Embed Size (px)
Citation preview

© 2014 IBM Corporation
計算機科学特別講義第三及び数理・計算科学特論第四
プログラミング言語処理系の実装技術第7講 inliningとdevirtualization2014年12月24日石崎 一明 [email protected]日本アイビーエム(株) 東京基礎研究所
IBM Research - Tokyo

© 2014 IBM Corporation
IBM Research - Tokyo
自己紹介
石崎 一明(いしざき かずあき) http://ibm.co/kiszk1992年3月 早稲田大学理工学研究科修士課程電気工学専攻を修了。
1992年4月 日本アイ・ビー・エム(株)入社、東京基礎研究所勤務。以来、並列化コンパイラ、動的コンパイラ、アプリケーション最適化、などの研究に従事。最近は、GPGPUのためのコンパイル技術の研究に従事。現在、同研究所シニア・リサーチ・スタッフ・メンバー
2002年12月 早稲田大学理工学研究科にて、博士(情報科学)を取得。
2008年から2009年まで、IBMワトソン研究所に滞在。
2004年情報処理学会業績賞受賞。ACMシニアメンバー、情報処理学会・ソフトウェア科学会会員
最近の主なAcademic Activity2004年 日本ソフトウェア科学会PPL 2004ワークショップ プログラム委員
2005年 日本ソフトウェア科学会PPL 2004ワークショップ プログラム委員
2006年 日本ソフトウェア科学会PPL 2006ワークショップ プログラム共同委員長
2008年 PC Member of ACM OOPSLA 2013 Conference2010年度 日本ソフトウェア科学会PPLサマースクール幹事
2007~2009年度 日本ソフトウェア科学会プログラミング論研究会 運営委員
2011~2014年度 情報処理学会アーキテクチャ研究会 運営委員
2

© 2014 IBM Corporation
IBM Research - Tokyo
講義予定のおさらい と 今回のトピック
– 講義資料: http://bit.ly/CSIS2014AC ハッシュタグ: #CSIS2014AC
3
Topic Lecturer Date Time1 Introduction Onodera 12/5 13:20-14:502 Runtime – JVM Overview Ogata 12/5 15:05-16:353 Runtime – Object Management Kawachiya 12/10 15:05-16:354 Runtime – Synchronization &
Exception HandlingOgasawara 12/12 15:05-16:35
5 Compiler – Overview Nakaike 12/17 15:05-16:356 Compiler – Dataflow Analysis Inagaki 12/19 15:05-16:357 Compiler – Devirtualization &
InliningIshizaki 12/24 13:20-14:50
8 Hot Topic – Memory FootprintReduction
Ogata 12/24 15:05-16:35
9 Hot Topic – Architecture Exploitation Odaira 1/7 15:05-16:3510 Hot Topic – Trace Compilation Inoue 1/9 15:05-16:35

© 2014 IBM Corporation
IBM Research - Tokyo
今日の講義内容
メソッド呼び出しの実行時間に関する最適化
– Method inlining• 直接メソッド呼び出しにおいてInliningするメソッドの決定
– メソッド呼び出しのdevirtualization• 仮想メソッド呼び出しから直接メソッド呼び出しへの変換
異なるコード間の実行の遷移について
– コンパイルコードからインタープリタへ
– インタープリタからコンパイルコードへ
この講義の課題
4
講義資料は授業後にwebサイトにアップロードします無記名アンケートにもぜひご回答ください(成績とは無関係です)
講義資料とアンケート: http://bit.ly/CSIS2014AC パスワード: 授業中におみせした通りです
今日の話の前提は、コンパイル単位はメソッドです。
メソッド以外のコンパイル単位の話は、来年10講で。

© 2014 IBM Corporation
IBM Research - Tokyo
今日の授業でわかること(1/2) メソッド呼び出しの最適化
– Super.div()の呼び出しとその実行を、どうやって高速化するか?
– s.add()のような、仮想メソッド呼び出し(呼び出し先が一意に決まらない可能性がある)の実行を、どうやって高速化するか?
5
class Super {public int add(int i) { return i + 9; }public int mul(int i) { return i * 9; }public static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
public static int calc() {int r = Super.div(2) + 3;return r;
}}
class Sub1 extends Super {public int add(int i) { return i + 1; }public int foo(...) { ... }
public static int calc1(Super s) {int r = s.add(2) + 3;return r;
}}

© 2014 IBM Corporation
IBM Research - Tokyo
今日の授業でわかること(2/2) メソッドの実行遷移の最適化
– s.add()でSub2.add()がよく呼ばれることがわかった時、”長いコード”をコンパイルしないようにできないか?
– 1度だけ呼び出されるmain()メソッド内にあるSuper.div()へのメソッド呼び出しを、どうやってmethod inliningするか?
6
class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
class Super {public static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
public static void main(String args[]) {for (int i = 0; i < 100000; i++) {
int r = Super.div(2) + 3;System.println(r);
}}
}

© 2014 IBM Corporation
IBM Research - Tokyo
Method inlining
7

© 2014 IBM Corporation
IBM Research - Tokyo
Method inining(inline expansion – インライン展開)
あるメソッド呼び出しによって呼びされるメソッド(呼び出し先)の本体のコピーで、メソッド呼び出しを置き換えること
8

© 2014 IBM Corporation
IBM Research - Tokyo
なぜmethod inliningを行うのか?
プロセッサ上での問題の軽減
– 直接メソッド呼び出し
– 仮想メソッド呼び出し
コンパイラによって生成されるコードの問題の軽減
– 一般にオブジェクト指向言語では、メソッドの大きさが小さくなりがちなので、コンパイル単位を大きくしたい
• 仮想メソッドの場合にはdevirtualizationが必要
Method inliningの前提
– 元の動作を変更してはいけない
• 外部から見える値(volatile変数など)
• 例外・同期が起きた時
– 実行時間をMethod inliningしないときより減らしたい
• ハードウェアのリソース(メモリ、命令キャッシュなど)を使いすぎない
– コンパイル時間の増加をほどほどに
9

© 2014 IBM Corporation
IBM Research - Tokyo
直接メソッド呼び出し(direct method call)コンパイル時に、プログラム上の情報から呼び出し先が一意に決定可能
– 直接分岐命令(call address)の使用
10
...call method_div...
method_div:...ret
class Super {public static finalint div(int i) { ... }
public static int calc() {... Super.div(2) ......
}}
プログラム 機械語命令
© 2014 IBM Corporation
IBM Research - Tokyo
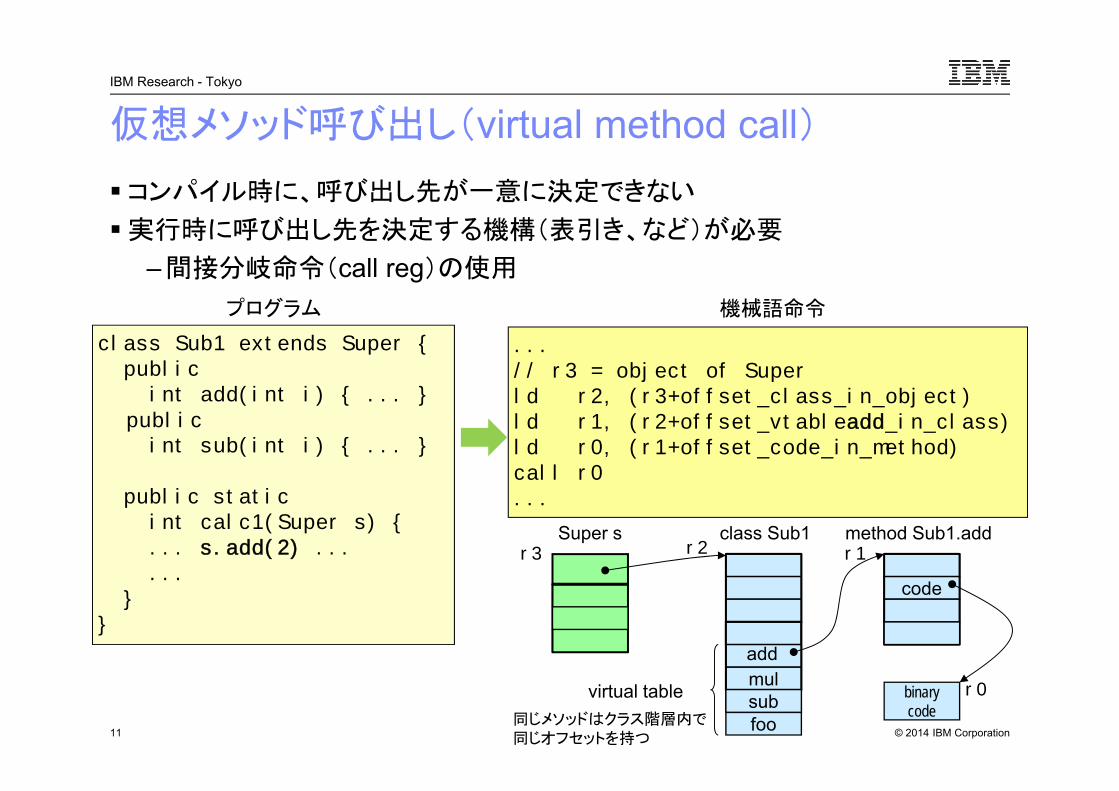
仮想メソッド呼び出し(virtual method call)コンパイル時に、呼び出し先が一意に決定できない
実行時に呼び出し先を決定する機構(表引き、など)が必要
– 間接分岐命令(call reg)の使用
11
Super s
class Sub1 extends Super {publicint add(int i) { ... }
publicint sub(int i) { ... }
public staticint calc1(Super s) {... s.add(2) ......
}}
...// r3 = object of Superld r2, (r3+offset_class_in_object)ld r1, (r2+offset_vtableadd_in_class)ld r0, (r1+offset_code_in_method)call r0...
プログラム 機械語命令
class Sub1
mul
foo
virtual table
add
code
method Sub1.addr3 r2 r1
binary code
r0sub同じメソッドはクラス階層内で同じオフセットを持つ

© 2014 IBM Corporation
IBM Research - Tokyo
(昔の)プロセッサ上での問題の軽減
直接分岐のオーバヘッド
– 命令アドレスが連続する次の命令アドレス、ではなくなるので、命令パイプライン内の実行を乱す(ハザードの発生)
– 最近のプロセッサは、命令パイプラインの早い段階(Idecなど)で分岐先アドレスを生成するので、ハザードは少ない
12
IFetch IDec Exec WBIFetch IDec Exec WB
IFetch IDec Exec WB
IFetch IDec Exec WB
call method_div
add r3 = r11, r12
mov r4 = r3
method_div:mov r4 = r3
method_div
IFetch 命令フェッチIDec 命令デコードExec 命令実行WB 結果書込

© 2014 IBM Corporation
IBM Research - Tokyo
(昔の)プロセッサ上での問題の軽減
間接分岐のオーバヘッド
– 分岐先の命令アドレスが決定するのに時間がかかるので、命令パイプライン内の実行を乱し、ハザードを発生する
– 最近のプロセッサは命令パイプラインの早い段階で(Idecなど)、強力な分岐予測機構によって、分岐先アドレスを生成するので、ハザードは少ない
• 命令アドレスから、過去の分岐履歴に基づいて分岐先アドレスを予測する
13
IFetch IDec Exec WBIFetch IDec Exec WB
IFetch IDec Exec WB
IFetch IDec Exec
Load r0,...(r1)
call r0
...
method_Sub1add:...
method_Sub1add
r0
WB
IFetch 命令フェッチIDec 命令デコードExec 命令実行WB 結果書込

© 2014 IBM Corporation
IBM Research - Tokyo
コンパイラによって生成されるコードの問題の軽減
メソッド呼び出しの際には、プログラムからは見えない、application binary interface(ABI)にもとづいた処理が必要になる
// s.add(2)の呼び出し...mov r4 = 2 // 第2引数 2mov r3 = r10 // 第1引数 scall method_addmov r4 = r3 // 戻り値
...
sp
loweraddress
スタックフレーム
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
コンパイラによって生成されるコードの問題の軽減
メソッド呼び出しの際には、プログラムからは見えない、application binary interface(ABI)にもとづいた処理が必要になる
– メソッド呼び出しがなくなれば、これらの処理は減る
15
// s.add(2)の呼び出し...mov r4 = 2 // 第2引数 2mov r3 = r10 // 第1引数 scall method_addmov r4 = r3 // 戻り値
...
// s.add(2)のメソッド入り口method_add:st (sp+8), Return// 前のスタックフレーム上へ
// 戻りアドレスを保存mov r0, sp // 古いスタック値の保存sub sp = sp - 64 // 新しいスタックの作成st (sp+0), r0 // 新しいスタックから
// 古いスタックへのリンク作成mov r16 = r4 // 第2引数の受け取り...
sp
sp
Return
loweraddress
スタックフレーム
s.add()
Return
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
コンパイラによって生成されるコードの問題の軽減
引数渡しの際に、プログラムからは見えない、重い処理を伴うことがある
– 可変長引数
• Javaの場合、オブジェクトが生成される
– キーワード引数(ruby, pythonなど)
• ハッシュ表を生成して渡している
16
class Super {void print(int i, int j, int k) {System.out.printf(“%d %d¥n”, i, j);
}}
class Super {void print(int i, int j, int k) {
System.out.printf("%d %d¥n", new Object[] {Integer.valueOf(i), Integer.valueOf(j)
});}
}
プログラム javacでコンパイルされた結果
def add(a:1, b:2)a + b
end
add(a: 1.2, b: 3.4)
def add(a:1, b:2)a + b
end
add(a: 1.2, b: 3.4)
{a=>1.2, b=>3.4}
キーワード引数で渡される実体プログラム

© 2014 IBM Corporation
IBM Research - Tokyo
コンパイラによって生成されるコードの問題の軽減
コンパイル単位の範囲の増加
– 最適化(特にデータフロー解析)の適用範囲が広がる
17
class Super {public static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
public static int calc() {int r = Super.div(2) + 3;return r;
}}
public static int calc() {int r = ((2 != 0) ? (4 / 2) : 0) + 3;return r;
}
public static int calc() {return 5;
}
Super.div(2)を、呼び出し先のコードで置き換え
コンパイル時に式を評価する

© 2014 IBM Corporation
IBM Research - Tokyo
Method inliningを行うメソッドの特定
呼び出し先メソッドが、容易に一意に特定できる場合
– 直接メソッド呼び出しの場合
18
class Super {public int add(int i) { return i + 9; }public static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
public static int calc() {int r = Super.div(2) + 3;return r;
}}

© 2014 IBM Corporation
IBM Research - Tokyo
Method inliningを行うか行わないかの判断
(私見では)決定解はこれまでにない。時代(プロセッサアーキテクチャ、言語)によって良い解法が異なるのでは?
– 静的情報
• 呼び出し先メソッドの大きさ
• 制御フローの形
–呼び出し先メソッドを先読みして、method inliningを行った場合最適化が適用できるか判断する
• …– 動的情報
• 実行中に集められた実行時のメソッド実行頻度に基づく
• 実行中に集められた引数の値にもとづいて、 method inliningを行った場合最適化が適用できるか判断する
• …
19

© 2014 IBM Corporation
IBM Research - Tokyo
Devirtualization
20

© 2014 IBM Corporation
IBM Research - Tokyo
Method inliningを行う呼び出し先メソッドの特定
メソッドの呼び出し先を一意に特定することが難しい場合
– 仮想メソッド呼び出し
– インターフェースメソッド呼び出し
21
call s.add() Sub1.add()Super.add()
Sub2.add()...

© 2014 IBM Corporation
IBM Research - Tokyo
Devirtualizationによって特定
複数の呼び出し先を、特定した1つとその他、に分ける
– 仮想呼び出しではなくなっている、のでdevirtualization(脱仮想化)
分ける方法
– Guarded devirtualization– Direct devirtualization
22
call s.add()call Sub2.add() call s.add()
Sub1.add()Super.add()
Sub2.add()...

© 2014 IBM Corporation
IBM Research - Tokyo
Guarded devirtualizationによって特定
複数の呼び出し先を条件分岐(ガード)によって、特定した1つとその他、に分ける
実行時情報などからガードを挿入して、呼び出し先を特定
– Method test [Calder1994]– Class test [Grove1995]
複数の呼び出し先を特定
– Polymorphic inline cache [Holzle1991]
23
call s.add()call Sub2.add()
ガード
call s.add()Sub1.add()Super.add()
Sub2.add()...

© 2014 IBM Corporation
IBM Research - Tokyo
Direct devirtualizationによって特定
プログラム解析などによってガード無しで1つであることを特定する
– 解析の結果、複数個に特定できる場合もある
(通常)ガード無しで、1つの呼び出し先を特定
– Type analysis [Chamber1990]– Class hierarchy analysis [Dean1995, Ishizaki2000]– Rapid type analysis [Bacon1996] – Preexistence [Detletf1999]
24
call s.mul()call Super.mul()
Super.mul()
...

© 2014 IBM Corporation
IBM Research - Tokyo
Guarded devirtualizationの手法
元のコード
直接メソッド呼び出しもしくはmethod inliningされているコードを呼び出してよいか、ガードの比較結果に基づいて判断する。
25
Super s
...// r3 = object in sld r2, offset_class_in_object(r3)ld r1, offset_vtableadd_in_class(r2)ld r0, offset_code_in_method(r1)call r0...
class Sub2
virtual table
add
code
method Sub2.add
Method test(メソッドの一致で判断)Class test(クラスの一致で判断)
// r3 = object in sld r2, offset_class_in_object(r3)if (r2 == #address_of_classSub1) {call Sub2.add / exec inlined code
} else {ld r1, offset_vtableadd_in_class(r2)ld r0, offset_code_in_method(r1)call r0
}
// r3 = object in sload r2, offset_class_in_object(r3)load r1, offset_vtableadd_in_class(r2)if (r1 == #address_of_methodSub1add) {call Sub2.add / exec inlined code
} else {load r0, offset_code_in_method(r1)call r0
}
機械語命令 機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
Class testとMethod testの違い
Method testのほうがメモリからのロードが1つ多いが、呼び出し先を特定する精度が高い
– 下記のプログラムにおいて、sにSub3のインスタンスが渡されると
• Class test(s.mul()はSuperでガードされていると仮定)では、Super != Sub3でガードの条件が成立せず、仮想メソッド呼び出しを実行する必要がある。
• Method testでは、&Super.mul() == &Sub3.mul()となりガードの条件が
成立し、呼び出し先を一意に決定することができ、直接メソッド呼び出しを実行可能。
–Sub3ではmul()が定義されていないがSuperからvirtual tableを継承して同じメソッド情報を持つ
public int foo(Super s) {... s.mul(3) ...
}
class Supermul()
class Sub326

© 2014 IBM Corporation
IBM Research - Tokyo
Polymorphic inline cache (PIC)複数の呼び出し先を持つメソッド呼び出しの高速化のために、複数のガードを
挿入する
– 複数のメソッドがオーバライドしている仮想メソッド呼び出し
– 複数のクラスがimplementしているインターフェース呼び出し
27
class Superadd()
class Sub1add()
class Sub2add()
// r1 = object in sload r2, offset_class_in_object(r1)if (r2 == #address_of_classSuper) {call Super.add / exec inlined code
else if (r2 == #address_of_classSub1) {call Sub1.add / exec inlined code
else if (r2 == #address_of_classSub2) {call Sub2.add / exec inlined code
} else {load r3, offset_vtableadd_in_class(r2)load r4, offset_code_in_method(r3)call r4
}
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
Direct devirtualizationの必要性
ガードを挿入したguarded devirtualization、はSmalltalkなどの動的型付け言語で盛んに研究されてきた
– 仮想メソッド呼び出しの実行コストが大きいので、実行時間の短縮に貢献
Javaなどの静的型付け言語では、仮想メソッド呼び出しの実行コストと、guarded devirtualization+直接呼び出しによる実行コストは、あまり差がない
– guarded devirtualization+method inlining– ガード無しのdirect devirtualizationによる、実行時間の短縮の要求
28

© 2014 IBM Corporation
IBM Research - Tokyo
Direct devirtualizationの手法
クラス階層解析(Class hierarchy analysis, CHA)を必要としない方法
– Type analysis [Chamber1990]– Value type analysis (VTA) [Sundaresan2000]– Extended type analysis (XTA) [Tip2000]
• Type analysisをメソッド間に拡張
クラス階層解析を必要とする方法
– Class hierarchy analysis (CHA) [Dean1995]– Rapid type analysis (RTA) [Bacon1996]– Class hierarchy analysis with code patching [Ishizaki2000]– Preexistence [Detletf1999]
29

© 2014 IBM Corporation
IBM Research - Tokyo
形解析(type analysis)
メソッド呼び出しのレシーバーに到達するオブジェクトの型をデータフロー解析によって求める。
型が一意に決定する場合には、呼び出し先のメソッドを一意に決定可能。
– 仮想メソッド呼び出しを、直接メソッド呼び出しに変換、もしくはMethod inliningが可能
30
...// r3 = scall method_Sub1add...
method_Sub1add:...ret
s.add()のsに到達するのはSub1だけなので、Sub1.add()が必ず呼び出される
public int bar() {
Super s = new Sub1();...... s.add(4) ...
} レシーバー
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
クラス階層解析(Class hierarchy analysis - CHA)
プログラム全体のクラス階層においてどのメソッドが定義されているかを調べる
– 各クラスがとり得るメソッド集合を集める
• 集合内のメソッド数が少ないほど、devirtualizationの効率が高くなる
Javaの場合、実行中にクラスロード・アンロードが発生するので、常に正しい状態に保つ必要がある。
31
class Supermul()
class Sub3 class Sub4mul()
Classがレシーバーの型となった時とり得るメソッド集合 {}
Super:{Super.mul()}
Super:{Super.mul(),Sub4.mul()}
Sub3:{Super.mul()}
Sub3:{Super.mul()}
Sub4:{Sub4.mul()}
class Supermul()
class Sub3
Classがレシーバーの型となった時とり得るメソッド集合 {}

© 2014 IBM Corporation
IBM Research - Tokyo
Rapid type analysis(RTA)
CHAより、とりえるメソッド集合を減らす方法
– メソッド集合内のメソッド数が少ないほど、devirtualizationの効率が高い
CHAに加えて、プログラム中でクラスがinstantiation(Javaならnew)されてるか調べる。
– Instantiationされないクラスのメソッド(Sub4.mul())は、メソッド集合に入らない
32
class Supermul()
class Sub3 class Sub4mul()
Super:{Super.mul(),Sub4.mul(),Sub5.mul()}
Sub3:{Super.mul()}
Sub4:{Sub4.mul(),Sub5.mul()}
プログラム中に、new Super(),new Sub3(),new Sub5()が存在し、new Sub4()が存在しないならば
Super:{Super.mul(),Sub5.mul()}
Sub3:{Super.mul()}
Sub4:{Sub5.mul()}
Classがレシーバーの型となった時とり得るメソッド集合 {}
Classがレシーバーの型となった時とり得るメソッド集合 {}
class Sub5mul() Sub5:
{Sub5.mul()}
Sub4:{Sub5.mul()}

© 2014 IBM Corporation
IBM Research - Tokyo
CHAやRTAを使ったdevirtualization CHAやRTAで求めたメソッド集合を用いて、メソッド呼び出しのレシーバーのオ
ブジェクトの型から、呼び出し先となり得るメソッド集合を取得する
メソッド集合の中にメソッドが1つだけ存在するならば、呼び出し先のメソッドを一意に決定可能
– 直接メソッド呼び出しに変換、もしくはmethod inliningが可能
33
...// r3 = scall method_Supermul...
method_Supermul:...ret
s.mul()ではSuper.mul()が必ず呼び出される
public int foo(Super s) {... s.mul(3) ...
}
Super:{Super.mul()}
Sub3:{Super.mul()}
class Supermul()
class Sub3
機械語命令
Classがレシーバーの型となった時とり得るメソッド集合 {}

© 2014 IBM Corporation
IBM Research - Tokyo
CHA(RTA)とcode patchingによるdevirtualization Javaではクラス階層が固定ではないので、ある時点のコンパイル時に一意で
あった呼び出し先メソッドが、突然複数になることがある
– コンパイル時にs.mul()の呼び出し先メソッドが一意であれば、直接メソッド
呼び出しと間接メソッド呼び出しの両方を用意し、直接メソッド呼び出しを実行する。
34
...call method_Supermul // 直接呼び出し
after_call:...
dynamic_call:ld r2,(r3+offset_class_in_object)ld r1,(r2+offset_vtablemul_in_class)ld r0,(r1+offset_code_in_method)call r0 // 間接呼び出しjmp after_call
public int foo(Super s) {... s.mul(3) ...
}
class Supermul()
class Sub3
Super:{Super.mul()}
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
CHA(RTA)とcode patchingによるdevirtualization Javaではクラス階層が固定ではないので、ある時点のコンパイル時に一意で
あった呼び出し先メソッドが、突然複数になることがある
– 動的クラスローディングの結果、クラスSub4がロードされメソッドmul()がオーバライドされた時は、コードを書き換えて間接メソッド呼び出しを実行する
35
...jmp dynamic_call
after_call:...
dynamic_call:ld r2,(r3+offset_class_in_object)ld r1,(r2+offset_vtablemul_in_class)ld r0,(r1+offset_code_in_method)call r0 // 間接呼び出しjmp after_call
public int foo(Super s) {... s.mul(3) ...
}
class Supermul()
class Sub3 class Sub4mul()
Super:{Super.mul(),Sub4.mul()}
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
Preexistence CHAやRTAの結果から、仮想メソッド呼び出しの呼び出し先のメソッドが一意
であることがわかる
– Direct devirtualizationによるコードを生成する
動的クラスロードの結果、メソッドがオーバライドされたら、他の呼び出し先メソッドの呼び出し、にも対応する必要がある
– 一般には、実行中のコードの再生成が必要
– 実行中のコードの再生成、ではなく次回の実行までに再コンパイル、とすることはできないか?
• そんな条件は?
36

© 2014 IBM Corporation
IBM Research - Tokyo
Preexistence CHAやRTAの結果から、仮想メソッド呼び出しの呼び出し先のメソッドが一意
であることがわかる
– Direct devirtualizationによるコードを生成する
動的クラスロードの結果、メソッドがオーバライドされたら、他の呼び出し先メソッドの呼び出し、にも対応する必要がある
– 一般には、実行中のコードの再生成が必要
– 実行中のコードの再生成、ではなく次回の実行までに再コンパイル、とすることはできないか?
37
メソッド呼び出しのレシーバーが、呼び出し側のメソッドを実行する前に決定したオブジェクトのまま変わらない→例えば、メソッドの引数

© 2014 IBM Corporation
IBM Research - Tokyo
Preexistenceの例
下記のプログラムにおいて、foo()が呼び出される前に、sに渡されるオブジェクトは存在する(pre-exist) foo()が実行されれば、引数sはSuperかSub3であり、何が起きても変わらない
s.mul()では、必ずSuper.mul()が呼び出される
38
public int foo(Super s) {... s.mul(3) ...
}
class Supermul()
class Sub3
...// r3 = scall method_Supermul...
method_Supermul:...ret
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
Preexistenceの例
foo()の実行中に、Sub4が動的クラスロードされて、mul()がオーバライドされても、引数sに関するメソッド呼び出しは、Super.mul()でよい
次回のfoo()の呼び出しでは、sにSuperかSub4が渡るかで、s.mul()の呼び出し先が異なる
– それまでにメソッドfoo()を、再コンパイルすればよい
39
public int foo(Super s) {... s.mul(3) ...
}
class Supermul()
class Sub3 class Sub4mul()
...// r3 = sld r2,(r3+offset_class_in_object)ld r1,(r2+offset_vtablemul_in_class)ld r0,(r1+offset_code_in_method)call r0 // 間接呼び出し...
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
Guarded devirtualization+method inliningによる問題点
Method inliningした場合と仮想メソッド呼び出しの制御が合流する
– データーフロー解析結果(rの値は?)の精度が悪くなる
• Method test, Class test• CHA + code patching
解決手段
– Splitting– Deoptimization [Holze1992]
• すこし後に説明します
40
r = Sub2.add(-2)-> -2 + 2 = 0
ガード
r = s.add(-2)
class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
r != 0
// 長いコード
r = 0

© 2014 IBM Corporation
IBM Research - Tokyo
Splitting
コードを複製して、制御の合流点の位置を変更して、データフロー解析結果の精度を下げない(条件分岐におけるrの値は?)
– 場合によっては、複製するコード量が増えることがある
41
r = Sub2.add(-2)-> -2 + 2 = 0
ガード
r = s.add(-2)class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
r != 0
// 長いコード
r = 0
r != 0
r != 0

© 2014 IBM Corporation
IBM Research - Tokyo
Splitting
左側のパスは、r = 0が確定しているので、条件分岐を除去可能
42
r = Sub2.add(-2)-> -2 + 2 = 0
ガード
r = s.add(-2)class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
r != 0
// 長いコード
r = 0 r != 0

© 2014 IBM Corporation
IBM Research - Tokyo
今日の授業でわかること
メソッド呼び出しの最適化
– Super.div()の呼び出しの実行を、どうやって高速化するか? → method inlining
– s.add()のような、仮想メソッド呼び出し(呼び出し先が一意に決まらない可能性がある)の実行を、どうやって高速化するか? → devirtualization
43
class Super {public int add(int i) { return i + 9; }public int mul(int i) { return i * 9; }public static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
public static int calc() {int r = Super.div(2) + 3;return r;
}}
class Sub1 extends Super {public int add(int i) { return i + 1; }
public static int calc1(Super s) {int r = s.add(2) + 3;return r;
}}

© 2014 IBM Corporation
IBM Research - Tokyo
今日の授業でわかること
メソッドの実行遷移の最適化
– s.add()でSub2.add()がよく呼ばれることがわかった時、”長いコード”をコンパイルしないようにできないか? → splitting
44
class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}

© 2014 IBM Corporation
IBM Research - Tokyo
コードの実行遷移
45

© 2014 IBM Corporation
IBM Research - Tokyo
コンパイルコードとインタープリタ間の実行の遷移について
コンパイルコードからインタープリタへ
インタープリタからコンパイルコードへ
– 通常はメソッドの先頭で遷移する
– メソッドの実行途中に遷移したいことがある
46
コンパイルされたコードbar() {......
}
インタープリタのコードfoo() {...bar();...
}
インタープリタのコードfoo() { bar() {... ...bar(); ...... }
}
コンパイルされたコードbar() {... ...
}

© 2014 IBM Corporation
IBM Research - Tokyo
用語について
統一された用語がないように思われる
– コンパイルコードからインタープリタへ
– インタープリタからコンパイルコードへ
47
コンパイルコードからインタープリタへ
インタープリタからコンパイルコードへ
Self(コンパイルコードから別のコンパイルコードへ)
Deoptimization ない
OpenJDK Deoptimization On-stack replacement (OSR)IBM Java Decompilation using OSR Dynamic loop transferJikes RVM(コンパイルコードから別のコンパイルコードへ)
OSR OSR
V8(コンパイルコードから別のコンパイルコードへ)
Deoptimization OSR
McJIT Optimize OSR Deoptimize OSR

© 2014 IBM Corporation
IBM Research - Tokyo
Deoptimizationコンパイラ内部表現は、ある条件を満たさなかったとき、分岐先がコンパイルコ
ード外となる
– コンパイルするコード量が減る
– コンパイラコード内の制御合流点が減る
典型的な使われ方
– Specialization(特殊化)を行った場合、その効果を高める
4848
r = Sub2.add(-2)-> -2 + 2 = 0
条件
r = s.add(-2)
class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
r != 0
// 長いコード
r = 0
インタプリタで実行

© 2014 IBM Corporation
IBM Research - Tokyo
Deoptimizationによるコード最適化
コンパイルコード内では、rの値が0と決まるので、条件分岐と条件が成立しない場合のコードを削除可能
4949
r = Sub2.add(-2)-> -2 + 2 = 0
条件
r = s.add(-2)
class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
インタプリタで実行
© 2014 IBM Corporation
IBM Research - Tokyo
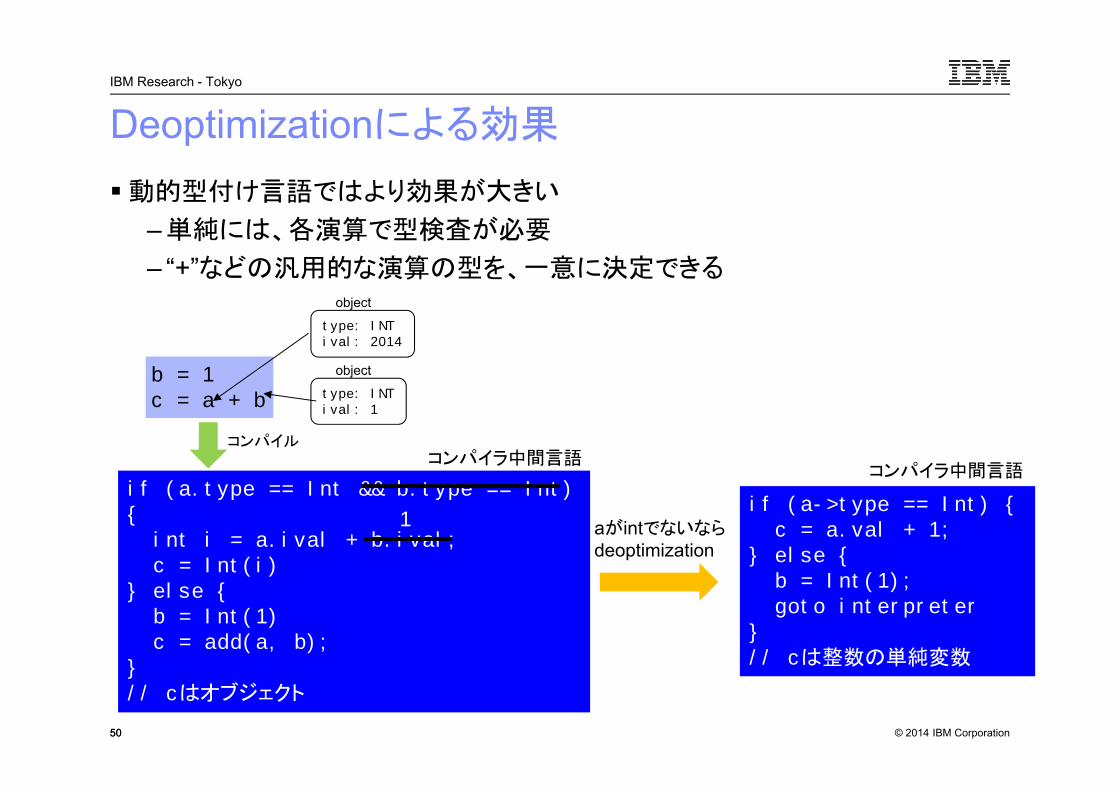
Deoptimizationによる効果
動的型付け言語ではより効果が大きい
– 単純には、各演算で型検査が必要
– “+”などの汎用的な演算の型を、一意に決定できる
5050
b = 1c = a + b
type: INTival: 2014
object
type: INTival: 1
object
if (a.type == Int && b.type == Int) {int i = a.ival + b.ival;c = Int(i)
} else {b = Int(1)c = add(a, b);
}// cはオブジェクト
if (a->type == Int) {c = a.val + 1;
} else {b = Int(1);goto interpreter
}// cは整数の単純変数
1 aがintでないならdeoptimization
コンパイラ中間言語コンパイラ中間言語
コンパイル

© 2014 IBM Corporation
IBM Research - Tokyo
Deoptimizationの実装について
最適化されたコンパイルコードからインタプリタへの、実行遷移
– 実行時にそれぞれのコードが持つcontextの変換
51
CONST 1 intSTORE bLOAD aLOAD bADDSTORE c
バイトコードif (a->type == Int) {c = a.val + 1;
} else {b = Int(1);//後続使用変数の参照点goto interpreter
}// cは整数の単純変数
インタプリタで実行
コンパイルコード インタプリタ上のバイトコード
計算スタック レジスタ インタプリタの独自計算stackLocal変数 レジスタ インタプリタの独自stack frameStack frame コンパイルコードの独自stack
(method inliningした場合、複数メソッドが1つに変換されている)
インタプリタの独自stack frame(各メソッドごと)
...mov r3, object_amov r4, object_1
a
1
計算stack
変換
機械語命令

© 2014 IBM Corporation
IBM Research - Tokyo
On-Stack Replacementインタプリタ実行中から、コンパイルコードの途中に遷移する
– 一般的には、インタプリタでプログラムのループのback edgeを検出した際に、コンパイルコードのループの先頭に移ることが多い
• 任意の点で移ると、実装の複雑さが増すが、得られるメリットはそれほど多くない
52
int div(int i){return (i!=0) ? (4/i):0;}
public static void main(String args[]) {for (int i = 0; i < 100000; i++) {int r = Super.div(2) + 3;System.println(r);
}}

© 2014 IBM Corporation
IBM Research - Tokyo
On-Stack Replacementの実行例
main()がインタプリタで起動されて、ループが何度も実行される
ループのback edgeで、main()のコンパイル要求が出される
53
int div(int i){return (i!=0) ? (4/i):0;}
public static void main(String args[]) {for (int i = 0; i < 100000; i++) {int r = Super.div(2) + 3;System.println(r);
}}

© 2014 IBM Corporation
IBM Research - Tokyo
On-Stack Replacementの実行例
54
int div(int i){return (i!=0) ? (4/i):0;}
public static void main(String args[]) {for (int i = 0; i < 100000; i++) {int r = Super.div(2) + 3;System.println(r);
}}

© 2014 IBM Corporation
IBM Research - Tokyo
On-Stack Replacementの実行例
main()はdiv()をmethod inliningしながらコンパイルされる
– メソッド先頭とループ先頭に、実行遷移点を持つコードが生成される
55
main_entry:...
loophead:...bne loophead...ret
main_loop_entry:...goto loophead
int div(int i){return (i!=0) ? (4/i):0;}
public static void main(String args[]) {for (int i = 0; i < 100000; i++) {int r = Super.div(2) + 3;System.println(r);
}}
コンパイル

© 2014 IBM Corporation
IBM Research - Tokyo
On-Stack Replacementの実行例
実行遷移点では、下記の変換を行う
56
main_entry:...
loophead:...bne loophead...ret
main_loop_entry:...goto loophead
int div(int i){return (i!=0) ? (4/i):0;}
public static void main(String args[]) {for (int i = 0; i < 100000; i++) {int r = Super.div(2) + 3;System.println(r);
}}
変換
インタプリタ上のバイトコード コンパイルコード
計算スタック インタプリタの独自計算stack レジスタ
Local変数 インタプリタの独自stack frame レジスタ
Stack frame インタプリタの独自stack frame コンパイルコードの独自stack

© 2014 IBM Corporation
IBM Research - Tokyo
今日の授業でわかること
メソッドの実行遷移の最適化
– s.add()でSub2.add()がよく呼ばれることがわかった時、”長いコード”をコンパイルしないようにできないか? → deoptimization
– main()メソッドから呼び出されるSuper.div()を、どうやってmethod inliningするか? → On-stack replacement
57
class Sub2 extends Super {public int add(int i) { return i + 2; }
public static int calc2(Super s) {int r = s.add(-2);if (r != 0) { ... // 長いコード }return r;
}}
class Super {public static final int div(int i) { return (i != 0) ? (4 / i) : 0;}
public static void main(String args[]) {for (int i = 0; i < 100000; i++) {
int r = Super.div(2) + 3;System.println(r);
}}
}

© 2014 IBM Corporation
IBM Research - Tokyo
今日の講義内容のまとめ
メソッド呼び出しの実行時間に関する最適化
– Method inlining• 直接メソッド呼び出しにおいてInliningするメソッドの決定
– メソッド呼び出しのdevirtualization• 仮想メソッド呼び出しから直接メソッド呼び出しへの変換
–Guarded devirtualization, direct devirtualization異なるコード間の実行の遷移について
– コンパイルコード ⇔ インタープリタ
• Deoptimization, On-stack replacement
58

© 2014 IBM Corporation
IBM Research - Tokyo
参考文献 (1/2) Guarded devirtualization
– Calder et al. Reducing Indirect Function Call Overhead In C++ Programs, POPL, 1994.– Grove et al. Profile-guided receiver class prediction, OOPSLA, 1995– Holzle et al. Optimizing dynamically-typed object-oriented languages with polymorphic inline caches, ECOOP, 1991– Arnold et al. Thin Guards: A Simple and Effective Technique for Reducing the Penalty of Dynamic Class Loading,
ECOOP, 2002. 型解析
– Chambers et al. Interactive type analysis and extended message splitting; optimizing dynamically-typed object-oriented programs, PLDI, 1990.
– Palsberg et al. Object-Oriented Type Inference, OOPSLA, 1991.– Gagnon et al. Efficient Inference of Static Types for Java Bytecode, SAS, 2000.– Sundaresan et al. Practical Virtual Method Call Resolution for Java, OOSPLA, 2000.– Tip et al. Scalable propagation-based call graph construction algorithms, OOSPLA, 2000.
クラス階層解析
– Dean et al. Optimization of object-oriented programs using static class hierarchy, ECOOP, 1995.– Bacon et al. Fast Static Analysis of C++ Virtual Function Calls, OOPSLA, 1996.– Ishizaki et al. A Study of Devirtualization Techniques for a Java Just-In-Time Compiler, OOPSLA, 2000.– Detlefs et al. Inlining of virtual methods, ECOOP, 1999.
Spilitting– Chambers et al. Interactive type analysis and extended message splitting; optimizing dynamically-typed object-
oriented programs, PLDI, 1990. インタフェースメソッド呼び出し
– Alpern et al. Efficient Implementation of Java Interfaces: Invokeinterface Considered Harmless, OOPSLA, 2001. 適応最適化のサーベイ論文
– Arnold et al. A Survey of Adaptive Optimization in Virtual Machines. IBM Research Report RC23143, 2003.59

© 2014 IBM Corporation
IBM Research - Tokyo
参考文献 (2/2) On stack replacement / deoptimization
– Holzle et al. Debugging Optimized Code with Dynamic Deoptimization, PLDI, 1992.– Paleczny et al. The Java HotSpot Server Compiler, JVM, 2001.– Fink et al. Design, Implementation and Evaluation of Adaptive Recompilation with On-Stack Replacement, CGO,
2003.– Soman et al. Efficient and general on-stack replacement for aggressive program specialization, PLC, 2006.– Adaptive inlining and on-stack replacement in the CACAO virtual machine, PPPJ, 2007.– Lameed et al. A Modular Approach to On-Stack Replacement in LLVM, VEE, 2013.– Kedlaya et al. Deoptimization for Dynamic Language JITs on Typed, Stack-based Virtual Machines, VEE, 2014.
60






![Boletín Vigilancia Tecnológica Biotecnología Sanitaria(1º ......UNIV HELSINKI [FI] Protamine in treatment of neuronal injuries WO2014202833 A1 20141224 UNIV HELSINKI [FI] Treatment](https://img.pdfslide.net/doc/110x75/6108ead06a8de270a1425ba0/boletn-vigilancia-tecnolgica-biotecnologa-sanitaria1-univ-helsinki.jpg)





















