ughp
ut (M
B/se
c)
PCI-E SSD buffered read

25This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Scalable Lock for Many-Core CPU
• Access radix tree in Linux kernel- For adding/removing/updating a page into the tree.- spin_lock_irq : tree_lock. non-scalable.
• Possible approaches for scalable lock- Less contented lock structure.
8 With help of application hint. 8 Finer-grained lock 8 With sacrifice of memory resource.
- Remote Core Locking8 No cache invalidation storm.

26This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
Conclusion
User applications
Broad & Thin I/O stack for NVM SSD
NVM SSD
High throughput (Broad way)
Low-latency(Thin layer)
Extended inter-faces for NVM
SSD
Software Storage Stack Optimizations for Next-generation SSD

27This information is confidential and was prepared by G-Cube solely for the use of our client and investor; it is not to be relied on by any 3rd party without G-Cube's prior written consent 141028-IR-Business proposal v05SEO
References
• Young Jin Yu, Dong In Shin, Woong Shin, Nae Young Song, Jae Woo Choi, Hyeong Seog Kim, Hyeonsang Eom, Heon Young Yeom, Optimizing the Block I/O Subsystem for Fast Storage Devices, ACM Transactions on Computer Sys-tems (TOCS), Volume 32 Issue 2, June 2014, Article No. 6
• Dong In Shin, †Young Jin Yu, †Hyeong S. Kim, Jae Woo Choi,Do Yung Jung, †Heon Y. Yeom, "Dynamic Interval Polling and Pipelined Post I/O Processing for Low-Latency Storage Class Memory", USENIX HotStorage 2013, San Jose, June 26-28, 2013
• Jae Woo Choi, Young Jin Yu, Hyeonsang Eom,Heon Young Yeom, Dong In Shin, "SAN Optimization for High Performance Storage with RDMA Data Trans-fer", 7th parallel data storage workshop (PDSW) in conjunction with SC'12, Saltlake City, USA, 10-16 Nov. 2012
• Young Jin Yu, Dong In Shin, Woong Shin, Nae Young Song, Hyeonsang Eom, and Heon Young Yeom, "Exploiting Peak Device Throughput from Random Ac-cessWorkload", USENIX HotStorage 2012, Boston, USA, 13-14 Jun. 2012
![SSD - ESOS LAB€¦ · SSD . 1 SSD Block Diagram 3.2 SSD NAND HDD . . SSD FTL . FTL NAND out-of-place update address mapping . Gabage Collection, Wear-leveling . 4. 4.1 SSD . Disksim[8]](https://img.pdfslide.net/doc/110x75/5ea6b67696cb1838a26c1ab1/ssd-esos-ssd-1-ssd-block-diagram-32-ssd-nand-hdd-ssd-ftl-ftl-nand-out-of-place.jpg)





















![[Share+discussion] Step by step SSD Optimization with Win 7 (Picture)](https://img.pdfslide.net/doc/110x75/55cf8f2d550346703b99adb8/sharediscussion-step-by-step-ssd-optimization-with-win-7-picture.jpg)






