Embed Size (px)
Citation preview

Binary class and Multi Class Strategies for Machine learning
By Vaibhav Arora

Two popular Approaches to algorithm design

contd..
Approach 1 the benefit is that we have much better and scalable algorithms we may come up with new, elegant, learning algorithms and contribute to basic research in machine learning.With sufficient time at hand this approach should be followed. Approach 2 Will often get your algorithm working more quickly[3].it has faster time to market.This approach really gives us a timely feedback and helps us in utilizing our resources better.

What can go wrong?
1) High bias(underfit)2) high variance(overfit)

How to detect it?There are a no of ways we can do it but i will mention two:-firstly, If you have a 2d or 3d dataset then you can visualize the decision boundary and try to figure out what is possibly wrong with your implementation.ie if it overly fits the training set but fails on the validation set then there is an overfitting problem (High variance).Or if it fails to fit both the training or validation set then there may be a high bias problem (underfitting).

Learning Curves Secondly, In case you have more than three dimensions we can’t visualize them so we use learning curves instead to see what problem we have.Def:-A learning curve is a plot of the training and validation error as a function of the number of training examples.These are meant to give us important ideas about the problems associated with our model.

LEARNING CURVES Procedure1) let Xtr denote the training examples and Ytr denote the training targets and let the no of training examples be n. 2) Then dofor i=1:n train the learning algorithm on the training subset ie (Xtr(1:i),Ytr(1:i)) pairs calculate train error
train_error(i)=Training set error(on Xtr(1:i),Ytr(1:i)) calculate validation error valid_error(i)=validation set error(on complete validation set)
note that if you are using regularization then set regularization parameter to 0 while calculating the train_error and valid_error.3) plot them

Learning Curves (typical plots)

contd..

What we want ?

How can you correct it?● To Fix high variance
o Get more training examples. o Get a smaller set of features. o Tweak algo parameters
● To Fix high Biaso Get a larger set of features. o use polynomial featureso Tweak algo parameters

Multi class classification strategieswhenever we have a multi class classification problem there are actually many strategies that we can follow 1) Use a multi class classifier ie a NNet etc
2) Use an no of binary classifiers to solve the problem at hand we can combine a no of binary classifiers using these strategies:-
a)one vs allb)one vs onec)ECOC
There are advantages and disadvantages of both approaches (you can experiment with both and try to find out!!) but for the purpose of this presentation we are only going to discuss the latter.

one vs all
In a one vs all strategy we would divide the data sets such that a hypothesis separates one class label from all of the rest.
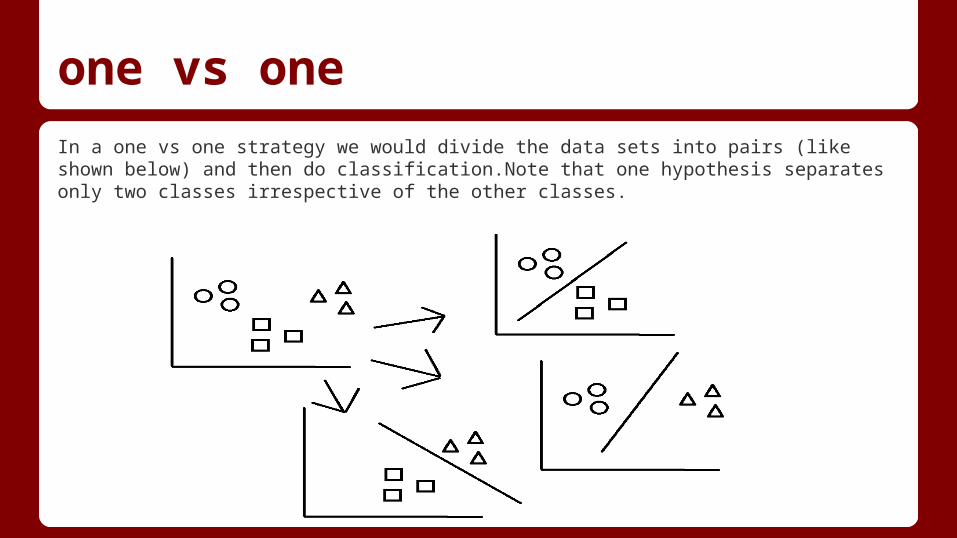
one vs oneIn a one vs one strategy we would divide the data sets into pairs (like shown below) and then do classification.Note that one hypothesis separates only two classes irrespective of the other classes.

How to select the class of a test example
Now that we have trained a number of classifiers in one vs one configuration we may choose a class for a training example as follows(note that this can be done for both the one vs one or one vs all, for the examples i have considered there are three hypothesis for both the cases):
a) Feed the training sample to all the three hypothesis (classifiers)
b) Select the class(label) for which the hypothesis function is maximum.

Error correcting output codesIn an ECOC strategy we try to build classifiers which target classification between different class subsets ie divide the main classification problem into sub-classification tasks

How do we do that?1) first use a no of binary classifiers,we make a matrix
as shown(three classifiers C1,C2,C3 and three labels L1,L2 and L3) ,here one contains positive class and zero contains negative class.(it is also possible to exclude certain classes in which case you can use 1,-1,and 0 ,0 indicating the removed class)

contd..2) Next when we have a new example we feed it to all the classifiers and the resultant output can then be compared with the labels (in terms of a distance measure say hamming[1]) and the label with the minimum hamming distance is assigned to the training example(if more than one rows are equidistant then assign arbitrarily).3)Eg suppose we have a training example t1 and when we feed it to the classifiers we get output 001 now its difference with label 1 is 2, with label 2 is 3 and with label 3 is 1 therefore label 1 will be assigned to the training example.

contd..4) something that we have to keep in mind :-if n is the no of classifiers and m is the no of labels then n>logm (base 2)
5) there are also a no of ways by which we select the coding matrix(the classifier label matrix) one can be through the use of generator matrix.other possible strategies include learning from data(via genetic algorithms) .For more info check references.

Personal experienceok this is all based on personal experience so you may choose to agree or not1) When working with svms ECOC one vs one seems to work better so try that
first when using svms.2) With logistic regression try one vs all approach first.3) When you have a large no of training examples choose to fit logistic
regression as best as possible instead of a support vector machines with linear kernel because they may work well but you will have a lot of support vectors (storage).
So with reasonable compromise on accuracy you can do with a lot less storage.4) When programming try to implement all these strategies by implementing the ECOC coding matrix and then you can choose to select the label either by maximum hypothesis or on the basis of hamming distance.

References1) https://en.wikipedia.org/wiki/Hamming_distance
2) for detail on learning curves and classification strategies prof Andrew ng’s machine learning course coursera.
3) Prof Andrew ng course slides at http://cs229.stanford.edu/materials/ML-advice.pdf
4) for ecoc classification a nice paper ,”Error-Correcting Output Coding for Text Classification”,by Adam Berger, School of Computer Science Carnegie Mellon University.can be found at
www.cs.cmu.edu/~aberger/pdf/ecoc.pdf

Thank You..
You can contact us at [email protected] Your feedback is appreciated.





























