Embed Size (px)
Citation preview

Before Kaggle From a business goal to a ML problem
Pierre Gu(errez @prrgu(errez

• Data Science competitions platform (There are others : DataScience.net in France)
• 332,000 Data Scientists
• today : 192 competitions, 18 active + 516 In class, 12 active • Prestigious clients : Axa, Cern, Caterpillar, Facebook, GM, Microsoft, Yandex…
What is ?

• Price pool? • 325,000 $ to make on August 31st • Good luck with that ! • Not a good hourly wage
• today : 192 competitions, 18 active Understand : • Lot’s of datasets about approximately every DS topic • Lot’s of winner solutions, tip and tricks, etc… • Lot’s of “beat the benchmark” for beginners
I discovered/tested there : GBT, xgboost, Keras, word2vec, BeautifulSoup, hyperopt, ...
Why should I join ?

Most of the time:
• You have a train set with labels and a test set without labels. • You need to learn a model using the train features and predict the test set labels • Your prediction is evaluated using a specific metric • The best prediction wins
What is a Data Science Competition ?

Most of the time:
• You have a train set with labels and a test set without labels. • You need to learn a model using the train features and predict the test set labels • Your prediction is evaluated using a specific metric • The best prediction wins
What is a Data Science Competition?
Why AUC? F1 score? Log loss?
Could that depend on my train/test split?
Where do they come from ? Do you always have some?
Why is the split this way? Random? Time?

What you don’t learn on Kaggle (or in class?): • How to model a business question into a ML problem. • How to manage/create labels. (proxy / missing…) • How to evaluate a model:
• How to choose your metric • How to design your train/test split • How to account for this in feature engineering
Understanding this actually helps you in Kaggle competition : • How to design your cross validation scheme (and not overfit) • How to create relevant features • Hacks and tricks (leak exploitation J)
What is a Data Science Competition?
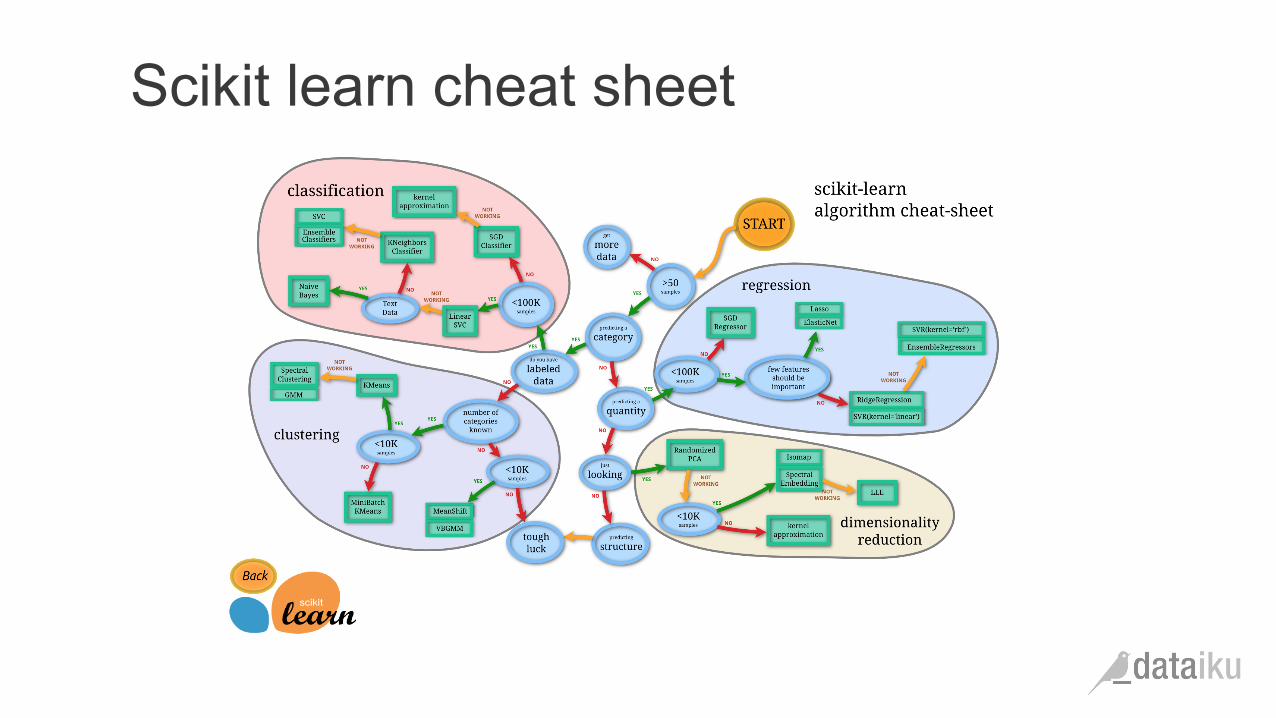
Scikit learn cheat sheet
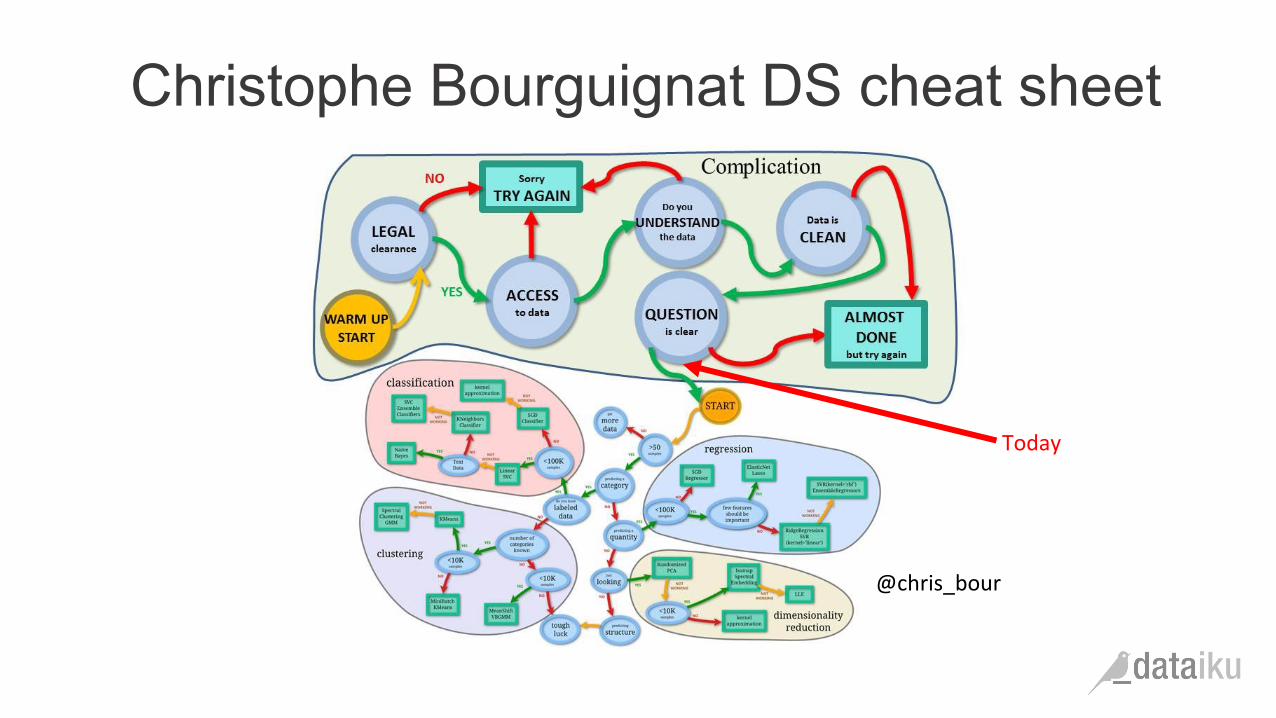
Christophe Bourguignat DS cheat sheet
@chris_bour
Today

• Introduction • Labels? • Train and test split? • Feature Engineering? • Evaluation Metric?
Introduction

• Introduction • Labels? • Train and test split? • Feature Engineering? • Evaluation Metric?
Introduction The newcomer disillusion
The produc(on bad surprise
The business obfusca(on

• Senior Data Scientist at Dataiku (worked on churn prediction, fraud detection, bot detection, recommender systems, graph analytics, smart cities,…)
• (More than) Occasional Kaggle competitor • Twitter @prrgutierrez
Who I am

• Senior Data Scientist at Dataiku (worked on churn prediction, fraud detection, bot detection, recommender systems, graph analytics, smart cities,…)
• (More than) Occasional Kaggle competitor • Twitter @prrgutierrez
Who I am


• Everywhere is fraud E-business, Telco, Medicare,…
• Easily defined as a classification problem
• Target well defined ? • E-business : yes with lag • Elsewhere : need checks, labels are expensive
Fraud Detection

• Wikipedia: “Churn rate (sometimes called attrition rate), in its broadest sense, is a measure of the number of individuals or items moving out of a collective group over a specific period of time” = Customer leaving
Churn

• Subscription models: • Telco • E-gamming (Wow) • Ex : Coyote -> 1 year subscription
-> you know when someone leave • Non subscription models:
• E-Business (Amazon, Price Minister, Vente Privée) • E-gamming (Candy Crush, free MMORPG)
-> you approximate someone leaving Candy Crush: days / weeks MMORPG: 2 months (holidays) Price Minister: months
Two types of Churn

• Predict if a vehicle / machine / part is going to fail • Classification Problem:
• Given a future horizon and a failure type. Will this happen for a given vehicle ? -> 2 parameters describe the target • Vary a lot the target -> spurious correlation • Just choose it as the result of the exact business need
Predictive Maintenance
• Target is “will like” or “will buy” • Target is often proxy of real interest (implicit feedback)
Recommender System

• Can you model the problem as a ML problem? • Ex : predictive maintenance • Ask the right question from a business point of view. Not what you know how to do.
• Is your target a proxy? • Recommendation system • May need bandit algorithm
• Is it easy to get labels? • Ex : Fraud detection • Can be expensive • Mechanical Turk can be the answer
Summary on Labels

• Random Split • Just like in school
Train / test split
• When and why ? -‐> When each line is independent from the rest (not that common !)
image, document classifica(on, sen(ment analysis (“but aha is the new lol” ) -‐> When you want to quickly iterate / benchmark: “is it even possible?” -‐> When you want to sell something to your boss
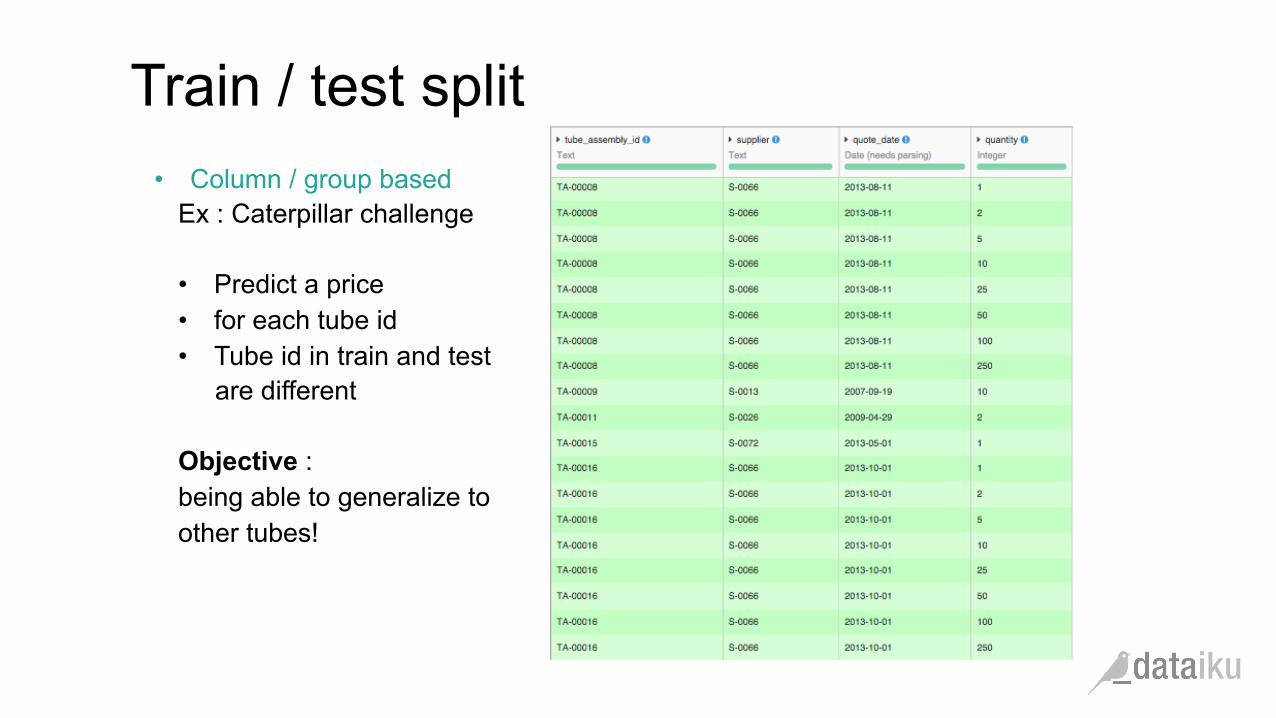
• Column / group based Ex : Caterpillar challenge • Predict a price • for each tube id • Tube id in train and test are different
Objective : being able to generalize to other tubes!
Train / test split

• Time based • Simply separate train and test on a time variable
• When and Why? -> When you want a model that “predict the future” -> When things evolve with time! (most problems!) -> Examples :
Add click prediction, Churn prediction, E-business Fraud detection, Predictive maintenance,…
Train / test split

• No subscription example • Target : 4 month without buying • Features ?
Train / test split : Churn example
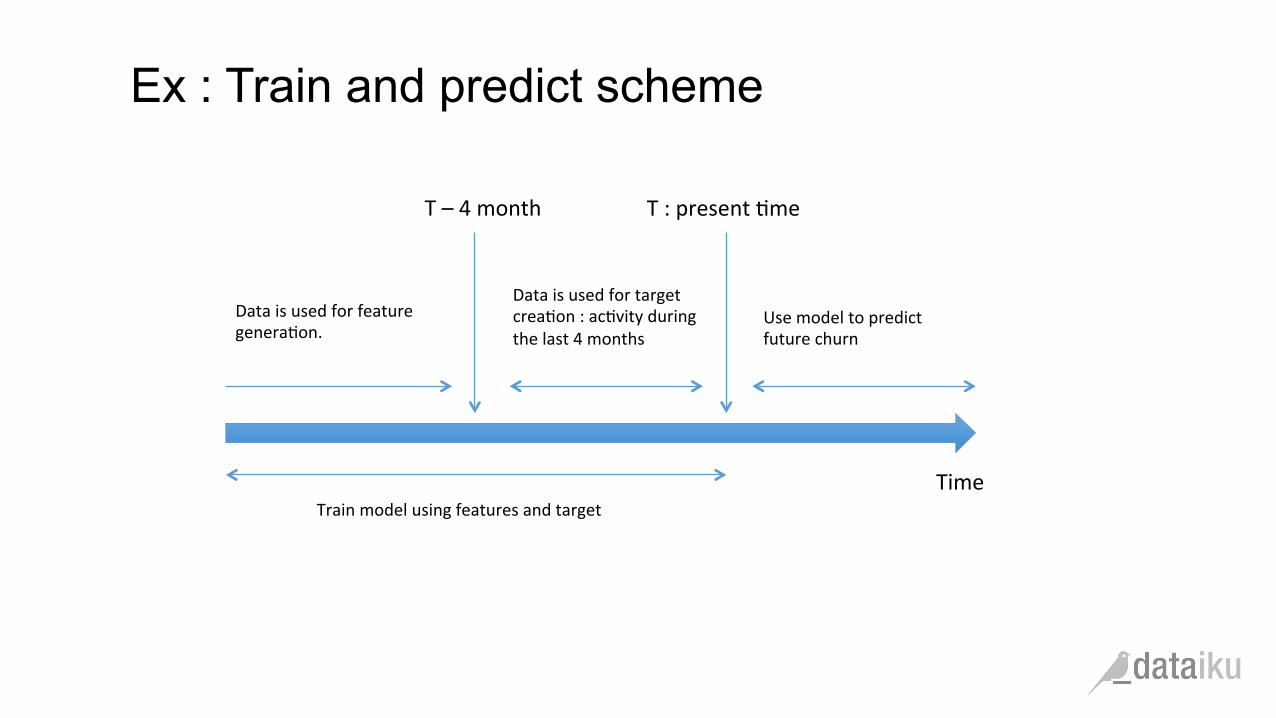
Ex : Train and predict scheme
Time
T : present (me T – 4 month
Data is used for target crea(on : ac(vity during the last 4 months
Data is used for feature genera(on.
Use model to predict future churn
Train model using features and target
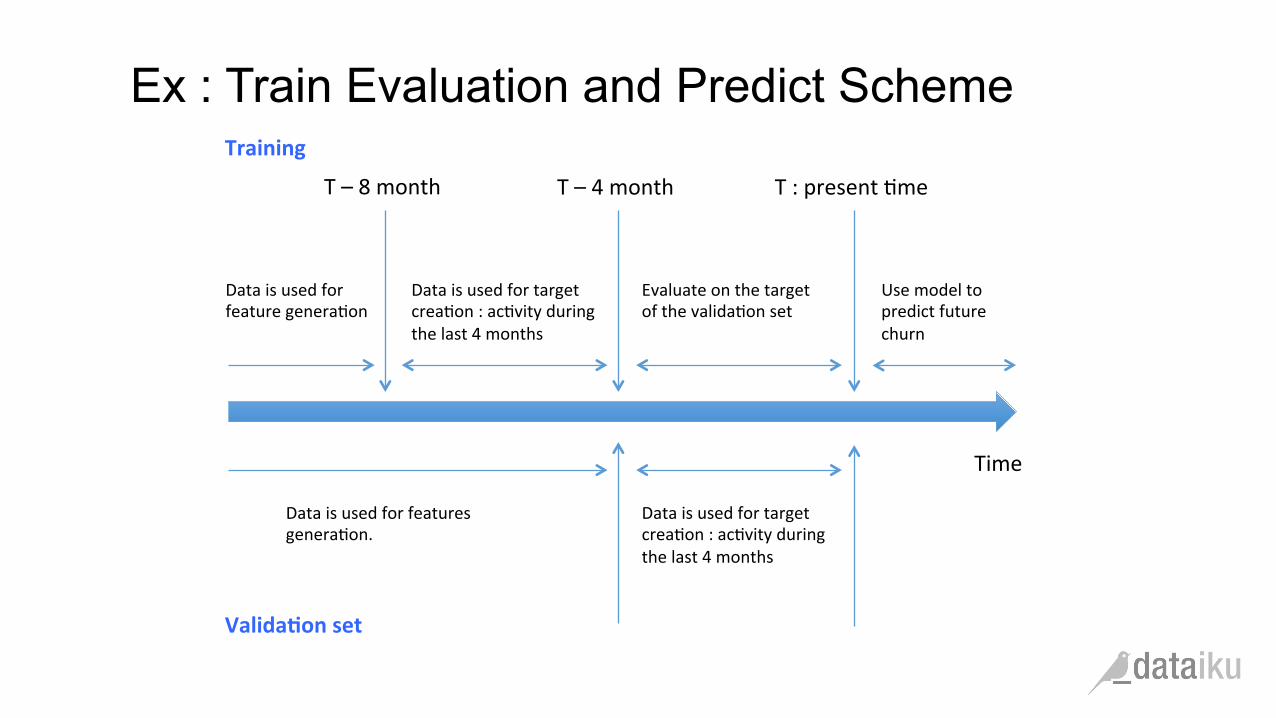
Ex : Train Evaluation and Predict Scheme
Time
T : present (me T – 4 month
Data is used for target crea(on : ac(vity during the last 4 months
Data is used for feature genera(on
Valida&on set
Use model to predict future churn
Training
Evaluate on the target of the valida(on set
T – 8 month
Data is used for features genera(on.
Data is used for target crea(on : ac(vity during the last 4 months

• More complex design • Graph sampling (fraud rings ? ) • Random sampling in client / machine life • Mix of column based and time based …
• The rule : 1) What is the problem ? 2) To what would I like to generalize my model ?
Future ? Other individuals ? … 3) => Train / Test split
Train / test split

• Predictive Maintenance problem
• Objective : predict failure in next 3 days.
• Metric is proportional to accuracy (and 0.57 is the best score !) • Link to data : https://www.phmsociety.org/events/conference/phm/14/data-challenge
EX PHM Society (Fail example)
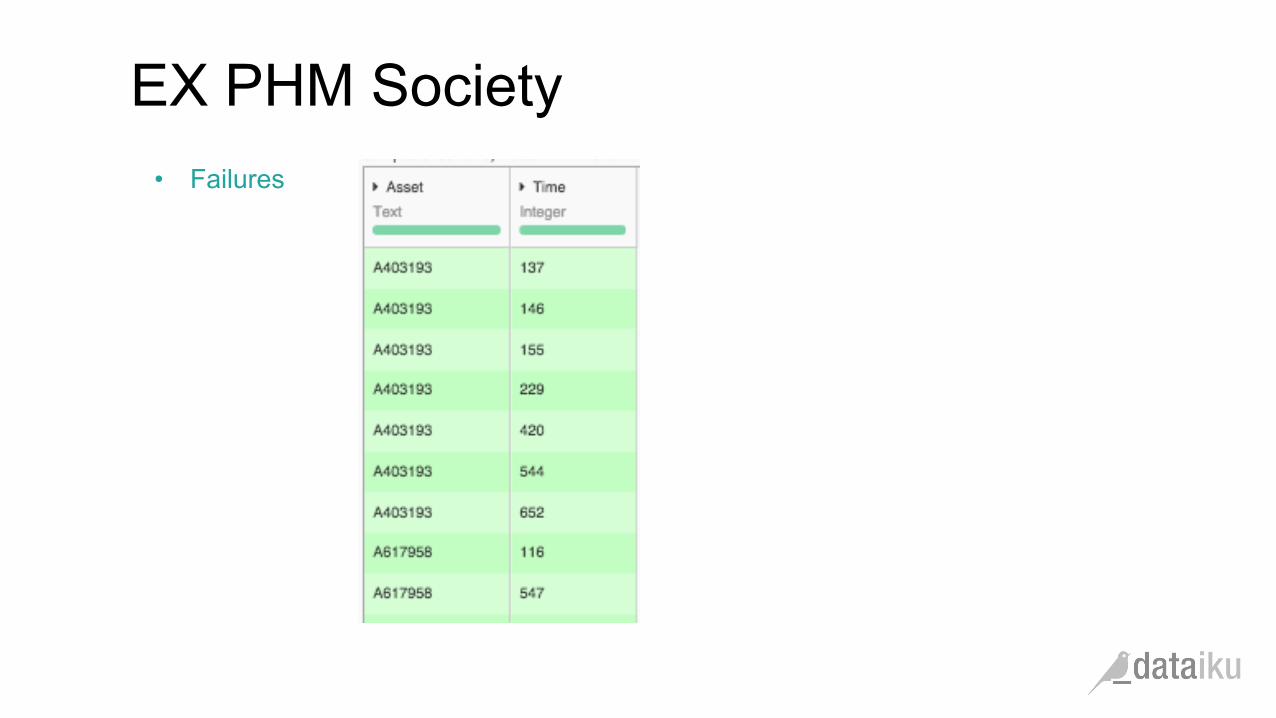
• Failures
EX PHM Society
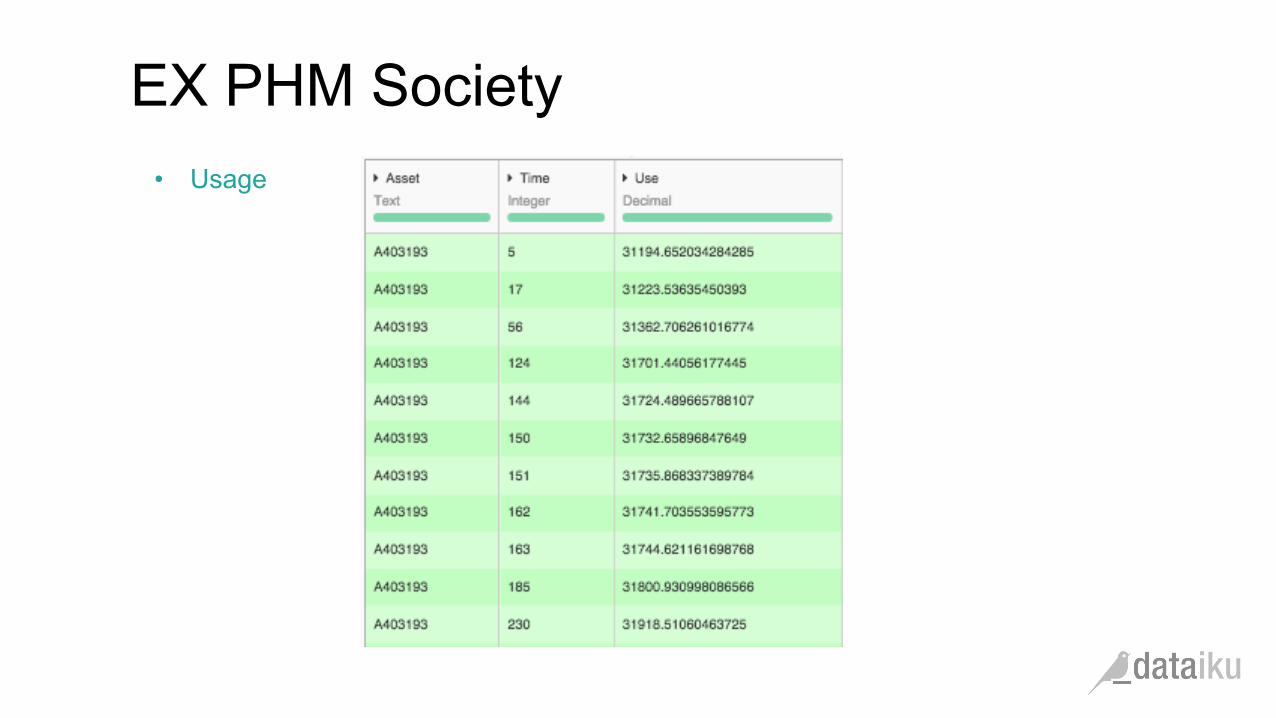
• Usage
EX PHM Society
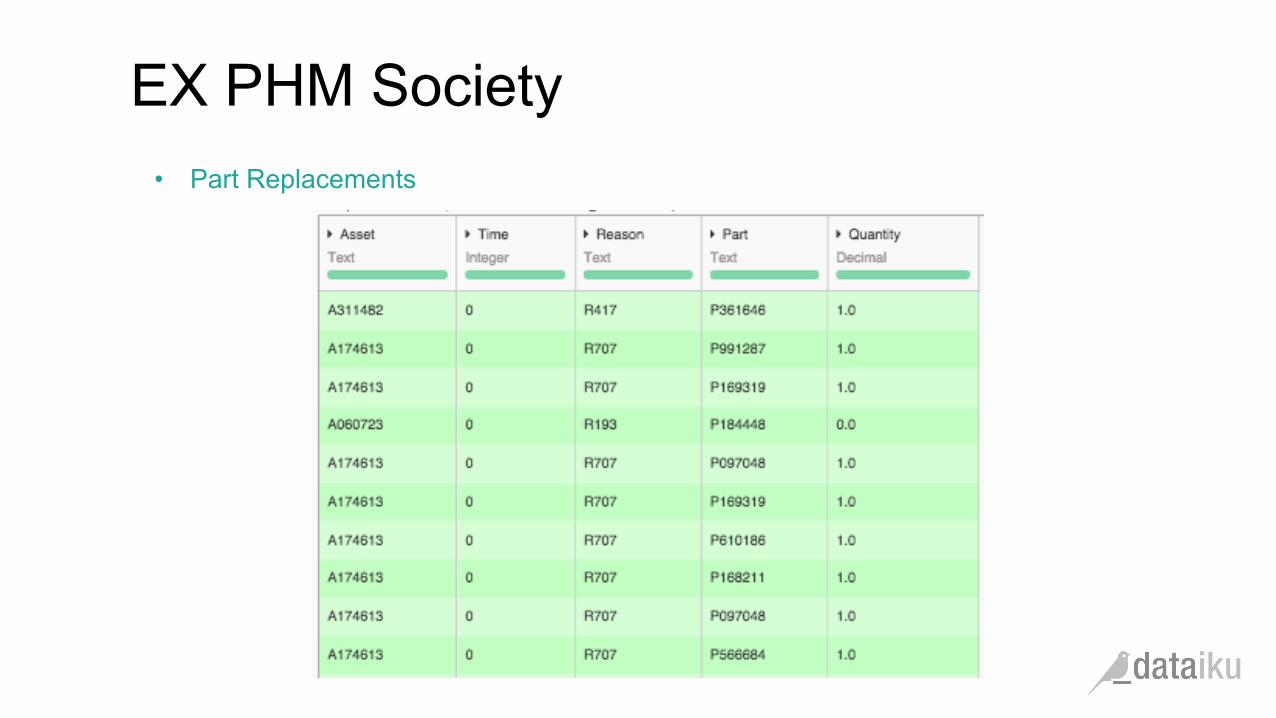
• Part Replacements
EX PHM Society

• How to design the evaluation scheme? • What is the probability that an asset fail in the next 3 days from Now? -> classification problem -> Time based split -> but how do I create a train and a test? • Choose a date and evaluate what happens 3 days later? -> pb : not enough failures happening • Choose several dates for each asset? -> beware of asset over-fitting • In the challenge : random selection of (asset, date) in the future + over sampling of
failures.
EX PHM Society
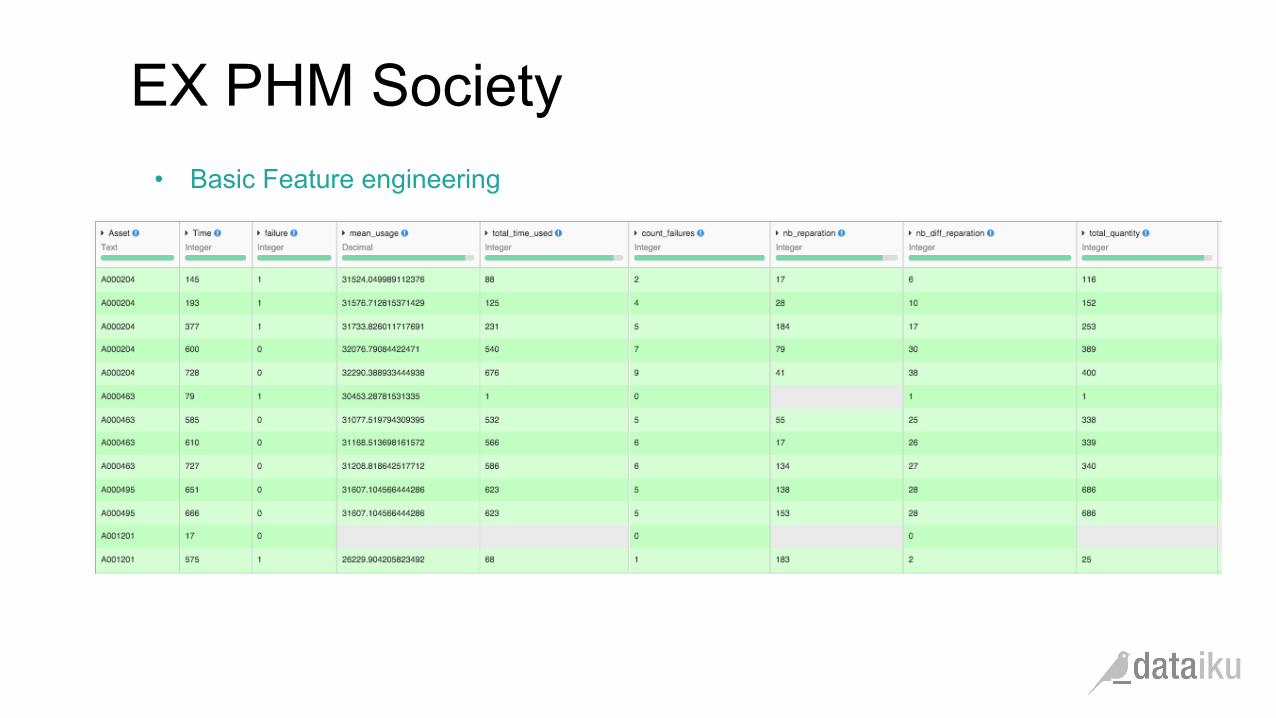
• Basic Feature engineering
EX PHM Society
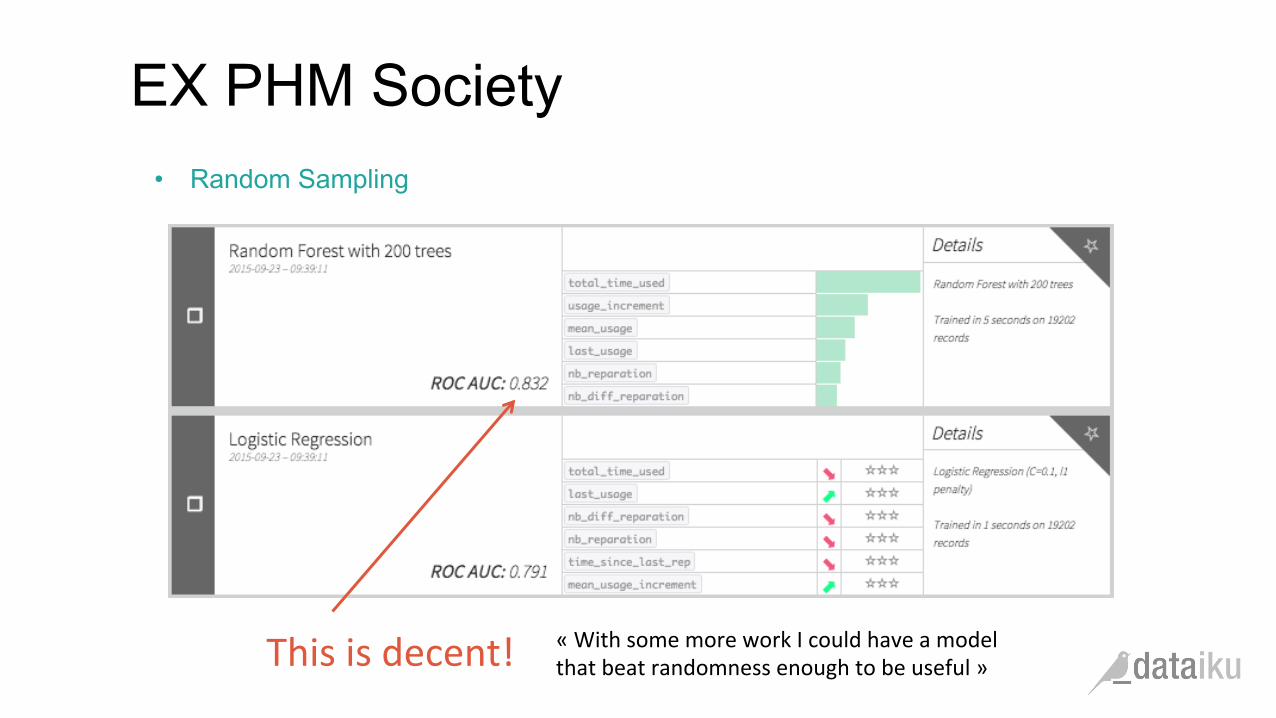
• Random Sampling
EX PHM Society
This is decent! « With some more work I could have a model that beat randomness enough to be useful »

• Time based split
EX PHM Society
Wait what?

• TIME LEAK
EX PHM Society
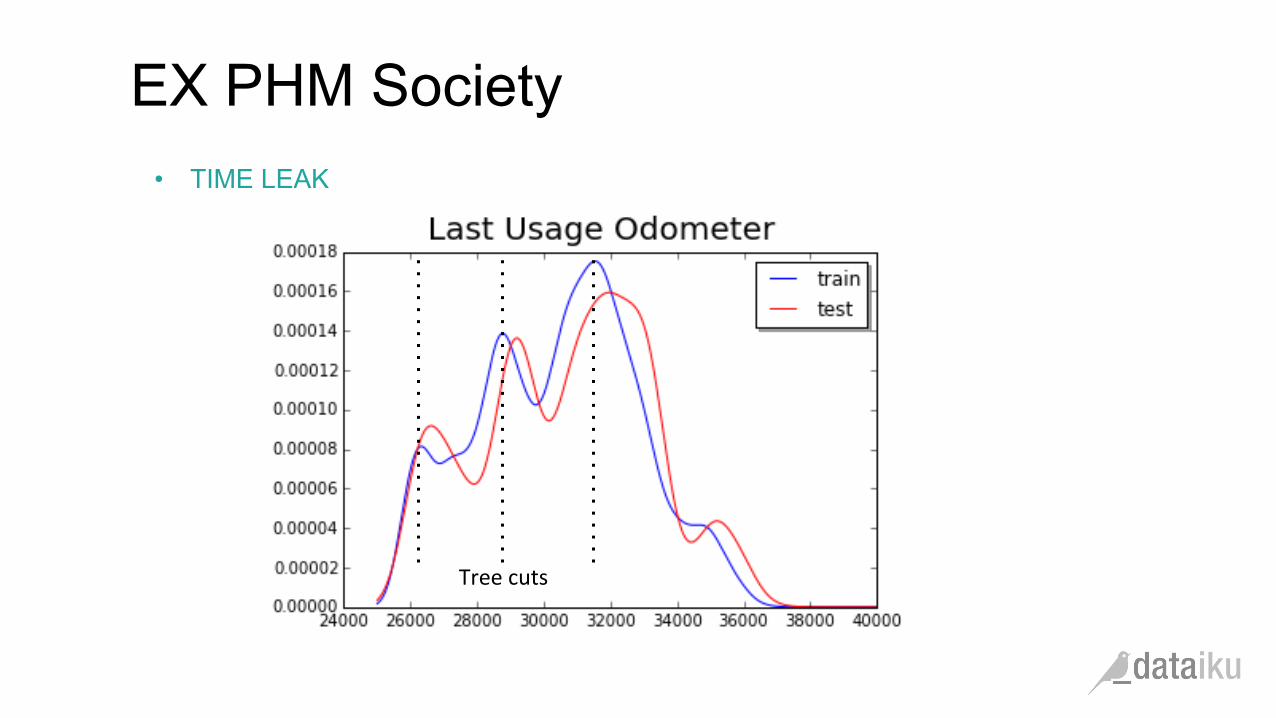
• TIME LEAK
EX PHM Society
Tree cuts

• Beware of the distribution of you features! • Is there a time dependency?
• Ex : count, sum, … that will only increase with time • -> Calculate count and sum rescaled by time / in moving windows instead. • Can be found in Churn, Fraud detection, Ad click prediction,…
• A categorical variable dependency? • Ex : email flag in fraud detection
• Is there a Network dependency? • Ex : Fraud / Bot detection (network features can be useful but leaky)
Feature Engineering

• Final trick : - Stack train and test and add is_test boolean - Try to predict is_test - Check if the model is able to predict - If so :
- check the feature importance - Remove / modify feature and iterate
Feature Engineering

• Final trick:
• Back to Phm example:
Feature Engineering
Huge (me leak !

• “Treshold dependant” • Accuracy • Precision and Recall • F1 score
• “Treshold independant” • AUC • Log Loss • Others (Mean average precision)…
Evaluation metric : Classification

• “Treshold dependant” • Accuracy • Precision and Recall • F1 score
• “Treshold independant” • AUC • Log Loss • Others (Mean average precision)…
• Customs
Evaluation metric : Classification Not good if unbalanced target
When you have an order problem
When you are going stochas(c
When you need to s(ck to business
Accuracy alterna(ve

• Custom metrics • Cost based
• Ex Fraud: • Mean loss of 50 $ / fraud (FN) • Mean loss of 20 $ / wrongly cancelled transaction (FP)
• F1 score often used in papers • in practice, you often have a business cost
Evaluation metric : Classification
TP FN
TN FP

• Custom metrics • Fraud Example 1:
• “I have fraudsters on my e-business website” • I generate a score for each transaction • I handle this by manually handling transactions with score higher than threshold • I have 1 person that does this fulltime and able to deal with 100 transactions / day • The rest is automatically accepted
-> AUC is not bad -> Recall in 100 transactions / day -> Total money blocked 100 transactions / day In practice AUC more stable… But the money metric can also be used for communication.
Evaluation metric : Classification

• Custom metrics • Fraud Example 2:
• “I have fraudsters on my e-business website” • I generate a score for each transaction • I handle this automatically by blocking all transactions with score higher than threshold
-> AUC is not bad… But don’t give threshold value. -> F1–Score? -> Cost based is better
Evaluation metric : Classification
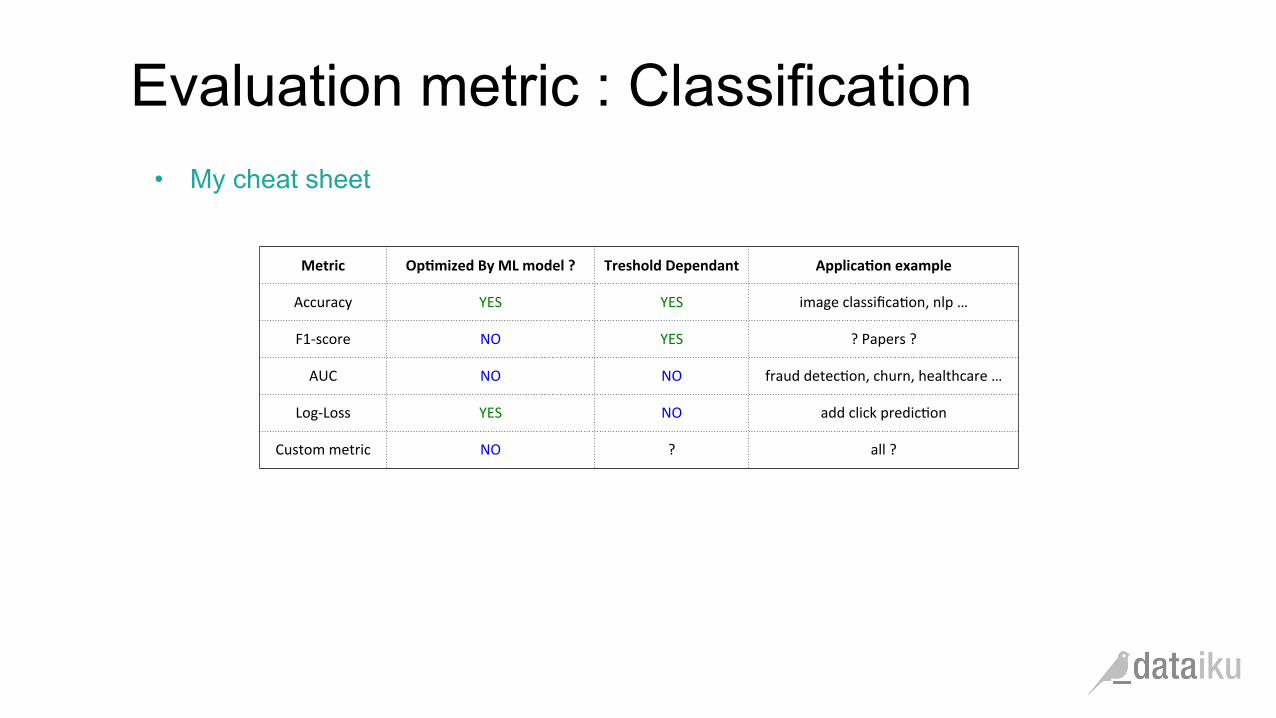
• My cheat sheet
Evaluation metric : Classification
Metric Op&mized By ML model ? Treshold Dependant Applica&on example
Accuracy YES YES image classifica(on, nlp …
F1-‐score NO YES ? Papers ?
AUC NO NO fraud detec(on, churn, healthcare …
Log-‐Loss YES NO add click predic(on
Custom metric NO ? all ?

• Business Question dictates Evaluation Scheme! • test set design • evaluation metric • Indirectly impact feature engineering • Indirectly impact label quality
• Think (not too much) before coding
• Don’t try to optimize the wrong problem!
Conclusion

Thank you for your attention!