Embed Size (px)
Citation preview

DATA SCIENCE lets put some Netflix into jobmensa.de
Steven Stadler Twitter: @joermungandr Email: [email protected]

2
AGENDA

1. WHAT IS MY BACKGROUND 2. WHAT IS DATA SCIENCE 3. WHY SHOULD WE USE IT 4. WHAT IS MACHINE LEARNING 5. WHICH CONCEPTS COULD WE USE 6. WHAT IS VERY IMPORTANT 7. PROFIT
3

4
MY TECHNICAL BACKGROUND

5
IMPLEMENTATION OF AN A.I. FOR REVERSI

HEURISTICS GAME THEORY
COMPETITION + SCALABILITY = HARD
6

7
MACHINE TRANSLATION SEMINAR

LANGUAGE PROCESSING MODEL DEVELOPMENT
8

9
IMAGE RETRIEVAL SEMINAR

FEATURE EXTRACTION MODEL DEVELOPMENT
PAGE RANK IS NOT ONLY FOR SEARCHES
10

11
2 YEARS DATA MINING @ iAMB

DATA ANALYTICS OF GENES WITH R/RUBY DATA CRAWLER FOR AUTOMATIC MODEL
ADAPTIONS WITH PYTHON BEING A SCIENTIST ;-)
12


14

15
WHAT IS DATA SCIENCE?

16
CONTEXT-DEPENDENT WAY OF THINKING AND WORKING WITH DATA [5]

17
DATA-DRIVEN DECISION MAKING

18
[9]

19
WHO DOES IT?
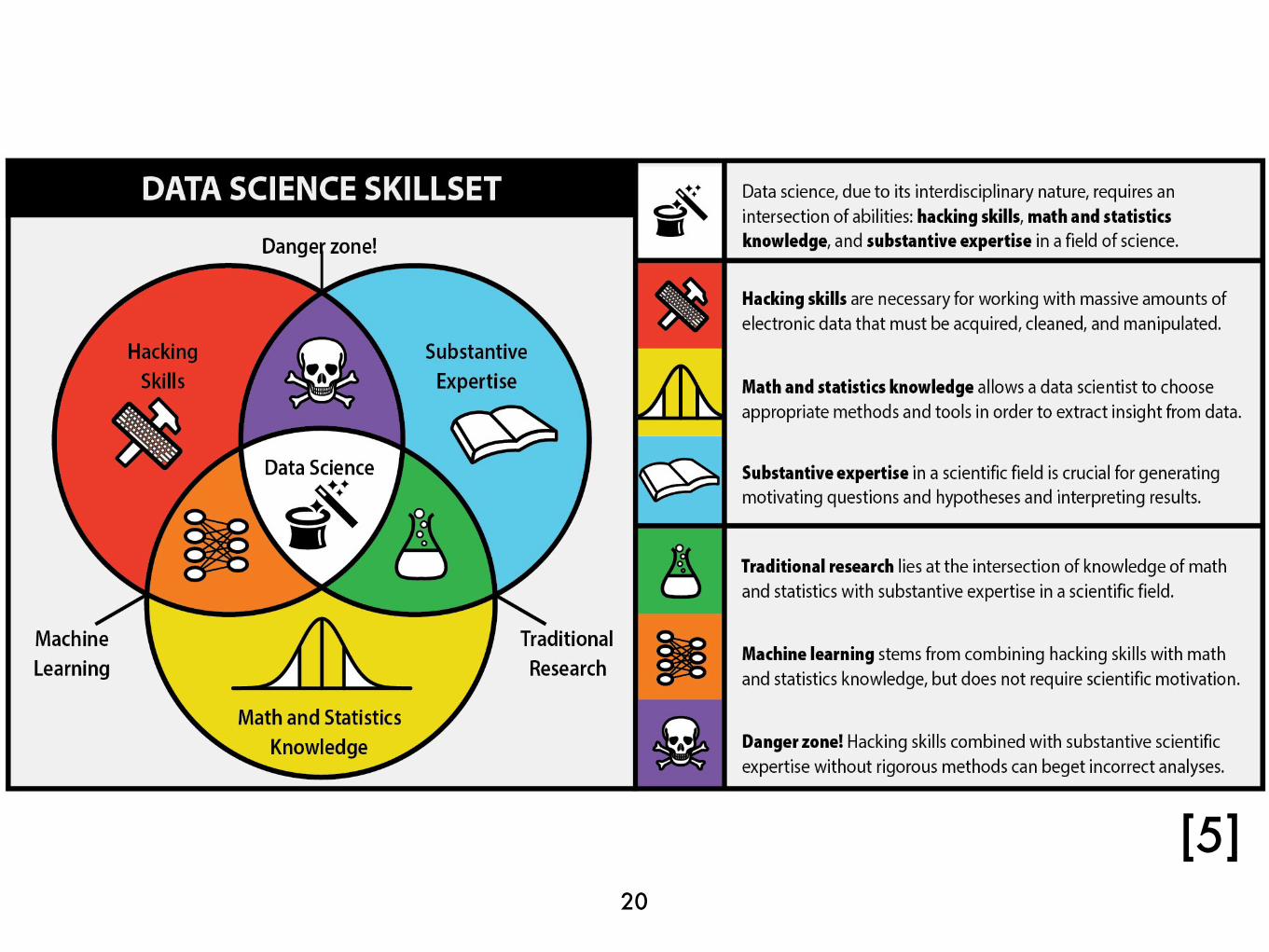
20
[5]

21
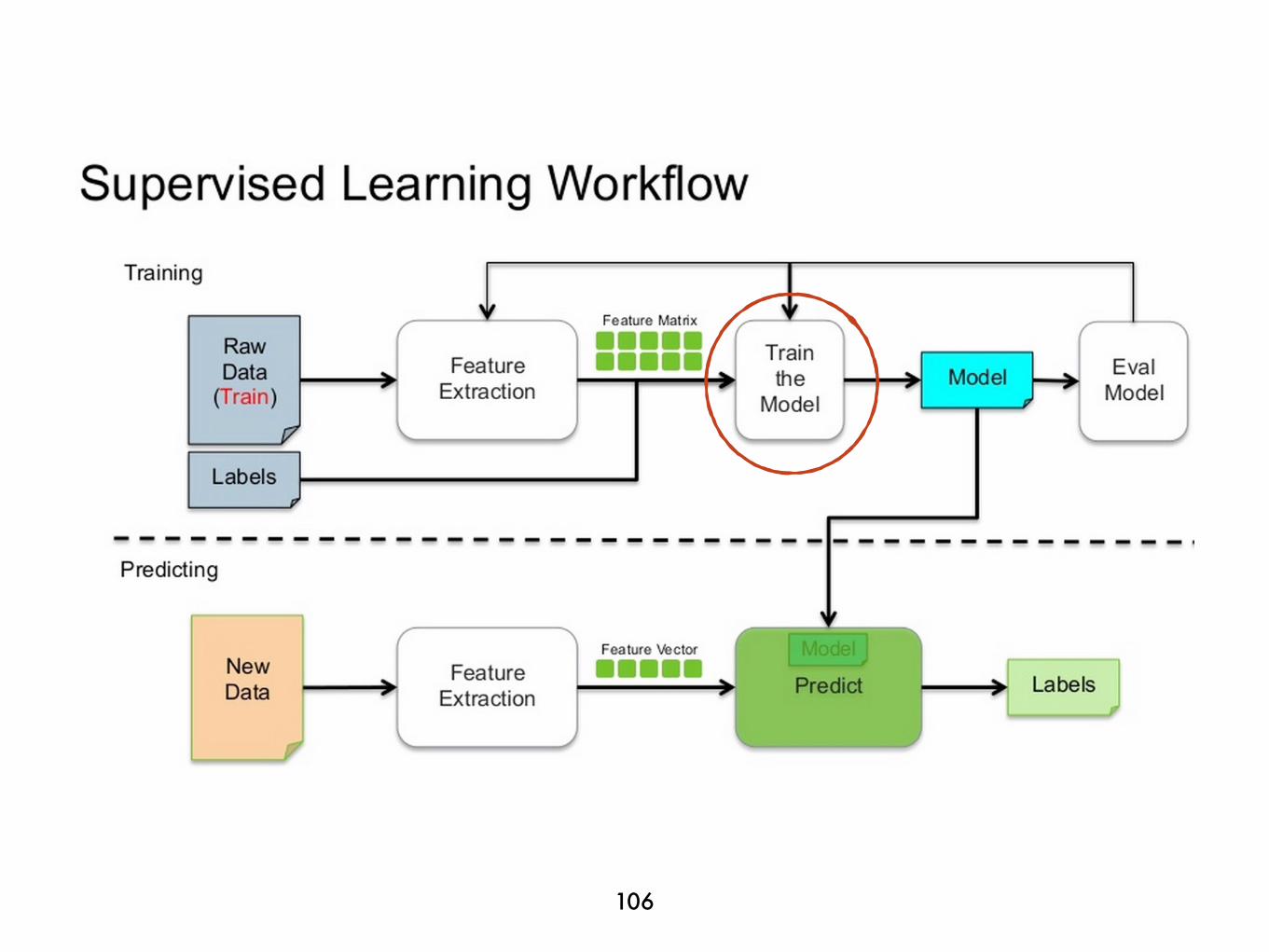
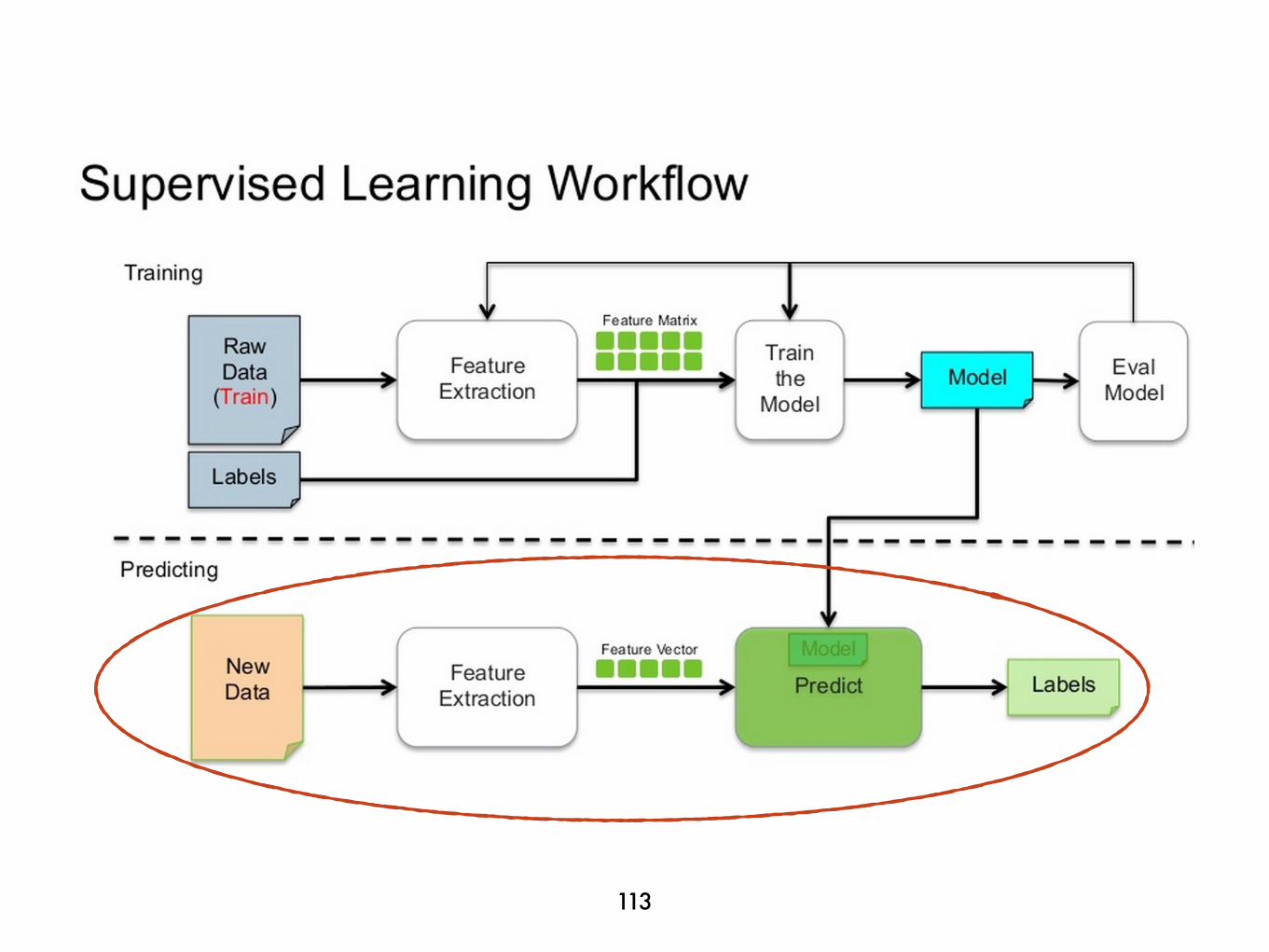
WORKFLOW?

22

23
BACK TO REALITY

24

25
MOST INTENSE PART IS THE CLEANING

26
BUSINESS VALUE

27
SAT TELECOM INCREASED EFFICIENCY [1]

28
SAVED AROUND 44% ON RECRUITMENT COSTS

AVERAGE TIME TO FILL VACANCIES HAS FALLEN FROM 70 TO 37 DAYS
29

IT’S COOL, BUT WHAT ABOUT US?
30


32
CONSUMER PERSPECTIVE

33
IT’S NOT EASY TO FIND A PROPER JOB

34
It’s not easy to find a proper job

35
1. RECOMMENDED JOB FITS

36
2. HAPPY STUDENT

37
3. BIGGER POOL OF STUDENTS FOR STUDITEMPS

38
4. PROFIT



41
PRODUCER PERSPECTIVE

42
TO BE HONEST. MOST APPLICANTS ARE CRAP.

43
1. SCORE THEM

44
2. RANK THEM

45
3. CHOOSE THEM

46
4. PROFIT

Rank applicants according to their job fit — PROFIT
47
First student on the list, was the best fit

48

49
LEARN ALL ABOUT THE CONTEXT OF YOUR PROJECT

50
TALK WITH ALL INVOLVED PEOPLE

51
LEARN THEIR NEEDS

52
DEFINE A MEASURABLE AND QUANTIFABLE GOAL

53

54

55
WHICH DATA IS AVAILABLE?

56
WILL IT HELP TO ANSWER MY QUESTIONS?

57
DO WE NEED MORE DATA?

58
IS THE QUALITY GOOD ENOUGH?

59

60
DATA WRANGLING

61

62
CLEAN

63

64

65
VISUALIZE

66
IMPORT OF STUDENT DATA

Age Distribution

68

69
Name Distribution

70
Surname Distribution

71
#experiences
count

classified :-)
72

73
THERE ARE 2,7 MILLION STUDENTS IN GERMANY

74

75

76
FIND THE FEATURES DESCRIBING YOUR “PRODUCT”

77
DEFINE THE CATEGORY OF YOUR PROBLEM

78
CONTINOUS VS CATEGORICAL VS PROBABILITY VS …

79

80

81
CHOOSE ALGORITHM OR A SAAS

82
BUT SAAS ARE IN THEIR EARLY STAGES OF DEVELOPMENT

83
AND MOSTLY A BLACK BOX

84
<THEORY>


OBJECTIVE
EFFICIENT
TRANSPARENT

87
now we start with some MACHINE LEARNING

MACHINE LEARNING is the science of getting computers to learn from data and act without
explicitly programmed
88

89
THERE ARE 2 TYPES OF MACHINE LEARNING

90
SUPERVISED LEARNING

91
COMPUTER IS PRESENETED WITH LABELED INPUTS

92

93

94
UNSUPERVISED LEARNING

95
NO LABELS ARE GIVEN TO THE ALGORITHM

96

97

98
NOT YET ;-)

110
99

100
LET’S CONCENTRATE ON SUPERVISED LEARNING

101

102

103
FEATURES?

104

job_id payment_hourly
keyword_1 keyword_2 exp_german exp_english exp_french …
11 19 1 0 1 1 0
7 20 1 0 0 0
3 10 0 0 0 0 0
… … … … … … …
105
106

107
MATH

108

109

110

111

112
113

114
</Theory>

115
I THINK I KNOW MACHINE LEARNING NOW


117
WHAT IS OUR AIM AGAIN?

118
JOB RECOMMENDATIONS FOR STUDENTS

119
SCORING OF STUDENTS FOR RECRUITERS

120
BUT WHY?

121
BECAUSE WE ARE A TECH START UP

122
PART 1: JOB RECOMMENDATIONS

123
MVP?

124
SUCCES RATE > 90% ? (XING: 50%? ;-) )

125
BETTER THAN NORMAL JOB SEARCH

126
HERE COMES A FIRST CONCEPT

127

128
WHERE IS THIS MACHINE LEARNING I HEARD ABOUT?

129
THERE ARE TWO BIG RECOMMENDATION YPES

130
1. CONTENT-BASED

131
SUGGEST ITEMS WITH SIMILAR CONTENT

132

133
TO MUCH MATH STEVEN!!

134
146
bad text
good text
magic box

147
do this 1000 times … ;-)
135

148
some text magic box good/bad
136

137
2. COLLABORATIVE-BASED

138
THERE’S A HIGH PROBABILITY THAT I LIKE JOBS, MY FRIENDS ALSO LIKE

139
THERE’S A HIGH PROBABILITY THAT I LIKE JOBS FROM A COMPANY I LIKE

140
LETS REPEAT THE STANDARD MACHINE LEARNING PROCESS

141
ANALYZE THE DATASET

142
FIND PATTERNS

143
BUILD A MODEL

144
TRAIN IT

145
YOUR MASTER: `PREDICTION QUOTE IS TOO BAD`

146
FIND CONCEPTS/DATA TO IMPROVE QUALITY

147
MASTER: `DU BIST MEIN BESTER MANN`

148
DEPLOY

149
LET’S COMBINE ALL WE KNOW

i.e. most of a company’s jobs are very similar
every favorated job creates a own list similar to it.
liked jobs are used to fill the pool with more jobs the user can favorate
150

151
WHICH DATA COULD HELP?

152
HOW THEY INTERACT WITH THE APP [3]

153
WORTH OF A COMPANY

154
APPLICATION SUCCES QUOTE

155
SOCIAL NETWORK DATA

156
REJECTION REASONS

157
PAY ATTENTION!!!

158

159
DATA HAS TO BE NORMALISED AND UNIFIED

160
AND THE MOST IMPORTANT PART

161
FEEDBACK

162
PART 2: APPLICANT SCORING

163

164
FURTHER PLANS

165
COOPERATION WITH KISS

166
DATA EXCHANGE

167
COULD KISS DATA IMPROVE OUR MODELS?

168
DATA-DRIVEN COMPANY

169
A MORE TECHNICAL TECH TALK ;-)

170
OR CONSTRAINED ON CERTAIN TOPICS

171

1. Sharon Pande, (2011),"E-recruitment creates order out of chaos at SAT Telecom”
3. Wenxing Hong, (2013),“Dynamic User Profile-Based Job Recommender System”
5. Yao Lu, (2012 - École Polytechnique Fédérale de Lausanne), “Analyzing User Patterns to Derive Design Guidelines for Job Seeking and Recruiting Website”
7. Al Mamunur Rashid, (2002 - University of Minnesota), “Getting to Know You: Learning New User Preferences in Recommender Systems”
8. http://berkeleysciencereview.com/article/first-rule-data-science/ 9. Craig Milroy, (2015), “Chief Data Officer: Evolution to the Chief Analytics Officer and
Data Science”
172

173





























