Embed Size (px)
Citation preview

[email protected] www.rittmanmead.com @rittmanmead
Big Data for Oracle Developers & DBAs - Towards Spark, Real-Time and Predictive Analytics
Mark Rittman, CTO, Rittman Mead Riga Dev Day 2016, Riga, March 2016

[email protected] www.rittmanmead.com @rittmanmead 2
•Mark Rittman, Co-Founder of Rittman Mead‣Oracle ACE Director, specialising in Oracle BI&DW‣14 Years Experience with Oracle Technology‣Regular columnist for Oracle Magazine
•Author of two Oracle Press Oracle BI books‣Oracle Business Intelligence Developers Guide‣Oracle Exalytics Revealed‣Writer for Rittman Mead Blog :http://www.rittmanmead.com/blog
•Email : [email protected]•Twitter : @markrittman
About the Speaker

[email protected] www.rittmanmead.com @rittmanmead
•Everyone’s talking about Hadoop and “Big Data”
Hadoop is the Big Hot Topic In IT / Analytics

[email protected] www.rittmanmead.com @rittmanmead
•Gives us an ability to store more data, at more detail, for longer•Provides a cost-effective way to analyse vast amounts of data•Hadoop & NoSQL technologies can give us “schema-on-read” capabilities•There’s vast amounts of innovation in this area we can harness•And it’s very complementary to Oracle BI & DW
Why is Hadoop of Interest to Us?

[email protected] www.rittmanmead.com @rittmanmead
Flexible Cheap Storage for Logs, Feeds + Social Data
$50k
Hadoop Node
Voice + Chat Transcripts
Call Center LogsChat Logs iBeacon Logs Website LogsCRM Data Transactions Social FeedsDemographics
Raw Data
Customer 360 Apps
Predictive Models
SQL-on-Hadoop
Business analytics
Real-time Feeds,batch and API

[email protected] www.rittmanmead.com @rittmanmead
•Extend the DW with new data sources, datatypes, detail-level data•Offload archive data into Hadoop but federate it with DW data in user queries•Use Hadoop, Hive and MapReduce for low-cost ETL staging
Deploy Alongside Traditional DW as “Data Reservoir”
DataTransfer DataAccess
DataFactory DataReservoir
BusinessIntelligenceTools
HadoopPlatform
FileBasedIntegration
StreamBased
Integration
Datastreams
Discovery&DevelopmentLabsSafe&secureDiscoveryandDevelopment
environment
Datasetsandsamples
Models andprograms
Marketing/SalesApplications
Models
MachineLearning
Segments
OperationalData
Transactions
CustomerMasterata
UnstructuredData
Voice+ChatTranscripts
ETLBasedIntegration
RawCustomerData
Datastoredintheoriginal
format(usuallyfiles)suchasSS7,ASN.1,JSONetc.
MappedCustomerData
Datasetsproducedbymappingandtransformingrawdata

[email protected] www.rittmanmead.com @rittmanmead
Incorporate Hadoop Data Reservoirs into DW Design
Virtu
aliz
atio
n &
Q
uery
Fed
erat
ion
Enterprise Performance Management
Pre-built & Ad-hoc BI Assets
Information Services
Data Ingestion
Information Interpretation
Access & Performance Layer
Foundation Data Layer
Raw Data Reservoir
Data Science
Data Engines & Poly-structured sources
Content
Docs Web & Social Media
SMS
Structured Data Sources
•Operational Data •COTS Data •Master & Ref. Data •Streaming & BAM
Immutable raw data reservoir Raw data at rest is not interpreted
Immutable modelled data. Business Process Neutral form. Abstracted from business process changes
Past, current and future interpretation of enterprise data. Structured to support agile access & navigation
Discovery Lab Sandboxes Rapid Development Sandboxes
Project based data stores to support specific discovery objectives
Project based data stored to facilitate rapid content / presentation delivery
Data Sources

[email protected] www.rittmanmead.com @rittmanmead 8
•Oracle Engineered system for big data processing and analysis•Start with Oracle Big Data Appliance Starter Rack - expand up to 18 nodes per rack•Cluster racks together for horizontal scale-out using enterprise-quality infrastructure
Oracle Big Data Appliance Starter Rack + Expansion
• Cloudera CDH + Oracle software • 18 High-spec Hadoop Nodes with
InfiniBand switches for internal Hadoop traffic, optimised for network throughput
• 1 Cisco Management Switch• Single place for support for H/W + S/
W
Deployed on Oracle Big Data Appliance
Oracle Big Data Appliance Starter Rack + Expansion
• Cloudera CDH + Oracle software • 18 High-spec Hadoop Nodes with
InfiniBand switches for internal Hadoop traffic, optimised for network throughput
• 1 Cisco Management Switch• Single place for support for H/W + S/
W
Enriched Customer Profile
Modeling
Scoring
Infiniband

[email protected] www.rittmanmead.com @rittmanmead
•Hadoop, through MapReduce, breaks processing down into simple stages‣Map : select the columns and values you’re interested in, pass through as key/value pairs‣Reduce : aggregate the results
•Most ETL jobs can be broken down into filtering, projecting and aggregating
•Hadoop then automatically runs job on cluster‣Share-nothing small chunks of work‣Run the job on the node where the data is‣Handle faults etc‣Gather the results back in
Hadoop Tenets : Simplified Distributed Processing
Mapper Filter, Project
Mapper Filter, Project
Mapper Filter, Project
Reducer Aggregate
Reducer Aggregate
Output One HDFS file per reducer,in a directory

[email protected] www.rittmanmead.com @rittmanmead
•MapReduce jobs are typically written in Java, but Hive can make this simpler•Hive is a query environment over Hadoop/MapReduce to support SQL-like queries•Hive server accepts HiveQL queries via HiveODBC or HiveJDBC, automaticallycreates MapReduce jobs against data previously loaded into the Hive HDFS tables
•Approach used by ODI and OBIEEto gain access to Hadoop data
•Allows Hadoop data to be accessed just like any other data source (sort of...)
Hive as the Hadoop SQL Access Layer

[email protected] www.rittmanmead.com @rittmanmead
•Data integration tools such as Oracle Data Integrator can load and process Hadoop data•BI tools such as Oracle Business Intelligence 12c can report on Hadoop data•Generally use MapReduce and Hive to access data‣ODBC and JDBC access to Hive tabular data‣Allows Hadoop unstructured/semi-structureddata on HDFS to be accessed like RDBMS
Hive Provides a SQL Interface for BI + ETL Tools
Access direct Hive or extract using ODI12c for structured OBIEE dashboard analysis
What pages are people visiting? Who is referring to us on Twitter? What content has the most reach?

[email protected] www.rittmanmead.com @rittmanmead
•Most Oracle DBAs and developers know about Hadoop, but assume…
Common Developer Understanding of Hadoop Today
‣Hadoop is just for batch (because of the MapReduce JVN spin-up issue) ‣Hadoop is just for large datasets, not ad-hoc work or micro batches ‣Hadoop will always be slow because it stages everything to disk ‣All Hadoop can do is Map (select, filter) and Reduce (aggregate) ‣Hadoop == MapReduce

Hadoop is slowand only for batch jobs
…isn’t it?
but …

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Hadoop is Now Real-Time, In-Memory and Analytics-Optimised
[email protected] www.rittmanmead.com @rittmanmead 15
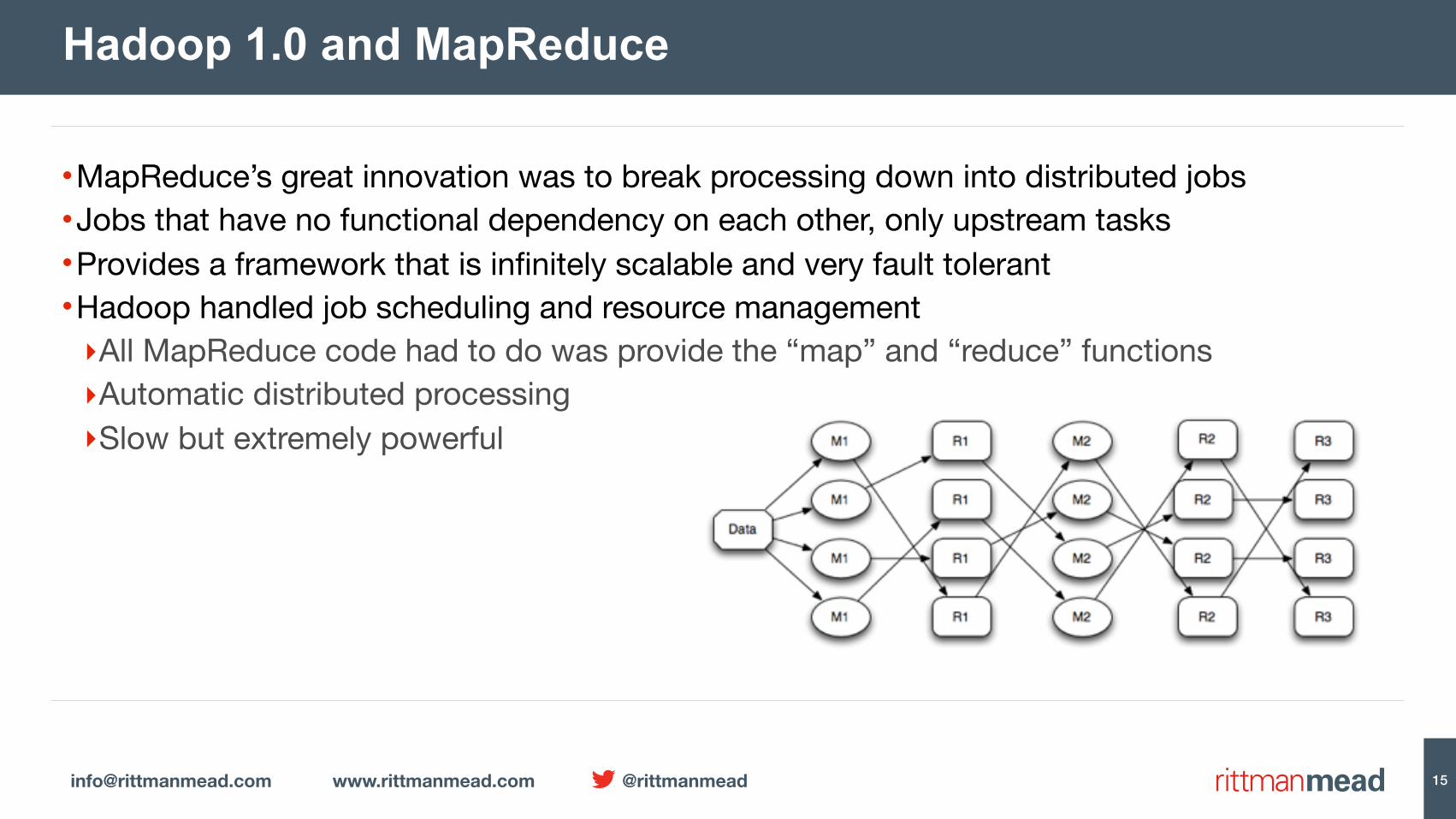
•MapReduce’s great innovation was to break processing down into distributed jobs•Jobs that have no functional dependency on each other, only upstream tasks•Provides a framework that is infinitely scalable and very fault tolerant•Hadoop handled job scheduling and resource management‣All MapReduce code had to do was provide the “map” and “reduce” functions‣Automatic distributed processing‣Slow but extremely powerful
Hadoop 1.0 and MapReduce

[email protected] www.rittmanmead.com @rittmanmead 16
•A typical Hive or Pig script compiles down into multiple MapReduce jobs•Each job stages its intermediate results to disk•Safe, but slow - write to disk, spin-up separate JVMs for each job
Compiling Hive/Pig Scripts into MapReduce
register /opt/cloudera/parcels/CDH/lib/pig/piggybank.jar raw_logs = LOAD '/user/mrittman/rm_logs' USING TextLoader AS (line:chararray); logs_base = FOREACH raw_logs GENERATE FLATTEN (REGEX_EXTRACT_ALL(line,'^(\\S+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+\\-]\\d{4})\\] "(.+?)" (\\S+) (\\S+) "([^"]*)" "([^"]*)"') )AS (remoteAddr: chararray, remoteLogname: chararray, user: chararray,time: chararray); logs_base_nobots = FILTER logs_base BY NOT (browser matches '.*(spider|robot|bot|slurp|bot.*'); logs_base_page = FOREACH logs_base_nobots GENERATE SUBSTRING(time,0,2) as day) AS (method:chararray, request_page:chararray, protocol:chararray), remoteAddr, status; logs_base_page_cleaned = FILTER logs_base_page BY NOT (SUBSTRING(request_page,0,3) == '/wp' or request_page == '/' or SUBSTRING(request_page,0,7) == '/files/' or SUBSTRING(request_page,0,12) == '/favicon.ico'); logs_base_page_cleaned_by_page = GROUP logs_base_page_cleaned BY request_page; page_count = FOREACH logs_base_page_cleaned_by_page GENERATE FLATTEN(group) as request_page, COUNT(logs_base_page_cleaned) as hits; … store pages_and_post_top_10 into 'top_10s/pages'; JobId Maps Reduces Alias Feature Outputs
job_1417127396023_0145 12 2 logs_base,logs_base_nobots,logs_base_page,logs_base_page_cleaned, logs_base_page_cleaned_by_page,page_count,raw_logs GROUP_BY,COMBINER job_1417127396023_0146 2 1 pages_and_post_details,pages_and_posts_trim,posts,posts_cleaned HASH_JOIN job_1417127396023_0147 1 1 pages_and_posts_sorted SAMPLER job_1417127396023_0148 1 1 pages_and_posts_sorted ORDER_BY,COMBINER job_1417127396023_0149 1 1 pages_and_posts_sorted

[email protected] www.rittmanmead.com @rittmanmead 17
•MapReduce 2 (MR2) splits the functionality of the JobTrackerby separating resource management and job scheduling/monitoring
• Introduces YARN (Yet Another Resource Manager)•Permits other processing frameworks to MR‣For example, Apache Spark
•Maintains backwards compatibility with MR1• Introduced with CDH5+
MapReduce 2 and YARN
Node Manager
Node Manager
Node Manager
Resource Manager
Client
Client

[email protected] www.rittmanmead.com @rittmanmead 18
•Runs on top of YARN, provides a faster execution engine than MapReduce for Hive, Pig etc•Models processing as an entire data flow graph (DAG), rather than separate job steps‣DAG (Directed Acyclic Graph) is a new programming style for distributed systems‣Dataflow steps pass data between them as streams, rather than writing/reading from disk
•Supports in-memory computation, enables Hive on Tez (Stinger) and Pig on Tez•Favoured In-memory / Hive v2 route by Hortonworks
Apache Tez
Inpu
t Dat
a
TEZ DAGMap()
Map()
Map()
Reduce()
Out
put D
ata
Reduce()
Reduce()
Reduce()
Inpu
t Dat
a Map()
Map()
Reduce()
Reduce()

[email protected] www.rittmanmead.com @rittmanmead 19
Tez Advantage - Drop-In Replacement for MR with Hive, Pig
set hive.execution.engine=mr
set hive.execution.engine=tez
4m 17s
2m 25s



[email protected] www.rittmanmead.com @rittmanmead 22
•Another DAG execution engine running on YARN•More mature than TEZ, with richer API and more vendor support•Uses concept of an RDD (Resilient Distributed Dataset)‣RDDs like tables or Pig relations, but can be cached in-memory‣Great for in-memory transformations, or iterative/cyclic processes
•Spark jobs comprise of a DAG of tasks operating on RDDs•Access through Scala, Python or Java APIs•Related projects include‣Spark SQL‣Spark Streaming
Apache Spark

[email protected] www.rittmanmead.com @rittmanmead 23
•Native support for multiple languages with identical APIs‣Python - prototyping, data wrangling‣Scala - functional programming features‣Java - lower-level, application integration
•Use of closures, iterations, and other common language constructs to minimize code
• Integrated support for distributed +functional programming
•Unified API for batch and streaming
Rich Developer Support + Wide Developer Ecosystem
scala> val logfile = sc.textFile("logs/access_log") 14/05/12 21:18:59 INFO MemoryStore: ensureFreeSpace(77353) called with curMem=234759, maxMem=309225062 14/05/12 21:18:59 INFO MemoryStore: Block broadcast_2 stored as values to memory (estimated size 75.5 KB, free 294.6 MB) logfile: org.apache.spark.rdd.RDD[String] = MappedRDD[31] at textFile at <console>:15 scala> logfile.count() 14/05/12 21:19:06 INFO FileInputFormat: Total input paths to process : 1 14/05/12 21:19:06 INFO SparkContext: Starting job: count at <console>:1 ... 14/05/12 21:19:06 INFO SparkContext: Job finished: count at <console>:18, took 0.192536694 s res7: Long = 154563
scala> val logfile = sc.textFile("logs/access_log").cache scala> val biapps11g = logfile.filter(line => line.contains("/biapps11g/")) biapps11g: org.apache.spark.rdd.RDD[String] = FilteredRDD[34] at filter at <console>:17 scala> biapps11g.count() ... 14/05/12 21:28:28 INFO SparkContext: Job finished: count at <console>:20, took 0.387960876 s res9: Long = 403

[email protected] www.rittmanmead.com @rittmanmead 24
Accompanied by Innovations in Underlying Platform
Cluster Resource Management tosupport multi-tenant distributed services
In-Memory Distributed Storage,to accompany In-Memory Distributed Processing

[email protected] www.rittmanmead.com @rittmanmead 25
•Most Oracle DWs process data in batches (or at best, micro-batches)•Tools like ODI typically work in this way, often linking up with database CDC
•Hadoop systems are usually real-time, from the start‣In the past, via Hadoop streaming, Flume etc‣Batch loading then added for initial data load into system
Combining Real-Time Processing with Real-Time Loading
Hadoop Node
Voice + Chat Transcripts
Call Center LogsChat Logs iBeacon Logs Website Logs
Real-time Feeds
Raw Data

[email protected] www.rittmanmead.com @rittmanmead 26
•Apache Flume is the standard way to transport log files from source through to target‣Initial use-case was webserver log files, but can transport any file from A>B‣Does not do data transformation, but can send to multiple targets / target types‣Mechanisms and checks to ensure successful transport of entries
•Has a concept of “agents”, “sinks” and “channels”‣Agents collect and forward log data‣Sinks store it in final destination‣Channels store log data en-route
•Simple configuration through INI files‣Handled outside of ODI12c
Apache Flume : Distributed Transport for Log Activity

[email protected] www.rittmanmead.com @rittmanmead 27
•Oracle GoldenGate is also an option, for streaming RDBMS transactions to Hadoop•Leverages GoldenGate & HDFS / Hive Java APIs•Sample Implementations on MOS Doc.ID 1586210.1 (HDFS) and 1586188.1 (Hive)•Likely to be formal part of GoldenGate in future release - but usable now•Can also integrate with Flume for delivery to HDFS - see MOS Doc.ID 1926867.1
GoldenGate for Continuous Streaming to Hadoop

[email protected] www.rittmanmead.com @rittmanmead 28
•Developed by LinkedIn, designed to address Flume issues around reliability, throughput‣(though many of those issues have been addressed since)
•Designed for persistent messages as the common use case‣Website messages, events etc vs. log file entries
•Consumer (pull) rather than Producer (push) model•Supports multiple consumers per message queue•More complex to set up than Flume, and can useFlume as a consumer of messages‣But gaining popularity, especially alongside Spark Streaming
Apache Kafka : Reliable, Message-Based

[email protected] www.rittmanmead.com @rittmanmead 29
•Add mid-stream processing to ingestion process•Sessionization, classification, more complex transformation and ref data lookup•Access to machine learning algorithms using MLib‣Example implementation at:http://blog.cloudera.com/blog/2014/11/how-to-do-near-real-time-sessionization-with-spark-streaming-and-apache-hadoop/
Adding Real-Time Processing to Loading : Spark Streaming

Hadoop developmentis only for Java programmers
…isn’t it?
but …

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
SQL Increasingly Used in Hadoop for Data Access

[email protected] www.rittmanmead.com @rittmanmead 32
•Cloudera’s answer to Hive query response time issues•MPP SQL query engine running on Hadoop, bypasses MapReduce for direct data access•Mostly in-memory, but spills to disk if required
•Uses Hive metastore to access Hive table metadata•Similar SQL dialect to Hive - not as rich though and no support for Hive SerDes, storage handlers etc
Cloudera Impala - Fast, MPP-style Access to Hadoop Data
[email protected] www.rittmanmead.com @rittmanmead 33
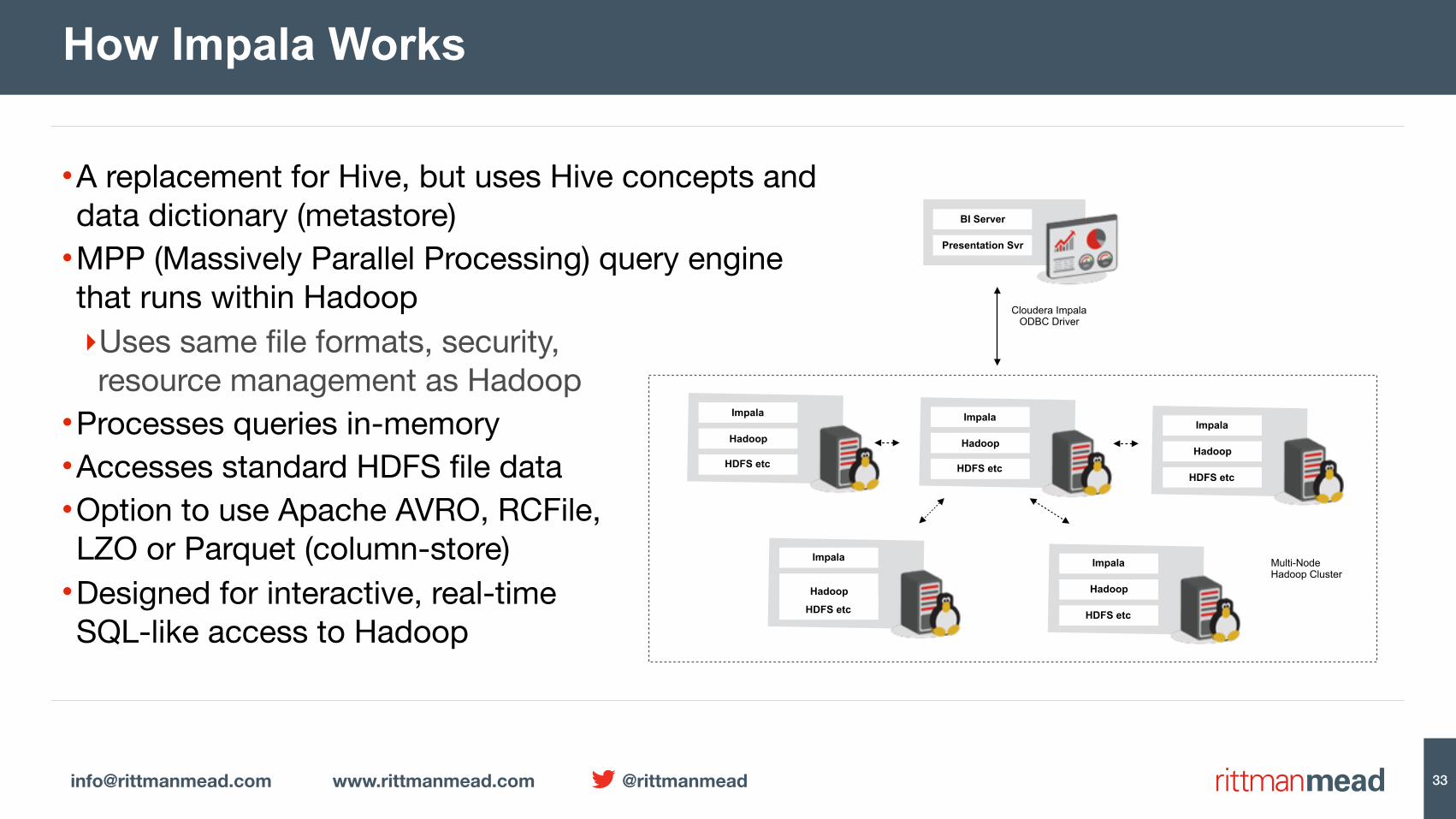
•A replacement for Hive, but uses Hive concepts anddata dictionary (metastore)
•MPP (Massively Parallel Processing) query enginethat runs within Hadoop‣Uses same file formats, security,resource management as Hadoop
•Processes queries in-memory•Accesses standard HDFS file data•Option to use Apache AVRO, RCFile,LZO or Parquet (column-store)
•Designed for interactive, real-timeSQL-like access to Hadoop
How Impala Works
Impala
Hadoop
HDFS etc
BI Server
Presentation Svr
Cloudera ImpalaODBC Driver
Impala
Hadoop
HDFS etc
Impala
Hadoop
HDFS etc
Impala
Hadoop
HDFS etc
Impala
Hadoop
HDFS etc
Multi-NodeHadoop Cluster

[email protected] www.rittmanmead.com @rittmanmead 34
•Log into Impala Shell, run INVALIDATE METADATA command to refresh Impala table list•Run SHOW TABLES Impala SQL command to view tables available•Run COUNT(*) on main ACCESS_PER_POST table to see typical response time
Enabling Hive Tables for Impala
[oracle@bigdatalite ~]$ impala-shell Starting Impala Shell without Kerberos authentication
[bigdatalite.localdomain:21000] > invalidate metadata; Query: invalidate metadata
Fetched 0 row(s) in 2.18s [bigdatalite.localdomain:21000] > show tables; Query: show tables +-----------------------------------+ | name | +-----------------------------------+ | access_per_post | | access_per_post_cat_author | | … | | posts | |——————————————————————————————————-+ Fetched 45 row(s) in 0.15s
[bigdatalite.localdomain:21000] > select count(*) from access_per_post; Query: select count(*) from access_per_post +----------+ | count(*) | +----------+ | 343 | +----------+ Fetched 1 row(s) in 2.76s

[email protected] www.rittmanmead.com @rittmanmead 35
•Significant improvement over Hive response time•Now makes Hadoop suitable for ad-hoc querying
Significantly-Improved Ad-Hoc Query Response Time vs Hive
|
Logical Query Summary Stats: Elapsed time 2, Response time 1, Compilation time 0 (seconds)
Logical Query Summary Stats: Elapsed time 50, Response time 49, Compilation time 0 (seconds)Simple Two-Table Join against Hive Data Only
Simple Two-Table Join against Impala Data Only
vs

[email protected] www.rittmanmead.com @rittmanmead 36
•Part of Oracle Big Data 4.0 (BDA-only)‣Also requires Oracle Database 12c, Oracle Exadata Database Machine
•Extends Oracle Data Dictionary to cover Hive•Extends Oracle SQL and SmartScan to Hadoop•Extends Oracle Security Model over Hadoop‣Fine-grained access control‣Data redaction, data masking‣Uses fast c-based readers where possible(vs. Hive MapReduce generation)‣Map Hadoop parallelism to Oracle PQ‣Big Data SQL engine works on top of YARN‣Like Spark, Tez, MR2
Oracle Big Data SQL
Exadata Storage Servers
HadoopCluster
Exadata DatabaseServer
Oracle Big Data SQL
SQL Queries
SmartScan SmartScan

[email protected] www.rittmanmead.com @rittmanmead 37
•Oracle Database 12c 12.1.0.2.0 with Big Data SQL option can view Hive table metadata‣Linked by Exadata configuration steps to one or more BDA clusters
•DBA_HIVE_TABLES and USER_HIVE_TABLES exposes Hive metadata•Oracle SQL*Developer 4.0.3, with Cloudera Hive drivers, can connect to Hive metastore
View Hive Table Metadata in the Oracle Data Dictionary
SQL> col database_name for a30 SQL> col table_name for a30 SQL> select database_name, table_name 2 from dba_hive_tables;
DATABASE_NAME TABLE_NAME ------------------------------ ------------------------------ default access_per_post default access_per_post_categories default access_per_post_full default apachelog default categories default countries default cust default hive_raw_apache_access_log

[email protected] www.rittmanmead.com @rittmanmead 38
•Big Data SQL accesses Hive tables through external table mechanism‣ORACLE_HIVE external table type imports Hive metastore metadata‣ORACLE_HDFS requires metadata to be specified
•Access parameters cluster and tablename specify Hive table source and BDA cluster
Hive Access through Oracle External Tables + Hive Driver
CREATE TABLE access_per_post_categories( hostname varchar2(100), request_date varchar2(100), post_id varchar2(10), title varchar2(200), author varchar2(100), category varchar2(100), ip_integer number) organization external (type oracle_hive default directory default_dir access parameters(com.oracle.bigdata.tablename=default.access_per_post_categories));

[email protected] www.rittmanmead.com @rittmanmead 39
•Brings query-offloading features of Exadatato Oracle Big Data Appliance
•Query across both Oracle and Hadoop sources• Intelligent query optimisation applies SmartScanclose to ALL data
•Use same SQL dialect across both sources•Apply same security rules, policies, user access rights across both sources
Extending SmartScan, and Oracle SQL, Across All Data

[email protected] www.rittmanmead.com @rittmanmead 40
•SQL query engine that doesn’t require a formal (HCatalog) schema• Infers the schema from the semi-structured dataset (JSON etc)‣Allows users to analyze data without any ETL or up-front schema definitions.‣Data can be in any file format such as text, JSON, or Parquet‣Improved agility and flexibilityvs formal modelling in Hive etc
Apache Drill
0: jdbc:drill:zk=local> select state, city, count(*) totalreviews from dfs.`/<path-to-yelp-dataset>/yelp/yelp_academic_dataset_business.json` group by state, city order by count(*) desc limit 10;
+------------+------------+--------------+ | state | city | totalreviews | +------------+------------+--------------+ | NV | Las Vegas | 12021 | | AZ | Phoenix | 7499 | | AZ | Scottsdale | 3605 | | EDH | Edinburgh | 2804 | | AZ | Mesa | 2041 | | AZ | Tempe | 2025 | | NV | Henderson | 1914 | | AZ | Chandler | 1637 | | WI | Madison | 1630 | | AZ | Glendale | 1196 | +------------+------------+--------------+

[email protected] www.rittmanmead.com @rittmanmead 41
•Addition of Spark as a back-end execution engine for Hive (and Pig)•Has the advantage of making use of all existing Hive scripts, infrastructure•But … probably is even more of a dead-end than Tez‣Is still faster than Hive on MR‣But Hive with column/in-memory optimizedstorage is now typically CPU bound‣Spark consumes more CPU, Disk & Network IO than Tez‣Additional translation overhead from RDDs to Hive’s “Row Containers”
Hive-on-Spark (and Pig-on-Spark)

[email protected] www.rittmanmead.com @rittmanmead 42
•Spark SQL, and Data Frames, allow RDDs in Spark to be processed using SQL queries•Bring in and federate additional data from JDBC sources•Load, read and save data in Hive, Parquet and other structured tabular formats
Spark SQL - Adding SQL Processing to Apache Spark
val accessLogsFilteredDF = accessLogs .filter( r => ! r.agent.matches(".*(spider|robot|bot|slurp).*")) .filter( r => ! r.endpoint.matches(".*(wp-content|wp-admin).*")).toDF() .registerTempTable("accessLogsFiltered") val topTenPostsLast24Hour = sqlContext.sql("SELECT p.POST_TITLE, p.POST_AUTHOR, COUNT(*) as total FROM accessLogsFiltered a JOIN posts p ON a.endpoint = p.POST_SLUG GROUP BY p.POST_TITLE, p.POST_AUTHOR ORDER BY total DESC LIMIT 10 ") // Persist top ten table for this window to HDFS as parquet file topTenPostsLast24Hour.save("/user/oracle/rm_logs_batch_output/topTenPostsLast24Hour.parquet" , "parquet", SaveMode.Overwrite)

[email protected] www.rittmanmead.com @rittmanmead 43
Choosing the Appropriate SQL Engine to Add to Hadoop

[email protected] www.rittmanmead.com @rittmanmead 44
•Beginners usually store data in HDFS using text file formats (CSV) but these have limitations•Apache AVRO often used for general-purpose processing‣Splitability, schema evolution, in-built metadata, support for block compression
•Parquet now commonly used with Impala due to column-orientated storage‣Mirrors work in RDBMS world around column-store‣Only return (project) the columns you require across a wide table
Apache Parquet - Column-Orientated Storage for Analytics

[email protected] www.rittmanmead.com @rittmanmead 45
•But Parquet (and HDFS) have significant limitation for real-time analytics applications‣Append-only orientation, focus on column-store makes streaming ingestion harder
•Cloudera Kudu aims to combine best of HDFS + HBase‣Real-time analytics-optimised ‣Supports updates to data‣Fast ingestion of data‣Accessed using SQL-style tablesand get/put/update/delete API
Cloudera Kudu - Combining Best of HBase and Column-Store

Hadoop is insecureand has fragmented security
…doesn’t it?
but …

[email protected] www.rittmanmead.com @rittmanmead 47
Consistent Security and Audit Now Emerging on Platform

[email protected] www.rittmanmead.com @rittmanmead 48
•Clusters by default are unsecured (vunerable to account spoofing) & need Kerberos enabled•Data access controlled by POSIX-style permissions on HDFS files•Hive and Impala can Apache Sentry RBAC‣Result is data duplication and complexity‣No consistent API or abstracted security model
Hadoop Security Initially Was a Mess
/user/mrittman/scratchpad /user/ryeardley/scratchpad /user/mpatel/scratchpad /user/mrittman/scratchpad /user/mrittman/scratchpad /data/rm_website_analysis/logfiles/incoming /data/rm_website_analysis/logfiles/archive /data/rm_website_analysis/tweets/incoming /data/rm_website_analysis/tweets/archive

[email protected] www.rittmanmead.com @rittmanmead 49
•Use standard Oracle Security over Hadoop & NoSQL‣Grant & Revoke Privileges‣Redact Data‣Apply Virtual Private Database‣Provides Fine-grain Access Control
•Great solution to extend existing Oraclesecurity model over Hadoop datasets
Oracle Big Data SQL : Extend Oracle Security to Hadoop
Redacteddatasubset
SQLJSON
CustomerdatainOracleDB
DBMS_REDACT.ADD_POLICY( object_schema => 'txadp_hive_01', object_name => 'customer_address_ext', column_name => 'ca_street_name', policy_name => 'customer_address_redaction', function_type => DBMS_REDACT.RANDOM, expression => 'SYS_CONTEXT(''SYS_SESSION_ROLES'', ''REDACTION_TESTER'')=''TRUE''' );

[email protected] www.rittmanmead.com @rittmanmead 50
•Provides a higher level, logical abstraction for data (ie Tables or Views) ‣Can be used with Spark & Spark SQL, with Predicate pushdown, projection
•Returns schemed objects (instead of paths and bytes) in similar way to HCatalog•Unified data access path allows platform-wide performance improvements•Secure service that does not execute arbitrary user code‣Central location for all authorization checks using Sentry metadata.
Cloudera RecordService

any predictive modellinghas to be done outside Hadoop, in R
…doesn’t it?
but …

[email protected] www.rittmanmead.com @rittmanmead 52
•Part of Spark, extends Scala, Java & Python API• Integrated workflow including ML pipelines•Currently supports following algorithms:‣Binary classification‣Regression‣Clustering‣Collaborative filtering‣Dimensionality Reduction
Spark MLLib : Adding Machine Learning Capabilities to Spark
// Compute raw scores on the test set. val scoreAndLabels = test.map { point => val score = model.predict(point.features) (score, point.label) }
// Get evaluation metrics. val metrics = new BinaryClassificationMetrics(scoreAndLabels) val auROC = metrics.areaUnderROC()
println("Area under ROC = " + auROC)
// Save and load model model.save(sc, "myModelPath") val sameModel = SVMModel.load(sc, "myModelPath")

[email protected] www.rittmanmead.com @rittmanmead 53
•Data enrichment tool aimed at domain experts, not programmers •Uses machine-learning to automate data classification + profiling steps
•Automatically highlight sensitive data,and offer to redact or obfuscate
•Dramatically reduce the time requiredto onboard new data sources
•Hosted in Oracle Cloud for zero-install‣File upload and download from browser‣Automate for production data loads
Raw Data
Data stored in the original format (usually files) such as SS7, ASN.
1, JSON etc.
Mapped Data
Data sets produced by mapping and
transforming raw data
Voice + Chat Transcripts
Example Usage : Oracle Big Data Preparation Cloud Service

[email protected] www.rittmanmead.com @rittmanmead 54
Identifying Schemas in Semi-/Unstructured Data

[email protected] www.rittmanmead.com @rittmanmead 55
Use of Machine Learning to Identify Data Patterns
•Automatically profile, parse and classify incoming datasets using Spark MLLib Word2Vec •Spot and obfuscate sensitive data automatically, automatically suggest column names


[email protected] www.rittmanmead.com @rittmanmead 57
•Hadoop is evolving‣Hadoop 2.0 breaks the dependency on MapReduce‣Spark, Tez etc allow us to create execution plans that run in-memory, faster than before‣New streaming models allow us to process data via sockets, micro batches or continuously
•And Oracle developers can make use of these new capabilities‣Oracle Big Data SQL can access Hadoop data loaded in real-time‣OBIEE, particularly in 11.1.1.9, can access Impala‣ODI is likely to support Hive on Tez and Hive on Spark shortly, and will have support for Spark in the future
Summary

[email protected] www.rittmanmead.com @rittmanmead
Big Data for Oracle Devs - Towards Spark, Real-Time and Predictive Analytics
Mark Rittman, CTO, Rittman Mead Riga Dev Day 2016, Riga, March 2016





























