Embed Size (px)
Citation preview

Agile Data Scienceby @DataFellas
Xavier [email protected]
@xtordoir
Andy [email protected]
@noootsab

© Data Fellas SPRL 2016
● Distributed Data Science… ○ A genomics use case○ Spark Notebook○ Interactive Distributed Data Science
● Distributed Data Science… Pipeline○ Pipeline: productizing Data Science○ Demo of Distributed Pipeline (ADAM, Akka, Cassandra, Parquet, Spark)○ Why Micro Services?○ Painful points:
■ Data science is Discontiguous■ Context Lost in Translation
○ Solution: Data Fellas’ Agile Data Science Toolkit
LineupSo if you’re not sure you want to stay...
Data Fellas
Andy Petrella
MathsGeospatialDistributed Computing
Spark NotebookTrainer Spark/ScalaMachine Learning
Xavier Tordoir
PhysicsBioinformaticsDistributed Computing
Scala (& Perl)trainer SparkMachine Learning

© Data Fellas SPRL 2016
● Say we have genomics data, i.e. we collected genomics variation data in different
populations
● We want to know if the global population is heterogeneous (stratified)
● We want to check if this stratification corresponds to the pre-selected populations in the
data collection
● Then I want to make some descriptive statistics on these populations
● Make them available to my users
● Let them compute such statistics for populations they define themselves
● Let them discover what is available as data and service
A use casesay...
© Data Fellas SPRL 2016
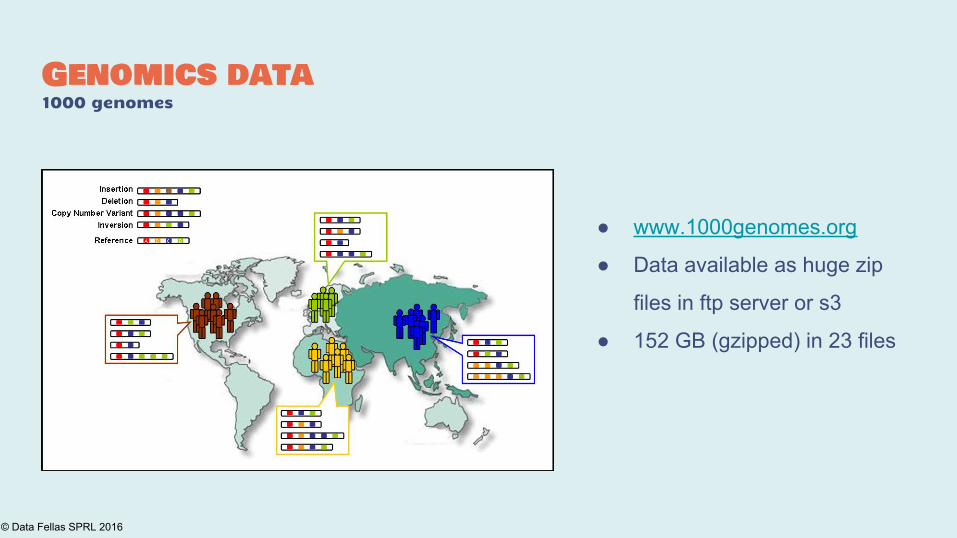
Genomics data1000 genomes
● www.1000genomes.org
● Data available as huge zip
files in ftp server or s3
● 152 GB (gzipped) in 23 files

© Data Fellas SPRL 2016
Genomics data1000 genomes: 43,372,735,220 genotypes
Tens of millions
1000’s…...(1,000,000’s)…

© Data Fellas SPRL 2016
Spark ?Distributed Computing Framework
● SQL & Dataframes
● Streaming
● Graph Processing
● Machine Learning
● Scalability
● Resilience
● Fault tolerance
● Optimize memory usage
● Optimize computation execution
● Easy programming model

© Data Fellas SPRL 2016
Spark NotebookDistributed Data Science tool
● Interactive
● Scala (types, production quality)
● Reactive & pluggable charts API (scala = no.js)
● easy install, no deps.
● multiple sparkContexthttp://spark-notebook.io/

© Data Fellas SPRL 2016
Development environmentDefine and chain functions
© Data Fellas SPRL 2016
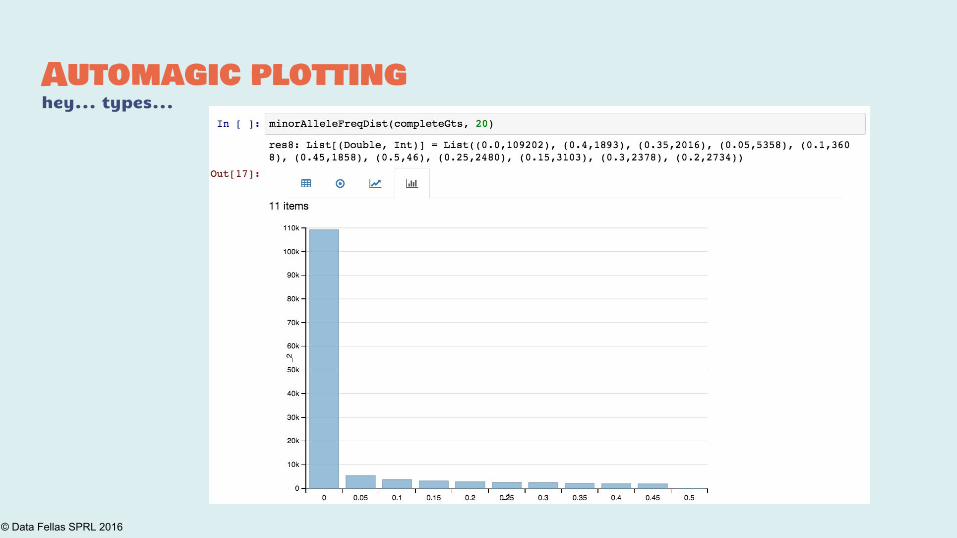
Automagic plottinghey... types...

© Data Fellas SPRL 2016
Population stratificationMLLib
© Data Fellas SPRL 2016
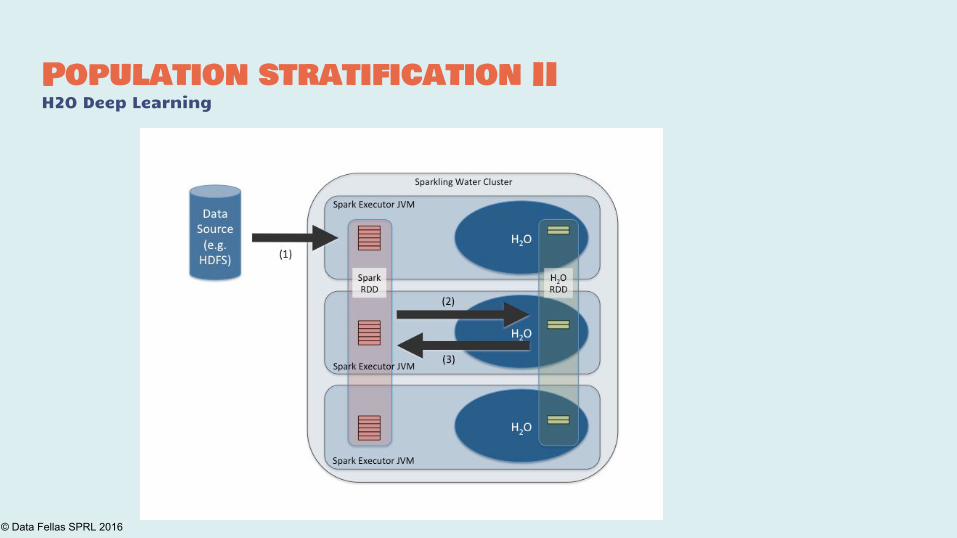
Population stratification IIH2O Deep Learning

© Data Fellas SPRL 2016
Population stratification IIH2O Deep Learning
Spark notebook demoH2O.world Video

© Data Fellas SPRL 2016
Save to CassandraPersist output for service exposure...

© Data Fellas SPRL 2016
Service exposureGlobal Alliance For Genomics and Health (GA4GH)
Global Alliance for Genomic and Health
http://genomicsandhealth.org/http://ga4gh.org/
Framework for responsible data sharing● Define schemas● Define services
Along with Ethical, Legal, security, clinical aspects
The output of the Data Science work is a service...

© Data Fellas SPRL 2016
What else?This becomes harder...
● Say we have genomics data, i.e. we collected genomics variation data in different populations● We want to know if the global population is heterogeneous (stratified)● We want to check if this stratification corresponds to the pre-selected populations in the data
collection● Then I want to make some descriptive statistics on these populations● Make them available to my users● Let them compute such statistics for populations they define themselves● Let them discover what is available as data and service

Distributed Data Science…
Pipeline

© Data Fellas SPRL 2016
What’s all aboutTopics
● Pipeline: productizing Data Science● Demo of Distributed Pipeline (ADAM, Akka, Cassandra, Parquet, Spark)
● Extended Pipeline: Micro Services● Painful points:
○ Data science is Discontiguous○ Context Lost in Translation
● Solution: Data Fellas’ Agile Data Science Toolkit
© Data Fellas SPRL 2016
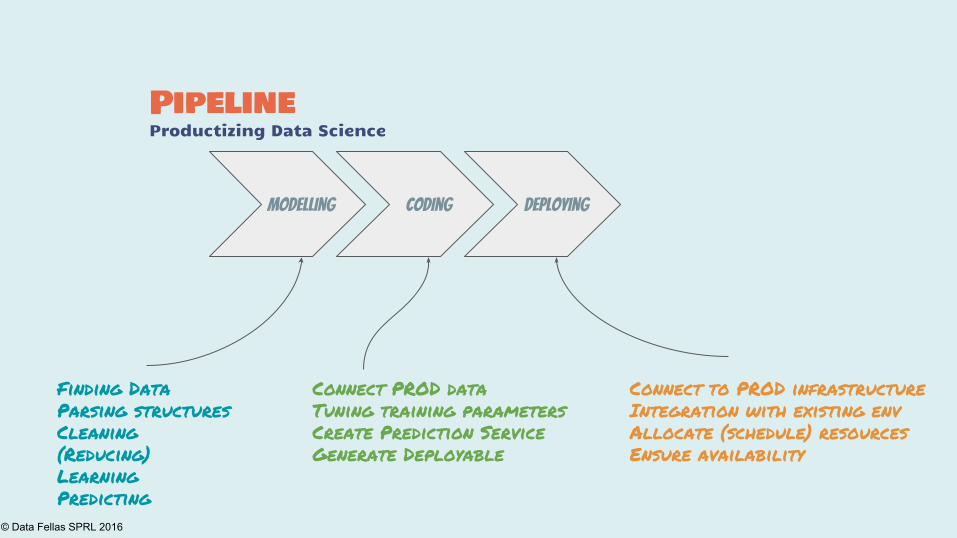
PipelineProductizing Data Science
Modelling Coding Deploying
Finding Data
Parsing structures
Cleaning
(Reducing)
Learning
Predicting
Connect PROD data
Tuning training parameters
Create Prediction Service
Generate Deployable
Connect to PROD infrastructure
Integration with existing env
Allocate (schedule) resources
Ensure availability

© Data Fellas SPRL 2016
Distributed Data ScienceDemo
All-In Spark NotebooksPrepare Data: ADAM → Parquet
Prepare View: Parquet → Cassandra
Create Server: Cassandra → Akka Http
Create Client: Json → Html Form, Chart, table, ...(Docker can be provided… just need to clean and pack it a bit :-D)
© Data Fellas SPRL 2016
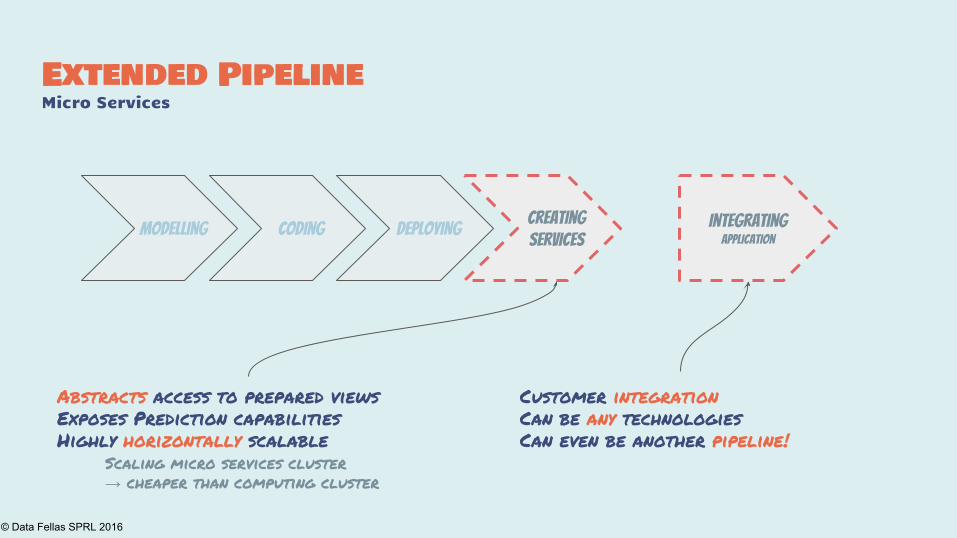
Extended PipelineMicro Services
Modelling Coding Deploying IntegratingApplication
Creating Services
Abstracts access to prepared views
Exposes Prediction capabilities
Highly horizontally scalable
Scaling micro services cluster
→ cheaper than computing cluster
Customer integration
Can be any technologies
Can even be another pipeline!
© Data Fellas SPRL 2016
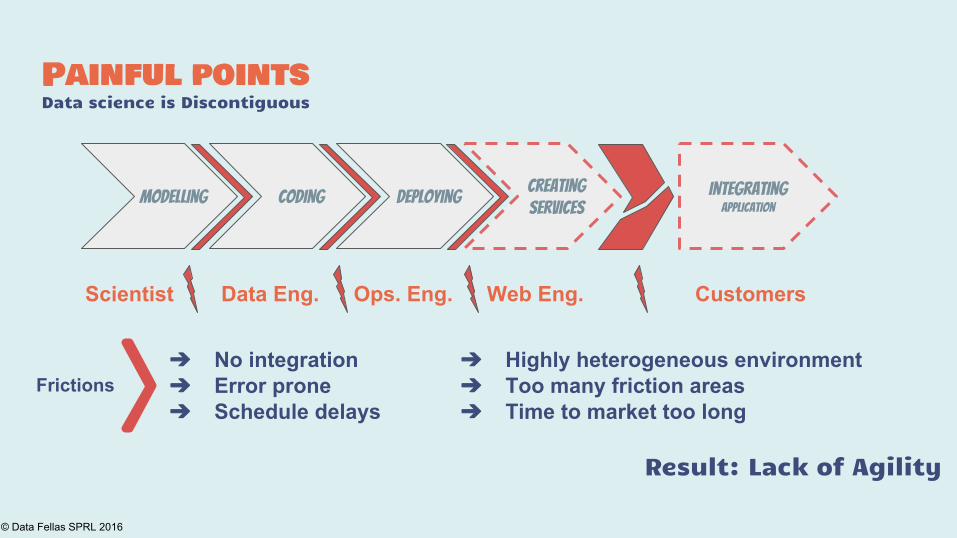
Painful pointsData science is Discontiguous
➔ Highly heterogeneous environment➔ Too many friction areas➔ Time to market too long
Modelling Coding Deploying IntegratingApplication
Scientist Data Eng. Ops. Eng. Web Eng. Customers
➔ No integration ➔ Error prone➔ Schedule delays
Creating Services
Frictions
Result: Lack of Agility
© Data Fellas SPRL 2016
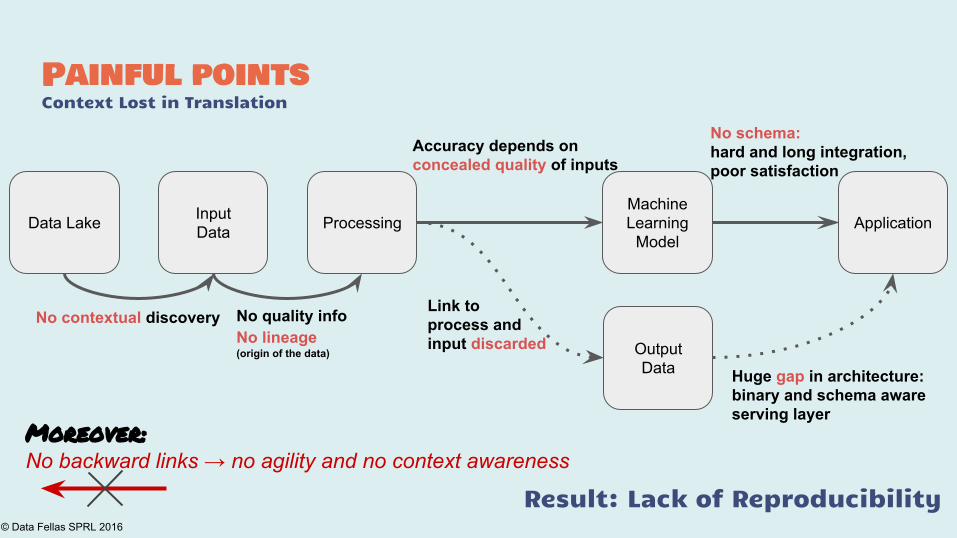
Painful pointsContext Lost in Translation
Data Lake ProcessingMachineLearning
Model
OutputData
InputData
No contextual discovery No quality infoNo lineage (origin of the data)
Link to process and input discarded
Huge gap in architecture: binary and schema aware serving layer
Accuracy depends on concealed quality of inputs
No schema: hard and long integration, poor satisfaction
Moreover:
No backward links → no agility and no context awareness
Result: Lack of Reproducibility
Application

Data Fellas…
Agile Data Science Toolkit
© Data Fellas SPRL 2016
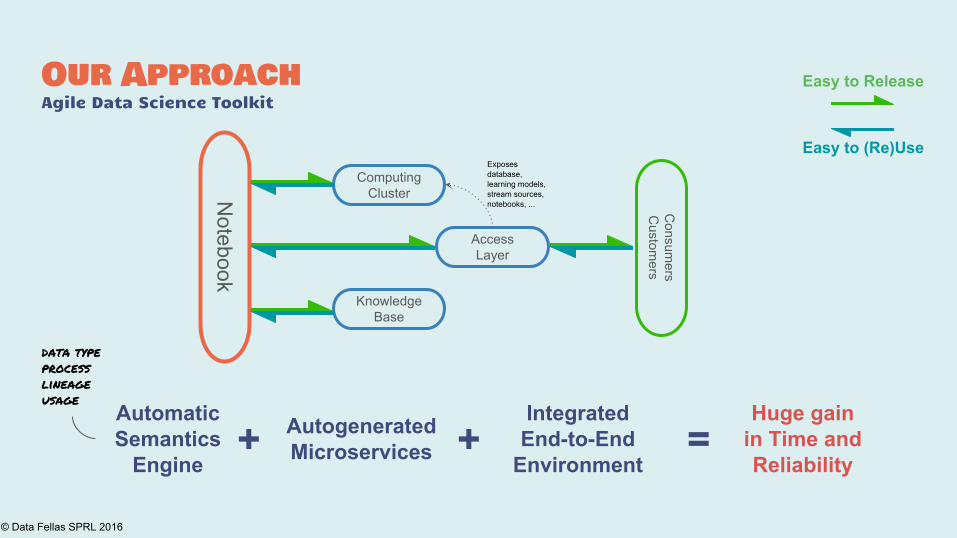
Our ApproachAgile Data Science Toolkit
AutomaticSemantics
Engine+ Autogenerated
Microservices
IntegratedEnd-to-End
Environment
Huge gainin Time and Reliability
+ =
Notebook
ComputingCluster
AccessLayer
KnowledgeBase
Consum
ersC
ustomers
Exposesdatabase,learning models,stream sources,notebooks, ...
data type
process
lineage
usage
Easy to Release
Easy to (Re)Use
© Data Fellas SPRL 2016
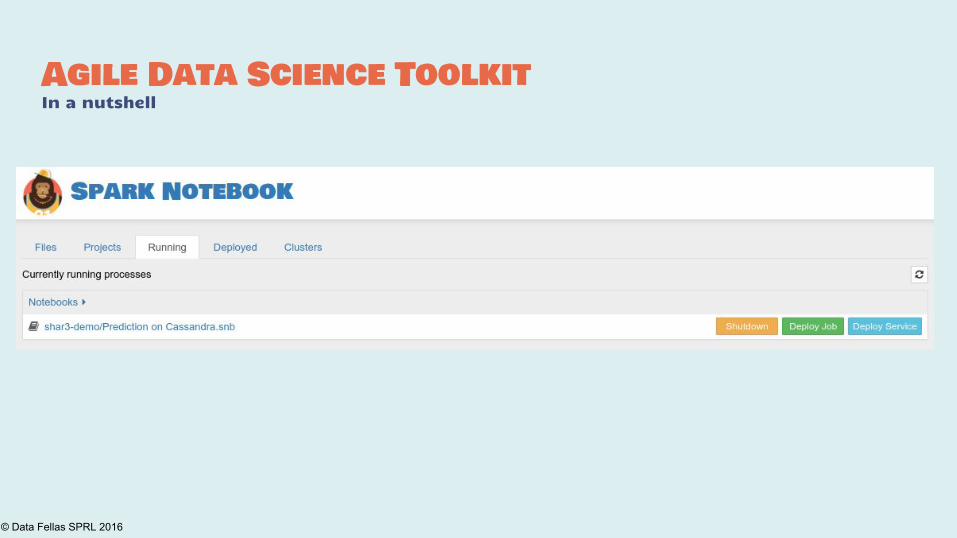
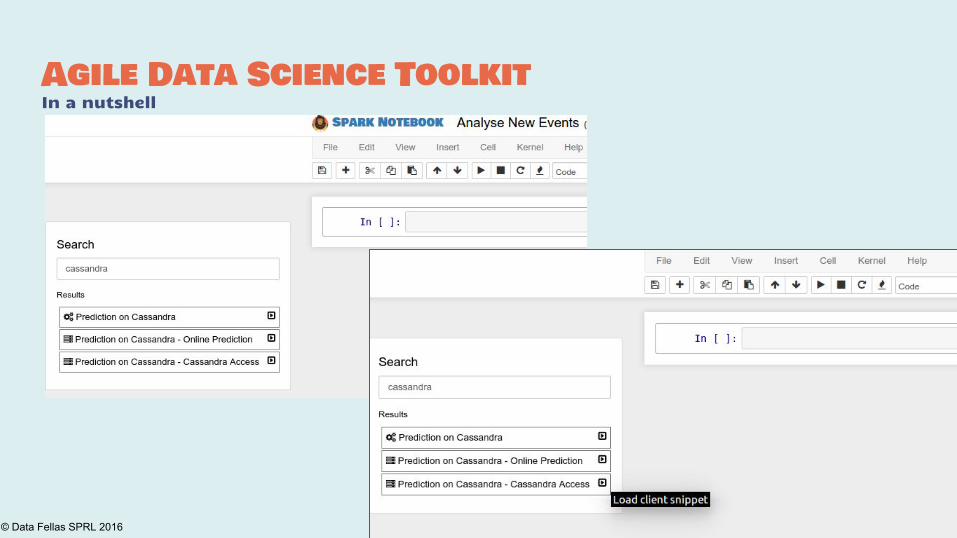
Agile Data Science ToolkitIn a nutshell
© Data Fellas SPRL 2016
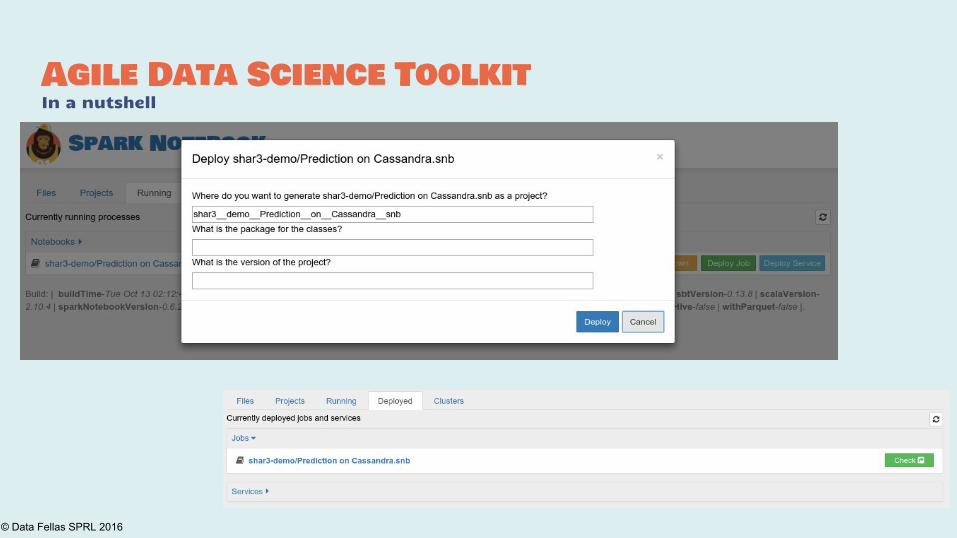
Agile Data Science ToolkitIn a nutshell
© Data Fellas SPRL 2016
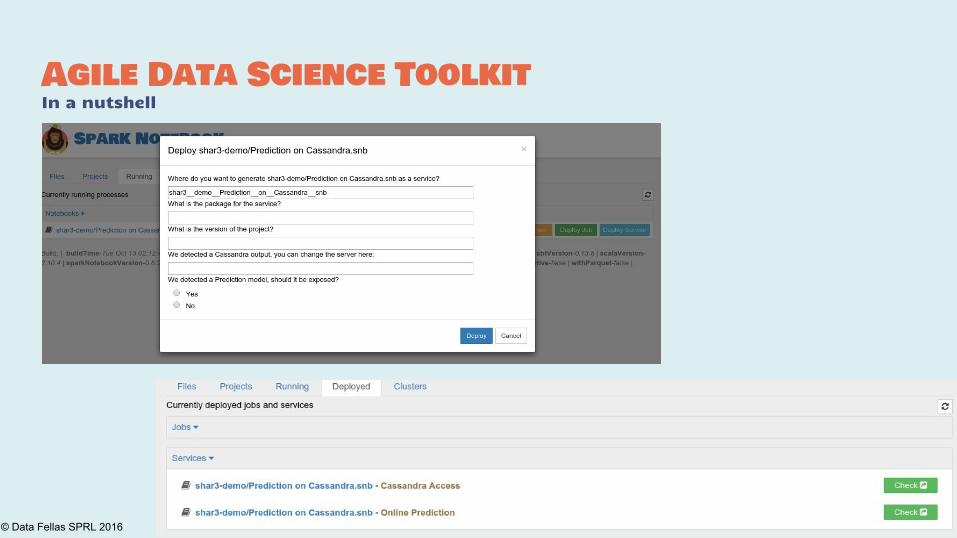
Agile Data Science ToolkitIn a nutshell
© Data Fellas SPRL 2016
Agile Data Science ToolkitIn a nutshell
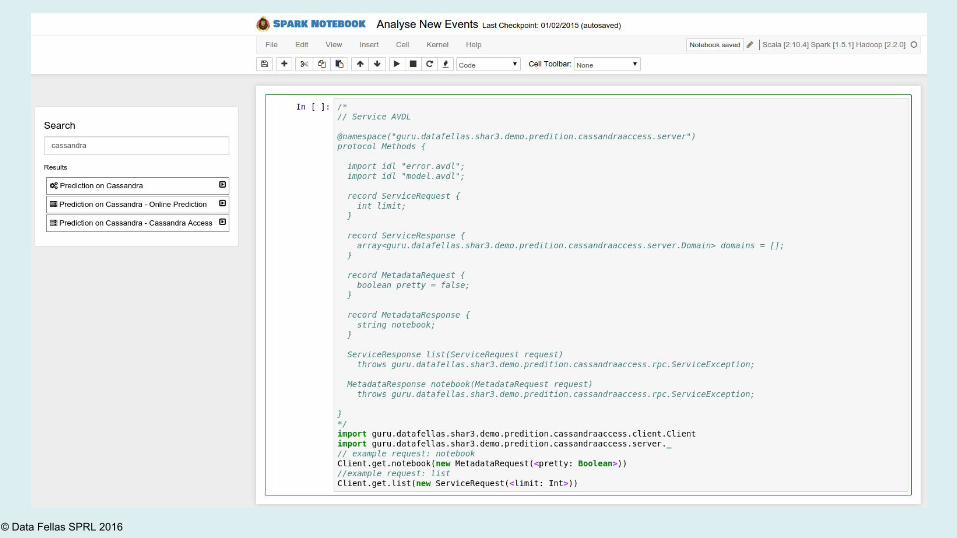
© Data Fellas SPRL 2016
Agile Data Science ToolkitIn a nutshell

© Data Fellas SPRL 2016
Agile Data Science ToolkitIn a nutshell

Data Fellas…
Announcements!!!
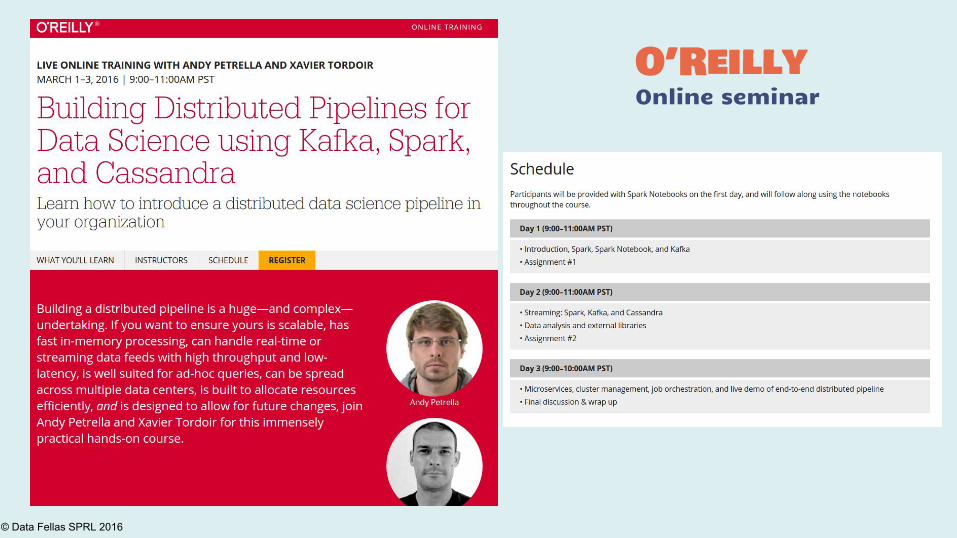
© Data Fellas SPRL 2016
O’ReillyOnline seminar

© Data Fellas SPRL 2016
GrowingWe’re Hiring! http://www.data-fellas.guru/#skillsjobs

Q/AReferences
http://www.data-fellas.guru/
http://spark-notebook.io/
https://github.com/andypetrella/spark-notebook/
https://gitter.im/andypetrella/spark-notebook
Come at Strata -- London at least -- We have two talks :-)
Acknowledgments
@jaguarul
@stratman1958 @joeljacobson
@mhausenblas





























